
The Task Decomposition and Dedicated Reward-System-Based Reinforcement Learning Algorithm for Pick-and-Place


Abstract
:1. Introduction
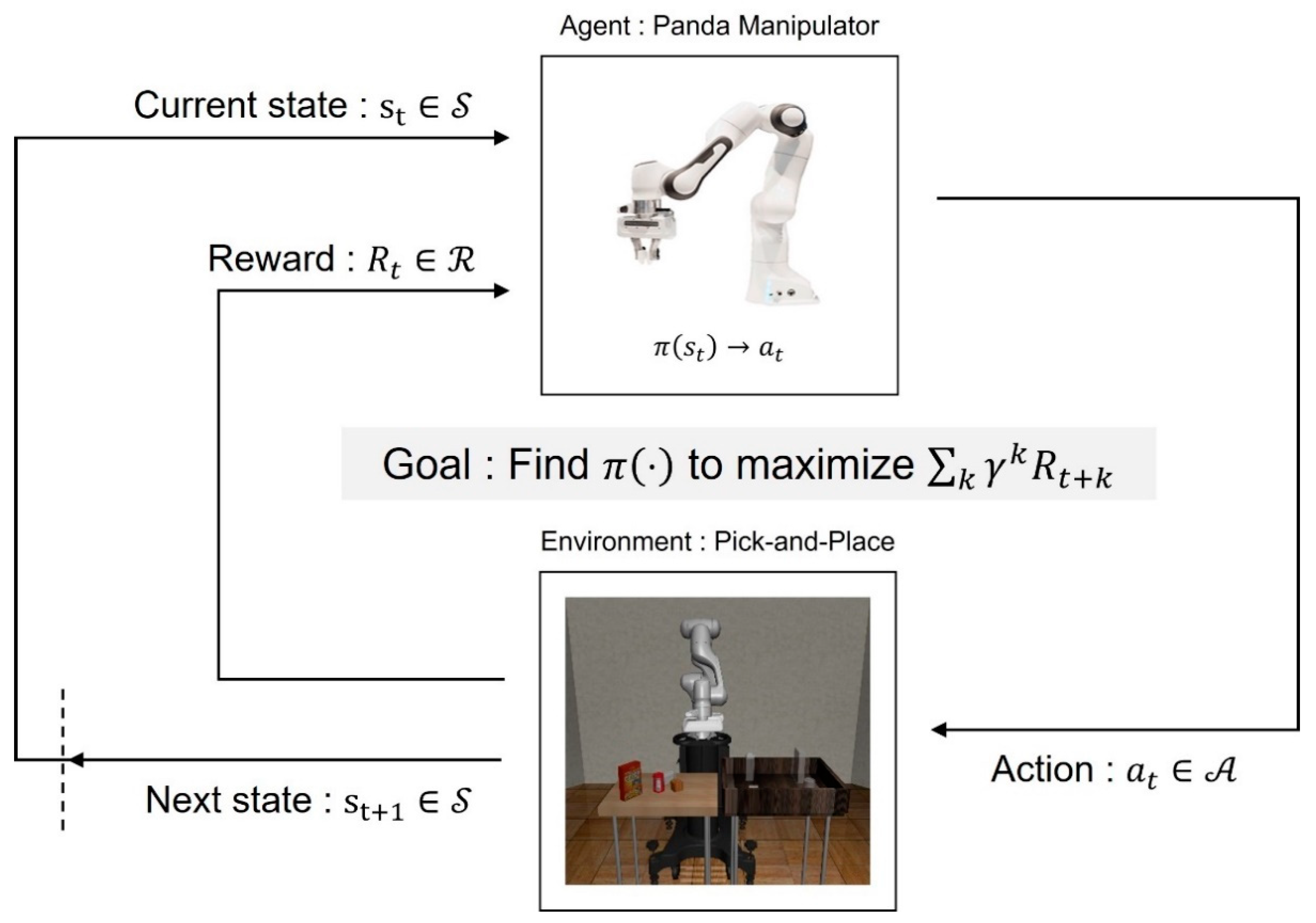
2. Problem Statement
3. Existing Solutions
3.1. Deep Reinforcement Learning
3.2. Soft Actor-Critic
4. Proposed Solution
4.1. Designing States, Actions, and a Dedicated Reward System
4.2. Architecture of Soft Actor-Critic
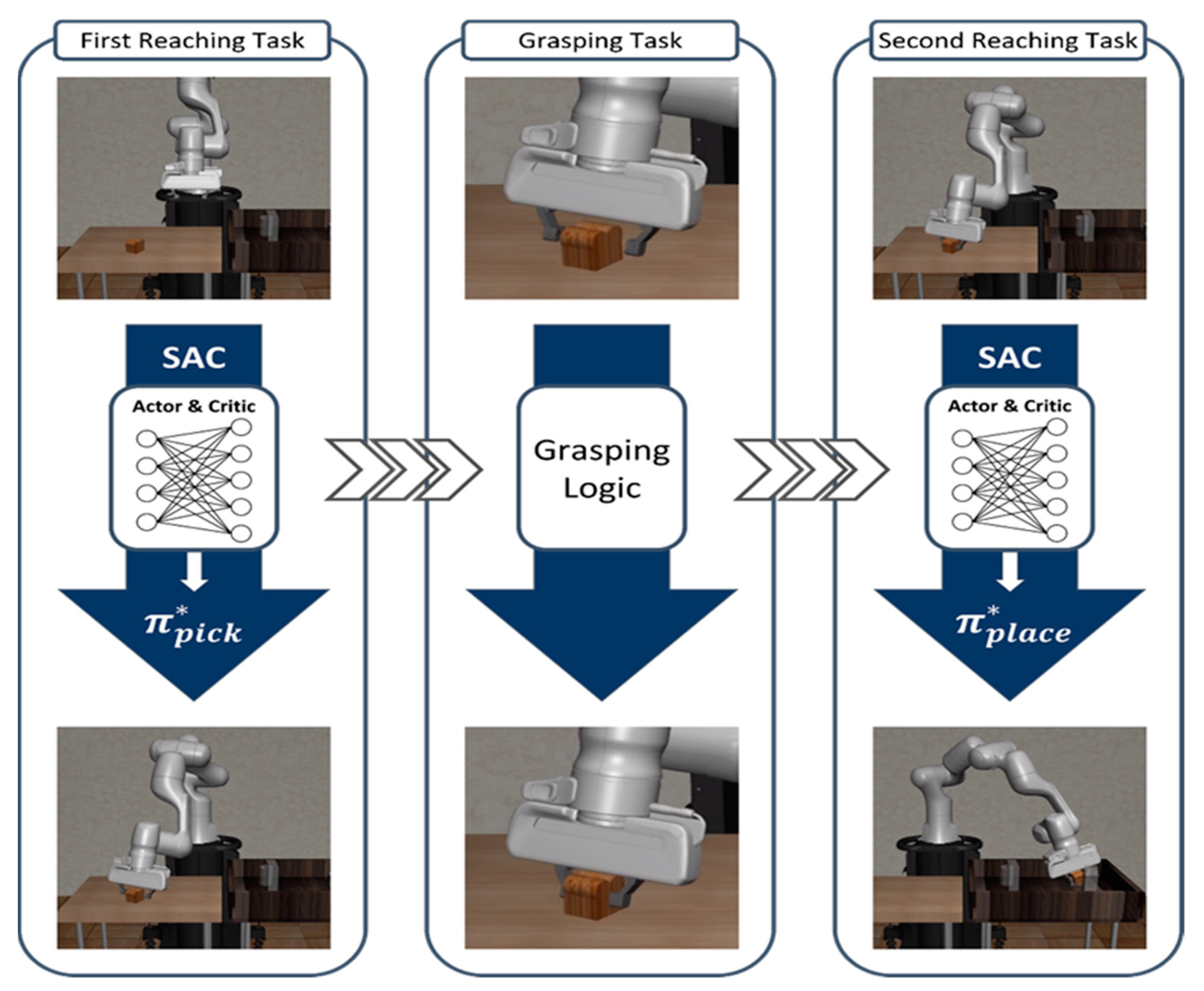
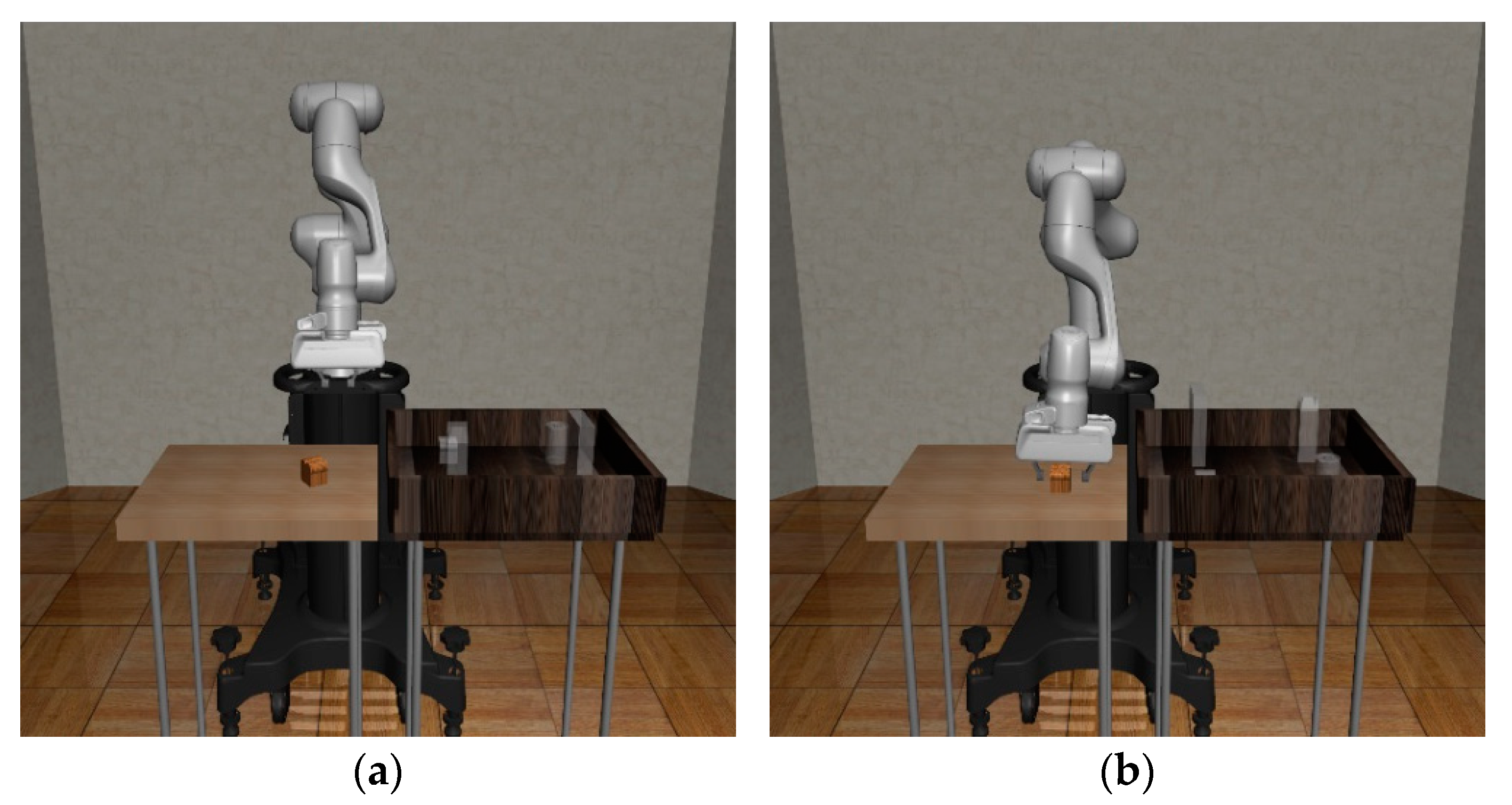
4.3. Proposed Method: Task Decomposition for the Pick-and-Place Task
5. Implemetation
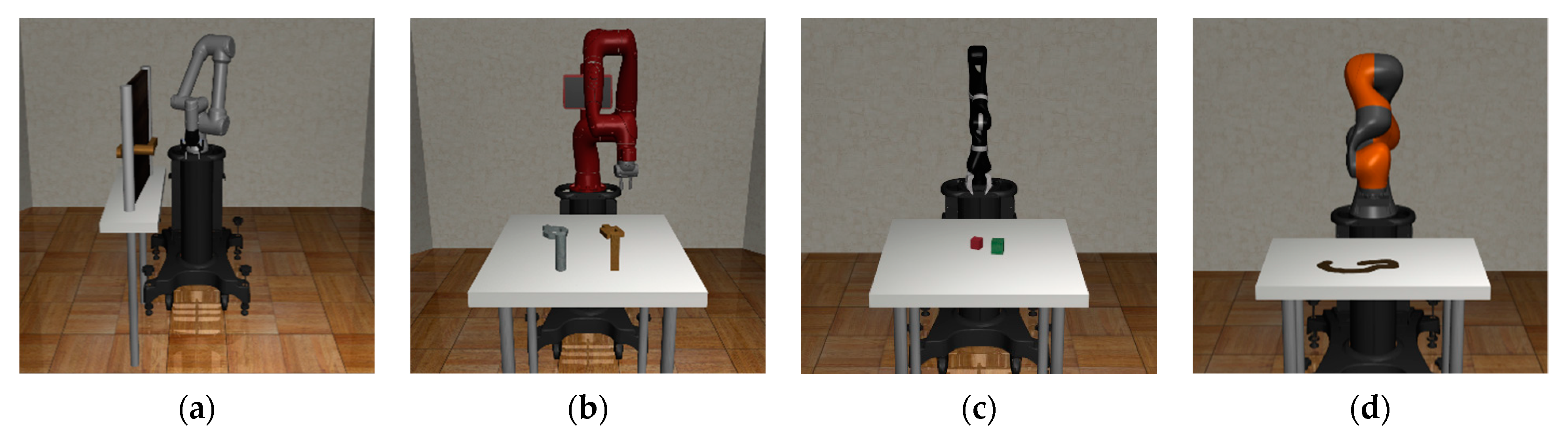
5.1. MuJoCo Physics Engine
5.2. Robosuite
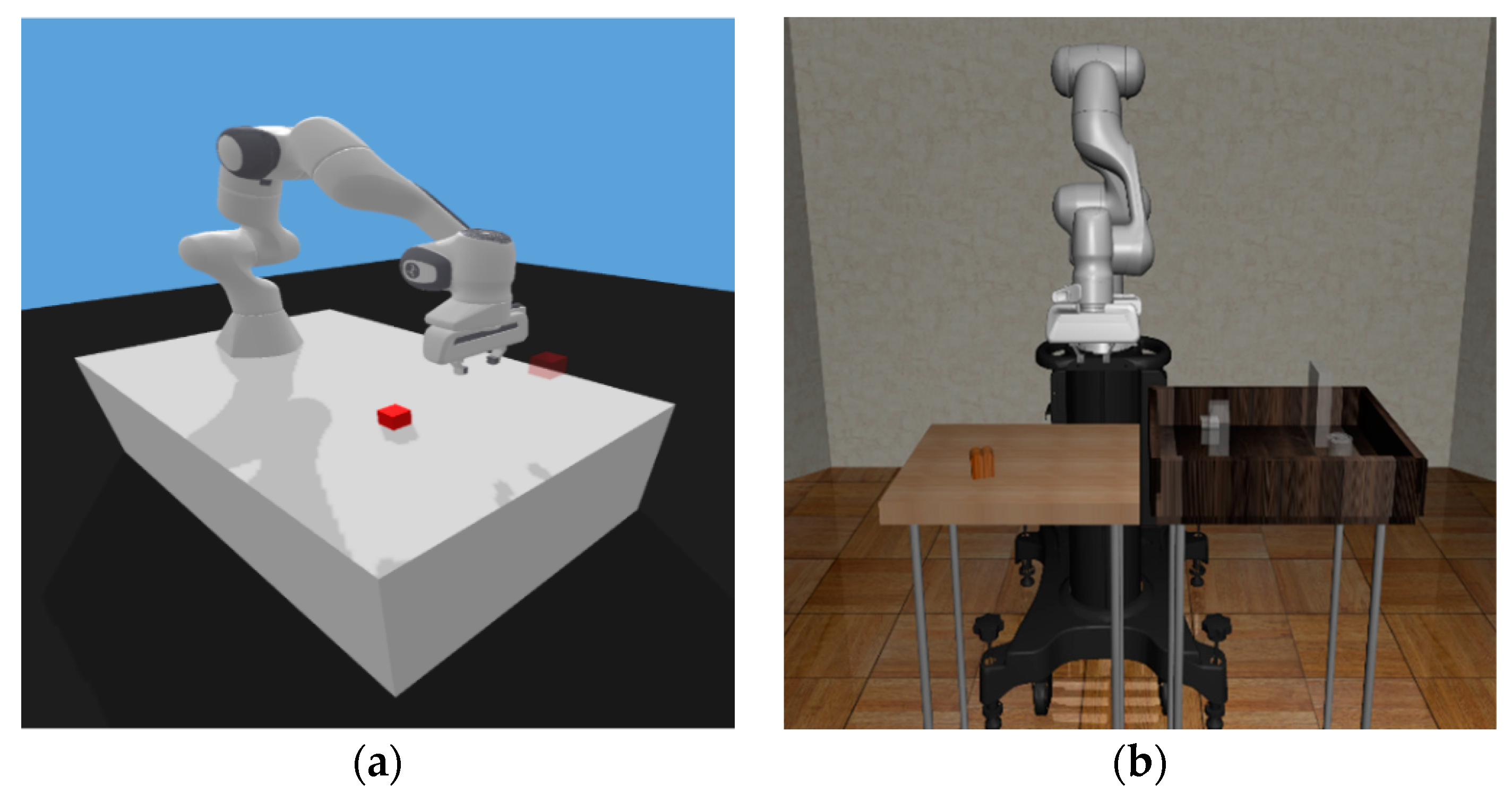
5.3. Environment Implementation
5.4. Training and Test Methods
| Algorithm 1: Training method for both reaching agents using SAC | |
| Input of reaching task: | Load parameter of the first reaching agent |
| Input of placing task: | Initial parameters of the second reaching agent |
| Initialize parameters of the target Q network | |
| Initialize an empty replay buffer | |
| for each iteration do | |
| if training the second reaching agent do | |
| for each reaching step do | |
| Sample action from reaching policy | |
| Sample transition from the environment | |
| end for | |
| end if | |
