
TKGQA Dataset: Using Question Answering to Guide and Validate the Evolution of Temporal Knowledge Graph

Abstract
:1. Introduction
2. Data Description
3. Methods
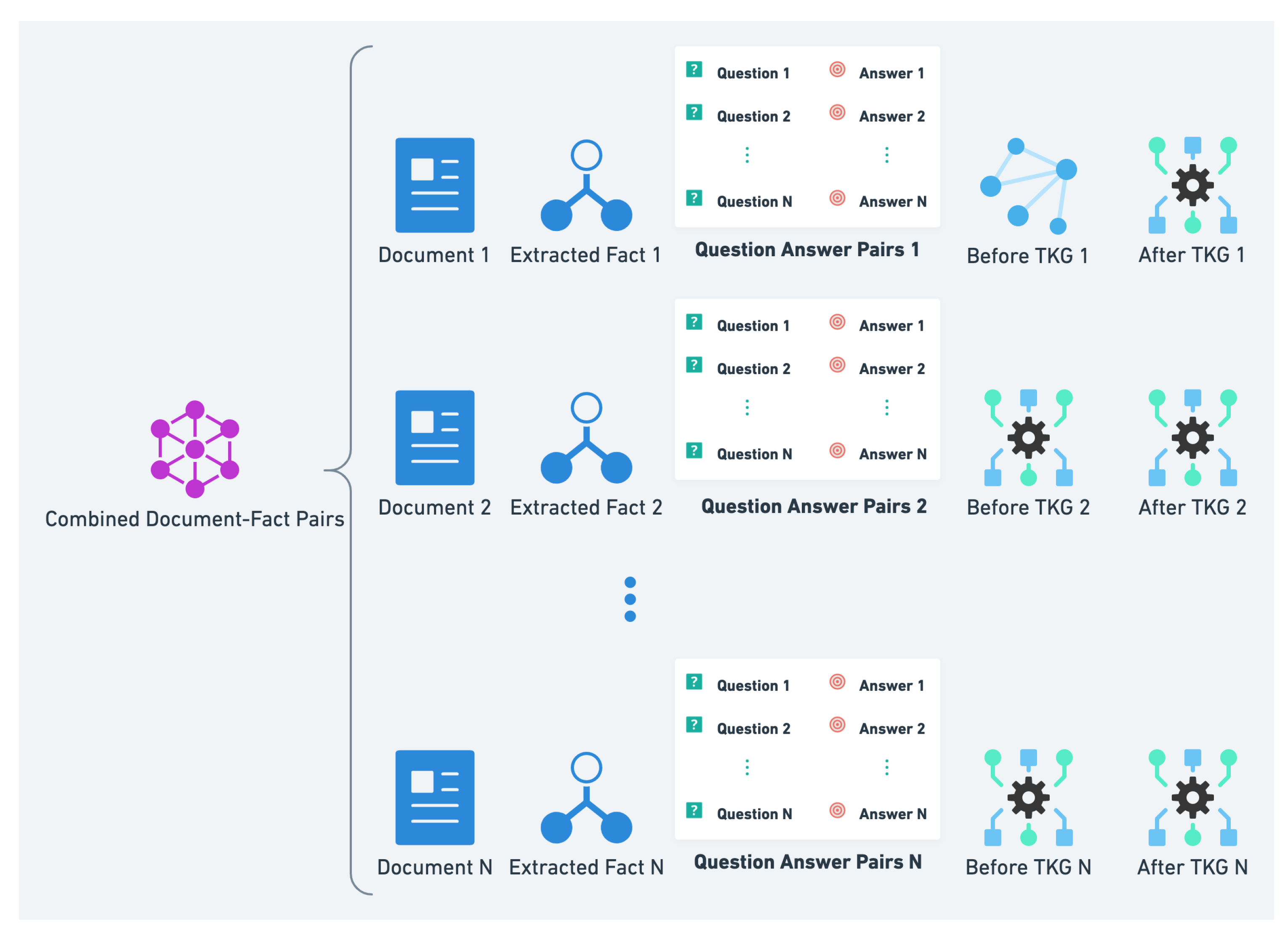
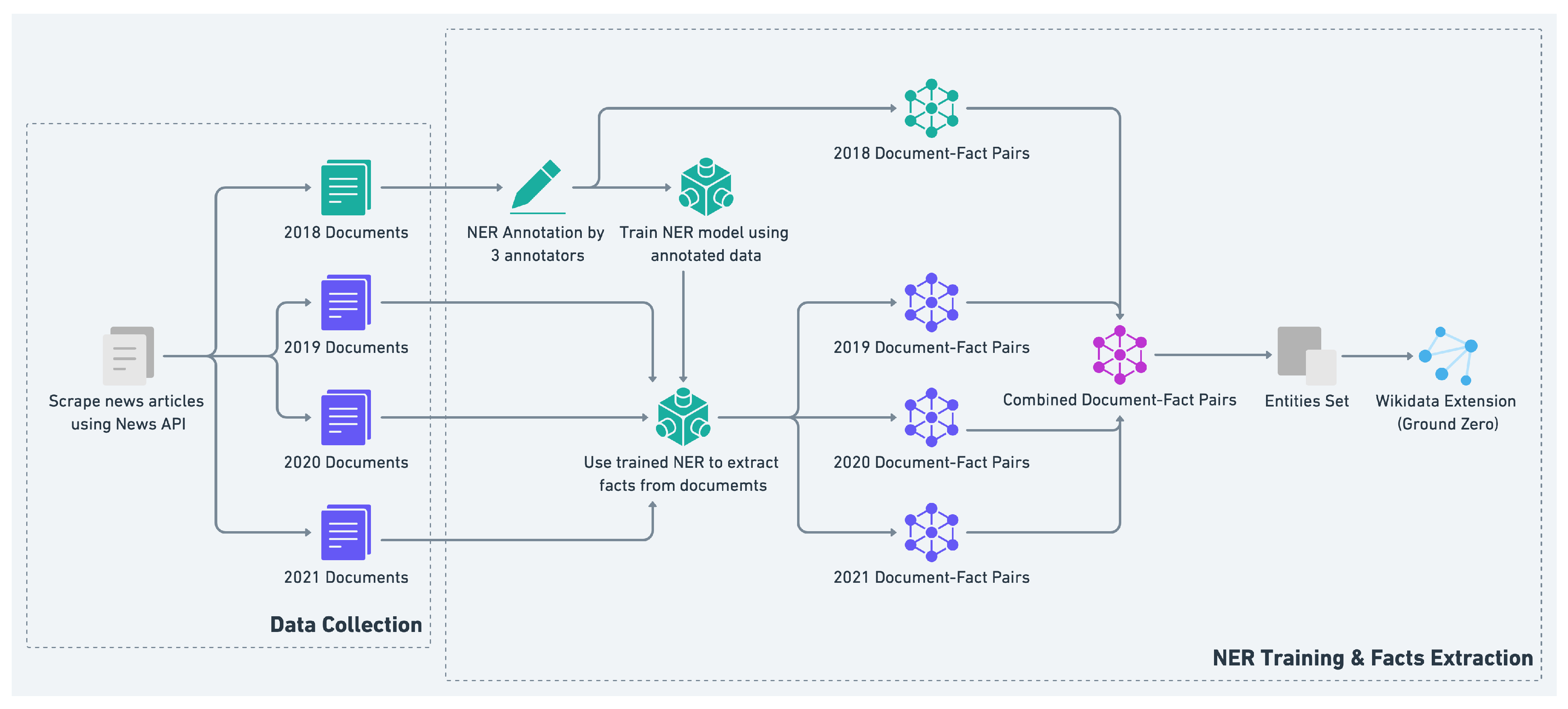
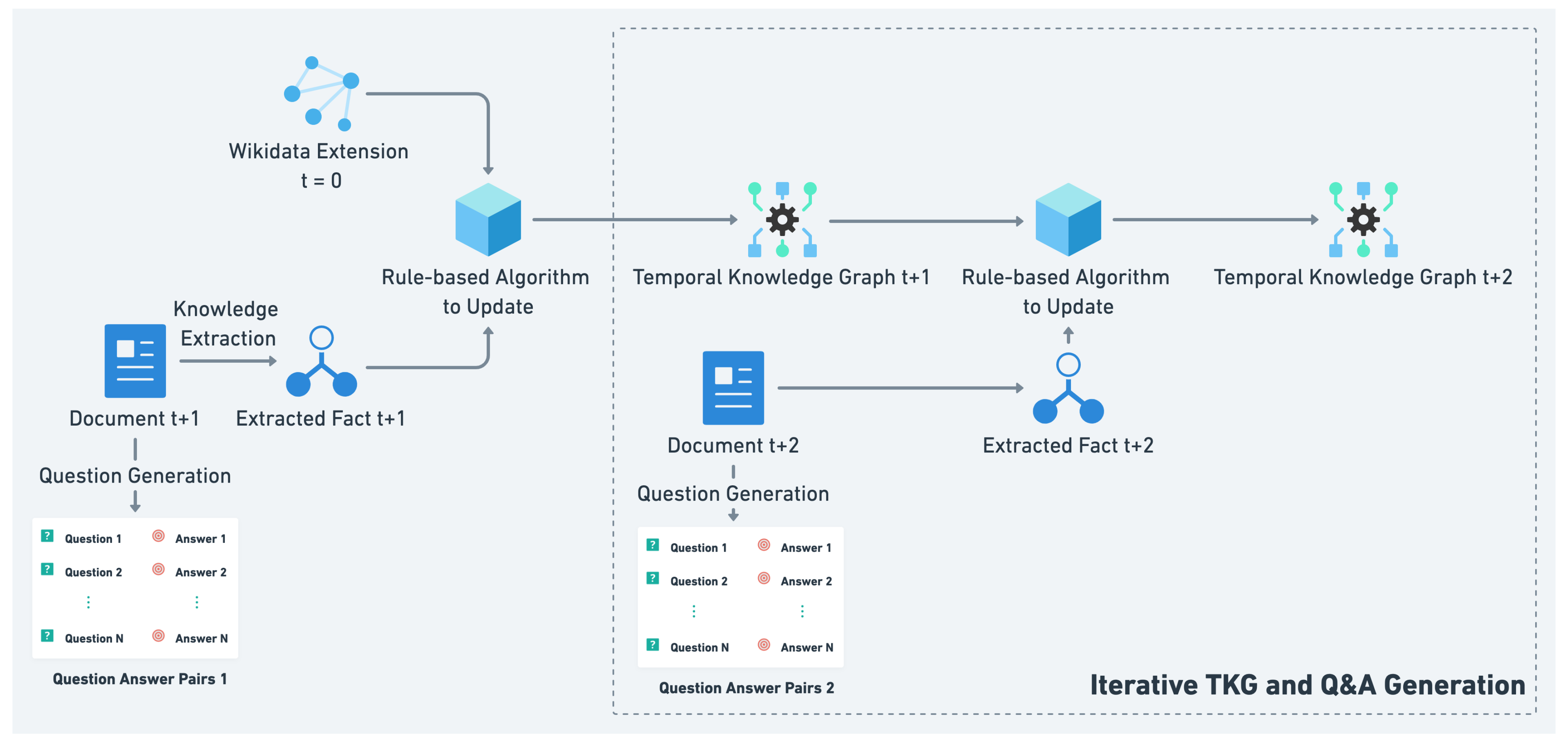
3.1. Data Creation
- Data Collection
- Facts Extraction
- TKG Generation
- Q&A Generation
- Bidder—the company looking to merge or acquire another company
- Target—the company being merged/acquired
- Considering—early stage of discussion/talks, pre-approval
- Expecting—anything that signifies high probability of the deal going through
- Success—deals completed, agreed/signed to acquire, merged, acquired, entered/reached
- Terminated—deals cancelled, refused
- Org—general companies that are not part of the M&A deal
- owner of (P1830)—QA
- subsidiary (P355)—QA
- owned by (P127)—QA
- business division (P199)—QA
- board member (P3320)—QA
- industry (P452)—EDA
- founded by (P112)—EDA
- inception (P571)—EDA
- stock exchange (P414)—EDA
- country (P17)—EDA
- part of (P361)—EDA
3.2. Evaluation Metrics
4. Technical Validation
4.1. Inter-Annotator Agreement (IAA)
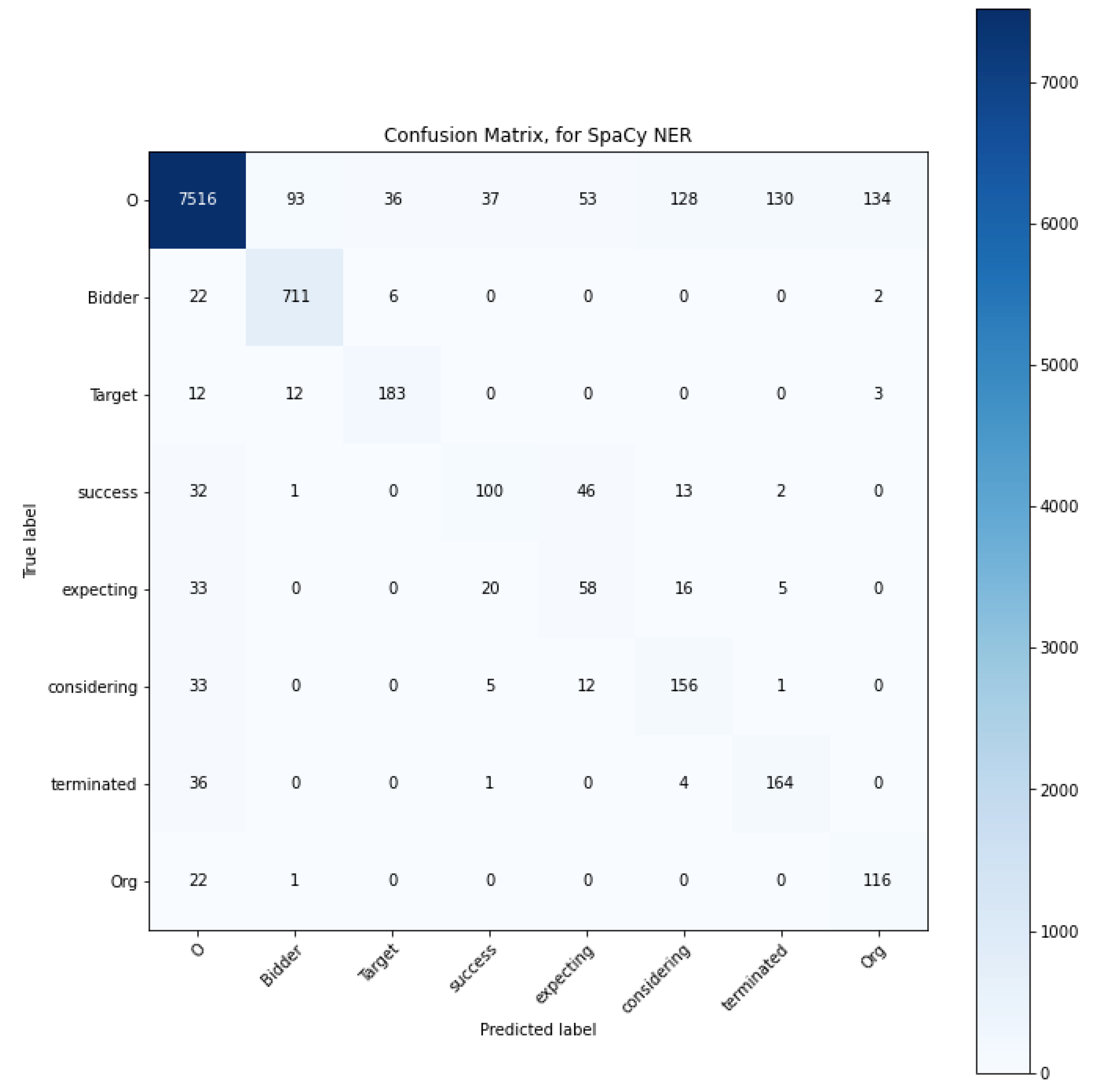
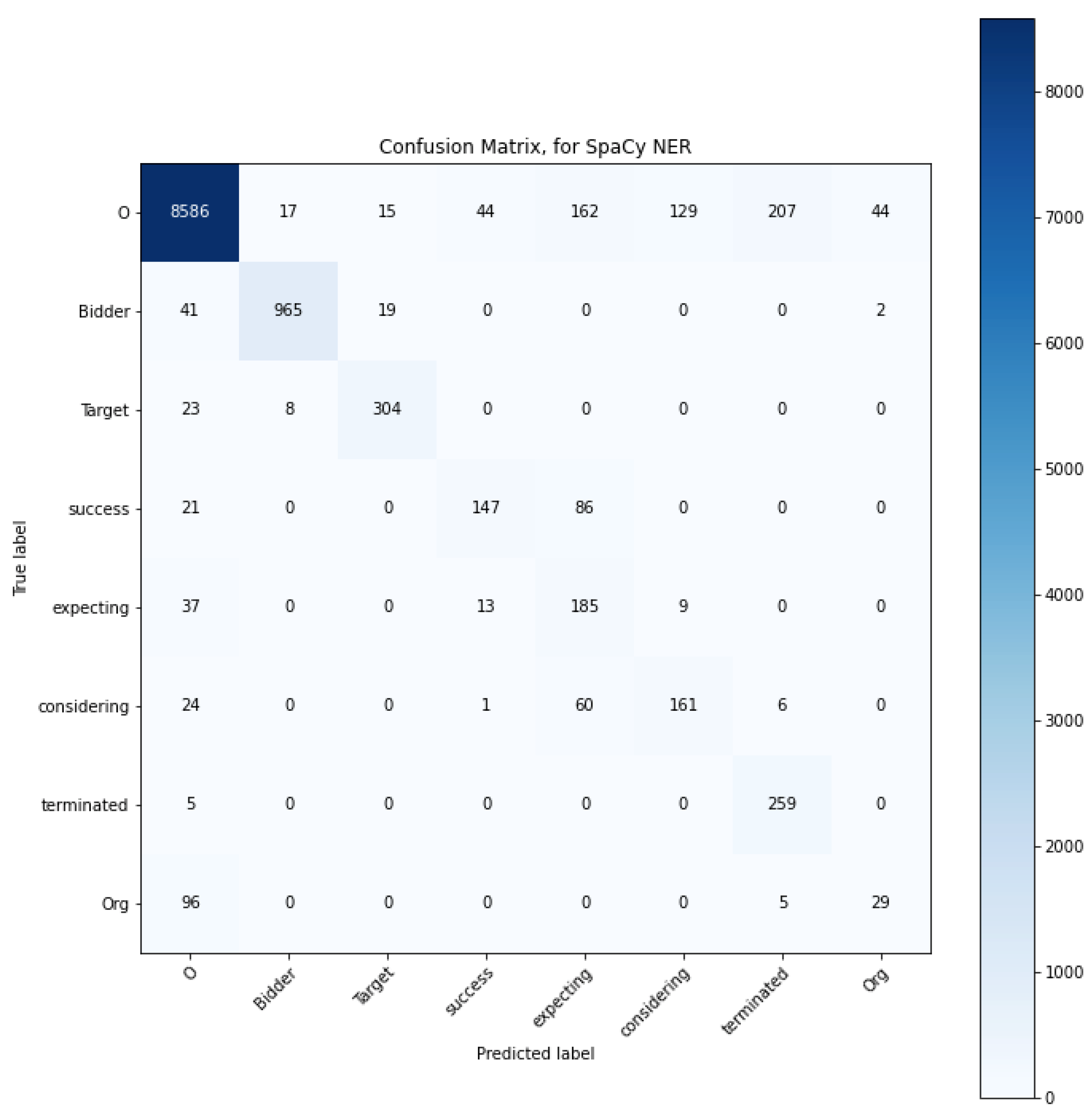
4.2. Confusion Matrix
5. User Notes
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| TKG | Temporal Knowledge Graph |
| M&A | Mergers and Acquisitions |
| Q&A | Questions and Answers |
| NER | Named Entity Recognition |
| EDA | Explanatory Data Analysis |
| IAA | Inter-Annotator Agreement |
| TKGQA | Temporal Knowledge Graph Question Answering |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Article ID 5 | |
|---|---|
