
A Robust Hammerstein-Wiener Model Identification Method for Highly Nonlinear Systems

Abstract
:1. Introduction
- Two parsimonious models with fewer parameters constructed to characterize the H-W system instead of an over-parametrization model, and a projection based LS iterative method is proposed to estimate all system parameters in a parallel fashion. The proposed method avoids the estimating extra parameters and a low rank approximation step in classical over-parametrization model based methods, which leads to improved results compared to existing over-parametrization model based methods, because that estimating extra parameters and performing low rank approximation may result into a degradation of the accuracy of the estimated quantities.
- The variance analysis is given to demonstrate that the new method generally gives smaller variance compared to conventional TSA method. Note that the results of variance analysis explains why the proposed identfication methods can lead to improved results compared to existing over-parametrization model based methods for H-W systems.
2. Problem Statement and Analysis
- A1
- The first nonzero elements of and are positive and and .
- A2
- The functions and and degrees , , and are known.
- A3
- {} is a zero-mean white noise sequence with finite variance uncorrelated with {} for all , and uncorrelated with {} for .
3. The Proposed Method
3.1. Parsimonious Parametrization Model Formulation
3.2. Parsimonious Identification Method
- An LS estimate can be obtained by substituting into (12) aswhere the estimate of is a function of .
- The unique solution can be obtained by performing a normalization operation as follows:
- An LS estimate can be obtained by substituting into (12) aswhere the estimate of is a function of .
- An LS estimate can be estimated by substituting into (16) aswhere the estimate of is a function of .
- The unique solution can be obtained by performing a normalization operation as follows:
- An LS estimate can be estimated by substituting into (16) aswhere the estimate of is a function of .
- A4
- Matrices F and G are full row rank.
| Algorithm 1: |
|
4. Variance Analysis
5. Case Studies
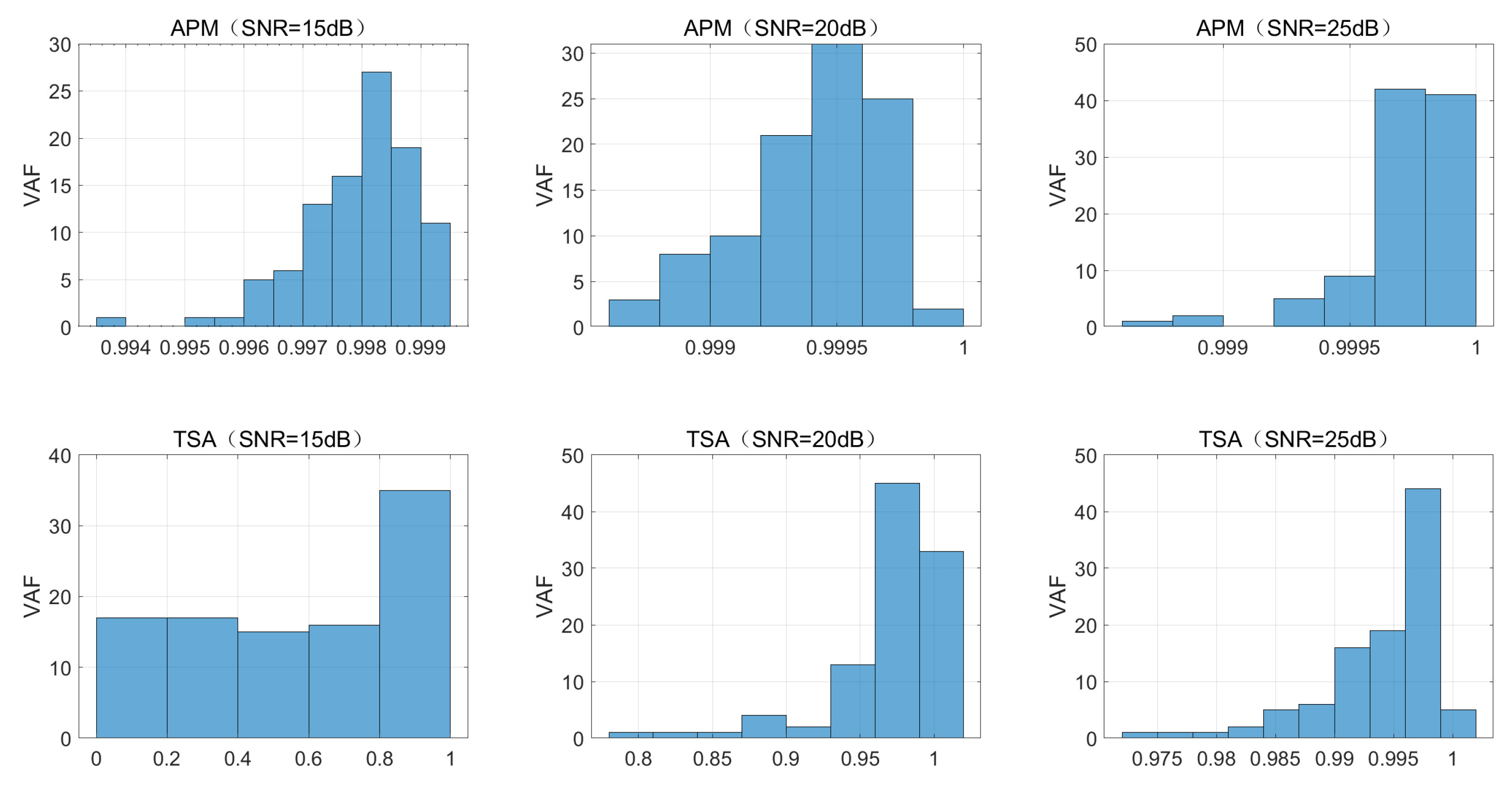
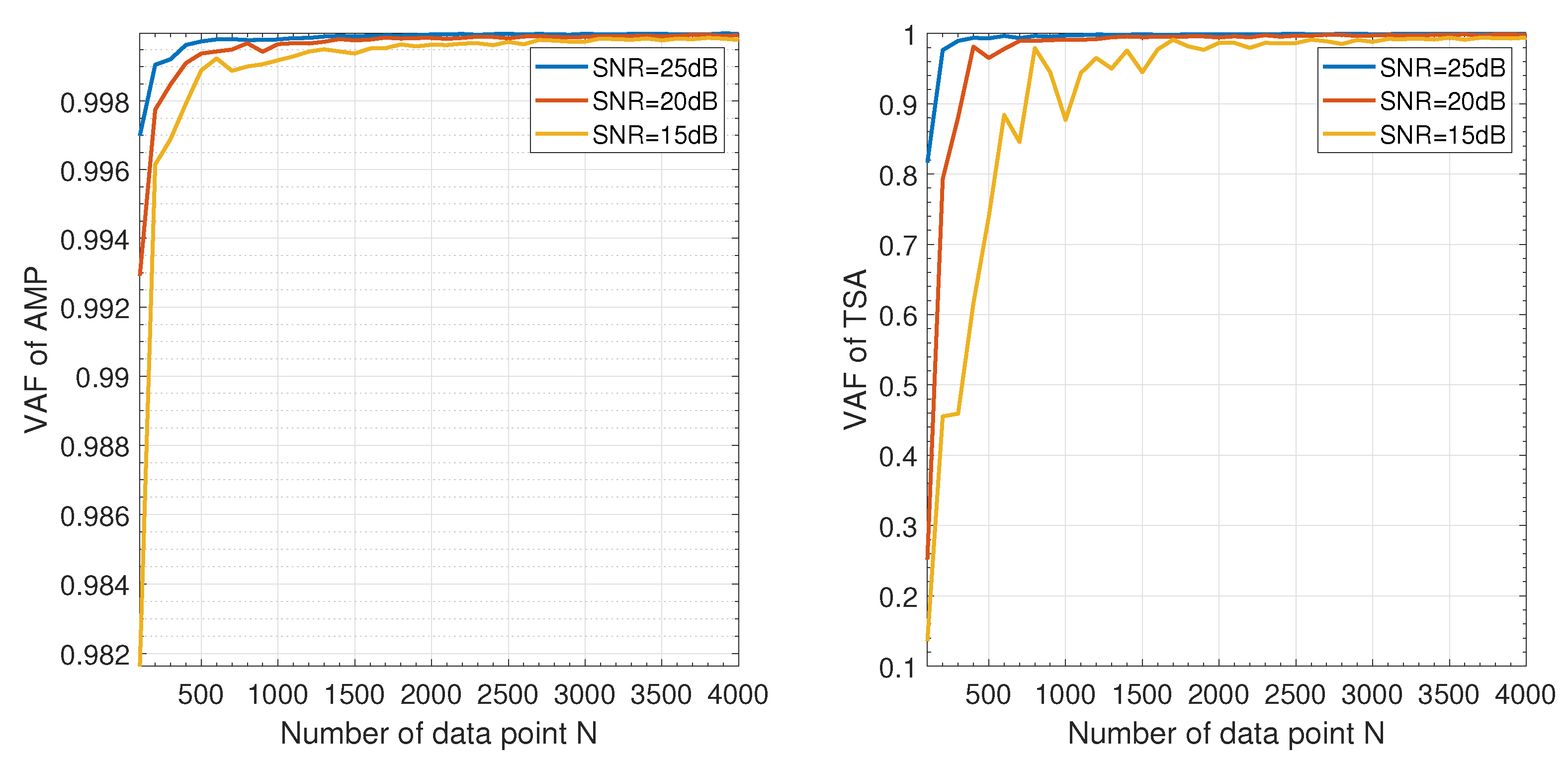
- Under the same noise levels, the proposed APM provides better estimation results in terms of accuracy and standard deviations than TSA.
- The two methods yield similar results for dB (the corresponding PEEs are and , respectively). The performance of APM is obviously better than the performance of TSA for , PEE for dB, and for dB. The attenuation of the signal levels does not obviously affect the APM while it deteriorates the performance of TSA significantly, showing that proposed APM is more robust to noise and data size.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| H-W | Hammerstein–Wiener |
| N-L-N | Nonlinear-Linear-Nonlinear |
| BELS | Bias-Eliminating Least-Squares |
| TSA | Two-Step Algorithms |
| OPM | over-parametrization model |
| SVDs | Singular Value Decompositions |
| AM-MISG | auxiliary model multi-innovation stochastic gradient |
| APM | Asynchronous Parsimonious Method |
| TSA | Two-Step Algorithms |
| SNR | Signal-to-Noise Ratio |
| PEE | Parameter Estimation Errors |
| VAF | Variance Accounted For |
References
- Schoukens, M.; Tiels, K. Identification of block-oriented nonlinear systems starting from linear approximations: A survey. Automatica 2017, 85, 272–292. [Google Scholar] [CrossRef] [Green Version]
- Wang, D.; Ding, F. Hierarchical least squares estimation algorithm for Hammerstein-Wiener systems. IEEE Signal Process. Lett. 2012, 19, 825–828. [Google Scholar] [CrossRef]
- Li, F.; Jia, L. Parameter estimation of Hammerstein-Wiener nonlinear system with noise using special test signals. Neurocomputing 2019, 344, 37–48. [Google Scholar] [CrossRef]
- Bai, E. An optimal two-stage identification algorithm for Hammerstein-Wiener nonlinear systems. Automatica 1998, 34, 333–338. [Google Scholar] [CrossRef]