| for each reaching step do | |
| Sample action from placing policy | |
| Sample transition from the environment | |
| Store the transition in the replay buffer | |
| end for | |
| for each gradient step do | |
| Update the Q-function parameters | |
| Update the policy parameters | |
| Adjust temperature parameters | |
| Update target network parameters | |
| end for | |
| end for | |
| Output: | Optimized parameters |
6. Experimental Results
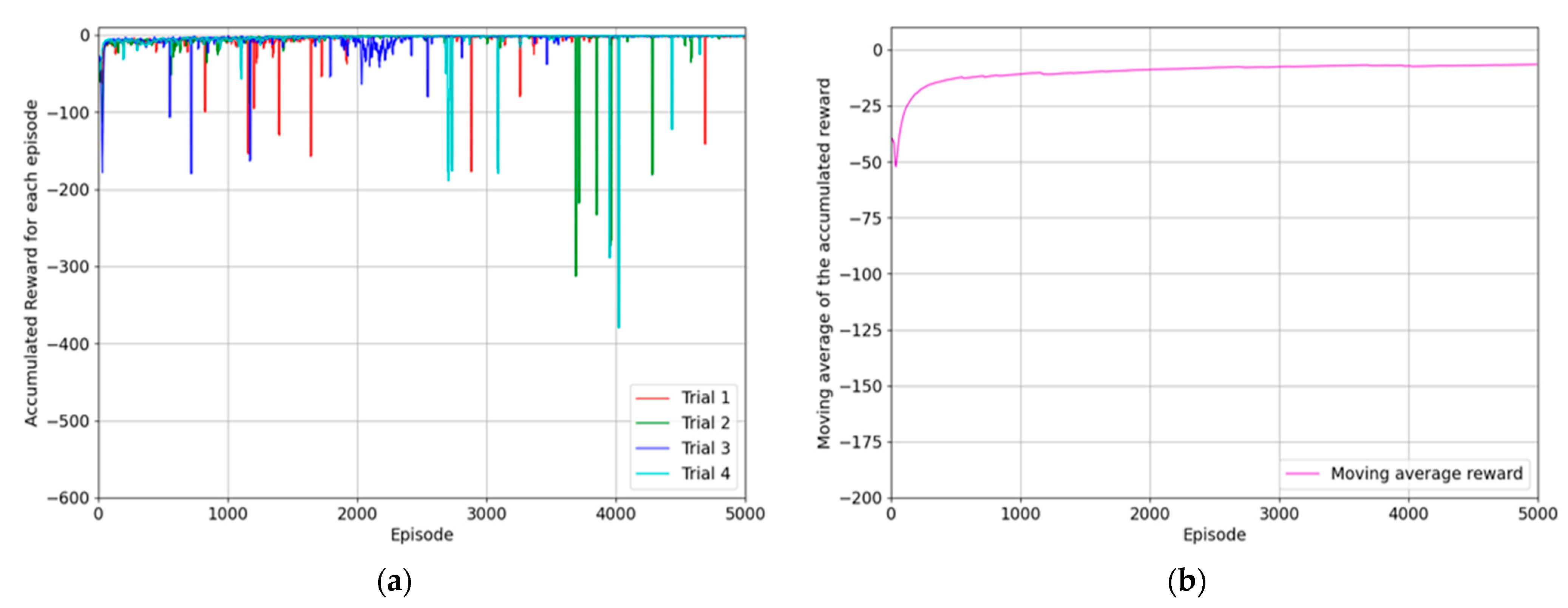
6.1. Reaching Agent for Approaching the Object
6.2. Reaching Agent for Placing the Object
7. Discussion
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yudha, H.M.; Dewi, T.; Risma, P.; Oktarina, Y. Arm robot manipulator design and control for trajectory tracking; a review. In Proceedings of the 2018 5th International Conference on Electrical Engineering, Computer Science and Informatics (EECSI), Malang, Indonesia, 16–18 October 2018; pp. 304–309. [Google Scholar]
- Kasera, S.; Kumar, A.; Prasad, L.B. Trajectory tracking of 3-DOF industrial robot manipulator by sliding mode control. In Proceedings of the 2017 4th IEEE Uttar Pradesh Section International Conference on Electrical, Computer and Electronics (UPCON), Mathura, India, 26–28 October 2017; pp. 364–369. [Google Scholar]