| Sentence Text | Under the terms of the transaction, upon completion of the acquisition, Bard became a wholly owned subsidiary of BD, and each outstanding share of Bard common stock was converted to the right to receive (1) $222.93 in cash without interest and (2) 0.5077 of a share of BD common stock. |
| Extracted Tuple | (‘bd_(company)’, ‘success_acq’, ‘bard’, ‘2018-01-02 00:00:00’) |
| General Questions | (“Who’s the bidder of the acquisition deal on 2018-01-02 00:00:00?”, ‘bd_(company)’, ‘entity’) (“Who’s the target of the acquisition deal on 2018-01-02 00:00:00?”, ‘bard’, ‘entity’) (“What’s the status of the deal between bd_(company) and bard on 2018-01-02 00:00:00?”, ‘success_acq’, ‘relation’) |
| After Head Entity Q&As | (‘Who does FlowJo LLC (Q106573956) belong to after the latest status of the deal between bd_(company) and bard?’, ‘bd_(company)’, ‘entity’) (‘Who owns Becton, Dickinson and Company headquarters (Q4878931) after the latest status of the deal between bd_(company) and bard?’, ‘bd_(company)’, ‘entity’) |
| After Tail Entity Q&As | [] |
| Before TKG | 8321 |
| After TKG | 8322 |
| Article ID 124 | |
|---|---|
| Sentence Text | Foresight has completed the acquisition of Canadian Solar’s Australian solar project pipeline. |
| Extracted Tuple | (‘foresight’, ‘success_acq’, ‘canadian solar’s australian solar project pipeline’, ‘2018-01-03 18:16:00’) |
| General Questions | (“Who’s the bidder of the acquisition deal on 2018-01-03 18:16:00?”, ‘foresight’, ‘entity’) (“Who’s the target of the acquisition deal on 2018-01-03 18:16:00?”, ‘canadian solar’s australian solar project pipeline’, ‘entity’) (“What’s the status of the deal between foresight and canadian solar’s australian solar project pipeline on 2018-01-03 18:16:00?”, ‘success_acq’, ‘relation’) |
