
Modeling the Influence of Fake Accounts on User Behavior and Information Diffusion in Online Social Networks
Abstract
:1. Introduction
2. Related Work
2.1. Information Diffusion Models
2.1.1. Classical SIR Model Extensions with New Node

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Description |
|---|---|
| SIHR | Extended the classical SIR model by adding a group called hibernators to model the forgetting and remembering mechanisms of the infected accounts [43]. |
| SKIR | Studied the effect of the competition between the users who adopt the rumor and those who adopt an anti-rumor on the propagation process [18]. |
| SEIR | Added an Exposed node that represents people who are infected but not yet infectious [17]. |
| SICR | Introduced the Counterattack node to represent susceptible individuals who may not agree with the rumor [46]. |
| SEIRS-C | Updated the SICR in [46] by adding the exposed state along with the Counterattack state [41]. |
| SPIR | Adopted the concept of a Potential Spreader set of users to model the susceptible node that is likely to become infective at the next unit time [44]. |
| IRCSS | Added a collector state to model the value of the news [35]. |
| SEIR1R2 | Proposed a rumors purification model that contains exposed nodes and two types of recovered nodes: those who had never been exposed to the rumor or recovered from a rumor, and those who purified the rumor [34]. |
| SHAR | Added a hesitating state to include the users who heard the rumor, but they are uncertain whether to propagate the rumor or not [33]. |
| ICST | Added a commentor node to model the susceptible node that is likely to become infective at the next unit time [42]. |
| ILSR | Added a lurker node that heard the rumor but temporarily is not publishing it. In addition, they consider two types of users (important users and normal users) based on the degree of each node [45]. |
2.1.2. Classical SIR Model with the Consideration of New Factors
2.1.3. Classical SIR Model with Divided Nodes
| Model | Description |
|---|---|
| Mb-RP | Considered the reading rate as the susceptible node read the rumor many times, he/she may retweet and spread it [48]. |
| ISIR | Considered the infection rate is not a static value, but it differs according to the number of infected nodes [37]. |
| FSIR | Considered the diffusion rate of the neighbor’s behavior. Once a person has a lot of information from neighbors, the information may not be well diffused [49]. |
| irSIR | Added infection recovery process. Each user who joins the network is expected to continue forever and then eventually lose interest as their friends lose interest [40]. |
| Model | Description |
|---|---|
| SIRuRa | Divided the removed states into Ra (users accepted the rumor but lose interest) and Ru (users do not accept information at all) [50]. |
| OL-SFI | Studied the impact of opinion leaders as the opinion leaders will spread the news faster than the normal ones as they have many followers [20]. |
| SAIR | Introduced super-spreaders to the classical SIR model as they can impact more individuals than ordinary ones and make them influential to impact others [51]. |
| INSR | The age of infection is considered to have new and old spreaders [36]. |
2.2. Measuring Social Influence
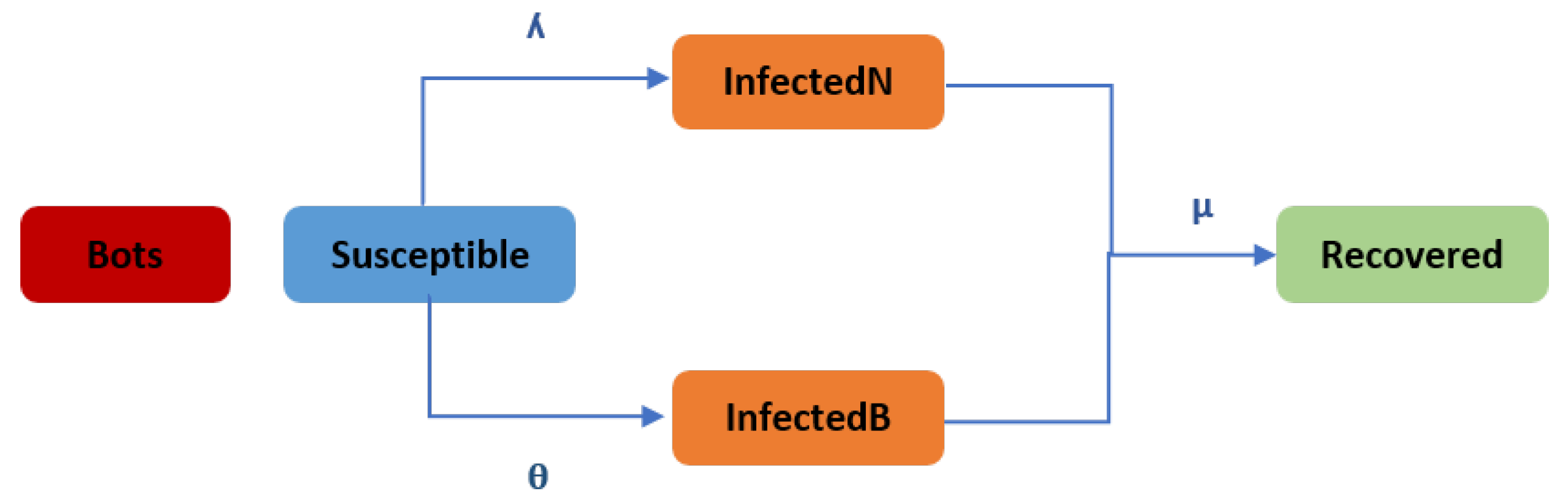
3. The Proposed Model
- Users are in a closed environment, meaning that the number of users (N) remains unchanged.
