1. Introduction
Despite significant efforts and relevant progress in the improvement of road safety, road crashes remain a persistent major issue worldwide with enormous economic and social costs. According to the latest global road safety assessment of the World Health Organization, 1.35 million road users lose their lives because of road crashes annually, making them the eighth leading cause of death for citizens of all ages [
1]. Substantial inequalities can be observed in road safety performance across the different world regions, with the lowest figures of fatalities per population being recorded in Europe [
1]. Significant differences can be also found across the countries of the same regions which could be associated with various socioeconomic factors as well [
2].
The European Commission (EC) has committed to improving the safety of the European road network. For that purpose, the EC had previously adopted the Road Safety Programme, which aimed to halve the number of road fatalities by 2020, compared to the 2010 level. However, this collective target was not met as the recorded fatalities reduction was equal to 37% [
3]. Among the countries of the European Union (EU), Greece was the only country that achieved this target, with a performance of −54%. This significant decrease in road fatalities in Greece over the last decade could be attributed not only to the fact that Greece was affected by an ongoing economic major recession but also due to a considerable improvement of the main road network from 750 km of motorways in 2007 to 2200 km in 2018 [
3]. However, in 2021, Greece was ranked 22nd among the 27 EU countries (57 road fatalities per million inhabitants), which is significantly higher than the EU average (44 road fatalities per million inhabitants) [
4]. Consequently, it can be perceived that in order to effectively address this major issue of road crashes, concerted and continuous efforts are required.
However, budgets for road safety policies and actions are finite. Therefore, decision-makers and road safety stakeholders need to determine the optimal possible use of available funds. Regarding improvements in the existing road infrastructure, several quantitative methodologies have been developed over the years, to enhance evidence-based decision-making. These methodologies include crash analyses, inspections, assessment of the “in-built” safety of roads, etc. A frequently used and very detailed approach is offered through the application of Crash Prediction Models (CPMs), a practice well described in the AASHTO Highway Safety Manual (HSM) [
5] and referred to as the HSM Predictive Method. Another alternative is a more economic prioritization of road safety interventions driven by estimates and monetization of their effectiveness resulting in cost-benefit ratios (e.g., [
6]).
Nonetheless, such methodological approaches require high-quality data in order to predict crash frequency in specific road elements (e.g., segments, intersections, etc.) and produce reliable results. More specifically, the availability of detailed and actionable data on road crashes, infrastructure geometric characteristics (e.g., curve radius, lane width, etc.), and traffic attributes consist a basic prerequisite for this type of modeling [
7]. Apart from such characteristics, in recent years increased attention has been given to Surrogate Safety Measures (SSMs). SSMs are parameters that describe attributes of the network and of the vehicle movement on roads that are more easily recordable or collectible and do not stem directly from or rely on crash data. These measures are being used more and more in recent road safety studies as they can become an alternative to road safety analyses or even complement analyses that are based on historical crash records [
8,
9].
Within this context, the objective of this research is threefold, specifically:
Investigate the relationship between road crash frequency in motorway segments and various explanatory variables based on road design characteristics and SSMs;
Create risk-level clusters of the motorway segments based on crash and traffic data;
Develop a classification model that could predict the class of motorway segments by exploiting road design data and SSMs.
The rest of the paper is organized as follows.
Section 2 presents an overview of international scientific literature regarding CPMs and SSMs.
Section 3 presents data used for the analyses, and
Section 4 provides the main components of the theoretical background of the statistical models that were developed in the framework of this study. The key results of the analyses are presented and discussed in
Section 5. Lastly, conclusions are highlighted, and the limitations along with some ideas for future research are clearly stated in
Section 6.
2. Literature Review
Over the previous two decades, several researchers have investigated the safety effects of various elements of the road infrastructure in an attempt to quantitatively estimate crash frequency and crash severity. As a result of this research, a large amount of relevant knowledge has been generated, as well as various methodologies and techniques to estimate future crash frequency and severity and to identify and evaluate options to reduce them. These methodologies are commonly known in the research community as CPMs, and they essentially are the empirical statistical models behind road assessment methodology based on the design and operational characteristics of roads.
