1. Introduction
With the development of optical imaging technology and unmanned aerial vehicle (UAV) technology, airborne hyperspectral imaging (HSI) has become increasingly abundant. HSI differs from RGB images in that it contains a large amount of spectral and spatial information. The continuous spectral curve of HSI can identify various objects, as different objects have different spectral curves [
1]. As a result, the airborne hyperspectral image has been widely used in applications such as urban planning [
2], agricultural monitoring [
3], disaster detection [
4].
Table 1 shows the common airborne hyperspectral image datasets captured by UAVs or aircraft covering urban and agricultural areas.
HSI classification aims to predict the corresponding category for each pixel. Based on how features are extracted, HSI classification methods are roughly divided into traditional and deep learning methods. The traditional methods [
7,
8] typically extract hyperspectral spatial-spectral features using handcrafted features, followed by a feature-classifying module. This paper [
7] proposed using Independent Component Discriminant Analysis (ICDA) for classification. Cao et al. [
9] used the three-dimensional discrete wavelet transform (3D-DWT) to extract the spatial-spectral feature for HSI classification. While traditional methods [
10,
11,
12] have achieved good results, the handcrafted features are generally shallow features with limited feature representation capability, making it challenging to achieve satisfactory performance.
In recent years, deep learning methods have been the mainstream approach in HSI classification [
13]. Hyperspectral images contain rich spectral information, with each category having unique spectral information [
1]. Based on the different information methods, deep learning methods are broadly divided into two categories: spectral feature methods [
14,
15,
16] and spectral-spatial feature methods [
17,
18,
19].
Spectral feature algorithms extract features along the 1D spectral dimension. For instance, Chen et al. [
20] first applied deep learning to HSI classification. According to Hu et al.’s research [
14], 1D convolution neural networks (CNNs) were employed to classify HSI based on spectral features. A novel recurrent neural network (RNN) module [
21] was employed in HSI classification. Wu et al. [
15] developed an RNN-based semi-supervised classifier for HSI classification. Hang et al. [
22] utilized cascaded RNNs for HSI classification. This work used RNNs to model the sequence and effectively represent the relationship between adjacent spectral bands. However, while the spectral dimension can distinguish different land-cover categories, adjacent pixels in HSI may belong to the same land-cover categories [
23,
24].
In order to achieve an accurate classification of land-cover classes, it is necessary to consider both spectral and spatial features [
25]. The spatial-spectral feature methods [
19,
26,
27] have been proposed to address the issues associated with spectral feature methods. For example, Zhang et al. [
4] employed a method of learning contextual interaction features using inputs based on different regions. Song et al. [
28] introduced residual learning and fused the output of the hierarchical features for HSI classification. To expedite the forward progression of 2D CNN, Mei et al. [
18] proposed a novel step activation quantization method. Since HSIs are 3D cubes, 3D CNN has been employed for HSI classification. Wei et al. [
29] utilized the edge-preserving sied window filters as the convolution kernels. He et al. [
30] proposed a multiscale 3D CNN for classification. A hybrid network [
31] that combines 2D CNN and 3D CNN was presented to issue the classification of HSIs. Mei et al. [
17] employed an unsupervised 3D CNN autoencoder for HSI classification. Multiple spectral resolution 3D CNN [
32] has also been introduced for classification. In addition, attention modules have been embedded in the network to extract spectral-spatial features in HSIs. Zheng et al. [
13] proposed an attention mechanism to suppress redundant bands and improve classification accuracy. A novel spectral-spatial attention network [
26] was introduced to capture the correlation of the pixels. In most cases [
33,
34,
35,
36], these attention modules are independent. This means these modules are flexibly put into the network.
HSIs contain rich spectral information. Meanwhile, the 2D convolution neural networks have significantly affected computer vision, with applications including biomedical image classification [
37], remote sensing image classification [
3,
38], change detection [
39,
40], and image deblurring [
2]. However, when convolving along the spectral dimension of HSI, hundreds of bands need plenty of parameters. There is no doubt that this dramatically increases computational time and cost. The number of channels is usually reduced before using 2D convolution kernels for feature extraction and classification to solve this problem. The mainstream methods include two main types. One is to reduce the spectral dimension. For instance, [
31,
41] used PCA [
42] and variants of PCA [
16] to reduce the number of spectral channels. The authors of [
43] utilized the enhancing transformation reduction (ETR) for reducing dimensionality and HSI classification. Another option is to suppress the redundant bands using spectral attention methods [
25,
26]. The spectral attention methods usually change the weights of each band.
The vision transformer (ViT) [
44] has recently performed remarkably on some vision-related tasks. As a result, some studies [
45,
46,
47] have attempted to apply ViT to hyperspectral classification. For instance, a novel local transformer [
48] with an integrated spatial partition restore module is proposed for classification. He et al. [
49] utilized a spatial-spectral transformer with a dense connection, which was proposed to capture sequential spectra relationships. Extended morphological profiles [
50] were employed for HSI classification in a deep global-local transformer network. These transformer methods [
50,
51,
52,
53] process the hyperspectral images in a token style. Generally, the 3D HSI is divided into patches and treated as tokens. The transformer network extracts the features and relationships of these tokens for hyperspectral classification.
