


Analysis of 2D and 3D Convolution Models for Volumetric Segmentation of the Human Hippocampus


Abstract
:1. Introduction
2. Related Works
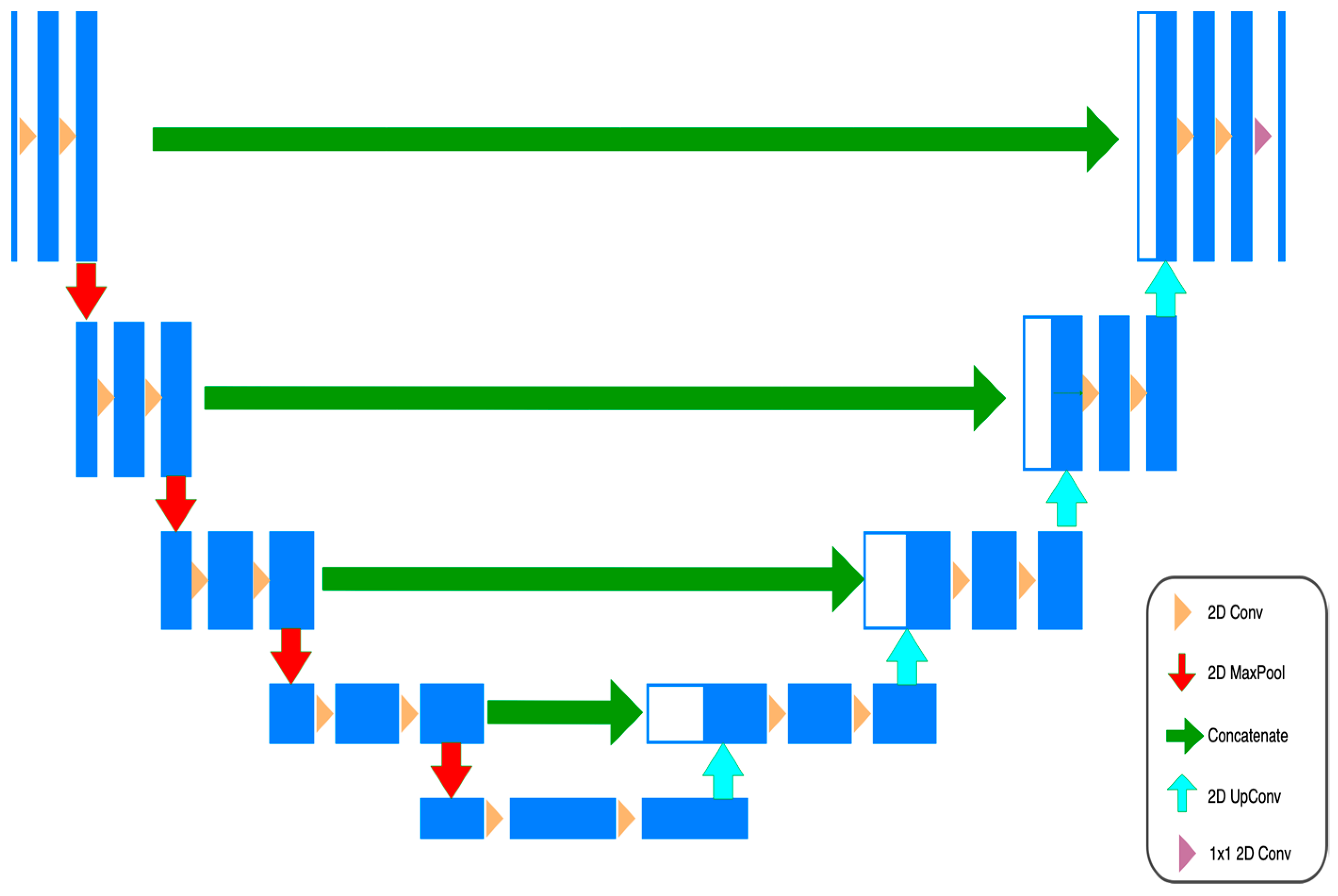
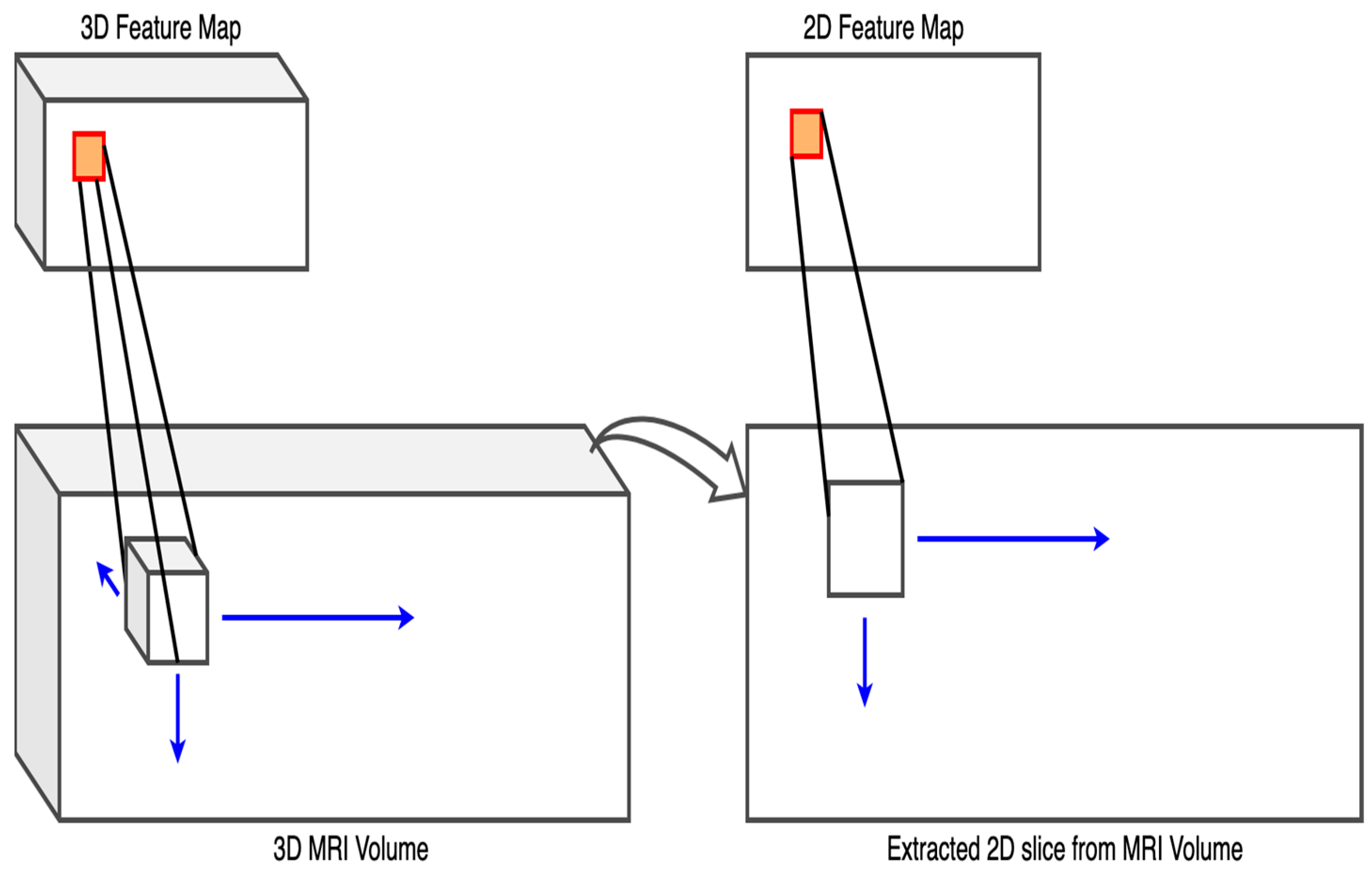
3. Methodology
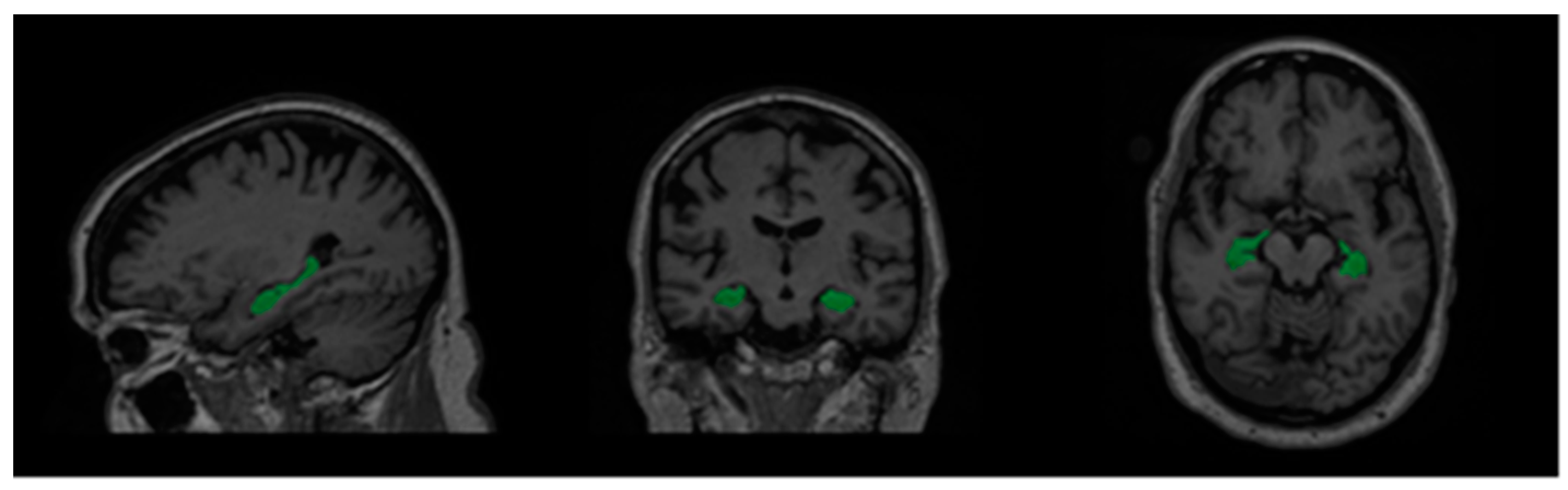
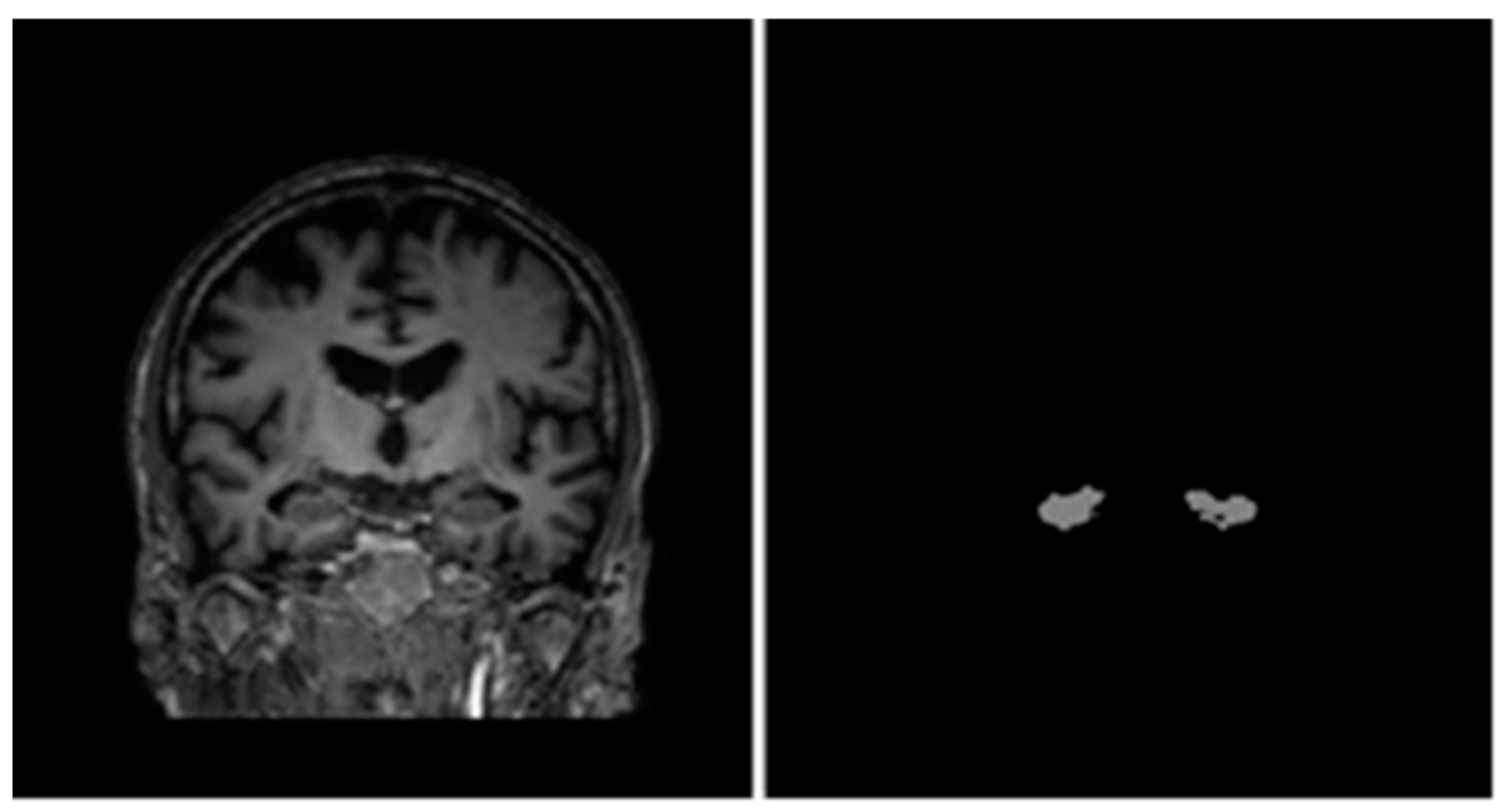
3.1. Data Description
- Have high-quality hippocampus segmentation masks (preferably from manual segmentation), which have been proven to closely follow the morphometric characteristics of the actual hippocampi;
