
Comparing the Effectiveness of Robust Statistical Estimators of Proficiency Testing Schemes in Outlier Detection
Abstract
:1. Introduction
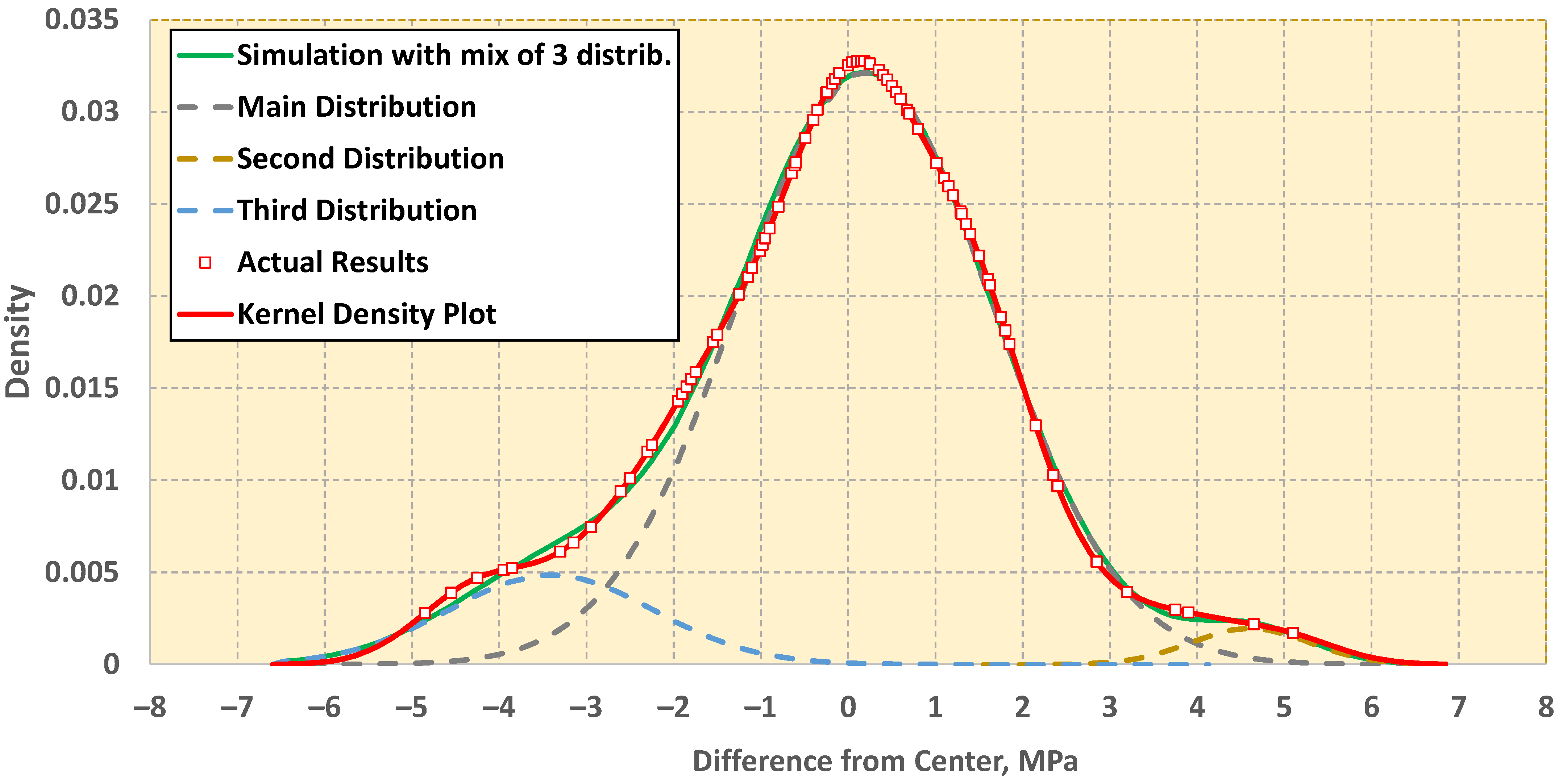
2. Kernel Density Plots
3. Model Development Using Monte Carlo Simulation and Initial Simulations
3.1. Monte Carlo Simulation
- number of participating laboratories, Nlab;
- number of replicate analyses per laboratory, Nrep;
- repeatability standard deviation, sr;
- number of iterations, Niter;
- number of simulations, Ns;
- number of bins to create histograms, Nb.
- (i)
- It creates a main normal distribution D1 with mean value m1 and standard deviation s1 and two contaminating distributions D2, D3 with mean values m2, m3, and standard deviations s2, s3.
- (ii)
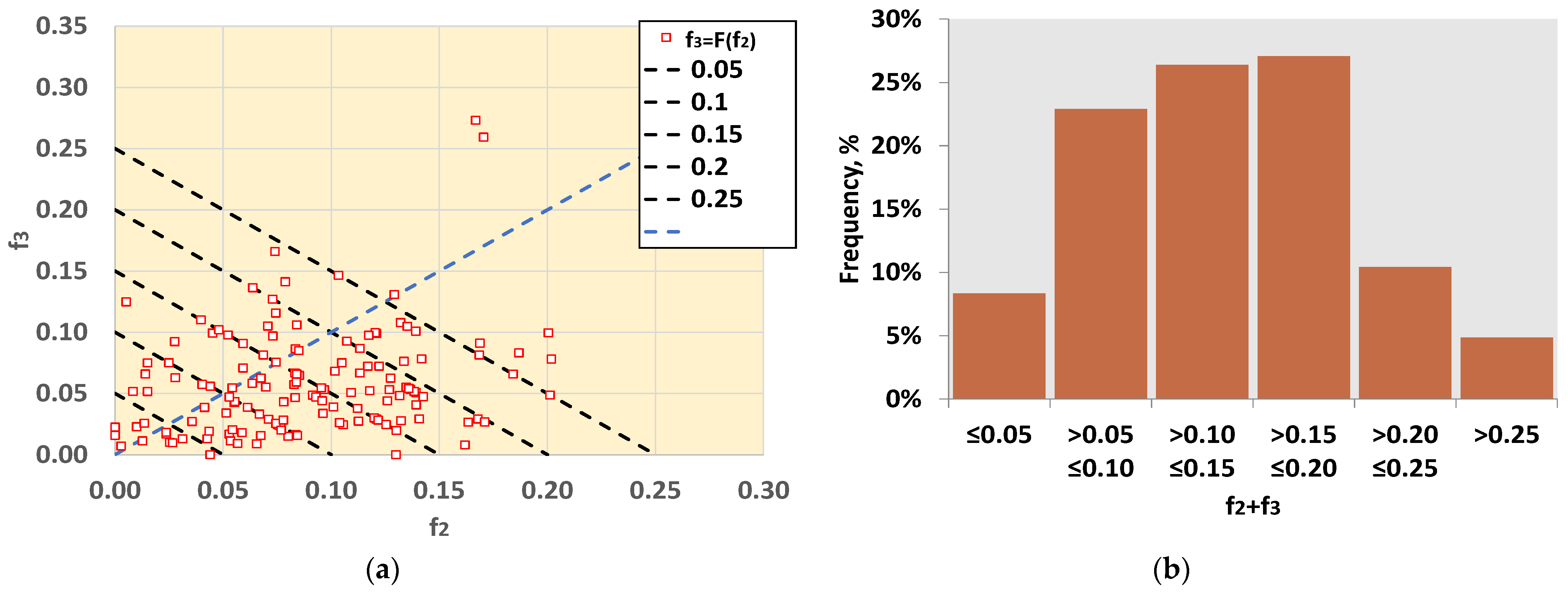
- The fractions of the contaminating distributions are fr2 and fr3, and, depending on these two values, the total distribution can be unimodal, bimodal, or trimodal.
