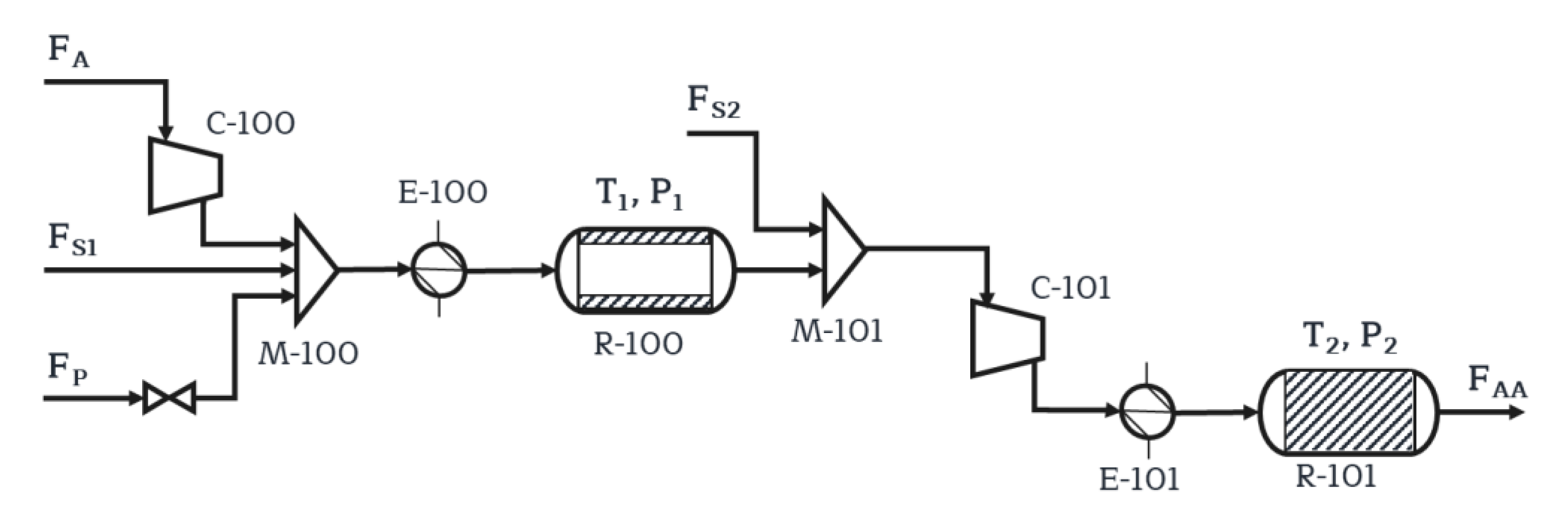
4.1. Construction of the Meta-Model
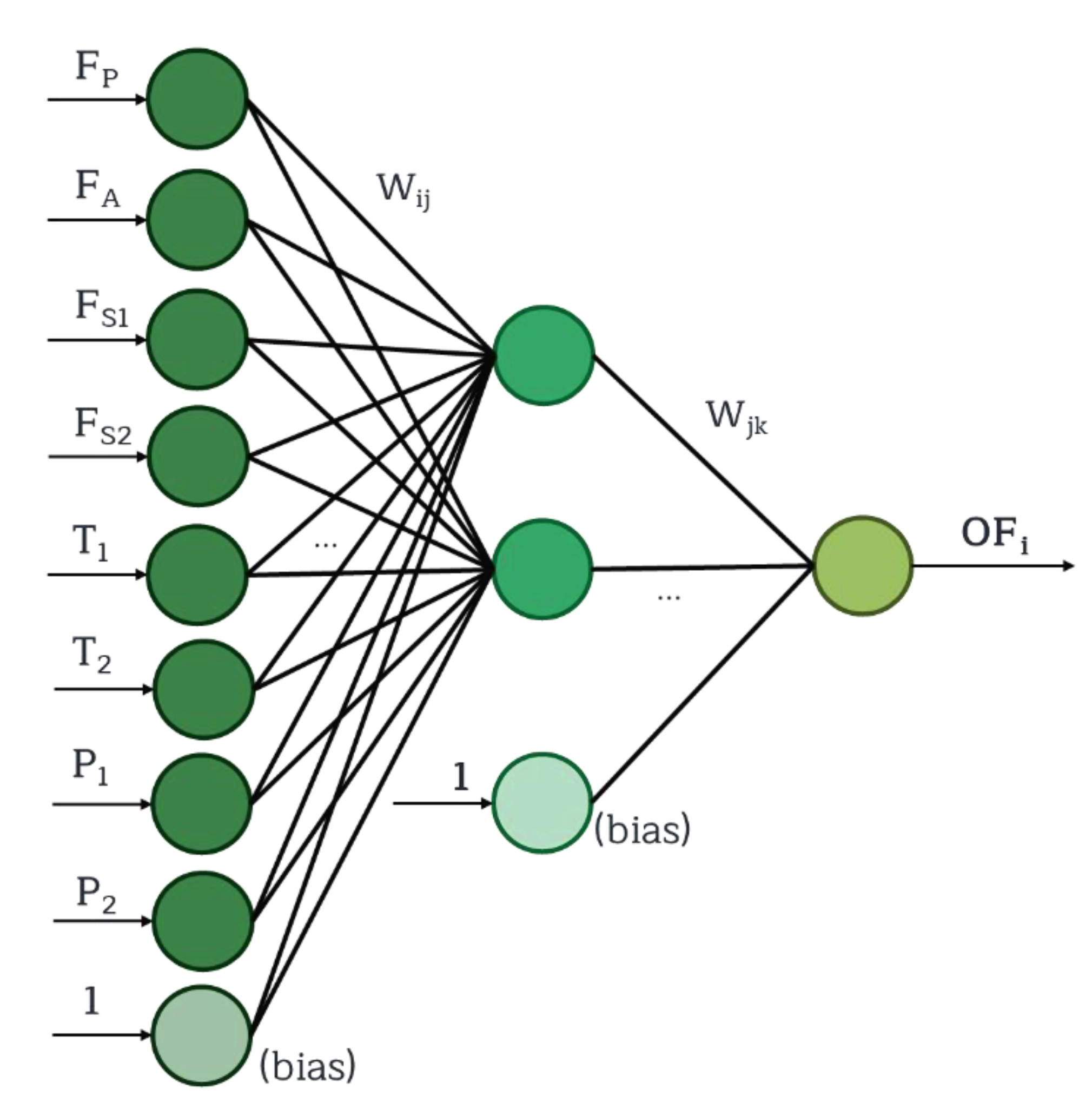
The initial attempt to develop the nine ANNs, as a surrogate model to represent each of the nine objective functions, was performed with training and validation data sets that were the design points of the uniform design. In this first attempt, 50 and 20 design points were used for the training and validation data sets, respectively. Eight decision variables and five levels were used to separate the ranges of the decision variables, which correspond to U
50(5
8) and U
20(5
8) for the training and validation data sets, respectively. The coefficients of determination (R
2) for each of the nine objective functions (
Table 1) are plotted as a function of the number of hidden neurons (
Figure 5).