- Have hippocampus segmentation masks that are obtained using a clinically validated and standardized set of rules in order to ensure their inter-rater reliability;
- Contain sufficient data for both training and evaluation of our models.
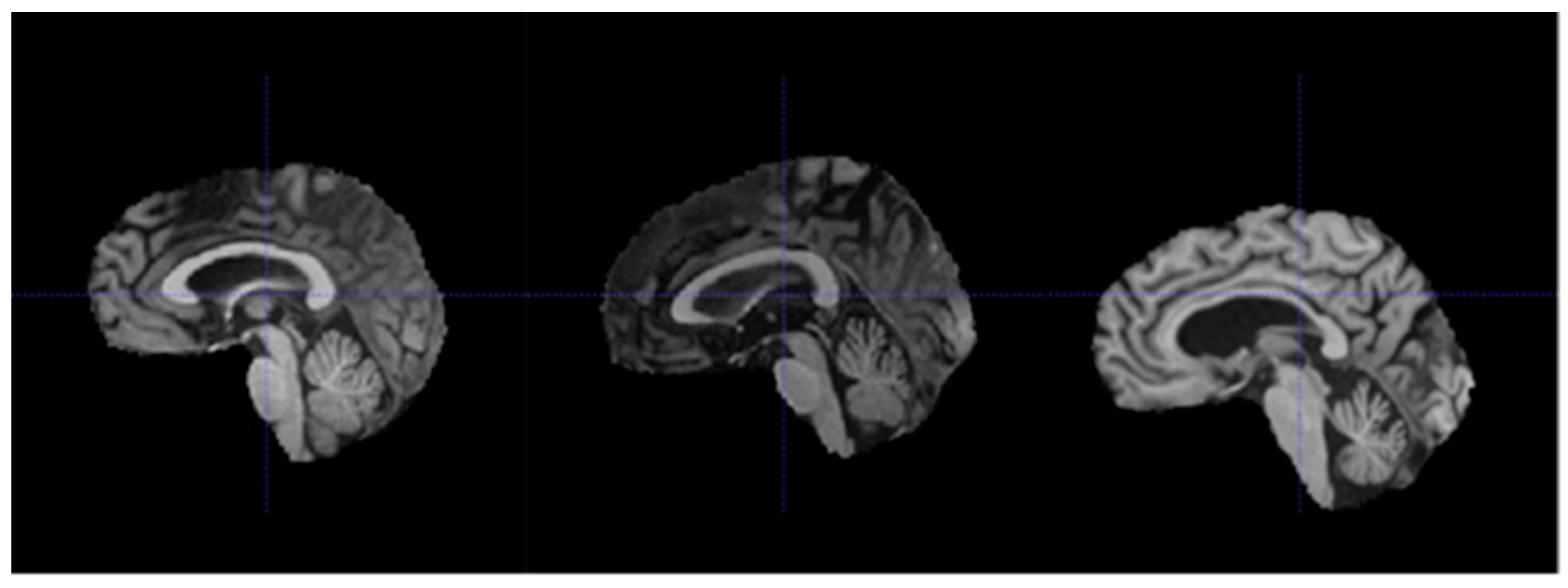
3.2. Data Preparation
- Re-orientation and registration: achieves good alignment of all MRI volumes.
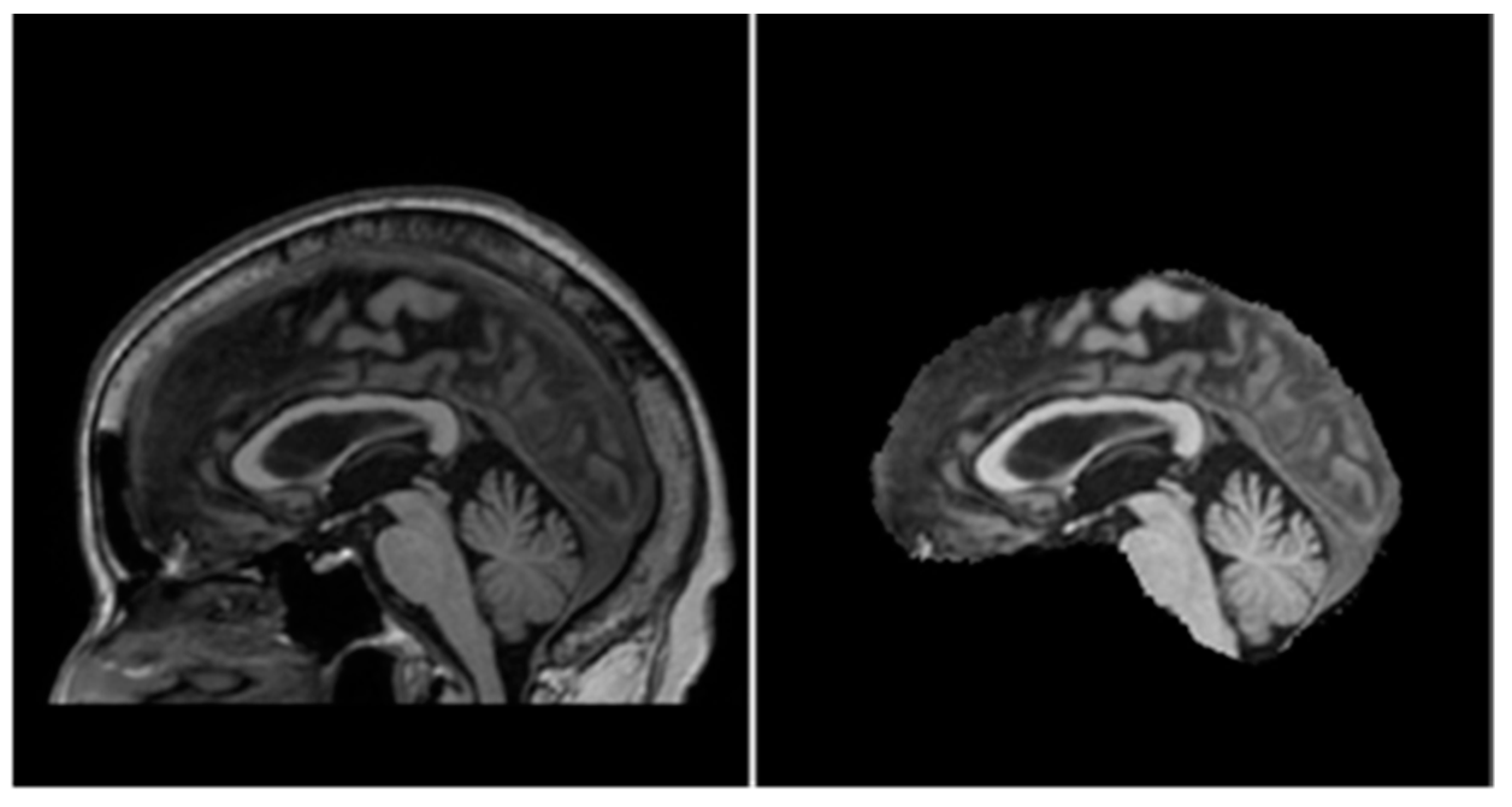
- Field inhomogeneity correction: corrects abnormally dark or bright regions in the MRI volumes caused by inconsistencies in the magnetic field of the scanner.
