AI-Enabled Intelligent Visible Light Communications: Challenges, Progress, and Future

 ,
,  ,
,
Abstract
:1. Introduction
2. Statues and Challenges of VLC
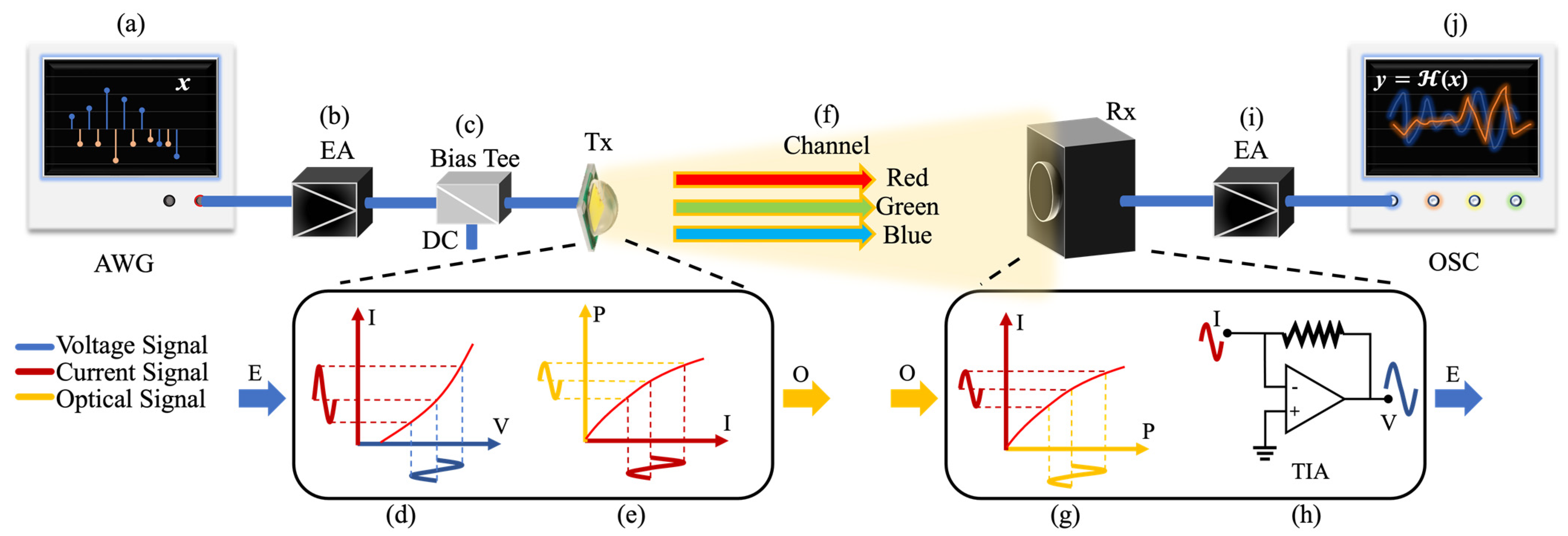
2.1. Visible Light Communication E2E Channel
2.2. Modulation Format in VLC
2.3. Advantages and Disadvantages of ML in VLC
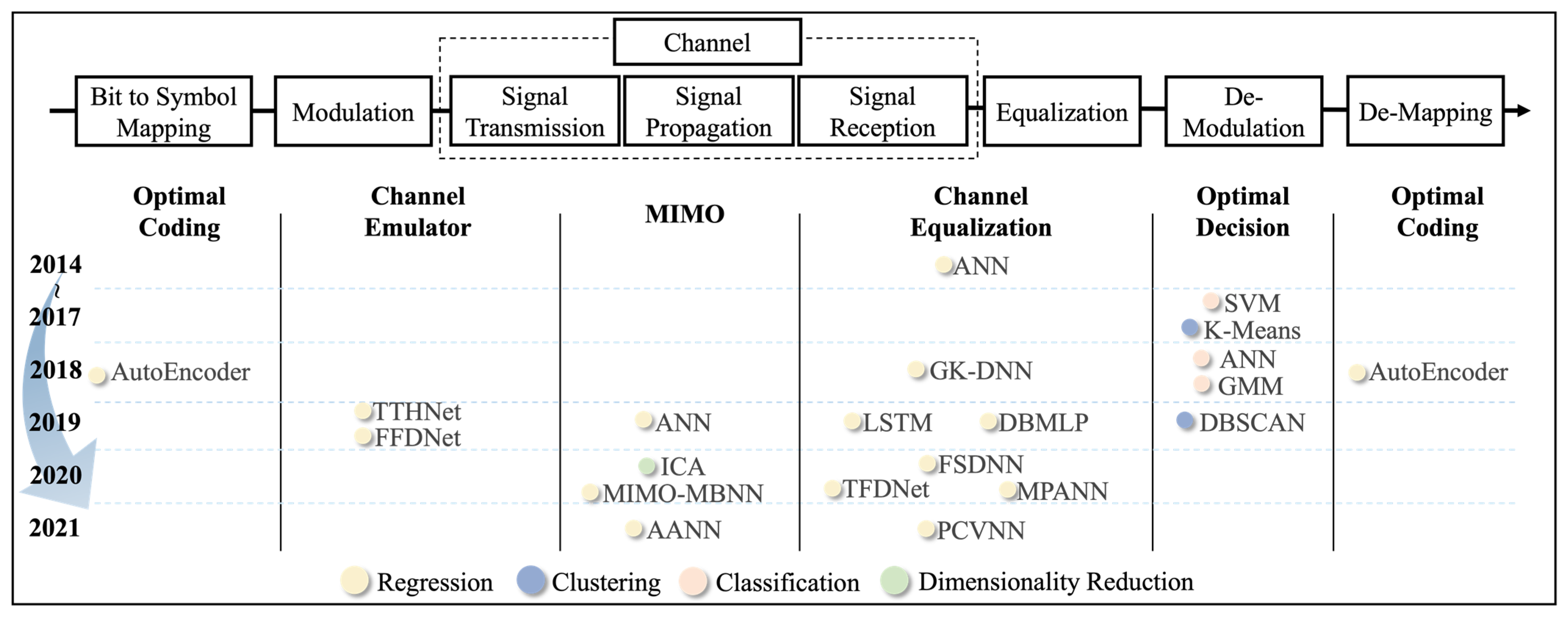
3. Machine Learning in Physical Layer of IVLC
3.1. Channel Emulator
3.1.1. TTHNet
3.1.2. FFDNet
3.1.3. Conclusions
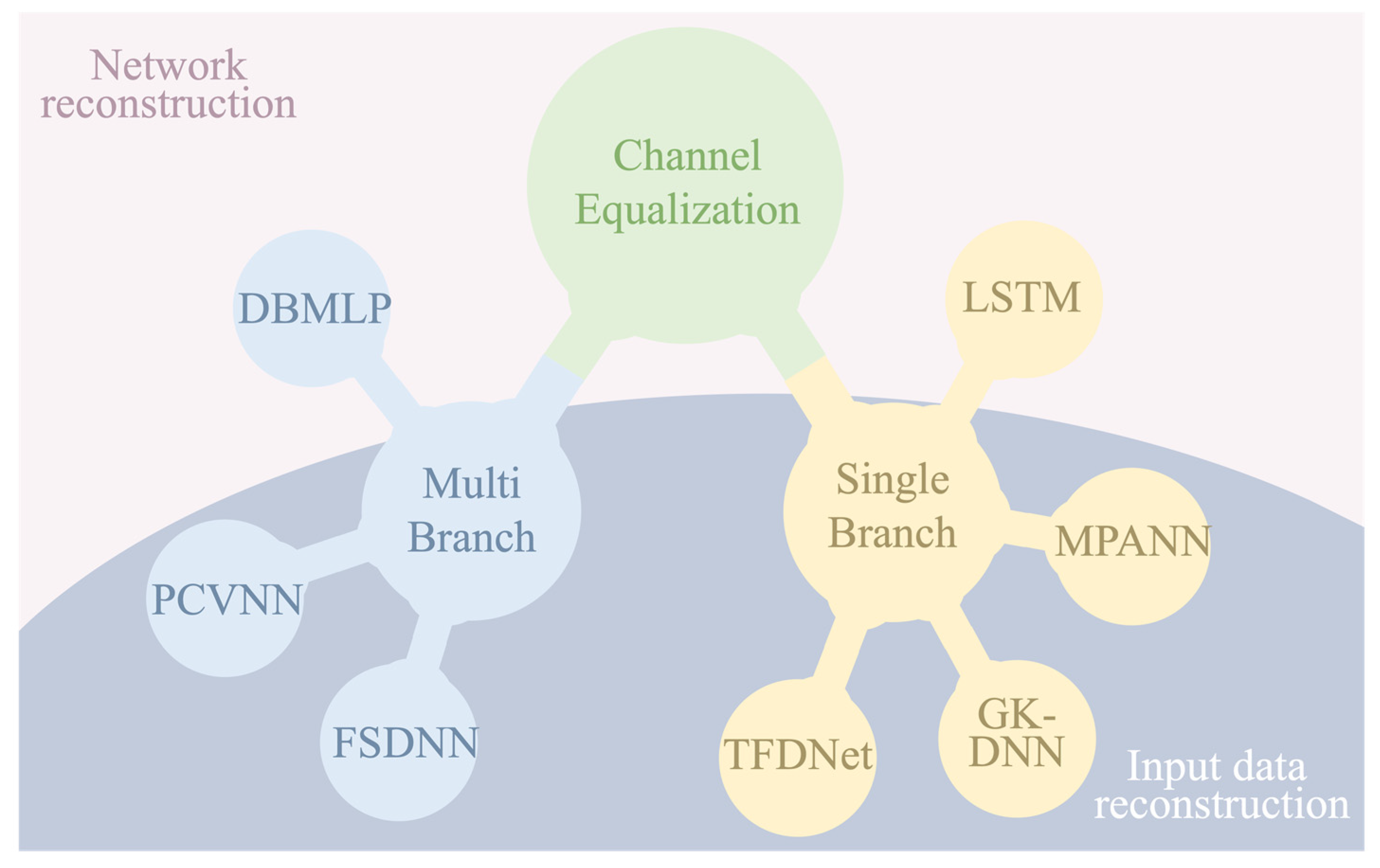
3.2. Channel Equalization
3.2.1. Pre-Equalization GK-DNN
3.2.2. Postequalization GK-DNN
3.2.3. Postequalization FSDNN
3.2.4. Postequalization TFDNet
3.2.5. Postequalization DBMLP
3.2.6. Post-Equalization PCVNN
3.2.7. Postequalization LSTM-Equalizer
3.2.8. Postequalization MPANN
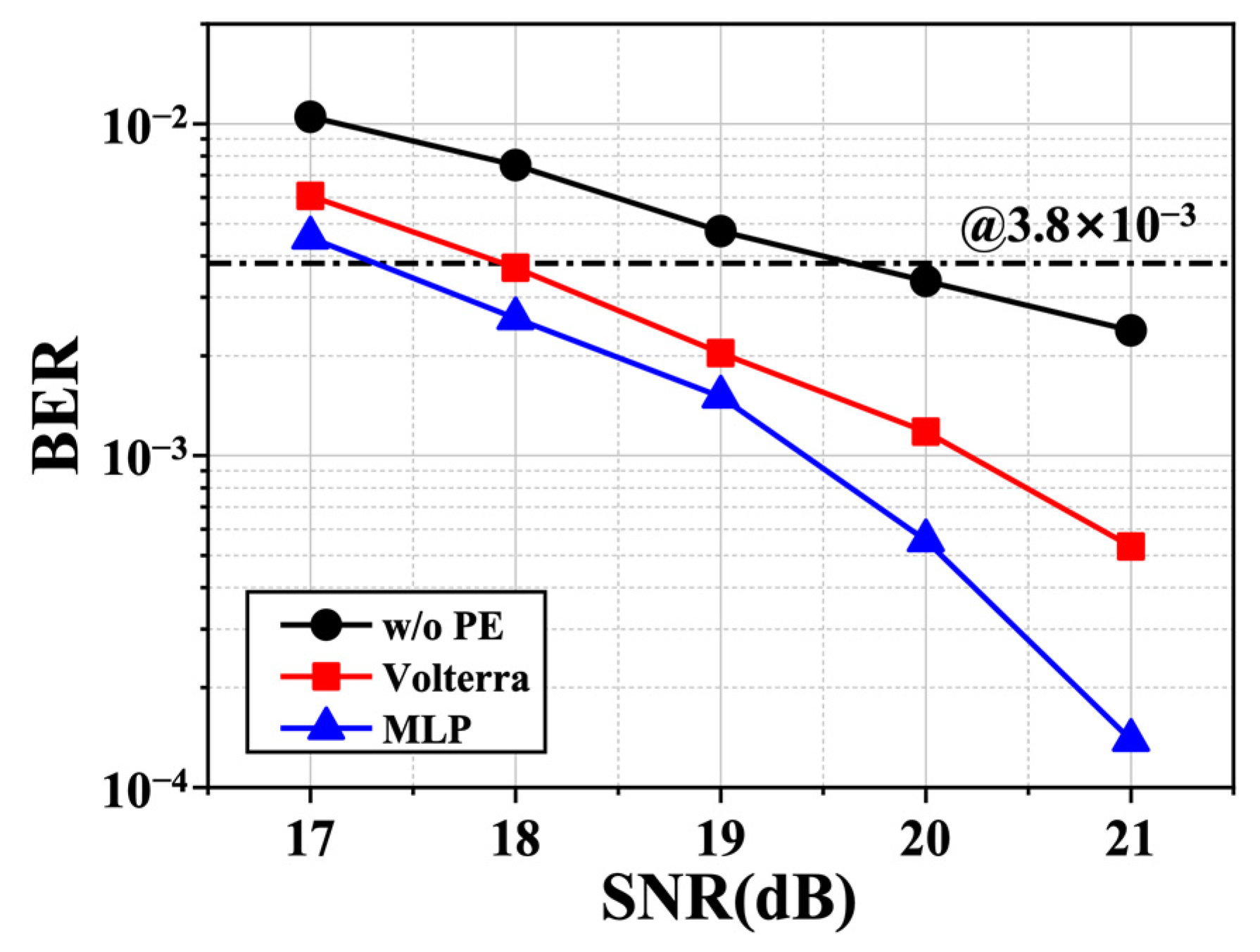
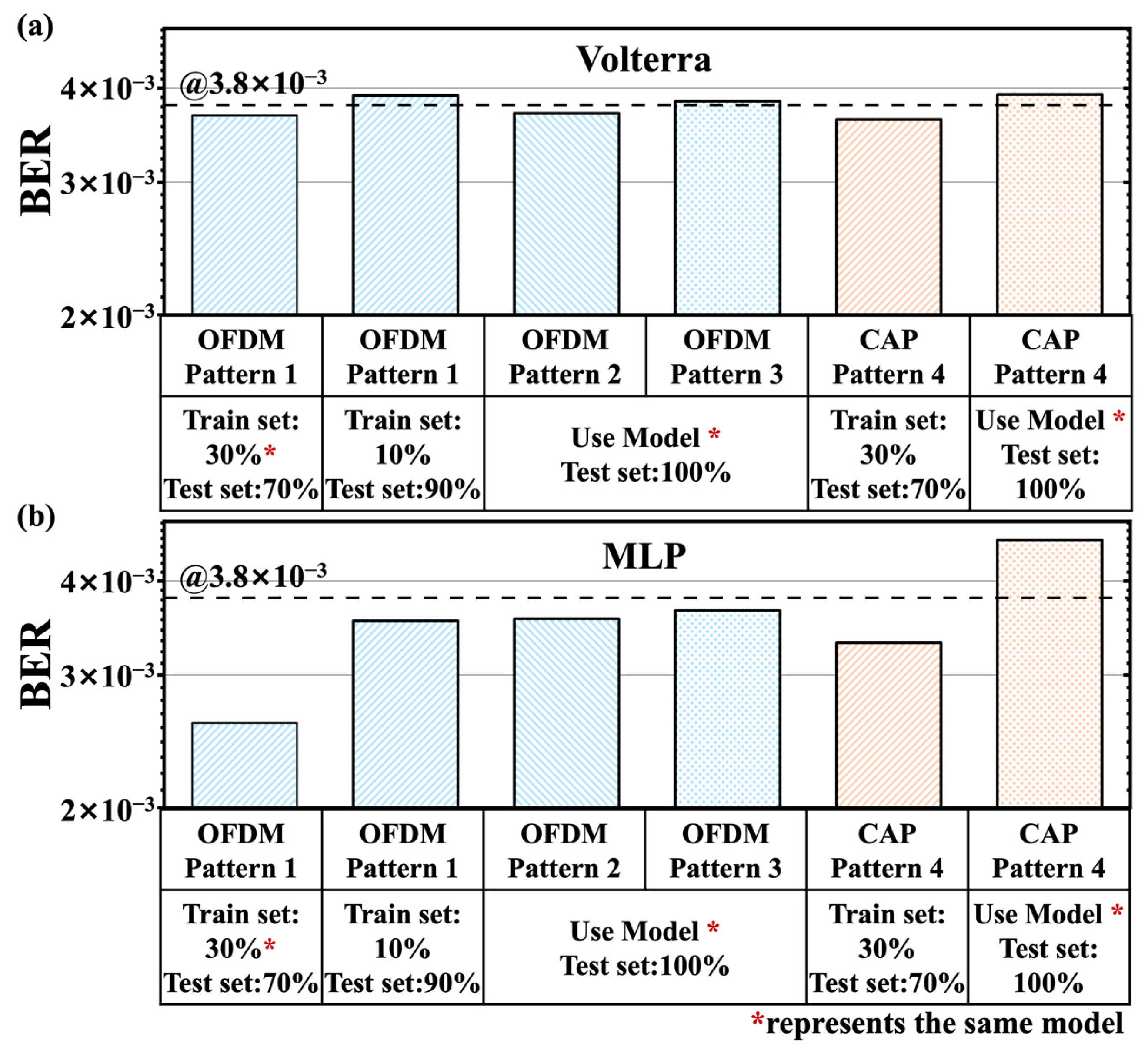
3.2.9. Conclusions
3.3. Optimal Decision
3.3.1. K-Means
3.3.2. DBSCAN
3.3.3. GMM
3.3.4. SVM
3.3.5. ANN
3.3.6. Conclusions
3.4. MIMO
3.4.1. ICA
3.4.2. MIMO-MBNN
3.4.3. Joint Spatial and Temporal ANN Equalizer
3.4.4. Adaptive ANN Equalizer
3.4.5. Conclusions
3.5. Optimal Coding


3.5.1. VLC-Based Autoencoder
3.5.2. Fiber/Wireless-Based Autoencoder
3.5.3. Conclusions
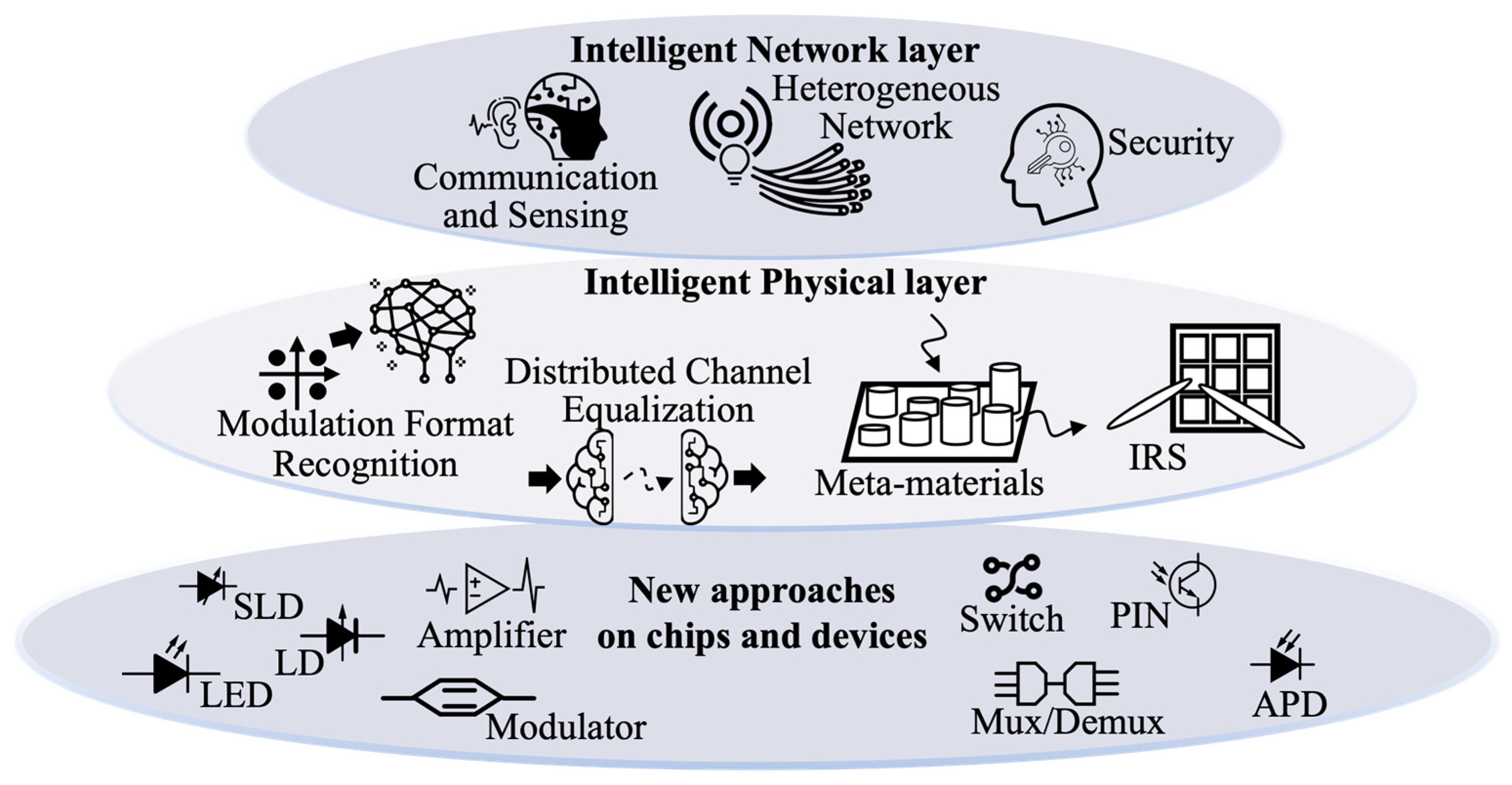
4. Future Trend of ML in IVLC
4.1. Intelligent Physical Layer
4.1.1. Fundamental Electromagnetism Theory and Frontiers in Optical Physics
4.1.2. Distributed Channel Equalization
4.1.3. Modulation Format Recognition
4.2. Intelligent Network Layer
4.2.1. Converged Communication and Sensing
4.2.2. Heterogeneous Network
4.2.3. Security Network
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- You, X.; Wang, C.-X.; Huang, J.; Gao, X.; Zhang, Z.; Wang, M.; Huang, Y.; Zhang, C.; Jiang, Y.; Wang, J. Towards 6G wireless communication networks: Vision, enabling technologies, and new paradigm shifts. Sci. China Inf. Sci. 2021, 64, 110301. [Google Scholar] [CrossRef]
- Latva-aho, M.; Leppänen, K.; Clazzer, F.; Munari, A. Key Drivers and Research Challenges for 6G Ubiquitous Wireless Intelligence; University of Oulu: Oulu, Finland, 2020. [Google Scholar]
- Zong, B.; Fan, C.; Wang, X.; Duan, X.; Wang, B.; Wang, J. 6G technologies: Key drivers, core requirements, system architectures, and enabling technologies. IEEE Veh. Technol. Mag. 2019, 14, 18–27. [Google Scholar] [CrossRef]
- Chi, N.; Haas, H.; Kavehrad, M.; Little, T.D.; Huang, X.-L. Visible light communications: Demand factors, benefits and opportunities [Guest Editorial]. IEEE Wirel. Commun. 2015, 22, 5–7. [Google Scholar] [CrossRef]
- Akasaki, I.; Amano, H.; Kito, M.; Hiramatsu, K. Photoluminescence of Mg-doped p-type GaN and electroluminescence of GaN pn junction LED. J. Lumin. 1991, 48, 666–670. [Google Scholar] [CrossRef]
- Neokosmidis, I.; Kamalakis, T.; Walewski, J.W.; Inan, B.; Sphicopoulos, T. Impact of nonlinear LED transfer function on discrete multitone modulation: Analytical approach. J. Lightwave Technol. 2009, 27, 4970–4978. [Google Scholar] [CrossRef]
- Linnartz, J.-P.M.G.; Deng, X.; Alexeev, A.; Mardanikorani, S. Wireless Communication over an LED Channel. IEEE Commun. Mag. 2020, 58, 77–82. [Google Scholar] [CrossRef]
- Wang, Y.; Tao, L.; Huang, X.; Shi, J.; Chi, N. 8-Gb/s RGBY LED-based WDM VLC system employing high-order CAP modulation and hybrid post equalizer. IEEE Photonics J. 2015, 7, 7904507. [Google Scholar]
- Ying, K.; Qian, H.; Baxley, R.J.; Yao, S. Joint optimization of precoder and equalizer in MIMO-VLC systems. IEEE J. Sel. Areas Commun. 2015, 33, 1949–1958. [Google Scholar] [CrossRef]