- The total population is divided into five groups: the susceptible nodes (s), the normal infected nodes , the bot-infected nodes , the bot nodes (B), and the recovered nodes (r).
- Each user, except bots, may be in one of four states at any given time: the susceptible state (S), the infected state influenced by bots , the infected state influenced by human users , and the recovered state (R).
- Correspondingly, if a susceptible node (S) contacts an infective node, the susceptible node will become infective with probability if the infected node is a human account or with probability if the infected node is a bot account .
- Bot accounts do not change their status. In other words, they will remain infected during one rumor propagation.
- Both infected types of nodes will recover with µ rate.
- It is not assumed that the user knows the identity of the account (fake or real) that posts the information, as fake accounts usually hide their identity. The effect of the fake accounts is reflected in the diffusion rate that differs from the normal rate. This is because social bots have a deliberate and continuous intent to post the rumor. Normal accounts post the information only once, whereas fake accounts keep posting the rumors for a while until it diffuses.
- S: The strength is mapped to the number of accounts that can see the rumor.
- d: The immediacy is mapped to the shortest distance between the bot account and the susceptible accounts.
- N: represents the number of accounts in the influence group.
- a: means that the persuasion of a specific belief does not increase linearly with the number of bots holding it.
- b: represents the possibility of the bias of bot accounts in expressing the belief.
4. Simulation and Numerical Results
4.1. Experimental Design
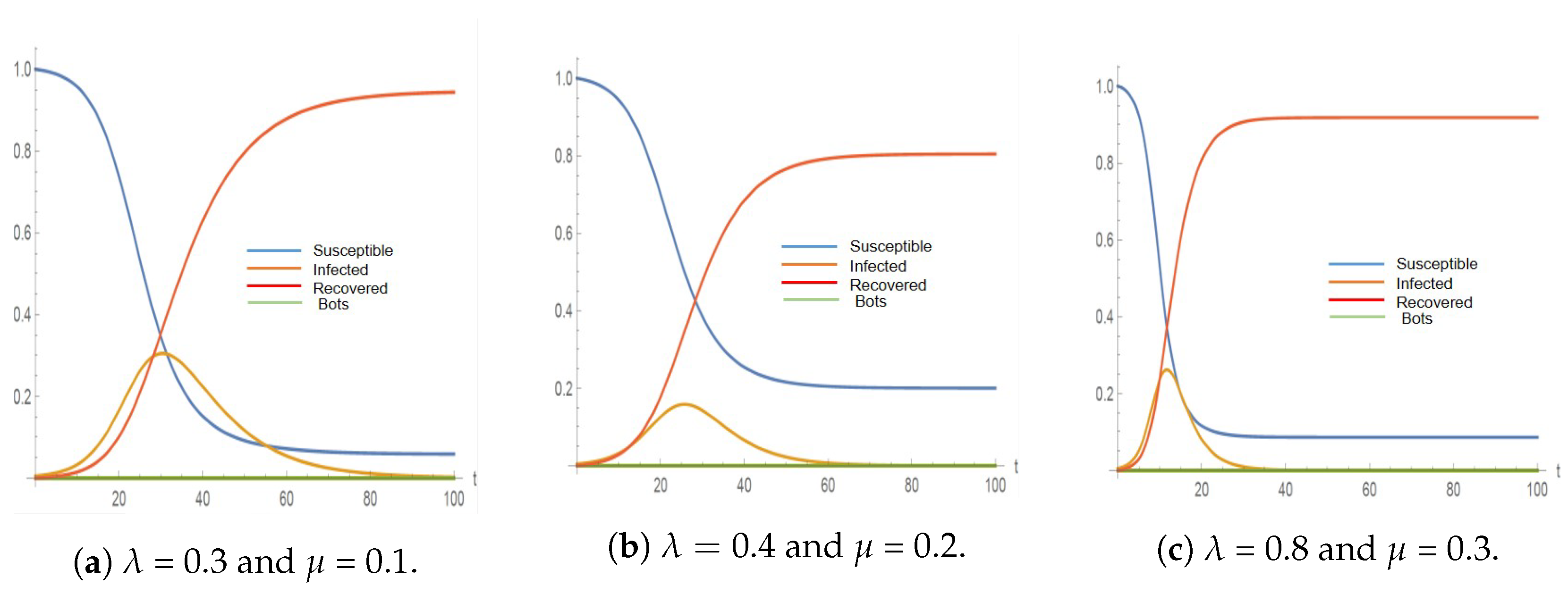
4.2. Testing the SIR Model
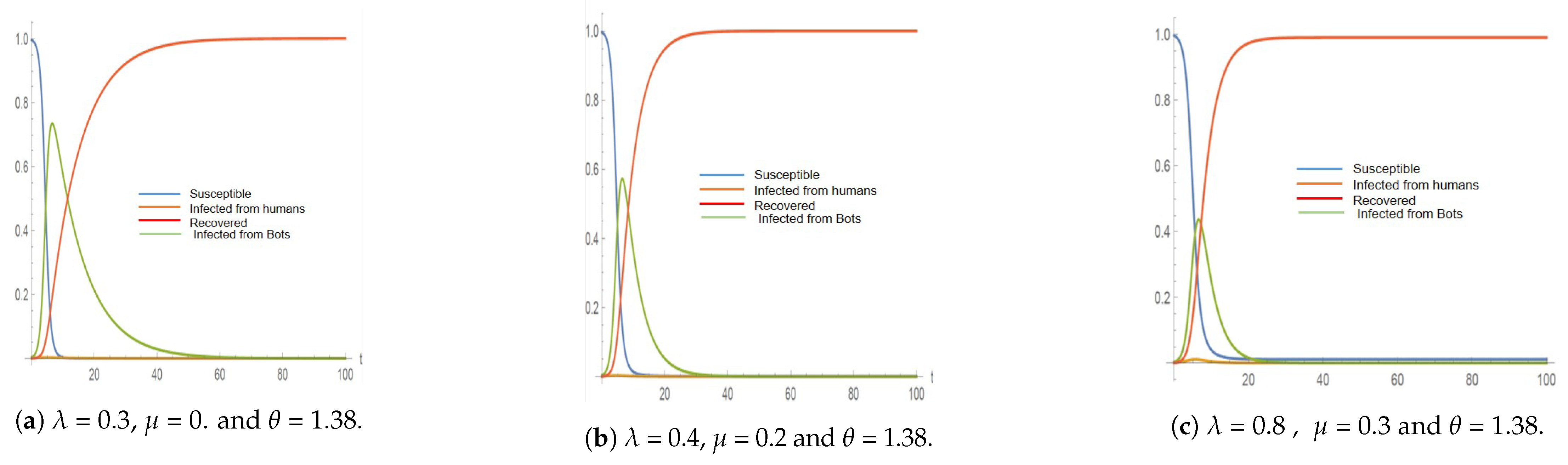