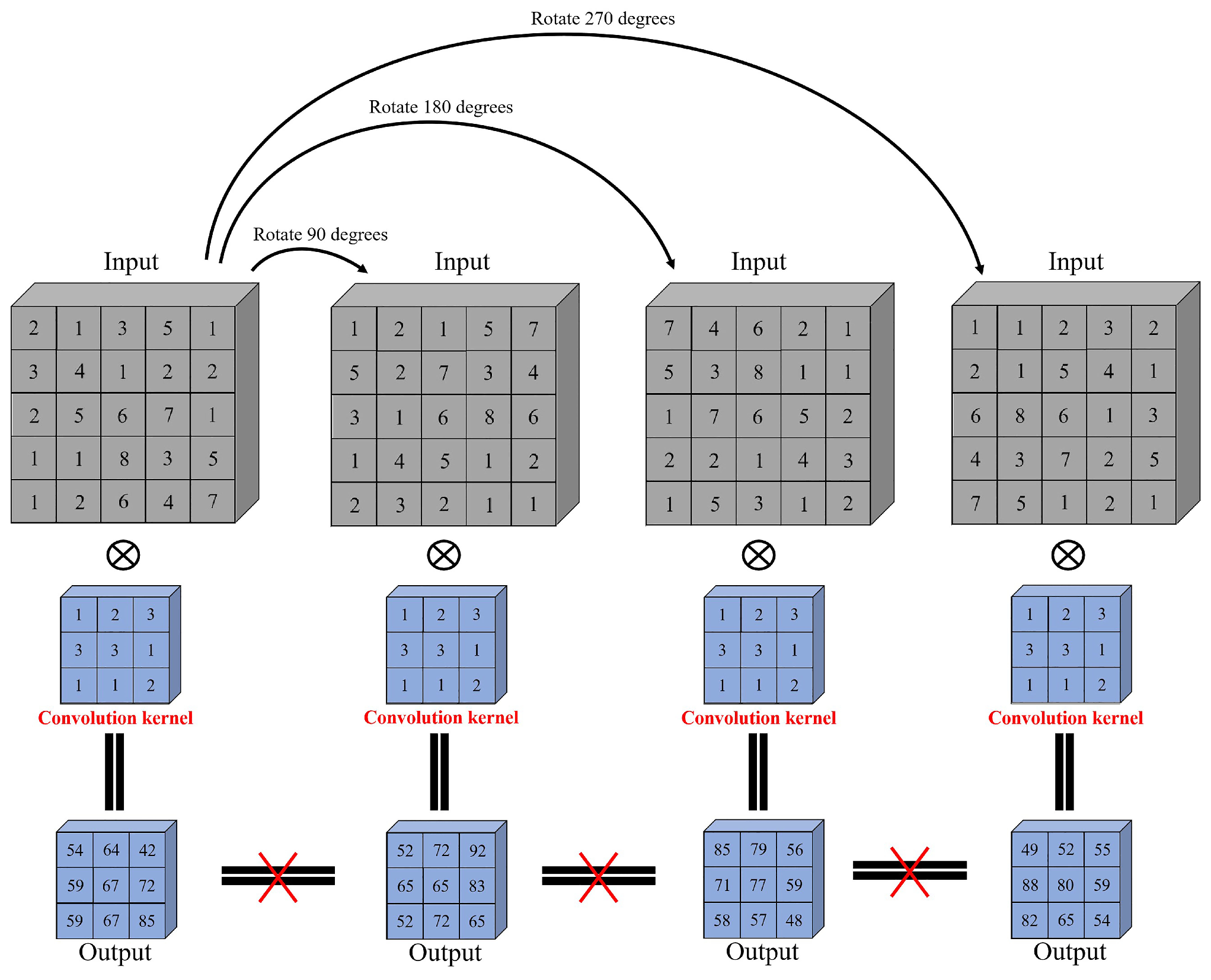
An airborne hyperspectral imaging system is typically equipped on an aircraft or UAV to capture ground scenes from an overlooking perspective. As a result of the rotation of the UAV, the HSI in the same area has different perspectives [
13]. While spatial rotation does not typically cause degradation of classification accuracy for spectral-based methods, spectral feature methods do not perform as well as spectral-spatial feature methods, which are sensitive to spatial rotation, as shown in
Figure 1. For convenience, the input is set to have one spectral band. The kernel size is
. The image size is
. The stride and padding of convolution are 1 and 0, respectively.
Figure 1 shows that different features are extracted from the same image with different input angles using the same convolutional kernel. transformer-based methods face similar problems. The input image rotation causes a change in the output. Therefore, the spatial-spectral methods perform poorly when the images are rotated. In order to address this issue, some work has made meaningful attempts to explore it. Tao et al. [
54] utilized vector sorting to extract rotation-invariant features. Zheng et al. [
13] used spectral convolution to extract spatial features to maintain rotation invariance. Chen et al. [
55] presented using feature rotation to address the rotation invariance of UAV images.
Figure 2 illustrates common methods for addressing rotation invariance.
Figure 2A shows that the image-level rotation may lose samples or changes the image size. According to [
55], the coordinates of each feature are
. The rotation by
degrees is expressed as:
where
and
denote the new coordinates of the rotated feature. However, without additional constraint conditions, the feature-level rotation may still lose features, which are shown in
Figure 2B. For instance, according to Equation (
1), the feature at the coordinate position (−2, −2) will be lost after rotation, while the features at the coordinate positions (−2, 0) and (−1, 0) will have the same new coordinate position (−1, −1) after rotation, resulting in two overlapping features.
