
The Art of the Masses: Overviews on the Collective Visual Heritage through Convolutional Neural Networks


Abstract
:1. Introduction
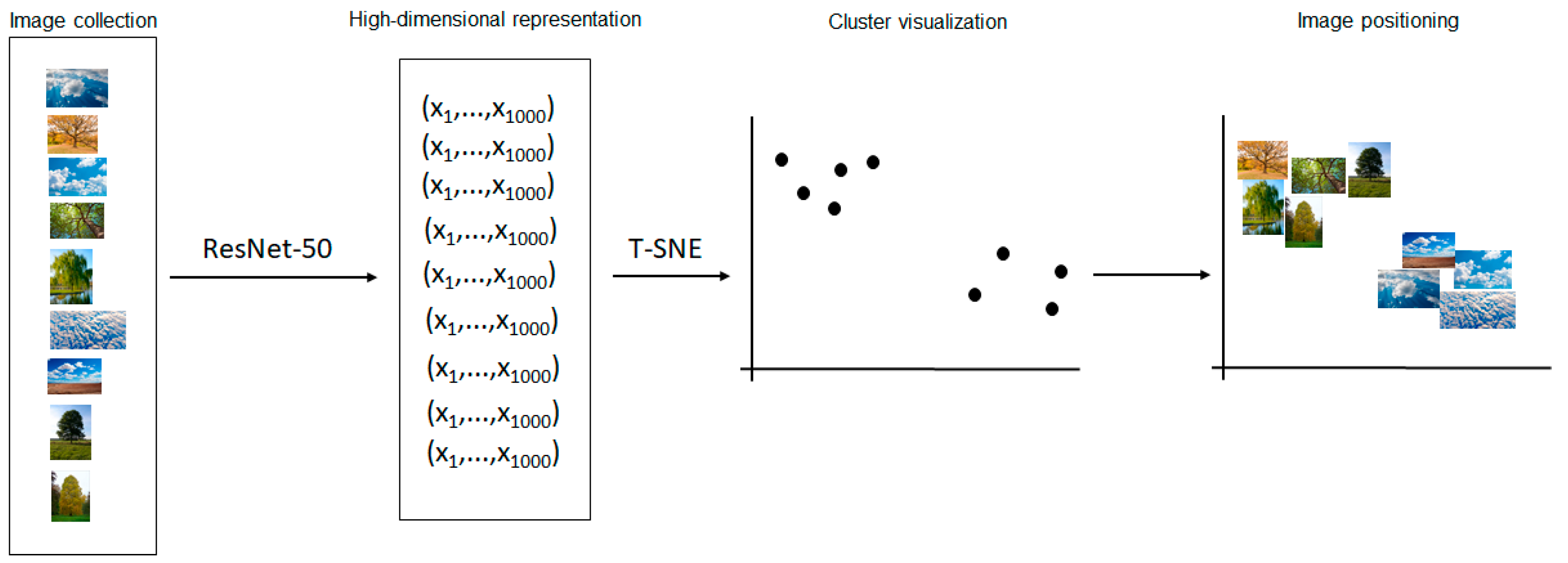
2. Materials and Methods
3. Results
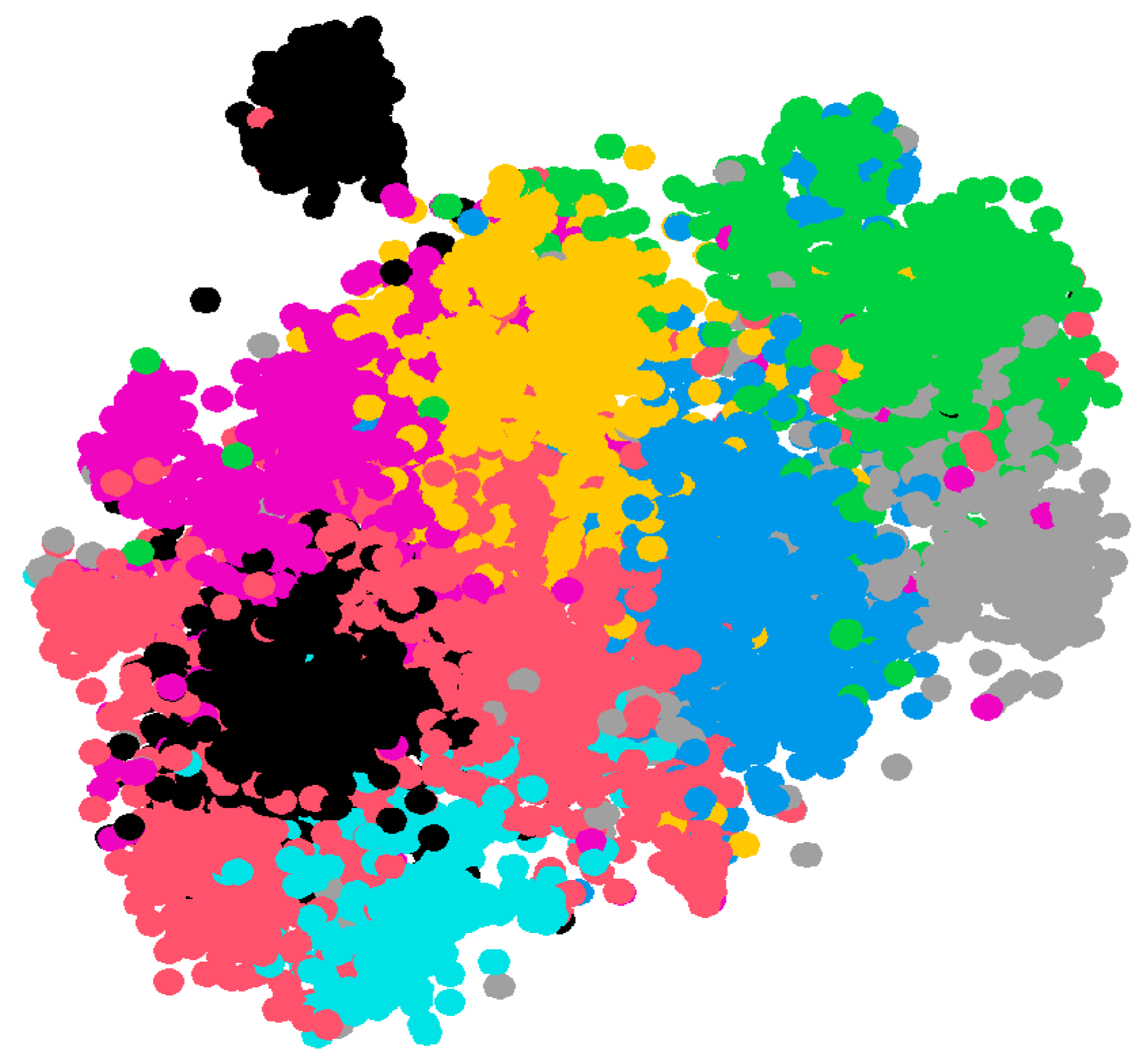
3.1. Computational Cartography of Visual Memory
3.2. Demonstrations around the World
3.3. COVID-19 Pandemic
3.4. Manifestations of Popular Culture
3.5. Climate Change
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Fontcuberta, J. La Furia de las Imágenes. Notas Sobre la Postfotografía; Galaxia Gutenberg: Barcelona, Spain, 2016. [Google Scholar]
- Manovich, L. Computer vision, human senses, and language of art. AI Soc. 2021, 36, 1–8. [Google Scholar] [CrossRef]
- Manovich, L. Rethinking AI: Neural Networks, Biometrics and the New Artificial Intelligence. Digit. Cult. Soc. 2018, 4, 17–28. [Google Scholar] [CrossRef]
- Manovich, L. Data. In Critical Terms in Futures Studies; Paul, H., Ed.; Palgrave Macmillan: Cham, Switzerland, 2019. [Google Scholar]
- Warburg, A. Atlas Mnemosyne; Mielke, J.C., Translator; Akal: Madrid, Spain, 2010. [Google Scholar]
- The Warburg Institute. Aby Warburg Bilderatlas Mnemosyne Virtual Exhibition. Available online: https://warburg.sas.ac.uk/aby-warburg-bilderatlas-mnemosyne-virtual-exhibition (accessed on 20 February 2022).
