
Time Series-Based Edge Resource Prediction and Parallel Optimal Task Allocation in Mobile Edge Computing Environment
 ,
,  and
and
Abstract
:1. Introduction
- (i)
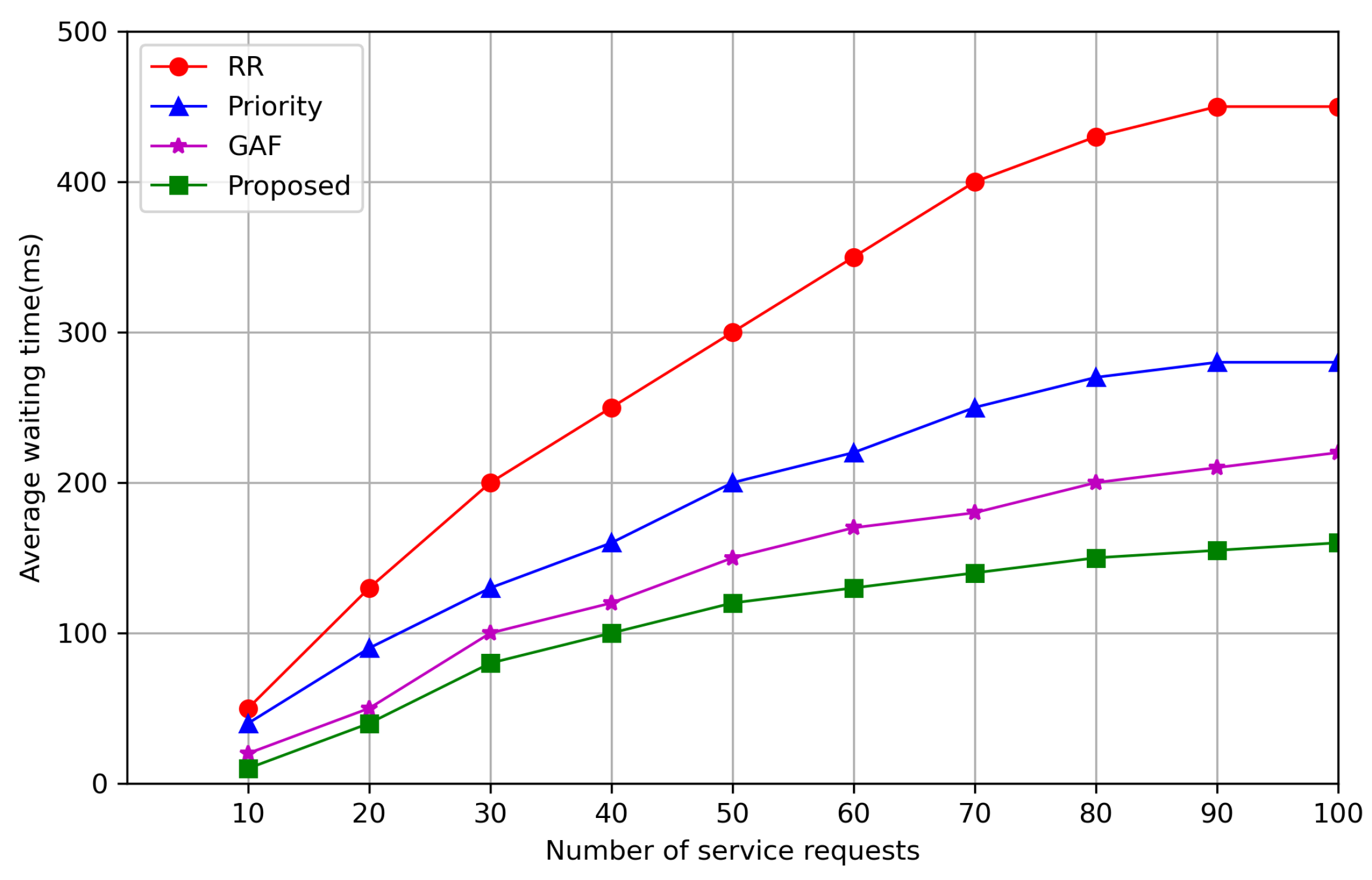
- A delay sensitivity-based priority scheduling (DSPS) policy is presented to schedule the tasks as per their deadline.
- (ii)
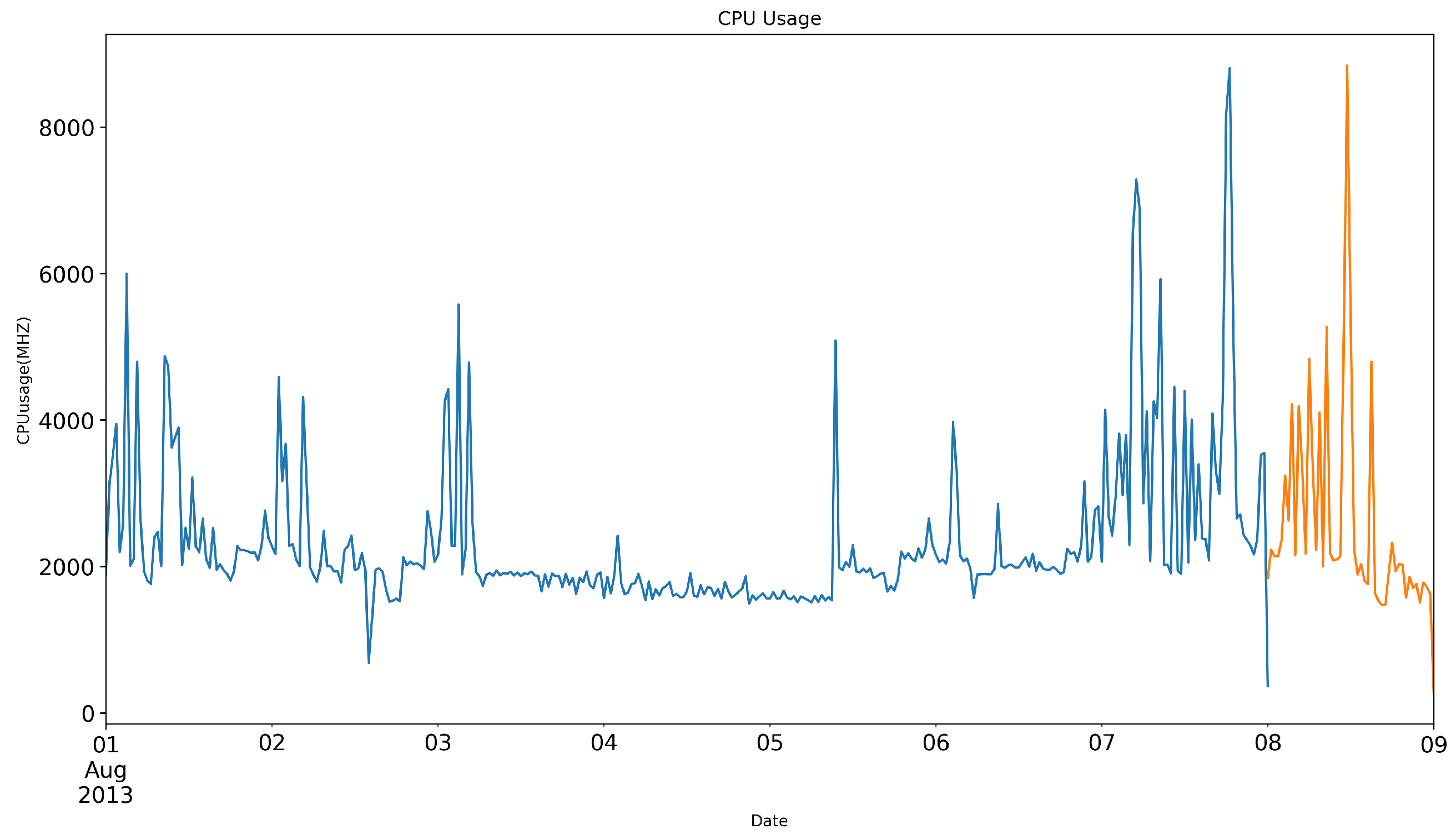
- An exploratory data analysis is carried out, and inference is made regarding seasonal patterns in the usage of edge CPU resources from the GWA-T-12 Bitbrains VM utilization dataset.
- (iii)
- The availability of VM resources is predicted by using HWVMR and VARVMR.
- (iv)
- For optimal and fast task assignment, a parallel differential evolution-based task allocation (pDETA) strategy is proposed.
