
White Box Watermarking for Convolution Layers in Fine-Tuning Model Using the Constant Weight Code

Abstract
:1. Introduction
1.1. Background
1.2. Our Contributions
- In the DNN model, a suitable layer for embedding the watermark is quantitatively evaluated among multiple layers. Because the number of parameters for convolutional operations is considerably larger than for other operations, the secrecy of the choice of weight parameters can be controlled. Even if these weight parameters are modified by embedding the watermark at the initial setup and are fixed during the training phase, local minima whose model performance is close to other local minima can be determined.
- Under the assumption that the weight parameters are uniformly distributed or Gaussian, if the watermark is encoded by CWC, the statistical bias of the weight parameters extracted from the watermarked and nonwatermarked DNN models is formulated in the analysis. Therefore, a simple threshold calculated from the statistical distribution can be used to determine the presence of a hidden message.
- To protect against overwriting attacks, we introduced a nonfungible token (NFT) in the watermark. This token enables us to check the history of the hidden message; the tokenId of the NFT is encoded in the CWC code word and embedded as a watermark.
1.3. Organization
2. Preliminaries
2.1. DNN Watermarking
2.2. Threats of DNN Watermark
2.2.1. Transfer Learning and Fine-Tuning
2.2.2. Pruning DNN Model
2.2.3. Overwriting
3. DNN Watermarking Robust against Pruning
3.1. Embedding
- If , then ; otherwise, , where and are thresholds satisfying .
3.2. Extraction
3.3. Design of Detector
3.4. Recovery of Watermark
4. Proposed DNN Watermarking Method
4.1. Embedding Layers
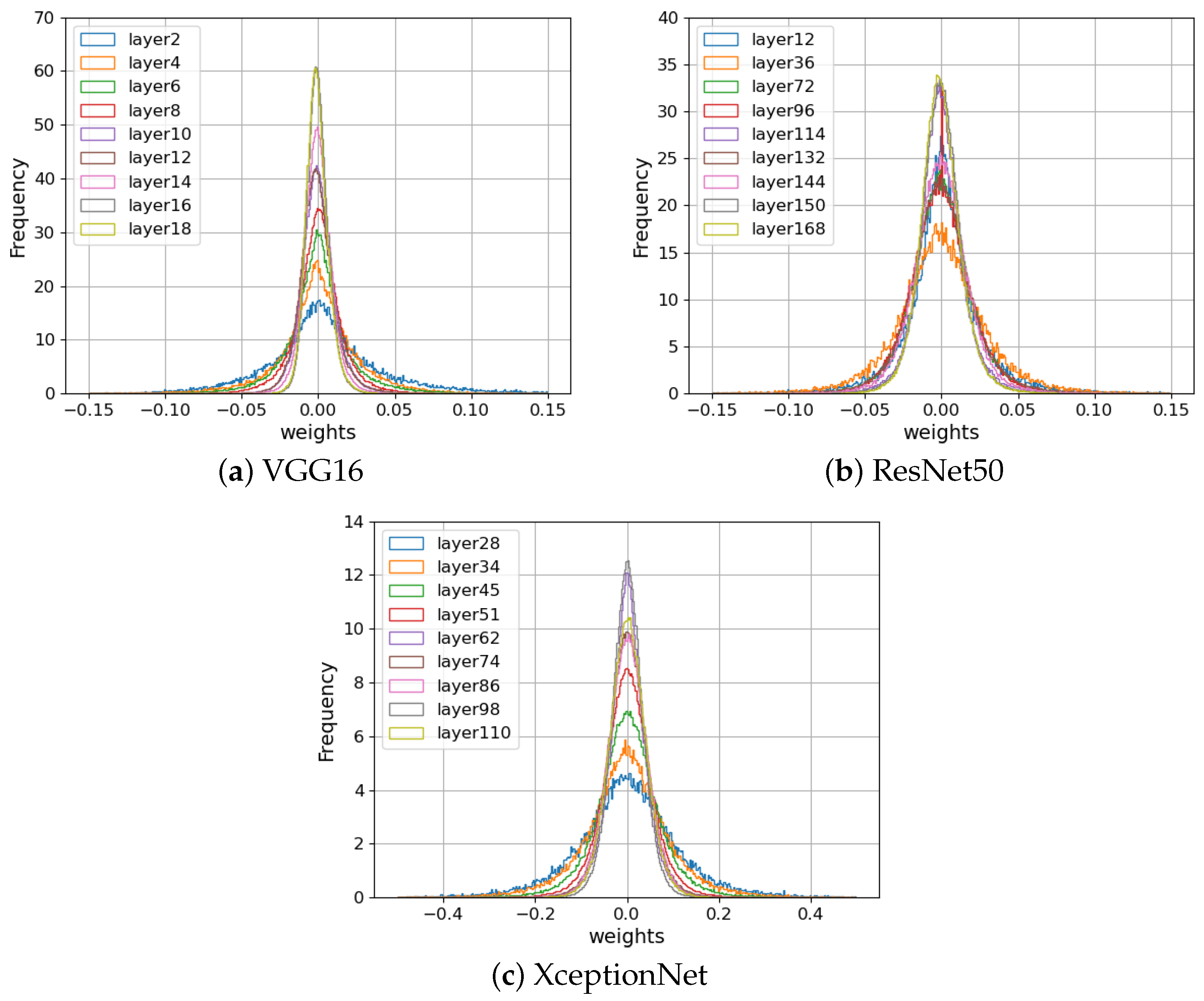
4.1.1. Characteristics of Convolution Layers
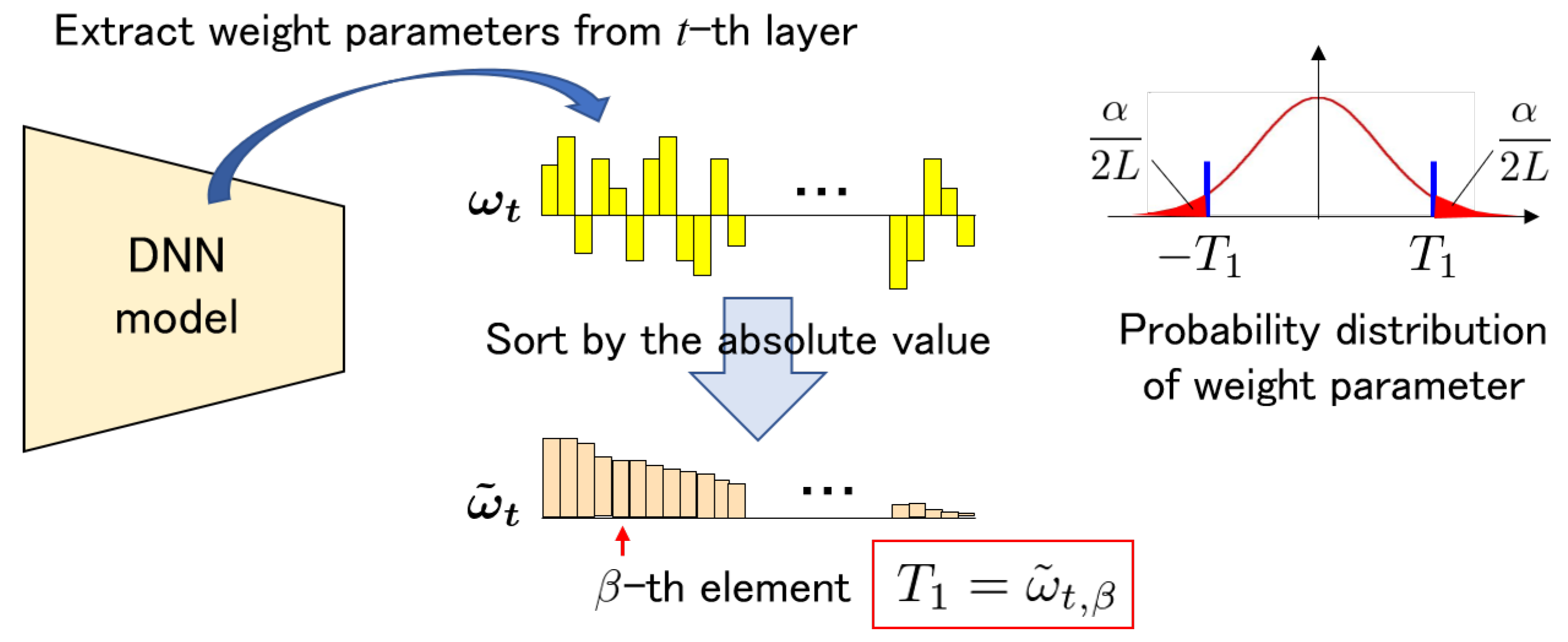
4.1.2. Design of Threshold
4.2. Detector
4.2.1. Measurement
- Extract L weight parameters based on the secret key from the DNN model.
- Sort in descending order:where , , and
- Calculate the modified from satisfying , except for the top parameters.
- Determine the presence of the watermark if the value exceeds a detection threshold.
