1. Introduction
Real-world optimization problems are usually multiobjective, in which multiple conflicting objectives must be taken into account simultaneously. Manly, there are two ways to tackle these types of problems, scalarization functions and population-based algorithms. The use of scalarization functions presented some drawbacks, which led to the development of population-based metaheuristics that use the concept of Pareto-dominance and niching to evolve a population of solutions in the direction of the Pareto-optimal front [
1,
2].
There are at least three basic types of population-based algorithms commonly employed to solve Multiobjective Optimization Problems MOPs, namely, evolutionary algorithms, swarm-based methods, and colony-based algorithms, which can use the dominance concept, the metric indicators, or the decomposition strategy [
3]. In most of these algorithms, a random initial population of solutions is generated and the new populations are consecutively obtained by selection and variation strategies until a stop criterion is met. It is expected from this procedure that the successive populations evolve towards, or to a good approximation of, the Pareto-optimal frontier. In each one of these populations, complex relations exist between the Decision Variables (DVs) and the objectives, as well as between DVs and DVs and objectives and objectives.
These algorithms work well when the number of objectives is low; however, as the number of objectives grows, the percentage of non-dominated solutions decreases, making it difficult for an algorithm based on Pareto-dominance to work effectively, a problem that is known as the curse of dimensionality. There is no consensus on the number of objectives for which this problem occurs; some authors indicate this number as ten [
4] and others as four [
5], but in reality, these difficulties arise when the number of objectives is four or more.
Two different methods are used to deal with this problem, either using relaxed forms of Pareto optimality or reducing the number of objectives [
5]. The reduction of the number of objectives is useful either for the search process or for the decision-making process during and/or at the end of the optimization.
In previous years, some work related to objective reduction for many objectives optimization was proposed in the literature, which can be sub-divided into four different categories: (i) methods in which the aim is to maintain the dominance relation for the non-dominated solutions [
6,
7]; (ii) methods based on unsupervised feature selection [
8]; (iii) methods based into a comparative analysis between the results obtained when the number of objectives is reduced [
9]; (iv) methods based on data mining [
5,
10,
11,
12]; and methods based on the use of multi-objective formulations [
13]. These approaches will be presented in more detail here.
Brockoff and Zitzler [
6,
7] suggested the use of two different approaches for objectives reduction, which are based on the definition of two types of problems. The first problem aims to obtain the minimum objective subset that produces a certain error (
δ), designated by
δ-MOSS problem (
δ- Minimum Objective Subset problem), and the second problem aims to obtain an objective subset of a predefined size (
k) with the minimum possible error, designated by
k-EMOSS problem. For each one of these cases, two algorithms were presented, an exact and a greedy algorithm, characterized for maintaining the dominance relation. They were tested using different knapsack problems and the DTLZ2, DTLZ5, and DTLZ7 benchmark problems for different numbers of objectives.
In López et al. [
8], a methodology based on unsupervised feature selection was proposed to address the
δ-MOSS and
k-EMOSS problems. A correlation matrix obtained from the non-dominated set is used to divide the objective set into homogeneous neighbourhoods. Then, based on the idea that if the distance between the objectives is higher, this signifies that those objectives are more conflicting. Thus, only the objectives in the centre of those neighbourhoods are chosen and the others are discarded. The algorithms were validated by comparing the results obtained with those of the reference [
7].
Singh et al. [
9] proposed an algorithm, designated by the Pareto Corner Search Evolutionary Algorithm (PCSEA) that, instead of searching for the complete Pareto front, searches for the corners of the Pareto front based on a ranking scheme. Those solutions are used to identify the relevant objectives and the others are discarded. Some benchmark problems and two engineering problems were used to show the performance of the methodology proposed.
Deb and Saxena [
10] suggested an approach based on Principal Component Analysis (PCA) for the same purpose of objectives reduction, considering the hypothesis that if two objectives are negatively correlated, they are conflicting. In this way, they maintain the objectives that can explain most of the variance in the objective space, which are the most positive and the most negative of the eigenvectors of the correlation matrix. The authors designated this method as PCA-NSGAII. Afterwards, due to the problem of misinterpreting the data when it lies in sub-manifolds, a new proposal is made based on nonlinear dimensionality reduction [
11]. For that purpose, the authors developed two new algorithms to replace the linear PCA, one based on correntropy [
14] and the other on Maximum Variance Unfolding (MVU). However, the method lacks information on the means by which objective reduction alters the dominance structure, cannot guarantee the preservation of the dominance relation and provides no measure to specify how much the dominance relation changes when objectives are disregarded. The different procedures proposed were applied to solve DTLZ2 and DTLZ5 benchmark problems for different numbers of objectives.
Later, the same group, Saxena et al. [
5], proposed a framework for using linear and nonlinear objective reduction algorithms, namely, L-PCA and NL-MVU-PCA, which are based on machine learning techniques, PCA and MVU, to remove the secondary higher-order dependencies in the non-dominated solutions. The idea was very similar to that of given in previous work by the same authors [
10,
11], but this time, they proposed a reduction of the number of algorithm parameters and an error measure. The algorithms were tested on a broad range of problems and the results were compared with others in the literature. Based on the same methodology, Sinha et al. [
15] proposed an iterative procedure to reduce the objectives in which a Decision Maker (DM) chose the best solutions. The methodology was applied to solve some real-world problems, namely storm drainage and car-side impact. Finally, Duro et al. [
12] proposed to extend the methodology presented in reference [
5] to rank all objectives by a preference order, as well as to solve the
δ-MOSS and
k-EMOSS problems, i.e., to obtain the smallest set of objectives that can originate the same POF, and the smallest objective set corresponding to a minimum pre-defined error and the objective sets of a certain size that originates a minimum error.
The main drawback of all these methodologies based on PCA is that they need to use a kernel and, as a consequence, to optimize the kernel parameters. The characteristics of this methodology, NL-MVU-PCA, were compared with the one proposed in the present paper at the end of the next section.
Yuan et al. [
13] proposed a methodology based on the use of multi-objective evolutionary algorithms to solve a MOOP formulation. The authors applied this approach to some benchmark problems and two real optimization problems. In both cases, the calculation of the objective functions is based on simple analytical equations where the computational cost is not relevant when compared with the problems that we intend to solve here, which are based on numerical calculation. Therefore, besides performance, this type of methodology will not be explored in the present work.
The present paper aims to propose a method for objectives reduction based on data mining that:
can be applied independently on the type and the size of the data and the shape of the Pareto-optimal front,
is independent from the choice/definition of the algorithm parameters,
considers the relations DVs-DVs and objectives-objectives (and not only the relations between the DVs and objectives), and
can provide explainable results for a DM that is a non-expert in optimization or machine learning.
The central aim of the works cited above was to find a reduced set of objectives that could exactly reproduce the results from the original set. Thus, only the redundant objectives could be discarded after a reduction process. That is not the aim of the present work, since our purpose is to apply the proposed methodology to real-world and complex problems where the relations between DVs and the objectives are complex, and the objectives are, in general, partially redundant. Thus, redundancy is not a helpful criterion to eliminate an objective.
For that purpose, a methodology was developed to capture those complex relations and define the relative importance of the objectives based on the determination of the objectives–objectives relations. Doing this makes it possible to determine objectives that can be discarded but with a certain error. In other words, the approximation of the Pareto optimal found (with the reduced number of objectives) has some error when compared with the approximation to the optimal Pareto front (when using all the objectives). Simultaneously, the redundant objectives are also eliminated. Such an approach has at least two significant advantages. First, it aids an optimization algorithm in finding a POF estimate; second, it makes it easier to explain the results found to the DM.
