

Multi-UAV Collaborative Absolute Vision Positioning and Navigation: A Survey and Discussion

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
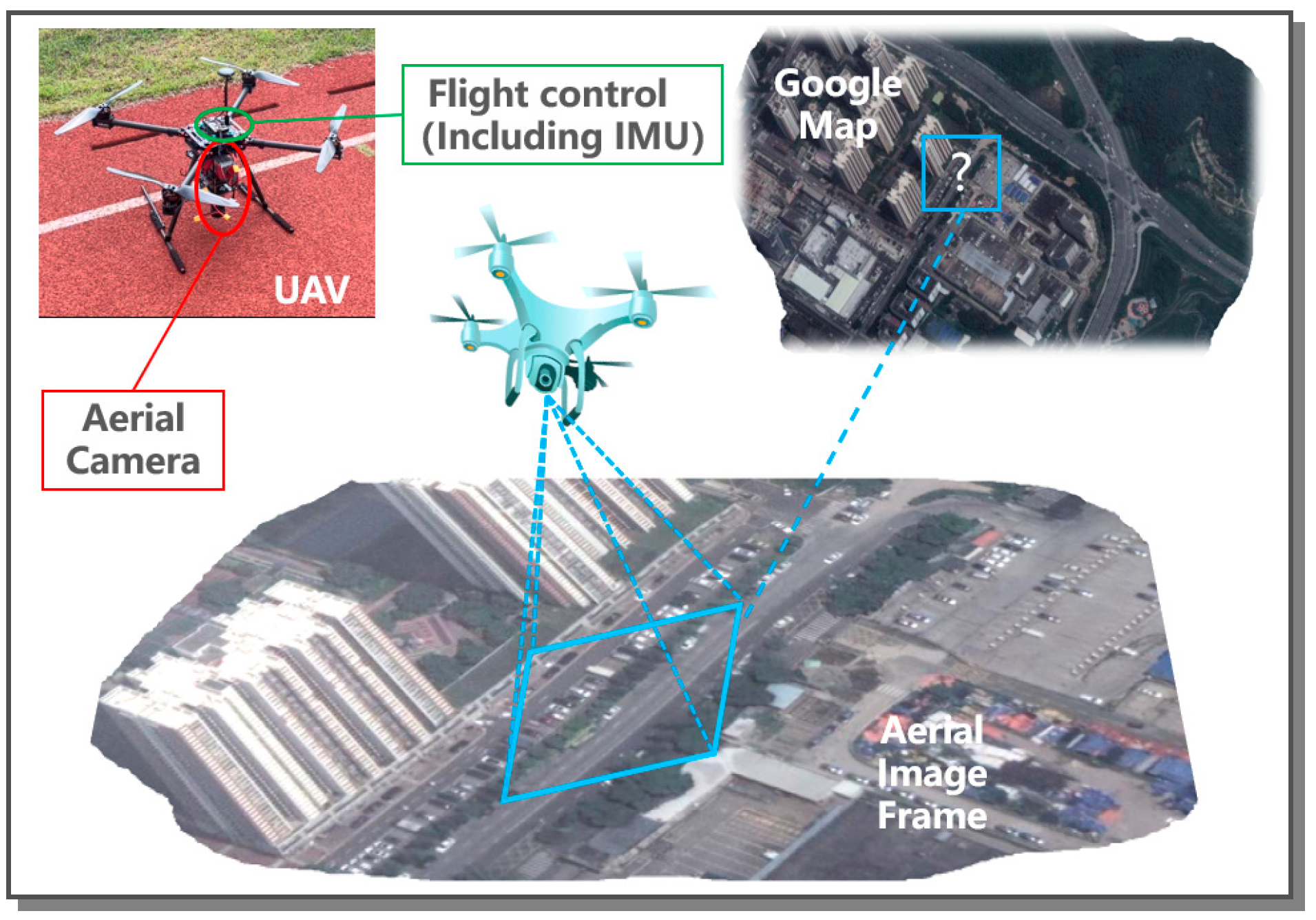
:1. Introduction
2. Autonomous Localization and Navigation of Vision Multi-Airborne Vehicles
2.1. Image Matching Based on Prior Map
2.1.1. UAV Location Based on Template Matching
2.1.2. UAV Location Based on Feature Matching
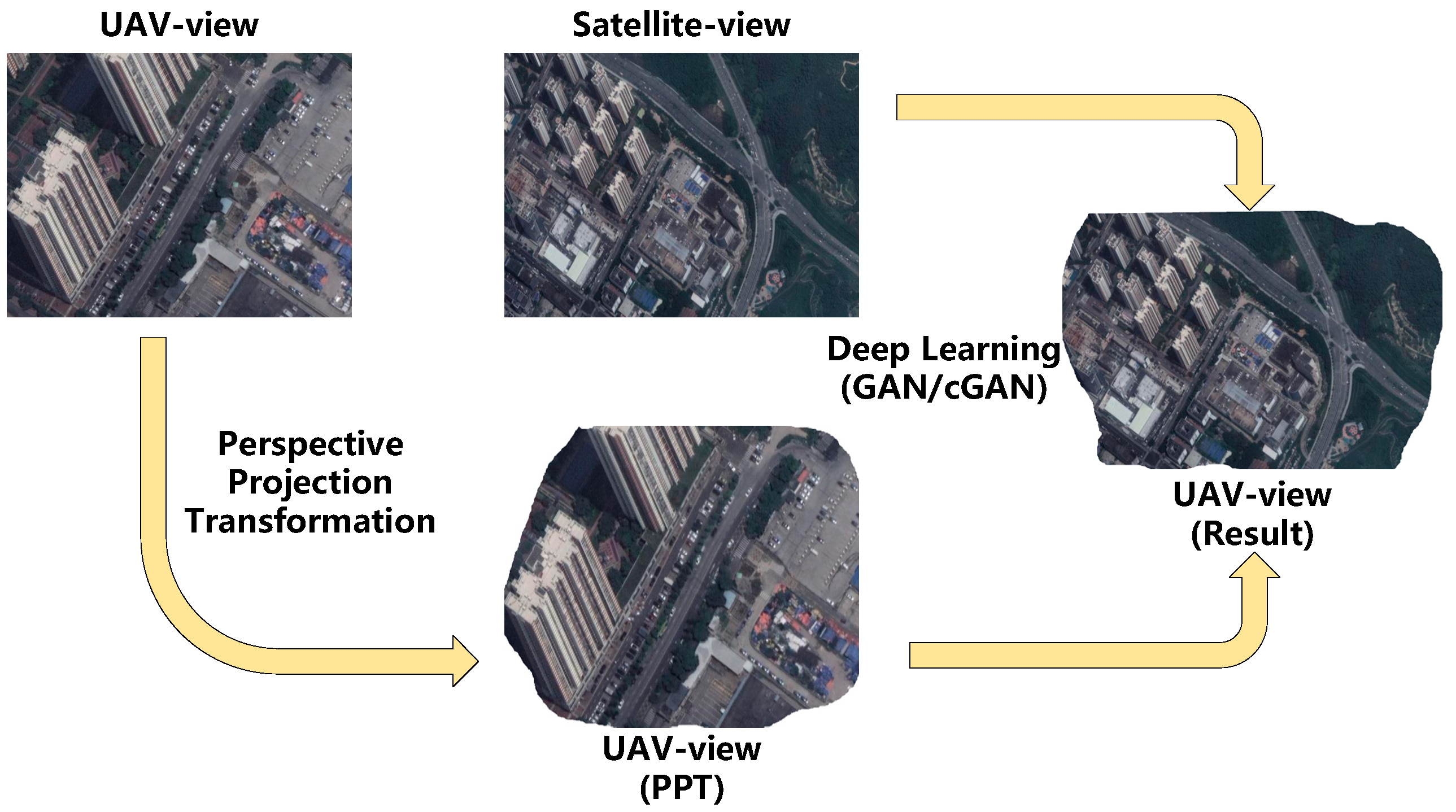
2.2. Cross-View Matching
2.3. Visual Odometry
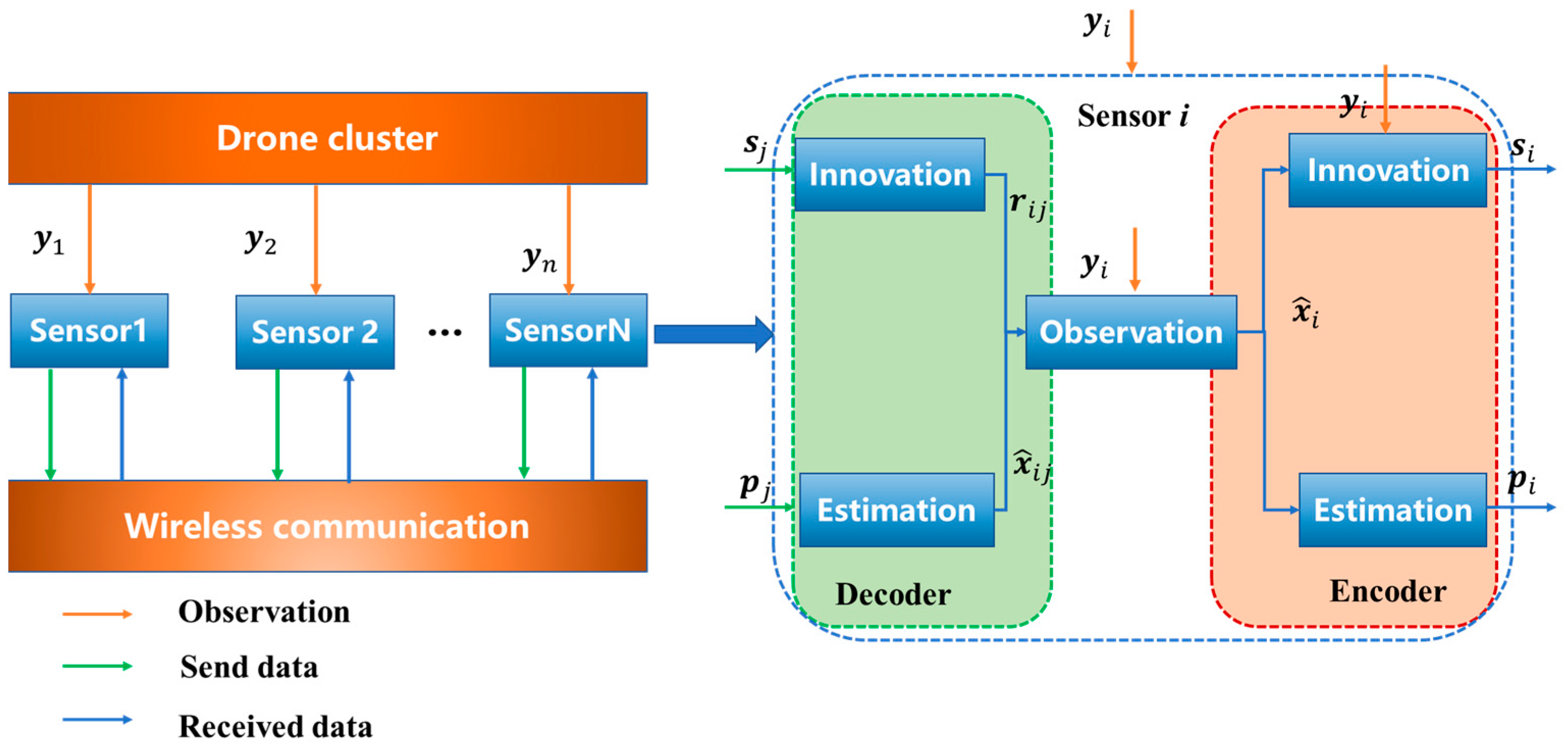
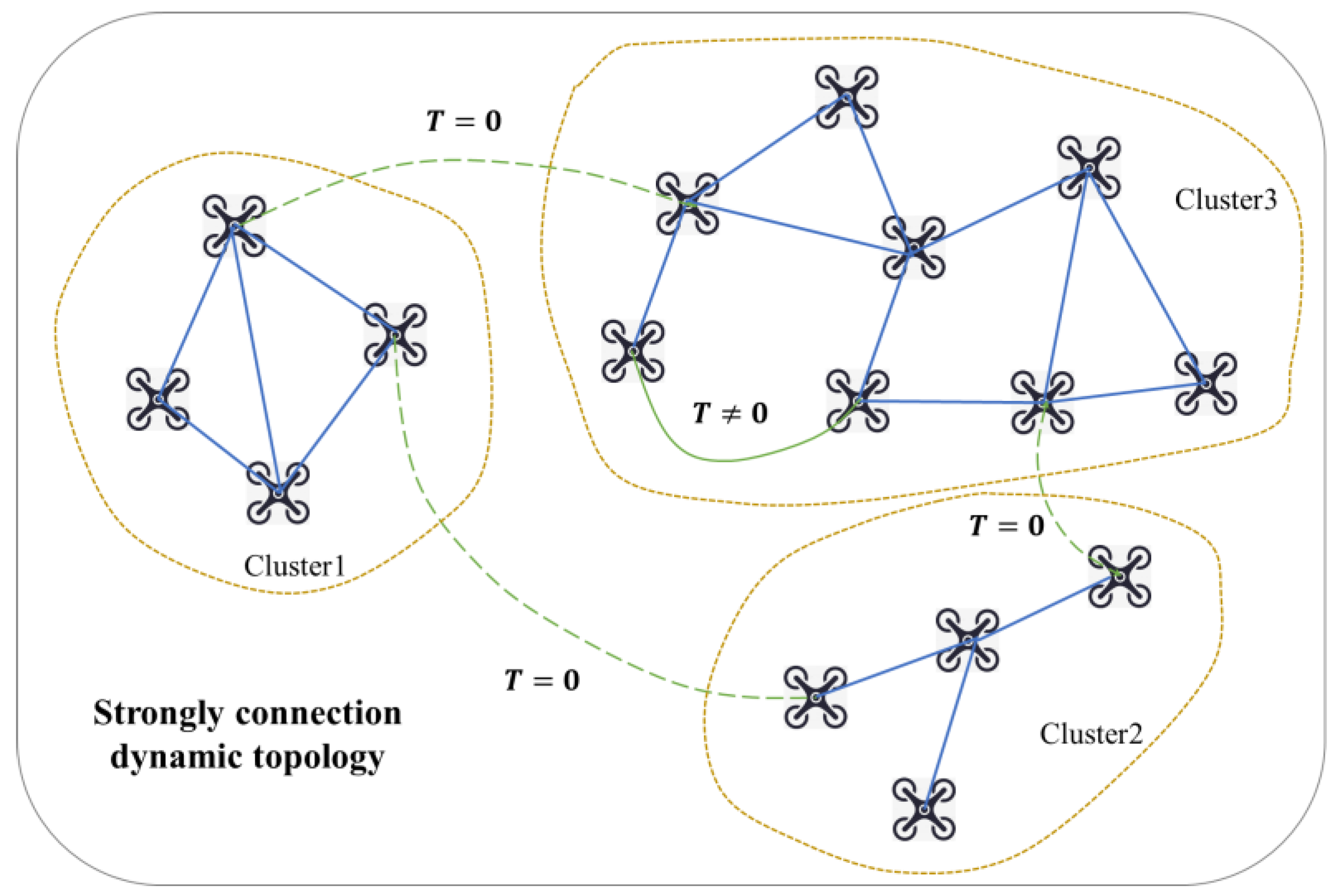
3. Distributed Collaborative Measurement Fusion under Cluster Dynamic Topology
4. Group Navigation Based on Active Behavior Control
4.1. Scene Reconstruction
4.2. Attitude Estimation
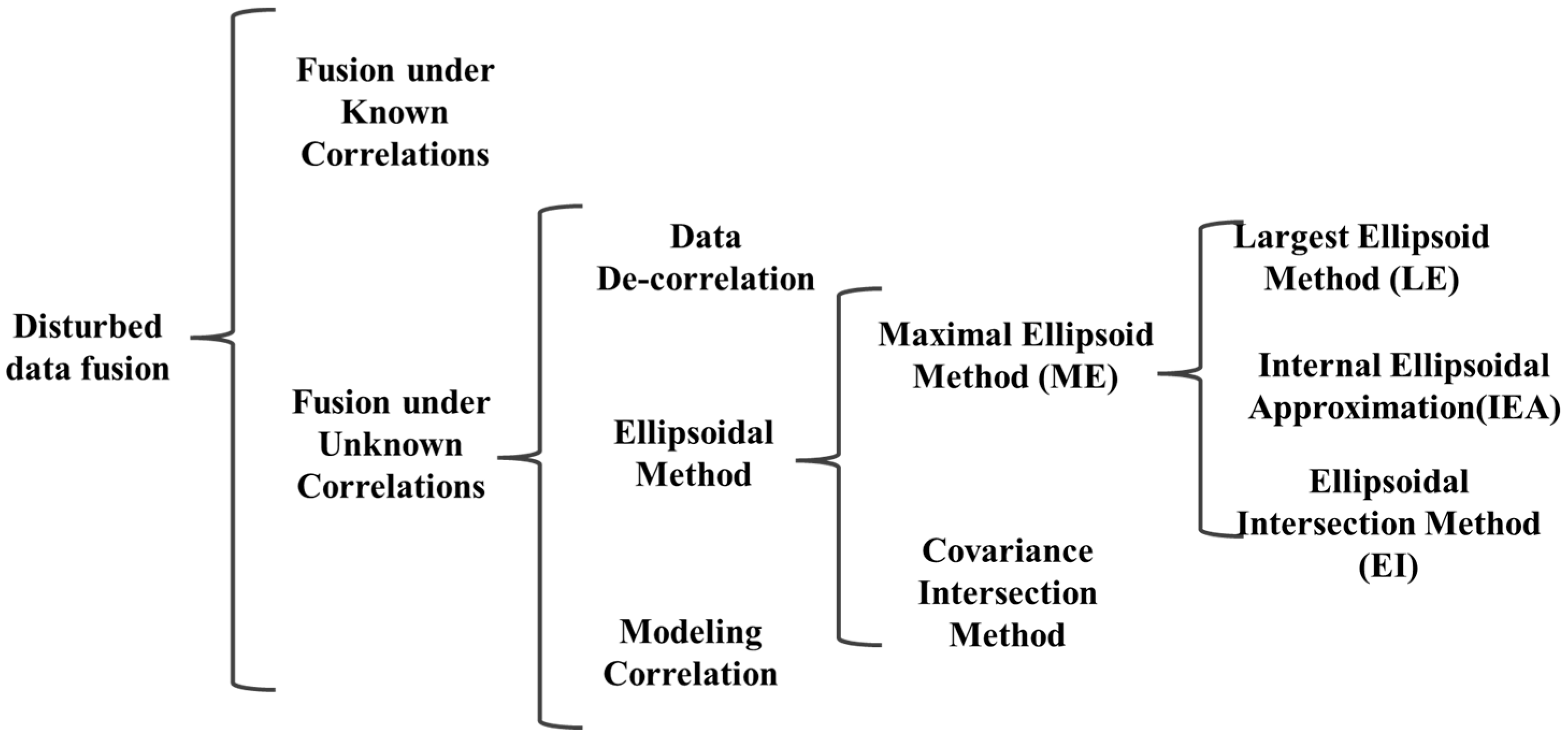
5. Distributed Fusion of Multi-Source Dynamic Sensing Information
5.1. Fusion under Known Correlations
5.2. Fusion under Unknown Correlation
5.2.1. Data De-Correlation
5.2.2. Modeling Correlation
5.2.3. Ellipsoidal Method
6. Open Problems and Possible Future Research Directions
6.1. Research on Feature Extraction and Modeling of Key Features in Geographic Information
6.2. Research on Fast Matching Method of Ground Objects Based on Mapping Base Map
6.3. Research on Pose Fusion Estimation Based on Multi-Sensor
6.4. Research on Absolute Position Estimation Method of Multi-UAV Scale Matching Based on Ground Features
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Radočaj, D.; Šiljeg, A.; Plaščak, I.; Marić, I.; Jurišić, M. A Micro-Scale Approach for Cropland Suitability Assessment of Permanent Crops Using Machine Learning and a Low-Cost UAV. Agronomy 2023, 13, 362. [Google Scholar] [CrossRef]
- Mohsan, S.A.H.; Othman, N.Q.H.; Khan, M.A.; Amjad, H.; Żywiołek, J. A comprehensive review of micro UAV charging techniques. Micromachines 2022, 13, 977. [Google Scholar] [CrossRef]
- Liu, X.; Li, H.; Yang, S. Optimization Method of High-Precision Control Device for Photoelectric Detection of Unmanned Aerial Vehicle Based on POS Data. Sci. Program. 2022, 2022, 2449504. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, H.; Liu, Q.; Huang, J. Key Technologies of the Cooperative Combat of Manned Aerial Vehicle and Unmanned Aerial Vehicle. In Advances in Guidance, Navigation and Control: Proceedings of 2022 International Conference on Guidance, Navigation and Control, Harbin, China, 5–7 August 2022; Springer Nature Singapore: Singapore, 2023; pp. 671–679. [Google Scholar]
- Lu, Y.; Qin, W.; Zhou, C.; Liu, Z. Automated detection of dangerous work zone for crawler crane guided by UAV images via Swin Transformer. Autom. Constr. 2023, 147, 104744. [Google Scholar] [CrossRef]
- Rehan, M.; Akram, F.; Shahzad, A.; Shams, T.A.; Ali, Q. Vertical take-off and landing hybrid unmanned aerial vehicles: An overview. Aeronaut. J. 2022, 126, 1–41. [Google Scholar] [CrossRef]
- Çoban, S. Autonomous performance maximization of research-based hybrid unmanned aerial vehicle. Aircr. Eng. Aerosp. Technol. 2020, 92, 645–651. [Google Scholar] [CrossRef]
- Alqurashi, F.A.; Alsolami, F.; Abdel-Khalek, S.; Sayed Ali, E.; Saeed, R.A. Machine learning techniques in internet of UAVs for smart cities applications. J. Intell. Fuzzy Syst. 2022, 42, 3203–3226. [Google Scholar] [CrossRef]
