
Analysis of Soft Skills and Job Level with Data Science: A Case for Graduates of a Private University


Abstract
:1. Introduction
2. Review of Related Studies
3. Materials and Methods
3.1. Sample
3.2. Instrument and Measures
3.2.1. Input Features
3.2.2. Target Variable
3.3. Data Analysis
- is true positive
- is true negative
- is false positive
- is false negative.
4. Results
4.1. Correlational Analysis and Chi-Squared Test
4.2. Supervised Learning Models
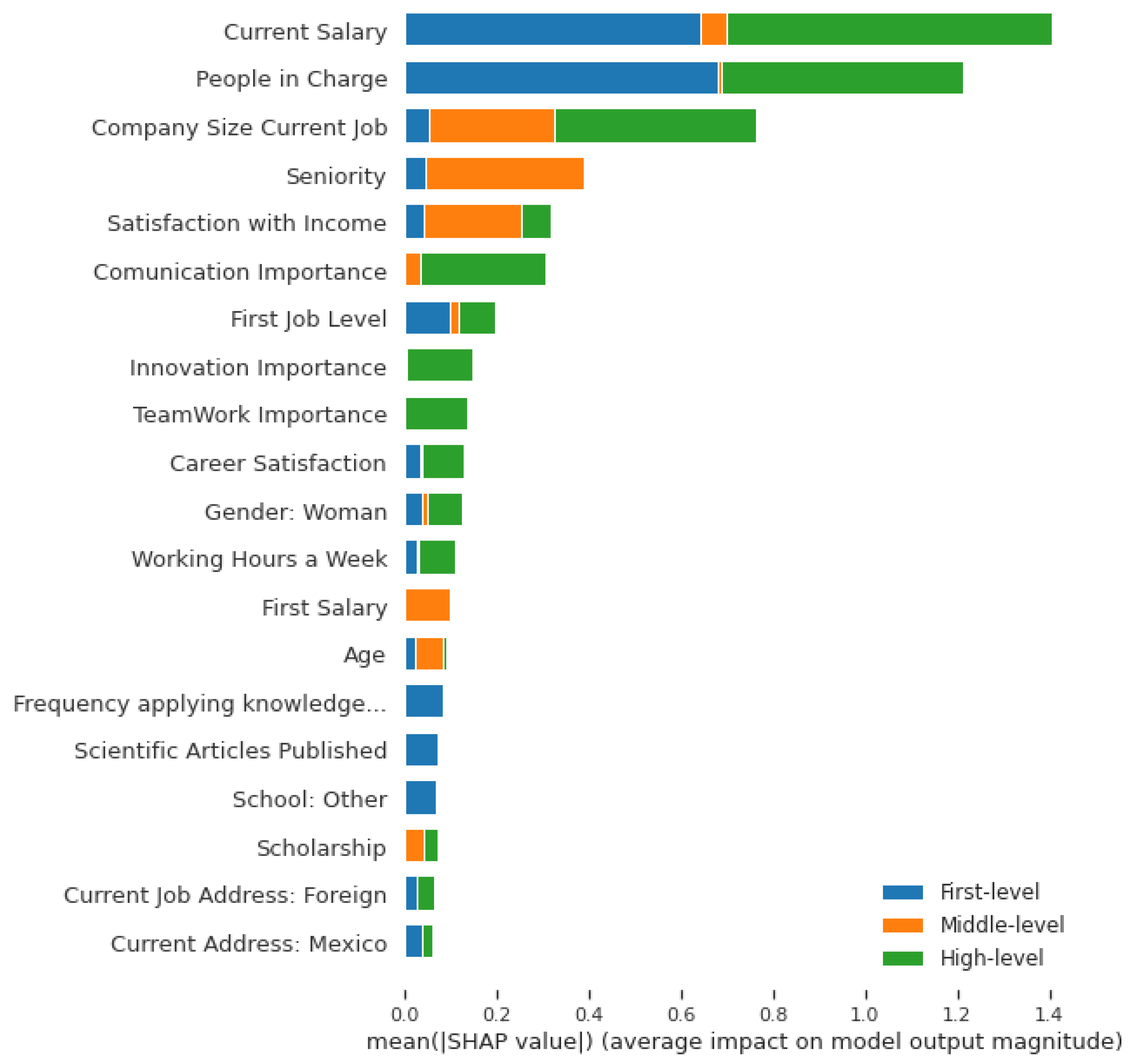
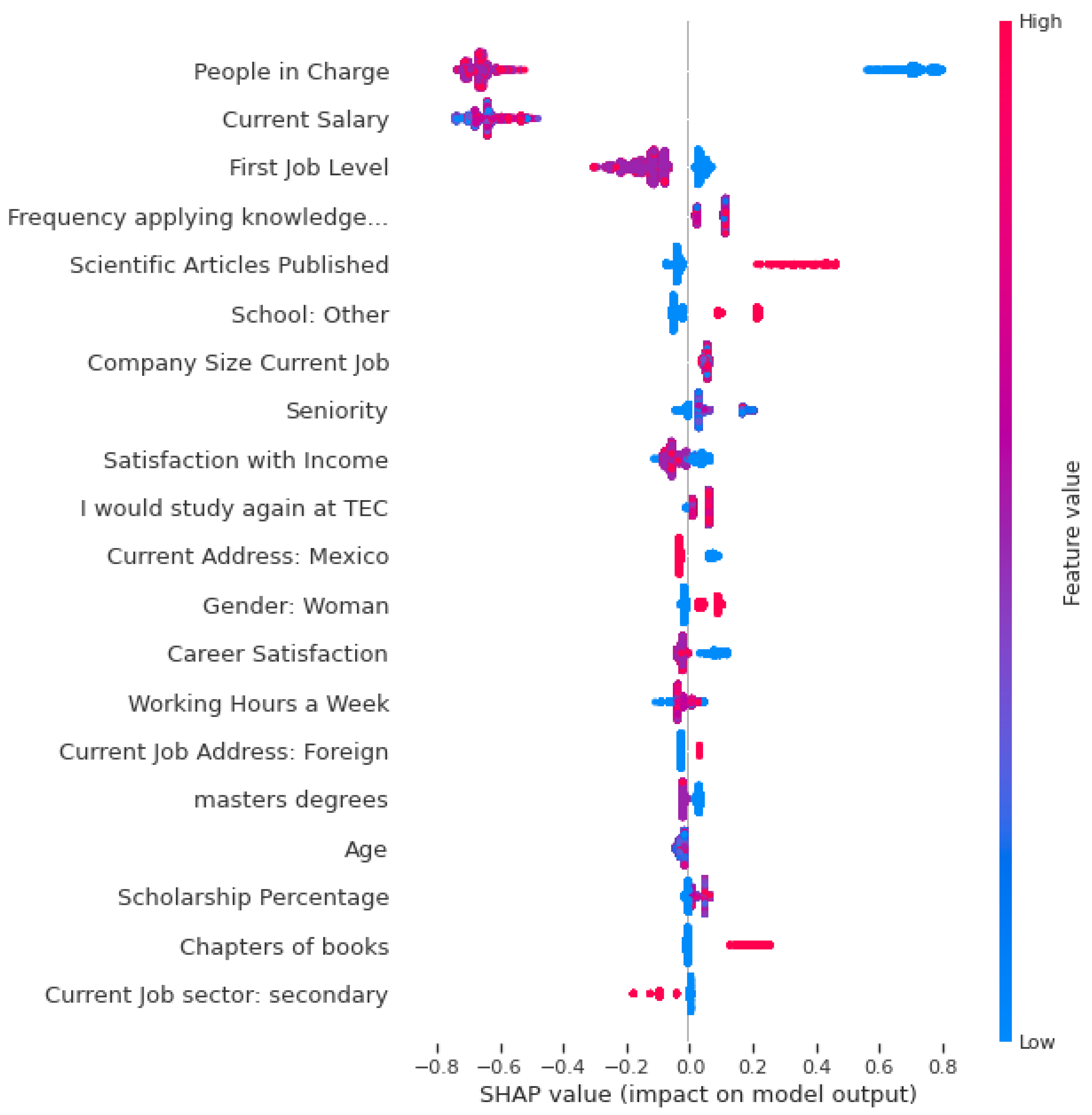
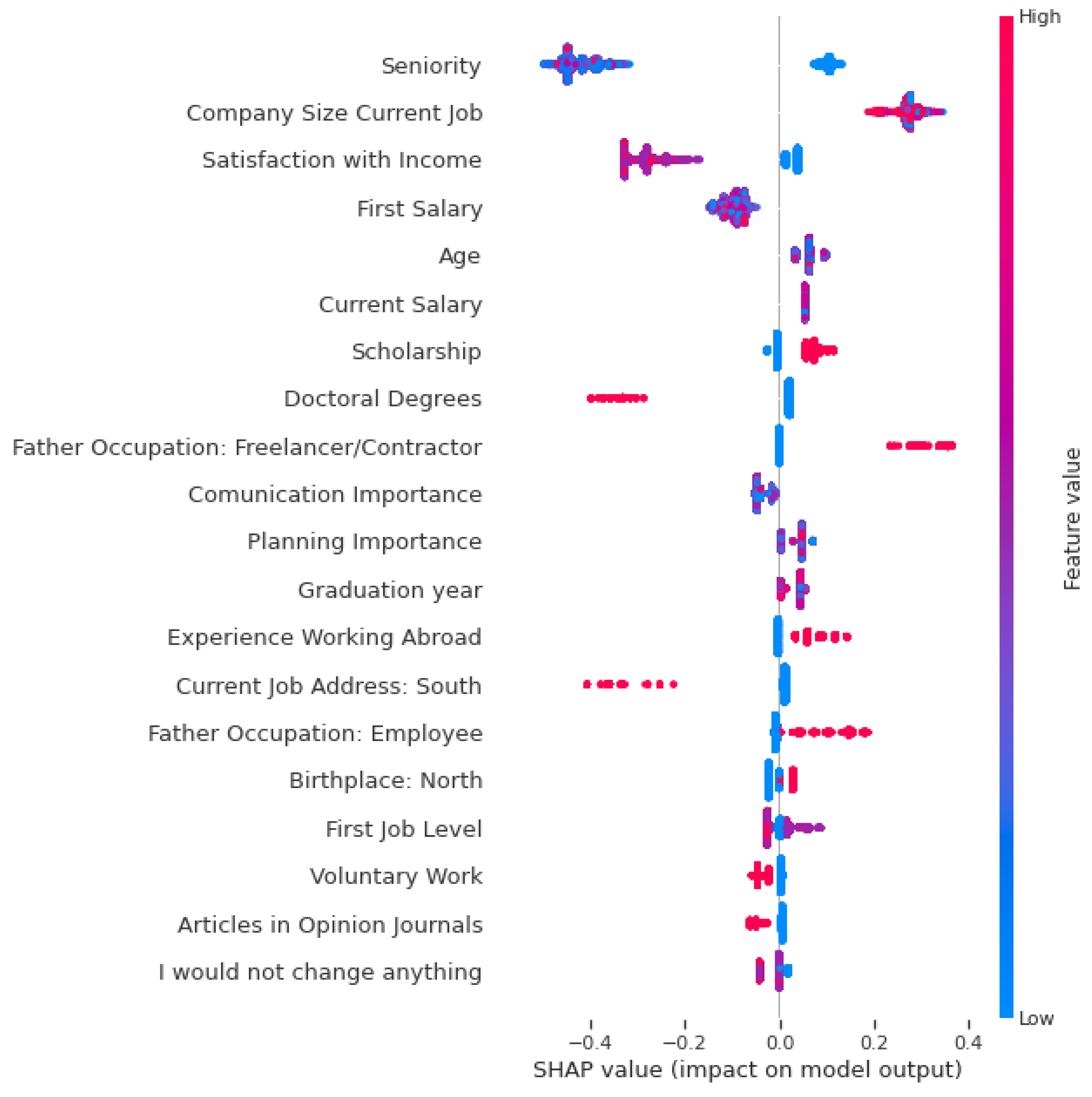
5. Important Features with Gradient Boosting
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| DT | Decision trees |
| GB | Gradient boosting |
| RF | Random Forest |
| LR | Logistic Regression |
| OLR | Ordinal Logistic Regression |
| SHAP | SHapley Additive exPlanations |
| Acc | Accuracy |
| CV | Cross Validation |
| ROC | Receiver operating characteristics |
Appendix A

References
- Alumni Impact Survey. Available online: https://alumni.utoronto.ca/alumni-impact-survey (accessed on 11 November 2022).
