1. Introduction
In the context of online services, ambient services, and recommendation systems, user preferences are usually related to multiple attributes specified by the user based on certain factors such as environment, culture, and psychological factors. In general, preference analysis includes the perception and sentiment of the users toward selecting the target services or items. Users are becoming more attracted to tailored preferences in on-demand online services related to health, music, movies, food, and fashion. Online service providers are always keeping up with recommendation technology to tune and match user preferences so that current users will continue using their services. For some preference analyses, it is hard to recommend accurate results that match the user’s experience due to the limitation of references in the database. A system that supports user decision-making or provides personalized services can only be implemented if the users explicitly define their preferences. In general, these systems can only provide excellent and meaningful results during certain events when these explicit and implicit preferences or actions take place. Based on the insight and related information, the systems can analyze the causal relationship between these references.
For recommendation of preferences, explicit and implicit references are always related to spatio-temporal concepts where the time and space of the users are considered. For example, a system can judge the user’s motives for entering a space, such as entering a kitchen in a house to prepare breakfast in the morning. Smart systems can identify their implicit needs to suggest meals with low calories, such as coffee and scrambled eggs, by relating the reference to information on available ingredients in the house. The information here shows that users may have many other choices for breakfast, but it is hard to decide what to choose. Spatio-temporal reasoning is usually effective when the references include a sequence of actions, frequencies, and repetitions of the user’s behavior. However, recommending implicit preferences requires a method to analyze the causal relationship with the user’s explicit preference and determine the best selection based on the relationship.
Learning and identifying the implicit preferences of users is challenging due to limited spatial-temporal references. Moreover, the causal relationship between explicit and implicit preferences must be strong enough for the recommendation to be meaningful and reliable. It is also essential to differentiate the user’s ‘needs’ and ‘wants’. Usually, the ’needs’ of the users are defined explicitly. In contrast, identifying the ’wants’ is the problem that should be addressed. Decisions are even harder for spatio-temporal needs to learn the specific attributes of the available options. Moreover, users are always influenced by the gain of making certain decisions and the fear of loss. Users usually do not make purely analytical decisions and are affected by sentiments, cultures, and psychological factors. Hence, we often see that users always make decisions by relying on other users’ sentiments, news, or rumors. This is even harder for inexperienced or first-time users who spend extra time and effort comparing and choosing based on limited information.
The motivation of this research is many research focuses on finding explicit preferences from existing data such as product specification, sales log, reviews, and surveys but do not focus on highly related implicit preference. Explicit preference can be easily extracted from existing data mining methods such as clustering analysis, machine learning, associative mining, and genetic algorithm. However, the gap lies when extracting implicit preference [
1]. He et al. [
2] stated the problem in extracting implicit reference where even though the explicit preference was given, we need to determine the co-occurrences in the explicit preference of another user. However, there are some cases where users do not have any explicit preference at all. Implicit preference in our study is regarded as an
“unknown preference” by the user. Moreover, the implicit preference must have strong relations with each other. It means that the customer only knows their implicit preference if some relation related to their explicit preferences is given. In this method, we use a combination of process and associative mining to extract implicit preferences even if the users do not specify their explicit preferences.
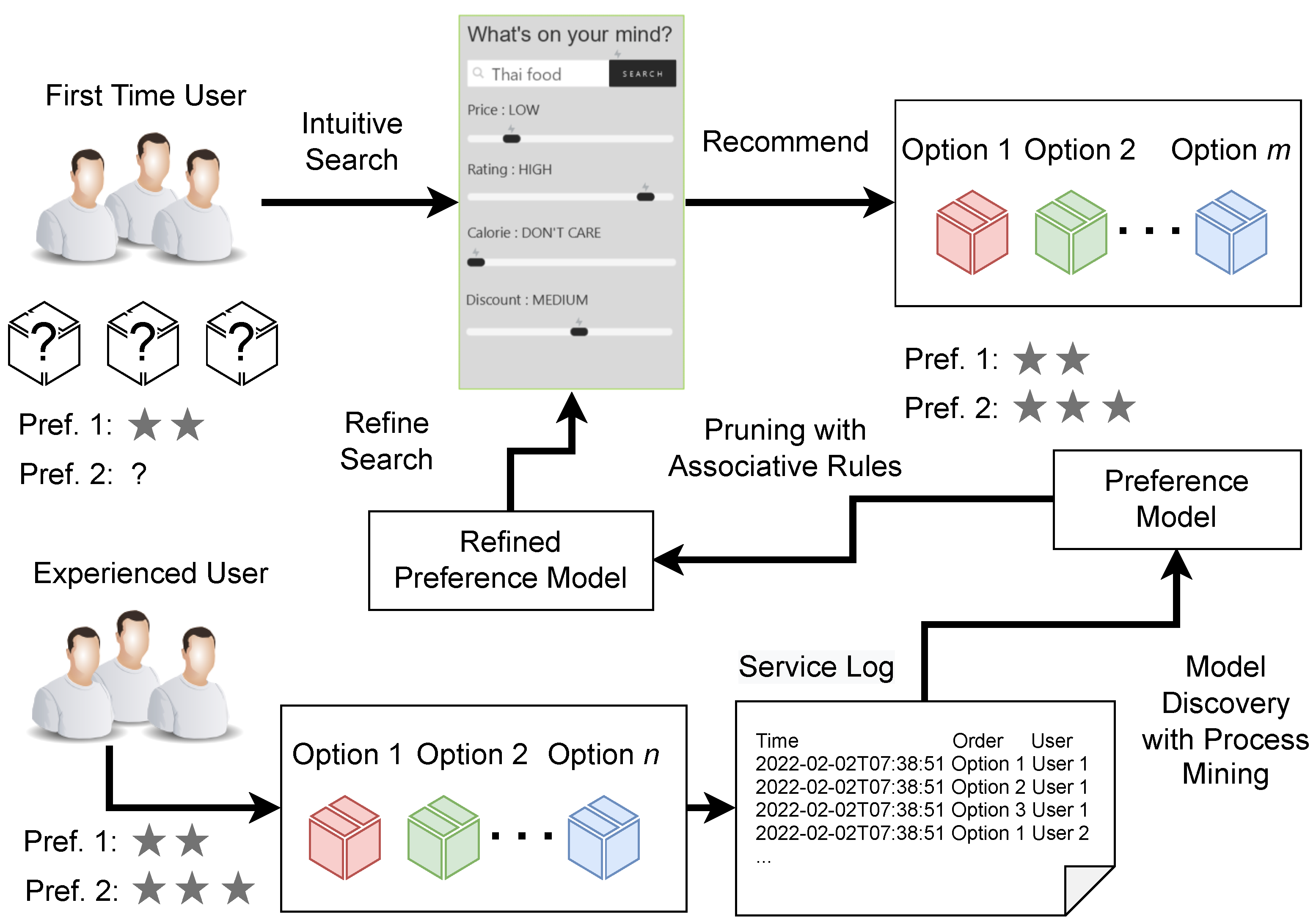
In this paper, we proposed a method to extract associative rules with a high correlation between X and Y based using process mining, associative mining, and correlation distance. The overview is shown in
Figure 1. The figure shows that for first-time users, it is easier to make decisions intuitively. Therefore, they need an ‘intuitive recommendation’ based on their preference. Our approach takes a service log and extracts the preference model using process mining. Then the service model is refined by pruning associative rules. A result is an option for selection that discovers the implicit preference that even the user does not know before.
The main contributions of this paper are as follows:
A method that combines process mining and data mining to extract preference models for implicit preferences.
Extract implicit preferences that have a strong correlation between attributes even if the user sets some of their preferences as ‘no-interest.’
The method outputs not a single choice of an item but multiple combinations of highly correlated items as recommendations to both first-time users and experienced users.
The benefit of this study is that even though the users do not give any explicit preference, which is ‘no preference’ set for all attributes of any item, the method can still extract what they might prefer by referring to the previous preference of previous customer as a starting point. If any explicit preferences are given, the preferences will be used as a reference. Intuitively, the user requires less effort but more flexibility in making a decision.
This paper is organized as follows; After the introduction, we give the preliminary to introduce process mining, association rule, and Cook’s distance. Next, we define the problem of service preference extraction and explain the problem. Finally, we evaluate the proposed method to show its effectiveness.
2. Preliminary
2.1. Process Mining
Process mining [
3] is a technique to extract process models from event logs such as sales logs, system logs, and business process logs. For example, a sales record of a transaction between a client and business or customer purchase records. We can utilize process mining to extract a process model called Petri net from an event log. Petri net [
4] can represent the execution order or sequence of actions. Process mining links data and processes where some data can only be visualized as a process or as the action of a sequence. Process mining can be performed with process mining tools such as ProM [
5], Disco [
6], or RapidProM [
7].
In this paper, we utilize a process mining method called inductive miner [
8]. Inductive miner is a method to extract logically correct and sound processes. A logically correct process does not contain any conflict, such as deadlock or overflow. An inductive miner can extract sound Petri net or an equivalent form of Petri net called process tree [
9]. The representation of the process using sound Petri net and process trees ensures that the process does not fall into spaghetti conditions. Therefore, the inductive miner is suitable for our approach. We utilize the Petri net to represent items’ selections in sequences with strong correlation and frequency.