Figure 2C shows that the proposed feature-level rotation is capable of effectively maintaining all features to address the problem of rotational invariance without the introduction of additional conditions.
A spectral-spatial attention rotation-invariant classification network (SSARIN) is presented based on the above issues. The SSARIN can address the issue of spatial rotation sensitivity in spectral-spatial feature methods of HSI classification. SSARIN is composed of a Band Selection (BS) module, a Local Spatial Feature Enhancement (LSFE) module, and a Lightweight Feature Enhancement (LWFE) module. The BS module is the initial component that reduces redundant spectral channels. The LSFE module generates a multi-angle parallel feature encoding network, which enhances the center pixel’s discrimination ability and learns the positional relationship between each pixel, ensuring rotation invariance. The LWFE module enhances significant features and suppresses insignificant ones as the final layer. At the same time, a dynamically weighted cross-entropy loss function is employed.
This paper has the following contributions.
- 1.
We present spectral-spatial attention rotation-invariant classification network (SSARIN) that utilizes convolutional neural networks (CNNs) to extract spectral-spatial features. The SSARIN not only achieves good performance in HSI classification, but is also a rotation-invariant network. Additionally, a dynamically weighted cross-entropy loss is introduced that considers the complexities of samples with different categories to improve classification accuracy.
- 2.
A local spatial feature enhancement module is proposed to address the issue of spatial rotation sensitivity. This module not only captures spatial-spectral features but also learns the position relationship between pixels. Doing so enhances the discriminative power of the center pixel and alleviates the impact of spatial rotation on classification accuracy.
The paper is divided into the following sections.
Section 2 shows the proposed method in more detail.
Section 3 discusses the experimental results. The discussion is presented in
Section 4. Finally, a conclusion is drawn in
Section 5.
2. Proposed Method
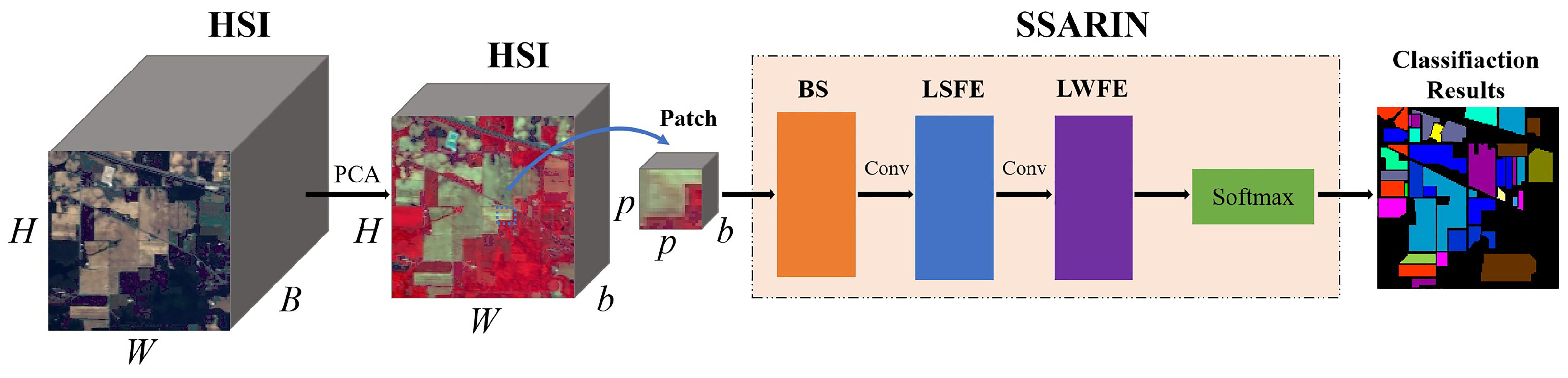
This section describes the various components of the proposed network in detail. The overview of the algorithm is shown in
Section 2.1.
Section 2.2 contains the details of the band selection module. The local spatial feature enhancement module is explained in
Section 2.3.
Section 2.4 introduces the lightweight feature enhancement. Finally, the loss function is reported in
Section 2.5.
2.1. Overview
The HSI is a 3D cube [
26]. Suppose that
denotes the HSIs, where
represents the spatial size of the image.
is the number of channels. The
represents the land-cover categories.
denotes the number of classes. The
is a one-hot label vector. Classification aims to make each hyperspectral image pixel have a corresponding category.
Let represent the patch, a square area cut from the HSI . represents the hyperspectral image after principal components analysis (PCA). denotes the i-th patch of the hyperspectral image . is the spatial size. The pixel represents the center pixel of the patch . Each pixel has a corresponding patch in the HSIs. Thus, the proposed SSARIN is utilized to determine the class of the pixel based on patch .
Figure 3 shows the proposed HSI classification method, which mainly contains a band selection (BS) module, a local spatial feature enhancement (LSFE) module, and a lightweight feature enhancement (LWFE) module. Hundreds of bands need many parameters. Many bands are redundant, so PCA can be used to retain the primary spectral information and reduce the number of bands. PCA reduces the number of channels from
B to
b. In this paper,
b is set to 50. Furthermore, a spectral attention mechanism is employed to recalibrate surplus spectral bands. The spectral attention is also named the band selection (BS) in this paper. The HSI patch
is fed into the BS module. This module has the effect of suppressing redundant spectral channels. The main benefits are the following. PCA not only reduces the number of channels but also reduces the number of parameters. The main thing is that the HSIs after PCA retains the primary information. Then, a local spatial feature enhancement module is employed to extract the spectral-spatial features. Meanwhile, the output of the LSFE module consists of rotation-invariant features. Finally, a lightweight feature enhancement is leveraged to enhance essential features, suppressing insignificance features and improving classification accuracy. The core component of SSARIN is the LSFE module.
