1. Creating Implicit Measure Stimulus Sets Using a Multi-Step Piloting Method
Over the past three decades, there has been an increasing interest in the use of experimental tasks as measures to assess non-conscious constructs such as implicit attitudes, implicit self-concepts, and approach biases. Such measures have, in general, been successful in augmenting traditional self-reported scales to improve the prediction of outcomes and have coincided with renewed interest in dual-process models to conceptualize the role of automatic processes in human behavior [
1,
2,
3,
4].
However, despite the increasing popularity and interest in dual-process research, questions remain about the validity of measures used to assess implicit constructs like implicit attitude and implicit beliefs [
5,
6,
7,
8,
9]. One persistent concern raised by dual-process researchers is that the characteristics of stimulus items used may introduce extraneous variability into measures [
10,
11,
12,
13], as all currently available implicit measures require target objects and concepts to be represented by a set of stimulus items [
14,
15,
16]. Most commonly, these stimulus sets are made up of pictures or words of prototypical exemplars that are thought to represent that category (e.g., the target concept of alcohol might be represented by names of common alcoholic beverages). Tasks then infer nonconscious constructs like implicit attitudes through patterns of responding to these stimuli in experimental tasks. The ability of researchers to create stimulus sets to represent a wide range of categories has contributed to the growing use of implicit measures in a variety of fields, including social psychology [
17], health promotion [
18,
19,
20,
21], and business [
22]. However, the methodology and process of stimulus selection is often treated as a minor or trivial part of the research design, as pilot testing and data-driven stimulus selection processes are rarely reported in the current dual-process literature.
This dearth of research in piloting and robust stimulus selection occurs in spite of evidence that stimulus characteristics can influence results from implicit measures. For example, several studies have produced notable changes in mean effects and correlations with outcome measures by altering stimulus in terms of context [
23], modality [
24], or task irrelevant stimulus-valence associations [
25]. Of the potential effects of stimulus selection, one of the more subtle yet broad findings has been evidence that seemingly minor variations in the correspondence between a stimulus item and its target concept can alter the effects found on implicit measures [
12,
13]. This proposition is supported by experimental evidence [
26], showing that, when administering multiple versions of the racial bias IAT across four experiments, IATs produced stronger effects when stimuli were rated as more representative of their target concepts. Findings such as these reaffirm the recommendation that researchers employing implicit measures should be cautious in their stimulus selection, and seek to use highly relevant stimulus items, rather than many stimuli with a range of conceptual correspondences [
11].
Further, even when highly relevant stimulus items are selected, characteristics of how exemplars are used in everyday life may also affect results [
27]. For example, experimental evidence has found that implicit measures are more sensitive when target stimulus comprise of words which are frequently used and familiar to the target sample [
28]. While this effect is minor when all categories are equally familiar or unfamiliar to participants, the effects of stimulus familiarity and use frequency can notably change effects on implicit measures when one category has a higher use frequency than another [
29].
Another common consideration in implicit measure research is the length of stimulus words in each category, as there is evidence of slower word processing when words are particularly short (three or fewer letters) or long (10 or more letters) [
30]. As a result, some researchers opt to match the mean length of stimulus words between categories [
29,
31,
32,
33,
34,
35]. Research has demonstrated, however, that there is little evidence of variation in implicit measures as a function of word length [
36]. One potential reason this effect has not been found in implicit measure studies is that, as reading skills advance, known words are generally processed as a whole, contributing to reduced variability in processing speed as a function of word length [
37,
38,
39]. However, in younger samples where reading skills are less advanced, the same studies found significantly slower processing speeds for long compared to short words. Thus, it is a plausible hypothesis that word length should remain a consideration, but its relevance may be minimal outside of younger samples or those with a reading impairment.