- Luan, N.; Zhang, H.; Tong, S. Optimum motion control of palletizing robots based on iterative learning. Ind. Robot. Int. J. 2012, 39, 162–168. [Google Scholar] [CrossRef]
- Knudsen, M.; Kaivo-Oja, J. Collaborative robots: Frontiers of current literature. J. Intell. Syst. Theory Appl. 2020, 3, 13–20. [Google Scholar] [CrossRef]
- Bendel, O. Co-robots from an Ethical Perspective. In Business Information Systems and Technology 4.0: New Trends in the Age of Digital Change; Springer: Berlin/Heidelberg, Germany, 2018; pp. 275–288. [Google Scholar]
- Gualtieri, L.; Rauch, E.; Vidoni, R. Emerging research fields in safety and ergonomics in industrial collaborative robotics: A systematic literature review. Robot. Comput.-Integr. Manuf. 2021, 67, 101998. [Google Scholar] [CrossRef]
- Pauliková, A.; Gyurák Babeľová, Z.; Ubárová, M. Analysis of the impact of human–cobot collaborative manufacturing implementation on the occupational health and safety and the quality requirements. Int. J. Environ. Res. Public Health 2021, 18, 1927. [Google Scholar] [CrossRef]
- Lamon, E.; Leonori, M.; Kim, W.; Ajoudani, A. Towards an intelligent collaborative robotic system for mixed case palletizing. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 9128–9134. [Google Scholar]