- Letaief, K.B.; Chen, W.; Shi, Y.; Zhang, J.; Zhang, Y.-J.A. The roadmap to 6G: AI empowered wireless networks. IEEE Commun. Mag. 2019, 57, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Khan, F.N.; Lu, C.; Lau, A.P.T. Machine learning methods for optical communication systems. In Proceedings of the Signal Processing in Photonic Communications 2017, New Orleans, LA, USA, 24–27 July 2017. [Google Scholar]
- Zhu, G.; Liu, D.; Du, Y.; You, C.; Zhang, J.; Huang, K. Toward an intelligent edge: Wireless communication meets machine learning. IEEE Commun. Mag. 2020, 58, 19–25. [Google Scholar] [CrossRef] [Green Version]
- Mitola, J.; Maguire, G.Q. Cognitive radio: Making software radios more personal. IEEE Pers. Commun. 1999, 6, 13–18. [Google Scholar] [CrossRef] [Green Version]
- Hosmer, D.W., Jr.; Lemeshow, S.; Sturdivant, R.X. Applied Logistic Regression; John Wiley & Sons: Hoboken, NJ, USA, 2013; Volume 398. [Google Scholar]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Routledge: London, UK, 2017. [Google Scholar]
- Ester, M.; Kriegel, H.-P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining (KDD-96), Portland, OR, USA, 2–4 August 1996; pp. 226–231. [Google Scholar]
- Roweis, S.T.; Saul, L.K. Nonlinear dimensionality reduction by locally linear embedding. Science 2000, 290, 2323–2326. [Google Scholar] [CrossRef] [Green Version]
- Windisch, R.; Knobloch, A.; Kuijk, M.; Rooman, C.; Dutta, B.; Kiesel, P.; Borghs, G.; Dohler, G.; Heremans, P. Large-signal-modulation of high-efficiency light-emitting diodes for optical communication. IEEE J. Quantum Electron. 2000, 36, 1445–1453. [Google Scholar] [CrossRef]
- Le Minh, H.; O’Brien, D.; Faulkner, G.; Zeng, L.; Lee, K.; Jung, D.; Oh, Y.; Won, E.T. 100-Mb/s NRZ visible light communications using a postequalized white LED. IEEE Photonics Technol. Lett. 2009, 21, 1063–1065. [Google Scholar] [CrossRef]
- Kaushal, H.; Kaddoum, G. Underwater optical wireless communication. IEEE Access 2016, 4, 1518–1547. [Google Scholar] [CrossRef]
- Elgala, H.; Mesleh, R.; Haas, H. An LED model for intensity-modulated optical communication systems. IEEE Photonics Technol. Lett. 2010, 22, 835–837. [Google Scholar] [CrossRef]
- Costa, E.; Pupolin, S. M-QAM-OFDM system performance in the presence of a nonlinear amplifier and phase noise. IEEE Trans. Commun. 2002, 50, 462–472. [Google Scholar] [CrossRef]
- Lin, R.-L.; Chen, Y.-F. Equivalent circuit model of light-emitting-diode for system analyses of lighting drivers. In Proceedings of the 2009 IEEE Industry Applications Society Annual Meeting, Houston, TX, USA, 4–8 October 2009; pp. 1–5. [Google Scholar]
- Kamalakis, T.; Walewski, J.W.; Ntogari, G.; Mileounis, G. Empirical Volterra-series modeling of commercial light-emitting diodes. J. Lightwave Technol. 2011, 29, 2146–2155. [Google Scholar] [CrossRef]
- Ying, K.; Yu, Z.; Baxley, R.J.; Qian, H.; Chang, G.-K.; Zhou, G.T. Nonlinear distortion mitigation in visible light communications. IEEE Wirel. Commun. 2015, 22, 36–45. [Google Scholar] [CrossRef]
- Schwarz, U.T.; Braun, H.; Kojima, K.; Kawakami, Y.; Nagahama, S.; Mukai, T. Interplay of built-in potential and piezoelectric field on carrier recombination in green light emitting InGaN quantum wells. Appl. Phys. Lett. 2007, 91, 123503. [Google Scholar] [CrossRef]
- Schwarz, U.T. Emission of biased green quantum wells in time and wavelength domain. In Proceedings of the Gallium Nitride Materials and Devices IV (International Society for Optics and Photonics—SPIE), San Jose, CA, USA, 26–29 January 2009; p. 72161U. [Google Scholar]
