
Classification of Tea Quality Levels Using Near-Infrared Spectroscopy Based on CLPSO-SVM


Abstract
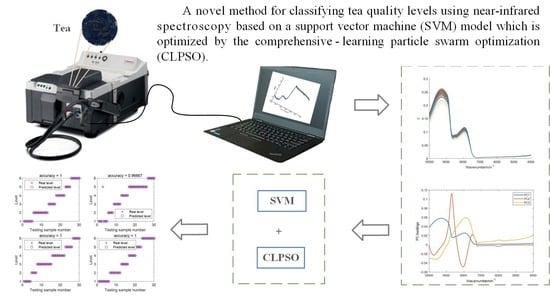
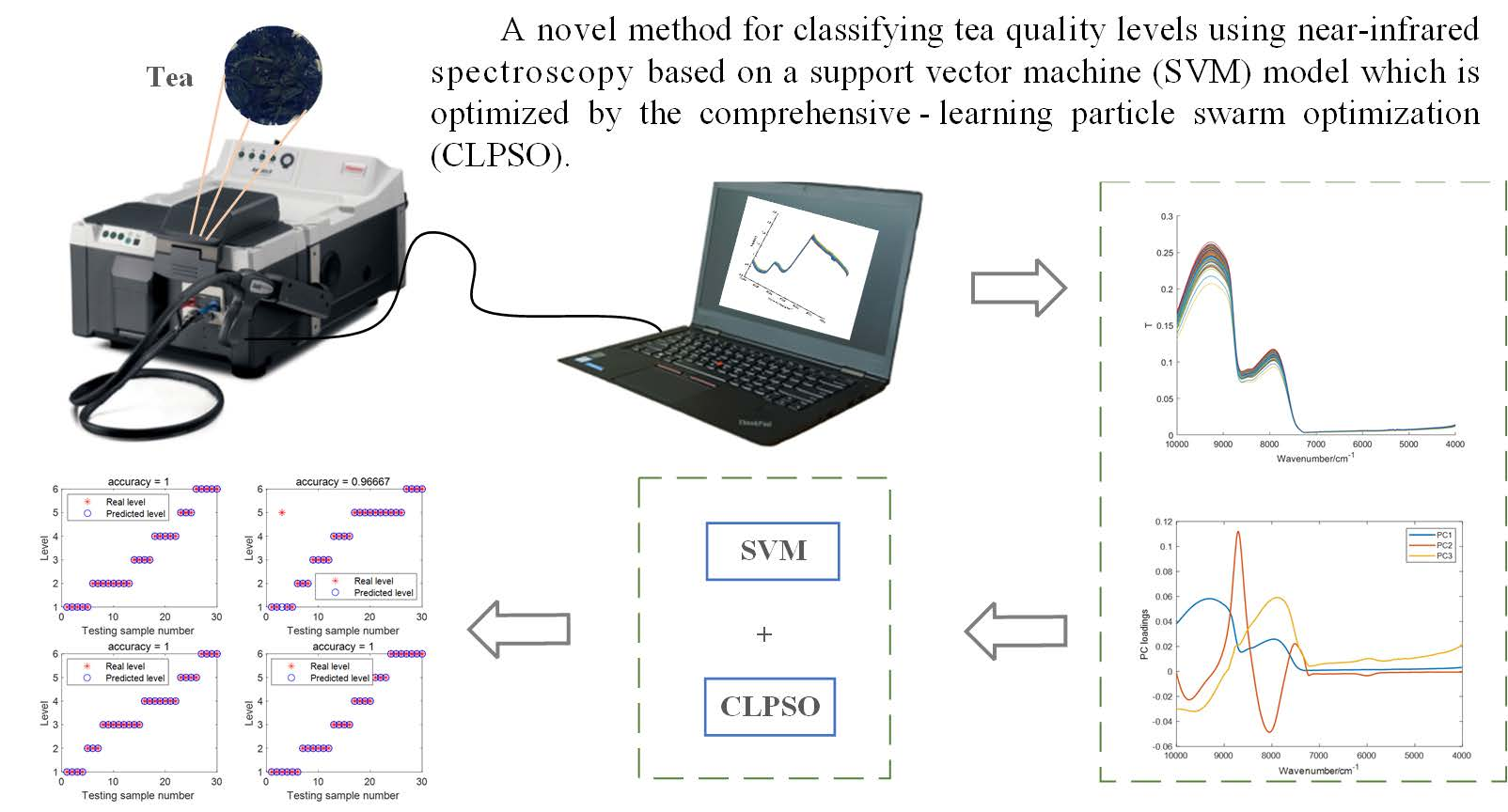
:
1. Introduction
2. Materials and Methods
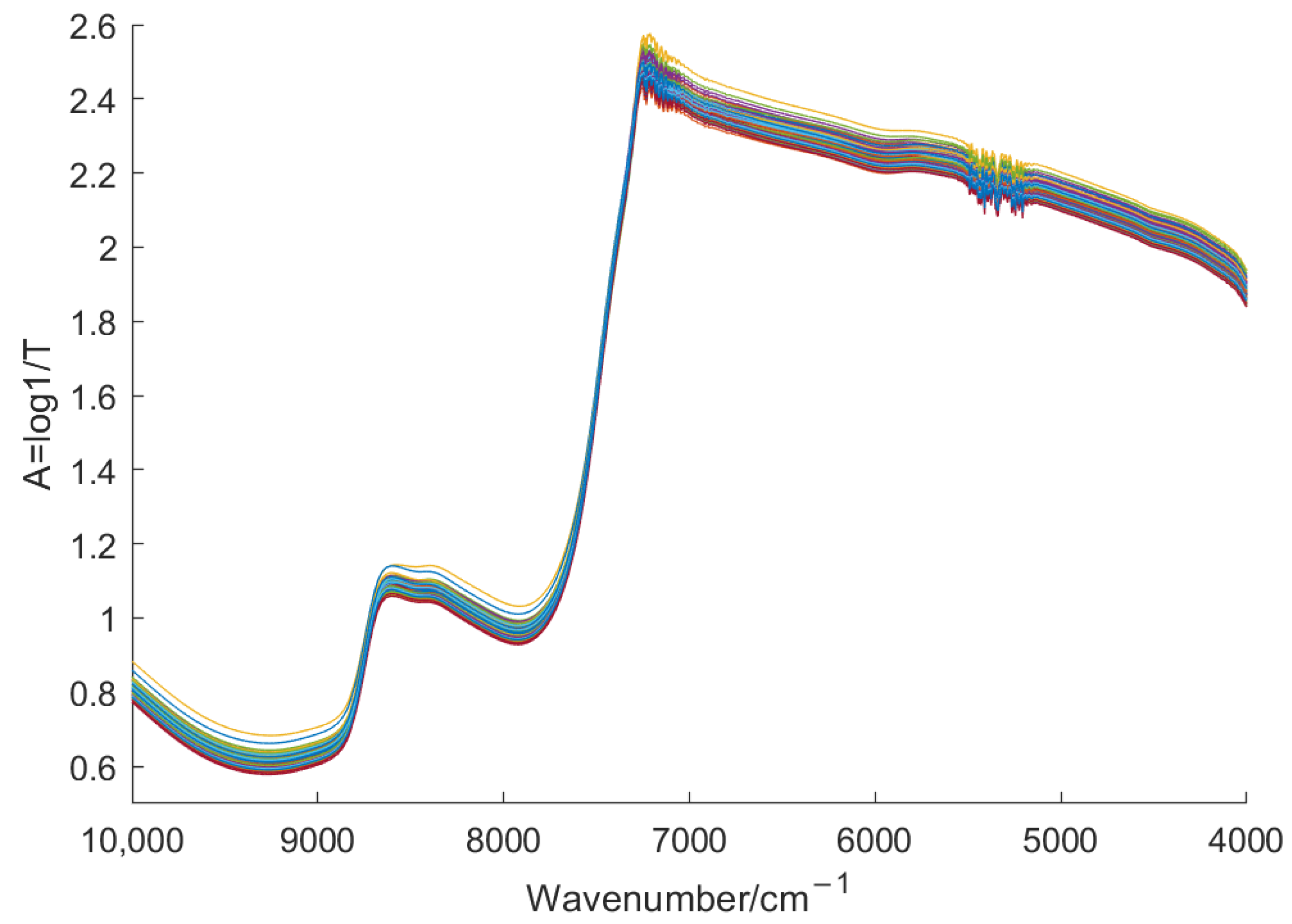
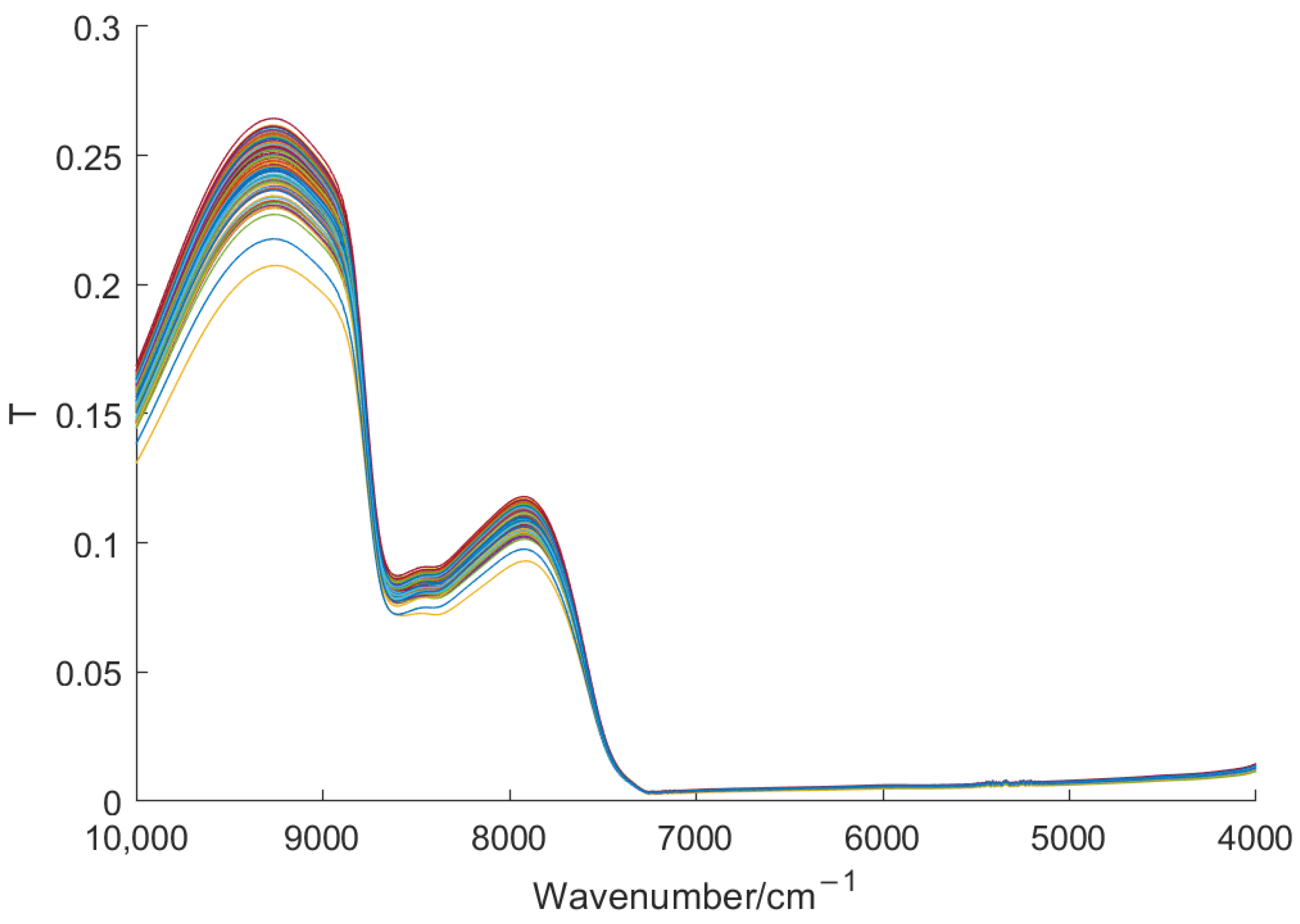
2.1. Tea Sample Preparation and Spectral Acquisition
2.2. Data Preprocessing
2.3. SVM Model
2.4. PSO Algorithm
2.5. CLPSO Algorithm
2.6. Software
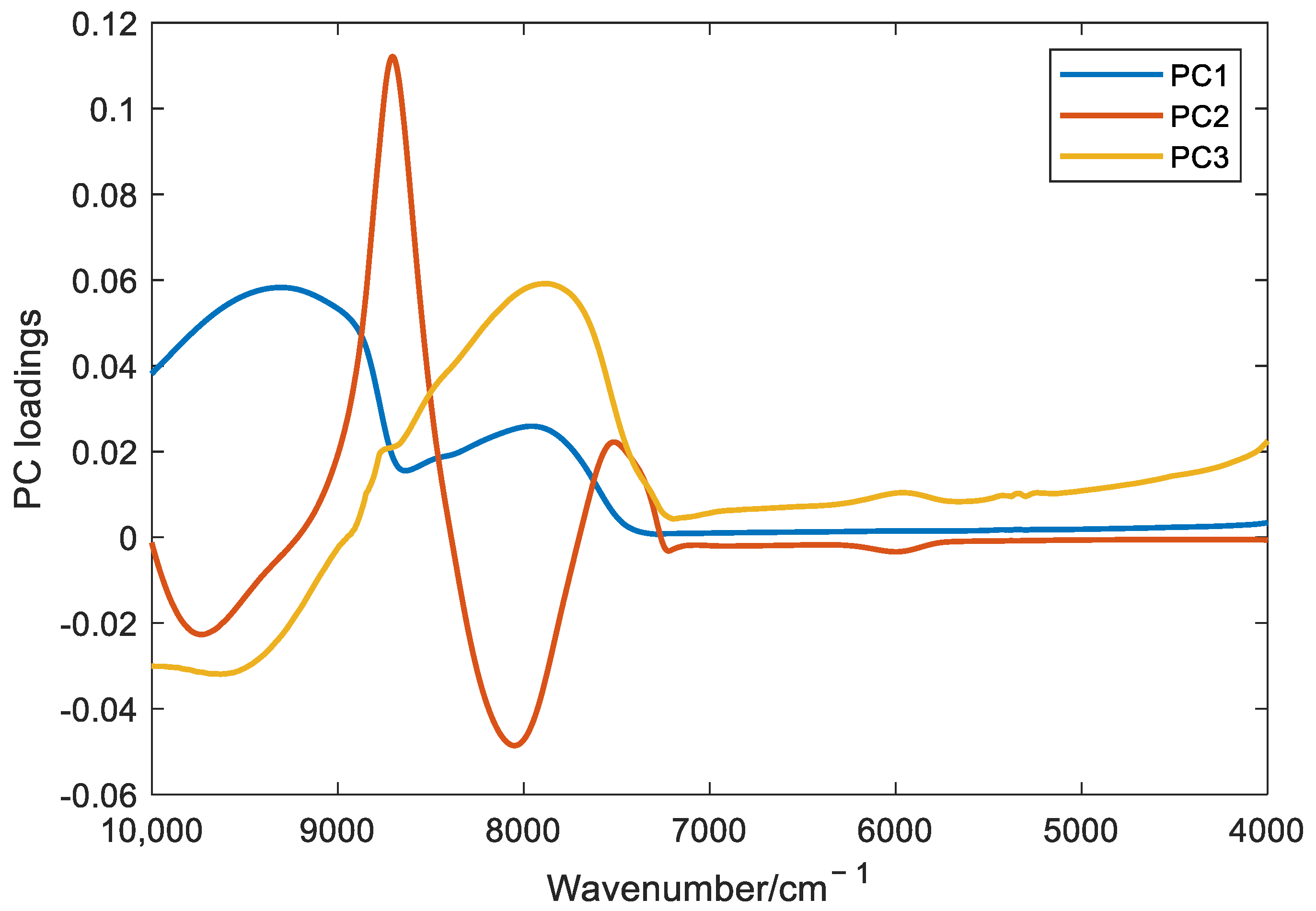
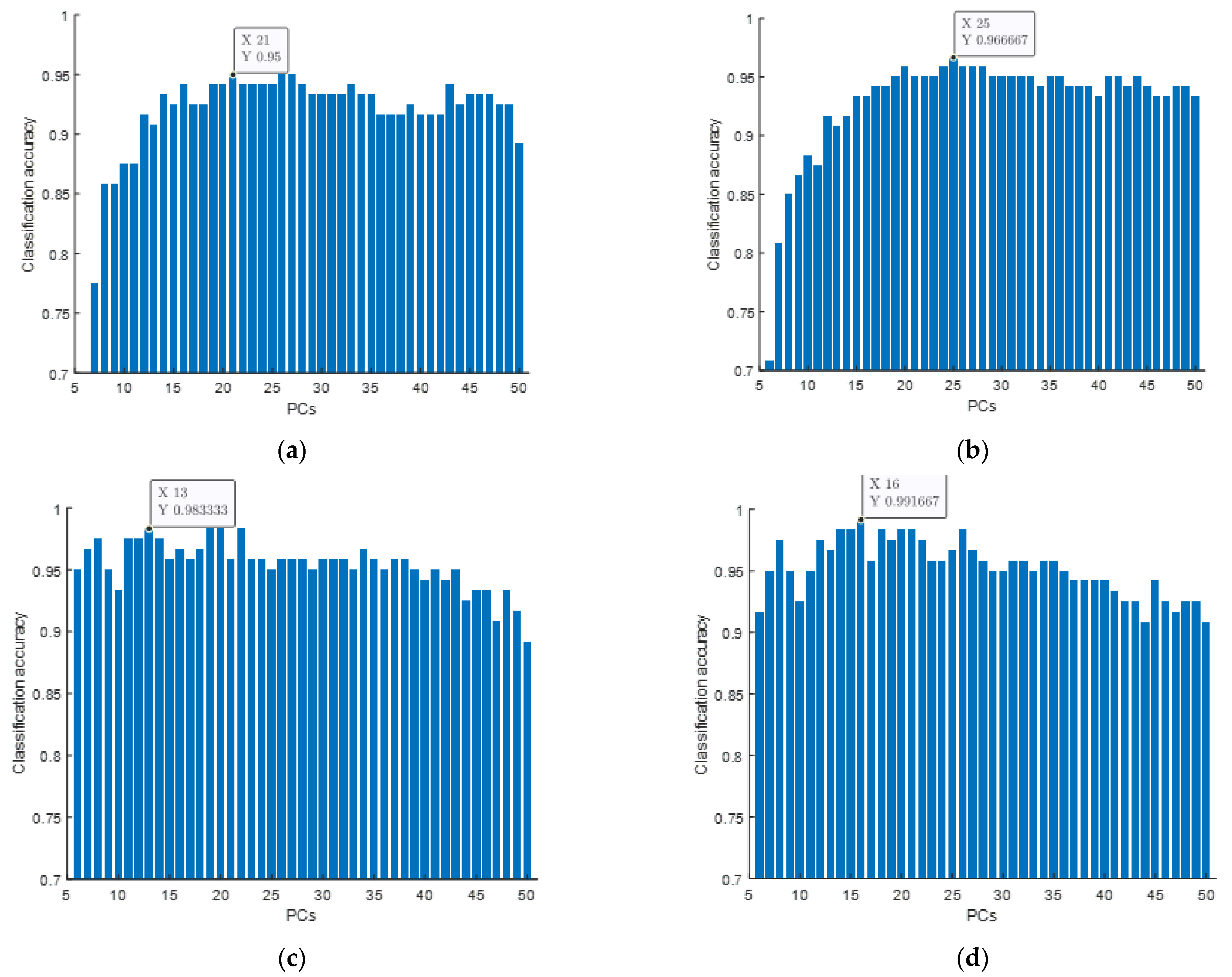
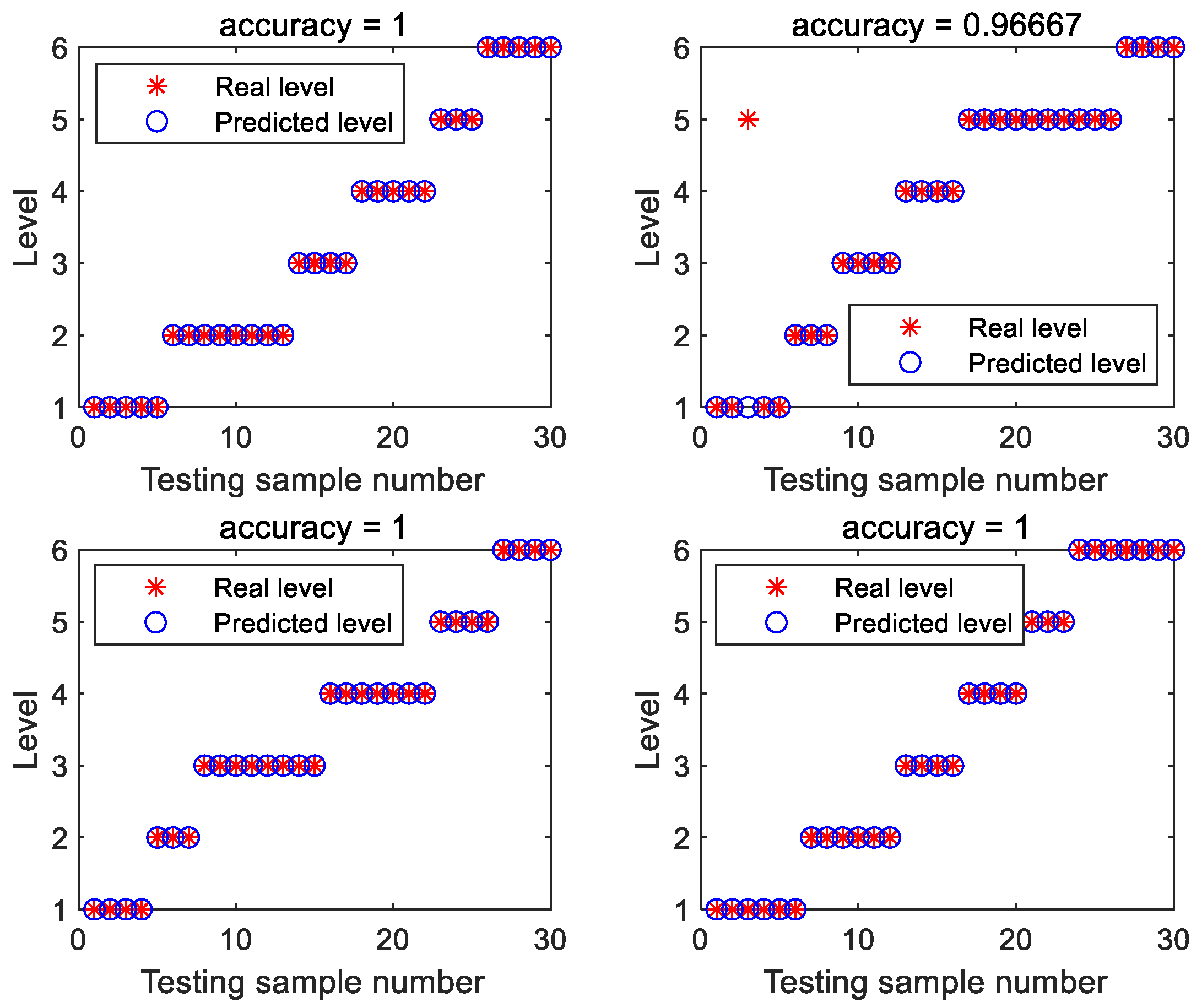
3. Results and Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, Q.; Zhao, J.; Vittayapadung, S. Identification of the green tea grade level using electronic tongue and pattern recognition. Food Res. Int. 2008, 41, 500–504. [Google Scholar] [CrossRef]
- Huang, J.; Ren, G.; Sun, Y.; Jin, S.; Li, L.; Wang, Y.; Ning, J.; Zhang, Z. Qualitative discrimination of Chinese dianhong black tea grades based on a handheld spectroscopy system coupled with chemometrics. Food Sci. Nutr. 2020, 8, 2015–2024. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Blanco, M.; Villarroya, I. NIR spectroscopy: A rapid-response analytical tool. TrAC Trends Anal. Chem. 2002, 21, 240–250. [Google Scholar] [CrossRef]
