
Flexible and Efficient Multi-Keyword Ranked Searchable Attribute-Based Encryption Schemes



1
Department of Computer Science and Information Engineering, National Taiwan University, Taipei City 10617, Taiwan
2
Graduate Institute of Networking and Multimedia, National Taiwan University, Taipei City 10617, Taiwan
*
Authors to whom correspondence should be addressed.
Cryptography 2023, 7(2), 28; https://doi.org/10.3390/cryptography7020028
Submission received: 6 March 2023
/
Revised: 10 May 2023
/
Accepted: 11 May 2023
/
Published: 15 May 2023
Abstract
:Currently, cloud computing has become increasingly popular and thus, many people and institutions choose to put their data into the cloud instead of local environments. Given the massive amount of data and the fidelity of cloud servers, adequate security protection and efficient retrieval mechanisms for stored data have become critical problems. Attribute-based encryption brings the ability of fine-grained access control and can achieve a direct encrypted data search while being combined with searchable encryption algorithms. However, most existing schemes only support single-keyword or provide no ranking searching results, which could be inflexible and inefficient in satisfying the real world’s actual needs. We propose a flexible multi-keyword ranked searchable attribute-based scheme using search trees to overcome the above-mentioned problems, allowing users to combine their fuzzy searching keywords with AND–OR logic gates. Moreover, our enhanced scheme not only improves its privacy protection but also goes a step further to apply a semantic search to boost the flexibility and the searching experience of users. With the proposed index-table method and the tree-based searching algorithm, we proved the efficiency and security of our schemes through a series of analyses and experiments.
1. Introduction
1.1. Motivations
Cloud and IoT [1] services have become increasingly popular because of the rise in streaming services [2] and the development of machine learning, especially in the era of COVID-19. Outsourcing data to the cloud saves space for local storage and brings convenience so that users can access and share their data without any space and time limitations. However, since cloud service providers, or cloud servers for short, are not fully trustable, directly uploading sensitive data to the cloud is dangerous and undermines user privacy. Encrypting data and then uploading them seems a safer approach. Nevertheless, in many situations, traditional public key encryption (PKE) [3] schemes can only achieve secrecy but lack proper access controllability. For example, in some cases, we want to authorize files to only a specified group of people. Under PKE, we must copy files many times and encrypt them, respectively. Moreover, the management of secret keys is increasingly cumbersome and difficult. This challenge is specifically severe for medical and financial data because users have the right to decide who can review their sensitive medical and financial records. With attribute-based encryption (ABE) [4,5,6,7,8,9], we can make fine-grained access control much more manageable by only allowing some people with specified attributes (i.e., conditions) to access and view the files.
In addition to the access control, how to fetch the required data rapidly among the massive data stored in the cloud is also a critical issue. Downloading and decrypting all the data and then performing a search can reach the target, but it is not feasible because a massive amount of computation and storage is required on the user end. Apart from the excessive time overhead, these operations may be unsafe. Searchable encryption (SE) algorithms [10,11,12,13,14,15] bring reasonable solutions to this problem. Go a step further; combining the ABE and SE schemes allows users to have fine-grained access controls and searching capabilities regarding encrypted data.
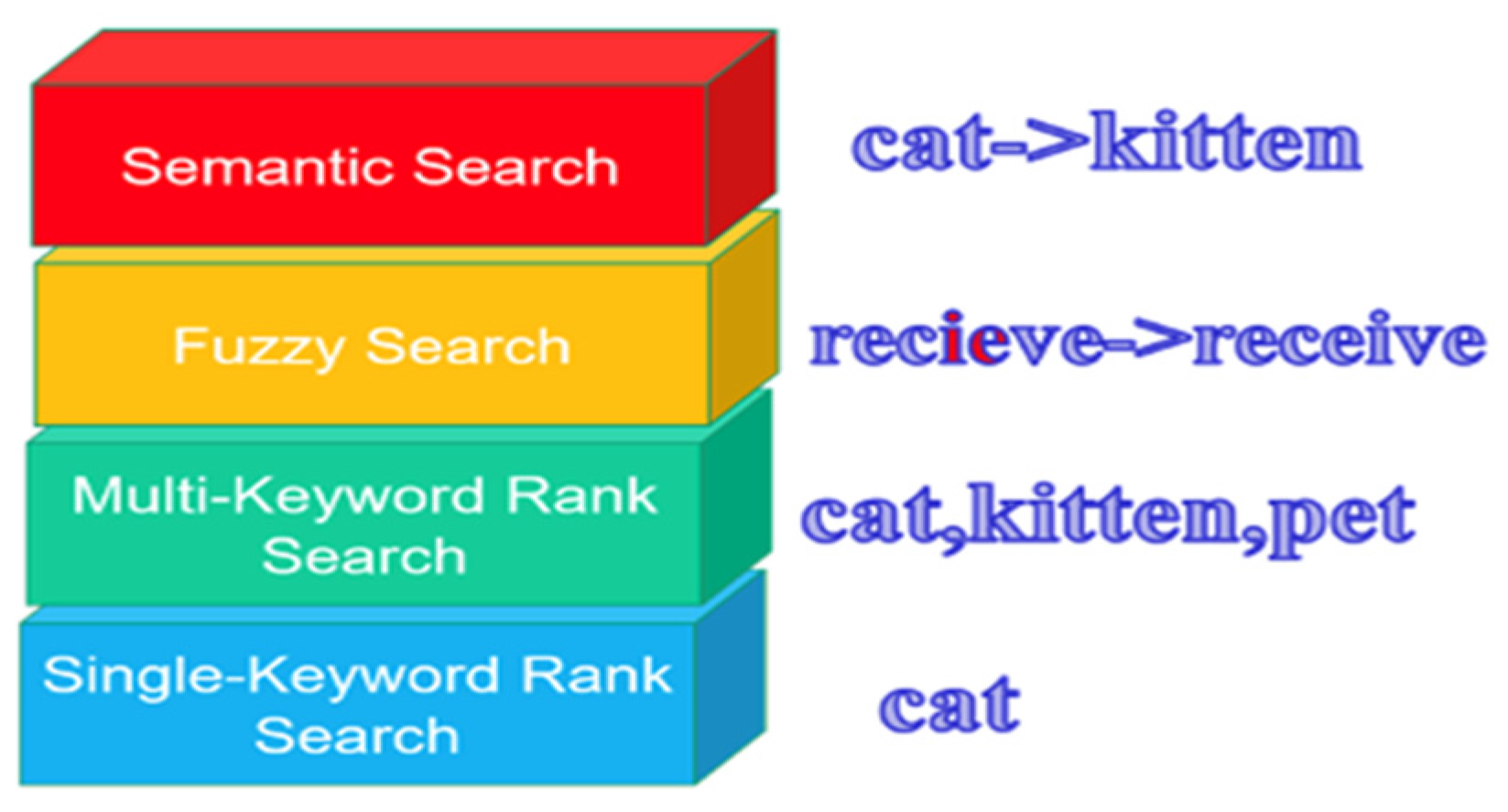
Many searchable attribute-based encryption schemes (ABS) [16,17,18,19,20,21,22,23,24] have provided fine-grained access control, dynamic updates, and attribute revocations. However, searching capabilities could be more potent in most schemes to fulfill actual needs. Usually, they can embed only a single keyword into ciphertexts, which could be inconvenient and make searching more cumbersome. Although some schemes allow for combining multiple keywords and provide ranked search results, users can only fetch files containing all the keywords. More complicated relationships between keywords such as disjunctive logic “OR” can usually not be expressed. In addition, some advanced designs in searchable encryption algorithms have rarely been implemented on such systems. We summarize the standard advanced searching modes in Figure 1. The basic search mode is the keyword rank search which does the exact match of single or multiple keywords. However, in practice, the user’s input commonly contains some typos or uses synonyms. As a result, two high-level search modes, fuzzy search and semantic search, are induced to allow users to obtain the results without using the exact keyword.
To tackle the problems listed above, we proposed two flexible and efficient multi-keyword ranked searchable attribute-based encryption schemes (FEMRSABE), which are especially suitable for E-health applications. In our basic scheme, we designed a search tree data structure to enhance the expressiveness of the search, as shown in Figure 2. The server matches the trapdoors in leaf nodes with index files, traversing the tree and inducing the searching results of parent nodes by union or intersection. Finally, the aggregated search result of the root node is the final result, sorted according to the associated relevance score. The cloud server can only read the user-inputted logic structure but knows nothing about what users have searched. In addition, inspired by [25], we built an index table to boost search efficiency. We replaced the encryption mechanism from symmetric key encryption with pure attribute-based encryption. Data owners do not need to exchange keys with users in advance, making the scheme more realistic. It shows that the search speed is much faster than the case without the index table through experiments. We also provide fuzzy keyword searching ability by calculating the fingerprints of keywords. We refer to the generating method and the similarity score in [11] to ensure the search range is manageable.
Moreover, in our enhanced scheme, we reorganized the system architecture to minimize possible data leakages, such as the logical structure of search trees and the file list of a particular keyword. We further implemented the semantic search functionality with WordNet’s help [26]. As a consequence, we considered the actual semantics of the keywords. Users only need to express their intention of searching without considering the constraints on the data owners’ actual keywords and their perfect spellings. These advanced search modes make the search procedure more flexible and easier to use. The functionality comparisons in later sections show that our scheme has more desirable searching capabilities than other benchmarking searchable attribute-based encryption schemes.
Flexible and efficient multi-keyword ranked searchable attribute-based encryption schemes (FEMRSABE) target the E-health use case. Users, who are equipped with IoT devices that can collect body data such as heart rate and body temperature, can upload their data to the server in encryption form. Doctors or other healthcare professionals can access the data with appropriate permission. Most importantly, the system does not require the accessor to input the exact identical keyword used for encryption. With the benefit of fuzzy and semantic search, FEMRSABE can automatically match and discover the possible meaning and search. This brings flexibility in that IoT providers and healthcare professionals do not need to negotiate the keyword beforehand, and the different IoT devices’ cross-time can also pick up a suitable keyword rather than be limited to the previous choice.