| After Head Entity Q&As | [] |
| After Tail Entity Q&As | [] |
| Before TKG | 8436 |
| After TKG | 8437 |
| Article ID 16719 | |
|---|---|
| Sentence Text | Walmart acquired a grocery wholesaler and distributor called McLane to manage its grocery distribution needs when Walmart first began to sell groceries in its stores. |
| Extracted Tuple | (‘walmart’, ‘success_acq’, ‘mclane’, ‘2018-12-30 21:02:00’) |
| General Questions | (“Who’s the bidder of the acquisition deal on 2018-12-30 21:02:00?”, ‘walmart’, ‘entity’) (“Who’s the target of the acquisition deal on 2018-12-30 21:02:00?”, ‘mclane’, ‘entity’) (“What’s the status of the deal between walmart and mclane on 2018-12-30 21:02:00?”, ‘success_acq’, ‘relation’) |
| After Head Entity Q&As | (‘Who has influence over mclane after the latest status of the deal between walmart and mclane?’, ‘Marissa Mayer (Q14086)’, ‘entity’) (‘Who owns TodoDia (Q10382887) after the latest status of the deal between walmart and mclane?’, ‘walmart’, ‘entity’) (“Who does Sam’s Club (Q1972120) belong to after the latest status of the deal between walmart and mclane?”, ‘walmart’, ‘entity’) |
| After Tail Entity Q&As | [] |
| Before TKG | 12921 |
| After TKG | 12938 |
References
- Ji, S.; Pan, S.; Cambria, E.; Marttinen, P.; Yu, P.S. A survey on knowledge graphs: Representation, acquisition and applications. arXiv 2020, arXiv:2002.00388. [Google Scholar] [CrossRef] [PubMed]
- Trivedi, R.S.; Dai, H.; Wang, Y.; Song, L. Know-Evolve: Deep Temporal Reasoning for Dynamic Knowledge Graphs. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Cai, B.; Xiang, Y.; Gao, L.; Zhang, H.; Li, Y.; Li, J. Temporal Knowledge Graph Completion: A Survey. arXiv 2022, arXiv:2201.08236. [Google Scholar]
