

Learned Sorted Table Search and Static Indexes in Small-Space Data Models †

Abstract
:1. Introduction
1.1. Literature Review
1.1.1. Core Methods and Benchmarking Platform
1.1.2. Applications
1.1.3. The Emergence of a New Role of Machine Learning for Data Processing and Analysis
1.2. Our Contributions to Learned Indexing
- How space-demanding should a predictive model be in order to speed up Sorted Table Search procedures.
- To what extent can one enjoy the speeding up of the search procedures provided by Learned Indexes with respect to the additional space one needs to use.
1.3. Road Map of the Paper
2. Learning from a Static Sorted Set to Speed Up Searching
2.1. Solution with a Sorted Search Routine
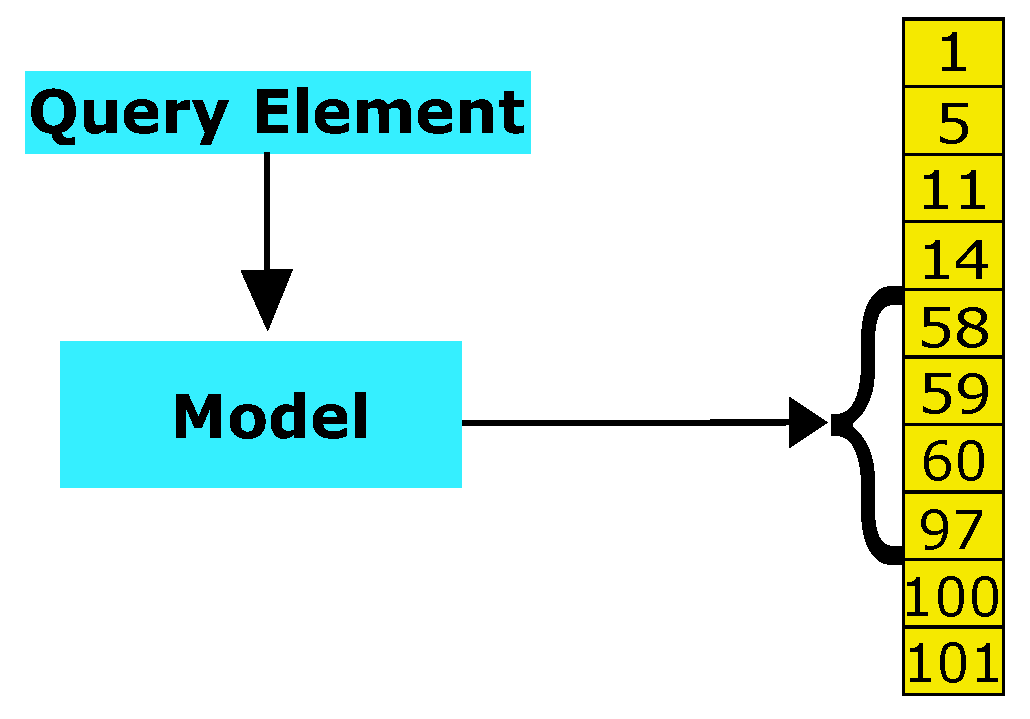
2.2. Learning from Data to Speed Up Sorted Table Search: A Simple View with an Example
- Ingredient One of Learned Indexing: The Cumulative Distribution Function of a Sorted Table. With reference to Figure 2a, we can plot the elements of A in a graph, where the abscissa reports the value of the elements in the table and the ordinates are their corresponding ranks. The result of the plot is reminiscent of a discrete Cumulative Distribution Function that underlines the table. The specific construction exemplified here can be generalized to any sorted table as discussed in Marcus et al. [9]. In the literature, for a given table, such a discrete curve is referenced as CDF.
- Ingredient Two of Learned Indexing: A Model for theCDF. Now, it is essential to transform the discrete CDF into a continuous curve. The simplest way to do this is to fit a straight line of equation to the CDF (this process is shown in Figure 2b). In this example, we use Linear Regression with Mean Square Error Minimization in order to obtain a and b. They are 0.01 and 0.85, respectively.
- Ingredient Three of Learned Indexing: The Model Error Correction. Since F is an approximation of the ranks of the elements in the table, in applying it to an element in order to predict its rank, we may produce an error e. With reference to Figure 2c, applying the model to the element 398, we obtain a predicted rank of , instead of 7, which is the real rank. Thus, the error made by the model on this element is . Therefore, in order to use the equation F to predict where an element x is in the table, we must correct for this error. Indeed, we consider the maximum error computed as the maximum distance between the real rank of the elements in the table and the corresponding rank predicted by the model. The maximum error is used to set the search interval of an element x to be . In the example we are discussing, is 3.
2.3. A Classification of Learned Indexing Models
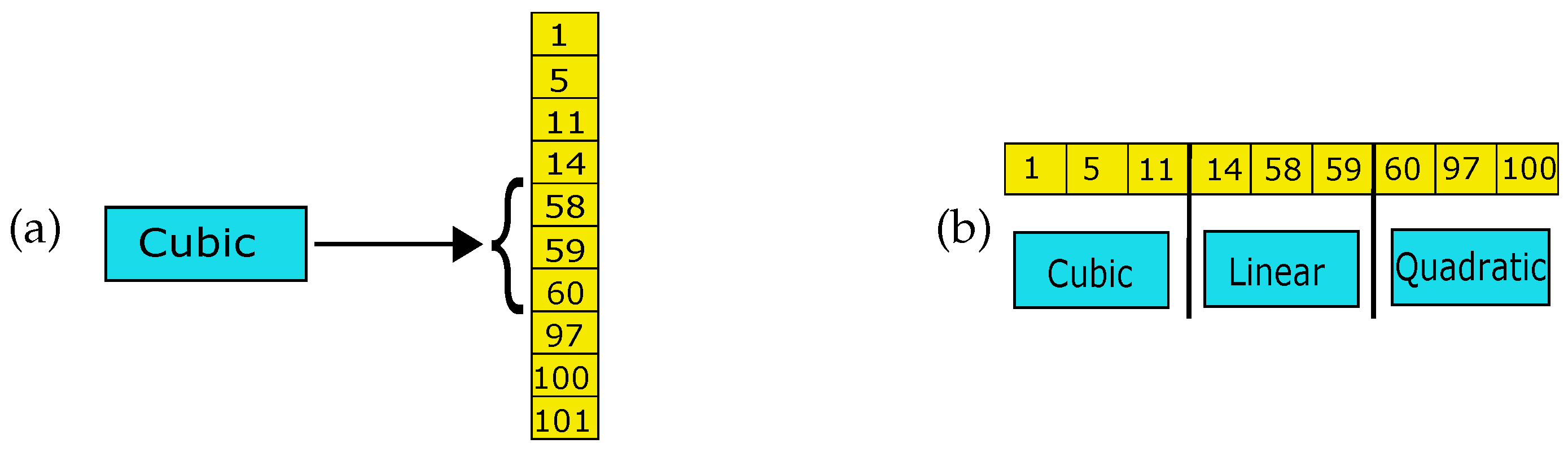
2.3.1. Atomic Models: One Level and No Branching Factor
- Simple Regression [52]. We use linear, quadratic and cubic regression models. Each can be thought of as an Atomic Model in the sense that it cannot be divided into “sub-models”. Figure 3a provides an example. We report that the most appropriate regression model in terms of the query times and a reduction factor is the cubic one. We omit those results for brevity and to keep our contribution focused on the important findings. However, they can be found in [51]. For this reason, the cubic model, indicated in the rest of the manuscript by C, is the only one that is included in what follows.