In the security aspect, our FEMRSABE system can defend against selective cipher-text-policy and chosen-plaintext attack (IND-SCP-CPA) by building it on the general bilinear map cryptographic techniques and the associated assumptions.
1.2. Contributions of This Work
We proposed a flexible and efficient scheme, FEMRSABE. The possible contributions of this work include the following:
Flexible Access and Searching Structure: We used linear secret-sharing schemes (LSSS) to build the basic data access structure, allowing data owners to express their data access policy by combining AND–OR logic gates as their wish. Furthermore, the conventional multi-keyword scheme can only find documents containing all the searching keywords. We designed a much more flexible tree structure so that users can express what they want to search by both conjunctive and disjunctive logic.
Ranked Searching Results: Following the techniques presented in [25], we built an index-table structure that can diminish the searching time and make ordered searching results possible. Users can obtain the most desired search results as soon as possible, avoiding unnecessary file decryption or filtering among many matched results.
Fuzzy and Semantic Search Mode: We further included advanced search mechanisms into the enhanced scheme, such as fuzzy and semantic search, by integrating with fingerprints introduced by [11]. Query keywords can now be inaccurate or have spelling errors, making it easier for users to obtain what they want.
Multi-Authority: Allowing the central authority to take over all the jobs of generating user keys is neither efficient nor secure. If the central authority shuts down, the whole system will be affected, which is called the “single-point” failure. We set up multiple attribute authorities to spread the traffic and generate intermediate user keys to solve this problem and shorten the key-generating time.
1.3. Organization
This paper is organized as follows. We review some related attribute-based and searchable encryption schemes in Section 2. Some preliminaries and cryptography backgrounds are addressed in Section 3. Section 4 defines the problem formally and depicts the proposed architecture, while Section 5 addresses our concrete constructions in detail. We present our schemes’ performances and security levels through a series of experiments in Section 6. Finally, Section 7 concludes this write-up.
2. Related Work
2.1. Attribute-Based Encryption
Attribute-based encryption (ABE) is a technique that allows data owners to declare their access policies such as: “(Doctor OR Researcher) AND (Chest OR Surgery)”. Only data users who meet the policy’s attribute requirements are qualified to access the files. For instance, users with the attributes “Doctor and Surgery” can read the text, but ones with “Doctor and Researcher” cannot. Most ABE schemes can be categorized into the following two classes: ciphertext-policy attribute-based encryption (CP-ABE) and key-policy attribute-based encryption (KP-ABE). Wang et al. [27] proposed a constant-size ciphertext KP-ABE scheme, while Water et al. [4] proposed the first practical CP-ABE scheme. The main difference between KP-ABE and CP-ABE is that CP-ABE puts the access policy into ciphertexts while KP-ABE puts it into the users’ secret keys. In CP-ABE schemes, data owners can easily decide who can access the files, so it is more suitable for cloud storage applications. Hence, we adopted it to construct our systems. Over time, more powerful ABE schemes have been developed. Li [7] proposed an attribute-revocable scheme, and Chi et al. [5] proposed a policy-hiding scheme to protect data owners’ privacy further. In addition, most ABE schemes involve bilinear pairing operations, which are very time-expensive, especially for resource-restricted devices such as mobiles and IoT devices. Han et al. [6] proposed a decentralized scheme to reduce the burden of data users by outsourcing the corresponding computational tasks.
2.2. Searchable Encryption
The main characteristic of searchable encryption (SE) is it allows users to search over many encrypted data without the decrypting of the documents in the dataset. High-level concepts of SE are that data owners extract keywords from plaintext files to build a “Secure Index” and then encrypt plaintexts with symmetric encryption schemes. Data owners transform searching keywords into corresponding trapdoors afterward. Finally, cloud servers match the Secure Indexes with the trapdoors to produce search results containing the target keywords the user longs for.
For this purpose, there are many ways to build the pre-described Secure Index. Most of the existing SE schemes involve calculating the term frequency-index document frequency (TF-IDF) values of keywords. Cao et al. [28] and Tzouramanis et al. [12] both use the K-nearest neighbors (KNN) method to build the Secure Index. It is effective; however, the associated neighborhood-related matrix will be too large, and therefore, the associated operations become time-consuming when too many keywords are involved in the system. Other methods include secure random masking, tree-based, and secure linked-list ones. The scheme proposed by Zhang et al. [25] used the secure linked-list method to build an index table, which we also adopted in our work for its efficiency.
Many functional search schemes have been developed to provide a more powerful search capability. For example, Wang et al. [13] proposed a tree-based method to provide range search. It is especially suitable for numerical datasets such as financial records. Aritomo et al. [29] and Fu et al. [10] both achieved semantic-based searching, while Zhang et al. [15] provided an efficient predicate search. Liu et al. [11] proposed a robust scheme combining semantic and fuzzy searches using fingerprint methods, which will also be adopted in our schemes. However, this scheme did not take any access control mechanism into account. They used fully homomorphic encryption (FHE) schemes [30,31,32] to encrypt the index table instead. Due to complexity considerations, our work has not considered FHE schemes in our current system implementation. However, FHE schemes have lots of potential for constructing effective ABE schemes if the required complexity can be handled properly. An FHE-based ABE approach is exciting and can reduce the storage requirement of ciphertexts. We choose to put it into our future investigations.
2.3. Searchable ABE Schemes
Many ABE schemes have searching abilities. For this kind of scheme, it is crucial to allow only the qualified files to be searched. Otherwise, malicious users may launch keyword attacks to guess the contents of files and breach privacy. On the other hand, it is a waste of time for users to decrypt those unqualified files with failure. Sun et al. [22] proposed a famous searchable attribute scheme (ABKS) to hide the access policy. However, they use AND GATE as the access structure for policy hiding, which limits the access policy’s expressiveness. Wang et al. [23] proposed a scheme that is aimed at E-health applications. They achieve a constant computational overhead, constant storage overhead, and policy hiding by hashing user attributes and keywords. However, the access policy’s flexibility and searching are restricted due to its data structures. Moreover, they directly embed keyword hashes into ciphertexts, so it takes much time to match search results when there are many files in the dataset or only a single keyword can be used at a time. Miao et al. [21] and Sun et al. [33] proposed ABKS schemes with the ability for attribute revocations. Nevertheless, the searching capabilities of these schemes are weak because users can only use a single keyword once without any modifications to protocols.
3. Preliminaries
3.1. Bilinear Pairing
Following the definitions in [33], let and be two multiplicative cyclic finite groups of prime order . Let be a generator in . The following equations hold to fulfill the definition of the bilinear pairing equations.
- Bilinearity: For all and all holds. That is, the exponentiation operations inside pairings can be moved outside directly.
- Non-degeneracy:
- Computability: For all and any additive or multiplicative operations on it can be efficiently computed.
3.2. Access Structure
By definition in [4]: Let be a set of parties. A collection is monotone if : if and then . An access structure (respectively, monotone access structure) is a collection (respectively, monotone collection), A, of non-empty subsets of , i.e., . The sets in are called the authorized sets, and the sets not in are called the unauthorized sets.
3.3. Linear Secret-Sharing Schemes
We choose the linear secret-sharing schemes as our access structure due to their full expressiveness in the access policy. Some papers [16,18,19,22,23] use the AND gate to bring efficiencies and policy-hiding capabilities. However, they do not apply to disjunctive operators. Thus, the flexibility of the access policy is quite limited.
The definition of a linear secret-sharing scheme can be found in [34]:
Definition 1.
Linear Secret-Sharing Schemes (LSSS)
A secret-sharing scheme
over a set of parties
is called linear over () if
- The shares for each party form a vector over .
- There exists a matrix with is the vector of rows and columns called the share-generating matrix for . For the i-th row of M, we let the function define the party labeling row , for all as . When we consider the column vector , where is the secret to be shared, and are randomly chosen, then is the vector representing the shares of the secret according to the scheme . The share belongs to party .
3.4. Relevance Score
We use the TFxIDF measurement to express the relevance between the keyword, and the document, , which has been widely adopted in many data mining and searchable encryption schemes. Term frequency (TF) represents the frequency of a keyword in the file. Nevertheless, only TF values are insufficient because some common words, such as prepositions, usually differ from what users want to search for, even if they have high occurrence frequencies in the text. Index document frequency (IDF) brings the solution. Engaged readers can find the definitions of TF and IDF in [11].
4. Problem Definitions
4.1. Threat Model
There are several players (or parties) in the investigated systems. Their role and the threat model are listed below.
Central Authority (CA): The central authority (CA) sets up the system and verifies intermediate user keys obtained from attribute authorities. After that, the CA produces the final user keys based on the master key generated by itself. In addition, the CA delivers the public key to the other parties. Notice that the CA is believed to be entirely trustworthy in most schemes and our systems.
Attribute Authority (AA): An attribute authority (AA) is equipped with some necessary cryptographic techniques, accepting the request of data users to generate user keys. They verify and generate intermediate user keys according to the attributes the data users provided. Their behavior is also honest so that they do not misbehave in the process of KeyGen and will not collide with data users.
Data Owner (DO): Data owners may be patients in a medical application. They extract some keywords from their medical records to build the Secure Index. After that, they upload encrypted data and the Secure Index to the cloud server. We also assume that DOs are fully credible. They will correctly extract keywords and perform succeeding encryption to the accessible files themselves.
Cloud Server (CSP): The cloud server provides storage to the encrypted files and performs encryption-domain searches. Their threat model is assumed to be honest but curious once again. They will honestly execute protocols but may attempt to obtain documents and keywords in plaintext form through statistical analyses. They are also interested in finding trapdoors uploaded by users, trying to guess what users are searching for, and tracing their search records.
Data User (DU): Data users may be doctors or researchers in an E-health application scenario. They request the encrypted files by transforming the searching keywords into respective trapdoors to perform searching. They may want to access or guess the contents of unqualified data by selective keyword attacks. However, they do not leak decrypted data to other unauthorized users.
