
A Scoping Literature Review of Natural Language Processing Application to Safety Occurrence Reports


Abstract
:1. Introduction
2. Method
- Original work.
- Full text is available.
- Written in English.
- NLP is specifically applied to safety occurrence reports.
- Published between 2012–2022.
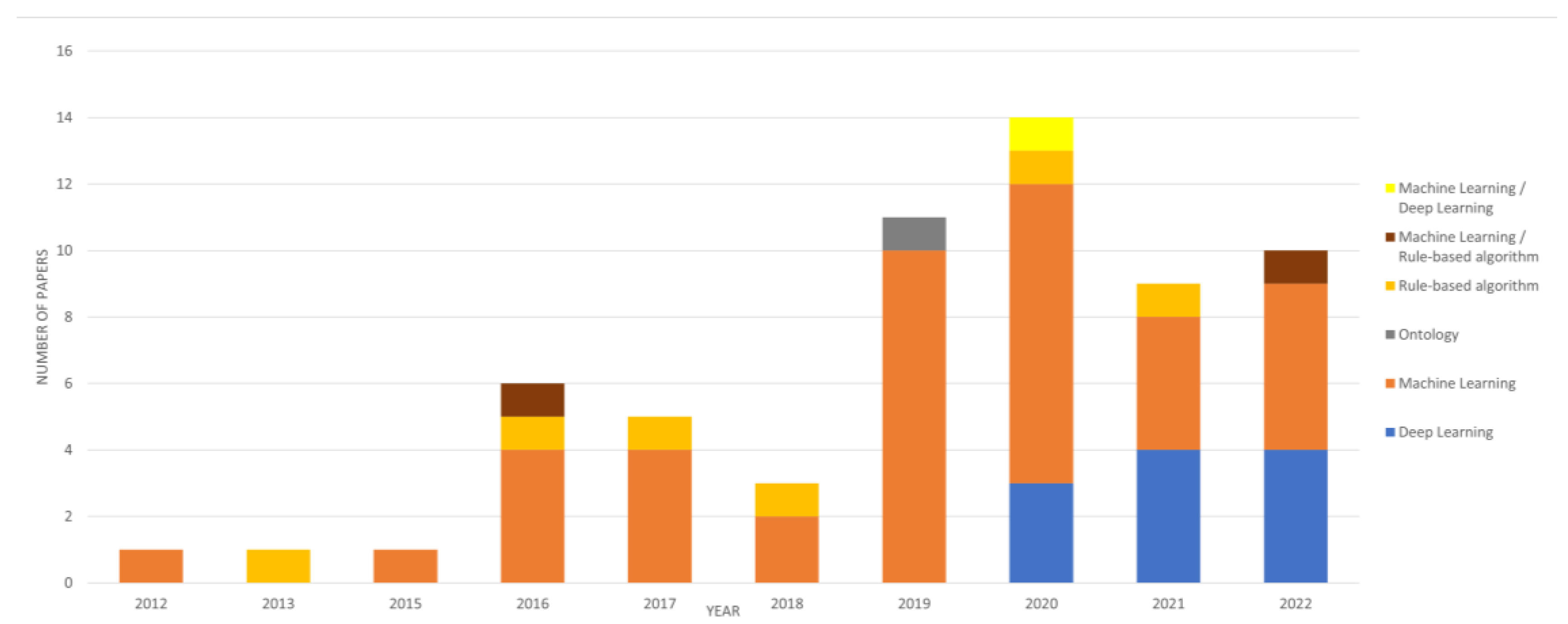
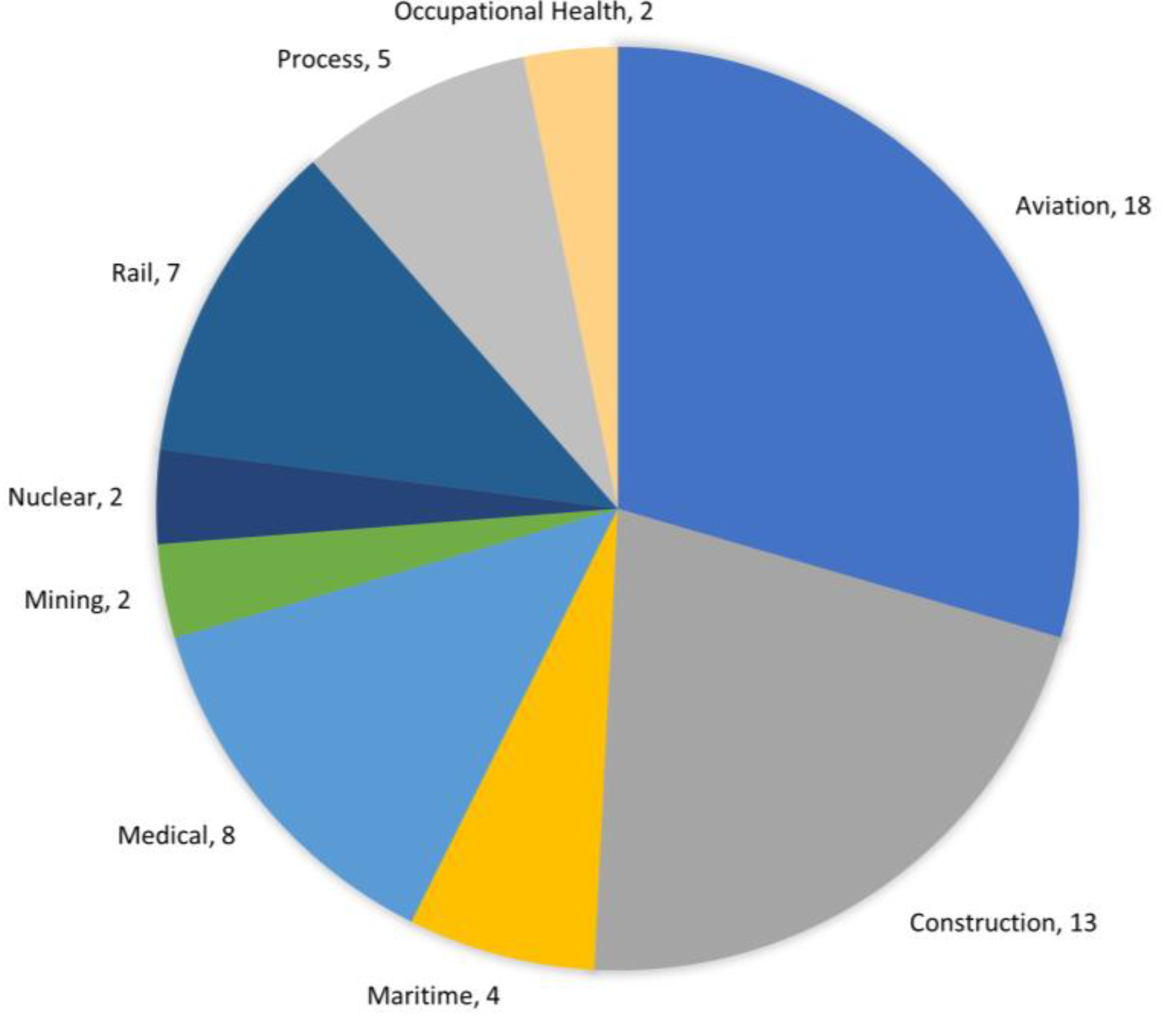
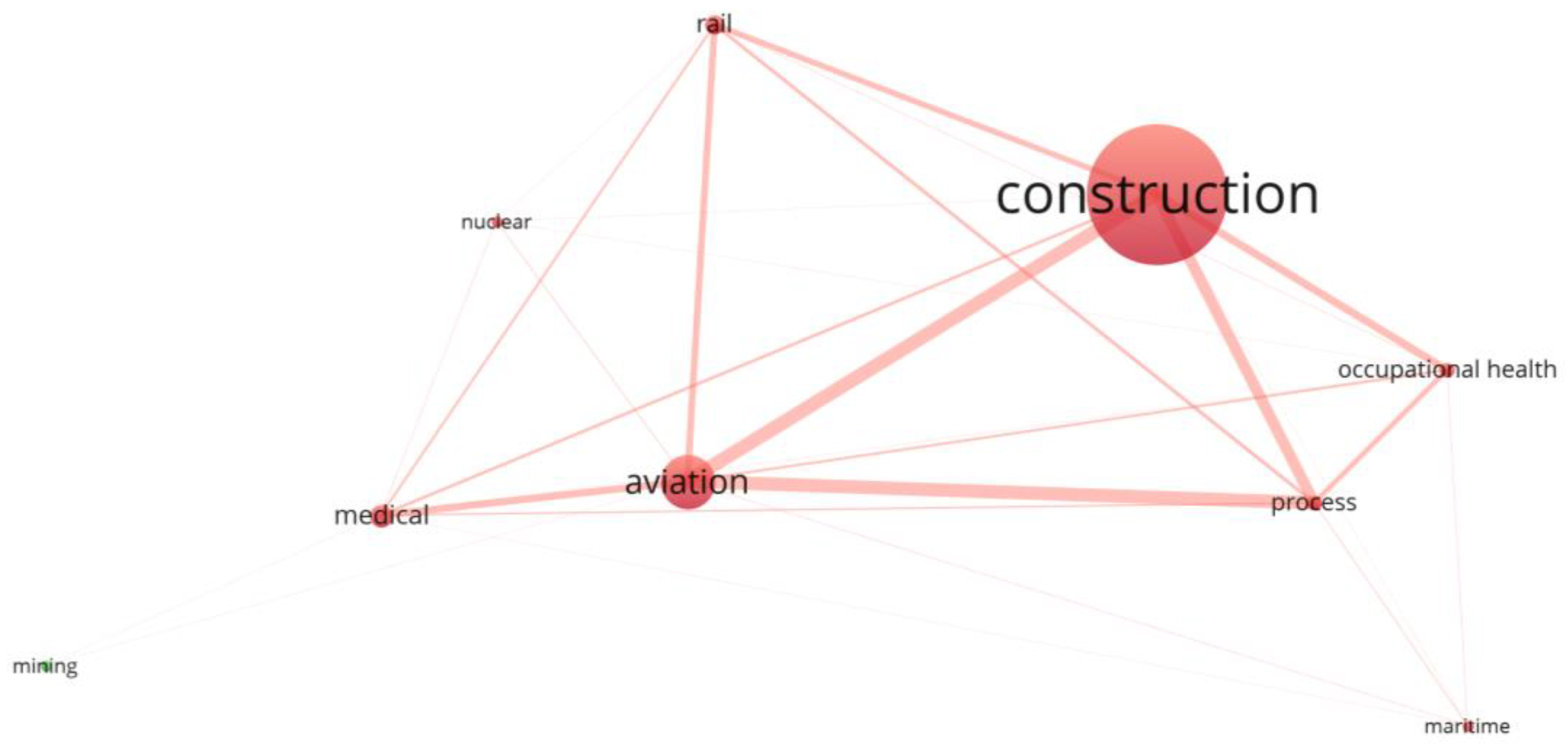
3. Results