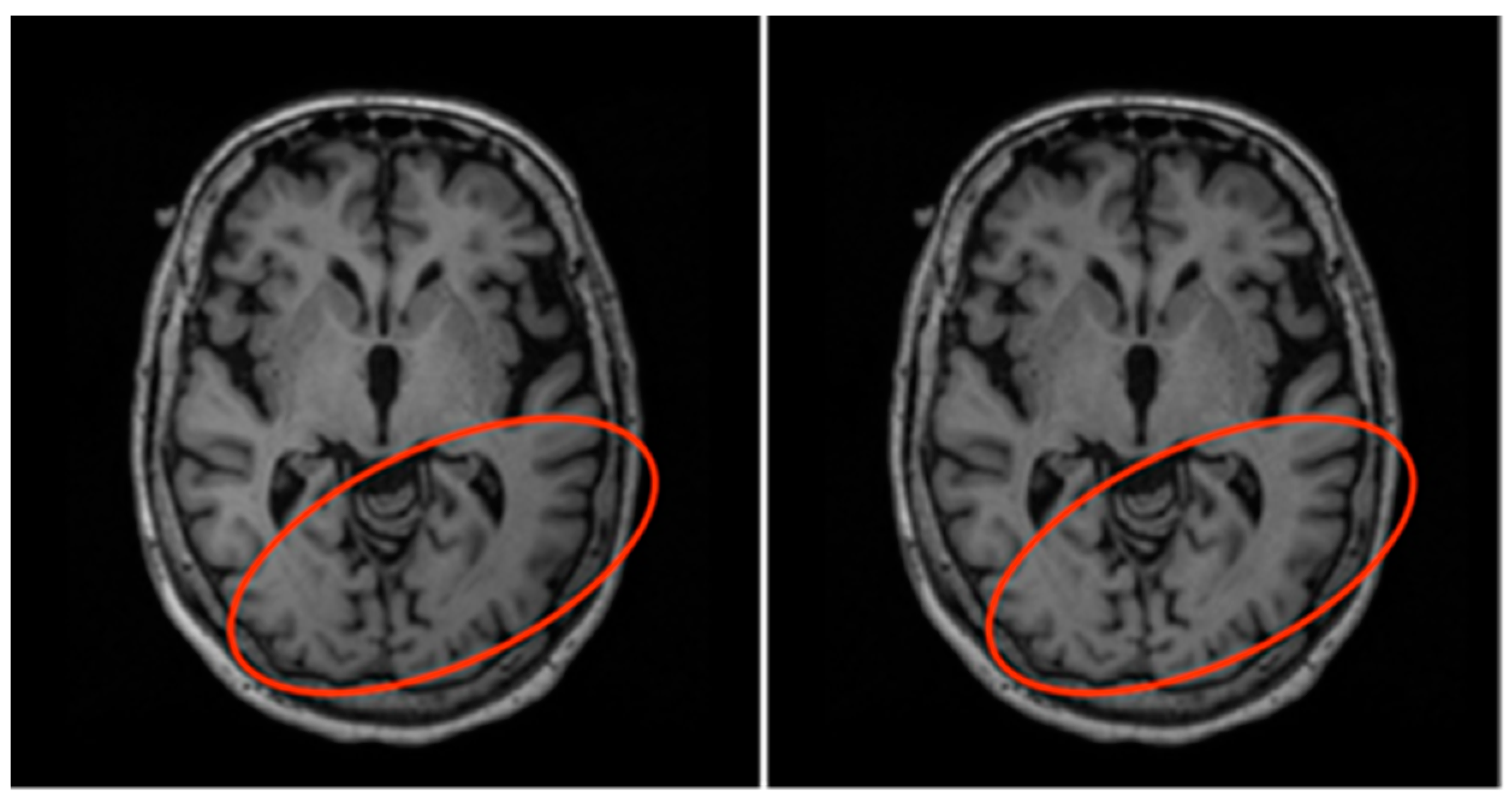
- Non-brain tissue removal: removes irrelevant tissues such as that of the skull, eyes, and nose, leaving only the brain tissues in each volume.
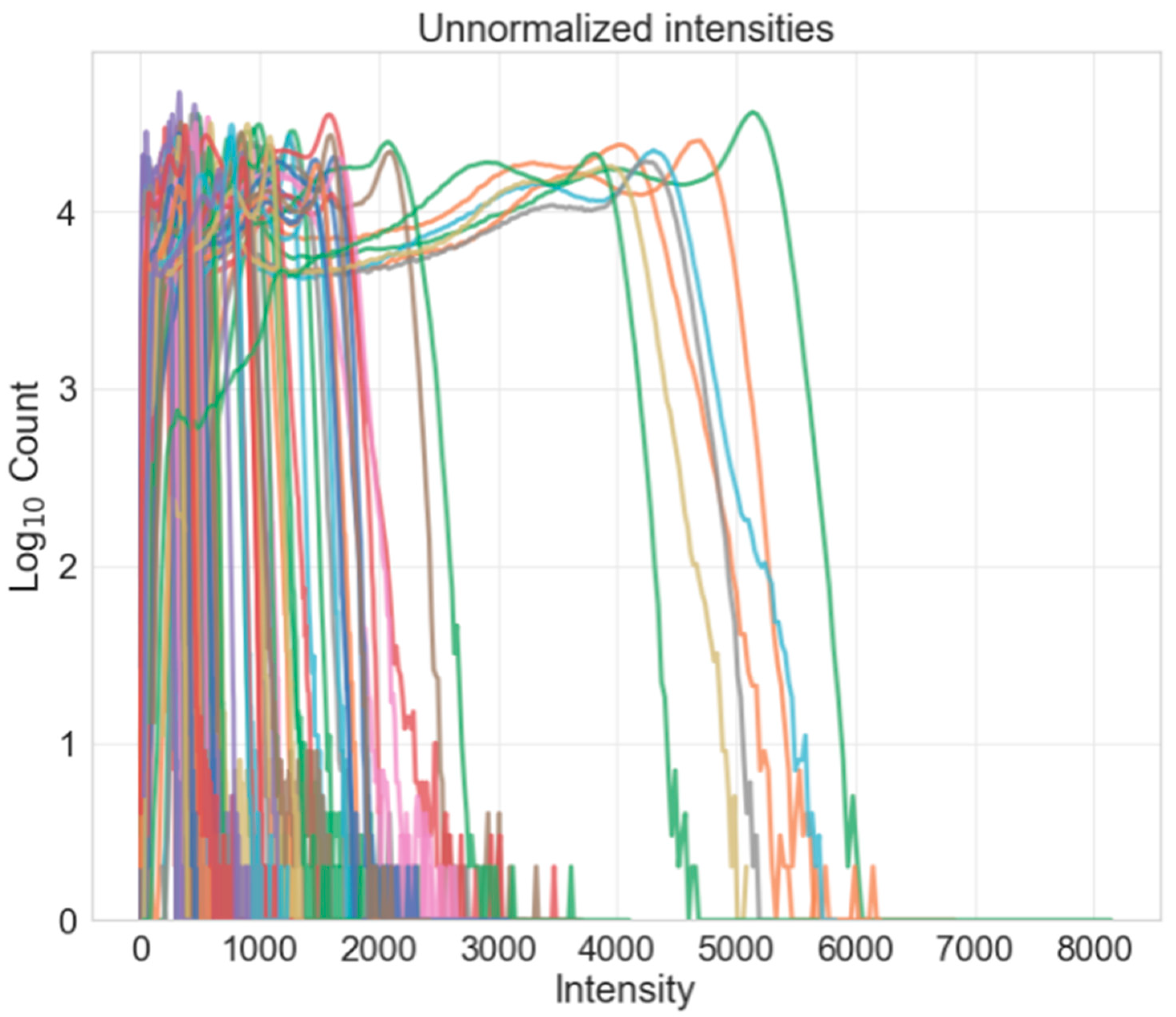
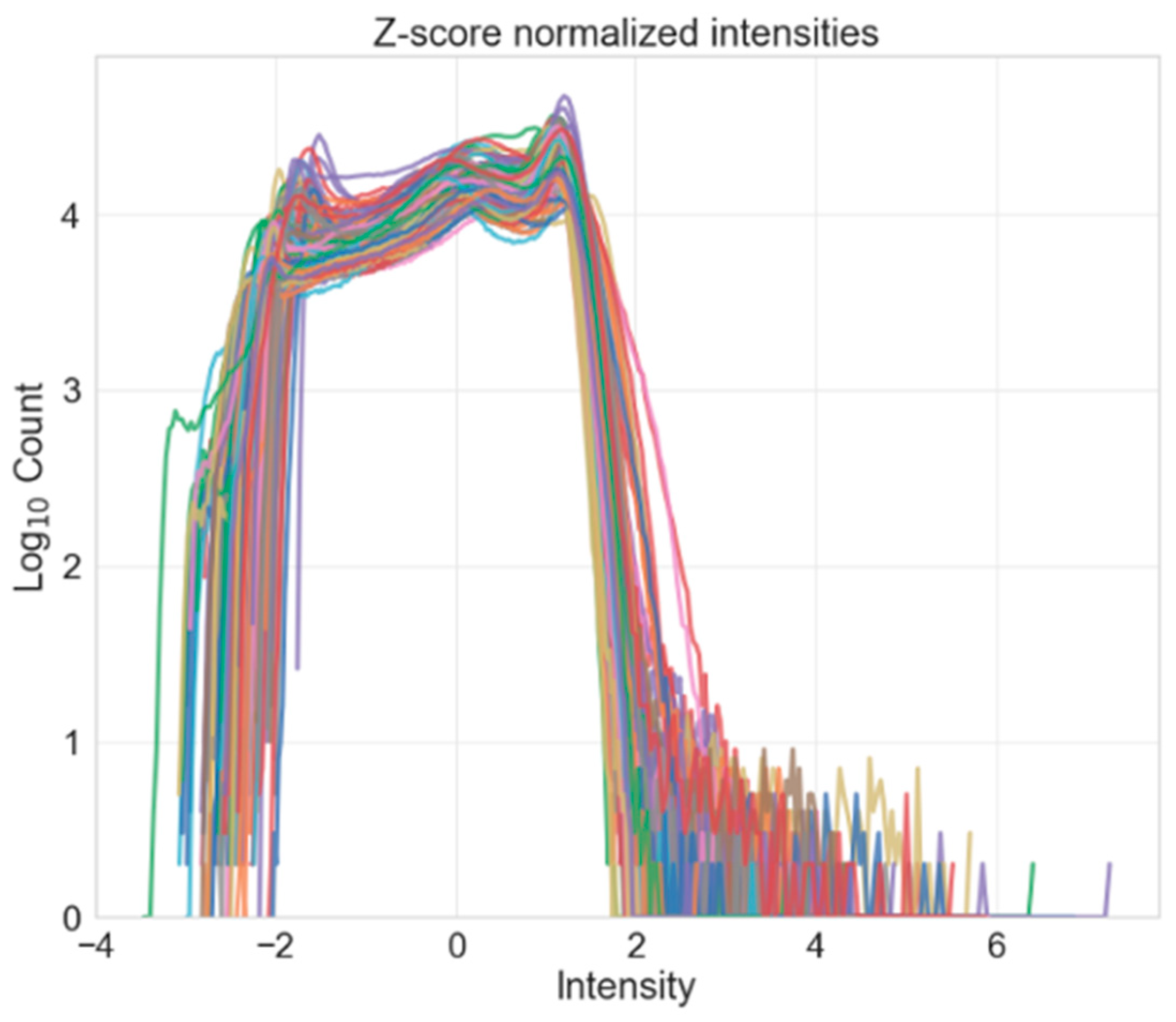
- Intensity normalization: standardizes the intensities of each volume such that the same tissue types in each volume should have the same range of intensity values.