- Zhang, H.-B.; Liu, T.-A.; Shu, R.-X.; Yang, K.; Ye, S.; You, J.-L.; Ge, J. Using EN-NIR with Support Vector Machine for Classification of Producing Year of Tobacco. Spectrosc. Spectr. Anal. 2018, 38, 1620–1625. [Google Scholar]
- Lu, M.; Zhou, Q.; Chen, T.E.; Li, J.; Jiang, S.; Gao, Q.; Wang, C.; Chen, D. Qualitative Discrimination of Intact Tobacco Leaves Based on Near-Infrared Technology. J. Spectrosc. 2021, 2021, 8807199. [Google Scholar] [CrossRef]
- Huck, C.W.; Guggenbichler, W.; Bonn, G.K. Analysis of caffeine, theobromine and theophylline in coffee by near infrared spectroscopy (NIRS) compared to high-performance liquid chromatography (HPLC) coupled to mass spectrometry. Anal. Chim. Acta 2005, 538, 195–203. [Google Scholar] [CrossRef]
- Ribeiro, J.S.; Garcia Salva, T.d.J.; Silvarolla, M.B. Prediction of a wide range of compounds concentration in raw coffee beans using NIRS, PLS and variable selection. Food Control 2021, 125, 107967. [Google Scholar] [CrossRef]
- Boehmer, S.; Budzier, H.; Krause, V.; Pusch, T.; Gerlach, G.; Cherif, C.; Hehl, J.; Heitmann, U.; Planck, H. NIR-measurement system to detect foreign matter in row cotton. Tm-Tech. Mess. 2008, 75, 406–412. [Google Scholar] [CrossRef]
