
Development of a Machine-Learning-Based Novel Framework for Travel Time Distribution Determination Using Probe Vehicle Data


Abstract
:1. Introduction
2. Study Area and Data Collection
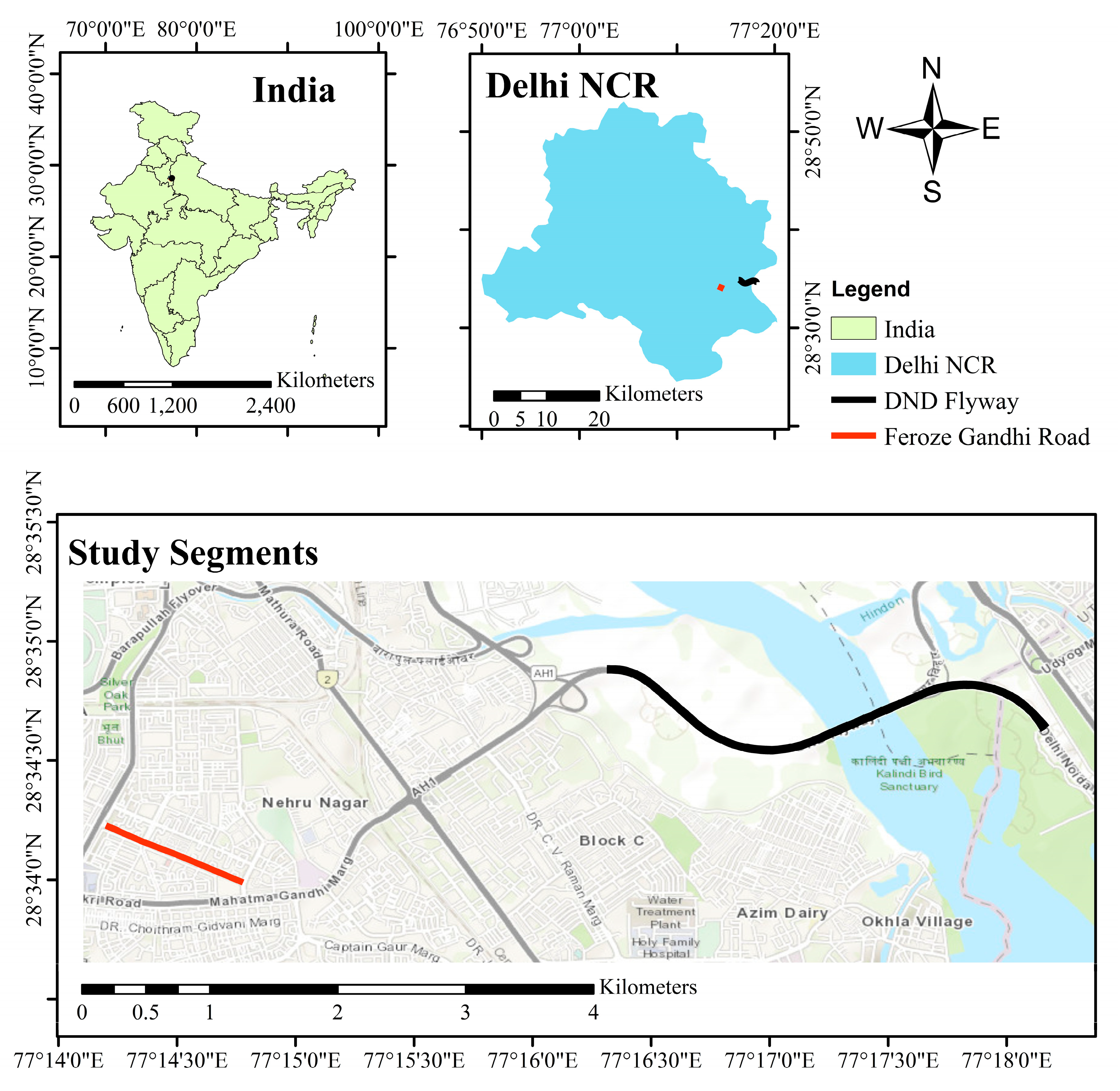
2.1. Study Area
2.2. Data Collection
- Non-Interfering Weather Conditions: Weather conditions such as fair, partly cloudy, mostly cloudy, cloudy, haze, smoke, and blowing dust have no discernible effect on the traffic conditions. Hence, these are grouped into the non-interfering weather conditions class.
- Interfering Weather Conditions: all weather situations, such as drizzle, light rain, rain, heavy rain, thunderstorm, mist, shallow fog, fog, etc., that are expected to have a considerable effect on travel times and speed. Hence, these are grouped into interfering weather conditions class.