- Solanes, J.E.; Muñoz, A.; Gracia, L.; Martí, A.; Girbés-Juan, V.; Tornero, J. Teleoperation of industrial robot manipulators based on augmented reality. Int. J. Adv. Manuf. Technol. 2020, 111, 1077–1097. [Google Scholar] [CrossRef]
- Nascimento, H.; Mujica, M.; Benoussaad, M. Collision avoidance interaction between human and a hidden robot based on kinect and robot data fusion. IEEE Robot. Autom. Lett. 2020, 6, 88–94. [Google Scholar] [CrossRef]
- Chen, C.; Pan, Y.; Li, D.; Zhang, S.; Zhao, Z.; Hong, J. A virtual-physical collision detection interface for AR-based interactive teaching of robot. Robot. Comput. Integr. Manuf. 2020, 64, 101948. [Google Scholar] [CrossRef]
- Nguyen, H.; La, H. Review of deep reinforcement learning for robot manipulation. In Proceedings of the 2019 Third IEEE International Conference on Robotic Computing (IRC), Naples, Italy, 25–27 February 2019; pp. 590–595. [Google Scholar]
- Zhao, W.; Queralta, J.P.; Westerlund, T. Sim-to-real transfer in deep reinforcement learning for robotics: A survey. In Proceedings of the 2020 IEEE Symposium Series on Computational Intelligence (SSCI), Orlando, FL, USA, 1–4 December 2020; pp. 737–744. [Google Scholar]
- Dalgaty, T.; Castellani, N.; Turck, C.; Harabi, K.-E.; Querlioz, D.; Vianello, E. In situ learning using intrinsic memristor variability via Markov chain Monte Carlo sampling. Nat. Electron. 2021, 4, 151–161. [Google Scholar] [CrossRef]
