1. Introduction
The analysis of fluid–structure interaction (FSI) problems is important for several applications in science and engineering; typical examples that we have in mind are, for instance, the study of fluid-dynamics of heart valves, particulate flows, and propagation of free surfaces. FSI problems are challenging both from the mathematical and computational point of view: the difficulties originate from the necessity of handling interactions between several objects and the presence of nonlinear terms in the governing equations. As a consequence, in past years, several approaches have been presented for the numerical modeling of FSI problems: among those, we mention the Arbitrary Lagrangian Eulerian formulation (ALE) [
1,
2,
3,
4], the unfitted Nitsche method [
5], the level set formulation [
6], and the fictitious domain approach [
7,
8]. It is important to notice that each method is effective for a selected class of problems, since there is no method that can be applied to all possible situations.
Our fictitious domain approach with distributed Lagrange multiplier was considered first in [
9] as evolution of the immersed boundary method [
10,
11], originally introduced by C. Peskin during the Seventies for cardiac simulations of heart valves. This approach is based on the idea that the fluid domain is fictitiously extended also to the region occupied by the immersed body. In particular, the fluid is governed by the incompressible time dependent Navier–Stokes equations, while the structure can be characterized by either linear or nonlinear constitutive laws for viscous elastic materials. The fluid dynamics is studied on a fixed Eulerian mesh, while we resort to a Lagrangian description to represent the motion and the deformation of the immersed structure; the Lagrangian frame is built by introducing a reference domain which is mapped, at each time step, into the actual position of the body.
In order to get accurate results, simulations of FSI problems require, in general, huge computational resources, both in terms of time and memory. In this framework, the design of robust parallel solvers is an important tool to perform, in a reasonable amount of time, computations involving a large number of time steps and fine space discretizations. Several works are focused on this task, mainly in the setting of ALE formulations [
12,
13,
14,
15,
16,
17,
18] or by applying a variational transfer in order to couple fluid and solids [
19,
20]. To the best of our knowledge, preconditioners for the fictitious domain formulation with distributed Lagrange multiplier have been introduced only recently in [
21].
Here, we continue the analysis of the parallel solver introduced in [
21]: we focus our attention on the robustness with respect to mesh refinement, with different choices of time step, and to the weak scalability. We also describe some implementation issues. The finite element discretization is performed by choosing the
element for velocities and pressures of the fluid and the
element for the structure variables; the time marching scheme is a first order semi-implicit finite difference algorithm. Moreover, the fluid–structure coupling matrix is assembled by exact computations over non-matching meshes as described in [
22]; the computational costs of this procedure will be described. At each time step, the linear system arising from the discretization is solved by the GMRES method, combined with either a block-diagonal or a block-triangular preconditioner. Our parallel implementation is based on the PETSc library from Argonne National Laboratory [
23,
24] and on the parallel direct solver Mumps [
25,
26], which is used to invert the diagonal blocks in the block preconditioners.
After recalling some functional analysis notation, in
Section 3, we present the mathematical model describing fluid structure interaction problems in the spirit of the fictitious domain approach. In
Section 4, we describe the numerical method we implemented for our simulations and in
Section 5 we introduce two possible choices of preconditioner for our parallel solver. Finally, in
Section 6 we present some numerical tests aiming at assessing the robustness with respect to mesh refinement and the weak scalability.
3. Continuous Formulation
We simulate fluid–structure interaction problems characterized by a visco-elastic incompressible solid body immersed in a viscous incompressible fluid. We denote by and the two regions in (with ) occupied by the fluid and the structure, respectively, at the time instant t; the interface between these two regions is denoted by . The evolution of such a system takes place inside , that is the union of and : this new domain is independent of time and we assume that it is connected and bounded with Lipschitz continuous boundary . It is worth mentioning that, even if we are going to consider only thick solids, also the evolution of thin structures can be treated by our mathematical model.
The dynamics of the fluid is studied by considering an Eulerian description, associated with the variable
. On the other hand, the evolution of the immersed body is modeled by a Lagrangian description: we introduce the solid reference domain
, associated with the variable
, so that the deformation can be represented by the map
. This means that
is the image at the time
t of a certain point
and the motion of the structure is represented by the kinematic equation
where the material velocity is denoted by
. The deformation gradient
is denoted by
and
. Since we are assuming that the solid body is incompressible, the determinant
J is constant in time.