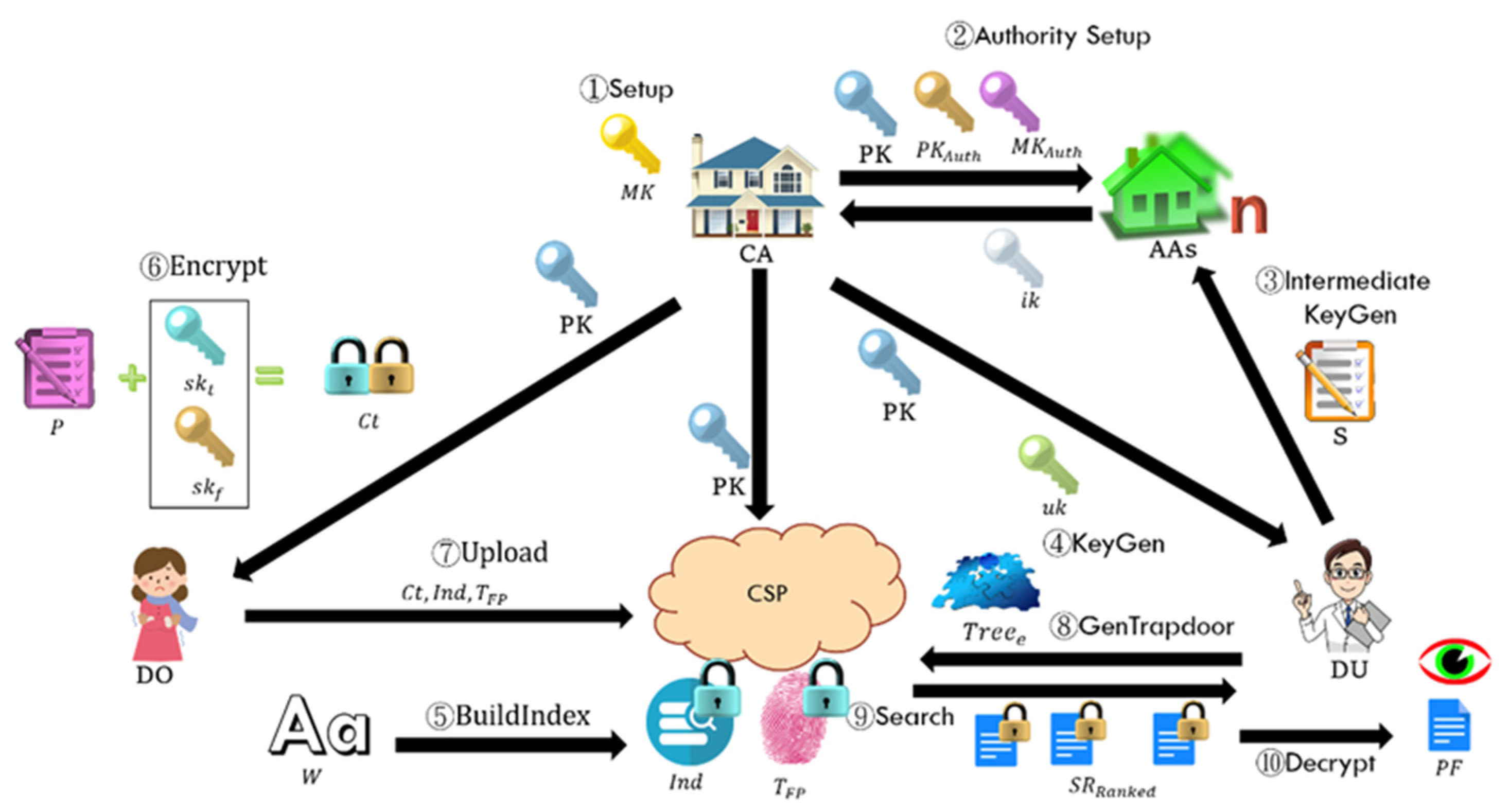
4.2. System Architecture
Figure 3 shows the players, the functional blocks, and the detailed information flow of the proposed system. From Figure 3, nine polynomial-time algorithms (PTAs), as listed below, compose our system. Table 1 demonstrates the symbols used in this write-up.
Setup : The CA runs the setup algorithm and generates the master key pair. It delivers the public key, to the other parties and keeps the master key, for itself.
Authority Setup : The CA executes the authority setup algorithm to set up all the AAs. It grants authority to the master key, and authority to the public key, for each AA.
IntermediateKeyGen : The AA verifies the user attribute set, and runs the intermediate key generation algorithm to generate the intermediate user secret key, using its authority keypair.
KeyGen : The CA verifies the validity of the intermediate user key, and then generates the final user secret key, by the key generation algorithm.
BuildIndex : DOs build an index table for each keyword, in the keyword set, . In addition, they run a fingerprint generation algorithm to support fuzzy matching and build a fingerprint lookup table as one of the outputs. Figure 4 shows the data structure used to construct our index table.
Encrypt : DOs extract keywords from the plaintext to obtain the keyword list, W, and then input the public key, , access policy, , and the session key, , to the encrypted algorithm for generating the ciphertext. Finally, it encrypts the tables with . DUs recover the session keys and decrypt files and tables associated with this ciphertext.
GenTrapdoor : DUs use the user key, , the public key, , and the search condition, to generate the trapdoor, based on the trapdoor-generating algorithm. This algorithm has two phases: DUs obtain the hash values of the most proper keywords using the fingerprint-matching algorithm in the first phase. A search tree, is constructed according to and the hash values. Each keyword, , in is converted into a corresponding trapdoor, . In the second phase, all leaf nodes in are replaced by to become an encrypted search tree, .
Search : The CSP parses the encrypted search tree, , and executes the search algorithm to match with to obtain the searching result, SR. The CSP sorts SR and outputs the top-k files as the final search result, . In our enhanced scheme, the CSP only matches the trapdoor, leaving the jobs of traversing searching trees and ranking for DUs to ensure better data privacy.
Decrypt : DUs input their user key, , ciphertext, , and the ranked searching result, to the decryption algorithm to obtain the plaintext files, PFs.
4.3. Security Model
The security model of the proposed system is built on general bilinear map cryptographic techniques and the associated assumptions. As addressed in the following paragraphs, we designed a security game to explore our system’s security level. It shows that our system can defend against selective ciphertext-policy and chosen-plaintext attack (IND-SCP-CPA).
The Ciphertext-domain Keyword Privacy Game.
Init: Firstly, A delivers the challenge access matrix to .
Setup: runs the same setup algorithm in the keyword private game.
Phase I: provides an oracle, for a query. Furthermore, builds a secret key list, to hold the query results. The oracle functions as follows:
: submits and the user attribute set, to obtain the corresponding user key, . Notice that sent by cannot satisfy the access structure, . If has been in the keyword list, , looks up the list and returns the result directly. Otherwise, executes the key-generating algorithm and inserts the result into the list.
Challenge: prepares two equal-length messages, and for the challenge. then decides on a random bit, and encrypts them under . Finally, sends back the ciphertext, , to .
Phase II: can continue to query for ciphertexts after receiving . The operation is the same as Phase I.
Guess: makes a guess, , for if the bit, is or . If , A wins the security game.
The advantage of A to win the security game is . Our system is IND-SCP-CPA secure if all polynomial-time adversaries only have negligible advantages at most in the security game above.
5. Concrete Construction
Construction of the Basic FERMSABE Scheme
With the pre-described nine PTAs, the basic FERMSABE system can be constructed as follows.
Step 1. The CA sets up the security parameter, and the global parameters , where pairing operations e: . Then, the CA generates three generators, , , and , for the finite group, . The Setup algorithm randomly chooses , , , and from the group and chooses for each attribute in the universe. The rest of the public and the master keys are organized as follows.
After that, the CA publishes the master key pair to other parties. The CA further defines a hash function, , to map keywords into elements of .
Step 2. The CA sets up each AA and grants the authority key pair, and to the authority with an identifier, . The AuthoritySetup algorithm generates a random element, t, from while the authority key pair comprises and .
Step 3. When a user requests the user key, the corresponding AA runs the IntermediateKeyGen algorithm to generate the intermediate user keys using his authority key pair. The AA randomly picks an from and sends this value to the CA. The intermediate user key, is generated as: and . The AA sends this value to the CA to generate the final user key.
Step 4. The CA verifies the validity of the intermediate user key, and then uses it to run the KeyGen algorithm for generating the final user secret key set, , which is composed of seven components. Then, the CA chooses and from . The first six components of are:
Notice that and are random elements taken from such that . The CA generates for each attribute in , that is . The final user key = and will be sent back to the data user.