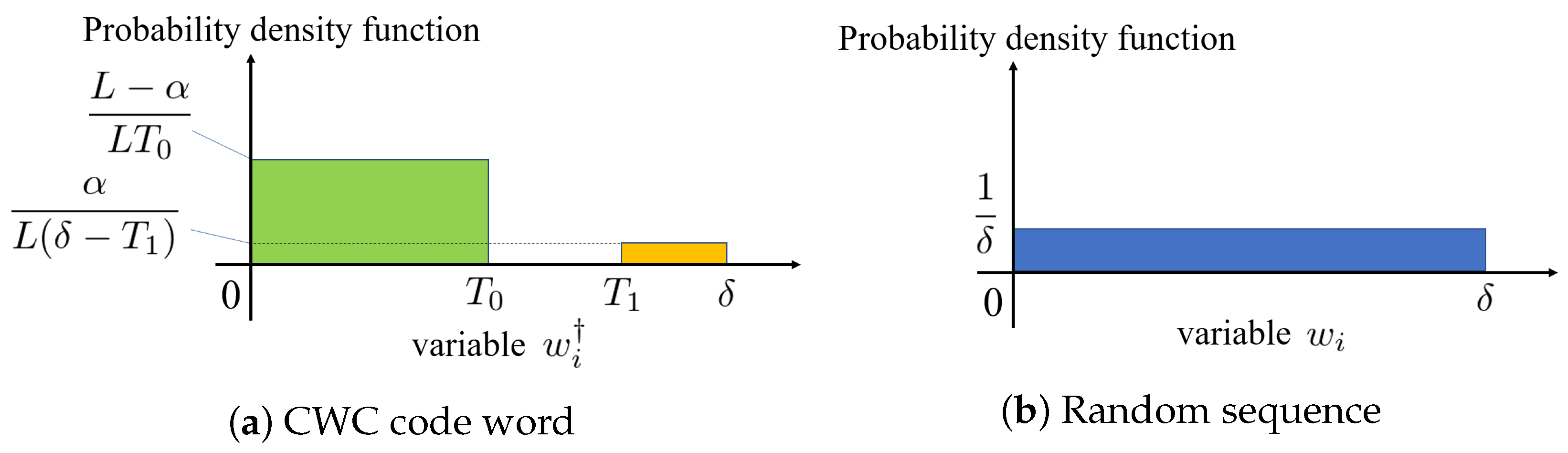
4.2.2. Uniform Distribution
- CWC codword:
- Random sequence:
4.2.3. Gaussian Distribution
- CWC code word:
- Random sequence:
4.3. Non-Fungible Token
5. Simulations
5.1. Experimental Conditions
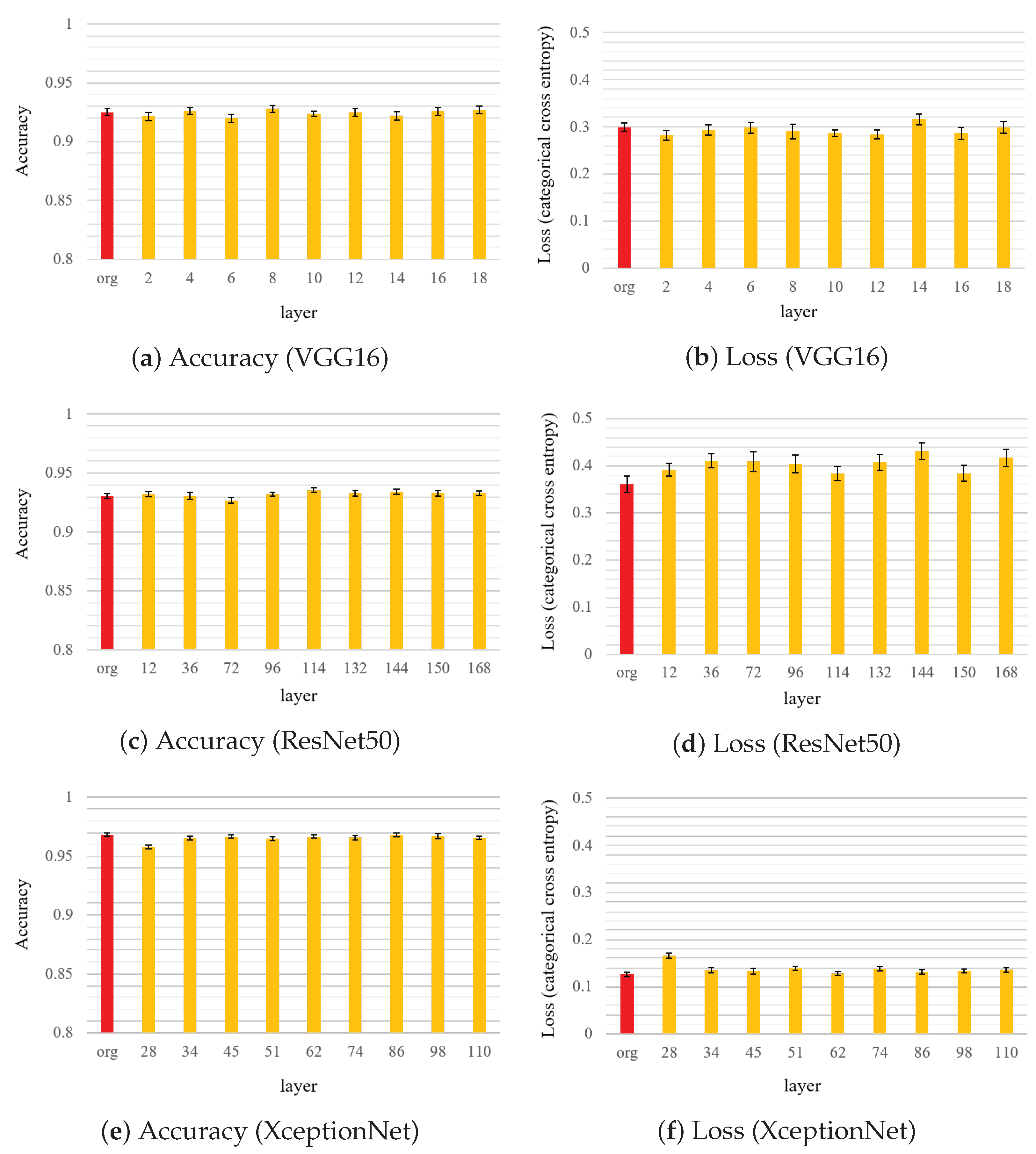
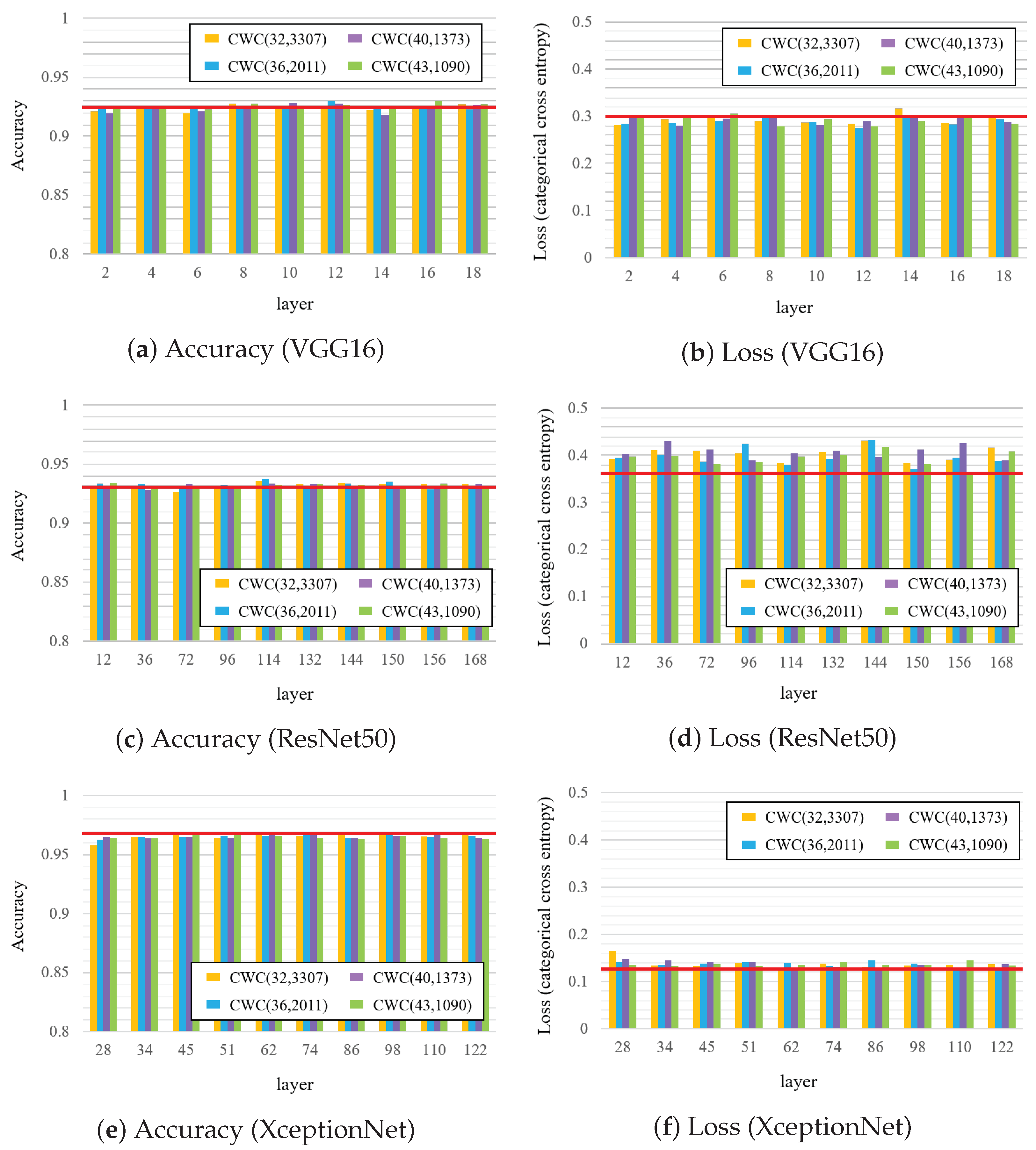
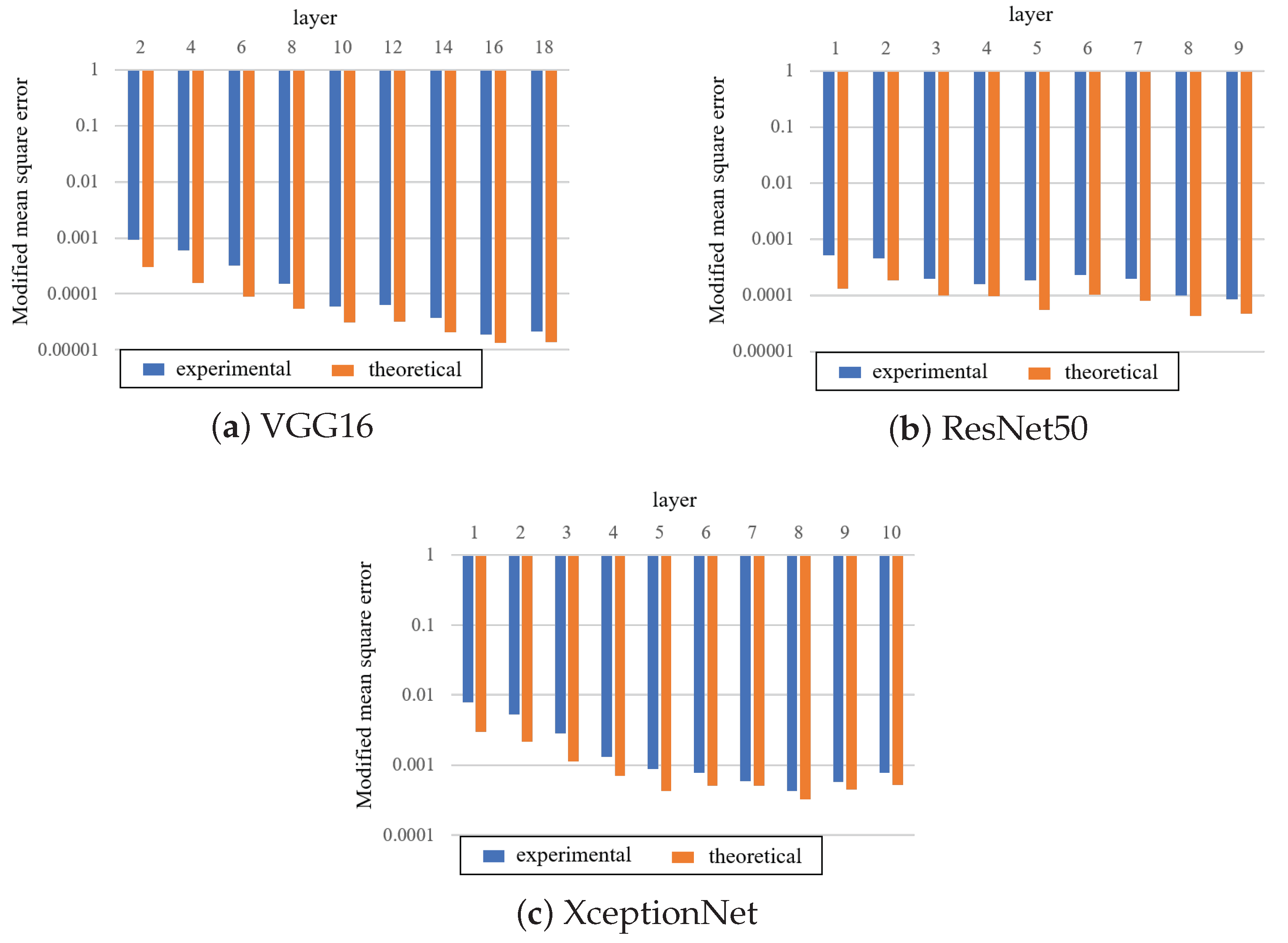
5.2. Dependency of Embedding Layer
5.3. Detection
5.4. Comparison
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cox, I.J.; Kilian, J.; Leighton, F.T.; Shamson, T. Secure spread spectrum watermarking for multimedia. IEEE Trans. Image Process. 1997, 6, 1673–1687. [Google Scholar] [CrossRef] [PubMed]