- Amarasingam, N.; Salgadoe, S.; Powell, K.; Gonzalez, L.F.; Natarajan, S. A review of UAV platforms, sensors, and applications for monitoring of sugarcane crops. Remote Sens. Appl. Soc. Environ. 2022, 26, 100712. [Google Scholar] [CrossRef]
- Li, B.; Liu, B.; Han, D.; Wang, Z. Autonomous Tracking of ShenZhou Reentry Capsules Based on Heterogeneous UAV Swarms. Drones 2023, 7, 20. [Google Scholar] [CrossRef]
- Akter, R.; Golam, M.; Doan, V.S.; Lee, J.M.; Kim, D.S. Iomt-net: Blockchain integrated unauthorized uav localization using lightweight convolution neural network for internet of military things. IEEE Internet Things J. 2022, 10, 6634–6651. [Google Scholar] [CrossRef]
- AL-Dosari, K.; Hunaiti, Z.; Balachandran, W. Systematic Review on Civilian Drones in Safety and Security Applications. Drones 2023, 7, 210. [Google Scholar] [CrossRef]
- Maddikunta, P.K.R.; Hakak, S.; Alazab, M.; Bhattacharya, S.; Gadekallu, T.R.; Khan, W.Z.; Pham, Q.V. Unmanned aerial vehicles in smart agriculture: Applications, requirements, and challenges. IEEE Sens. J. 2021, 21, 17608–17619. [Google Scholar] [CrossRef]
- Sal, F. Simultaneous swept anhedral helicopter blade tip shape and control-system design. Aircr. Eng. Aerosp. Technol. 2023, 95, 101–112. [Google Scholar] [CrossRef]
- Khan, A.; Zhang, J.; Ahmad, S.; Memon, S.; Qureshi, H.A.; Ishfaq, M. Dynamic positioning and energy-efficient path planning for disaster scenarios in 5G-assisted multi-UAV environments. Electronics 2022, 11, 2197. [Google Scholar] [CrossRef]
- Gyagenda, N.; Hatilima, J.V.; Roth, H.; Zhmud, V. A review of GNSS-independent UAV navigation techniques. Robot. Auton. Syst. 2022, 152, 104069. [Google Scholar] [CrossRef]
- Gao, W.; Yue, F.; Xia, Z.; Liu, X.; Zhang, C.; Liu, Z.; Jin, S.; Zhang, Y.; Zhao, Z.; Zhang, T.; et al. Weak Signal Processing Method for Moving Target of GNSS-S Radar Based on Amplitude and Phase Self-Correction. Remote Sens. 2023, 15, 969. [Google Scholar] [CrossRef]
- Gao, W.; Xu, Z.; Han, X.; Pan, C. Recent advances in curved image sensor arrays for bioinspired vision system. Nano Today 2022, 42, 101366. [Google Scholar] [CrossRef]
- Liu, Z.; Cao, Y.; Gao, P.; Hua, X.; Zhang, D.; Jiang, T. Multi-UAV network assisted intelligent edge computing: Challenges and opportunities. China Commun. 2022, 19, 258–278. [Google Scholar] [CrossRef]
- Tang, J.; Duan, H.; Lao, S. Swarm intelligence algorithms for multiple unmanned aerial vehicles collaboration: A comprehensive review. Artif. Intell. Rev. 2022, 1–33. [Google Scholar] [CrossRef]
- Shen, S.; Mulgaonkar, Y.; Michael, N.; Kumar, V. Multi-sensor fusion for robust autonomous flight in indoor and outdoor environments with a rotorcraft MAV. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 4974–4981. [Google Scholar]
- Mueller, M.W.; Hamer, M.; D’Andrea, R. Fusing ultra-wideband range measurements with accelerometers and rate gyroscopes for quadrocopter state estimation. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 1730–1736. [Google Scholar]
- Engel, J.; Sturm, J.; Cremers, D. Camera-based navigation of a low-cost quadrocopter. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 2815–2821. [Google Scholar]