- (iii)
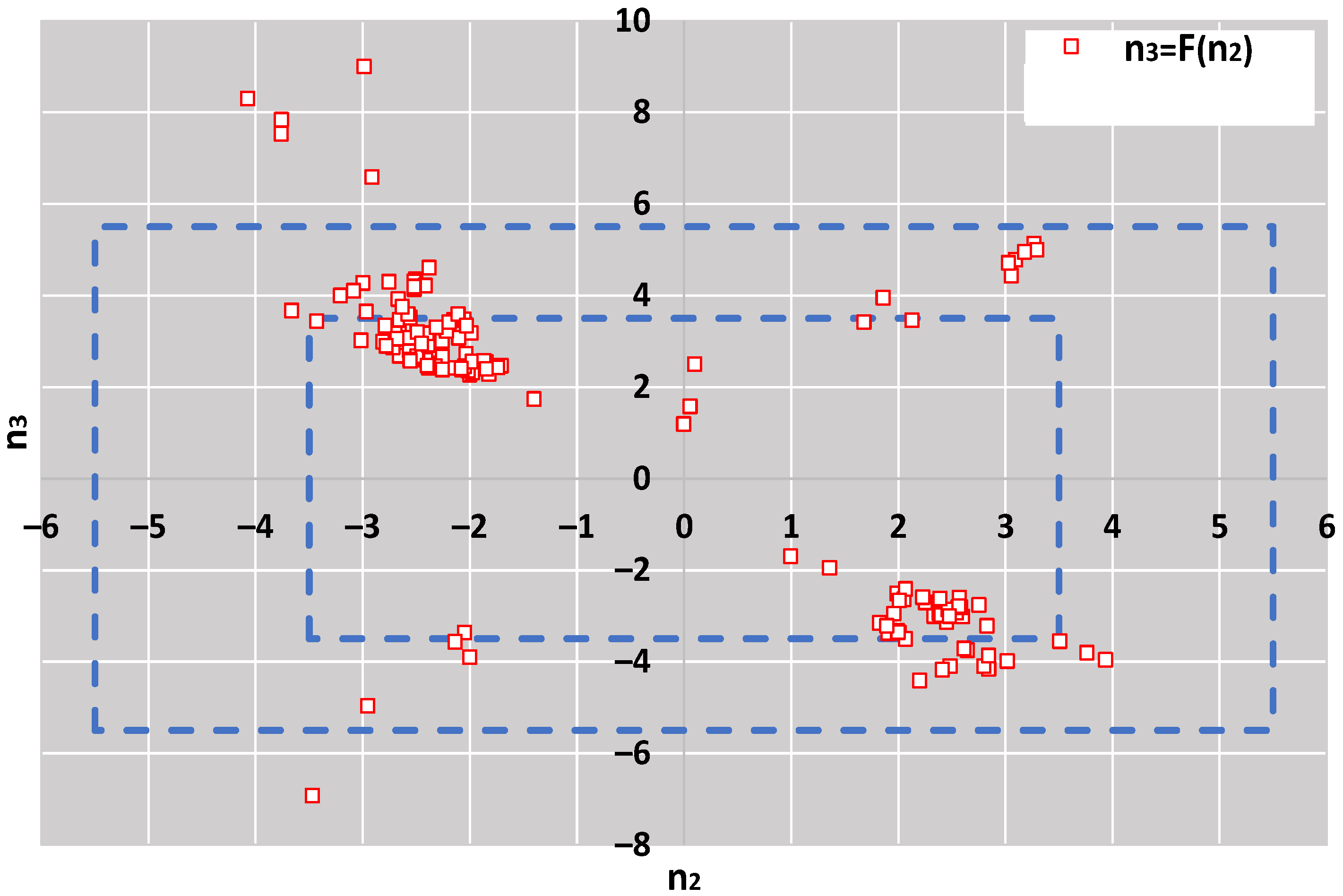
- The mean values m2 and m3 differ by an integer number of standard deviations s1 from m1, n2 and n3, shown in Equation (3). In the case of trimodal distribution, if n2·n3 > 0, then D2 and D3 are both to the same side of the D1. Otherwise, one is to the left and the other to the right of D1.
- (iv)
- According to the values of fr2, fr3, n2, and n3, the software calculates the values of Zu%, which are unsatisfactory compared to the normal distribution function with mean and standard deviation m1 and s1 correspondingly. These values are the initial values. For example, if m1 = 0, s1 = 2, s2 = s3 = 1, n2 = −5, n3 = 7, fr2 = 0.05, and fr3 = 0.05, then Zu% = 0.24 (from D1) + 5.0 (from D2) + 5.0 (from D3) = 10.24.
- (v)
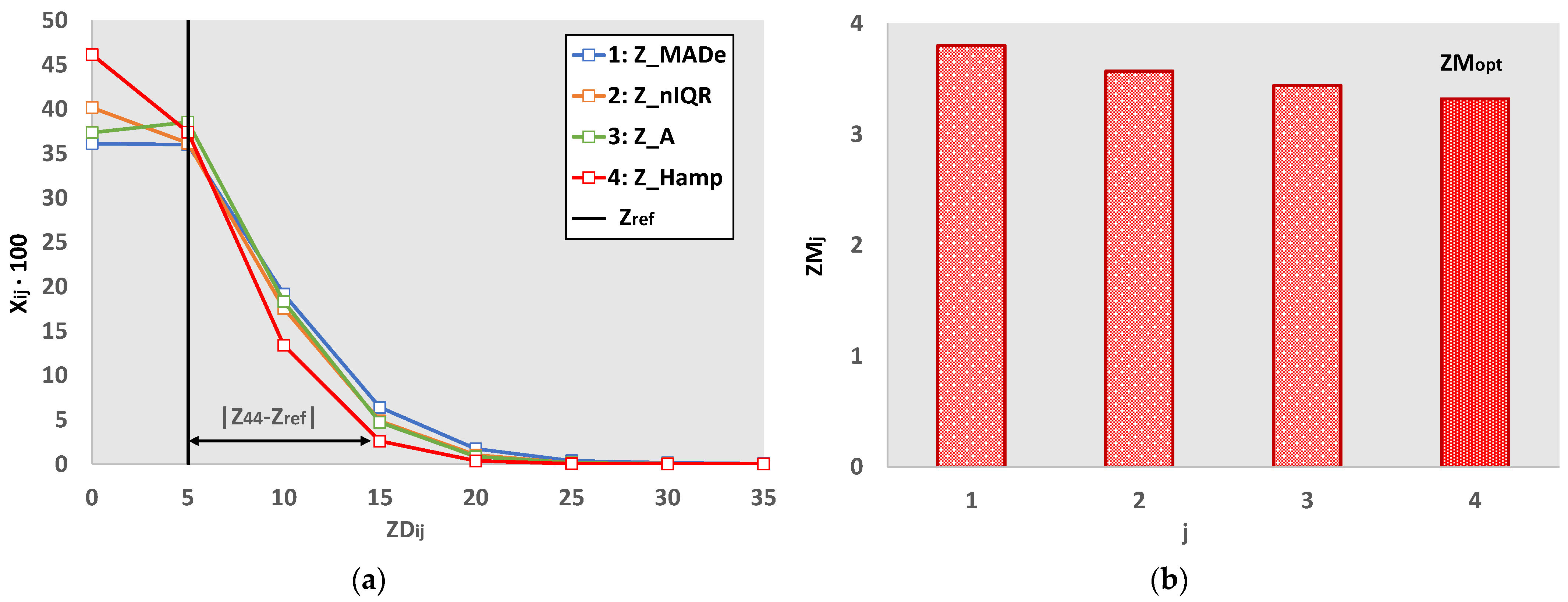
- The algorithm calculates all the estimators for the mean and standard deviation shown in Table 4 and the Zu% for the absolute values of the four Z-factors presented in the same table using a Nlab = 1000. For this number of participants, all estimators converge to their final value. As demonstrated in [24], Nlab = 400 is adequate for such convergence.
- (vi)
- This previous study found that Z_MADe was the closest estimator of unacceptable Z-factors to the estimation based on the main normal distribution of step (iv). Its values corresponding to Nlab = 1000 represent the reference values, Zref.
- (vii)
- The simulations implemented all the settings shown in Table 5 for participants up to 100. The populations correspond to unimodal, bimodal, and trimodal distributions with a maximum total fraction of secondary distributions up to 0.2.
- (viii)
- For each mix of the three normal distributions, the software performs Niter iterations and Ns simulations for each Nlab. Then it calculates the differential distribution of each of the four Zu% in at least twenty bins. The algorithm compares these results with the reference value using the distance of the distribution’s points from Zref provided by Equation (4). The Z-factor with the closest distance to the reference value is optimal.