Table 2 reports the details of the presented algorithm.
2.2. Band Selection Module
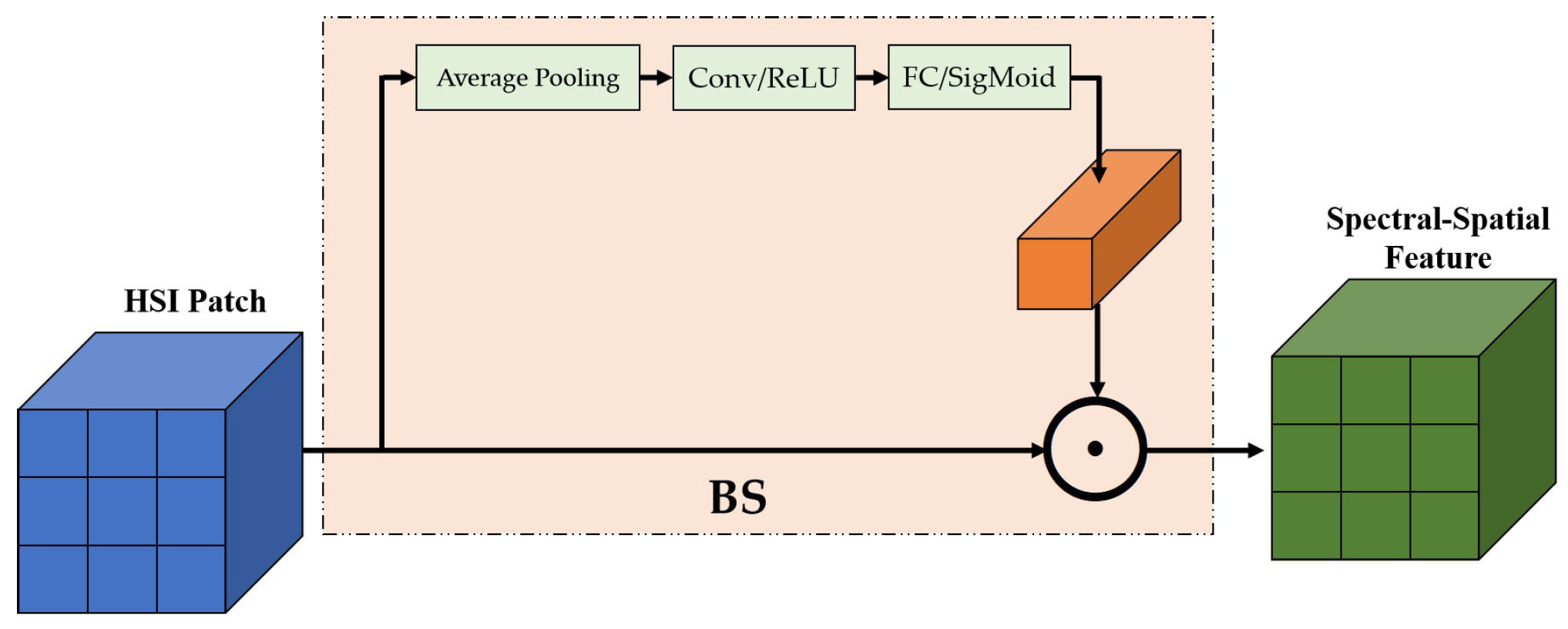
The band selection module contains three layers: one average pooling and two convolution layers. This module emphasizes the useful bands and suppresses the redundant ones by adaptive weights. The BS module recalibrates the spectral bands and adjusts the weight of each band.
Figure 4 shows the details of the BS module.
Table 3 lists detailed information on the BS module. The formulation of this module is defined as Equation (
2):
where AP
represents the global average pooling;
denotes the 2D convolutional layer;
denotes the activate function, which is defined as
;
is the SigMoid activate function, which is formulated as
1/
; ⊙ denotes the channel-wise multiplication;
denotes the corresponding
image patches cropped from the original hyperspectral image; and
denotes spectral-spatial feature after the band selection.
The BS module has the following functions. First, the module suppresses redundant bands by recalibrating the band weights. Second, the principal components analysis and
convolution kernel only needed a small number of parameters. Furthermore, the most important thing is that the
convolution has rotation invariance [
13].
2.3. Local Spatial Feature Enhancement
In order to obtain the class of the pixel
, the spectral and spatial features are taken into account [
26,
56]. The method based on spatial-spectral features is widely used for HSI classification [
19,
57]. Meanwhile, the adjacent samples may belong to the same class [
58]. Thus, the spatially adjacent pixel of the center pixel
can be used to help to classify pixel
[
59]. However, the methods based on spatial-spectral features are sensitive to spatial rotation [
13]. The existing spatial-spectral feature methods do not sufficiently consider the position relationship between pixels. For the same area, the rotation of the imaging devices causes the collected hyperspectral images to have various viewing angles. The change in spatial location between pixels leads to a decline in classification accuracy.