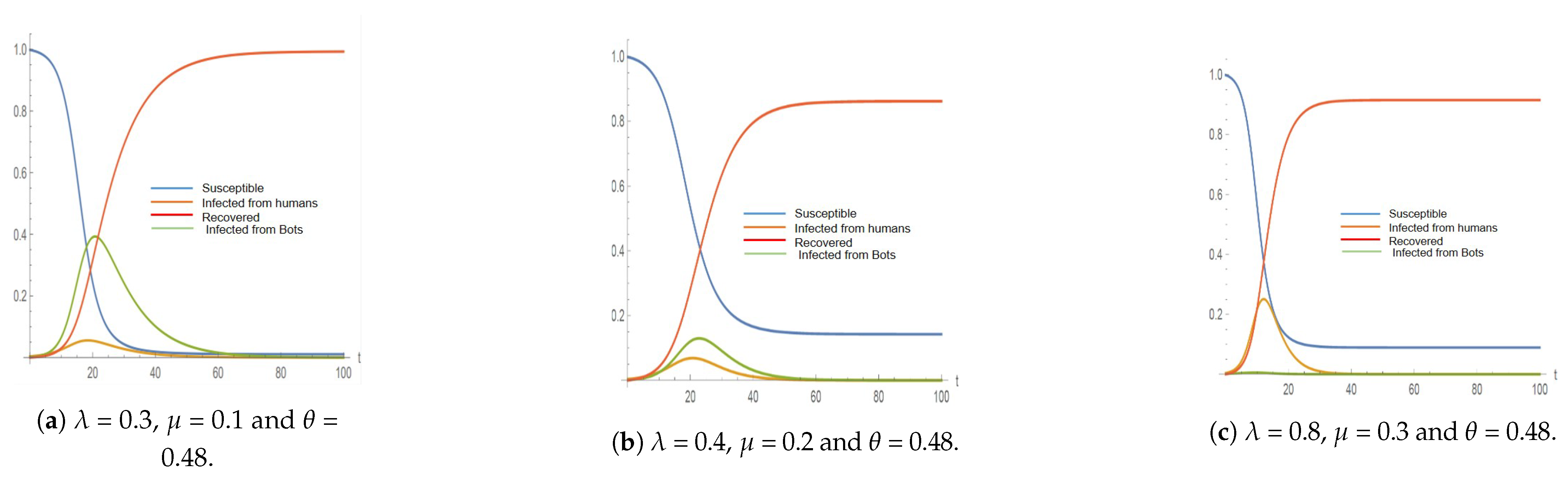
4.3. Testing the Model
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, M.; Wang, X.; Gao, K.; Zhang, S. A survey on information diffusion in online social networks: Models and methods. Information 2017, 8, 118. [Google Scholar] [CrossRef] [Green Version]
- Andriotis, P.; Takasu, A. Emotional bots: Content-based spammer detection on social media. In Proceedings of the 2018 IEEE international workshop on information forensics and security (WIFS), Hong Kong, China, 11–13 December 2018; pp. 1–8. [Google Scholar]
- Jin, F.; Dougherty, E.; Saraf, P.; Cao, Y.; Ramakrishnan, N. Epidemiological modeling of news and rumors on twitter. In Proceedings of the 7th Workshop on Social Network Mining and Analysis, Chicago, IL, USA, 11 August 2013; pp. 1–9. [Google Scholar]
- Razaque, A.; Rizvi, S.; Almiani, M.; Al Rahayfeh, A. State-of-art review of information diffusion models and their impact on social network vulnerabilities. J. King Saud Univ.-Comput. Inf. Sci. 2019, 34, 1275–1294. [Google Scholar] [CrossRef]
- Cresci, S.; Di Pietro, R.; Petrocchi, M.; Spognardi, A.; Tesconi, M. The paradigm-shift of social spambots: Evidence, theories, and tools for the arms race. In Proceedings of the 26th International Conference on World Wide Web Companion, Perth, Australia, 3–7 April 2017; pp. 963–972. [Google Scholar]
- Ferrara, E. Measuring social spam and the effect of bots on information diffusion in social media. In Complex Spreading Phenomena in Social Systems; Springer: Berlin/Heidelberg, Germany, 2018; pp. 229–255. [Google Scholar]
- Pozzana, I.; Ferrara, E. Measuring Bot and Human Behavioral Dynamics; Frontiers in Physics: Lausanne, Switzerland, 2020; p. 125. [Google Scholar]
