
Addressing Binary Classification over Class Imbalanced Clinical Datasets Using Computationally Intelligent Techniques

 , , , , , , and
, , , , , , and 
Abstract
:1. Introduction
2. Related Works
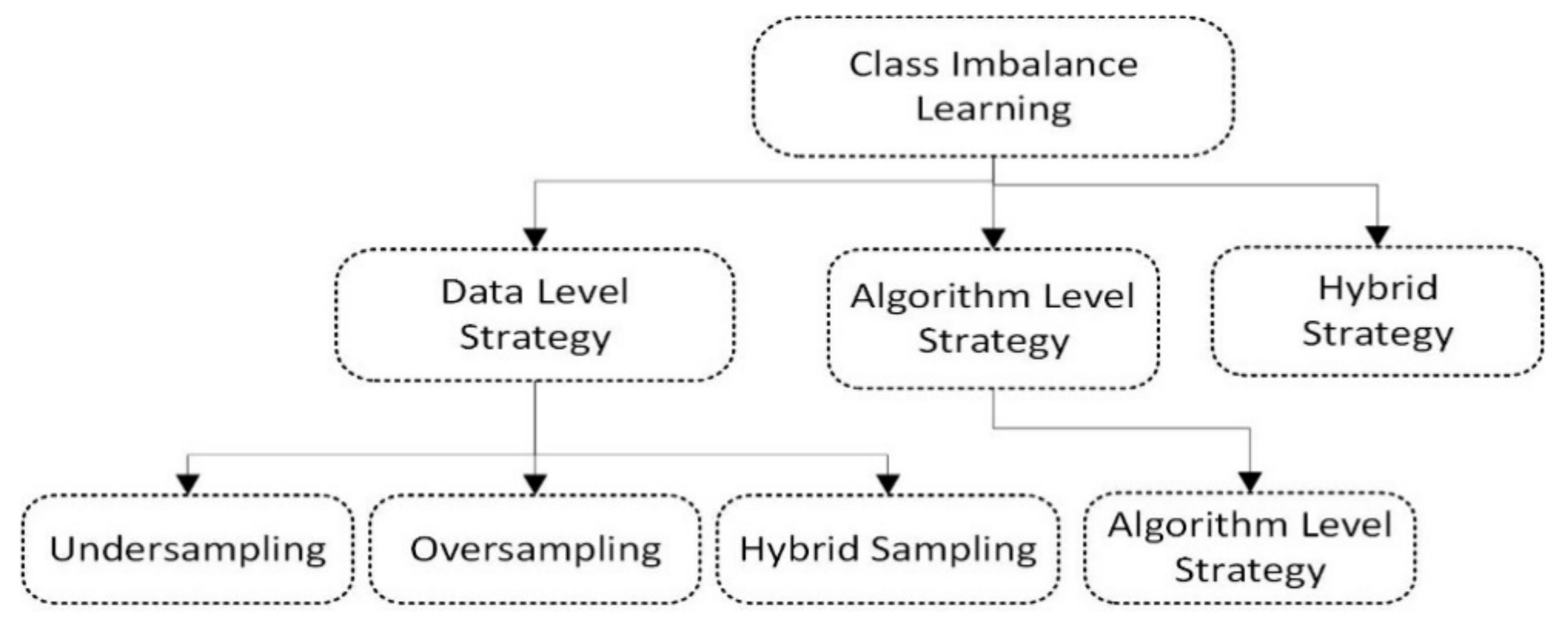
3. Description of Data-Balancing Algorithms
3.1. Undersampling
| Algorithm 1: Pseudo code for Under Sampling |
| Input: Original Training dataset 1. Select instance(xi) from the dataset (i.e., xi ∈D) 2. Randomly delete member (xi) if it belongs to the majority class in dataset 3. Continue the process until pre-set threshold is reached 4. Stop Output: Balanced Dataset |
3.2. Random Oversampling
| Algorithm 2: Pseudo code for oversampling |
| Input: Original Training dataset 1. Select instance(xi) from the dataset (i.e., xi ∈D) 2. Randomly duplicate examples in the minority class 3. Continue the process until pre-set threshold is reached 4. Stop Output: Balanced Dataset |
3.3. SMOTE
| Algorithm 3: Pseudo code of SMOTE |
