The ADCS of skCube contains two magnetometers (used to measure the intensity of the earth’s magnetic field), gyroscope (used to measure the satellite’s angular rotation), sun-sensors (used to determine the position of the satellite respecting to the sun), and earth-sensor (used to determine earth’s horizon). By the optimal fusion of these sensors, the position and orientation of the satellite in the space can be determined.
5.2.2. Data Description
Owing to the difficulty of getting enough information about ADCS telemetry data from domain experts, we have given the data further in-depth study. The following information has been concluded. ADCS telemetry data is basically composed of 45 parameters, 10 out of them are not included in the packets received, and 8 of them are irrelevant because they are constant all the time. Therefore, we exclude these 18 parameters. We deal only with the 27 remaining workable parameters. ADCS telemetry data contains 793 observations for the 15 days of the mission. These 15 days begin with the beginning of the mission and end when the ADCS subsystem stops sending telemetry packets. Basically, all observations were collected only from six daily time windows. The first three time windows containing 382 nominal observations which we call day-time windows, and the second three time windows containing 400 nominal observations which we call night-time windows. The other 11 observations constitute point anomalies and rare events of the two magnetometers. These 11 observations are discussed and explained below.
The designers of skCube used two magnetometers for measuring earth’s magnetic field intensity, each in three axes (X, Y, and Z). Therefore, we have six observed measurements for each observation (named ‘MAG1 X’, ‘MAG1 Y’, ‘MAG1 Z’, ‘MAG2 X’, ‘MAG2 Y’, and ‘MAG2 Z’).
- i.
Rare Measurement of Magnetometer
There is only one observation that contains unusual and/or out-of-range values in the three measurements of the second magnetometer. The out-of-range values of ‘MAG2 X’, ‘MAG2 Y’, and ‘MAG2 Z’ sensors are 66.05[uT], −133.25[uT], and −234.32[uT] respectively. The reason we consider these values out-of-range is explained in the following. All measurement values of the sensor ‘MAG2 X’ are negative and they range from −56.59[uT] to −12.31[uT]. On the contrary, 66.05[uT] is the only positive value that exceptionally deviates from the values of the aforementioned measurement interval. All measurement values of the sensor ‘MAG2 Y’ range from −27.51[uT] to +5.27[uT], whereas −133.25[uT] is the lowest value that exceptionally deviates from the values of the aforementioned measurement interval. All measurement values of the sensor ‘MAG2 Z’ range from −22.29[uT] to +12.13[uT], whereas −234.32[uT] is the lowest value that exceptionally deviates from the values of the aforementioned measurement interval. Furthermore, the above-described measurement values occurred simultaneously only one time in the whole operational period at timestamp ‘27-06-2017 12:39:29′. For these reasons, we define this observation as a rare event.
- ii.
Zero Measurement of Magnetometers
There are other observations with zero values in the six measurements of the two magnetometers. These observations occurred only ten times among all the operational period observations; five in the day-time windows and five in the night-time windows. We define these ten observations as point anomalies because it is unusual to get an observation with 0[uT] for all of the six measurements of the two magnetometers simultaneously.
