
Cryptoblend: An AI-Powered Tool for Aggregation and Summarization of Cryptocurrency News

Abstract
:1. Introduction
2. Related Work
3. Materials and Methods
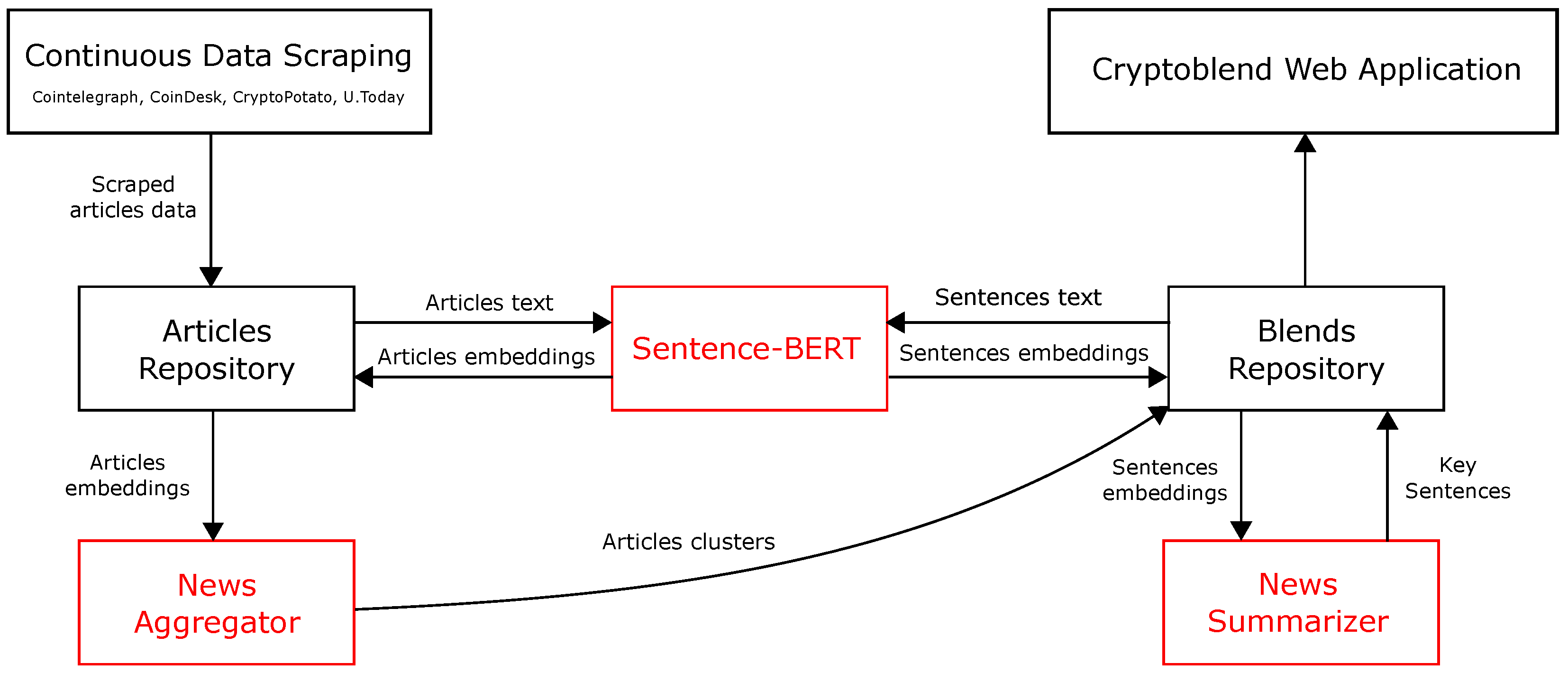
3.1. Continuous Data Scraping
3.2. Data Elaboration Pipeline
3.2.1. News Aggregation
- Case 1: there are no blends in the cluster. A new blend is generated from the articles of the cluster;
- Case 2: only one blend is present in the cluster. If there are no articles in the cluster, the blend is left unchanged; otherwise, is updated by appending the articles in the cluster to the list contained in the articles field and modifying the blend_embedding one to be the average embedding of the contained articles;
- Case 3: two or more blends are present in the cluster. If there are no articles in the cluster, all of the blends are left unchanged; otherwise, only a randomly selected blend is updated as carried out for the Case 2, while the other blends are left unchanged;
3.2.2. News Summarization
- Invoke BERT to compute the embedding D of the whole document and the embedding of every sentence in the document;
- Consider as the set of all of the sentences in the document, as the set of sentences selected for the summarization (initialized as an empty set), and as the set of non-selected sentences in ;
- Rank the sentences in the document according to maximum marginal relevance by repeatedly solving the following optimization problem:where is a tuning parameter and computes the cosine similarity between the documents a and b;
- Select the desired number of sentences with the highest rank to form the summary of the document.