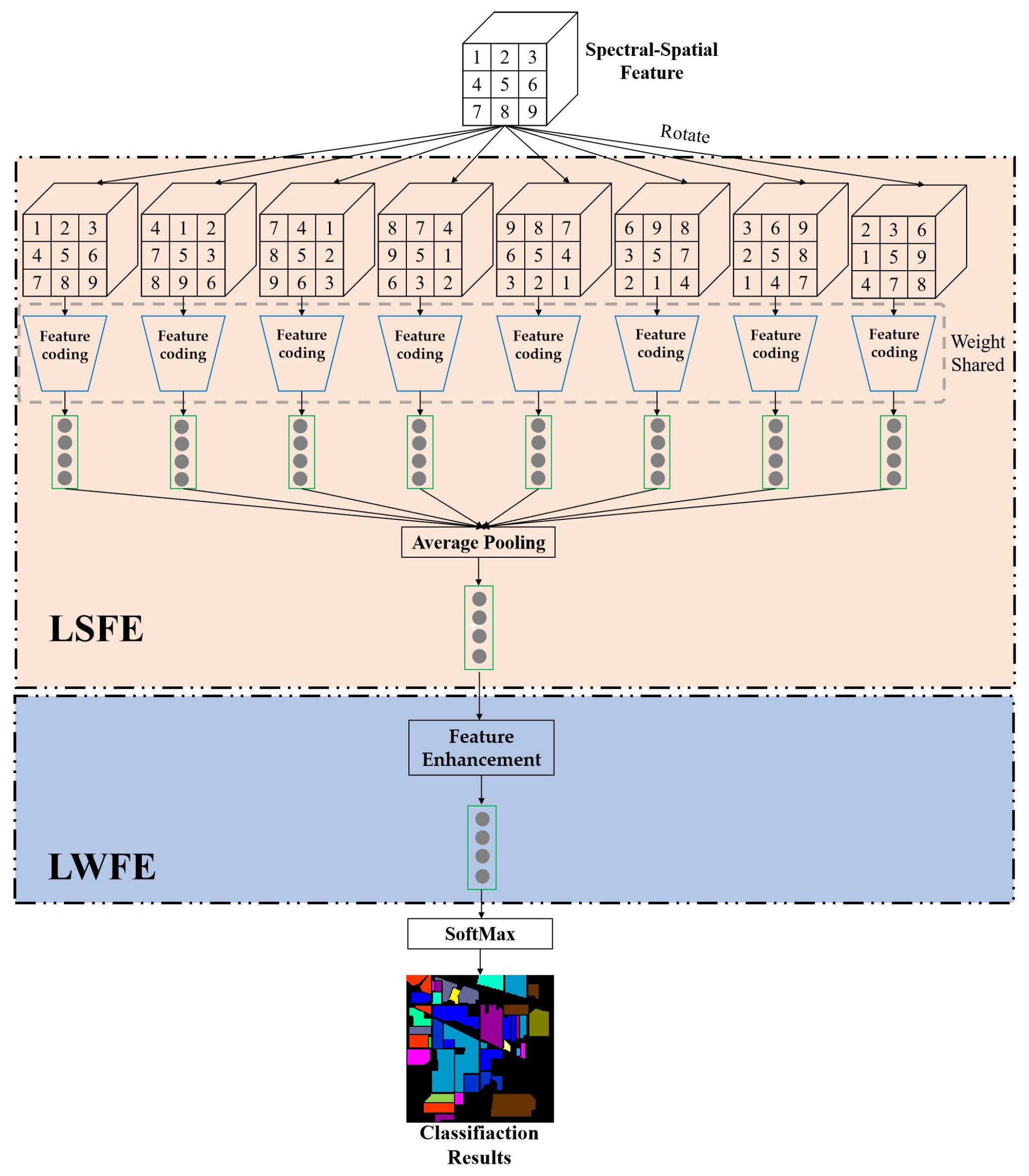
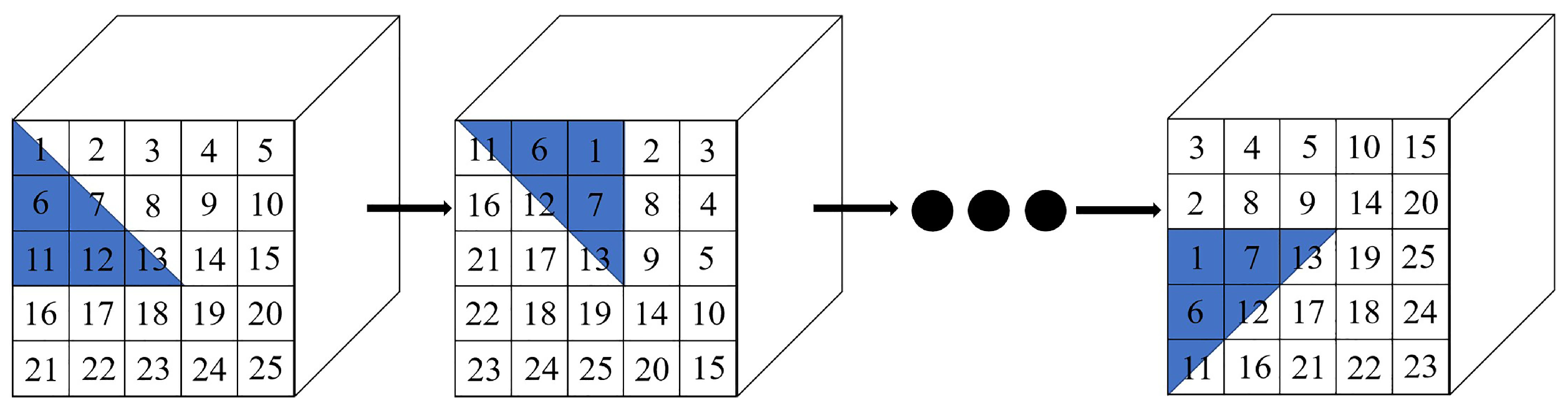
This paper proposes a simple and effective module named Local Spatial Feature Enhancement (LSFE) to solve the above problem. The LSFE module contains a rotate operator, a feature coding module, and an average pooling layer, as shown in
Figure 5.