- Chang, H.C.H.; Chen, E.; Zhang, M.; Muric, G.; Ferrara, E. Social bots and social media manipulation in 2020: The year in review. In Handbook of Computational Social Science; Routledge: Abingdon, UK, 2021; Volume 1, pp. 304–323. [Google Scholar]
- Santini, R.M.; Salles, D.; Tucci, G.; Ferreira, F.; Grael, F. Making up audience: Media bots and the falsification of the public sphere. Commun. Stud. 2020, 71, 466–487. [Google Scholar] [CrossRef]
- Li, H.; Xia, C.; Wang, T.; Wen, S.; Chen, C.; Xiang, Y. Capturing Dynamics of Information Diffusion in SNS: A Survey of Methodology and Techniques. ACM Comput. Surv. (CSUR) 2021, 55, 1–51. [Google Scholar] [CrossRef]
- Wei, Z.; Yanqing, Y.; Hanlin, T.; Qiwei, D.; Taowei, L. Information diffusion model based on social network. In Proceedings of the 2012 International Conference of Modern Computer Science and Applications, San Francisco, CA, USA, 24–26 October 2012; Springer: Berlin/Heidelberg, Germany, 2013; pp. 145–150. [Google Scholar]
- Safari, R.M.; Rahmani, A.M.; Alizadeh, S.H. User behavior mining on social media: A systematic literature review. Multimed. Tools Appl. 2019, 78, 33747–33804. [Google Scholar] [CrossRef]
- Yang, T.; Jin, R.; Chi, Y.; Zhu, S. Combining link and content for community detection: A discriminative approach. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Moscow, Russia, 23–25 January 2009; pp. 927–936. [Google Scholar]
- Jung, K.; Heo, W.; Chen, W. Irie: Scalable and robust influence maximization in social networks. In Proceedings of the 2012 IEEE 12th International Conference on Data Mining, Brussels, Belgium, 10–13 December 2012; pp. 918–923. [Google Scholar]
- D’Angelo, G.; Severini, L.; Velaj, Y. Influence Maximization in the Independent Cascade Model. In Proceedings of the ICTCS, Lecce, Italy, 7–9 September 2016; Volume 1, pp. 269–274. Available online: https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=7780d9796c0041c9b6ba8ad7b5afbd7b6d25e4d2 (accessed on 1 September 2021).