5.2.3. Results and Analysis of ADCS Telemetry
- ▪
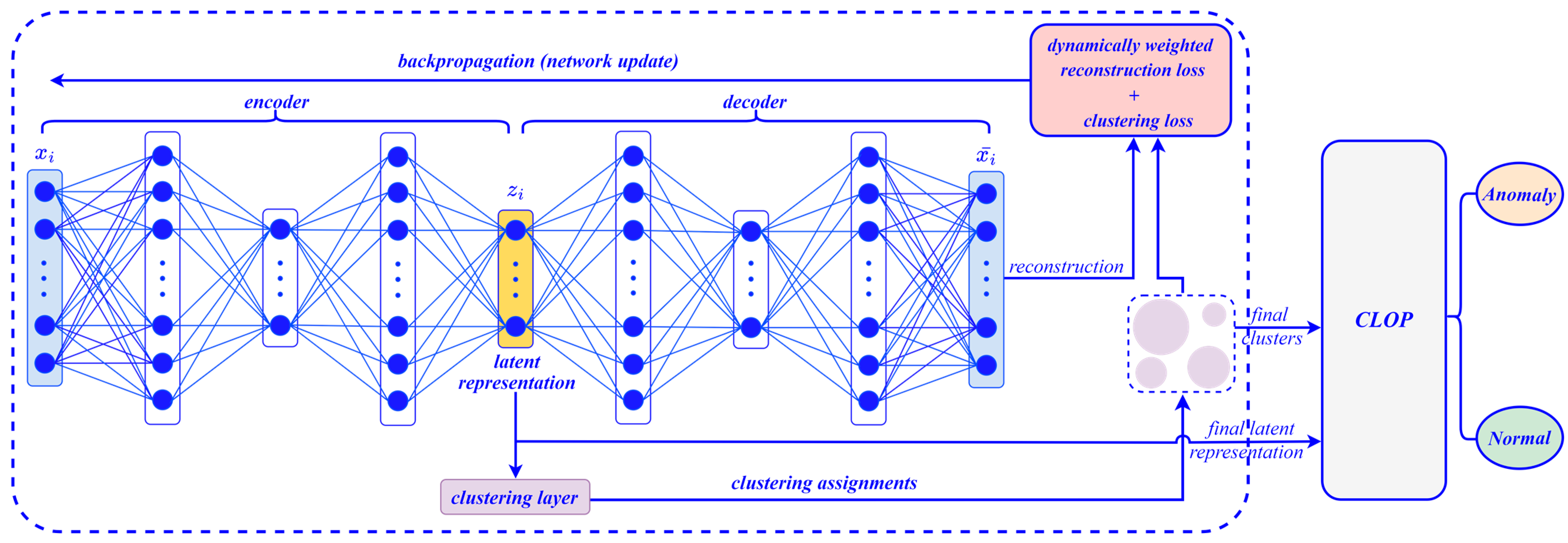
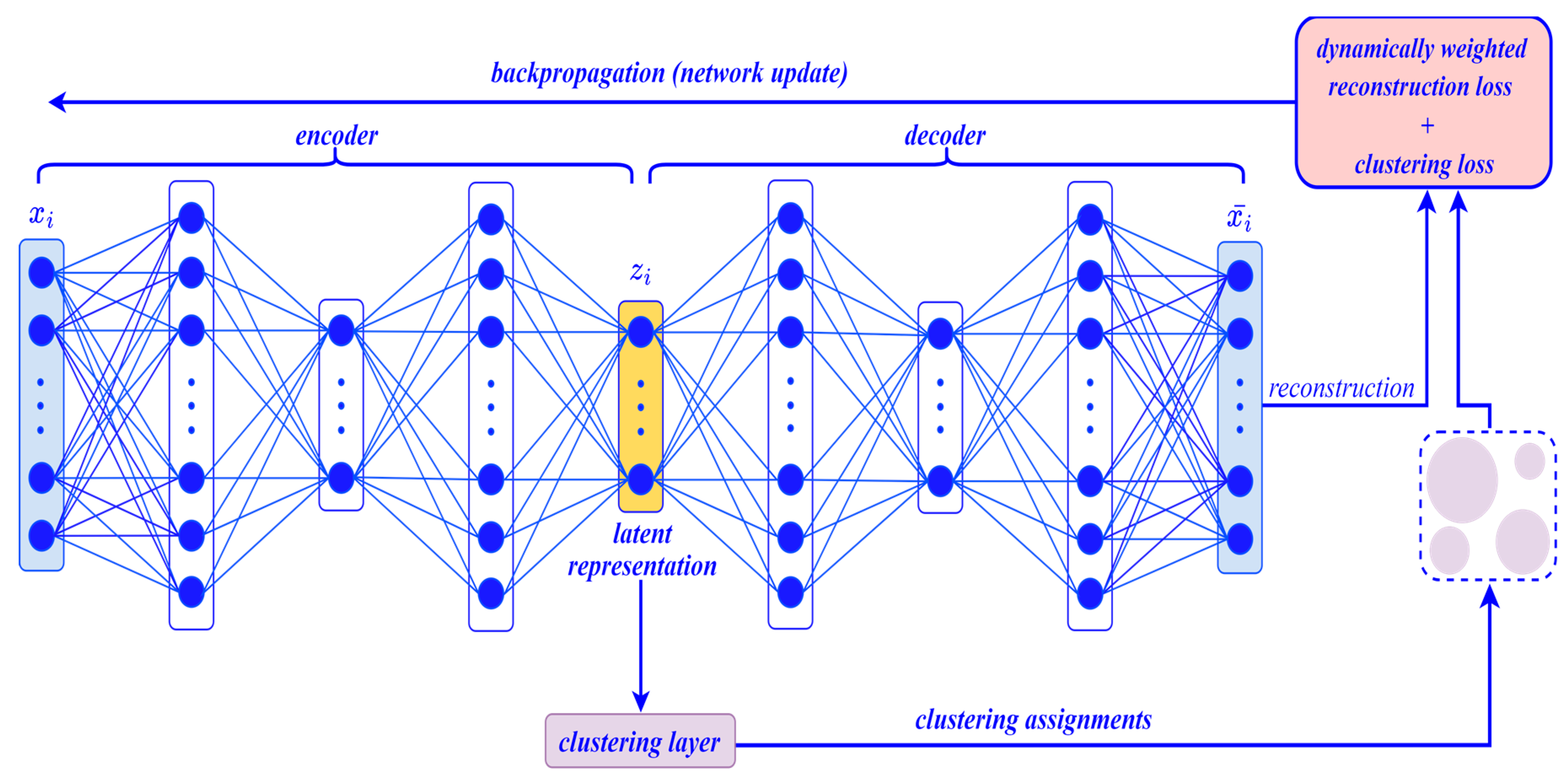
Deep Clustering
Concerning ADCS telemetry data, our proposed deep clustering method presents realistic and explainable results as explained below.
- (a)
The method successfully distinguishes day observations (collected by day-time windows) from night observations (collected by night-time windows). Based on the number of the clusters (i.e., 7), the method clusters day observations into two clusters and night observations into four clusters, each expresses a real state of the skCube. By studying the data, we found that the ‘Sun Irradiation’ parameter which is used to detect solar irradiance is the most contributive parameter in distinguishing day observations from night observations. The ‘Sun Irradiation’ parameter includes six irradiation sensors. Five sensors effectively contribute in five separate clusters (as explained below), while the sixth one has 0 irradiance at all times.
- ▪
Day-time windows: two clusters
- (1)
Cluster 1: The most contributive sensor to this cluster is ‘SUN X+ IRRAD’; the high irradiance measured by this sensor is the most significant feature of this cluster.
- (2)
Cluster 2: The most contributive sensor to this cluster is ‘SUN Y+ IRRAD’; the high irradiance measured by this sensor is the most significant feature of this cluster.
- ▪
Night-time windows: four clusters
- (1)
Cluster 3: The most contributive sensor to this cluster is ‘SUN X− IRRAD’; the high irradiance measured by this sensor is the most significant feature of this cluster.