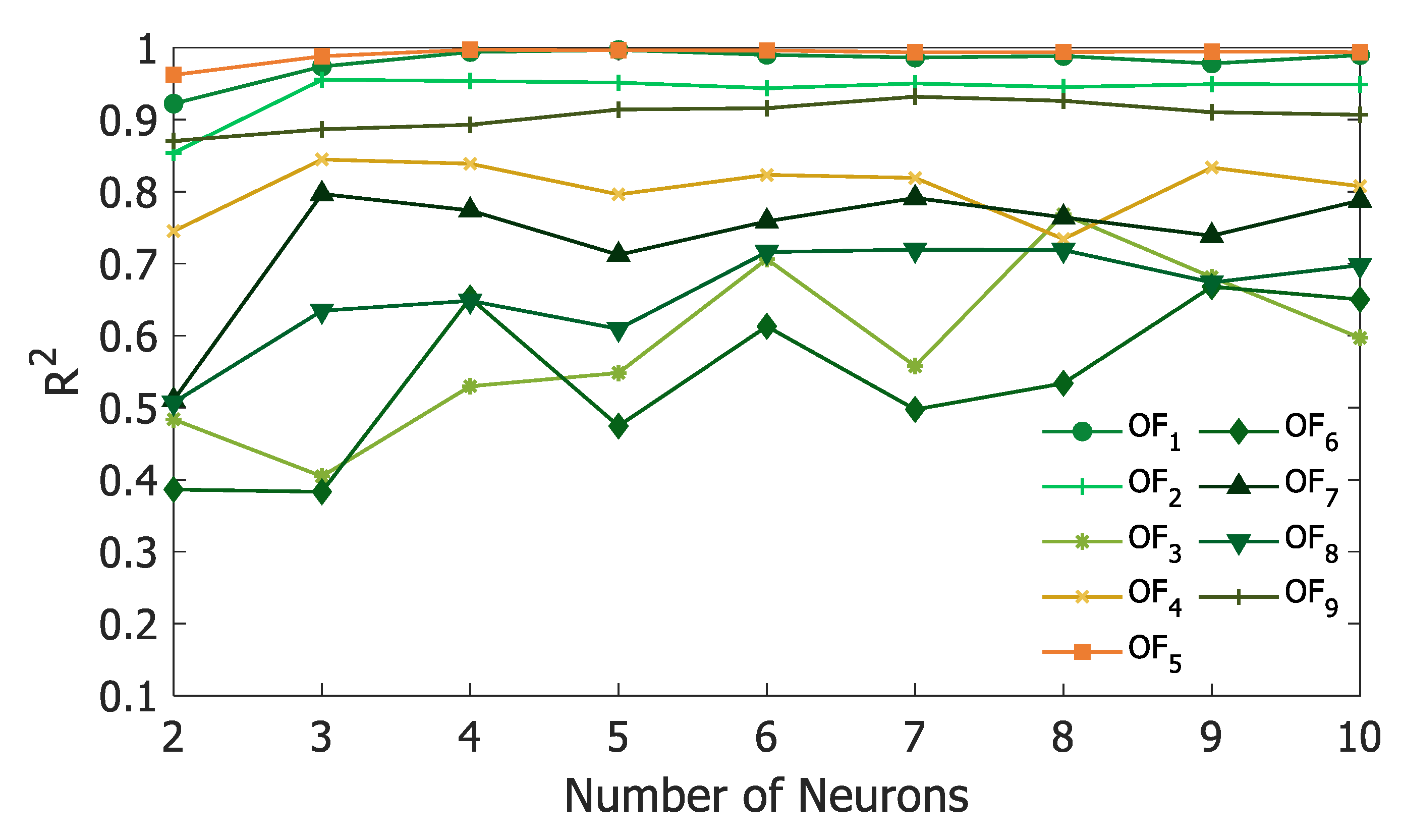
Results of
Figure 5 show that some objectives, namely the power of the two compressors (OF
1 and OF
5) and the heat recovery of the first reactor (OF
2), are relatively well predicted. However, the ANNs of the other six objectives show poorer predictions with R
2 values below 0.90. Furthermore, it is not possible to observe a clear trend for those OFs when one would expect the R
2 value to increase as the number of neurons increases. These results suggest that, for these objectives, the number of design data points is insufficient to allow the ANN to capture the underlying relationships that exist between the decision variables and the objectives. The large number of input variables as inputs to the ANNs also points to the necessity to present the neural networks with richer information. Since the available tables of uniform design are limited to a relatively small number of design points, it was decided to use well-distributed random design points, which offer the possibility of using any desired number of design points.