| Input: X (original training data), bal (balance parameter), k (number of nearest neighbors) a set of minority samples in X a set of majority samples in X a set of synthesized minority samples */ do to G do 6.3 End For 7. End For |
3.4. ADASYN
| Algorithm 4: Pseudo code for ADAYSN method |
| Input: X (original training data), bal (balance parameter), k (number of nearest neighbors) a set of minority samples in X a set of majority samples in X 5. End for 7. End For 11. End For Output: X′ (new training data) |
3.5. SVM-SMOTE
| Algorithm 5: Pseudo code of SVM-SMOTE |
| Borderline Oversampling (X, N, k, m) Input: • X: Training set • N: Sampling level (100, 200, 300, … percent) • k: Number of nearest neighbors • m: Number of nearest neighbors to decide sampling type (interpolation or extrapolation) Variables: amount: Array contains the number of artificial instances corresponding to each positive SV nn Array contains k positive nearest neighbors of each positive SV
|
3.6. SMOTEEN
| Algorithm 6: Pseudo code of SMOTEEN |
| Input: Imbalance Training Data 1. 2. 3. Generate 4. Does balancing ratio satisfy if no goto 1 else 5. Remove noise sample using ENN ENN { For every observation O Find the three nearest neighbors of O If O gets misclassified by its three nearest neighbors Then delete O End IF End For } 6. End Output: Balanced Training Data |
3.7. SMOTETOMEK
| Algorithm 7: Pseudo code of SMOTETOMEK |
| Input: Imbalance Training Data 1. 2. 3. 4. Does balancing ratio satisfy IF No goto 1 Else 5. Remove noise sample using TOMEK TOMEK (l, m) { l is the nearest neigbhour of m. m is the nearest neigbhour of l. l and m belong to different classes. } 6. End Output: Balanced Training Data |
4. Description of Classification Methods
4.1. Logistic Regression
4.2. Decision Tree
4.3. Support Vector Machine
4.4. k-Nearest Neighbour
4.5. Gaussian Naïve Bayes
4.6. Artificial Neural Network
5. Performance Metrics of Classifiers
- Accuracy alone is not a sufficient metric to evaluate a classification model time it is misleading.
- High recall and high precision—This is a good model.