- Lin, L.; He, Y.; Xiao, Z.; Zhao, K.; Dong, T.; Nie, P. Rapid-Detection Sensor for Rice Grain Moisture Based on NIR Spectroscopy. Appl. Sci. 2019, 9, 1654. [Google Scholar] [CrossRef] [Green Version]
- Zhao, J.; Chen, Q.; Huang, X.; Fang, C.H. Qualitative identification of tea categories by near infrared spectroscopy and support vector machine. J. Pharm. Biomed. Anal. 2006, 41, 1198–1204. [Google Scholar] [CrossRef]
- Anindya, R.O.; Muninggar, J.; Rondonuwu, F.S. Indonesian Black Tea Classification Using Fourier-Transform Near-Infrared Spectroscopy and a Principal Component Analysis. J. Phys. Conf. Ser. 2018, 1093, 012008. [Google Scholar] [CrossRef] [Green Version]
- Li, C.; Guo, H.; Zong, B.; He, P.; Fan, F.; Gong, S. Rapid and non-destructive discrimination of special-grade flat green tea using Near-infrared spectroscopy. Spectrochim. Acta Part A-Mol. Biomol. Spectrosc. 2019, 206, 254–262. [Google Scholar] [CrossRef] [PubMed]
- Firmani, P.; De Luca, S.; Bucci, R.; Marini, F.; Biancolillo, A. Near infrared (NIR) spectroscopy-based classification for the authentication of Darjeeling black tea. Food Control 2019, 100, 292–299. [Google Scholar] [CrossRef]
- Li, C.; Zong, B.; Guo, H.; Luo, Z.; He, P.; Gong, S.; Fan, F. Discrimination of white teas produced from fresh leaves with different maturity by near-infrared spectroscopy. Spectrochim. Acta Part A-Mol. Biomol. Spectrosc. 2020, 227, 117697. [Google Scholar] [CrossRef] [PubMed]