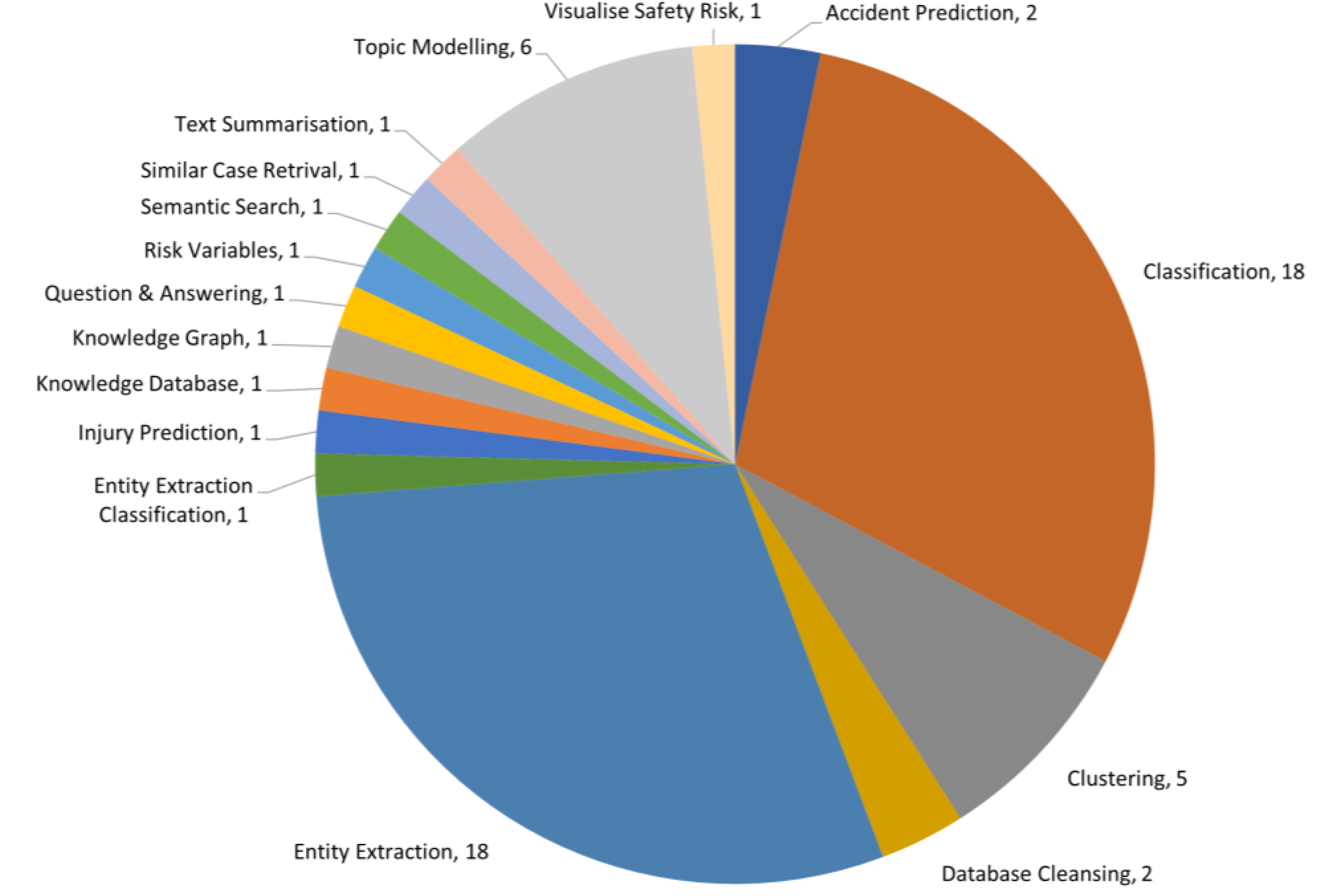
3.1. Classification
3.2. Entity Extraction
3.3. Topic Modelling
3.4. Semantic Search, Database Cleansing and Visualisation
4. Discussion
4.1. Key Challenge of Applying NLP to Safety Occurrence Reports
“DURING FINAL APCH TO LNDG ZONE, R-HAND ENG COWLING EXITED ACFT STRIKING MAIN ROTOR BLADE AND REAR CTR MAIN VERT STABILIZER. THE SHATTERED COWLING DROPPED TO GND IN PIECES APPROX 4 BLOCKS NNE OF THE LNDG ZONE CAUSING NO INJURIES OR PROPERTY DAMAGE.” [75]
- Train model from scratch. The model is trained on the safety-specific data, although this is where the second challenge is presented: quantity. If we take BERT as an example, this was trained on 3300 M words [77]. Unless the organisation has an equally large repository of information or is able to accumulate data from a number of regulators, then it is unlikely to match a similar level of data input.
