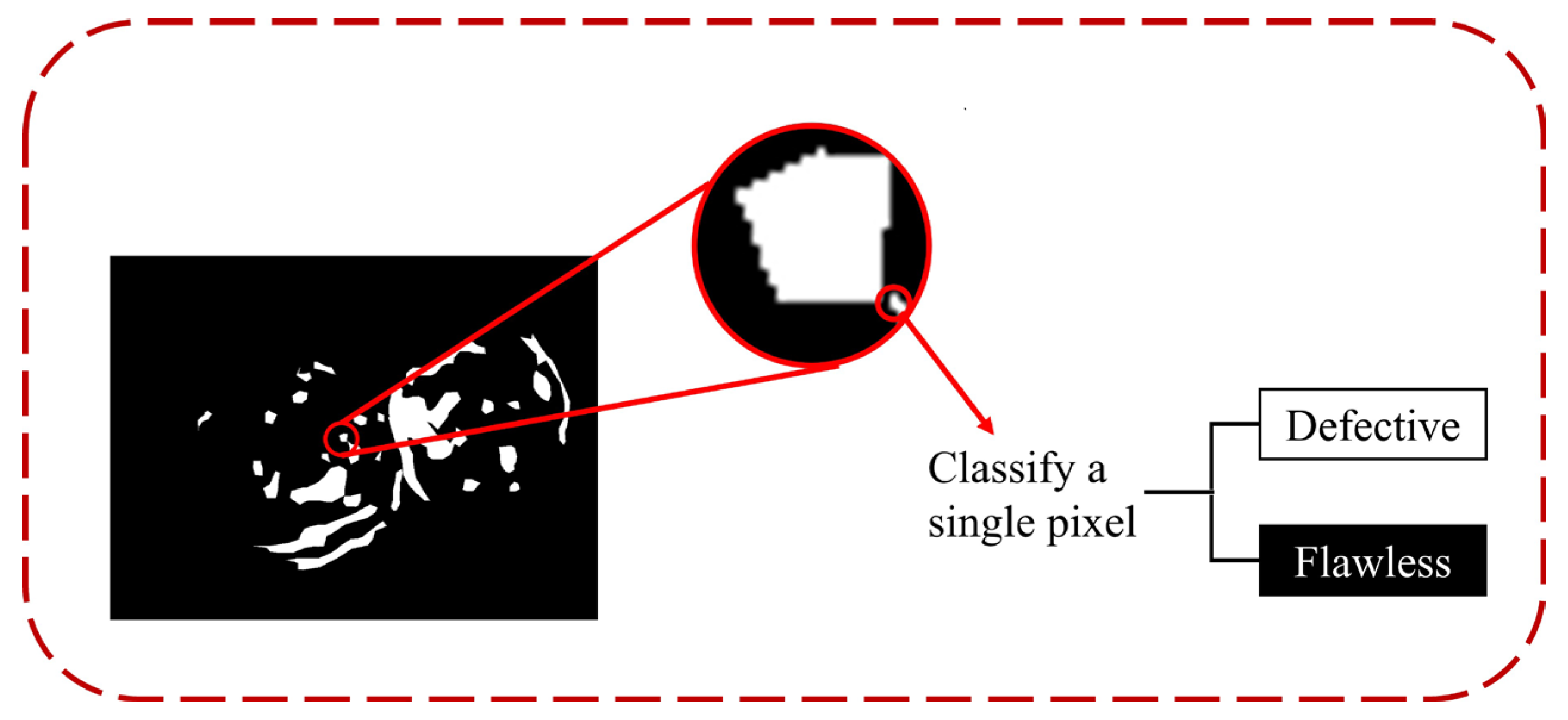
We treated the problem of surface defect detection as a binary image classification problem. In apple post-harvest quality sorting and grading, the accurate classification of defective apples is more important than the precise location of defects. However, existing defect detection methods often rely on large-scale finely labeled data training, which obviously does not meet the needs of actual production benefits. To overcome this difficulty, we designed an apple surface defect inspection network (ASDINet) suitable for few-shot learning. The network structure diagram is shown in
Figure 3. First, the AU-Net performs pixel-level localization of surface defects. Training this network with a pixel-wise loss effectively treats each pixel as a separate training sample, increasing the effective number of training samples and preventing overfitting. Next, binary image classification is performed, including an additional network GDM built on top of the AU-Net, and uses the output of the AU-Net. The GDM exists to better predict whether an image has anomalies.