- Jimenez-Carvelo, A.M.; Martin-Torres, S.; Ortega-Gavilan, F.; Camacho, J. PLS-DA vs sparse PLS-DA in food traceability. A case study: Authentication of avocado samples. Talanta 2021, 224, 121904. [Google Scholar] [CrossRef] [PubMed]
- Moreno, R.; Corona, F.; Lendasse, A.; Grana, M.; Galvao, L.S. Extreme learning machines for soybean classification in remote sensing hyperspectral images. Neurocomputing 2014, 128, 207–216. [Google Scholar] [CrossRef]
- Murugan, A.; Nair, S.A.H.; Kumar, K.P.S. Detection of Skin Cancer Using SVM, Random Forest and kNN Classifiers. J. Med. Syst. 2019, 43, 269. [Google Scholar] [CrossRef]
- Genrikhov, I.E.; Djukova, E.V. Classification based on full decision trees. Comput. Math. Math. Phys. 2012, 52, 653–663. [Google Scholar] [CrossRef]
- Ng, C.-B.; Tay, Y.-H.; Goi, B.-M. Pedestrian gender classification using combined global and local parts-based convolutional neural networks. Pattern Anal. Appl. 2019, 22, 1469–1480. [Google Scholar] [CrossRef]
- Chi, M.; Feng, R.; Bruzzone, L. Classification of hyperspectral remote-sensing data with primal SVM for small-sized training dataset problem. Adv. Space Res. 2008, 41, 1793–1799. [Google Scholar] [CrossRef]