The contents of the paper are as follows: in
Section 2, the concepts of machine learning and the methodology proposed are presented; in
Section 3, the methodology is tested using some benchmarks; in
Section 4, the methodology is applied in a real polymer extrusion problem and the results obtained are discussed and, finally, the conclusions are stated in
Section 5.
2. Machine Learning Approach
2.1. Concepts
Bandaru et al. [
4] reviewed several proposals from Statistics, Data Mining, and Machine Learning to improve optimization techniques for MaOPs. The approaches usually apply data-driven methods to the solutions in a non-dominated set. The authors arranged the proposals based on the knowledge representation and summarized them into three main classes: (i) Descriptive Statistics, (ii) Visual Data Mining and (iii) Machine Learning itself. Those methods have an origin outside the MOO literature. Thus, they usually are not applied to find properties between variables, objectives, and the non-dominated set. In general, the relatively complex nature of those relations makes their performance inadequate for MaOPs. Other drawbacks relate to some classes of real-world MaOPs that require interactions with a practitioner due to the complexity of the system modelled or for a stakeholder making decisions. Usually, such classes of problems also involve raw or observed data or small datasets (due to the expensiveness of generating, collecting, or simulating samples) involving different data types, varying from continuous to nominal variables. This way, methods that produce explainable models and work with distinct data types are essential for those real-world problems. The strategies proposed by Duro et al. [
12] and Bandaru et al. [
16] have overcome some of those challenges, including an interactive approach for dealing with two and three objectives and pattern recognition from nominal variables. Another proposal facing those challenges is FS-OPA, initially designed for multidimensional analysis focused on MaOPs. FS-OPA generates explainable (explicit) models, has a relatively low computational cost (aiming at working with high dimensional decisions and objective spaces), and can deal with different data types and their mixtures.
First, this paper compares the principal features of an extension of FS-OPA to the NL-MVU-PCA approach (Duro et al. [
12]) for determining the essential objective set. NL-MVU-PCA learns a Kernel matrix by unfolding a high-dimensional data manifold subject to local constraints that preserve the local isometry. Then, eigenvalues are used to identify the principal dimensions that should correspond to a set of conflicting objectives. On the other hand, FS-OPA uses no manifold learning; it maps the problem’s fundamental structures into one or more phylograms (not a Cartesian graphical representation). FS-OPA employs data clustering, but not in the usual way, since it instantiates DAMICORE [
17], a pipeline with Normalized-compressions distance (NCD), Neighbor-Joining (NJ), and Fast Newman algorithm, that produces intermediate representations enabling the detection of the strongest associations of dimensions. The embedding produced by FS-OPA does not focus on reducing the decision (or objective) space; otherwise, it augments the space by adding new variables, the internal nodes of the phylogram (while the terminal nodes correspond to the original variables). The phylogram construction also searches for preserving the isometry for different neighborhood sizes. Finally, FS-OPA can obtain similar results as manifold learning (i.e., the determination of the essential dimensions) by finding the closest common ancestors in a phylogram (a clade) and the frequency of common ancestors between clades (obtained from several phylograms by data resampling). Such ancestors highlight the principal relationships between variables and/or objectives.
Second, this paper applies the extension FS-OPA to the MOO of extruders, which requires dealing with the relatively poor data from initial populations of an MOEA. In other words, there is an assumption that the solutions belonging to a specific Pareto-optimal front have some characteristics that identify the optimal behavior of the process considered. The critical question is to know if it is possible, from a set of random solutions, as the initial population of an MOEA, to extract information about the complex relationship between the DVs and the objectives and between objectives and objectives. Therefore, the idea is to capture this type of information using data mining methods from multivariate data, independently of its location on the objectives or decision variables spaces, i.e., if the data represents or is not optimal (or near optimal) solutions. Moreover, no distinction between DVs and objectives will be made.
2.2. FS-OPA
The foundations of FS-OPA are based on two methodologies that deal with large-scale and multidimensional data of any type, named DAMICORE [
17] and FS-OPA [
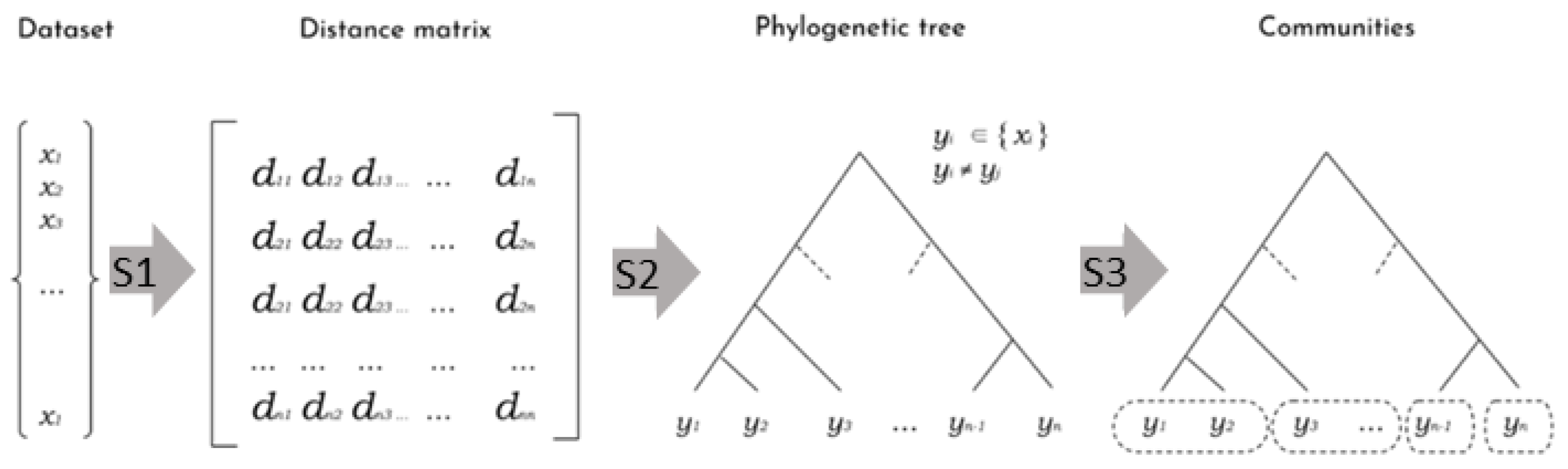
18]. The latter is a pipeline involving methods from Information Theory, Complex Networks, and Phylogenetic Inference, aiming at revealing hidden relationships of objects from an unstructured (raw) dataset. It runs in three main Steps: (S1) given a metric of similarity, build a distance matrix comparing every two objects; (S2) convert the matrix into a phylogenetic tree by connecting close objects according to hierarchical levels of similarity; (S3) apply a community detection process to group near subtrees into clusters.
Figure 1 shows a set of generic objects
xi. The elements
dij of the distance matrix correspond to a measure of dissimilarities between objects xi and
xj, according to some given metric. The matrix is broken down into a tree, where the distance between any two objects (leaves) corresponds to the sum of the lengths of the branches connecting them. Finally, the third step merges objects strongly connected (according to the tree topology) into a community, generating a set of different similarity clusters.
The first implementation of DAMICORE used three specific algorithms for S1, S2, and S3 (
Figure 1), respectively, Normalized Compression Distance (NCD) [
19], as it works with for any data type and mixed types; Neighbor-Joining (NJ) [
20], widely employed in bioinformatics; and Fast Newman (FN) [
21], that constructs a graph partition using a greedy algorithm based on a bottom-up strategy for maximizing the graph modularity function [
22]. The pipeline with NCD, NJ, and FN possesses some distinctive properties. NCD makes DAMICORE a data-type agnostic method; in the sense that it works with any object (continuous, discrete, categorical-ordinal, and nominal variables, texts, images, audio, etc.) and a mixture of data types.