Concretely, the inductive miner extracts the process model in a block model representing a sequence, exclusive choice, parallel, and loop constructs. These four constructs represent the basic constructs in ost business process workflows. Business workflows, including customer services, can be modeled with Petri net.
2.2. Association Rule
An association rule represents a rule of antecedent and consequent. An association rule can be expressed with
where
is the antecedent for consequent
such that when
occurs then
will occur. As an example, we take an association rule such as
represents that if the outlook is sunny or windy, then do play outside. Association rule can be extracted from popular algorithms such as Apriori [
10,
11] or FPGrowth [
12]. The rule is decided by proportional values such as support, confidence, and lift. To extract associative rules, we utilize the Apriori algorithm.
Let
or
be an itemset. Support
is the number of instances that satisfy the rule. The confidence ratio is the ratio of a rule to be true in a dataset. It is given as in Equation (
1).
Lift is the ratio of confidence and unconditional probability of the consequent. lift > 1.0 shows that
L and
R are dependent on each other.
2.3. Cook’s Distance
Cook’s distance
[
13] is used to measure the influence of an independent variable against another multi-dependent variable. The approach is by removing the target independent variable from the observation. The Cook’s distance can be calculated with Equation (
3). Equation (
3) shows the average of
y at observation
j when
i is removed from the observation.
r is the regression model’s coefficient.
The sum of
is calculated at each observation
j where the distance is calculated based on the regression line of each observation when
i-th observation is removed. Since all points on the distribution are considered, Cook’s distance is calculated based on the regression by the concept of ‘leave-one-out.’ We can say that Cook’s distance is the distance between the point of regression line produced by averaged
y value and when
i is removed from the observation. The calculated distance can measure the influence of
i in the distribution group because Equation (
3) averages the sum of residuals
y with the MSE.
The given Cook distance shown in Equation (
3) utilizes Manhattan distance [
14] when calculating the absolute sum of
. It is the
-norm (Manhattan’s generalized form) derived from a multidimensional numerical distance called Minkowski distance [
15] as shown in Equation (
4). Given an
-norm in Equation (
4), the sum of the absolute value of
in Equation (
3) satisfies
-norm when p
1.
Cook’s distance is simply the distance between averaged regression value of
(when
i is removed) and the normal average value
. By replacing the numerator with
-norm, we can obtain the Euclidean version of Equation (
3).
Distance
is a metric if it satisfies (i)
≥ 0 (non-negativity); (ii)
=
(symmetry); (iii)
if and only if
(coincidence axiom); and (iv)
(triangular inequality axiom) where
is the distance between
x and
y, and
z is the point between them. The properties (i), (ii), and (iii) are trivial when
x and
y are obtained from absolute value, and if
x and
y are the same, the distance is 0, also symmetrically, the distance is the same. To show Cook’s distance satisfies the triangular inequality axiom in (iv), we can utilize the generalized form of Manhattan distance and Euclidean distance shown in Equation (
4). Since Cook’s distance is
-norm, it is well known that we can set
to obtain the
-norm (Euclidean distance). Therefore, we can write the distance
shown in Equation (
5). From Equation (
5), we can identify that
is Euclidean and satisfies the triangular inequality axiom.
As stated by Chai et al. [
16], the value of
satisfies triangular inequality (see Equation (
6)). The regression coefficients are represented by
p, and
is the regression’s Mean Squared Error (MSE). The value of
is the Euclidean distance of residual error on how close a point
y is to the regression line (when averaging the
y values), assuming that the distribution is a Gaussian distribution. The value of
can be calculated as in Equation (
6). The Euclidean distance is divided with
where
n is the number of samples in the distribution.
The residuals
can be represented by
n-dimensional vector
V. Let
X,
Y, and
Z be
n-dimensional vectors. Based on the metric properties [
17], Equation (
7) shows that
satisfies the triangular inequality axiom [
16] such that
We can also obtain
-norm (the Euclidean version) of Cook’s distance as follows:
Cook’s distance is usually used for outlier detection where the outlier value deviates far from other independent variables’ values. From Equations (
3) and (
8),
can be used to remove outlier or weak associative rules. For simplicity, we utilize Equation (
3) in this paper.
3. Related Work
Mining customer preferences involves various parameters and decision support tools such as user preferences attributes, product specifications, and sentiments. Many related works focus on both user preferences and product specifications. The commonly used method includes cluster analysis, machine learning, genetic algorithm, and associative mining. The related works are shown in
Table 1.
Clustering analysis groups preferences by performing clusters on the available data. Zhang et al. [
18] consider product competitiveness when mining customer preferences. They proposed an information mining method that utilizes entropy and density-based clustering analysis to the customer preferences. Chong et al. [
19] proposed a method to identify preference by clustering items based on multi-attributes such as consumer sensory scores. Seo et al. [
20] proposed a recommender system for a group of items that are based on genre preference that may reduce clustering computation cost. Other clustering-based analyses were also proposed by Osama et al. [
21] and Wang et al. [
22].
Machine learning can predict user preferences by learning from recorded transaction data. Xiao et al. [
23] focus on the sentiment tendencies of the customer to extract their preferences. These tendencies are fine-grained to improve the performance of the analysis. The fine-grained sentiment analysis problem is converted into a sequence labeling problem to predict the polarity of user reviews. Since the problem involves sentiment analysis, the user-feature focus on the review dataset with text information, such as words with emotional words. Conditional Random Field (CRF) and neural networks were applied to analyze the text sequence. Zheng et al. [
24] focus on immersive marketing and applied graph neural network models that consider essential attributes to improve the consumer shopping experience. Other related works related to machine learning were also proposed by Sun et al. [
25], Aldayel et al. [
26], and Bi et al. [
27].
Genetic algorithms can find the most optimal preferences from various preferences patterns based on evolutionary algorithms. Gkikas et al. [
28] proposed a combination of a method using binary decision trees and genetic algorithm wrappers to enhance marketing decisions. They focus on customer survey data to classify customer behaviors. As a model to classify customer behavior, Optimal decision trees are generated from binary decision trees, representing the chromosomes handled in the genetic algorithm wrapper. Das et al. [
29] used a genetic algorithm to predict the premium of life insurance based on consumer behavior toward the insurance policies before and after-pandemic situations. Other work was proposed by Jiang et al. [
30] and Petiot [
31].
Collaborative filtering collects preferences from many customers and predicts a user’s preferences. Alhiijawi et al. [
32] applied a genetic algorithm with collaborative filtering to generate recommended preferences using multi-filtering criteria. Liu et al. used weighted attribute similarity and rating similarity in collaborative filtering that can alleviate data sparseness. Liang et al. [
34] focus on diversifying recommendations using neural collaborative filtering that can achieve high diversity in a recommendation. Valera et al. [
35] proposed a method that uses collaborative filtering not for single-user preferences but for group preferences. The method takes into account taking individual preferences and context in the group. Other work includes Fkih et al. [
36] and Davis et al. [
37].
Associative mining extracts associative rules from available data to recognize patterns based on basket analysis. Qi et al. [
38] proposed an algorithm that utilized weighted associative rules to discover frequent item sets with high values. Tan et al. [
39] proposed top-k rules mining based on MaxClique for contextual preferences mining. In the method, they applied the problem to association rules extracted from preference databases. They offered a conditional preference rule with context constraints to model the user’s positive or negative interests. Other work includes Ait-Mlouk et al. [
41] and Kaur et al. [
42].
The given related works focus only on the interestingness of an item, such as buyer sentiments towards one attribute, i.e., rating or prices. However, it is hard to simultaneously extract implicit preferences with multi-variate attributes such as price, rating, and discount. There exists a trade-off between choices and attributes of target items. Moreover, it is hard for users to decide on many multi-variate attributes simultaneously. Therefore, there is a need to balance between choices and attributes in customer preferences.
4. The Problem of Implicit Preference Extraction
First, we formalized the problem of extracting service preference from the service model representing the business rule based on the sales log. First, we define preference as follows:
Definition 1 (Preference). A preference σ is denoted by n-tuple where is called as preference attribute of σ.
We formalize a problem which is to achieve a goal for service preference extraction.
Definition 2 (Service Preference Extraction Problem).
Input:Sales log S containing items , explicit preferences set
Output:Implicit preferences set
Based on the problem definition above, we input a sales log S and explicit preferences . The sales log contains items . The preferences corresponds to each item . Example of explicit preferences P and implicit preferences can be given as and (High, Low, High) where abstract attributes value such as High, Low and No-Interest corresponds to the preference of item . Here, the implicit preference reveals No-Interest in attribute Discount can be replaced with High value.
First, we extract implicit preferences set then output the new preference to represent the choices of items that have strong correlation between attributes. The implicit preferences do not satisfy for all of its elements. If , then the explicit preference for item does not change. However, if there is at least one element that satisfies , we can call as implicit preference. Therefore, we define implicit preference as follows:
Definition 3 (Implicit Preference). For a given item set and its explicit preference , implicit preference is defined as where and satisfy the following:
- (i)
There exists at least one such that each and represents the preference of item .
- (ii)
Item set for explicit preference σ and item set for implicit preference π satisfy .
Definition 3 denotes implicit preference that satisfies , respectively. Implicit preferences are regarded as preferences that are not shown in explicit preferences. However, no implicit preferences are extracted if holds for all elements.