- Wang, B.; Yu, M.; Zhu, X.; Zhu, L. Soft-sensing modeling based on ABC-MLSSVM inversion for marine low-temperature alkaline protease MP fermentation process. BMC Biotechnol. 2020, 20, 9. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, C.; An, X.; Li, R. A chaos embedded GSA-SVM hybrid system for classification. Neural Comput. Appl. 2015, 26, 713–721. [Google Scholar] [CrossRef]
- Tharwat, A.; Hassanien, A.E. Quantum-Behaved Particle Swarm Optimization for Parameter Optimization of Support Vector Machine. J. Classif. 2019, 36, 576–598. [Google Scholar] [CrossRef]
- Yu, X.; Dong, H. Remote sensing image classification based on dynamic Co-evolutionary parameter optimization of SVM. J. Intell. Fuzzy Syst. 2018, 35, 343–351. [Google Scholar] [CrossRef]
- Zhu, X.; Li, N.; Pan, Y. Optimization Performance Comparison of Three Different Group Intelligence Algorithms on a SVM for Hyperspectral Imagery Classification. Remote Sens. 2019, 11, 734. [Google Scholar] [CrossRef] [Green Version]
- Maruyama, T.; Igarashi, H. Effective robust optimization based on genetic algorithm. IEEE Trans. Magn. 2008, 44, 990–993. [Google Scholar] [CrossRef] [Green Version]
- Khilwani, N.; Prakash, A.; Shankar, R.; Tiwari, M.K. Fast clonal algorithm. Eng. Appl. Artif. Intell. 2008, 21, 106–128. [Google Scholar] [CrossRef]