A series of ANNs were developed for an increasing number of hidden neurons and different numbers of design points. The total number of design points were divided in an approximate ratio of 70:30 for the learning and validation data, respectively. Results for objective functions that showed the best and worst predictions, namely the compression power of the first compressor (OF
1) and the heat recovery of the second reactor (OF
6) respectively are presented in
Figure 6. The total number of design points (training and validation) in the data set varied between 70 and 1430. The predictions for OF
1 wwere very good for a relatively low number of hidden neurons and a small number of training data points. Indeed, the very high R
2 value indicates that the predictions of the neural network for the compression power of the first compressor were independent of the number of design data points above approximately 140. For the heat recovery of the second reactor (OF
6), the coefficient of determination (R
2) increased with the number of design points, whereas it was not a function of the number of hidden neurons above five neurons. This trend was more significant for some objectives due to their dependency on the input or decision variables. For example, a simple dependency prevailed for OF
1 as it was mainly correlated to the air flowrate and the operating pressure of the first reactor. In contrast, OF
6 is a much more complex dependency as it is affected by a larger number of inputs, namely the four input flowrates and the operating temperature and pressure of the first reactor, and thereby requires more data points to capture the underlying relationships between the inputs of the ANN to properly predict this output.
Based on the previous discussion, we performed a sensitivity analysis to extract the contribution of all neural network inputs to explain each output. Numerous techniques have been proposed to provide this information, and they partly alleviate the black box character of neural networks. In this investigation, the modified Garson method was used [
35]. Results of this sensitivity analysis are presented in
Table 3 in terms of the percentages of the relative importance of the eight decision variables for each of the objective function in the ANNs. It is important to note that the percentages in
Table 3 are normalized such that the sum of each row associated to one objective function adds up to 100; if more variables are correlated to an output, the percentages will be obviously lower. First, these results show the paramount importance of the bias neuron of the input layer, which acts in a similar way to the intercept of a linear equation to shift the weighted sum to obtain a better fit. Some strong correlations are logically expected and indicate that the neural networks were trained adequately to capture the underlying behavior of the process. For instance, this is the case for the power of the two compressors that are strongly correlated with the desired pressures and the pertinent flow rates. These sensitivity coefficients offer a valuable introspection on the causal effect of each decision variable on the objective functions.