The Current Study
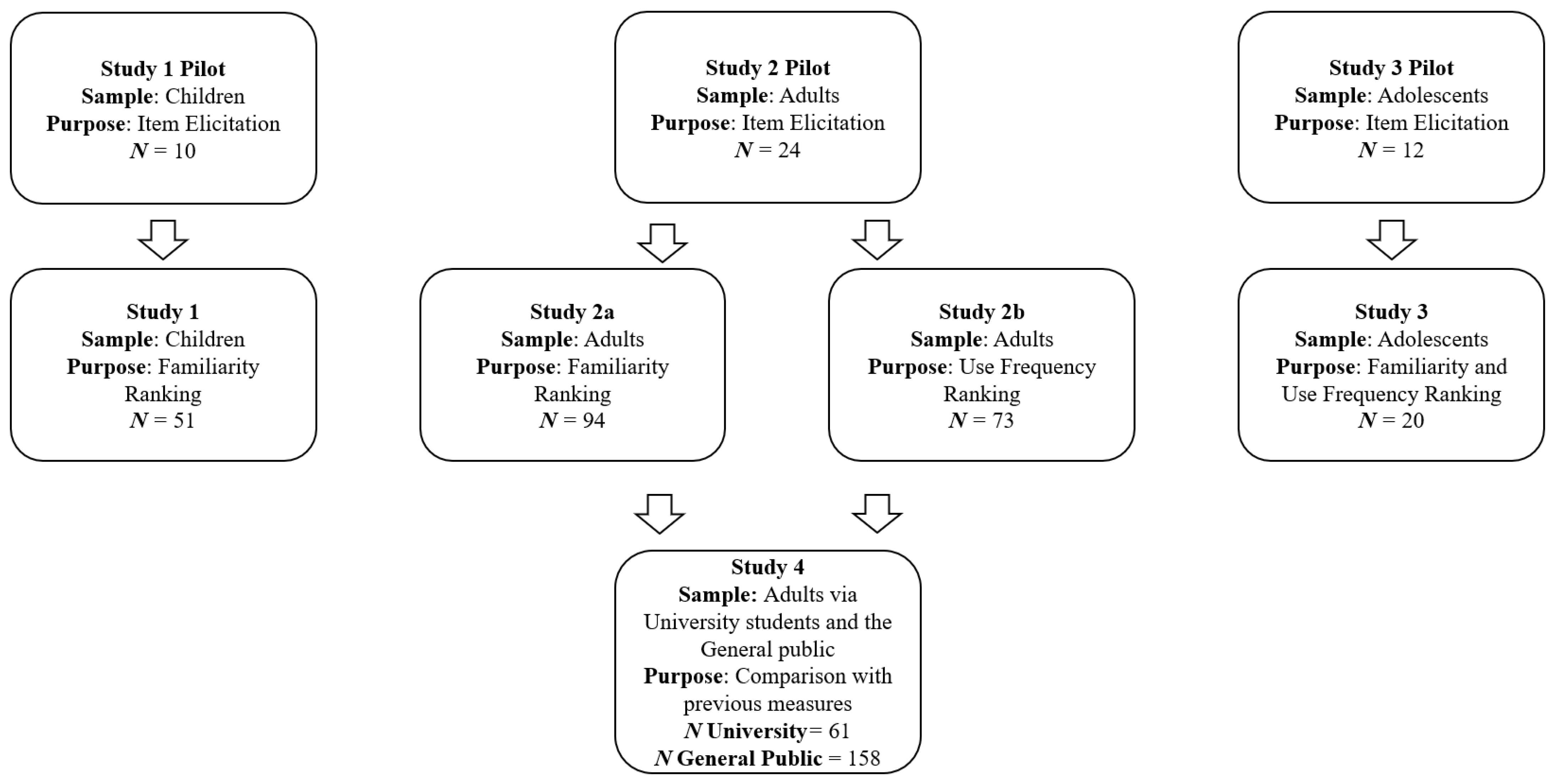
Despite the potential value of good stimulus selection flagged in the current literature, research comparing stimulus sets selected based on theoretically relevant empirical data and stimulus sets selected by researchers is lacking. Thus, the current study aimed to address this research gap by outlining and testing a multi-step process to create stimulus sets for implicit measures, which accounts for several theoretically important sources of heterogeneity as a function of stimulus selection: correspondence to the construct, use frequency and familiarity, and word length. In an attempt to minimize researcher bias in selecting stimulus items, a pool of potential stimulus words will first be extracted from the target sample in a free-recall format. Then, separate samples will explicitly rate the extent to which they believe these words correspond to the target construct. Lastly, each of the words will be assessed for frequency of use and word length. Ideally, from each set of words, the researchers can select a small set of exemplars to act as stimulus items that are highly corresponding to the target concept, are at low risk of being highly unfamiliar to the target sample, and of near equal average length. In the current study, we test this process in three populations:—children, adolescents, and young adults—creating a stimulus set for the target behaviors of healthy eating and sugar intake in each population. Following piloting, we assessed the stimulus sets created for how they compared to previously employed but unpiloted measures in terms of their reliability and convergent validity. A visual summary of the research project is presented in
Figure 1.