- (2)
Cluster 4: The most contributive sensor to this cluster is ‘SUN Y− IRRAD’; the high irradiance measured by this sensor is the most significant feature of this cluster.
- (3)
Cluster 5: The most contributive sensor to this cluster is ‘SUN Z+ IRRAD’; the high irradiance measured by this sensor is the most significant feature of this cluster.
- (4)
Cluster 6: The most contributive sensors to this cluster are ‘SUN X+ IRRAD’ and ‘SUN Z+ IRRAD’; the zero irradiance measured by these two sensors is the most significant feature of this cluster; whereas the irradiance measured by the other ones fluctuated between zero and small irradiance.
- (b)
The model successfully gathers the point anomalies and rare events (discussed in
Section 5.2.2) into one cluster (the seventh one). This cluster which contains 11 observations is shown in
Figure 5 in green.
We conclude that all credit for succeeding in clustering ADCS telemetry data into these realistic and reasonable clusters is ascribed to the fact that our proposed model has effectively learned powerful latent representations and non-linear mappings that allow transforming ADCS telemetry data into a more clustering-friendly representation. Therefore, the method is able to efficiently cluster ADCS telemetry data into significant and explainable clusters, each expressing a real state of the skCube. We believe that the detection of these patterns provides engineers with valuable information that helps them better monitor the state of the satellite and use it as a ground truth for comparing it with the corresponding upcoming telemetry packets.