4.2. Common Issues When Applying NLP to Safety Occurrence Reports
4.3. Limitations
4.3.1. Lack of Safety-Focused Datasets
4.3.2. Model Evaluation beyond Metrics
4.3.3. Trustworthiness and Model Interpretability
4.3.4. Data Protection
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Tixier, A.J.P.; Hallowell, M.R.; Rajagopalan, B.; Bowman, D. Automated Content Analysis for Construction Safety: A Natural Language Processing System to Extract Precursors and Outcomes from Unstructured Injury Reports. Autom. Constr. 2016, 62, 45–56. [Google Scholar] [CrossRef] [Green Version]
- De Vries, V. Classification of Aviation Safety Reports Using Machine Learning. In Proceedings of the 2020 International Conference on Artificial Intelligence and Data Analytics for Air Transportation, AIDA-AT 2020, Singapore, 3–4 February 2020; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar]
- Hughes, P.; Shipp, D.; Figueres-Esteban, M.; van Gulijk, C. From Free-Text to Structured Safety Management: Introduction of a Semi-Automated Classification Method of Railway Hazard Reports to Elements on a Bow-Tie Diagram. Saf. Sci. 2018, 110, 11–19. [Google Scholar] [CrossRef] [Green Version]
- Lane, H.; Howard, C.; Hapke, H. Natural Language Processing in Action; Manning Publications Co.: Shelter Island, NY, USA, 2019; ISBN 9781617294631. [Google Scholar]
- Ghosh, S.; Gunning, D. Natural Language Processing Fundamentals; Packt Publishing: Birmingham, UK, 2019. [Google Scholar]
- ISO 22989:2022(E); Information Technology—Artificial Intelligence—Artificial Intelligence Concepts and Terminology. International Organization for Standardization: Geneva, Switzerland, 2022.
- Posse, C.; Matzke, B.; Anderson, C.; Brothers, A.; Matzke, M.; Ferryman, T. Extracting Information from Narratives: An Application to Aviation Safety Reports. In Proceedings of the IEEE Aerospace Conference, Big Sky, MT, USA, 5–12 March 2005; IEEE: Piscataway, NJ, USA, 2005; pp. 3678–3690. [Google Scholar]
- Oza, N.; Castle, J.P.; Stutz, J. Classification of Aeronautics System Health and Safety Documents. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2009, 39, 670–680. [Google Scholar] [CrossRef]
- Wolfe, S. Wordplay: An Examination of Semantic Approaches to Classify Safety Reports. In Proceedings of the AIAA Infotech@Aerospace 2007 Conference and Exhibit, Rohnert Park, CA, USA, 7–10 May 2007. [Google Scholar]
- Robinson, S.D. Temporal Topic Modeling Applied to Aviation Safety Reports: A Subject Matter Expert Review. Saf. Sci. 2019, 116, 275–286. [Google Scholar] [CrossRef]
- Kuhn, K.D. Using Structural Topic Modeling to Identify Latent Topics and Trends in Aviation Incident Reports. Transp. Res. Part C Emerg. Technol. 2018, 87, 105–122. [Google Scholar] [CrossRef]
- Baker, H.; Hallowell, M.R.; Tixier, A.J.P. Automatically Learning Construction Injury Precursors from Text. Autom. Constr. 2020, 118, 103145. [Google Scholar] [CrossRef]
- Liu, C.; Yang, S. Using Text Mining to Establish Knowledge Graph from Accident/Incident Reports in Risk Assessment. Expert Syst. Appl. 2022, 207, 117991. [Google Scholar] [CrossRef]
- Rybak, N.; Hassall, M. Deep Learning Unsupervised Text-Based Detection of Anomalies in U.S. Chemical Safety and Hazard Investigation Board Reports. In Proceedings of the International Conference on Electrical, Computer, Communications and Mechatronics Engineering, ICECCME 2021, Mauritius, 7–8 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 7–8. [Google Scholar]
- Denyer, D.; Tranfield, D. Producing a Systematic Review. In The Sage Handbook of Organizational Research Methods; Sage Publications Ltd.: Thousand Oaks, CA, USA, 2009; pp. 671–689. ISBN 978-1-4129-3118-2. [Google Scholar]
- Perianes-Rodriguez, A.; Waltman, L.; van Eck, N.J. Constructing Bibliometric Networks: A Comparison between Full and Fractional Counting. J. Informetr. 2016, 10, 1178–1195. [Google Scholar] [CrossRef] [Green Version]
- Hughes, P.; Robinson, R.; Figueres-Esteban, M.; van Gulijk, C. Extracting Safety Information from Multi-Lingual Accident Reports Using an Ontology-Based Approach. Saf. Sci. 2019, 118, 288–297. [Google Scholar] [CrossRef]
- Figueres-Esteban, M.; Hughes, P.; van Gulijk, C. Visual Analytics for Text-Based Railway Incident Reports. Saf. Sci. 2016, 89, 72–76. [Google Scholar] [CrossRef]
- Fan, H.; Li, H. Retrieving Similar Cases for Alternative Dispute Resolution in Construction Accidents Using Text Mining Techniques. Autom. Constr. 2013, 34, 85–91. [Google Scholar] [CrossRef]
- Wu, H.; Zhong, B.; Medjdoub, B.; Xing, X.; Jiao, L. An Ontological Metro Accident Case Retrieval Using CBR and NLP. Appl. Sci. 2020, 10, 5298. [Google Scholar] [CrossRef]