- Dai, Q.; Shan, Q.; Wang, J.; Chhajed, S.; Cho, J.; Schubert, E.F.; Crawford, M.H.; Koleske, D.D.; Kim, M.-H.; Park, Y. Carrier recombination mechanisms and efficiency droop in GaInN/GaN light-emitting diodes. Appl. Phys. Lett. 2010, 97, 133507. [Google Scholar] [CrossRef] [Green Version]
- McKendry, J.J.; Massoubre, D.; Zhang, S.; Rae, B.R.; Green, R.P.; Gu, E.; Henderson, R.K.; Kelly, A.; Dawson, M.D. Visible-light communications using a CMOS-controlled micro-light-emitting-diode array. J. Lightwave Technol. 2011, 30, 61–67. [Google Scholar] [CrossRef] [Green Version]
- Deng, X.; Mardanikorani, S.; Wu, Y.; Arulandu, K.; Chen, B.; Khalid, A.M.; Linnartz, J.-P.M. Mitigating LED nonlinearity to enhance visible light communications. IEEE Trans. Commun. 2018, 66, 5593–5607. [Google Scholar] [CrossRef]
- Barry, J.R.; Kahn, J.M.; Krause, W.J.; Lee, E.A.; Messerschmitt, D.G. Simulation of multipath impulse response for indoor wireless optical channels. IEEE J. Sel. Areas Commun. 1993, 11, 367–379. [Google Scholar] [CrossRef] [Green Version]
- Lopez-Hernandez, F.J.; Perez-Jimenez, R.; Santamaria, A. Ray-tracing algorithms for fast calculation of the channel impulse response on diffuse IR wireless indoor channels. Opt. Eng. 2000, 39, 2775–2780. [Google Scholar]
- Zhang, M.; Zhang, Y.; Yuan, X.; Zhang, J. Mathematic models for a ray tracing method and its applications in wireless optical communications. Opt. Express 2010, 18, 18431–18437. [Google Scholar] [CrossRef]
- Tanaka, Y.; Komine, T.; Haruyama, S.; Nakagawa, M. Indoor visible communication utilizing plural white LEDs as lighting. In Proceedings of the 12th IEEE International Symposium on Personal, Indoor and Mobile Radio Communications (PIMRC 2001) (Cat. No. 01TH8598), San Diego, CA, USA, 30 September–3 October 2001; pp. 81–85. [Google Scholar]
- Fujimoto, N.; Yamamoto, S. The fastest visible light transmissions of 662 Mb/s by a blue LED, 600 Mb/s by a red LED, and 520 Mb/s by a green LED based on simple OOK-NRZ modulation of a commercially available RGB-type white LED using pre-emphasis and post-equalizing techniques. In Proceedings of the 2014 The European Conference on Optical Communication (ECOC), Cannes, France, 21–25 September 2014; pp. 1–3. [Google Scholar]
- Stepniak, G.; Maksymiuk, L.; Siuzdak, J. 1.1 GBIT/S white lighting LED-based visible light link with pulse amplitude modulation and Volterra DFE equalization. Microw. Opt. Technol. Lett. 2015, 57, 1620–1622. [Google Scholar] [CrossRef]
- Li, X.; Bamiedakis, N.; Guo, X.; McKendry, J.; Xie, E.; Ferreira, R.; Gu, E.; Dawson, M.; Penty, R.; White, I. Wireless visible light communications employing feed-forward pre-equalization and PAM-4 modulation. J. Lightwave Technol. 2016, 34, 2049–2055. [Google Scholar] [CrossRef]
- Wu, F.; Lin, C.; Wei, C.; Chen, C.; Huang, H.; Ho, C. 1.1-Gb/s white-LED-based visible light communication employing carrier-less amplitude and phase modulation. IEEE Photonics Technol. Lett. 2012, 24, 1730–1732. [Google Scholar] [CrossRef] [Green Version]
- Haigh, P.A.; Burton, A.; Werfli, K.; Le Minh, H.; Bentley, E.; Chvojka, P.; Popoola, W.O.; Papakonstantinou, I.; Zvanovec, S. A multi-CAP visible-light communications system with 4.85-b/s/Hz spectral efficiency. IEEE J. Sel. Areas Commun. 2015, 33, 1771–1779. [Google Scholar] [CrossRef] [Green Version]
- Chun, H.; Manousiadis, P.; Rajbhandari, S.; Vithanage, D.A.; Faulkner, G.; Tsonev, D.; McKendry, J.J.D.; Videv, S.; Xie, E.; Gu, E. Visible Light Communication Using a Blue GaN μ LED and Fluorescent Polymer Color Converter. IEEE Photonics Technol. Lett. 2014, 26, 2035–2038. [Google Scholar] [CrossRef] [Green Version]