- Nemra, A.; Aouf, N. Robust cooperative UAV visual SLAM. In Proceedings of the 2010 IEEE 9th International Conference on Cyberntic Intelligent Systems, Reading, UK, 1–2 September 2010; pp. 1–6. [Google Scholar]
- Loianno, G.; Thomas, J.; Kumar, V. Cooperative localization and mapping of MAVs using RGB-D sensors. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 4021–4028. [Google Scholar]
- Piasco, N.; Marzat, J.; Sanfourche, M. Collaborative localization and formation flying using distributed stereo-vision. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 1202–1207. [Google Scholar]
- Fei, W.; Jin-Qiang, C.U.I.; Ben-Mei, C.H.E.N.; Tong, H.L. A comprehensive UAV indoor navigation system based on vision optical flow and laser FastSLAM. Acta Autom. Sin. 2013, 39, 1889–1899. [Google Scholar]
- Bryson, M.; Sukkarieh, S. Building a Robust Implementation of Bearing-only Inertial SLAM for a UAV. J. Field Robot. 2007, 24, 113–143. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.; Sukkarieh, S. Real-time implementation of airborne inertial-SLAM. Robot. Auton. Syst. 2007, 55, 62–71. [Google Scholar] [CrossRef]
- Gandhi, D.; Pinto, L.; Gupta, A. Learning to fly by crashing. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 3948–3955. [Google Scholar]
- Pinto, L.; Gupta, A. Supersizing self-supervision: Learning to grasp from 50k tries and 700 robot hours. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 3406–3413. [Google Scholar]
- Fu, Q.; Quan, Q.; Cai, K.-Y. Robust pose estimation for multirotor UAVs using off-board monocular vision. IEEE Trans. Ind. Electron. 2017, 64, 7942–7951. [Google Scholar] [CrossRef]
- Zhou, H.; Zou, D.; Pei, L.; Ying, R.; Liu, P.; Yu, W. StructSLAM: Visual SLAM with building structure lines. IEEE Trans. Veh. Technol. 2015, 64, 1364–1375. [Google Scholar] [CrossRef]
- Zou, D.; Tan, P. Coslam: Collaborative visual slam in dynamic environments. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 354–366. [Google Scholar] [CrossRef]
- Wang, K.; Shen, S. Mvdepthnet: Real-time multiview depth estimation neural network. In Proceedings of the 2018 International Conference on 3d Vision (3DV), Verona, Italy, 5–8 September 2018; pp. 248–257. [Google Scholar]
- Leutenegger, S.; Lynen, S.; Bosse, M.; Siegwart, R.; Furgale, P. Keyframe-based visual–inertial odometry using nonlinear optimization. Int. J. Robot. Res. 2015, 34, 314–334. [Google Scholar] [CrossRef] [Green Version]
- Li, M.; Mourikis, A.I. High-precision, consistent EKF-based visual–inertial odometry. Int. J. Robot. Res. 2013, 32, 690–711. [Google Scholar] [CrossRef]
- Bloesch, M.; Omari, S.; Hutter, M.; Siegwart, R. Robust visual inertial odometry using a direct EKF-based approach. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 298–304. [Google Scholar]
- Leprince, S.; Barbot, S.; Ayoub, F.; Avouac, J.P. Automatic and precise orthorectification, coregistration, and subpixel correlation of satellite images, application to ground deformation measurements. IEEE Trans. Geosci. Remote Sens. 2007, 45, 1529–1558. [Google Scholar] [CrossRef] [Green Version]
- Google Earth, Google. 2022. Available online: https://www.google.com/earth/ (accessed on 15 July 2022).