- Low recall and high precision—Model cannot detect the classes, but it is highly trustable when it does.
- High recall and low precision—Model can detect the classes but includes points of other classes in it.
- Low recall and precision—Poor model.
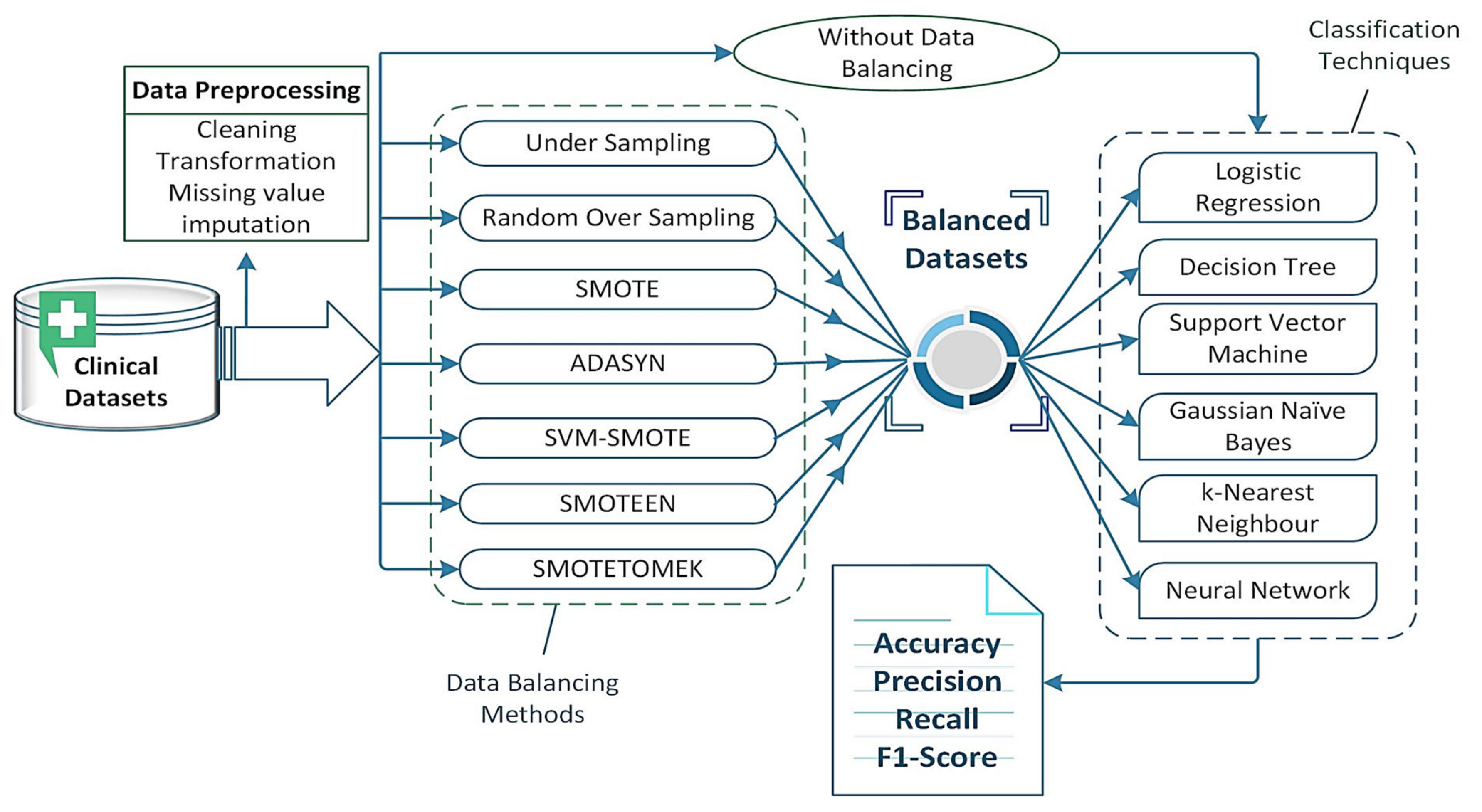
6. Experimental Setup
Clinical Datasets
7. Results and Discussion
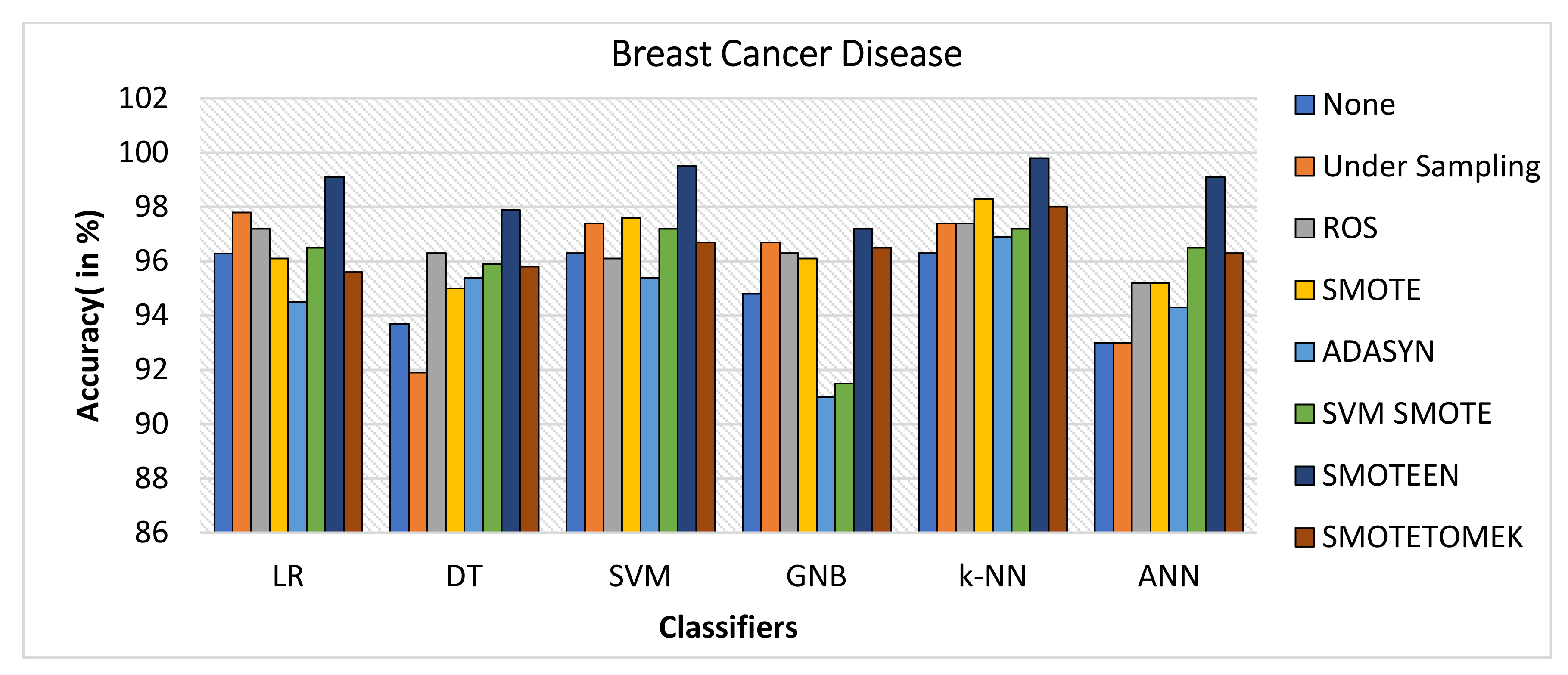
- The balancing technique SMOTEEN with k-NN, SVM, LR, and ANN shows the accuracy of 99.8%, 99.5%, 99.1%, and 99.1%, respectively. There is a 3% increase in the accuracy as compared to classification without data imbalance (Refer to Figure 6).
- Precision value for both SVM and ANN with SMOTEEN was reported as 100%. LR and k-NN also show a comparable precision value of 99.5% (Refer to Figure 7).
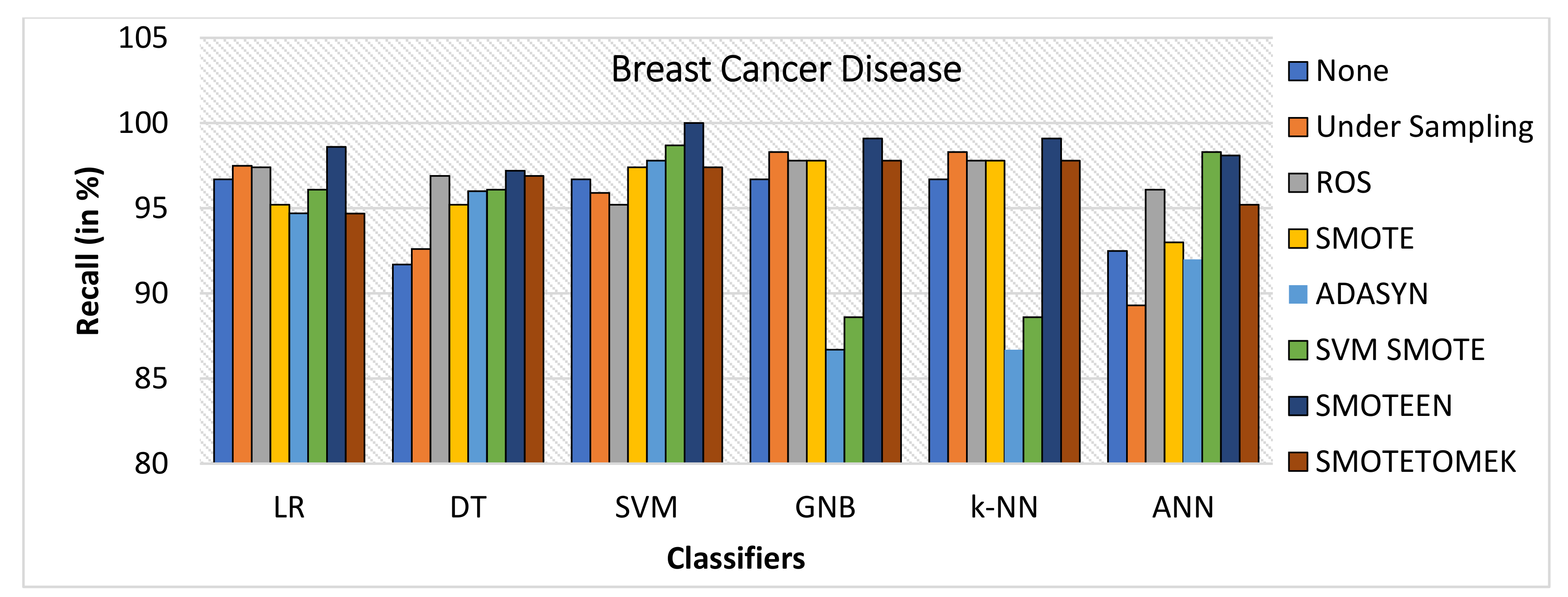
- Recall varies from 97.2 to 100% for all classifiers in general when SMOTEEN was applied. SVM reported the 100% recall for the BCD dataset (Refer to Figure 8).