- Sharma, H.; Bansal, J.C.; Arya, K.V. Fitness based Differential Evolution. Memetic Comput. 2012, 4, 303–316. [Google Scholar] [CrossRef]
- Pedersen, M.E.H.; Chipperfield, A.J. Simplifying Particle Swarm Optimization. Appl. Soft. Comput. 2010, 10, 618–628. [Google Scholar] [CrossRef]
- Alba, E.; Garcia-Nieto, J.; Jourdan, L.; Talbi, E.G. Gene Selection in Cancer Classification using PSO/SVM and GA/SVM Hybrid Algorithms. In Proceedings of the 2007 IEEE Congress on Evolutionary Computation, Singapore, 25–28 September 2007. [Google Scholar]
- Han, Z.; Wen, M.; Zhang, H.; Zhang, L.; Wan, X.; Ho, C.-T. LC-MS based metabolomics and sensory evaluation reveal the critical compounds of different grades of Huangshan Maofeng green tea. Food Chem. 2022, 374, 131796. [Google Scholar] [CrossRef]
- Lu, X.; Zhao, Y.; Sun, Y.; Yang, S.; Yang, X. Characterisation of polysaccharides from green tea of Huangshan Maofeng with antioxidant and hepatoprotective effects. Food Chem. 2013, 141, 3415–3423. [Google Scholar] [CrossRef] [PubMed]
- Jiang, H.; Liu, G.; Mei, C.; Yu, S.; Xiao, X.; Ding, Y. Measurement of process variables in solid-state fermentation of wheat straw using FT-NIR spectroscopy and synergy interval PLS algorithm. Spectrochim. Acta Part A-Mol. Biomol. Spectrosc. 2012, 97, 277–283. [Google Scholar] [CrossRef]