2.3.2. A Two-Level Hybrid Model with a Constant Branching Factor
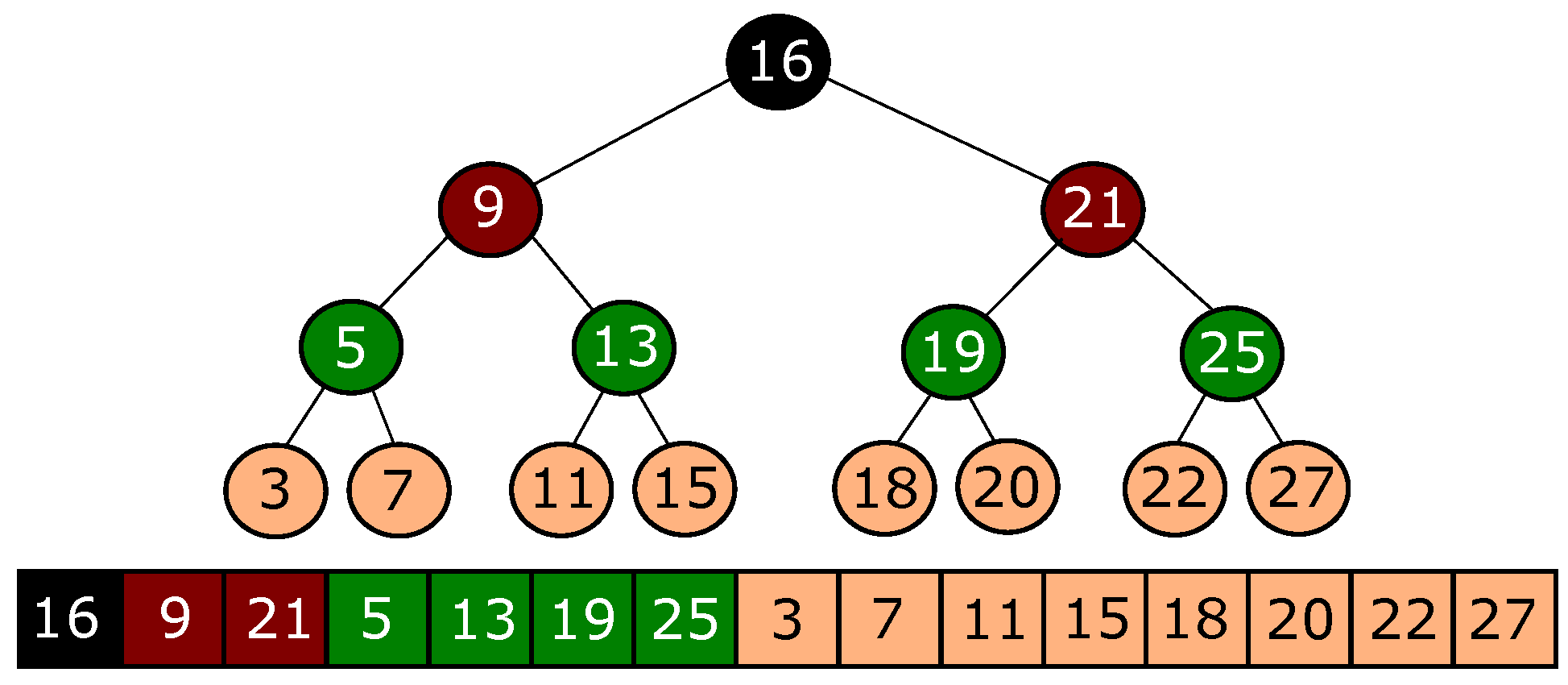
- KO-US: Learned k-ary Search. This model partitions the table into a fixed number of segments, bounded by a small constant, i.e., at most 20 in this study, in analogy with a single iteration of the k-ary Search routine [53,54]. An example is provided in Figure 3b. For each segment, Atomic Models are computed to approximate the CDF of the table elements in that segment. Finally, the model that guarantees the best reduction factor is assigned to each segment. As for the prediction, a sequential search is performed for the second level segment to pick and the corresponding model is used for the prediction, followed by Uniform Binary Search, since it is superior to the Standard one (data not reported and available upon request). We anticipate that, for the experiments conducted in this study, k is chosen in the interval . For conciseness, only results for the model with are reported, since it is the value with the best performance in terms of query time (data not reported and available upon request). Accordingly, from now on, KO-US indicates the model with .
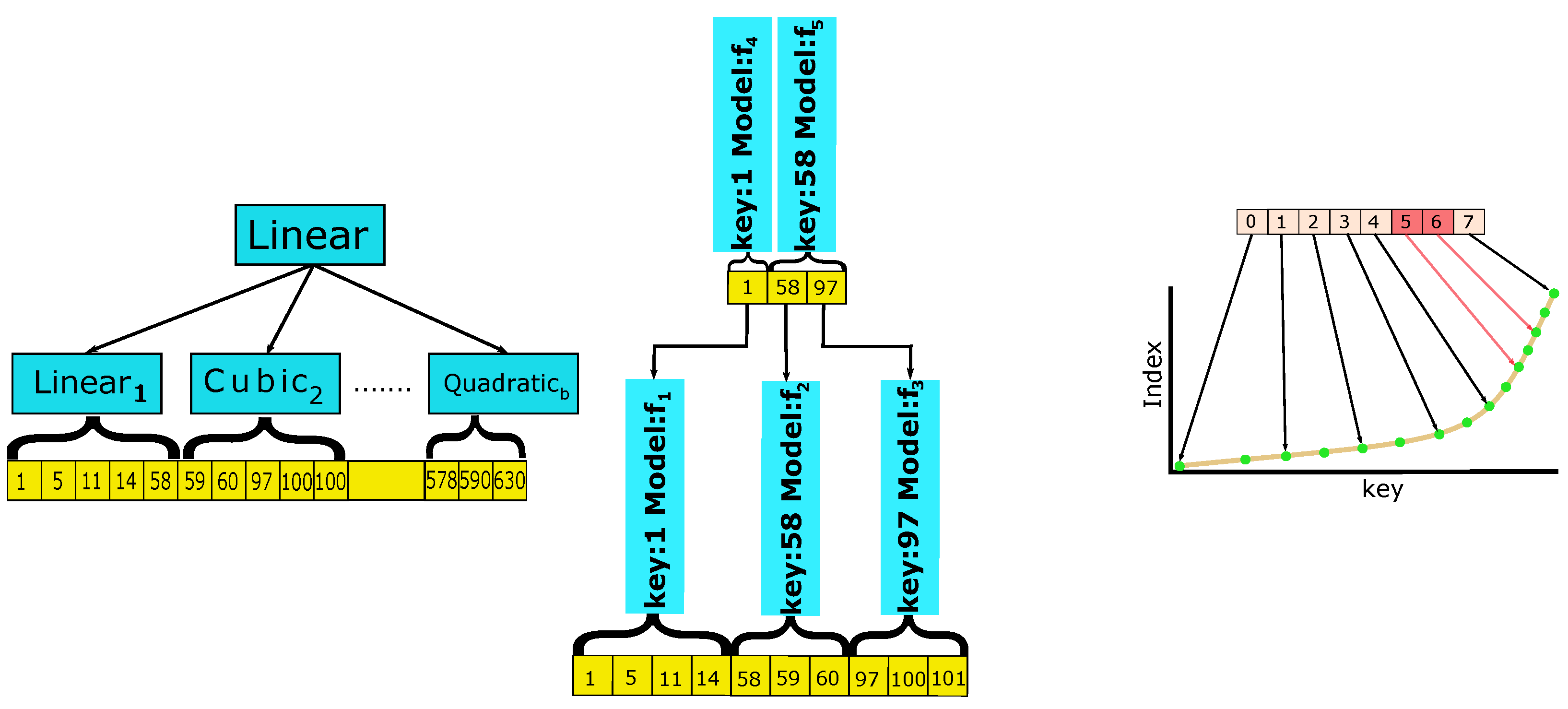
2.3.3. Two-Level RMIs with Parametric Branching Factor
- Heuristically Optimized RMIs. Informally, an RMI is a multi-level, directed graph, with Atomic Models at its nodes. When searching for a given key and starting with the first level, a prediction at each level identifies the model of the next level to use for the next prediction. This process continues until a final level model is reached. This latter is used to predict the table interval to search into. As indicated in the benchmarking study, in most applications, a generic RMI with two layers, a tree-like structure and a branching factor b suffices. An example is provided in Figure 4 on the left. It is to be noted that the Atomic Models are RMIs. Moreover, the difference between Learned k-ary Search and RMIs is that the first level in the former partitions the table, while that same level in the latter partitions the universe of the elements.Following the benchmarking study and for a given table, we use two-layer RMIs that we obtain using the optimization software provided in CDFShop, which returns up to ten versions of the generic RMI for a given input table. For each model, the optimization software picks an appropriate branching factor and the type of regression to use within each part of the model—the latter quantities being the parameters that control the precision of its prediction as well as its space occupancy. It is also to be remarked, as indicated in [12], that the optimization process provides only approximations to the real optimum and is heuristic in nature with no theoretic approximation performance guarantees. The problem of finding an optimal model in polynomial time is open.
- SY-RMI: A Synoptic RMI. For a given set of tables of approximately the same size, we use CDFShop as above to obtain a set of models (at most 10 for each table). For the entire set of models thus obtained and each model in it, we compute the ratio (branching factor)/(model space), and we take the median of those ratios as a measure of the branching factor per unit of model space, denoted as . Among the RMIs returned by CDFShop, we pick the relative majority winner, i.e., the one that provides the best query time, averaged over a set of simulations. When one uses such a model on tables of approximately the same size as the ones used as input to CDFShop, we set the branching factor to be a multiple of , which depends on how much space the model is expected to use relative to the input table size. This model can be intuitively considered as the one that best summarizes the output of CDFShop in terms of the query time for the given set of tables. The final model is informally referred to as Synoptic.
2.3.4. CDF Approximation-Controlled Models
- PGM [13]. This is also a multi-stage model, built bottom-up and queried top-down. It uses a user-defined approximation parameter , which controls the prediction error at each stage. With reference to Figure 4 in the center, the table is subdivided into three pieces. A prediction in each piece can be provided via a linear model guaranteeing an error of . A new table is formed by selecting the minimum values in each of the three pieces. This new table is possibly again partitioned into pieces, in which a linear model can make a prediction within the given error.The process is iterated until only one linear model suffices, as in the case in the figure. A query is processed via a series of predictions, starting at the root of the tree. Furthermore, in this case, for a given table, at most ten models were built as prescribed in the benchmarking study with the use of the parameters, software and methods provided there, i.e, SOSD. It is to be noted that the PGM index, in its bi-criteria version, is able to return the best query time index, within the given amount of space that the model is supposed to use. Experiments are also performed with this version of the PGM, denoted for brevity as B-PGM. The interested reader can find a discussion regarding more variants of this PGM version in [51].
- RS [17]. This is a two-stage model. It also uses a user-defined approximation parameter . With reference to Figure 4 on the right, a spline curve approximating the CDF of the data is built. Then, the radix table is used to identify spline points to use to refine the search interval. Furthermore, in this case, we performed the training as described in the benchmarking study.
