

CyL-GHI: Global Horizontal Irradiance Dataset Containing 18 Years of Refined Data at 30-Min Granularity from 37 Stations Located in Castile and León (Spain)



Abstract
:1. Introduction
- A dataset of public irradiance, CyL-GHI, is introduced, and the methodology applied to create it is described in detail.
- Three popular artificial intelligence algorithms were optimised and tested on CyL-GHI; their performance values being offered as baselines to compare other forecasting implementations. Furthermore, the ERA5 values corresponding to the studied area were analysed and compared with performance values delivered by the trained models.
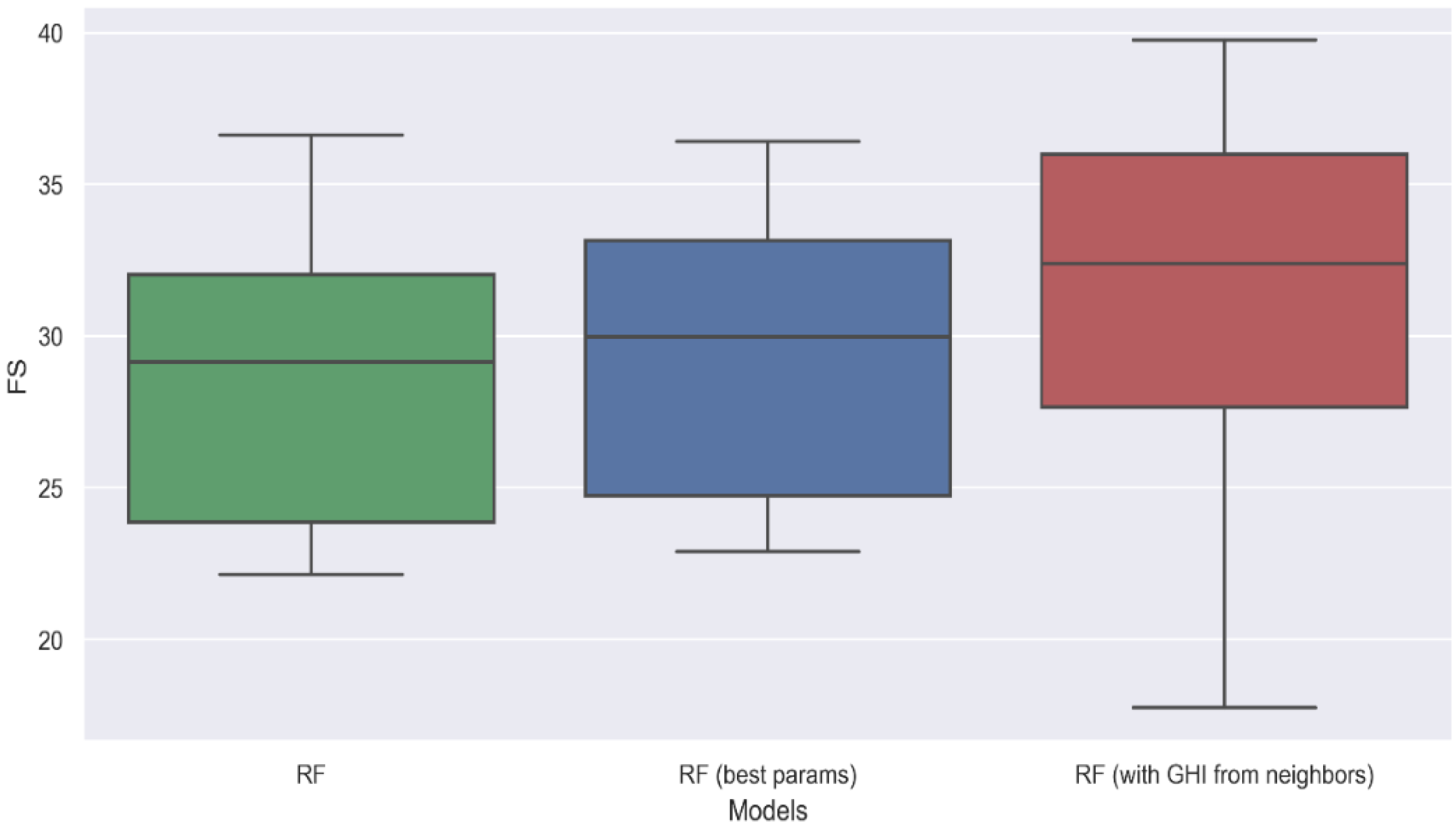
- The inclusion of previous observations of neighbours as input to an optimised Random Forest model (by applying a spatio-temporal approach) improved the predictive capability of the machine learning models by almost 3%, indicating the importance of approaching the irradiance prediction task considering the spatial component.
- Its temporal representation, because it presents irradiance data for an 18-year period from January 2002 to December 2019 with a temporal resolution of 30 min.
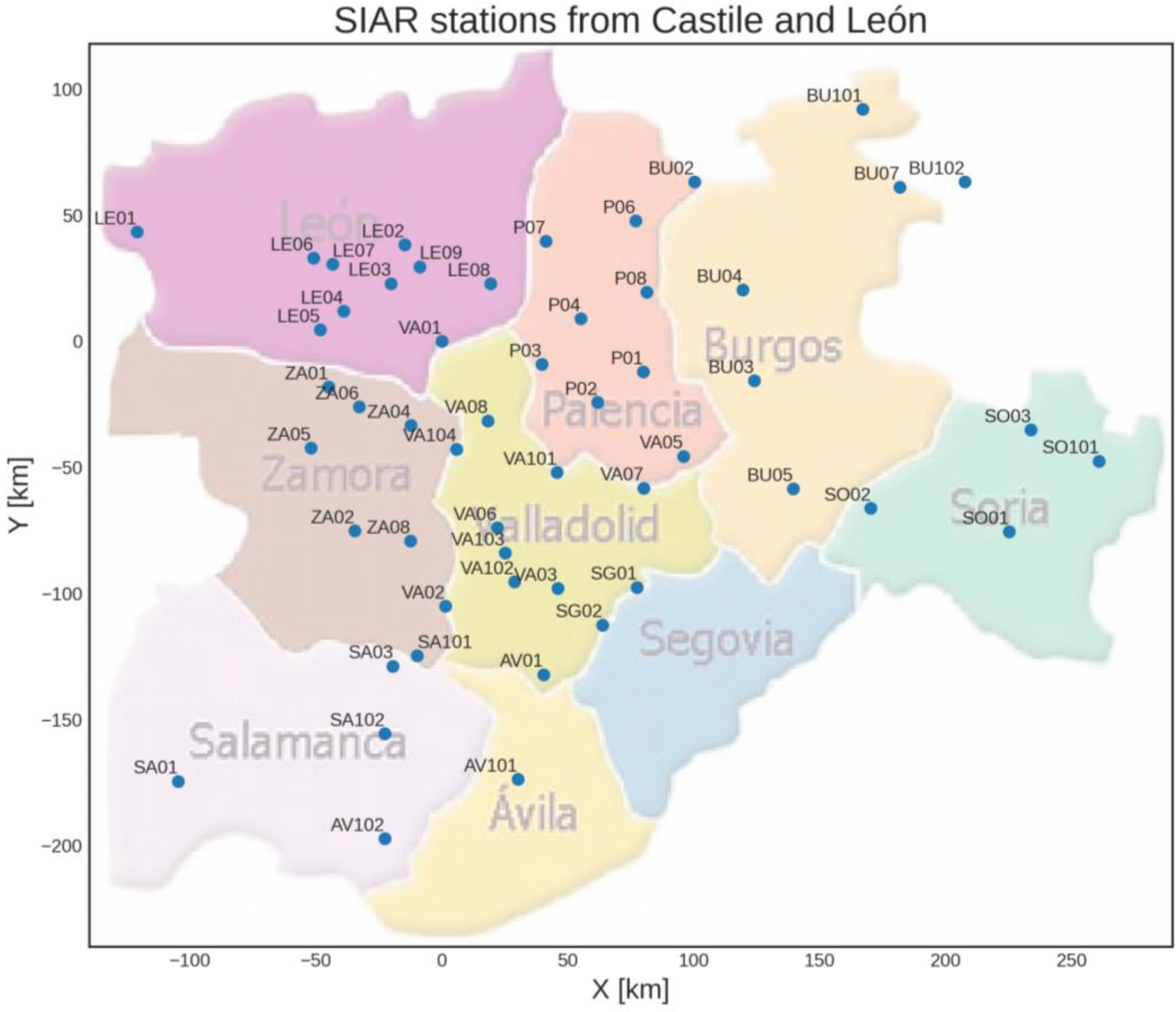
- In its spatial representation, as it contains data from 37 stations that allow for a regional-level analysis (it covers a land area of approximately 94,226 km2).