- Zelinka, M.; Yuan, X.; Côté, M.A.; Laroche, R.; Trischler, A. Building Dynamic Knowledge Graphs from Text-based Games. arXiv 2019, arXiv:abs/1910.09532. [Google Scholar]
- Das, R.; Munkhdalai, T.; Yuan, X.; Trischler, A.; McCallum, A. Building Dynamic Knowledge Graphs from Text using Machine Reading Comprehension. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Wijaya, D.; Nakashole, N.; Mitchell, T.M. CTPs: Contextual Temporal Profiles for Time Scoping Facts using State Change Detection. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014. [Google Scholar]
- Tang, J.; Feng, Y.; Zhao, D. Learning to Update Knowledge Graphs by Reading News. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), Hong Kong, China, 3–7 November 2019. [Google Scholar]
- Wang, A.; Cho, K.; Lewis, M. Asking and Answering Questions to Evaluate the Factual Consistency of Summaries. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020. [Google Scholar]
- Kazemi, A.; Li, Z.; Pérez-Rosas, V.; Mihalcea, R. Extractive and Abstractive Explanations for Fact-Checking and Evaluation of News. In Proceedings of the Fourth Workshop on NLP for Internet Freedom: Censorship, Disinformation, and Propaganda; Association for Computational Linguistics, Online, 6 June 2021; pp. 45–50. [Google Scholar] [CrossRef]
- Arumae, K.; Liu, F. Guiding Extractive Summarization with Question-Answering Rewards. arXiv 2019, arXiv:1904.02321. [Google Scholar]
- Gunasekara, C.; Feigenblat, G.; Sznajder, B.; Aharonov, R.; Joshi, S. Using Question Answering Rewards to Improve Abstractive Summarization. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), Punta Cana, Dominican Republic, 7–11 November 2021. [Google Scholar]