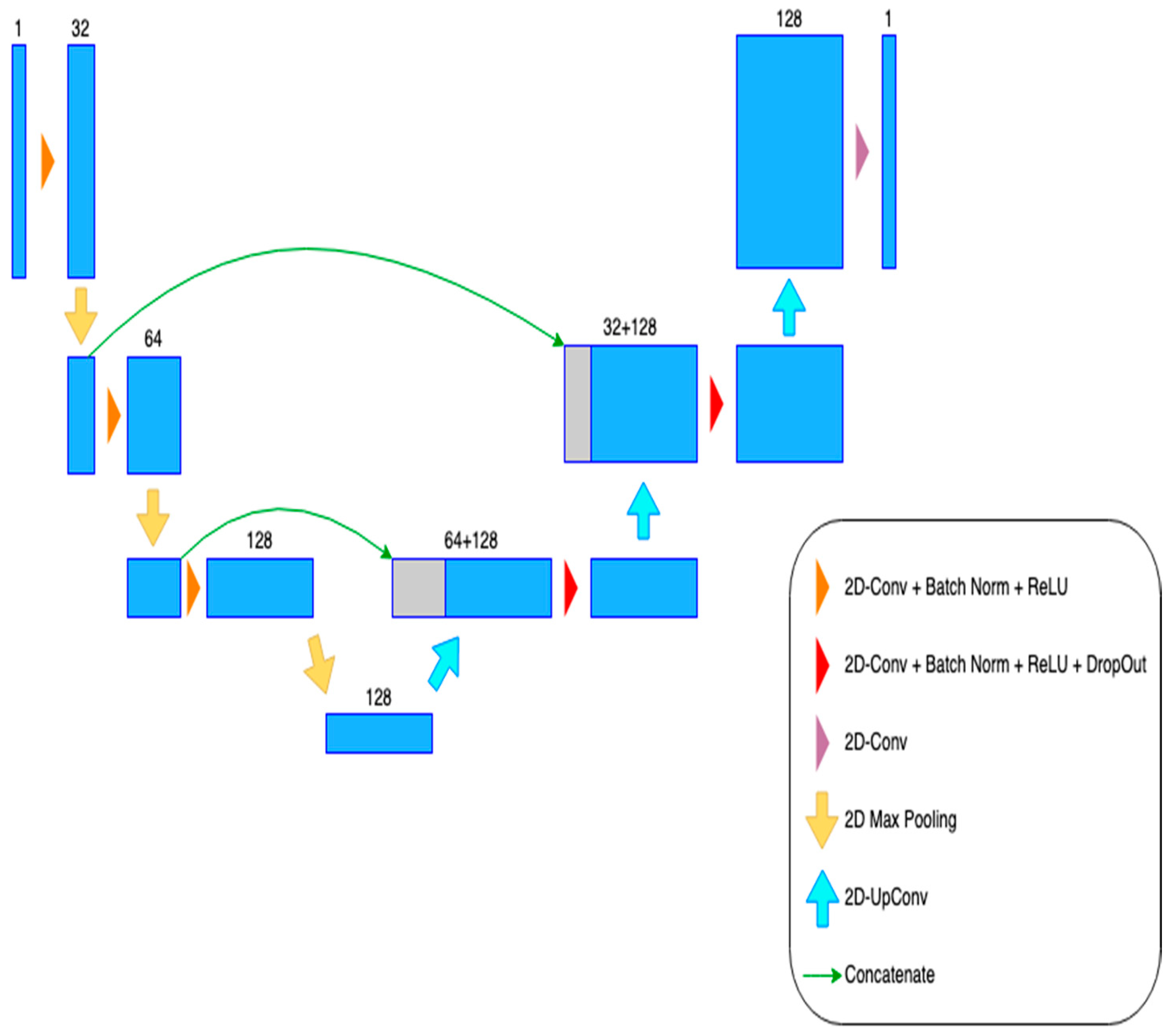
3.3. Training and Model Building
- Obtain models that can generalize well to the unseen test data (i.e., have good hippocampus segmentation performance on unseen MRI volumes).
- Train the models in as short amount of time as possible without sacrificing model performance.
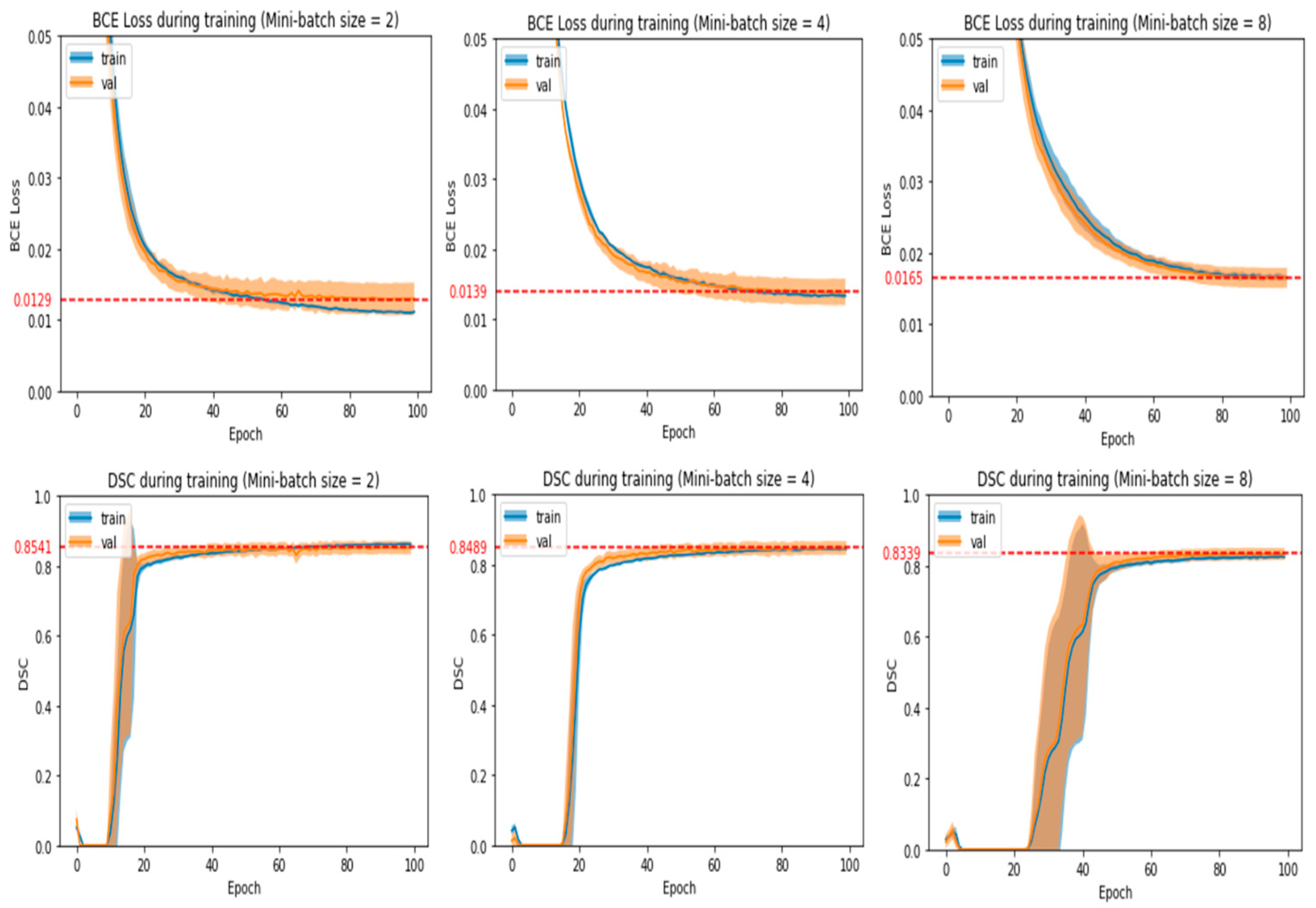
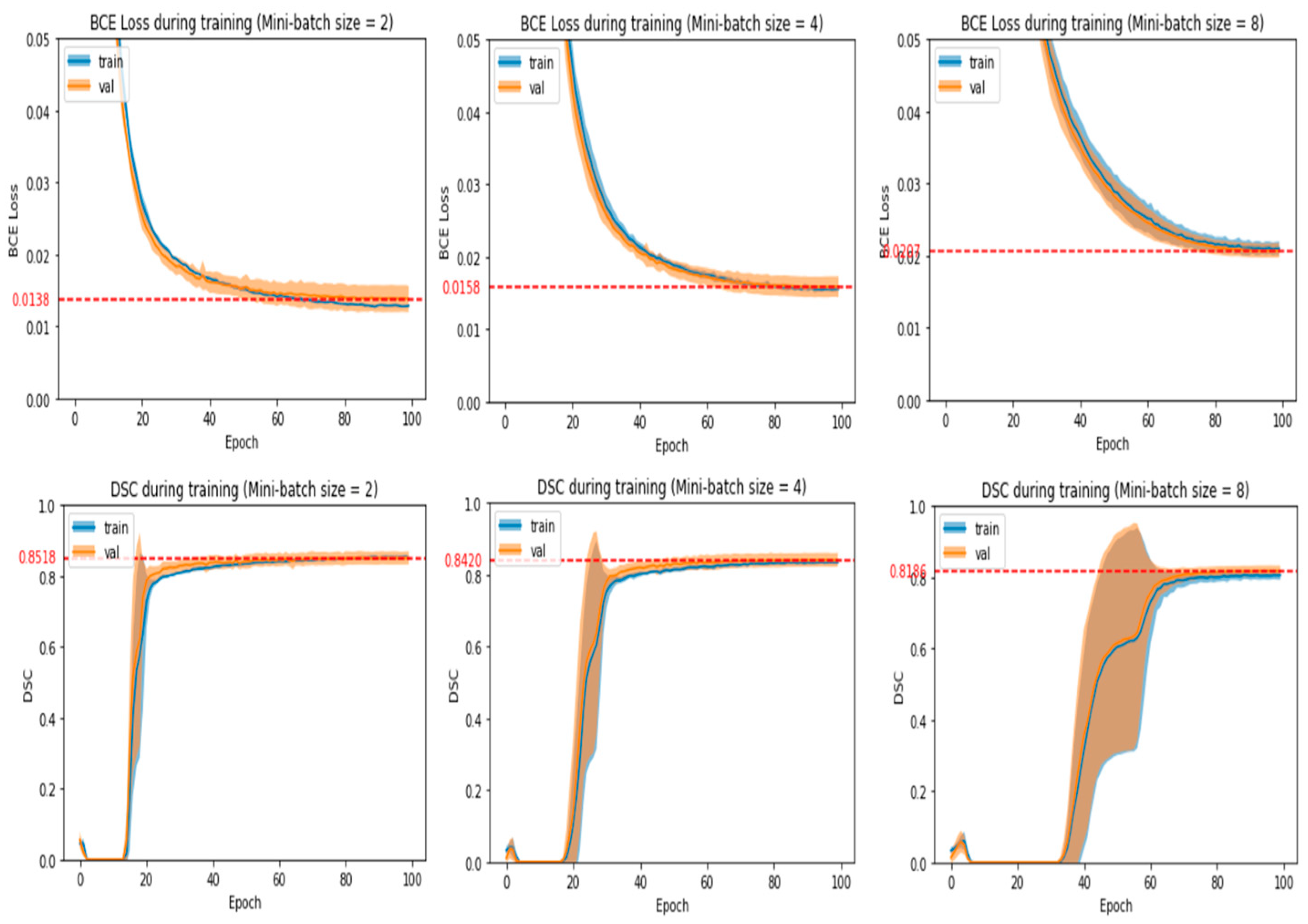
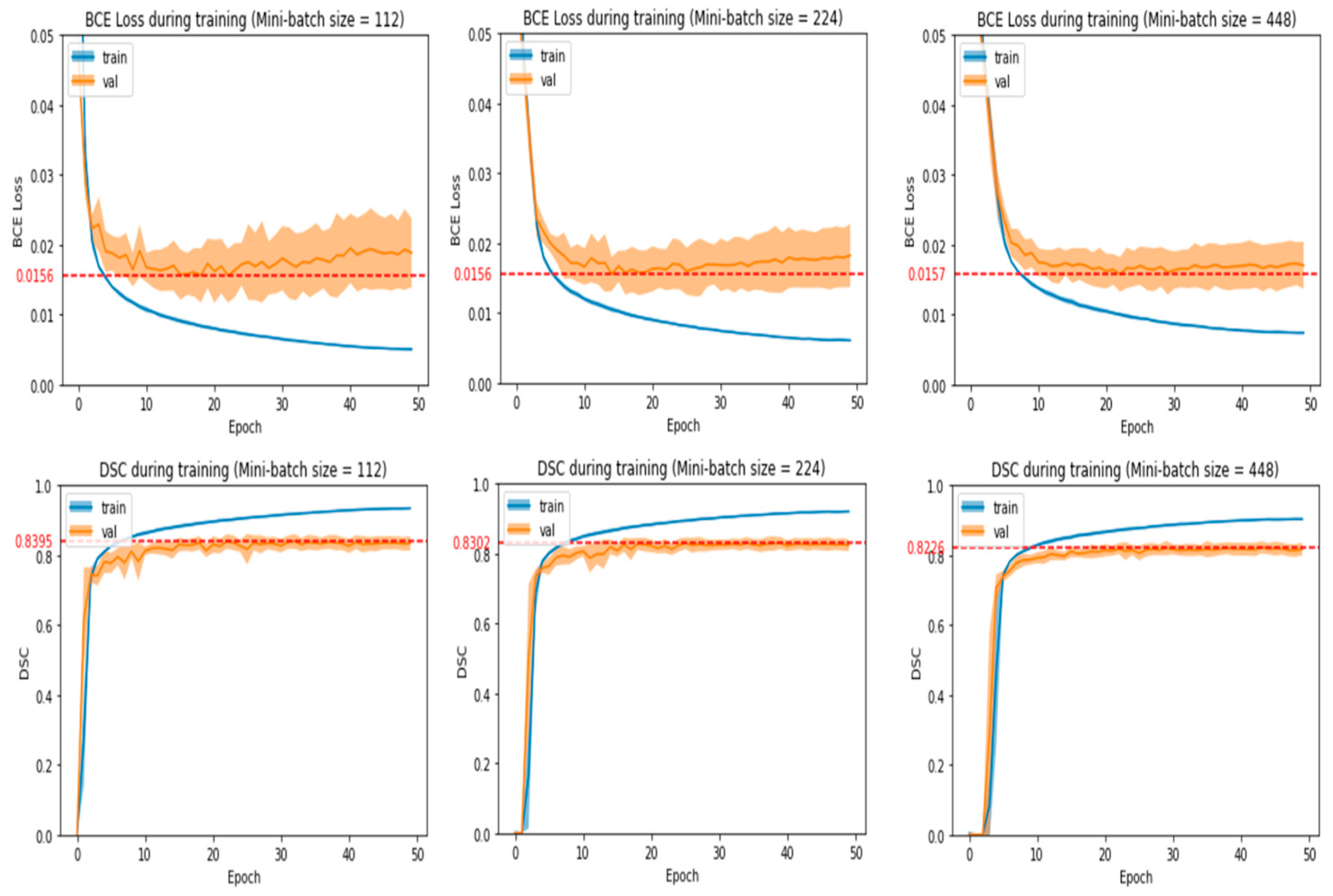
- The number of epochs and mini-batch size chosen should produce average validation loss and DSC that are near the best values obtained in the experiment run.
- Average validation loss and DSC should be stabilized around the chosen number of epochs with no large fluctuations around it. This means that training for a few more or a few less epochs would yield a similar validation loss and DSC.