- Xu, L.; Ding, F.; Yang, E.F. Auxiliary model multiinnovation stochastic gradient parameter estimation methods for nonlinear sandwich systems. Int. J. Robust Nonlinear Control 2020, 31, 148–165. [Google Scholar] [CrossRef]
- Ni, B.; Gilson, M.; Garnier, H. Refined instrumental variable method for Hammerstein-Wiener continuous-time model identification. IET Control Theory Appl. 2013, 7, 1276–1286. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, Y.; Ji, Z. A novel two-stage estimation algorithm for nonlinear Hammerstein-Wiener systems from noisy input and output data. J. Frankl. Inst. 2017, 354, 1937–1944. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Zhang, Q.; Ljung, L. Revisiting Hammerstein system identifification through the two-stage algorithm for bilinear parameter estimation. Automatica 2009, 45, 2627–2633. [Google Scholar] [CrossRef]
- Hou, J.; Su, H.; Yu, C.; Chen, F.; Li, P. Bias-Correction Errors-in-Variables Hammerstein Model Identification. IEEE Trans. Ind. Electron. 2022. [Google Scholar] [CrossRef]
- Gomez, J.; Baeyens, E. Identifification of block-oriented nonlinear systems using or thonormal bases. J. Process Control 2004, 14, 685–697. [Google Scholar] [CrossRef]
- Hou, J.; Chen, F.; Li, P.; Zhu, Z. Fixed point iteration-based subspace identification of Hammerstein state-space models. IET Control Theory Appl. 2019, 13, 1173–1181. [Google Scholar] [CrossRef]
- Hou, J.; Chen, F.; Li, P.; Shu, J.; Zhao, F. Recursive Parsimonious Subspace Identification for Closed-Loop Hammerstein Nonlinear Systems. IEEE Access 2019, 7, 173515–173523. [Google Scholar] [CrossRef]
- Hou, J.; Chen, F.; Li, P.; Zhu, Z. Gray-Box Parsimonious Subspace Identification of Hammerstein-Type Systems. IEEE Trans. Ind. Electron. 2021, 68, 9941–9951. [Google Scholar] [CrossRef]
- Hou, J. Parsimonious model based consistent subspace identification of Hammerstein systems under periodic disturbances. Int. J. Control. Autom. Syst. 2022. [Google Scholar] [CrossRef]