- ArcGIS Online, Esri. 2022. Available online: https://www.arcgis.com/index.html (accessed on 10 June 2022).
- Couturier, A.; Akhloufi, M.A. Relative visual localization (RVL) for UAV navigation. In Degraded Environments: Sensing, Processing, and Display 2018; SPIE: Bellingham, WA, USA, 2018; Volume 10642, pp. 213–226. [Google Scholar]
- Couturier, A.; Akhloufi, M.A. UAV navigation in GPS-denied environment using particle filtered RVL. In Situation Awareness in Degraded Environments 2019; SPIE: Bellingham, WA, USA, 2019; Volume 11019, pp. 188–198. [Google Scholar]
- Couturier, A.; Akhloufi, M. Conditional probabilistic relative visual localization for unmanned aerial vehicles. In Proceedings of the 2020 IEEE Canadian Conference on Electrical and Computer Engineering (CCECE), London, ON, Canada, 30 August–2 September 2020; pp. 1–4. [Google Scholar]
- Warren, M.; Greeff, M.; Patel, B.; Collier, J.; Schoellig, A.P.; Barfoot, T.D. There’s no place like home: Visual teach and repeat for emergency return of multirotor uavs during gps failure. IEEE Robot. Autom. Lett. 2018, 4, 161–168. [Google Scholar] [CrossRef] [Green Version]
- Brunelli, R. Template Matching Techniques in Computer Vision: Theory and Practice; John Wiley & Sons: Hoboken, NJ, USA, 2009. [Google Scholar]
- Brunelli, R.; Poggiot, T. Template matching: Matched spatial filters and beyond. Pattern Recognit. 1997, 30, 751–768. [Google Scholar] [CrossRef] [Green Version]
- Van Dalen, G.J.; Magree, D.P.; Johnson, E.N. Absolute localization using image alignment and particle filtering. In Proceedings of the AIAA Guidance, Navigation, and Control Conference, San Diego, CA, USA, 4–8 January 2016; p. 647. [Google Scholar]
- Lewis, J.P. Fast template matching. Vis. Interface. 1995, 95, 15–19. [Google Scholar]
- Thrun, S. Particle Filters in Robotics. UAI 2002, 2, 511–518. [Google Scholar]
- Bing Maps, Microsoft. 2022. Available online: https://www.bing.com/maps (accessed on 17 December 2022).
- Magree, D.P.; Johnson, E.N. A monocular vision-aided inertial navigation system with improved numerical stability. In Proceedings of the AIAA Guidance, Navigation, and Control Conference, Kissimmee, FL, USA, 5–9 January 2015; p. 97. [Google Scholar]
- Sasiadek, J.; Wang, Q.; Johnson, R.; Sun, L.; Zalewski, J. UAV navigation based on parallel extended Kalman filter. In Proceedings of the AIAA Guidance, Navigation, and Control Conference and Exhibit, Dever, CO, USA, 14–17 August 2000; p. 4165. [Google Scholar]
- Johnson, E.; Schrage, D. The Georgia Tech unmanned aerial research vehicle: GTMax. In Proceedings of the AIAA Guidance, Navigation, and Control Conference and Exhibit, Austin, TX, USA, 11–14 August 2003; p. 5741. [Google Scholar]
- Yol, A.; Delabarre, B.; Dame, A.; Dartois, J.É.; Marchand, E. Vision-based absolute localization for unmanned aerial vehicles. In Proceedings of the 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems, Chicago, IL, USA, 14–18 September 2014; pp. 3429–3434. [Google Scholar]
- Cover, T.M. Elements of Information Theory; John Wiley & Sons: Hoboken, NJ, USA, 1999. [Google Scholar]
- Gray, R.M. Entropy and Information Theory; Springer Science & Business Media: Berlin, Germany, 2011. [Google Scholar]
- Wan, X.; Liu, J.; Yan, H.; Morgan, G.L. Illumination-invariant image matching for autonomous UAV localisation based on optical sensing. ISPRS J. Photogramm. Remote Sens. 2016, 119, 198–213. [Google Scholar] [CrossRef]
- Keller, Y.; Averbuch, A. A projection-based extension to phase correlation image alignment. Signal Process. 2007, 87, 124–133. [Google Scholar] [CrossRef]
- Patel, B. Visual Localization for UAVs in Outdoor GPS-Denied Environments; University of Toronto (Canada): Toronto, ON, Canada, 2019. [Google Scholar]
- Pascoe, G.; Maddern, W.P.; Newman, P. Robust direct visual localization using normalised information distance. In Proceedings of the British Machine Vision Conference, Oxford, UK, 21–24 November 2015; pp. 70–71. [Google Scholar]
- Harris, C.; Stephens, M. A combined corner and edge detector. In Proceedings of the Alvey Vision Conference 1988, Manchester, UK, 1 January 1988; Volume 15, pp. 10–5244. [Google Scholar]
- Rosten, E.; Drummond, T. Machine learning for high-speed corner detection. In Computer Vision—ECCV 2006; Lecture Notes in Computer Science; Leonardis, A., Bischof, H., Pinz, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 430–443. [Google Scholar]
- Rosten, E.; Porter, R.; Drummond, T. Faster and better: A machine learning approach to corner detection. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 105–119. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tang, G.; Liu, Z.; Xiong, J. Distinctive image features from illumination and scale invariant keypoints. Multimed. Tools Appl. 2019, 78, 23415–23442. [Google Scholar] [CrossRef]
- Calonder, M.; Lepetit, V.; Strecha, C.; Fua, P. BRIEF: Binary robust independent elementary features. In Computer Vision—ECCV 2010; Lecture Notes in Computer Science; Daniilidis, K., Maragos, P., Paragios, N., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 778–792. [Google Scholar]
- Seema, B.S.; Hemanth, K.; Naidu, V.P.S. Geo-registration of aerial images using RANSAC algorithm. In NCTAESD-2014; Vemana Institute of Technology: Bangalore, India, 2014; pp. 1–5. [Google Scholar]
- Saranya, K.C.; Naidu, V.P.S.; Singhal, V.; Tanuja, B.M. Application of vision based techniques for UAV position estimation. In Proceedings of the 2016 International Conference on Research Advances in Integrated Navigation Systems (RAINS), Bangalore, India, 6–7 May 2016; pp. 1–5. [Google Scholar]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T.; Van Gool, L. SURF: Speeded up robust features. In Computer Vision—ECCV 2006; Lecture Notes in Computer Science; Leonardis, A., Bischof, H., Pinz, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 404–417. [Google Scholar]
- Shan, M.; Wang, F.; Lin, F.; Gao, Z.; Tang, Y.Z.; Chen, B.M. Google map aided visual navigation for UAVs in GPS-denied environment. In Proceedings of the 2015 IEEE International Conference on Robotics and Biomimetics (ROBIO), Zhuhai, China, 6–9 December 2015; pp. 114–119. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 25 July 2005; Volume 1, pp. 886–893. [Google Scholar]
- Horn, B.K.P.; Schunck, B.G. Determining optical flow. Artif. Intell. 1981, 17, 185–203. [Google Scholar] [CrossRef] [Green Version]
- Bolme, D.S.; Beveridge, J.R.; Draper, B.A.; Lui, Y.M. Visual object tracking using adaptive correlation filters. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2544–2550. [Google Scholar]
- Chiu, H.P.; Das, A.; Miller, P.; Samarasekera, S.; Kumar, R. Precise vision-aided aerial navigation. In Proceedings of the 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems, Chicago, IL, USA, 14–18 September 2014; pp. 688–695. [Google Scholar]
- Mantelli, M.; Pittol, D.; Neuland, R.; Ribacki, A.; Maffei, R.; Jorge, V.; Prestes, E.; Kolberg, M. A novel measurement model based on abBRIEF for global localization of a UAV over satellite images. Robot. Auton. Syst. 2019, 112, 304–319. [Google Scholar] [CrossRef]
- Masselli, A.; Hanten, R.; Zell, A. Localization of unmanned aerial vehicles using terrain classification from aerial images. In Advances in Intelligent Systems and Computing; Intelligent Autonomous Systems 13; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 831–842. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Cutler, A.; Cutler, D.R.; Stevens, J.R. Random forests. In Ensemble Machine Learning: Methods and Applications; Springer: New York, NY, USA, 2012; pp. 157–175. [Google Scholar]
- Shan, M.; Charan, A. Google map referenced UAV navigation via simultaneous feature detection and description. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015. [Google Scholar]
- Tombari, F.; Di Stefano, L. Interest points via maximal self-dissimilarities. In Computer Vision—ACCV 2014; Lecture Notes in Computer Science; Cremers, D., Reid, I., Saito, H., Yang, M.-H., Eds.; Springer International Publishing: Singapore, 2014; pp. 586–600. [Google Scholar]
- Shechtman, E.; Irani, M. Matching local self-similarities across images and videos. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Chen, X.; Luo, X.; Weng, J.; Luo, W.; Li, H.; Tian, Q. Multi-view gait image generation for cross-view gait recognition. IEEE Trans. Image Process. 2021, 30, 3041–3055. [Google Scholar] [CrossRef]
