
Synthetic Data Generation for Visual Detection of Flattened PET Bottles

Abstract
:1. Introduction
- Photo-realistic synthetic data generation pipeline tailored to the task of visually detecting piles of flattened plastic multi-class bottles.
- Detailed quality evaluation of the generated synthetic data against a real dataset gathered in a conventional way by comparing the performance of object detection in both cases.
2. Related Work
2.1. Object Detection
2.2. Synthetic Data
3. Methods
3.1. Synthetic Data Generation
3.1.1. Background Dataset Creation
3.1.2. Bottle Dataset Creation
3.1.3. Composition
3.2. Datasets
3.2.1. Synthetic Datasets
3.2.2. Real Datasets
3.3. Object Detector
3.4. Training
4. Results
4.1. Synthetic Data versus Real
4.2. Ablation Study
4.3. Comparison of Dataset Sizes
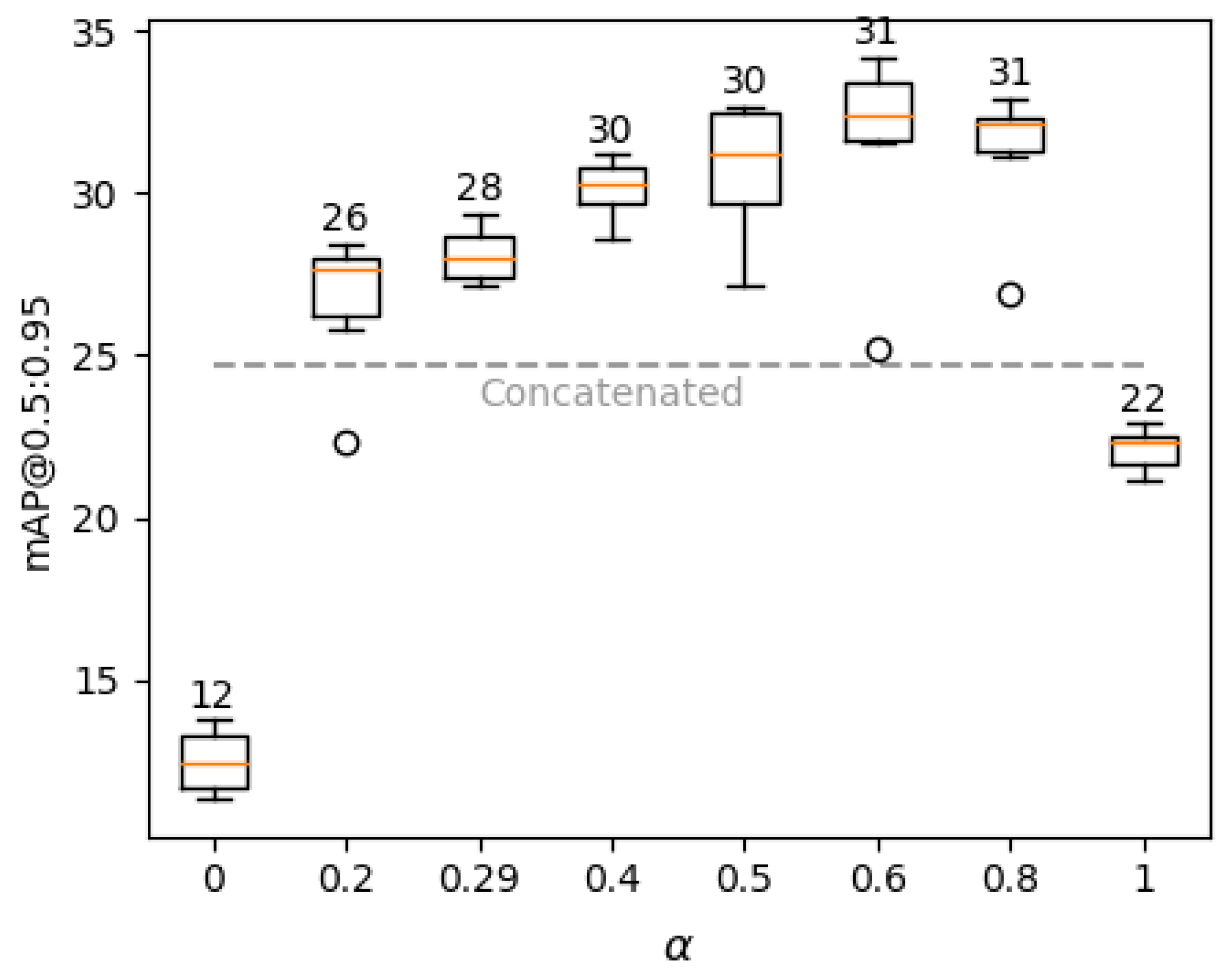
4.4. Contribution of Datasets
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Torres, P.; Arents, J.; Marques, H.; Marques, P. Bin-Picking Solution for Randomly Placed Automotive Connectors Based on Machine Learning Techniques. Electronics 2022, 11, 476. [Google Scholar] [CrossRef]
- Čech, M.; Beltman, A.J.; Ozols, K. Digital Twins and AI in Smart Motion Control Applications. In Proceedings of the 2022 IEEE 27th International Conference on Emerging Technologies and Factory Automation (ETFA), Stuttgart, Germany, 6–9 September 2022; pp. 1–7. [Google Scholar]
- Arents, J.; Greitans, M. Smart Industrial Robot Control Trends, Challenges and Opportunities within Manufacturing. Appl. Sci. 2022, 12, 937. [Google Scholar] [CrossRef]
- Racinskis, P.; Arents, J.; Greitans, M. A Motion Capture and Imitation Learning Based Approach to Robot Control. Appl. Sci. 2022, 12, 7186. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. (IJCV) 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Everingham, M.; Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2009, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the Computer Vision— ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014. [Google Scholar]