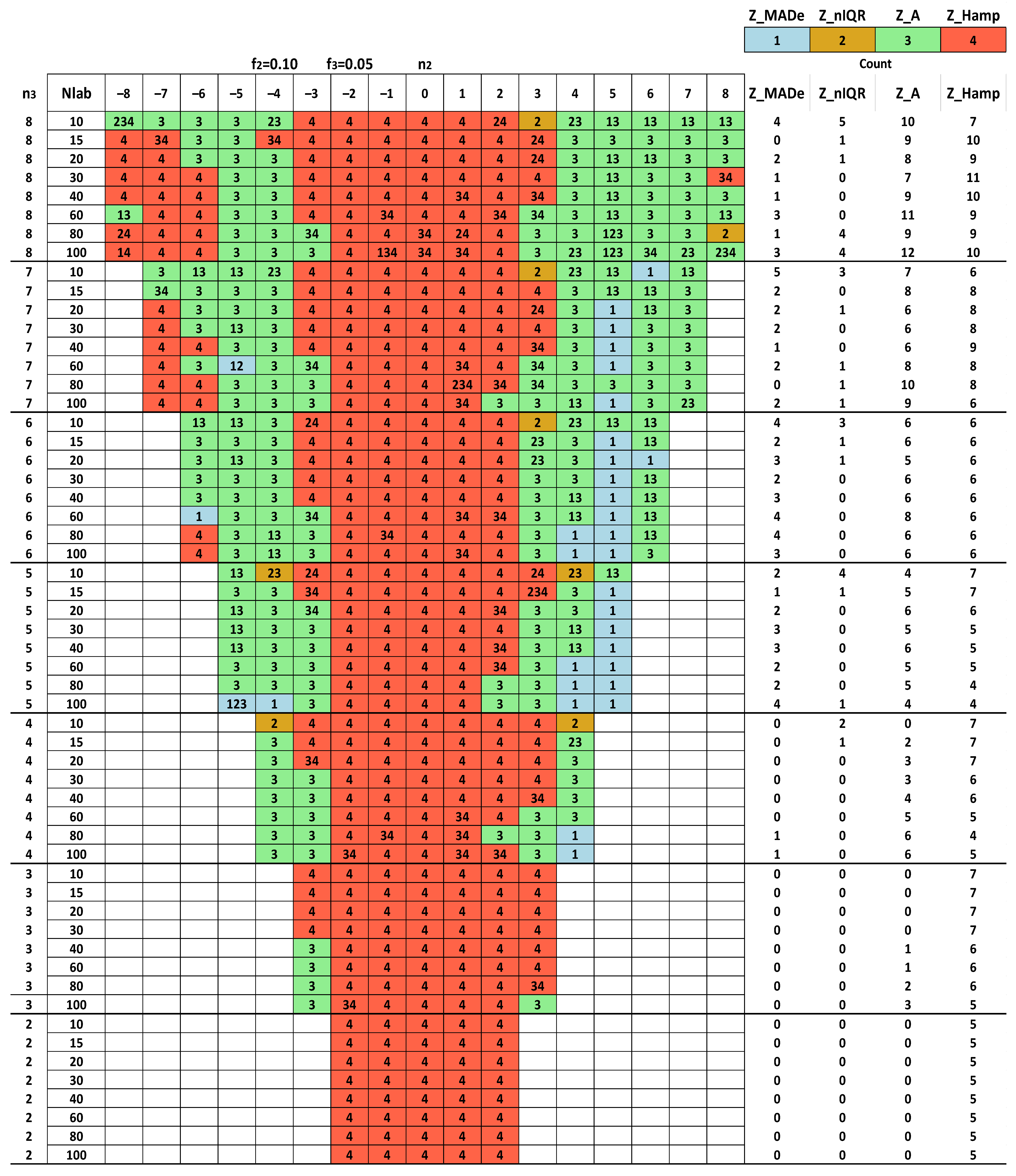
3.2. Initial Simulations
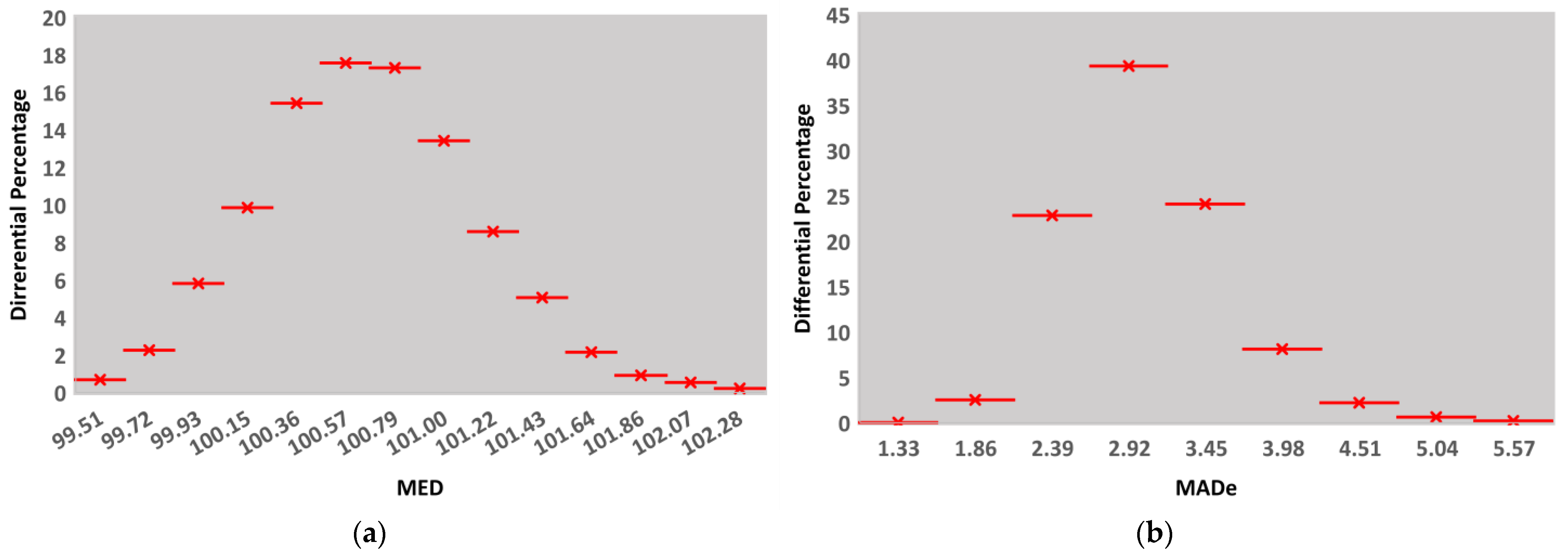
- (i)
- The distributions of mean are continuously positively skewed due to the assumption |n2| < |n3|. If n3 =−7, and supposing the same condition between n2, n3, the distributions are symmetrical to the ones shown, but μ < ν and SK < 0.
- (ii)
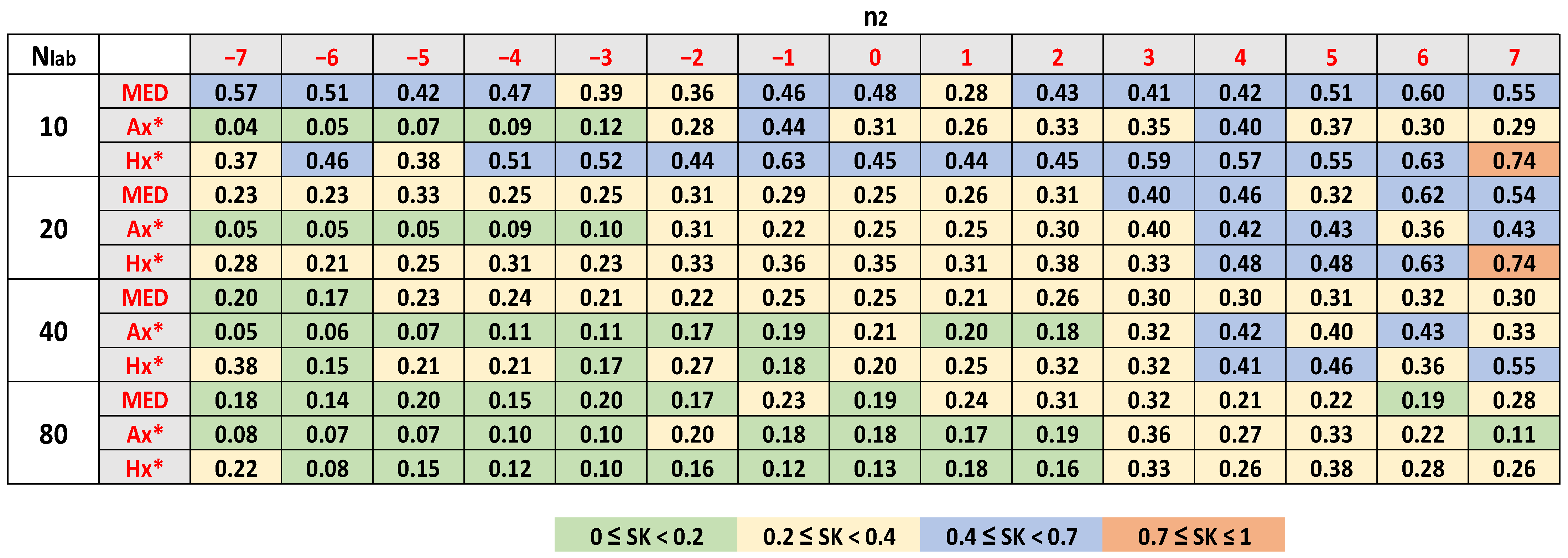
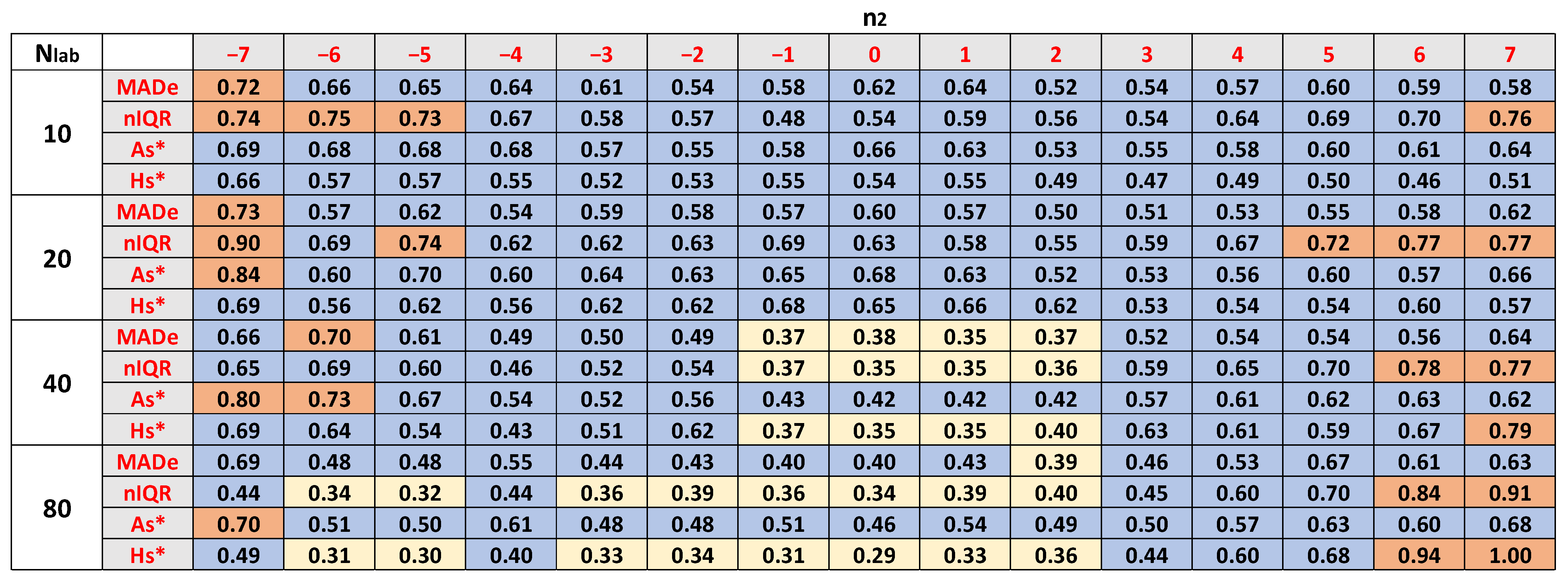
- We classified SK values into four regions: (a) 0 ≤ |SK| < 0.2; (b) 0.2 ≤ |SK| < 0.4; (c) 0.4 ≤ |SK| < 0.7; (d) 0.7 ≤ |SK| ≤ 1. As a rough guide, we can consider that if |SK| < 0.2, the departure from symmetry is low [41]. The skew is moderate for |SK| values in (b). The distribution is highly skewed for |SK| values in (c). Finally, the skew is very high for |SK| ≥ 0.7.