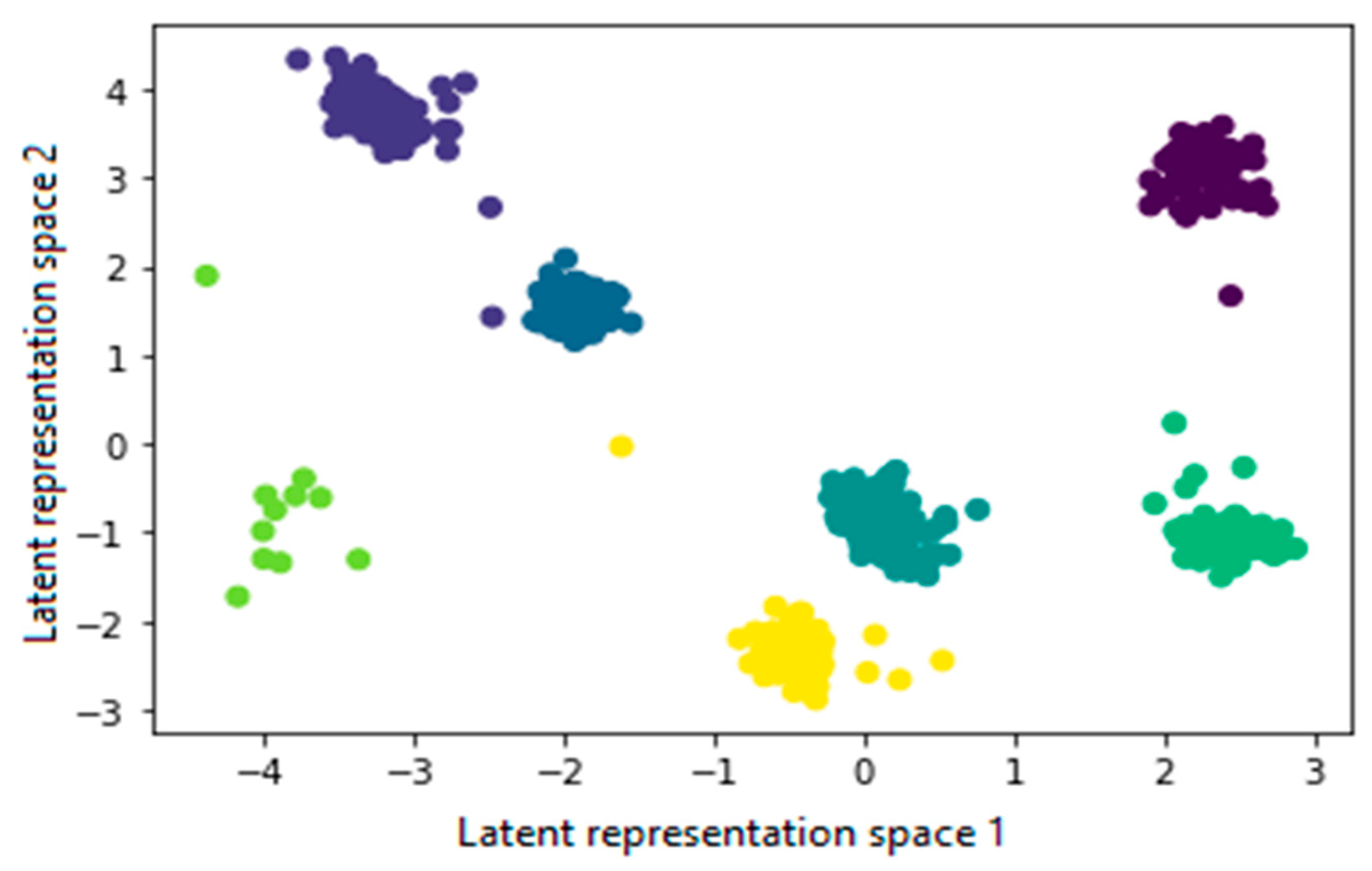
Figure 5 shows the result of the deep clustering model in two-dimensional space from the seven latent representation spaces. As shown in the depicted figure, all clusters are well separated; the two clusters of day observations are on the upper left corner, the four clusters of night observations are on the right side, while the seventh cluster containing anomalies and rare events is in green color on the lower left corner.
