

Computational Methods to Study DNA:DNA:RNA Triplex Formation by lncRNAs


{kind=link}
{kind=link}
{kind=link}
Abstract
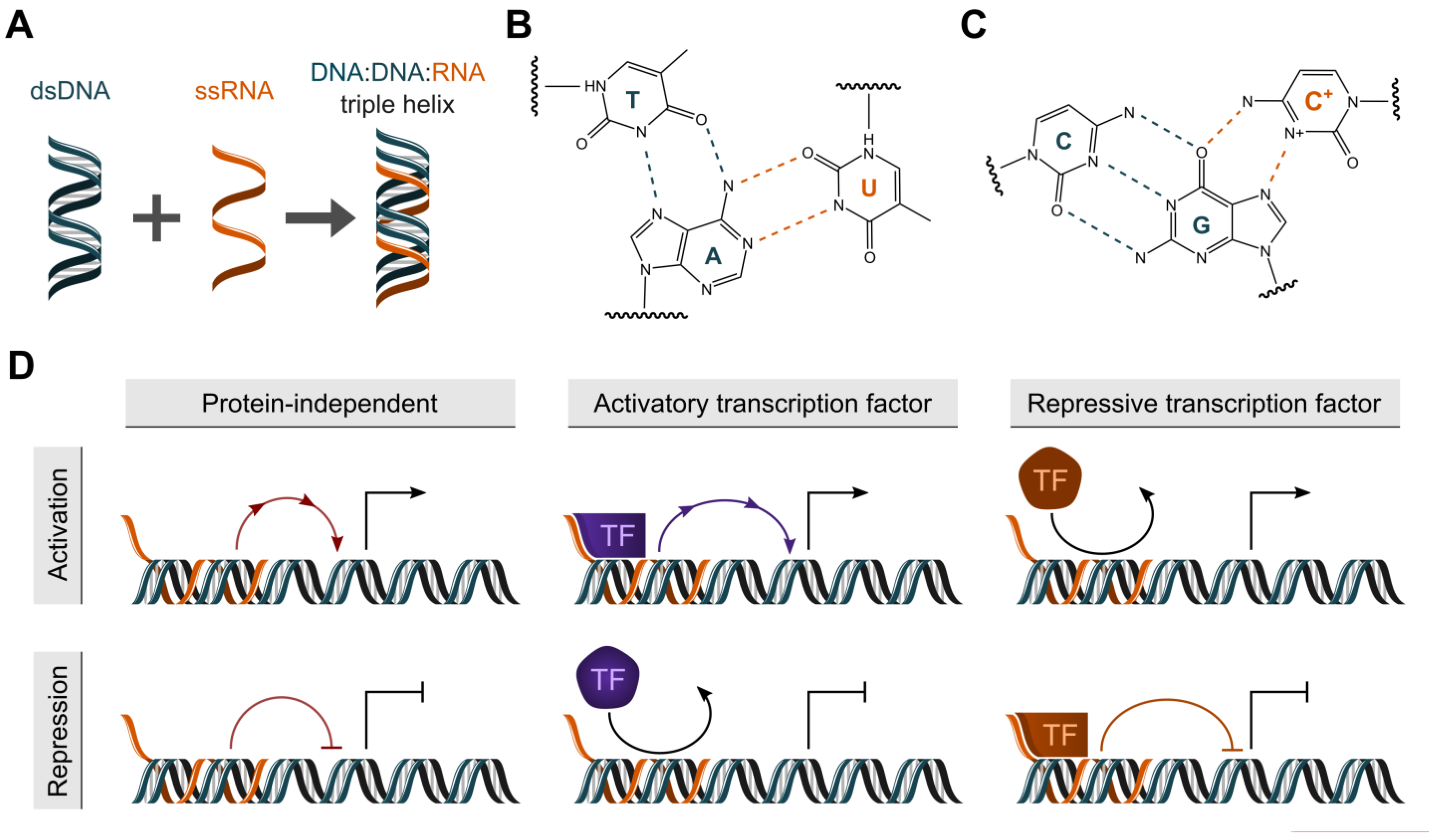
:1. Introduction
2. Computational Methods to Identify Triplex-Forming lncRNAs and their DNA Target Sites
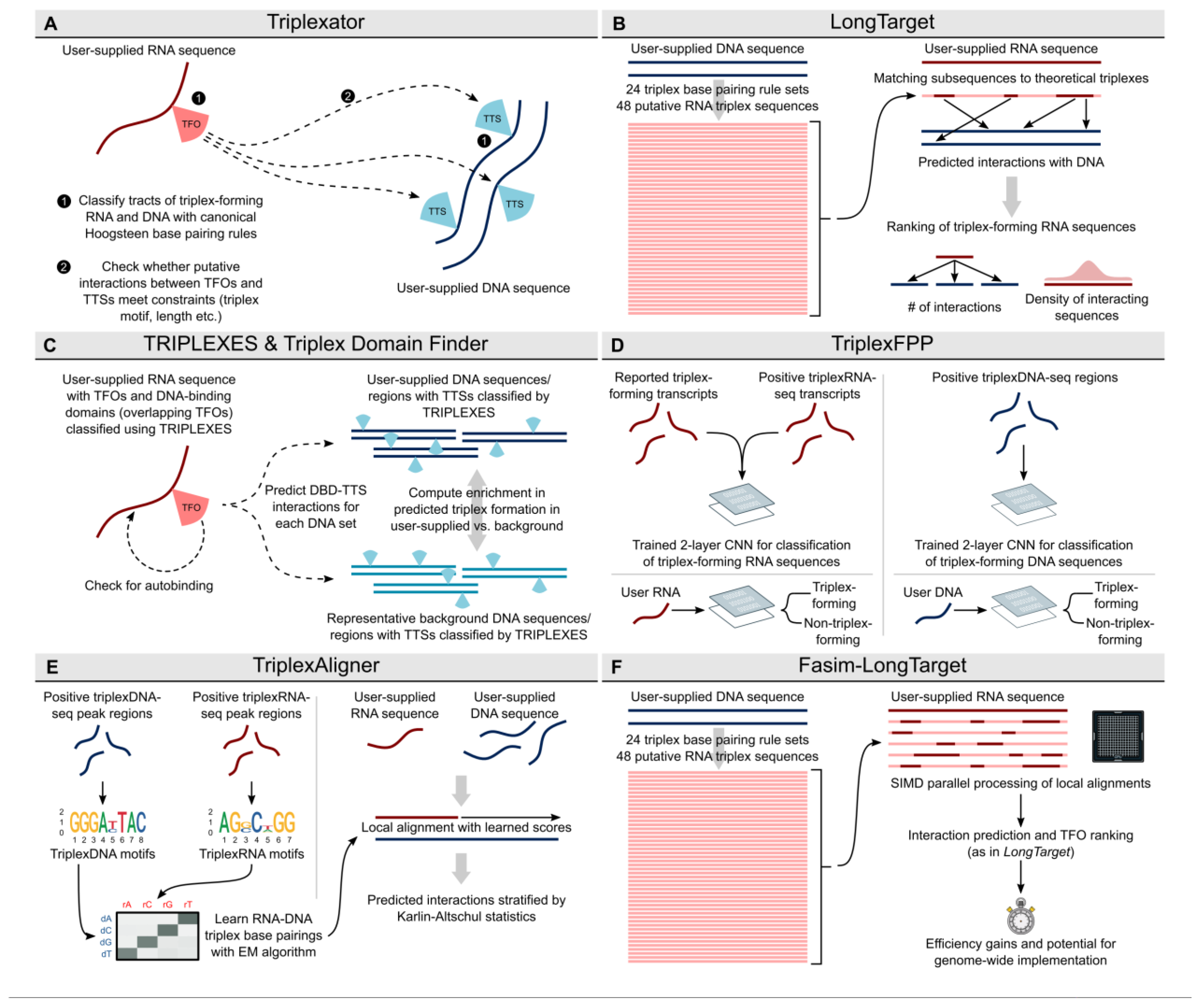
2.1. Triplexator: The First Triplex Prediction Tool
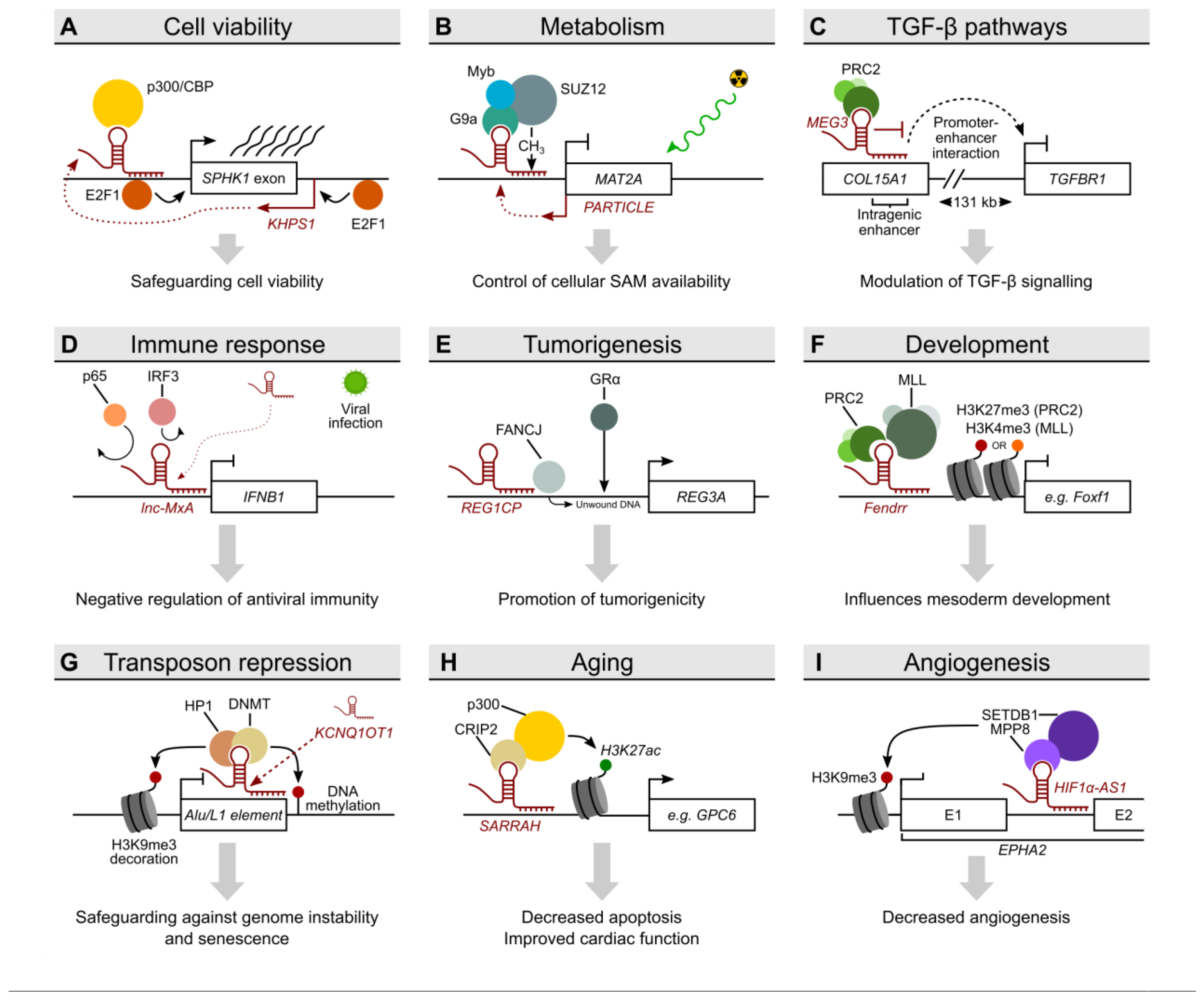
2.2. KHPS1 as an Example for Triplex-Mediated Transcriptional Activation and the Interchangeability of Triplex-Forming Regions
2.3. PARTICLE Links Triplex Formation to Irradiation, a Model System for Cellular Stress
2.4. MEG3-Dependent Triplex Formation Is Involved in the Regulation of Signalling Pathways
2.5. Lnc-MxA and REG1CP: Triplex Formation Meets Immune Response and Cancer
2.6. LongTarget
2.7. TRIPLEXES
2.8. Triplex Domain Finder
2.9. Triplex Domain Finder as a Tool to Analyse Large Datasets
2.10. SARRAH: Triplex Formation Associated with Aging and Myocardial Infarction
2.11. HIF1α-AS1 Is a Triplex-Forming lncRNA Validating the Concept of Interchangeability
2.12. TriplexFFP
2.13. TriplexAligner
2.14. Fasim-Longtarget
3. Conclusions and Outlook
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Statello, L.; Guo, C.-J.; Chen, L.-L.; Huarte, M. Gene regulation by long non-coding RNAs and its biological functions. Nat. Rev. Mol. Cell Biol. 2021, 22, 96–118. [Google Scholar] [CrossRef]
- Oo, J.A.; Brandes, R.P.; Leisegang, M.S. Long non-coding RNAs: Novel regulators of cellular physiology and function. Pflugers Arch. 2022, 474, 191–204. [Google Scholar] [CrossRef]
- Niehrs, C.; Luke, B. Regulatory R-loops as facilitators of gene expression and genome stability. Nat. Rev. Mol. Cell Biol. 2020, 21, 167–178. [Google Scholar] [CrossRef] [PubMed]
- Felsenfeld, G.; Davies, D.R.; Rich, A. FORMATION OF A THREE-STRANDED POLYNUCLEOTIDE MOLECULE. J. Am. Chem. Soc. 1957, 79, 2023–2024. [Google Scholar] [CrossRef]