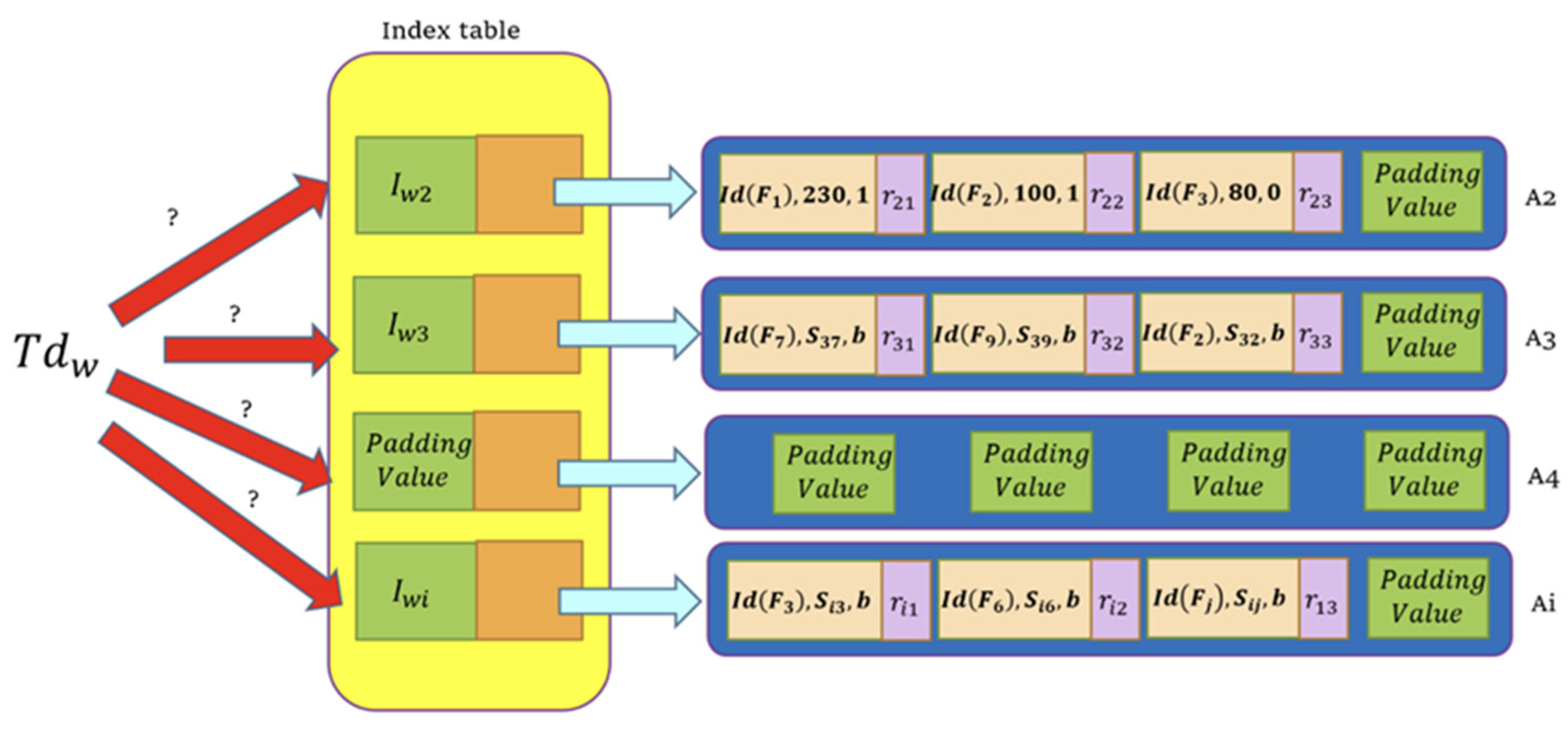
Step 5. DOs build an index table, Ind, based on keywords extracted from plaintext files. Our BuildIndex algorithm is founded on the approach presented in [35] to build our Ind. Figure 4 depicts the data structure of our index table, where each field in blocks of the linked list represents:
- −
- : The identifier of the file, , which contains the keyword, .
- −
- : The relevance score of the keyword, and the file, . Notice that the blocks will not be sorted according to this score for confusion.
- −
- : Random strings of the same length. We use this field to prevent producing two identity blocks.
- −
- Padding values: We add padding values to every linked list to make them of the same size. This setting implies that some linked lists composed of all padding values may also be appended to the table.
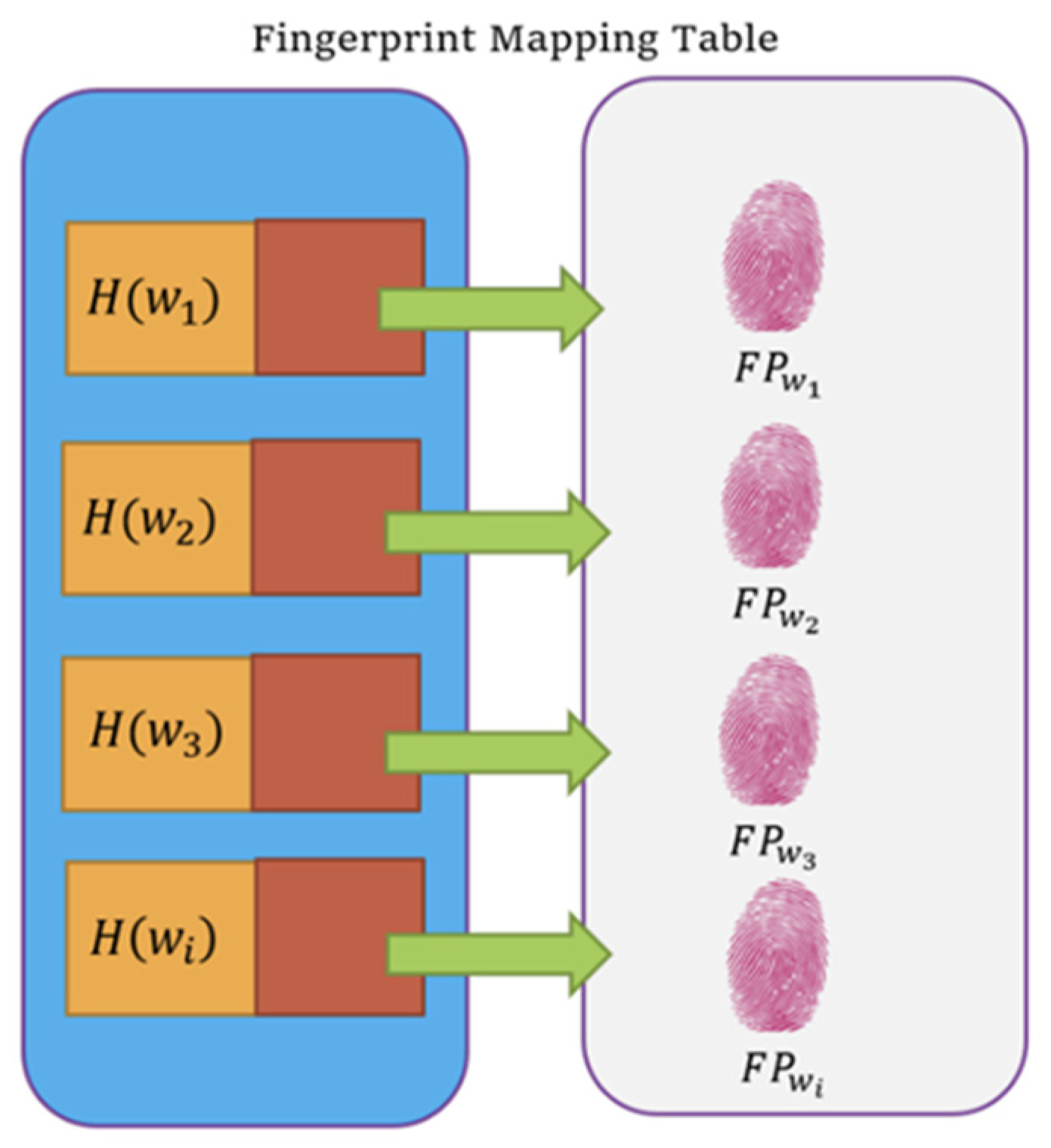
Furthermore, DOs build a fingerprint table to support fuzzy search. Figure 5 illustrates the structure of our fingerprint table, and the corresponding generation algorithm can be found in [15]. We store the hash value of a keyword instead of itself to prevent DUs from knowing the keywords of DOs directly. Only the hash value is enough for the subsequent matching and searching tasks.
In addition to these tables, the DO needs to put some extra data into the headers of Ind to allow the cloud server to perform matchings. We list the additional information in the following:
Finally, the DO uploads the encrypted Ind and ciphertexts to the cloud server.
Step 6. DOs extract keywords from the plaintext files, PF, to build the keyword list, and input the public key, , access policy, , and the session keys, and to the Encrypt
Algorithm. The former is used to encrypt PF, and the latter is used to encrypt by symmetric encryption algorithms such as AES. They choose two elements, and from for supporting secret sharing and, respectively, build the secret sharing vectors, and for by LSSS schemes as follows. They further compute
, , , , , and . Finally, DOs upload , , , to CSP.
Step 7. DUs first download the ciphertext pack from CSP and decrypt Ind and with uk by the Decrypt algorithm. If DUs own the right user key, can be obtained to decrypt these tables correctly. Otherwise, the algorithm halts. By using a fuzzy matching algorithm, DUs can find the fingerprint that best matches the fingerprint of the input keyword, where we adopt the fuzzy matching algorithm presented in [15] to realize this function. Nevertheless, we additionally set a matching threshold to 0.7. Suppose the relevance score between the best-matched fingerprint and the query fingerprint is lower than this threshold, the match will be discarded, and the corresponding leaf node will be removed to prevent fetching unrelated documents. Second, DUs look up to obtain the best-matching hash value, . After that, DUs parse to build a search tree, as shown in Figure 6. Finally, DU chooses a random element, , from to disturb all the values on the leaf nodes. That is, using the GenTrapdoor algorithm, we compute
DUs replace the plaintext domain to-be-searched keywords with these two values at the corresponding locations to produce for searching. Eventually, DUs provide and the decrypted Ind to the cloud server.
Step 8. The CSP first parses the encrypted search tree, . Then, it matches each Td in with each header information in . In other words, it compares whether ? If any index satisfies the previous condition, all the document indexes stored in the latter linked list will be appended to the tree node. Notice that we only need to compute the right-hand side term once because it is fixed. Therefore, our Search algorithm is quite efficient. After all the leaf nodes are searched, the CSP takes the intersection or union of the search results’ leaf nodes to become the final search results of the parent nodes depending on whether their parents are AND node or OR node. Finally, the CSP sorts the searching results, SR, in the root node and outputs the top-k files as the final searching result, . Then, will be sent back to the DUs.
Step 9. In the final phase, DUs use their user keys, , to match with the ciphertext, Ct, for finding the decryption keys. DUs will compute .
Using , they further compute .
Suppose the user key satisfies the access policy. In that case, R will be identical to the final decryption key, . Finally, DUs can use this key to decrypt encrypted data retrieved in the previous step and obtain the plaintext files. We will present the correctness proofs of searching and decryption in the next Section.
