1. Introduction
Many real-world applications in economics, mechanics and engineering can be formulated as multi-objective optimization problems (MOPs) that simultaneously optimize two or more objective functions [
1]. The basic statement of an MOP for a minimization task can be formulated as
where
is the decision space of decision variables,
is a decision vector with
D denoting the number of decision variables,
consists of
m objective functions, and
m is the number of objectives.
Usually, different objectives are conflicting with each other, which means that a decision vector that decreases the values of may increases that of . As a result, it is impossible to find only one solution that can optimize all the objectives simultaneously; however, a set of optimal solutions that trade off between different objectives are known as Pareto optimal solutions. The whole set of Pareto optimal solutions in the decision space is called the Pareto set (PS), and the projection of PS in the objective space is called the Pareto front. Various types of algorithms have been proposed for solving MOPs.
For example, the scalarization technique is one of the most popular methods and is used to convert an MOP into a single optimization problem. Scalarization can be achieved by the global criterion method [
2], the weighted min-max method [
3,
4], the
-constraint method [
5] and reference point methods [
6].
Another popular approach is based on evolutionary algorithms (EAs), which have been applied successfully to many real-world complex optimization problems [
7,
8]. Over the past decades, a large number of multi-objective evolutionary algorithms (MOEAs) have been proposed, such as nondominated sorting genetic algorithm II (NSGA-II) [
9], multi-objective evolutionary algorithm based on decomposition (MOEA/D) [
10], reference vector guided evolutionary algorithm (RVEA) [
11] and strength Pareto evolutionary algorithm 2 (SPEA2) [
12]. More recently, many variants have been proposed to further enhance the optimization performance of MOEAs and extend them to many-objective optimization problems, such as NSGA-III [
13],
-DEA [
14] and MOEA/DD [
15].
Particle filter (PF), also known as sequential Monte Carlo (SMC), is a class of importance sampling and resampling techniques designed to simulate from a sequence of probability distributions, and this has gained popularity over the last decade to solve sequential Bayesian inference problems. With the notable exception of linear-Gaussian signal-observation models, the PF theory has become the dominated approach to solving the state filtering problem in dynamic systems. Applications of particle filter theory have expanded to diverse fields, such as object tracking [
16], navigation and guidance [
17] and fault diagnosis [
18].
Recently, particle filters have been extended for optimization [
19,
20] by utilizing the ability to track a sequence of distributions. In order to deal with a global optimization problem, generally, a sequence of artificial dynamic distribution is designed to employ the particle filter algorithm [
21,
22]. The crucial element in particle filter optimization (PFO) is how to design the system dynamic function by formulating the optimization problem as a filtering problem, which forces the set of particles to move toward the promising area containing optima.
Although PFO has shown promising performance in certain applications, current PFO methods only work for single-objective optimization problems [
23]. As many real-world problems involve multiple objectives to be optimized simultaneously, it is interesting to extend PFO to MOPs. To fill this gap, we make an effort to extend the scope of the application of PFO to multi-objective cases. To achieve this, we propose a novel particle-filter-based multi-objective optimization algorithm (PF-MOA) by transferring knowledge acquired from the search experience.
The key insight adopted here is that, if we can construct a sequence of target distributions that can balance the multiple objectives and make the degree of the balance controllable, we can approximate the Pareto optimal solutions by simulating each target distribution via particle filters. Inspired by the ability of SMC samplers to sample sequentially from a sequence of probability distributions [
24], we design a particle filter to perform the optimization. The method of importance updating in particle filters makes it possible to leverage the knowledge readily available for the previous subproblem to optimize the current subproblem, guiding the new particles to concentrate on the more promising area found thus far. As a result, PF-MOA offers an efficient solution to optimize MOPs by tracking the Pareto optimal solutions on the Pareto front via a particle filter.
The rest of this paper is organized as follows.
Section 2 presents a brief introduction to particle filters and the application to single-objective optimization. In
Section 3, a particle-filter-based multi-objective optimization method is proposed. Numerical simulations are conducted in
Section 4, where the results are presented and discussed. Finally, our conclusions are drawn in
Section 5.
4. Comparative Studies
In this section, numerical experiments are conducted on nine three-objective benchmark problems taken from the DTLZ test suite. To examine the efficiency of the proposed strategies, the proposed PF-MOA is compared with state-of-the-art multi-objective evolutionary algorithms, NSGA-II [
9], RVEA [
11], MOEA/D [
10], NSGA-III [
13], MOEA/DD [
15] and
-DEA [
14]. Our code is available at
https://github.com/xw00616/PF-MOA (accessed on 1 November 2022).