- Deng, Z.; Chen, Q. Reinforcement learning of occupant behavior model for cross-building transfer learning to various HVAC control systems. Energy Build. 2021, 238, 110860. [Google Scholar] [CrossRef]
- Li, W.; Yue, M.; Shangguan, J.; Jin, Y. Navigation of Mobile Robots Based on Deep Reinforcement Learning: Reward Function Optimization and Knowledge Transfer. Int. J. Control Autom. Syst. 2023, 21, 563–574. [Google Scholar] [CrossRef]
- Sangiovanni, B.; Rendiniello, A.; Incremona, G.P.; Ferrara, A.; Piastra, M. Deep reinforcement learning for collision avoidance of robotic manipulators. In Proceedings of the 2018 European Control Conference (ECC), Limassol, Cyprus, 12–15 June 2018; pp. 2063–2068. [Google Scholar]
- Lin, G.; Zhu, L.; Li, J.; Zou, X.; Tang, Y. Collision-free path planning for a guava-harvesting robot based on recurrent deep reinforcement learning. Comput. Electron. Agric. 2021, 188, 106350. [Google Scholar] [CrossRef]
- Cesta, A.; Orlandini, A.; Bernardi, G.; Umbrico, A. Towards a planning-based framework for symbiotic human-robot collaboration. In Proceedings of the 2016 IEEE 21st International Conference on Emerging Technologies and Factory Automation (ETFA), Berlin, Germany, 6–9 September 2016; pp. 1–8. [Google Scholar]