- Yan, X.; Lou, Z.; Hu, S.; Ye, Y. Multi-task information bottleneck co-clustering for unsupervised cross-view human action categorization. ACM Trans. Knowl. Discov. Data (TKDD) 2020, 14, 1–23. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.; Liu, W.; Zheng, J.; Yan, C.; Mei, T. Beyond the parts: Learning multi-view cross-part correlation for vehicle re-identification. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020. [Google Scholar]
- Zhao, J.; Han, R.; Gan, Y.; Wan, L.; Feng, W.; Wang, S. Human identification and interaction detection in cross-view multi-person videos with wearable cameras. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020. [Google Scholar]
- Shao, Z.; Li, Y.; Zhang, H. Learning representations from skeletal self-similarities for cross-view action recognition. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 160–174. [Google Scholar] [CrossRef]
- Xu, C.; Makihara, Y.; Li, X.; Yagi, Y.; Lu, J. Cross-view gait recognition using pairwise spatial transformer networks. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 260–274. [Google Scholar] [CrossRef]
- Cai, S.; Guo, Y.; Khan, S.; Hu, J.; Wen, G. Ground-to-aerial image geo-localization with a hard exemplar reweighting triplet loss. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Shi, Y.; Yu, X.; Liu, L.; Zhang, T.; Li, H. Optimal feature transport for cross-view image geo-localization. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Regmi, K.; Borji, A. Cross-view image synthesis using geometry-guided conditional gans. Comput. Vis. Image Underst. 2019, 187, 102788. [Google Scholar] [CrossRef] [Green Version]
- Regmi, K.; Shah, M. Bridging the domain gap for ground-to-aerial image matching. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Shi, Y.; Liu, L.; Yu, X.; Li, H. Spatial-aware feature aggregation for image based cross-view geo-localization. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 February 2019; p. 32. [Google Scholar]
- Shi, Y.; Yu, X.; Campbell, D.; Li, H. Where am I looking at? joint location and orientation estimation by cross-view matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–20 June 2020. [Google Scholar]
- Toker, A.; Zhou, Q.; Maximov, M.; Leal-Taixé, L. Coming down to earth: Satellite-to-street view synthesis for geo-localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Kuala Lumpur, Malaysia, 18–20 December 2021. [Google Scholar]
- Zheng, Z.; Wei, Y.; Yang, Y. University-1652: A multi-view multi-source benchmark for drone-based geo-localization. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020. [Google Scholar]
- Wang, T.; Zheng, Z.; Yan, C.; Zhang, J.; Sun, Y.; Zheng, B.; Yang, Y. Each part matters: Local patterns facilitate cross-view geo-localization. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 867–879. [Google Scholar] [CrossRef]
- Ding, L.; Zhou, J.; Meng, L.; Long, Z. A practical cross-view image matching method between UAV and satellite for UAV-based geo-localization. Remote Sens. 2020, 13, 47. [Google Scholar] [CrossRef]
- Tian, X.; Shao, J.; Ouyang, D.; Shen, H.T. UAV-Satellite View Synthesis for Cross-View Geo-Localization. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 4804–4815. [Google Scholar] [CrossRef]
- Lin, T.Y.; Cui, Y.; Belongie, S.; Hays, J. Learning deep representations for ground-to-aerial geolocalization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Tian, Y.; Chen, C.; Shah, M. Cross-view image matching for geo-localization in urban environments. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Liu, L.; Li, H. Lending orientation to neural networks for cross-view geo-localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Workman, S.; Souvenir, R.; Jacobs, N. Wide-area image geolocalization with aerial reference imagery. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Workman, S.; Jacobs, N. On the location dependence of convolutional neural network features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Chen, C.; Qin, C.; Qiu, H.; Ouyang, C.; Wang, S.; Chen, L.; Tarroni, G.; Bai, W.; Rueckert, D. Realistic adversarial data augmentation for MR image segmentation. In Medical Image Computing and Computer Assisted Intervention—MICCAI 2020; Springer: Berlin, Germany, 2020. [Google Scholar]
- Zhang, H.; Xu, T.; Li, H.; Zhang, S.; Wang, X.; Huang, X.; Metaxas, D. Stackgan: Text to photo-realistic image synthesis with stacked generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Lu, X.; Li, Z.; Cui, Z.; Oswald, M.R.; Pollefeys, M.; Qin, R. Geometry-aware satellite-to-ground image synthesis for urban areas. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Forster, C.; Pizzoli, M.; Scaramuzza, D. SVO: Fast semi-direct monocular visual odometry. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 15–22. [Google Scholar]
- Nister, D.; Naroditsky, O.; Bergen, J. Visual odometry. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2004. CVPR 2004, Washington, DC, USA, 27 June–2 July 2004; Volume 1. [Google Scholar]
- Goforth, H.; Lucey, S. GPS-denied UAV localization using pre-existing satellite imagery. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 2974–2980. [Google Scholar]
- Torr, P.H.S.; Zisserman, A. MLESAC: A new robust estimator with application to estimating image geometry. Comput. Vis. Image Underst. 2000, 78, 138–156. [Google Scholar] [CrossRef] [Green Version]
- Anderson, S.; Barfoot, T.D. Full STEAM ahead: Exactly sparse gaussian process regression for batch continuous-time trajectory estimation on SE(3). In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 157–164. [Google Scholar]
- Olfati-Saber, R. Kalman-consensus filter: Optimality, stability, and performance. In Proceedings of the 48h IEEE Conference on Decision and Control (CDC) held jointly with 2009 28th Chinese Control Conference, Shanghai, China, 15–18 December 2009. [Google Scholar]
- Yu, L.; You, H.; Haipeng, W. Squared-root cubature information consensus filter for non-linear decentralised state estimation in sensor networks. IET Radar Sonar Navig. 2014, 8, 931–938. [Google Scholar] [CrossRef]
- De Souza, C.E.; Kinnaert, M.; Coutinho, D. Consensus-based distributed mean square state estimation. In Proceedings of the 2015 American Control Conference (ACC), Chicago, IL, USA, 1–3 July 2015. [Google Scholar]
- Tamjidi, A.; Chakravorty, S.; Shell, D. Unifying consensus and covariance intersection for decentralized state estimation. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Republic of Republic of Korea, 9–14 October 2016. [Google Scholar]
- Li, W.; Wei, G.; Han, F.; Liu, Y. Weighted average consensus-based unscented Kalman filtering. IEEE Trans. Cybern. 2015, 46, 558–567. [Google Scholar] [CrossRef]
- Shen, K.; Jing, Z.; Dong, P. A consensus nonlinear filter with measurement uncertainty in distributed sensor networks. IEEE Signal Process. Lett. 2017, 24, 1631–1635. [Google Scholar] [CrossRef]
- Soatti, G.; Nicoli, M.; Savazzi, S.; Spagnolini, U. Consensus-based algorithms for distributed network-state estimation and localization. IEEE Trans. Signal Inf. Process. Over Netw. 2016, 3, 430–444. [Google Scholar] [CrossRef]
- Gao, C.; Wang, Z.; Hu, J.; Liu, Y.; He, X. Consensus-Based Distributed State Estimation Over Sensor Networks with Encoding-Decoding Scheme: Accommodating Bandwidth Constraints. IEEE Trans. Netw. Sci. Eng. 2022, 9, 4051–4064. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, J.; Xu, C.; Wang, C.; Qi, L.; Ding, Z. Distributed consensus state estimation algorithm in asymmetric networks. Syst. Eng. Electron. 2018, 40, 1917–1925. [Google Scholar]
- Zhou, F.; Wang, Y.; Zheng, W.; Li, Z.; Wen, X. Fast Distributed Multiple-Model Nonlinearity Estimation for Tracking the Non-Cooperative Highly Maneuvering Target. Remote Sens. 2022, 14, 4239. [Google Scholar] [CrossRef]
- Cicala, M.; D’Amato, E.; Notaro, I.; Mattei, M. Scalable distributed state estimation in UTM context. Sensors 2020, 20, 2682. [Google Scholar] [CrossRef]
- He, S.; Shin, H.-S.; Xu, S.; Tsourdos, A. Distributed estimation over a low-cost sensor network: A review of state-of-the-art. Inf. Fusion 2020, 54, 21–43. [Google Scholar] [CrossRef]
- Chen, S.; Li, Y.; Kwok, N.M. Active vision in robotic systems: A survey of recent developments. Int. J. Robot. Res. 2011, 30, 1343–1377. [Google Scholar] [CrossRef]
- Scott, W.R.; Roth, G.; Rivest, J.-F. View planning for automated three-dimensional object reconstruction and inspection. ACM Comput. Surv. (CSUR) 2003, 35, 64–96. [Google Scholar] [CrossRef]
- Roy, S.D.; Chaudhury, S.; Banerjee, S. Active recognition through next view planning: A survey. Pattern Recognit. 2004, 37, 429–446. [Google Scholar]
- Scott, W.R. Model-based view planning. Mach. Vis. Appl. 2009, 20, 47–69. [Google Scholar] [CrossRef] [Green Version]