- (iii)
- The skewness of the estimators of mean increases, increasing n2 from −7 to 7. For these estimators, the skewness decreases, increasing the number of participants. The distributions are highly symmetric for Nlab ≥ 40 and n2 ≤ 0.
- (iv)
- The estimators of the mean have less skewness than those of standard deviation for the same Nlab and n2. The best symmetry in the distributions of the latter occurs for Nlab ≥ 40 and n2 between −1 and 1.
- (v)
- For low and high n2 values, the skewness standard deviation sometimes becomes very high.
- (vi)
- The asymmetry of the two distributions indicates that the search for the best method regarding outliers should focus on their distribution for each performance statistic mentioned in Table 4.
4. Optimal Robust Estimators for Outlier Detection
4.1. Shape of the Outliers Distribution
4.2. Implementation of the Simulator
- (i)
- For n3 ≤ 3 and |n2|< = 3, i.e., for relatively low differences between the mean values of contaminating and central distributions, Z_Hamp is almost always the best estimator.
- (ii)
- Considering all the combinations of [s1, s2, s3] and [fr2, fr3], Z_Hamp is almost always the best in this range of n2, n3. Therefore, when at most half the distribution of each contaminating population is outside, left or right, of the central distribution, there is only one optimal estimator.
- (iii)
- For higher values of n3 and |n2|, determining the most suitable estimator is a function of (a) the number of participants; (b) the distribution of the results, expressed by f2, f3, n2, and n3.
4.3. Simulation Results
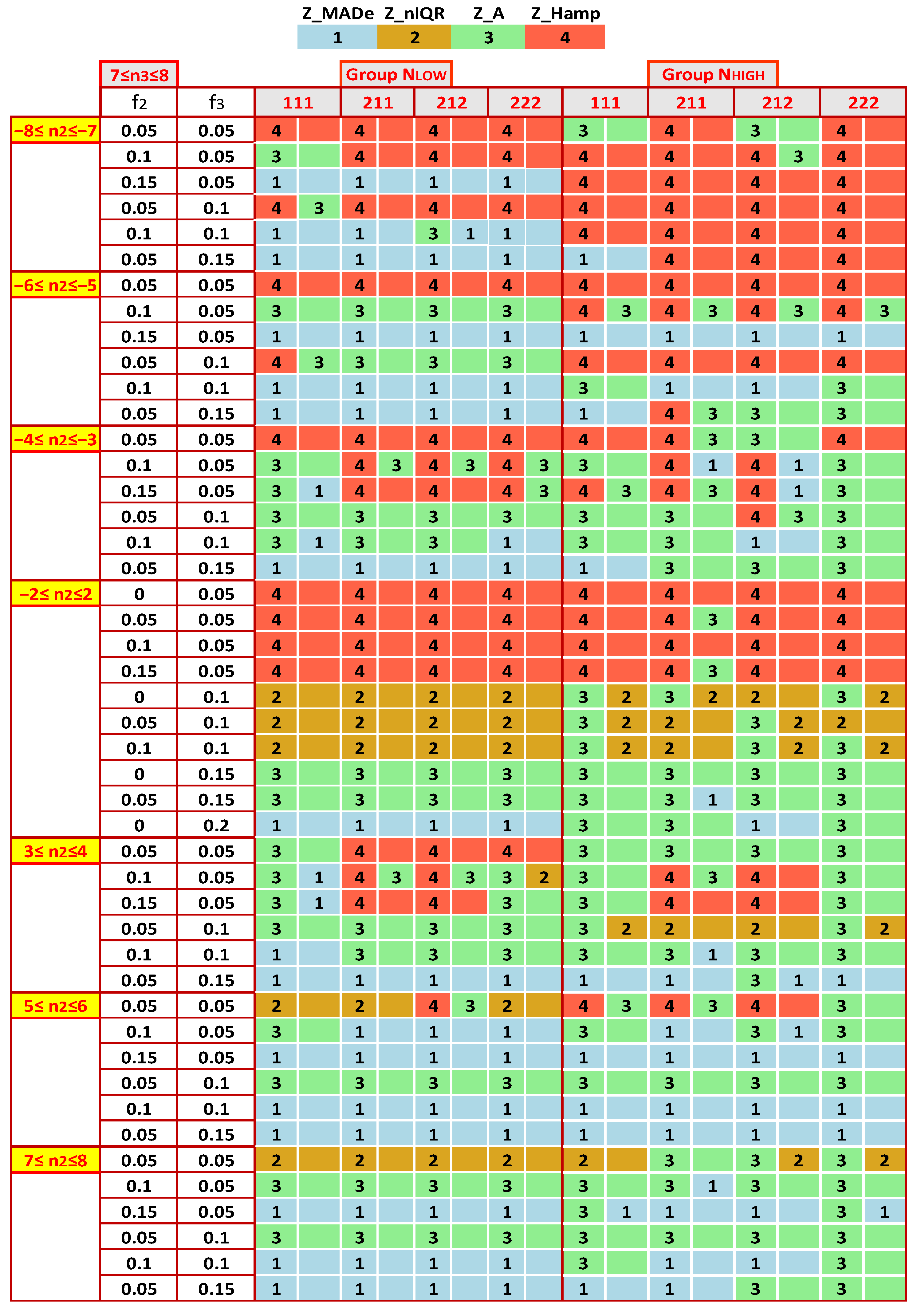
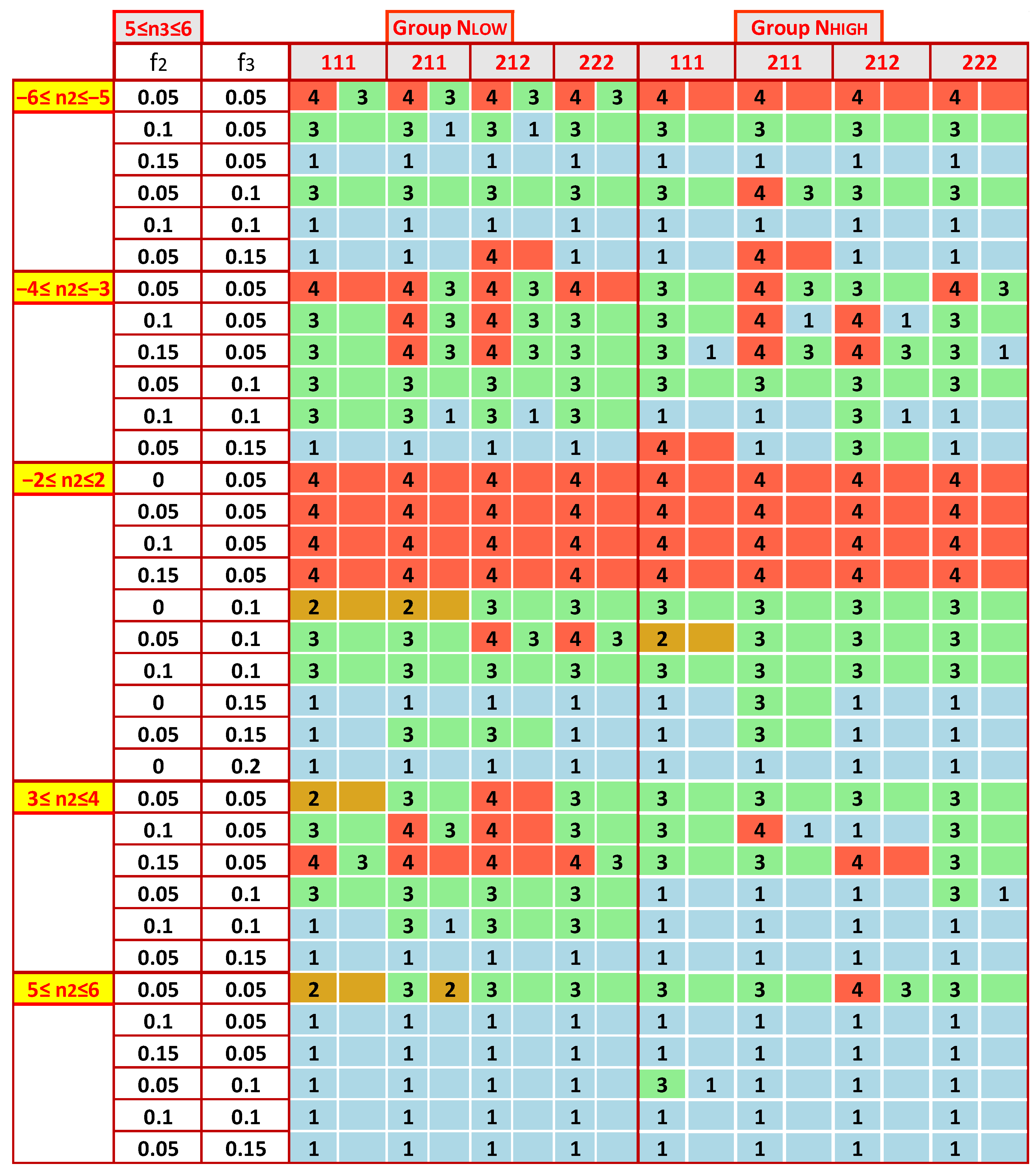
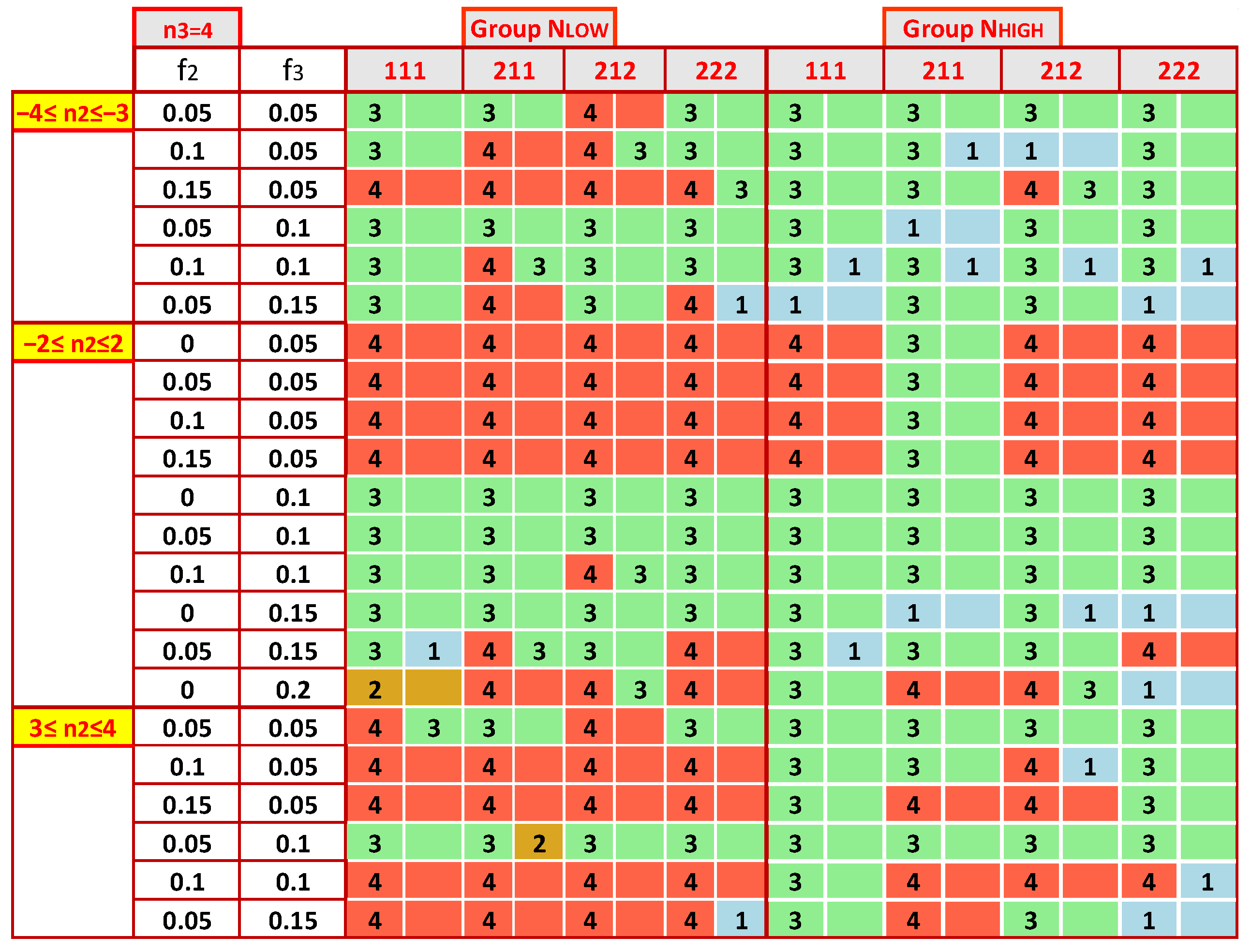
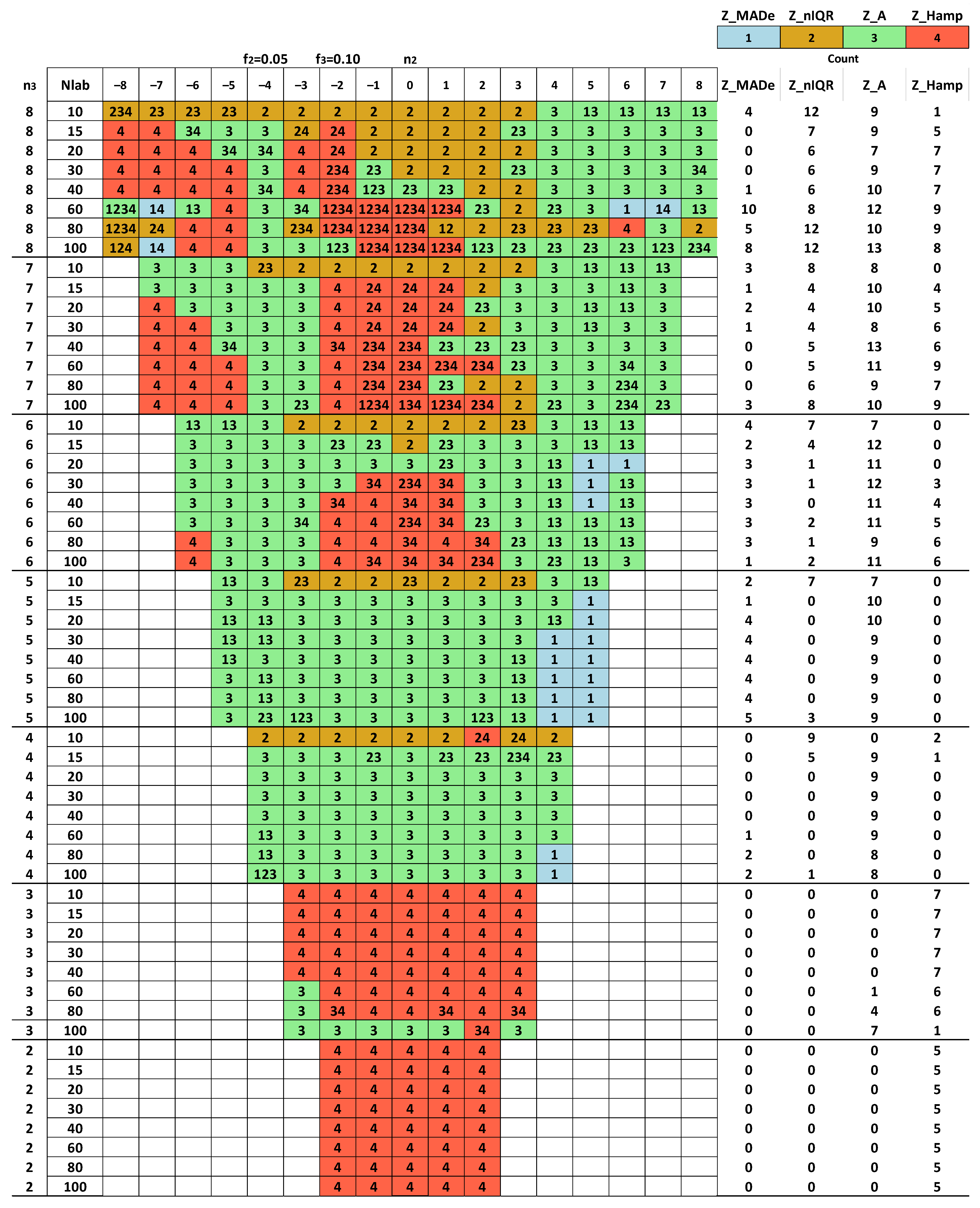
- (i)
- The algorithm initially generates two groups: (a) a small population of participants, NLOW, with Nlab = 10, 15, 20, and 30; (b) a large one, NHIGH, with Nlab = 40, 60, 80, and 100.
- (ii)
- It then creates at most seven regions of n2 by keeping|n2| < n3, the following: (a) −7 ≤ n2 ≤ −8; (b) −6 ≤ n2 ≤ −5; (c) −4 ≤ n2 ≤ −3; (d) −2 ≤ n2 ≤ 2 (e) 3 ≤ n2 ≤ 4 (f) 5 ≤ n2 ≤ 6 (g) 7 ≤ n2 ≤8. It is seven regions when n3MAX is 8, but five when n3MAX is less.