In our model, we consider a Newtonian fluid with density
and viscosity
, so that the Cauchy stress tensor can be written as
where
denotes the velocity of the fluid and
its pressure, and where
denotes the identity tensor. In particular, the symbol
refers to the symmetric gradient
. Therefore, the dynamics in
is governed by the incompressible Navier–Stokes equations
For the solid, we consider a viscous-hyperelastic material with density
and viscosity
; for this type of materials, the Cauchy stress tensor
can be seen as the sum of two contributions: a viscous part, similar to the one of the fluid
and an elastic part, which can be written, moving from Eulerian to Lagrangian setting, in terms of the Piola–Kirchhoff stress tensor
In particular, hyperelastic materials are characterized by a positive energy density
, which is related with
since
. Consequently, the elastic potential energy of the solid body can be expressed as
Finally, the system is described by the following equations in strong form
and completed by two transmission conditions to enforce continuity of velocity and stress along the interface
where
and
denote the outer normals to
and
, respectively. Moreover, we consider the following initial and boundary conditions
The idea of the fictitious domain approach is to extend the first two equations in (
7) to the whole domain
so that all the involved variables are defined on a domain which is independent of time. Consequently, following [
9], we introduce two new unknowns
In this new setting, (
1) becomes a constraint on
, since we have to impose that
This condition can be weakly enforced by employing a distributed Lagrange multiplier. To this end, we set
, the dual space of
, and denote by
the duality pairing between
and
. Notice that, for
, we have the following property
At this point, following [
9,
28], the equations in (
7), endowed with conditions (
8) and (
9), can be written in variational form.
Problem 1. For given and , find , , , and such that for almost all : Moreover,
is the extended viscosity with value
in
and
in
. For our numerical tests, we are going to consider
since it is a reasonable assumption for biological models [
29].
For our simulations, we consider a simplified version of the problem: we drop the convective term of the Navier–Stokes equations and we assume that fluid and solid materials have the same density, i.e.,
. We focus on this case since it is interesting to see how the solver behaves when this assumption is combined with a semi-implicit time advancing scheme in the setting of the fictitious domain approach. This is actually the critical situation when the added mass effect can cause instabilities. For instance, in [
30], a simplified one-dimensional setting is considered for which non implicit schemes are proved to be unconditionally unstable when applied to FSI problems modeled by ALE if fluid and solid have the same densities
. This phenomenon appears regardless of the discrete parameters. In order to alleviate such critical behavior, an appropriate treatment of the transmission conditions has been investigated, for instance, in [
31,
32]). Therefore, the problem we are going to simulate reads as follows.
Problem 2. Given and , find , , , and such that for almost all : 4. Discrete Formulation
Before discussing the discrete formulation, we remark that, from now on, we will focus on two-dimensional problems ().
The time semi-discretization of Problem 2 is based on the Backward Euler scheme. The time interval
is uniformly partitioned into
N parts with size
. We denote the subdivision nodes by
. For a generic function
g depending on time, setting
, the time derivative is approximated as
Moreover, the nonlinear coupling terms and are semi-implicitly treated by considering the position of the structure at the previous time step as and .
For the discretization in space, we work with quadrilateral meshes for both fluid and solid. For the fluid, we consider a partition of with meshsize and two finite element spaces and for velocity and pressure, respectively, satisfying the inf-sup condition for the Stokes problem. In particular, we work with the pair, which is one of the most popular Stokes elements, making use of continuous piecewise quadratic velocities and discontinuous piecewise linear pressures.
For the solid domain, we choose a partition
of
with meshsize
, independent of
. We then consider two finite dimensional spaces
and
. We assume that
and we approximate both the mapping
and the Lagrange multiplier
with piecewise bilinear elements on quadrilaterals. Other stable combinations of finite element spaces for our class of problems have been studied in [
33], both from the theoretical and the numerical point of view.
We notice that, since
is included in
, at a discrete level, the duality pairing can be replaced by the scalar product in
Therefore, we get the following fully discrete problem.
Problem 3. Given and , for all find , , , and fulfilling: Assuming for simplicity
, Problem 3 can be represented in matrix form as
with
Here, and denote the basis functions of and respectively, while are the basis functions of the space defined on . We observe that, since , is the mass matrix in or .
We can see that the matrix in (
16) splits into four blocks, defined as follows:
where
is related to the fluid dynamic,
to the solid evolution, while
and
contain the coupling term.
Particular attention has to be paid to the assembly of the coupling matrix
, since it involves the integration over
of solid and mapped fluid basis functions. In order to compute these integrals, we need to know how each element
E of
is mapped into the fluid domain. We implement an exact quadrature rule by computing, at each time step, the intersection between the fluid mesh
and a mapped solid element
. In order to detect all the intersections, each solid element is tested against all the fluid elements making use of a bounding box technique, which, in this particular case, is trivial since the fluid is discretized with a Cartesian mesh of squares; then the intersections are explicitly computed by means of the Sutherland–Hodgman algorithm. For more details about the procedure in a similar situation, we refer to [
22]. The implementation of this composite rule is quite involved and it is not straightforwardly parallelizable.