- If there is an alternative mini-batch size and number of epochs that greatly reduces training time without reducing model performance significantly, then that particular set of hyperparameters will be chosen. After observing some initial experiments, we empirically defined a model’s performance to be significantly affected if the average validation loss increased by more than 0.0004 or the average validation DSC decreased by more than 0.004.
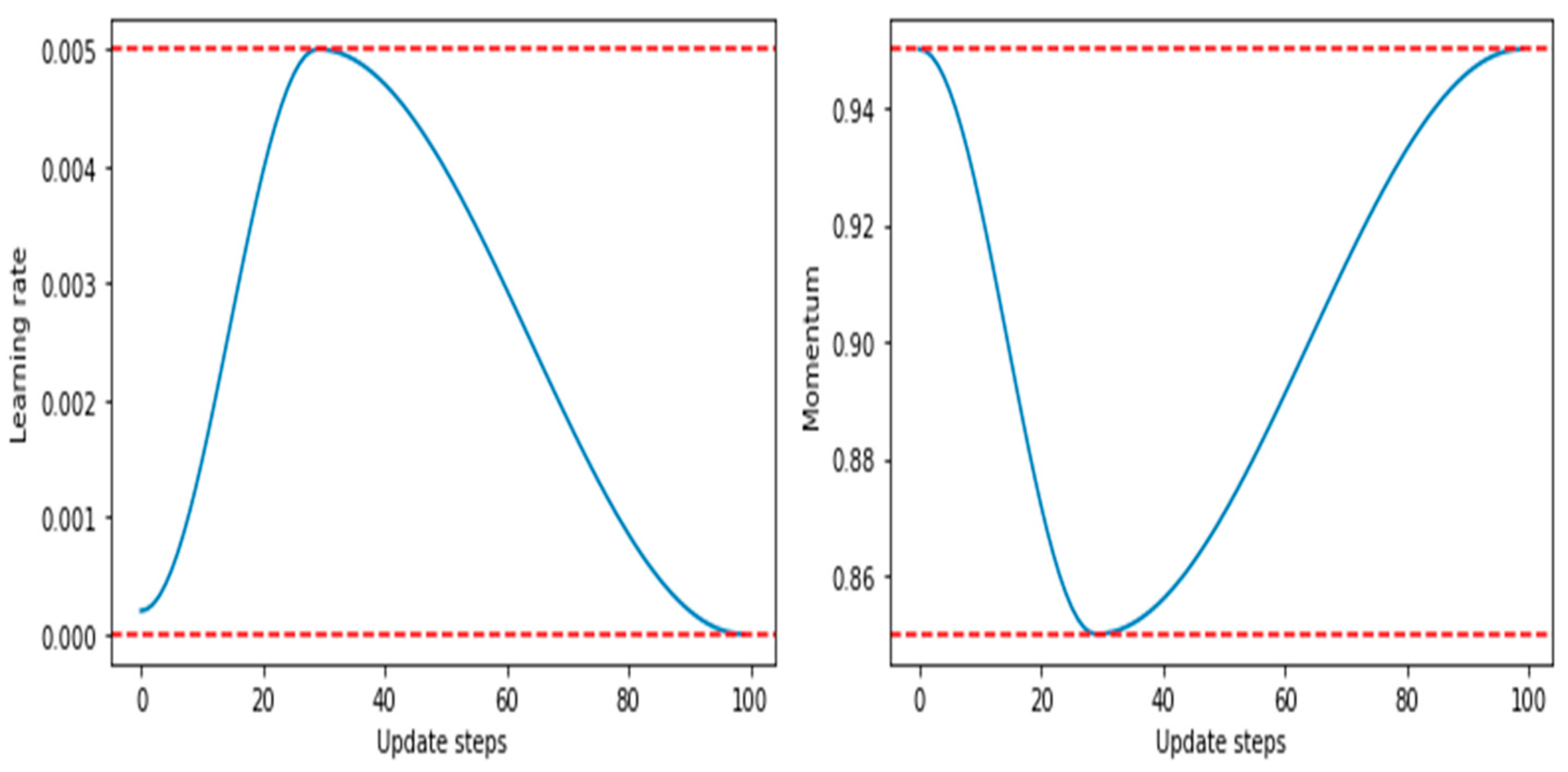
- It achieves a phenomenon termed as super-convergence, in which deep learning models can be trained much faster than with standard training methods.