2. Study 1
2.1. Pilot
A sample of 10 children aged 6–10 years old were interviewed at a convenient location, in order to provide a pool of potential stimulus words in a free-recall format. After obtaining parental and child consent, children were asked to provide the first five things they thought of when they think of healthy foods. The children were then asked to provide the first five things they think of when they think of sugary or sweet food and drinks.
2.2. Participants and Procedure
A sample of 51 children aged 6–10 years old (male = 22, female = 29, Mage = 7.55, SDAge = 1.53) were recruited to explicitly rate the extent to which they associated the words provided in the pilot with the target concepts. Participants were recruited through advertisements targeted at parents posted in parenting forums, online community noticeboards, Facebook advertisements, and an email broadcast to staff members of an Australian university.
Before beginning the survey, parents were presented with a detailed information sheet, asked to provide consent, and instructed that they may assist their child in reading and understanding, but should not attempt to influence children’s survey responses. Then, a simplified information and consent form was presented for children, which parents were asked to read and explain to their child. Once they began the survey, children were asked to rate how much they associated each of the exemplars provided in the pilot study with healthy food and sugary or sweet food and drinks (e.g., How much do apples make you think about healthy food? How much do doughnuts make you think about sweet and sugary things?). To increase readability and accessibility for children, simple language was used with a large font size, and all Likert items included a label on each possible response (0 = I do not know what that is, 1 = Not at all, 2 = A Little, 3 = Kind of, 4 = Very Much, 5 = Extremely). Researchers also recorded the length of each word in syllables and letters and its frequency of use in Australian children’s writing using the Oxford Word List [
40]. Note that, compared to other corpus data, the Oxford Word List presents use frequency as a rank of sampled words. Thus, lower numbers correspond to more frequent use.
2.3. Results and Discussion
Study 1 aimed to create sets of potential stimulus items representing healthy eating and high sugar items in children which were rated as highly corresponding to their respective target concept, familiar to the target sample, and of near equal word length. The children’s levels of association between exemplars and healthy foods are provided in
Table 1, and associations between exemplars and sweet and sugary foods and drinks are provided in
Table 2.
Regarding sweet and sugary foods and drinks in the children sample, the current data suggests the category is best represented by three exemplars: candy, ice cream, and lollipop. Each of these exemplar items was rated as strongly associated with the target concept (mean correspondence ≥ 4.00), was less than three syllables and/or ten letters, had no respondents reported not knowing the word, and was in frequent use according to corpus data. It is important to note that, while the category sweet and sugary foods and drinks included both foods and drinks, the highest ranked drink was soft drink as the seventh most associated. In the healthy eating category, however, results are not as clear cut. Although nine stimulus items were rated as highly corresponding to the target concept, the length of watermelon and strawberry may cause slower reactions, and some respondents reported not knowing the word cucumber. Thus, out of caution, these words are excluded. As a result, six exemplars are chosen for the healthy eating in children category: broccoli, fruit, carrots, apples, grape, and banana.
6. General Discussion
The aim of the current research was to test a multi-step process to extract sets of stimulus items for implicit measures. Through this process we aimed to make informed choices on stimulus selection, accounting for the correspondence of exemplars with the target concept, the frequency of exemplar uses in common language, and the length of the exemplars. We tested this process on two prominent health behaviors: healthy eating and the consumption of products high in sugar. Testing the piloted stimulus sets in a sample of university students and a general population sample, we found little difference between piloted and previously used implicit measures in terms of the reliability coefficients, but a slightly stronger implicit measure–behavior relationship in the piloted measures.