2.3. Data Pre-Processing
2.3.1. Data Cleaning
2.3.2. Data Visualization and Trip Extraction
3. Methodology
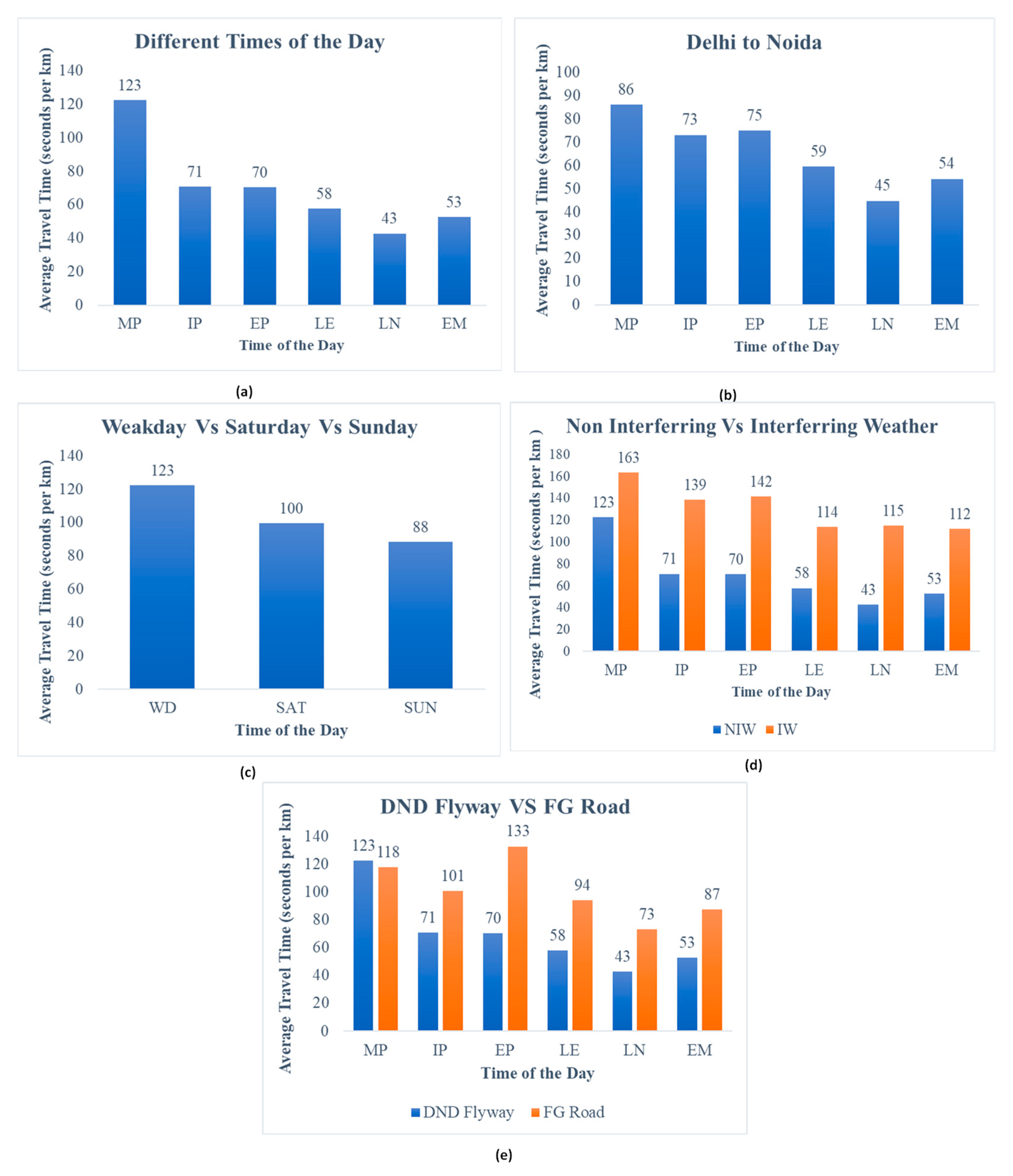
3.1. Analysis and Classification of Data
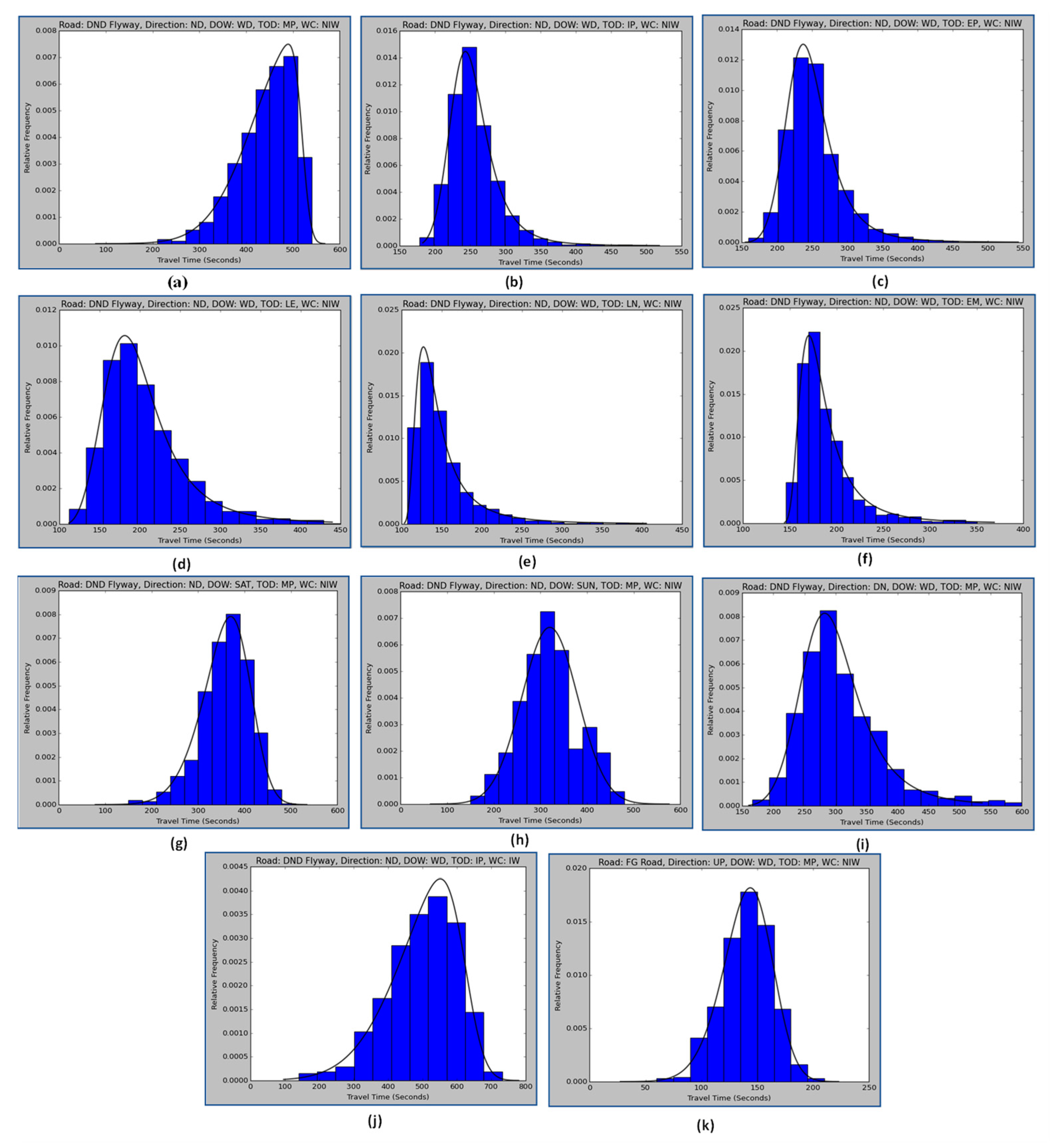
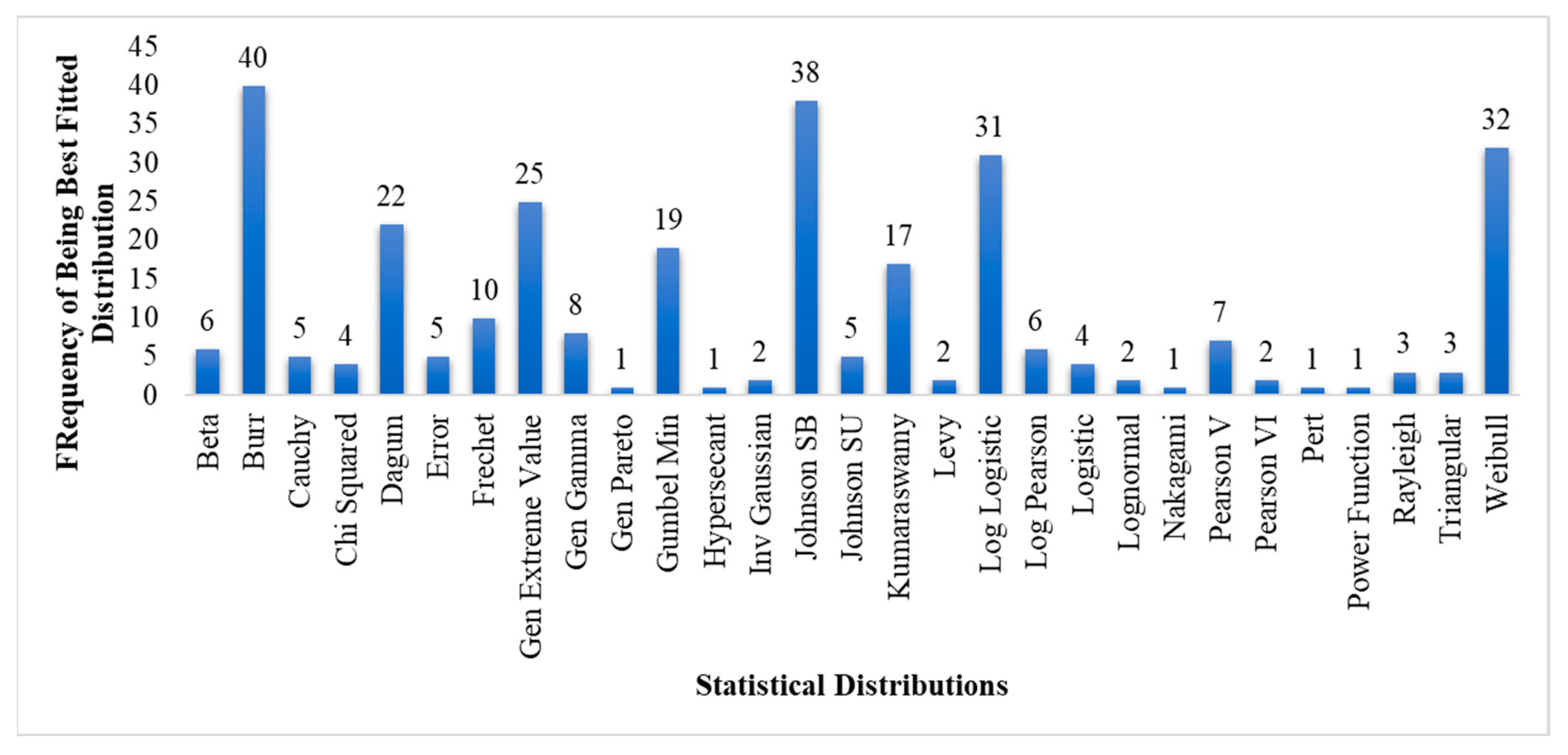
3.2. Distribution Fitting
- Bounded Distributions: Distributions that fall into this category include Uniform distributions, Triangular, Reciprocal, Power Functions, PERT, Beta, and Johnson-Simons-Brown (JSB). These distributions are bounded between a range of [a,b].
- Unbounded Distributions: Normal, Logistic, Cauchy, Error, Error Function, Johnson SU, Hyperbolic Secant, Student’s t distribution, and Laplace (Double Exponential) are among the unbounded distributions. These distributions are unbounded and have a range of (−∞, +∞).
- Non-Negative Distributions: The majority of these distributions are defined for the range x > γ, which is equivalent to x − γ ≥ 0, where γ is a continuous location parameter. Log-logistic, Inverse Gaussian, Weibull, Levy’s Log-Gamma, Rayleigh’s Rice, Nakagami’s Lognormal, Pearson V, Pearson VI, Pareto (first kind), and Pareto (second kind) are among the non-negative distributions supported by the EasyFit software. Most of the non-negative distributions supported by EasyFit are available in two versions or forms: a simplified version and a complete version.