Specifically, each spatial-spectral feature is divided into eight non-overlapping regions using the center pixel as a reference. It also means that the center angle of each area is . Let denote the i-th region, where . Then, each time, all regions are rotated to produce a new spectral-spatial feature. It needs to rotate seven times to produce eight different spectral-spatial features.
Figure 6 shows an example. The blue area has a central pixel angle of
. The radius of this area is
.
represents the size of the spectral-spatial feature.
stands for rounding up. For instance, the size of the spatial-spectral feature is
. The radius of the rotation area is 3. After determining the region’s size, each rotation of
produces a new spatial-spectral feature. As shown in the second spatial-spectral feature in
Figure 6, the blue region rotates to the corresponding position, and other regions rotate similarly. Therefore, the original spatial-spectral feature generates eight spatial-spectral features. This approach has the following benefits. (1) This approach is intuitive and straightforward to understand. (2) It can extract the position relationship between pixels without changing the shape of spatial-spectral features. (3) New spatial-spectral features can be directly fed into the network to extract features. (4) This module enhances the spatial features of the central pixel and improves the accuracy for the central pixel category.
After rotation, these spectral-spatial features are fed into a weight-shared feature coding module to obtain the corresponding spectral-spatial feature. The feature encoding network mainly includes two spatial attention layers and multi-layer feature extraction layers.
Table 4 lists the detailed structures of the feature encoding network.
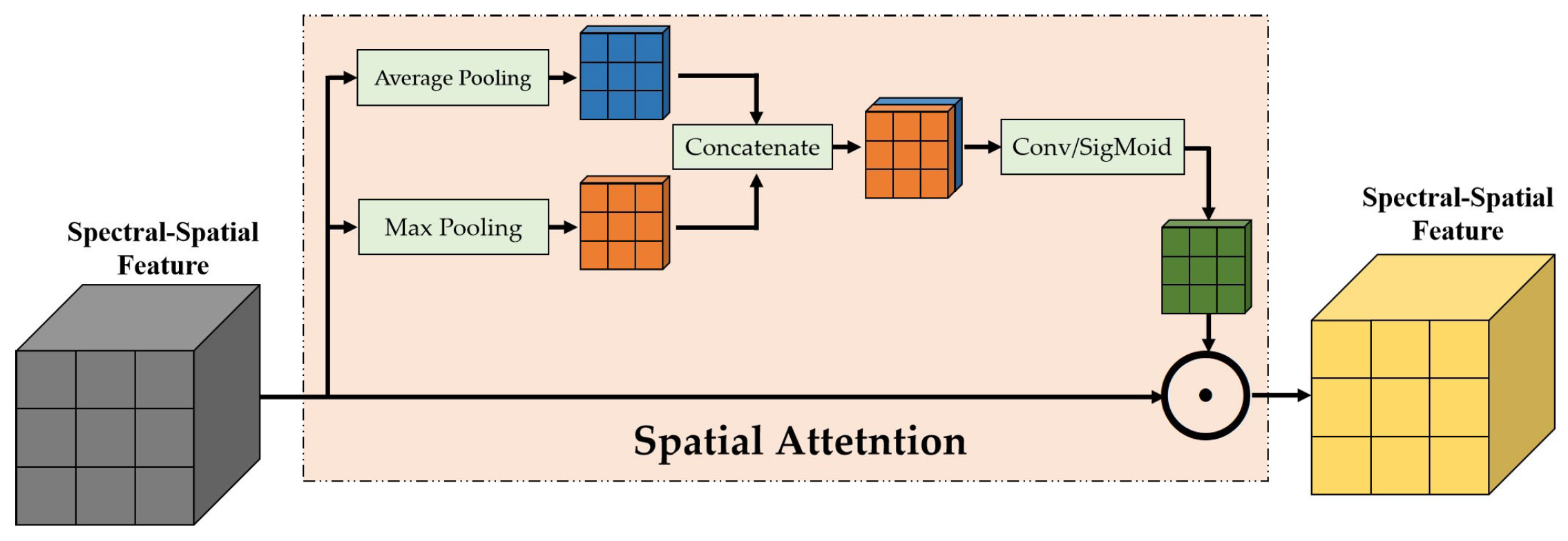
Each pixel surrounding the center pixel may have different effects on the center pixel. Thus, the weights of different pixels on the center pixel need to be recalibrated through the spatial attention mechanism. The spatial attention mechanism is shown in
Figure 7. Different spectral curves represent different land-cover categories. Thus, spectral features can be used to change the pixel weights. The formula is as follows:
where
and
represent the features after max pooling and average pooling and
is the spectral-spatial feature. Next, concatenate these features along the spectral dimension.
where
is the feature after concatenation. Then, spatial attention can be calculated as follows:
where
represents spectral-spatial features after spatial attention. Then, this feature is fed to multi-layer feature extraction layers. The output of the multi-layer feature extraction layers is
:
where
denotes the weight-shared feature coding module, which includes two spatial attention layers and multi-layer feature extraction layers and
represents the output feature of the
i-th branch. Finally,
is pooled into a feature vector, and the operation is defined with Equation (
8):
The output features of the LSFE module have the following functions. First, the output features extract the influence of surrounding pixels on the center pixel. Second, these features also contain the position relationship of each pixel and have rotation invariance.