- Singh, A.; Yang, L.; Hartikainen, K.; Finn, C.; Levine, S. End-to-end robotic reinforcement learning without reward engineering. arXiv 2019, arXiv:1904.07854. [Google Scholar]
- Zou, H.; Ren, T.; Yan, D.; Su, H.; Zhu, J. Reward shaping via meta-learning. arXiv 2019, arXiv:1901.09330. [Google Scholar]
- Iriondo, A.; Lazkano, E.; Susperregi, L.; Urain, J.; Fernandez, A.; Molina, J. Pick and place operations in logistics using a mobile manipulator controlled with deep reinforcement learning. Appl. Sci. 2019, 9, 348. [Google Scholar] [CrossRef] [Green Version]
- Kim, T.; Park, Y.; Park, Y.; Suh, I.H. Acceleration of actor-critic deep reinforcement learning for visual grasping in clutter by state representation learning based on disentanglement of a raw input image. arXiv 2020, arXiv:2002.11903. [Google Scholar]
- Deng, Y.; Guo, X.; Wei, Y.; Lu, K.; Fang, B.; Guo, D.; Liu, H.; Sun, F. Deep reinforcement learning for robotic pushing and picking in cluttered environment. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 619–626. [Google Scholar]
- Pateria, S.; Subagdja, B.; Tan, A.-h.; Quek, C. Hierarchical reinforcement learning: A comprehensive survey. ACM Comput. Surv. (CSUR) 2021, 54, 1–35. [Google Scholar] [CrossRef]