- Ding, F. Decomposition based fast least squares algorithm for output error systems. Signal Process. 2013, 93, 1235–1242. [Google Scholar] [CrossRef]
- Hou, J.; Su, H.; Yu, C.P.; Chen, F.; Li, P.; Xie, H.; Li, T. Consistent Subspace Identification of Errors-In-Variables Hammerstein Systems. IEEE Trans. Syst. Man Cybern. Syst. 2022. [Google Scholar] [CrossRef]
- Ding, F. Computational efficiency of the identification methods. PartB: Iterative algorithm. J. Nanjing Univ. Inf. Sci. Technol. Nat. Sci. Ed. 2021, 4, 385–401. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| True | APM (SNR = 15) | APM (SNR = 20) | APM (SNR = 25) | TSA (SNR = 15) | TSA (SNR = 20) | TSA (SNR = 25) |
|---|---|---|---|---|---|---|
| 0.1604 (±0.0793) | 0.1654 (±0.0617) | 0.1477 (±0.0423) | 0.1643 (±0.0840) | 0.1669 (±0.0597) | 0.1470 (±0.0467) | |
| 0.0912 (±0.0632) | 0.0906 (±0.0443) | 0.0979 (±0.0326) | 0.0855 (±0.0836) | 0.0907 (±0.0485) | 0.0928 (±0.0367) | |
| 0.5442 (±0.1472) | 0.5480 (±0.1187) | 0.5465 (±0.0277) | 0.5162 (±0.1961) | 0.5407 (±0.0413) | 0.5474 (±0.0280) | |
| 0.0009 (±0.0500) | 0.0032 (±0.0357) | 0.0002 (±0.0267) | 0.0014 (±0.00826) | 0.0041 (±0.0413) | 0.0026 (±0.0333) | |
| −0.7218 (±0.0481) | −0.7178 (±0.1473) | −0.7271 (±0.0252) | −0.6758 (±0.2514) | −0.7317 (±0.0419) | −0.7249 (±0.0257) | |
| −0.3597 (±0.07317) | −0.3478 (±0.0839) | −0.3690 (±0.0228) | −0.3164 (±0.1460) | −0.3510 (±0.0398) | −0.3713 (±0.0267) | |
| 0.1572 (±0.0128) | 0.1577 (±0.0068) | 0.1558 (±0.0040) | 0.2757 (±0.2053) | 0.1515 (±0.0770) | 0.1620 (±0.0377) | |
| 0.0930 (±0.0121) | 0.0931 (±0.0060) | 0.0939 (±0.0038) | 0.0039 (±0.3265) | 0.0692 (±0.1037) | 0.0913 (±0.0367) | |
| 0.5465 (±0.0155) | 0.5478 (±0.0112) | 0.5468 (±0.0079) | 0.1405 (±0.4996) | 0.4736 (±0.2627) | 0.5469 (±0.0313) | |
| 0.7293 (±0.0114) | 0.7306 (±0.0074) | 0.7299 (±0.0050) | 0.1432 (±0.5629) | 0.6178 (±0.3892) | 0.7220 (±0.0511) | |
| 0.3676 (±0.0176) | 0.3634 (±0.0156) | 0.3675 (±0.0093) | 0.1299 (±0.4004) | 0.3028 (±0.2003) | 0.3720 (±0.1045) | |