- All Alumni: Impact of MIT. Available online: https://ir.mit.edu/all-alumni-impact-of-mit (accessed on 11 November 2022).
- Alumni Surveys. Available online: https://www.hedsconsortium.org/heds-alumni-survey/ (accessed on 11 November 2022).
- Greenhaus, J.H.; Callanan, G.A. Career Dynamics; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2013; Volume 12. [Google Scholar]
- April Chang, W.J.; Chun Huang, T. The distinctive effects of earnings determinants across different job levels. Int. J. Hum. Resour. Manag. 2005, 16, 2094–2112. [Google Scholar] [CrossRef]
- Baker, G.; Gibbs, M.; Holmstrom, B. The internal economics of the firm: Evidence from personnel data. Q. J. Econ. 1994, 109, 881–919. [Google Scholar] [CrossRef]
- Tourangeau, R.; Yan, T. Sensitive questions in surveys. Psychol. Bull. 2007, 133, 859. [Google Scholar] [CrossRef] [PubMed]
- Job Levels in the Workplace. Available online: https://www.indeed.com/career-advice/career-development/job-level (accessed on 17 November 2022).
- Gomez-Cravioto, D.A.; Diaz-Ramos, R.E.; Hernandez-Gress, N.; Preciado, J.L.; Ceballos, H.G. Supervised machine learning predictive analytics for alumni income. J. Big Data 2022, 9, 1–31. [Google Scholar] [CrossRef]
- Chernik, D.A.; Phelan, J.G. Attitudes of women in management: I. Job satisfaction: A study of perceived need satisfaction as a function of job level. Int. J. Soc. Psychiatry 1974, 20, 94–98. [Google Scholar] [CrossRef]
- Sawyer, J.E. Measuring attitudes across job levels: When are scale scores truly comparable? Organ. Behav. Hum. Decis. Process. 1988, 42, 324–342. [Google Scholar] [CrossRef]
- Robie, C.; Ryan, A.M.; Schmieder, R.A.; Parra, L.F.; Smith, P.C. The relation between job level and job satisfaction. Group Organ. Manag. 1998, 23, 470–495. [Google Scholar] [CrossRef]
- Huang, X.; Vliert, E.V.D. Job level and national culture as joint roots of job satisfaction. Appl. Psychol. 2004, 53, 329–348. [Google Scholar] [CrossRef]
- Aronson, K.R.; Laurenceau, J.P.; Sieveking, N.; Bellet, W. Job satisfaction as a function of job level. Admin. Policy Ment. Health 2005, 32, 285. [Google Scholar] [CrossRef]
- Kim, W.H.; Ra, Y.A.; Park, J.G.; Kwon, B. Role of burnout on job level, job satisfaction, and task performance. Leadersh Organ. Dev. J. 2017, 38, 630–645. [Google Scholar] [CrossRef]
- Kerber, K.W.; Campbell, J.P. Component structure of a measure of job facet satisfaction: Stability across job levels. Educ. Psychol. Meas. 1987, 47, 825–835. [Google Scholar] [CrossRef]
- DiRenzo, M.S.; Greenhaus, J.H.; Weer, C.H. Job level, demands, and resources as antecedents of work–family conflict. J. Vocat. Behav. 2011, 78, 305–314. [Google Scholar] [CrossRef]
- Cole, P.L.; Secret, M.C. Factors associated with work–family conflict stress among African American women. Soc. Work Public Health 2012, 27, 307–329. [Google Scholar] [CrossRef] [PubMed]
- Basford, T.E.; Offermann, L.R. Beyond leadership: The impact of coworker relationships on employee motivation and intent to stay. J. Manag. Organ. 2012, 18, 807–817. [Google Scholar] [CrossRef]
- Verheyen, T.; Deschacht, N.; Guerry, M.A. The occurrence of demotions regarding job level, salary and job authority. Pers. Rev. 2016, 45, 1217–1239. [Google Scholar] [CrossRef]