- Ning, Q.; Wu, H.; Han, R.; Peng, N.; Gardner, M.; Roth, D. TORQUE: A Reading Comprehension Dataset of Temporal Ordering Questions. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Association for Computational Linguistics, Online, 16–20 November 2020; pp. 1158–1172. [Google Scholar] [CrossRef]
- Jia, Z.; Abujabal, A.; Saha Roy, R.; Strötgen, J.; Weikum, G. TempQuestions: A Benchmark for Temporal Question Answering. In Proceedings of the Companion Proceedings of The Web Conference, Lyon, France, 23–27 April 2018; pp. 1057–1062. [Google Scholar] [CrossRef] [Green Version]
- Souza Costa, T.; Gottschalk, S.; Demidova, E. Event-QA: A Dataset for Event-Centric Question Answering over Knowledge Graphs. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Association for Computing Machinery, New York, NY, USA, 19–23 October; 2020; pp. 3157–3164. [Google Scholar] [CrossRef]
- Jia, Z.; Abujabal, A.; Roy, R.S.; Strotgen, J.; Weikum, G. TEQUILA: Temporal Question Answering over Knowledge Bases. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Turin, Italy, 22–26 October 2018. [Google Scholar]
- Wu, W.; Zhu, Z.; Lu, Q.; Zhang, D.; Guo, Q. Introducing External Knowledge to Answer Questions with Implicit Temporal Constraints over Knowledge Base. Future Internet 2020, 12, 45. [Google Scholar] [CrossRef] [Green Version]
- Saxena, A.; Chakrabarti, S.; Talukdar, P.P. Question Answering Over Temporal Knowledge Graphs. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Bangkok, Thailand, 1–6 August 2021. [Google Scholar]
- Ong, R.; Sun, J.; Serban, O.; Guo, Y.K. TKGQA Dataset. Available online: https://doi.org/10.17605/OSF.IO/XQWA4 (accessed on 24 August 2022).