- It contains meteorological variables that enable the analysis of correlation and the use of explanatory variables in the models to study their influence on performance.
- Its publication allows other researchers to train their forecasting model implementations, without reapplying data cleaning and quality control procedures.
- It can be used with emerging trends based on deep machine learning for solar irradiance forecasting and serve as a benchmark dataset where comparisons can be established between novel implementation models tested on the same data (as a train-data data split procedure is also proposed).
2. Data
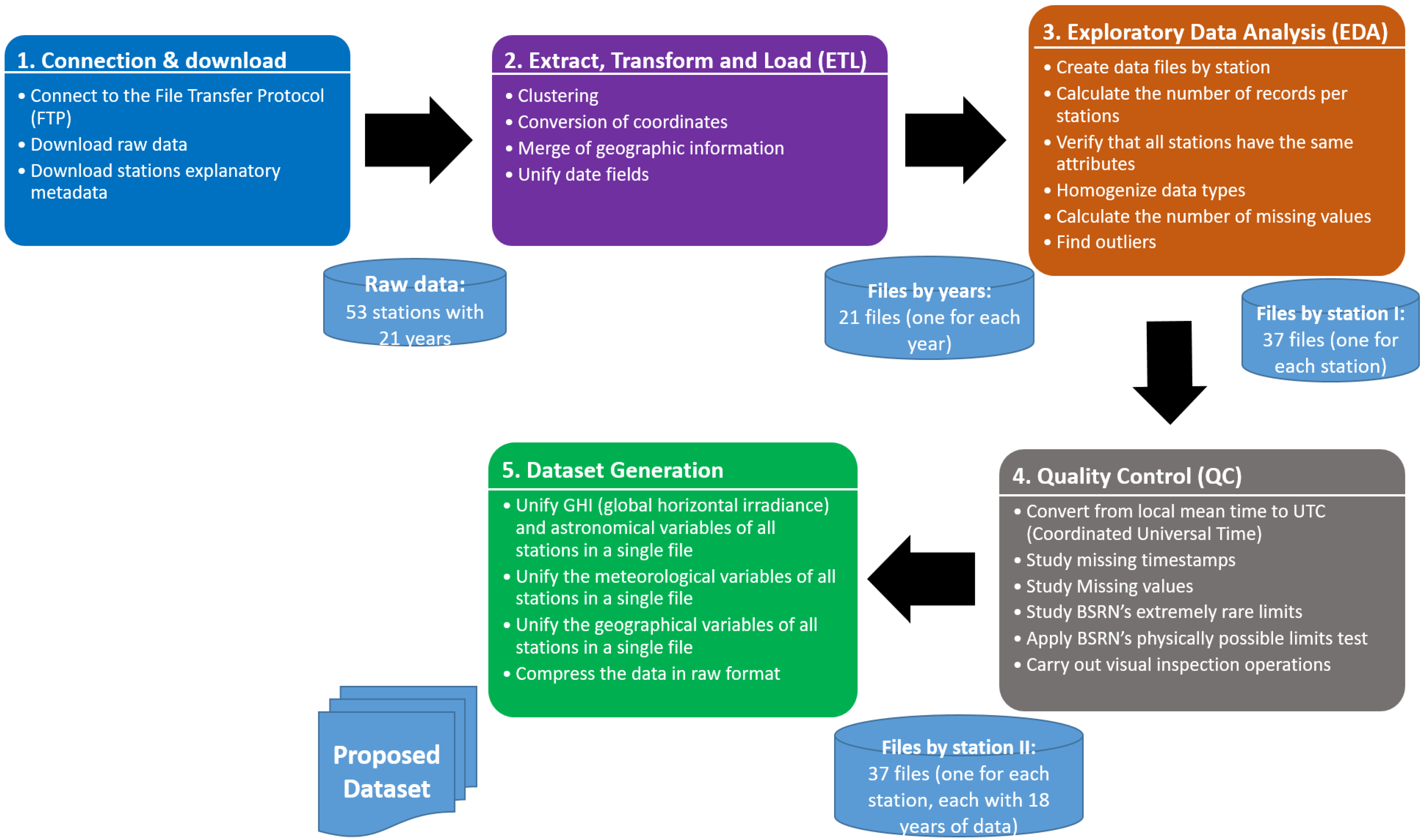
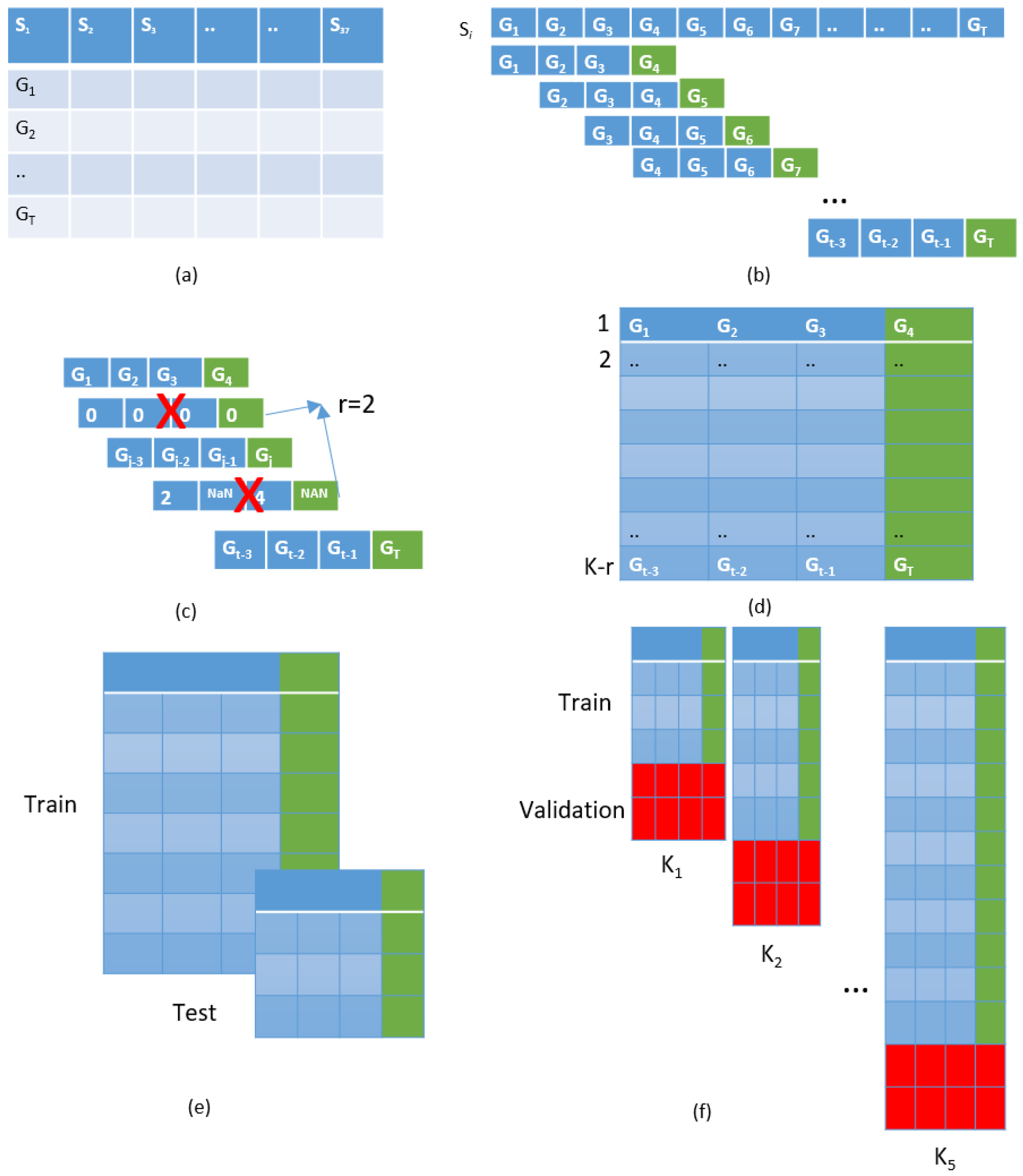
2.1. Procedure Applied for the Dataset Creation
2.1.1. Raw Data