A large number of ANNs were obtained to represent the nine objective functions. The final selection was made as a compromise of the following criteria: (1) the minimum number of data for training and validating the neural networks; (2) higher than 0.9 values for the coefficient of determination (R2); and (3) the minimum number of neurons. The selected set of nine ANNs, one for each objective function, can now be used as the surrogate model to generate the Pareto domain and find the optimal operating set of decisions variables.
Before proceeding, the quality of the predictions will be examined.
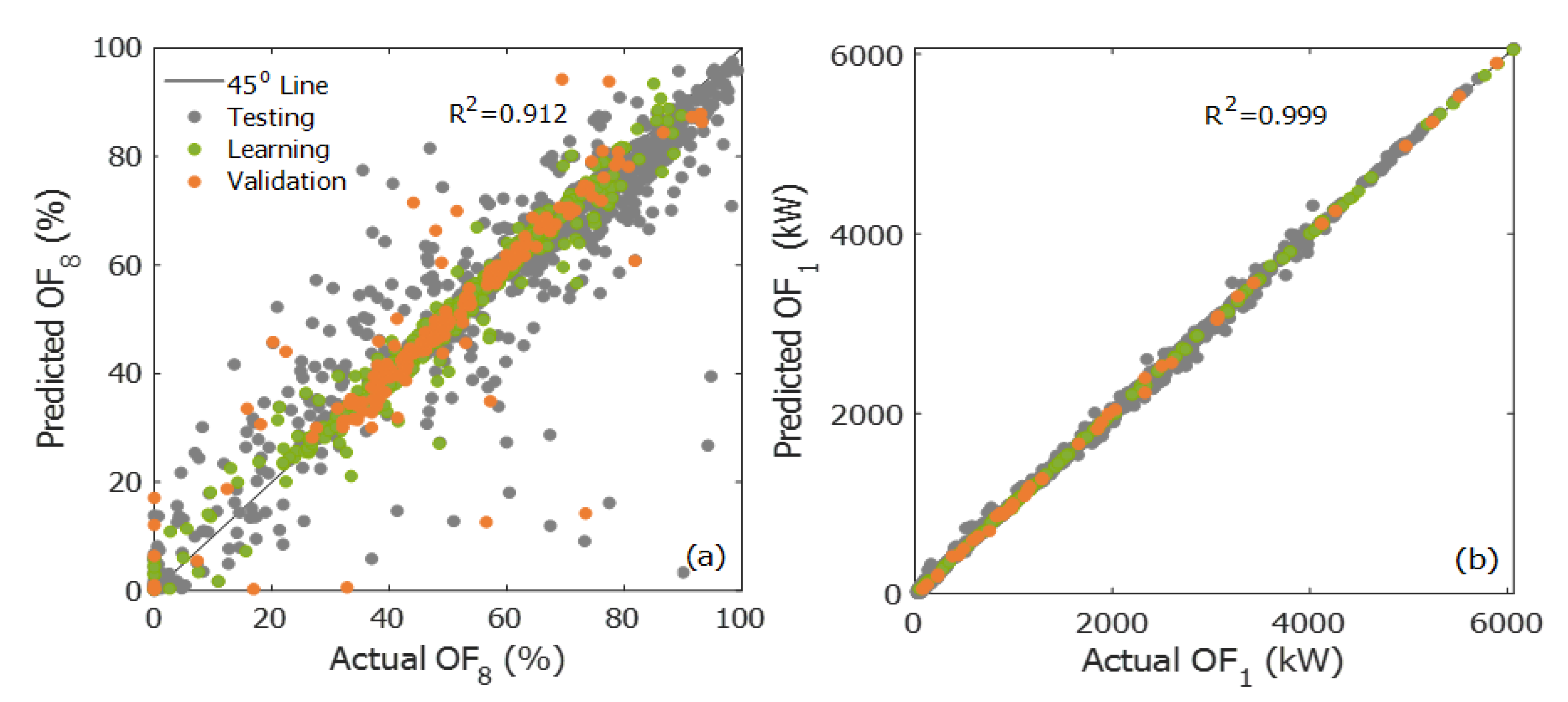
Figure 7a,b present the ANN predictions of the conversion of the second reactor (OF
8) and the compression power of the first compressor (OF
1), respectively, as a function of the values calculated using the phenomenological model. The green points represent the learning data, the orange points correspond to the validation data, and the grey points to the testing data. The testing data were generated using the phenomenological model by randomly selecting the decision variables within their allowable ranges, as defined in
Table 2. This data set was used as a “second validation” to confirm the good adjustment and precision of the ANNs when exposed to new input data. As previously mentioned, it had no impact on the meta-model training. The predictions of
Figure 7a,b correspond to the ANNs with the lowest and highest R
2 values for all data presented: 0.912 and 0.999, respectively. Predictions for the other OFs were very good as well, having R
2 values between the two previous values. The predicted conversion in the second reactor (R-101) had the majority of the points near the 45o-line, but with the lowest R
2 value due to few scattered points with poor predictions. When examining the sensitivity parameters of
Table 3, the two objective functions that are influenced by a larger number of input variables are the conversions of the first and second reactors (OF
4 and OF
8). As mentioned before, the more an objective function is correlated to a larger number of decision variables, the more learning data points are required to obtain better predictions. As a compromise needs to be made between the R
2 value and the number of learning data, a value of R
2 above 0.9 was considered a good result.
4.2. Multi-Objective Optimization
After having obtained a good surrogate model, i.e., one consisting of nine AANs, one for each objective function, the Pareto domain was circumscribed with the DPEA and all Pareto-optimal solutions were ranked with the NFM, using both the phenomenological model and the surrogate model for the reactor section to compare the results.
Since there are nine objective functions, the Pareto front is in fact a surface of a nine-dimensional space. To visualize the ranked Pareto domain, it is necessary to resort to two-dimensional projections. In this paper, the ranked Pareto domain of four objective functions are presented for the surrogate and phenomenological models.
