

Solving the Min-Max Clustered Traveling Salesmen Problem Based on Genetic Algorithm

Abstract
:1. Introduction
2. Problem Description and Mathematical Modeling
- objective function:
3. Algorithm Design
3.1. Phase 1
3.2. Phase 2
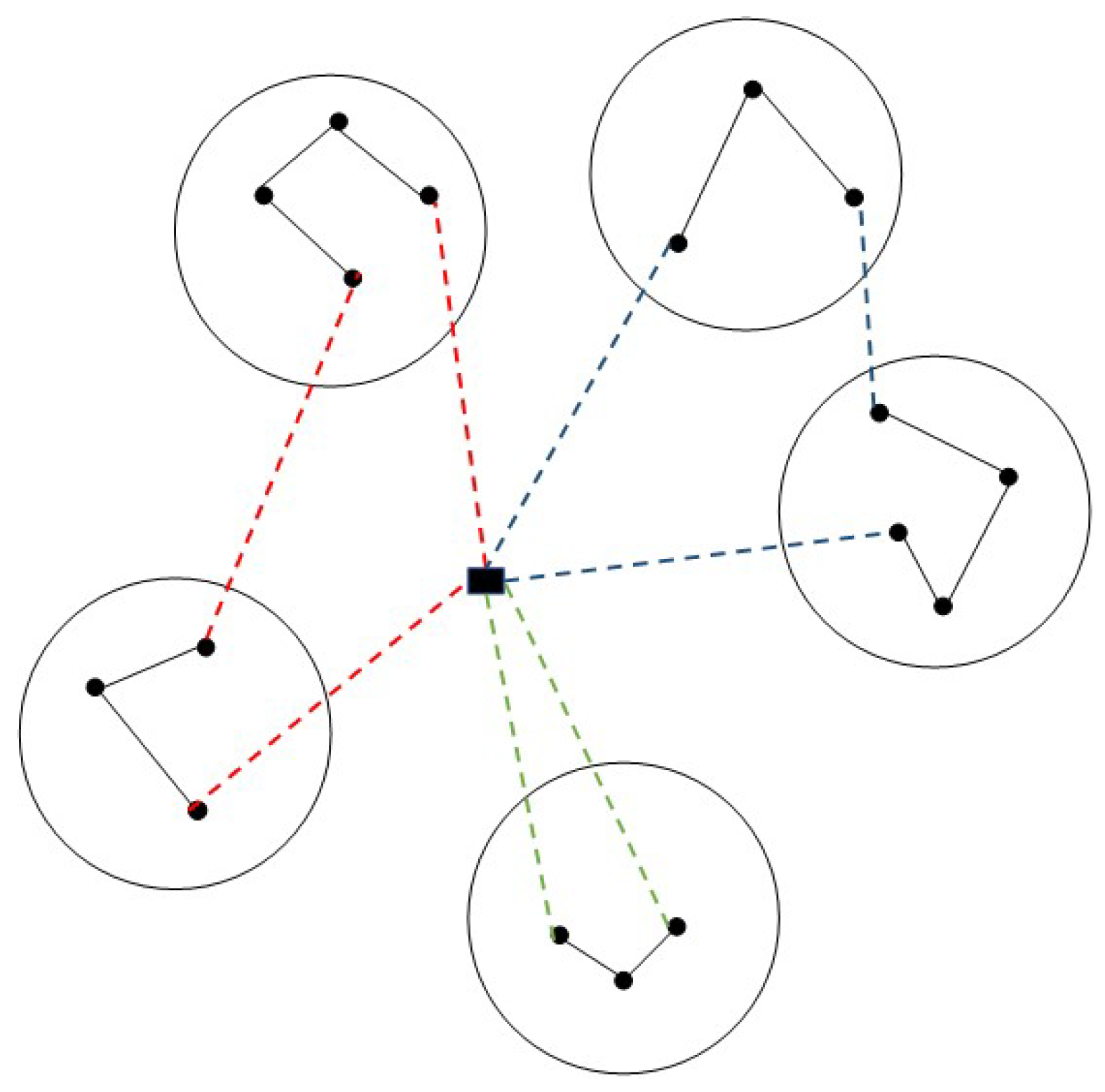
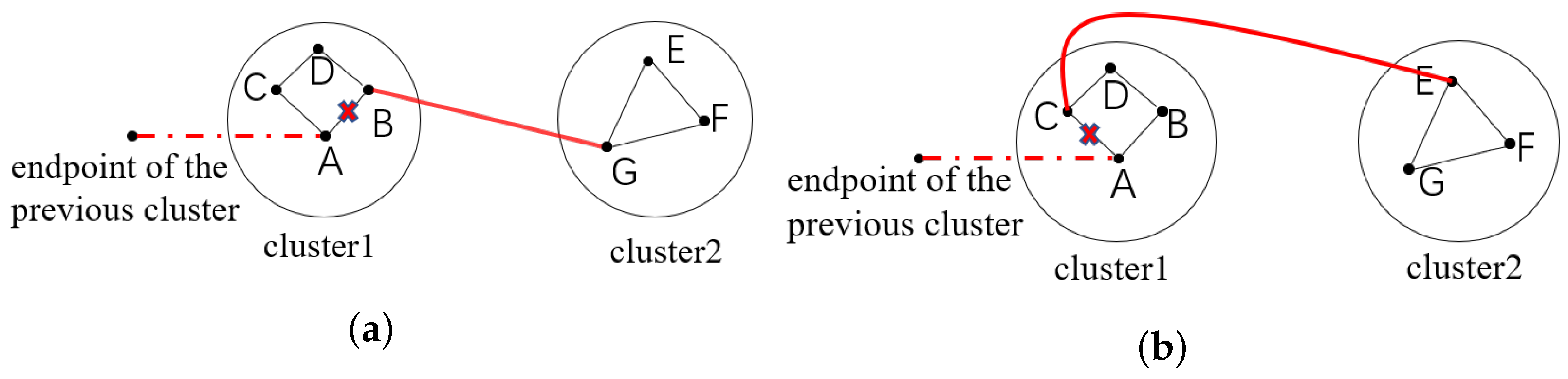
3.2.1. Connections between Clusters