- It has a proven approach to finding bounds for learning rates (LR range test to find LRmax).
- Its larger learning rates during certain parts of training help to regularize the models, thus reducing the need for other forms of regularization such as weight decay.
4. Results and Findings
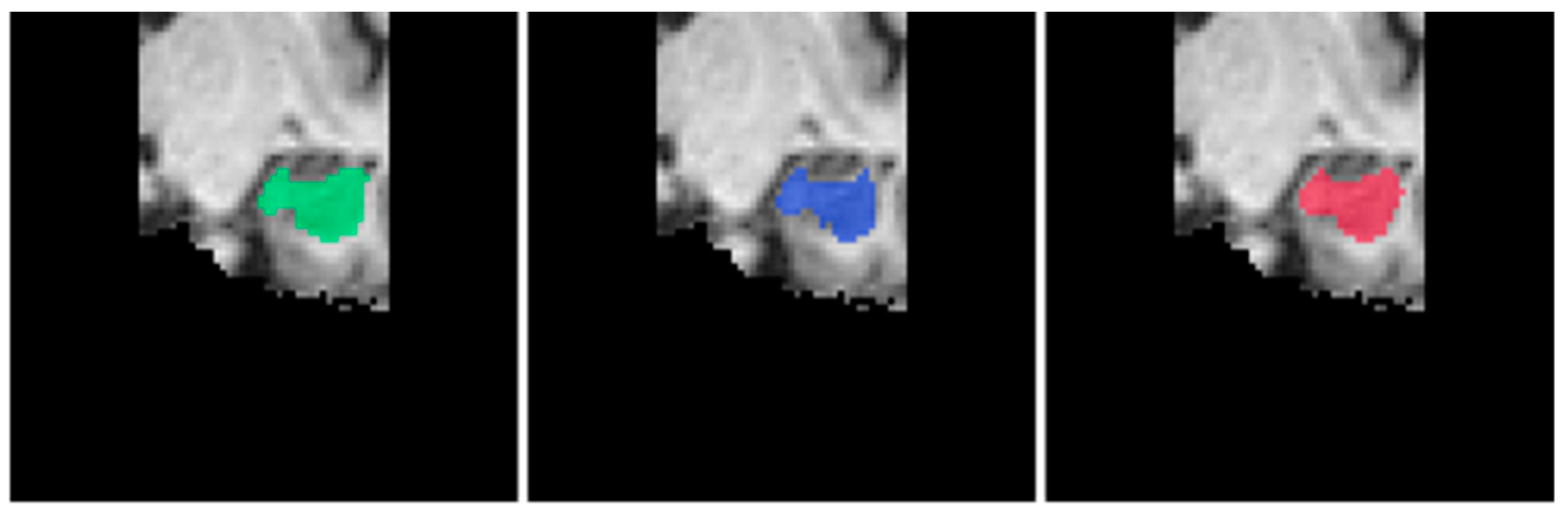
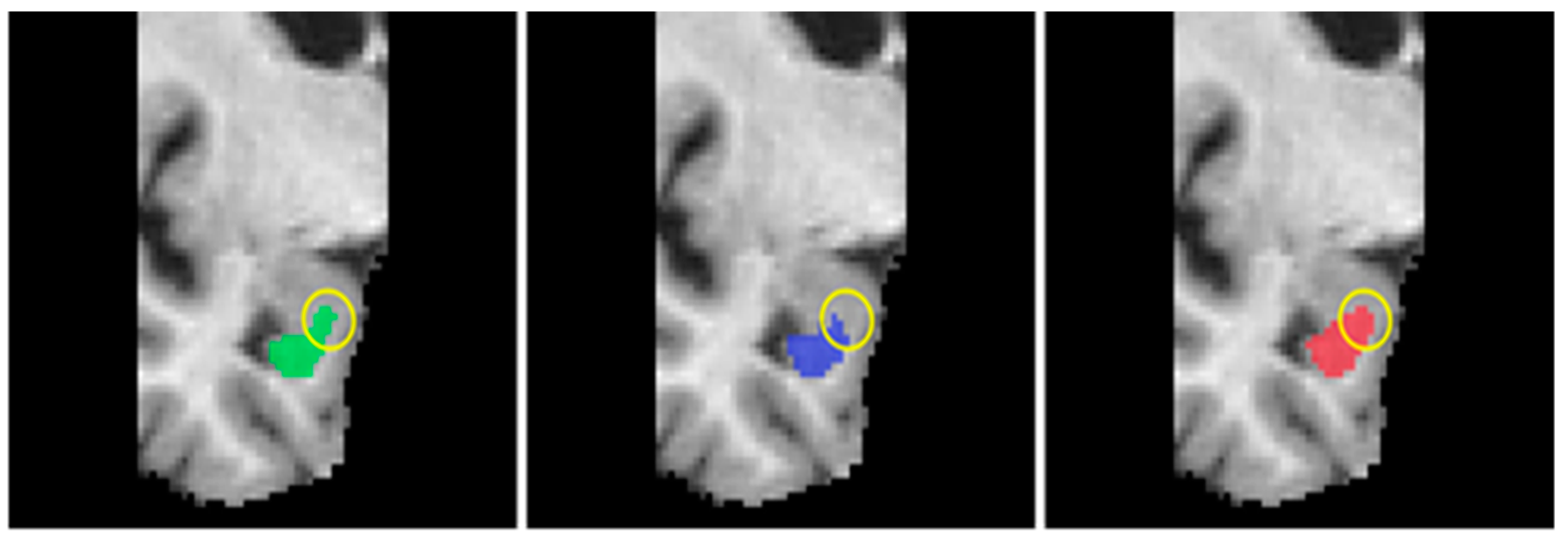
4.1. Segmentation Performance Comparison
4.2. Evaluation Metrics
4.3. Training and Speed Comparison
4.4. Discussion
4.5. Limitations
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Grover, V.P.; Tognarelli, J.M.; Crossey, M.M.; Cox, I.J.; Taylor-Robinson, S.D.; McPhail, M.J. Magnetic Resonance Imaging: Principles and Techniques: Lessons for Clinicians. J. Clin. Exp. Hepatol. 2015, 5, 246–255. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Almarzouqi, S.J.; Morgan, M.L.; Lee, A.G. T1-weighted image. In Encyclopedia of Ophthalmology; Schmidt-Erfurth, U., Kohnen, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2018; pp. 1747–1750. ISBN 978-3-540-69000-9. [Google Scholar] [CrossRef]
- Symms, M.; Jäger, H.R.; Schmierer, K.; Yousry, T.A. A review of structural magnetic resonance neuroimaging. J. Neurol. Neurosurg. Psychiatry 2004, 75, 1235–1244. [Google Scholar] [CrossRef] [PubMed]
- Lisman, J.; Buzsáki, G.; Eichenbaum, H.; Nadel, L.; Ranganath, C.; Redish, A.D. Viewpoints: How the hippocampus con-tributes to memory, navigation and cognition. Nat. Neurosci. 2017, 20, 1434–1447. [Google Scholar] [CrossRef] [PubMed]
- Peng, G.-P.; Feng, Z.; He, F.-P.; Chen, Z.-Q.; Liu, X.-Y.; Liu, P.; Luo, B.-Y. Correlation of Hippocampal Volume and Cognitive Performances in Patients with Either Mild Cognitive Impairment or Alzheimer’s disease. CNS Neurosci. Ther. 2014, 21, 15–22. [Google Scholar] [CrossRef]
- Small, S.A.; Schobel, S.A.; Buxton, R.B.; Witter, M.P.; Barnes, C.A. A pathophysiological framework of hippocampal dysfunction in ageing and disease. Nat. Rev. Neurosci. 2011, 12, 585–601. [Google Scholar] [CrossRef]
- Morey, R.A.; Petty, C.M.; Xu, Y.; Hayes, J.P.; Wagner, H.R.; Lewis, D.V.; LaBar, K.S.; Styner, M.; McCarthy, G. A comparison of automated segmentation and manual tracing for quantifying hippocampal and amygdala volumes. Neuroimage 2009, 45, 855–866. [Google Scholar] [CrossRef]
- Frisoni, G.B.; Jack, C.R.; Bocchetta, M.; Bauer, C.; Frederiksen, K.S.; Liu, Y.; Preboske, G.; Swihart, T.; Blair, M.; Cavedo, E.; et al. The EADC-ADNI Harmonized Protocol for manual hippocampal segmentation on magnetic resonance: Evidence of validity. Alzheimer’s Dement. 2014, 11, 111–125. [Google Scholar] [CrossRef]
- Dill, V.; Franco, A.R.; Pinho, M.S. Automated Methods for Hippocampus Segmentation: The Evolution and a Review of the State of the Art. Neuroinformatics 2015, 13, 133–150. [Google Scholar] [CrossRef]
- Cabezas, M.; Oliver, A.; Lladó, X.; Freixenet, J.; Cuadra, M.B. A review of atlas-based segmentation for magnetic reso-nance brain images. Comput. Methods Programs Biomed. 2011, 104, e158–e177. [Google Scholar] [CrossRef]
- Zhang, X.; Feng, Y.; Chen, W.; Li, X.; Faria, A.V.; Feng, Q.; Mori, S. Linear registration of brain MRI using knowledge-based multiple intermediator libraries. Front. Neurosci. 2019, 13, 909. [Google Scholar] [CrossRef]
- Fonov, V.; Collins, L. ICBM 152 Nonlinear Atlases. 2009. Available online: https://nist.mni.mcgill.ca/icbm-152-nonlinear-atlases-2009/ (accessed on 5 May 2022).