- Wang, F.; Liu, Y.; Jiang, F.; Chi, N. High speed underwater visible light communication system based on LED employing maximum ratio combination with multi-PIN reception. Opt. Commun. 2018, 425, 106–112. [Google Scholar] [CrossRef]
- Ryu, S.-B.; Choi, J.-H.; Bok, J.; Lee, H.; Ryu, H.-G. High power efficiency and low nonlinear distortion for wireless visible light communication. In Proceedings of the 2011 4th IFIP International Conference on New Technologies, Mobility and Security, Paris, France, 7–10 February 2011; pp. 1–5. [Google Scholar]
- Ma, X.; Yang, F.; Liu, S.; Song, J. Channel estimation for wideband underwater visible light communication: A compressive sensing perspective. Opt. Express 2018, 26, 311–321. [Google Scholar] [CrossRef]
- Zhao, Y.; Zou, P.; Yu, W.; Chi, N. Two tributaries heterogeneous neural network based channel emulator for underwater visible light communication systems. Opt. Express 2019, 27, 22532–22541. [Google Scholar] [CrossRef]
- Gao, Z.; Wang, Y.; Liu, X.; Zhou, F.; Wong, K.-K. FFDNet-based channel estimation for massive MIMO visible light communication systems. IEEE Wirel. Commun. Lett. 2019, 9, 340–343. [Google Scholar] [CrossRef] [Green Version]
- He, H.; Wen, C.-K.; Jin, S.; Li, G.Y. Deep learning-based channel estimation for beamspace mmWave massive MIMO systems. IEEE Wirel. Commun. Lett. 2018, 7, 852–855. [Google Scholar] [CrossRef] [Green Version]
- Jin, Y.; Zhang, J.; Jin, S.; Ai, B. Channel estimation for cell-free mmWave massive MIMO through deep learning. IEEE Trans. Veh. Technol. 2019, 68, 10325–10329. [Google Scholar] [CrossRef]
- Burse, K.; Yadav, R.N.; Shrivastava, S. Channel equalization using neural networks: A review. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2010, 40, 352–357. [Google Scholar] [CrossRef]
- Le Minh, H.; O’Brien, D.; Faulkner, G.; Zeng, L.; Lee, K.; Jung, D.; Oh, Y. High-speed visible light communications using multiple-resonant equalization. IEEE Photonics Technol. Lett. 2008, 20, 1243–1245. [Google Scholar] [CrossRef] [Green Version]
- Haigh, P.A.; Ghassemlooy, Z.; Rajbhandari, S.; Papakonstantinou, I.; Popoola, W. Visible light communications: 170 Mb/s using an artificial neural network equalizer in a low bandwidth white light configuration. J. Lightwave Technol. 2014, 32, 1807–1813. [Google Scholar] [CrossRef]
- Liang, S.; Jiang, Z.; Qiao, L.; Lu, X.; Chi, N. Faster-than-Nyquist precoded CAP modulation visible light communication system based on nonlinear weighted look-up table predistortion. IEEE Photonics J. 2018, 10, 7900709. [Google Scholar] [CrossRef]
- Zhao, Y.; Zou, P.; Shi, M.; Chi, N. Nonlinear predistortion scheme based on Gaussian kernel-aided deep neural networks channel estimator for visible light communication system. Opt. Eng. 2019, 58, 116108. [Google Scholar] [CrossRef]
- Xue, L.; Yi, L.; Lin, R.; Huang, L.; Chen, J. SOA pattern effect mitigation by neural network based pre-equalizer for 50G PON. Opt. Express 2021, 29, 24714–24722. [Google Scholar] [CrossRef]
- Chi, N.; Zhao, Y.; Shi, M.; Zou, P.; Lu, X. Gaussian kernel-aided deep neural network equalizer utilized in underwater PAM8 visible light communication system. Opt. Express 2018, 26, 26700–26712. [Google Scholar] [CrossRef]
- Chi, N.; Hu, F.; Li, G.; Wang, C.; Niu, W. AI based on frequency slicing deep neural network for underwater visible light communication. Sci. China Inf. Sci. 2020, 63, 160303. [Google Scholar] [CrossRef]
- Chen, H.; Zhao, Y.; Hu, F.; Chi, N. Nonlinear Resilient Learning Method Based on Joint Time-Frequency Image Analysis in Underwater Visible Light Communication. IEEE Photonics J. 2020, 12, 7901610. [Google Scholar] [CrossRef]