2.1.2. Extract, Transform and Load
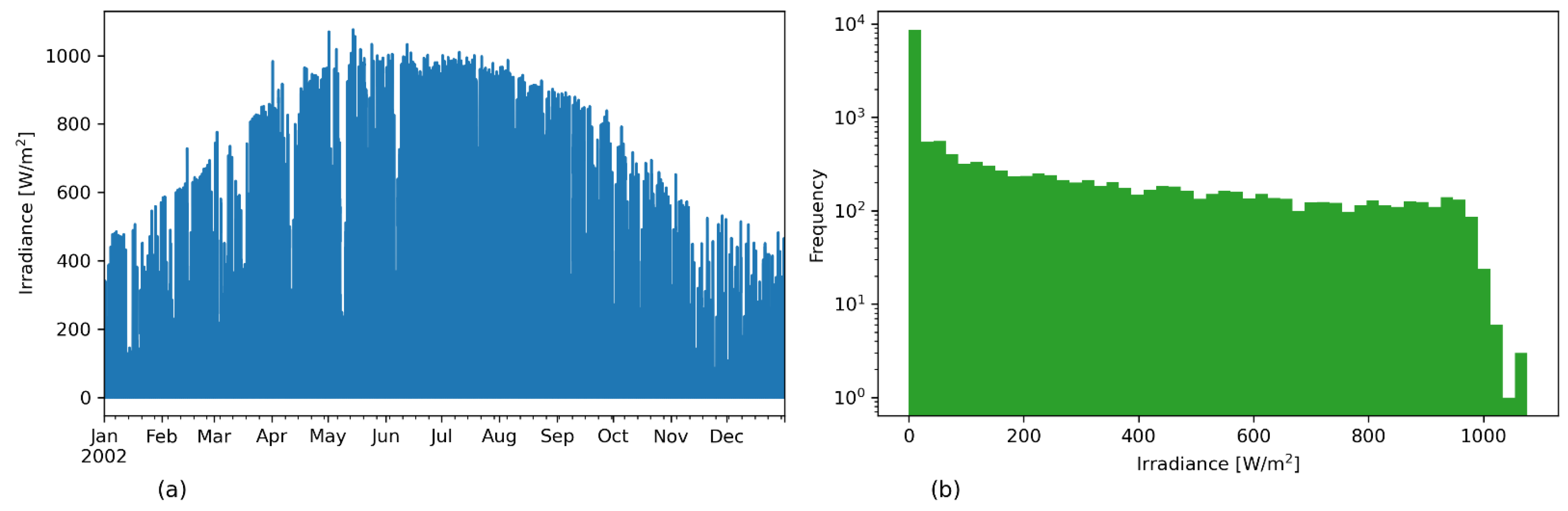
2.1.3. Exploratory Data Analysis
2.2. Quality Control of Dataset
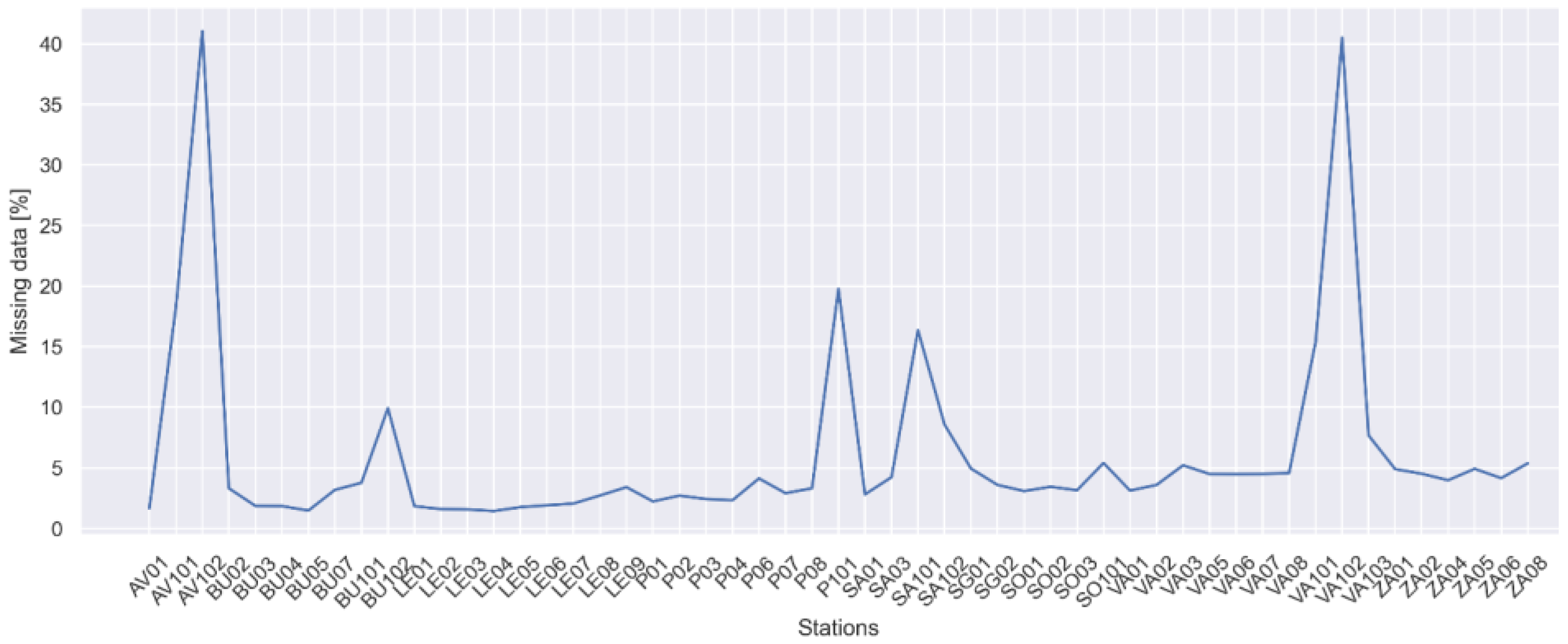
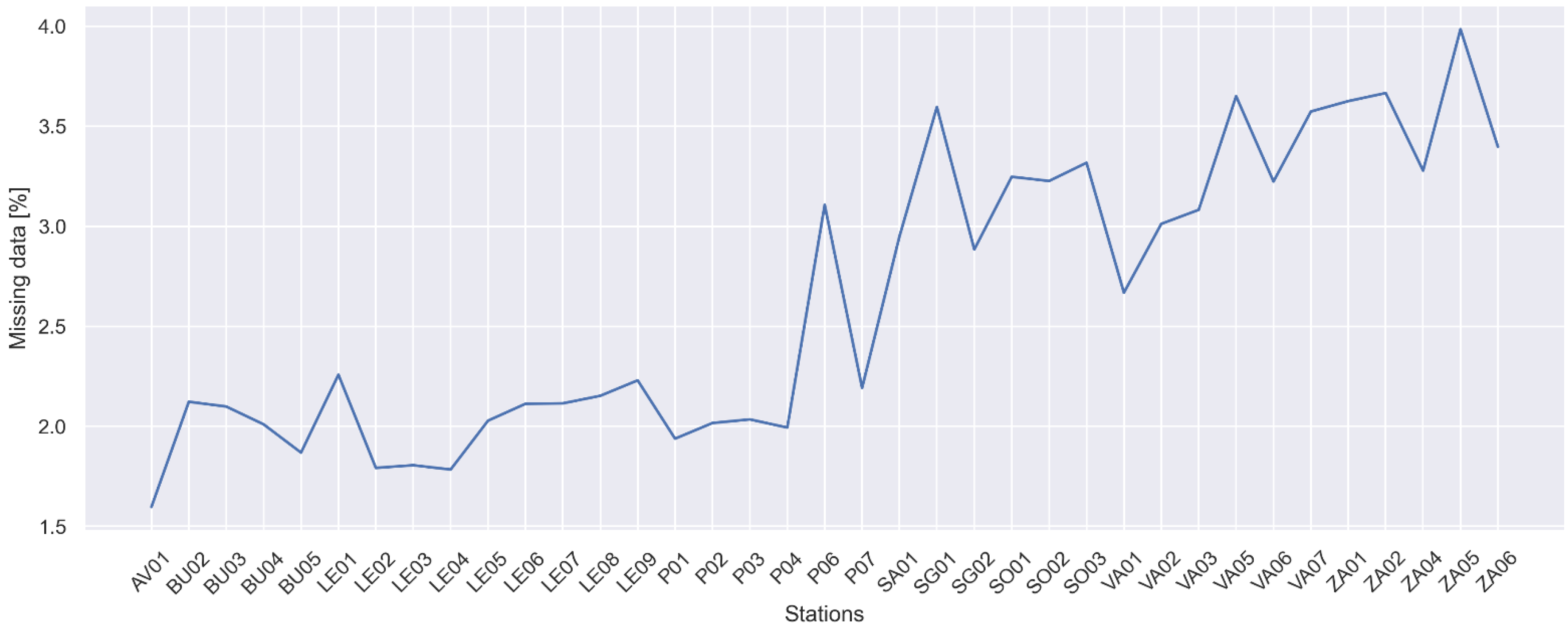
2.2.1. Missing Timestamps
2.2.2. Missing Values
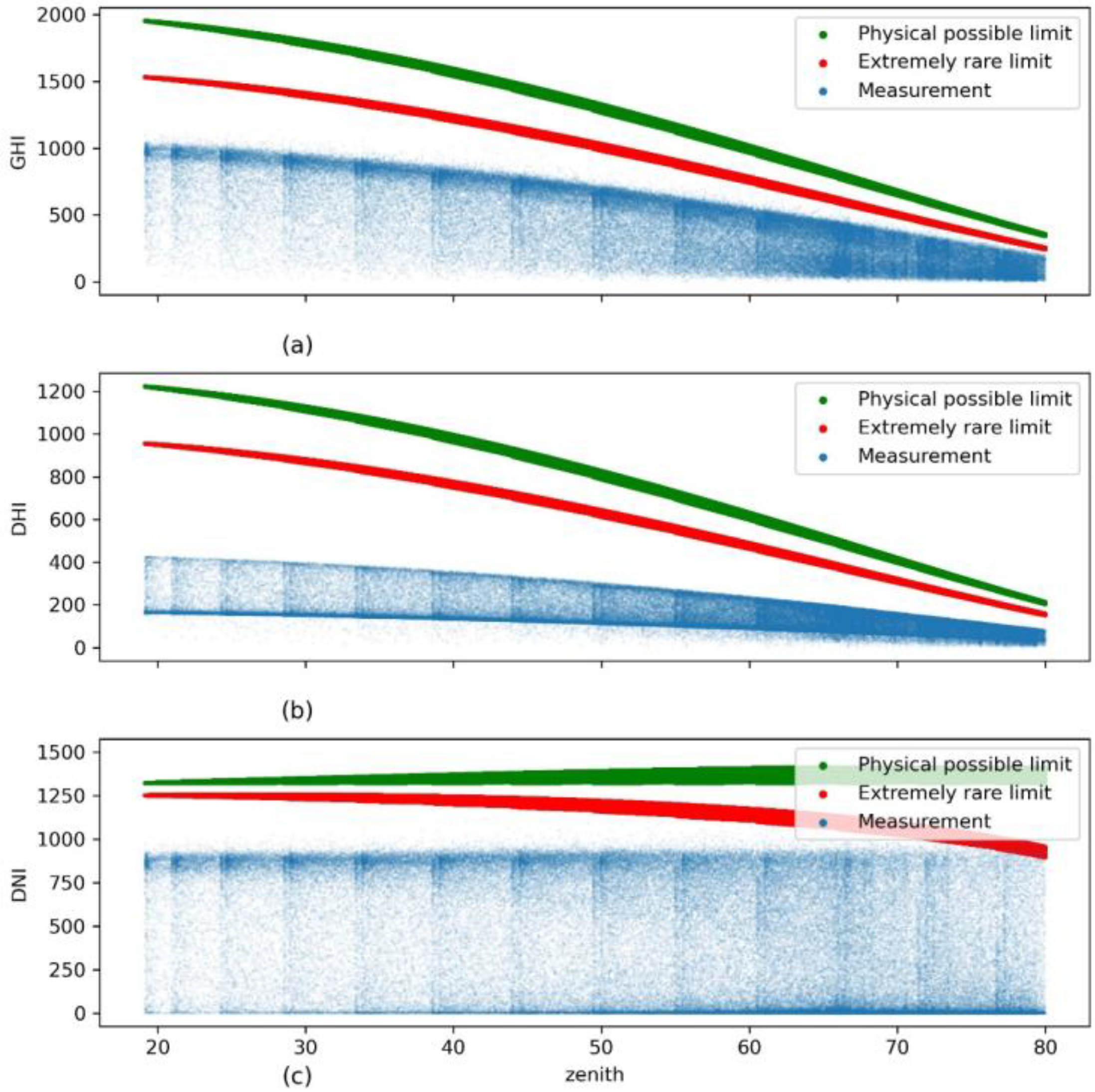
2.2.3. BSRN’s Limits Test
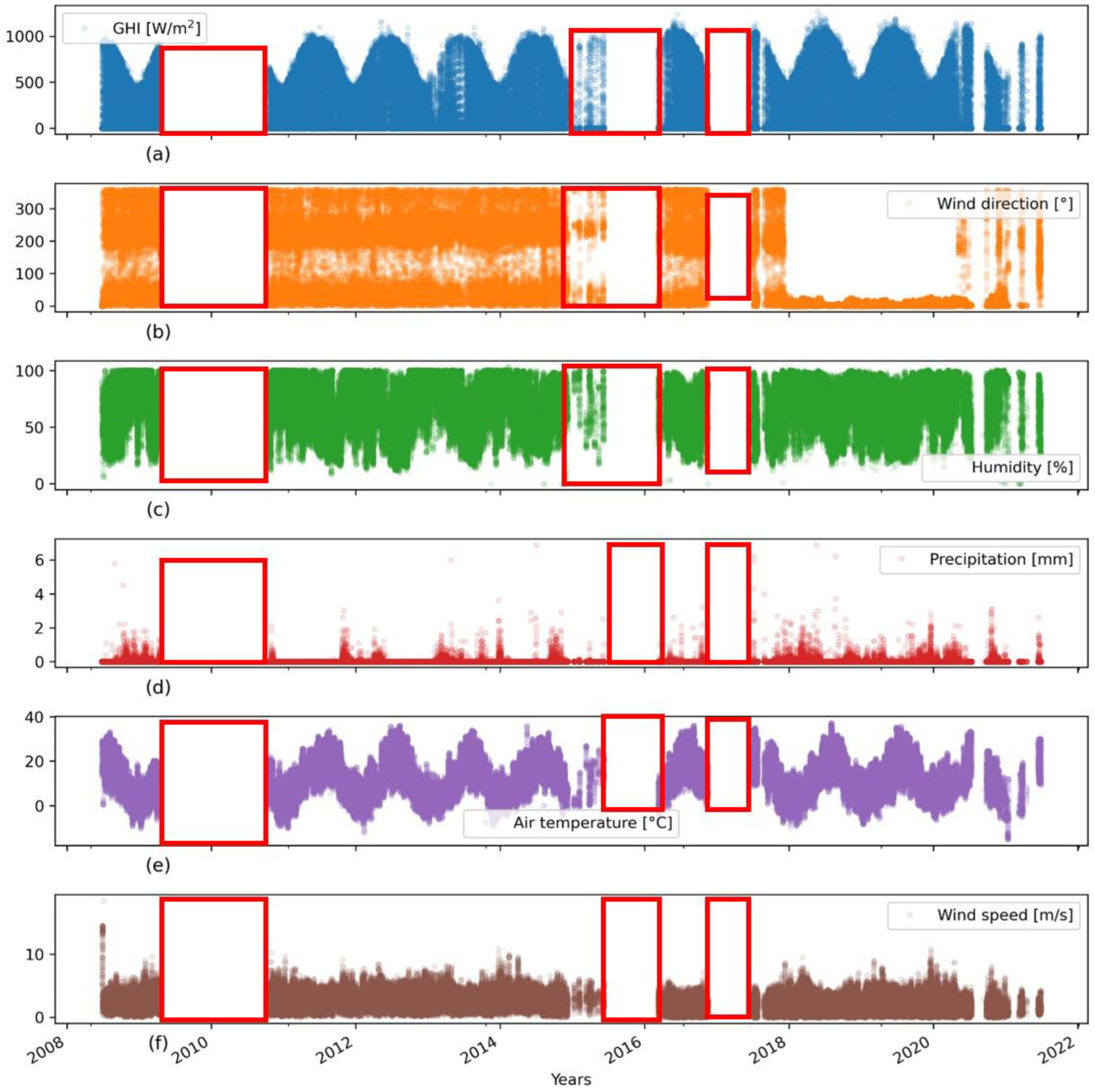
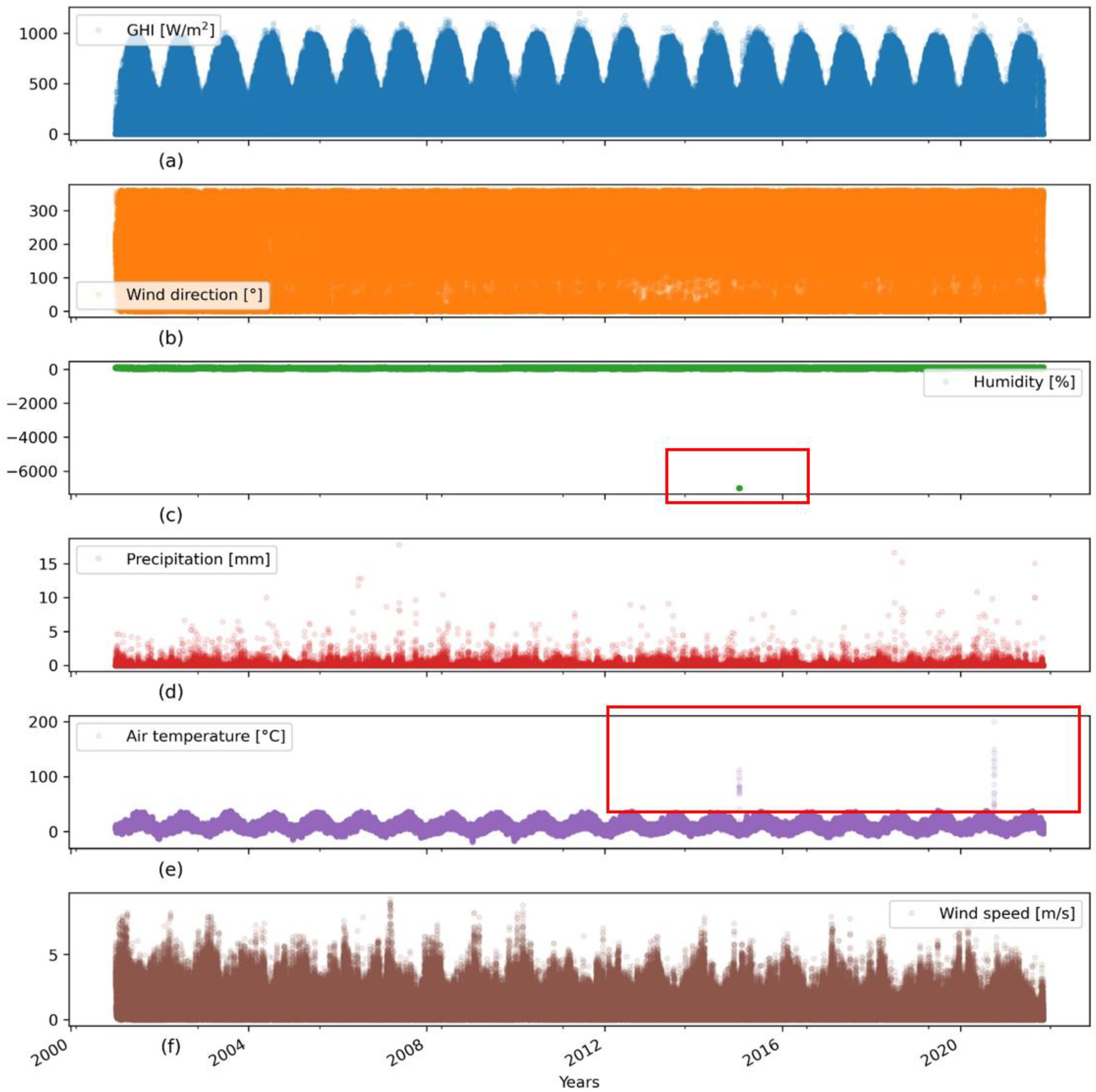
2.2.4. Visual Inspection
2.3. Dataset Description
2.4. ERA5
3. Baseline Models
4. Experiments, Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yang, D. A guideline to solar forecasting research practice: Reproducible, operational, probabilistic or physically-based, ensemble, and skill (ROPES). J. Renew. Sustain. Energy 2019, 11, 022701. [Google Scholar] [CrossRef]