- Hou, Q.; Wang, L.; Yuan, T. Research on Automatic Classifying Method for Incident Reports with Runway Incursion. In Proceedings of the 4th International Conference on Information Science, Electrical, and Automation Engineering (ISEAE 2022), Guangzhou, China, 1 August 2022; p. 122573T. [Google Scholar] [CrossRef]
- Zhang, F. A Hybrid Structured Deep Neural Network with Word2Vec for Construction Accident Causes Classification. Int. J. Constr. Manag. 2022, 22, 1120–1140. [Google Scholar] [CrossRef] [Green Version]
- Madeira, T.; Melício, R.; Valério, D.; Santos, L. Machine Learning and Natural Language Processing for Prediction of Human Factors in Aviation Incident Reports. Aerospace 2021, 8, 47. [Google Scholar] [CrossRef]
- Evans, H.P.; Anastasiou, A.; Edwards, A.; Hibbert, P.; Makeham, M.; Luz, S.; Sheikh, A.; Donaldson, L.; Carson-Stevens, A. Automated Classification of Primary Care Patient Safety Incident Report Content and Severity Using Supervised Machine Learning (ML) Approaches. Health Inform. J. 2020, 26, 3123–3139. [Google Scholar] [CrossRef] [PubMed]
- Goodrum, H.; Roberts, K.; Bernstam, E.V. Automatic Classification of Scanned Electronic Health Record Documents. Int. J. Med. Inform. 2020, 144, 104302. [Google Scholar] [CrossRef] [PubMed]
- Cheng, M.-Y.; Kusoemo, D.; Gosno, R.A. Text Mining-Based Construction Site Accident Classification Using Hybrid Supervised Machine Learning. Autom. Constr. 2020, 118, 103265. [Google Scholar] [CrossRef]
- Fang, W.; Luo, H.; Xu, S.; Love, P.E.D.; Lu, Z.; Ye, C. Automated Text Classification of Near-Misses from Safety Reports: An Improved Deep Learning Approach. Adv. Eng. Inform. 2020, 44, 101060. [Google Scholar] [CrossRef]
- Marev, K.; Georgiev, K. Automated Aviation Occurrences Categorization. In Proceedings of the ICMT 2019—7th International Conference on Military Technologies, Brno, Czech Republic, 30–31 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–5. [Google Scholar]
- Zhang, F.; Fleyeh, H.; Wang, X.; Lu, M. Construction Site Accident Analysis Using Text Mining and Natural Language Processing Techniques. Autom. Constr. 2019, 99, 238–248. [Google Scholar] [CrossRef]
- Heidarysafa, M.; Kowsari, K.; Barnes, L.; Brown, D. Analysis of Railway Accidents’ Narratives Using Deep Learning. In Proceedings of the 17th IEEE International Conference on Machine Learning and Applications, ICMLA 2018, Orlando, FL, USA, 17–20 December 2018; IEEE: Piscataway, NJ, USA, 2019; pp. 1446–1453. [Google Scholar]
- Tanguy, L.; Tulechki, N.; Urieli, A.; Hermann, E.; Raynal, C. Natural Language Processing for Aviation Safety Reports: From Classification to Interactive Analysis. Comput. Ind. 2016, 78, 80–95. [Google Scholar] [CrossRef] [Green Version]
- Jidkov, V.; Abielmona, R.; Teske, A. PE Enabling Maritime Risk Assessment Using Natural Language Processing-Based Deep Learning Techniques. In Proceedings of the 2020 IEEE Symposium Series on Computational Intelligence, SSCI 2020, Canberra, Australia, 1–4 December 2020; pp. 2469–2476. [Google Scholar]
- Miyamoto, A.; Bendarkar, M.V.; Mavris, D.N. Natural Language Processing of Aviation Safety Reports to Identify Inefficient Operational Patterns. Aerospace 2022, 9, 450. [Google Scholar] [CrossRef]
- Rose, R.L.; Puranik, T.G.; Mavris, D.N. Natural Language Processing Based Method for Clustering and Analysis of Aviation Safety Narratives. Aerospace 2020, 7, 143. [Google Scholar] [CrossRef]
- Liu, J.; Wong, Z.S.Y.; Tsui, K.L.; So, H.Y.; Kwok, A. Exploring Hidden In-Hospital Fall Clusters from Incident Reports Using Text Analytics. Stud. Health Technol. Inform. 2019, 264, 1526–1527. [Google Scholar] [CrossRef] [PubMed]
- Chokor, A.; Naganathan, H.; Chong, W.K.; Asmar, M. El Analyzing Arizona OSHA Injury Reports Using Unsupervised Machine Learning. Procedia Eng. 2016, 145, 1588–1593. [Google Scholar] [CrossRef] [Green Version]
- Tirunagari, S.; Hanninen, M.; Stahlberg, K.; Kujala, P. Mining Causal Relations and Concepts in Maritime. In Proceedings of the TechSamudra 2012, International Conference cum Exhibition on Technology of the Sea, Visakhapatnam, India, 6–8 December 2012; Volume 1, pp. 548–566. [Google Scholar]
- Ricketts, J.; Pelham, J.; Barry, D.; Guo, W. An NLP Framework for Extracting Causes, Consequences, and Hazards from Occurrence Reports to Validate a HAZOP Study. In Proceedings of the 2022 IEEE/AIAA 41st Digital Avionics Systems Conference (DASC), Portsmouth, VA, USA, 18–22 September 2022; IEEE: Portsmouth, VA, USA, 2022; pp. 1–8. [Google Scholar]
- Liu, G.; Boyd, M.; Yu, M.; Halim, S.Z.; Quddus, N. Identifying Causality and Contributory Factors of Pipeline Incidents by Employing Natural Language Processing and Text Mining Techniques. Process Saf. Environ. Prot. 2021, 152, 37–46. [Google Scholar] [CrossRef]