- (v)
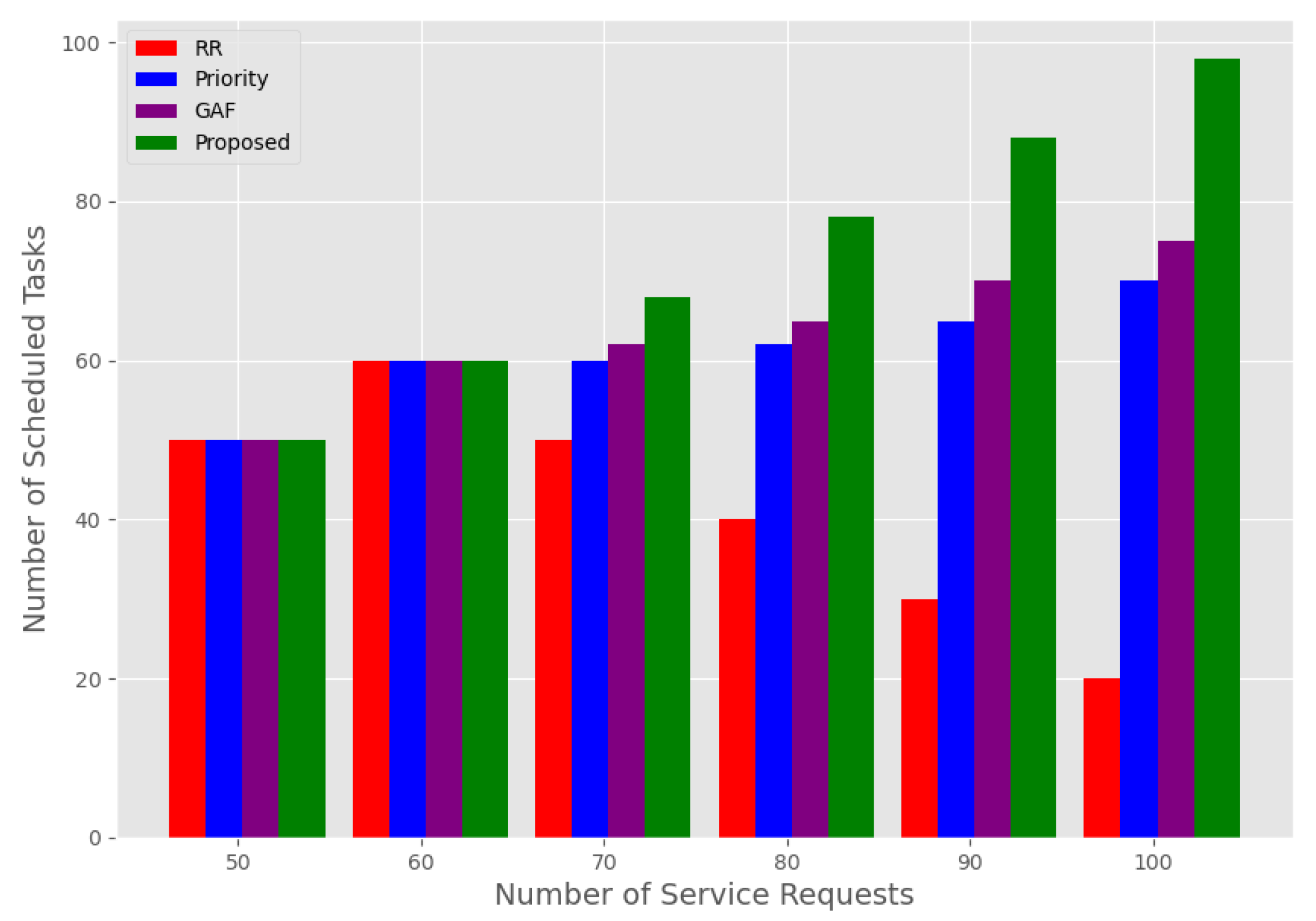
- The proposed algorithms are evaluated extensively by using standard performance metrics, e.g., execution time, cost, and energy.
2. Related Work
3. System Model
3.1. Task Model
3.2. VM Model
3.3. Cost Model
3.4. Energy Model
3.5. Load Model
4. Problem Formulation
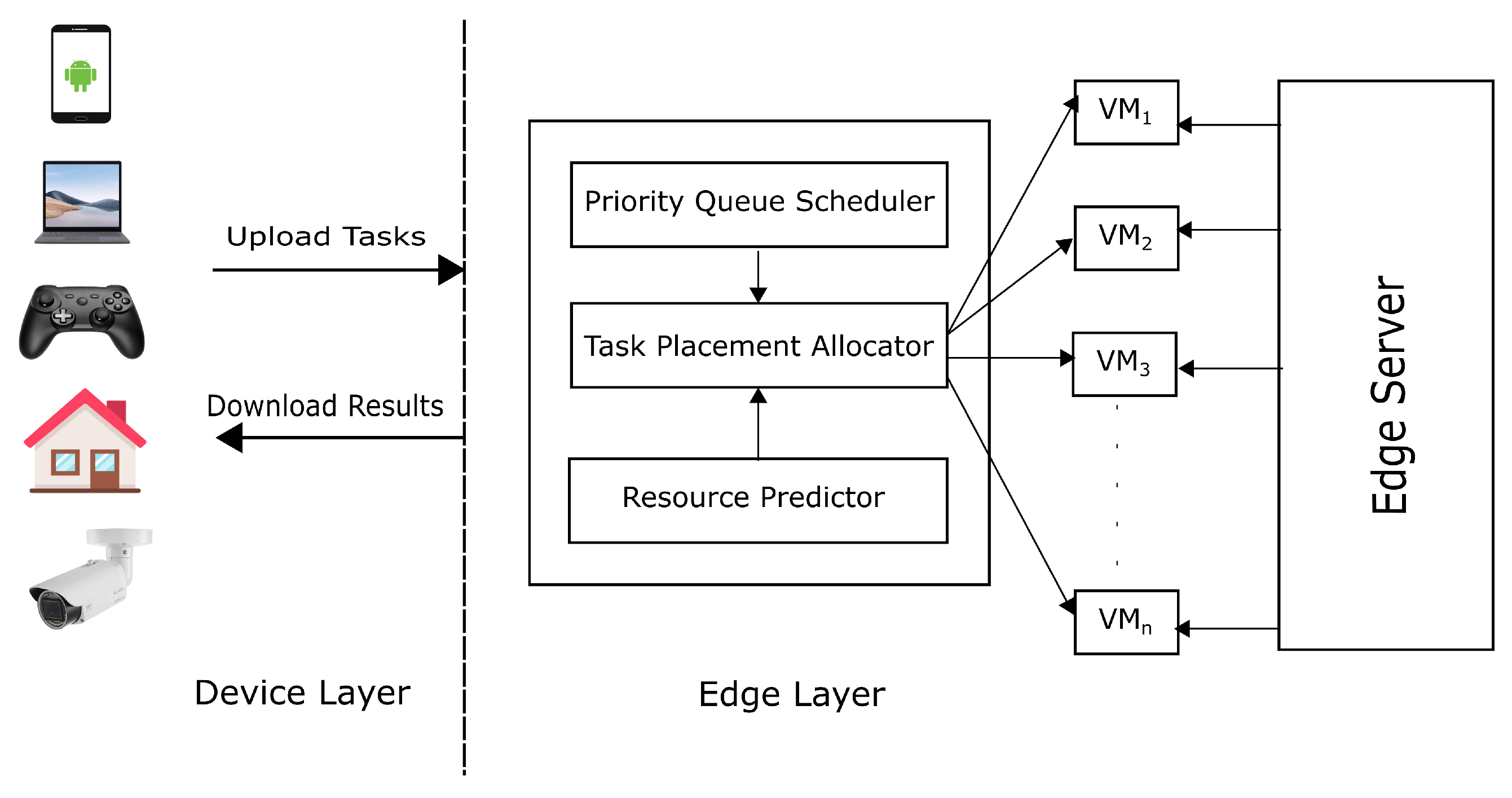
5. Network Architecture
| Algorithm 1: Delay sensitivity-based priority scheduling (DSPS) |
 |
| Algorithm 2: Holt–Winters-based univariate algorithm (HWVMR) |
 |
| Algorithm 3: VAR-based multivariate algorithm (VARVMR) |
 |
| Algorithm 4: Parallel differential evolution-based task allocation (pDETA) |
 |
6. Proposed Methodologies
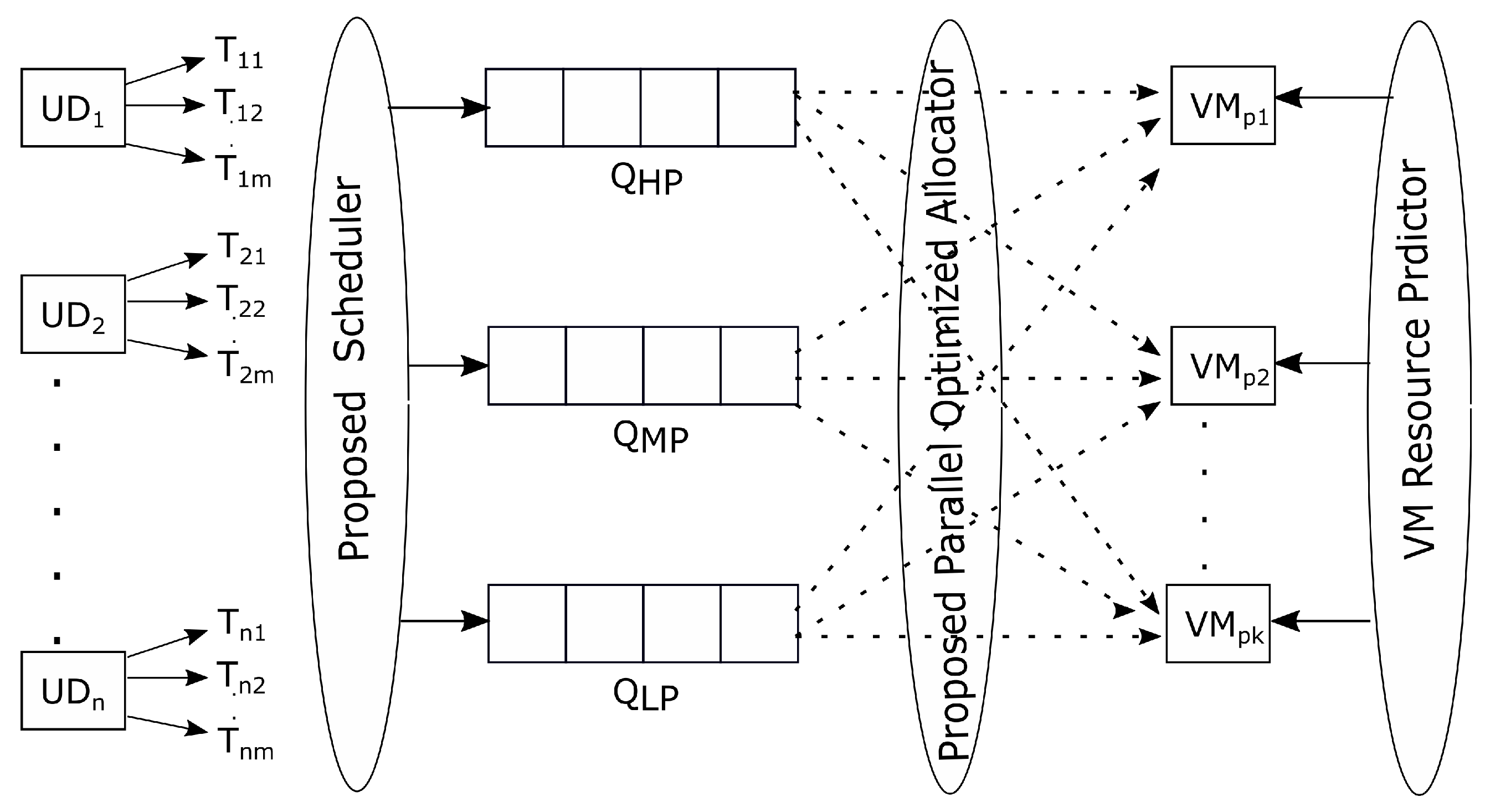
6.1. Delay Sensitivity-Based Priority Scheduler
- , the task is placed in .