In the following section, we begin with briefly introducing the test problems and performance metrics adopted in our paper. Afterwards, the details of the experimental settings concerning the four compared algorithms are described. Lastly, the experimental results together with the Wilcoxon rank sum test are presented and discussed.
4.1. Test Problems
In our experiments, the proposed algorithm is compared with three state-of-the-art multi-objective optimization algorithms on DTLZ [
34] and WFG [
35] test suites with three objectives. The number of decision variables for the DTLZ test instances is set to
, where
is adopted for DTLZ1,
is used for DTLZ2 to DTLZ6, and
is employed in DTLZ7. The number of decision variables for the WFG test instances is set to 12.
M represents the number of objectives; here, we set
.
4.2. Performance Metrics
The inverted generational distance (IGD) [
36] metric and hypervolume (HV) [
37] metric are adopted to assess the performance of the algorithms. IGD and HV provide a combined information of the convergence and diversity of the obtained set of solutions. The PlatEMO toolbox [
38] is used to calculate values of the performance metric in our experiments. Let
be a set of uniformly distributed solutions sampled from objective space along the theoretical Pareto front. Let
P be an obtained approximation to the Pareto front. Let
be a set of uniformly distributed solutions sampled from objective space along the theoretical Pareto front. IGD measures the inverted generational distance from
to
P, defined as
where
is the minimum Euclidean distance between
and all points in
P. The smaller IGD value, the better the achieved solution set is.
HV calculates the volume of the objective space dominated by an approximation set
P and dominates
sampled from the PF.
where
represents the hypervolume contribution of the
i-th solutions relative to the reference points. All HV values presented in this paper are normalized to
. Algorithms achieving a larger HV value are better.
4.3. Experimental Settings
We ran each algorithm on each benchmark problem 20 independent times, and the Wilcoxon rank sum test was calculated to compare the mean of 20 running results obtained by PF-MOA and by the compared algorithms at a significance level of 0.05. Symbols “(–)”, “(+)” and “())” indicate that the proposed algorithm shows significantly better, worse and similar performance than the compared algorithm, respectively.
The PF-MOA was implemented in MATLAB R2019a on an Intel Core i7 with 2.21 GHz CPU, and the compared algorithms were implemented in PlatEMO toolbox [
38]. The general parameter settings in the experiments are given as follows: (1) The maximum number of function evaluations
. (2) For PF-MOA: the population size was set to 100 and the maximum number of generations was set to 100. (3) For the three multiobjective evolutionary algorithms: the population size was set to 100 and the maximum number of generations was set to 100. The specific parameter settings for each compared algorithm were the same as recommended in their original papers.
4.4. Experimental Results
The statistical results in terms of IGD and HV values obtained by the four algorithms are summarized in
Table 1 and
Table 2, respectively. For the DTLZ test problems, it is apparent that the proposed PF-MOA achieved the best approximate Pareto front on all test problems except for DTLZ6 and DTLZ7 (NSGA-II obtained the best IGD values). The reason behind this may be that DTLZ6 has a plenty of disconnected Pareto optimal regions in the decision space, and DTLZ7 has a discontinuous Pareto front. Hence, it is challenging to design proper target distributions in PF-MOA, which further degrades PF-MOA’s performance.
According to the Wilcoxon rank sum test, the proposed algorithm significantly outperformed the compared algorithms on most of the test problems. For the WFG test instances, PF-MOA showed significantly better performance than the algorithms under comparison on six out of nine test instances, confirming the promising performance of the proposed PF-MOA. More specifically, taking WFG5 as an example, the objective multimodality was combined with landscape deception, and the proposed PF-MOA showed the worst performance compared with the other algorithms.
A possible explanation for this is that the deceptive objectives may impact the design of the target distributions, and the information form the previous subproblem does not provide sufficient information to help the algorithm generate good tradeoff solutions for the current subproblem. Moreover, similar observations can be made from
Table 2.