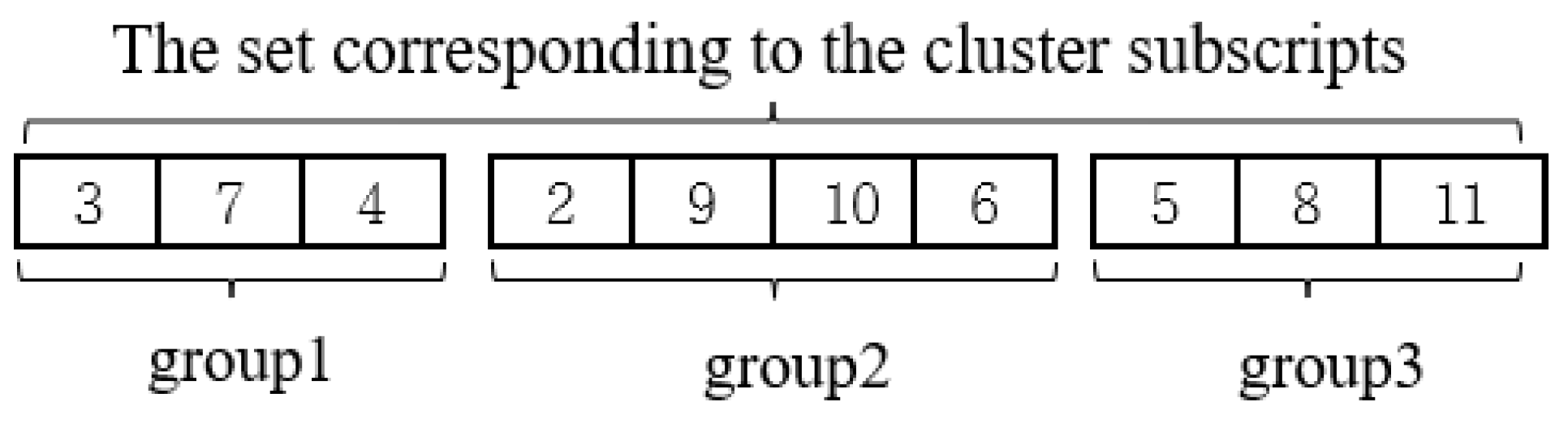
3.2.2. Chromosome Coding
3.2.3. Fitness Function
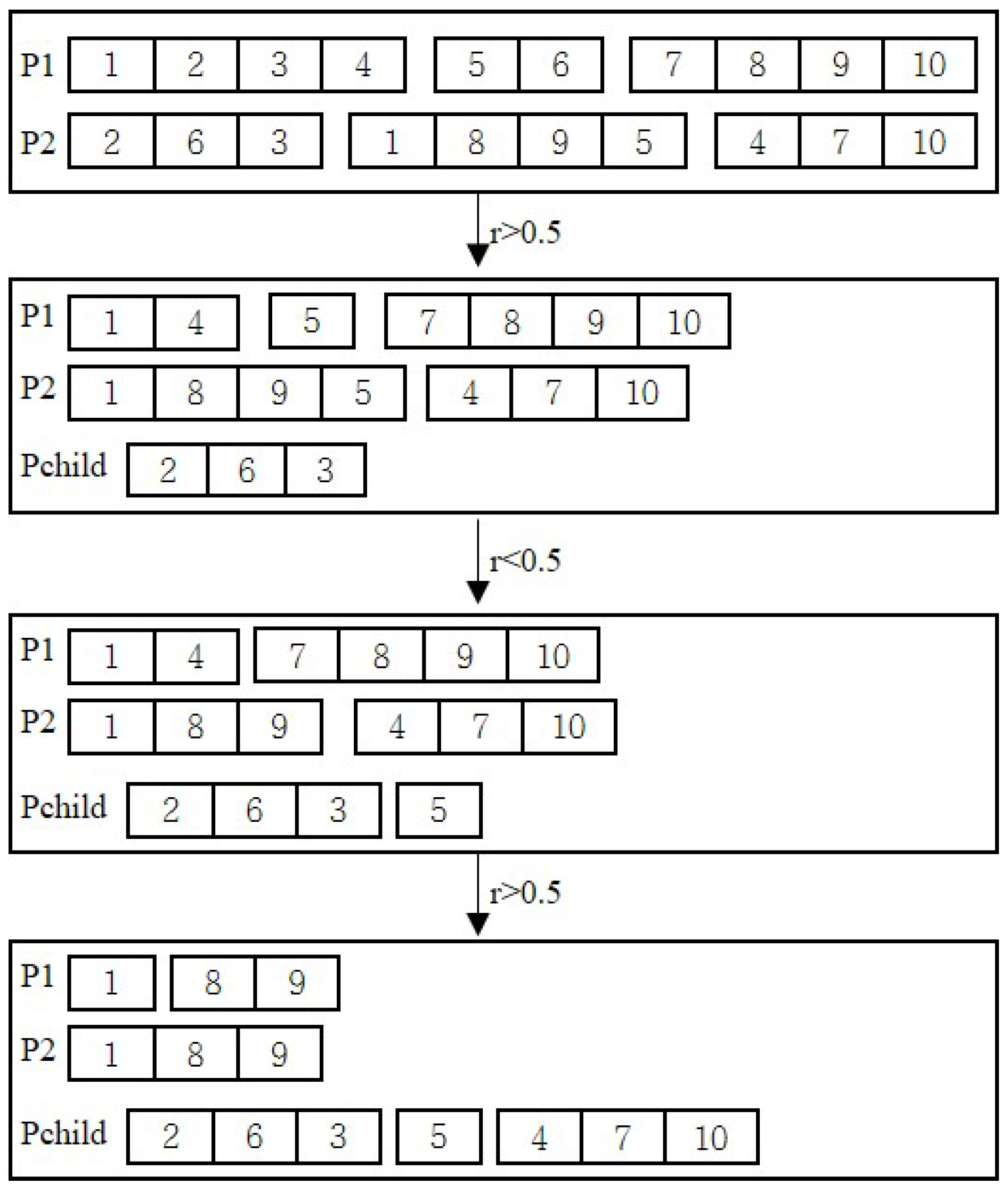
3.2.4. Crossover Operator
3.2.5. Mutation Operator
3.2.6. Mutually Exclusive Execution
3.3. Comparisons of Methods
4. Experimental Results and Analysis
4.1. Test Environment and Experimental Instances
4.2. Parameter Determination
4.2.1. Small-Scale Instances Experiments
- In terms of computational accuracy, our algorithm achieved optimal results in for six instances, including att48-4, att48-5, st70-4, st70-5, rd100-4 and rd100-5. Although did not reach the optimal results in kroc100-4 and kroc100-5, the best relative error was no more than 1.5%.