On one hand, the HSM predictive method [
5] estimates the expected average crash frequency of an individual site based on regression models for specific facility types called Safety Performance Functions (SPFs). These functions contain only a few variables, primarily average annual daily traffic (AADT) volumes and segment length. In this approach, various crash modification factors (CMFs) are also used in order to account for differences in geometric design or in traffic control features between the base conditions of the model and the local conditions of the examined site. Besides the HSM predictive method that utilizes the concept of base SPFs used in conjunction with CMFs to account for site specificities, significant research efforts have also concentrated on the development of stand-alone CPMs, based on locally available data concerning road infrastructure design, traffic volumes, road crashes, and other, for example, weather conditions. The key difference between such models and the SPF-CMF approach is that multivariate CPMs usually include more explanatory variables compared to the simple form of HSM SPFs in order to consider site characteristics.
Stand-alone CPMs have been developed for various road types. An early crash prediction attempt was performed by Ivan et al. for rural two-lane highway segments in the state of Connecticut, USA [
10]. Specifically, a Poisson generalized linear modeling (GLM) approach was selected for modeling single- and multi-vehicle crashes. For single-vehicle crashes, the following variables were found to be significant: daytime, volume/capacity ratio, percent of the segment with no passing zones, shoulder width, and number of intersections, and driveways. Multi-vehicle CPMs had quite different variables, such as daylight conditions, number of intersections, and driveways. Cafiso et al. attempted to define CPMs for two-lane rural road sections based on a combination of exposure, geometry, consistency, and context variables directly related to safety performance [
11]. This study was based on a sample of 168 km of Italian two-lane local rural roads, with a 5-year crash analysis period to compensate for the low traffic flow and crash frequencies anticipated on local roads. The models proposed are also based on the GLM approach, assuming a negative binomial distribution error structure. In more recent research, Yan et al. focused on the issue of unobserved heterogeneity of collected data and experimented with the development of negative binomial and random effects negative binomial models for two-lane rural roads in Washington State [
12]. Horizontal alignment type, speed limit, visibility, road surface condition, and AADT were identified to have significant random effects on crash frequency.
Several CPMs have also been developed for rural intersections. Kim et al. developed separate crash prediction models for various crash types for rural intersections in Georgia, USA, as well as a model for all crash types for comparison [
13]. The analysis revealed that factors such as AADT, the presence of turning lanes, and the number of driveways have a positive association with each type of crash, whereas median widths and the presence of lighting are negatively associated. Biancardo et al. developed CPMs for three- and four-leg stop-controlled intersections on two-lane rural roads in southern Italy [
14]. Explanatory variables were the presence or absence of a left-turn lane, mean lane width including an approach lane and a left-turn lane width on the major road per travel direction, the number of legs, and the total AADT entering the intersection.
As far as urban roads are concerned, an early attempt to develop CPMs in the Greater Vancouver Regional District in Canada is reported by Sawalha and Sayed in 2001 [
15]. Data from 392 road segments of 58 arterials, without including intersections, in the cities of Vancouver and Richmond were used, and it was revealed that the variables that had a significant effect on crash occurrence were traffic volume, section length, unsignalized intersection density, driveway density, pedestrian crosswalk density, number of traffic lanes, type of median, and nature of land use. In another research, Greibe reported the development of multivariate CPMs for urban junctions and urban road segments in Denmark [
16]. Four models for different types of junctions were developed as well as a model for road links, using the GLM approach and assuming a Poisson distribution for variation in crash numbers. For road link models, a large number of explanatory variables was used, including AADT, speed limits, number of lanes, road width, speed-reducing measures, number of accesses, number of minor side roads, parking conditions, land use, urban road type, median divider, presence of bus stops, etc. However, the model fit was not very satisfactory, possibly due to the strong internal correlation within the selected explanatory variables.