- , the task is placed in .
- , the task is placed in .
6.2. Time Series-Based VM Resource Predictor
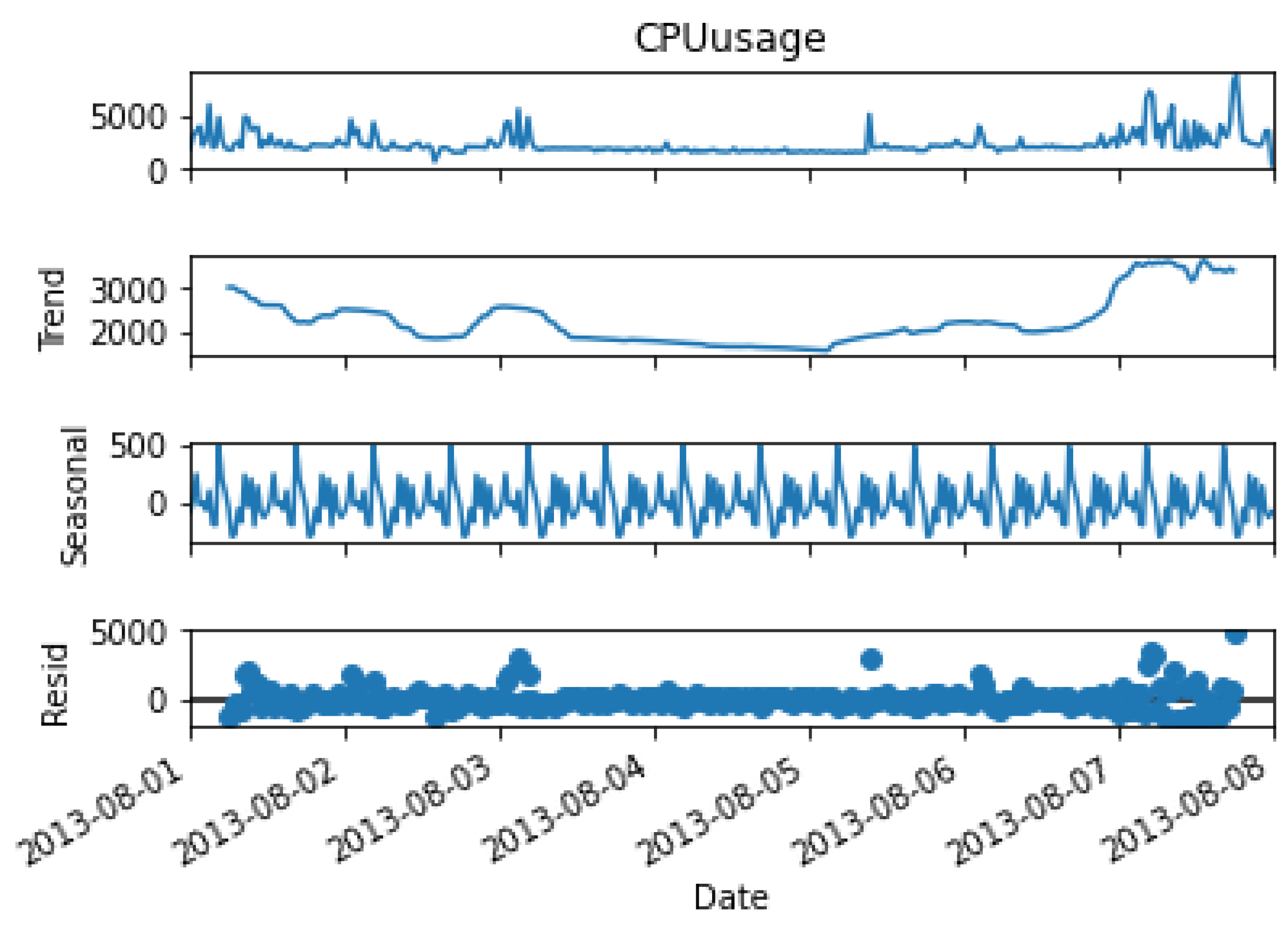
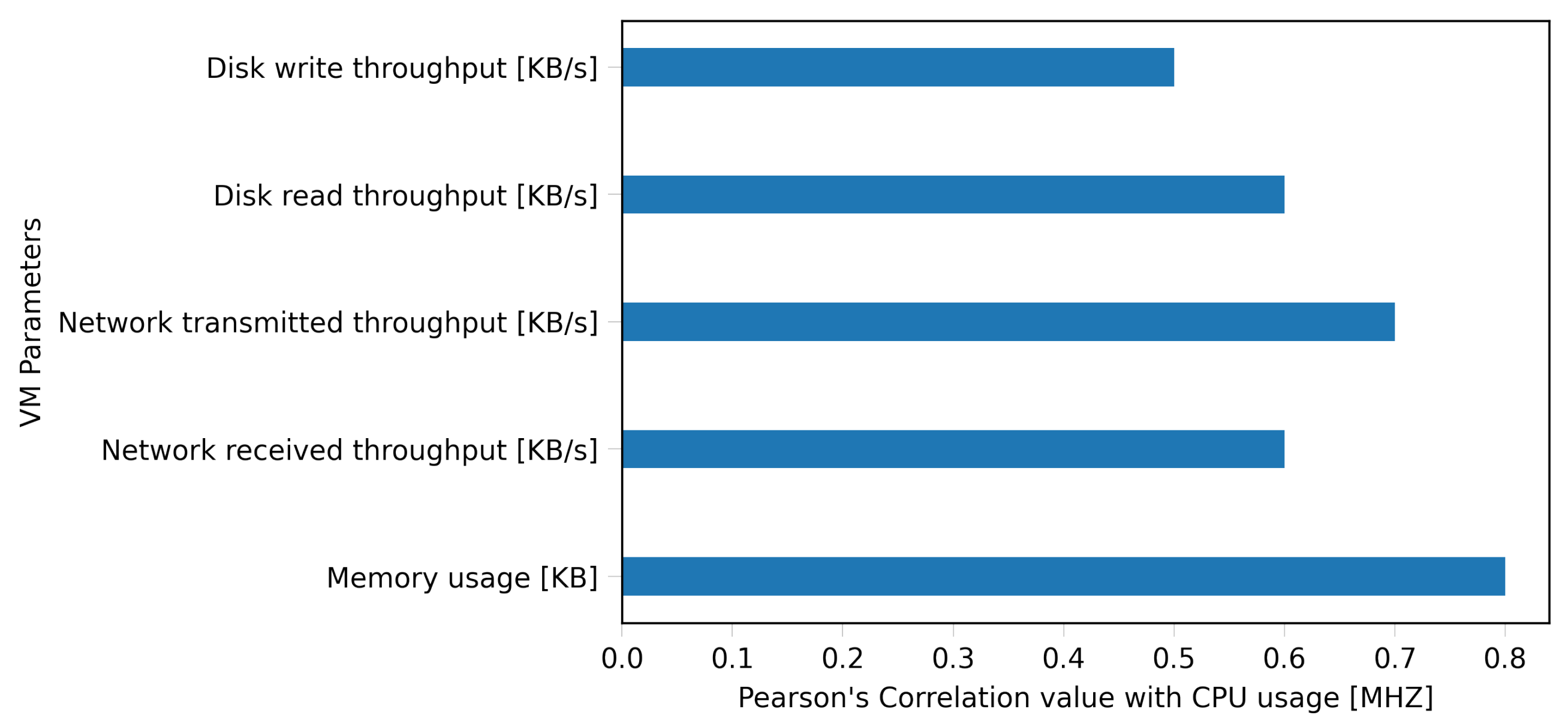
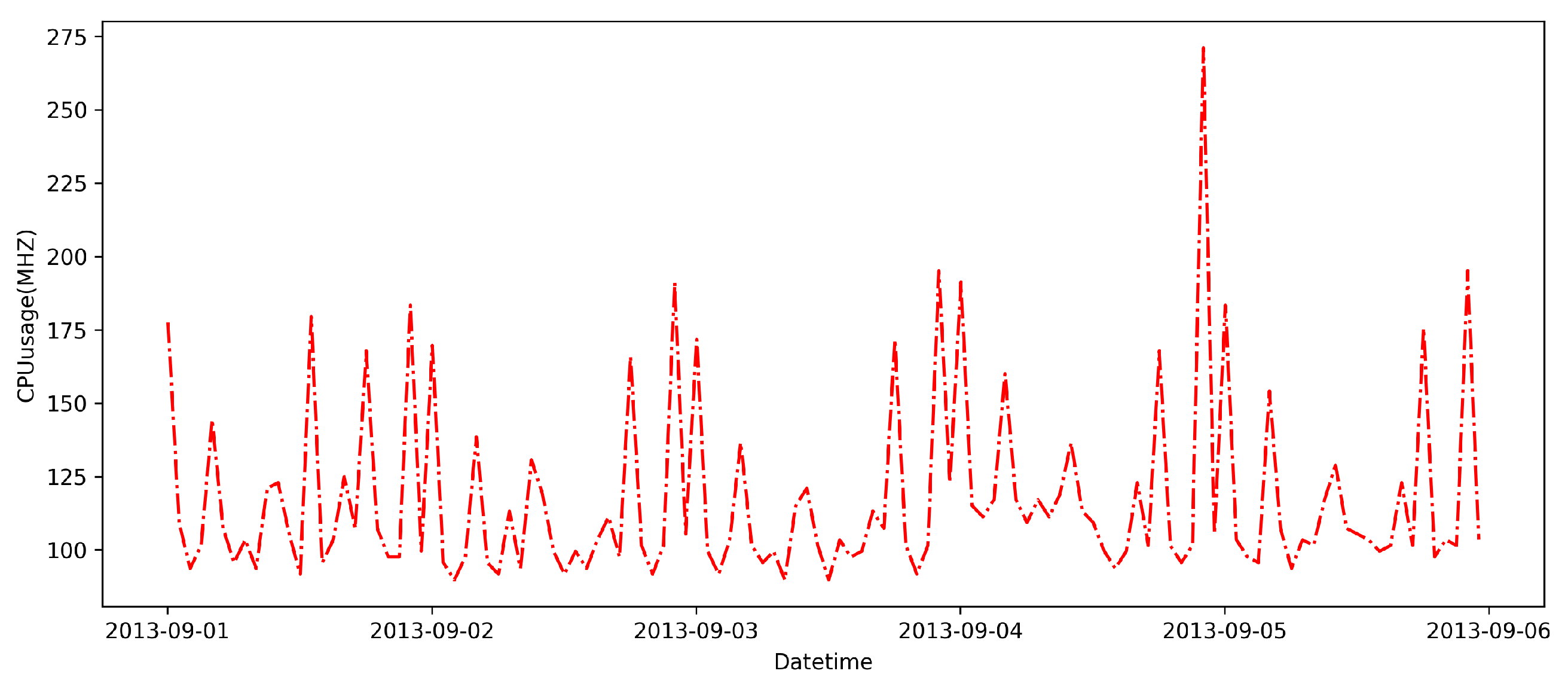
6.2.1. Exploratory Analysis of Resource Prediction
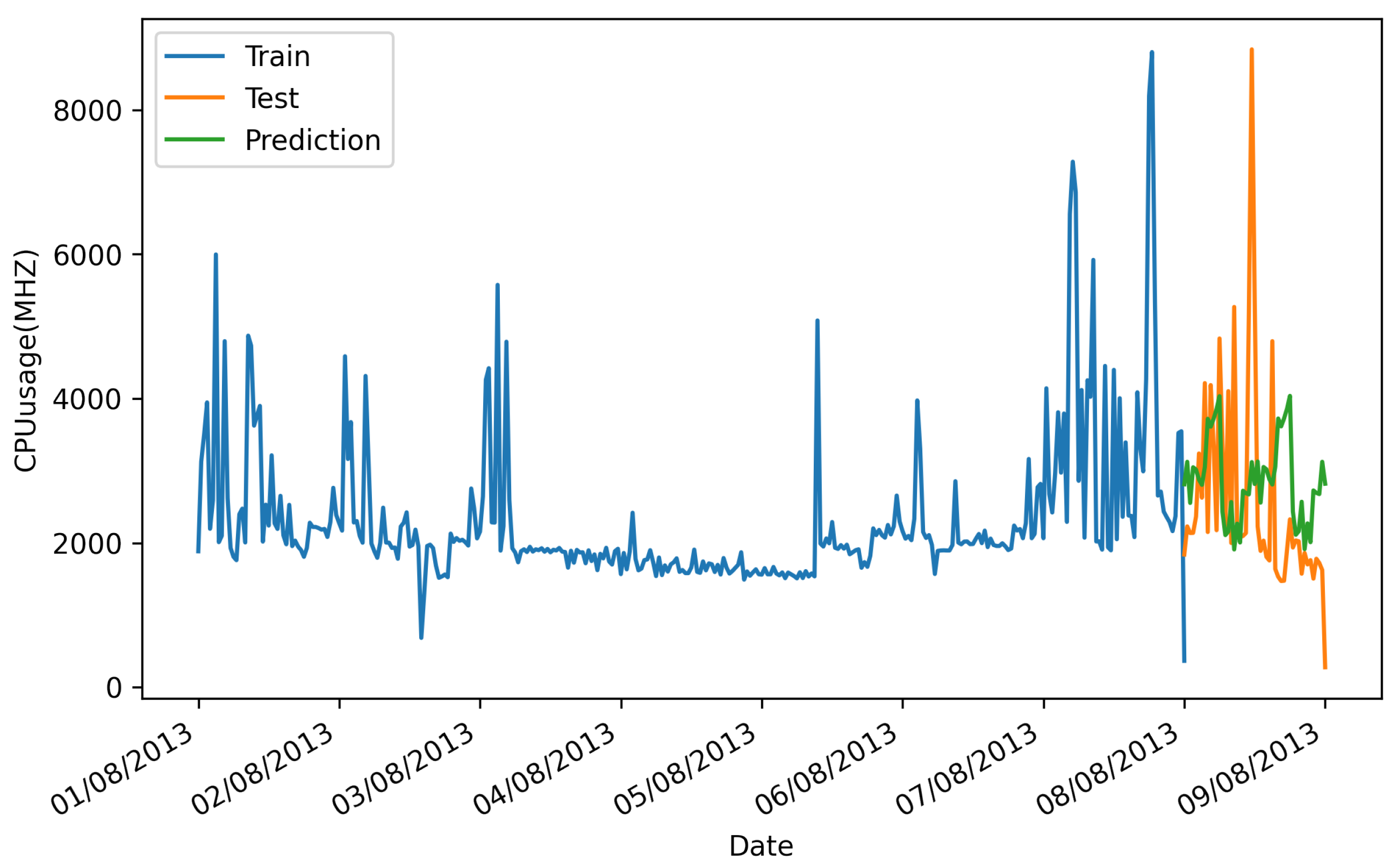
6.2.2. Applied Holt–Winters-Based Resource Prediction
6.2.3. Applied VAR Based Resource Prediction
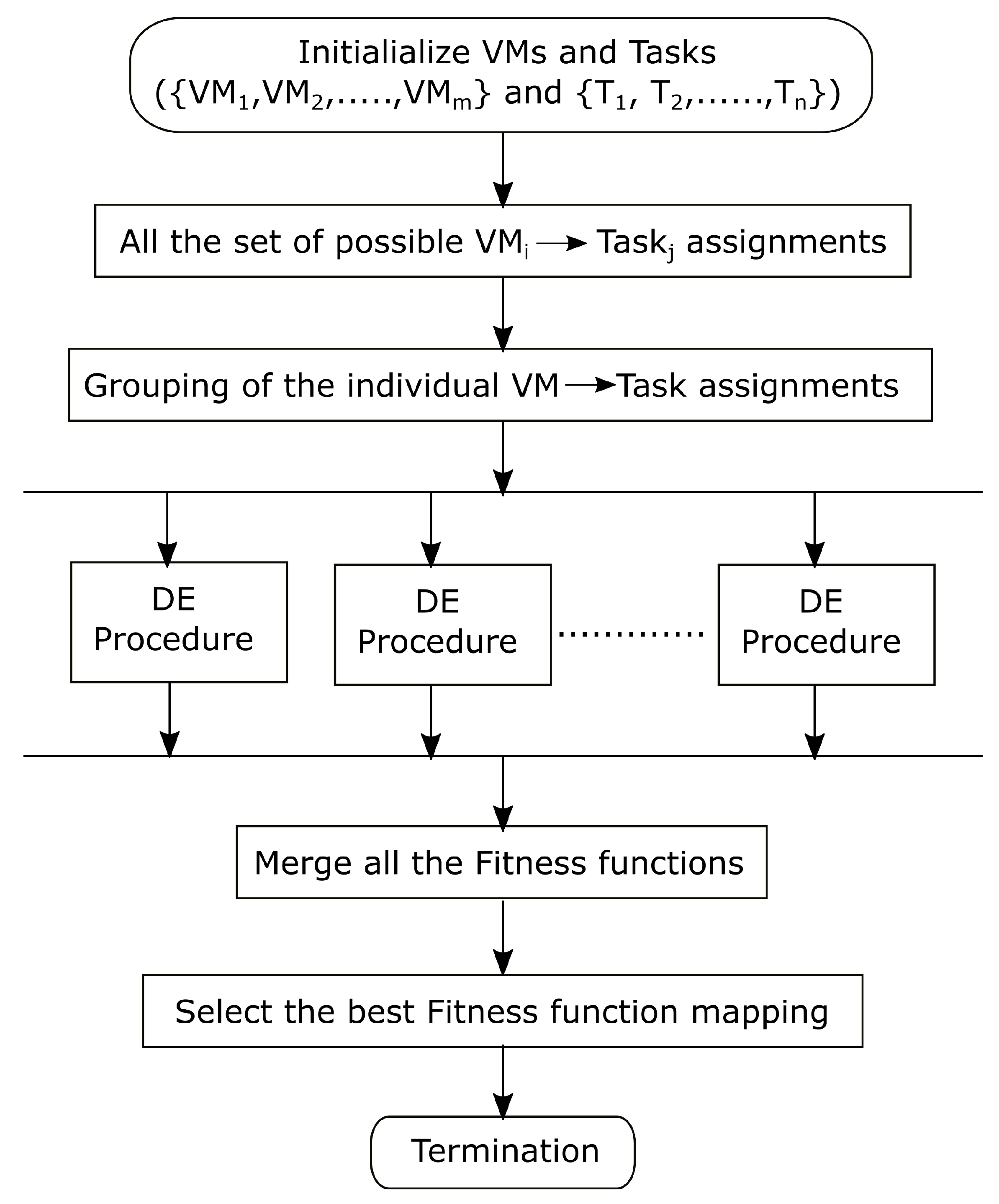
6.3. Parallel Optimal Allocator
6.3.1. Finding Suitable VM by Using Minkowski Distance
6.3.2. Parallel Differential Evolution Algorithm
- Problem definition: Our aim is to assign the task to a suitable predicted VM from the predicted VM lists with the optimum allocation of resources considering minimum distance by applying Equation (22). The mapping of the available VM resources with the required task resources. Here, the resources are CPU usage and memory usage for the VMs and tasks. The task is assigned to the VM only when the following equation will be satisfied:
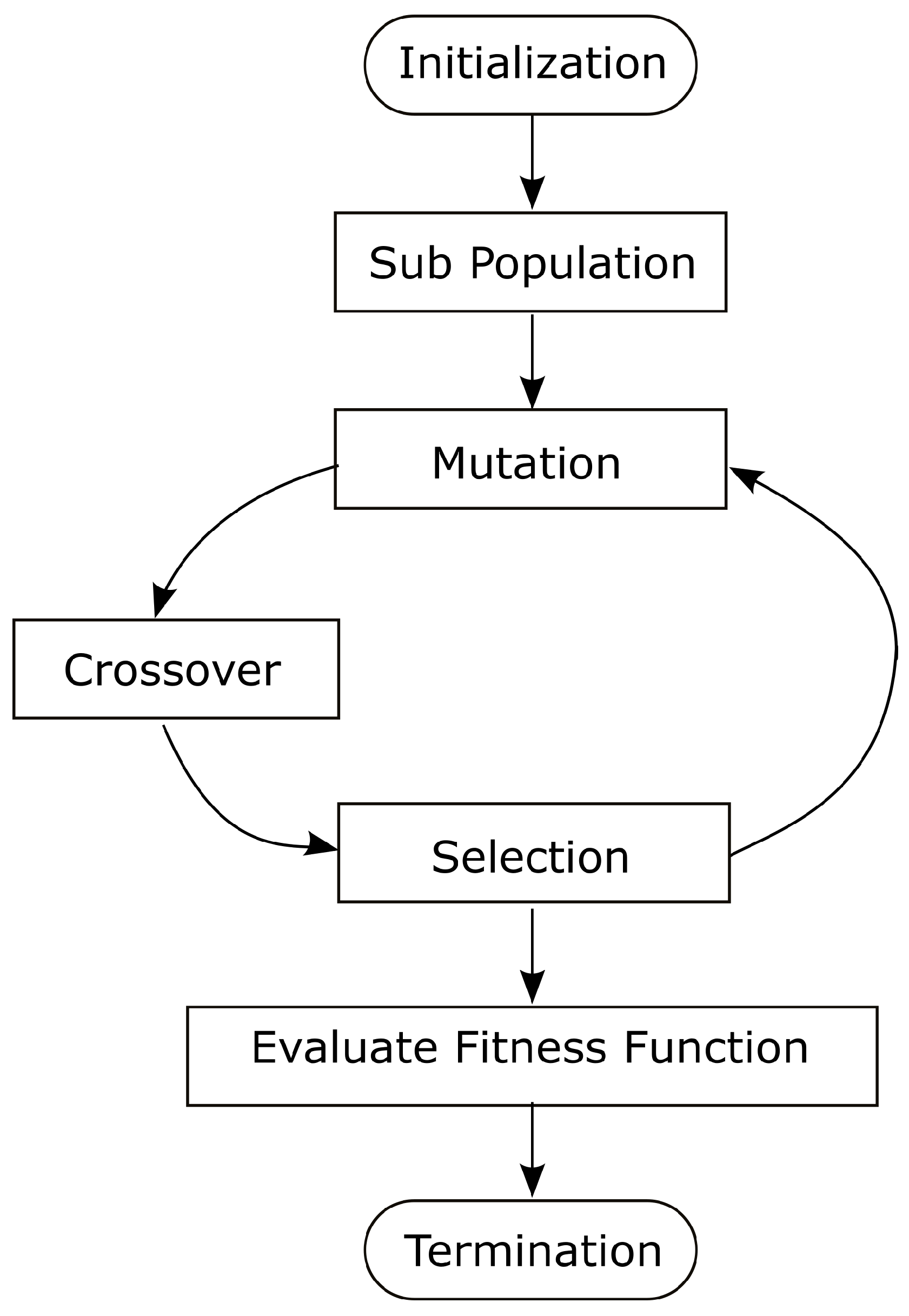
- Problem parameters: The population size (N) is , the dimension of the problem (D) is 4, the stopping criteria (maximum number of iterations) is set to 5, the scaling factor (F) is 0.5, and the crossover probability is 0.7. The value of the scaling factor is inversely proportional to the local search ability, so we have considered a minimum value for the scaling factor, i.e., 0.5 to become strong in the local search algorithm.Figure 9. Differential evolution procedure.
![Processes 11 01017 g009]()
- Initialization: Based on , the number of initial solutions are obtained by satisfying the problem definition. Here, all the possible assignments take place and discover the best solution having minimum result by applying Equation (22).
- Differential evolution position update: Here we have considered the suitable strategy as DE/Best/1/2 for binomial crossover based on two randomly assigned pairs. The generations are formed based on the above procedure. Here, we have discussed the process followed in one generation.
- Chromosome formation: In the beginning, we assign the predicted VM resources from the set of , , ……, with the set of requested tasks available in the priority scheduled queues. The active tasks will become 1, and the inactive tasks will become 0 in the different task sets present in the chromosome. The chromosome is represented in Figure 10.Figure 10. Representation of chromosome.