- Kuo, C.-C.; Hänzelmann, S.; Sentürk Cetin, N.; Frank, S.; Zajzon, B.; Derks, J.-P.; Akhade, V.S.; Ahuja, G.; Kanduri, C.; Grummt, I.; et al. Detection of RNA-DNA binding sites in long noncoding RNAs. Nucleic Acids Res. 2019, 47, e32. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cerritelli, S.M.; Crouch, R.J. Ribonuclease H: The enzymes in eukaryotes. FEBS J. 2009, 276, 1494–1505. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Z.; Giles, K.E.; Felsenfeld, G. DNA·RNA triple helix formation can function as a cis-acting regulatory mechanism at the human β-globin locus. Proc. Natl. Acad. Sci. USA. 2019, 116, 6130–6139. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Syed, J.; Sugiyama, H. RNA-DNA Triplex Formation by Long Noncoding RNAs. Cell Chem. Biol. 2016, 23, 1325–1333. [Google Scholar] [CrossRef] [Green Version]
- Mondal, T.; Subhash, S.; Vaid, R.; Enroth, S.; Uday, S.; Reinius, B.; Mitra, S.; Mohammed, A.; James, A.R.; Hoberg, E.; et al. MEG3 long noncoding RNA regulates the TGF-β pathway genes through formation of RNA-DNA triplex structures. Nat. Commun. 2015, 6, 7743. [Google Scholar] [CrossRef] [Green Version]
- Jalali, S.; Singh, A.; Maiti, S.; Scaria, V. Genome-wide computational analysis of potential long noncoding RNA mediated DNA:DNA:RNA triplexes in the human genome. J. Transl. Med. 2017, 15, 186. [Google Scholar] [CrossRef]
- Trembinski, D.J.; Bink, D.I.; Theodorou, K.; Sommer, J.; Fischer, A.; van Bergen, A.; Kuo, C.-C.; Costa, I.G.; Schürmann, C.; Leisegang, M.S.; et al. Aging-regulated anti-apoptotic long non-coding RNA Sarrah augments recovery from acute myocardial infarction. Nat. Commun. 2020, 11, 2039. [Google Scholar] [CrossRef] [PubMed]
- Leisegang, M.S.; Bains, J.K.; Seredinski, S.; Oo, J.A.; Krause, N.M.; Kuo, C.-C.; Günther, S.; Sentürk Cetin, N.; Warwick, T.; Cao, C.; et al. HIF1α-AS1 is a DNA:DNA:RNA triplex-forming lncRNA interacting with the HUSH complex. Nat. Commun. 2022, 13, 6563. [Google Scholar] [CrossRef] [PubMed]