DAMICORE has some properties that make it proper for dealing with problems with a low level of previous knowledge, carried out by non-experts, or that would require a large multidisciplinary team of experts. First, it can run without any data pre-processing (such as filtering, outlier detection, feature extraction, parameter setup, and knowledge of the problem domain). Second, it requires no parameters setup to run and is therefore not biased toward arbitrary tuning constants. Naturally, pre-processing steps and some execution options may improve the DAMICORE performance. Its success in such a challenge has been checked for problems in a variety of fields, such as software-hardware co-design [
23,
24,
25], compiler optimization [
26], student profiling in e-learning environments [
27,
28], identification of phytopathology from sensor data [
29], systematic literature review, identification of cross-cut concerns [
30], and electrical distribution systems [
31].
A Feature Sensitivity (FS) analysis aims to make salient the principal features of a problem (that may differ from selecting the main components), facing common challenges in some classes of real-world problems. For example, the quality of observed data, the database consistency and representativeness, and the discovery of interactions between features and their contributions to each target or objective are hard to check from a raw dataset with low previous domain knowledge. Thus, such a scope differs from those where the standard feature selection algorithms have usually succeeded. Moreover, an FS strategy is expected to aid in learning the fundamental structures of a complex problem from scratch. The learned structures can induce a probabilistic model used by optimization algorithms, such as in the Estimation of Distribution Algorithms [
32]. In this research, we use phylogram-based models since they can work with small datasets, they are computationally efficient, and there is an optimization approach designed to use such models: Optimization based on Phylogram Analysis (OPA).
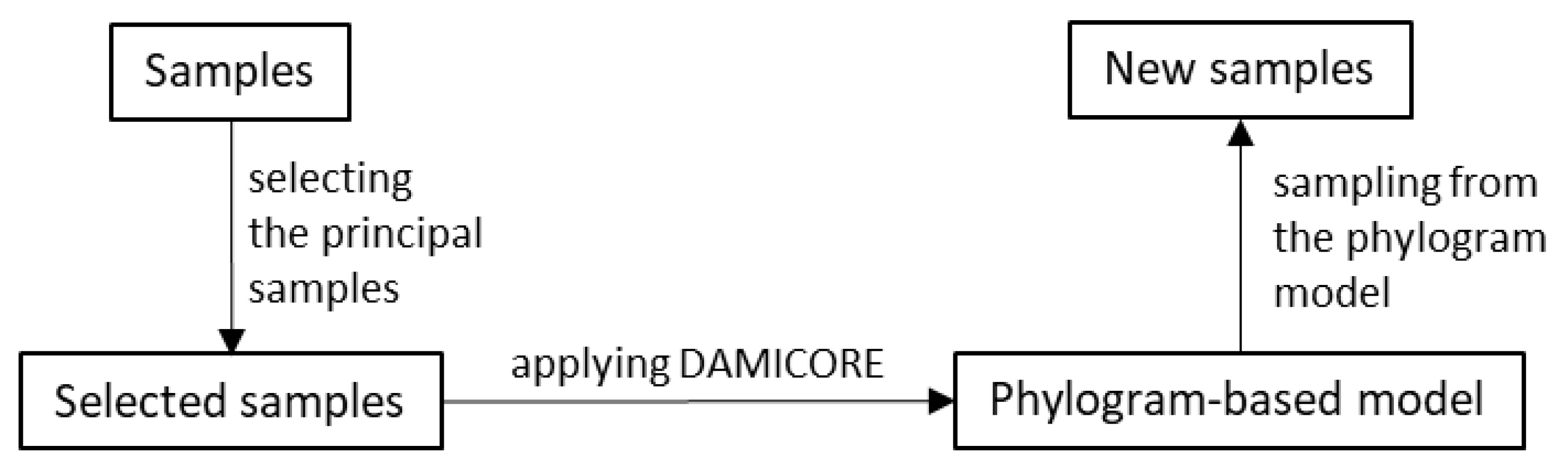
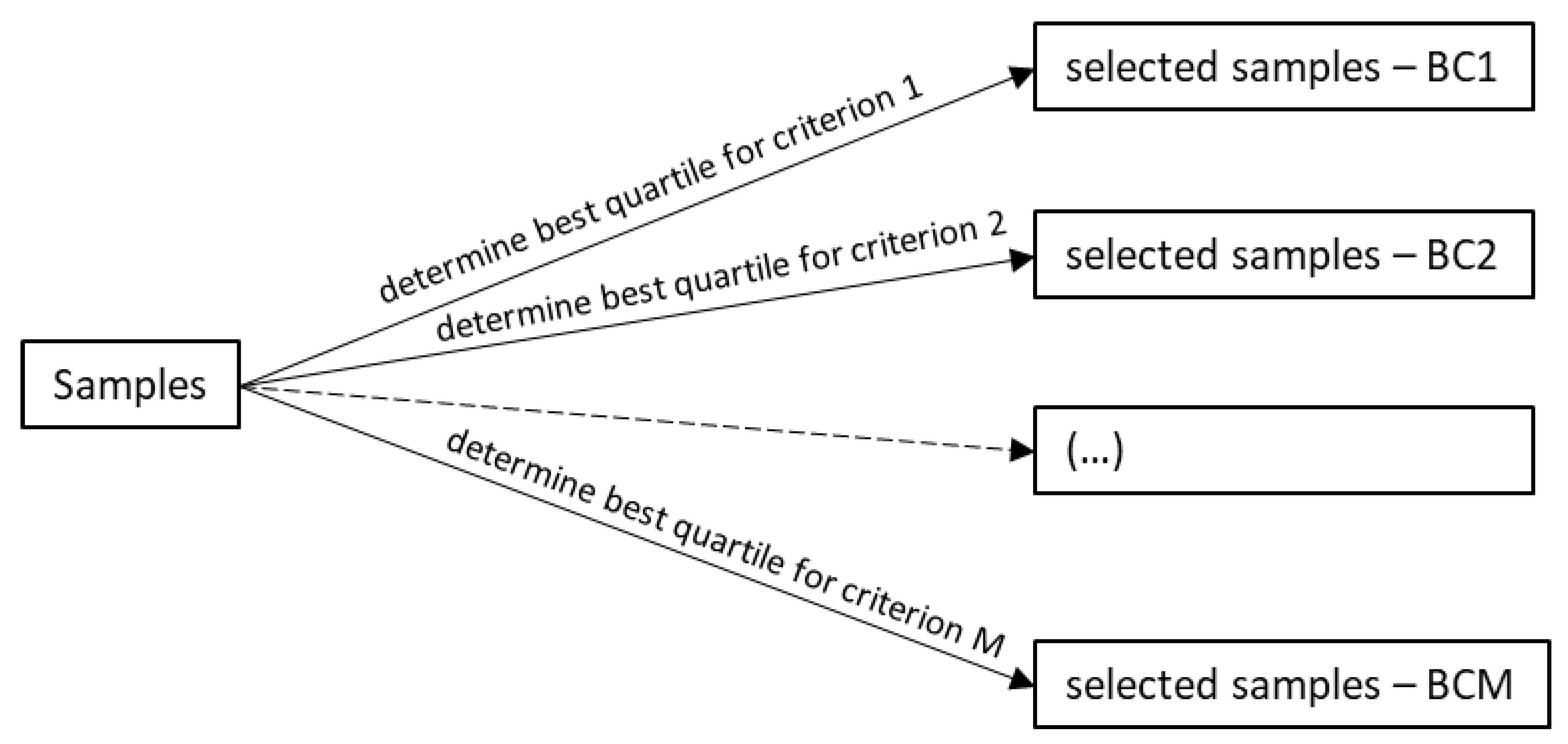
Figure 2 shows a diagram summarizing OPA and its use of the FS analysis. Such a combination is called FS-OPA. The two main FS steps are (A) "Salienting Samples (SS) according to a criterion" and (B) applying DAMICORE to construct a phylogram-based model. SS ranks the samples according to each of the M criteria (or non-dominated fronts), producing the sets of selected samples (
Figure 3), denoted BC1 (the samples in the best quantile according to Criterion 1), BC2, …, BCM. DAMICORE constructs a phylogram (a rough model) from BCi, i = 1, …, M, generating M models (BC1-based model, …, BCM-based model). Then, a consensus strategy produces a unified phylogram-based model. An OPA cycle completes when the unified model generates new samples.