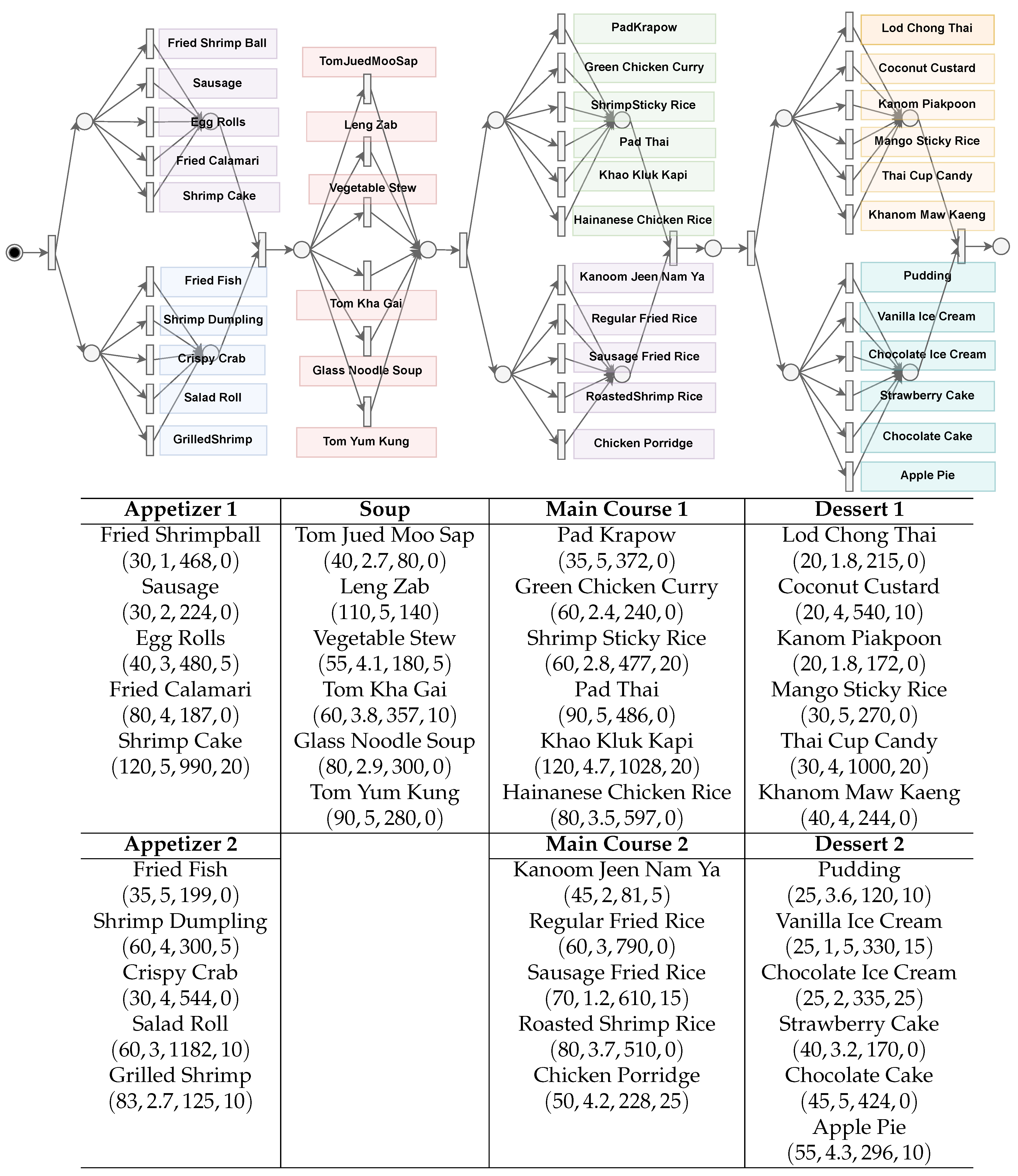
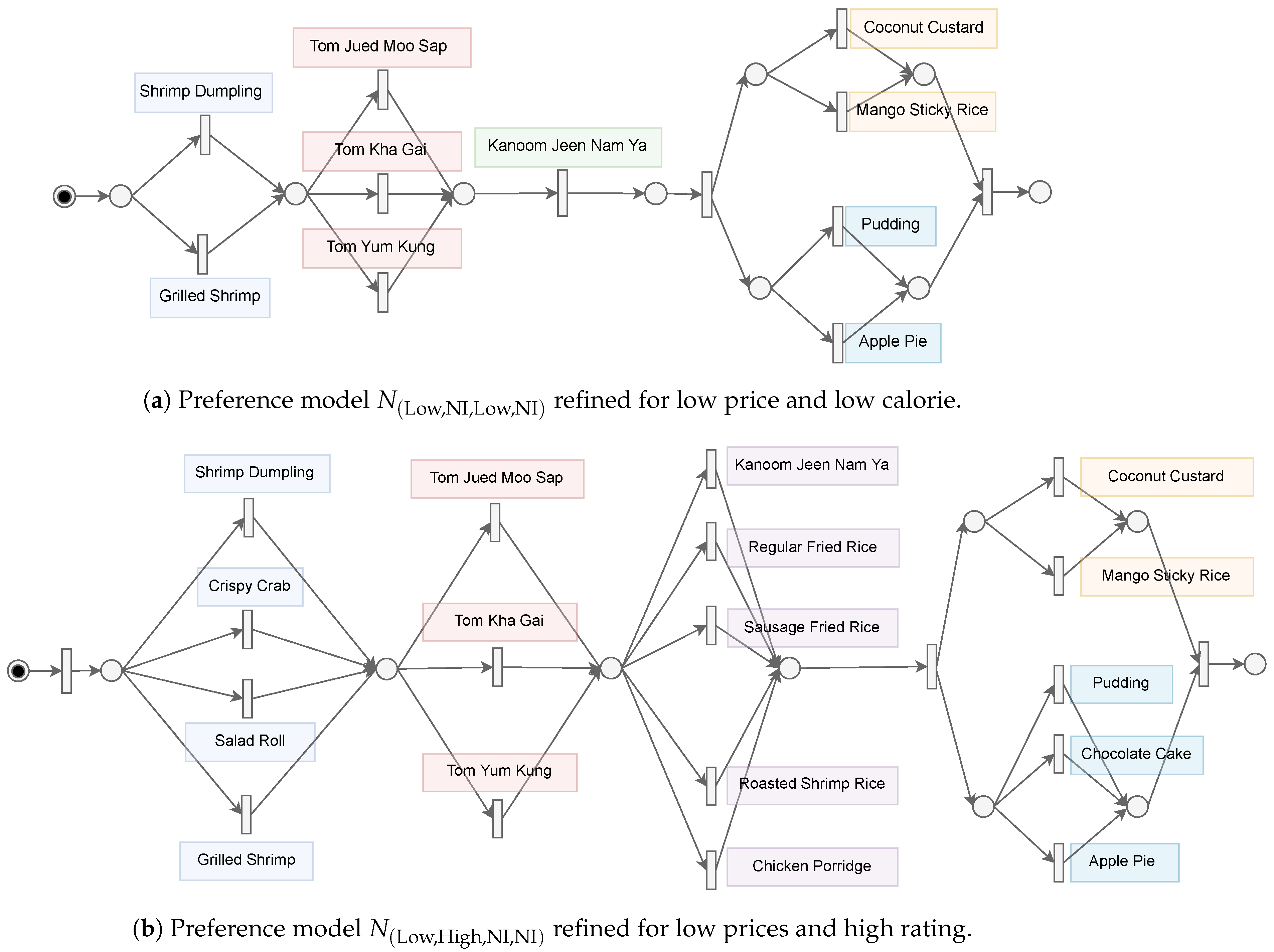
We use an online ordering system as an example to demonstrate our ideas and approach. The online ordering system takes orders for a Thai cuisine menu. The menu can be modeled with Petri net as shown in
Figure 2.
Figure 2 is represented by a Petri net that shows a selection of items from the menu in a sequence form from left to right. Each node and arc shown in the model represents a possible combination of the items. The menu contains eight categories, which are
Appetizer1,
Appetizer2,
Soup,
MainCourse1,
MainCourse2,
Dessert1, and
Dessert2 is shown in
Figure 2 as a group of connected nodes and arc from left to right. The combination of items can be decided by looking at each attribute, i.e.,
Price,
Rating,
Calorie,
Discount. The customer can choose to select one from each category as their choice from the course menu. The menu shows the restaurant’s price, rating, calories, and discounts. The combination of selections that the user can make is 192,400 combinations. Therefore, it is hard for users to decide on the course that suits their preferences.
For further explanation, we give an example of three customers with different preferences. Customers usually express their preferences intuitively. We can conclude that customers make decisions based on specific attributes, but it is hard to look into the details of attribute values, especially for first-time customers. Moreover, they usually depend on the server or service advisor for recommendations. Therefore, the server or service advisor must make suitable recommendations that satisfy the customer. Let us consider the preference of the following customers:
Alice: She prefers food with low calories and prices. She will usually ask, “I prefer a healthy diet. What is the food with low calories but not too expensive.” However, she might be implicitly attracted to try highly-rated food or discounted menu.
Bob: He prefers food with a less expensive and good rating. Therefore, he will ask, “What is the best affordable food you recommend?”. It seems he does not care about calorie consumption and is also not interested in discounted food.
John: He has no specific preference. Therefore, he will ask, “What is today’s special?” or “What is your recommendation?”.