- Iglesias, J.E.; Augustinack, J.C.; Nguyen, K.; Player, C.M.; Player, A.; Wright, M.; Roy, N.; Frosch, M.P.; McKee, A.C.; Wald, L.L.; et al. A computational atlas of the hippocampal formation using ex vivo, ultra-high resolution MRI: Application to adaptive seg-mentation of in vivo MRI. NEUROIMAGE 2015, 115, 117–137. [Google Scholar] [CrossRef] [PubMed]
- Patenaude, B.; Smith, S.M.; Kennedy, D.N.; Jenkinson, M. A Bayesian model of shape and appearance for subcortical brain segmentation. NeuroImage 2011, 56, 907–922. [Google Scholar] [CrossRef] [PubMed]
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. Available online: http://arxiv.org/abs/1512.03385 (accessed on 2 March 2022).
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. 2014. Available online: https://arxiv.org/abs/1409.1556 (accessed on 2 March 2022).
- Galisot, G.; Brouard, T.; Ramel, J.-Y.; Chaillou, E. A Comparative Study on Voxel Classification Methods for Atlas based Segmentation of Brain Structures from 3D MRI Images. In Proceedings of the 14th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2019), Prague, Czech Republic, 25–27 February 2019; pp. 341–350. [Google Scholar]
- De Feo, R.; Hämäläinen, E.; Manninen, E.; Immonen, R.; Valverde, J.M.; Ndode-Ekane, X.E.; Gröhn, O.; Pitkänen, A.; Tohka, J. Convolutional Neural Networks Enable Robust Automatic Segmentation of the Rat Hippocampus in MRI After Traumatic Brain Injury. Front. Neurol. 2022, 13, 820267. [Google Scholar] [CrossRef] [PubMed]
- Nobakht, S.; Schaeffer, M.; Forkert, N.D.; Nestor, S.; Black, S.E.; Barber, P. Combined atlas and convolutional neural net-work-based segmentation of the hippocampus from MRI according to the ADNI Harmonized Protocol. Sensors 2021, 21, 2427. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. Available online: http://arxiv.org/abs/1505.04597 (accessed on 3 June 2022).
- Içek, Ö.; Abdulkadir, A.; Lienkamp, S.S.; Brox, T.; Ronneberger, O. 3D U-Net: Learning Dense Volumetric Segmentation from Sparse Annotation. arXiv 2016, arXiv:160606650. Available online: http://arxiv.org/abs/1606.06650 (accessed on 25 July 2021).
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. arXiv 2015, arXiv:1512.00567. Available online: http://arxiv.org/abs/1512.00567 (accessed on 24 May 2022).
- Lin, L.; Kang, W.; Wu, Y.; Zhao, Y.; Wang, S.; Lin, D.; Gao, J. A 3D multi-scale multi-attention UNet for automatic hippo-campal segmentation. In Proceedings of the 2021 7th Annual International Conference on Network and Information Systems for Computers (ICNISC), Guiyang, China, 23–25 July 2021; pp. 89–93. [Google Scholar]
- Dinsdale, N.K.; Jenkinson, M.; Namburete, A.I.L. Spatial Warping Network for 3D Segmentation of the Hippocampus in MR Images; Springer: Berlin/Heidelberg, Germany, 2019; pp. 284–291. ISBN 978-3-030-32247-2. [Google Scholar]
- Chen, Y.; Shi, B.; Wang, Z.; Zhang, P.; Smith, C.D.; Liu, J. Hippocampus segmentation through multi-view ensemble ConvNets. In Proceedings of the 2017 IEEE 14th International Symposium on Biomedical Imaging (ISBI 2017), Melbourne, Australia, 18–21 April 2017; pp. 192–196. [Google Scholar]
- Ataloglou, D.; Dimou, A.; Zarpalas, D.; Daras, P. Fast and precise hippocampus segmentation through deep convolutional neural network ensembles and transfer learning. Neuroinformatics 2019, 17, 563–582. [Google Scholar] [CrossRef]
- Kamnitsas, K.; Ledig, C.; Newcombe, V.; Simpson, J.; Kane, A.; Menon, D.; Rueckert, D.; Glocker, B. Efficient multi-scale 3D CNN with fully connected CRF for accurate brain lesion segmentation. Med. Image Anal. 2017, 36, 61–78. [Google Scholar] [CrossRef] [PubMed]
- Hesamian, M.H.; Jia, W.; He, X.; Kennedy, P. Deep Learning Techniques for Medical Image Segmentation: Achievements and Challenges. J. Digit. Imaging 2019, 32, 582–596. [Google Scholar] [CrossRef] [PubMed]
- Starke, S.; Leger, S.; Zwanenburg, A.; Leger, K.; Lohaus, F.; Linge, A.; Schreiber, A.; Kalinauskaite, G.; Tinhofer, I.; Guberina, N.; et al. 2D and 3D convolutional neural networks for outcome modelling of locally advanced head and neck squamous cell carcinoma. Sci. Rep. 2020, 10, 15625. [Google Scholar] [CrossRef]
- Menghani, G. Efficient Deep Learning: A Survey on Making Deep Learning Models Smaller, Faster, and Better. arXiv 2021, arXiv:2106.08962. Available online: https://arxiv.org/abs/2106.08962 (accessed on 2 August 2022). [CrossRef]
- Boccardi, M.; Bocchetta, M.; Apostolova, L.G.; Barnes, J.; Bartzokis, G.; Corbetta, G.; DeCarli, C.; Detoledo-Morrell, L.; Firbank, M.; Ganzola, R.; et al. Delphi definition of the EADC-ADNI Harmonized Protocol for hippocampal segmentation on magnetic resonance. Alzheimer’s Dement. 2015, 11, 126–138. [Google Scholar] [CrossRef]
- Bocchetta, M.; Boccardi, M.; Ganzola, R.; Apostolova, L.G.; Preboske, G.; Wolf, D.; Ferrari, C.; Pasqualetti, P.; Robitaille, N.; Duchesne, S.; et al. Harmonized benchmark labels of the hippocampus on magnetic resonance: The EADC-ADNI project. Alzheimer’s Dement. 2014, 11, 151–160.e5. [Google Scholar] [CrossRef]
- Apostolova, L.G.; Zarow, C.; Biado, K.; Hurtz, S.; Boccardi, M.; Somme, J.; Honarpisheh, H.; Blanken, A.E.; Brook, J.; Tung, S.; et al. Relationship between hippocampal atrophy and neuropathology markers: A 7T MRI validation study of the EADC-ADNI Harmonized Hippocampal Segmentation Protocol. Alzheimer’s Dement. 2015, 11, 139–150. [Google Scholar] [CrossRef] [PubMed]
- Boccardi, M.; Bocchetta, M.; Morency, F.C.; Collins, D.L.; Nishikawa, M.; Ganzola, R.; Grothe, M.J.; Wolf, D.; Redolfi, A.; Pievani, M.; et al. Training labels for hippocampal segmentation based on the EADC- ADNI harmonized hippocampal protocol. Alzheimer’s Dement. 2015, 11, 175–183. [Google Scholar] [CrossRef]
- A Harmonized Protocol for Hippocampal Volumetry: An EADC-ADNI Effort. Available online: http://www.hippocampal-protocol.net/SOPs/index.php (accessed on 22 April 2022).
- Park, B.-Y.; Byeon, K.; Park, H. FuNP (Fusion of Neuroimaging Preprocessing) Pipelines: A Fully Automated Preprocessing Software for Functional Magnetic Resonance Imaging. Front. Neuroinform. 2019, 13, 5. [Google Scholar] [CrossRef]
- Reinhold, J.C.; Dewey, B.E.; Carass, A.; Prince, J.L. Evaluating the impact of intensity normalization on MR image synthesis. In Medical Imaging 2019: Image Processing; Angelini, E.D., Landman, B.A., Eds.; International Society for Optics and Photonics: Bellingham, WA, USA, 2019; Volume 10949, p. 109493H. [Google Scholar] [CrossRef]
- Carre, A.; Klausner, G.; Edjlali, M.; Lerousseau, M.; Briend-Diop, J.; Sun, R.; Ammari, S.; Reuzé, S.; Andres, E.; Estienne, T.; et al. Standardization of brain MR images across machines and protocols: Bridging the gap for MRI-based radiomics. Sci. Rep. 2020, 10, 12340. [Google Scholar] [CrossRef]
- NiBabel: Coordinate Systems and Affines. Available online: https://nipy.org/nibabel/coordinate_systems.html (accessed on 11 May 2022).
- Tustison, N.J.; Avants, B.B.; Cook, P.A.; Zheng, Y.; Egan, A.; Yushkevich, P.A.; Gee, J.C. N4ITK: Improved N3 bias correction. IEEE Trans. Med. Imaging 2010, 29, 1310–1320. [Google Scholar] [CrossRef] [PubMed]
- Iglesias, J.E.; Liu, C.Y.; Thompson, P.M.; Tu, Z. Robust brain extraction across datasets and comparison with publicly available methods. IEEE Trans. Med. Imaging 2011, 30, 1617–1634. [Google Scholar] [CrossRef] [PubMed]
- Perez, L.; Wang, J. The effectiveness of data augmentation in image classification using deep learning. arXiv 2017, arXiv:1712.04621. Available online: http://arxiv.org/abs/1712.04621 (accessed on 24 June 2022).
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Zou, K.; Warfield, S.; Bharatha, A.; Tempany, C.; Kaus, M.; Haker, S.; Wells, W.; Jolesz, F.; Kikinis, R. Statistical validation of image segmentation quality based on a spatial overlap index. Acad. Radiol. 2004, 11, 178–189. [Google Scholar] [CrossRef]
- Müller, D.; Soto-Rey, I.; Kramer, F. Towards a Guideline for Evaluation Metrics in Medical Image Segmentation. 2022. Available online: https://arxiv.org/abs/2202.05273 (accessed on 5 May 2022).
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An imperative style, high-performance deep learning library. In Advances in Neural Information Processing Systems 32; Curran Associates, Inc.: New York, NY, USA, 2019; pp. 8024–8035. Available online: http://papers.neurips.cc/paper/9015-pytorch-an-imperative-style-high-performance-deep-learning-library.pdf (accessed on 15 August 2022).
- Wang, Y.; Wei, G.; Brooks, D. Benchmarking TPU, GPU, and CPU platforms for deep learning. arXiv 2019, arXiv:1907.10701. Available online: http://arxiv.org/abs/1907.10701 (accessed on 15 August 2022).
- Smith, L. A disciplined approach to neural network hyper-parameters: Part 1—Learning rate, batch size, momentum, and weight decay. arXiv 2018, arXiv:1803.09820. [Google Scholar]
- Yu, T.; Zhu, H. Hyper-parameter optimization: A review of algorithms and applications. arXiv 2020, arXiv:2003.05689. Available online: https://arxiv.org/abs/2003.05689 (accessed on 13 July 2022).