OPA performance has been verified for relatively complex combinatorial mono- and multi-objective optimization problems [
32]. Basic proofs concerning (stochastic) convergence to optima and time–space complexity have been provided [
32,
33].
2.3. Comparison of FS-OPA with NL-MVU-PCA for MaOPs Data-Driven Structural Learning
NL-MVU-PCA is the primary method used by Duro et al. [
12] for finding the essential objective set in MaOPs. Such a scheme also runs PCA based on the objective–function correlation matrix, aiming to improve objectives’ preference ranking. On the other hand, NL-MVU-PCA maximizes the variance in objective space while preserving the local isometry (common property in dimensionality reduction through embedding’s). NL-MVU-PCA is computationally more complex than PCA since the former solves an optimization problem. The non-linear (NL) approach performs the optimization of the Kernel (Gram) matrix values by minimizing the Maximum Variance Unfolding (MVU) to find the best mapping that preserves the geometric properties of each neighbourhood.
Table 1 synthesizes some relevant properties of NL-MVU-PCA and FS-OPA for MaOPs. The latter analyses three types of associations: variable-variable (producing results similar to the Gibbs measure for Ising Models or Markov Random fields [
34]), objective–objective (the dissimilarities, when found, can favour the construction of (non-dominated) front distributions [
35]), and the variable–objective (that may benefit inference as Markov Blankets [
36]). The former works on the objective space for space reduction to determine the essential objective set [
12]. FS-OPA also has other properties that are relevant for some classes of real-world problems: (i) it preserves the original variable space, which favours non-experts interpretability; (ii) it works with any data type (continuous, discrete, categorical—not only ordinal, but also nominal data, addressed by Bandaru et al. [
4]) and mixed types (proper for multiple heterogeneous databases with observed data); (iii) it has a relatively low time complexity; (iv) and, finally, it has generated applicable models when applied to learn from small datasets [
17,
23,
24,
25,
26,
27,
28,
29,
30,
31].
Reference [
5] shows the use of NL-MVU-PCA for a mixed-variable problem, the gearbox problem (with continuous and discrete variables and continuous objectives). NL-MVU-PCA works on the (continuous) objective vectors for the gearbox problem. It differs from the meaning of mixed in
Table 1, which relates to both the variable and objective representation (important for the "explicit explainability"), i.e., the mixture may include data vectors simultaneously from both spaces with different types. Moreover, FS-OPA can naturally work with any number of combinations of data types due to its foundation on NCD.
Concerning Explainability, "Explicit" means to provide a knowledge representation (with clues for "The Why" as the potential influence of variables on objectives) that benefits decision-maker interaction, while "Implicit" refers to the capacity to reveal the objectives’ relative importance for an optimization problem, e.g., by ranking them.
The Feature Sensitivity (FS) analysis of FS-OPA aims at finding the variable and/or objective data-driven interactions to construct structural (graph-based) and probabilistic modelling. Probabilistic results are fundamental when dealing with the odds of bias in observed data or small-data sampling. Explainability is also essential for some classes of real-world problems, mainly those concerning decisions by stakeholders. Moreover, a user-friendly tool (instantiating the FS-OPA methodology) is relevant for real-world applications involving practitioners or stakeholders who are not optimization or artificial intelligence experts. Variable–variable and variable–objective interactions can also benefit practitioners’ comprehension (The Why), increasing their confidence. Finally, the phylogram-based representation of those interactions has scaled up the understanding of results for some problems with dozens of variables or objectives (note that the interactive data mining approach proposed by Bandaru et al. [
4] works with two or three objectives).
Table 1 also shows the time complexity for usual cases and the worst case to estimate the overhead of both procedures. The number of clusters in NL-MVU-PCA relates to the number of constraints to maintain the local isometry (
M q; but in the worst case
q =
M − 1, resulting in M2) [
12]. FS-OPA with usual resampling is O(
l3) since
n ⩽ l (as in leave-one-out resampling) [
34]. Moreover,
l =
M in a space analysis only uses objectives. Thus, the time complexities of FS-OPA and NL-MVU-PCA have a ratio (
n +
M)/
M4 (
l/
q3) of running time for
l =
M in the worst case (in the usual case).
Another relevant factor is the minimal samples required to ensure reliable findings. Usually, the sample size for the PCA-based approach is empirically determined. FS-OPA has a theoretical model to decide the minimal amount of samples that guarantees high confidence in the results, which has been empirically corroborated for relatively complex problems in the decision space of binary variables [
32].
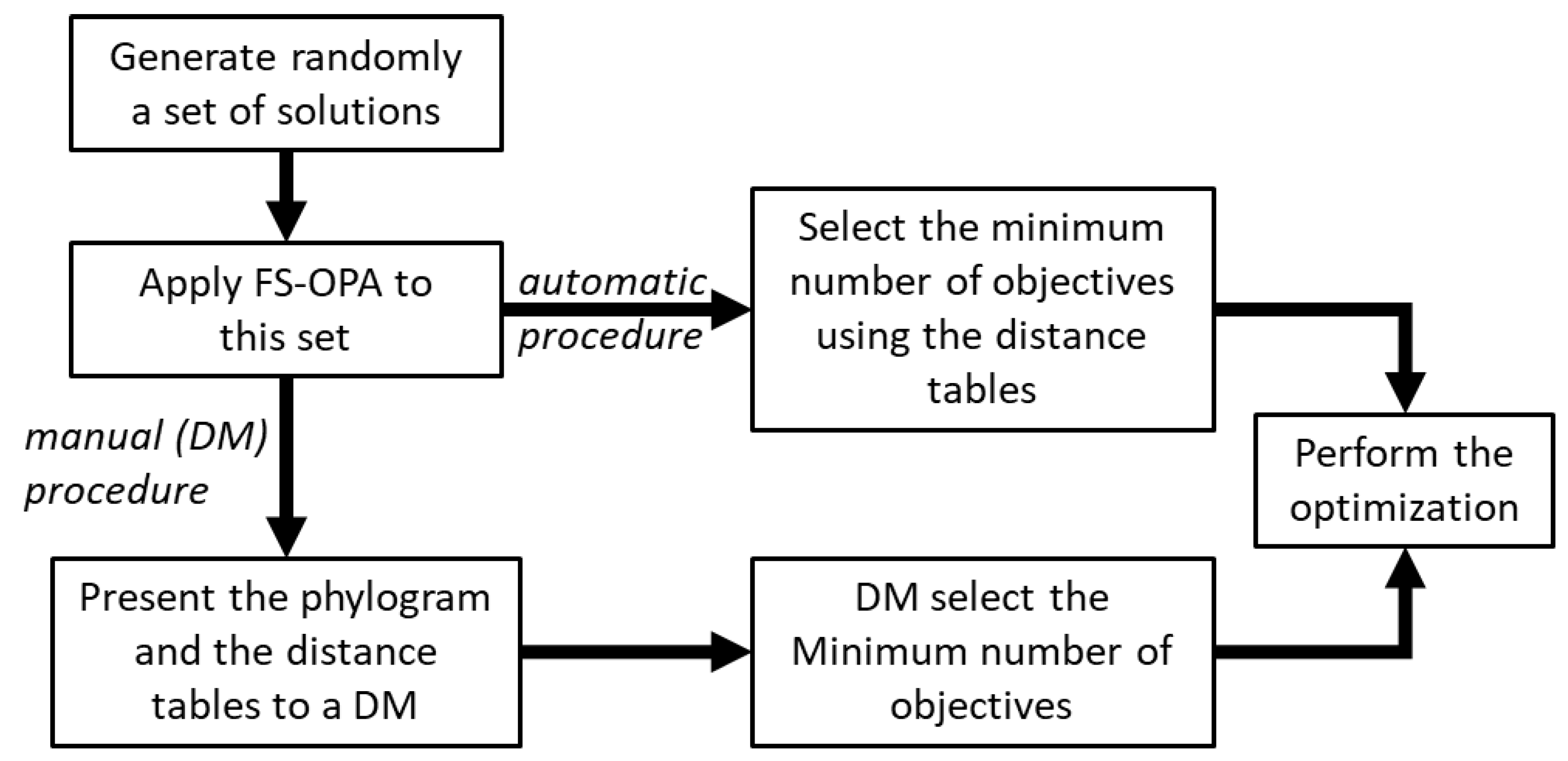
2.4. FS-OPA Framework
Figure 4 shows a flowchart of the global procedure of FS-OPA to reduce the number of objectives. Two options exist (i) automatic procedure, and (ii) procedure with the intervention of the DM(s). In the first case, the selection of the number of objectives to be used in the optimization is defined by the program automatically, using the table of the distance between objectives and applying the following rules:
choose the objective(s) of the less distant clusters;
choose one objective of the more distant (single) cluster;
choose one objective from each of the remaining clusters.