- Bobulski, J.; Piatkowski, J. PET Waste Classification Method and Plastic Waste DataBase–WaDaBa. In Proceedings of the Image Processing and Communications Challenges 9; Choraś, M., Choraś, R.S., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 57–64. [Google Scholar] [CrossRef]
- Thung, G.; Yang, M. Trashnet Dataset for Garbage Classification. 2016. Available online: https://github.com/garythung/trashnet (accessed on 20 October 2022).
- Proença, P.F.; Simões, P. TACO: Trash Annotations in Context for Litter Detection. arXiv 2020, arXiv:2003.06975. [Google Scholar] [CrossRef]
- Lai, Y.L.; Lai, Y.K.; Shih, S.Y.; Zheng, C.Y.; Chuang, T.H. Deep-learning Object Detection for Resource Recycling. J. Phys. Conf. Ser. 2020, 1583, 012011. [Google Scholar] [CrossRef]
- Jeon, Y.; Um, S.; Yoo, J.; Seo, M.; Jeong, E.; Seol, W.; Kang, D.; Song, H.; Kim, K.S.; Kim, S. Development of real-time automatic sorting system for color PET recycling process. In Proceedings of the 2020 20th International Conference on Control, Automation and Systems (ICCAS), Busan, Republic of Korea, 13–16 October 2020; pp. 995–998. [Google Scholar] [CrossRef]
- Rajpura, P.S.; Bojinov, H.; Hegde, R.S. Object Detection Using Deep CNNs Trained on Synthetic Images. arXiv 2017, arXiv:1706.06782. [Google Scholar] [CrossRef]
- Tremblay, J.; To, T.; Sundaralingam, B.; Xiang, Y.; Fox, D.; Birchfield, S. Deep Object Pose Estimation for Semantic Robotic Grasping of Household Objects. arXiv 2018, arXiv:1809.10790. [Google Scholar]
- Wang, K.; Shi, F.; Wang, W.; Nan, Y.; Lian, S. Synthetic Data Generation and Adaption for Object Detection in Smart Vending Machines. arxiv 2019, arXiv:1904.12294. [Google Scholar] [CrossRef]
- Blender Online Community. Blender—A 3D modelling and rendering package (Version 2.80); Blender Foundation, Stichting Blender Foundation: Amsterdam, The Netherlands, 2019; Available online: http://www.blender.org (accessed on 20 October 2022).
- Girshick, R.B. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. arXiv 2016, arXiv:1612.08242. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar] [CrossRef]
- Jocher, G. Ultralytics “YOLOv5”. 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 20 October 2022).