6. Analyses
6.1. Security Analyses
In this section, we explore the proofs of the security model as mentioned above and other functional modules of our system.
Theorem 1: Assume the -parallel bilinear Diffie–Hellman (-BDHE) assumptions hold in both and groups. There is no probability that any polynomial-time adversary, A, can break the security of our schemes with a non-negligible advantage.
Proof: Assume the advantage of distinguishing a valid ciphertext from a random element for is . We built a simulator, B, that can break the -BDHE assumption with a non-negligible advantage .
The -BDHE challenger, , first selects random elements , , ,…, from and sets . According to the definition of -BDHE, A is still hard to distinguish even if he knows the above arguments. Then, C chooses a random bit, . If , C sets . Otherwise, is set to a random element in .
Init: The simulator, B, received a -BDHE challenge instance . The adversary, A, announces a challenge access structure and sends it to B, where is an matrix and .
Setup: B selects an element, , in randomly and sets . which implicitly makes . In addition, B initializes a for each attribute by choosing at random, and also randomly selects an element, , from the same group. Finally, B sets and gives the partial public key parameters to A.
Phase I: B keeps a list of the tuple represented as . Initially, the list is empty. A can query the following oracle in the polynomial form:
- −
- : Assume that B received a secret key query for , in which does not match the access structure . B performs the following operations: if A has previously asked for , B retrieves from the list, , directly and returns it to A.
Otherwise, B chooses a vector, , such that and for all . This matrix must exist according to the properties of LSSS. Then, B randomly picks and represents t as: further selects at random, such that mod , and sets and . Then, B, respectively, calculates and as: and . Through the definition of , we noticed that contains a term of , which can be ignored with the unknown terms in when calculating . That is, B computes as: . Notice that and are irrelevant to , , and , so we omit the generation of them here. Finally, B puts into and sends the keys to A.
Challenge: A prepares two equal-length messages, and , for the challenge. B then decides on a random bit, , and encrypts them under computes as , and is generated as .
It is hard for B to simulate since it includes the term . To overcome this difficulty, B splits the secret to eliminate the above-mentioned terms. That is, B selects randomly, and then shares the secret vector, , with A. For , we describe as the set of all making . B calculates as: .
We produce , , and in the similar way. Finally, B returns the challenge ciphertext, , to A.
Phase II: A continues to make queries similar to Phase I.
Guess T: A outputs which is a guess of . If , B returns to guess . Otherwise, B returns , indicating that is a random element chosen from . In this case, A won the security game and obtained an effective ciphertext. Now, the advantage of A is . Conversely, A cannot obtain any information about b and the ciphertext; thus, . In conclusion, the advantage of A in winning the IND-SCP-CPA security game is: . Since A only has a negligible advantage in solving the -DBHE problem, hence no polytime adversary, A can break the security of our schemes with a non-negligible advantage.
As for the keyword privacy, we will prove that any polytime adversary, A, cannot guess the input keyword, w, from the Secure Index, , nor forge it.
Firstly, because the secret value, s, masked the term . Even if A has produced the value on its own, the only term which contains is . A cannot obtain the value, , because it is one of the components of the master key, , to tell or forge the Secure Indices. To change the keyword of a trapdoor, A needs to modify . However, it is hard due to the difficulty in solving the discrete log problem.
In summary, the unmalleability of the index and trapdoor of our scheme has now been proved.
6.2. Functional Comparisons
We compared some existing ABKS schemes with ours in terms of access control, keyword search, multi-keyword, ranked result, fuzzy search, and semantic search capabilities, as shown in Table 2. We use the symbol “ “ to mean that the scheme has the indicated function, while the symbol “-“represents the lack of this kind of function. Our scheme is the most functional from the table, providing fine-grained access control and supporting a multi-keyword ranked search result with various powerful search modes.
6.3. Computational Complexity Analyses
Table 3 compares the theoretical computation costs with some recent ABKS schemes and ours. Let denote the universe size and the size of user attributes, while we use to represent the number of attributes the DO used in the access policy. We use to symbolize pairing operations. and represent the exponentiation operations in groups and . Hash functions are excluded from our comparison because they are much more efficient than exponentiation and pairing operations. The table shows that our scheme is the most efficient one most of the time, especially for searching.
We concluded our theoretical storage costs compared with the above-mentioned schemes in Table 4. , , and are bit lengths required to store an element in the respective finite group. Our theoretical storage costs are similar to the MABKS [17] scheme. However, our scheme has lower constant terms and has little relevance to the user attribute size. Furthermore, our trapdoor size is quite reasonable compared with the other schemes. We put extra data into ciphertexts to eliminate the need for DOs to exchange keys with DUs. Even so, the space complexity of ciphertexts is still acceptable in actual cases.
6.4. Experimental Analyses
We designed a series of experiments to simulate the actual performance of our schemes. We used the real Enron email dataset [35] for testing. Moreover, we tested our schemes on a Windows machine with 2.80 GHz Intel(R) Core(TM) i7-1165G7 @ 2.80 GHz CPU and 8 GB ROM. We used JPBC (Java Pairing-Based Cryptography) as the pairing operation library and executed the programs on Java SDK 17 and JPBC 2.0.0. According to the most popular setting, we set bit and bit, and the Type-A elliptic curve: is picked. For practical uses, the universe size is between [20, 100], and the user attribute size is between [3, 100]. In the subsequent experiments, we assumed at least one authorized document for DUs to retrieve.
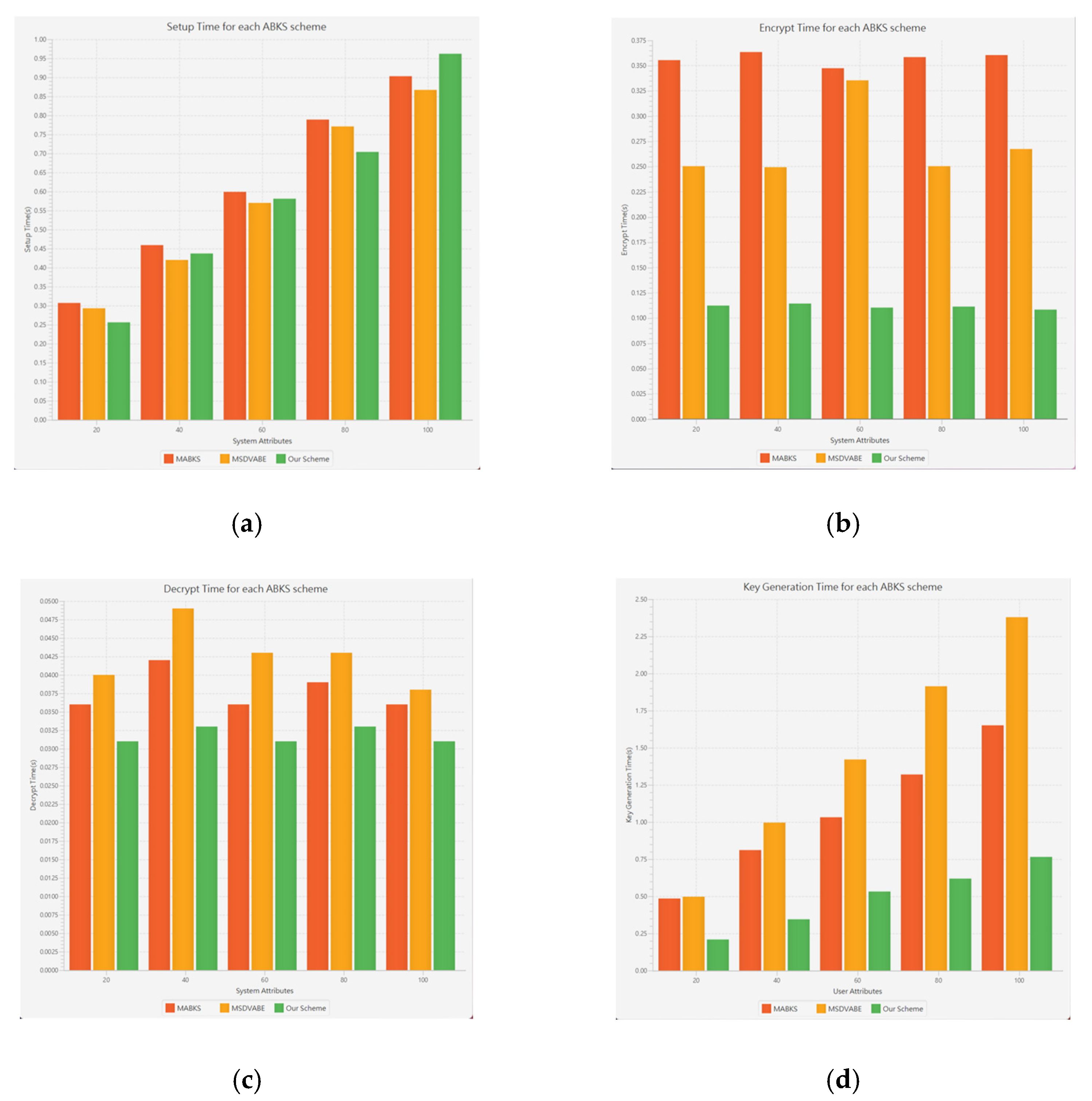
Figure 7a–d shows the simulation results of our basic scheme compared with others. The universe and the user attribute sizes have been mentioned above. Because some of these schemes do not support multi-keyword ranked search, we only examined one document and one searching condition for ease of simulations. However, it is sufficient to express the effectiveness of the proposed scheme. Figure 7a shows the setup time, demonstrating a linear dependency on the size of the system attributes. While the encryption time is irrelevant to the size of the system attributes, as shown in Figure 7b, our setup time is similar to the other benchmarking schemes, but we use a much shorter time for encryption. Our scheme shows superiority in decryption and user-key generation time, as demonstrated in Figure 7c,d. Notice that the required key-generation time is proportional to the size of the user attributes rather than that of the universe. Clearly, our scheme has more advantages when massive user attributes are required. Our approaches are the most efficient compared to the MABKS [21] and MSDVABE [33] schemes.