Several models have also been developed for motorways. Caliendo et al. developed a CPM for Italian four-lane median-divided motorways, based on crash and road geometry data from a 46 km long section, which was monitored from 1999 to 2003 [
17]. The model, estimating crash frequency as a function of traffic flow, infrastructure characteristics, pavement surface conditions, and sight distance, was developed using a stepwise forward procedure based on the Generalized Likelihood Ratio Test (GLRT). Montella et al. developed separate CPMs for total crashes and severe crashes in Italian rural motorways, using GLM techniques and assuming a negative binomial distribution error structure [
18]. The study used a sample of 2245 crashes (728 severe crashes) that occurred from 2001 to 2005 on Motorway A16 between Naples and Canosa in Italy. The developed model for total crashes included as variables: curvature, operating speed reduction, length of the tangent preceding the curve, and traffic effect, all with a positive sign; the difference between the friction demand and supply, deflection, and upgrade, all with a negative sign.
CPMs consist of a reactive modeling approach as they are mainly based on historical crash records that are collected within a long period of time [
19]. Consequently, such approaches force road safety experts to wait for the occurrence of road crashes in order to identify the problems and examine measures for their prevention. Therefore, in recent years, researchers have increasingly started using indicators that are not based on historical crash data. In the road safety literature, these indicators have been termed SSMs and can certainly be a proactive approach to road safety analyses [
20]. SSMs can also complement analyses that are based on historical road crashes [
8]. SSMs can be collected either through traffic simulation models [
21,
22] or under real driving conditions through smartphones [
23], equipped vehicles [
24], and video recordings [
25]. On one hand, SSMs can be time-based, deceleration-based, and energy-based. Among the most prevalent indicators of this subcategory of SSMs are post encroachment time (PET), time-to-collision (TTC), and deceleration rate to avoid the crash (DRAC) [
26]. On the other hand, the recording of driving behavior through sensors in vehicles and mobile phones has made harsh driving behavior events an alternative subcategory of SSMs [
9,
27].
3. Data Collection
Statistical analyses of this research focus on the Olympia Odos motorway in Southern Greece, a rural motorway from Athens to Patras that comprises 201.5 km of rural motorway in total, with two or three lanes per direction and 29 interchanges. Part of the motorway of 63 km (Elefsina-Korinthos) is in operation since 2010, whereas the rest (Korinthos-Patra) was fully operational since the summer of 2017. Crash data of all severity levels including property-damage-only (PDO) crashes as well as AADT were available for 2015–2020. As the entire motorway (i.e., from Athens to Patras) was finalized and started operating in 2017, AADT and crash data for the entire length were available for the years 2018–2020. Therefore, it was decided to focus on a smaller time period (2018–2020) but for a longer, road network. The motorway is operated by a private road operator firm, Olympia Odos Operation SA, who kindly provided data for the current research.
For the objectives of this study, a road geometry database that focuses on the section from the toll station of Elefsina (CH.26 + 500) to the end of the motorway (CH.223 + 200) was developed through a multi-step process. As a first step, a draft centerline of Olympia Odos Motorway was preliminarily retrieved from Open GIS software, using the Blender application (
https://www.blender.org/, accessed on 18 January 2023), as follows: the Open GIS polylines representing the existing road network in the vicinity of the motorway were exported in shapefile format and imported to CAD environment; then, all neighboring road centerlines were removed and centerlines for the motorway, for transverse roads and entrance/exit ramps at interchanges were isolated. At this stage, the CAD drawing of the motorway was developed in the official national coordinate system in Greece (EGSA 87). It is noted that only horizontal alignment information on the road centerlines was retrieved.
Following the zone of the centerline defined in the first step, a series of high-detail satellite images (pixel size approximately 1.2 × 1.7 m) were retrieved using the respective GIS module of the free online software HEC-RAS (
https://www.hec.usace.army.mil/software/hec-ras/, accessed on 18 January 2023) and georeferenced as the background of the CAD drawing. Combining information from the Open GIS road centerline and the detailed satellite imagery, the centerline of the motorway was subsequently refined, as follows: the preliminary centerline from Open GIS software is a polyline with dense points. This was manually replaced in the CAD environment by a “road design equivalent” centerline, consisting of tangents, circular curves, and spiral (clothoid) curves. Spiral curves were introduced on the entrance and exit of all curves with a radius of less than R = 1000, assuming a clothoid curve parameter A ranging from R/3 to R (R/3 < A < R), according to Greek road design guidelines. In segments where the two directions of travel follow different paths, the main centerline was the direction from Elefsina to Patras and a secondary centerline was created for the opposite direction.