3. Experimental Methodology
3.1. Hardware
3.2. Datasets
- amzn: book popularity data from Amazon. Each key represents the popularity of a particular book. Although two versions of this dataset, i.e., 32-bit and 64-bit, are used in the benchmarking, no particular differences were observed in the results of our experiments, and, for this reason, we report only those for the 64-bit dataset. The interested reader can find the results for the 32-bit version in [51].
- face: randomly sampled Facebook user IDs. Each key uniquely identifies a user.
- osm: cell IDs from Open Street Map. Each key represents an embedded location.
- wiki: timestamps of edits from Wikipedia. Each key represents the time an edit was committed.
- Fitting in L1 cache: cache size 64 Kb. Therefore, was chosen.
- Fitting in L2 cache: cache size 256 Kb. Therefore, was chosen.
- Fitting in L3 cache: cache size 8 Mb. Therefore, was chosen.
- Fitting in PC main memory (L4): memory size 32 Gb. Therefore, was chosen, i.e., the entire dataset.
4. Training of the Novel Models: Analysis and Insights into Model Training
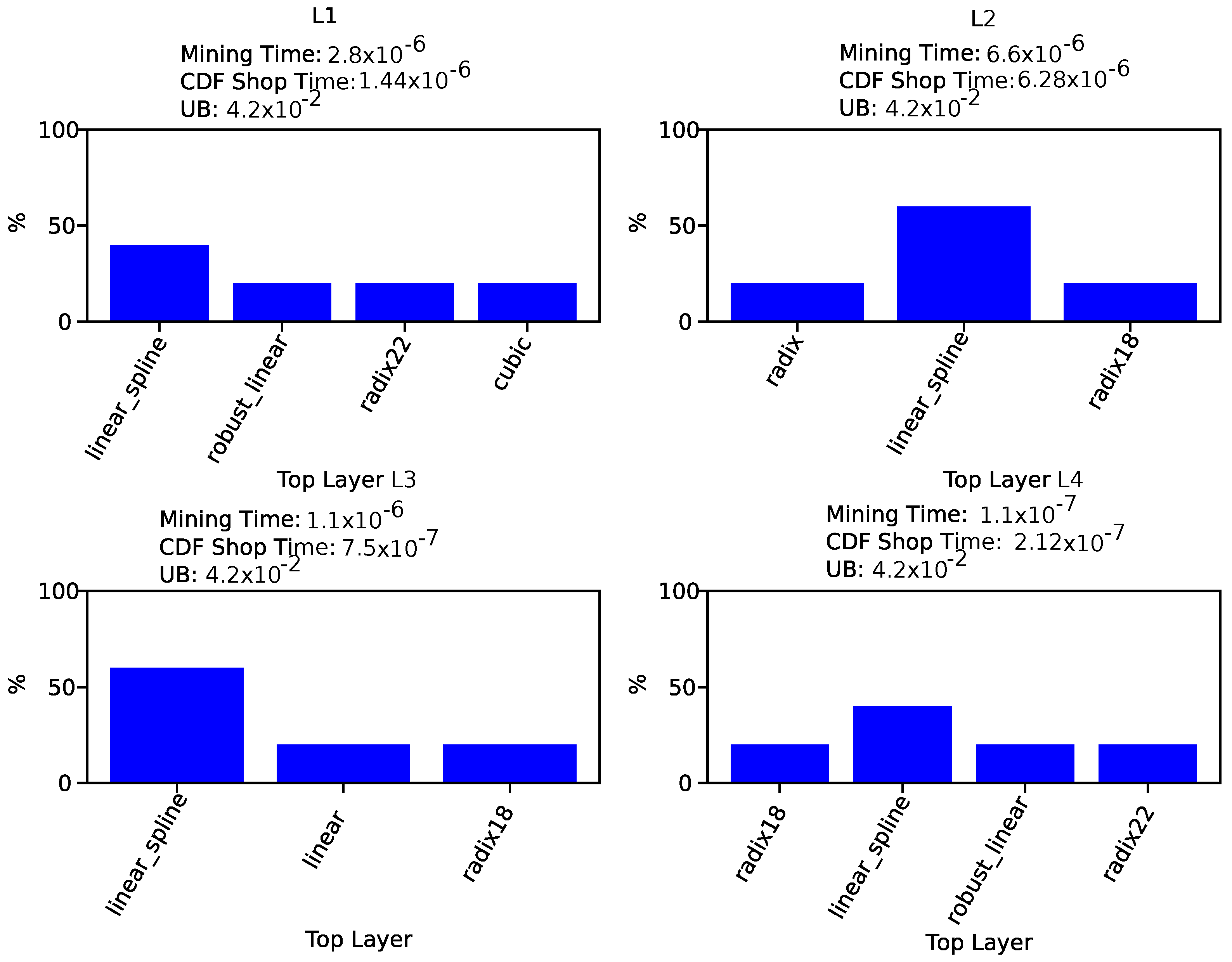
4.1. Mining SOSD Output for the Synoptic RMI
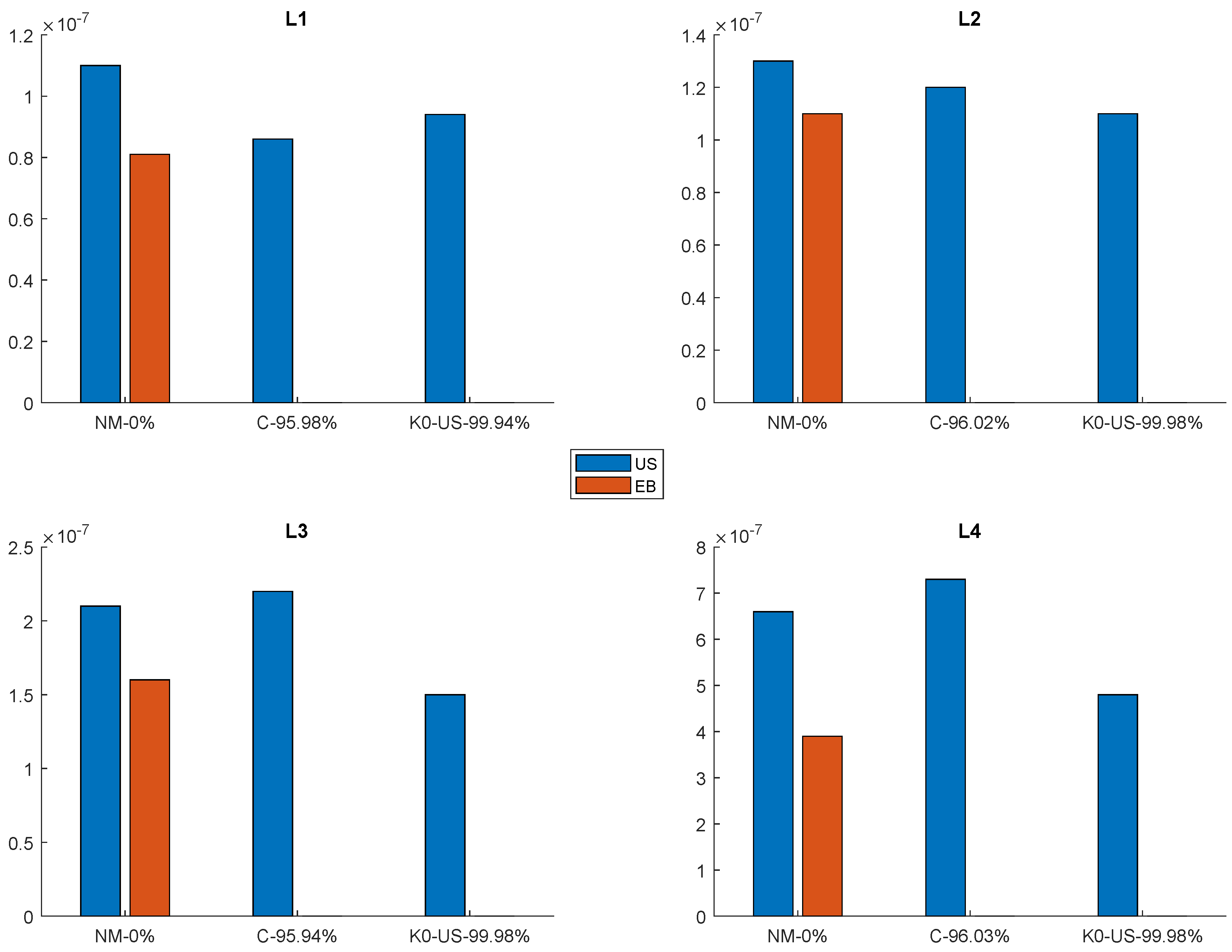
4.2. Training Time Comparison between Novel Models and the State of the Art
4.3. Insights into the Training Time of the RS and PGM Models
5. Query Experiments
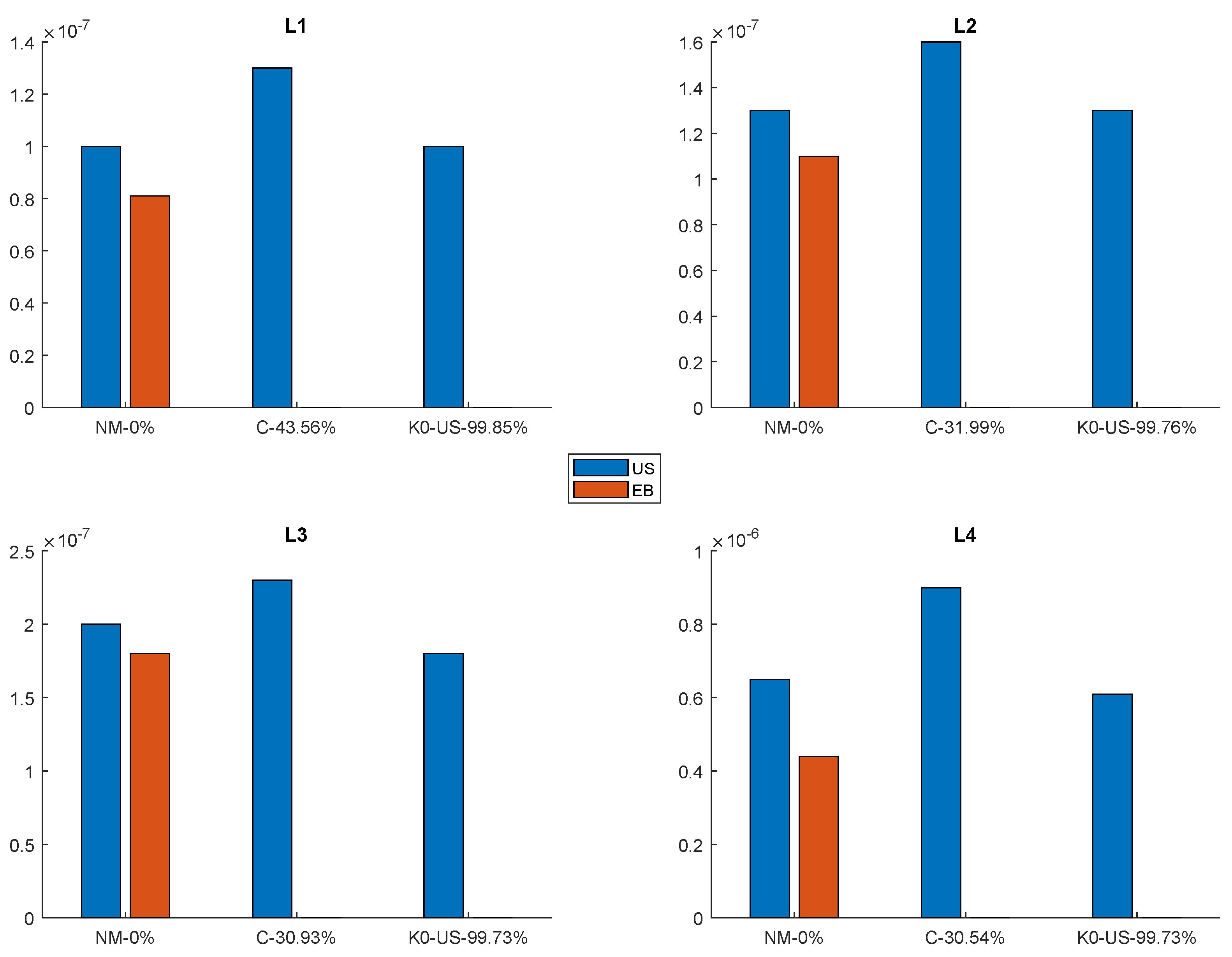
5.1. Constant-Space Models
- The Cubic Model achieved a high reduction factor, i.e., , on the versions of the face dataset for the first three levels of the internal memory hierarchy, and it was also the best performing, even compared to the Eytzinger Layout routine. This is a quite remarkable achievement; however, the involved datasets had an almost uniform CDF, while a few outliers disrupt this uniformity on the L4 version of that dataset (see Figure 5 and the discussion regarding the face dataset in Section 3.2).
- The Learned k-ary Search Model achieved a high reduction factor on all versions of the amzn and the wiki datasets, i.e., and was faster than the Uniform Binary Search and the Cubic Model. Those datasets have a regular CDF across all the internal memory levels. It is to be noted that the Eytzinger Layout routine is competitive with the Learned k-ary Search Model.