- Shekhar, H.; Agarwal, S. Automated Analysis through Natural Language Processing of DGMS Fatality Reports on Indian Non-Coal Mines. In Proceedings of the 5th International Conference on Information Systems and Computer Networks, ISCON 2021, Mathura, India, 22–23 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar]
- Valcamonico, D.; Baraldi, P.; Zio, E. Natural Language Processing and Bayesian Networks for the Analysis of Process Safety Events. In Proceedings of the 2021 5th International Conference on System Reliability and Safety, ICSRS 2021, Palermo, Italy, 24–26 November 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 216–221. [Google Scholar]
- Dong, T.; Yang, Q.; Ebadi, N.; Luo, X.R.; Rad, P. Identifying Incident Causal Factors to Improve Aviation Transportation Safety: Proposing a Deep Learning Approach. J. Adv. Transp. 2021, 2021, 5540046. [Google Scholar] [CrossRef]
- Wang, G.; Liu, M.; Cao, D.; Tan, D. Identifying High-Frequency–Low-Severity Construction Safety Risks: An Empirical Study Based on Official Supervision Reports in Shanghai. Eng. Constr. Archit. Manag. 2021, 29, 940–960. [Google Scholar] [CrossRef]
- Feng, D.; Chen, H. A Small Samples Training Framework for Deep Learning-Based Automatic Information Extraction: Case Study of Construction Accident News Reports Analysis. Adv. Eng. Inform. 2021, 47, 101256. [Google Scholar] [CrossRef]
- Hua, L.; Zheng, W.; Gao, S. Extraction and Analysis of Risk Factors from Chinese Railway Accident Reports. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference, ITSC 2019, Auckland, New Zealand, 27–30 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 869–874. [Google Scholar]
- Zhao, Y.; Diao, X.; Huang, J.; Smidts, C. Automated Identification of Causal Relationships in Nuclear Power Plant Event Reports. Nucl. Technol. 2019, 205, 1021–1034. [Google Scholar] [CrossRef]
- Song, B.; Suh, Y. Narrative Texts-Based Anomaly Detection Using Accident Report Documents: The Case of Chemical Process Safety. J. Loss Prev. Process Ind. 2019, 57, 47–54. [Google Scholar] [CrossRef]
- Zhao, Y.; Diao, X.; Smidts, C. Preliminary Study of Automated Analysis of Nuclear Power Plant Event Reports Based on Natural Language Processing Techniques. In Proceedings of the Probabilistic Safety Assessment and Management PSAM 14, Los Angeles, CA, USA, 16–21 September 2018. [Google Scholar]
- Cohan, A.; Ratwani, R.; Fong, A.; Goharian, N. Identifying Harm Events in Clinical Care through Medical Narratives. In Proceedings of the 8th ACM International Conference on Bioinformatics, Computational Biology and Health Informatics, Boston, MA, USA, 20–23 August 2017; pp. 52–59. [Google Scholar] [CrossRef] [Green Version]
- Fong, A.; Harriott, N.; Walters, D.M.; Foley, H.; Morrissey, R.; Ratwani, R.R. Integrating Natural Language Processing Expertise with Patient Safety Event Review Committees to Improve the Analysis of Medication Events. Int. J. Med. Inform. 2017, 104, 120–125. [Google Scholar] [CrossRef]
- Tixier, A.J.P.; Hallowell, M.R.; Rajagopalan, B.; Bowman, D. Construction Safety Clash Detection: Identifying Safety Incompatibilities among Fundamental Attributes Using Data Mining. Autom. Constr. 2017, 74, 39–54. [Google Scholar] [CrossRef] [Green Version]
- Tixier, A.J.P.; Hallowell, M.R.; Rajagopalan, B.; Bowman, D. Application of Machine Learning to Construction Injury Prediction. Autom. Constr. 2016, 69, 102–114. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Yin, J. Risk Assessment of Inland Waterborne Transportation Using Data Mining. Marit. Policy Manag. 2020, 47, 633–648. [Google Scholar] [CrossRef]
- Denecke, K. Concept-Based Retrieval from Critical Incident Reports. Stud. Health Technol. Inform. 2017, 236, 1–7. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Z.; Yang, Y.; Wang, Y.; Zhang, J.; Wang, D.; Luo, X. Summarization of Coal Mine Accident Reports: A Natural-Language-Processing-Based Approach. Commun. Comput. Inf. Sci. 2020, 1329, 103–115. [Google Scholar] [CrossRef]
- Luo, Y.; Shi, H. Using Lda2vec Topic Modeling to Identify Latent Topics in Aviation Safety Reports. In Proceedings of the 2019 IEEE/ACIS 18th International Conference on Computer and Information Science (ICIS), Beijing, China, 17–19 June 2019; pp. 518–523. [Google Scholar] [CrossRef]
- Kuhn, K.D. Topics and Trends in Incident Reports Using Structural Topic Modeling to Explore Aviation Safety Reporting System Data. In Proceedings of the 12th USA/EUROPE Air Traffic Management R&D Seminar, Seattle, WA, USA, 27–30 June 2017. [Google Scholar]
