
Genealogical Data Mining from Historical Archives: The Case of the Jewish Community in Pisa

 ,
, 
Abstract
:1. Introduction
2. The Jewish Presence in Pisa
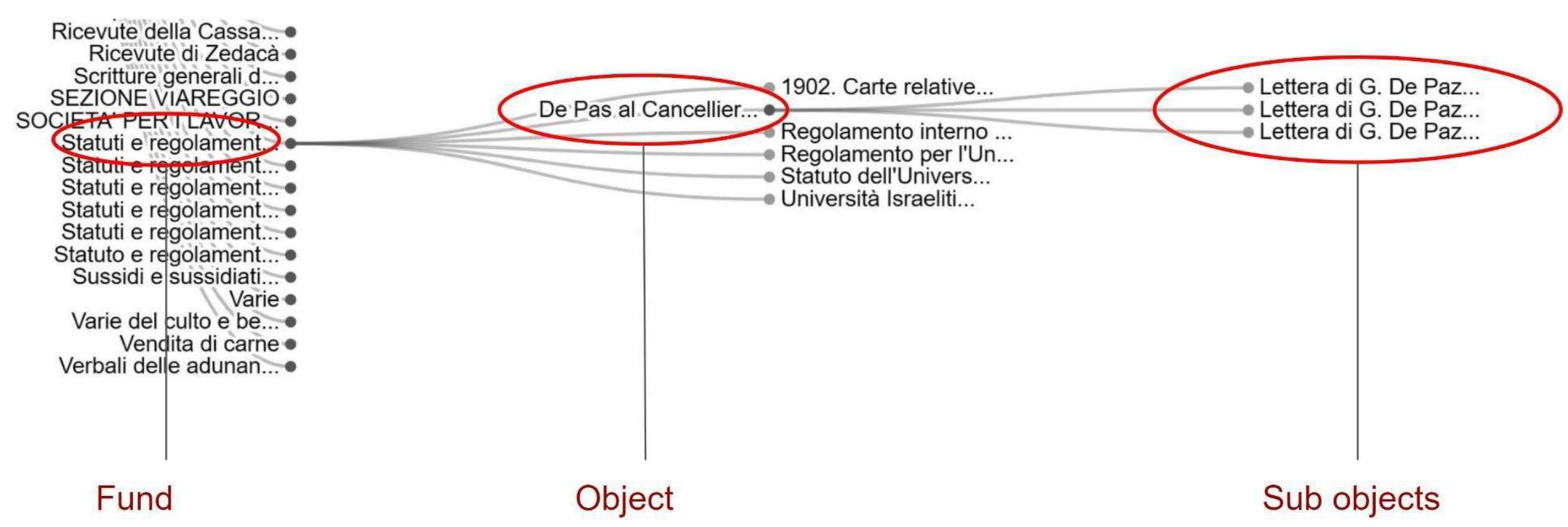
3. Overview of the Archive of the Jewish Community
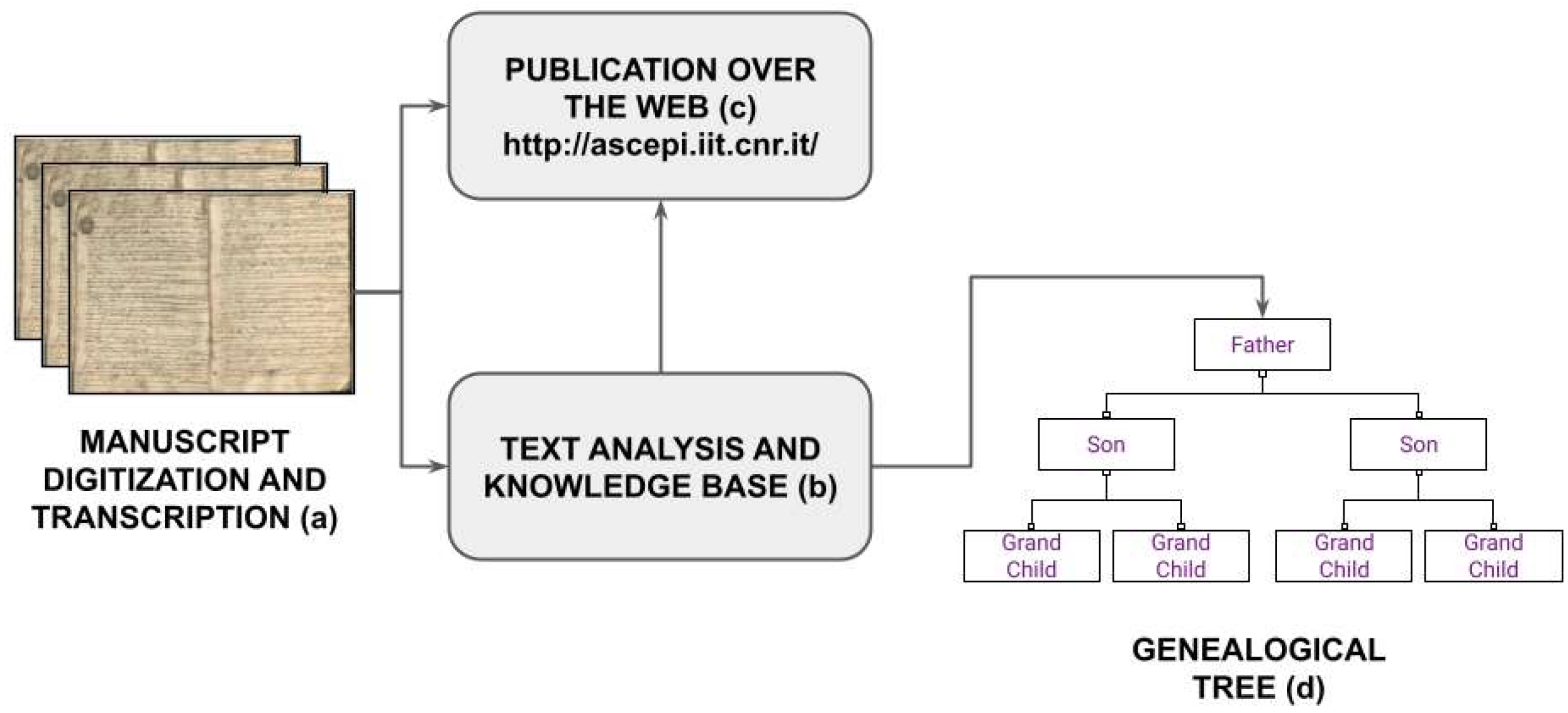
4. Entity Extraction from the NMB Registry
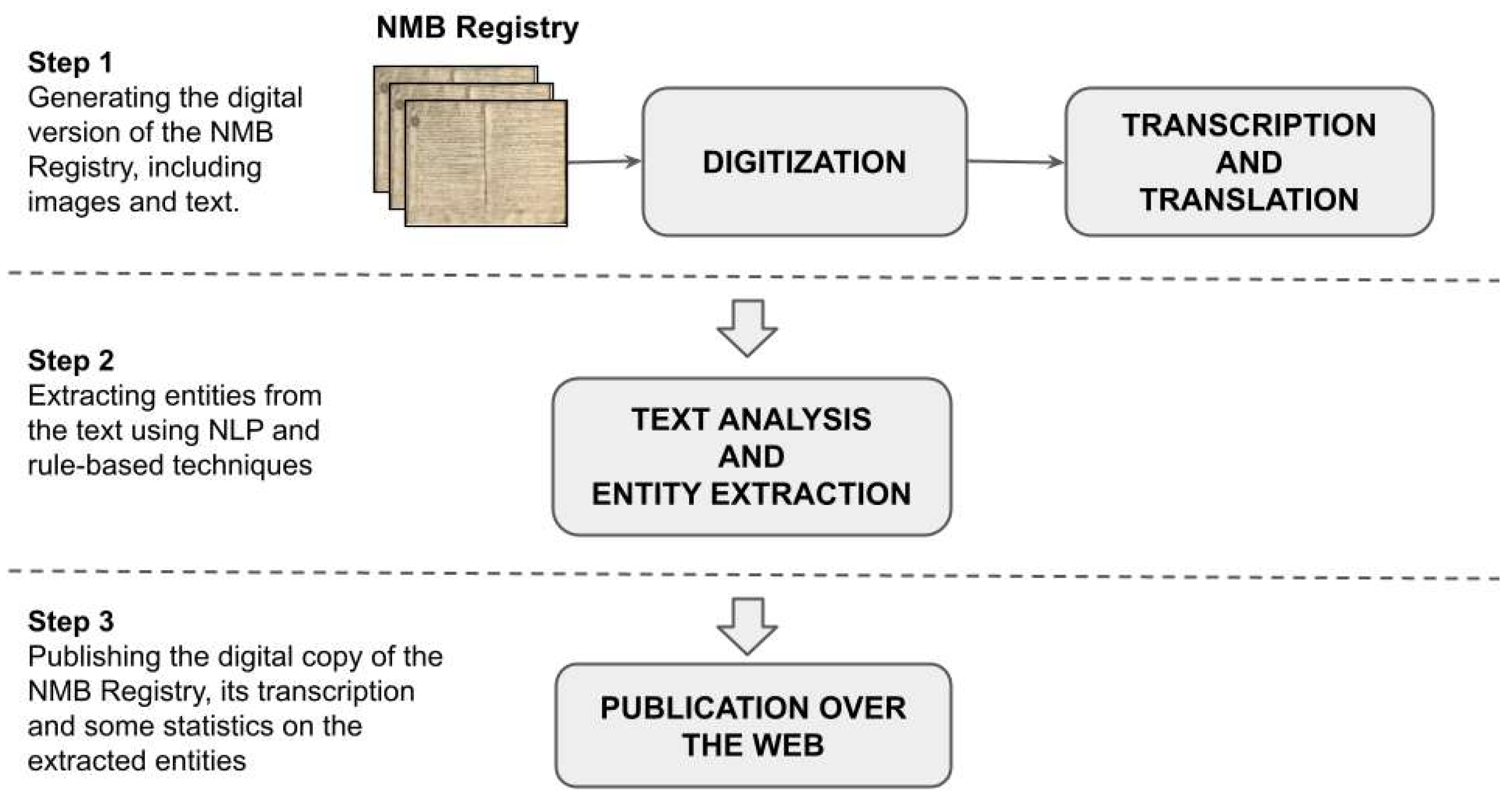