- Sentürk Cetin, N.; Kuo, C.-C.; Ribarska, T.; Li, R.; Costa, I.G.; Grummt, I. Isolation and genome-wide characterization of cellular DNA:RNA triplex structures. Nucleic Acids Res. 2019, 47, 2306–2321. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Postepska-Igielska, A.; Blank-Giwojna, A.; Grummt, I. Analysis of RNA-DNA Triplex Structures In Vitro and In Vivo. Methods Mol. Biol. 2020, 2161, 229–246. [Google Scholar] [CrossRef] [PubMed]
- Grote, P.; Wittler, L.; Hendrix, D.; Koch, F.; Währisch, S.; Beisaw, A.; Macura, K.; Bläss, G.; Kellis, M.; Werber, M.; et al. The tissue-specific lncRNA Fendrr is an essential regulator of heart and body wall development in the mouse. Dev. Cell 2013, 24, 206–214. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Postepska-Igielska, A.; Giwojna, A.; Gasri-Plotnitsky, L.; Schmitt, N.; Dold, A.; Ginsberg, D.; Grummt, I. LncRNA Khps1 Regulates Expression of the Proto-oncogene SPHK1 via Triplex-Mediated Changes in Chromatin Structure. Mol. Cell 2015, 60, 626–636. [Google Scholar] [CrossRef]
- Zhao, Z.; Sentürk, N.; Song, C.; Grummt, I. lncRNA PAPAS tethered to the rDNA enhancer recruits hypophosphorylated CHD4/NuRD to repress rRNA synthesis at elevated temperatures. Genes Dev. 2018, 32, 836–848. [Google Scholar] [CrossRef]
- Bell, J.C.; Jukam, D.; Teran, N.A.; Risca, V.I.; Smith, O.K.; Johnson, W.L.; Skotheim, J.M.; Greenleaf, W.J.; Straight, A.F. Chromatin-associated RNA sequencing (ChAR-seq) maps genome-wide RNA-to-DNA contacts. Elife 2018, 7, 27024. [Google Scholar] [CrossRef]
- Zhou, B.; Li, X.; Luo, D.; Lim, D.-H.; Zhou, Y.; Fu, X.-D. GRID-seq for comprehensive analysis of global RNA-chromatin interactions. Nat. Protoc. 2019, 14, 2036–2068. [Google Scholar] [CrossRef]
- Wu, W.; Yan, Z.; Nguyen, T.C.; Bouman Chen, Z.; Chien, S.; Zhong, S. Mapping RNA-chromatin interactions by sequencing with iMARGI. Nat. Protoc. 2019, 14, 3243–3272. [Google Scholar] [CrossRef]