- Griffin, D.; Lim, J. Signal estimation from modified short-time Fourier transform. IEEE Trans. Acoust. Speech Signal Process. 1984, 32, 236–243. [Google Scholar] [CrossRef]
- Zhao, Y.; Chi, N. Partial pruning strategy for a dual-branch multilayer perceptron-based post-equalizer in underwater visible light communication systems. Opt. Express 2020, 28, 15562–15572. [Google Scholar] [CrossRef]
- Zhao, Z.; Vuran, M.C.; Guo, F.; Scott, S.D. Deep-waveform: A learned OFDM receiver based on deep complex-valued convolutional networks. IEEE J. Sel. Areas Commun. 2021, 39, 2407–2420. [Google Scholar] [CrossRef]
- Chen, H.; Niu, W.; Zhao, Y.; Zhang, J.; Chi, N.; Li, Z. Adaptive deep-learning equalizer based on constellation partitioning scheme with reduced computational complexity in UVLC system. Opt. Express 2021, 29, 21773–21782. [Google Scholar] [CrossRef]
- Lu, X.; Lu, C.; Yu, W.; Qiao, L.; Liang, S.; Lau, A.P.T.; Chi, N. Memory-controlled deep LSTM neural network post-equalizer used in high-speed PAM VLC system. Opt. Express 2019, 27, 7822–7833. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, Z.; Hu, F.; Li, G.; Zou, P.; Wang, C.; Chi, N. Convolution-enhanced LSTM neural network post-equalizer used in probabilistic shaped underwater VLC system. In Proceedings of the 2020 IEEE International Conference on Signal Processing, Communications and Computing (ICSPCC), Macau, China, 21–24 August 2020; pp. 1–5. [Google Scholar]
- Hu, F.; Holguin-Lerma, J.A.; Mao, Y.; Zou, P.; Shen, C.; Ng, T.K.; Ooi, B.S.; Chi, N. Demonstration of a low-complexity memory-polynomial-aided neural network equalizer for CAP visible-light communication with superluminescent diode. Opto-Electron. Adv. 2020, 3, 200009. [Google Scholar] [CrossRef]
- Lu, X.; Wang, K.; Qiao, L.; Zhou, W.; Wang, Y.; Chi, N. Nonlinear compensation of multi-CAP VLC system employing clustering algorithm based perception decision. IEEE Photonics J. 2017, 9, 7906509. [Google Scholar] [CrossRef]
- Lu, X.; Zhao, M.; Qiao, L.; Chi, N. Non-linear compensation of multi-CAP VLC system employing pre-distortion base on clustering of machine learning. In Proceedings of the Optical Fiber Communication Conference (Optical Society of America), San Diego, CA, USA, 11–15 March 2018; p. M2K.1. [Google Scholar]
- Lu, X.; Qiao, L.; Zhou, Y.; Yu, W.; Chi, N. An IQ-Time 3-dimensional post-equalization algorithm based on DBSCAN of machine learning in CAP VLC system. Opt. Commun. 2019, 430, 299–303. [Google Scholar] [CrossRef]
- Lu, F.; Peng, P.-C.; Liu, S.; Xu, M.; Shen, S.; Chang, G.-K. Integration of multivariate gaussian mixture model for enhanced pam-4 decoding employing basis expansion. In Proceedings of the Optical Fiber Communication Conference (Optical Society of America), San Diego, CA, USA, 11–15 March 2018; p. M2F.1. [Google Scholar]
- Yuan, Y.; Zhang, M.; Luo, P.; Ghassemlooy, Z.; Lang, L.; Wang, D.; Zhang, B.; Han, D. SVM-based detection in visible light communications. Optik 2017, 151, 55–64. [Google Scholar] [CrossRef]
- Niu, W.; Ha, Y.; Chi, N. Support vector machine based machine learning method for GS 8QAM constellation classification in seamless integrated fiber and visible light communication system. Sci. China Inf. Sci. 2020, 63, 202306. [Google Scholar] [CrossRef]
- Li, J.; Guan, W. The optical barcode detection and recognition method based on visible light communication using machine learning. Appl. Sci. 2018, 8, 2425. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Chi, N. Demonstration of high-speed 2 × 2 non-imaging MIMO Nyquist single carrier visible light communication with frequency domain equalization. J. Lightwave Technol. 2014, 32, 2087–2093. [Google Scholar] [CrossRef]