In general, when is nonlinear, we use a solver for nonlinear systems of equations such as the Newton iterator method.
6. Numerical Tests
The proposed preconditioners have been widely studied in [
21] in terms of robustness with respect to mesh refinement, strong scalability and refinement of the time step. In this work, after reporting new results in terms of optimality, we analyze the weak scalability of our solver. We focus on both linear and nonlinear models describing the solid material.
In the GMRES solver, we adopt as stopping criterion a reduction of the Euclidean norm of the relative residual and a restart parameter of 200. In the case of the nonlinear model, the stopping criterion adopted for the Newton method is a reduction of the Euclidean norm of the relative residual.
Our simulations were run on the Shaheen cluster at King Abdullah University of Science and Technology (KAUST, Saudi Arabia). It is a Cray XC40 cluster constituted by 6174 dual sockets computing nodes, based on 16 core Intel Haswell processors running at 2.3 GHz. Each node has 128 GB of DDR4 memory running at 2300 MHz.
6.1. Linear Solid Model
We consider a quarter of the elastic annulus
included in
: in particular, the solid reference domain corresponds to the resting configuration of the body; that is
The dynamics of the system is generated by stretching the annulus and observing how internal forces bring it back to the resting condition. In this case,
coincides with the stretched annulus. Four snapshots of the evolution are shown in
Figure 1.
The solid behavior is governed by a linear model; therefore,
, with
. We choose fluid and solid materials with the same density
and the same viscosity
. We impose no slip conditions for the velocity on the upper and right edge of
, while on the other two edges, we allow the motion of both fluid and structure along the tangential direction. Finally, the following initial conditions are considered
In
Table 1, we report the results for the optimality test, where the robustness of the solver is studied by refining the mesh and keeping fixed the number of processors. In particular, we set the time step to
and the final time of our simulation to
. The number of processors used for the simulation is 32. The time
needed to assemble the matrix of the problem increases moderately, while the time
, needed for the assembly of the coupling matrix by computing the intersection between the involved meshes, exhibits a superlinear growth. In terms of preconditioners, we can see that block-diag is not robust with respect to mesh refinement since the number of GMRES iterations grows from 13 to 430; clearly, this phenomenon affects also the time
we need to solve the system. On the other hand, block-tri is robust since the number of GMRES iterations remains bounded by 14 when the mesh is refined. Therefore,
presents only a moderate growth and, for 1,074,054 dofs, it is 30 times smaller than the value we obtain for block-diag preconditioner.
The weak scalability of the proposed parallel solver is analyzed in
Table 2. Again, we choose
and
. We perform six tests by doubling both the global number of dofs and the number of processors. Thanks to the resources provided by PETSc, the time
to assemble stiffness and mass matrices is perfectly scalable. On the other hand, the assembly procedure for the coupling matrix is much more complicated: in order to detect all the intersections between solid and fluid elements, the algorithm consists of two nested loops. For each solid element (outer loop), we check its position with respect to all the fluid elements (inner loop). In particular, only the outer loop is distributed over all the processors. Consequently,
is not scalable since the number of fluid dofs, analyzed in serial, increases at each test. We now discuss the behavior of the two proposed preconditioners. It is evident that block-diag is not scalable since the number of GMRES iteration drastically increases as we increase dofs and procs, clearly affecting
and
. On the other hand, block-tri behaves well: even if it is not perfectly scalable, the number of iterations slightly increases from 8 to 18 and
ranges from
s to
s.