- Gavrilov, A.A.; Zharikova, A.A.; Galitsyna, A.A.; Luzhin, A.V.; Rubanova, N.M.; Golov, A.K.; Petrova, N.V.; Logacheva, M.D.; Kantidze, O.L.; Ulianov, S.V.; et al. Studying RNA-DNA interactome by Red-C identifies noncoding RNAs associated with various chromatin types and reveals transcription dynamics. Nucleic Acids Res. 2020, 48, 6699–6714. [Google Scholar] [CrossRef] [PubMed]
- Gavrilov, A.A.; Sultanov, R.I.; Magnitov, M.D.; Galitsyna, A.A.; Dashinimaev, E.B.; Lieberman Aiden, E.; Razin, S.V. RedChIP identifies noncoding RNAs associated with genomic sites occupied by Polycomb and CTCF proteins. Proc. Natl. Acad. Sci. USA 2022, 119, e2116222119. [Google Scholar] [CrossRef] [PubMed]
- Bonetti, A.; Agostini, F.; Suzuki, A.M.; Hashimoto, K.; Pascarella, G.; Gimenez, J.; Roos, L.; Nash, A.J.; Ghilotti, M.; Cameron, C.J.F.; et al. RADICL-seq identifies general and cell type-specific principles of genome-wide RNA-chromatin interactions. Nat. Commun. 2020, 11, 1018. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Antonov, I.V.; Mazurov, E.; Borodovsky, M.; Medvedeva, Y.A. Prediction of lncRNAs and their interactions with nucleic acids: Benchmarking bioinformatics tools. Brief. Bioinform. 2019, 20, 551–564. [Google Scholar] [CrossRef] [PubMed]
- Buske, F.A.; Bauer, D.C.; Mattick, J.S.; Bailey, T.L. Triplexator: Detecting nucleic acid triple helices in genomic and transcriptomic data. Genome Res. 2012, 22, 1372–1381. [Google Scholar] [CrossRef] [Green Version]
- Hoogsteen, K. The structure of crystals containing a hydrogen-bonded complex of 1-methylthymine and 9-methyladenine. Acta Cryst 1959, 12, 822–823. [Google Scholar] [CrossRef]
- Blank-Giwojna, A.; Postepska-Igielska, A.; Grummt, I. lncRNA KHPS1 Activates a Poised Enhancer by Triplex-Dependent Recruitment of Epigenomic Regulators. Cell Rep. 2019, 26, 2904–2915.e4. [Google Scholar] [CrossRef] [Green Version]