- In terms of computational time, our algorithm exhibited significantly lower solving time than the CPLEX solver on all eight instances, indicating a clear advantage in computational efficiency.
4.2.2. Medium-Scale Instances Experiments: Comparisons with Algorithms A1 and A2
4.2.3. Large-Scale Instances Experiments: Comparisons with Algorithms A1 and A2
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Chisman, J.A. The clustered traveling salesman problem. Comput. Oper. Res. 1975, 2, 115–119. [Google Scholar] [CrossRef]
- Hoeft, J.; Palekar, U.S. Heuristics for the plate-cutting traveling salesman problem. IIE. Trans. 1997, 29, 719–731. [Google Scholar] [CrossRef]
- Horspool, R.N.; Laks, J.M.S. An improved block sequencing method for program restructuring. J. Syst. Softw. 1983, 3, 245–250. [Google Scholar] [CrossRef]
- Laporte, G.; Semet, F.; Dadeshidze, V.V.; Olsson, L.J.S. A tiling and routing heuristic for the screening of cytological samples. J. Oper. Res. Soc. 1998, 49, 1233–1238. [Google Scholar] [CrossRef]
- Laporte, G.; Palekar, U. Some applications of the clustered travelling salesman problem. J. Oper. Res. Soc. 2002, 53, 972–976. [Google Scholar] [CrossRef]
- Gorenstein, S. Printing press scheduling for multi-edition periodicals. Manag. Sci. 1970, 16, 363–373. [Google Scholar] [CrossRef]
- Okonjo-Adigwe, C. An effective method of balancing the workload amongst salesmen. Omega 1988, 16, 159–163. [Google Scholar] [CrossRef]
- Angel, R.D.; Caudle, W.L.; Noonan, R.; Whinston, A.N.D.A. Computer-assisted school bus scheduling. Manag. Sci. 1972, 18, 279–288. [Google Scholar] [CrossRef]
- Saleh, H.A.; Chelouah, R. The design of the global navigation satellite system surveying networks using genetic algorithms. Eng. Appl. Artif. Intell. 2004, 17, 111–122. [Google Scholar] [CrossRef]
- Potvin, J.Y.; Guertin, F. The clustered traveling salesman problem: A genetic approach. In Meta-Heuristics: Theory and Applications; Springer: Boston, MA, USA, 1996; pp. 619–631. [Google Scholar]
- Ding, C.; Cheng, Y.; He, M. Two-level genetic algorithm for clustered traveling salesman problem with application in large-scale TSPs. Tsinghua Sci. Technol. 2007, 12, 459–465. [Google Scholar] [CrossRef]
- Ahmed, Z.H. The ordered clustered travelling salesman problem: A hybrid genetic algorithm. Sci. World J. 2014, 2014, 258207. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tang, L.; Liu, J.; Rong, A.; Yang, Z. A multiple traveling salesman problem model for hot rolling scheduling in Shanghai Baoshan Iron & Steel Complex. Eur. J. Oper. Res. 2000, 124, 267–282. [Google Scholar]
- Malmborg, C. A genetic algorithm for service level based vehicle scheduling. Eur. J. Oper. Res. 1996, 93, 121–134. [Google Scholar] [CrossRef]
- Park, Y.B. A hybrid genetic algorithm for the vehicle scheduling problem with due times and time deadlines. Int. J. Prod. Econ. 2001, 73, 175–188. [Google Scholar] [CrossRef]
- Carter, A.E.; Ragsdale, C.T. A new approach to solving the multiple traveling salesperson problem using genetic algorithms. Eur. J. Oper. Res. 2006, 175, 246–257. [Google Scholar] [CrossRef]