6.2. Nonlinear Solid Model
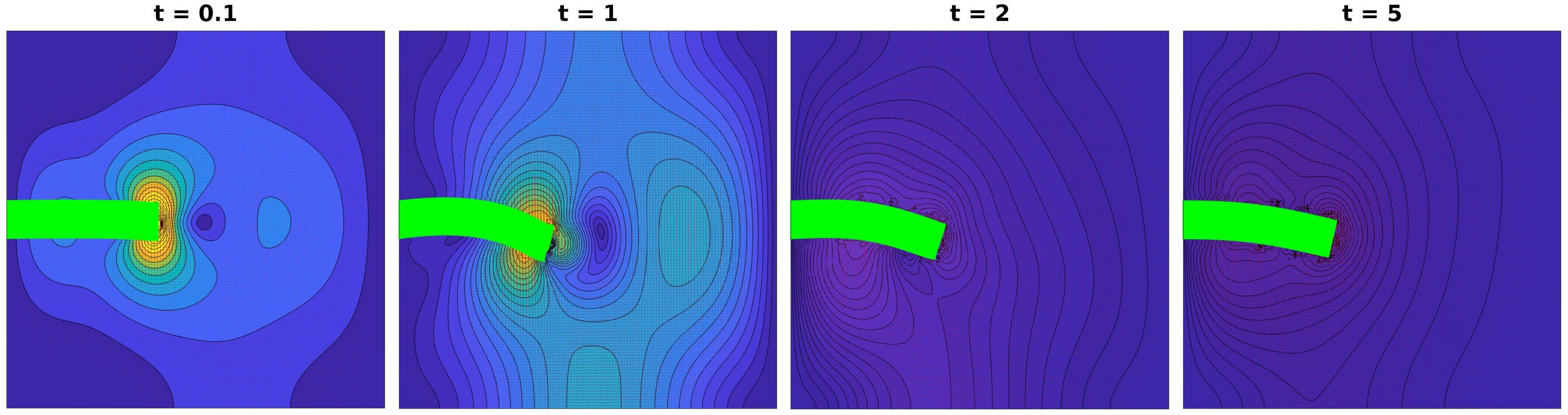
For this test, we set again the fluid domain
to be the unit square; the immersed solid body is a bar represented, at resting configuration, by the rectangle
. During the time interval
, the structure is pulled down by a force applied at the middle point of the right edge. Therefore, when released, the solid body returns to its resting configuration by the action of internal forces. Four snapshots of the evolution are shown in
Figure 2.
The energy density of the solid material is given by the potential strain energy function of an isotropic hyperelastic material; in particular, we have
where
denotes the trace of
, while
and
. It can be proved that
W is a strictly locally convex strain energy function, as discussed in [
34,
35,
36].
Also for this test we assume that fluid and solid materials share the same density, equal to 1, and the same viscosity, equal to
. The velocity is imposed to be zero at the boundary of
, while the following initial conditions are imposed
Results for the mesh refinement test are reported in
Table 3: we consider the evolution of the system during the time interval
, with time step
. The number of processors for the simulations is set to 64, while the number of dofs increases from 21,222 to 741,702. As for the linear case,
increases moderately and
follows a superlinear growth. Both preconditioners are robust with respect to mesh refinement: the number of Newton iterations is 2 for each test and the average number of GMRES iterations per nonlinear iteration is bounded by 15 for block-diag and by 10 for block-tri. This behavior of block-diag is in contrast with the results we obtained for the linear solid model: this is due to the finer time step chosen for this simulation.
In order to study the weak scalability, we choose
and
. The results, reported in
Table 4, are similar to the results obtained for the linear case. As before,
is not scalable due to the algorithm we implemented for the assembling of the coupling term. Even if it is not perfectly scalable, block-tri performs pretty well since the average number of linear iterations per nonlinear iteration increases only from 15 to 19. On the other hand, the good behavior of block-diag registered in
Table 3 is not confirmed: the average number of linear iterations reaches 101, showing a lack of weak scalability, as already seen in
Table 2.
7. Conclusions
We analyzed two preconditioners, block-diagonal and block-triangular, for saddle point systems originating from the finite element discretization of fluid–structure interaction problems with fictitious domain approach. We have focused only on the case where the fluid and solid domains have the same densities, which, based on previous studies, should be the most challenging to solve. In particular, the analysis has been conducted by studying the robustness with respect to mesh refinement and weak scalability, applying the parallel solver to both linear and nonlinear problems.
Only block-triangular appears to be robust in terms of mesh refinement for linear and nonlinear problems; on the other hand, block-diagonal works well when the time step is very small.
Moreover, by studying the weak scalability, we can notice two further limitations of the proposed method, which will be the subject of future studies. First, the time to assemble the coupling matrix is not scalable: it is based on two nested loops, related to solid and fluid elements, respectively; but only the external one is conducted in parallel over the processors. In order to improve this procedure, one may subdivide the involved meshes into clusters or, alternatively, one may keep track of the position of the solid body at the previous time instant. Second, since the action of the preconditioners consists of the exact inversion of two matrices, the time for solving the linear system slightly increases when the mesh is refined. Some preliminary results have shown that, in contrast with the fluid block , the solid block does not behave well when an inexact inversion is applied: our future studies will be primarily focused on overcoming this problem.
As concerns the modeling approach, several extensions are possible. First of all, we have neglected the convective term in the Navier–Stokes equation; second, we have considered an isotropic nonlinear constitutive law for the structure instead of anisotropic variants and, finally, we have focused only on two dimensional problems.






{kind=link}
{kind=link}