- Camal, S.; Kariniotakis, G.; Sossan, F.; Libois, Q.; Legrand, R.; Raynaud, L.; Lange, M.; Mehrens, A.; Pinson, P.; Pierrot, A.; et al. Smart4RES: Next generation solutions for renewable energy forecasting and applications with focus on distribution grids. In Proceedings of the CIRED 2021—The 26th International Conference and Exhibition on Electricity Distribution, Online, 20–23 September 2021; pp. 2899–2903. [Google Scholar] [CrossRef]
- Yang, D. SolarData: An R package for easy access of publicly available solar datasets. Sol. Energy 2018, 171, A3–A12. [Google Scholar] [CrossRef]
- Feng, C.; Yang, D.; Hodge, B.-M.; Zhang, J. OpenSolar: Promoting the openness and accessibility of diverse public solar datasets. Sol. Energy 2019, 188, 1369–1379. [Google Scholar] [CrossRef]
- Peterson, J.; Vignola, F. Structure of a comprehensive solar radiation dataset. Sol. Energy 2020, 211, 366–374. [Google Scholar] [CrossRef]
- Yang, D.; Wang, W.; Hong, T. A historical weather forecast dataset from the European Centre for Medium-Range Weather Forecasts (ECMWF) for energy forecasting. Sol. Energy 2022, 232, 263–274. [Google Scholar] [CrossRef]
- Dua, D.; Graff, C. UCI Machine Learning Repository; University of California, School of Information and Computer Science: Irvine, CA, USA, 2017; [Online]; Available online: http://archive.ics.uci.edu/ml (accessed on 1 December 2022).
- Goldbloom, A. Kaggle. 2010. Available online: https://www.kaggle.com/datasets (accessed on 1 December 2022).