- Brown, E.C.; Ragsdale, C.T.; Carter, A.E. A grouping genetic algorithm for the multiple traveling salesperson problem. Int. J. Inf. Tech. Decis. 2007, 6, 333–347. [Google Scholar] [CrossRef]
- Singh, A.; Baghel, A.S. A new grouping genetic algorithm approach to the multiple traveling salesperson problem. Soft. Comput. 2009, 13, 95–101. [Google Scholar] [CrossRef]
- Frederickson, G.N.; Hecht, M.S.; Kim, C.E. Approximation algorithms for some routing problems. Siam. J. Sci. Comput. 1978, 7, 178–193. [Google Scholar] [CrossRef]
- Xu, W.; Liang, W.; Lin, X. Approximation algorithms for min-max cycle cover problems. IEEE. Trans. Comput. 2015, 64, 600–613. [Google Scholar] [CrossRef]
- Jorati, A. Approximation Algorithms for Some Min-Max Vehicle Routing Problems. Master’s Thesis, University of Alberta, Edmonton, AB, Canada, 2013. [Google Scholar]
- Yu, W.; Liu, Z. Improved approximation algorithms for some min-max and minimum cycle cover problems. Theor. Comput. Sci. 2016, 654, 45–58. [Google Scholar] [CrossRef]
- Battarra, M.; Erdoğan, G.; Vigo, D. Exact algorithms for the clustered vehicle routing problem. Oper. Res. 2014, 62, 58–71. [Google Scholar] [CrossRef] [Green Version]
- Vidal, T.; Battarra, M.; Subramanian, A.; Erdoğan, G. Hybrid metaheuristics for the clustered vehicle routing problem. Comput. Oper. Res. 2015, 58, 87–99. [Google Scholar] [CrossRef] [Green Version]
- Expósito-Izquierdo, C.; Rossi, A.; Sevaux, M. A two-level solution approach to solve the clustered capacitated vehicle routing problem. Comput. Ind. Eng. 2016, 91, 274–289. [Google Scholar] [CrossRef]
- Defryn, C.; Sörensen, K. A fast two-level variable neighborhood search for the clustered vehicle routing problem. Comput. Oper. Res. 2017, 83, 78–94. [Google Scholar] [CrossRef] [Green Version]
- Pop, P.C.; Fuksz, L.; Marc, A.H.; Sabo, C. A novel two-level optimization approach for clustered vehicle routing problem. Comput. Ind. Eng. 2018, 115, 304–318. [Google Scholar] [CrossRef]
- Hintsch, T.; Irnich, S. Large multiple neighborhood search for the clustered vehicle-routing problem. Eur. J. Oper. Res. 2018, 270, 118–131. [Google Scholar] [CrossRef] [Green Version]
- Bao, X.; Xu, L.; Yu, W.; Song, W. Approximation algorithms for the min-max clustered k-traveling salesmen problems. Theor. Comput. Sci. 2023, 933, 60–66. [Google Scholar] [CrossRef]
- Han, L.; Wang, Y.; Lan, S. Graph Coloring algorithm based on ordered partition encoding. Acta Electron. Sin. 2010, 38, 146–150. [Google Scholar]
- Wang, Y.; Chen, Y.; Yu, Y. Improved grouping genetic algorithm for solving multiple traveling salesman problem. J. Electro. Inf. Tech. 2017, 39, 198–205. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Instance Information | CPLEX | Algorithm of This Paper | Gaps | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Name | n | m | k | Time (s) | Time (s) | ||||
| att48-4 | 48 | 4 | 8 | 17,492 | 8216 | 17,492 | 17,492 | 5.21 | 0.00 |