- Robinson, S.D. Visual Representation of Safety Narratives. Saf. Sci. 2016, 88, 123–128. [Google Scholar] [CrossRef]
- Zhang, X.; Srinivasan, P.; Mahadevan, S. Sequential Deep Learning from NTSB Reports for Aviation Safety Prognosis. Saf. Sci. 2021, 142, 105390. [Google Scholar] [CrossRef]
- Baker, H.; Hallowell, M.R.; Tixier, A.J.P. AI-Based Prediction of Independent Construction Safety Outcomes from Universal Attributes. Autom. Constr. 2020, 118, 103146. [Google Scholar] [CrossRef]
- Kierszbaum, S.; Lapasset, L. Applying Distilled BERT for Question Answering on ASRS Reports. In Proceedings of the 2020 New Trends in Civil Aviation (NTCA), Prague, Czech Republic, 23–24 November 2020; pp. 33–38. [Google Scholar] [CrossRef]
- Macedo, J.B.; Ramos, P.M.S.; Maior, C.B.S.; Moura, M.J.C.; Lins, I.D.; Vilela, R.F.T. Identifying Low-Quality Patterns in Accident Reports from Textual Data. Int. J. Occup. Saf. Ergon. 2022. [Google Scholar] [CrossRef]
- Dorsey, L.C.; Wang, B.; Grabowski, M.; Merrick, J.; Harrald, J.R. Self Healing Databases for Predictive Risk Analytics in Safety-Critical Systems. J. Loss Prev. Process Ind. 2020, 63, 104014. [Google Scholar] [CrossRef]
- Ramos, P.; Macêdo, J.B.; Maior, C.B.S.; Moura, M.C.; Lins, I.D. Combining BERT with Numerical Features to Classify Injury Leave Based on Accident Description. Proc. Inst. Mech. Eng. Part O J. Risk Reliab. 2022, 1–12. [Google Scholar] [CrossRef]
- Kierszbaum, S.; Klein, T.; Lapasset, L. ASRS-CMFS vs. RoBERTa: Comparing Two Pre-Trained Language Models to Predict Anomalies in Aviation Occurrence Reports with a Low Volume of In-Domain Data Available. Aerospace 2022, 9, 591. [Google Scholar] [CrossRef]
- Jiao, Y.; Dong, J.; Han, J.; Sun, H. Classification and Causes Identification of Chinese Civil Aviation Incident Reports. Appl. Sci. 2022, 12, 10765. [Google Scholar] [CrossRef]
- Gillespie, A.; Reader, T.W. Online Patient Feedback as a Safety Valve: An Automated Language Analysis of Unnoticed and Unresolved Safety Incidents. Risk Anal. 2022, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Wong, Z.S.Y.; So, H.Y.; Kwok, B.S.C.; Lai, M.W.S.; Sun, D.T.F. Medication-Rights Detection Using Incident Reports: A Natural Language Processing and Deep Neural Network Approach. Health Inform. J. 2020, 26, 1777–1794. [Google Scholar] [CrossRef] [Green Version]
- Thompson, P.; Yates, T.; Inan, E.; Ananiadou, S. Semantic Annotation for Improved Safety in Construction Work. In Proceedings of the Twelfth Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; pp. 1990–1999. [Google Scholar]
- Han, L.; Ball, R.; Pamer, C.A.; Altman, R.B.; Proestel, S. Development of an Automated Assessment Tool for MedWatch Reports in the FDA Adverse Event Reporting System. J. Am. Med. Inform. Assoc. 2017, 24, 913–920. [Google Scholar] [CrossRef] [Green Version]
- Deerwester, S.; Furnas, G.W.; Landauer, T.K.; Harshman, R. Indexing by Latent Semantic Analysis Scott. J. Am. Soc. Inf. Sci. 1990, 41, 391–407. [Google Scholar] [CrossRef]
- Hofmann, T. Unsupervised Learning by Probabilistic Latent Semantic Analysis. Mach. Learn. 2001, 42, 177–196. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet Allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Denecke, K. Automatic Analysis of Critical Incident Reports: Requirements and Use Cases. Stud. Health Technol. Inform. 2016, 223, 85–92. [Google Scholar] [CrossRef] [PubMed]
- ASRS Report ACN 353289; ASRS: Kitty Hawk, NC, USA, 1996.
- Macêdo, J.B.; das Chagas Moura, M.; Aichele, D.; Lins, I.D. Identification of Risk Features Using Text Mining and BERT-Based Models: Application to an Oil Refinery. Process Saf. Environ. Prot. 2022, 158, 382–399. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the NAACL HLT 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 4171–4186. [Google Scholar]
- Unbias Project. Available online: https://unbias.wp.horizon.ac.uk/ (accessed on 14 September 2020).
- Saeidi, M.; Bartolo, M.; Lewis, P.; Singh, S.; Rocktäschel, T.; Sheldon, M.; Bouchard, G.; Riedel, S. Interpretation of Natural Language Rules in Conversational Machine Reading. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, EMNLP 2018, Brussels, Belgium, 31 October–4 November 2018; Volume 1, pp. 2087–2097. [Google Scholar]
- Newman, J. A Taxonomy of Trustworthiness for Artificial Intelligence; CLTC: North Charleston, SC, USA, 2023. [Google Scholar]
- Rudin, C. Stop Explaining Black Box Machine Learning Models for High Stakes Decisions and Use Interpretable Models Instead. Nat. Mach. Intell. 2019, 1, 206–215. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- OpenAI ChatGPT: Optimizing Language Models for Dialogue. Available online: https://openai.com/blog/chatgpt/ (accessed on 10 February 2023).