- Tarabanis, K.; Tsai, R.Y.; Allen, P.K. Automated sensor planning for robotic vision tasks. In Proceedings of the IEEE International Conference on Robotics & Automation, Sacramento, CA, USA, 9–11 April 1991. [Google Scholar]
- Tarabanis, K.; Allen, P.; Tsai, R. A survey of sensor planning in computer vision. IEEE Trans. Robot. Autom. 1995, 11, 86–104. [Google Scholar] [CrossRef] [Green Version]
- Ye, Y.; Tsotsos, J.K. Sensor planning for 3D object search. Comput. Vis. Image Underst. 1999, 73, 145–168. [Google Scholar] [CrossRef] [Green Version]
- Pito, R. A solution to the next best view problem for automated surface acquisition. IEEE Trans. Pattern Anal. Mach. Intell. 1999, 21, 1016–1030. [Google Scholar] [CrossRef]
- Pito, R. A sensor-based solution to the “next best view” problem. In Proceedings of the 13th International Conference on Pattern Recognition, Vienna, Austria, 25–29 August 1996. [Google Scholar]
- Banta, J.; Wong, L.; Dumont, C.; Abidi, M. A next-best-view system for autonomous 3-D object reconstruction. IEEE Trans.Syst. Man Cybern.-Part A Syst. Hum. 2000, 30, 589–598. [Google Scholar] [CrossRef]
- Kriegel, S.; Rink, C.; Bodenmüller, T.; Suppa, M. Efficient next-best-scan planning for autonomous 3D surface reconstruction of unknown objects. J. Real-Time Image Process. 2015, 10, 611–631. [Google Scholar] [CrossRef]
- Corsini, M.; Cignoni, P.; Scopigno, R. Efficient and flexible sampling with blue noise properties of triangular meshes. IEEE Trans. Vis. Comput. Graph. 2012, 18, 914–924. [Google Scholar] [CrossRef] [Green Version]
- Khalfaoui, S.; Seulin, R.; Fougerolle, Y.; Fofi, D. An efficient method for fully automatic 3D digitization of unknown objects. Comput. Ind. 2013, 64, 1152–1160. [Google Scholar] [CrossRef]
- Krainin, M.; Curless, B.; Fox, D. Autonomous generation of complete 3D object models using next best view manipulation planning. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011. [Google Scholar]
- Kriegel, S.; Rink, C.; Bodenmüller, T.; Narr, A.; Suppa, M.; Hirzinger, G. Next-best-scan planning for autonomous 3d modeling. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012. [Google Scholar]
- Wu, C.; Zeng, R.; Pan, J.; Wang, C.C.L.; Liu, Y.-J. Plant phenotyping by deep-learning-based planner for multi-robots. IEEE Robot. Autom. Lett. 2019, 4, 3113–3120. [Google Scholar] [CrossRef]
- Dong, S.; Xu, K.; Zhou, Q.; Tagliasacchi, A.; Xin, S.; Nießner, M.; Chen, B. Multi-robot collaborative dense scene reconstruction. ACM Trans. Graph. (TOG) 2019, 38, 1–16. [Google Scholar] [CrossRef]
- Liu, L.; Xia, X.; Sun, H.; Shen, Q.; Xu, J.; Chen, B.; Huang, H.; Xu, K. Object-aware guidance for autonomous scene reconstruction. ACM Trans. Graph. (TOG) 2018, 37, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Durrant-Whyte, H.; Bailey, T. Simultaneous localization and mapping: Part I. IEEE Robot. Autom. Mag. 2006, 13, 99–110. [Google Scholar] [CrossRef] [Green Version]
- Bailey, T.; Durrant-Whyte, H. Simultaneous localization and mapping (SLAM): Part II. IEEE Robot. Autom. Mag. 2006, 13, 108–117. [Google Scholar] [CrossRef] [Green Version]
- Blaer, P.S.; Allen, P.K. Data acquisition and view planning for 3-D modeling tasks. In Proceedings of the 2007 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Diego, CA, USA, 29 October–2 November 2007. [Google Scholar]
- Nüchter, A.; Surmann, H.; Hertzberg, J. Planning robot motion for 3d digitalization of indoor environments. In Proceedings of the 11th International Conference on Advanced Robotics (ICAR), Coimbra, Portugal, 30 June–3 July 3 2003. [Google Scholar]
- Gonzalez-Banos, H.; Mao, E.; Latombe, J.C.; Murali, T.M.; Efrat, A.; Tomasi, C.; Zhang, J. Planning robot motion strategies for efficient model construction. In Robotics Research; Springer: Berlin, Germany, 2000; pp. 345–352. [Google Scholar]
- Blaer, P.; Allen, P.K. Topbot: Automated network topology detection with a mobile robot. In Proceedings of the 2003 IEEE International Conference on Robotics and Automation (Cat. No. 03CH37422), Taipei, Taiwan, 14–19 September 2003. [Google Scholar]
- Bircher, A.; Kamel, M.; Alexis, K.; Oleynikova, H.; Siegwart, R. Receding horizon “next-best-view” planner for 3d exploration. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016. [Google Scholar]
- Lavalle, S.M. Rapidly-Exploring Random Trees: A New Tool for Path Planning; Computer Science Department, Iowa State University: Ames, IA, USA, 1998; p. 98. [Google Scholar]
- Karaman, S.; Frazzoli, E. Sampling-based algorithms for optimal motion planning. Int. J. Robot. Res. 2011, 30, 846–894. [Google Scholar] [CrossRef] [Green Version]
- Xu, K.; Huang, H.; Shi, Y.; Li, H.; Long, P.; Caichen, J.; Sun, W.; Chen, B. Autoscanning for coupled scene reconstruction and proactive object analysis. ACM Trans. Graph. (TOG) 2015, 34, 1–14. [Google Scholar] [CrossRef]
- Xu, K.; Shi, Y.; Zheng, L.; Zhang, J.; Liu, M.; Huang, H.; Su, H.; Cohen-Or, D.; Chen, B. 3D attention-driven depth acquisition for object identification. ACM Trans. Graph. (TOG) 2016, 35, 1–14. [Google Scholar] [CrossRef]
- Song, S.; Yu, F.; Zeng, A.; Chang, A.X.; Savva, M.; Funkhouser, T. Semantic scene completion from a single depth image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Dai, A.; Chang, A.X.; Savva, M.; Halber, M.; Funkhouser, T.; Nießner, M. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zheng, L.; Zhu, C.; Zhang, J.; Zhao, H.; Huang, H.; Niessner, M.; Xu, K. Active scene understanding via online semantic reconstruction. In Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2019. [Google Scholar]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3d shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Han, X.; Zhang, Z.; Du, D.; Yang, M.; Yu, J.; Pan, P.; Yang, X.; Liu, L.; Xiong, Z.; Cui, S. Deep reinforcement learning of volume-guided progressive view inpainting for 3d point scene completion from a single depth image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Liu, G.; Reda, F.A.; Shih, K.J.; Wang, T.C.; Tao, A.; Catanzaro, B. Image inpainting for irregular holes using partial convolutions. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Dai, A.; Ritchie, D.; Bokeloh, M.; Reed, S.; Sturm, J.; Nießner, M. Scancomplete: Large-scale scene completion and semantic segmentation for 3d scans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, CA, USA, 18–22 June 2018. [Google Scholar]
- Eidenberger, R.; Scharinger, J. Active perception and scene modeling by planning with probabilistic 6d object poses. In Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems, Taipei, Taiwan, 18–22 October 2010. [Google Scholar]
- Wu, K.; Ranasinghe, R.; Dissanayake, G. Active recognition and pose estimation of household objects in clutter. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015. [Google Scholar]
- Richtsfeld, A.; Mörwald, T.; Prankl, J.; Zillich, M.; Vincze, M. Segmentation of unknown objects in indoor environments. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012. [Google Scholar]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-up robust features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Arun, K.S.; Huang, T.S.; Blostein, S.D. Least-squares fitting of two 3-D point sets. IEEE Trans. Pattern Anal. Mach. Intell. 1987, 9, 698–700. [Google Scholar] [CrossRef] [Green Version]
- Doumanoglou, A.; Kim, T.-K.; Zhao, X.; Malassiotis, S. Active random forests: An application to autonomous unfolding of clothes. In European Conference on Computer Vision; Springer: Berlin, Germany, 2014. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Doumanoglou, A.; Kouskouridas, R.; Malassiotis, S.; Kim, T.K. Recovering 6D object pose and predicting next-best-view in the crowd. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, CA, USA, 26 June–1 July 2016. [Google Scholar]
- Gall, J.; Yao, A.; Razavi, N.; Van Gool, L.; Lempitsky, V. Hough forests for object detection, tracking, and action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2188–2202. [Google Scholar] [CrossRef] [PubMed]
- Sock, J.; Kasaei, S.H.; Lopes, L.S.; Kim, T.-K. Multi-view 6D object pose estimation and camera motion planning using RGBD images. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Tejani, A.; Tang, D.; Kouskouridas, R.; Kim, T.-K. Latent-class hough forests for 3d object detection and pose estimation. In Computer Vision—ECCV 2014; Springer: Berlin, Germany, 2014. [Google Scholar]
- Coates, A.; Ng, A.; Lee, H. An analysis of single-layer networks in unsupervised feature learning. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Ft. Lauderdale, FL, USA, 11–13 April2011. [Google Scholar]