- Shakarian, P.; Bhatnagar, A.; Aleali, A.; Shaabani, E.; Guo, R. The independent cascade and linear threshold models. In Diffusion in Social Networks; Springer: Berlin/Heidelberg, Germany, 2015; pp. 35–48. [Google Scholar]
- Liu, X.; Li, T.; Tian, M. Rumor spreading of a SEIR model in complex social networks with hesitating mechanism. Adv. Differ. Equa. 2018, 2018, 1–24. [Google Scholar] [CrossRef] [Green Version]
- Xiao, Y.; Chen, D.; Wei, S.; Li, Q.; Wang, H.; Xu, M. Rumor propagation dynamic model based on evolutionary game and anti-rumor. Nonlinear Dyn. 2019, 95, 523–539. [Google Scholar] [CrossRef]
- Wang, C.; Guan, X.; Qin, T.; Zhou, Y. Modelling on opinion leader’s influence in microblog message propagation and its application. J. Softw. 2015, 26, 1473–1485. [Google Scholar]
- Yin, F.; Xia, X.; Song, N.; Zhu, L.; Wu, J. Quantify the role of superspreaders-opinion leaders-on COVID-19 information propagation in the Chinese Sina-microblog. PLoS ONE 2020, 15, e0234023. [Google Scholar] [CrossRef]
- Das, K.; Samanta, S.; Pal, M. Study on centrality measures in social networks: A survey. Soc. Netw. Anal. Min. 2018, 8, 1–11. [Google Scholar] [CrossRef]
- Weng, Z.; Lin, A. Public Opinion Manipulation on Social Media: Social Network Analysis of Twitter Bots during the COVID-19 Pandemic. Int. J. Environ. Res. Public Health 2022, 19, 16376. [Google Scholar] [CrossRef] [PubMed]
- Liu, Q.; Xiang, B.; Yuan, N.J.; Chen, E.; Xiong, H.; Zheng, Y.; Yang, Y. An influence propagation view of pagerank. ACM Trans. Knowl. Discov. Data (TKDD) 2017, 11, 1–30. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Hou, X.; Li, K.; Ding, Y. A novel weight neighborhood centrality algorithm for identifying influential spreaders in complex networks. Phys. A Stat. Mech. Its Appl. 2017, 475, 88–105. [Google Scholar] [CrossRef]
- Cai, M.; Luo, H.; Meng, X.; Cui, Y. Differences in Behavioral Characteristics and Diffusion Mechanisms: A Comparative Analysis Based on Social Bots and Human Users; Frontiers in Physics: Lausanne, Switzerland, 2022; p. 343. [Google Scholar]
- Adegbola, I.; Jimoh, R. Spambot detection: A review of techniques and trends. Network 2014, 6, 9. [Google Scholar]
- Guzmán Rincón, A.; Carrillo Barbosa, R.L.; Segovia-García, N.; Africano Franco, D.R. Disinformation in social networks and bots: Simulated scenarios of its spread from system dynamics. Systems 2022, 10, 34. [Google Scholar] [CrossRef]
- Paudel, P.; Nguyen, T.T.; Hatua, A.; Sung, A.H. How the tables have turned: Studying the new wave of social bots on Twitter using complex network analysis techniques. In Proceedings of the 2019 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Vancouver, BC, Canada, 27–30 August 2019; pp. 501–508. [Google Scholar]