- Leach-Murray, S. The Linked Open Data Cloud. Tech. Serv. Q. 2021, 38, 193–194. [Google Scholar] [CrossRef]
- Bright, J.M.; Killinger, S.; Engerer, N.A. Data article: Distributed PV power data for three cities in Australia. J. Renew. Sustain. Energy 2019, 11, 035504. [Google Scholar] [CrossRef]
- Driemel, A.; Augustine, J.; Behrens, K.; Colle, S.; Cox, C.; Cuevas-Agulló, E.; Denn, F.M.; Duprat, T.; Fukuda, M.; Grobe, H.; et al. Baseline Surface Radiation Network (BSRN): Structure and data description (1992–2017). Earth Syst. Sci. Data 2018, 10, 1491–1501. [Google Scholar] [CrossRef] [Green Version]
- Haysom, J.E.; McVey-White, P.; De La Salle, L.; Hinzer, K.; Schriemer, H. Multi-year ground-based irradiance dataset in a northern urban climate. In Proceedings of the 2017 IEEE 44th Photovoltaic Specialist Conference, PVSC 2017, Washington, DC, USA, 25–30 June 2017; pp. 796–801. [Google Scholar] [CrossRef]
- Pedro, H.T.C.; Larson, D.P.; Coimbra, C.F.M. A comprehensive dataset for the accelerated development and benchmarking of solar forecasting methods. J. Renew. Sustain. Energy 2019, 11, 036102. [Google Scholar] [CrossRef] [Green Version]
- Terrén-Serrano, G.; Bashir, A.; Estrada, T.; Martínez-Ramón, M. Girasol, a sky imaging and global solar irradiance dataset. Data Brief 2021, 35, 106914. [Google Scholar] [CrossRef]
- Charabi, Y.; Gastli, A.; Al-Yahyai, S. Production of solar radiation bankable datasets from high-resolution solar irradiance derived with dynamical downscaling Numerical Weather prediction model. Energy Rep. 2016, 2, 67–73. [Google Scholar] [CrossRef] [Green Version]
- Qin, W.; Wang, L.; Gueymard, C.A.; Bilal, M.; Lin, A.; Wei, J.; Zhang, M.; Yang, X. Constructing a gridded direct normal irradiance dataset in China during 1981–2014. Renew. Sustain. Energy Rev. 2020, 131, 110004. [Google Scholar] [CrossRef]
- Williamson, S.; Businger, S.; Matthews, D. Development of a solar irradiance dataset for Oahu, Hawaii. Renew. Energy 2018, 128, 432–443. [Google Scholar] [CrossRef]
- Simeunovic, J.; Schubnel, B.; Alet, P.-J.; Carrillo, R.E. Spatio-Temporal Graph Neural Networks for Multi-Site PV Power Forecasting. IEEE Trans. Sustain. Energy 2022, 13, 1210–1220. [Google Scholar] [CrossRef]
- Cesar, L.B.; e Silva, R.A.; Callejo, M.M.; Cira, C.-I. Review on Spatio-Temporal Solar Forecasting Methods Driven by in Situ Measurements or Their Combination with Satellite and Numerical Weather Prediction (NWP) Estimates. Energies 2022, 15, 4341. [Google Scholar] [CrossRef]
- e Silva, R.A.; Brito, M. Spatio-temporal PV forecasting sensitivity to modules’ tilt and orientation. Appl. Energy 2019, 255, 113807. [Google Scholar] [CrossRef]
- Khodayar, M.; Mohammadi, S.; Khodayar, M.E.; Wang, J.; Liu, G. Convolutional Graph Autoencoder: A Generative Deep Neural Network for Probabilistic Spatio-Temporal Solar Irradiance Forecasting. IEEE Trans. Sustain. Energy 2019, 11, 571–583. [Google Scholar] [CrossRef]
- Yu, Y.; Hu, G. Short-term solar irradiance prediction based on spatiotemporal graph convolutional recurrent neural network. J. Renew. Sustain. Energy 2022, 14, 053702. [Google Scholar] [CrossRef]
- Karimi, A.M.; Wu, Y.; Koyuturk, M.; French, R.H. Spatiotemporal Graph Neural Network for Performance Prediction of Photovoltaic Power Systems. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; Volume 35, pp. 15323–15330, [Online]. Available online: https://ojs.aaai.org/index.php/AAAI/article/view/17799 (accessed on 15 January 2022).
- Agoua, X.; Girard, R.; Kariniotakis, G. Photovoltaic Power Forecasting: Assessment of the Impact of Multiple Sources of Spatio-Temporal Data on Forecast Accuracy. Energies 2021, 14, 1432. [Google Scholar] [CrossRef]
- AEMET. Agencia Estatal de Meteorología. Available online: http://www.aemet.es/es/portada (accessed on 22 February 2022).
- SIAR. Sistema de Información Agroclimática para el Regadío. Available online: https://eportal.mapa.gob.es/websiar/Inicio.aspx (accessed on 12 January 2022).
- Rodríguez-Amigo, M.; Díez-Mediavilla, M.; González-Peña, D.; Pérez-Burgos, A.; Alonso-Tristán, C. Mathematical interpolation methods for spatial estimation of global horizontal irradiation in Castilla-León, Spain: A case study. Sol. Energy 2017, 151, 14–21. [Google Scholar] [CrossRef]
- Eschenbach, A.; Yepes, G.; Tenllado, C.; Gomez-Perez, J.I.; Pinuel, L.; Zarzalejo, L.F.; Wilbert, S. Spatio-Temporal Resolution of Irradiance Samples in Machine Learning Approaches for Irradiance Forecasting. IEEE Access 2020, 8, 51518–51531. [Google Scholar] [CrossRef]
- Gutierrez-Corea, F.-V.; Manso-Callejo, M.-A.; Moreno-Regidor, M.-P.; Manrique-Sancho, M.-T. Forecasting short-term solar irradiance based on artificial neural networks and data from neighboring meteorological stations. Sol. Energy 2016, 134, 119–131. [Google Scholar] [CrossRef]
- Urraca, R.; Antonanzas, J.; Sanz-Garcia, A.; Martinez-De-Pison, F.J. Analysis of Spanish Radiometric Networks with the Novel Bias-Based Quality Control (BQC) Method. Sensors 2019, 19, 2483. [Google Scholar] [CrossRef] [Green Version]
- ITACYL. Instituto Tecnológico Agrario de Castilla y León. 2014. Available online: http://www.itacyl.es/opencms_wf/opencms/itacyl/quienes_somos/que_es_itacyl/index.html (accessed on 12 January 2022).
- ITACYL. Geoportal. 2015. Available online: ftp://ftp.itacyl.es (accessed on 10 November 2021).
- SIAR. Mantenimiento de las Estaciones del Siar. Available online: https://servicio.mapa.gob.es/es/desarrollo-rural/temas/gestion-sostenible-regadios/Mantenimiento%20de%20las%20estaciones_tcm30-82950.pdf (accessed on 15 January 2023).
- Forstinger, A.; Wilbert, S.; Kraas, B.; Peruchena, C.F.; Gueymard, C.A.; Collino, E.; Ruiz-Arias, J.A.; Martinez, J.P.; Saint-Drenan, Y.-M.; Ronzio, D.; et al. Expert Quality Control of Solar Radiation Ground Data Sets. In Proceedings of the ISES Solar World Congress, New Delhi, India, 25–29 October 2021. [Google Scholar]
- Long, N.; Dutton, G. BSRN Global Network Recommended QC Tests, V2.0, BSRN Technical Report. 2002. [Online]. Available online: https://bsrn.awi.de/fileadmin/user_upload/bsrn.awi.de/Publications/BSRN_recommended_QC_tests_V2.pdf (accessed on 24 June 2022).
- Blanc, P.; Wald, L. The SG2 algorithm for a fast and accurate computation of the position of the Sun for multi-decadal time period. Sol. Energy 2012, 86, 3072–3083. [Google Scholar] [CrossRef] [Green Version]
- Jensen, A.R.; Saint-Drenan, Y.-M. Solar Resource Assessment in Python. 2022. Available online: https://assessingsolar.org/intro.html (accessed on 16 November 2022).
- Holmgren, W.F.; Hansen, C.W.; Mikofski, M.A. Pvlib python: A python package for modeling solar energy systems. J. Open Source Softw. 2018, 3, 884. [Google Scholar] [CrossRef] [Green Version]
- Cesar, L.B.; Callejo, M.Á.M.; Cira, C.-I.; Garrido, R.P.A. CyL_GHI [Data Set]. Zenodo. 2022. [CrossRef]
- ECMWF. ERA5 Data Documentation; European Centre for Medium-Range Weather Forecast (ECMWF): Reading, UK, 2017; Available online: https://confluence.ecmwf.int/display/CKB/ERA5%3A+data+documentation (accessed on 14 February 2023).
- ECWMF. ERA5-Land Hourly Data from 1950 to Present. Available online: https://cds.climate.copernicus.eu/cdsapp#!/dataset/reanalysis-era5-land?tab=form (accessed on 14 February 2023).