Figure 5.
Result of deep clustering.
Figure 5.
Result of deep clustering.
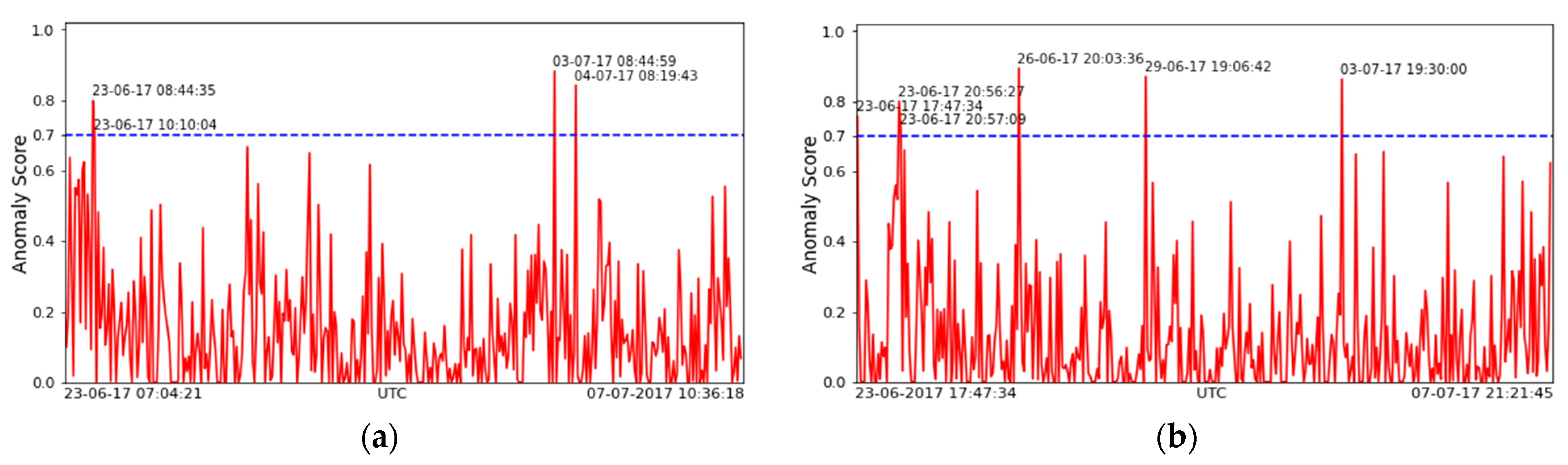
The CLOP anomaly score of these six clusters most frequently remains within the range of 0 to 0.7 in general. Therefore, we choose an anomaly score value of 0.7 to be our threshold. The observations with anomaly scores higher than the threshold (i.e., 0.7) are repeated four times only in clusters that represent day observations, and six times only in clusters that represent night observations. We conclude that the increase in the anomaly score of these observations is definitely a false alarm as the skCube operators did not report any symptoms of abnormal behaviors for such observations.
Figure 6 shows the CLOP anomaly score for the above-mentioned normal period operation.
- 2.
Case Study 2: Anomalous and Rare Events (Magnetometer Events)
The aforementioned point anomalies and rare events are represented by one cluster in which the model collects only 11 observations. The collected observations represent one rare and ten unusual measurements of the two magnetometers. These measurements may occur due to an error in the monitored value, an error in the sending packet, an error in converting the sending packet, or a real value. In all cases, the model should detect these unusual measurements regardless of the reason why they rise. The detected observations in this cluster are discussed and explained below.
- i.
Rare Measurement of Magnetometer
The model successfully detects the aforementioned rare event and puts it into a separate cluster (the green one in
Figure 5) together with the other point anomalies explained below.