![Processes 11 01017 g010]()
- Population: We collect all the chromosomes, and make them ready for the parallel computation of the individual population by using the differential evolution algorithm.
- Subpopulation: We consider a single population for finding the fitness function until the termination condition arrives. Here, the subpopulations are implemented in parallel to finding the fitness function for an individual one.
- Fitness function: This refers to the calculation of the computation time, cost, and energy required for the computation in edge resources.The best fitness function = {, , }.
- Mutation: The predicted VM resource is assigned with the possible set of requested tasks from the priority scheduled queues. The output of the mutation module is the input to the crossover module. Once the single output is released to the crossover module for the individual assignment, the mutation module is ready with the next possible assignment of the task to the VM resource. The best suitable mutation strategy is the “DE/Best/1/2” aswhere is the best solution produced during the initialization process, and are the random solutions selected from the population, and , F is a scaling factor, and is mutant donor vector.
- Crossover: The crossover method increases the diversity of the population. This module is ready for the calculation of the fitness function for the input to the mutation module. The crossover method is shown below,where is the ith variable of the trial vector, is the ith variable of the donor vector, is the ith variable of the target vector, r is the random number between 0 and 1, is the crossover probability, is the randomly selected variable location, and {1, 2, 3, …, D}.
- Selection: This module selects the best mapping of the predicted VM resource with the requested task by applying Equation (22). It takes the output of the crossover module and finds the best fitness function for the selection of the task placement of the individual subpopulation.
- Termination: The termination condition arrives when we obtained the best fitness function with the minimum computation time, cost, and energy after merging all the fitness functions calculated from the individual subpopulations. After the termination condition was reached, we obtained the optimized placement of the requested task in the VM.