| 1.0774 (±0.2146) | 0.9999 (±0.1701) | 1.0022 (±0.0967) | 0.2651 (±0.8143) | 0.8495 (±0.5122) | 0.9914 (±0.3376) | |
| 4.0237 (±0.8490) | 3.9649 (±0.4590) | 4.0077 (±0.2340) | 1.1182 (±3.0569) | 3.3149 (±1.7629) | 3.9646 (±0.4040) | |
| 2.6377 (±1.3845) | 2.9785 (±0.6425) | 3.0432 (±0.3804) | 0.9981 (±2.5809) | 2.5448 (±1.6301) | 3.0505 (±0.3848) | |
| 7.1772 (±1.6055) | 7.0295 (±1.4038) | 7.0416 (±0.7487) | 1.9601 (±10.3455) | 6.1131 (±4.6544) | 7.1346 (±0.8611) | |
| 1.0199 (±1.3840) | 1.0168 (±0.5661) | 0.9645 (±0.3401) | 0.0885 (±1.6670) | 0.8553 (±0.7665) | 0.9455 (±0.3612) | |
| 3.5277 (±1.3443) | 3.4013 (±1.0777) | 3.3914 (±0.5844) | 0.7933 (±5.1063) | 2.7925 (±1.8014) | 3.2967 (±0.6655) | |
| 0.5043 (±0.1304) | 0.4927 (±0.1017) | 0.5014 (±0.0040) | 0.4731 (±0.1723) | 0.5027 (±0.0071) | 0.5064 (±0.0045) | |
| 0.2551 (±0.0675) | 0.2481 (±0.0595) | 0.2500 (±0.0211) | 0.2518 (±0.1244) | 0.2549 (±0.0330) | 0.2501 (±0.0216) | |
| PPE (%) | 38.7442 (±21.5544) | 18.7887 (±10.3743) | 10.8245 (±5.8194) | 130.4982 (±71.5442) | 36.6713 (±48.9617) | 11.8245 (±7.0916) |
| Methods | VAF |
|---|---|
| APM (SNR = 15 dB) | 99.79 (±0.0977) |
| APM (SNR = 20 dB) | 99.94 (±0.0270) |
| APM (SNR = 25 dB) | 99.97 (±0.0214) |
| TSA (SNR = 15 dB) | 56.81 (±31.1700) |
| TSA (SNR = 20 dB) | 97.03 (±3.5800) |
| TSA (SNR = 25 dB) | 99.40 (±0.5200) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, L.; Hou, J.; Xing, C.; Fang, Z. A Robust Hammerstein-Wiener Model Identification Method for Highly Nonlinear Systems. Processes 2022, 10, 2664. https://doi.org/10.3390/pr10122664
Sun L, Hou J, Xing C, Fang Z. A Robust Hammerstein-Wiener Model Identification Method for Highly Nonlinear Systems. Processes. 2022; 10(12):2664. https://doi.org/10.3390/pr10122664
Chicago/Turabian StyleSun, Lijie, Jie Hou, Chuanjun Xing, and Zhewei Fang. 2022. "A Robust Hammerstein-Wiener Model Identification Method for Highly Nonlinear Systems" Processes 10, no. 12: 2664. https://doi.org/10.3390/pr10122664