- Nakayama, H.; Kubo, T.; Kamura, J.; Taniguchi, Y.; Liang, X. doccano: Text Annotation Tool for Human. Software. 2018. Available online: https://github.com/doccano/doccano (accessed on 24 October 2022).
- Cohen, J. A Coefficient of Agreement for Nominal Scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- García-Durán, A.; Dumančić, S.; Niepert, M. Learning Sequence Encoders for Temporal Knowledge Graph Completion. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, Brussels, Belgium, 31 October–4 November 2018; pp. 4816–4821. [Google Scholar] [CrossRef]
- Goel, R.; Kazemi, S.M.; Brubaker, M.; Poupart, P. Diachronic Embedding for Temporal Knowledge Graph Completion. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 November 2020. [Google Scholar]
- Lacroix, T.; Obozinski, G.; Usunier, N. Tensor Decompositions for temporal knowledge base completion. In Proceedings of the Eighth International Conference on Learning Representations, Online, 26 April–1 May 2020. [Google Scholar]
- Messner, J.; Abboud, R.; Ceylan, I.I. Temporal Knowledge Graph Completion using Box Embeddings. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2021. [Google Scholar]
- Xu, C.; Nayyeri, M.; Alkhoury, F.; Shariat Yazdi, H.; Lehmann, J. TeRo: A Time-aware Knowledge Graph Embedding via Temporal Rotation. In Proceedings of the 28th International Conference on Computational Linguistics, International Committee on Computational Linguistics, Barcelona, Spain (Online), 13–18 September 2020; pp. 1583–1593. [Google Scholar] [CrossRef]






| TKGQA Dataset Documents | Count |
|---|---|
| Total number of documents | 5721 |
| Total number of general questions per document | 3 |
| Total number of documents having head questions | 2425 |
| Average number of questions for head entity | 15.32 |