- Advanced Distributions: EasyFit’s classification of continuous distributions is based on various definitions. As a result, some of the continuous distributions do not fall into any of the categories listed above. Simultaneously, they frequently represent more valid models than a large number of other distributions. EasyFit supports advanced distributions such as generalized Pareto, generalized extreme value (GEV), Log-Pearson III, Wakeby, generalized logistic, Phased Bi-Exponential, and Phased Bi-Weibull. These distributions are generated by combining two or more basic distributions. For instance, the GEV distribution is generated by combining Weibull, Gumbel, and Frechet distributions.
3.2.1. Kolmogorov–Smirnov Test
3.2.2. Anderson–Darling Test
3.2.3. Chi-Squared Test
3.3. Determination of Distribution Suitable for Travel Time Data
4. Results and Discussion
- Classification xi is a true positive for class c if both the actual and the predicted classes of xi are the same as c.
- Classification xi is a true negative for class c if neither of the actual or predicted classes of xi matches with c.
- Classification xi is a false positive for class c if the predicted class of xi matches c but the actual class does not.
- Classification xi is a false negative for class c if the actual class of xi matches c but the predicted class does not.
5. Conclusions
- Disagreement on the best distribution option for fitting to travel time data among the studies available in the literature is possibly due to differences in the traffic situations prevailing in their study area.
- An RUS Boosted decision-tree-classifier-based novel framework proposed in the study can determine the best-fitted distribution for the travel time data with 91% accuracy.
- Travel time distributions determined by the novel framework proposed in the current study have an acceptance rate of 98.4%, even in heterogeneous disordered traffic conditions. This acceptance rate is expected to increase if the framework is applied to travel time data in developed countries with lane-disciplined homogeneous traffic.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Abdel-Aty, M.; Kitamura, R.; Jovanis, P.P. Exploring Route Choice Behavior Using Geographic Information System-Based Alternative Routes and Hypothetical Travel Time Information Input. Transp. Res. Rec. 1995, 1493, 74–80. [Google Scholar]
- Koster, P.; Verhoef, E.T. A Rank-Dependent Scheduling Model. J. Transp. Econ. Policy 2012, 46, 123–1338. [Google Scholar] [CrossRef] [Green Version]
- Li, H.; Tu, H.; Hensher, D.A. Integrating the Mean–Variance and Scheduling Approaches to Allow for Schedule Delay and Trip Time Variability under Uncertainty. Transp. Res. Part A Policy Pract. 2016, 89, 151–163. [Google Scholar] [CrossRef]
- Chen, A.; Ji, Z.; Recker, W. Travel Time Reliability with Risk-Sensitive Travelers. Transp. Res. Rec. 2002, 1783, 27–33. [Google Scholar] [CrossRef]
- Han, J.; Lee, C.; Park, S. A Robust Scenario Approach for the Vehicle Routing Problem with Uncertain Travel Times. Transp. Sci. 2013, 48, 373–390. [Google Scholar] [CrossRef] [Green Version]
- Bhat, C.R.; Sardesai, R. The Impact of Stop-Making and Travel Time Reliability on Commute Mode Choice. Transp. Res. Part B Methodol. 2006, 40, 709–730. [Google Scholar] [CrossRef] [Green Version]
- Van Loon, R.; Rietveld, P.; Brons, M. Travel-Time Reliability Impacts on Railway Passenger Demand: A Revealed Preference Analysis. J. Transp. Geogr. 2011, 19, 917–925. [Google Scholar] [CrossRef]
- Bates, J.; Polak, J.; Jones, P.; Cook, A. The Valuation of Reliability for Personal Travel. Transp. Res. Part E Logist. Transp. Rev. 2001, 37, 191–229. [Google Scholar] [CrossRef]
- Polus, A. A Study of Travel Time and Reliability on Arterial Routes. Transportation 1979, 8, 141–151. [Google Scholar] [CrossRef]