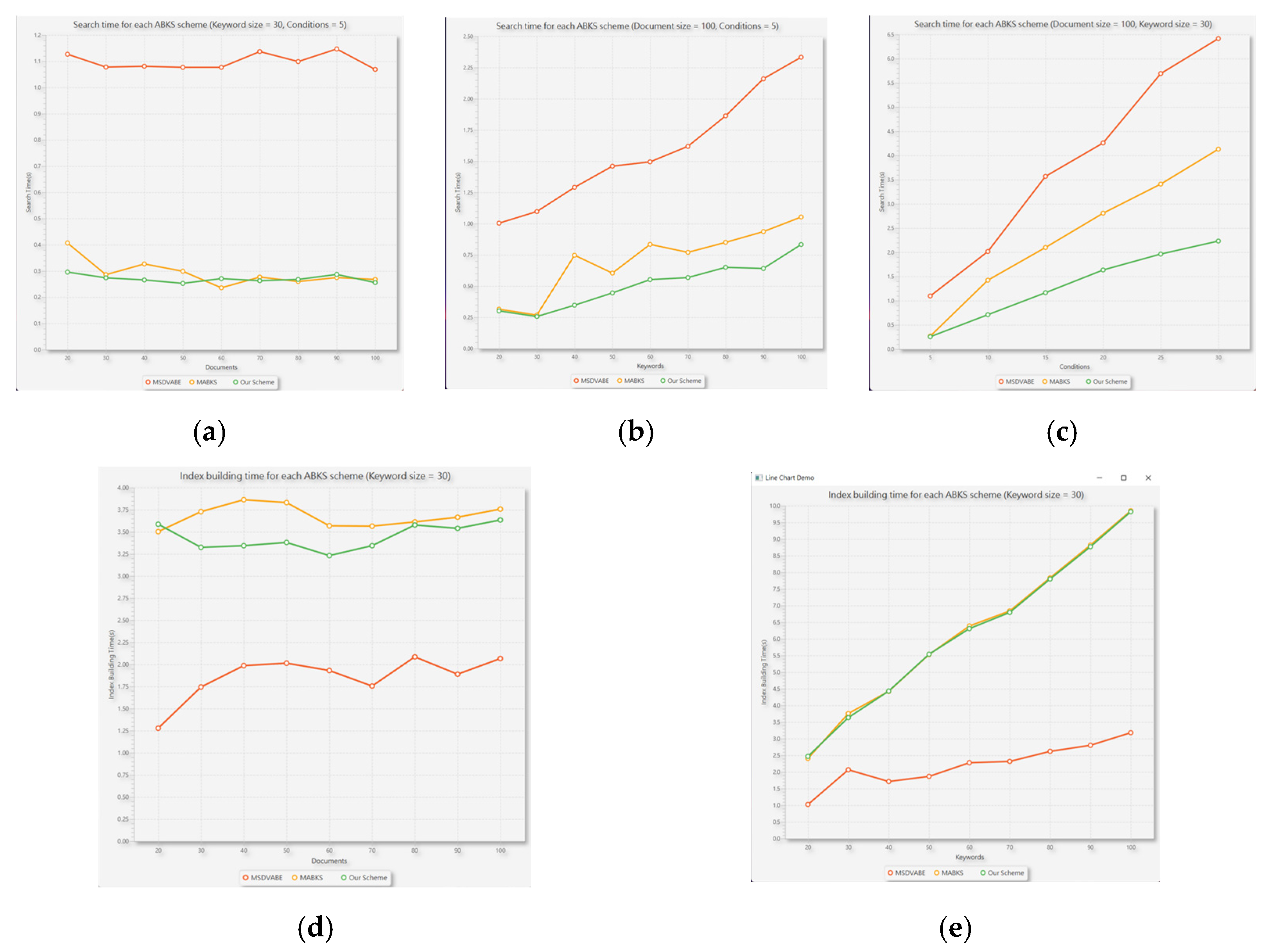
We constructed a practical system for the implementation of our enhanced scheme. Figure 8a–e shows this system’s actual data retrieval and index-table building times. For ease of simulations, we realized the same extensions on the other benchmarked schemes to support more powerful searching modes. In these experiments, we set the universe size to 27, and the user attributes size to 3 for simulating real scenarios. These attributes are categorized into position, subject, and level classes. This setting does not affect the experiment results in any case. In Figure 8a, we fixed the size of the keywords.
We set the number of Provided by DOs to 30 and the number of search conditions selected by DUs to 5. Furthermore, we set the size of the document database to vary from 20 to 100. In this circumstance, our search time is almost constant and is similar to that of MABKS [21]; both are better than the MSDVABE [33]. In Figure 8b, the keyword size varies from 20 to 100 while the database size and searching conditions are fixed to 100 and 5, respectively. Our searching time is linearly proportional to the size of the keywords, while that of the MSDVABE [33] scheme varies more dramatically than ours. The same conclusion can be drawn from Figure 8. When the search conditions increase from 5 to 30, our scheme performs better than the others.
Figure 8d–f demonstrates the actual consuming times for building an index table. Although the MSDVABE [33] scheme takes the shortest time in this experiment, it has a poor performance on searching. With a similar opinion to MABKS [21], we conducted one pairing operation in the index-building phase to prevent performing too many pairing operations in the searching phase. Therefore, some of the performance on building index tables is sacrificed. However, data owners usually build index tables only once, but data users may search the database many times. Therefore, our schemes are most realistic and practical in actual use. Furthermore, these two schemes take much more time, even making it impossible to perform fuzzy and semantic keyword-ranked searches combined with multiple keywords without our extensions. We proved that our schemes are efficient, flexible, and universal to apply to other performance-oriented AMKS schemes.
7. Conclusions
In this paper, we showed that the proposed FEMRSABE scheme has a powerful search capability that can satisfy most users’ needs. Even if the user inputs do not fully match the keywords set up by the DO or have some minor spelling errors, users can still obtain the desired and most-related documents. Our basic protocol competes with the state-of-the-art schemes through the performance analyses given in the previous Section.
The state-of-the-art takes much more time to search and does not perform fuzzy and semantic keyword ranked searches which is the main contribution of our work.
Moreover, the enhanced one brings many more functionalities with a slight efficiency loss, which is tolerable in real-world scenarios. Moreover, we proved that our scheme is secure under the IND-SCP-CPA and the IND-CKA security requirements. However, there are some limitations in our system as well. For example, the attributes of users may frequently vary in the real world, while fine-grained attribute revocation and updating mechanisms are needed but are not included in our work currently. Furthermore, we tackle the single-point failure problem by setting up multiple attribute authorities, but there are probably malicious attribute authorities that can determine users’ privacy by mis-operations.
We plan to add the attribute revocation and verification mechanisms mentioned above to make the system more steady and secure.
Author Contributions
Formal analysis, J.-K.L.; Funding acquisition, J.-L.W.; Investigation, J.-K.L., W.-T.L. and J.-L.W.; Methodology, J.-K.L.; Project administration, W.-T.L. and J.-L.W.; Resources, J.-L.W.; Software, J.-K.L.; Supervision, W.-T.L. and J.-L.W.; Writing—original draft, J.-K.L.; Writing—review & editing, W.-T.L. and J.-L.W. All authors have read and agreed to the published version of the manuscript.