3.3. Implementation of the Web Application
3.3.1. Technical Details for Scraping and Data Elaboration
- Cointelegraph (accessed on 3 January 2023);
- CoinDesk (accessed on 3 January 2023);
- U.Today (accessed on 3 January 2023);
- CryptoPotato (accessed on 3 January 2023).
3.3.2. Web Application
- A presentation layer consisting of a front-end web server, serving static and cached dynamic content that are rendered by the browser. This level relies on documents written in the well-known HyperText Markup Language (HTML), assisted by Cascading Style Sheets (CSS) [30] to define the content style and layout, as well as JavaScript [31] to make the pages interactive. Note that the pages’ style and layout are based on the CSS template provided by Bootstrap [32], which is an open-source front-end framework for faster and easier web development. In particular, Bootstrap includes HTML and CSS-based design templates for typography, forms, buttons, tables, navigation, modals, image carousels, and many others;
- A middle logic layer for dynamic content processing and generation based on FastAPI (accessed on 3 January 2023), which is a modern high-performance web framework for building APIs based on standard Python type hints;
- A data layer, made up of a back-end database and Create/Retrieve/Update/Delete (CRUD) APIs, including both data sets and the database management system software that manages and provides access to the data. This tier is based on MongoDB Atlas, which is a global cloud database service built and run by MongoDB Inc., New York, NY, USA.
3.3.3. Availability
4. Results and Discussion
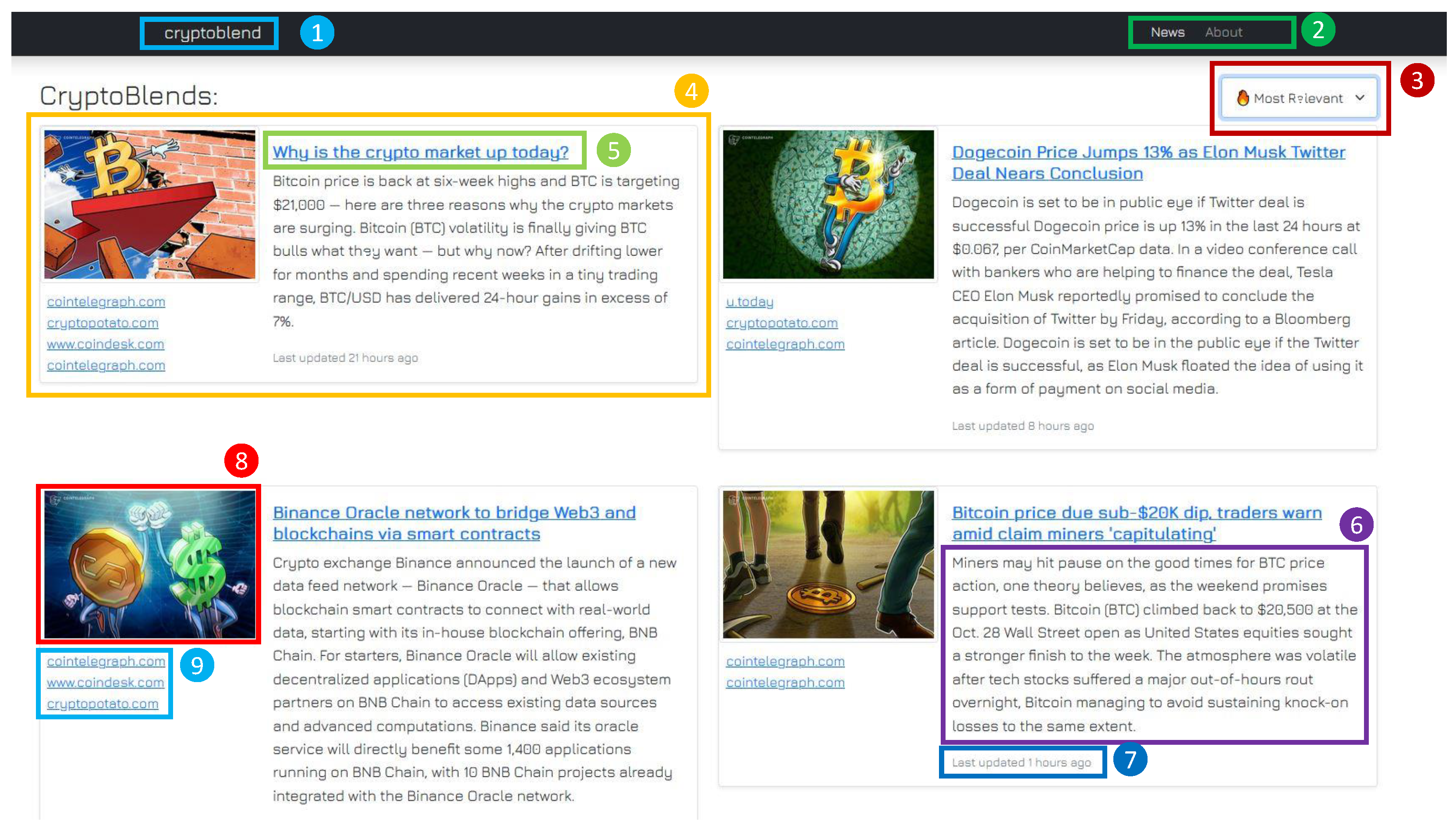
4.1. User Experience and User Interface
- The website title cryptoblend in the header, which allows the user to refresh the page if clicked (1);
- A navigation bar to navigate between the news feed and the about page (2);
- A button that allows the user to sort the news according to their relevance (computed as a weighted score between number of articles and elapsed time from the last update) or according to their last update instant (3);
- The boxes of the different blends constituting the news feed that can be uploaded in groups of ten due to the exploitation of the infinite scroll paradigm (4).
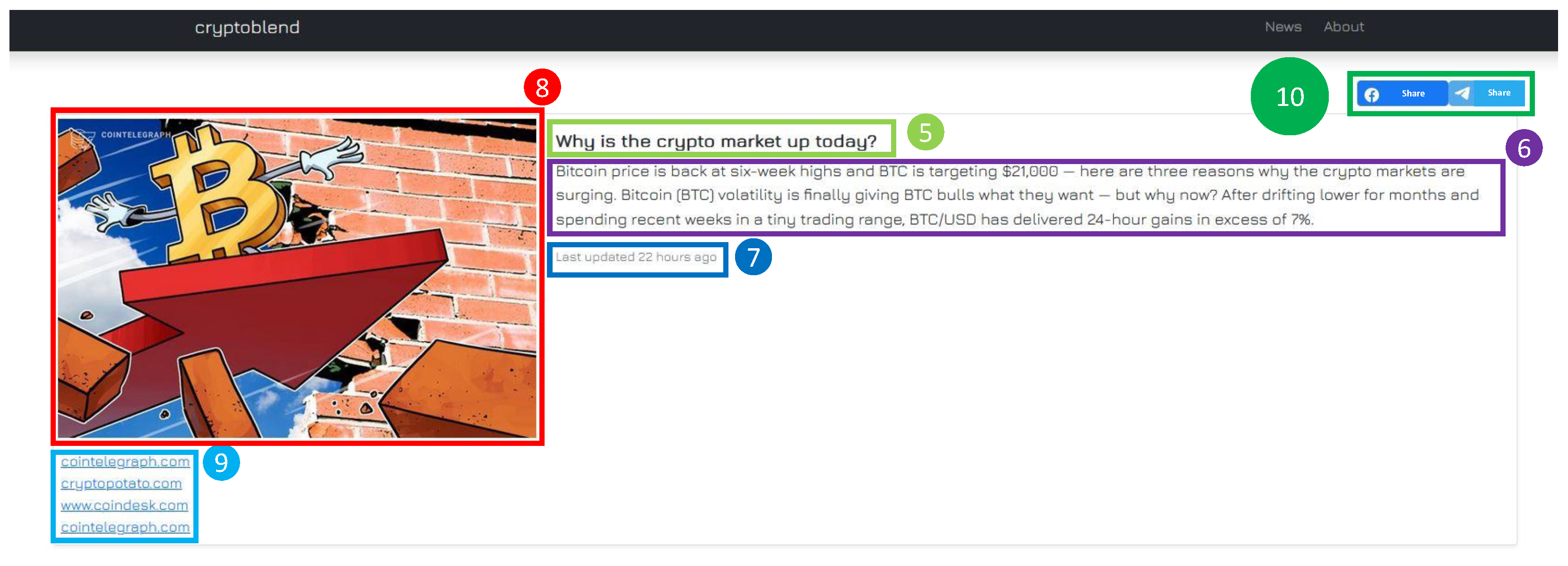
- The title of the blend (5);
- The text corresponding to the extractive summary of the original articles (6);
- The time of the last update for the blend (7);
- A picture describing the content addressed by the text, which is taken from one of the articles that constitute the blend (8);
- A list of the url addresses of the original articles (9).