2.4. Lightweight Feature Enhancement
A lightweight feature enhancement module (LWFE) is proposed to enhance the output features of the local spatial feature enhancement module. This module mainly focuses on enhancing important features, suppressing insignificance features, and improving classification accuracy.
The LWFE is shown in
Figure 5. The output feature of the LSFE is fed to the LWFE module.
Table 5 lists the datails of the LWFE module. Its formulation is defined with Equation (
9):
where
denotes the average pooling;
represents the 2D convolutional layer;
is the activate function, which is defined as
;
denotes the output feature of the LSFE module, and
denotes the size of the feature; and
represents the output feature of the LWFE module, which is also an enhanced feature.
The kernel size of all convolutional layers of LWFE is . The reasons for using a convolution kernel of this size are as follows. (1) This convolution kernel can reduce the network parameters while enhancing the features. (2) It also maintains rotational invariance. Therefore, the whole LWFE module also retains rotation invariance. The output feature of the lightweight feature enhancement module is rotation invariant, while the LWFE module is also rotation invariant, so the whole network is also rotation invariant.
Finally, the enhanced feature is fed into a classifier to complete the classification.
where
is the predicted category.
and
are the
i-th and
j-th features of the feature vector of the LWFE module, respectively; that is, the category with the highest probability value is the prediction category of the network.
2.5. Loss Function
Due to the imbalance of samples, the feature of small samples may be lost during network training, which leads to the low classification accuracy of small samples. Therefore, this paper presents a dynamically weighted cross entropy loss according to the complexities of samples with different categories to improve the accuracy.
The proposed dynamical weighted cross entropy loss in
m-th training epoch is defined as Equation (
11):
where
represents the loss;
and
denote the
t-th patch cube and corresponding category label;
denotes the parameters of the softmax layer;
T denotes the number of samples in a training batch;
C denotes the number of categories of the dataset;
denotes the indicator function, which equals one if the condition is satisfied and zero otherwise; and
denotes the weight coefficient of the
c-th category in the
m-th training epoch, defined by Equation (
12):
where
denotes the validated accuracy of the
k-th category in the
m-th training epoch and
is a small constant to avoid dividing by zero, which is set to
in this work.
The proposed SSARIN consists of the above three modules BS, LSFE, and LWFE. The corresponding loss functions are proposed according to the network characteristics. We introduce the experiments to demonstrate the proposed algorithm in the following.
4. Discussion
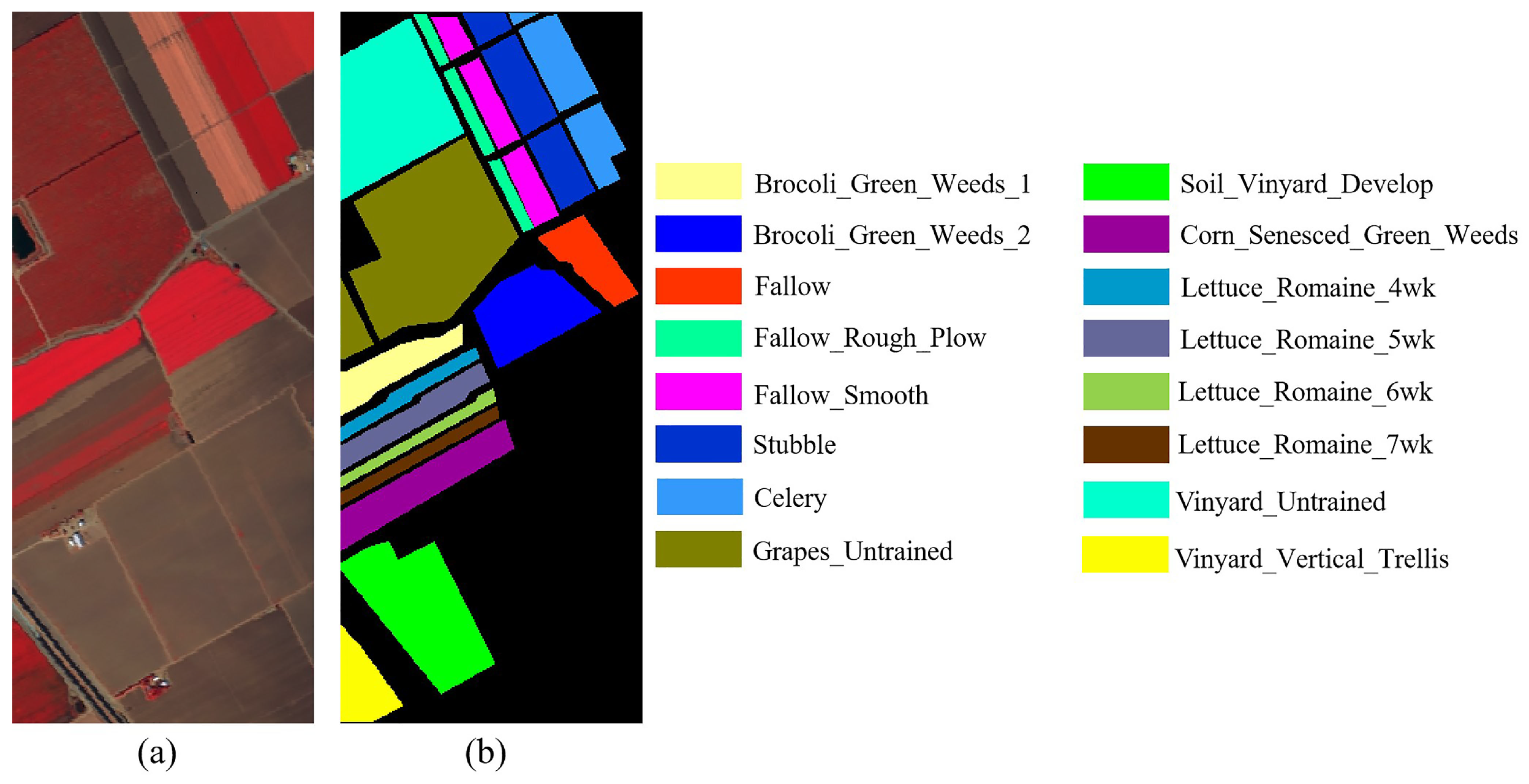
Figure 14,
Figure 15,
Figure 16,
Figure 17 and
Figure 18 illustrate the classification maps of different methods on five datasets.
Table 13,
Table 14,
Table 15,
Table 16,
Table 17,
Table 18,
Table 19,
Table 20,
Table 21,
Table 22 and
Table 23 detail the class accuracy, AA, OA, and kappa coefficient for these algorithms on corresponding datasets. Our algorithm not only delivers superior results, but also maintains consistent overall accuracy at varying rotation angles. Building upon this analysis, we explore the time efficiency of the models.
Table 24 outlines the training and testing time for each algorithm. Notably, 3D CNN consistently exhibits the fastest training times across all datasets. 1D CNN emerges as the model with the fastest testing times for each dataset, indicating that it performs well in terms of time efficiency during the testing phase. In contrast, SSARIN displays the longest training and testing times. There are two main reasons for this. (1) The network contains eight branches, resulting in a more complex structure. (2) When rotating the features, it is necessary to load the features from the GPU to the CPU for rotation and then reload the rotated features from the CPU back to the GPU.