- Malraux, A. Le Musée Imaginaire; Skira: Geneva, Switzerland, 1949. [Google Scholar]
- Manovich. TimeLine. Available online: http://manovich.net/index.php/exhibitions/timeline (accessed on 20 October 2022).
- Manovich. How to Compare One Million Images. Available online: http://manovich.net/index.php/projects/how-to-compare (accessed on 20 October 2022).
- Manovich, L. 2007 Cultural Analytics: About Software Studies Lab. Available online: http://lab.softwarestudies.com/p/overview-slides-and-video-articles-why.html (accessed on 15 April 2022).
- Park, S.; Song, H.; Han, S.; Weldegebriel, B.; Manovich, L.; Arielli, E.; Cha, M. Using Web Data to Reveal 22-Year History of Sneaker Designs. Www’22 Proc. ACM Web Conf. 2022, 2022, 2967–2977. [Google Scholar] [CrossRef]
- Manovich, L. Defining AI Arts: Three Proposals. In AI and Dialog of Cultures, Exhibition Catalog; Hermitage Museum: Saint-Petersburg, Russia, 2019. [Google Scholar]
- Google. Cómo Funcionan los Algoritmos de Google. Available online: https://www.google.com/intl/es_es/search/howsearchworks/algorithms/ (accessed on 10 April 2022).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. Available online: http://openaccess.thecvf.com/content_cvpr_2016/html/He_Deep_Residual_Learning_CVPR_2016_paper.html (accessed on 3 June 2022).
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Karpathy, A. t-SNE Visualization of CNN Codes. 2017. Available online: https://cs.stanford.edu/people/karpathy/cnnembed/ (accessed on 8 January 2020).
- Pérez-Hita, F. Pilar Rosado y la resurrección de los archivos. In Mnemosyne 2.0. Cartografías Computacionales de la Memoria Visual; Roca Umbert Fàbrica de les Arts: Granollers, Spain, 2019; pp. 1–2. [Google Scholar]
- Grebe, A. Museum and Mnemosyne. Aby Warburg, André Malraux and the re-/construction of art history as social history. In Le Musée Imaginaire and Temptations of the Orient and Japan; Hidemichi, T., Ed.; Akita: Tokyo, Japan, 2010; pp. 55–61. [Google Scholar]
- Koffka, K. Principles of Gestalt Psychology; Mimesis International: New York, NY, USA, 1967. [Google Scholar]
- Köhler, W. Gestalt Psychology: An Introduction to New Concepts in Modern Psychology; Liveright: New York, NY, USA, 1947. [Google Scholar]
- Boden, M.A. AI: Its Nature and Future; Oxford University Press: Oxford, UK, 2016. [Google Scholar]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Climate Change | COVID-19 Pandemic | Demonstrations | Popular Culture |
|---|---|---|---|
| pollution | coronavirus | in Russia | circus shows |
| big dumps | lockdown | in China | street theater |
| deforestation | field hospital | in South Africa | concerts |
| industrial spills | pandemic | police in riots | dances |
| clean energy | empty shows | in Catalonia | cinema |
| oil spills | coronavirus death | in Nicaragua | traditional music |
| climate change | epidemic | in Egypt | popular culture |
| nuclear disasters | coronavirus outbreak | demonstrations | street show |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rosado-Rodrigo, P.; Reverter, F. The Art of the Masses: Overviews on the Collective Visual Heritage through Convolutional Neural Networks. Big Data Cogn. Comput. 2023, 7, 33. https://doi.org/10.3390/bdcc7010033
Rosado-Rodrigo P, Reverter F. The Art of the Masses: Overviews on the Collective Visual Heritage through Convolutional Neural Networks. Big Data and Cognitive Computing. 2023; 7(1):33. https://doi.org/10.3390/bdcc7010033
Chicago/Turabian StyleRosado-Rodrigo, Pilar, and Ferran Reverter. 2023. "The Art of the Masses: Overviews on the Collective Visual Heritage through Convolutional Neural Networks" Big Data and Cognitive Computing 7, no. 1: 33. https://doi.org/10.3390/bdcc7010033