4.1. Digitization
4.2. Transcription and Translation
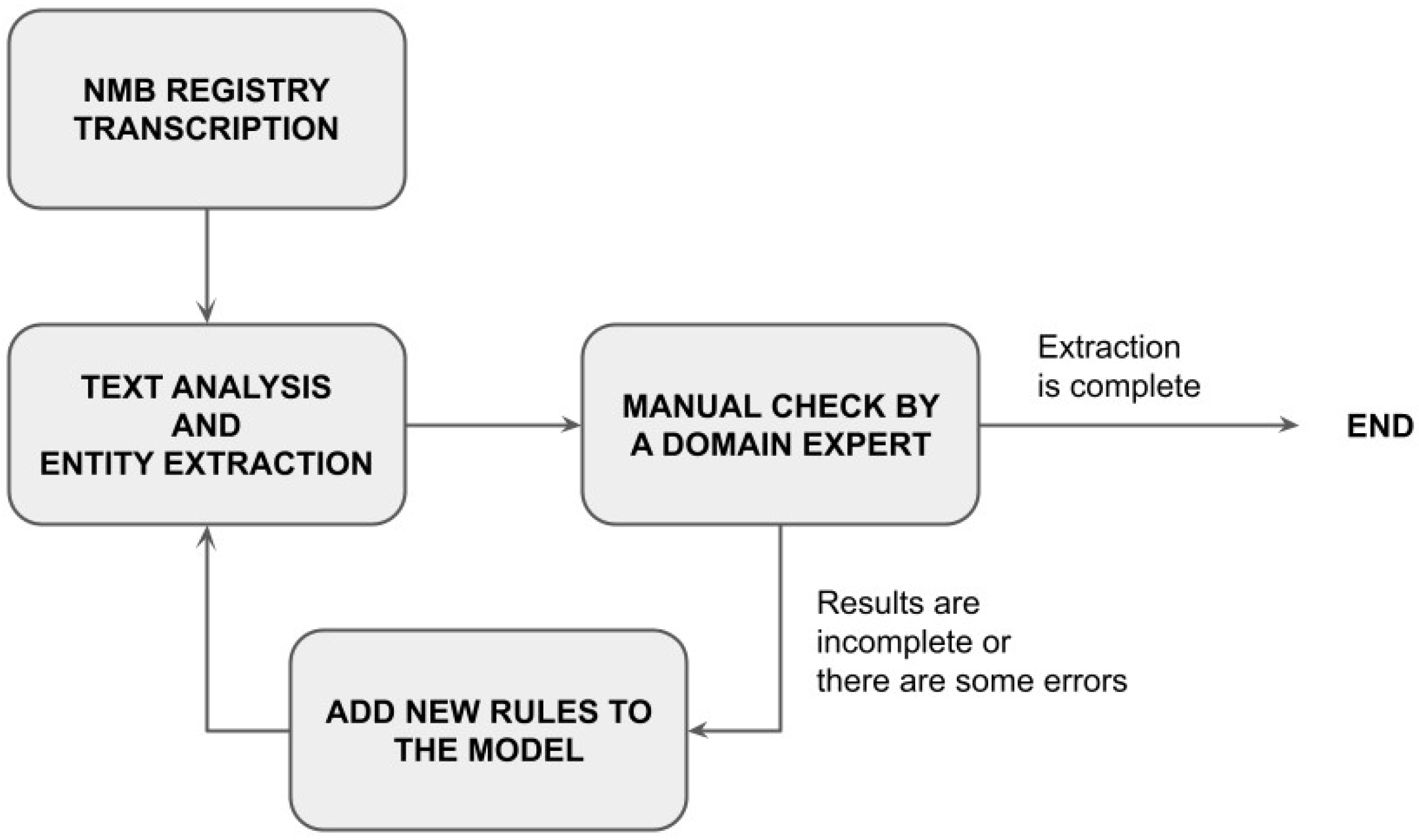
4.3. Text Analysis and Entity Extraction
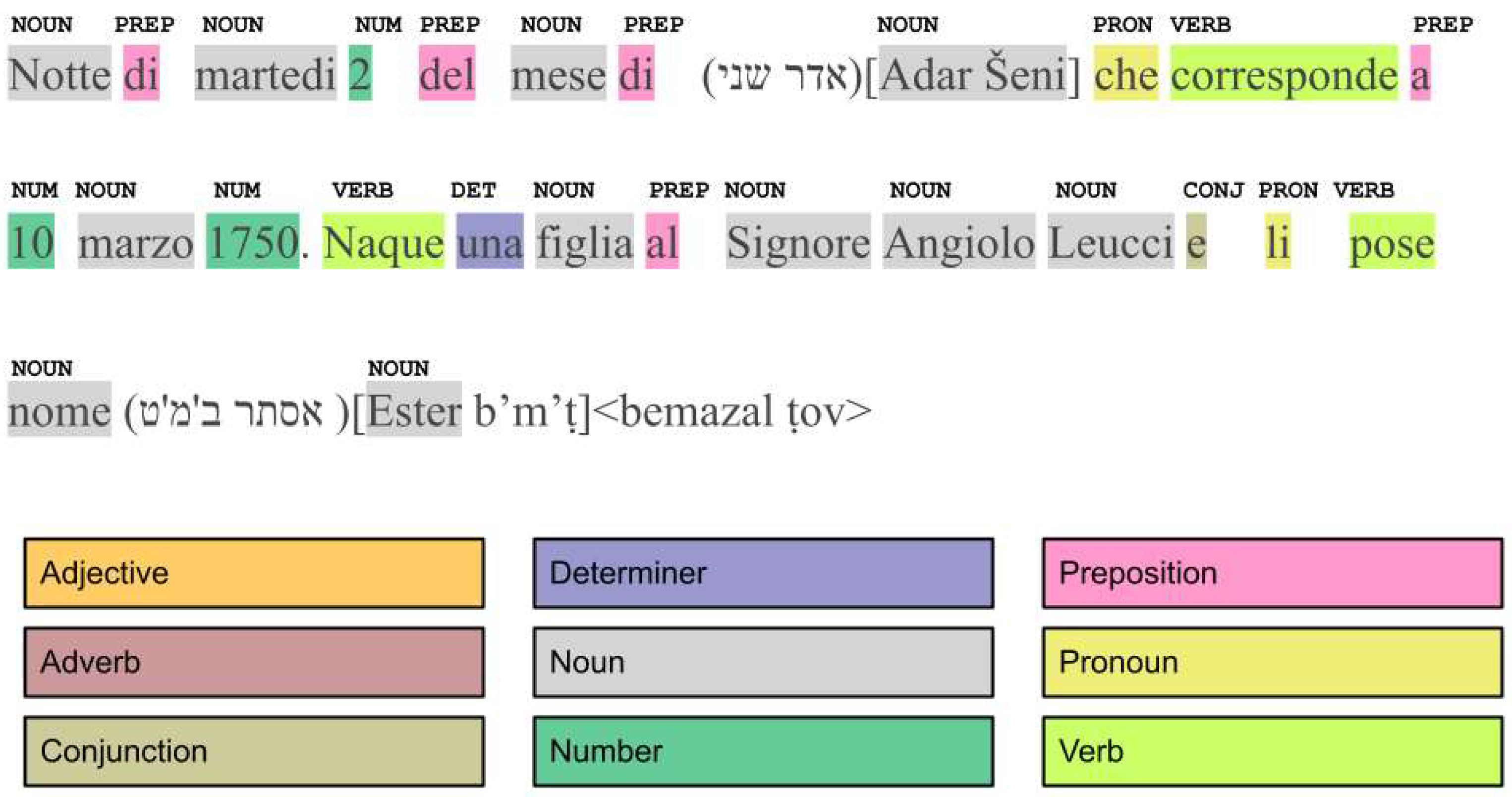
- A manual POS tagging of the first records is conducted, as shown in Figure 8.
- Based on the POS tagging, an initial set of rules is defined to extract the father entity, as shown by the following code.