Table 25 enumerates the parameters for each method. SSARIN possesses a relatively high parameter count (41,694,672), making it the second most complex model in this list. The main reason is that the network contains eight branches, and the structure of each branch is the same. Therefore, the network requires a larger number of parameters. This complexity is a factor in its longer training and testing times, as observed in the previous analysis.
1D CNN has the fewest parameters (74,196), indicating that it is the simplest model in terms of architecture. This simplicity contributes to the model’s previously observed fast testing times, as there are fewer parameters to compute during the testing phase. However, the trade-off is a limited capacity to capture complex patterns in the data, which impacts performance in classification. 2D CNN has the highest number of parameters (109,613,786), indicating that this model has the most complex architecture among the models listed. The main reason is that it uses multiple fully connected layers, and the fully connected layers contain many network nodes. This intricacy results in heightened computational demands during training and testing and increased processing times.
The parameter numbers and training time for other algorithms do not differ significantly. This section discusses the classification performance of various algorithms on different datasets. Although the proposed SSARIN requires more parameters and computation time, it is within a reasonable and acceptable range.
5. Conclusions
This paper proposes a spectral-spatial attention rotation-invariant classification network for the airborne hyperspectral image. The SSARIN is specifically designed to explore rotation-invariant features for hyperspectral classification. It mainly contains a band selection module, a local spatial feature enhancement module, and a lightweight feature enhancement module.
In the data pre-processing stage, using PCA to reduce the spectral dimensions can effectively reduce the network parameters and training time. However, PCA is not mandatory. After pre-processing, the HSI patch is fed into the band selection module for feature extraction. The band selection (BS) module achieves redundant band suppression by recalibrating the weights of each band. Furthermore, a local spatial feature enhancement (LSFE) module is introduced to extract spectral-spatial features while maintaining rotational invariance. The LSFE module not only extracts spatial-spectral features but also records position information to maintain rotational invariance, providing a robust solution for hyperspectral classification. The proposed method is capable of extracting rotation-invariant spectral-spatial features without requiring additional parameters or constraints. Finally, a lightweight feature enhancement (LWFE) module enhances significant features and suppresses insignificant ones.
Extensive experiments conducted on five airborne hyperspectral image datasets demonstrate the superior performance of SSARIN compared to other methods, proving its robustness against spatial rotations. Moreover, SSARIN effectively extracts urban and countryside features, showcasing its versatility in various scenarios.
However, it is worth noting that the SSARIN network is more complex than the compared methods, resulting in increased computational time and a larger number of parameters. To address this issue, future research will focus on developing new lightweight rotational invariance features for hyperspectral classification, aiming to strike a balance between performance and computational efficiency.

 ,
, 


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}