- F1 Score for k-NN, SVM, and ANN with SMOTEEN observed 99.8, 99.5, and 99.1%, respectively (Refer to Figure 9).
- Thus, the balancing technique SMOTEEN for BCD provides the highest accuracy, Recall, Precision, and F1 score over all the Machine learning techniques, especially k-NN outperforms all others.
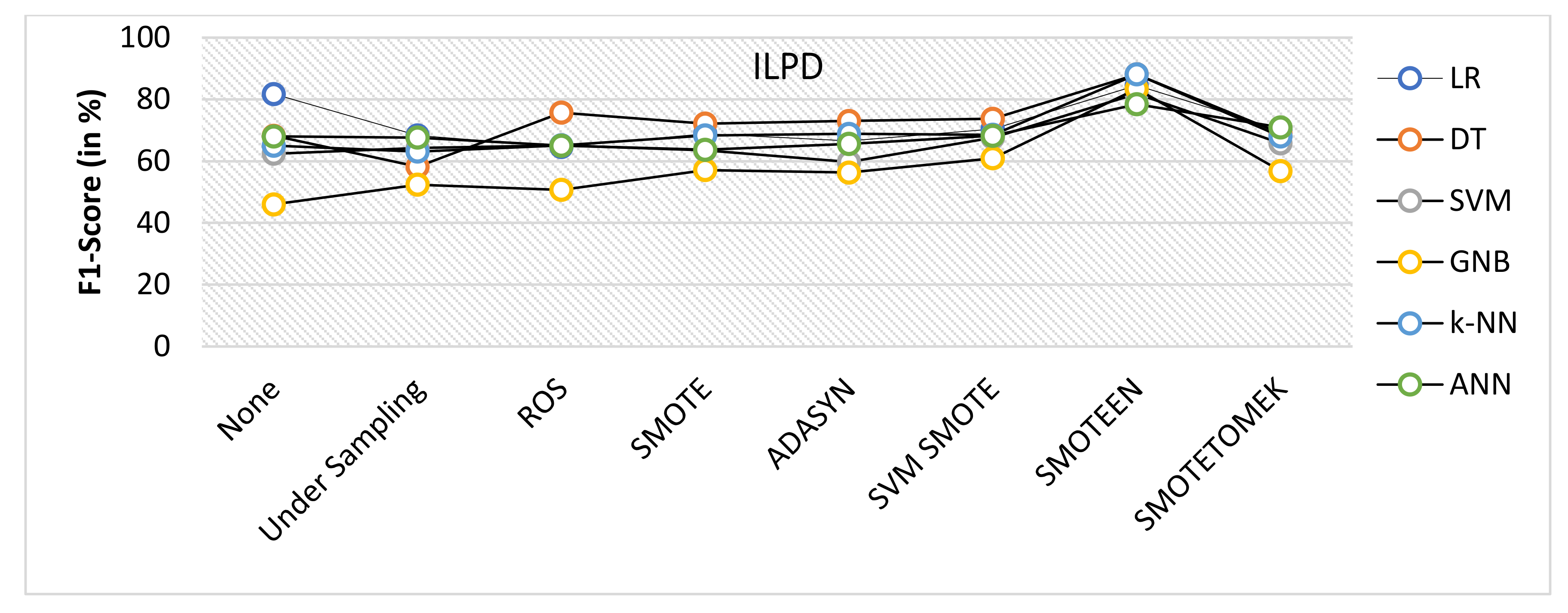
- SMOTEEN for ILPD SMOTEEN as compared to other six data-balancing techniques– Undersampling, ROS, SMOTE ADASYN, SVM-SMOTE, and SMOTETOMEK give high Accuracy 89.4%, 89.4, 86.6%, 86.1 with k-NN, DT, GNB, and LR respectively (Refer to Figure 10).