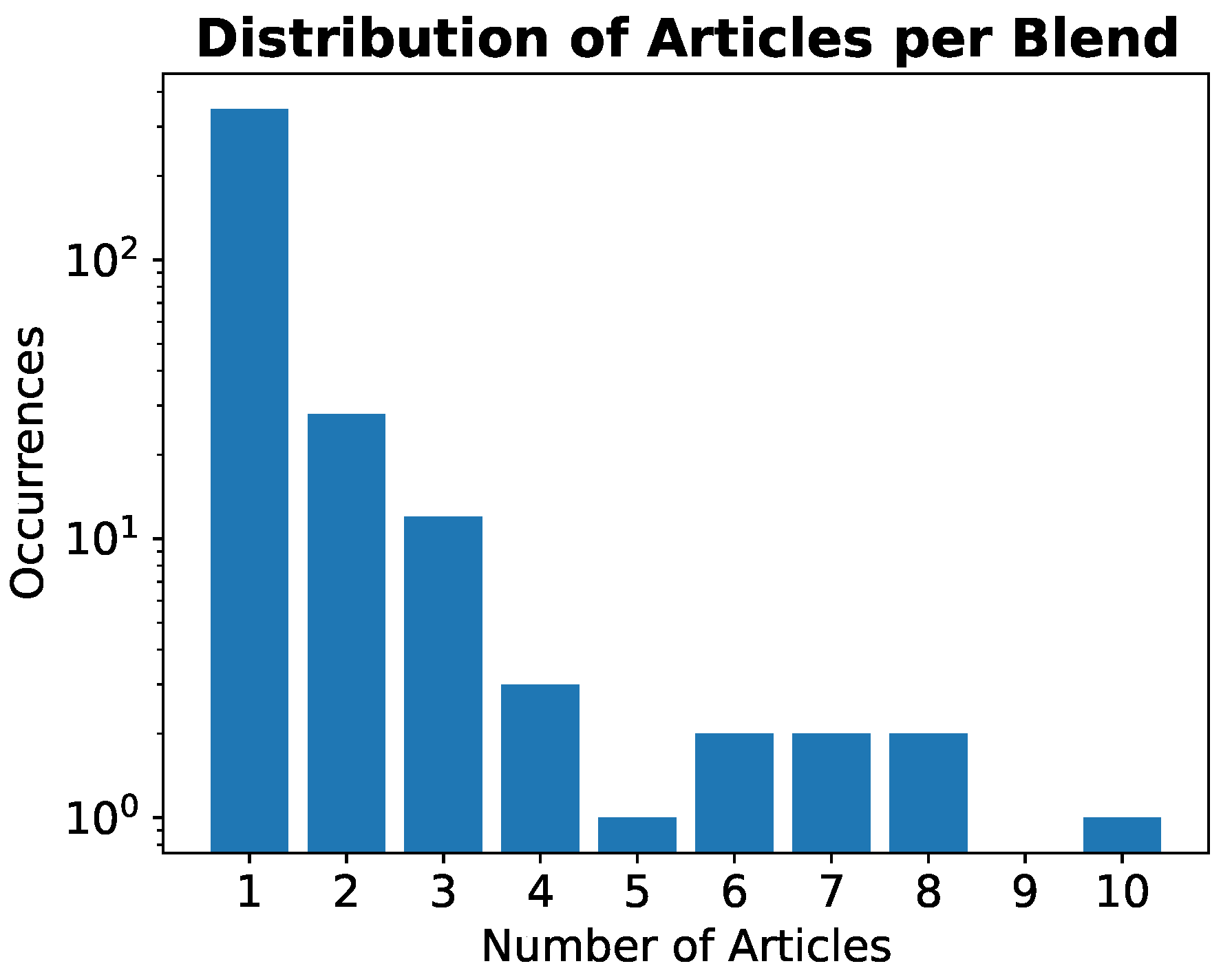
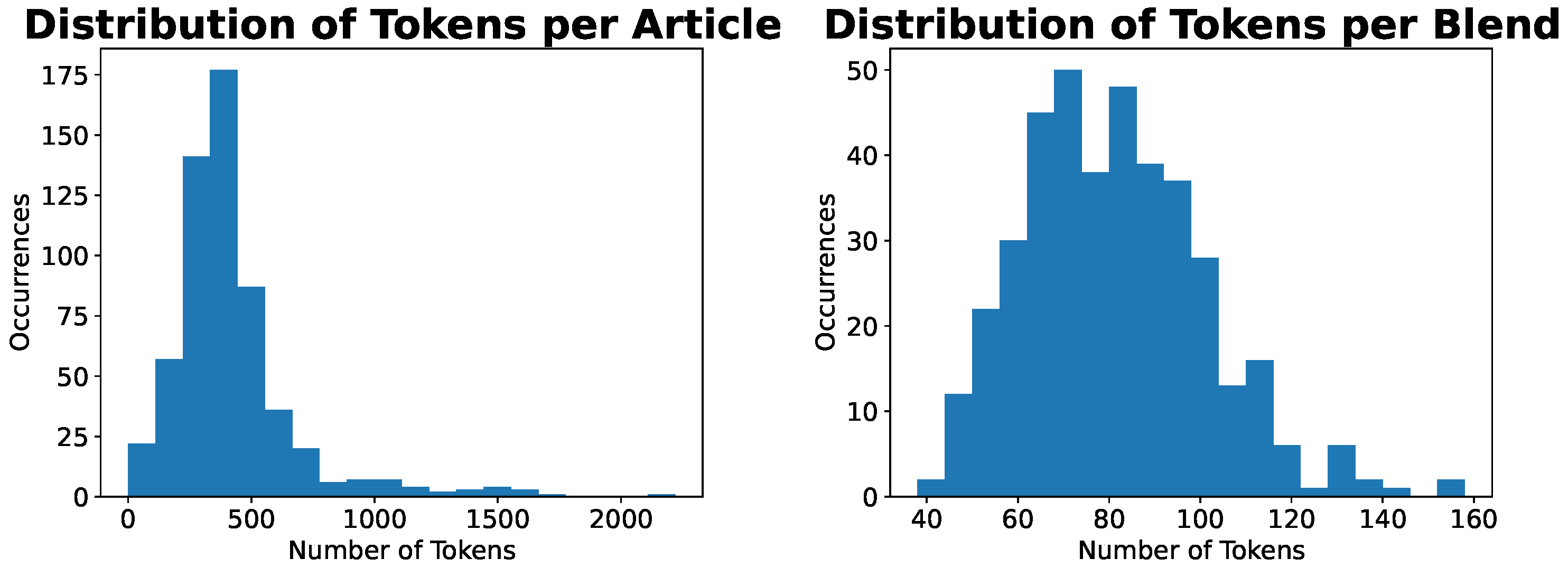
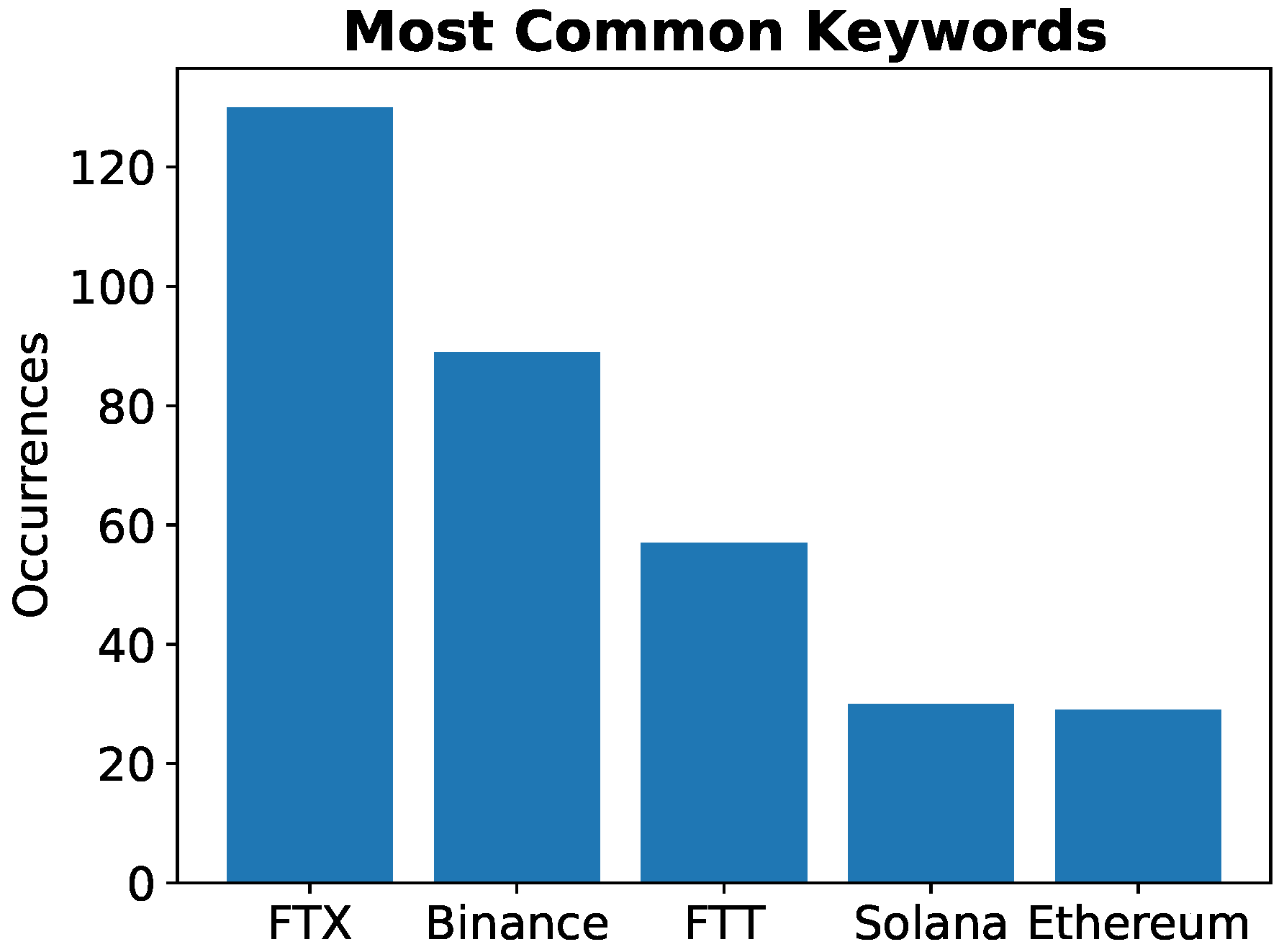
4.2. Statistical Analysis of Collected and Elaborated Data
4.3. Validation of the Data Elaboration Pipeline
obtained by four different original articles:“Deribit, the largest cryptocurrency options exchange, has suffered a $28 million hack, according to an announcement posted on Twitter. It is unclear when the exchange will be able to reopen. The exchange has stressed that it remains in a strong financial position, and the recent hack will not affect its operations.”
- U.Today Article (accessed on 3 January 2023): “Breaking: Largest Cryptocurrency Options Exchange Deribit Suffers $28 Million Hack”;