- Mazloumi, E.; Currie, G.; Rose, G. Using GPS Data to Gain Insight into Public Transport Travel Time Variability. J. Transp. Eng. 2009, 136, 623–631. [Google Scholar] [CrossRef]
- Uno, N.; Kurauchi, F.; Tamura, H.; Iida, Y. Using Bus Probe Data for Analysis of Travel Time Variability. J. Intell. Transp. Syst. 2009, 13, 2–15. [Google Scholar] [CrossRef] [Green Version]
- Susilawati, S.; Taylor, M.A.P.; Somenahalli, S.V.C. Distributions of Travel Time Variability on Urban Roads. J. Adv. Transp. 2013, 47, 720–736. [Google Scholar] [CrossRef]
- Lei, F.; Wang, Y.; Lu, G.; Sun, J. A Travel Time Reliability Model of Urban Expressways with Varying Levels of Service. Transp. Res. Part C Emerg. Technol. 2014, 48, 453–467. [Google Scholar] [CrossRef]
- Kieu, L.M.; Bhaskar, A.; Chung, E. Public Transport Travel-Time Variability Definitions and Monitoring. J. Transp. Eng. 2015, 141, 04014068. [Google Scholar] [CrossRef] [Green Version]
- Ma, Z.; Ferreira, L.; Mesbah, M.; Zhu, S. Modeling Distributions of Travel Time Variability for Bus Operations. J. Adv. Transp. 2016, 50, 6–24. [Google Scholar] [CrossRef]
- Chen, P.; Tong, R.; Lu, G.; Wang, Y. Exploring Travel Time Distribution and Variability Patterns Using Probe Vehicle Data: Case Study in Beijing. J. Adv. Transp. 2018, 2018, 3747632. [Google Scholar] [CrossRef] [Green Version]
- Chepuri, A.; Borakanavar, M.; Amrutsamanvar, R.; Arkatkar, S.; Joshi, G. Examining Travel Time Reliability under Mixed Traffic Conditions: A Case Study of Urban Arterial Roads in Indian Cities. Asian Transp. Stud. 2018, 5, 30–46. [Google Scholar] [CrossRef]
- Jairam, R.; Kumar, B.A.; Arkatkar, S.S.; Vanajakshi, L. Performance Comparison of Bus Travel Time Prediction Models across Indian Cities. Transp. Res. Rec. 2018, 2672, 87–98. [Google Scholar] [CrossRef]
- Rahman, M.M.; Wirasinghe, S.C.; Kattan, L. Analysis of Bus Travel Time Distributions for Varying Horizons and Real-Time Applications. Transp. Res. Part C Emerg. Technol. 2018, 86, 453–466. [Google Scholar] [CrossRef]
- Guo, J.H.; Li, C.G.; Qin, X.; Huang, W.; Wei, Y.; Cao, J. De Analyzing Distributions for Travel Time Data Collected Using Radio Frequency Identification Technique in Urban Road Networks. Sci. China Technol. Sci. 2018, 62, 106–120. [Google Scholar] [CrossRef]
- Amrutsamanvar, R.; Joshi, G.; Arkatkar, S.S.; Chalumuri, R.S. Empirical Travel Time Reliability Assessment of Indian Urban Roads. Lect. Notes Civ. Eng. 2020, 69, 165–182. [Google Scholar] [CrossRef]
- Chen, Z.; Fan, W.D. Analyzing Travel Time Distribution Based on Different Travel Time Reliability Patterns Using Probe Vehicle Data. Int. J. Transp. Sci. Technol. 2020, 9, 64–75. [Google Scholar] [CrossRef]
- Chepuri, A.; Joshi, S.; Arkatkar, S.; Joshi, G.; Bhaskar, A. Development of New Reliability Measure for Bus Routes Using Trajectory Data. Transp. Lett. 2019, 12, 363–374. [Google Scholar] [CrossRef]
- Xu, Z.; Jabari, S.E.; Prassas, E. Applying Finite Mixture Models to New York City Travel Times. J. Transp. Eng. Part A Syst. 2020, 146, 05020001. [Google Scholar] [CrossRef]
- Adnan, M.; Gazder, U.; Yasar, A.U.H.; Bellemans, T.; Kureshi, I. Estimation of Travel Time Distributions for Urban Roads Using GPS Trajectories of Vehicles: A Case of Athens, Greece. Pers. Ubiquitous Comput. 2021, 25, 237–246. [Google Scholar] [CrossRef]
- Harsha, M.M.; Mulangi, R.H. Probability Distributions Analysis of Travel Time Variability for the Public Transit System. Int. J. Transp. Sci. Technol. 2021, 11, 790–803. [Google Scholar] [CrossRef]
- Ghavidel, M.; Khademi, N.; Bahrami Samani, E.; Kieu, L.-M. A Random Effects Model for Travel-Time Variability Analysis Using Wi-Fi and Bluetooth Data. J. Transp. Eng. Part A Syst. 2022, 148, 05021012. [Google Scholar] [CrossRef]
- Sihag, G.; Parida, M.; Kumar, P. Travel Time Prediction for Traveler Information System in Heterogeneous Disordered Traffic Conditions Using GPS Trajectories. Sustainability 2022, 14, 10070. [Google Scholar] [CrossRef]