- Babar, B.; Luppino, L.T.; Boström, T.; Anfinsen, S.N. Random forest regression for improved mapping of solar irradiance at high latitudes. Sol. Energy 2020, 198, 81–92. [Google Scholar] [CrossRef]
- Srivastava, R.; Tiwari, A.; Giri, V. Solar radiation forecasting using MARS, CART, M5, and random forest model: A case study for India. Heliyon 2019, 5, e02692. [Google Scholar] [CrossRef] [Green Version]
- Alfadda, A.; Adhikari, R.; Kuzlu, M.; Rahman, S. Hour-ahead solar PV power forecasting using SVR based approach. In Proceedings of the 2017 IEEE Power & Energy Society Innovative Smart Grid Technologies Conference (ISGT), Washington, DC, USA, 23–26 April 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Silva, R.A.E.; da Silva, L.C.C.T.; Brito, M.C. Support vector regression for spatio-temporal PV forecasting PV variability The need for PV forecasting. In Proceedings of the 35th EUPVSEC 2018, Brussels, Belgium, 24–28 September 2018. [Google Scholar] [CrossRef]
- Voyant, C.; Notton, G.; Kalogirou, S.; Nivet, M.-L.; Paoli, C.; Motte, F.; Fouilloy, A. Machine learning methods for solar radiation forecasting: A review. Renew. Energy 2017, 105, 569–582. [Google Scholar] [CrossRef]
- Moncada, A.; Richardson, J.W.; Vega-Avila, R. Deep Learning to Forecast Solar Irradiance Using a Six-Month UTSA SkyImager Dataset. Energies 2018, 11, 1988. [Google Scholar] [CrossRef] [Green Version]
- Ghimire, S.; Deo, R.C.; Raj, N.; Mi, J. Deep Learning Neural Networks Trained with MODIS Satellite-Derived Predictors for Long-Term Global Solar Radiation Prediction. Energies 2019, 12, 2407. [Google Scholar] [CrossRef] [Green Version]
- Feng, C.; Zhang, J. SolarNet: A Deep Convolutional Neural Network for Solar Forecasting via Sky Images. In Proceedings of the 2020 IEEE Power & Energy Society Innovative Smart Grid Technologies Conference (ISGT), Washington, DC, USA, 17–20 February 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Park, J.; Moon, J.; Jung, S.; Hwang, E. Multistep-Ahead Solar Radiation Forecasting Scheme Based on the Light Gradient Boosting Machine: A Case Study of Jeju Island. Remote Sens. 2020, 12, 2271. [Google Scholar] [CrossRef]
- Yang, T.; Li, B.; Xun, Q. LSTM-Attention-Embedding Model-Based Day-Ahead Prediction of Photovoltaic Power Output Using Bayesian Optimization. IEEE Access 2019, 7, 171471–171484. [Google Scholar] [CrossRef]
- Zhou, S.; Zhou, L.; Mao, M.; Xi, X. Transfer Learning for Photovoltaic Power Forecasting with Long Short-Term Memory Neural Network. In Proceedings of the 2020 IEEE International Conference on Big Data and Smart Computing (BigComp), Busan, Republic of Korea, 19–22 February 2020; pp. 125–132. [Google Scholar] [CrossRef]
- Simeunović, J.; Schubnel, B.; Alet, P.-J.; Carrillo, R.E.; Frossard, P. Interpretable temporal-spatial graph attention network for multi-site PV power forecasting. Appl. Energy 2022, 327, 120127. [Google Scholar] [CrossRef]
- Sodsong, N.; Yu, K.M.; Ouyang, W. Short-Term Solar PV Forecasting Using Gated Recurrent Unit with a Cascade Model. In Proceedings of the 2019 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Okinawa, Japan, 11–13 February 2019; pp. 292–297. [Google Scholar]
- Khodayar, M.; Liu, G.; Wang, J.; Kaynak, O.; Khodayar, M.E. Spatiotemporal Behind-the-Meter Load and PV Power Forecasting via Deep Graph Dictionary Learning. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 4713–4727. [Google Scholar] [CrossRef] [PubMed]
- Aslam, M.; Lee, J.-M.; Kim, H.-S.; Lee, S.-J.; Hong, S. Deep Learning Models for Long-Term Solar Radiation Forecasting Considering Microgrid Installation: A Comparative Study. Energies 2019, 13, 147. [Google Scholar] [CrossRef] [Green Version]
- Jebli, I.; Belouadha, F.-Z.; Kabbaj, M.I.; Tilioua, A. Prediction of solar energy guided by pearson correlation using machine learning. Energy 2021, 224, 120109. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Belaid, S.; Mellit, A.; Boualit, H.; Zaiani, M. Hourly global solar forecasting models based on a supervised machine learning algorithm and time series principle. Int. J. Ambient. Energy 2020, 43, 1707–1718. [Google Scholar] [CrossRef]
- Huang, C.; Wang, L.; Lai, L.L. Data-Driven Short-Term Solar Irradiance Forecasting Based on Information of Neighboring Sites. IEEE Trans. Ind. Electron. 2019, 66, 9918–9927. [Google Scholar] [CrossRef]
- Lazzaroni, M.; Ferrari, S.; Piuri, V.; Salman, A.; Cristaldi, L.; Faifer, M. Models for solar radiation prediction based on different measurement sites. Measurement 2015, 63, 346–363. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, C.; Li, Q.; Tai, Y.; Gao, B.; Shi, J. A Comparison of Hour-Ahead Solar Irradiance Forecasting Models Based on LSTM Network. Math. Probl. Eng. 2020, 2020, 1–15. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Format/Measuring Unit | Description |
|---|---|---|
| id | - | Station identifier |
| date | (AAAA-MM-DD) | Date of the observation |
| hour | (HHMM) | Hour of the observation |
| precipitation | (mm) | Precipitation |
| temperature | (°C) | Temperature |
| relative-humidity | (%) | Relative humidity |
| irradiance | (W/m2) | Irradiance |
| wind-speed | (m/s) | Wind speed |
| wind-direction | (°) | Wind direction |
| Meteorological Variable | Sensor Accuracy | Measurement Range | Measurement Units | Instruments |
|---|---|---|---|---|
| Irradiance | 3% | 350 to 1100 nm | Wm−2 | Pyranometer SKYE SP1110 (CAMPBELL) |
| Wind speed | ±0.3 m/s for 1 to 60 m/s ±1 ms−1 for 60 to 100 m/s | 1 to 60 m/s | m/s | Wind Monitor RM YOUNG 05103 |
| Wind direction | ±3° | 0 to 360° | ° | Wind Monitor RM YOUNG 05103 |
| Temperature | ±0.2 °C | −39.2 °C to 60 °C | °C | Probe VAISALA HMP45C (CAMPBELL) |
| Relative humidity | ±2% | 0.8 to 100% | % | Probe VAISALA HMP45C (CAMPBELL) |
| ID | File Name | Description | Data | Names of the Variables Contained |
|---|---|---|---|---|
| 1 | CyL_raw.zip | Downloaded raw data, with no refinement operations applied | 18 folders (named with the year number). Each folder contains the data in its raw format saved at day-level. | Spanish: “Código”, “Fecha”, “Hora”, “Precipitacion”, “Temperatura”, “Humedad_relativa”, “Radiación”, “Vel. Viento”, “Dir. Viento” |
| 2 | CyL_GHI_ast.csv | GHI data combined with astronomical variables | Data from all stations was combined in a single csv file | GHI, sun_elev, toa, sun_azim |
| 3 | CyL_meteo.csv | Meteorological data for the considered period | Data from all stations was combined in a single csv file | air_temp, humidity, wind_sp, wind_dir, precipitation |