- Schuchard, R.; Crooks, A.T.; Stefanidis, A.; Croitoru, A. Bot stamina: Examining the influence and staying power of bots in online social networks. Appl. Netw. Sci. 2019, 4, 1–23. [Google Scholar] [CrossRef] [Green Version]
- Suárez-Serrato, P.; Roberts, M.E.; Davis, C.; Menczer, F. On the influence of social bots in online protests. In International Conference on Social Informatics; Springer: Berlin/Heidelberg, Germany, 2016; pp. 269–278. [Google Scholar]
- Cai, M.; Luo, H.; Meng, X.; Cui, Y.; Wang, W. Network distribution and sentiment interaction: Information diffusion mechanisms between social bots and human users on social media. Inf. Process. Manag. 2023, 60, 103197. [Google Scholar] [CrossRef]
- Mullen, B.; Goethals, G.R. Theories of Group Behavior; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Hu, Y.; Pan, Q.; Hou, W.; He, M. Rumor spreading model with the different attitudes towards rumors. Phys. A Stat. Mech. Its Appl. 2018, 502, 331–344. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, F.; Koura, Y.H.; Wang, H. Analysing rumours spreading considering self-purification mechanism. Connect. Sci. 2021, 33, 81–94. [Google Scholar] [CrossRef]
- Wang, T.; He, J.; Wang, X. An information spreading model based on online social networks. Phys. A Stat. Mech. Its Appl. 2018, 490, 488–496. [Google Scholar] [CrossRef]
- Choi, S.H.; Seo, H.; Yoo, M. A multi-stage SIR model for rumor spreading. Discret. Contin. Dyn. Syst.-B 2020, 25, 2351. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Wang, H.; Wang, C.; Fang, H. Modeling epidemics spreading on social contact networks. IEEE Trans. Emerg. Top. Comput. 2015, 3, 410–419. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Meel, P.; Vishwakarma, D.K. Fake news, rumor, information pollution in social media and web: A contemporary survey of state-of-the-arts, challenges and opportunities. Expert Syst. Appl. 2020, 153, 112986. [Google Scholar] [CrossRef]
- Yujie, Y. A Survey on Information Diffusion in Online Social Networks. In Proceedings of the 2020 European Symposium on Software Engineering, Rome, Italy, 6–8 November 2020; pp. 181–186. [Google Scholar]
- Cannarella, J.; Spechler, J.A. Epidemiological modeling of online social network dynamics. arXiv 2014, arXiv:1401.4208. [Google Scholar]
- Hosseini, S.; Zandvakili, A. The SEIRS-C model of information diffusion based on rumour spreading with fuzzy logic in social networks. Int. J. Comput. Math. 2022, 99, 1918–1940. [Google Scholar] [CrossRef]
- Liu, X.; Li, T.; Xu, H.; Liu, W. Spreading dynamics of an online social information model on scale-free networks. Phys. A Stat. Mech. Its Appl. 2019, 514, 497–510. [Google Scholar] [CrossRef]
- Zhao, L.; Wang, J.; Chen, Y.; Wang, Q.; Cheng, J.; Cui, H. SIHR rumor spreading model in social networks. Phys. A Stat. Mech. Its Appl. 2012, 391, 2444–2453. [Google Scholar] [CrossRef]