| att48-5 | 48 | 5 | 8 | 15,936 | 4217 | 15,936 | 15,936 | 5.21 | 0.00 |
| st70-4 | 70 | 4 | 10 | 660 | 6213 | 660 | 660 | 7.28 | 0.00 |
| st70-5 | 70 | 5 | 10 | 518 | 3987 | 518 | 518 | 7.30 | 0.00 |
| kroc100-4 | 100 | 4 | 10 | 14,000 | 13,762 | 14,210 | 14,482 | 10.67 | 0.015 |
| kroc100-5 | 100 | 5 | 10 | 10,836 | 10,826 | 10,863 | 11,339 | 10.69 | 0.002 |
| rd100-4 | 100 | 4 | 10 | 4396 | 24,676 | 4396 | 4396 | 10.65 | 0.00 |
| rd100-5 | 100 | 5 | 10 | 3643 | 16,385 | 3643 | 3643 | 10.74 | 0.00 |
| Instance Information | Algorithm of This Paper | Algorithm A1 | Algorithm A2 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Name | n | m | k | Time (s) | Time (s) | Time (s) | ||||||
| ch130-3 | 130 | 3 | 13 | 2331 | 2425 | 26.36 | 3076 | 3721 | 29.53 | 2764 | 2882 | 19.8 |
| ch130-5 | 130 | 5 | 13 | 1573 | 1639 | 37.68 | 2176 | 2851 | 35.46 | 1983 | 2068 | 19.14 |
| ch130-10 | 130 | 10 | 13 | 1342 | 1404 | 51.30 | 2239 | 2239 | 47.68 | 1492 | 1553 | 17.48 |
| ch150-3 | 150 | 3 | 15 | 6821 | 7212 | 28.92 | 9184 | 10744 | 44.62 | 7669 | 7778 | 33.33 |
| ch150-5 | 150 | 5 | 15 | 4365 | 4451 | 42.36 | 6224 | 7284 | 54.75 | 4874 | 4874 | 35.87 |
| ch150-10 | 150 | 10 | 15 | 3109 | 3158 | 67.24 | 5518 | 6297 | 61.12 | 3733 | 3733 | 32.11 |
| kroB200-3 | 200 | 3 | 20 | 40,823 | 41,798 | 36.21 | 56,364 | 65,108 | 52.82 | 42,806 | 44,451 | 42.75 |
| kroB200-5 | 200 | 5 | 20 | 25,062 | 25,831 | 56.30 | 38,511 | 45,109 | 71.82 | 27,822 | 29,099 | 41.67 |
| kroB200-10 | 200 | 10 | 2 | 15,602 | 15,722 | 92.77 | 22,329 | 28,783 | 79.14 | 17,423 | 18,347 | 40.73 |
| gr229-3 | 229 | 3 | 23 | 1654 | 1741 | 41.15 | 3097 | 3509 | 59.41 | 1969 | 2027 | 35.63 |
| gr229-5 | 229 | 5 | 23 | 1061 | 1125 | 61.42 | 2038 | 2507 | 73.63 | 1254 | 1316 | 34.84 |
| gr229-10 | 229 | 10 | 23 | 676.10 | 709.27 | 103.17 | 1145 | 1531 | 78.06 | 722.29 | 796.53 | 38.60 |
| lin318-3 | 318 | 3 | 32 | 84,797 | 85,915 | 57.64 | 104,810 | 133,910 | 87.39 | 88,476 | 89,740 | 73.48 |
| lin318-5 | 318 | 5 | 32 | 54,858 | 55,273 | 81.56 | 72,122 | 81,894 | 87.30 | 56,093 | 58,220 | 70.35 |
| lin318-10 | 318 | 10 | 32 | 29,540 | 30,211 | 159.41 | 41,242 | 51,173 | 112.46 | 31,866 | 34,450 | 66.00 |
| rd400-3 | 400 | 3 | 40 | 30,983 | 31,738 | 68.98 | 39,959 | 43020 | 99.06 | 33253 | 33,483 | 85.53 |
| rd400-5 | 400 | 5 | 40 | 19,696 | 19,874 | 100.82 | 25,287 | 28,449 | 124.17 | 20,663 | 21,480 | 83.78 |
| rd400-10 | 400 | 10 | 40 | 10,506 | 10,602 | 194.65 | 14158 | 17,085 | 143.61 | 12,328 | 13,168 | 85.19 |
| d493-3 | 493 | 3 | 49 | 65,827 | 67,969 | 115.84 | 93,084 | 113,684 | 129.72 | 71,669 | 72,592 | 108.73 |
| d493-5 | 493 | 5 | 49 | 44,124 | 44,714 | 153.97 | 57,537 | 73,767 | 133.92 | 46,260 | 48,768 | 105.41 |
| d493-10 | 493 | 10 | 49 | 25,902 | 26,170 | 236.36 | 35,458 | 41,956 | 169.01 | 29,055 | 30,506 | 105.72 |
| Instance Information | Algorithm of This Paper | Algorithm A1 | Algorithm A2 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Name | n | m | k | Time (s) | Time (s) | Time (s) | ||||||