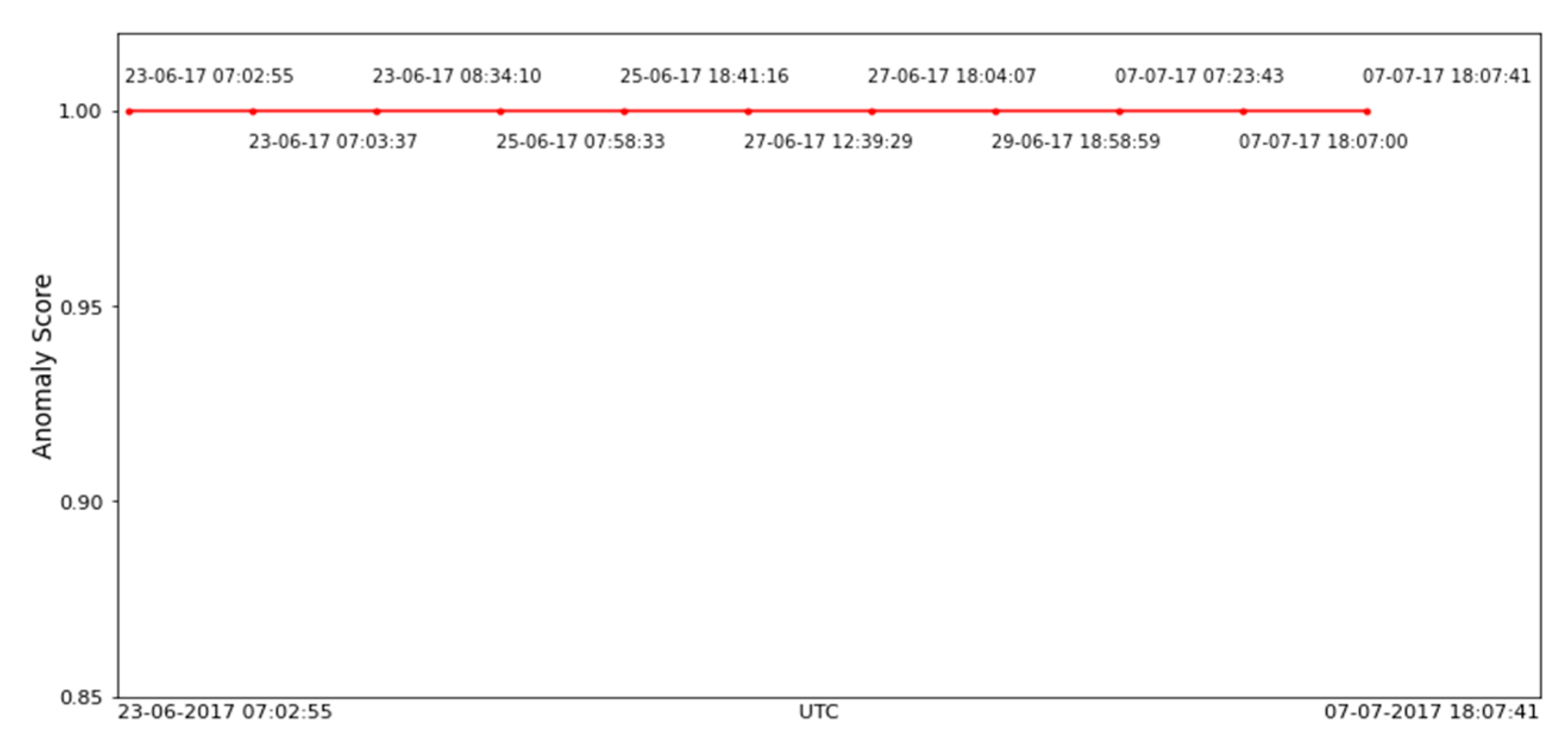
Figure 7 shows that the CLOP anomaly score of this rare observation is of the value of 1.0 (the maximum value of CLOP score).
- ii.
Zero Measurement of Magnetometer
The model successfully detects all these 10 observations as point anomalies and puts them together into one cluster (the green one in
Figure 5).