- O’Leary, V.B.; Ovsepian, S.V.; Carrascosa, L.G.; Buske, F.A.; Radulovic, V.; Niyazi, M.; Moertl, S.; Trau, M.; Atkinson, M.J.; Anastasov, N. PARTICLE, a Triplex-Forming Long ncRNA, Regulates Locus-Specific Methylation in Response to Low-Dose Irradiation. Cell Rep. 2015, 11, 474–485. [Google Scholar] [CrossRef] [Green Version]
- O’Leary, V.B.; Smida, J.; Buske, F.A.; Carrascosa, L.G.; Azimzadeh, O.; Maugg, D.; Hain, S.; Tapio, S.; Heidenreich, W.; Kerr, J.; et al. PARTICLE triplexes cluster in the tumor suppressor WWOX and may extend throughout the human genome. Sci. Rep. 2017, 7, 7163. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Guo, G.; Lu, M.; Chai, W.; Li, Y.; Tong, X.; Li, J.; Jia, X.; Liu, W.; Qi, D.; et al. Long Noncoding RNA Lnc-MxA Inhibits Beta Interferon Transcription by Forming RNA-DNA Triplexes at Its Promoter. J. Virol. 2019, 93, 11827–11832. [Google Scholar] [CrossRef]
- Yari, H.; Jin, L.; Teng, L.; Wang, Y.; Wu, Y.; Liu, G.Z.; Gao, W.; Liang, J.; Xi, Y.; Feng, Y.C.; et al. LncRNA REG1CP promotes tumorigenesis through an enhancer complex to recruit FANCJ helicase for REG3A transcription. Nat. Commun. 2019, 10, 5334. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, S.; Zhang, H.; Liu, H.; Zhu, H. LongTarget: A tool to predict lncRNA DNA-binding motifs and binding sites via Hoogsteen base-pairing analysis. Bioinformatics 2015, 31, 178–186. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Duca, M.; Vekhoff, P.; Oussedik, K.; Halby, L.; Arimondo, P.B. The triple helix: 50 years later, the outcome. Nucleic Acids Res. 2008, 36, 5123–5138. [Google Scholar] [CrossRef] [PubMed]
- Abu Almakarem, A.S.; Petrov, A.I.; Stombaugh, J.; Zirbel, C.L.; Leontis, N.B. Comprehensive survey and geometric classification of base triples in RNA structures. Nucleic Acids Res. 2012, 40, 1407–1423. [Google Scholar] [CrossRef]
- Goujon, M.; McWilliam, H.; Li, W.; Valentin, F.; Squizzato, S.; Paern, J.; Lopez, R. A new bioinformatics analysis tools framework at EMBL-EBI. Nucleic Acids Res. 2010, 38, W695-9. [Google Scholar] [CrossRef]