The refined CAD centerline was then imported into the Google Earth online platform (
https://earth.google.com, access on 18 January 2023) and using the satellite views and the Google Street View imagery in conjunction, the location of km posts was determined. This location is of utmost importance for microscopic road safety analyses, as all elements of the analysis (crashes, speed limits, etc.) are recorded according to those locations (GPS use for crash location recording is not performed in Greece). The km posts, as identified in Google Earth, were subsequently imported into the base CAD drawing of the motorway and a road chainage system (stations) was established.
In the next step, all available road infrastructure data were imported into the CAD drawing as well as the Google Earth interface, mostly based on their respective road station (chainage) but also cross-checking their location against the Google Earth satellite imagery and Street View images. An important source of information at this stage was the motorway schematic provided by the road operator (Olympia Odos Operation SA) with the exact locations (road station-chainage) of interchanges (with entrance/exit ramps), toll stations, motorway service stations, parking areas, tunnel and cut-and-cover entrance and exits, and speed limit signs.
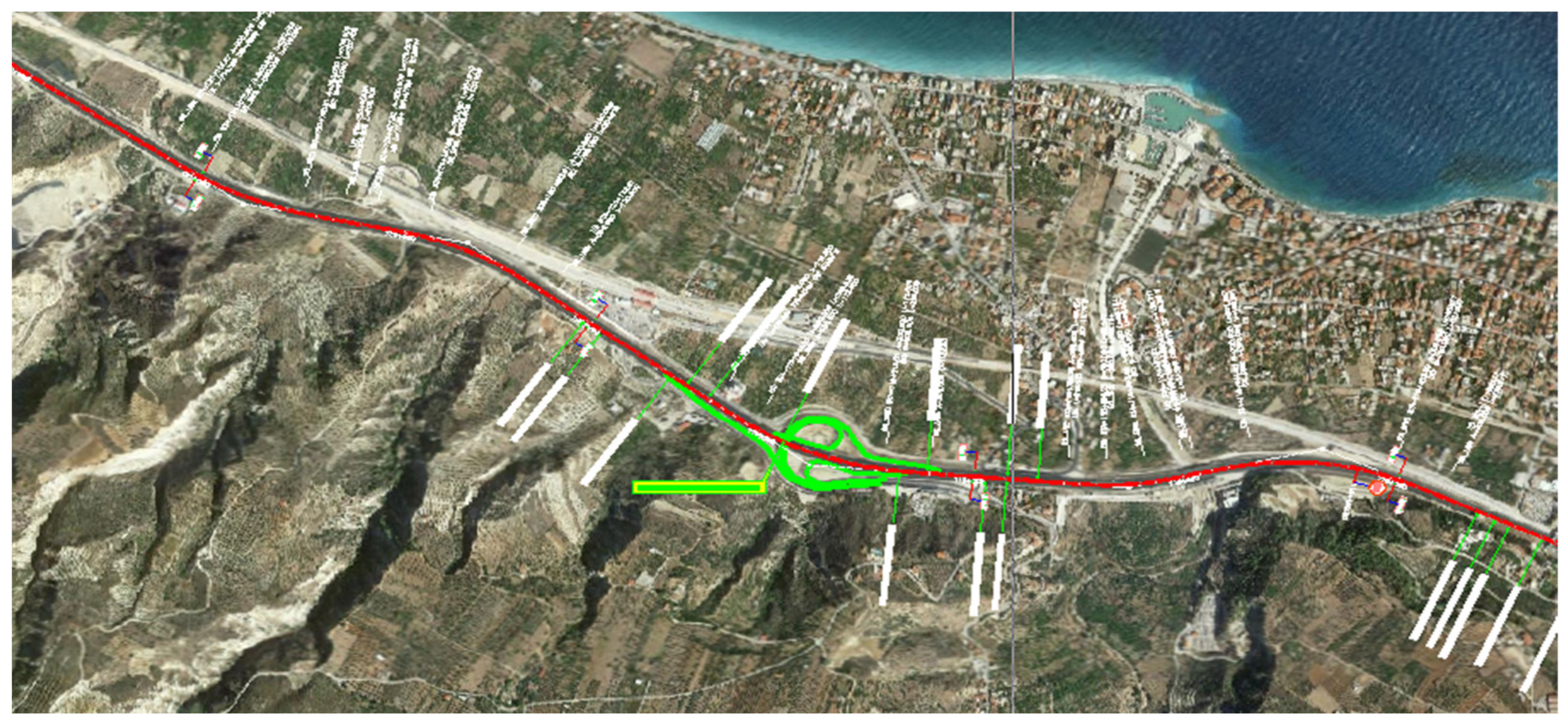
The above procedure produced a CAD drawing, as presented in
Figure 1, with georeferenced satellite images as the background, including motorway centerline geometry, chainage, speed limits, and visualization of other important road infrastructure elements: toll stations, interchanges (with transverse roads, entrance and exit ramps), km posts, location of lane addition or lane drop, weaving segments, etc., and a Google Earth Dataset in .kmz file form, presented in
Figure 2, with several layers of information: centerline, chainage, tunnels, additional lane points (gore, start, and end), lane drops/additions, etc. These two powerful tools were utilized in order to code road infrastructure data for further analysis and create a database that forms the basis for subsequent analysis.
Another database on road user behavior data on Olympia Odos Motorway was developed, in order to be jointly investigated with the road infrastructure, crash, and traffic data. Naturalistic driver behavior data were recorded via a smartphone application and processed in the platform, both developed by OSeven (
https://oseven.io/, accessed on 18 January 2023). Drivers install the application developed by OSeven on their smartphones and subsequently engage in normal driving activities. The application engages automatically when driving is initiated and records different data types such as vehicle location, speed, acceleration, deceleration, duration of engagement with the phone, etc. These data are further processed to develop metrics to describe driver behavior.