3.2.1. AU-Net
U-Net [
39] is a fully convolutional neural network for medical image segmentation proposed by Ronneberger et al. in 2015. The network architecture consists of a down-sampling path and an up-sampling path, where skip connections between the up- and down-sampling paths ensure that the network can fuse shallow and deep features. The U-Net++ [
40] is an improved network based on the U-Net. It is an architecture with nested and dense skip connections that can capture features at different levels and integrate them through feature superposition. However, the U-Net++ does not express enough information from multiple scales, and its parameter volume is larger than that of the U-Net. Compared with the U-Net and U-Net++, the U-Net3+ [
41] combines multi-scale features, redesigns skip connections, and utilizes multi-scale deep supervision. The U-Net3+ provides fewer parameters, but can generate more accurate location-aware and boundary-enhanced segmentation maps. However, the noise information from the background remains in the shallower layers, which easily leads to over-segmentation. In contrast, the U-Net not only integrates shallow features and deep semantic information but is lighter, has fewer parameters, and is not prone to over-segmentation. Therefore, we chose to upgrade on the basis of the U-Net and designed the AU-Net. Its structure is shown in
Figure 3b. It consists of 14 convolutional layers, three max-pooling layers, and three upper convolutional layers. Compared with the traditional U-Net, the AU-Net replaces the ordinary convolution block of the down-sampling path with Dep-conv, and uses the segmentation map and mask as the input of the GDM.
- (a)
Dep-conv module
In the down-sampling process, we designed the Dep-conv module (shown in
Figure 3c) to replace the traditional convolution block. Dep-conv is a convolutional module that increases the number of convolutional layers with the network architecture. Compared with traditional convolutional blocks, the number of convolutional layers is changed to have fewer convolutional layers in the shallow layers of the architecture and more convolutional layers in the deep layers. This greatly increases the feature capacity of the receptive field. Dilated convolution [
42] is a new convolutional network module proposed by Yu et al. It systematically aggregates multi-scale contextual information without loss of resolution using dilated convolution. Dilated convolution supports exponential expansion of the receptive field without loss of resolution or coverage. However, there is a phenomenon of “The Gridding Effect” in the whole convolution that causes the loss of local information, and no correlation exists between the information obtained by long-distance convolution, thus affecting the classification results. In contrast, Dep-conv preserves local feature information well while increasing the feature capacity of the receptive field, and there is a strong correlation between the information obtained by convolution, which has little impact on the classification results. As shown in
Figure 3c, each convolutional layer is followed by a normalization layer (batch normalization) and a nonlinear ReLU [
43] layer, both of which help to improve the convergence speed during the learning process. The formula of the ReLU [
43] layer is shown below, and the algorithm flow of batch normalization is shown in Algorithm 1.
| Algorithm 1: Batch Normalization |
| 1 | Input: Values of over a mini-batch: ; , (parameters to be learned) |
| 2 | Begin: |
| 3 | //Calculate the mean of mini-batch data |
| 4 | //Calculate mini-batch data variance |
| 5 | //Normalization |
| 6 | //Scaling and offset |
| 7 | Return and
Output: normalized network response |
Among them, represents the number of samples in a batch; represents the feature vector of a sample; is the average value of set ; is the variance of set ; is a very small number (such as ), used to avoid the situation where the variance is 0; is the feature after normalization; is the scaling factor; is the offset; is the output of the BN layer. BN normalizes input data during training using the mean and variance of each mini-batch, adjusting the input distribution of each layer. During testing, it uses the mean and variance of the entire training set for normalization, while keeping scaling and translation parameters constant. This consistency in statistical characteristics between training and testing helps improve the model’s generalization performance.
In the process of deep network training, due to the change in network parameters, the distribution of internal node data changes so that the upper network needs to be constantly adjusted to adapt to the evolution of input data distribution. This will reduce the speed of network learning, and the training process of the network will easily fall into the gradient saturation area, slowing down the convergence speed of the network. For the activation function gradient saturation problem, we chose to use the unsaturated activation function (linear rectification function ReLU [
43]) and kept the input distribution of the activation function in a stable state (adding the normalization layer batch normalization) to solve it, thus avoiding them from becoming stuck in the gradient saturation region as much as possible. In batch normalization, we also used the mean and variance of the mini-batch as an estimate of the mean and variance of the overall training samples. Although the data in each batch were sampled from the overall sample, the mean and variance of different mini-batches would be different, adding random noise to the network’s learning process. This was the same as dropout bringing noise by turning off neurons, and it had a regularizing effect on the model to a certain extent.
All convolutional layers in Dep-conv used a kernel. The number of channels increased as the feature resolution decreased, so the computational requirements were the same for each layer.
- (b)
Shortcut: mask
In semiconductor manufacturing, photolithography is used for many of the chip processing steps, and the patterned “negatives” used for these steps are called masks (also called “masks”). Their function is to cover the selected area so that operations such as erosion or diffusion only affect the area outside the selected area. Image masking is similar to it, it is used to block the image to be processed (all or part) with a selected image, figure, or object, and controls the area or process of image processing. In digital image processing, a mask represents a “logical image” or a 2-bit image consisting of a matrix whose elements have only 2 values: 0 or 1. It is mainly used for the extraction of regions of interest, the extraction of structural features, and for the production of special-shaped images. In the AU-Net, we obtained masks after applying an additional 1 × 1 convolutional layer, which reduced the number of output channels. This resulted in a single-channel output map. The resolution of its input image was reduced by a factor of 8. Dropout was not used in this approach because weight sharing in convolutional layers provides sufficient regularization.