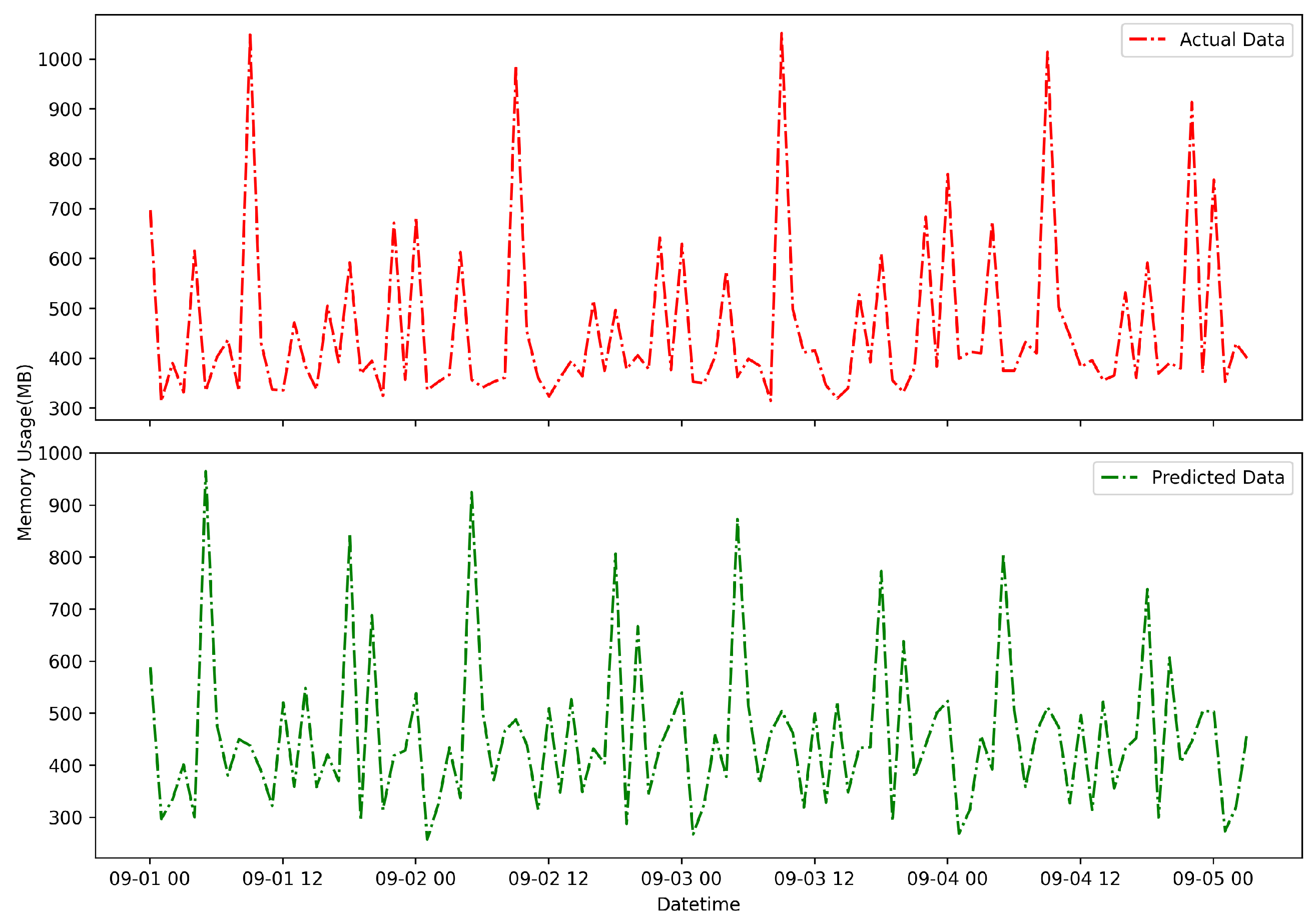
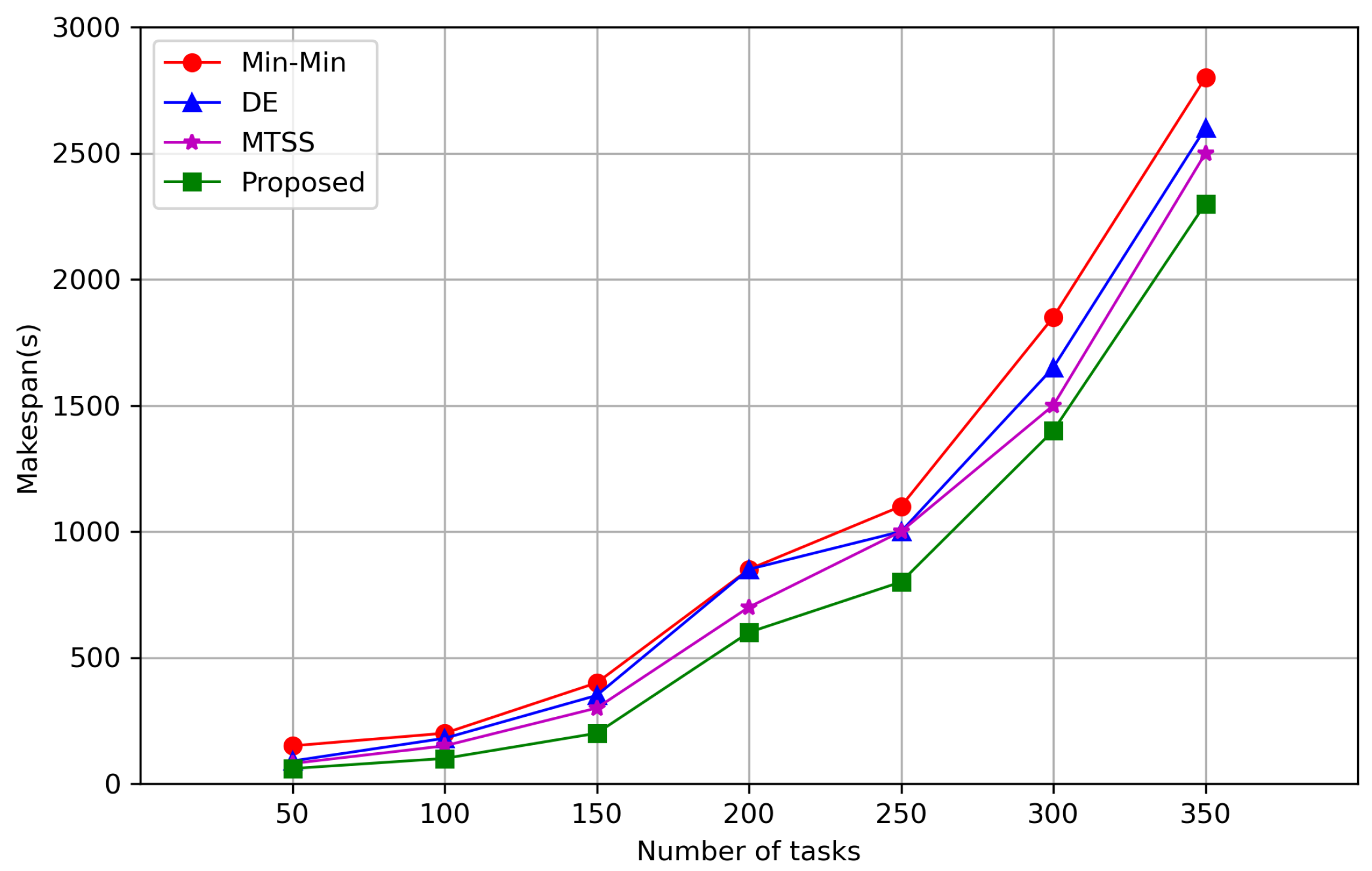
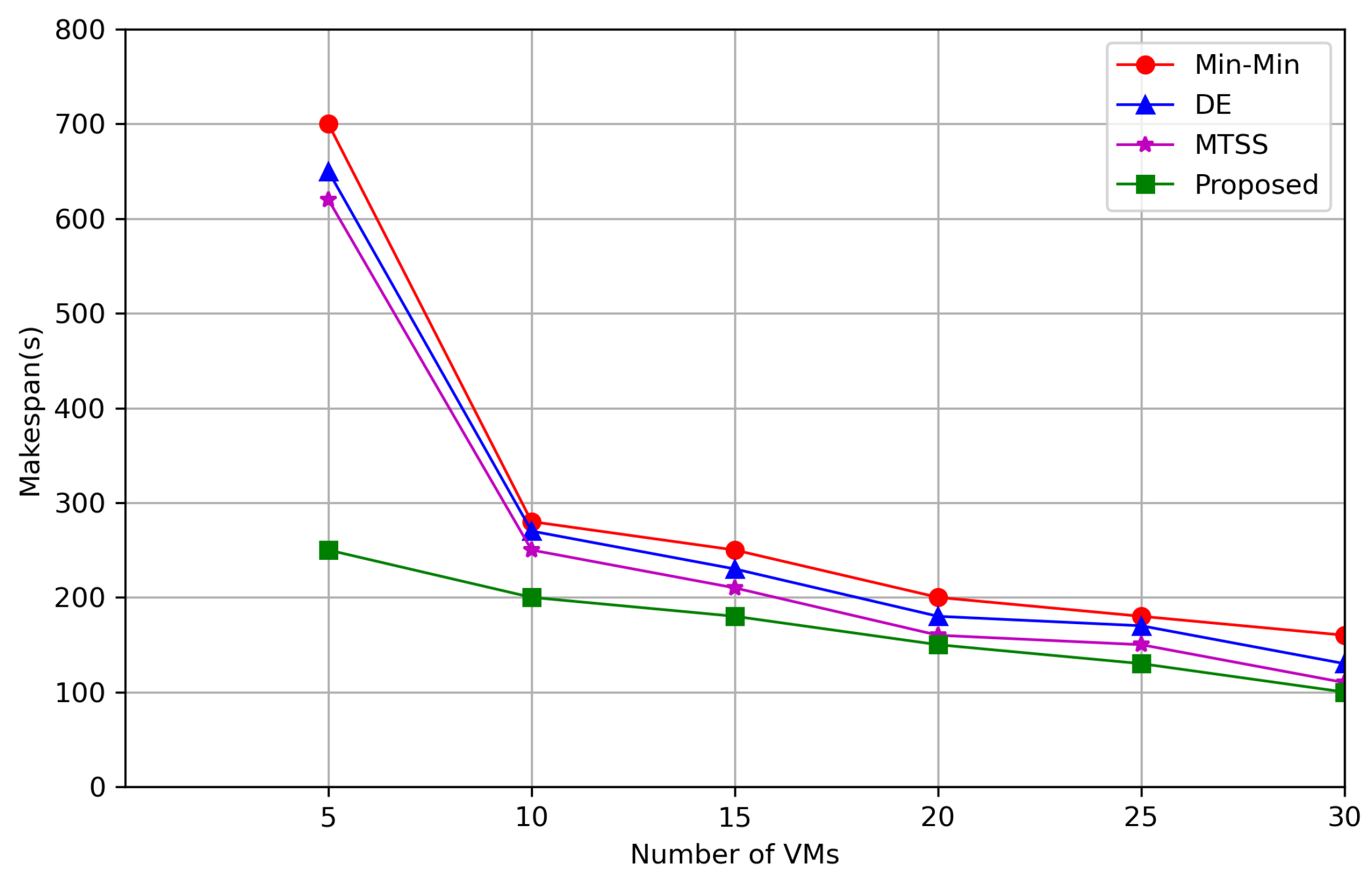
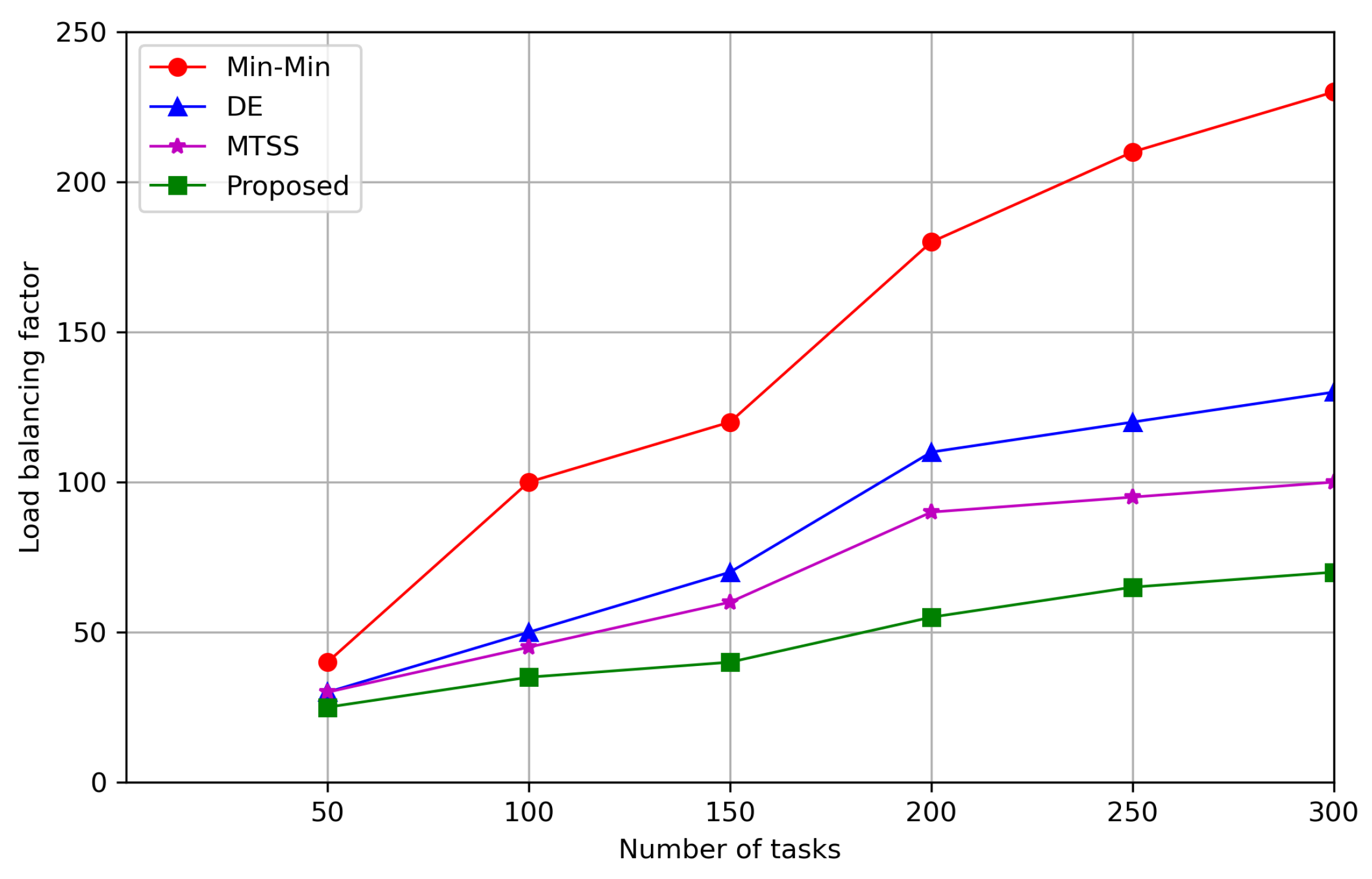
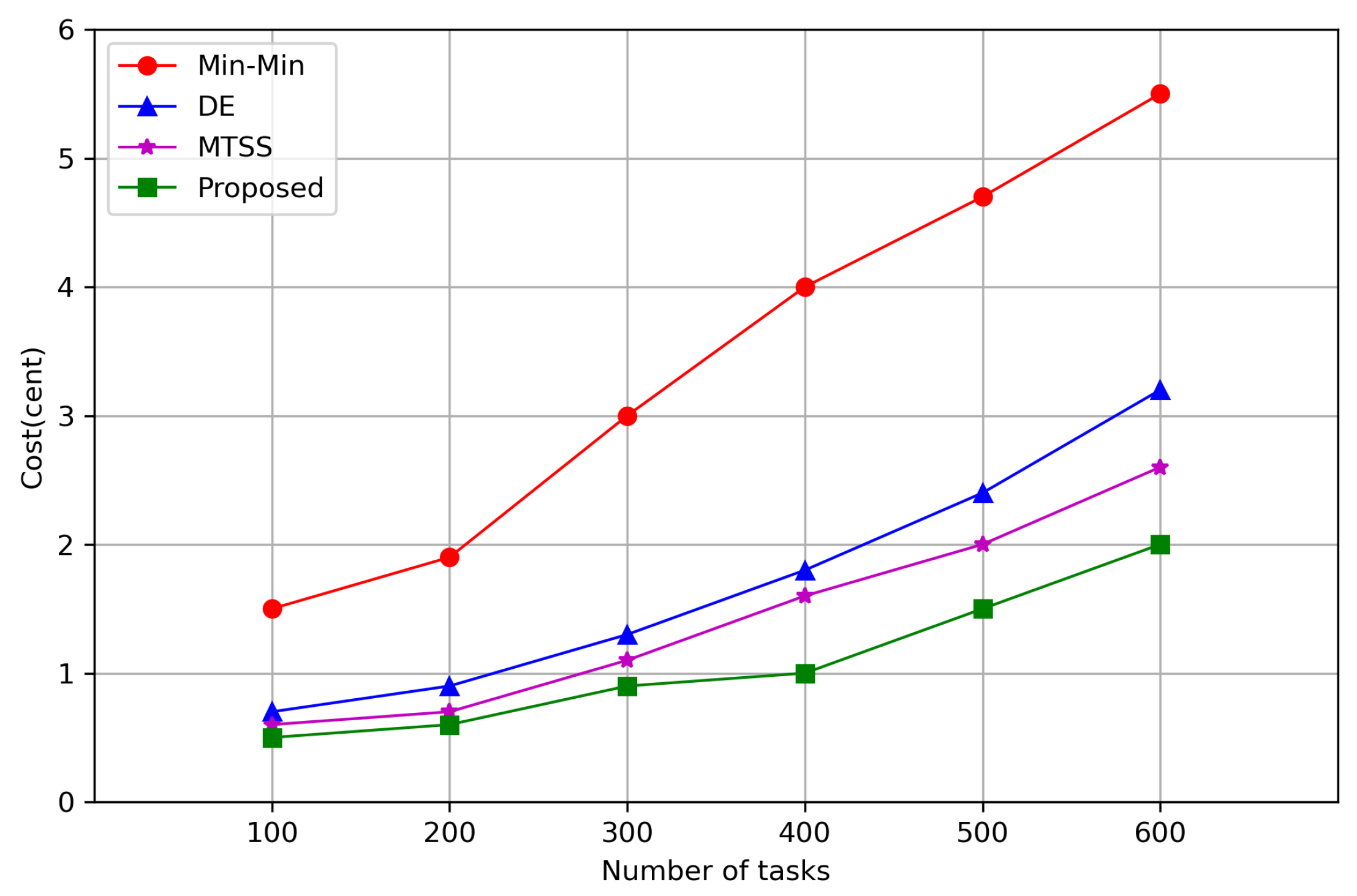
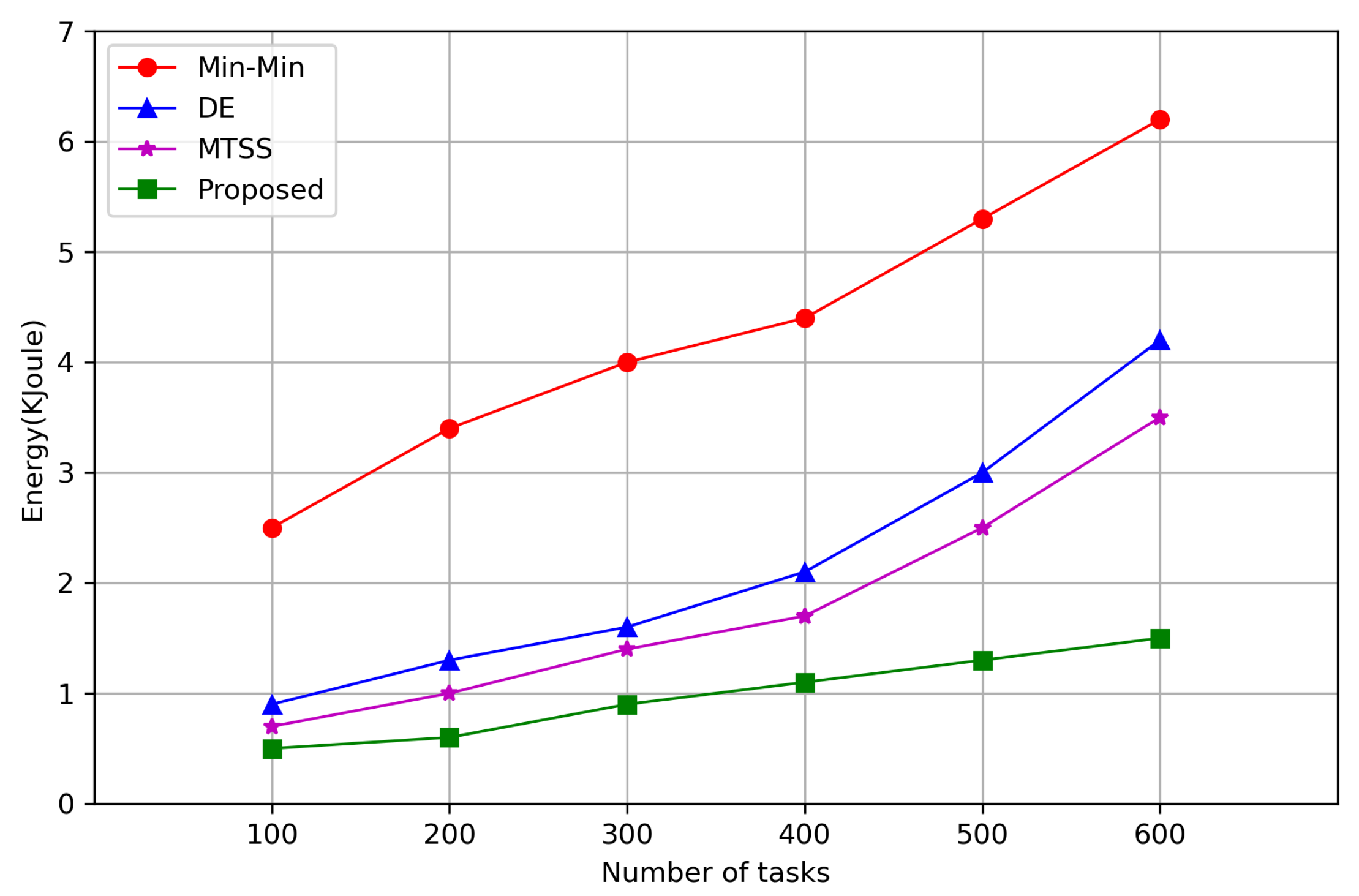
7. Simulation Results
8. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| T | Task |
| VM | Virtual machine resource |
| High-priority queue | |
| Medium-priority queue | |
| Low-priority queue | |
| High-priority task | |
| Medium-priority task | |
| Low-priority task | |
| Delay of the task | |
| Delay sensitivity of the task | |
| Estimation time of the service request | |
| Threshold value | |
| Predicted VM | |
| Sorted VM | |
| t | Time period |
| Computation time of the task | |
| Level at time t | |
| Level at time t−1 | |
| Trend at time t | |
| Trend at time t−1 | |
| Season at time t | |
| Season at time t−1 | |
| Forecasting at time t+1 | |
| Forecasting at time t+k | |
| Data at time t |
References
- Abdullah, A.; Ibrahim, E.; Muthanna, A.; Alghamdi, A.; Mohammed, A.; Adel, A. Efficient multi-player computation offloading for VR edge-cloud computing systems. Appl. Sci. 2020, 10, 5515. [Google Scholar]
- Kai, P.; Peichen, L.; Tao, H. A privacy-aware computation offloading method for virtual reality application. CEUR Workshop Proc. 2021, 3052. [Google Scholar]
- Ke, Z.; Yuming, M.; Supeng, L.; Quanxin, Z.; Longjiang, L.; Xin, P.; Li, P.; Sabita, M.; Yan, Z. Energy-efficient offloading for mobile edge computing in 5g heterogeneous networks. IEEE Access 2016, 4, 5896–5907. [Google Scholar]
- Jinke, R.; Guanding, Y.; Yunlong, C.; Yinghui, H. Latency optimization for resource allocation in mobile-edge computation offloading. IEEE Trans. Wirel. Commun. 2018, 17, 5506–5519. [Google Scholar]
- Mian, G.; Mithun, M.; Gen, L.; Jinyou, Z. Computation offloading for machine learning in industrial environments. In Proceedings of the IECON 2020 The 46th Annual Conference of the IEEE Industrial Electronics Society, Singapore, 18–21 October 2020; pp. 4465–4470. [Google Scholar]
- Juan, F.; Jiamei, S.; Shuaibing, L.; Mengyuan, Z.; Zhiyuan, Y. An efficient computation offloading strategy with mobile edge computing for IoT. Micromachines 2021, 12, 204. [Google Scholar]