- 3
- The model is run with this initial rule. Then, the domain expert reviews the output and finds some errors. For example, the father contained in the following entity is not extracted because the list of first_tokens does not contain the word Signor:
- 4.
- In the next round, the rule is updated. In the previous example, this would be accomplished by including the word Signor in the first_token list. Then, the algorithm is run.
- 5.
- The process terminates when the father entity is extracted from all the records.


4.4. Model Evaluation
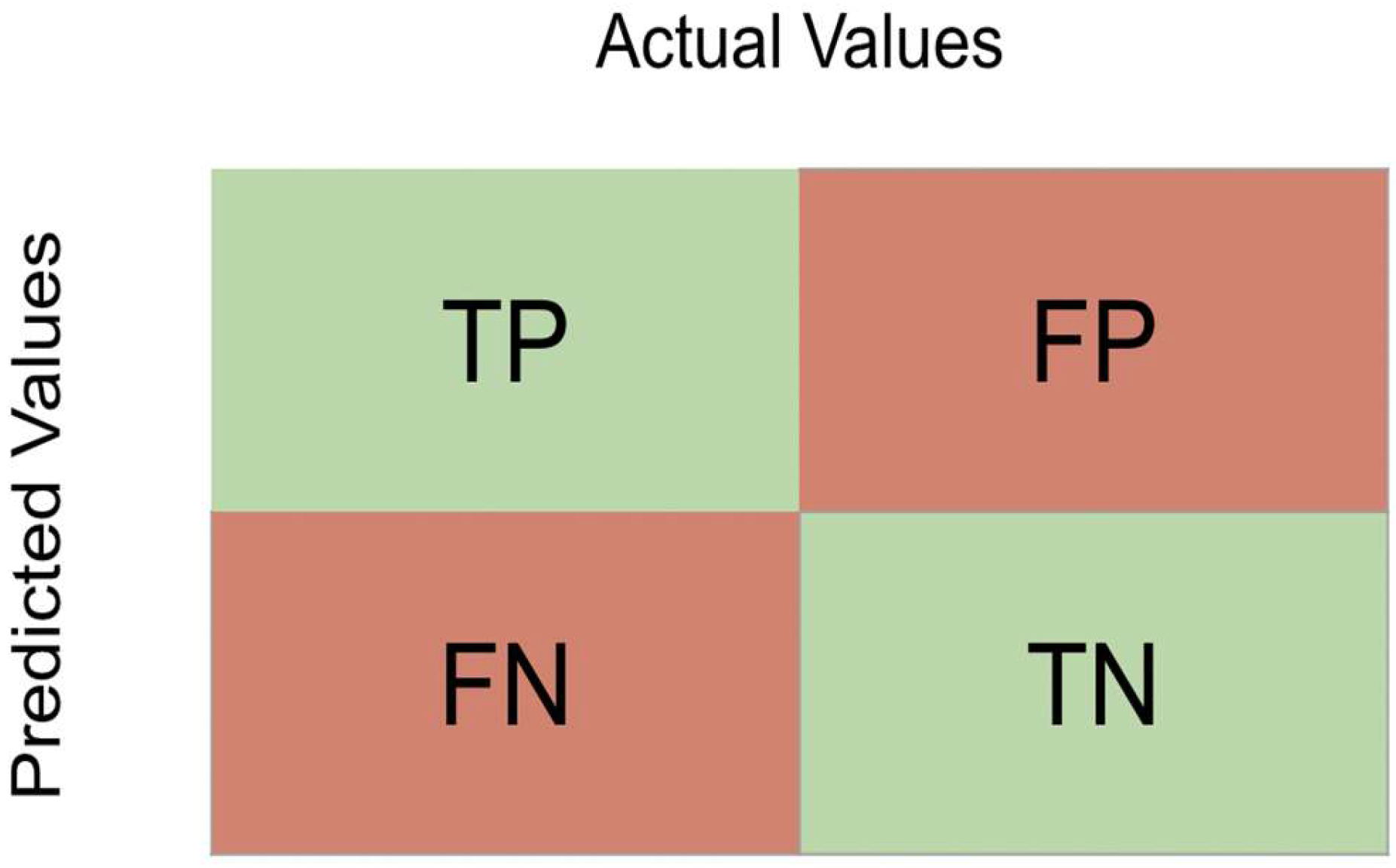
- True Positive (TP): The record contains an entity, and the algorithm extracts it correctly.