- Wang, Z.; Han, S.; Chi, N. Performance enhancement based on machine learning scheme for space multiplexing 2 × 2 MIMO-VLC system employing joint IQ independent component analysis. Opt. Commun. 2020, 458, 124733. [Google Scholar] [CrossRef]
- Zou, P.; Zhao, Y.; Hu, F.; Chi, N. Enhanced performance of MIMO multi-branch hybrid neural network in single receiver MIMO visible light communication system. Opt. Express 2020, 28, 28017–28032. [Google Scholar] [CrossRef]
- Wolniansky, P.W.; Foschini, G.J.; Golden, G.D.; Valenzuela, R.A. V-BLAST: An architecture for realizing very high data rates over the rich-scattering wireless channel. In Proceedings of the 1998 URSI International Symposium on Signals, Systems, and Electronics (Cat. No. 98EX167), Pisa, Italy, 2 October 1998; pp. 295–300. [Google Scholar]
- Rajbhandari, S.; Chun, H.; Faulkner, G.; Haas, H.; Xie, E.; McKendry, J.J.; Herrnsdorf, J.; Gu, E.; Dawson, M.D.; O’Brien, D. Neural network-based joint spatial and temporal equalization for MIMO-VLC system. IEEE Photonics Technol. Lett. 2019, 31, 821–824. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Y.; Zou, P.; He, Z.; Li, Z.; Chi, N. Low spatial complexity adaptive artificial neural network post-equalization algorithms in MIMO visible light communication systems. Opt. Express 2021, 29, 32728–32738. [Google Scholar] [CrossRef]
- O’shea, T.; Hoydis, J. An introduction to deep learning for the physical layer. IEEE Trans. Cogn. Commun. Netw. 2017, 3, 563–575. [Google Scholar] [CrossRef] [Green Version]
- Dörner, S.; Cammerer, S.; Hoydis, J.; Ten Brink, S. Deep learning based communication over the air. IEEE J. Sel. Top. Signal Process. 2017, 12, 132–143. [Google Scholar] [CrossRef] [Green Version]
- Felix, A.; Cammerer, S.; Dörner, S.; Hoydis, J.; Ten Brink, S. OFDM-autoencoder for end-to-end learning of communications systems. In Proceedings of the 2018 IEEE 19th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Kalamata, Greece, 25–28 June 2018; pp. 1–5. [Google Scholar]
- Cammerer, S.; Aoudia, F.A.; Dörner, S.; Stark, M.; Hoydis, J.; Ten Brink, S. Trainable communication systems: Concepts and prototype. IEEE Trans. Commun. 2020, 68, 5489–5503. [Google Scholar] [CrossRef]
- Balevi, E.; Andrews, J.G. Autoencoder-based error correction coding for one-bit quantization. IEEE Trans. Commun. 2020, 68, 3440–3451. [Google Scholar] [CrossRef] [Green Version]
- Lee, H.; Lee, I.; Lee, S.H. Deep learning based transceiver design for multi-colored VLC systems. Opt. Express 2018, 26, 6222–6238. [Google Scholar] [CrossRef]
- Liang, X.; Yuan, M.; Wang, J.; Ding, Z.; Jiang, M.; Zhao, C. Constellation design enhancement for color-shift keying modulation of quadrichromatic LEDs in visible light communications. J. Lightwave Technol. 2017, 35, 3650–3663. [Google Scholar] [CrossRef]
- Hao, L.; Wang, D.; Cheng, W.; Li, J.; Ma, A. Performance enhancement of ACO-OFDM-based VLC systems using a hybrid autoencoder scheme. Opt. Commun. 2019, 442, 110–116. [Google Scholar] [CrossRef]
- Lee, H.; Lee, S.H.; Quek, T.Q.S.; Lee, I. Deep Learning Framework for Wireless Systems: Applications to Optical Wireless Communications. IEEE Commun. Mag. 2019, 57, 35–41. [Google Scholar] [CrossRef] [Green Version]
- Ulkar, M.G.; Baykas, T.; Pusane, A.E. VLCnet: Deep learning based end-to-end visible light communication system. J. Lightwave Technol. 2020, 38, 5937–5948. [Google Scholar] [CrossRef]