- Leontis, N.B.; Stombaugh, J.; Westhof, E. The non-Watson-Crick base pairs and their associated isostericity matrices. Nucleic Acids Res. 2002, 30, 3497–3531. [Google Scholar] [CrossRef]
- Zhao, H.; Xu, Q. Long non-coding RNA DLX6-AS1 mediates proliferation, invasion and apoptosis of endometrial cancer cells by recruiting p300/E2F1 in DLX6 promoter region. J. Cell. Mol. Med. 2020, 24, 12572–12584. [Google Scholar] [CrossRef]
- Ou, M.; Li, X.; Zhao, S.; Cui, S.; Tu, J. Long non-coding RNA CDKN2B-AS1 contributes to atherosclerotic plaque formation by forming RNA-DNA triplex in the CDKN2B promoter. EBioMedicine 2020, 55, 102694. [Google Scholar] [CrossRef]
- Wang, X.; Li, Q.; He, S.; Bai, J.; Ma, C.; Zhang, L.; Guan, X.; Yuan, H.; Li, Y.; Zhu, X.; et al. LncRNA FENDRR with m6A RNA methylation regulates hypoxia-induced pulmonary artery endothelial cell pyroptosis by mediating DRP1 DNA methylation. Mol. Med. 2022, 28, 126. [Google Scholar] [CrossRef]
- Kalwa, M.; Hänzelmann, S.; Otto, S.; Kuo, C.-C.; Franzen, J.; Joussen, S.; Fernandez-Rebollo, E.; Rath, B.; Koch, C.; Hofmann, A.; et al. The lncRNA HOTAIR impacts on mesenchymal stem cells via triple helix formation. Nucleic Acids Res. 2016, 44, 10631–10643. [Google Scholar] [CrossRef]
- Benjamini, Y.; Hochberg, Y. Controlling the False Discovery Rate: A Practical and Powerful Approach to Multiple Testing. J. R. Stat. Soc. Ser. B 1995, 57, 289–300. [Google Scholar] [CrossRef]
- Zhang, X.; Jiang, Q.; Li, J.; Zhang, S.; Cao, Y.; Xia, X.; Cai, D.; Tan, J.; Chen, J.; Han, J.-D.J. KCNQ1OT1 promotes genome-wide transposon repression by guiding RNA-DNA triplexes and HP1 binding. Nat. Cell Biol. 2022, 24, 1617–1629. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Long, Y.; Kwoh, C.K. Deep learning based DNA:RNA triplex forming potential prediction. BMC Bioinformatics 2020, 21, 522. [Google Scholar] [CrossRef]