- True Negative (TN): The record contains no entity, and the algorithm does not extract any entities.
- False Positive (FP): The record contains an entity, but the algorithm does not extract it, or it extracts a wrong entity.
- False Negative (FN): The record contains no entity, but the algorithm extracts an entity.

- Precision is calculated as TP/(TP + FP) and measures how many predicted positives are true positives.
- Recall is calculated as TP/(TP + FN) and measures how many actual positives are correctly predicted as positives.
- Accuracy is calculated as (TP + TN)/(TP + TN + FP + FN) and measures how many predictions are correct out of all predictions made.
4.5. Publication over the Web
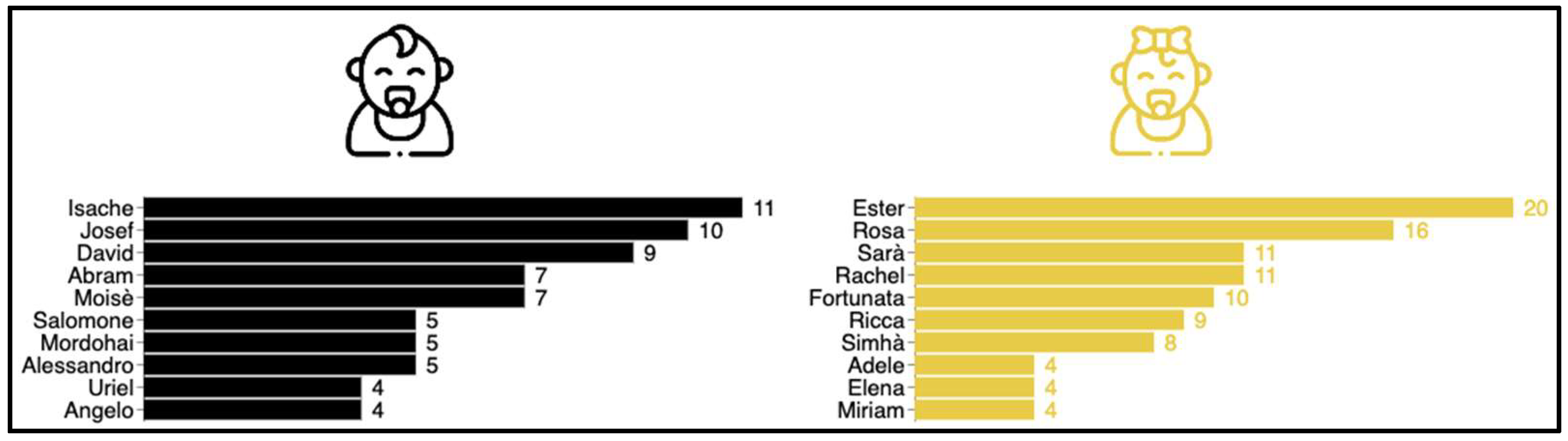
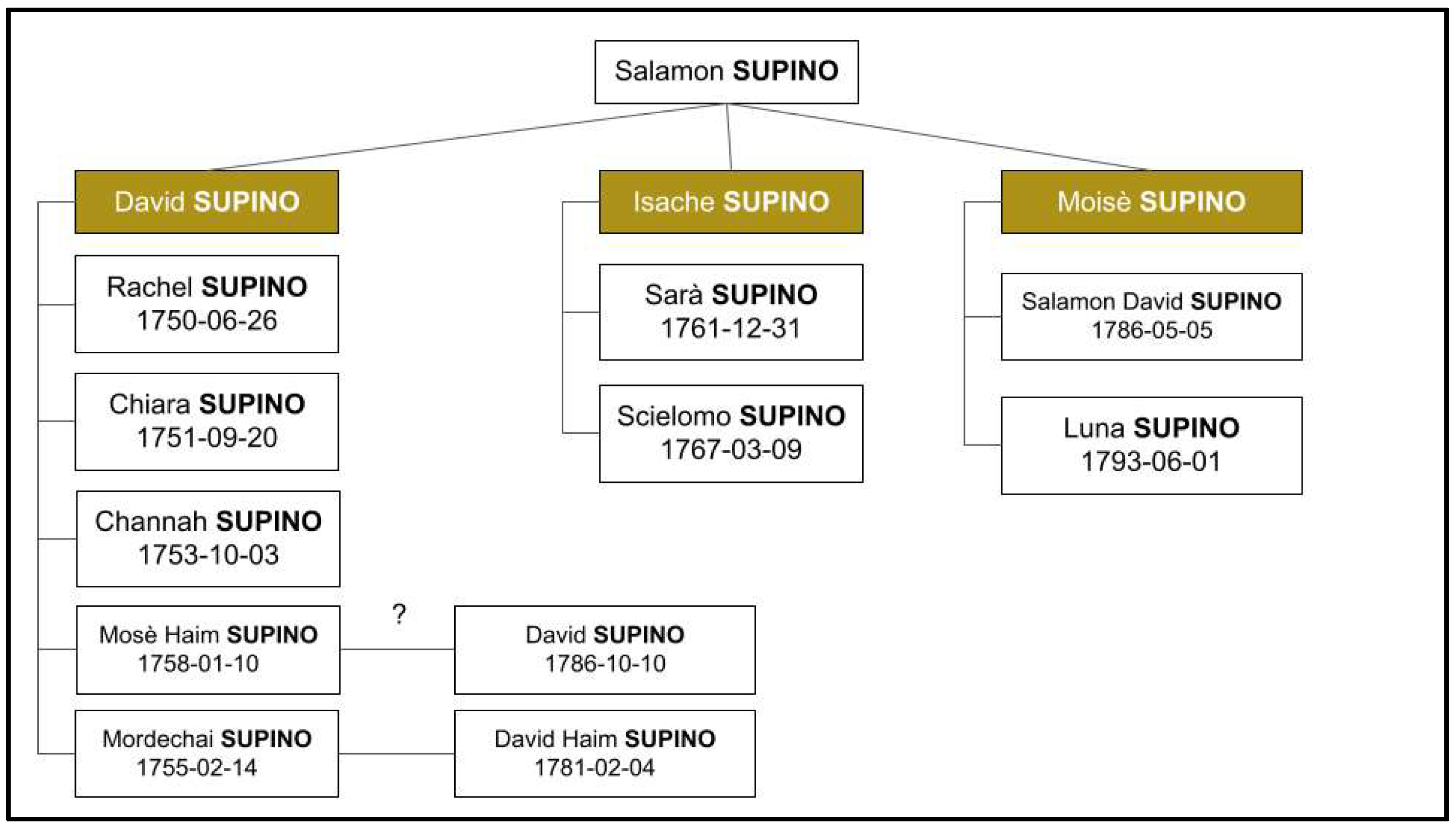
5. Case Study: The Supino Family Tree
6. Related Work
6.1. Digitization of Documents and Website Creation
6.2. Entity Extraction
6.3. Genealogical Tree
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ball, R. Visualizing genealogy through a family-centric perspective. Inf. Vis. 2017, 16, 74–89. [Google Scholar] [CrossRef]
- The ASCEPI Project. Available online: http://ascepi.iit.cnr.it/ (accessed on 16 March 2023).
- Tudelensis, B. Itinerarium; Colorni, V., Ed.; Bologna, Italy, (anastatic reprint); 1967; p. 18. [Google Scholar]
- Lonardo, P.M. Gli Ebrei a Pisa; Doc. VII; Forni: Bologna, Italy, 1982; pp. 40–41. [Google Scholar]