For this research, the following metrics for unsafe driver behaviors were used: counts of harsh accelerations and braking behaviors, average speed, average speed over the speed limit, count of trips with speeding, and duration of average speeding. Harsh events are determined by the OSeven algorithms which are private and under intellectual property protection. To provide more context, OSeven uses data from all the axes of the accelerometer as well as GPS for the determination of harsh events. Harsh events are calculated via data fusion and machine learning algorithms and not a rule-based approach using as input the values of the accelerometer as well as values from additional sensors (e.g., orientation, magnetometer, GPS, gyroscope). These algorithms evaluate the processed time series from the smartphone sensors of the complete trip and increase the overall detection accuracy of harsh events. It should be noted that the algorithms do not include specific threshold values but rather exploit ML-based detection of spikes in the sensor data [
28].
OSeven has provided a representative dataset from its database in a completely anonymized format that corresponds to the period from 1 June 2019 to 31 December 2020. The data were recorded from a driver sample equal to 327 drivers for 2019 and 330 drivers for 2020. It is possible that some drivers were mindful that their driving behavior was recorded through the application and were even more aware than usual. However, these effects have been reported to decrease over time as drivers gradually forget that they are being recorded [
29]. For the total considered time period the average number of recorded trips per motorway segment was 2035 trips. Subsequently, driving behavior metrics from naturalistic data, which are driver-based, needed to be assigned to the examined motorway segments, which are infrastructure-based data. This was achieved via isolating each trip portion to the corresponding segment within the internal recording of trips conducted in GIS by OSeven using ESRI polygons at 200 m intervals.
At this point, it should be noted that the recording of driver behavior through the smartphone app was not feasible within the tunnel road segments due to the loss of GPS signal. Furthermore, toll station segments are not typical motorway segments both in terms of geometric design and driver behavior. Consequently, these two types of road segments were not included in the statistical analyses of the present research. The variables that were included and analyzed within the present study are presented in
Table 1, along with their abbreviations and some key descriptive statistics. As also mentioned in
Section 2, the variables related to road design characteristics, traffic attributes, and road crashes are widely used in CPMs, whereas harsh driving behavior events are SSMs that can complement road safety analyses.