- (iii)
- Afterwards, it counts the occurrences of each estimator as optimal in each region and calculates their percentages.
- (iv)
- An optimal estimator is the one with the highest percentage and those whose percent of appearance differs by up to 10% from the maximum.
- (v)
- Next is the creation of tables with the results per n3 and [s1, s2, s3].
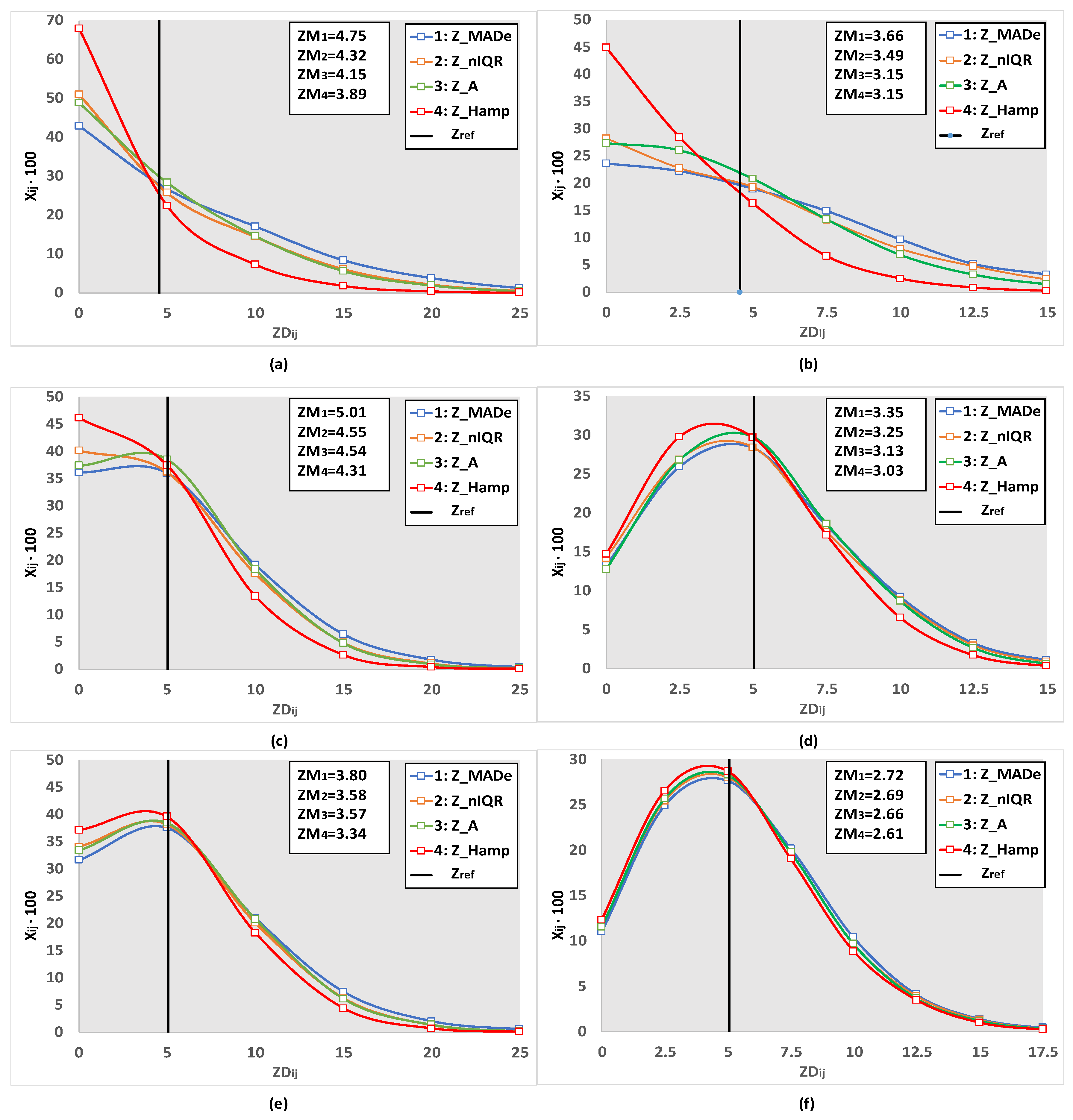
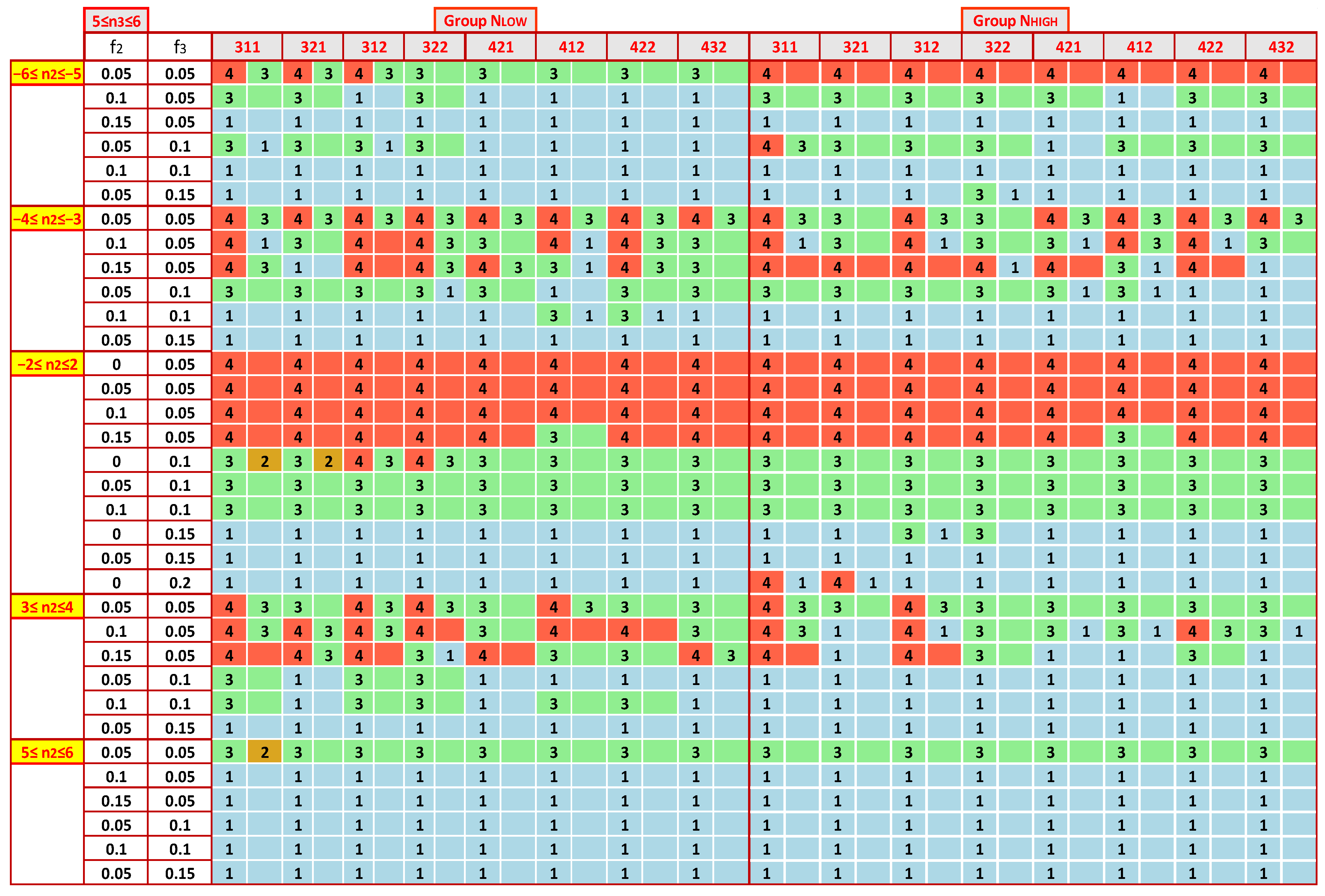
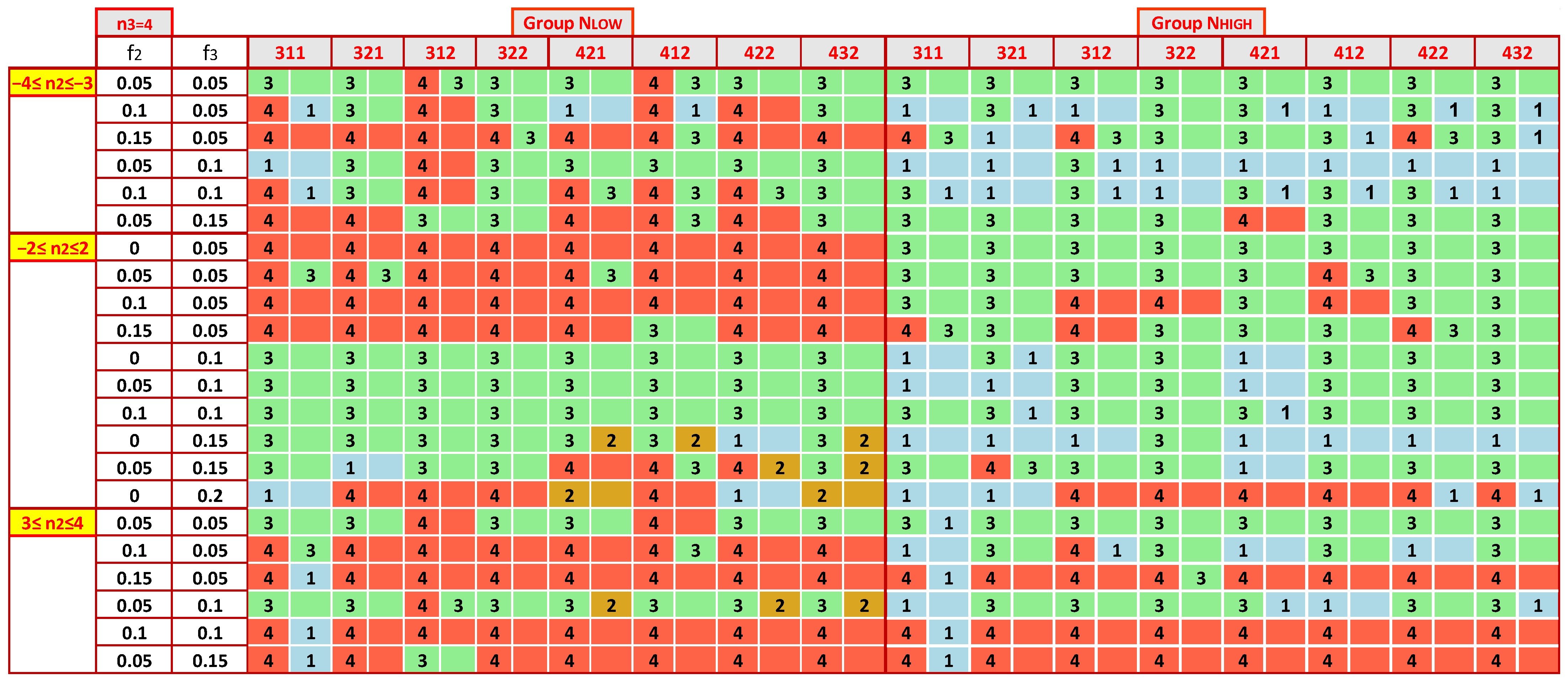
- (i)
- (ii)
- For the same n3, the distribution of the most accurate performance statistics as a function of n2 is not symmetrical around the center. For all n3, the estimators for −8 ≤ n2 ≤ −7 and −6 ≤ n2 ≤ −5 differ significantly from the ones for 7 ≤ n2 ≤ 8 and 5 ≤ n2 ≤ 6. More symmetrical patterns appear in zones −4 ≤ n2 ≤ −3 and 3 ≤ n2 ≤ 4.