Since Alice prefers low-price and low-calorie, we can offer a new menu that allows the customer to choose items that strongly relate to low-price and low-calorie, for example, Grilled Shrimp for appetizers are low cost and always requested with Pudding because it has low calories. However, because only appetizers and desserts have a frequent pattern for a low price and low calories, other types of items more explanation, we’d like to give you Jued for soup and Kanoom Jeen Namya, will also be requested by the customer because they have attributes with low price and low calorie. In the case of Bob, he prefers low-price but good ratings. Similarly, he might be attracted to calorie and discounted food if he looks into the details. In the case of John, it is the hardest to meet his demands since he also needs to know what he prefers so that he will set all his preferences as No-Interest.
Customers with explicit preferences will be restricted to a few uninteresting choices. Fewer choices may reduce repeat customers. The case is similar to Bob, who prefers inexpensive food with high ratings where he does not care about calorie consumption and discount. Sometimes, customers such as John do not know what he likes. Therefore, to respond to preferences that are not specific, the customers should be given a range of attractive selections on the menu that might satisfy their implicit preferences.
5. Preference Refinement by Associative Rule and Process Mining
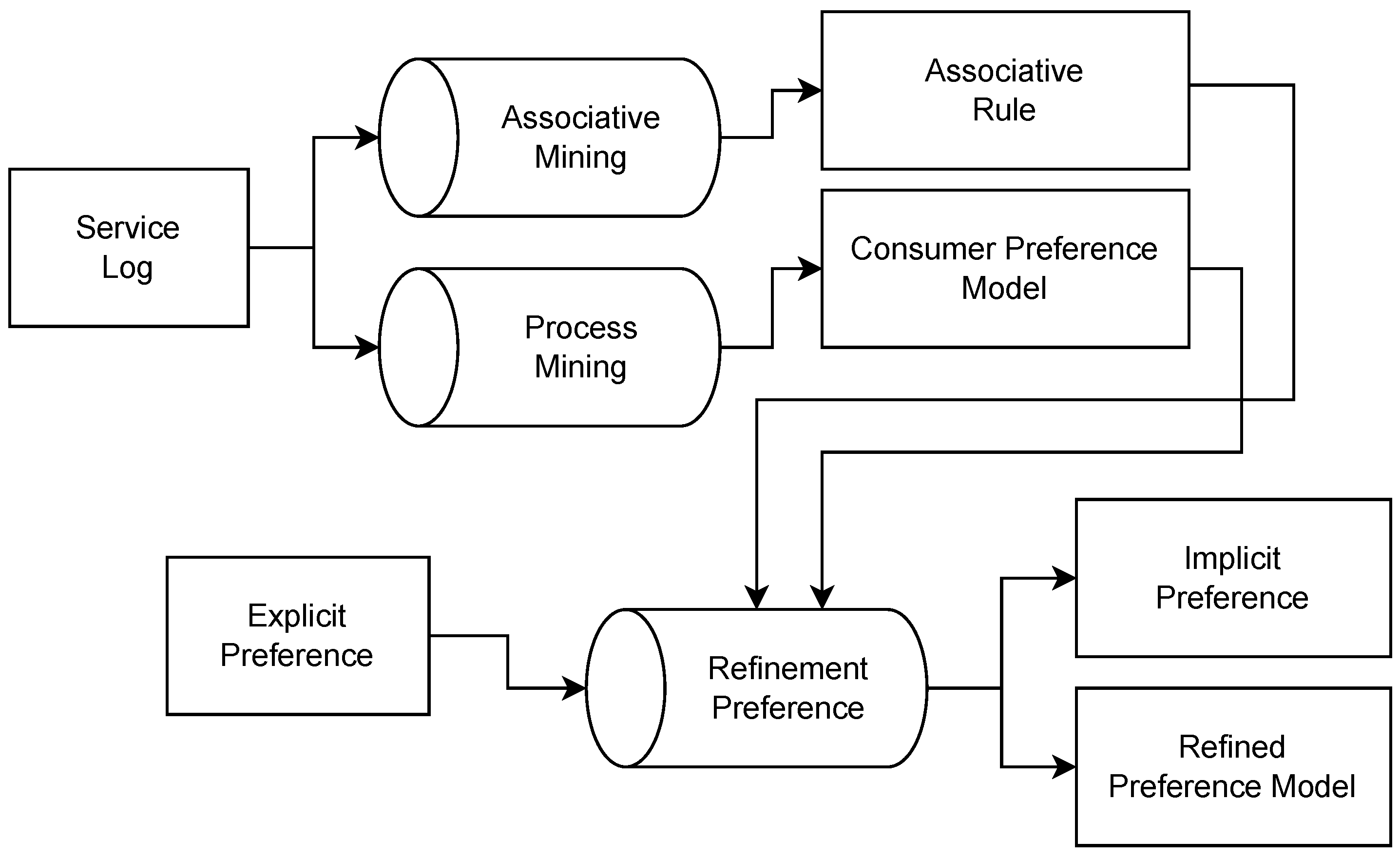
We illustrate the details of our method in
Figure 3. First, we extract frequent items that include associative rules with low confidence and lift value using Apriori. Then, we remove irrelevant rules that are (i) duplicate rules, (ii) not satisfying user preferences, and (iii) outlier rules in which correlation distances are too high.
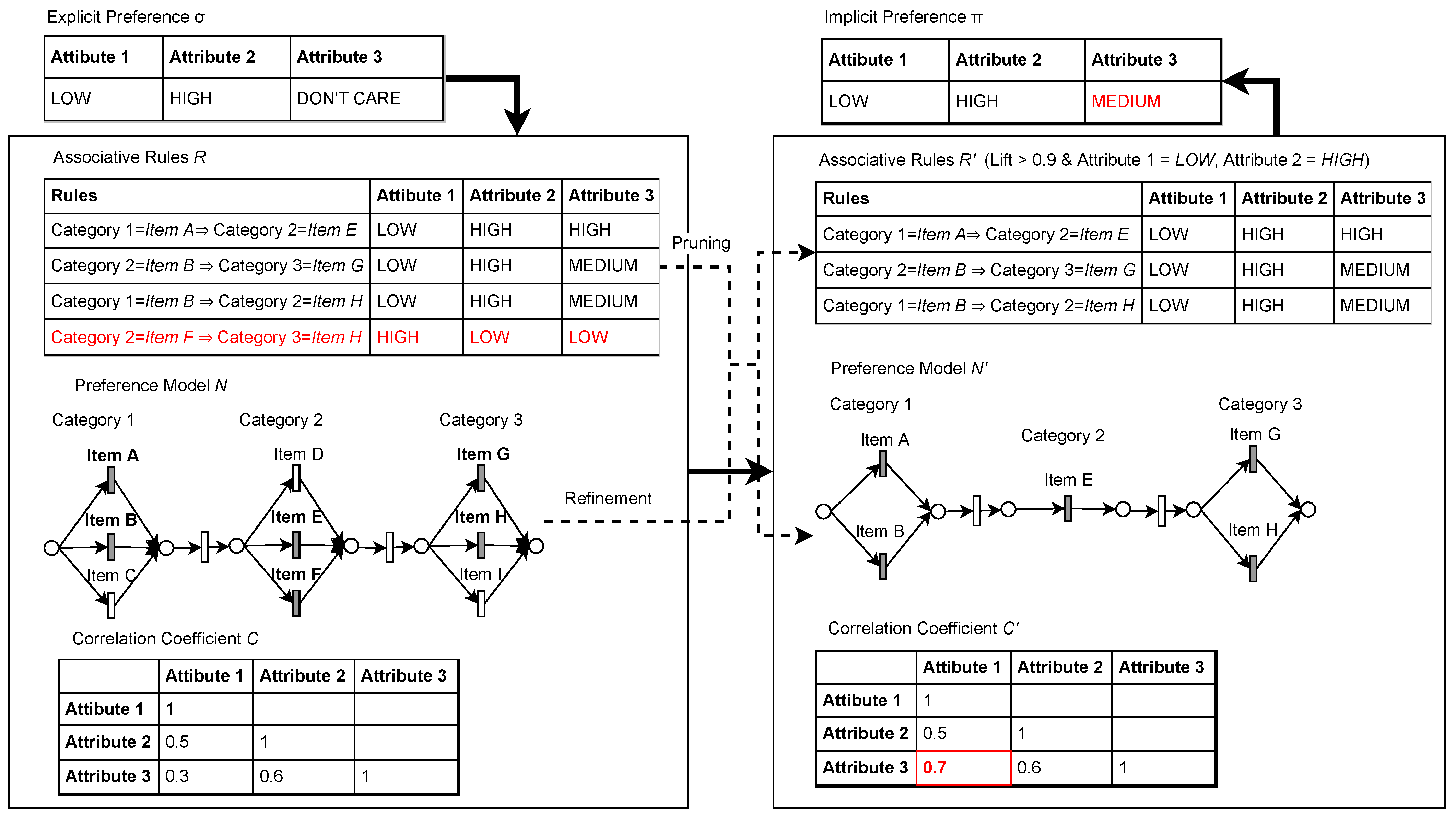
Figure 4 shows the overview of our approach. Given a preference
P of some attributes such as
Attribute 1,
Attribute 2, and
Attribute 3. For example,
Price,
Calorie and
Rating. These attributes as given as
where each represents the preference of
Price,
Calorie, and
Rating. The value can describe a range of values, such as 0 to 100. For example, if the value is 0 to 50, then the value is represented by
; if the value is between 51 to 100, then the value is represented by
. If no preferences are given, then the value can be between 0 to 100, which
represents.