- Sharma, V.; Rai, V.P.; Sharma, K.K. Edge computing: Needs, concerns and challenges. Int. J. Sci. Eng. Res. 2017, 8, 154–166. [Google Scholar]
- Junaid, Q.; Beatriz, S.-D.-A.; Anwar, K.; Begoña, G.-Z.; Isabel, D.L.T.-D.; Hasan, M. Towards mobile edge computing: Taxonomy, challenges, applications and future realms. IEEE Access 2020, 8, 189129–189162. [Google Scholar]
- Huaming, W.; William, K.; Katinka, W. An efficient application partitioning algorithm in mobile environments. IEEE Trans. Parallel Distrib. Syst. 2019, 30, 1464–1480. [Google Scholar]
- Delowar, H.M.; Tangina, S.; Alamgir, H.M.; Imtiaz, H.M.; Junyoung, H.L.N.P.; Nam, H.E. Fuzzy decision-based efficient task offloading management scheme in multi-tier MEC-enabled networks. Sensors 2021, 21, 1–26. [Google Scholar]
- Jiuyun, X.; Zhuangyuan, H.; Xiaoting, S. Optimal offloading decision strategies and their influence analysis of mobile edge computing. Sensors 2019, 19, 3231. [Google Scholar]
- Jun, C.; Dejun, G. Research on task-offloading decision mechanism in mo- bile edge computing-based internet of vehicle. Eurasip J. Wirel. Commun. Netw. 2021, 2021, 1–14. [Google Scholar]
- Changsheng, Y.; Kaibin, H.; Hyukjin, C.; Byoung-Hoon, K. Energy-efficient resource allocation for mobile-edge computation offloading. IEEE Trans. Wirel. Commun. 2017, 16, 1397–1411. [Google Scholar]
- Xihan, C.; Yunlong, C.; Liyan, L.; Minjian, Z.; Benoit, C.; Lajos, H. Energy-efficient resource allocation for latency-sensitive mobile edge computing. IEEE Trans. Veh. Technol. 2020, 69, 2246–2262. [Google Scholar]
- Jiadai, W.; Lei, Z.; Jiajia, L.; Nei, K. Smart resource allocation for mobile edge computing: A deep reinforcement learning approach. IEEE Trans. Emerg. Top. Comput. 2021, 9, 1529–1541. [Google Scholar]
- Deng, X.; Li, J.; Liu, E.; Zhang, H. Task allocation algorithm and optimization model on edge collaboration. J. Syst. Archit. 2020, 110, 1–12. [Google Scholar] [CrossRef]
- The Grid Workloads Gwa-t-12 Bitbrains. Available online: http://gwa.ewi.tudelft.nl/datasets (accessed on 27 September 2022).
- Zeyi, T.; Qi, X.; Zijiang, H.; Cheng, L.; Lele, M.; Shanhe, Y.; Qun, L. A survey of virtual machine management in edge computing. Proc. IEEE 2019, 107, 1482–1499. [Google Scholar]
- Sun, L.; Li, Z.; Lv, J.; Wang, C.; Wang, Y.; Chen, L.; He, D. Edge computing task scheduling strategy based on load balancing. MATEC Web Conf. 2020, 309, 3025. [Google Scholar] [CrossRef] [Green Version]