- Kathuria, A.; Parida, M.; Chalumuri, R.S. Travel-Time Variability Analysis of Bus Rapid Transit System Using GPS Data. J. Transp. Eng. Part A Syst. 2020, 146, 05020003. [Google Scholar] [CrossRef]
- Kieu, L.M.; Bhaskar, A.; Chung, E. Benefits and Issues of Bus Travel Time Estimation and Prediction. In Proceedings of the Australasian Transport Research Forum, ATRF 2012, Perth, Australia, 26–28 September 2012; pp. 1–16. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Year | Location | Data Source | Dataset Duration/Size | Types of Vehicles Considered | Recommended Distribution | Limitations |
|---|---|---|---|---|---|---|---|
| [9] | 1979 | Chicago, USA | Drivers who measured TT on their regular daily trips to and from work | 179 trips on 14 routes | - | Gamma | Considered only 179 trips |
| [10] | 2009 | Melbourne, Australia | GPS-equipped buses | 3351 trips | Buses | Normal (peak hour) Lognormal (off-peak) | Considered travel time data of only buses and used a small dataset (only 3351 trips) |
| [11] | 2009 | Hirakata City, Japan | Buses operated by Keihan Bus Company | 12 Days | Buses | Lognormal | Considered travel time data of only buses |
| [12] | 2013 | Adelaide, Australia | GPS-equipped probe vehicles | 180, 67 runs for Route 1 and Route 2, respectively | N/A | Burr Type XII | Used a very small travel time dataset |
| [13] | 2014 | Beijing, China | Historical floating car data | Seven days | N/A | Generalized extreme value (GEV) and generalized Pareto | Used travel time data of one week only |
| [14] | 2015 | Brisbane, Australia | Transit Signal Priority (TSP) data | 1 year | Buses | Lognormal | Considered travel time data of only buses |
| [15] | 2016 | Brisbane, Australia | TransLink Division, Department of Transport and Major Roads (DTMR) | 6 months | Buses | Gaussian mixture | Considered travel time data of only buses |
| [16] | 2018 | Beijing, China | Taxis equipped with GPS devices (Probe Vehicles) | 1 week | Taxis | Lognormal | Used travel time data of one week only, also used only taxis as probe vehicles |
| [17] | 2018 | Surat and Ahmedabad City, India | Video graphic survey | 5 h a day for two working days | Two-wheelers, Three wheelers, cars, buses, LCVs, Truck | Burr | Used travel time data of 10 h only |
| [18] | 2018 | Surat, Mysore, and Chennai, India | SITILINK Ltd., Metropolitan Transport Corporation (MTC), Karnataka State Road Transport Corporation (KSRTC) | N/A | Buses | GEV | Considered travel time data of only buses |
| [19] | 2018 | Calgary, Alberta, Canada, | Calgary Transit | From 6 a.m. to 9 a.m. for six months | Buses | Lognormal (For pseudo horizon range = 7–8 km), Normal (For pseudo horizon range > 8 km) | Considered travel time data of only buses that also for morning peak only |
| [20] | 2019 | Nanjing, China | RFID Base Stations | One month | N/A | Gaussian mixture model | Used travel time data of one month only |
| [21] | 2020 | Surat, India | Video graphic survey | 5 h | N/A | Burr (2 Lane), Log-logistic (3 Lane) | Used travel time data of 5 h only |
| [22] | 2020 | Charlotte, North Carolina, USA | Regional Integrated Transportation Information System (RITIS) | N/A | N/A | Burr | Used aggregated travel time data Dataset description, i.e., dataset duration and types of vehicles considered, is missing |
| [23] | 2020 | Mysore, India | KSRTC | 4 months | Buses | Normal (peak hours), GEV (off-peak conditions) | Considered travel time data of only buses and used dataset of only four months |
| [24] | 2020 | New York City, USA | Department of Transportation, New York City, USA | 8:00 a.m. to 8:00 p.m. for one week | N/A | Gamma Mixture | Considered travel time data for only one week |
| [25] | 2021 | Athens, Greece | Vodafone Innovus S.A | Three months | Passenger cars, taxis, minivans, vans, minibuses, buses, mini trucks | Lognormal | Considered travel time data for three months only |