Funding
The Minister of Science and Technology, Taiwan: MOST 111-2221-E-002-134-MY3 and Taiwan Semiconductor Manufacturing Company: TSMC: 112H1002-D.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Saxena, A.; Shinghal, K.; Misra, R.; Agarwal, A. Automated Enhanced Learning System using IoT. In Proceedings of the 2019 4th International Conference on Internet of Things: Smart Innovation and Usages (IoT-SIU), Ghaziabad, India, 18–19 April 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Korupolu, M.; Jannabhatla, S.; Kommineni, V.S.; Kalyanam, H.; Vasantham, V. Video Streaming Platform Using Distributed Environment in Cloud Platform. In Proceedings of the 2021 7th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 19–20 March 2021; Volume 1, pp. 1414–1417. [Google Scholar] [CrossRef]
- Xiong, H.; Yao, T.; Wang, H.; Feng, J.; Yu, S. A Survey of Public-Key Encryption with Search Functionality for Cloud-Assisted IoT. IEEE Internet Things J. 2021, 9, 401–418. [Google Scholar] [CrossRef]
- Bethencourt, J.; Sahai, A.; Waters, B. Ciphertext-Policy Attribute-Based Encryption. In Proceedings of the 2007 IEEE Symposium on Security and Privacy (SP’07), Berkeley, CA, USA, 20–23 May 2007; pp. 321–334. [Google Scholar] [CrossRef]
- Chi, P.-W.; Wang, M.-H.; Shiu, H.-J. How to Hide the Real Receiver Under the Cover Receiver: CP-ABE with Policy Deniability. IEEE Access 2020, 8, 89866–89881. [Google Scholar] [CrossRef]
- Han, J.; Susilo, W.; Mu, Y.; Zhou, J.; Au, M.H.A. Improving Privacy and Security in Decentralized Ciphertext-Policy Attribute-Based Encryption. IEEE Trans. Inf. Forensics Secur. 2015, 10, 665–678. [Google Scholar] [CrossRef]
- Li, J.; Yao, W.; Han, J.; Zhang, Y.; Shen, J. User Collusion Avoidance CP-ABE with Efficient Attribute Revocation for Cloud Storage. IEEE Syst. J. 2017, 12, 1767–1777. [Google Scholar] [CrossRef]
- Moffat, S.; Hammoudeh, M.; Hegarty, R. A Survey on Ciphertext-Policy Attribute-based Encryption (CP-ABE) Approaches to Data Security on Mobile Devices and its Application to IoT. In Proceedings of the ICFNDS’17: Proceedings of the International Conference on Future Networks and Distributed Systems, Cambridge, UK, 19–20 July 2017; Association for Computing Machinery: New York, NY, USA, 2017; p. 34. [Google Scholar] [CrossRef]
- Yahiatene, Y.; Menacer, D.E.; Riahla, M.A.; Rachedi, A.; Tebibel, T.B. Towards a distributed ABE based approach to protect privacy on online social networks. In Proceedings of the 2019 IEEE Wireless Communications and Networking Conference (WCNC), Marrakesh, Morocco, 15–18 April 2019; pp. 1–7. [Google Scholar] [CrossRef]
- Fu, Z.; Shu, J.; Sun, X.; Zhang, D. Semantic keyword search based on tree over encrypted cloud data. In Proceedings of the SCC’14—Proceedings of the 2nd International Workshop on Security in Cloud Computing, Kyoto, Japan, 3 June 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 59–62. [Google Scholar] [CrossRef]
- Liu, G.; Yang, G.; Bai, S.; Zhou, Q.; Dai, H. FSSE: An Effective Fuzzy Semantic Searchable Encryption Scheme over Encrypted Cloud Data. IEEE Access 2020, 8, 71893–71906. [Google Scholar] [CrossRef]
- Tzouramanis, T.; Manolopoulos, Y. Secure reverse k-nearest neighbors search over encrypted mult-dimensional databases. In Proceedings of the IDEAS’18: Proceedings of the 22nd International Database Engineering & Applications Symposium, Calabria, Italy, 18–20 June 2018; Association for Computing Machinery: New York, NY, USA, 2018. [Google Scholar] [CrossRef]
- Wang, B.; Hou, Y.; Li, M.; Wang, H.; Li, H. Maple: Scalable multi-dimensional range search over encrypted cloud data with tree-based index. In Proceedings of the 9th ACM Symposium on Information, Computer and Communications Security, Kyoto, Japan, 4–6 June 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 111–122. [Google Scholar] [CrossRef]
- Yoshino, M.; Naganuma, K.; Kunihiro, N.; Sato, H. Practical Query-based Order Revealing Encryption from Symmetric Searchable Encryption. In Proceedings of the 2020 15th Asia Joint Conference on Information Security (AsiaJCIS), Taipei, Taiwan, 20–21 August 2020; pp. 16–23. [Google Scholar] [CrossRef]
- Zhang, M.; Wang, X.A.; Yang, X.; Cai, W. Efficient Predicate Encryption Supporting Construction of Fine-Grained Searchable Encryption. In Proceedings of the 2013 5th International Conference on Intelligent Networking and Collaborative Systems, Xi’an, China, 9–11 September 2013; pp. 438–442. [Google Scholar] [CrossRef]
- Cao, L.; Kang, Y.; Wu, Q.; Wu, R.; Guo, X.; Feng, T. Searchable encryption cloud storage with dynamic data update to support efficient policy hiding. China Commun. 2020, 17, 153–163. [Google Scholar] [CrossRef]
- Chaudhari, P.; Das, M.L. A2BSE: Anonymous attribute based searchable encryption. In Proceedings of the 2017 ISEA Asia Security and Privacy (ISEASP), Surat, India, 29 January–1 February 2017; pp. 1–10. [Google Scholar] [CrossRef]
- Khan, S.; Khan, S.; Zareei, M.; Alanazi, F.; Kama, N.; Alam, M.; Anjum, A. ABKS-PBM: Attribute-Based Keyword Search with Partial Bilinear Map. IEEE Access 2021, 9, 46313–46324. [Google Scholar] [CrossRef]
- Li, H.; Liu, D.; Jia, K.; Lin, X. Achieving authorized and ranked multi-keyword search over encrypted cloud data. In Proceedings of the 2015 IEEE International Conference on Communications (ICC), London, UK, 8–12 June 2015; pp. 7450–7455. [Google Scholar] [CrossRef]
- Liu, L.; Wang, S.; He, B.; Zhang, D. A Keyword-Searchable ABE Scheme from Lattice in Cloud Storage Environment. IEEE Access 2019, 7, 109038–109053. [Google Scholar] [CrossRef]
- Miao, Y.; Deng, R.; Liu, X.; Choo, K.-K.R.; Wu, H.; Li, H. Multi-authority Attribute-Based Keyword Search over Encrypted Cloud Data. IEEE Trans. Dependable Secur. Comput. 2019, 18, 1667–1680. [Google Scholar] [CrossRef]
- Sun, W.; Yu, S.; Lou, W.; Hou, Y.T.; Li, H. Protecting your right: Attribute-based keyword search with fine-grained owner-enforced search authorization in the cloud. In Proceedings of the IEEE INFOCOM 2014—IEEE Conference on Computer Communications, Toronto, ON, Canada, 27 April–2 May 2014; pp. 226–234. [Google Scholar] [CrossRef]
- Wang, H.; Ning, J.; Huang, X.; Wei, G.; Poh, G.S.; Liu, X. Secure Fine-grained Encrypted Keyword Search for e-Healthcare Cloud. IEEE Trans. Dependable Secur. Comput. 2019, 18, 1307–1319. [Google Scholar] [CrossRef]
- Wang, S.; Zhang, D.; Zhang, Y.; Liu, L. Efficiently Revocable and Searchable Attribute-Based Encryption Scheme for Mobile Cloud Storage. IEEE Access 2018, 6, 30444–30457. [Google Scholar] [CrossRef]
- Zhang, L.; Su, J.; Mu, Y. Outsourcing Attributed-Based Ranked Searchable Encryption with Revocation for Cloud Storage. IEEE Access 2020, 8, 104344–104356. [Google Scholar] [CrossRef]
- Miller, G.A. Wordnet: A lexical database for English. Communications. ACM 1995, 38, 39–41. [Google Scholar] [CrossRef]
- Wang, C.-J.; Luo, J.-F. A Key-policy Attribute-based Encryption Scheme with Constant Size Ciphertext. In Proceedings of the 2012 Eighth International Conference on Computational Intelligence and Security, Guangzhou, China, 17–18 November 2012; pp. 447–451. [Google Scholar] [CrossRef]
- Cao, N.; Wang, C.; Li, M.; Ren, K.; Lou, W. Privacy-Preserving Multi-Keyword Ranked Search over Encrypted Cloud Data. IEEE Trans. Parallel Distrib. Syst. 2013, 25, 222–233. [Google Scholar] [CrossRef]
- Aritomo, D.; Watanabe, C.; Matsubara, M.; Morishima, A. A Privacy-Preserving Similarity Search Scheme over Encrypted Word Embed-Dings; Association for Computing Machinery: New York, NY, USA, 2019; pp. 403–412, iiWAS2019. [Google Scholar] [CrossRef]
- Fan, J.; Vercauteren, F. Somewhat practical fully homomorphic encryption. IACR Cryptol. ePrint Arch. 2012, 144. [Google Scholar]
- Gentry, C. A Fully Homomorphic Encryption Scheme. Ph.D. Thesis, Stanford University, Stanford, CA, USA, 2009. aAI3382729. [Google Scholar]
- Yu, J.; Lu, P.; Zhu, Y.; Xue, G.; Li, M. Toward Secure Multikeyword Top-k Retrieval over Encrypted Cloud Data. IEEE Trans. Dependable Secur. Comput. 2013, 10, 239–250. [Google Scholar] [CrossRef]
- Sun, J.; Ren, L.; Wang, S.; Yao, X. Multi-Keyword Searchable and Data Verifiable Attribute-Based Encryption Scheme for Cloud Storage. IEEE Access 2019, 7, 66655–66667. [Google Scholar] [CrossRef]
- Waters, B. Ciphertext-policy attribute-based encryption: An expressive, efficient, and provably secure realization. In International Workshop on Public Key Cryptography; Springer: Berlin/Heidelberg, Germany, 2011; pp. 53–70. [Google Scholar]
- William, W.; Cohen, M.L.D.C. Enron Email Dataset. Tech. Rep. 2015. Available online: https://www.cs.cmu.edu/enron/ (accessed on 10 May 2023).
Figure 1.
The hierarchy of standard searching modes and the concrete associated examples. Unlike single and multi-keyword rank search, fuzzy and semantic search belong to high-level searching modes.
Figure 1.
The hierarchy of standard searching modes and the concrete associated examples. Unlike single and multi-keyword rank search, fuzzy and semantic search belong to high-level searching modes.