- Hansun, S.; Charles, V.; Indrati, C.R.; Saleh, S.S. Revisiting the holt-winters’ additive method for better forecasting. Int. J. Enterp. Inf. Syst. 2019, 15, 43–57. [Google Scholar] [CrossRef]
- Shahin, A.A. Using Multiple Seasonal Holt-Winters Exponential Smoothing to Predict Cloud Resource Provisioning. Int. J. Adv. Comput. Sci. Appl. 2016, 7, 91–96. [Google Scholar]
- Sarikaa, S.; Niranjana, S.; Deepika, K.S.V. Time Series Forecasting of Cloud Resource Usage. In Proceedings of the 2021 IEEE 6th International Conference on Computing, Communication and Automation (ICCCA), Arad, Romania, 17–19 December 2021; pp. 372–382. [Google Scholar]
- Ouhame, S.; Hadi, Y. Multivariate workload prediction using Vector Autoregressive and Stacked LSTM models. In Proceedings of the ACM SMC Conference (SMC’19), ACM, Kenitra, Morocco, 28–29 March 2019; pp. 1–7. [Google Scholar]
- Tseng, C.W.; Tseng, F.H.; Yang, Y.T.; Liu, C.C.; Chou, L.D. Task Scheduling for Edge Computing with Agile VNFs On-Demand Service Model toward 5G and beyond. Wirel. Commun. Mob. Comput. 2018, 2018, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Z.; Li, F.; Yang, S. A Novel Resource Optimization Algorithm Based on Clustering and Improved Differential Evolution Strategy under a Cloud Environment. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2021, 20, 5. [Google Scholar] [CrossRef]
- Sardaraz, M.; Tahir, M. A parallel multi-objective genetic algorithm for scheduling scientific workflows in cloud computing. Int. J. Distrib. Sens. Netw. 2020, 16, 8. [Google Scholar] [CrossRef]
- Skorpil, V.; Oujezsky, V. Parallel genetic algorithms’ implementation using a scalable concurrent operation in python. Sensors 2022, 22, 2389. [Google Scholar] [CrossRef]
- Laili, Y.; Guo, F.; Ren, L.; Li, X.; Li, Y.; Zhang, L. Parallel scheduling of large-scale tasks for industrial cloud-edge collaboration. IEEE Internet Things J. 2021, 4662, 1–13. [Google Scholar] [CrossRef]
- Sun, Y.; Song, C.; Yu, S.; Liu, Y.; Pan, H.; Zeng, P. Energy-efficient task offloading based on differential evolution in edge computing system with energy harvesting. IEEE Access 2021, 9, 16383–16391. [Google Scholar] [CrossRef]
- Li, X.; Zeng, F.; Fang, G.; Huang, Y.; Tao, X. Load balancing edge server placement method with QoS requirements in wireless metropolitan area networks. IET Commun. 2020, 14, 3907–3916. [Google Scholar] [CrossRef]