- Chen, B.; Wornel, G.W. Quantization index modulation: A class of provably good methods for digital watermarking and information embedding. IEEE Trans. Inform. Theory 2001, 47, 1423–1443. [Google Scholar] [CrossRef] [Green Version]
- Cox, I.J.; Miller, M.L.; Bloom, J.A. Digital Watermarking; Morgan Kaufmann Publishers Inc.: Burlington, MA, USA, 2002; Volume 53. [Google Scholar]
- Cox, I.J.; Miller, M.L.; Bloom, J.A. Digital Watermarking and Steganography, 2nd ed.; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2008. [Google Scholar]
- Li, Y.; Wang, H.; Barni, M. A survey of deep neural network watermarking techniques. Neurocomputing 2021, 461, 171–193. [Google Scholar] [CrossRef]
- Chen, H.; Rouhani, B.D.; Fan, X.; Kilinc, O.C.; Koushanfar, F. Performance Comparison of Contemporary DNN Watermarking Techniques. CoRR; 2018. Available online: http://xxx.lanl.gov/abs/1811.03713 (accessed on 1 May 2023).
- Liu, K.; Dolan-Gavitt, B.; Garg, S. Fine-Pruning: Defending Against Backdooring Attacks on Deep Neural Networks. In Research in Attacks, Intrusions, and Defenses; Bailey, M., Holz, T., Stamatogiannakis, M., Ioannidis, S., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 273–294. [Google Scholar]
- Uchida, Y.; Nagai, Y.; Sakazawa, S.; Satoh, S. Embedding Watermarks into Deep Neural Networks. In Proceedings of the 2017 ACM on international conference on multimedia retrieval, New York, NY, USA, 6 June 2017; pp. 269–277. [Google Scholar]
- Li, Y.; Tondi, B.; Barni, M. Spread-Transform Dither Modulation Watermarking of Deep Neural Network. J. Inf. Secur. Appl. 2021, 63, 103004. [Google Scholar] [CrossRef]
- Zhao, X.; Yao, Y.; Wu, H.; Zhang, X. Structural Watermarking to Deep Neural Networks via Network Channel Pruning. CoRR; 2021. Available online: http://xxx.lanl.gov/abs/2107.08688 (accessed on 1 May 2023).
- Tondi, B.; Costanzo, A.; Barni, M. Robust DNN Watermarking via Fixed Embedding Weights with Optimized Distribution. CoRR; 2022. Available online: http://xxx.lanl.gov/abs/2208.10973 (accessed on 1 May 2023).