- Zhu, M.-Z.; Wen, B.; Wu, H.; Li, J.; Lin, H.; Li, Q.; Li, Y.; Huang, J.; Liu, Z. The Quality Control of Tea by Near-Infrared Reflectance (NIR) Spectroscopy and Chemometrics. J. Spectrosc. 2019, 2019, 8129648. [Google Scholar] [CrossRef]
- Li, K.; Xie, X.; Xue, W.; Dai, X.; Chen, X.; Yang, X. A hybrid teaching-learning artificial neural network for building electrical energy consumption prediction. Energy Build. 2018, 174, 323–334. [Google Scholar] [CrossRef]
- Liu, G.Q.; Gao, X.D.; You, D.Y.; Zhang, N.F. Prediction of high power laser welding status based on PCA and SVM classification of multiple sensors. J. Intell. Manuf. 2019, 30, 821–832. [Google Scholar] [CrossRef]
- Chen, T.B.; Zhang, L.Y.; Huang, L.; Liu, M.H.; Chen, J.Y.; Yao, M.Y. Quantitative analysis of chromium in pork by PSO-SVM chemometrics based on laser induced breakdown spectroscopy. J. Anal. At. Spectrom. 2019, 34, 884–890. [Google Scholar] [CrossRef]
- Liang, J.J.; Qin, A.K.; Suganthan, P.N.; Baskar, S. Comprehensive learning particle swarm optimizer for global optimization of multimodal functions. IEEE Trans. Evol. Comput. 2006, 10, 281–295. [Google Scholar] [CrossRef]