- Cointelegraph Article (accessed on 3 January 2023): “Deribit crypto exchange halts withdrawals amid $28M hot wallet hack”;
- CoinDesk Article (accessed on 3 January 2023): “Crypto Exchange Deribit Loses $28M in Hot Wallet Hack, Pauses Withdrawals”;
- CryptoPotato Article (accessed on 3 January 2023): “Crypto’s Biggest Options Exchange Deribit Hacked for $28 Million, Loss Covered by Company Reserves”.
- CoinDesk Article 1 (accessed on 3 January 2023): “Stablecoin Issuer Paxos Receives Operating License From Singapore Regulator”;
- CoinDesk Article 2 (accessed on 3 January 2023): “Singapore Grants Stablecoin Issuer Circle In-Principle License to Offer Payment Products”;
- Cointelegraph Article (accessed on 3 January 2023): “Stablecoin issuers Circle and Paxos gain approvals in Singapore”;
- CryptoPotato Article (accessed on 3 January 2023): “Circle and Paxos Secure Regulatory Approval in Singapore”.
“Binance confirmed on Friday that it was as an equity investor in billionaire technology entrepreneur Elon Musk’s takeover of microblogging service Twitter (TWTR). CZ said in a tweet that Binance had wired some $500 million as part of the deal two days ago. The Binance CEO said the company wired $500 million to take a share of equity as Elon Musk’s Twitter takeover is finally sealed.”