From here, the preferences are taken as a reference when extracting the associative rules from the service log. The associative rules can be represented such as ( . is the category of item that corresponds to the general options available in the services. For example, Appetizer, Main Dish, Soup, and, Desert. Each item, such as , represents the selection within the category. For example, for Appetizer, some items such as are available for selection. The rules are accompanied by a set of attributes with values calculated from the average of the attributes of each item found in the rules. For example, for rules , the preference of attributes found in the rules is .
Next, the correlation between attributes is calculated. Based on the correlation values, i.e., Pearson correlation [
43], we filter out some rules with attributes that have a high distance value using Cook’s distance [
13]. Then, we recalculate the correlation and value of attributes of the rules. Since the rules with high correlation were pruned, we can obtain the new preferences
that are optimized for the customer. The changes are then used for the refinement of the service workflow. The new service workflow represents a workflow that satisfies the new preference
. The rules which satisfy
are preserved. Associative rules with a Lift value that is larger than 1 show a strong relationship between an item set
X and
Y. Rules with
are considered strong. Note that the value is not absolute; some rules with a high lift value do not always have higher confidence than those with a lower lift value. If we increase the threshold of the Lift value, the number of extracted rules will be reduced. Therefore, we recommend reducing the Lift value to
.
The next step is to find out which menu the customer prefers. We set the parameters within a specific range to identify the relationship between items. For example, for
Price attribute, we set the range between 0.0 to 80.0 as
Low, and 81.0 to 140.0 as
High. This range can be decided using discretization such as the binning method [
44] or pre-defined by the user. We call the set of values as preference class
.
Definition 4 (Preference Class). For a given attribute value α, the value of α can be represented with preference class γ if α ranges between denoted by .
For example, we separate Low and High values based on the median value. Therefore, we can give the parameters of preference based on preference class as follows:
- (i)
Price: ,
- (ii)
Rating: ,
- (iii)
Calorie: ,
- (iv)
Discount: ,
- (v)
No-Interest:
As a practical method to capture customers’ intuitive preferences, Based on the range of values, we allow setting the preferences intuitively rather than giving specific values.
First, we extract the set of associative rules R from the sales logs. A threshold of more than 0.9 is used for Apriori. Next, we extract the customer process model using process mining. The process model represents the ordering sequence of items shown in the sales log. Then, all rules with a low Pearson’s correlation coefficient, i.e., less than 0.5 are removed. For rules , we check the regression. If the Cook’s distance of is more than the threshold , we remove the rule . The reason for setting the threshold value of 1.5 times is that most distance that is too high exceeds 1.5 times more said to deviate from the average value. However, depending on the analysis of the services, the user must decide on a suitable value.
The procedure for extracting implicit preference is given in Procedure ≪Procedure of Implicit Preference Extraction≫. The procedure discovers the process model
N, and extracts the set of associative rules
R. Then the procedure filters out weakly correlated associative rules and items in preference model
N and the set of rules
R using Cook’s distance.
Table A2 shows the rules that satisfy the explicit preferences, and the Pearson correlation value is shown for each relation between attributes
Price-Rating (PR),
Price-Calorie (PC),
Price-Discount (PD),
Rating-Calorie (RC),
Rating-Discount (RD), and
Calorie-Discount (CD). The table also shows the number of rules extracted. We only focus on preferences that can extract more than 30 variations of rules. Note that the set of rules also includes duplicated rules at this phase. From the set of rules, we filter out the weak rules that have weak correlation values.
We utilize Cook’s distance and associative mining. Cook’s distance characteristic is that during regression, it can detect highly influential items from a set of items. The measurement is regarded as the value of the influence of an item if it is removed from the group. In Cook distance, we can control how large the influence can be tolerated for an item by maintaining the sensitivity of the distance. For example, as a rule of thumb, a distance 1.5 times above the mean indicates that an item correlates less with other items in the group. Depending on the situation, the user can adjust the control parameter. Cook’s distance is a distance based on regression and is suitable for multivariate analysis. Therefore, we handle all items as a highly correlated group with high sensitivity between them. Items that are far from the group have more distance. In Cook’s distance, we perform a least-squares regression analysis to measure the influence of one item on another item in the same group.
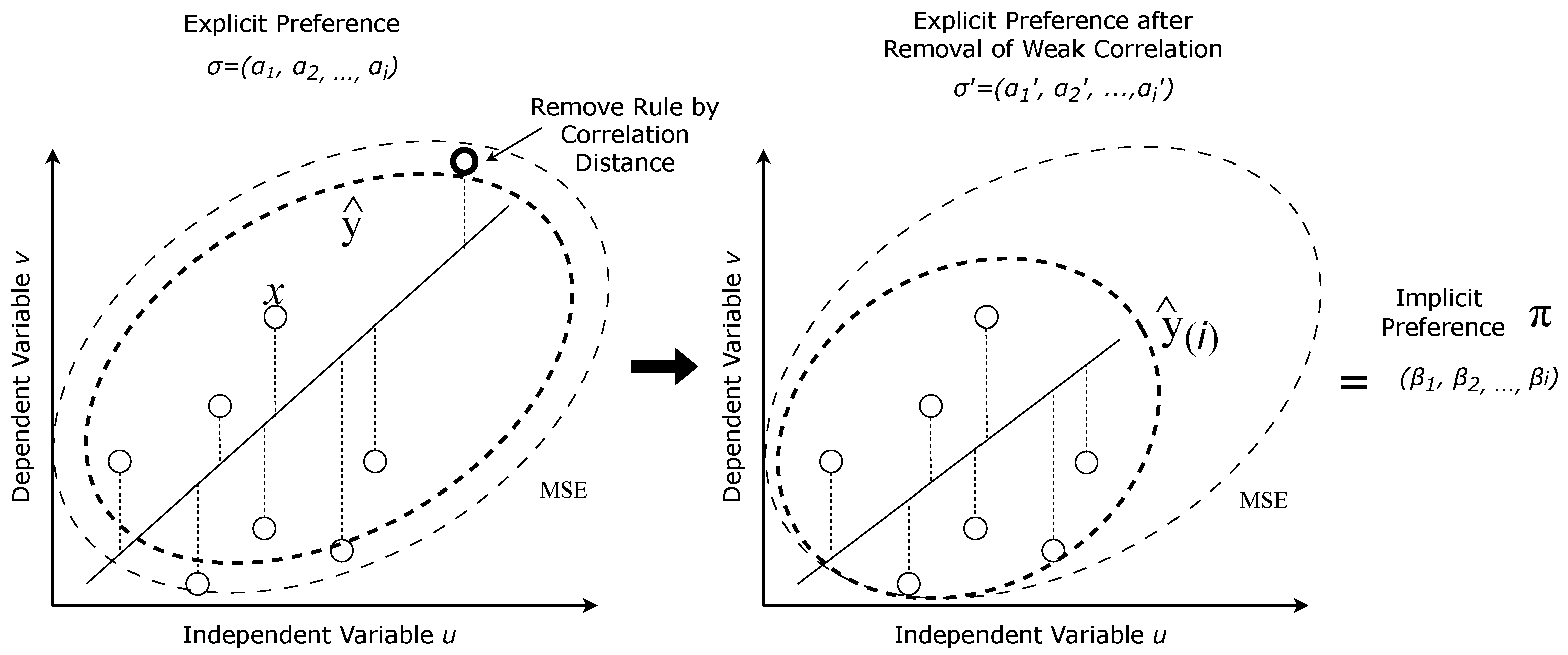
Figure 5 illustrates the overview of removing weak correlated multivariate associative rules with our method. The rule is removed by averaging the value of
when
is removed from the attributes observation
i. Value
u and
v represent the value of each rule shown as ∘. The dotted line between ∘ and the regression line (solid line) shows the residual of the regression. The absolute difference
is averaged by regression MSE using the residual value. Implicit preference
can be produced from the difference of explicit preference before and after the removal such that
.
Next, to calculate the cut-off point, we utilize Cook’s distance, denoted by
as shown in Equation (
3). We calculate the correlation distance if the set or extracted associative rules is not an empty set such as
. Therefore, the equation can be given as in Equation (
9).
is the adjusted mean value for the cut-off point of the correlation distance.
The value of
denotes the mean of the correlation distance calculated by Cook’s distance. The sensitivity of the outlier removal is controlled by variable
h, which is the distance ratio from the mean value that is calculated from
using Cook’s distance formula shown in Equation (
3).
Algorithm 1 shows our main procedure in extracting the implicit preference. The complexity of the Algorithm 1 is where is the number of rules, is the number of preference attributes and is the number of action labels. The ≪Procedure of Implicit Preference Extraction≫ shows the whole procedure using process mining, associative mining, and implicit preference extraction using Cook’s distance.
≪Procedure of Implicit Preference Extraction≫
Input: Sales Log S, set explicit preference , lift threshold
Output: Refined Preference model and set of implicit preference
- 1°
Discover process model from order log E using process mining.
- 2°
Extract associative rules where from event log E which satisfies .
- 3°
Extract implicit preference for N using Algorithm 1.