- Wu, H.; Geng, J.P.; Jin, R.H.; Qiu, J.Z.; Liu, W.; Chen, J.; Liu, S.N. An Improved Comprehensive Learning Particle Swarm Optimization and Its Application to the Semiautomatic Design of Antennas. IEEE Trans. Antennas Propag. 2009, 57, 3018–3028. [Google Scholar] [CrossRef]
- Chen, X.; Xu, B.; Du, W.L. An Improved Particle Swarm Optimization with Biogeography-Based Learning Strategy for Economic Dispatch Problems. Complexity 2018, 2018, 7289674. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | PCs | Training Accuracy | Testing Accuracy |
|---|---|---|---|
| SVM | 21 | 99.17% | 95% |
| PLS-DA | 25 | 99.17% | 96.67% |
| PSO-SVM | 13 | 100% | 98.33% |
| CLPSO-SVM | 16 | 100% | 99.17% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, Y.; Yan, Y.; Li, J.; Chen, X.; Jiang, H. Classification of Tea Quality Levels Using Near-Infrared Spectroscopy Based on CLPSO-SVM. Foods 2022, 11, 1658. https://doi.org/10.3390/foods11111658
Ding Y, Yan Y, Li J, Chen X, Jiang H. Classification of Tea Quality Levels Using Near-Infrared Spectroscopy Based on CLPSO-SVM. Foods. 2022; 11(11):1658. https://doi.org/10.3390/foods11111658
Chicago/Turabian StyleDing, Yuhan, Yuli Yan, Jun Li, Xu Chen, and Hui Jiang. 2022. "Classification of Tea Quality Levels Using Near-Infrared Spectroscopy Based on CLPSO-SVM" Foods 11, no. 11: 1658. https://doi.org/10.3390/foods11111658