- Luzzati, M. La Casa dell’Ebreo Saggi sugli Ebrei a Pisa e in Toscana nel Medioevo e nel Rinascimento; Nistri Lischi: Pisa, Italy, 1985. [Google Scholar]
- Toaff, T. La Nazione Ebrea a Livorno e a Pisa (1591–1700); Olschki: Firenze, Italy, 1990. [Google Scholar]
- Frattarelli Fischer, L. L’insediamento ebraico nella Pisa del ‘600. Crit. Stor. 1987, 24, 3–54. [Google Scholar]
- Salvadori, R. Breve Storia Degli Ebrei Toscani IX–XX Secolo; Le Lettere: Firenze, Italy, 1995; p. 89. [Google Scholar]
- Guetta, A. Vita Religiosa ed Erudizione Ebraica a Pisa: Yechiel Nissim da Pisa e la crisi Dell’aristotelismo. In Gli Ebrei di Pisa (Secoli IX–XX); Luzzati, M., Ed.; Pacini Editore: Pisa, Italy, 1998; pp. 45–67. [Google Scholar]
- Mortara, M. Indice Alfabetico dei Rabbini e Scrittori Israeliti; Sacchetto: Padova, Italy, 1886; p. 38. [Google Scholar]
- Amram, D. The Makers of Hebrew Books in Italy, London; The Holland Press Limited: London, UK, 1963; p. 397. [Google Scholar]
- Grassi, R. Sesamo 4. In Archivi&Computer: Automazione e Beni Culturali; Carocci: Rome, Italy, 2003; p. XIII/3. ISBN 884302597X. [Google Scholar]
- The SpaCy library. Available online: https://spacy.io/ (accessed on 16 March 2023).
- The iPages Flipbook Plugin. Available online: https://wordpress.org/plugins/ipages-flipbook/ (accessed on 16 March 2023).