- 4°
Output refined process model with implicit preferences and stop.
| Algorithm 1:Implicit Preference Extraction |
Input: Preference Model , Explicit preference , Cut-off threshold h, Set of associative rules R Output: Refined Preference model and implicit preference - 1:
, - 2:
for each do - 3:
for each of do - 4:
if then - 5:
▹ Add to new set of rules if satisfies - 6:
end if - 7:
end for - 8:
end for - 9:
for each do - 10:
for each () do - 11:
if and then - 12:
▹ Remove duplicated rules - 13:
end if - 14:
end for - 15:
if Cook’s distance then - 16:
▹ Remove outliers with low correlation - 17:
end if - 18:
end for - 19:
for each task label do - 20:
for each do - 21:
if or then - 22:
▹ Remove label t from N if t is not in item sets X or Y - 23:
▹ Create new process model with - 24:
end if - 25:
end for - 26:
for each do - 27:
▹ Calculate mean of attribute for each - 28:
▹ Set with value δ by mapping to preference class - 29:
- 30:
end for - 31:
▹ Construct the implicit preference π - 32:
end for - 33:
return ▹ Output refined process model with implicit preferences and stop
|
The proposed procedure utilizes the mechanism of Cook’s distance when removing one variable
from the observation. For example, for a given preference on
,
,
, and
, we can observe the influence of
by setting
as target
i. We can observe the improvement of residual coefficient
in the regression.
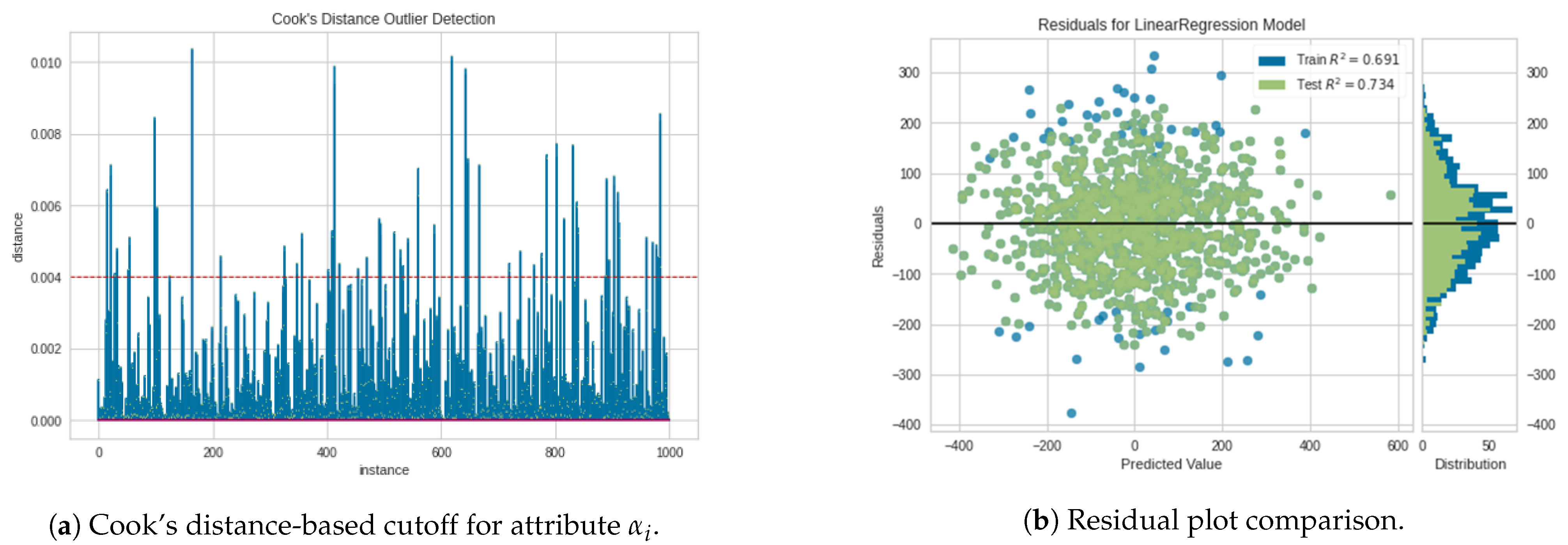
Figure 6a shows the distance for each item of
rules. The cutoff line shows the threshold at
.
Figure 6b compares residuals before and after removing weakly correlated rules. The
value was
, but the normal distribution distorted slightly to the positive value.
Figure 6b shows the residual coefficient improved to
.
Figure 6b shows that the correlation improved because the distribution changed from a more dispersed distribution into a tighter distribution resulting in a higher
value. The green dots represent the distribution after weakly correlated rules were removed, and the blue dot shows the distribution before the removal. We can see the blue dots are the outliers that were removed from the set of rules. Here, we confirmed that Cook’s distance is effective in our procedure.
6. Application Example and Evaluation
We applied our method to an order transaction that included 40 items, as shown in
Figure 2. As stated in
Section 4, customers can have at most 192,400 combinations of unique orders. Here, we evaluated the data with at least 60,000 data recorded in the sales log. Based on the steps in Procedure 1, we perform data cleaning to remove duplicate rules. We filter rules using Cook’s distance to preserve rules with strong correlations. The procedure will remove rules that exceed the threshold value such that
.
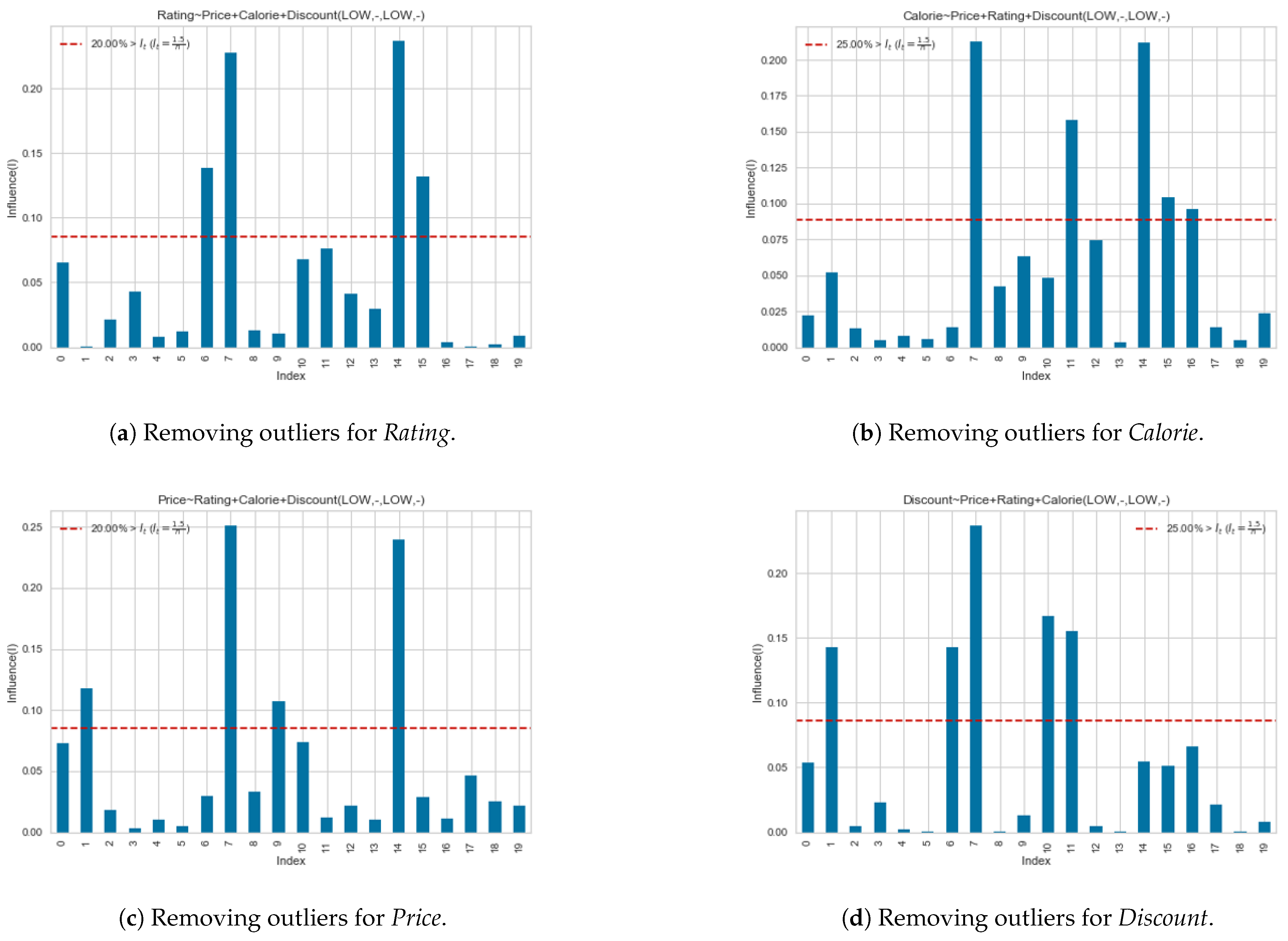
Figure A1a,b shows the detection of irrelevant rules which are over the threshold value. Each figure shows
Price,
Rating, and
Calorie as independent variables. The same procedure also applies to
Price and
Discount. Cook’s distance is calculated by taking the independent variables from the observation. The figures show that the Cook’s distance of index
i that is over the red line corresponds to rule
will be removed. For example,
Figure A1a show that rules
, and
were removed from the set of rules R.