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sethi, P.; Sonawane, S.; Khanwalker, S.; Keskar, R. Automatic text summarization of news articles. In Proceedings of the 2017 International Conference on Big Data, IoT and Data Science (BID), Pune, India, 20–22 December 2017; pp. 23–29. [Google Scholar]
- Saggion, H.; Poibeau, T. Automatic text summarization: Past, present and future. In Multi-Source, Multilingual Information Extraction and Summarization; Springer: Berlin/Heidelberg, Germany, 2013; pp. 3–21. [Google Scholar]
- Hamborg, F.; Meuschke, N.; Gipp, B. Matrix-based news aggregation: Exploring different news perspectives. In Proceedings of the 2017 ACM/IEEE Joint Conference on Digital Libraries (JCDL), Toronto, ON, Canada, 19–23 June 2017; pp. 1–10. [Google Scholar]
- Hamborg, F.; Donnay, K.; Gipp, B. Automated identification of media bias in news articles: An interdisciplinary literature review. Int. J. Digit. Libr. 2019, 20, 391–415. [Google Scholar] [CrossRef] [Green Version]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems 30 (NIPS 2017); Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Barnes, P.A. Crypto Currency and its Susceptibility to Speculative Bubbles, Manipulation, Scams and Fraud. J. Adv. Stud. Financ. 2018, 9, 60–77. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bratulescu, R.A.; Vatasoiu, R.I.; Mitroi, S.A.; Suciu, G.; Sachian, M.A.; Dutu, D.M.; Calescu, S.E. Fraudulent Activities in the Cyber Realm: DEFRAUDify Project: Fraudulent Activities in the Cyber Realm: DEFRAUDify Project. In Proceedings of the 17th International Conference on Availability, Reliability and Security, ARES ’22, Vienna, Austria, 23–26 August 2022; Association for Computing Machinery: New York, NY, USA, 2022. [Google Scholar] [CrossRef]
- Sureshbhai, P.N.; Bhattacharya, P.; Tanwar, S. KaRuNa: A Blockchain-Based Sentiment Analysis Framework for Fraud Cryptocurrency Schemes. In Proceedings of the 2020 IEEE International Conference on Communications Workshops (ICC Workshops), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Sawhney, R.; Agarwal, S.; Mittal, V.; Rosso, P.; Nanda, V.; Chava, S. Cryptocurrency Bubble Detection: A New Stock Market Dataset, Financial Task and Hyperbolic Models. arXiv 2022, arXiv:2206.06320. [Google Scholar] [CrossRef]
- Wojcieszak, M.; Menchen-Trevino, E.; Goncalves, J.F.; Weeks, B. Avenues to news and diverse news exposure online: Comparing direct navigation, social media, news aggregators, search queries, and article hyperlinks. Int. J. Press. 2022, 27, 860–886. [Google Scholar] [CrossRef]
- Liotsiou, D.; Kollanyi, B.; Howard, P.N. The Junk News Aggregator: Examining junk news posted on Facebook, starting with the 2018 US Midterm Elections. arXiv 2019, arXiv:1901.07920. [Google Scholar] [CrossRef]
- Hong, K.; Conroy, J.; Favre, B.; Kulesza, A.; Lin, H.; Nenkova, A. A repository of state of the art and competitive baseline summaries for generic news summarization. In Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC’14), Reykjavik, Iceland, 26–31 May 2014; pp. 1608–1616. [Google Scholar]
- Fabbri, A.R.; Li, I.; She, T.; Li, S.; Radev, D.R. Multi-News: A Large-Scale Multi-Document Summarization Dataset and Abstractive Hierarchical Model. arXiv 2019, arXiv:1906.01749. [Google Scholar] [CrossRef]
- Varab, D.; Schluter, N. MassiveSumm: A very large-scale, very multilingual, news summarisation dataset. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Online, Punta Cana, Dominican Republic, 7–11 November 2021; Association for Computational Linguistics: Punta Cana, Dominican Republic, 2021; pp. 10150–10161. [Google Scholar] [CrossRef]
- He, J.; Kryściński, W.; McCann, B.; Rajani, N.; Xiong, C. CTRLsum: Towards Generic Controllable Text Summarization. arXiv 2020, arXiv:2012.04281. [Google Scholar] [CrossRef]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. arXiv 2019, arXiv:1910.13461. [Google Scholar] [CrossRef]
- Gupta, A.; Chugh, D.; Katarya, R. Automated news summarization using transformers. In Sustainable Advanced Computing; Springer: Singapore, 2022; pp. 249–259. [Google Scholar]
- Mohamed, A.; Ibrahim, M.; Yasser, M.; Mohamed, A.; Gamil, M.; Hassan, W. News Aggregator and Efficient Summarization System. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 636–641. [Google Scholar] [CrossRef]
- Balcerzak, B.; Jaworski, W.; Wierzbicki, A. Application of TextRank Algorithm for Credibility Assessment. In Proceedings of the 2014 IEEE/WIC/ACM International Joint Conferences on Web Intelligence (WI) and Intelligent Agent Technologies (IAT), Warsaw, Poland, 11–14 August 2014; Volume 1, pp. 451–454. [Google Scholar] [CrossRef]
- Gadi, M.F.A.; Sicilia, M.Á. Cryptocurrency Curated News Event Database From GDELT 2022.