Figure 7 shows that the CLOP anomaly scores of these point anomalies (five to the right and five to the left of the above-mentioned rare event) are of the value of 1.0 (the maximum value of CLOP score). The CLOP anomaly scores are the highest among all other anomaly scores of the observations of the normal operation.
Figure 7.
CLOP anomaly score of anomalies and rare events.
Figure 7.
CLOP anomaly score of anomalies and rare events.
- ▪
Evaluation Metrics and Comparison
The evaluation of our proposed DCLOP is two-fold. The first one is the evaluation and analysis of the quality of the proposed clustering method using unsupervised metrics. The second one is the evaluation of the proposed DCLOP as an anomaly detection method. Although the ADCS telemetry data, which is transmitted from a live skCube satellite, is unlabeled, we managed to create a ground truth using the study discussed in
Section 5.2.2. Based on this ground truth, ADCS telemetry data contains (i) 782 nominal observations (382 day observations and 400 night observations) and (ii) 11 point anomalies and rare events.
- i.
Deep Clustering Evaluation
The clustering of normal operational data into day and night observations is one major concern of this paper. From the perspective of the day- and night-time windows, this clustering operation can be considered a binary clustering problem and can consequently be evaluated using performance metrics of the binary classification confusion matrix [
37].
The evaluation measures are reported in the form of a confusion matrix as shown in
Table 1, where TP represents day observations that are clustered correctly, while FN represents day observations that are clustered incorrectly. For night observations, TN represents night observations that are clustered correctly, while FP represents night observations that are clustered incorrectly.
Based on the confusion matrix, the standard performance measures [
38,
39] can be defined and calculated to evaluate the performance of the deep clustering method. Since the deep clustering results are not deterministic, the performance measures of anomaly detection have been averaged over 10 runs.
Regarding the clustering performance measures,
Table 2 reveals that the deep clustering method (in DCLOP) with dynamically weighted loss achieved slightly higher performance measures in all the evaluation measures when compared to the one with static loss.
On the other hand, the clustering quality is evaluated using the following three unsupervised metrics: (i) silhouette score [
40], (ii) Calinski–Harabasz Index [
41], and (iii) Davies–Bouldin Index [
42].
According to the clustering evaluation metrics,
Table 3 reveals that the deep clustering method (in DCLOP) with dynamically weighted loss had better performance on all the 3 metrics when compared to the one with static loss.
- ii.
Anomaly Detection Evaluation
The evaluation measures are reported in the form of a confusion matrix, as shown in
Table 4 [
37], where TP represents anomalies that are predicted correctly, while FN represents anomalies that are predicted incorrectly. For normal observations, TN represents normal observations that are predicted correctly, while FP represents normal observations that are predicted incorrectly.
The technical challenge ADCS telemetry data poses while predicting anomalies is the highly imbalanced distribution between nominal and anomalous observations. Based on the aforementioned created ground truth, the anomaly percentage in our case is 1.37% (11 out of 793 observations) of the total observations. Choosing appropriate metrics is particularly difficult for such an imbalanced anomaly detection model. This difficulty is attributed to the fact that (i) most of the widely used standard metrics assume a balanced class distribution and (ii) not all classes (and therefore not all prediction errors) are equal for an imbalanced anomaly detection problem. Therefore, additional evaluation metrics that focus on the minority class are required. For this purpose, standard metrics such as sensitivity, specificity, FPR, FNR, and accuracy are used. Evaluation metrics for imbalanced anomaly detection are listed below.
G-performance [
43] is the geometric mean of the percentage of anomalies correctly predicted (TPR, Sensitivity) and the percentage of normal observations correctly predicted (TNR, Specificity).
For a better and more qualitative evaluation, the ROC curve is used by varying the outlier threshold [
44,
45]. The computation is as follows: The true positive rate (TPR) is the proportion of the observations correctly predicted as anomalies to the total number of anomalous observations. The false positive rate (TPR) is the proportion of the normal observations incorrectly predicted as anomalies to the total number of normal observations. These proportions are both in the range of [0.0, 1.0] and are plotted against each other to get the ROC curve. The area under the ROC curve (Auroc) can be computed as another quality measure to evaluate the proposed DCLOP.