Figure A1b,c also shows the removal of rules that exceeds the threshold value.
Apriori extracted 40 associative rules. The procedure outputs 11 rules with strong correlation such as
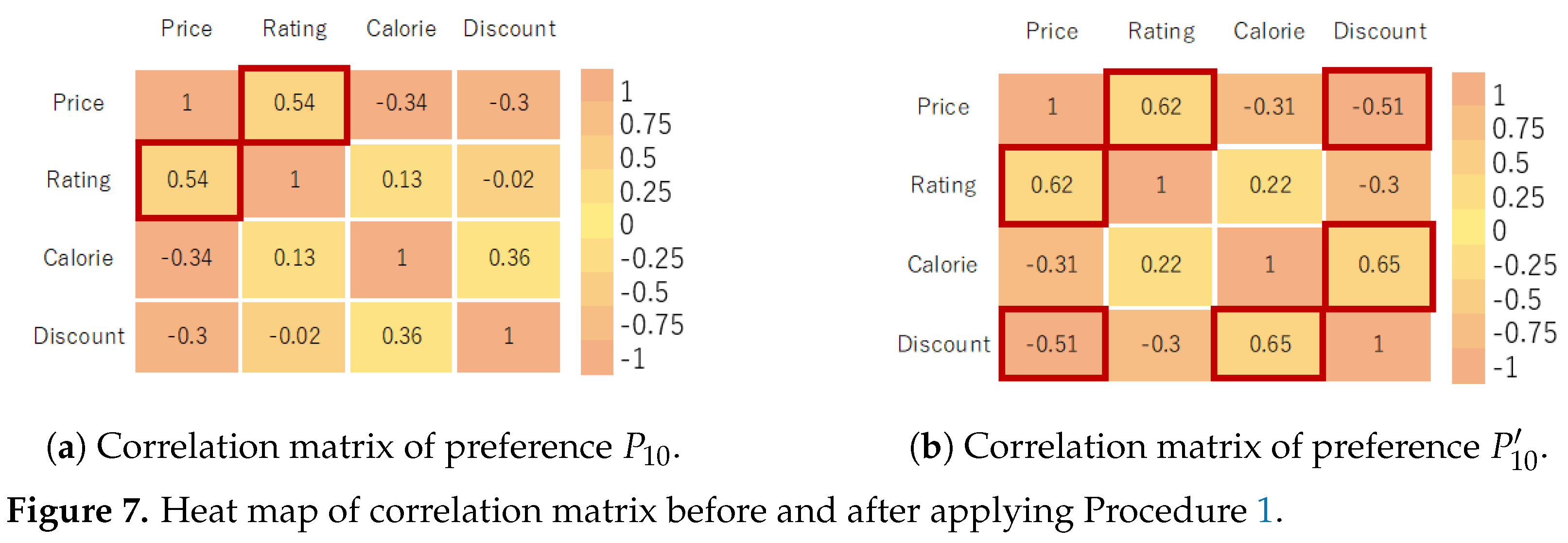
Price-Rating and
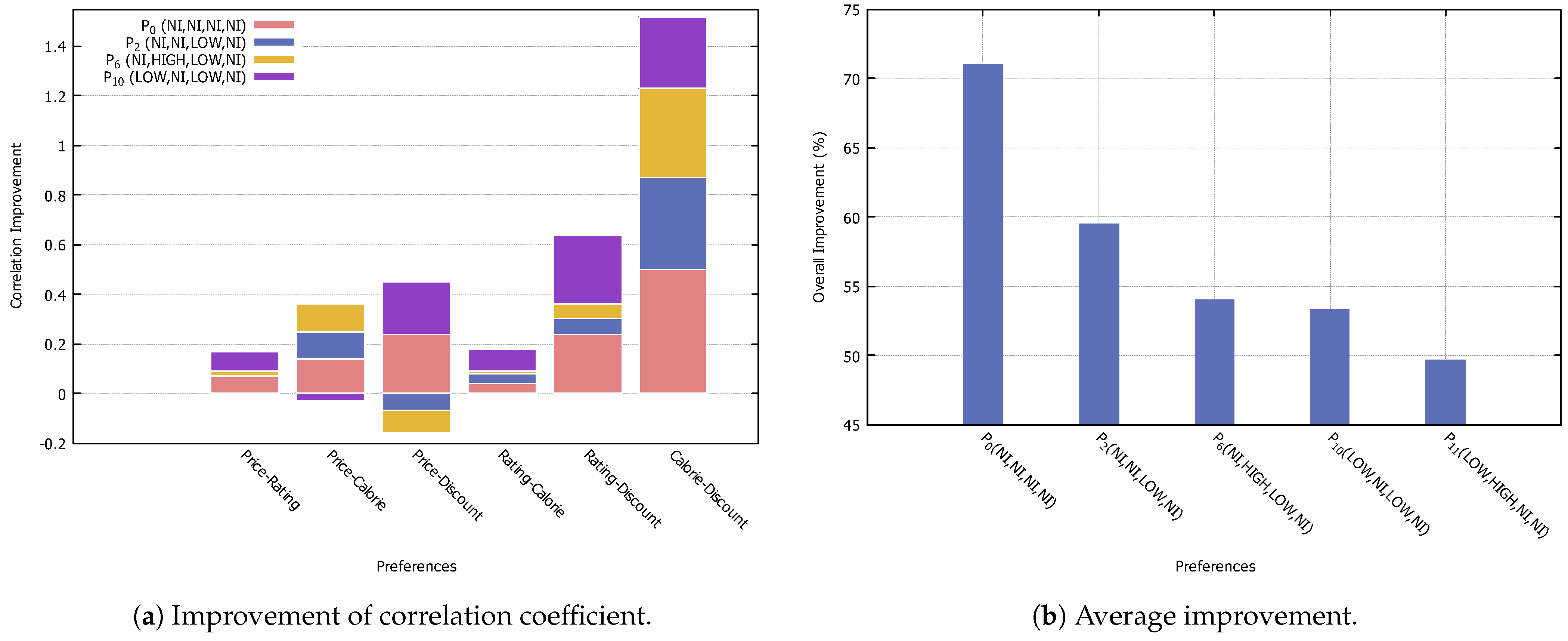
Calorie-Discount. From the result, the preferences for low prices and low calories strongly correlate with ratings and discounts. By successfully identifying this factor, we can motivate the customer to decide on this menu by offering more selections with a high rating and discount. The improvement of correlation, i.e., preference
is shown in
Figure 7a,b. After applying our method, the figures show the improved correlation of preference
.
The pruned and optimized preferences result is shown in
Table 2. For a given preference with high correlation, 6 preferences (
,
,
,
,
and
) were extracted. The refined preferences is shown as
,
,
,
,
and
. The course menu selection is optimized as shown in
Figure 8a,b.
Next, we evaluate our approach. First, we calculate the correlation coefficient rule removal based on Cook’s distance. From
Table A2, the value for the correlation coefficient of rules
and
was around 0.54.
Figure A1 shows the removal of rules with a distance that exceeds the threshold value for
. One independent variable is removed from each observation. Around 20% of the total rules were removed. Here, we found that preferences with
No-Interest (NI) reveal implicit preference with the highest correlation. For example, in
,
Rating and
Discount was set to
No-Interest, but
shows the preference have strong relation to high discount.
The mining result shows that Calorie-Discount and Price-Discount show an increase in correlation from 0.4 to 0.7 and −0.3 to −0.5. Here, the price and calorie attributes have high correlations to discounts. Based on this information, the seller of course menu can focus on discounted items for low prices and low calories. Preference can be refined as as . In the case of , low-price items and low-calorie item menus usually attract customers that prefer highly discounted menus.