- Porter, L.W. Job attitudes in management: II. Perceived importance of needs as a function of job level. J. Appl. Psychol. 1963, 47, 141. [Google Scholar] [CrossRef]
- Sypher, B.D.; Zorn, T.E., Jr. Communication-related abilities and upward mobility: A longitudinal investigation. Hum. Commun. Res. 1986, 12, 420–431. [Google Scholar] [CrossRef]
- Miles, E.W.; Patrick, S.L.; King, W.C., Jr. Job level as a systemic variable in predicting the relationship between supervisory communication and job satisfaction. J. Occup. Organ. Psychol. 1996, 69, 277–292. [Google Scholar] [CrossRef]
- Mainert, J.; Kretzschmar, A.; Neubert, J.C.; Greiff, S. Linking complex problem solving and general mental ability to career advancement: Does a transversal skill reveal incremental predictive validity? Int. J. Lifelong Educ. 2015, 34, 393–411. [Google Scholar] [CrossRef]
- Gøtzsche-Astrup, O.; Jakobsen, J.; Furnham, A. The higher you climb: Dark side personality and job level. Scand. J. Psychol. 2016, 57, 535–541. [Google Scholar] [CrossRef]
- MBA for Executives. Available online: https://executivemba.wharton.upenn.edu/top-executive-management-skills-needed-in-the-c-suite/martech-su-form-wrapper (accessed on 17 November 2022).
- Senior Leadership Skills: What Experienced Leaders Need to Know to Succeed. Available online: https://www.ccl.org/articles/leading-effectively-articles/senior-level-trade-offs-what-experienced-leaders-need-to-know/ (accessed on 18 November 2022).
- What Are the Important Skill Sets for Senior Management Roles? Available online: https://www.linkedin.com/pulse/what-important-skill-sets-senior-management-roles-amit-mundra/ (accessed on 18 November 2022).
- Ghiselli, E.E. Traits Differentiating Management Personnel. Wiley Online Libr. 1959, 12, 535–544. [Google Scholar] [CrossRef]
- Kingsford, C.; Salzberg, S.L. What are decision trees? Nat. Biotechnol. 2008, 26, 1011–1013. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning; Springer: New York, NY, USA, 2013; Volume 112. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Wang, M.; Zheng, K.; Yang, Y.; Wang, X. An explainable machine learning framework for intrusion detection systems. IEEE Access 2020, 8, 73127–73141. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. Adv. Neural Inf. Process. Syst. 2017, arXiv:1705.07874v2. [Google Scholar]
- Lundberg, S.M.; Erion, G.G.; Lee, S.I. Consistent individualized feature attribution for tree ensembles. arXiv 2018, arXiv:1802.03888. [Google Scholar]
- Lundberg, S.M.; Scott, M.; Erion, G.; Chen, H.; DeGrave, A.; Prutkin, J.M.; Nair, B.; Katz, R.; Himmelfarb, J.; Bansal, N.; et al. From local explanations to global understanding with explainable AI for trees. Nat. Mach. Intell. 2020, 2, 2522–5839. [Google Scholar] [CrossRef]
- Back, A.L.; Arnold, R.M.; Baile, W.F.; Fryer-Edwards, K.A.; Alexander, S.C.; Barley, G.E.; Gooley, T.A.; Tulsky, J.A. Efficacy of communication skills training for giving bad news and discussing transitions to palliative care. Arch. Intern. Med. 2007, 167, 453–460. [Google Scholar] [CrossRef] [PubMed]