- No constant space Learned Model won on the difficult-to-learn dataset. The osm dataset has a difficult-to-learn CDF (see Figure 5), and such a characteristic is preserved across the internal memory levels. The Learned k-ary Search Model achieved a respectable reduction factor, i.e., , but no speed increase with respect to Uniform Binary Search. In order to obtain insights into such a counter-intuitive behavior, we performed an additional experiment.For each representative dataset and as far as the Learned k-ary Search Model is concerned, we computed two kinds of reduction factors: the first was the global one, achieved considering the size of the entire table, while the second was the local one, computed as the average among the reduction factors of each segment. Those results are reported in Table 4. For the osm dataset, it is evident that the local reduction factors are consistently lower than the global ones, highlighting that its CDF is also locally difficult to approximate, which, in turn, implies an ineffective use of the local prediction for the Learned k-ary Search, resulting in poor time performance. Finally, it is to be noted that the Eytzinger Layout routine was the best performing.
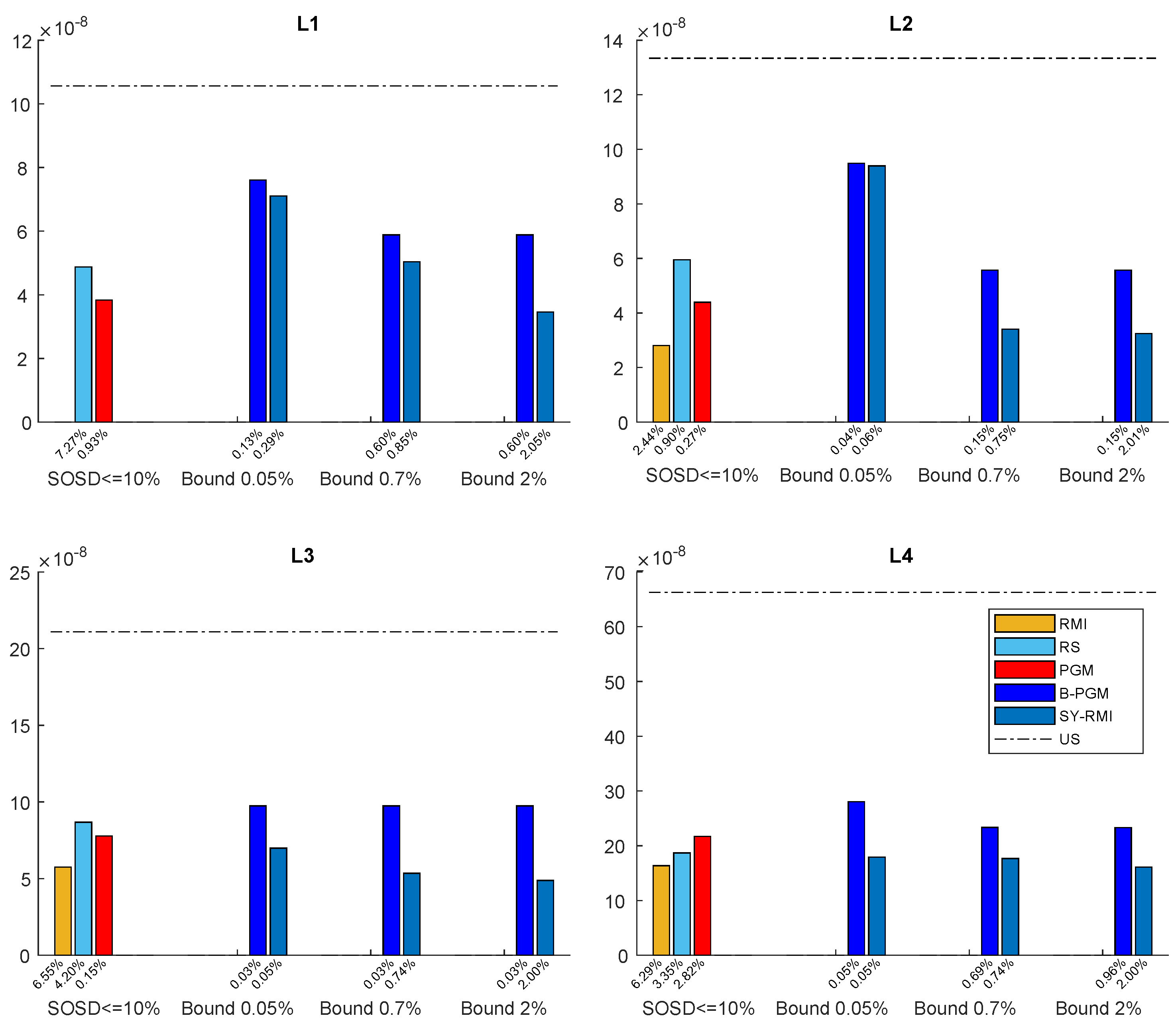
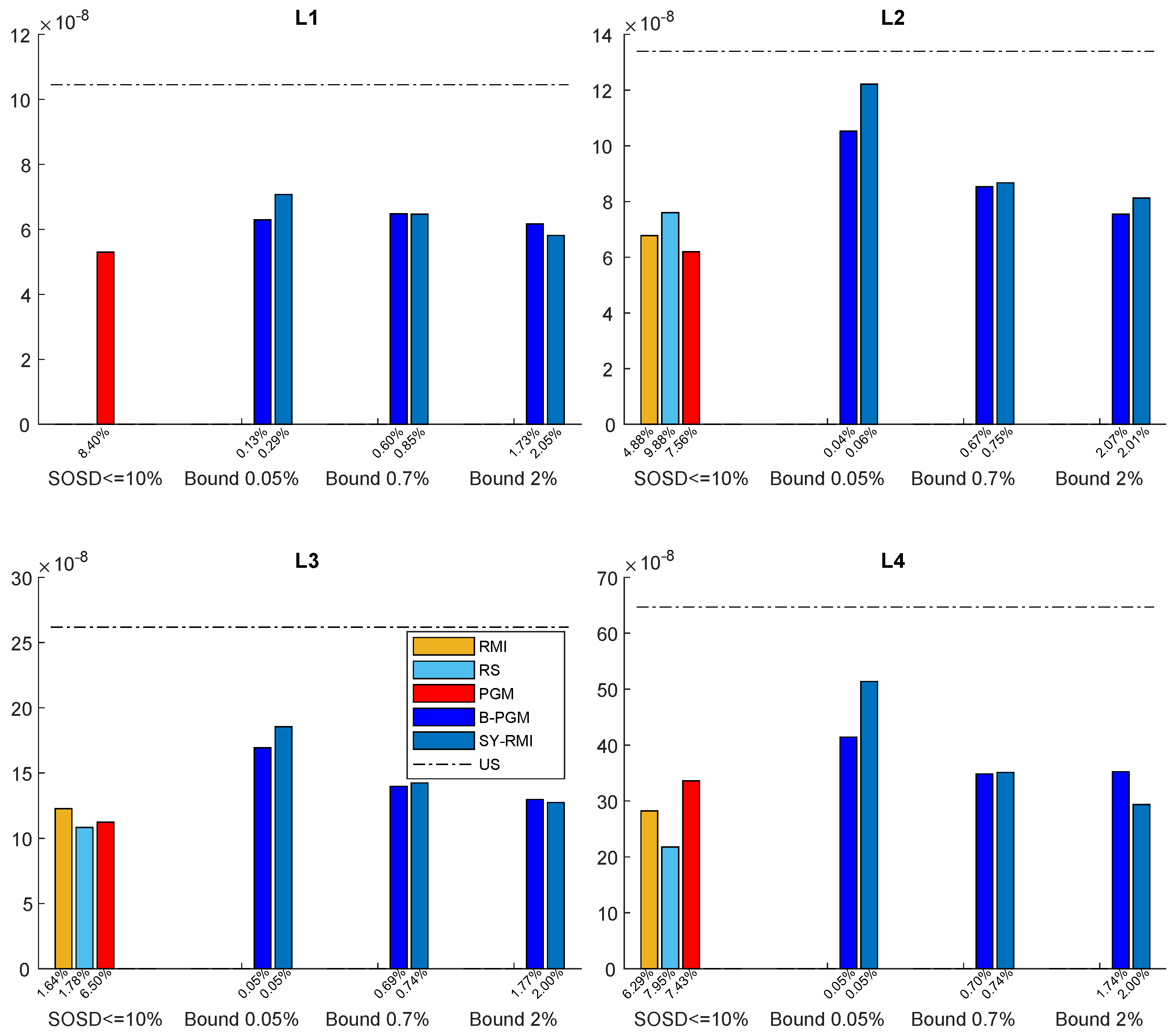
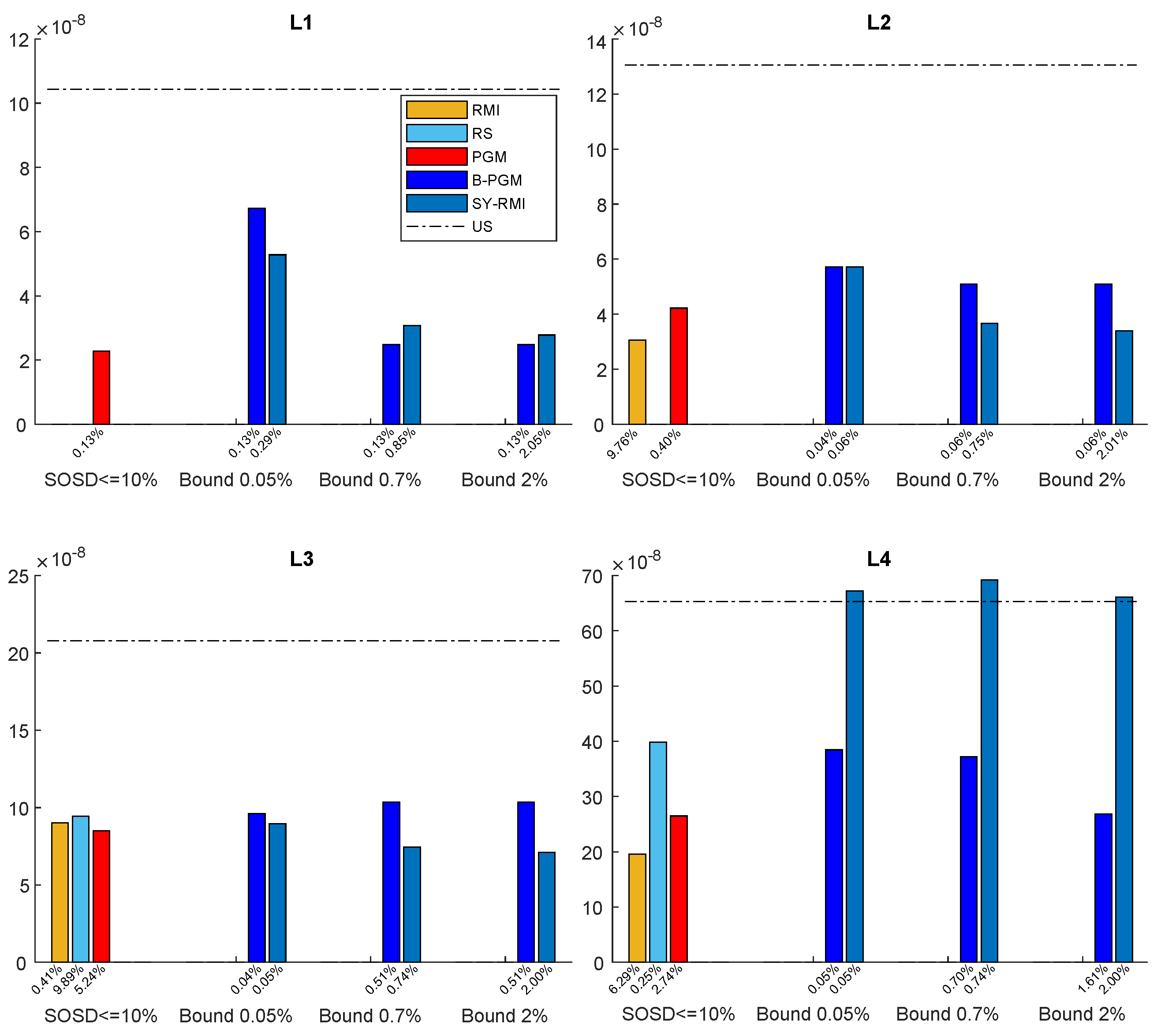
5.2. Parametric-Space Models
- Space Constraints and the Models Provided by SOSD. We fixed a rather small space budget, i.e., at most of additional space in order for a model returned by SOSD to be considered. The RS Index was not competitive with respect to the other Learned Indexes. Those latter consistently use less space and time across datasets and memory levels. As for the RMIs coming out of SOSD, they were not able to operate in a small space at the L1 memory level. On the other memory levels, they were competitive with respect to the bi-criteria PGM and the Synoptic RMI; however, they required more space with respect to them.