- Li, Z.; Liu, F.; Yang, W.; Peng, S.; Zhou, J. A Survey of Convolutional Neural Networks: Analysis, Applications, and Prospects. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 6999–7019. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Ke, H.; Zhang, H.; Ma, Y.; Ao, L.; Zou, L.; Yang, Q.; Zhu, H.; Nie, J.; Wu, C.; et al. LncRNA MIR100HG promotes cell proliferation in triple-negative breast cancer through triplex formation with p27 loci. Cell Death Dis 2018, 9, 753. [Google Scholar] [CrossRef] [Green Version]
- Warwick, T.; Seredinski, S.; Krause, N.M.; Bains, J.K.; Althaus, L.; Oo, J.A.; Bonetti, A.; Dueck, A.; Engelhardt, S.; Schwalbe, H.; et al. A universal model of RNA.DNA:DNA triplex formation accurately predicts genome-wide RNA-DNA interactions. Brief. Bioinform. 2022, 23, bbac445. [Google Scholar] [CrossRef]
- Lesluyes, T.; Johnson, J.; Machanick, P.; Bailey, T.L. Differential motif enrichment analysis of paired ChIP-seq experiments. BMC Genomics 2014, 15, 752. [Google Scholar] [CrossRef] [Green Version]
- Do, C.B.; Batzoglou, S. What is the expectation maximization algorithm? Nat. Biotechnol. 2008, 26, 897–899. [Google Scholar] [CrossRef]
- Kunkler, C.N.; Hulewicz, J.P.; Hickman, S.C.; Wang, M.C.; McCown, P.J.; Brown, J.A. Stability of an RNA•DNA-DNA triple helix depends on base triplet composition and length of the RNA third strand. Nucleic Acids Res. 2019, 47, 7213–7222. [Google Scholar] [CrossRef] [Green Version]
- Karlin, S.; Altschul, S.F. Methods for assessing the statistical significance of molecular sequence features by using general scoring schemes. Proc. Natl. Acad. Sci. USA 1990, 87, 2264–2268. [Google Scholar] [CrossRef]
- Kleinjung, J.; Douglas, N.; Heringa, J. Parallelized multiple alignment. Bioinformatics 2002, 18, 1270–1271. [Google Scholar] [CrossRef] [Green Version]
- Wen, Y.; Wu, Y.; Xu, B.; Lin, J.; Zhu, H. Fasim-LongTarget enables fast and accurate genome-wide lncRNA/DNA binding prediction. Comput. Struct. Biotechnol. J. 2022, 20, 3347–3350. [Google Scholar] [CrossRef] [PubMed]