| [26] | 2021 | Mysore, India | KSRTC (public transport) | Two months | Buses | GEV | Considered travel time data of only buses and used dataset of only two months |
| [27] | 2022 | Tehran, Iran | Wi-Fi and Bluetooth sensors | Two months | N/A | Lognormal | Considered travel time data for two months only |
| Encrypted Device ID | Timestamp | Latitude | Longitude | Altitude | Bearing | Engine Status | Speedometer Reading |
|---|---|---|---|---|---|---|---|
| 8493 | 31-07-2018 03:20:54 | 28.65647095 | 77.43452638 | 204 | 0 | 1 | 0 |
| 458 | 31-07-2018 03:20:53 | 28.66622667 | 77.32199333 | N/A | 16.34 | 1 | 60.5 |
| 459 | 31-07-2018 03:20:51 | 28.646855 | 77.41362333 | N/A | 36.6 | 1 | 36.6 |
| 8487 | 31-07-2018 03:20:50 | 28.64896978 | 77.34511459 | 187 | 0 | 1 | 0 |
| 12533 | 31-07-2018 03:20:52 | 28.68999299 | 77.35131744 | 196 | 241 | 0 | 0 |
| Travel Direction | DOW | TOD | Non-Interfering Weather Conditions | Interfering Weather Conditions | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| N | TMin | TMax | ATT | SD | N | TMin | TMax | ATT | SD | |||
| Noida to Delhi | Weekdays | MP | 1625 | 165 | 547 | 441 | 60 | 386 | 170 | 810 | 588 | 137 |
| IP | 3722 | 178 | 654 | 255 | 36 | 503 | 140 | 732 | 500 | 100 | ||
| EP | 1751 | 159 | 640 | 253 | 42 | 264 | 193 | 705 | 510 | 100 | ||
| LE | 2788 | 112 | 1192 | 208 | 63 | 650 | 121 | 591 | 410 | 81 | ||
| LN | 1038 | 107 | 958 | 154 | 55 | 332 | 139 | 585 | 414 | 80 | ||
| EM | 1311 | 146 | 556 | 189 | 37 | 251 | 101 | 536 | 403 | 78 | ||
| Saturdays | MP | 749 | 168 | 489 | 359 | 52 | 58 | 257 | 673 | 499 | 94 | |
| IP | 749 | 188 | 529 | 271 | 42 | 101 | 103 | 707 | 480 | 94 | ||
| EP | 322 | 173 | 521 | 256 | 41 | 49 | 226 | 695 | 494 | 107 | ||
| LE | 369 | 129 | 499 | 218 | 57 | 87 | 187 | 573 | 411 | 79 | ||
| LN | 221 | 116 | 681 | 165 | 67 | 55 | 165 | 565 | 433 | 76 | ||
| EM | 330 | 160 | 493 | 191 | 28 | 63 | 225 | 569 | 415 | 68 | ||
| Sundays | MP | 209 | 145 | 555 | 318 | 65 | 49 | 256 | 669 | 495 | 91 | |
| IP | 801 | 175 | 413 | 251 | 38 | 110 | 219 | 649 | 475 | 100 | ||
| EP | 354 | 175 | 386 | 258 | 35 | 54 | 154 | 699 | 467 | 113 | ||
| LE | 346 | 121 | 536 | 208 | 58 | 81 | 224 | 581 | 417 | 78 | ||
| LN | 145 | 120 | 359 | 161 | 37 | 37 | 170 | 559 | 415 | 85 | ||
| EM | 305 | 160 | 320 | 188 | 21 | 59 | 133 | 557 | 413 | 85 | ||
| Delhi to Noida | Weekdays | MP | 981 | 166 | 972 | 310 | 72 | 230 | 137 | 680 | 516 | 116 |
| IP | 2513 | 181 | 740 | 263 | 44 | 343 | 102 | 669 | 491 | 96 | ||
| EP | 2019 | 187 | 629 | 270 | 35 | 302 | 200 | 720 | 551 | 112 | ||
| LE | 2164 | 124 | 933 | 214 | 57 | 508 | 157 | 582 | 425 | 77 | ||
| LN | 966 | 115 | 577 | 161 | 50 | 242 | 165 | 596 | 431 | 81 | ||
| EM | 1663 | 153 | 769 | 195 | 42 | 317 | 120 | 588 | 421 | 75 | ||
| Saturdays | MP | 168 | 168 | 452 | 318 | 55 | 41 | 104 | 677 | 491 | 117 | |
| IP | 463 | 192 | 504 | 263 | 39 | 65 | 291 | 672 | 495 | 81 | ||
| EP | 442 | 171 | 559 | 261 | 46 | 65 | 197 | 670 | 493 | 111 | ||
| LE | 417 | 125 | 768 | 211 | 59 | 96 | 178 | 584 | 422 | 90 | ||
| LN | 202 | 112 | 490 | 163 | 51 | 51 | 121 | 579 | 428 | 83 | ||
| EM | 333 | 153 | 500 | 187 | 30 | 62 | 170 | 583 | 413 | 79 | ||
| Sundays | MP | 159 | 126 | 481 | 301 | 59 | 36 | 214 | 674 | 497 | 95 | |
| IP | 466 | 163 | 427 | 246 | 40 | 64 | 195 | 639 | 474 | 98 | ||
| EP | 480 | 166 | 527 | 253 | 43 | 71 | 195 | 662 | 492 | 103 | ||
| LE | 410 | 106 | 748 | 205 | 54 | 97 | 212 | 568 | 440 | 73 | ||
| LN | 192 | 117 | 493 | 169 | 57 | 49 | 155 | 591 | 438 | 68 | ||
| EM | 324 | 166 | 293 | 191 | 18 | 65 | 148 | 575 | 406 | 87 | ||
| Travel Direction | DOW | TOD | Non-Interfering Weather Conditions | Interfering Weather Conditions | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| N | TMin | TMax | ATT | SD | N | TMin | TMax | ATT | SD | |||