In the second case, the selection is made by the DM(s), using both the phylogram and the table with the distance of objectives–objectives, as follows:
choose the objective(s) of the less distant clusters;
choose one objective of the more distant (single) cluster;
choose objective(s) from each of the remaining clusters taking into account, also, the phylogram and the knowledge of the DM(s) about the process.
The reasons for rules 1 and 2 are different: the less distant cluster is the one that transports more information concerning the entire process, since it is near most of the decision variables, while the more distant cluster, besides everything, also has some information about the process that cannot be lost. The idea is that the intermediate clusters, selected by rule 3, have some information regarding the process that is already present in the objectives selected by rules 1 and 2, and thus, the objectives that can be discarded are those that belong to these clusters.
Both cases will be illustrated in the next section using a practical example. However, there are advantages and disadvantages to using one or the other. The first procedure provides the final solution directly, but the DM(s) does not take part in the process, which can imply some discomfort and distrust with the solution found. This does not happen when, after the analysis of the initial population of solutions, the DM(s) is confronted with relevant information about the process and, given these intermediate results, is asked about a possible way to advance. We are facing a situation in which the results may be explainable to the DM(s).
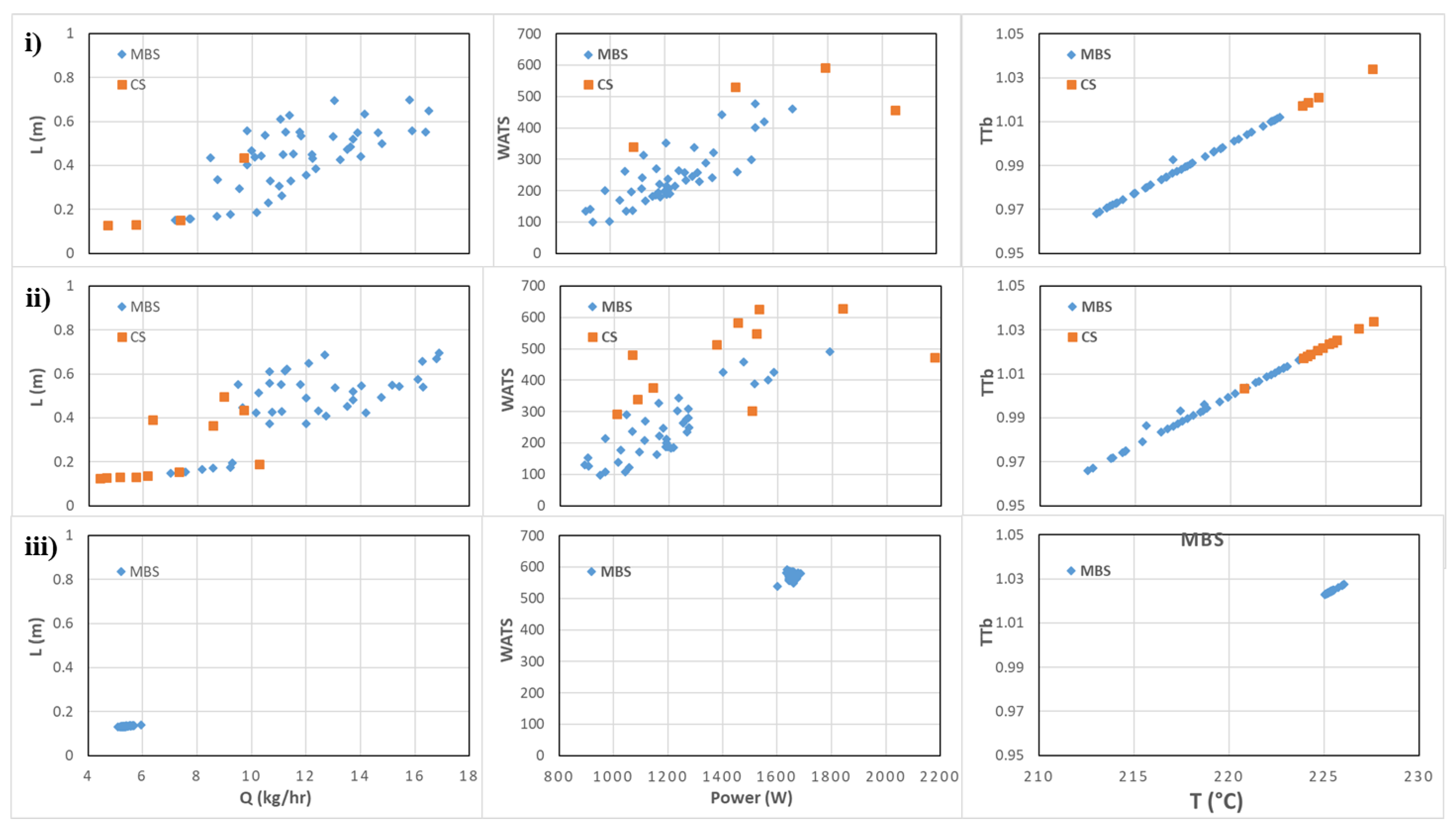
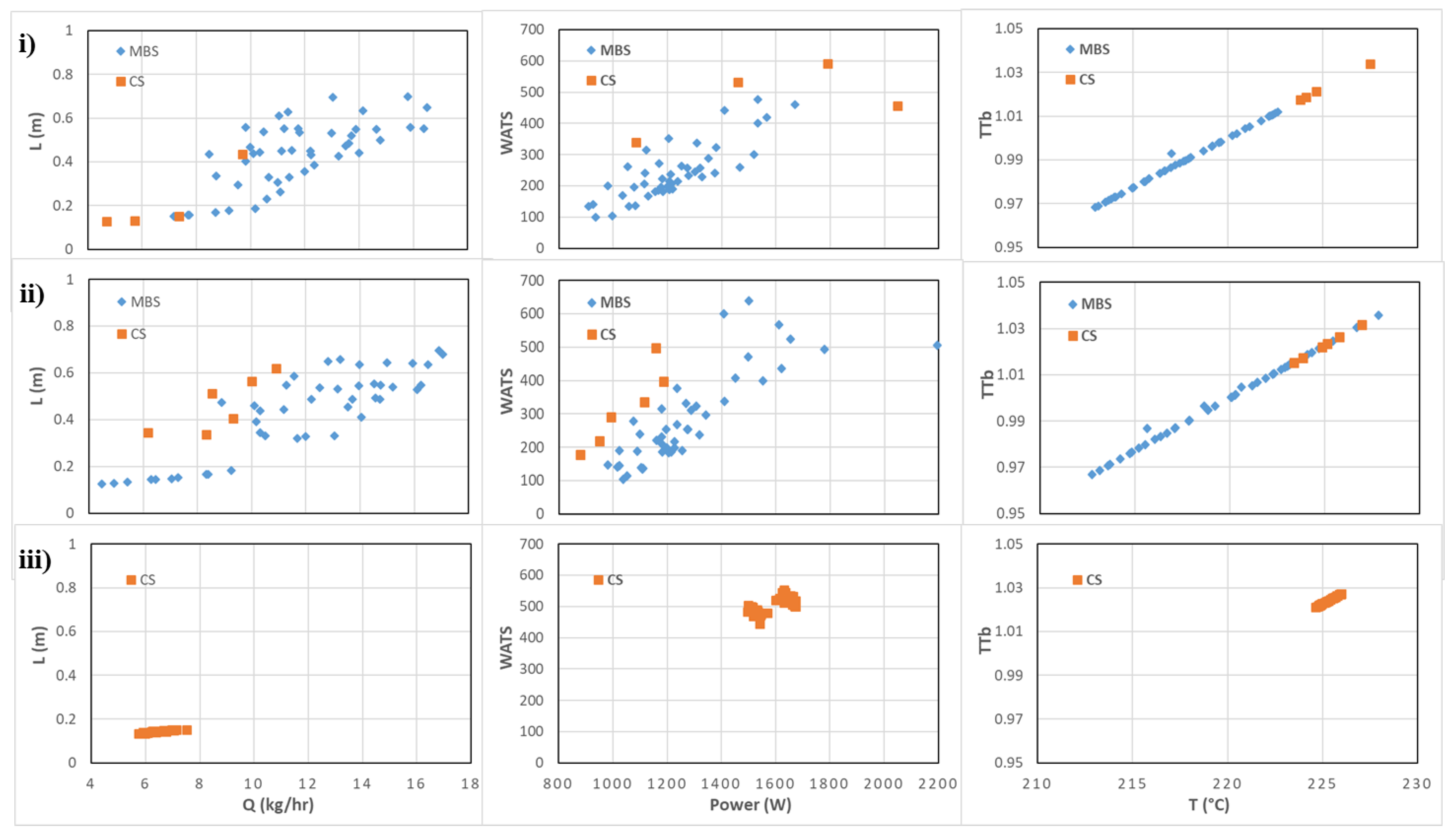
3. Examples of Application: DTLZ Benchmark Problems