- Jayanthi, N.; Indu, S.; Hasija, S.; Tripathi, P. Digitization of ancient manuscripts and inscriptions-a review. In Advances in Computing and Data Sciences: First International Conference, ICACDS 2016, Ghaziabad, India, 11–12 November 2016; Revised Selected Papers 1; Springer: Singapore, 2017; pp. 605–612. [Google Scholar]
- Abrate, M.; Del Grosso, A.M.; Giovannetti, E.; Duca, A.L.; Luzzi, D.; Mancini, L.; Marchetti, A.; Pedretti, I.; Piccini, S. Sharing Cultural Heritage: The Clavius on the Web Project. In Proceedings of the LREC 2014, Ninth International Conference on Language Resources and Evaluation, Reykjavik, Iceland, 26–31 May 2014; pp. 627–634. [Google Scholar]
- The New York Public Library. Available online: https://www.nypl.org/collections/nypl-recommendations/guides/goodspeed-manuscript-collection (accessed on 12 April 2023).
- The Schoenberg Database of Manuscripts. Available online: https://sdbm.library.upenn.edu/ (accessed on 12 April 2023).
- Sicuro, M. Una Piccola Comunità Ebraica al Confine Orientale Veneto-Asburgico in età Moderna: Ontagnano (1577–1797); EUT Edizioni Università di Trieste: Trieste, Italy, 2022. [Google Scholar]
- The Friedberg Jewish Manuscript Society Project. Available online: https://fjms.genizah.org/ (accessed on 13 March 2023).
- The Hebrew Manuscripts Digitisation Project. Available online: https://www.bl.uk/hebrew-manuscripts (accessed on 13 March 2023).
- The Cairo Genizah Collection. Available online: https://cudl.lib.cam.ac.uk/collections/genizah/1 (accessed on 13 March 2023).
- The Judaica Collection. Available online: https://www.nli.org.il/en/at-your-service/who-we-are/collections/judaism-collection (accessed on 13 March 2023).
- The Jewish Atlantic World Project. Available online: https://rdc.reed.edu/c/jewishatl/home/ (accessed on 14 March 2023).
- Ehrmann, M.; Hamdi, A.; Pontes, E.L.; Romanello, M.; Doucet, A. Named entity recognition and classification on historical documents: A survey. arXiv 2021, arXiv:2109.11406. [Google Scholar]
- Trias, F.; Wang, H.; Jaume, S.; Idreos, S. Named entity recognition in historic legal text: A transformer and state machine ensemble method. In Proceedings of the Natural Legal Language Processing Workshop 2021, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 172–179. [Google Scholar]
- Aejas, B.; Bouras, A.; Belhi, A.; Gasmi, H. Named Entity Recognition for Cultural Heritage Preservation. In Data Analytics for Cultural Heritage; Belhi, A., Bouras, A., Al-Ali, A.K., Sadka, A.H., Eds.; Springer: Cham, Switzerland, 2021. [Google Scholar] [CrossRef]
- van Hooland, S.; De Wilde, M.; Verborgh, R.; Steiner, T.; Van de Walle, R. Exploring entity recognition and disambiguation for cultural heritage collections. Digit. Sch. Humanit. 2013, 30, 262–279. [Google Scholar] [CrossRef]
- Erdmann, A.; Wrisley, D.J.; Allen, B.; Brown, C.; Cohen-Bodénès, S.; Elsner, M.; Feng, Y.; Joseph, B.; Joyeux-Prunel, B.; De Marneffe, M.-C. Practical, efficient, and customizable active learning for named entity recognition in the digital humanities. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 3–5 June 2019. [Google Scholar]
- Pontes, E.L.; Cabrera-Diego, L.A.; Moreno, J.G.; Boros, E.; Hamdi, A.; Sidère, N.; Coustaty, M.; Doucet, A. Entity linking for historical documents: Challenges and solutions. In Digital Libraries at Times of Massive Societal Transition: 22nd International Conference on Asia-Pacific Digital Libraries, ICADL 2020, Kyoto, Japan, 30 November–1 December 2020; Springer International Publishing: Cham, Switzerland, 2020; pp. 215–231. [Google Scholar]
- Manjavacas, E.; Fonteyn, L. Adapting vs. Pre-training Language Models for Historical Languages. J. Data Min. Digit. Humanit. 2022, 1–19. [Google Scholar] [CrossRef]
- Ehrmann, M.; Romanello, M.; Najem-Meyer, S.; Doucet, A.; Clematide, S.; Faggioli, G.; Potthast, M. Extended Overview of HIPE-2022: Named Entity Recognition and Linking in Multilingual Historical Documents. In CEUR Workshop Proceedings (No. 3180); CEUR-WS: Aachen, Germany, 2022; pp. 1038–1063. [Google Scholar]
- Bezerianos, A.; Dragicevic, P.; Fekete, J.D.; Bae, J.; Watson, B. Geneaquilts: A system for exploring large genealogies. IEEE Trans. Vis. Comput. Graph. 2010, 16, 1073–1081. [Google Scholar] [CrossRef] [PubMed]
- Gonzalez, J.; Nguyen, N.V.; Dang, T. VisFCAC: An Interactive Family Clinical Attribute Comparison. arXiv 2022, arXiv:2208.11688. [Google Scholar]