| Average number of questions for tail entity | 1.014 |
| Maximum number of questions for head entity | 289 |
| Maximum number of questions for tail entity | 195 |
| Total number of extracted entities | 2527 |
| Average deal per entity | 1.83 |
| Maximum deal per entity | 74 |
| Industries | Count |
|---|---|
| financial service (Q837171) | 179 |
| telecommunications industry (Q25245117) | 84 |
| retail (Q126793) | 75 |
| pharmaceutical industry (Q507443) | 69 |
| petroleum industry (Q862571) | 65 |
| software industry (Q880371) | 65 |
| Finanzwesen (Q1416657) | 61 |
| banking industry (Q806718) | 56 |
| automotive industry (Q190117) | 49 |
| video game industry (Q941594) | 49 |
| Temporal Knowledge Graph | Count |
|---|---|
| Total number of TKG Snapshots | 5722 |
| Total number of facts (last state) | 21,725 |
| Total original facts | 8319 |
| Total added facts | 13,406 |
| Total modified facts | 1605 |
| Total number of unique entities | 14,756 |
| Total number of unique relations | 13 |
| Attributes | Template |
|---|---|
| owner of (P1830) | Who owns [SUBJECT ENTITY] before the latest status of the deal between [HEAD] and [TAIL]? |
| subsidiary (P355) | Who does [SUBJECT ENTITY] belong to before the latest status of the deal between [HEAD] and [TAIL]? |
| owned by (P127) | Who owns [HEAD] after the latest status of the deal between [HEAD] and [TAIL]? |
| business division (P199) | Who does [SUBJECT ENTITY] belong to after the latest status of the deal between [HEAD] and [TAIL]? |
| board member (P3320) | Who has influence over [TAIL] after the latest status of the deal between [HEAD] and [TAIL]? |
| Computations | IAA (Cohen Kappa Score) |
|---|---|
| Annotator 1 vs. Annotator 2 (with O tags) | 0.75 |