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10778–10787. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the Computer Vision—ECCV 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Dwibedi, D.; Misra, I.; Hebert, M. Cut, Paste and Learn: Surprisingly Easy Synthesis for Instance Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1310–1319. [Google Scholar] [CrossRef] [Green Version]
- Buls, E.; Kadikis, R.; Cacurs, R.; Ārents, J. Generation of synthetic training data for object detection in piles. Proc. SPIE Int. Soc. Opt. Eng. 2019, 11041, 110411Z. [Google Scholar] [CrossRef]
- Hinterstoisser, S.; Pauly, O.; Heibel, H.; Martina, M.; Bokeloh, M. An Annotation Saved is an Annotation Earned: Using Fully Synthetic Training for Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Republic of Korea, 27–28 October 2019; pp. 2787–2796. [Google Scholar] [CrossRef]
- Dvornik, N.; Mairal, J.; Schmid, C. Modeling Visual Context Is Key to Augmenting Object Detection Datasets. In Proceedings of the Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 375–391. [Google Scholar] [CrossRef] [Green Version]
- Peng, X.; Sun, B.; Ali, K.; Saenko, K. Learning Deep Object Detectors from 3D Models. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1278–1286. [Google Scholar] [CrossRef] [Green Version]
- Tobin, J.; Fong, R.; Ray, A.; Schneider, J.; Zaremba, W.; Abbeel, P. Domain randomization for transferring deep neural networks from simulation to the real world. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 23–30. [Google Scholar] [CrossRef] [Green Version]
- Tremblay, J.; To, T.; Birchfield, S. Falling Things: A Synthetic Dataset for 3D Object Detection and Pose Estimation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 2119–21193. [Google Scholar] [CrossRef] [Green Version]
- Chang, A.X.; Funkhouser, T.; Guibas, L.; Hanrahan, P.; Huang, Q.; Li, Z.; Savarese, S.; Savva, M.; Song, S.; Su, H.; et al. ShapeNet: An Information-Rich 3D Model Repository. arXiv 2015, arXiv:1512.03012. [Google Scholar] [CrossRef]
- Calli, B.; Singh, A.; Walsman, A.; Srinivasa, S.; Abbeel, P.; Dollar, A.M. The YCB object and Model set: Towards common benchmarks for manipulation research. In Proceedings of the 2015 International Conference on Advanced Robotics (ICAR), Istanbul, Turkey, 27–31 July 2015; pp. 510–517. [Google Scholar] [CrossRef]
- Sela, M.; Xu, P.; He, J.; Navalpakkam, V.; Lagun, D. GazeGAN—Unpaired Adversarial Image Generation for Gaze Estimation. arXiv 2017, arXiv:1711.09767. [Google Scholar] [CrossRef]
- Arents, J.; Lesser, B.; Bizuns, A.; Kadikis, R.; Buls, E.; Greitans, M. Synthetic Data of Randomly Piled, Similar Objects for Deep Learning-Based Object Detection. In Proceedings of the International Conference on Image Analysis and Processing; Springer: Berlin/Heidelberg, Germany, 2022; pp. 706–717. [Google Scholar]
- Rahnemoonfar, M.; Sheppard, C. Deep Count: Fruit Counting Based on Deep Simulated Learning. Sensors 2017, 17, 905. [Google Scholar] [CrossRef] [Green Version]
- Georgakis, G.; Mousavian, A.; Berg, A.C.; Kosecka, J. Synthesizing training data for object detection in indoor scenes. arXiv 2017, arXiv:1702.07836. [Google Scholar]
- Caruana, R. Multitask Learning: A Knowledge-Based Source of Inductive Bias. In Proceedings of the Tenth International Conference on Machine Learning, Amherst, MA, USA, 27–29 June 1993; Morgan Kaufmann: San Francisco, CA, USA; pp. 41–48. [Google Scholar]
- Garrido-Jurado, S.; Muñoz-Salinas, R.; Madrid-Cuevas, F.; Marín-Jiménez, M. Automatic generation and detection of highly reliable fiducial markers under occlusion. Pattern Recognit. 2014, 47, 2280–2292. [Google Scholar] [CrossRef]
- Bradski, G. The OpenCV Library. 2000. Available online: https://github.com/opencv/opencv/wiki/CiteOpenCV (accessed on 19 October 2022).
- Burt, P.; Adelson, E. The Laplacian Pyramid as a Compact Image Code. IEEE Trans. Commun. 1983, 31, 532–540. [Google Scholar] [CrossRef]
- Jack, K. Digital Video Processing. In Video Demystified (Fourth Edition); Elsevier: Burlington, NJ, USA, 2005; Chapter 7; pp. 219–230. [Google Scholar]
- Rossini, M. Blender Add-On: Camera Calibration Using Perspective Views of Rectangles. 2017. Available online: https://github.com/mrossini-ethz/camera-calibration-pvr (accessed on 20 October 2022).