- Karanov, B.; Chagnon, M.; Thouin, F.; Eriksson, T.A.; Bülow, H.; Lavery, D.; Bayvel, P.; Schmalen, L. End-to-end deep learning of optical fiber communications. J. Lightwave Technol. 2018, 36, 4843–4855. [Google Scholar] [CrossRef]
- Chagnon, M.; Karanov, B.; Schmalen, L. Experimental demonstration of a dispersion tolerant end-to-end deep learning-based IM-DD transmission system. In Proceedings of the 2018 European Conference on Optical Communication (ECOC), Roma, Italy, 23–27 September 2018; pp. 1–3. [Google Scholar]
- Häger, C.; Pfister, H.D. Wideband time-domain digital backpropagation via subband processing and deep learning. In Proceedings of the 2018 European Conference on Optical Communication (ECOC), Roma, Italy, 23–27 September 2018; pp. 1–3. [Google Scholar]
- Häger, C.; Pfister, H.D. Physics-based deep learning for fiber-optic communication systems. IEEE J. Sel. Areas Commun. 2020, 39, 280–294. [Google Scholar] [CrossRef]
- Xie, E.; Bian, R.; He, X.; Islim, M.S.; Chen, C.; McKendry, J.J.; Gu, E.; Haas, H.; Dawson, M.D. Over 10 Gbps VLC for long-distance applications using a GaN-based series-biased micro-LED array. IEEE Photonics Technol. Lett. 2020, 32, 499–502. [Google Scholar] [CrossRef] [Green Version]
- Rajbhandari, S.; McKendry, J.J.; Herrnsdorf, J.; Chun, H.; Faulkner, G.; Haas, H.; Watson, I.M.; O’Brien, D.; Dawson, M.D. A review of gallium nitride LEDs for multi-gigabit-per-second visible light data communications. Semicond. Sci. Technol. 2017, 32, 023001. [Google Scholar] [CrossRef]
- Polese, M.; Jornet, J.M.; Melodia, T.; Zorzi, M. Toward End-to-End, Full-Stack 6G Terahertz Networks. IEEE Commun. Mag. 2020, 58, 48–54. [Google Scholar] [CrossRef]
- Pan, C.; Ren, H.; Wang, K.; Kolb, J.F.; Elkashlan, M.; Chen, M.; Di Renzo, M.; Hao, Y.; Wang, J.; Swindlehurst, A.L. Reconfigurable intelligent surfaces for 6G systems: Principles, applications, and research directions. IEEE Commun. Mag. 2021, 59, 14–20. [Google Scholar] [CrossRef]
- Rawat, M.; Ghannouchi, F.M. Distributed spatiotemporal neural network for nonlinear dynamic transmitter modeling and adaptive digital predistortion. IEEE Trans. Instrum. Meas. 2011, 61, 595–608. [Google Scholar] [CrossRef]
- Hu, X.; Liu, Z.; Yu, X.; Zhao, Y.; Chen, W.; Hu, B.; Du, X.; Li, X.; Helaoui, M.; Wang, W. Convolutional neural network for behavioral modeling and predistortion of wideband power amplifiers. IEEE Trans. Neural Netw. Learn. Syst. 2021; Early Access, 1–15. [Google Scholar] [CrossRef]
- Fehske, A.; Gaeddert, J.; Reed, J.H. A new approach to signal classification using spectral correlation and neural networks. In Proceedings of the First IEEE International Symposium on New Frontiers in Dynamic Spectrum Access Networks, 2005 (DySPAN 2005), Baltimore, MD, USA, 8–11 November 2005; pp. 144–150. [Google Scholar]
- Khan, F.N.; Zhong, K.; Zhou, X.; Al-Arashi, W.H.; Yu, C.; Lu, C.; Lau, A.P.T. Joint OSNR monitoring and modulation format identification in digital coherent receivers using deep neural networks. Opt. Express 2017, 25, 17767–17776. [Google Scholar] [CrossRef] [PubMed]
- Xu, W.; Wang, Y.; Wang, F.; Chen, X. PSK/QAM modulation recognition by convolutional neural network. In Proceedings of the 2017 IEEE/CIC International Conference on Communications in China (ICCC), Qingdao, China, 22–24 October 2017; pp. 1–5. [Google Scholar]
- Yashashwi, K.; Sethi, A.; Chaporkar, P. A learnable distortion correction module for modulation recognition. IEEE Wirel. Commun. Lett. 2018, 8, 77–80. [Google Scholar] [CrossRef] [Green Version]
- Tang, Y.; Huang, Y.; Wu, Z.; Meng, H.; Xu, M.; Cai, L. Question detection from acoustic features using recurrent neural network with gated recurrent unit. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 6125–6129. [Google Scholar]