- (iii)
- With the same model parameters, the results are similar for the two groups NLOW and NHIGH, but not in all cases. For example, for 7 ≤ n3 ≤ 8 and −7 ≤ n2 ≤ −8, Z_Hampel appears as the optimal performance statistic much more in the NHIGH group than in NLOW. In contrast, this estimator is found significantly more frequently in the low number of labs than in NHIGH when n3 = 4.
- (iv)
- The selection of the most appropriate estimator is not so sensitive to the choice of the mixture of standard deviations, [s1, s2, s3]. When comparing Figure 10, Figure 11, Figure A3 and Figure A4, one finds that in enough cases, the optimal statistic is the same for the same group of labs, n3, n2, f2, and f3, concluding that the impact of [s1, s2, s3] is less strong than that of the other parameters.
- (v)
- With a contaminating population fraction f3 of 0.05 and distribution diverging relatively little from the bimodal with −2 ≤ n2 ≤ 2, the Z_Hamp is most often found. However, this rule is not absolute. Figure A4 demonstrates that for the group NHIGH, n3 = 4, and s1 = 3 or 4, Z_A is the most suitable.
- (vi)
- In some cases, there are expanded zones where one estimator outperforms the others, increasing the robustness of the suggested solution. For example, in Figure 10 and Figure A3, for 5 ≤ n2 ≤ 6, the first choice is the Z_MADe. In Figure 10, Figure 11, Figure A3 and Figure A4, for −2 ≤ n2 ≤ 2 and f3 = 0.10 the correct selection is Z_A.
- (vii)
- For NLOW and NHIGH groups, Figure 12 illustrates a rough tendency for the preferred statistics as a function of the zones of n2, n3, and f3. For each region, the algorithm counts the occurrences of each estimator in the maps depicted in Figure 9, Figure 10, Figure 11, Figure A3 and Figure A4. It calculates their percentages and considers as optimal statistics those that are up to 10% below the maximum.
- (viii)
- The results of Figure 12 are only a rough guide to choosing the most appropriate estimator, demonstrating that there is no unique solution, and the best selection depends on the data distribution.
5. Conclusions
- ▪
- direct use of the kernel density plots in determining the best statistic
- ▪
- estimators’ comparisons for Z-factors of absolute value between two and three.
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A


Appendix B


References
- EN ISO/IEC 17043:2010; Conformity Assessment—General Requirements for Proficiency Testing. CEN Management Centre: Brussels, Belgium, 1994; pp. 2–3, 8–9,30–33.
- Hampel, F.R.; Ronchetti, E.M.; Peter, J.; Rousseeuw, P.J.; Stahel, W.A. Robust Statistics: The Approach Based on Influence Functions; John Wiley & Sons, Inc.: New York, NY, USA, 1986. [Google Scholar]
- Huber, P.J.; Ronchetti, E.M. Robust Statistics, 2nd ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2009. [Google Scholar]
- Wilcox, R. Introduction to Robust Estimation and Hypothesis Testing, 3rd ed.; Elsevier, Inc.: Waltham, MA, USA, 2013. [Google Scholar]
- Maronna, R.A.; Martin, R.D.; Yohai, V.J.; Salibián-Barrera, M. Robust Statistics: Theory and Methods (with R), 2nd ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2018. [Google Scholar]
- Hund, E.; Massart, D.L.; Smeyers-Verbeke, J. Inter-laboratory Studies in Analytical Chemistry. Anal. Chim. Acta 2000, 424, 145–165. [Google Scholar] [CrossRef]
- Daszykowski, M.; Kaczmarek, K.; Vander Heyden, Y.; Walczaka, B. Robust statistics in data analysis—A review: Basic concepts. Chemom. Intell. Lab. Syst. 2007, 85, 203–219. [Google Scholar] [CrossRef]
- Shevlyakov, G. Highly Efficient Robust and Stable M-Estimates of Location. Mathematics 2021, 9, 105. [Google Scholar] [CrossRef]
- Ghosh, I.; Fleming, K. On the Robustness and Sensitivity of Several Nonparametric Estimators via the Influence Curve Measure: A Brief Study. Mathematics 2022, 10, 3100. [Google Scholar] [CrossRef]
- Zimek, A.; Filzmoser, P. There and back again: Outlier detection between statistical reasoning and data mining algorithms. WIREs Data Min. Knowl. Discov. 2018, 8, e1280. [Google Scholar] [CrossRef] [Green Version]
- Roelant, E.; Van Aelst, S.; Willems, G. The minimum weighted covariance determinant estimator. Metrika 2009, 70, 177–204. [Google Scholar] [CrossRef]
- Cerioli, A. Multivariate outlier detection with high-breakdown estimators. J. Am. Stat. Assoc. 2010, 105, 147–156. [Google Scholar] [CrossRef]
- Rousseeuw, P.J.; Leroy, A.M. Robust Regression and Outlier Detection; John Wiley & Sons, Inc.: New York, NY, USA, 1987. [Google Scholar]
- Kalina, J.; Tichavský, J. On Robust Esti ation of Error Variance in (Highly) Robust Regression. Meas. Sci. Rev. 2020, 20, 6–14. [Google Scholar] [CrossRef] [Green Version]
- ISO 13528:2015; Statistical Methods for Use in Proficiency Testing by Interlaboratory Comparison. 2nd ed, ISO: Geneva, Switzerland, 2015; pp. 10–12, 32–33,44–51, 52–62.
- ISO 5725-2:1994; Accuracy (Trueness and Precision) of Measurement Methods and Results—Part 2: Basic Method for the Determination of Repeatability and Reproducibility of a Standard Measurement Method. 1st ed. ISO: Geneva, Switzerland, 1994; pp. 10–14, 21–22.
- ISO 5725-5:1998; Accuracy (Trueness and Precision) of Measurement Methods and Results—Part 5: Alternative Methods for the Determination of the Precision of a Standard Measurement Method. 1st ed. ISO: Geneva, Switzerland, 1998; pp. 35–36.
- Rosário, P.; Martínez, J.L.; Silván, J.M. Evaluation of Proficiency Test Data by Different Statistical Methods Comparison. In Proceedings of the First International Proficiency Testing Conference, Sinaia, Romania, 11–13 October 2007. [Google Scholar]
- Srnková, J.; Zbíral, J. Comparison of different approaches to the statistical evaluation of proficiency tests. Accredit. Qual. Assur. 2009, 14, 373–378. [Google Scholar] [CrossRef]
- Tripathy, S.S.; Saxena, R.K.; Gupta, P.K. Comparison of Statistical Methods for Outlier Detection in Proficiency Testing Data on Analysis of Lead in Aqueous Solution. Am. J. Theor. Appl. Stat. 2013, 2, 233–242. [Google Scholar] [CrossRef]
- Skrzypczak, I.; Lesniak, A.; Ochab, P.; Górka, M.; Kokoszka, W.; Sikora, A. Interlaboratory Comparative Tests in Ready-Mixed Concrete Quality Assessment. Materials 2021, 14, 3475. [Google Scholar] [CrossRef]
- De Oliveira, C.C.; Tiglea, P.; Olivieri, J.C.; Carvalho, M.; Buzzo, M.L.; Sakuma, A.M.; Duran, M.C.; Caruso, M.; Granato, D. Comparison of Different Statistical Approaches Used to Evaluate the Performance of Participants in a Proficiency Testing Program. Available online: https://www.researchgate.net/publication/290293736_Comparison_of_different_statistical_approaches_used_to_evaluate_the_performance_of_participants_in_a_proficiency_testing_program (accessed on 2 November 2022).