In total, 668 motorway segments were considered in the analyses of this study with an AADT equal to 10,786 vehicles per day for the period of 2018–2020. The length of the examined segments varies from 200 m to 600 m and among these segments, 435 include two through lanes while the rest 233 include three through lanes. In terms of road safety outcomes for the period 2018–2020, 80 injury road crashes and 1270 PDO crashes were recorded.
6. Conclusions
The aim of this research was to exploit various road geometry data and SSMs for various road crash investigations in road segments of the Olympia Odos motorway in Greece. To that end, a unified database containing data on historical injury and PDO road crashes, road design characteristics, and SSMs of 668 motorway segments was utilized.
While the observational area and the data are singular for this study, they are viewed with three different approaches, each with a unique context. In particular, the first approach aimed to provide initial insights into the relationship significance and magnitude between road crash frequency, road geometry and SSM variables. However, since SSMs are still a new concept and their connection with hard road safety metrics such as crashes remains uncertain, it was fruitful to consider how these variables would perform for a clustering approach. To that end, the second model was applied as a first step, to reveal clusters that the segments can formulate based on crash and AADT data. The predictive power of road geometry and SSM variables was then tested on these clusters, having removed the variables used to obtain the clusters. Thus, in the present approach, the developed models contributed to prove that contextually, SSMs can be used to model crashes directly (negative binomial regression model), or indirectly, even without crashes, (RF model) when a type of safety categorization is established (clustering model).
To provide more detail, the negative binomial regression model was first developed to model motorway segment crash frequency. The results of this model pointed out that road crash frequency in the considered motorway segments is positively correlated with the traffic volume, the length of the segment, and the number of harsh accelerations and harsh braking. This analysis contributes to existing road safety literature by demonstrating a positive and statistically significant relationship between crash frequency and harsh driving behavior events. Therefore, it can be concluded that such events can be a valid subcategory of naturalistic SSMs which can be used either to complement CPMs or as dependent variables of various road safety proactive analyses when historical road crash data are not available.
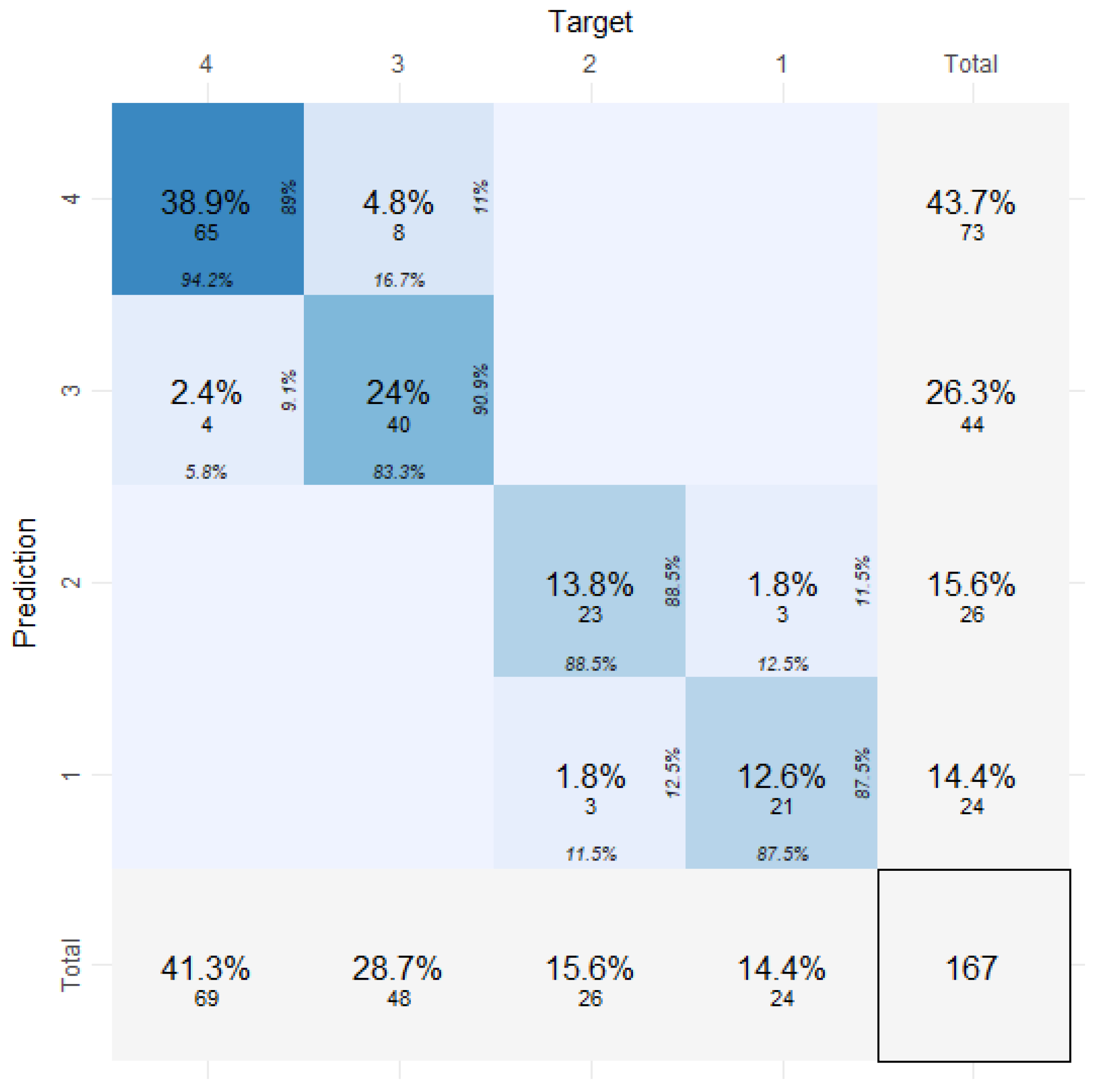