- Guruprasad, H.S.; Dakshayini, M. An optimal model for priority based service scheduling policy for cloud computing environment. Int. J. Comput. Appl. 2011, 32, 975–8887. [Google Scholar]
- Tu, Y.; Chen, H.; Yan, L.; Zhou, X. Task offloading based on LSTM prediction and deep reinforcement learning for efficient edge computing in IoT. Future Internet 2022, 14, 30. [Google Scholar] [CrossRef]
- Rob, H.J.; Anne, K.B.; Ralph, S.D.; Simone, G. A state space framework for automatic forecasting using exponential smoothing methods. Int. J. Forecast. 2002, 18, 439–454. [Google Scholar]
- Prieto, O.J.; Alonso-González, C.J.; Rodríguez, J.J. Stacking for multivariate time series classification. Pattern Anal. Appl. 2015, 18, 297–312. [Google Scholar] [CrossRef]
- Dissanayake, B.; Hemachandra, O.; Lakshitha, N.; Haputhanthri, D.; Wijayasiri, A. A comparison of ARIMAX, VAR and LSTM on multivariate short-term traffic volume forecasting. In Proceedings of the 2021 28th Conference of Open Innovations Association, Moscow, Russia, 27–29 January 2021; pp. 564–570. [Google Scholar]
- Zoltan, B.; Laszlo, D.; Janos, A. Dynamic principal component analysis in multivariate time-series segmentation. Conserv. Inf. Evol. 2011, 1, 11–24. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Number of tasks | 50 to 600 |
| Size of the task | 2 to 20 GI |
| Number of VMs | 5 to 30 |
| VM processing speed | 10 GIPS |
| Latency–sensitivity | 0 to 10 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Behera, S.R.; Panigrahi, N.; Bhoi, S.K.; Sahoo, K.S.; Jhanjhi, N.Z.; Ghoniem, R.M. Time Series-Based Edge Resource Prediction and Parallel Optimal Task Allocation in Mobile Edge Computing Environment. Processes 2023, 11, 1017. https://doi.org/10.3390/pr11041017
Behera SR, Panigrahi N, Bhoi SK, Sahoo KS, Jhanjhi NZ, Ghoniem RM. Time Series-Based Edge Resource Prediction and Parallel Optimal Task Allocation in Mobile Edge Computing Environment. Processes. 2023; 11(4):1017. https://doi.org/10.3390/pr11041017
Chicago/Turabian StyleBehera, Sasmita Rani, Niranjan Panigrahi, Sourav Kumar Bhoi, Kshira Sagar Sahoo, N.Z. Jhanjhi, and Rania M. Ghoniem. 2023. "Time Series-Based Edge Resource Prediction and Parallel Optimal Task Allocation in Mobile Edge Computing Environment" Processes 11, no. 4: 1017. https://doi.org/10.3390/pr11041017