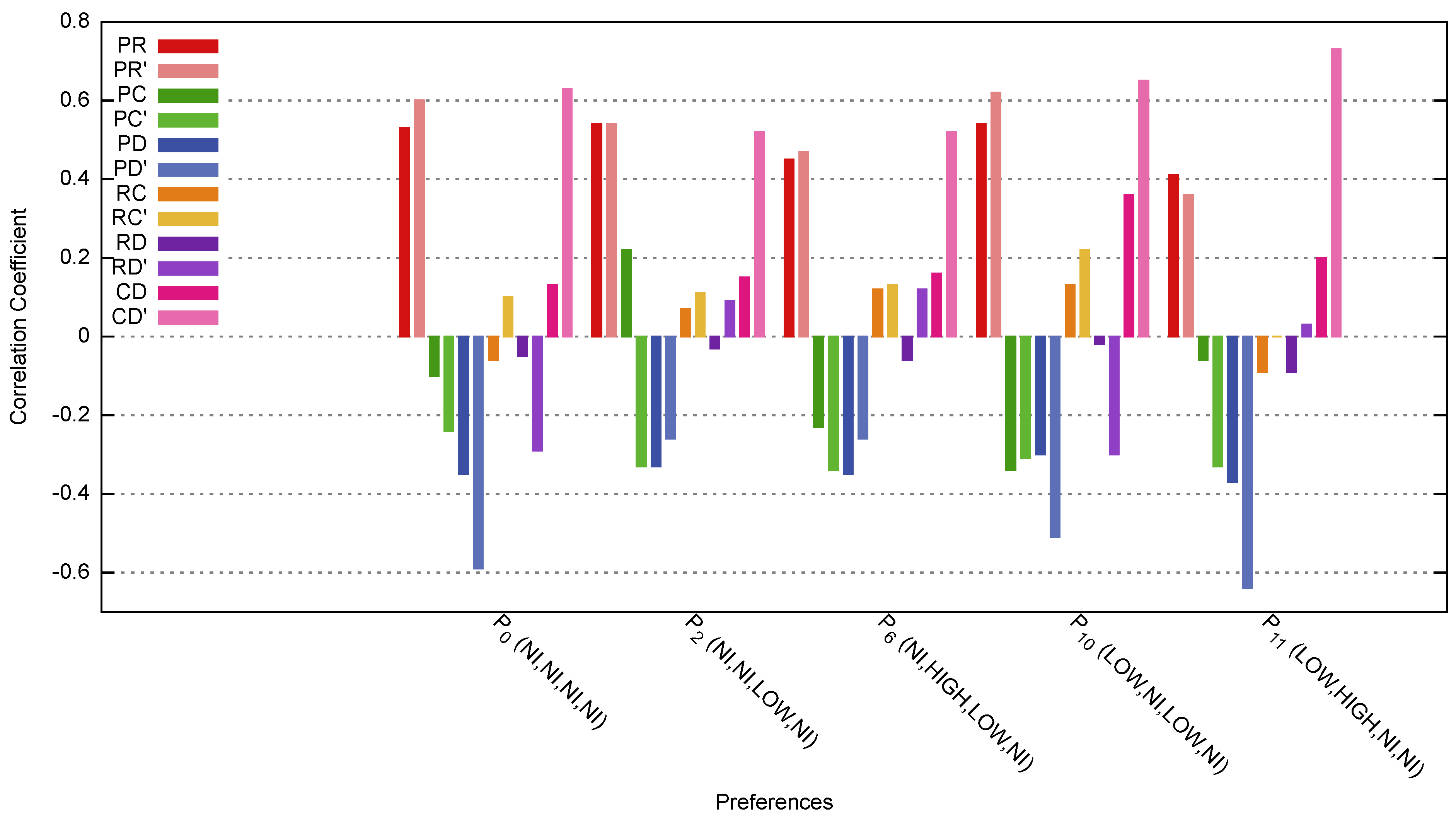
Figure 9 shows the correlation coefficient
for
Price-Calorie (PC),
Rating-Calorie (RC), and
Rating-Discount (RD).
PR’,
PC’,
PD’,
RC’ and
RD’ is the correlation after applying our method. Most of the attributes’ correlation increased. Here, some of the correlation changes from a negative correlation to a positive correlation. The correlation between negativity and positivity does not give much meaning other than the increase and decrease relationship of either attribute. In this paper, we focus on the strength of the correlation regardless of the negativity and positivity of the correlation.
Figure 10a shows the comparison of the correlation coefficient between attributes. The
Calorie-Discount relation shows the most improvement in preferences
,
,
, and
.
Rating-Discount and
Price-Discount show significant improvement in preference
and
. This is because
do not specify any interest where all attributes were set to no-interest (
N/I) and
is almost similar to
because the attribute values were set to
Low and
No-Interest.
Price-Calorie shows significant improvement in preferences
,
, and
. In contrast,
Price-Rating and
Rating-Calorie correlation shows an improvement. From here, we can conclude that
Price-Rating and
Rating-Calorie are explicitly expressed in the preferences. Therefore, relations such as
Calorie-Discount should be considered when recommending a new menu.
Figure 10b shows the comparison for the average improvement of the coefficient for each preference. From the result, preferences with more no-interest specifications show the most improvement. This shows that our method can extract implicit preferences. However, depending on the pattern of preferences of customers, the preferences with more specifications, such as
High and
Low, may have different improvement values. This may be caused by the variations of selections and combinations allowed in the services, i.e., the business rules.
7. Discussion
Previous research focuses on finding explicit preferences from existing data such as product specifications, sales logs, reviews, and surveys. Explicit preference can be easily extracted from existing data mining methods such as clustering analysis, machine learning, associative mining, and genetic algorithm. The explicit preference can be gathered from the mining result. However, the gap lies when extracting implicit preference. Implicit preference in our study is regarded as an ‘unknown preference’ by the user. It means that the customer does not know their true preference unless some relation related to their explicit preferences are given. In this method, we use a combination of process mining and associative mining to extract implicit preferences. The ultimate benefit is that even if they do not give any explicit preference, which is ‘no preference’ set for all attributes of an item, the method can still extract what they might prefer by referring to the previous preference of the previous customer as a starting point in making a decision on their preferences. Intuitively, the user requires less effort but more flexibility in making decisions.
The proposed method’s main characteristic is to partially extract implicit preferences where specific preferences for certain attributes related to a service or product are not the same. For example, in the given menu, course attributes such as Price, Rating, Discount, and Calories are four attributes the customer must consider. Therefore, even if they have a certain preference, such as low price and high rating, the approach can find implicit preferences that are most likely to be preferred by the user, such as high discount and low calorie. By converting numerical values in the attributes into abstract values such as category, i.e., High and Low, we can intuitively present the result to the customer. From the example, most restaurant managers generally refer to the best-selling items to improve their menu. However, the best-selling item is independent of each other, and sometimes there is no reason why such best-selling items perform better than other items. We assume that best-selling items usually is driven by other items but with less frequency. We can extract related items (mostly in sequence) from process mining to be selected by frequency. In addition, associative mining strengthens the correlation with support and lift value.
The main difference with previous works that focus on extracting explicit and implicit differences is in combination with the process mining model. Nguyen et al. [
45] focused on integrating explicit and implicit ratings by using latent factors in the recommendation system. They proposed two models, which is for experienced user and inexperienced user. The method is solely based on the user’s rating of each product or service item. Vu et al. [
46] proposed a method to analyze and reveal implicit references using the probabilistic method. The method depends on exploratory analysis and a large group of samples to accurately extract implicit preferences.
In our process mining model, i.e., Petri net, we can explicitly represent relations between items from process mining and compare the sequence of items with associative rules. In our approach, our method emphasizes relations based on combinations of sequentially connected choices. It is optimized based on the frequency of items identified by process mining and the frequency identified by associative rule.
In extracting highly correlated associative rules, we utilized Cook’s distance. The Cook’s distance can be given in two versions; the
-norm (Manhattan distance-based) shown in Equation (
3) and
-norm (Euclidean distance-based) version shown in Equation (
5). According to Aggarwal et al. [
47], the difference in
-norms is that due to the high dimensional data,
-norm is constantly preferable. The larger the value of
p, the less qualitative meaning a distance metric holds. In our research, we perform multivariate data mining where the scale for each attribute in data variables differs. Therefore, Cook’s distance in Manhattan-based form is preferable compared to Euclidean-based form due to sensitivity and scale in terms of the value of observation
y.
We highlight the advantages of our method in extracting implicit preferences. At first, a customer intuitively set their preferences. In our method, we regard the preferences as explicit preferences. Implicit preference is a preference that the customer does not know. In general, even a service user only knows their preference once they experience using the service. This is most likely to happen to first-time users. Therefore, by extracting previous users’ experiences, we can extract the options of services most likely to be selected by the first-time user. This is done by filtering our weakly correlated selections from the service processes in the form of associative rules.
As a result, we can obtain optimized preferences for the first-time user. The extracted preferences also apply to the experienced user so they can experience a better service. In the example given in this paper, a Thai restaurant’s course menu was taken as an example. The result is the optimized menu course for a user that prefers
,
,
,
,
, and
as shown in
Table 2. The method is effective for applications such as travel planning services, learning courses, and interior design or fashion coordination services.
8. Conclusions
In this paper, we proposed a method to extract implicit preference based on process mining and data mining (associative mining). The model removes a refined preference model represented by Petri net and implicit preferences with a stronger correlation than the given explicit model. The proposed procedure was able to extract various associative rules and filter the rules to implicit output preferences based on Cook’s distance and Pearson correlation coefficient. The process model supports associative mining by giving confidence in filtering up highly correlated rules and representing the combination of associative rules as a process model. The model serves as multiple options for items with multi-variate attributes. The proposed approach was evaluated and showed more than 70% of improvements even if the customer did not specify any interests towards any attributes for the item selection. The method is suitable for recommending a set of options rather than a single option. It is effective when used with services that offer many variations of combinations for the customer. For example, for the problem where more choices cause harder decision-making due to various possible combinations such as travel route planning services, meal ordering services, learning courses, and interior design or fashion coordination services. In future work, we will use the proposed method to identify sentiments in selecting options in a service. The proposed method is useful for supporting user experience by extracting customized preferences.
In future work, we will use the proposed method to identify sentiments in selecting options in a service. The proposed method is useful for supporting user experience by extracting customized preferences. We plan to extract the sentiments of previous customers to support the decision-making of new customers. Even though we can find the preference of ‘no preference’ set for any attributes in the recommendation, the customer should be able to understand why the preference is recommended. We plan to provide sentiment recommendations for new customers so that the reason for the recommendation can be further understood and trusted. We will also consider correlation distances such as Mahalanobis distance and cosine similarity to compare the proposed method’s effectiveness.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