- Farrar, M. Striped Smith-Waterman speeds database searches six times over other SIMD implementations. Bioinformatics 2007, 23, 156–161. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- West, J.A.; Davis, C.P.; Sunwoo, H.; Simon, M.D.; Sadreyev, R.I.; Wang, P.I.; Tolstorukov, M.Y.; Kingston, R.E. The long noncoding RNAs NEAT1 and MALAT1 bind active chromatin sites. Mol. Cell 2014, 55, 791–802. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Paugh, S.W.; Coss, D.R.; Bao, J.; Laudermilk, L.T.; Grace, C.R.; Ferreira, A.M.; Waddell, M.B.; Ridout, G.; Naeve, D.; Leuze, M.; et al. MicroRNAs Form Triplexes with Double Stranded DNA at Sequence-Specific Binding Sites; a Eukaryotic Mechanism via which microRNAs Could Directly Alter Gene Expression. PLoS Comput. Biol. 2016, 12, e1004744. [Google Scholar] [CrossRef]
- Martianov, I.; Ramadass, A.; Serra Barros, A.; Chow, N.; Akoulitchev, A. Repression of the human dihydrofolate reductase gene by a non-coding interfering transcript. Nature 2007, 445, 666–670. [Google Scholar] [CrossRef]
- Schmitz, K.-M.; Mayer, C.; Postepska, A.; Grummt, I. Interaction of noncoding RNA with the rDNA promoter mediates recruitment of DNMT3b and silencing of rRNA genes. Genes Dev. 2010, 24, 2264–2269. [Google Scholar] [CrossRef]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Warwick, T.; Brandes, R.P.; Leisegang, M.S. Computational Methods to Study DNA:DNA:RNA Triplex Formation by lncRNAs. Non-Coding RNA 2023, 9, 10. https://doi.org/10.3390/ncrna9010010
Warwick T, Brandes RP, Leisegang MS. Computational Methods to Study DNA:DNA:RNA Triplex Formation by lncRNAs. Non-Coding RNA. 2023; 9(1):10. https://doi.org/10.3390/ncrna9010010
Chicago/Turabian StyleWarwick, Timothy, Ralf P. Brandes, and Matthias S. Leisegang. 2023. "Computational Methods to Study DNA:DNA:RNA Triplex Formation by lncRNAs" Non-Coding RNA 9, no. 1: 10. https://doi.org/10.3390/ncrna9010010