- Rui, X.; Meng, F.; Wang, Z.; Yuan, G.; Du, C. SPIR: The potential spreaders involved SIR model for information diffusion in social networks. Phys. A Stat. Mech. Its Appl. 2018, 506, 254–269. [Google Scholar] [CrossRef]
- Yang, A.; Huang, X.; Cai, X.; Zhu, X.; Lu, L. ILSR rumor spreading model with degree in complex network. Phys. A Stat. Mech. Its Appl. 2019, 531, 121807. [Google Scholar] [CrossRef]
- Zan, Y.; Wu, J.; Li, P.; Yu, Q. SICR rumor spreading model in complex networks: Counterattack and self-resistance. Phys. A Stat. Mech. Its Appl. 2014, 405, 159–170. [Google Scholar] [CrossRef]
- Qian, Z.; Tang, S.; Zhang, X.; Zheng, Z. The independent spreaders involved SIR rumor model in complex networks. Phys. A Stat. Mech. Its Appl. 2015, 429, 95–102. [Google Scholar] [CrossRef]
- Zhao, J.; Wang, L. Research on Public Opinion Propagation in Micro-Blogging Based on Epidemic Models. In Proceedings of the ISCRAM, Rio de Janeiro, Brasil, 22–25 May 2016. [Google Scholar]
- Feng, L.; Hu, Y.; Li, B.; Stanley, H.E.; Havlin, S.; Braunstein, L.A. Competing for attention in social media under information overload conditions. PLoS ONE 2015, 10, e0126090. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, J.; Zhao, L.; Huang, R. SIRaRu rumor spreading model in complex networks. Phys. A Stat. Mech. Its Appl. 2014, 398, 43–55. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, B.; Wu, B.; Shang, S.; Zhang, Y.; Shi, C. Characterizing super-spreading in microblog: An epidemic-based information propagation model. Phys. A Stat. Mech. Its Appl. 2016, 463, 202–218. [Google Scholar] [CrossRef] [PubMed]
- Li, K.; Zhang, L.; Huang, H. Social influence analysis: Models, methods, and evaluation. Engineering 2018, 4, 40–46. [Google Scholar] [CrossRef]
- Alshahrani, M.; Fuxi, Z.; Sameh, A.; Mekouar, S.; Huang, S. Efficient algorithms based on centrality measures for identification of top-K influential users in social networks. Inf. Sci. 2020, 527, 88–107. [Google Scholar] [CrossRef]
- Zhao, J.; Song, Y.; Deng, Y. A novel model to identify the influential nodes: Evidence Theory Centrality. IEEE Access 2020, 8, 46773–46780. [Google Scholar] [CrossRef]
- Nettle, D. Using social impact theory to simulate language change. Lingua 1999, 108, 95–117. [Google Scholar] [CrossRef] [Green Version]
- Baumeister, R.F. Encyclopedia of Social Psychology; Sage: Thousand Oaks, CA, USA, 2007; Volume 1. [Google Scholar]
- Harton, H.C.; Bullock, M. Dynamic social impact: A theory of the origins and evolution of culture. Soc. Personal. Psychol. Compass 2007, 1, 521–540. [Google Scholar] [CrossRef]
- Bogacki, P.; Shampine, L.F. An efficient runge-kutta (4, 5) pair. Comput. Math. Appl. 1996, 32, 15–28. [Google Scholar] [CrossRef] [Green Version]
- Abd-Elhamed, A.; Fathy, M.; Abdelgaber, K.M. Numerical Analysis of Laterally Loaded Long Piles in Cohesionless Soil. Cmc-Comput. Mater. Contin. 2022, 71, 2175–2190. [Google Scholar] [CrossRef]