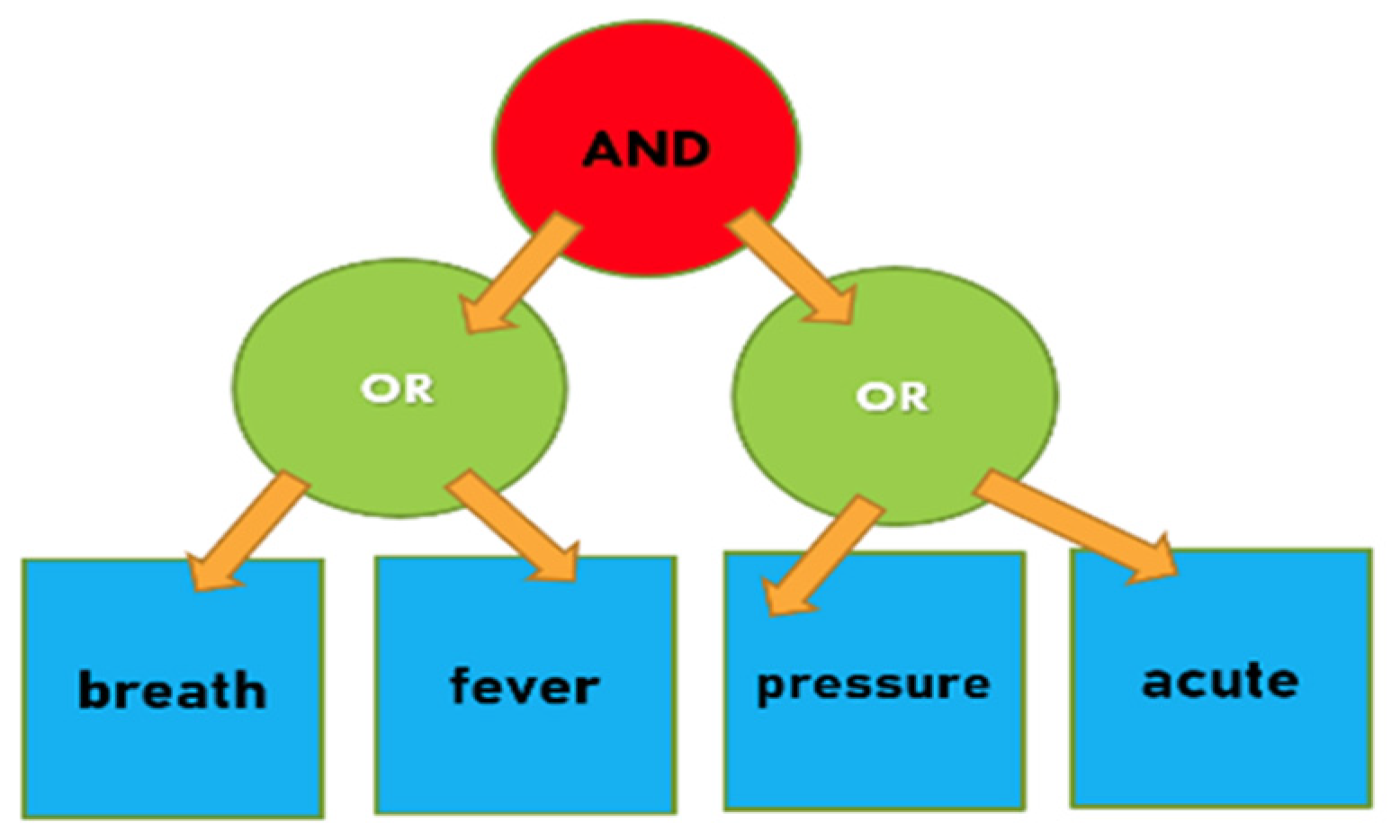
Figure 2.
This work uses a tree-based data structure and AND–OR gates to complete a complicated keyword search task in the encryption domain. This is an example of an E-health use case.
Figure 2.
This work uses a tree-based data structure and AND–OR gates to complete a complicated keyword search task in the encryption domain. This is an example of an E-health use case.

Figure 3.
The players, the functional blocks, and the detailed information flow of the proposed system.
Figure 3.
The players, the functional blocks, and the detailed information flow of the proposed system.

Figure 4.
We use a link-list structure to construct our Index Table.

Figure 5.
Data Structure of our Fingerprint Mapping Table.

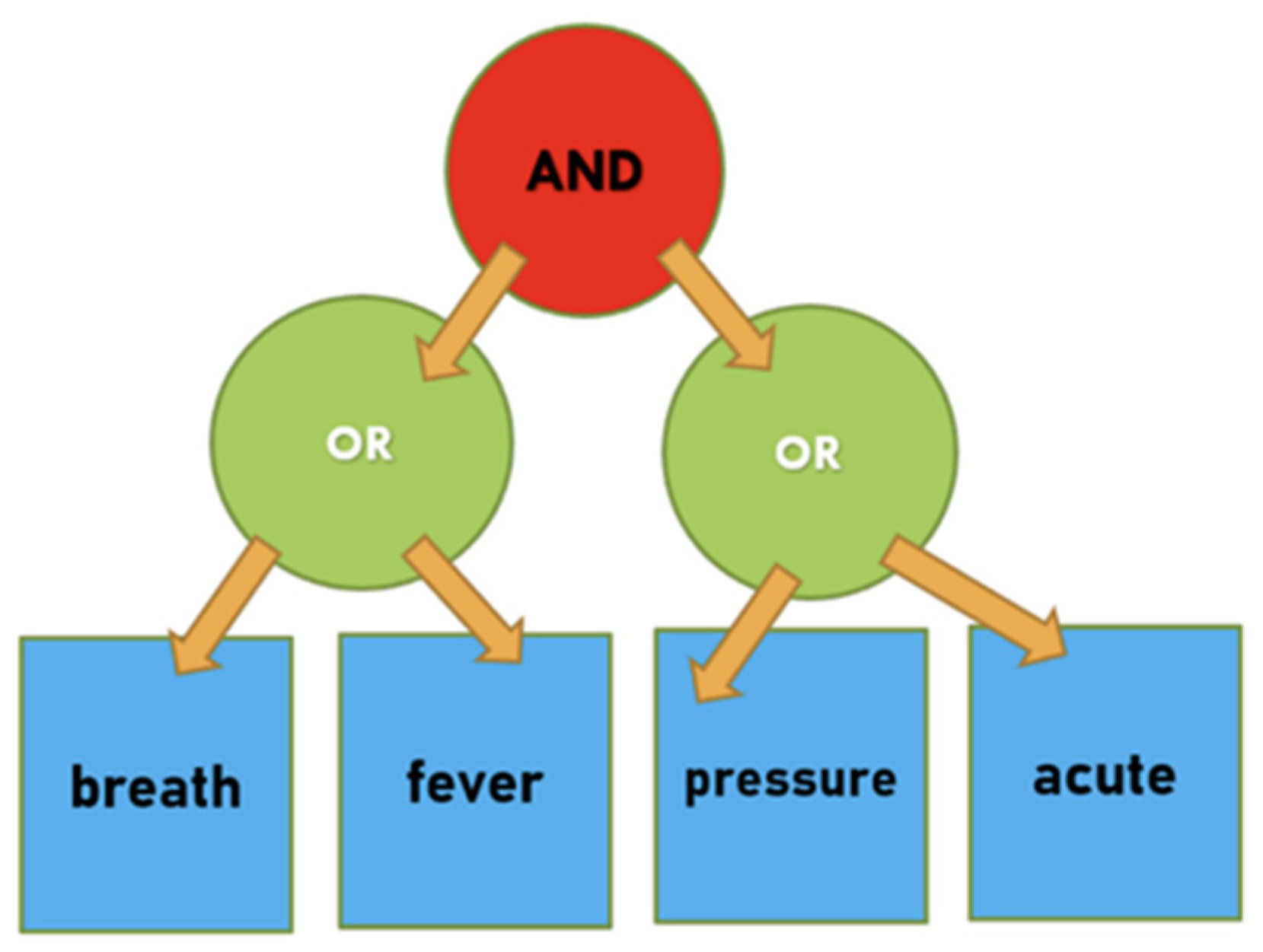
Figure 6.
The Query keyword tree in plaintext form. This table is generated for the access condition of (breath OR fever) AND (pressure OR acute). Notice that this figure is for demonstration purposes only. In actuality, DUs need not know which keywords they have precisely matched.
Figure 6.
The Query keyword tree in plaintext form. This table is generated for the access condition of (breath OR fever) AND (pressure OR acute). Notice that this figure is for demonstration purposes only. In actuality, DUs need not know which keywords they have precisely matched.

Figure 7.
Timing Performance Comparisons. (a) Setup time, (b) Encryption time, (c) Decryption time, and (d) Time cost of user secret-key generation.
Figure 7.
Timing Performance Comparisons. (a) Setup time, (b) Encryption time, (c) Decryption time, and (d) Time cost of user secret-key generation.

Figure 8.
Experiment results in Our Realized Practical Systems. Data retrieval time for (a) different document sizes, (b) different keyword sizes, and (c) different searching conditions. Index-Table building time for (d) different documents and (e) different keyword sizes.
Figure 8.
Experiment results in Our Realized Practical Systems. Data retrieval time for (a) different document sizes, (b) different keyword sizes, and (c) different searching conditions. Index-Table building time for (d) different documents and (e) different keyword sizes.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
The symbols and their corresponding definitions.
| Symbols | Description | Symbols | Description |
|---|---|---|---|
| Master secret key | Searching keyword | ||
| Public key | Keyword set | ||
| Authority master key | Plaintext files | ||
| Authority public key | A document | ||
| User secret key | Fingerprint | ||
| Intermediate user secret key | Ciphertexts | ||
| Session key | Relevance score | ||
| The universe of user attributes | Search condition string | ||
| User attribute set | Fingerprint table | ||
| An attribute | Trapdoor | ||
| Hash function | Search tree (plaintext) | ||
| Access policy | Search tree (encrypted) | ||
| User id | Maximum size of searching results | ||
| Attribute authority id | Searching results | ||
| Secure index | Ranked searching results |
Table 2.
Functional Comparison between the proposed and the benchmarked ABKS schemes.
| Function | MABKS [21] | MSDVABE [33] | FSSE [11] | Ours |
|---|---|---|---|---|
| Access control | - | |||
| Keyword search | ||||
| Multi-keyword | - | |||
| Ranked result | - | - | ||
| Fuzzy search | - | - | ||
| Semantic search | - | - |
Table 3.
Comparisons of Theoretical Computational Costs Between Our Scheme and the Benchmarked Ones.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Lin, J.-K.; Lin, W.-T.; Wu, J.-L. Flexible and Efficient Multi-Keyword Ranked Searchable Attribute-Based Encryption Schemes. Cryptography 2023, 7, 28. https://doi.org/10.3390/cryptography7020028
AMA Style
Lin J-K, Lin W-T, Wu J-L. Flexible and Efficient Multi-Keyword Ranked Searchable Attribute-Based Encryption Schemes. Cryptography. 2023; 7(2):28. https://doi.org/10.3390/cryptography7020028
Chicago/Turabian StyleLin, Je-Kuan, Wun-Ting Lin, and Ja-Ling Wu. 2023. "Flexible and Efficient Multi-Keyword Ranked Searchable Attribute-Based Encryption Schemes" Cryptography 7, no. 2: 28. https://doi.org/10.3390/cryptography7020028