- Nar, K.; Sastry, S.S. Step size matters in deep learning. arXiv 2018, arXiv:1805.08890. Available online: http://arxiv.org/abs/1805.08890 (accessed on 14 July 2022).
- Wu, Y.; Liu, L.; Bae, J.; Chow, K.-H.; Iyengar, A.; Pu, C.; Wei, W.; Yu, L.; Zhang, Q. Demystifying Learning Rate Policies for High Accuracy Training of Deep Neural Networks. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 1971–1980. [Google Scholar]
- Smith, L.N.; Topin, N. Super-convergence: Very fast training of residual networks using large learning rates. arXiv 2017, arXiv:1708.07120. Available online: http://arxiv.org/abs/1708.07120 (accessed on 14 July 2022).
- Smith, L.N. No more pesky learning rate guessing games. arXiv 2015, arXiv:1506.01186. Available online: http://arxiv.org/abs/1506.01186 (accessed on 14 July 2022).
- FastAI: The 1cycle Policy. Available online: https://fastai1.fast.ai/callbacks.one_cycle.html#The-1cycle-policy (accessed on 15 July 2022).
- Smith, S.L.; Elsen, E.; De, S. On the generalization benefit of noise in stochastic gradient descent. arXiv 2020, arXiv:2006.15081. Available online: https://arxiv.org/abs/2006.15081 (accessed on 20 July 2022).
- Zhou, P.; Feng, J.; Ma, C.; Xiong, C.; Hoi, S.C.H.; Weinan, E. Towards theoretically understanding why SGD generalizes better than ADAM in deep learning. arXiv 2020, arXiv:2010.05627. Available online: https://arxiv.org/abs/2010.05627 (accessed on 20 July 2022).
- Keskar, N.S.; Mudigere, D.; Nocedal, J.; Smelyanskiy, M.; Tang, P.T.P. On large-batch training for deep learning: Generalization gap and sharp minima. arXiv 2016, arXiv:1609.04836. Available online: http://arxiv.org/abs/1609.04836 (accessed on 21 July 2022).
- Ezzati, A.; Katz, M.J.; Zammit, A.R.; Lipton, M.L.; Zimmerman, M.E.; Sliwinski, M.J.; Lipton, R.B. Differential association of left and right hippocampal volumes with verbal episodic and spatial memory in older adults. Neuropsychologia 2016, 93, 380–385. [Google Scholar] [CrossRef] [PubMed]
- Lee, K.; Lee, Y.M.; Park, J.-M.; Lee, B.-D.; Moon, E.; Jeong, H.-J.; Kim, S.Y.; Chung, Y.-I.; Kim, J.-H. Right hippocampus atrophy is independently associated with Alzheimer’s disease with psychosis. Psychogeriatrics 2019, 19, 105–110. [Google Scholar] [CrossRef] [PubMed]
- Thompson, D.K.; Wood, S.; Doyle, L.; Warfield, S.; Egan, G.F.; Inder, T.E. MR-determined hippocampal asymmetry in full-term and preterm neonates. Hippocampus 2009, 19, 118–123. [Google Scholar] [CrossRef]
- Postma, T.S.; Cury, C.; Baxendale, S.; Thompson, P.J.; Msc, I.C.; De Tisi, J.; Burdett, J.L.; Sidhu, M.K.; Caciagli, L.; Winston, G.P.; et al. Hippocampal Shape Is Associated with Memory Deficits in Temporal Lobe Epilepsy. Ann. Neurol. 2020, 88, 170–182. [Google Scholar] [CrossRef] [PubMed]
- Barnes, J.; Scahill, R.I.; Schott, J.M.; Frost, C.; Rossor, M.N.; Fox, N.C. Does Alzheimer’s Disease Affect Hippocampal Asymmetry? Evidence from a Cross-Sectional and Longitudinal Volumetric MRI Study. Dement. Geriatr. Cogn. Disord. 2005, 19, 338–344. [Google Scholar] [CrossRef]
- Dekeyzer, S.; Kock, I.D.; Nikoubashman, O.; Bossche, S.V.; Eetvelde, R.V.; Groote, J.D.; Acou, M.; Wiesmann, M.; Deblaere, K.; Achten, E. “Unforgettable”—A pictorial essay on anatomy and pathology of the hippocampus. Insights Imaging 2017, 8, 199–212. [Google Scholar] [CrossRef]
- Choi, Y.Y.; Lee, J.J.; Choi, K.Y.; Seo, E.H.; Choo, I.H.; Kim, H.; Song, M.-K.; Choi, S.-M.; Cho, S.H.; Kim, B.C.; et al. The aging slopes of brain structures vary by ethnicity and sex: Evidence from a large magnetic resonance imaging dataset from a single scanner of cognitively healthy elderly people in Korea. Front. Aging Neurosci. 2020, 12, 233. [Google Scholar] [CrossRef] [PubMed]
- Turney, I.C.; Lao, P.J.; Arce Renterıa, M.; Igwe, K.; Berroa, J.; Rivera, A.; Benavides, A.; Morales, C.; Schupf, N.; Mayeux, R.; et al. Race and ethnicity-related differences in neuroimaging markers of neurodegen-eration and cerebrovascular disease in middle and older age. medRxiv 2021. [Google Scholar] [CrossRef]
- Fillmore, P.; Phillips-Meek, M.C.; Richards, J.E. Age-specific MRI brain and head templates for healthy adults from 20 through 89 years of age. Front. Aging Neurosci. 2015, 7, 44. [Google Scholar] [CrossRef] [PubMed]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset (n = 115) | CN Subjects | MCI Subjects | AD Subjects |
|---|---|---|---|
| Training (n = 90) | 29 (32.2%) | 30 (33.3%) | 31 (34.4%) |
| Test (n = 25) | 8 (32%) | 8 (32%) | 9 (36%) |
| Mini-Batch Size | Training Time per Epoch (s) |
|---|---|
| 2 | 8.58 |
| 4 | 8.57 |
| 8 | 8.64 |
| Mini-Batch Size | Training Time per Epoch (s) |
|---|---|
| 2 | 8.52 |
| 4 | 8.53 |
| 8 | 8.52 |
| Model | LRmax | Mini-Batch Size | Number of Epochs |
|---|---|---|---|
| 3D U-NetL | 0.005 | 2 | 50 |
| 3D U-NetR | 0.0035 | 2 | 60 |
| Ensemble Model | Constituent 2D Models | Hippocampus | View |
|---|---|---|---|
| EnsembleUSegNetL | U-Seg-NetL0 U-Seg-NetLl U-Seg-NetL2 | Left Left Left | Sagittal Coronal Axial |
| EnsembleUSegNetR | U-Seg-NetR0 U-Seg-NetR1 U-Seg-NetR2 | Right Right Right | Sagittal Coronal Axial |
| Mini-Batch Size | Training Time per Epoch (s) |
|---|---|
| 112 | 11.12 |
| 224 | 6.65 |
| 448 | 4.04 |
| Model | LRmax | Mini-Batch Size | Number of Epochs |
|---|---|---|---|
| U-Seg-NetL0 | 0.009 | 160 | 20 |
| U-Seg-NetL1 | 0.008 | 224 | 18 |
| U-Seg-NetL2 | 0.0085 | 288 | 22 |
| U-Seg-NetR0 | 0.009 | 80 | 25 |
| U-Seg-NetR1 | 0.008 | 224 | 25 |
| U-Seg-NetR2 | 0.008 | 288 | 20 |
| Model | DSC | Precision | Recall |
|---|---|---|---|
| 3D U-NetL | 0.86155 | 0.88132 | 0.84950 |
| EnsembleUSegNetL | 0.86843 | 0.88653 | 0.85543 |
| U-Seg-NetL0 | 0.83427 | 0.85802 | 0.82694 |
| U-Seg-NetL1 | 0.83976 | 0.82444 | 0.86088 |
| U-Seg-NetL2 | 0.82825 | 0.86929 | 0.79860 |
| Model | DSC | Precision | Recall |
|---|---|---|---|
| 3D U-NetR | 0.86604 | 0.87576 | 0.86122 |
| EnsembleUSegNetR | 0.86777 | 0.90486 | 0.83913 |
| U-Seg-NetR0 | 0.83850 | 0.88712 | 0.80544 |
| U-Seg-NetR1 | 0.85867 | 0.87402 | 0.84617 |
| U-Seg-NetR2 | 0.82817 | 0.86775 | 0.80240 |
| DSC | |||
|---|---|---|---|
| Model | CN | MCI | AD |
| 3D U-NetL | 0.87437 | 0.87558 | 0.83769 |
| 3D U-NetR | 0.88316 | 0.87047 | 0.84690 |
| EnsembleUSegNetL | 0.87801 | 0.87954 | 0.85004 |
| EnsembleUSegNetR | 0.88370 | 0.87916 | 0.84350 |
| Model | Training Time per Epoch (s) | Total Training Time (s) |
|---|---|---|
| 3D U-NetL | 10.31 | 515.60 |
| EnsembleUSegNetL | - | 447.01 |
| U-Seg-NetL0 | 6.11 | 122.24 |
| U-Seg-NetL1 | 8.32 | 149.69 |
| U-Seg-NetL2 | 7.96 | 175.08 |
| Model | Training Time per Epoch (s) | Total Training Time (s) |
|---|---|---|
| 3D U-NetR | 10.39 | 623.28 |
| EnsembleUSegNetR | - | 556.10 |
| U-Seg-NetR0 | 9.08 | 227.11 |
| U-Seg-NetR1 | 6.54 | 163.51 |
| U-Seg-NetR2 | 8.27 | 165.48 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Toh, Y.S.; Hargreaves, C.A. Analysis of 2D and 3D Convolution Models for Volumetric Segmentation of the Human Hippocampus. Big Data Cogn. Comput. 2023, 7, 82. https://doi.org/10.3390/bdcc7020082
Toh YS, Hargreaves CA. Analysis of 2D and 3D Convolution Models for Volumetric Segmentation of the Human Hippocampus. Big Data and Cognitive Computing. 2023; 7(2):82. https://doi.org/10.3390/bdcc7020082
Chicago/Turabian StyleToh, You Sheng, and Carol Anne Hargreaves. 2023. "Analysis of 2D and 3D Convolution Models for Volumetric Segmentation of the Human Hippocampus" Big Data and Cognitive Computing 7, no. 2: 82. https://doi.org/10.3390/bdcc7020082