- Schalkwijk, J.P.M. An algorithm for source coding. IEEE Trans. Inf. Theory 1972, IT-18, 395–399. [Google Scholar] [CrossRef]
- Brouwer, A.E.; Shearer, J.B.; Sloane, N.J.A.; Smith, W. A new table of constant weight codes. IEEE Trans. Inf. Theory 1990, 36, 1334–1380. [Google Scholar] [CrossRef]
- Yasui, T.; Tanaka, T.; Malik, A.; Kuribayashi, M. Coded DNN Watermark: Robustness against Pruning Models Using Constant Weight Code. J. Imaging 2022, 8, 152. [Google Scholar] [CrossRef] [PubMed]
- Nagai, Y.; Uchida, Y.; Sakazawa, S.; Satoh, S. Digital watermarking for deep neural networks. Int. J. Multimed. Inf. Retr. 2018, 7, 3–16. [Google Scholar] [CrossRef] [Green Version]
- Wang, T.; Kerschbaum, F. Attacks on digital watermarks for deep neural networks. In Proceedings of the ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 2622–2626. [Google Scholar]
- Choromanska, A.; Henaff, M.; Mathieu, M.; Arous, G.B.; Lecun, Y. The Loss Surfaces of Multilayer Networks. J. Mach. Learn. Res. 2015, 38, 192–204. [Google Scholar]
- Dauphin, Y.N.; Pascanu, R.; Gülçehre, Ç.; Cho, K.; Ganguli, S.; Bengio, Y. Identifying and attacking the saddle point problem in high-dimensional non-convex optimization. Adv. Neural Inf. Process. Syst. 2014, 2933–2941. [Google Scholar]
- Kuribayashi, M.; Tanaka, T.; Suzuki, S.; Yasui, T.; Funabiki, N. White-box watermarking scheme for fully-connected layers in fine-tuning model. In Proceedings of the 2021 ACM Workshop on Information Hiding and Multimedia Security, Virtual, 22–25 June 2021; pp. 165–170. [Google Scholar]
- Denil, N.; Shakibi, B.; Dinh, L.; Ranzato, M.A.; Freitas, N.D. Predicting parameters in deep learning. Adv. Neural Inf. Process. Syst. 2013, 26, 2148–2156. [Google Scholar]
- Nguyen, Q.A.; Gyorfi, L.; Massey, J.L. Constructions of binary constant-weight cyclic codes and cyclically permutable codes. IEEE Trans. Inf. Theory 1992, 38, 940–949. [Google Scholar] [CrossRef] [Green Version]
- Bitan, S.; Etzion, T. Constructions for optimal constant weight cyclically permutable codes and difference families. IEEE Trans. Inf. Theory 1995, 41, 77–87. [Google Scholar] [CrossRef] [Green Version]
- Etzion, T.; Vardy, A. A new construction for constant weight codes. In Proceedings of the 2014 International Symposium on Information Theory and Its Applications, Victoria, BC, Canada, 26–29 October 2014; pp. 338–342. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. Conference Track Proceedings. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2015 3rd IAPR Asian Conference on Pattern Recognition (ACPR), Kuala Lumpur, Malaysia, 3–6 November 2015. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, K.L.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Nakamoto, S. Bitcoin: A Peer-to-Peer Electronic Cash System. Decentralized Bus. Rev. 2008, 21260. [Google Scholar]
- Wood, D.D. Ethereum: A Secure Decentralised Generalised Transaction Ledger. Ethererum Proj. Yellow Pap. 2014, 151, 1–32. [Google Scholar]
- Wang, Q.; Li, R.; Wang, Q.; Chen, S. Non-Fungible Token (NFT): Overview, Evaluation, Opportunities and Challenges. CoRR; 2021. Available online: http://xxx.lanl.gov/abs/2105.07447 (accessed on 1 May 2023).
- Wang, J.; Hu, H.; Zhang, X.; Yao, Y. Watermarking in Deep Neural Networks via Error Back-Propagation. Electron. Imaging 2020, 2020, 22-1. [Google Scholar] [CrossRef]
- Liu, H.; Weng, Z.; Zhu, Y. Watermarking Deep Neural Networks with Greedy Residuals; PMLR; 2021. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021; Volume 139, pp. 6978–6988. [Google Scholar]
- Wang, T.; Kerschbaum, F. RIGA: Covert and Robust White-Box Watermarking of Deep Neural Networks; WWW ’21. In Proceedings of the Web Conference 2021, Association for Computing Machinery. New York, NY, USA, 3 June 2021; pp. 993–1004. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Name | Shape | #Param. |