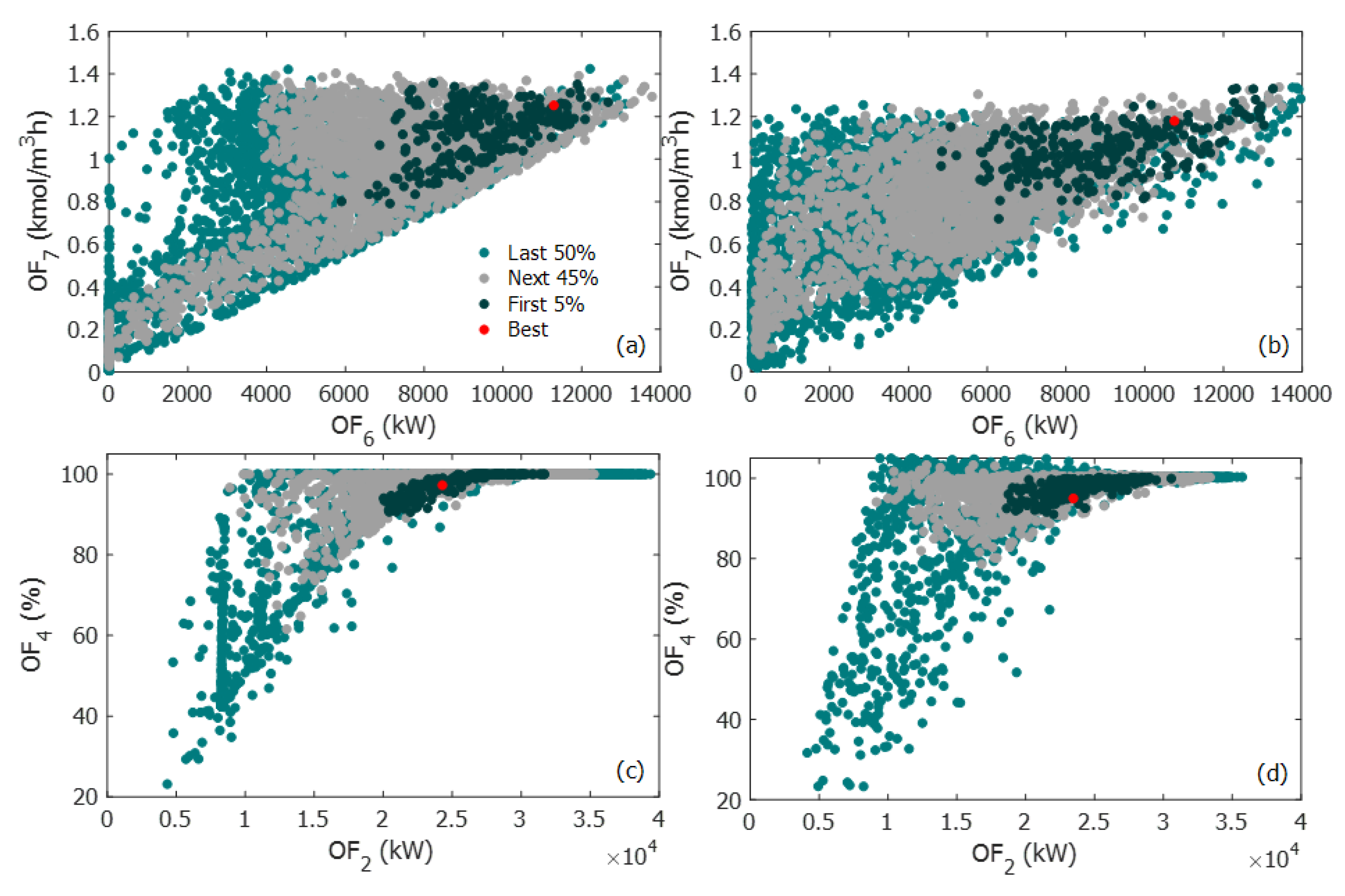
Figure 8a,b present the Pareto domain projected on the two-dimensional space of the productivity of acrylic acid (OF
7) and the heat recovery of the second reactor (OF
6), while
Figure 8c,d present the projection on the plane of the conversion of propylene (OF
4) and heat recovery of the first reactor (OF
2). Based on the NFM ranking, the Pareto domain was divided into four different regions: (i) the best solution in red; (ii) Pareto-optimal solutions ranked in the top 5%; (iii) solutions in the next 45%; and (iv) the remaining 50% of the solutions. The best ranked solution of
Figure 8b corresponds to a productivity of 1.179 kmol/m
3h and a heat recovery of 10,755 kW in the second reactor. When the values of the decision variables, associated with the best-ranked Pareto-optimal solution, were used within the first-principle based model for comparison purposes, the values for OF
7 and OF
6 were 1.202 kmol/m
3h and 11,104 kW, respectively, yielding errors in the vicinity of 2%–3%. This was also the case for the other objective functions, as shown in
Table 4. When the phenomenological model is used to circumscribe the Pareto domain and then Pareto-optimal solutions are ranked with NFM, as depicted by
Figure 8a, values of 1.2524 kmol/m
3h and 11 291 kW were obtained for OF
7 and OF
6, respectively, for differences of approximately 7% and 5%. The corresponding conversion in R-100 of the best ranked solution was 94.97% and 97.27% for the meta-model and the phenomenological model, respectively, as shown in
Figure 8c,d. In contrast, a conversion of 96.25% was predicted when the decision variables of the best-ranked solution identified with the ANNs were used in the first-principle based model.
The Pareto domains generated with the phenomenological and surrogate models were very similar, as illustrated in
Figure 8. Occasionally, some minor differences between the two Pareto domains occurred. For instance, there is a small region in
Figure 8a that is empty, whereas the same region is covered in
Figure 8b. Fortunately, it was observed in this investigation that these discrepancies very often appear in regions where Pareto-optimal solutions are ranked relatively low. These discrepancies were usually due to the inability of the neural network to recognize intrinsic constraints embedded in the code of the first-principle based model and that restricts the operation within those limits. As ANNs are built from experimental data of the model, it will not be possible for the meta-model to explicitly handle the constraints, unless they are treated as soft constraints as was the case for the oxygen concentration. In lieu, it filled the empty region by interpolating the data that is provided to train the ANNs. The best ranked solution as well as the first 5% of the Pareto-optimal solutions were well identified by the meta-model.