- Duan, J.; Eben Li, S.; Guan, Y.; Sun, Q.; Cheng, B. Hierarchical reinforcement learning for self-driving decision-making without reliance on labelled driving data. IET Intell. Transp. Syst. 2020, 14, 297–305. [Google Scholar] [CrossRef] [Green Version]
- Marzari, L.; Pore, A.; Dall’Alba, D.; Aragon-Camarasa, G.; Farinelli, A.; Fiorini, P. Towards hierarchical task decomposition using deep reinforcement learning for pick and place subtasks. In Proceedings of the 2021 20th International Conference on Advanced Robotics (ICAR), Ljubljana, Slovenia, 6–10 December 2021; pp. 640–645. [Google Scholar]
- Haarnoja, T.; Zhou, A.; Hartikainen, K.; Tucker, G.; Ha, S.; Tan, J.; Kumar, V.; Zhu, H.; Gupta, A.; Abbeel, P. Soft actor-critic algorithms and applications. arXiv 2018, arXiv:1812.05905. [Google Scholar]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 1861–1870. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Kim, M.; Han, D.-K.; Park, J.-H.; Kim, J.-S. Motion planning of robot manipulators for a smoother path using a twin delayed deep deterministic policy gradient with hindsight experience replay. Appl. Sci. 2020, 10, 575. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Y.; Wong, J.; Mandlekar, A.; Martín-Martín, R.; Joshi, A.; Nasiriany, S.; Zhu, Y. robosuite: A modular simulation framework and benchmark for robot learning. arXiv 2020, arXiv:2009.12293. [Google Scholar]