|---|---|---|---|
| 0 | block1_conv1/kernel:0 | (3, 3, 3, 64) | 1728 |
| 1 | block1_conv1/bias:0 | (64,) | 64 |
| 2 | block1_conv2/kernel:0 | (3, 3, 64, 64) | 36,864 |
| 3 | block1_conv2/bias:0 | (64,) | 64 |
| 4 | block2_conv1/kernel:0 | (3, 3, 64, 128) | 73,728 |
| 5 | block2_conv1/bias:0 | (128,) | 128 |
| 6 | block2_conv2/kernel:0 | (3, 3, 128, 128) | 147,456 |
| 7 | block2_conv2/bias:0 | (128,) | 128 |
| 8 | block3_conv1/kernel:0 | (3, 3, 128, 256) | 294,912 |
| 9 | block3_conv1/bias:0 | (256,) | 256 |
| 10 | block3_conv2/kernel:0 | (3, 3, 256, 256) | 589,824 |
| 11 | block3_conv2/bias:0 | (256,) | 256 |
| 12 | block3_conv3/kernel:0 | (3, 3, 256, 256) | 589,824 |
| 13 | block3_conv3/bias:0 | (256,) | 256 |
| 14 | block4_conv1/kernel:0 | (3, 3, 256, 512) | 1,179,648 |
| 15 | block4_conv1/bias:0 | (512,) | 512 |
| 16 | block4_conv2/kernel:0 | (3, 3, 512, 512) | 2,359,296 |
| 17 | block4_conv2/bias:0 | (512,) | 512 |
| 18 | block4_conv3/kernel:0 | (3, 3, 512, 512) | 2,359,296 |
| 19 | block4_conv3/bias:0 | (512,) | 512 |
| 20 | block5_conv1/kernel:0 | (3, 3, 512, 512) | 2,359,296 |
| 21 | block5_conv1/bias:0 | (512,) | 512 |
| 22 | block5_conv2/kernel:0 | (3, 3, 512, 512) | 2,359,296 |
| 23 | block5_conv2/bias:0 | (512,) | 512 |
| 24 | block5_conv3/kernel:0 | (3, 3, 512, 512) | 2,359,296 |
| 25 | block5_conv3/bias:0 | (512,) | 512 |
| 26 | dense/kernel:0 | (25,088, 256) | 6,422,528 |
| 27 | dense/bias:0 | (256,) | 256 |
| 28 | dense_1/kernel:0 | (256, 17) | 4352 |
| 29 | dense_1/bias:0 | (17,) | 17 |
| k | L | ||
|---|---|---|---|
| 256 | 32 | 3307 | 0.9903 |
| 36 | 2011 | 0.9821 | |
| 40 | 1373 | 0.9709 | |
| 43 | 1090 | 0.9606 |
| VGG16 | ResNet50 | XceptionNet | |
|---|---|---|---|
| Frozen layer | 15 | 150 | 80 |
| Epoch | 50 | 100 | 30 |
| Accuracy | 0.925 | 0.934 | 0.970 |
| Loss | 0.299 | 0.361 | 0.124 |
| (a) VGG16 | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Layer | 2 | 4 | 6 | 8 | 10 | 12 | 14 | 16 | 18 |
| #Param. | 36,864 | 73,728 | 147,456 | 294,912 | 589,824 | 589,824 | 1,179,648 | 2,359,296 | 2,359,296 |
| (b) ResNet50 | |||||||||
| Layer | 12 | 36 | 72 | 96 | 114 | 132 | 144 | 150 | 168 |
| #Param. | 36,864 | 36,864 | 147,456 | 147,456 | 147,456 | 147,456 | 131,072 | 589,824 | 262,144 |
| (c) XceptionNet | |||||||||
| Layer | 28 | 34 | 45 | 51 | 62 | 74 | 86 | 98 | 110 |
| #Param. | 32,768 | 65,536 | 186,368 | 529,984 | 529,984 | 529,984 | 529,984 | 529,984 | 529,984 |
| Embedding | Embedding | Fine- | Pruning | Overwriting | |
|---|---|---|---|---|---|
| Layer | Loss | Tuning | |||
| Uchida et al. [8] | Conv. | Need | ∘ | <65% | × |
| Li et al. [9] | Conv. | Need | ∘ | < 60% | × |
| Wang et al. [31] | MLP/Conv. | Need | ∘ | <90% | × |
| Liu et al. [32] | Conv. | Need | ∘ | <75% | △ |
| Wang et al. [33] | Conv. | Need | ∘ | <95% | △ |
| Tondi et al. [11] | Conv. | Need | ∘ | <90% | × |
| Yasui et al. [14] | FC | − | ∘ | < | △ |
| Proposed | Conv. | − | ∘ | < | ∘ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kuribayashi, M.; Yasui, T.; Malik, A. White Box Watermarking for Convolution Layers in Fine-Tuning Model Using the Constant Weight Code. J. Imaging 2023, 9, 117. https://doi.org/10.3390/jimaging9060117
Kuribayashi M, Yasui T, Malik A. White Box Watermarking for Convolution Layers in Fine-Tuning Model Using the Constant Weight Code. Journal of Imaging. 2023; 9(6):117. https://doi.org/10.3390/jimaging9060117
Chicago/Turabian StyleKuribayashi, Minoru, Tatsuya Yasui, and Asad Malik. 2023. "White Box Watermarking for Convolution Layers in Fine-Tuning Model Using the Constant Weight Code" Journal of Imaging 9, no. 6: 117. https://doi.org/10.3390/jimaging9060117