| UP | Weekdays | MP | 617 | 63 | 200 | 140 | 22 | 145 | 134 | 255 | 213 | 22 |
| IP | 1310 | 40 | 220 | 120 | 23 | 179 | 104 | 236 | 183 | 22 | ||
| EP | 885 | 82 | 204 | 158 | 18 | 132 | 157 | 270 | 227 | 23 | ||
| LE | 1004 | 98 | 195 | 112 | 9 | 235 | 135 | 261 | 219 | 23 | ||
| LN | 323 | 70 | 218 | 87 | 18 | 81 | 93 | 215 | 165 | 24 | ||
| EM | 649 | 91 | 162 | 104 | 7 | 124 | 137 | 243 | 198 | 22 | ||
| Saturdays | MP | 122 | 39 | 192 | 124 | 29 | 29 | 123 | 219 | 184 | 21 | |
| IP | 290 | 59 | 177 | 116 | 19 | 38 | 135 | 210 | 177 | 18 | ||
| EP | 176 | 77 | 194 | 162 | 18 | 26 | 171 | 256 | 224 | 22 | ||
| LE | 190 | 94 | 151 | 108 | 9 | 46 | 150 | 250 | 212 | 28 | ||
| LN | 51 | 68 | 148 | 83 | 12 | 14 | 120 | 198 | 168 | 22 | ||
| EM | 125 | 92 | 161 | 103 | 9 | 24 | 154 | 236 | 204 | 23 | ||
| Sundays | MP | 117 | 57 | 211 | 128 | 28 | 27 | 115 | 206 | 182 | 20 | |
| IP | 277 | 68 | 201 | 119 | 19 | 36 | 57 | 217 | 175 | 29 | ||
| EP | 167 | 80 | 193 | 162 | 18 | 25 | 158 | 252 | 219 | 25 | ||
| LE | 181 | 94 | 167 | 107 | 10 | 36 | 149 | 256 | 220 | 23 | ||
| LN | 48 | 67 | 195 | 82 | 18 | 10 | 112 | 192 | 165 | 26 | ||
| EM | 119 | 90 | 131 | 100 | 6 | 23 | 147 | 241 | 203 | 25 | ||
| DOWN | Weekdays | MP | 558 | 56 | 205 | 143 | 22 | 129 | 126 | 258 | 214 | 23 |
| IP | 1184 | 46 | 208 | 122 | 24 | 160 | 97 | 227 | 182 | 24 | ||
| EP | 796 | 88 | 205 | 160 | 18 | 122 | 165 | 264 | 225 | 21 | ||
| LE | 906 | 97 | 233 | 112 | 10 | 212 | 128 | 271 | 218 | 21 | ||
| LN | 291 | 64 | 188 | 80 | 14 | 73 | 82 | 213 | 158 | 25 | ||
| EM | 586 | 95 | 173 | 107 | 7 | 112 | 118 | 249 | 196 | 25 | ||
| Saturdays | MP | 121 | 70 | 191 | 127 | 25 | 28 | 105 | 208 | 182 | 22 | |
| IP | 284 | 83 | 180 | 126 | 17 | 39 | 115 | 216 | 180 | 21 | ||
| EP | 172 | 104 | 202 | 164 | 19 | 26 | 184 | 261 | 223 | 20 | ||
| LE | 185 | 94 | 186 | 109 | 10 | 44 | 157 | 259 | 220 | 20 | ||
| LN | 49 | 65 | 202 | 81 | 20 | 13 | 87 | 190 | 151 | 30 | ||
| EM | 122 | 96 | 150 | 105 | 9 | 24 | 137 | 241 | 197 | 22 | ||
| Sundays | MP | 110 | 75 | 200 | 127 | 28 | 27 | 135 | 211 | 183 | 20 | |
| IP | 262 | 65 | 183 | 118 | 19 | 37 | 89 | 238 | 173 | 29 | ||
| EP | 160 | 105 | 199 | 163 | 19 | 23 | 159 | 258 | 222 | 24 | ||
| LE | 172 | 93 | 148 | 106 | 8 | 40 | 160 | 264 | 223 | 19 | ||
| LN | 46 | 62 | 227 | 80 | 25 | 12 | 114 | 188 | 162 | 22 | ||
| EM | 114 | 94 | 133 | 104 | 7 | 21 | 145 | 237 | 203 | 21 | ||
| S. No. | Study | No. of Distributions Considered | Number of Traffic Scenarios Considered | Acceptance Rate |
|---|---|---|---|---|
| 1 | Present study | 60 | 144 | 98.4% |
| 2 | [25] | 7 | 6 | 91.6% |
| 3 | [16] | 4 | 16 | 87.5% |
| 4 | [22] | 4 | 24 | 79.2% |
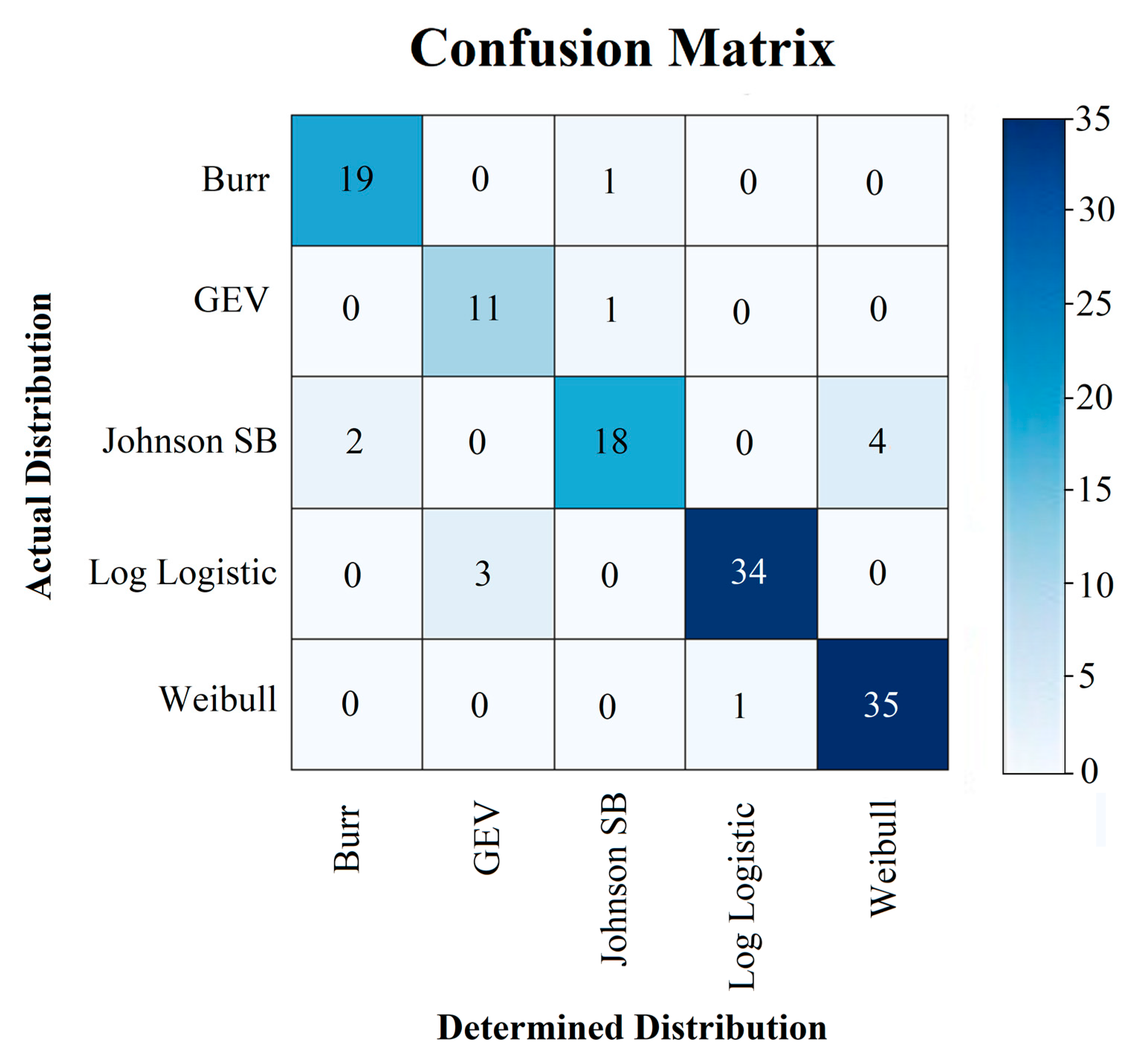
| S. No. | Class | Precision | Sensitivity | F1-Score | Specificity | FPR |
|---|---|---|---|---|---|---|
| 1 | Burr | 90.48 | 95.00 | 92.68 | 98.17 | 1.83 |
| 2 | GEV | 78.57 | 91.67 | 84.62 | 97.44 | 2.56 |
| 3 | Johnson SB | 90.00 | 75.00 | 81.82 | 98.10 | 1.90 |
| 4 | Log Logistic | 97.14 | 91.89 | 94.44 | 98.91 | 1.09 |
| 5 | Weibull | 89.74 | 97.22 | 93.33 | 95.70 | 4.30 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sihag, G.; Kumar, P.; Parida, M. Development of a Machine-Learning-Based Novel Framework for Travel Time Distribution Determination Using Probe Vehicle Data. Data 2023, 8, 60. https://doi.org/10.3390/data8030060
Sihag G, Kumar P, Parida M. Development of a Machine-Learning-Based Novel Framework for Travel Time Distribution Determination Using Probe Vehicle Data. Data. 2023; 8(3):60. https://doi.org/10.3390/data8030060
Chicago/Turabian StyleSihag, Gurmesh, Praveen Kumar, and Manoranjan Parida. 2023. "Development of a Machine-Learning-Based Novel Framework for Travel Time Distribution Determination Using Probe Vehicle Data" Data 8, no. 3: 60. https://doi.org/10.3390/data8030060