- Kojima, I.; Kakita, K. Comparative Study of Robustness of Statistical Methods for Laboratory Proficiency Testing. Anal. Sci. 2014, 30, 1165–1168. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tsamatsoulis, D. Comparing the Robustness of Statistical Estimators of Proficiency Testing Schemes for a Limited Number of Participants. Computation 2022, 10, 44. [Google Scholar] [CrossRef]
- Yohai, V. High Break-Down Point and High Efficiency Robust Estimates for Regression. Ann. Stat. 1987, 15, 642–656. [Google Scholar] [CrossRef]
- Gervini, D.; Yohai, V. A Class of Robust and Fully Efficient Regression Estimators. Ann. Stat. 2002, 30, 583–616. [Google Scholar] [CrossRef]
- Pitselis, G. A Review on Robust Estimators Applied to Regression Credibility. J. Comput. Appl. Math. 2013, 239, 231–249. [Google Scholar] [CrossRef]
- Yu, C.; Yao, W.; Bai, X. Robust Linear Regression: A Review and Comparison. Available online: https://arxiv.org/abs/1404.6274 (accessed on 4 November 2022).
- Kong, D.; Bondell, H.D.; Wu, Y. Fully Efficient Robust Estimation Outlier Detection and Variable Selection via penalized Regression. Stat. Sin. 2018, 28, 1031–1052. Available online: https://www3.stat.sinica.edu.tw/statistica/oldpdf/A28n222.pdf (accessed on 2 March 2023).
- Marazzi, A. Improving the Efficiency of Robust Estimators for the Generalized Linear Model. Stats 2021, 4, 88–107. [Google Scholar] [CrossRef]
- EN 197-1:2011; Cement. Part 1: Composition, Specifications and Conformity Criteria for Common Cements. Management Centre: Brussels, Belgium, 2011.
- Stancu, C.; Michalak, J. Interlaboratory Comparison as a Source of Information for the Product Evaluation Process. Case Study of Ceramic Tiles Adhesives. Materials 2022, 15, 253. [Google Scholar] [CrossRef]
- Humbert, P.; Le Bars, B.; Minvielle, L.; Vayatis, N. Robust Kernel Density Estimation with Median-of-Means principle. Available online: https://arxiv.org/pdf/2006.16590.pdf (accessed on 2 March 2023).
- Gallego, J.A.; González, F.A.; Nasraoui, O. Robust kernels for robust location estimation. Neurocomputing 2021, 429, 174–186. [Google Scholar] [CrossRef]
- EN 196-6:2010; Methods of Testing Cement—Part 6: Determination of Fineness. CEN Management Centre: Brussels, Belgium, 2010.
- EN 196-2:2013; Methods of Testing Cement—Part 2: Chemical Analysis of Cement. CEN Management Centre: Brussels, Belgium, 2013.
- EN 196-1:2016; Methods of Testing Cement—Part 1: Determination of Strength. CEN Management Centre: Brussels, Belgium, 2016.
- Groeneveld, R.A.; Meeden, G. Measuring Skewness and Kurtosis. J. R. Stat. Soc. Series D 1984, 33, 391–399. [Google Scholar] [CrossRef]
- Bulmer, M.G. Principles of Statistics, 3rd ed.; Dover Publications, Inc.: New York, NY, USA, 1979; pp. 61–63. [Google Scholar]
- Hotelling, H.; Solomons, L.M. The Limits of a Measure of Skewness. Ann. Math. Statist. 1932, 3, 141–142. [Google Scholar] [CrossRef]
- Nonparametric Skew. Available online: https://en.wikipedia.org/wiki/Nonparametric_skew (accessed on 14 November 2022).
- Vapnik, V.N. Robust Statistics: Statistical Learning Theory; John Wiley & Sons, Inc.: New York, NY, USA, 1998. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Symbol |
|---|---|
| Main distribution mean value | m1 |
| Main distribution standard deviation | s1 |
| Second distribution mean value | m2 |
| Second distribution standard deviation | s2 |
| Third distribution mean value | m3 |
| Third distribution standard deviation | s3 |
| Fraction of surface of the main distribution | fr1 |
| Fraction of surface of the second distribution | fr2 |
| Fraction of surface of the third distribution | fr3 = 1 − fr1 − fr2 |
| Algebraic distance from m1 to m2 | n2= (m2 − m1)/s1 |
| Algebraic distance from m1 to m3 | n3= (m3 − m1)/s1 |
| Test | Method |
|---|---|
| Specific surface—Blaine method | EN 196-6:2010 [35] |
| Loss on ignition, LOI | EN 196-2:2013 [36] |
| Sulphates content, SO3 | EN 196-2:2013 |
| 2-day, 7-day, and 28-day compressive strength | EN 196-1:2016 [37] |
| No | CV1 | CV2 | CV3 | Frequency % | No | CV1 | CV2 | CV3 | Frequency % |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 3 | 2 | 1 | 9.0 | 9 | 2 | 2 | 1 | 4.2 |
| 2 | 2 | 1 | 1 | 8.3 | 10 | 4 | 1 | 2 | 4.2 |
| 3 | 2 | 1 | 2 | 8.3 | 11 | 1 | 1 | 2 | 3.5 |
| 4 | 3 | 2 | 2 | 7.6 | 12 | 3 | 1 | 1 | 3.5 |
| 5 | 2 | 2 | 2 | 6.3 | 13 | 3 | 3 | 1 | 2.8 |
| 6 | 3 | 1 | 2 | 6.3 | 14 | 4 | 3 | 2 | 2.8 |
| 7 | 4 | 2 | 1 | 5.6 | 15 | 1 | 1 | 1 | 2.1 |
| 8 | 4 | 2 | 2 | 4.9 | 16 | 2 | 2 | 3 | 2.1 |
| Performance Statistic | Mean Value | Standard Deviation | Variable Name |
|---|---|---|---|
| Z-factor | Median value, MED ISO 13528:2015, C.2.1 | Scaled median absolute deviation, MADe ISO 13528:2015, C.2.2 | Z_MADe |
| Z-factor | Median value, MED ISO 13528:2015, C.2.1 | Normalized interquartile range, nIQR ISO 13528:2015, C.2.3 | Z_nIQR |
| Z-factor | Robust mean—Algorithm A with iterated scale, Ax* ISO 13528:2015, C.3.1 | Robust standard deviation—Algorithm A with iterated scale, As* ISO 13528:2015, C.3.1 | Z_A |
| Z-factor | Hampel estimator for mean, Hx* ISO 13528:2015, C.5.3.2 | Robust standard deviation—Q method, Hs* ISO 13528:2015, C.5.2.2 | Z_Hamp |
| Setting | Value |
|---|---|
| Nlab | 10, 15, 20, 30, 40, 60, 80, 100 and 1000 1 |
| Nrep | 2 |
| sr | 0.01 |
| m1 | 100 |
| s1 | 1, 2, 3, 4 |
| m2 | m2 = m1 + n2·s1, n2 = −8 to 8 and step 1 |
| fr2 | 0, 0.05, 0.1, 0.15, 0.20 2 |
| m3 | m3 = m1 + n3·s1, n3 = 1 to 8 and step 1 3 |
| fr3 | 0, 0.05, 0.1, 0.15 |
| s2 | 1, 2, 3 |
| s3 | 1, 2 |
| Niter | 1000 |
| Ns | Up to 25 4 |
| Nb | 20 5 |
| Percentages | ||||
|---|---|---|---|---|
| Estimator | |n3| ≤ 3 | 4 ≤ |n3| ≤ 5 | |n3| ≥ 6 | All n3 |
| Z_MADe | 0 | 2.5 | 0 | 0.7 |
| Z_nIQR | 0 | 0 | 0 | 0 |
| Z_A | 0 | 30 | 0 | 8.3 |
| Z_Hamp | 100 | 55 | 66.7 | 86.1 |
| Not Applicable | 0 | 12.5 | 33.3 | 4.9 |
| Percentage of each |n3| region | 68 | 27.8 | 4.2 | 100 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tsamatsoulis, D. Comparing the Effectiveness of Robust Statistical Estimators of Proficiency Testing Schemes in Outlier Detection. Standards 2023, 3, 110-132. https://doi.org/10.3390/standards3020010
Tsamatsoulis D. Comparing the Effectiveness of Robust Statistical Estimators of Proficiency Testing Schemes in Outlier Detection. Standards. 2023; 3(2):110-132. https://doi.org/10.3390/standards3020010
Chicago/Turabian StyleTsamatsoulis, Dimitris. 2023. "Comparing the Effectiveness of Robust Statistical Estimators of Proficiency Testing Schemes in Outlier Detection" Standards 3, no. 2: 110-132. https://doi.org/10.3390/standards3020010