| Annotator 1 vs. Annotator 3 (with O tags) | 0.75 |
| Annotator 2 vs. Annotator 3 (with O tags) | 0.80 |
| Annotator 1 vs. Annotator 2 (without O tags) | 0.63 |
| Annotator 1 vs. Annotator 3 (without O tags) | 0.61 |
| Annotator 2 vs. Annotator 3 (without O tags) | 0.69 |
| Authors’ Labels vs. Annotator 1 | 0.75 |
| Authors’ Labels vs. Annotator 2 | 0.77 |
| Authors’ Labels vs. Annotator 3 | 0.80 |
| Authors’ Labels vs. NER Algorithm (all annotators) | 0.66 |
| Authors’ Labels vs. NER Algorithm (annotator 1) | 0.64 |
| Authors’ Labels vs. NER Algorithm (annotator 2) | 0.67 |
| Authors’ Labels vs. NER Algorithm (annotator 3) | 0.66 |
| Gold Labels vs. Annotator 1 (with O tags) | 0.80 |
| Gold Labels vs. Annotator 2 (with O tags) | 0.84 |
| Gold Labels vs. Annotator 3 (with O tags) | 0.84 |
| Gold Labels vs. Annotator 1 (without O tags) | 0.75 |
| Gold Labels vs. Annotator 2 (without O tags) | 0.83 |
| Gold Labels vs. Annotator 3 (without O tags) | 0.82 |
| Gold Labels vs. Authors’ Labels | 0.77 |
| Gold Labels vs. NER Algorithm | 0.65 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ong, R.; Sun, J.; Șerban, O.; Guo, Y.-K. TKGQA Dataset: Using Question Answering to Guide and Validate the Evolution of Temporal Knowledge Graph. Data 2023, 8, 61. https://doi.org/10.3390/data8030061
Ong R, Sun J, Șerban O, Guo Y-K. TKGQA Dataset: Using Question Answering to Guide and Validate the Evolution of Temporal Knowledge Graph. Data. 2023; 8(3):61. https://doi.org/10.3390/data8030061
Chicago/Turabian StyleOng, Ryan, Jiahao Sun, Ovidiu Șerban, and Yi-Ke Guo. 2023. "TKGQA Dataset: Using Question Answering to Guide and Validate the Evolution of Temporal Knowledge Graph" Data 8, no. 3: 61. https://doi.org/10.3390/data8030061