A strategy to deal with many-objective real-world complex optimization problems (e.g., those with no explicit objective functions) is prioritizing objectives. In the case of unknown priorities, their relative importance can be estimated from samples of the decision space, as proposed in this paper. Such prioritization has a certain resemblance to the problem of determining the essential objective set, since a redundant objective has low priority.
The DTLZ problems (with and without redundant objectives) have been used to test the method’s capacity to find such a set and to evaluate algorithms for many-objective optimization.
Some algorithms have succeeded in finding the set from samples in POF, near POF, or, for example, from the last generation of an NSGAII run, although more recently, some of them failed for new challenging problems with other types of redundancies, as shown in [
37]. This way, evaluating how much FS-OPA can estimate objectives’ relevance for DTLZs from a random population (or from the first fronts of it) may be useful, since they are well-known problems.
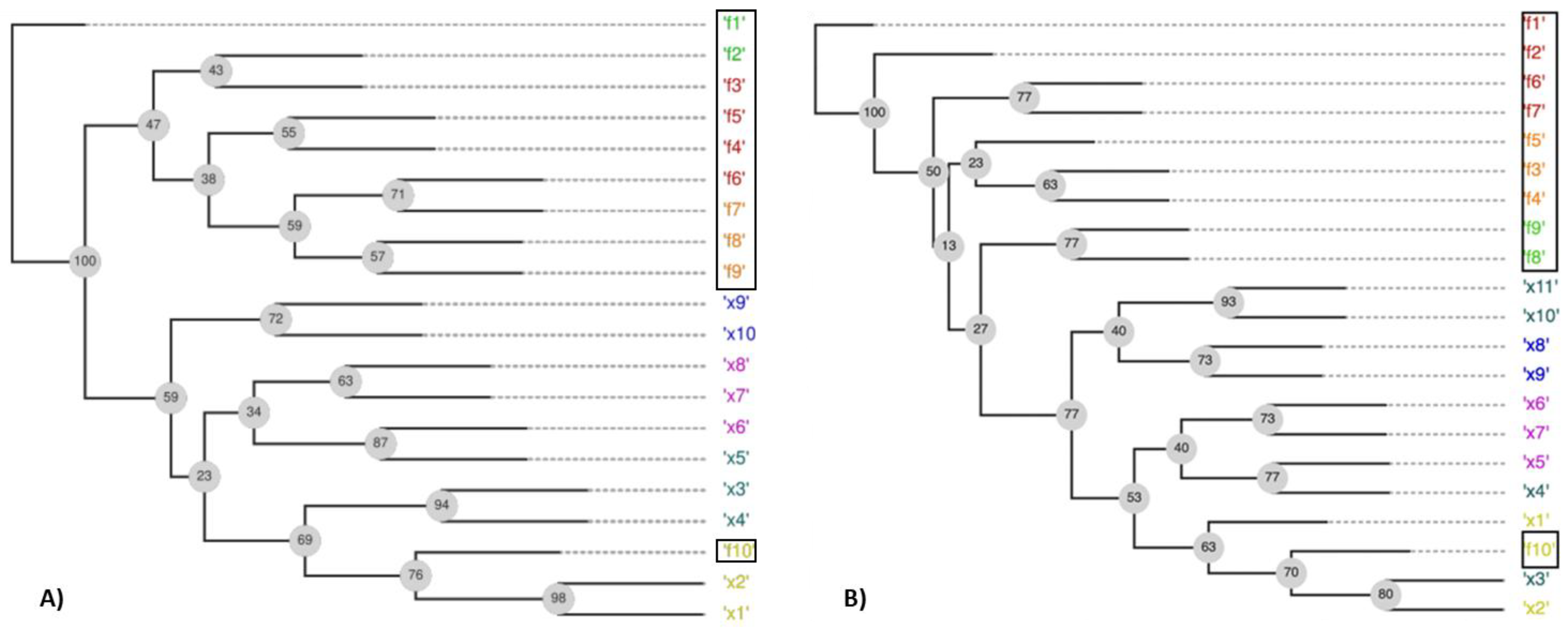
Figure 5A illustrates an FS-OPA output for unconstrained DTLZ5, also used by Duro et al. [
12] for explaining the capacity of their method to find redundant objectives (objectives
f1,
f2,
f3,
f4,
f5,
f6,
f7,
f8, and
f9 are linearly correlated in DTLZ5). A random population of size 31 with samples normalized and Euclidian distance was used to obtain a distance matrix. SS procedure in
Figure 3 was not applied. The output of
Figure 5A shows variables and objectives arranged into a phylogram with leaf nodes (the objects under analysis) composing clusters (similarly to the end of the pipeline in
Figure 1)—they are identified by the same color.