- Xiang, F.; Zhu, S.; Wang, Z.; Maher, K.; Liu, Y.; Zhu, Y.; Chen, K.; Liang, Z. Enhanced family tree: Evolving research and expression. In ACM SIGGRAPH 2020 Art Gallery; Association for Computing Machinery: New York, NY, USA, 2020; pp. 367–373. [Google Scholar]
- Liu, Y.; Dai, S.; Wang, C.; Zhou, Z.; Qu, H. GenealogyVis: A System for Visual Analysis of Multidimensional Genealogical Data. IEEE Trans. Hum.-Mach. Syst. 2017, 47, 873–885. [Google Scholar] [CrossRef]
- Korst, J.; Pronk, V.; van Wijk, J.J. A visualization of family relations inspired by the london metro map. In Proceedings of the 13th International Symposium on Visual Information Communication and Interaction, Eindhoven, The Netherlands, 8–10 December 2020; pp. 1–8. [Google Scholar]
- Mansueli, V.A.P.; Okano, M.T. Representations of genealogies in graph theory: K-Graphs. In Proceedings of the 27th International of Association for Management Technology, Birmingham, UK, 22–26 April 2018; pp. 1–10. [Google Scholar]
- Folkman, T.; Furner, R.; Pearson, D. GenERes: A genealogical entity resolution system. In Proceedings of the 2018 IEEE International Conference on Data Mining Workshops (ICDMW), Singapore, 17–20 November 2018; pp. 495–501. [Google Scholar]
- Leskinen, P.; Hyvönen, E. Reconciling and Using Historical Person Registers as Linked Open Data in the AcademySampo Portal and Data Service. In The Semantic Web–ISWC 2021: 20th International Semantic Web Conference, ISWC 2021, Virtual Event, October 24–28, 2021, Proceedings 20; Springer International Publishing: Cham, Switzerland, 2021; pp. 714–730. [Google Scholar]
- Wang, M.; Feng, J.; Shu, X.; Jie, Z.; Tang, J. Photo to family tree: Deep kinship understanding for nuclear family photos. In Proceedings of the Joint Workshop of the 4th Workshop on Affective Social Multimedia Computing and first Multi-Modal Affective Computing of Large-Scale Multimedia Data, Seoul, Republic of Korea, 22–26 October 2018; pp. 41–46. [Google Scholar]
- Koylu, C.; Guo, D.; Huang, Y.; Kasakoff, A.; Grieve, J. Connecting family trees to construct a population-scale and longitudinal geo-social network for the U.S. Int. J. Geogr. Inf. Sci. 2020, 35, 2380–2423. [Google Scholar] [CrossRef]
- Lo Duca, A.; Bacciu, C.; Marchetti, A. Towards a smart navigation of cemeteries as cultural sites. In Ancient Greek Art and European Funerary Art; Cambridge Scholars Publishing: Newcastle upon Tyne, UK, 2019; p. 321. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Son | Date | Gender | Surname | Grandfather | Father |
|---|---|---|---|---|---|
| Ribqa | 12 October 1749 | F | Sezzi | Salamon | |
| Rachel | 26 June 1750 | F | Supino | Salamon | David |
| Jacobbe Vita | 15 July 1814 | M | Soria | Aron |
| Round | Precision | Recall | Accuracy |
|---|---|---|---|
| 1 | 0.9433962264 | 1 | 0.9442379182 |
| 2 | 0.9962264151 | 1 | 0.9962825279 |
| 3 | 0.9962264151 | 1 | 0.9962825279 |
| 4 | 1 | 1 | 1 |
| Round | Precision | Recall | Accuracy |
|---|---|---|---|
| 1 | 0.9341085271 | 1 | 0.936802974 |
| 2 | 0.969348659 | 1 | 0.970260223 |
| 3 | 0.9652509653 | 1 | 0.9665427509 |
| 4 | 0.9543726236 | 1 | 0.9553903346 |
| 5 | 1 | 1 | 1 |
| Grand Father | Father | Son | Son Birth Date | Son Gender |
|---|---|---|---|---|
| Salamon | David | Rachel | 26 June 1750 | F |
| - | David | Chiara | 20 September 1751 | F |
| - | David | Channah | 3 October 1753 | F |
| Salamon | David | Mordechai Haim | 14 February 1755 | M |
| - | David | Mosè Haim | 10 January 1758 | M |
| Salomon | Isache | Sarà | 31 December 1761 | F |
| Salamone | Isache | Scielomo | 9 March 1767 | M |
| - | Mordehai Haim | David Haim | 4 February 1781 | M |
| Salamon | Moisè | Salamon David | 5 May 1786 | M |
| David | Moisè | David | 10 October 1786 | M |
| Salamon | Moise | Luna | 1 June 1793 | F |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lo Duca, A.; Marchetti, A.; Moretti, M.; Diana, F.; Toniazzi, M.; D’Errico, A. Genealogical Data Mining from Historical Archives: The Case of the Jewish Community in Pisa. Informatics 2023, 10, 42. https://doi.org/10.3390/informatics10020042
Lo Duca A, Marchetti A, Moretti M, Diana F, Toniazzi M, D’Errico A. Genealogical Data Mining from Historical Archives: The Case of the Jewish Community in Pisa. Informatics. 2023; 10(2):42. https://doi.org/10.3390/informatics10020042
Chicago/Turabian StyleLo Duca, Angelica, Andrea Marchetti, Manuela Moretti, Francesca Diana, Mafalda Toniazzi, and Andrea D’Errico. 2023. "Genealogical Data Mining from Historical Archives: The Case of the Jewish Community in Pisa" Informatics 10, no. 2: 42. https://doi.org/10.3390/informatics10020042