- Rognone, L.; Hyde, S.; Zhang, S.S. News sentiment in the cryptocurrency market: An empirical comparison with Forex. Int. Rev. Financ. Anal. 2020, 69, 101462. [Google Scholar] [CrossRef]
- Fabbri, A.R.; Kryściński, W.; McCann, B.; Xiong, C.; Socher, R.; Radev, D. SummEval: Re-evaluating Summarization Evaluation. Trans. Assoc. Comput. Linguist. 2021, 9, 391–409. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Müllner, D. Modern hierarchical, agglomerative clustering algorithms. arXiv 2011, arXiv:1109.2378. [Google Scholar]
- Carbonell, J.; Goldstein, J. The use of MMR, diversity-based reranking for reordering documents and producing summaries. In Proceedings of the 21st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Melbourne, Australia, 24–28 August 1998; pp. 335–336. [Google Scholar]
- Richardson, L. Beautiful Soup Documentation. 2007. Available online: Https://www. crummy. com/software/BeautifulSoup/bs4/doc/ (accessed on 7 July 2018).
- Banker, K.; Garrett, D.; Bakkum, P.; Verch, S. MongoDB in Action: Covers MongoDB Version 3.0; Simon and Schuster: Manhattan, NY, USA, 2016. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-bert: Sentence embeddings using siamese bert-networks. arXiv 2019, arXiv:1908.10084. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Lie, H.W.; Bos, B. Cascading Style Sheets: Designing for the Web; Addison-Wesley Longman Publishing Co., Inc.: Boston, MA, USA, 1997. [Google Scholar]
- Guha, A.; Saftoiu, C.; Krishnamurthi, S. The essence of JavaScript. In Proceedings of the European Conference on Object-Oriented Programming; Springer: Berlin/Heidelberg, Germany, 2010; pp. 126–150. [Google Scholar]
- Spurlock, J. Bootstrap: Responsive Web Development; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2013. [Google Scholar]
- Vasiliev, Y. Natural Language Processing with Python and SpaCy: A Practical Introduction; No Starch Press: San Francisco, CA, USA, 2020. [Google Scholar]
- Heimerl, F.; Lohmann, S.; Lange, S.; Ertl, T. Word cloud explorer: Text analytics based on word clouds. In Proceedings of the 2014 47th Hawaii International Conference on System Sciences, Waikoloa, HI, USA, 6–9 January 2014; pp. 1833–1842. [Google Scholar]
- Allahyari, M.; Pouriyeh, S.; Assefi, M.; Safaei, S.; Trippe, E.D.; Gutierrez, J.B.; Kochut, K. Text summarization techniques: A brief survey. arXiv 2017, arXiv:1707.02268. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Summarization Tools | ||
|---|---|---|
| Tool Name | Architecture | Data Source Used |
| Multi-news [13] | Based on a pointer-generator network and a maximal marginal relevance (MMR) component used to evaluate sentence ranking scores according to relevancy and redundancy | Newser (accessed on 3 January 2023) |
| CTRLsum [15] | Based on a neural network trained to learn the conditional distribution p(y|x), where x and y represent the source document and summary, respectively. | CNN/Dailymail news articles, arXiv scientific papers, and BIGPATENT patent documents |
| Based on a transformer paradigm [17] | Based on deep learning formalisms, such as recurrent neural networks (RNNs) | BBC news |
| News Aggregator [18] | Based on the Rank algorithm | BBC, World Health Organization |
| CryptoGDelt2022 [20] | Based on naive Bayes classification. The dataset is enriched with supervised machine learning scores for relevance, sentiment, and strength | Global Database of Events, Language and Tone (GDELT) |
| A generic tool [21] | Based on Ravenpack News Analytics 4.0 and an exogenous vector autoregressive model (VAR-X) | A leading global news database called RavenPack News Analytics, affiliated with Dow Jones Newswires. It analyzes relevant information from Dow Jones Newswires. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pozzi, A.; Barbierato, E.; Toti, D. Cryptoblend: An AI-Powered Tool for Aggregation and Summarization of Cryptocurrency News. Informatics 2023, 10, 5. https://doi.org/10.3390/informatics10010005
Pozzi A, Barbierato E, Toti D. Cryptoblend: An AI-Powered Tool for Aggregation and Summarization of Cryptocurrency News. Informatics. 2023; 10(1):5. https://doi.org/10.3390/informatics10010005
Chicago/Turabian StylePozzi, Andrea, Enrico Barbierato, and Daniele Toti. 2023. "Cryptoblend: An AI-Powered Tool for Aggregation and Summarization of Cryptocurrency News" Informatics 10, no. 1: 5. https://doi.org/10.3390/informatics10010005