Objective functions f1, …, f9 are partitioned into three neighbor clusters ({f1, f2}, {f3, f4, f5, f6}, and {f7, f8, f9}) in the phylogram structure; while f10 is together with the leaf nodes, corresponding to variables. The phylogram structure aggregates f1, …, and f9 into the same subtree, while f10 is isolated from the other objectives in the complementary subtree. The unique node with the label "100" (another type of result from a tree consensus) splits the phylogram into those two subtrees. Such a label (“100”) means that the leaf nodes f10 and x1, ..., x10, and f10 were in the same subtree (with the remaining leaf nodes in the complementary subtree) in 100% of all the constructed phylograms, independently of each subtree topology in a phylogram. Such an interpretation suggests a hypothesis: f10 is weakly correlated to the other objectives, which are significantly associated with themselves. Thus, f10 and one of the other objectives could compose an essential objective set; this result is consistent with the DTLZ5 problem structure.
Figure 5B shows the proposed phylogram for DTLZ5(2,10) with constraints (Saxena et al. [
5]). It requires an additional variable,
x11, to generate samples outside POF, as samples used to construct a phylogram from
Figure 5A. The phylogram from
Figure 5B shows that
f10 is isolated in a subtree, while
f1, …,
f9 are in the complementary subtrees. Such a result suggests that
f10 and
f1 (for example) would enable proper POF estimates; this result agrees with the DTLZ5(2,10) problem structure.
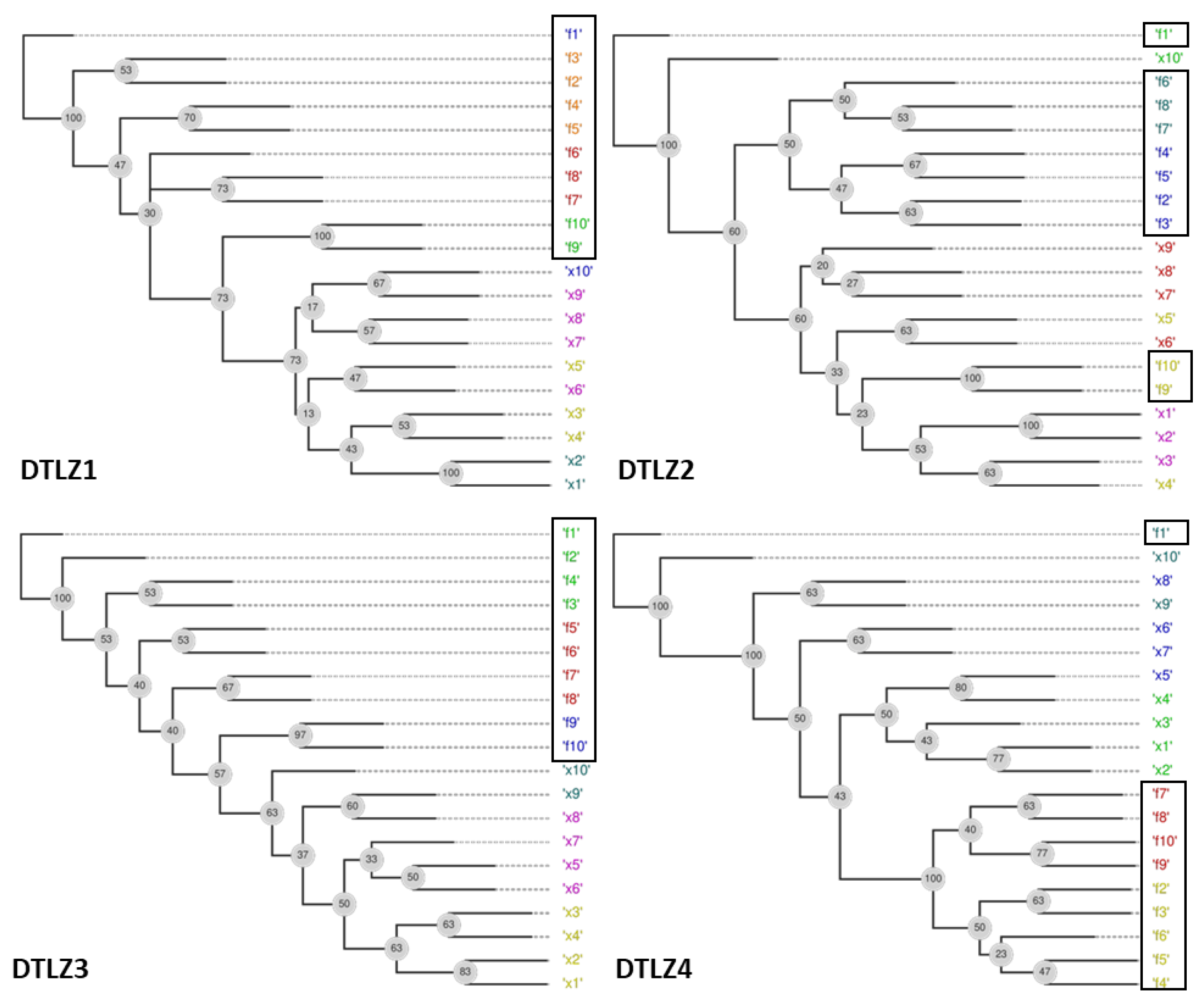
Figure 6 shows the phylograms obtained by FS-OPA for DTLZs 1–4 obtained from random populations of size 31 as a way to check if the FS-OPA clues about the objective relationships are plausible.
Given that these problems do not have redundant objectives, the unique possibility is to present some clue about the prioritization of objectives, considering that a reduction in the number of objectives only can be made with a certain error, as explained before. For example, the behaviours of functions DTLZ1, DTLZ2, and DTLZ3 are very similar. The simultaneous analysis of the clusters found and of the distances between objectives and the decision variables show that objectives can be portioned in the following sets:
DTLZ1: {f1}, {f2, f3, f4, f5}, {f6, f7, f8}, {f9} and {f10};
DTLZ2: {f1}, {f2, f3, f4, f5}, {f6, f7, f8}, {f9} and {f10};
DTLZ3: {f1}, {f2, f3, f4}, {f5, f6, f7, f8}, {f9} and {f10};
DTLZ4: {f1}, {f2, f3, f4}, {f5, f6} and {f7, f8, f9, f10};
This signifies that a possible hierarchization of the objectives for these problems can be made by selecting, in the first step, a single objective of the groups identified above and then, by selecting all the others to a second level.
In addition, all the objectives in the phylograms found for DTLZ2 and DTLZ4 are not in a subtree without a variable. That may mean that the disagreement of objectives of those two problems is more salient from an initial random sampling.
However, the objective of this paper is not only to define the minimum number of objectives that can be used without error but also to identify the situations where the reduction can be done with a certain error. Anyway, a deep analysis will be necessary here, which is outside of the scope of the present paper.