The output mask was one of the inputs to the GDM. At the same time, pixel positioning and precise boundary segmentation of surface defects were realized through the feature fusion of the mask and deep semantic information.
3.2.2. Global Decision Module (GDM)
Racki et al. [
37] proposed an efficient network to explicitly perform surface defect segmentation. They proposed an additional decision network on top of the features from the segmentation network to perform per-image classification of the presence of defects. This improved classification accuracy on synthetic surface defect datasets. Inspired by this, we proposed a GDM. The schematic diagram of the GDM is shown in
Figure 3b. The GDM is built on top of the AU-Net, taking the two outputs of the AU-Net as the input of the GDM. Next, to better predict whether an image is abnormal, we inserted a global spatial domain attention mechanism (GSAM) into the GDM. Finally, the classification network performed binary classification on the apple image, and since the segmentation network is a binary segmentation problem, the classification was performed at the level of individual image pixels.
- (a)
Double input for GDM
The input of the GDM is the output of the AU-Net. Different from Racki et al. [
37], two inputs were used in the GDM, and a global spatial domain attention mechanism (GSAM) was inserted. The input segmentation map and the mask were subjected to global max-pooling and global average pooling, respectively, and were connected in series to finally obtain 66 output neurons.
The design of the GDM followed two crucial principles. Firstly, using multiple down-sampling layers ensured an appropriate capacity for large complex shapes. This enabled our network to capture not only local shapes, but also global shapes spanning large regions of the image. Secondly, the GDM uses the features of the last layer of the AU-Net and the mask. The presence of the mask is a shortcut, and the output neuron from the mask provides a way to achieve perfect detection. If the user does not need it, the network can use only the mask to avoid using a large number of feature maps. At the same time, this also reduces the situation of overfitting caused by a large number of parameters.
- (b)
Global Spatial Domain Attention Mechanism (GSAM)
To better help the model pick up important information, we designed a global spatial domain attention mechanism (GSAM) and inserted it into the GDM module. Refer to
Figure 3d for details.
The attention mechanism originates from the study of human vision. At present, there are three main ways to add attention mechanism in the field of machine vision recognition: spatial attention mechanism, channel attention mechanism, and convolutional block attention module (CBAM). The channel attention mechanism focuses on the influence of different feature channels, assigns weights to feature channels by modeling the importance of each feature channel, and strengthens or suppresses different channels according to task requirements. The spatial attention mechanism focuses on the importance of the spatial location of features, generates spatial attention weights for the output feature map, and strengthens or suppresses different spatial location features according to the feature weights.
The traditional spatial attention mechanism generally only has one-way weight assignment, which will lose important information to a certain extent. In the detection of apple surface defects, because the model has difficulty in distinguishing the importance of feature information, important feature information may be lost, which affects the recognition of the network. Therefore, this study proposed a GSAM, which assigns weights in multiple directions to help the model select important information while reducing the loss of feature information.
The GSAM performs feature extraction for color, texture, and specificity of apple defects. First, it generates weighted features in the horizontal and vertical directions; then, it adds the two types of weights and expands the weight coefficient; finally, the weighted features are matched, a more significant weighted feature is selected, and the larger weight coefficient is determined. The “eye focus” to objects is brought into the image with a similar color and texture to an apple defect. The GSAM algorithm is shown in
Figure 3d.
Three strategies are used in the GSAM to amplify the differences in feature weight coefficients. They are described as follows.
First, we assign horizontal weight coefficients to each row feature using a horizontal attention mechanism, and give vertical weight coefficients to each column feature using a vertical attention mechanism [
26]:
In the above formula, represents the weight coefficient of the attention mechanism, represents the time feature, represents the sequence feature, means the hidden layer information of the feature sequence, represents the vertical attention mechanism feature sequence (), and illustrates the horizontal attention mechanism feature sequence ().
Next, we add the two class weights and expand the weight coefficients:
Subsequently, to determine the “visual focus”, taking the maximum value as the main factor and taking into account other features, the strategy is matched with two types of weighted features, which are used to supplement the results of the second step of weighted addition:
In the experiments in
Section 4.3.2, we confirmed that the optimal values of the weight assignment parameters were
and
.
Then, the three strategies in this method are combined in the following formula:
where
indicates additive weighting coefficient;
represents the maximum value operation;
indicates the minimum value operation;
shows the weight distribution strategy.
- (c)
Classification and output
A fully connected layer connects the 66 neurons’ output via the GDM, and then the output is converted into a probability distribution by SoftMax to obtain the classification result. Since segmentation networks are binary segmentation problems, classification is performed at the level of individual image pixels. We classify samples (pixels) into two categories: (a) with defects; (b) without defects.


 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}