The similarity of the Pareto domains (
Figure 8) obtained using the phenomenological and surrogate models is a clear indication that the ANNs were able to adequately predict the existing relationship between the decision variables and the objective functions. To make a more complete comparison between the two Pareto domains, the decision variables and the objective functions of the best-ranked solution of the surrogate model were normalized with respect to the best-ranked solution obtained with the phenomenological model, where a value of one was assigned to the latter. The normalized variables are presented in
Figure 9a,b. These results clearly show that the use of a surrogate model to perform the MOO is a viable solution, as the great majority of the decision variables and objective functions were very close to the best ranked solution of the phenomenological model. The steam flowrate input was the only variable that has an error above 10%, meaning that using the values obtained from the meta-model will result in 20% more steam usage that what would be required if the first-principle based model was used.
In order to compare the resulting solution using the weighted sum method instead, the results of the Pareto domain were used to determine the optimal solution that, as explained earlier, will be a single point in the feasible region for a SOO. All the objectives were assigned a weight of 0.1, except for OF
3 and OF
7 which were assigned a weight of 0.15. The resulting optimal solution corresponded to a solution ranked in the top 5% when using the NFM method, more specifically the solution ranked 232th out of 5000. The values of the objective functions of this solution are presented in
Table 5.
The computation time required to circumscribe the Pareto domain via the surrogate model was 38 s. On the other hand, to obtain the Pareto domain optimizing for the reactor section using the first-principle model took 558 s, which means that the optimization process was 15.5 times faster using the ANNs. In this particular instance, one simulation with the first-principle model was relatively fast. In other problems, it may take many days of computation time to obtain a sufficient number of Pareto-optimal solutions, and this is where the methodology proposed in this work would greatly benefit. In addition, once the surrogate model is ready, it also allows a large number of optimization scenarios to be rapidly analyzed. Even if small changes were to be made, the ANN could easily adapt to those changes.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