- Gallouédec, Q.; Cazin, N.; Dellandréa, E.; Chen, L. panda-gym: Open-source goal-conditioned environments for robotic learning. arXiv 2021, arXiv:2106.13687. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Trial 1 | Trial 2 | Trial 3 | Trial 4 | Average |
|---|---|---|---|---|
| 100% | 100% | 100% | 100% | 100% |
| Trial 1 | Trial 2 | Trial 3 | Trial 4 | Average |
|---|---|---|---|---|
| 94.2% | 92.7% | 93.5% | 92.6% | 93.2% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, B.; Kwon, G.; Park, C.; Kwon, N.K. The Task Decomposition and Dedicated Reward-System-Based Reinforcement Learning Algorithm for Pick-and-Place. Biomimetics 2023, 8, 240. https://doi.org/10.3390/biomimetics8020240
Kim B, Kwon G, Park C, Kwon NK. The Task Decomposition and Dedicated Reward-System-Based Reinforcement Learning Algorithm for Pick-and-Place. Biomimetics. 2023; 8(2):240. https://doi.org/10.3390/biomimetics8020240
Chicago/Turabian StyleKim, Byeongjun, Gunam Kwon, Chaneun Park, and Nam Kyu Kwon. 2023. "The Task Decomposition and Dedicated Reward-System-Based Reinforcement Learning Algorithm for Pick-and-Place" Biomimetics 8, no. 2: 240. https://doi.org/10.3390/biomimetics8020240