Previous evidence has indicated variability in response times to stimulus items as a function of a stimuli’s level of correspondence to its target concept [
26] and level of familiarity to its target sample [
27,
31]. Similarly, word length has also been theorized to effect response times [
30], especially in those with less developed reading skills [
37,
38,
39]. Thus, by using empirical data to minimize variability in stimulus items’ levels of correspondence, familiarity, and word length, the current research may represent a method of increasing the validity of research which utilizes implicit measures. Specifically, controlling for these features may serve as a pathway to increasing the accuracy of response time-based scoring metrics by reducing several potential sources of task-irrelevant variation in response times. However, in spite of evidence of the effects of stimulus characteristics on implicit measure responses, there is a dearth of research systematically investigating piloting methods and how they may affect metrics inferred from implicit measures.
In terms of the testing of implicit measures based on the extracted items, data provides preliminary support for the value in piloting stimulus sets. Although we observed the small sized implicit measure-behavior relationships typical of current dual process research [
46,
50,
51,
52], the implicit measure–behavior relationship was stronger when using the implicit measure with piloted stimulus items in both the university student and general population samples. This is consistent with previous evidence and theory that implicit measures using stimuli highly representative of their target constructs are liable to produce stronger effect sizes [
11,
26]. However, in contrast to our expectations, there were no systematic differences in reliability scores, as the piloted IAT had slightly higher reliability in the free sugar sample, while the previously used IAT had slightly higher reliability in the healthy eating sample. Given the fact that we expected homogenizing stimulus sets to consist of only highly relevant, familiar items to reduce the likelihood of extraneous variation in reaction times, this is somewhat surprising. However, it is also important to note that implicit measure internal consistency statistics should be interpreted with a degree of caution, given that they are subject to influences beyond the reliability of measurement, such as attitude polarity or personal importance [
53]. Thus, it is difficult to assess which characteristics affected reliability in the current study, if at all. Future research may seek to address this issue using investigations in large data sets, or through improvements to the mathematical basis for estimating implicit measure reliability statistics.
Beyond evidence for the efficacy of piloted stimulus sets, the current findings also have several notable implications for broader implicit measure research. The extracted stimulus sets present a data-driven, empirically grounded representation of their target concepts in three populations. In an immediate sense, these findings have inherent value in elucidating laypeople’s understanding of free sugar and healthy food items, and thus informing stimulus selection for implicit measures focused on these key health behaviors. However, it is also important to consider that the highest rated of the extracted exemplars differ notably from published statistics and guidelines regarding dietary choices. For example, despite high sugar beverages accounting for a disproportionately high amount of sugar in children’s diets [
54,
55], out of the 16 exemplars provided by the child sample, the highest ranked exemplar drink, soft drink, was ranked by children as seventh, and the highest contributor to children’s sugar intake [
56], juice, was ranked 14th. However, despite soft drinks making up a notably smaller portion of overall sugar intake in adults [
55,
56], Coke and soft drink were ranked the most associated with food and drinks high in free sugar in the adolescent and young adult samples, respectively. Similarly, with respect to healthy foods, fruits and vegetables ranked highly in all samples. While this is somewhat expected, it is important to consider that the highest rated exemplars do not match published definitions of a healthy and balanced diet [
57], as grains and lean proteins were ranked as being less associated with the concept of healthy foods.