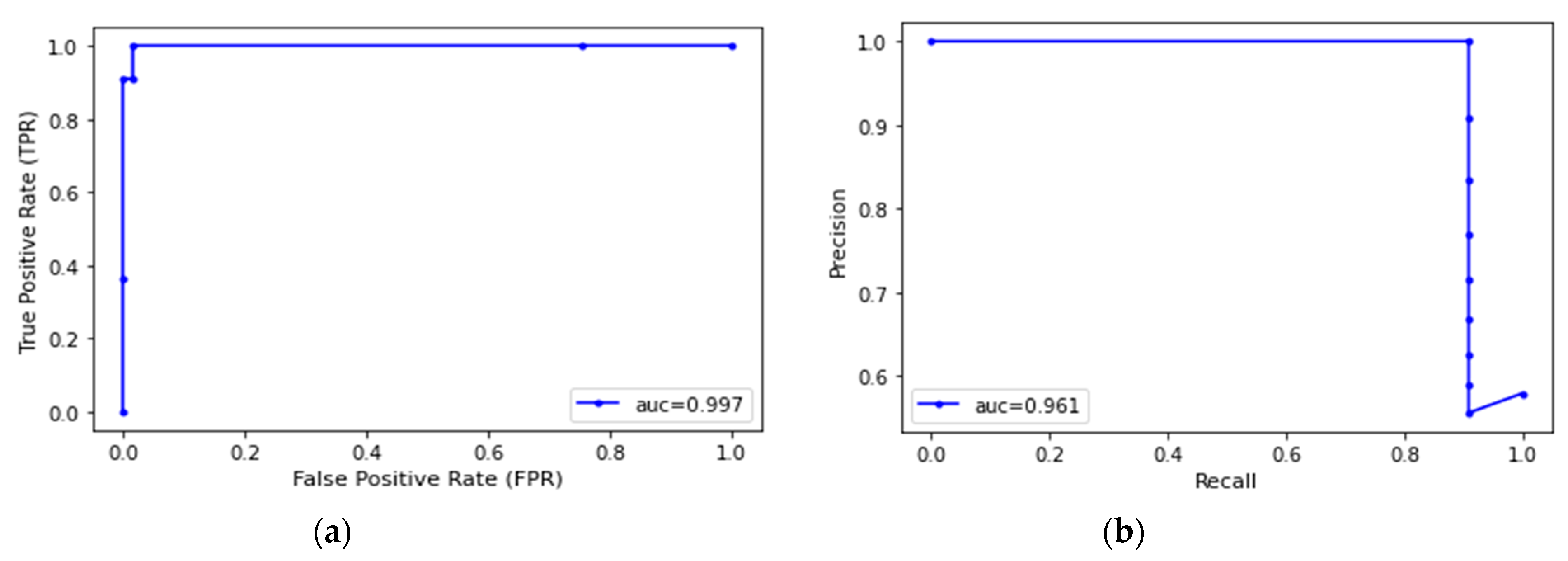
Figure 8a shows the ROC curve of the DCLOP approach with an AUC score of 0.997.
The PR curve shows the trade-off between precision and recall. The PR curve is an alternative to the ROC curve and can be used in a similar way. However, it focuses on the performance of the detector on the minority class; this makes it more useful for our imbalanced anomaly detection problem. The area under the PR curve (Auprc) can be computed as another quality measure to evaluate the proposed DCLOP.
Figure 8b shows the PR curve of the DCLOP approach with an AUC score of 0.961.
Figure 8.
ROC and PR curves of the DCLOP approach. (a) ROC curve; (b) PR curve.
Figure 8.
ROC and PR curves of the DCLOP approach. (a) ROC curve; (b) PR curve.
Since DCLOP is based on deep clustering results which are not deterministic, the performance measures of anomaly detection have been averaged over 10 runs.
According to the anomaly detection DCLOP performance measures,
Table 5 reveals that DCLOP with dynamically weighted loss achieved slightly higher performance measures on all the evaluation measures when compared to the one with static loss. The low values of Precision,
-Score, and MCC are due to the high imbalance in the used telemetry data.



 and
and 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}