- Space, Time and Accuracy of Models. As stated in the benchmarking study, a common view of Learned Indexing Data Structures is as a CDF lossy compressor; see also [2,13]. In this view, the quality of a Learned Index can be judged by the size of the structure and its reduction factor. In that study, it was also argued that this view does not provide an accurate selection criterion for Learned Indexes. Indeed, it may very well be that an index structure with an excellent reduction factor takes a long time to produce a search bound, while an index structure with a worse reduction factor that quickly generates an accurate search bound may be of better use. In the benchmarking study, they also provided evidence that the space–time trade-off is the key factor in determining which model to choose.Our contribution is to provide additional results supporting those findings. To this end, we conducted several experiments, whose results are reported in Table 5 and Table 6 and Table A9 and Table A10 in the Appendix A.5. In these Tables, for each dataset, we report a synopsis of three parameters, i.e., the query time and space used in addition by the model and reduction factor, across all datasets and memory levels. In particular, for each dataset, we compare the best-performing model with all the ones that use small space, taking, for each parameter, the ratio of the model/best model. The ratio values are reported from the second row of the table, and the first row shows the average values of the parameters for the best model.First, it is useful to note that, even in a small-space model, it is possible to obtain a good, if not nearly perfect, prediction (i.e., a very high reduction factor). However, prediction power is somewhat marginal to assess performance. Indeed, across memory levels, we see a space classification of model configurations. The most striking feature of this classification is that the gain in query time between the best model and the others is within small constant factors, while the difference in space occupancy may be, in most cases, several orders of magnitude different—that is, space is the key to efficiency.