As a further step of the statistical analysis, it was attempted to create crash risk level clusters of the motorway segments considering the number of road crashes by segment length and the traffic volume of each segment through the agglomerative hierarchical clustering technique. Segment length and traffic volume of each segment were taken into account in the clustering analysis, as the results of the negative binomial regression model revealed that these two variables have a statistically significant impact on the crash frequency of motorway segments. Based on the results of this clustering approach, four crash risk levels were defined. Afterward, these four levels formed the response variable of an RF machine-learning classification model which used various road geometry data and SSMs as predictors. This model was developed as a mechanism for predicting and classifying the road safety level of the investigated segments, taking also into consideration SSMs that were found to be statistically significant in predicting crash frequency. The overall and per crash risk level classification performance of the developed RF model was very high, averaging metric performance over 88% consistently. Therefore, it can be concluded that this approach could be utilized as a quite promising proactive approach for the identification of potentially hazardous motorway segments.
Naturally, this research is not without limitations. With regard to the extraction of road geometry data for Olympia Odos motorway, the results are obviously not an exact replication of the actual road design of the motorway and minor differences could be expected if a comparison with the as-built drawings of the project was made. Nevertheless, any differences would be minor and, although important from a designer’s point of view, they are not expected to be able to differentiate the study’s results. The negative binomial regression technique that was used for the development of the crash frequency regression model does not take into account unobserved heterogeneity and the effects of spatial characteristics of various road safety indicators. Another limitation of the current research is that tunnels and toll station segments were not considered in the analyses, leading to discontinuities in the research area.
However, these limitations can provide directions for future research efforts. Specifically, the inclusion of random effects in the crash frequency modeling approach could be considered in order to account for the unobserved heterogeneity. Moreover, spatial modeling approaches could be a promising alternative kind of modeling as it could consider the spatial dependency of road safety indicators. Regarding the RF classification model, different machine-learning methods could be also implemented in order to compare their classification performance and identify the best-performing model. Moreover, regardless of the machine learning classification model utilized, Shapley additive explanations (SHAP) can also be calculated and provided in order to deal with the difficult challenge of interpreting the results of machine learning algorithms. Furthermore, as several traffic restrictions were implemented during the considered time period due to the Covid-19 pandemic, it would be highly interesting to investigate to what extent these measures may affect the results of this study. Lastly, the possibility of applying the analyses presented in this research to other road environments, such as urban areas, could be considered as well.


 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}