| att532-3 | 532 | 3 | 53 | 215,743 | 220,341 | 119.71 | 289,158 | 318,530 | 138.06 | 228,991 | 232,097 | 116.04 |
| att532-5 | 532 | 5 | 53 | 137,012 | 138,704 | 168.22 | 184,605 | 207,937 | 143.48 | 146,175 | 156,059 | 111.77 |
| att532-10 | 532 | 10 | 53 | 72,866 | 74,939 | 263.21 | 98,817 | 124,253 | 181.24 | 80,924 | 91,853 | 109.59 |
| gr666-3 | 666 | 3 | 67 | 8065 | 8184 | 154.44 | 10,995 | 11,756 | 175.88 | 8585 | 8633 | 142.70 |
| gr666-5 | 666 | 5 | 67 | 5116 | 5145 | 203.38 | 6844 | 7863 | 170.93 | 5274 | 5668 | 140.14 |
| gr666-10 | 666 | 10 | 67 | 2713 | 2795 | 322.30 | 4055 | 4688 | 238.86 | 3135 | 3378 | 140.87 |
| rat783-3 | 783 | 3 | 78 | 24,431 | 24,561 | 184.07 | 30,672 | 33,129 | 185.00 | 25,240 | 25,668 | 172.77 |
| rat783-5 | 783 | 5 | 78 | 14,796 | 15,197 | 237.54 | 19,637 | 21,021 | 239.58 | 15,551 | 16,721 | 170.97 |
| rat783-10 | 783 | 10 | 78 | 7817 | 7978 | 374.08 | 11,152 | 12,747 | 266.16 | 9606 | 10,283 | 166.22 |
| pr1002-3 | 1002 | 3 | 100 | 984,119 | 994,034 | 223.48 | 1,150,203 | 1,224,429 | 250.80 | 997,444 | 1,009,880 | 210.33 |
| pr1002-5 | 1002 | 5 | 100 | 596,696 | 608,471 | 297.74 | 751,828 | 783,754 | 292.38 | 615,550 | 660,968 | 207.04 |
| pr1002-10 | 1002 | 10 | 100 | 312,674 | 315,691 | 469.51 | 401,110 | 452,747 | 356.00 | 379,443 | 413,564 | 208.75 |
| d1291-3 | 1291 | 3 | 129 | 271,403 | 276,562 | 295.72 | 324,725 | 34,473 | 344.27 | 278,225 | 282,548 | 283.36 |
| d1291-5 | 1291 | 5 | 129 | 168,879 | 170,007 | 388.43 | 194,747 | 231,967 | 348.42 | 177,698 | 190,622 | 280.13 |
| d1291-10 | 1291 | 10 | 129 | 89,356 | 90,421 | 606.09 | 116,666 | 157,610 | 472.67 | 98,753 | 114,074 | 287.97 |
| fl1577-3 | 1577 | 3 | 158 | 213,987 | 216,568 | 357.20 | 256,092 | 271,006 | 414.86 | 216,275 | 218,102 | 350.05 |
| fl1577-5 | 1577 | 5 | 158 | 132,424 | 133,564 | 474.69 | 158,467 | 184,102 | 420.36 | 137,305 | 143,273 | 341.93 |
| fl1577-10 | 1577 | 10 | 158 | 68,813 | 69,769 | 754.05 | 117,114 | 125,894 | 581.34 | 83,239 | 90,810 | 345.49 |
| d2103-3 | 2103 | 3 | 210 | 503,707 | 507,482 | 476.70 | 573,438 | 604,803 | 572.05 | 505,744 | 520,019 | 473.37 |
| d2103-5 | 2103 | 5 | 210 | 309,633 | 310,758 | 632.80 | 348,375 | 379,010 | 572.48 | 318,063 | 343,450 | 463.39 |
| d2103-10 | 2103 | 10 | 210 | 159,885 | 161,239 | 1007.44 | 186,445 | 266,479 | 763.19 | 190,118 | 212,572 | 454.45 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bao, X.; Wang, G.; Xu, L.; Wang, Z. Solving the Min-Max Clustered Traveling Salesmen Problem Based on Genetic Algorithm. Biomimetics 2023, 8, 238. https://doi.org/10.3390/biomimetics8020238
Bao X, Wang G, Xu L, Wang Z. Solving the Min-Max Clustered Traveling Salesmen Problem Based on Genetic Algorithm. Biomimetics. 2023; 8(2):238. https://doi.org/10.3390/biomimetics8020238
Chicago/Turabian StyleBao, Xiaoguang, Guojun Wang, Lei Xu, and Zhaocai Wang. 2023. "Solving the Min-Max Clustered Traveling Salesmen Problem Based on Genetic Algorithm" Biomimetics 8, no. 2: 238. https://doi.org/10.3390/biomimetics8020238