6. Conclusions and Future Directions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| CDF | Cumulative Distribution Function |
| RMI | Recursive Model Index |
| PGM | Piece-wise Geometric Model Index |
| RS | Radix Spline index |
| ALEX | Adaptive Learned index |
| SOSD | Searching on Sorted Data |
| KO-US | Learned k-ary Search |
| SY-RMI | Synoptic RMI |
| BS | lower_bound search routine |
| US | Uniform Binary Search |
| EB | Eytzinger Layout Search |
| C | Cubic regression model |
| B-PGM | Bicriteria Piece-wise Geometric Model Index |
| L1 | cache of size 64kb |
| L2 | cache of size 256kb |
| L3 | cache of size 12Mb |
| L4 | memory size 32Gb |
| amzn | the Amazon dataset |
| face | the Facebook dataset |
| osm | the OpenStreetMap dataset |
| wiki | the Wikipedia dataset |
Appendix A. Methods and Results: Additional Material
Appendix A.1. Binary Search and Its Variants
- 1
- Sorted. We use two versions of Binary Search for this layout. The template of the lower_bound routine is provided in Algorithm A1, while the Uniform Binary Search implementation is given in Algorithm A2. In particular, this implementation of Binary Search is as found in [23].
- 2
| Algorithm A1 Lower_bound Template. |
|
| Algorithm A2 Implementation of Uniform Binary Search. The code is as in [23] (see also [3,54]). |
|

| Algorithm A3 Uniform Binary Search with Eytzinger layout. The code is as in [23]. |
|
Appendix A.2. Datasets: Details
- Fitting in L1 cache: cache size 64 Kb. Therefore, we choose . For each dataset, the table corresponding to this type is denoted with the prefix L1, e.g., L1_amzn, when needed. For each dataset, in order to obtain a CDF that resembles one of the original tables, we proceed as follows. Concentrating on amzn, since for the other datasets the procedure is analogous, we extract uniformly and at random a sample of the data of the required size. For each sample, we compute its CDF. Then, we use the Kolmogorov–Smirnov test [57] in order to assess whether the CDF of the sample is different than the amzn CDF.If the test returns that we cannot exclude such a possibility, we compute the PDF of the sample and compute its KL divergence [58] from the PDF of amzn. We repeat such a process 100 times and, for our experiments, we use the sample dataset with the smallest KL divergence.
- Fitting in L2 cache: cache size 256 Kb. Therefore, we choose . For each dataset, the table corresponding to this type is denoted with the prefix L2, when needed. For each dataset, the generation procedure is the same as the one of the L1 dataset.
- Fitting in L3 cache: cache size 8 Mb. Therefore, we choose . For each dataset, the table corresponding to this type is denoted with the prefix L3, when needed. For each dataset, the generation procedure is the same as the one of the L1 dataset.
- Fitting in PC main memory: memory size 32 Gb. Therefore, we choose , i.e., the entire dataset. For each dataset, the table corresponding to this type is denoted with the prefix L4.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
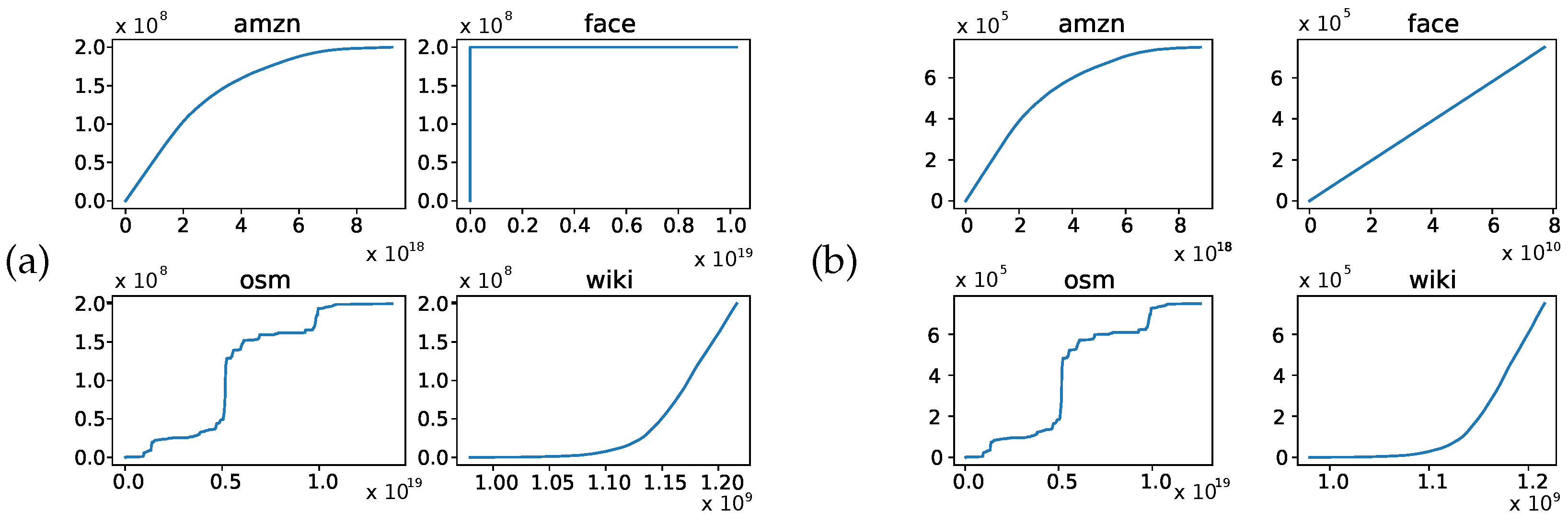{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| L1 | L2 | L3 | ||||
|---|---|---|---|---|---|---|
| Datasets | %succ | KLdiv | %succ | KLdiv | %succ | KLdiv |
| amzn | 100 | 100 | 100 | |||
| face | 100 | 100 | 100 | |||
| osm | 100 | 100 | 100 | |||
| wiki | 100 | 100 | 100 | |||
Appendix A.3. Training of the Novel Models: Analysis and Insights into Model Training—Additional Results
| KO-US | C | |
|---|---|---|
| amzn | ||
| face | ||
| osm | ||
| wiki |
| KO-BFS | C | |
|---|---|---|
| amzn | ||
| face | ||
| osm | ||
| wiki |
| KO-US | C | |
|---|---|---|
| amzn | ||
| face | ||
| osm | ||
| wiki |
| CDFShop SY-RMI 2% | CDFShop RMI | SOSD RS | SOSD PGM | |
|---|---|---|---|---|
| amzn | ||||
| face | ||||
| osm | ||||
| wiki |
| CDFShop SY-RMI 2% | CDFShop RMI | SOSD RS | SOSD PGM | |
|---|---|---|---|---|
| amzn | ||||
| face | ||||
| osm | ||||
| wiki |
| CDFShop SY-RMI 2% | CDFShop RMI | SOSD RS | SOSD PGM | |
|---|---|---|---|---|
| amzn | ||||
| face | ||||
| osm | ||||
| wiki |
Appendix A.4. Accuracy of Query Time Evaluation
| RMI | PGM | RS | SY-RMI 0.05 | KO-US | |
|---|---|---|---|---|---|
| L1 | |||||
| L2 | |||||
| L3 | |||||
| L4 |
Appendix A.5. Query Experiments—Additional Results
- Figure A2 and Figure A3 report the experiments concerning the constant-space models as in Section 5.1.
- Figure A4 and Figure A5 report the experiments concerning the parametric-space models as in Section 5.2.
- Table A9 and Table A10 report a synopsis of three parameters, i.e., the query time, space used in addition by the model and reduction factor as described in Section 5.2.