- Hall, D.; Chong, C.Y.; Llinas, J.; Liggins, M., II. Distributed Data Fusion for Network-Centric Operations; CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar]
- Julier, S.; Uhlmann, J.K. General decentralized data fusion with covariance intersection. In Handbook of Multisensor Data Fusion; CRC Press: Boca Raton, FL, USA, 2017; pp. 339–364. [Google Scholar]
- Kalman, R.E. A new approach to linear filtering and prediction problems. J. Basic Eng. 1960, 82, 35–45. [Google Scholar] [CrossRef] [Green Version]
- Pao, L.Y.; Kalandros, M. Algorithms for a class of distributed architecture tracking. In Proceedings of the 1997 American Control Conference (Cat. No. 97CH36041), Albuquerque, NM, USA, 6 June 1997. [Google Scholar]
- McLaughlin, S.; Evans, R.; Krishnamurthy, V. Data incest removal in a survivable estimation fusion architecture. In Proceedings of the International Conference on Information Fusion, Annapolis, MD, USA, 8–11 July 2002. [Google Scholar]
- McLaughlin, S.; Krishnamurthy, V.; Challa, S. Managing data incest in a distributed sensor network. In Proceedings of the 2003 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP’03), Hong Kong, China, 6–10 April 2003. [Google Scholar]
- Bakr, M.A.; Lee, S. Track level fusion with an estimation of maximum bound of unknown correlation. In Proceedings of the 2016 International Conference on Control, Automation and Information Sciences (ICCAIS), Ansan, Republic of Korea, 27–29 October 2016. [Google Scholar]
- Reinhardt, M.; Noack, B.; Baum, M.; Hanebeck, U.D. Analysis of set-theoretic and stochastic models for fusion under unknown correlations. In Proceedings of the 14th International Conference on Information Fusion, Chicago, IL, USA, 5–8 July 2011. [Google Scholar]
- Kaplan, L.M.; Blair, W.D.; Bar-Shalom, Y. Simulations studies of multisensor track association and fusion methods. In Proceedings of the 2006 IEEE Aerospace Conference, Big Sky, MT, USA, 4–11 March 2006. [Google Scholar]
- Zhu, H.; Zhai, Q.; Yu, M.; Han, C. Estimation fusion algorithms in the presence of partially known cross-correlation of local estimation errors. Inf. Fusion 2014, 18, 187–196. [Google Scholar] [CrossRef]
- Kumar, M.; Garg, D.P.; Zachery, R.A. A method for judicious fusion of inconsistent multiple sensor data. IEEE Sens. J. 2007, 7, 723–733. [Google Scholar] [CrossRef]
- Kumar, M.; Garg, D.P.; Zachery, R.A. A generalized approach for inconsistency detection in data fusion from multiple sensors. In Proceedings of the 2006 American Control Conference, Minneapolis, MN, USA, 14–16 June 2006. [Google Scholar]
- Kumar, M.; Garg, D.; Zachery, R. Stochastic adaptive sensor modeling and data fusion. In Smart Structures and Materials 2006: Sensors and Smart Structures Technologies for Civil, Mechanical, and Aerospace Systems; SPIE: Bellingham, WA, USA, 2006. [Google Scholar]
- Abdulhafiz, W.A.; Khamis, A. Handling Data Uncertainty and Inconsistency Using Multisensor Data Fusion. In Advances in Artificial Intelligence (16877470); Hindawi Limited: London, UK, 2013. [Google Scholar]
- Li, J.; Liu, M.; Latronico, E.A. Sensor Fault Detection and Isolation Using System Dynamics Identification Techniques. Ph.D. Thesis, The University of Michigan, Ann Arbor, MI, USA, 2011. [Google Scholar]
- Hwang, I.; Kim, S.; Kim, Y.; Seah, C.E. A survey of fault detection, isolation, and reconfiguration methods. IEEE Trans. Control. Syst. Technol. 2009, 18, 636–653. [Google Scholar] [CrossRef]
- Reece, S.; Roberts, S. Generalised covariance union: A unified approach to hypothesis merging in tracking. IEEE Trans. Aerosp. Electron. Syst. 2010, 46, 207–221. [Google Scholar] [CrossRef]
- Uhlmann, J.K. Covariance consistency methods for fault-tolerant distributed data fusion. Inf. Fusion 2003, 4, 201–215. [Google Scholar] [CrossRef]
- Li, X.R.; Zhu, Y.; Wang, J.; Han, C. Optimal linear estimation fusion. I. Unified fusion rules. IEEE Trans. Inf. Theory 2003, 49, 2192–2208. [Google Scholar] [CrossRef]
- Yan, L.; Liu, B.; Zhou, D. The modeling and estimation of asynchronous multirate multisensor dynamic systems. Aerosp. Sci. Technol. 2006, 10, 63–71. [Google Scholar] [CrossRef]
- Lin, H.; Sun, S. Distributed fusion estimator for multisensor multirate systems with correlated noises. IEEE Trans. Syst. Man Cybern. Syst. 2017, 48, 1131–1139. [Google Scholar] [CrossRef]
- Alouani, A.T.; Gray, J.E.; McCabe, D.H. Theory of distributed estimation using multiple asynchronous sensors. IEEE Trans. Aerosp. Electron. Syst. 2005, 41, 717–722. [Google Scholar] [CrossRef]
- Lin, H.; Sun, S. Distributed fusion estimation for multi-sensor asynchronous sampling systems with correlated noises. Int. J. Syst. Sci. 2017, 48, 952–960. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, D. Robust visual knowledge transfer via extreme learning machine-based domain adaptation. IEEE Trans. Image Process. 2016, 25, 4959–4973. [Google Scholar] [CrossRef]
- Zhang, L.; Zuo, W.; Zhang, D. LSDT: Latent sparse domain transfer learning for visual adaptation. IEEE Trans. Image Process. 2016, 25, 1177–1191. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, D. Visual understanding via multi-feature shared learning with global consistency. IEEE Trans. Multimed. 2015, 18, 247–259. [Google Scholar] [CrossRef] [Green Version]
- Safari, S.; Shabani, F.; Simon, D. Multirate multisensor data fusion for linear systems using Kalman filters and a neural network. Aerosp. Sci. Technol. 2014, 39, 465–471. [Google Scholar] [CrossRef]
- Liu, Q.; Brigham, K.; Rao, N.S. Estimation and fusion for tracking over long-haul links using artificial neural networks. IEEE Trans. Signal Inf. Process. Over Netw. 2017, 3, 760–770. [Google Scholar] [CrossRef] [Green Version]
- Luo, X.; Chang, X. A novel data fusion scheme using grey model and extreme learning machine in wireless sensor networks. Int. J. Control. Autom. Syst. 2015, 13, 539–546. [Google Scholar] [CrossRef]
- Yadaiah, N.; Singh, L.; Bapi, R.S.; Rao, V.S.; Deekshatulu, B.L.; Negi, A. Multisensor data fusion using neural networks. In Proceedings of the 2006 IEEE International Joint Conference on Neural Network Proceedings, Vancouver, BC, Canada, 16–21 July 2006. [Google Scholar]
- Brigham, K.; Kumar, B.V.; Rao, N.S. Learning-based approaches to nonlinear multisensor fusion in target tracking. In Proceedings of the 16th International Conference on Information Fusion, Istanbul, Turkey, 9–12 July 2013. [Google Scholar]
- Bréhard, T.; Krishnamurthy, V. Optimal data incest removal in Bayesian decentralized estimation over a sensor network. In Proceedings of the 2007 IEEE International Conference on Acoustics, Speech and Signal Processing-ICASSP’07, Honolulu, HI, USA, 15–20 April 2007. [Google Scholar]
- Nicholson, D.; Lloyd, C.M.; Julier, S.J.; Uhlmann, J.K. Scalable distributed data fusion. In Proceedings of the Fifth International Conference on Information Fusion. FUSION 2002. (IEEE Cat. No. 02EX5997), Annapolis, MD, USA, 8–11 July 2002. [Google Scholar]
- Khawsuk, W.; Pao, L.Y. Decorrelated state estimation for distributed tracking of interacting targets in cluttered environments. In Proceedings of the 2002 American Control Conference (IEEE Cat. No. CH37301), Anchorage, AK, USA, 8–10 May 2002. [Google Scholar]
- Mallick, M.; Schmidt, S.; Pao, L.Y.; Chang, K.C. Out-of-sequence track filtering using the decorrelated pseudo-measurement approach. In Signal and Data Processing of Small Targets 2004; SPIE: Bellingham, WA, USA, 2004. [Google Scholar]
- Trailovic, L.; Pao, L.Y. Variance estimation and ranking of Gaussian mixture distributions in target tracking applications. In Proceedings of the 41st IEEE Conference on Decision and Control, 2002, Las Vegas, NV, USA, 10–13 December 2002. [Google Scholar]
- Duraisamy, B.; Schwarz, T.; Wöhler, C. Track level fusion algorithms for automotive safety applications. In Proceedings of the 2013 International Conference on Signal Processing, Image Processing & Pattern Recognition, Coimbatore, India, 7–8 February 2013. [Google Scholar]
- Bar-Shalom, Y.; Willett, P.K.; Tian, X. Tracking and Data Fusion; YBS Publishing: Storrs, CT, USA, 2011. [Google Scholar]
- Hanebeck, U.D.; Briechle, K.; Horn, J. A tight bound for the joint covariance of two random vectors with unknown but constrained cross-correlation. In Proceedings of the Conference Documentation International Conference on Multisensor Fusion and Integration for Intelligent Systems. MFI 2001 (Cat. No. 01TH8590), Baden, Germany, 20–22 August 2001. [Google Scholar]