| Symbol | Description |
|---|---|
| s(t) | The number of susceptible accounts at a specific time. |
| The infected real accounts. | |
| The number of infected bot accounts. | |
| r(t) | The number of recovered accounts. |
| The infection rate for real accounts. | |
| The infection rate for bot accounts. | |
| Susceptible accounts transform to be infected accounts due to the existence of infected real accounts. | |
| Susceptible accounts transform to be infected accounts due to the existence of infected bot accounts. | |
| The recovery rate. | |
| The number of recovered accounts. | |
| The impact of a person on a target group. | |
| b | The possibility of bias in expressing the belief. |
| N | The number of people in the influence group |
| a | This means that the persuasion of a specific belief does not increase linearly with the number of people holding it. |
| The number of followers for an account. | |
| The distance (number of hubs) between the source and the target. | |
| B | The number of bot accounts (constant number). |
| Year | Initial Infected | Total Number of Infected Accounts | Days | ||
|---|---|---|---|---|---|
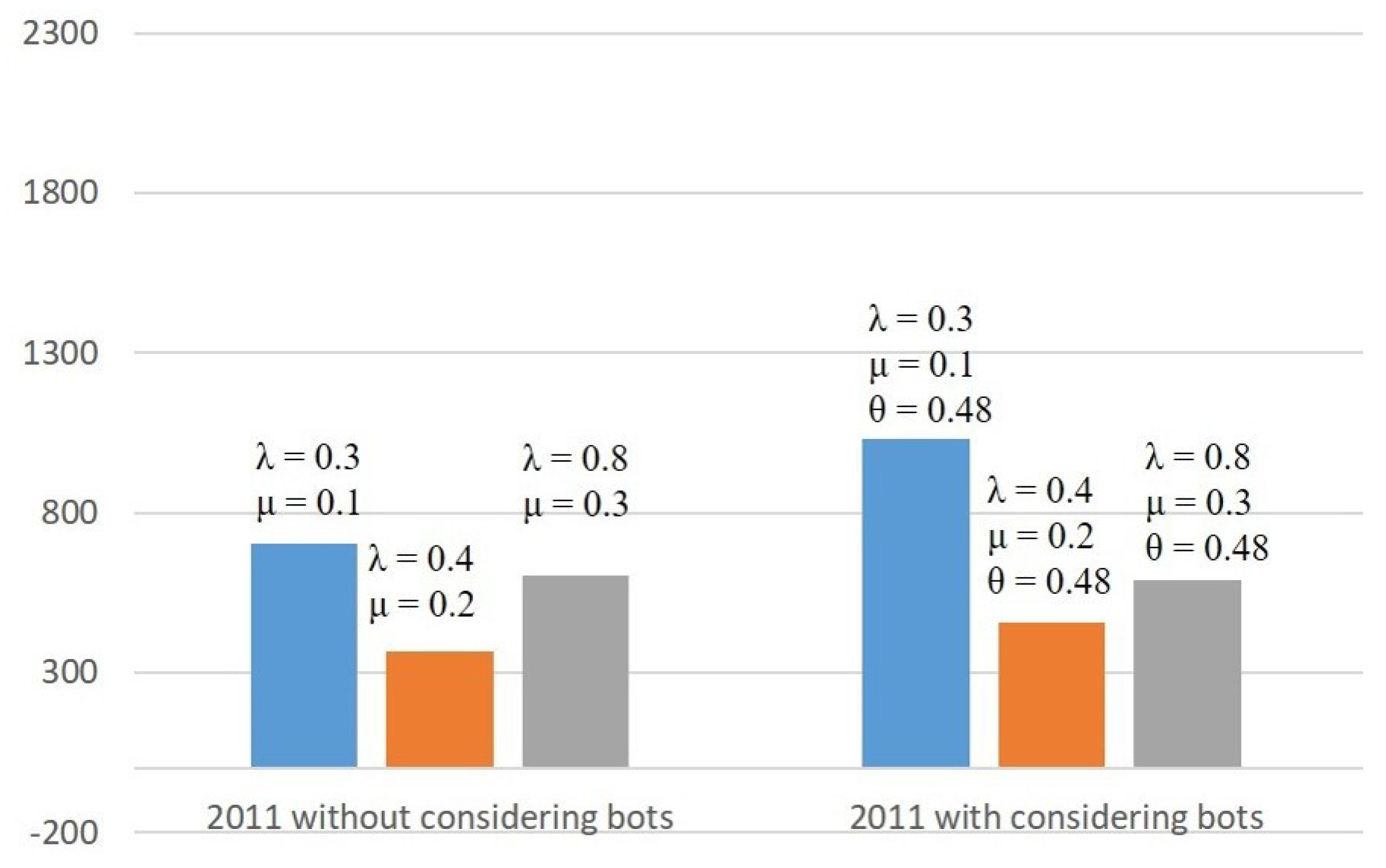
| 2011 | 9 Real Accounts | 0.3 | 0.1 | 704 | 30 |
| 4 Bot Accounts | 0.4 | 0.2 | 365 | 30 | |
| 0.8 | 0.3 | 604 | 12 | ||
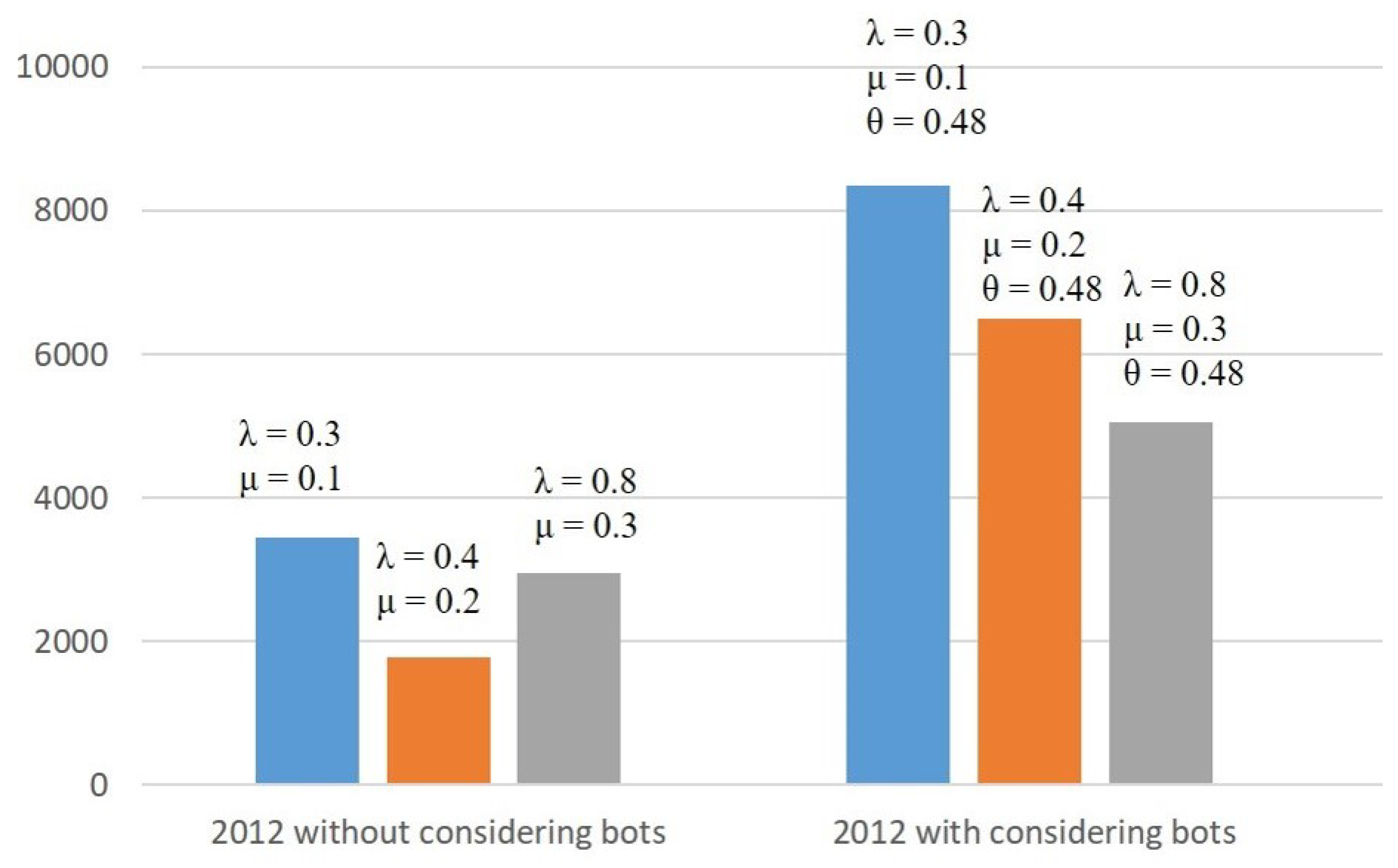
| 2012 | 16 Real Accounts | 0.3 | 0.1 | 3448 | 30 |
| 37 Bot Accounts | 0.4 | 0.2 | 1786 | 31 | |
| 0.8 | 0.3 | 2959 | 12 |
| Year | Initial Infected | Num of | Num of | Total Num of I | Days | |||
|---|---|---|---|---|---|---|---|---|
| 2011 | 9 Real Accounts | 0.3 | 0.1 | 0.48 | 904 | 128 | 1032 | 20 |
| 4 Bot Accounts | 0.4 | 0.2 | 0.48 | 298 | 158 | 456 | 22 | |
| 0.8 | 0.3 | 0.48 | 13 | 576 | 589 | 12 | ||
| 2012 | 16 Real Accounts | 0.3 | 0.1 | 1.38 | 8306 | 33 | 8359 | 7 |
| 37 Bot Accounts | 0.4 | 0.2 | 1.38 | 6467 | 32 | 6499 | 7 | |
| 0.8 | 0.3 | 1.38 | 4937 | 126 | 5063 | 6.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fahmy, S.G.; Abdelgaber, K.M.; Karam, O.H.; Elzanfaly, D.S. Modeling the Influence of Fake Accounts on User Behavior and Information Diffusion in Online Social Networks. Informatics 2023, 10, 27. https://doi.org/10.3390/informatics10010027
Fahmy SG, Abdelgaber KM, Karam OH, Elzanfaly DS. Modeling the Influence of Fake Accounts on User Behavior and Information Diffusion in Online Social Networks. Informatics. 2023; 10(1):27. https://doi.org/10.3390/informatics10010027
Chicago/Turabian StyleFahmy, Sara G., Khaled M. Abdelgaber, Omar H. Karam, and Doaa S. Elzanfaly. 2023. "Modeling the Influence of Fake Accounts on User Behavior and Information Diffusion in Online Social Networks" Informatics 10, no. 1: 27. https://doi.org/10.3390/informatics10010027