| L1 | |||
| Time | Space | Reduction Factor | |
| Best PGM | 99.52 | ||
| Best PGM | 1.00 | 1.00 | 1.00 |
| SY-RMI 0.05 | 2.33 | 2.20 | |
| Best RMI | 1.16 | 1.00 | |
| Best RS | 1.17 | 1.00 | |
| L2 | |||
| Time | Space | Reduction Factor | |
| Best RMI | 99.98 | ||
| B-PGM 0.05 | |||
| SY-RMI 0.05 | |||
| Best RMI | 1.00 | 1.00 | 1.00 |
| Best RS | 1.10 | 1.00 | |
| L3 | |||
| Time | Space | Reduction Factor | |
| Best RMI | 100.00 | ||
| B-PGM 0.05 | 1.57 | 1.00 | |
| RMI< 10 | 1.19 | 1.00 | |
| SY-RMI 0.7 | 1.22 | 1.00 | |
| RS < 10 | 1.53 | 1.00 | |
| L4 | |||
| Time | Space | Reduction Factor | |
| Best RMI | 100.00 | ||
| SY-RMI 0.05 | 3.74 | ||
| B-PGM 0.05 | 2.14 | 1.00 | |
| Best RS | 2.21 | 1.00 | |
| RMI < 10 | 1.06 | 1.00 | |
| L1 | |||
| Time | Space | Reduction Factor | |
| Best RMI | 3.09 | 99.84 | |
| B-PGM 0.05 | 2.50 | ||
| SY-RMI 0.05 | 2.24 | ||
| Best RMI | 1.00 | 1.00 | 1.00 |
| Best RS | 1.70 | 2.40 | |
| L2 | |||
| Time | Space | Reduction Factor | |
| Best RMI | 99.98 | ||
| B-PGM 0.05 | 2.66 | ||
| SY-RMI 0.05 | 2.59 | ||
| Best RS | 1.60 | ||
| RMI < 10 | 1.05 | 1.00 | |
| L3 | |||
| Time | Space | Reduction Factor | |
| Best RMI | 100.00 | ||
| B-PGM 0.05 | 2.26 | 1.00 | |
| SY-RMI 0.05 | 2.01 | 1.00 | |
| Best RS | 1.74 | 1.00 | |
| RMI < 10 | 1.14 | 1.00 | |
| L4 | |||
| Time | Space | Reduction Factor | |
| SY-RMI 2 | 100.00 | ||
| SY-RMI 0.05 | 1.39 | 1.00 | |
| B-PGM 0.05 | 1.82 | 1.00 | |
| Best RS | 1.30 | 1.00 | |
| RMI < 10 | 1.02 | 1.00 | |
References
- Cormen, T.H.; Leiserson, C.E.; Rivest, R.L.; Stein, C. Introduction to Algorithms, 3rd ed.; The MIT Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Kraska, T.; Beutel, A.; Chi, E.H.; Dean, J.; Polyzotis, N. The case for learned index structures. In Proceedings of the 2018 International Conference on Management of Data, Houston, TX, USA, 10–15 June 2018; pp. 489–504. [Google Scholar]
- Knuth, D.E. The Art of Computer Programming, Volume 3 (Sorting and Searching); Addison-Wesley: Boston, MA, USA, 1973; Volume 3, pp. 481–489. [Google Scholar]
- Aho, A.V.; Hopcroft, J.E.; Ullman, J.D. The Design and Analysis of Computer Algorithms; Addison Wesley: Boston, MA, USA, 1974. [Google Scholar]
- Comer, D. Ubiquitous B-Tree. ACM Comput. Surv. CSUR 1979, 11, 121–137. [Google Scholar] [CrossRef]
- Amato, D.; Lo Bosco, G.; Giancarlo, R. Learned Sorted Table Search and Static Indexes in Small Model Space. In Proceedings of the AIxIA 2021—Advances in Artificial Intelligence: 20th International Conference of the Italian Association for Artificial Intelligence, Virtual, 1–3 December 2021; Revised Selected Papers. Springer: Berlin/Heidelberg, Germany, 2021; pp. 462–477. [Google Scholar] [CrossRef]
- Ferragina, P.; Vinciguerra, G. Learned data structures. In Recent Trends in Learning from Data; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 5–41. [Google Scholar] [CrossRef]
- Mitzenmacher, M.; Vassilvitskii, S. Algorithms with Predictions. Commun. ACM 2022, 65, 33–35. [Google Scholar] [CrossRef]
- Marcus, R.; Kipf, A.; van Renen, A.; Stoian, M.; Misra, S.; Kemper, A.; Neumann, T.; Kraska, T. Benchmarking Learned Indexes. Proc. VLDB Endow. 2020, 14, 1–13. [Google Scholar] [CrossRef]
- Amato, D.; Lo Bosco, G.; Giancarlo, R. On the Suitability of Neural Networks as Building Blocks for the Design of Efficient Learned Indexes. In Proceedings of the Engineering Applications of Neural Networks, Crete, Greece, 17–20 June 2022; Iliadis, L., Jayne, C., Tefas, A., Pimenidis, E., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 115–127. [Google Scholar]
- Maltry, M.; Dittrich, J. A critical analysis of recursive model indexes. Proc. VLDB Endow. 2022, 15, 1079–1091. [Google Scholar] [CrossRef]
- Marcus, R.; Zhang, E.; Kraska, T. CDFShop: Exploring and optimizing learned index structures. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data, SIGMOD’20, Portland, OR, USA, 14–19 June 2020; pp. 2789–2792. [Google Scholar]
- Ferragina, P.; Vinciguerra, G. The PGM-index: A fully-dynamic compressed learned index with provable worst-case bounds. PVLDB 2020, 13, 1162–1175. [Google Scholar] [CrossRef]
- Chen, D.Z.; Wang, H. Approximating Points by a Piecewise Linear Function. Algorithmica 2012, 66, 682–713. [Google Scholar] [CrossRef]
- Galakatos, A.; Markovitch, M.; Binnig, C.; Fonseca, R.; Kraska, T. FITing-Tree: A data-aware index structure. In Proceedings of the 2019 International Conference on Management of Data, Amsterdam, The Netherlands, 30 June–5 July 2019; Association for Computing Machinery: New York, NY, USA, 2019. SIGMOD’19. pp. 1189–1206. [Google Scholar] [CrossRef] [Green Version]
- Kipf, A.; Marcus, R.; van Renen, A.; Stoian, M.; Kemper, A.; Kraska, T.; Neumann, T. SOSD: A benchmark for learned indexes. In Proceedings of the ML for Systems at NeurIPS, MLForSystems @ NeurIPS’19, Vancouver, BC, USA, 12–14 December 2019. [Google Scholar]
- Kipf, A.; Marcus, R.; van Renen, A.; Stoian, M.; Kemper, A.; Kraska, T.; Neumann, T. RadixSpline: A single-pass learned index. In Proceedings of the Third International Workshop on Exploiting Artificial Intelligence Techniques for Data Management, Portland, OR, USA, 14–20 June 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 1–5. [Google Scholar]
- Neumann, T.; Michel, S. Smooth Interpolating Histograms with Error Guarantees. In Proceedings of the Sharing Data, Information and Knowledge, Cardiff, UK, 7–10 July 2008. [Google Scholar] [CrossRef]
- Ding, J.; Minhas, U.F.; Yu, J.; Wang, C.; Do, J.; Li, Y.; Zhang, H.; Chandramouli, B.; Gehrke, J.; Kossmann, D.; et al. ALEX: An Updatable Adaptive Learned Index. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data, Portland, OR, USA, 14–19 June 2020; Association for Computing Machinery: New York, NY, USA, 2020. SIGMOD’20. pp. 969–984. [Google Scholar] [CrossRef]
- Amato, D.; Lo Bosco, G.; Giancarlo, R. Standard versus uniform binary search and their variants in learned static indexing: The case of the searching on sorted data benchmarking software platform. Softw. Pract. Exp. 2023, 53, 318–346. [Google Scholar] [CrossRef]
- Kipf, A.; Marcus, R.; van Renen, A.; Stoian, M.; Kemper, A.; Kraska, T.; Neumann, T. SOSD Leaderboard. Available online: https://learnedsystems.github.io/SOSDLeaderboard/leaderboard/ (accessed on 5 June 2022).
- Rao, J.; Ross, K.A. Cache conscious indexing for decision-support in main memory. In Proceedings of the 25th International Conference on Very Large Data, Edinburgh, Scotland, UK, 7–10 September 1999; pp. 78–89. [Google Scholar]
- Khuong, P.; Morin, P. Array layouts for comparison-based searching. J. Exp. Algorithmics 2017, 22, 1.3:1–1.3:39. [Google Scholar] [CrossRef] [Green Version]
- Wang, W.; Zhang, M.; Chen, G.; Jagadish, H.V.; Ooi, B.C.; Tan, K. Database Meets Deep Learning: Challenges and Opportunities. SIGMOD Rec. 2016, 45, 17–22. [Google Scholar] [CrossRef] [Green Version]
- Kraska, T.; Alizadeh, M.; Beutel, A.; Chi, E.H.; Ding, J.; Kristo, A.; Leclerc, G.; Madden, S.; Mao, H.; Nathan, V. Sagedb: A Learned Database System. In Proceedings of the CIDR 2019-9th Biennial Conference on Innovative Data Systems Research, Asilomar, CA, USA, 13–16 January 2019. [Google Scholar]
- Li, P.; Lu, H.; Zheng, Q.; Yang, L.; Pan, G. LISA: A Learned Index Structure for Spatial Data. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data, Portland, OR, USA, 14–19 June 2020; Association for Computing Machinery: New York, NY, USA, 2020. SIGMOD’20. pp. 2119–2133. [Google Scholar] [CrossRef]
- Wang, H.; Fu, X.; Xu, J.; Lu, H. Learned Index for Spatial Queries. In Proceedings of the 2019 20th IEEE International Conference on Mobile Data Management (MDM), Hong Kong, China, 10–13 June 2019; pp. 569–574. [Google Scholar] [CrossRef]
- Ol’ha, J.; Slanináková, T.; Gendiar, M.; Antol, M.; Dohnal, V. Learned Indexing in Proteins: Substituting Complex Distance Calculations with Embedding and Clustering Techniques. arXiv 2022, arXiv:2208.08910. [Google Scholar]
- Marcus, R.; Negi, P.; Mao, H.; Zhang, C.; Alizadeh, M.; Kraska, T.; Papaemmanouil, O.; Tatbul, N. Neo: A Learned Query Optimizer. Proc. VLDB Endow. 2019, 12, 1705–1718. [Google Scholar] [CrossRef] [Green Version]