- Tan, T.N.; Sullivan, G.D.; Baker, K.D. Recovery of Intrinsic and Extrinsic Camera Parameters Using Perspective Views of Rectangles. In Proceedings of the 1995 British Conference on Machine Vision (BMVC ’95); BMVA Press: Durham, UK, 1995; Volume 1, pp. 177–186. [Google Scholar]
- Gillies, S.; van der Wel, C.; Van den Bossche, J.; Taves, M.W.; Arnott, J.; Ward, B.C.; Tonnhofer, O.; Wasserman, J.; Caruso, T.; Adair, A.; et al. Shapely: Manipulation and Analysis of Geometric Objects (Version 1.7.0). 2020. Available online: https://github.com/Toblerity/Shapely (accessed on 20 October 2022).
- Padilla, R.; Netto, S.L.; da Silva, E.A.B. A Survey on Performance Metrics for Object-Detection Algorithms. In Proceedings of the 2020 International Conference on Systems, Signals and Image Processing (IWSSIP), Niteroi, Brazil, 1–3 July 2020; pp. 237–242. [Google Scholar] [CrossRef]
- Nesterov, Y. A method of solving a convex programming problem with convergence rate . Doklady Akademii Nauk SSSR 1983, 269, 543–547. Available online: http://mi.mathnet.ru/dan46009 (accessed on 20 October 2022).
- He, T.; Zhang, Z.; Zhang, H.; Zhang, Z.; Xie, J.; Li, M. Bag of Tricks for Image Classification with Convolutional Neural Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 558–567. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Random Hue | Camera Views | Bottle Photos | Random Light | Unique Cluttering | Test Set (Avg ± Std) | |
|---|---|---|---|---|---|---|
| Synthetic-only models | ||||||
| All (baseline) | 10.7 ± 1.1 | |||||
| Original Color | ✕ | 7.2 ± 1.0 | ||||
| Single Camera Viewpoint | ✕ | 9.1 ± 0.8 | ||||
| Single Bottle Photo | ✕ | 6.5 ± 0.5 | ||||
| Single Light | ✕ | 8.2 ± 0.9 | ||||
| Repeat Bottle Selections | ✕ | 11.1 ± 0.8 | ||||
| All off | ✕ | ✕ | ✕ | ✕ | ✕ | 3.9 ± 0.2 |
| Combined dataset models | ||||||
| Real + All (baseline) | 30.7 ± 2.0 | |||||
| Real + Original Color | ✕ | 31.1 ± 0.3 | ||||
| Real + Single Camera Viewpoint | ✕ | 28.1 ± 1.0 | ||||
| Real + Single Bottle Photo | ✕ | 26.3 ± 0.9 | ||||
| Real + Single Light | ✕ | 29.6 ± 1.7 | ||||
| Real + Repeat Bottle Selections | ✕ | 32.2 ± 1.5 | ||||
| Real + All off | ✕ | ✕ | ✕ | ✕ | ✕ | 23.4 ± 3.3 |
| Dataset | Test Set |
|---|---|
| (Avg ± Std) | |
| Real 25% | 13.6 ± 2.0 |
| Real 50% | 16.8 ± 1.5 |
| Real 75% | 18.8 ± 0.9 |
| Real 100% | 22.3 ± 1.0 |
| Synthetic + Real 25% | 22.4 ± 1.0 |
| Synthetic + Real 50% | 23.0 ± 3.5 |
| Synthetic + Real 75% | 28.6 ± 2.4 |
| Synthetic + Real 100% | 30.7 ± 2.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feščenko, V.; Ārents, J.; Kadiķis, R. Synthetic Data Generation for Visual Detection of Flattened PET Bottles. Mach. Learn. Knowl. Extr. 2023, 5, 14-28. https://doi.org/10.3390/make5010002
Feščenko V, Ārents J, Kadiķis R. Synthetic Data Generation for Visual Detection of Flattened PET Bottles. Machine Learning and Knowledge Extraction. 2023; 5(1):14-28. https://doi.org/10.3390/make5010002
Chicago/Turabian StyleFeščenko, Vitālijs, Jānis Ārents, and Roberts Kadiķis. 2023. "Synthetic Data Generation for Visual Detection of Flattened PET Bottles" Machine Learning and Knowledge Extraction 5, no. 1: 14-28. https://doi.org/10.3390/make5010002