- Liao, X.; Li, B.; Yang, B. A novel classification and identification scheme of emitter signals based on ward’s clustering and probabilistic neural networks with correlation analysis. Comput. Intell. Neurosci. 2018, 2018, 1458962. [Google Scholar] [CrossRef] [PubMed]
- Natalino, C.; Schiano, M.; Di Giglio, A.; Wosinska, L.; Furdek, M. Field demonstration of machine-learning-aided detection and identification of jamming attacks in optical networks. In Proceedings of the 2018 European Conference on Optical Communication (ECOC), Roma, Italy, 23–27 September 2018; pp. 1–3. [Google Scholar]
- Li, Y.; Hua, N.; Yu, Y.; Luo, Q.; Zheng, X. Light source and trail recognition via optical spectrum feature analysis for optical network security. IEEE Commun. Lett. 2018, 22, 982–985. [Google Scholar] [CrossRef]
- Liu, W.; Li, X.; Huang, Z.; Wang, X. Transmitter Fingerprinting for VLC Systems via Deep Feature Separation Network. IEEE Photonics J. 2021, 13, 7300407. [Google Scholar] [CrossRef]
- Xiao, L.; Sheng, G.; Liu, S.; Dai, H.; Peng, M.; Song, J. Deep reinforcement learning-enabled secure visible light communication against eavesdropping. IEEE Trans. Commun. 2019, 67, 6994–7005. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Challenges | Reasons | References |
|---|---|---|
| Optoelectronic and electro-optical conversion | Introduces additional nonlinearity | [26,27,28,29] |
| Large signals | Brings the device into the nonlinear region | [21] |
| Wide bandwidth | Introduces severe ISI | [19] |
| Different transmission channel modeling | Diverse application scenarios, such as indoor, underwater | [31,32,33] |
| Algorithm | Input Layer | 1st Weight Layer | 2nd Weight Layer | Drd Weight Layer | Trainable Parameters |
|---|---|---|---|---|---|
| MLP (general) | |||||
| Volterra (general) | / | / | / |
| Equalizers | GK-DNN | FSDNN | TFDNet | MPANN | DBMLP | PCVNN | LSTM |
|---|---|---|---|---|---|---|---|
| Main types of NN | MLP | MLP | MLP | MLP | MLP | MLP | RNN |
| Number of hidden layers | 2 | 1 | 1 | 1 | 1 | 1 | 1 |
| Activation function | ReLU | ReLU | ReLU | ReLU | Tanh | ReLU | Tanh, Sigmoid |
| Optimizer | Adagrad | Adam | Adam | Adam | Adam | Adam | Adam |
| Complexity | Moderate | Low | High | Low | High | Low | High |
| Convergence speed | Fast | Moderate | Moderate | Moderate | Slow | Slow | Slow |
| Pre-equ. | ✓ | ||||||
| Post-equ. | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Deployment location | Waveform | Waveform | Waveform | Waveform | Waveform | Symbol | Symbol |
| Algorithms | Supervision | Computational Complexity | Application |
|---|---|---|---|
| K-means | N | Low | Low nonlinearity |
| DBSCAN | N | Low | Time varying |
| GMM | Y | High | Moderate nonlinearity, ISI |
| SVM | Y | Moderate | Moderate nonlinearity |
| ANN | Y | High | High nonlinearity |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, J.; Niu, W.; Ha, Y.; Xu, Z.; Li, Z.; Yu, S.; Chi, N. AI-Enabled Intelligent Visible Light Communications: Challenges, Progress, and Future. Photonics 2022, 9, 529. https://doi.org/10.3390/photonics9080529
Shi J, Niu W, Ha Y, Xu Z, Li Z, Yu S, Chi N. AI-Enabled Intelligent Visible Light Communications: Challenges, Progress, and Future. Photonics. 2022; 9(8):529. https://doi.org/10.3390/photonics9080529
Chicago/Turabian StyleShi, Jianyang, Wenqing Niu, Yinaer Ha, Zengyi Xu, Ziwei Li, Shaohua Yu, and Nan Chi. 2022. "AI-Enabled Intelligent Visible Light Communications: Challenges, Progress, and Future" Photonics 9, no. 8: 529. https://doi.org/10.3390/photonics9080529