- Zhang, M.; Wang, H. LAQP: Learning-based approximate query processing. Inf. Sci. 2021, 546, 1113–1134. [Google Scholar] [CrossRef]
- Marcus, R.; Negi, P.; Mao, H.; Tatbul, N.; Alizadeh, M.; Kraska, T. Bao: Making Learned Query Optimization Practical. SIGMOD Rec. 2022, 51, 6–13. [Google Scholar] [CrossRef]
- Mikhaylov, A.; Mazyavkina, N.S.; Salnikov, M.; Trofimov, I.; Qiang, F.; Burnaev, E. Learned Query Optimizers: Evaluation and Improvement. IEEE Access 2022, 10, 75205–75218. [Google Scholar] [CrossRef]
- Bloom, B.H. Space/Time Trade-Offs in Hash Coding with Allowable Errors. Commun. ACM 1970, 13, 422–426. [Google Scholar] [CrossRef]
- Mitzenmacher, M. A model for learned bloom filters and optimizing by sandwiching. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 2–8 December 2018; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2018; Volume 31. [Google Scholar]
- Vaidya, K.; Knorr, E.; Kraska, T.; Mitzenmacher, M. Partitioned Learned Bloom Filter. arXiv 2020, arXiv:2006.03176. [Google Scholar]
- Dai, Z.; Shrivastava, A. Adaptive learned bloom filter (ada-bf): Efficient utilization of the classifier with application to real-time information filtering on the web. Adv. Neural Inf. Process. Syst. 2020, 33, 11700–11710. [Google Scholar]
- Fumagalli, G.; Raimondi, D.; Giancarlo, R.; Malchiodi, D.; Frasca, M. On the Choice of General Purpose Classifiers in Learned Bloom Filters: An Initial Analysis within Basic Filters. In Proceedings of the 11th International Conference on Pattern Recognition Applications and Methods (ICPRAM), Online, 3–5 February 2022; pp. 675–682. [Google Scholar]
- Singh, A.; Gupta, S. Learning to hash: A comprehensive survey of deep learning-based hashing methods. Knowl. Inf. Syst. 2022, 64, 2565–2597. [Google Scholar] [CrossRef]
- Lin, H.; Luo, T.; Woodruff, D. Learning Augmented Binary Search Trees. In Proceedings of the 39th International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; Chaudhuri, K., Jegelka, S., Song, L., Szepesvari, C., Niu, G., Sabato, S., Eds.; Volume 162, pp. 13431–13440. [Google Scholar]
- Boffa, A.; Ferragina, P.; Vinciguerra, G. A “learned” approach to quicken and compress rank/select dictionaries. In Proceedings of the SIAM Symposium on Algorithm Engineering and Experiments (ALENEX), Alexandria, VA, USA, 10–11 January 2021. [Google Scholar]
- Kirsche, M.; Das, A.; Schatz, M.C. Sapling: Accelerating suffix array queries with learned data models. Bioinformatics 2020, 37, 744–749. [Google Scholar] [CrossRef]
- Boffa, A.; Ferragina, P.; Tosoni, F.; Vinciguerra, G. Compressed string dictionaries via data-aware subtrie compaction. In Proceedings of the 29th International Symposium on String Processing and Information Retrieval (SPIRE), Concepcion, Chile, 8–10 November 2022; pp. 233–249. [Google Scholar] [CrossRef]
- Kristo, A.; Vaidya, K.; Çetintemel, U.; Misra, S.; Kraska, T. The Case for a Learned Sorting Algorithm. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data, Portland, OR, USA, 14–19 June 2020; Association for Computing Machinery: New York, NY, USA, 2020. SIGMOD’20. pp. 1001–1016. [Google Scholar] [CrossRef]
- Bishop, C.M. Neural Networks for Pattern Recognition; Oxford University Press, Inc.: New York, NY, USA, 1995. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; The MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Kraska, T. Towards Instance-Optimized Data Systems. Proc. VLDB Endow. 2021, 14, 3222–3232. [Google Scholar] [CrossRef]
- Abadi, D.; Ailamaki, A.; Andersen, D.; Bailis, P.; Balazinska, M.; Bernstein, P.A.; Boncz, P.; Chaudhuri, S.; Cheung, A.; Doan, A.; et al. The Seattle Report on Database Research. Commun. ACM 2022, 65, 72–79. [Google Scholar] [CrossRef]
- Available online: https://github.com/globosco/A-learned-sorted-table-search-library (accessed on 5 June 2022).
- Peterson, W.W. Addressing for random-access storage. IBM J. Res. Dev. 1957, 1, 130–146. [Google Scholar] [CrossRef]
- Van Sandt, P.; Chronis, Y.; Patel, J.M. Efficiently searching in-memory sorted arrays: Revenge of the interpolation search? In Proceedings of the 2019 International Conference on Management of Data, Amsterdam, The Netherlands, 30 June–5 July 2019; ACM: New York, NY, USA, 2019. SIGMOD’19. pp. 36–53. [Google Scholar]
- Amato, D. A Tour of Learned Static Sorted Sets Dictionaries: From Specific to Generic with an Experimental Performance Analysis. Ph.D. Thesis, University of Palermo, Palermo, Sicily, Italy, 2022. [Google Scholar]
- Freedman, D. Statistical Models: Theory and Practice; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
- Schlegel, B.; Gemulla, R.; Lehner, W. K-Ary Search on Modern Processors. In Proceedings of the Fifth International Workshop on Data Management on New Hardware, Providence, RI, USA, 28 June 2009; Association for Computing Machinery: New York, NY, USA, 2009. DaMoN’09. pp. 52–60. [Google Scholar] [CrossRef]
- Schulz, L.; Broneske, D.; Saake, G. An eight-dimensional systematic evaluation of optimized search algorithms on modern processors. Proc. VLDB Endow. 2018, 11, 1550–1562. [Google Scholar] [CrossRef] [Green Version]
- Kipf, A.; MIT Data Systems Group, Massachusetts Institute of Technology, Cambridge, MA, USA. Personal Communication, 2021.
- Available online: https://osf.io/qtyu7/?view_only=b48e6cc6e01b441383b26b81588090ec (accessed on 5 June 2022).
- Smirnov, N.V. Estimate of deviation between empirical distribution functions in two independent samples. Bull. Mosc. Univ. 1939, 2, 3–16. [Google Scholar]
- Kullback, S. Information Theory and Statistics; Dover Publications: New York, NY, USA, 1968. [Google Scholar]










| KO-US | C | |
|---|---|---|
| amzn | ||
| face | ||
| osm | ||
| wiki |
| CDFShop SY-RMI 2% | CDFShop RMI | SOSD RS | SOSD PGM | |
|---|---|---|---|---|
| amzn | ||||
| face | ||||
| osm | ||||
| wiki |
| Panel (a) | ||||
| L1 | L2 | |||
| SOSD RS | SOSD PGM | SOSD RS | SOSD PGM | |
| amzn | ||||
| face | ||||
| osm | ||||
| wiki | ||||
| Panel (b) | ||||
| L3 | L4 | |||
| SOSD RS | SOSD PGM | SOSD RS | SOSD PGM | |
| amzn | ||||
| face | ||||
| osm | ||||
| wiki | ||||
| amzn | osm | |
|---|---|---|
| L1 | 99.94−99.48 | 98.12−86.70 |
| L2 | 99.98−99.56 | 98.07−86.57 |
| L3 | 99.98−99.53 | 97.98−86.43 |
| L4 | 99.98−99.54 | 98.03−86.57 |
| L1 | |||
| Time | Space | Reduction Factor | |
| Best RMI | |||
| B-PGM 0.05 | |||
| SY-RMI 0.05 | |||
| RS < 10 | |||
| Best RMI | |||
| L2 | |||
| Time | Space | Reduction Factor | |
| Best RMI | |||
| B-PGM 0.05 | |||
| SY-RMI 0.05 | |||
| Best RS < 10 | |||
| Best RMI | |||
| L3 | |||
| Time | Space | Reduction Factor | |
| Best RMI | |||
| B-PGM 0.05 | |||
| SY-RMI 0.05 | |||
| RS < 10 | |||
| RMI < 10 | |||
| L4 | |||
| Time | Space | Reduction Factor | |
| Best RMI | |||
| B-PGM 0.05 | |||
| SY-RMI 0.05 | |||
| Best RS | |||
| RMI < 10 | |||
| L1 | |||
| Time | Space | Reduction Factor | |
| Best RMI | |||
| B-PGM 0.05 | |||
| SY-RMI 0.05 | |||
| Best RMI | |||
| Best RS | |||
| L2 | |||
| Time | Space | Reduction Factor | |
| Best RMI | |||
| B-PGM 0.05 | |||
| SY-RMI 0.05 | |||
| RMI < 10 | |||
| RS < 10 | |||
| L3 | |||
| Time | Space | Reduction Factor | |
| Best RS | |||
| B-PGM 0.05 | |||
| SY-RMI 0.05 | |||
| RMI < 10 | |||
| RS < 10 | |||
| L4 | |||
| Time | Space | Reduction Factor | |
| Best RS | |||
| SY-RMI 0.05 | |||
| B-PGM 0.05 | |||
| RMI < 10 | |||
| RS < 10 | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Amato, D.; Giancarlo, R.; Lo Bosco, G. Learned Sorted Table Search and Static Indexes in Small-Space Data Models. Data 2023, 8, 56. https://doi.org/10.3390/data8030056
Amato D, Giancarlo R, Lo Bosco G. Learned Sorted Table Search and Static Indexes in Small-Space Data Models. Data. 2023; 8(3):56. https://doi.org/10.3390/data8030056
Chicago/Turabian StyleAmato, Domenico, Raffaele Giancarlo, and Giosué Lo Bosco. 2023. "Learned Sorted Table Search and Static Indexes in Small-Space Data Models" Data 8, no. 3: 56. https://doi.org/10.3390/data8030056