- Chatterjee, J.; Dethlefs, N. This New Conversational AI Model Can Be Your Friend, Philosopher, and Guide. and Even Your Worst Enemy. Patterns 2023, 4, 1–3. [Google Scholar] [CrossRef] [PubMed]
- Wreathall, J. Leading? Lagging? Whatever! Saf. Sci. 2009, 47, 493–494. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Database | (“NLP” or “Natural Language Processing”) and (“Report” or “Occurrence”) and “Safety” | “Text Mining” and (“Report” or “Occurrence”) and “Safety” |
|---|---|---|
| ScienceDirect | 60 | 56 |
| Web of Science | 92 | 78 |
| Scopus | 306 | 223 |
| Paper Categories | Definition | |
|---|---|---|
| Paper Aim | Classification | Methods that seek to predict a category or class (e.g., assigning occurrence reports to given categories). |
| Clustering | The partitioning of data into similar groups. | |
| Entity Extraction | The extraction of given entities from the text such as hazards, causes, consequences, etc. | |
| Injury Prediction | Forecasting injury based upon available data. | |
| Reveal Knowledge | Methods that focus on revealing knowledge from the data such as production of knowledge graphs or case-based reasoning methods. | |
| Risk Variables | Methods that explicitly highlight risks from the data and demonstrate risk relationships. | |
| Semantic Search | Ability to semantically search the data rather than traditional lexical searches. | |
| Text Summarisation | The summarisation of a larger body of text into a smaller, concise version. | |
| Topic Modelling | Topic modelling methods that seek to generate a number of topics from the data, providing an alternative method of analysis. | |
| Accident Prediction | Forecasting given accidents based on available data. | |
| Question and Answering | Methods that allow for specific questions to be answered from the data. | |
| Database Cleansing | Methods used to improve database quality. | |
| Computational Method | Machine Learning | Any paper utilising machine learning methods that are defined as computational techniques enabling systems to learn from data or experience. Employing a set of statistical methods to find patterns in existing data and to then use patterns to make predictions [6]. |
| Deep Learning | Papers explicitly stating a deep learning method. Deep learning is a subset of machine learning creating rich hierarchical representations through the training of neural networks with many hidden layers [6]. | |
| Rule-based algorithm | Methods that do not use machine learning but rather programmed rules to parse text and provide results. | |
| Ontology | Methods that explicitly state the development of an ontology. Ontologies generally describe taxonomic relationships [17]. |
| Paper Categories | Papers | |
|---|---|---|
| Paper Aim | Classification | [2,3,21,22,23,24,25,26,27,28,29,30,31,32] |
| Clustering | [33,34,35,36,37] | |
| Entity Extraction | [1,12,14,17,32,38,39,40,41,42,43,44,45,46,47,48,49,50,51] | |
| Injury Prediction | [52] | |
| Reveal Knowledge | [13,20] | |
| Risk Variables | [53] | |
| Semantic Search | [54] | |
| Text Summarisation | [55] | |
| Topic Modelling | [10,11,56,57,58] | |
| Accident Prediction | [59,60] | |
| Question and Answering | [61] | |
| Visualise Safety Risk | [18] | |
| Similar Case Retrieval | [19] | |
| Database Cleansing | [62,63] | |
| Computational Method | Deep Learning | [13,14,22,27,32,42,44,59,61,64,65] |
| Machine Learning | [2,10,11,12,21,23,24,26,28,29,30,31,33,34,35,36,37,38,39,41,43,45,46,47,48,49,50,51,52,53,55,56,57,58,60,62,63,66,67] | |
| Rule-based algorithm | [1,3,19,20,38,40] | |
| Ontology | [17] |
| Challenge | Potential Solution |
|---|---|
| Use of language/semantics including the use of acronyms and spelling errors, which can confuse algorithms and require extensive effort to normalise text prior to machine learning. | Use the data to train a model from scratch or fine-tune a model, enabling the model to “learn” the new terminology. Alternatively, standardise the text by parsing it through a bespoke dictionary of acronyms and domain specific terms. |
| Language can differ across a single organisation/domain. | As above, standardisation rules can also be applied to reduce the text into common terms. |
| Contextual safety knowledge is often required to understand if the results are useful. | Incorporate the knowledge of domain safety experts through review or workshops. Construct bespoke datasets to capture context and feed into machine learning models. |
| Data cleaning itself can require significant effort at the start of a project. | Allocate enough time to clean and normalise data at the start of the project. As above, handwritten rules can be used to speed up this process, organising the text into appropriate formats for onward processing. |
| Model overfitting leading to erroneous results. | Depends upon the language model; however, one aim is to reduce the amount of “noise” in the data and ensuring training data are appropriate. |
| Classification errors occur between labels that share similar expressions. | Analyse model output samples and fine-tune parameters of the model. |
| Data may fit multiple categories, adding complexity to the machine learning model. | Consider using a multi-classifier machine learning model. |
| Component failure can be difficult to recognize, given that it can form part of a wider event leading to surplus information that detracts the classifier from the actual cause. | As suggested by Tanguy et al. [31] “build a relationship with the data” taking time to understand what is required and adapt the model accordingly. |
| Care needs to be taken to avoid bias and properly train/maintain models. | Algorithmic bias is unavoidable; however, it can be reduced by targeted sampling or re-weighting. The “UnBias: Emancipating Users Against Algorithmic Biases for a Trusted Digital Economy” project offers solutions and tools to reduce bias [78]. |
| The results are only as good as the training data. Therefore it is important to ensure the training data are accurate. | Invest time and resources at the start of the project to cleanse and check the training data are suitable for the task. |
| Incident reports typically only detail “what went wrong”. For a balanced view, knowledge of what went well is required. | Dependent upon the safety system in use and if data on “successes” are recorded. Alternatively, data could be gathered from employees as to what safety mitigations work well. |
| Distrust in model outputs or unable to achieve high levels of accuracy. | Dependent upon the intended use of the output, due to the nature of safety engineering, the model may be used initially to enhance a safety practitioners’ role as a support tool. Evaluation of the completed model can be carried out via case studies using experienced safety practitioners. |
| The data might be imbalanced where one of the classes (minority class) contains a much smaller number of examples than the remaining class (majority class). | Undersampling can be used to remove some instances of the majority class or oversampling to create new instances of the minority class. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ricketts, J.; Barry, D.; Guo, W.; Pelham, J. A Scoping Literature Review of Natural Language Processing Application to Safety Occurrence Reports. Safety 2023, 9, 22. https://doi.org/10.3390/safety9020022
Ricketts J, Barry D, Guo W, Pelham J. A Scoping Literature Review of Natural Language Processing Application to Safety Occurrence Reports. Safety. 2023; 9(2):22. https://doi.org/10.3390/safety9020022
Chicago/Turabian StyleRicketts, Jon, David Barry, Weisi Guo, and Jonathan Pelham. 2023. "A Scoping Literature Review of Natural Language Processing Application to Safety Occurrence Reports" Safety 9, no. 2: 22. https://doi.org/10.3390/safety9020022