| 4 | CyL_geo.csv | Geographical data for localising the 37 stations | A single csv files with the geographical location of the 37 stations. | station_code, name, latitude, longitude, height |
| 5 | CyL_by_stations.zip | For each of the 37 stations, data from sets with IDs 2, 3, and 4 have been combined. | 37 csv files, one for each weather station, named with the corresponding station_code | GHI, sun_elev, toa, sun_azim, air_temp, humidity, wind_sp, wind_dir, precipitation, station_code, latitude, longitude, height |
| Model | Hyperparameter | Values Considered |
|---|---|---|
| Random Forest | “min_samples_leaf” | 0.0001, 0.001, 0.01, 0.05, 0.025 |
| “n_estimators” | 100, 200, 250, 300, 350, 450, 500, 600 | |
| Support Vector Regressor | “epsilon” | 0.05, 0.1, 0.15, 0.2, 0.25 |
| “C” | 0.5, 1, 2, 3, 4 |
| Model | Persistence | ERA5 | Linear Regressor | Random Forest | Support Vector Regressor | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Station | MAE (W/m2) | RMSE (W/m2) | MAE (W/m2) | RMSE (W/m2) | MAE (W/m2) | RMSE (W/m2) | FS (%) | MAE (W/m2) | RMSE (W/m2) | FS (%) | MAE (W/m2) | RMSE (W/m2) | FS (%) | |
| AV01 | 73.90 | 96.84 | 54.74 | 98.16 | 45.91 | 74.16 | 23.42 | 39.89 | 70.03 | 27.68 | 43.72 | 74.96 | 22.59 | |
| BU02 | 73.06 | 98.39 | 53.78 | 101.13 | 49.69 | 76.35 | 22.41 | 44.49 | 72.98 | 25.83 | 47.55 | 77.23 | 21.51 | |
| BU03 | 70.43 | 94.24 | 49.55 | 92.12 | 47.78 | 74.29 | 21.17 | 40.53 | 69.63 | 26.11 | 45.42 | 75.14 | 20.26 | |
| BU04 | 69.69 | 93.13 | 51.99 | 95.81 | 45.18 | 72.49 | 22.17 | 39.54 | 68.32 | 26.64 | 43.44 | 73.09 | 21.52 | |
| BU05 | 69.26 | 88.89 | 56.25 | 103.15 | 43.48 | 69.29 | 22.05 | 37.39 | 65.24 | 26.61 | 41.19 | 69.51 | 21.8 | |
| LE01 | 60.95 | 80.61 | 46.78 | 90.45 | 34.25 | 57.27 | 28.95 | 31.24 | 55.54 | 31.1 | 33.37 | 58.45 | 27.49 | |
| LE02 | 63.54 | 83.17 | 47.85 | 90.00 | 38.99 | 62.12 | 25.31 | 33.83 | 58.25 | 29.97 | 37.41 | 62.98 | 24.28 | |
| LE03 | 65.41 | 85.73 | 50.78 | 93.71 | 37.88 | 59.79 | 30.26 | 33.86 | 56.54 | 34.05 | 36.06 | 60.45 | 29.49 | |
| LE04 | 67.16 | 87.82 | 52.66 | 96.82 | 37.64 | 61.22 | 30.29 | 33.55 | 57.9 | 34.07 | 36.12 | 62.36 | 29 | |
| LE05 | 66.01 | 86.11 | 48.50 | 91.17 | 36.5 | 58.63 | 31.91 | 32.29 | 55.27 | 35.82 | 35.04 | 59.64 | 30.75 | |
| LE06 | 66.72 | 88.30 | 55.30 | 101.20 | 39.66 | 62.46 | 29.26 | 34.59 | 58.72 | 33.5 | 37.78 | 63.11 | 28.53 | |
| LE07 | 64.89 | 84.75 | 51.37 | 98.82 | 37.13 | 58.29 | 31.22 | 31.97 | 53.91 | 36.39 | 35.28 | 58.8 | 30.62 | |
| LE08 | 66.21 | 88.35 | 51.80 | 94.11 | 40.87 | 63.44 | 28.2 | 35.82 | 59.66 | 32.47 | 38.83 | 63.98 | 27.59 | |
| LE09 | 68.34 | 90.83 | 49.69 | 92.65 | 42.76 | 66.61 | 26.67 | 38.22 | 63.31 | 30.3 | 41.01 | 67.36 | 25.84 | |
| P01 | 72.53 | 96.15 | 54.42 | 97.43 | 46.56 | 77.39 | 19.51 | 40.54 | 73.1 | 23.98 | 44.69 | 78.77 | 18.08 | |
| P02 | 73.04 | 96.81 | 51.98 | 93.81 | 49.59 | 78.2 | 19.22 | 43.84 | 74.51 | 23.03 | 47.61 | 79.61 | 17.77 | |
| P03 | 71.51 | 93.72 | 52.39 | 94.73 | 47.89 | 75.54 | 19.4 | 42.33 | 72.09 | 23.08 | 45.92 | 76.67 | 18.19 | |
| P04 | 72.33 | 95.66 | 50.65 | 92.48 | 47.39 | 75.34 | 21.24 | 42.11 | 71.86 | 24.88 | 45.01 | 75.97 | 20.59 | |
| P06 | 67.97 | 89.33 | 51.81 | 95.40 | 43.54 | 68.06 | 23.81 | 37.64 | 64.44 | 27.86 | 41.53 | 68.59 | 23.21 | |
| P07 | 69.78 | 101.96 | 60.06 | 108.58 | 53.39 | 80.49 | 21.06 | 46.39 | 77.27 | 24.22 | 51.27 | 82.03 | 19.55 | |
| SA01 | 62.69 | 79.54 | 46.28 | 87.17 | 31.45 | 52.12 | 34.48 | 29.17 | 50.57 | 36.42 | 30.52 | 53.05 | 33.3 | |
| SG01 | 72.97 | 96.01 | 52.57 | 97.43 | 48.54 | 77.47 | 19.31 | 42.92 | 73.73 | 23.21 | 46.73 | 78.89 | 17.83 | |
| SG02 | 72.17 | 95.13 | 51.47 | 94.67 | 47.27 | 75.25 | 20.89 | 41.13 | 71.61 | 24.73 | 45.33 | 76.62 | 19.46 | |
| SO01 | 66.79 | 83.94 | 49.34 | 90.85 | 42.32 | 63.81 | 23.98 | 37.21 | 61.2 | 27.1 | 40.96 | 64.63 | 23.01 | |
| SO02 | 67.71 | 86.73 | 51.85 | 94.80 | 41.59 | 68.33 | 21.21 | 36.82 | 66.42 | 23.41 | 39.67 | 69.74 | 19.59 | |
| SO03 | 66.86 | 83.94 | 51.27 | 94.20 | 43.56 | 67.48 | 19.61 | 39.01 | 64.71 | 22.91 | 42.27 | 68.59 | 18.29 | |
| VA01 | 69.21 | 91.26 | 50.53 | 93.38 | 40.88 | 63.86 | 30.02 | 35.97 | 60.28 | 33.94 | 39.32 | 64.89 | 28.9 | |
| VA02 | 70.79 | 92.14 | 47.83 | 88.36 | 42.51 | 67.08 | 27.2 | 37.6 | 63.82 | 30.74 | 40.7 | 68.03 | 26.17 | |
| VA03 | 73.35 | 96.62 | 49.86 | 90.92 | 47.49 | 76.29 | 21.04 | 41.13 | 72.71 | 24.74 | 44.96 | 77.19 | 20.11 | |
| VA05 | 73.60 | 111.11 | 46.92 | 91.63 | 55.36 | 86.92 | 21.77 | 42.96 | 73.34 | 34 | 53 | 89.17 | 19.75 | |
| VA06 | 69.23 | 90.93 | 53.16 | 96.62 | 40.81 | 64.84 | 28.69 | 36.68 | 61.78 | 32.06 | 39.04 | 65.81 | 27.62 | |
| VA07 | 72.47 | 95.48 | 49.54 | 91.26 | 47.4 | 76.87 | 19.49 | 41.67 | 72.55 | 24.02 | 45.73 | 78.16 | 18.13 | |
| ZA01 | 62.65 | 81.75 | 47.22 | 87.88 | 37.4 | 58.48 | 28.46 | 33.12 | 55.88 | 31.65 | 35.97 | 59.3 | 27.46 | |
| ZA02 | 68.53 | 88.67 | 47.08 | 87.77 | 40.09 | 62.1 | 29.97 | 36.14 | 59.29 | 33.14 | 38.72 | 62.84 | 29.13 | |
| ZA04 | 68.02 | 88.82 | 48.34 | 89.87 | 40.32 | 64.86 | 26.98 | 36.13 | 61.76 | 30.46 | 38.78 | 65.62 | 26.12 | |
| ZA05 | 63.58 | 83.31 | 49.89 | 93.27 | 35.29 | 57.86 | 30.55 | 31.73 | 55.53 | 33.34 | 34.09 | 58.35 | 29.96 | |
| ZA06 | 68.09 | 89.24 | 47.93 | 89.11 | 40.09 | 64.12 | 28.15 | 35.34 | 60.58 | 32.12 | 38.9 | 65.16 | 26.99 | |
| Average | 68.69 | 90.69 | 50.90 | 94.08 | 42.93 | 68.09 | 25.12 | 37.70 | 64.44 | 29.07 | 41.16 | 69.05 | 24.07 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Benavides Cesar, L.; Manso Callejo, M.Á.; Cira, C.-I.; Alcarria, R. CyL-GHI: Global Horizontal Irradiance Dataset Containing 18 Years of Refined Data at 30-Min Granularity from 37 Stations Located in Castile and León (Spain). Data 2023, 8, 65. https://doi.org/10.3390/data8040065
Benavides Cesar L, Manso Callejo MÁ, Cira C-I, Alcarria R. CyL-GHI: Global Horizontal Irradiance Dataset Containing 18 Years of Refined Data at 30-Min Granularity from 37 Stations Located in Castile and León (Spain). Data. 2023; 8(4):65. https://doi.org/10.3390/data8040065
Chicago/Turabian StyleBenavides Cesar, Llinet, Miguel Ángel Manso Callejo, Calimanut-Ionut Cira, and Ramon Alcarria. 2023. "CyL-GHI: Global Horizontal Irradiance Dataset Containing 18 Years of Refined Data at 30-Min Granularity from 37 Stations Located in Castile and León (Spain)" Data 8, no. 4: 65. https://doi.org/10.3390/data8040065