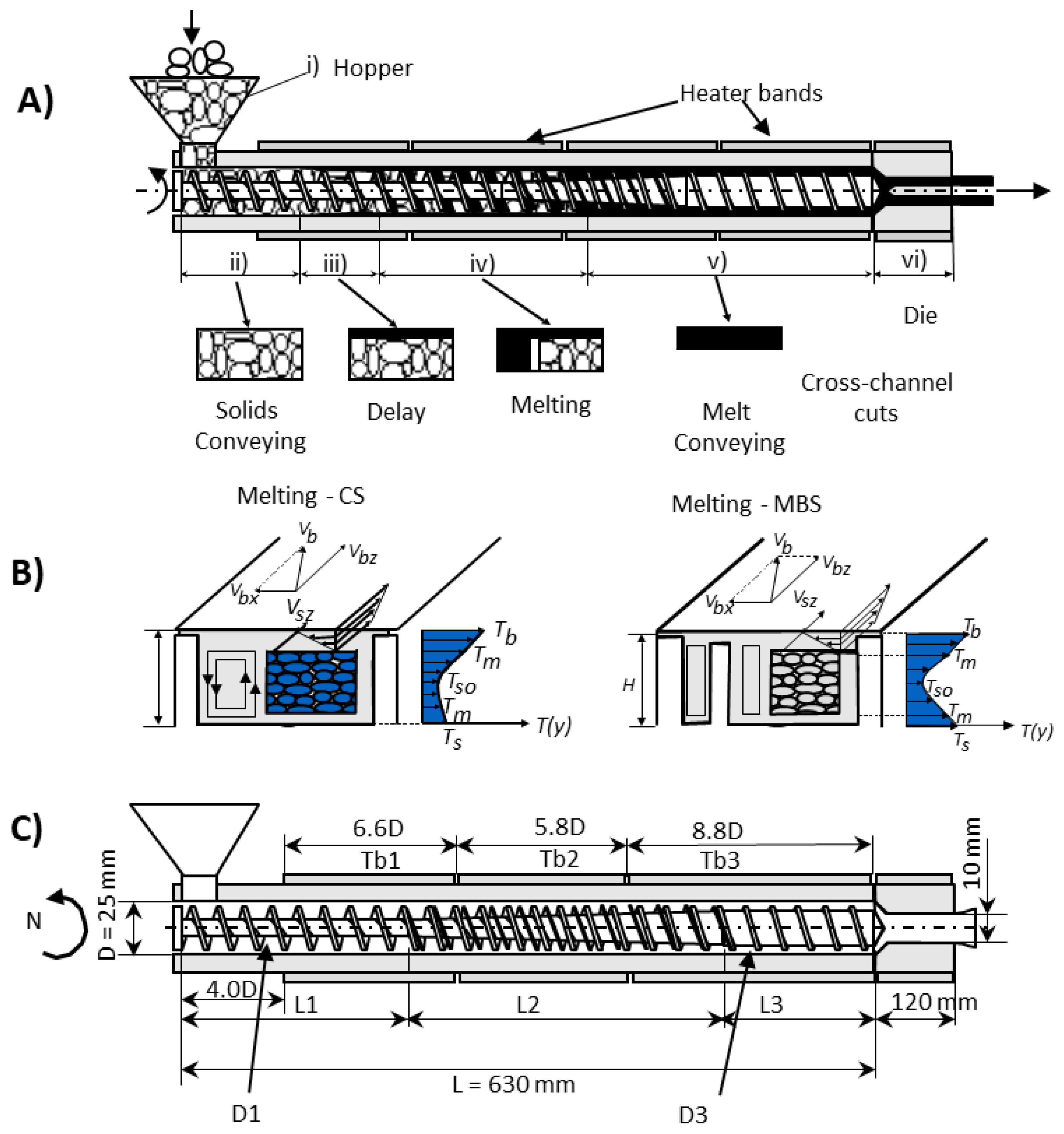
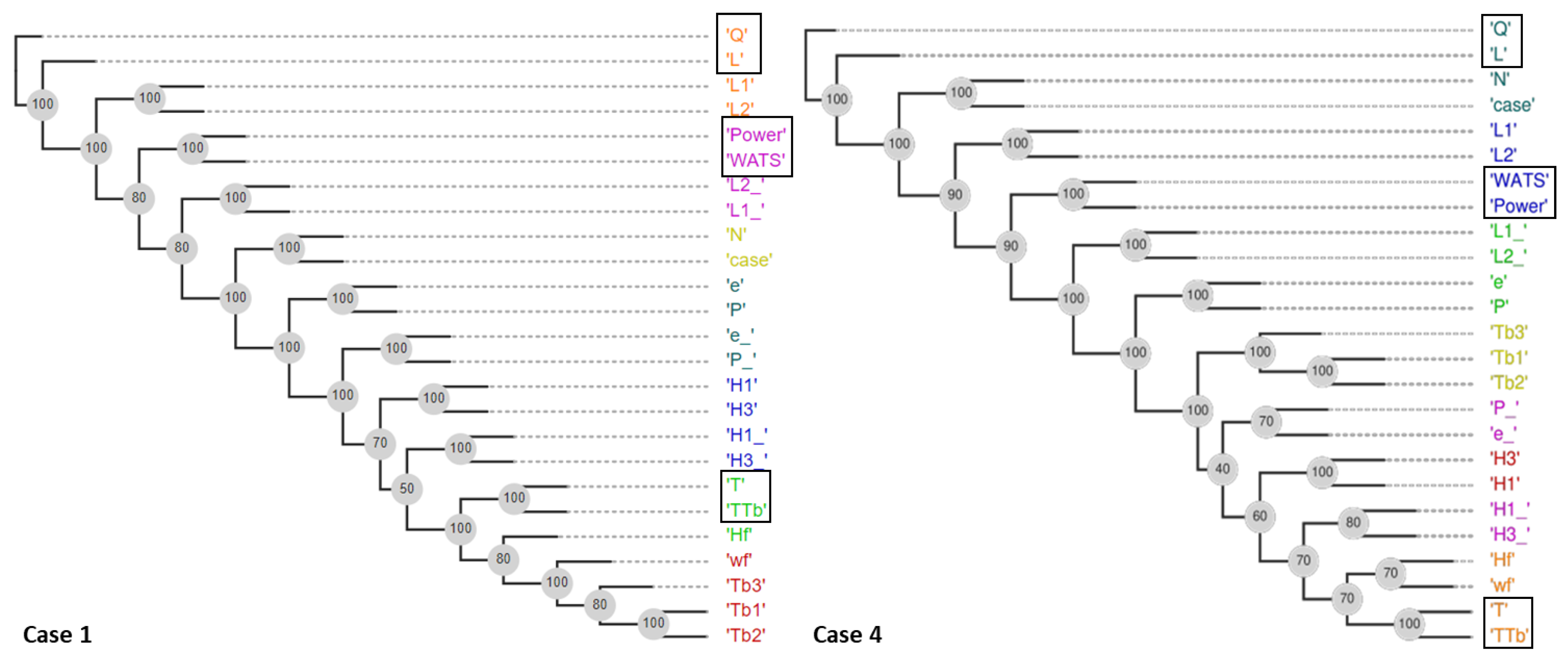
The FS-OPA also produces other outputs (useful for human comprehension of some classes of real-world problems), which are explored in Sections related to the extrusion problem.
5. Conclusions
A methodology for reducing the number of objectives for many-objective optimization problems using population-based algorithms is proposed. This approach, based on machine learning, is an improvement over similar state-of-the-art methodologies; namely, it allows analysis of the relations variable–variable and variable–objective relations (and not only objective–objective), does not need kernel function choice and parameters optimization, allows for obtaining explainable solutions to assist the decision maker with interpreting the results, its time complexity is also low, and it supports theoretical and empirical sample sizes.
The approach showed its potential to reduce the number of objectives by capturing the complex relations between the different objectives with an additional possibility, which is to capture the objective-variable relations. This is done by applying the methodology to a set of benchmark and real-world problems. The comparison of the Pareto-optimal fronts obtained with another machine learning approach in the literature allows for the conclusion that its performance is very competitive, but with the great advantage of being much easier to use. Additionally, there is the possibility of strong interaction with the DM(s).
The application of the proposed approach to a difficult real-world problem has proven that it is automatically possible to reduce the number of objectives by losing only around ten percent of the Pareto-optimal frontier obtained, for the case of 100 individuals in the population. The use of a second possibility, which is to require the intervention of the decision maker during the process, e.g., when selecting the objectives to be considered in the optimization, can be very useful because the person interested can see how the process works and interpret the results obtained. Finally, an important characteristic of the method proposed is the capacity to explain the solutions found.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}