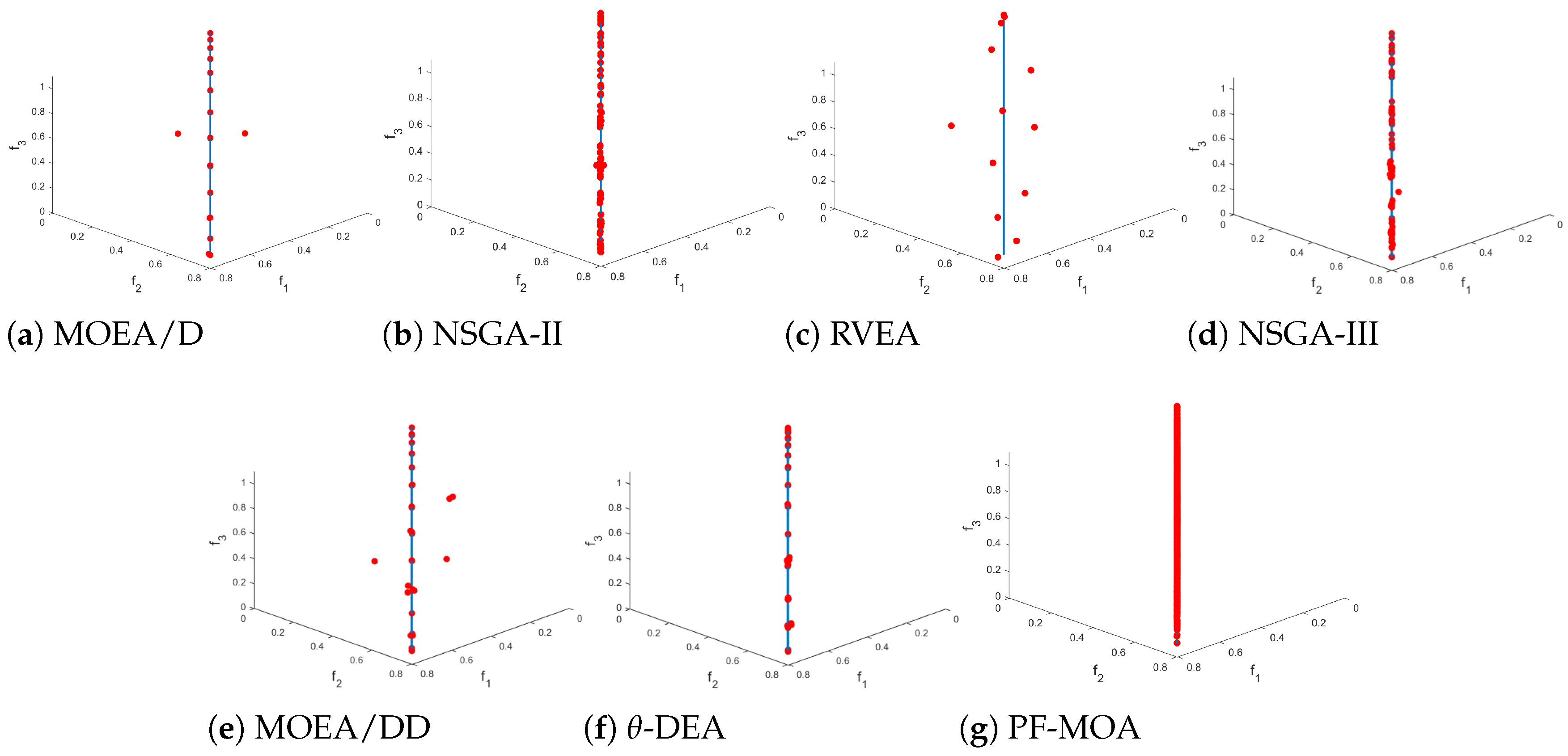
To further illustrate the performance of the proposed algorithm, the obtained Pareto front for each algorithm is illustrated in
Figure 1. We observed that the proposed method can find a set of well-converged and diverse Pareto optimal solutions, thereby, confirming the effectiveness of the particle filter in the PF-MOA.
5. Conclusions
In this paper, we extended the particle filter optimization method from single-objective optimization to multiobjective optimization. The Tchebycheff decomposition was used to decompose a multi-objective optimization into a set of single-objective problems so that a sequence of target distribution was defined. Subsequently, the particle filter was adopted to simulate these target distributions by using its tracking ability, and genetic operators were employed to perform the particle move. The experimental results on the DTLZ test suite showed the promising performance of PF-MOA compared with three state-of-the-art multi-objective evolutionary algorithms.
However, PF-MOA cannot effectively solve certain problems with discontinuous optimization problems, such as DTLZ6 and DTLZ7. The reason may be that PF-MOA always searches around the best particle, thereby, reducing the diversity of all the particles; however, the lack of diversity cannot be addressed by the resampling step, which should be considered in future work. Moreover, for real-world multiobjective optimization problems, uncertainty is an unavoidable issue, and it directly affects the optimization performance. As the filtering methods have been successfully applied to noisy MOPs, the particle filter may benefit MOEAs for solving MOPs with uncertainty.






{kind=link}