- Fallowfield, L.; Jenkins, V.; Farewell, V.; Solis-Trapala, I. Enduring impact of communication skills training: Results of a 12-month follow-up. Br. J. Cancer 2003, 89, 1445–1449. [Google Scholar] [CrossRef] [PubMed]
- Shuman, L.J.; Besterfield-Sacre, M.; McGourty, J. The ABET “professional skills”—Can they be taught? Can they be assessed? J. Eng. Educ. 2005, 94, 41–55. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metric/Model | Correlation | p-Value | p-Value | |
|---|---|---|---|---|
| People in charge | 0.41 | 0.00 *** | 2161.2 | 0.00 *** |
| Current salary | 0.38 | 0.00 *** | 2005.8 | 0.00 *** |
| Company size | −0.29 | *** | 1991.1 | 0.00 *** |
| First salary | 0.17 | *** | 402.6 | *** |
| Career satisfaction | 0.17 | *** | 403.8 | *** |
| Income satisfaction | 0.17 | *** | 394.8 | *** |
| Working hours a week | 0.15 | *** | 833.8 | *** |
| Job Levels | Current Salary | People in Charge | |||||
|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 1 | 2 | 3 | |
| First | 65% | 39% | 26% | 12% | 66% | 31% | 15% |
| Middle | 19% | 40% | 37% | 37% | 26% | 38% | 35% |
| High | 16% | 21% | 37% | 51% | 8% | 31% | 50% |
| Metric/Model | DT | GB | RF | LR | OR |
|---|---|---|---|---|---|
| Accuracy | 0.61 | 0.67 | 0.62 | 0.63 | 0.61 |
| Precision | 0.61 | 0.67 | 0.62 | 0.63 | 0.61 |
| Recall | 0.62 | 0.67 | 0.62 | 0.63 | 0.61 |
| F1 | 0.61 | 0.67 | 0.62 | 0.63 | 0.61 |
| AUC | 0.78 | 0.83 | 0.80 | 0.80 | 0.78 |
| Features | Job Level | Features | Job Level | ||||||
|---|---|---|---|---|---|---|---|---|---|
| First | Middle | High | First | Middle | High | ||||
| Salary | 65% | 19% | 16% | Company size | 27% | 12% | 61% | ||
| 39% | 40% | 21% | 21% | 26% | 53% | ||||
| 26% | 37% | 27% | 38% | 38% | 24% | ||||
| 12% | 37% | 51% | ≥100 | 41% | 42% | 17% | |||
| Communication imp | 1 | 39% | 36% | 25% | Teamwork imp | 1 | 35% | 36% | 29% |
| 2 | 38% | 36% | 26% | 2 | 35% | 36% | 29% | ||
| 3 | 37% | 36% | 27% | 3 | 38% | 35% | 27% | ||
| 4 | 31% | 29% | 40% | 4 | 33% | 30% | 27% | ||
| 5 | 28% | 30% | 42% | 5 | 35% | 31% | 34% | ||
| 6 | 15% | 28% | 57% | 6 | 32% | 26% | 43% | ||
| Innovation imp | 1 | 37% | 26% | 37% | Age | 1 | 58% | 26% | 16% |
| 2 | 33% | 31% | 36% | 2 | 35% | 40% | 25% | ||
| 3 | 37% | 34% | 29% | 3 | 27% | 36% | 37% | ||
| 4 | 34% | 34% | 32% | 4 | 28% | 27% | 45% | ||
| 5 | 36% | 37% | 27% | 5 | 28% | 27% | 46% | ||
| 6 | 34% | 38% | 28% | ||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ramos-Pulido, S.; Hernández-Gress, N.; Torres-Delgado, G. Analysis of Soft Skills and Job Level with Data Science: A Case for Graduates of a Private University. Informatics 2023, 10, 23. https://doi.org/10.3390/informatics10010023
Ramos-Pulido S, Hernández-Gress N, Torres-Delgado G. Analysis of Soft Skills and Job Level with Data Science: A Case for Graduates of a Private University. Informatics. 2023; 10(1):23. https://doi.org/10.3390/informatics10010023
Chicago/Turabian StyleRamos-Pulido, Sofía, Neil Hernández-Gress, and Gabriela Torres-Delgado. 2023. "Analysis of Soft Skills and Job Level with Data Science: A Case for Graduates of a Private University" Informatics 10, no. 1: 23. https://doi.org/10.3390/informatics10010023