- Reece, S.; Roberts, S. Robust, low-bandwidth, multi-vehicle mapping. In Proceedings of the 2005 7th International Conference on Information Fusion, Philadelphia, PA, USA, 25–28 July 2005. [Google Scholar]
- Schreier, P.J. A unifying discussion of correlation analysis for complex random vectors. IEEE Trans. Signal Process. 2008, 56, 1327–1336. [Google Scholar] [CrossRef]
- Qu, X.; Zhou, J.; Song, E.; Zhu, Y. Minimax robust optimal estimation fusion in distributed multisensor systems with uncertainties. IEEE Signal Process. Lett. 2010, 17, 811–814. [Google Scholar]
- Gao, Y.; Li, X.R.; Song, E. Robust linear estimation fusion with allowable unknown cross-covariance. IEEE Trans. Syst. Man Cybern. Syst. 2015, 46, 1314–1325. [Google Scholar] [CrossRef]
- Chen, L.; Arambel, P.O.; Mehra, R.K. Fusion under unknown correlation-covariance intersection as a special case. In Proceedings of the Fifth International Conference on Information Fusion. FUSION 2002. (IEEE Cat. No. 02EX5997), Annapolis, MD, USA, 8–11 July 2002. [Google Scholar]
- Julier, S.J.; Uhlmann, J.K. A non-divergent estimation algorithm in the presence of unknown correlations. In Proceedings of the 1997 American Control Conference (Cat. No. 97CH36041), Albuquerque, NM, USA, 6 June 1997. [Google Scholar]
- Benaskeur, A.R. Consistent fusion of correlated data sources. In Proceedings of the IEEE 2002 28th Annual Conference of the Industrial Electronics Society. IECON 02, Seville, Spain, 5–8 November 2002. [Google Scholar]
- Zhou, Y.; Li, J. Robust decentralized data fusion based on internal ellipsoid approximation. IFAC Proc. Vol. 2008, 41, 9964–9969. [Google Scholar] [CrossRef] [Green Version]
- Luo, R.C.; Chen, O.; Tu, L.C. Nodes localization through data fusion in sensor network. In Proceedings of the 19th International Conference on Advanced Information Networking and Applications (AINA’05), Taipei, Taiwan, 28–30 March 2005; Volume 1. (AINA papers). [Google Scholar]
- Luo, R.C.; Liao, C.T.; Lin, S.C. Multi-sensor fusion for reduced uncertainty in autonomous mobile robot docking and recharging. In Proceedings of the 2009 IEEE/RSJ International Conference on Intelligent Robots and Systems, St. Louis, MO, USA, 10–15 October 2009. [Google Scholar]
- Lazarus, S.B.; Ashokaraj, I.; Tsourdos, A.; Zbikowski, R.; Silson, P.M.; Aouf, N.; White, B.A. Vehicle localization using sensors data fusion via integration of covariance intersection and interval analysis. IEEE Sens. J. 2007, 7, 1302. [Google Scholar] [CrossRef]
- Wang, Y.; Li, X.R. Distributed estimation fusion with unavailable cross-correlation. IEEE Trans. Aerosp. Electron. Syst. 2012, 48, 259–278. [Google Scholar] [CrossRef]
- de Campos Ferreira, J.C.B.; Waldmann, J. Covariance intersection-based sensor fusion for sounding rocket tracking and impact area prediction. Control. Eng. Pract. 2007, 15, 389–409. [Google Scholar] [CrossRef]
- Julier, S.J.; Uhlmann, J.K. Using covariance intersection for SLAM. Robot. Auton. Syst. 2007, 55, 3–20. [Google Scholar] [CrossRef]
- Guo, Q.; Chen, S.; Leung, H.; Liu, S. Covariance intersection based image fusion technique with application to pansharpening in remote sensing. Inf. Sci. 2010, 180, 3434–3443. [Google Scholar] [CrossRef]
- Uhlmann, J.K.; Julier, S.J.; Kamgar-Parsi, B.; Lanzagorta, M.O.; Shyu, H.J.S. NASA Mars rover: A testbed for evaluating applications of covariance intersection. In Unmanned Ground Vehicle Technology; SPIE: Bellingham, WA, USA, 1999. [Google Scholar]
- Zhou, Y.; Li, J. Data fusion of unknown correlations using internal ellipsoidal approximation. IFAC Proc. Vol. 2008, 41, 2856–2860. [Google Scholar] [CrossRef]
- Zhou, Y.; Wang, D.; Pei, T.; Tian, S. Robust estimation fusion in wireless senor networks with outliers and correlated noises. Int. J. Distrib. Sens. Netw. 2014, 10, 393802. [Google Scholar] [CrossRef] [Green Version]
- Sijs, J.; Lazar, M.; Bosch, P. State fusion with unknown correlation: Ellipsoidal intersection. In Proceedings of the 2010 American Control Conference, Baltimore, MD, USA, 30 June–2 July 2010. [Google Scholar]
- Ping Tian, D. A review on image feature extraction and representation techniques. Int. J. Multimed. Ubiquitous Eng. 2013, 8, 385–396. [Google Scholar]
- Srivastava, D.; Wadhvani, R.; Gyanchandani, M. A review: Color feature extraction methods for content based image retrieval. Int. J. Comput. Eng. Manag. 2015, 18, 9–13. [Google Scholar]
- Latif, A.; Rasheed, A.; Sajid, U.; Ahmed, J.; Ali, N.; Ratyal, N.I.; Zafar, B.; Dar, S.H.; Sajid, M.; Khalil, T. Content-based image retrieval and feature extraction: A comprehensive review. Math. Probl. Eng. 2019, 2019, 1–21. [Google Scholar] [CrossRef]
- Kong, L.; Peng, X.; Chen, Y.; Wang, P.; Xu, M. Multi-sensor measurement and data fusion technology for manufacturing process monitoring: A literature review. Int. J. Extrem. Manuf. 2020, 2, 022001. [Google Scholar] [CrossRef]
- Munnaf, M.A.; Haesaert, G.; Van Meirvenne, M.; Mouazen, A.M. Site-specific seeding using multi-sensor and data fusion techniques: A review. Adv. Agron. 2020, 161, 241–323. [Google Scholar]
- Montanari, A.N.; Aguirre, L.A. Observability of network systems: A critical review of recent results. J. Control. Autom. Electr. Syst. 2020, 31, 1348–1374. [Google Scholar] [CrossRef]
- Usman, M.; Ferlin, S.; Brunstrom, A.; Taheri, J. A Survey on Observability of Distributed Edge & Container-based Microservices. IEEE Access 2022, 10, 86904–86919. [Google Scholar]
- Chowdhary, C.L.; Acharjya, D.P. Segmentation and feature extraction in medical imaging: A systematic review. Procedia Comput. Sci. 2020, 167, 26–36. [Google Scholar] [CrossRef]
- Ali, H.; Sharif, M.; Yasmin, M.; Rehmani, M.H.; Riaz, F. A survey of feature extraction and fusion of deep learning for detection of abnormalities in video endoscopy of gastrointestinal-tract. Artif. Intell. Rev. 2020, 53, 2635–2707. [Google Scholar] [CrossRef]
- Mutlag, W.K.; Ali, S.K.; Aydam, Z.M.; Taher, B.H. Feature extraction methods: A review. J. Phys. Conf. Series 2020, 1591, 012028. [Google Scholar] [CrossRef]
- Ma, J.; Jiang, X.; Fan, A.; Jiang, J.; Yan, J. Image matching from handcrafted to deep features: A survey. Int. J. Comput. Vis. 2021, 129, 23–79. [Google Scholar] [CrossRef]
- Xie, C.; Tan, M.; Gong, B.; Wang, J.; Yuille, A.L.; Le, Q.V. Adversarial examples improve image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 819–828. [Google Scholar]
- Zheng, H.; Fu, J.; Zha, Z.J.; Luo, J. Looking for the devil in the details: Learning trilinear attention sampling network for fine-grained image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5012–5021. [Google Scholar]
- Yuan, Y.; Chen, L.; Wu, H.; Li, L. Advanced agricultural disease image recognition technologies: A review. Inf. Process. Agric. 2022, 9, 48–59. [Google Scholar] [CrossRef]
- Armi, L.; Fekri-Ershad, S. Texture image analysis and texture classification methods—A review. arXiv 2019, arXiv:1904.06554. [Google Scholar]
- Fujiyoshi, H.; Hirakawa, T.; Yamashita, T. Deep learning-based image recognition for autonomous driving. IATSS Res. 2019, 43, 244–252. [Google Scholar] [CrossRef]
- Liang, X.; Bai, X.; Zhang, S. Review of three-dimensional environment information perception and reconstruction methods for mobile robot based on multi-sensor fusion. In Proceedings of the Sixth Symposium on Novel Optoelectronic Detection Technology and Applications, Beijing, China, 3–5 December 2019; SPIE: Bellingham, WA, USA, 2020; Volume 11455, pp. 1966–1974. [Google Scholar]
- Qiu, S.; Zhao, H.; Jiang, N.; Wang, Z.; Liu, L.; An, Y.; Zhao, H.; Miao, X.; Liu, R.; Fortino, G. Multi-sensor information fusion based on machine learning for real applications in human activity recognition: State-of-the-art and research challenges. Inf. Fusion 2022, 80, 241–265. [Google Scholar] [CrossRef]
- Abdelkader, M.; Güler, S.; Jaleel, H.; Shamma, J.S. Aerial swarms: Recent applications and challenges. Curr. Robot. Rep. 2021, 2, 309–320. [Google Scholar] [CrossRef]














Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tong, P.; Yang, X.; Yang, Y.; Liu, W.; Wu, P. Multi-UAV Collaborative Absolute Vision Positioning and Navigation: A Survey and Discussion. Drones 2023, 7, 261. https://doi.org/10.3390/drones7040261
Tong P, Yang X, Yang Y, Liu W, Wu P. Multi-UAV Collaborative Absolute Vision Positioning and Navigation: A Survey and Discussion. Drones. 2023; 7(4):261. https://doi.org/10.3390/drones7040261
Chicago/Turabian StyleTong, Pengfei, Xuerong Yang, Yajun Yang, Wei Liu, and Peiyi Wu. 2023. "Multi-UAV Collaborative Absolute Vision Positioning and Navigation: A Survey and Discussion" Drones 7, no. 4: 261. https://doi.org/10.3390/drones7040261