This inconsistency poses an interesting question for research design, as to whether stimulus sets should consist of those exemplars the target population rates as most corresponding with the target concept, or exemplars which cover the breadth of a concept as defined by professionals. As the aim of the current study was to test a method of piloting stimulus items which minimized any potential for extraneous input from researchers, a purely data-driven approach was employed, prioritizing the inclusion of stimulus words by their ratings of correspondence. As a result, the stimulus sets chosen may not reflect what experts define as the key exemplars for each category. An alternative approach might be to combine data with the professional opinion of experts. For example, for healthy eating exemplars in the young adult sample, the exemplars beans, fish, and eggs met the criteria of being highly corresponding to the target concept and in regular use, but were excluded as they were less highly corresponding than the selected items. Using guidelines [
57] in combination with our data, a stimulus set which better covers the breadth of the concept of healthy eating in young adults might be vegetables, lettuce, fruit, broccoli, salad, eggs, tomatoes, bananas, fish, and beans to include a range of fruits, vegetables, and proteins. This is arguably a superior stimulus set than a purely data-driven approach. For example, behavior measures designed by experts to assess healthy eating often cover multiple facets of a good diet [
49], rather than simply fruit and vegetable consumption. Thus, it is plausible that a stimulus set which is based on both published guidelines and empirical data may produce stronger findings through a closer correspondence to validated behavior measures that have also been designed with guidelines in mind. However, even in the current data, such a mixed approach is not always possible. In both the child and young adult samples, no grains were rated as highly associated with healthy food. Additionally, in the child sample, few proteins were provided in the free-recall experiment, and those provided were ranked as poorly associated with healthy eating in the rating task. Such a finding leaves researchers in a difficult position with regard to decisions about stimulus selection, as providing full coverage of the target concept may mean introducing extraneous variance into implicit measure results.
Such a predicament is not unique to methodology utilizing implicit measures, and the current findings are also likely to have implications for research using the more traditional self-report methods of data collection. For example, a researcher asking a simple Likert scale question on healthy eating (e.g., eating a healthy diet in the next two weeks would be [
1] boring to [
7] enjoyable) will receive responses based upon the participants salient definition of healthy eating. However, according to current research, this salient definition may be incongruent with conceptualizations from researchers and experts. To an extent, these findings highlight the value of providing clear definitions of key constructs in survey and self-report research. Yet, even with a clear definition provided, the extent to which findings are affected by discrepancies between provided definitions of key constructs and participants salient understanding is unclear.
6.1. Strengths, Limitations, and Future Directions
The current study had several notable strengths, including the use of multiple samples and an empirically grounded design. However, the current research is not without its limitations. Firstly, examining the mean level of correspondence and familiarity in samples does not account for individual differences within each sample. In the current literature, there is suggestion this could be addressed through the use of individualized stimulus items, rather than creating stimulus sets via piloting. While some studies have found this individualization technique to be useful [
58,
59,
60], it may be impractical for many researchers in terms of creating implicit measures using currently available experimental software packages, and may in itself introduce additional variance to scores inferred from implicit measures. Future research may seek to compare the relative value of addressing stimulus variation issues through piloting or measure individualization to inform best practice implicit research. Further, while the stimulus sets created in the current study have natural value to their target populations, it is possible that cultural variations may inhibit their usefulness outside the Australian context. For example, some extracted items such as lollies or soft drink may not be familiar in US samples, where candy or soda may be more likely items. Thus, replication of the current process in alternative samples may serve as a useful avenue for future research.
6.2. Conclusions
The current study presented a multi-step method of creating stimulus sets for use in implicit measures including extracting potential exemplars using free-recall piloting, testing the level of correspondence between potential stimulus items and target constructs, and investigating word characteristics, such as length and use frequency, which may impact responses on implicit measures. From analysis, six sets of stimulus items were created, representing healthy eating and sugar consumption in children, adolescents, and young adults. By controlling for potentially extraneous sources of variance on reaction times, this process may represent an avenue for increasing the validity and precision of implicit measures. This was reflected in two samples where an implicit measure based upon the piloted stimuli had a slightly stronger relationship with behavior than previously used implicit measures drawn from the published literature. Thus, the current research has notable practical implications for research employing implicit measures like the implicit association test or affective misattribution procedure, providing preliminary support for the value in empirically grounded stimulus selection to ensure more accurate and valid findings, and reaffirming concerns that arbitrary stimulus selection may be an avenue of introducing biases to results. There are also practical implications for wider research design beyond the stimulus sets created, as the exemplars rated as the most corresponding to the target concepts in each sample did not accurately reflect published guidelines and known patterns of consumption. These deviations from expected patterns pose difficult questions for implicit research overall, and reaffirm the need for clear conceptualizations of key constructs for both implicit measure and traditional survey research. Future research may consider the impact of potential trade-offs when defining constructs to match the understanding of the target sample or to cover the breadth of concepts in the eyes of professionals.




{kind=link}