- Undersampling underperforms with all the classification methods due to loss in significant data while data balancing in ILPD.
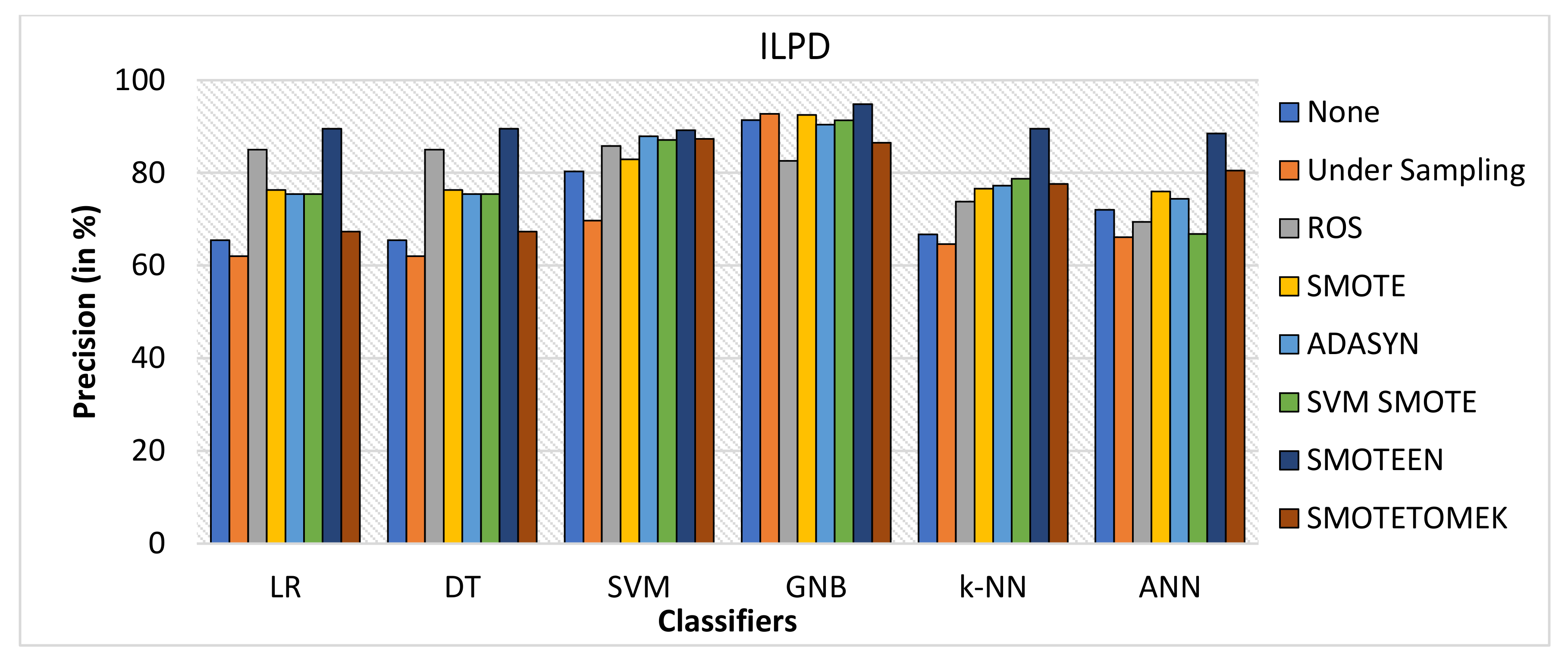
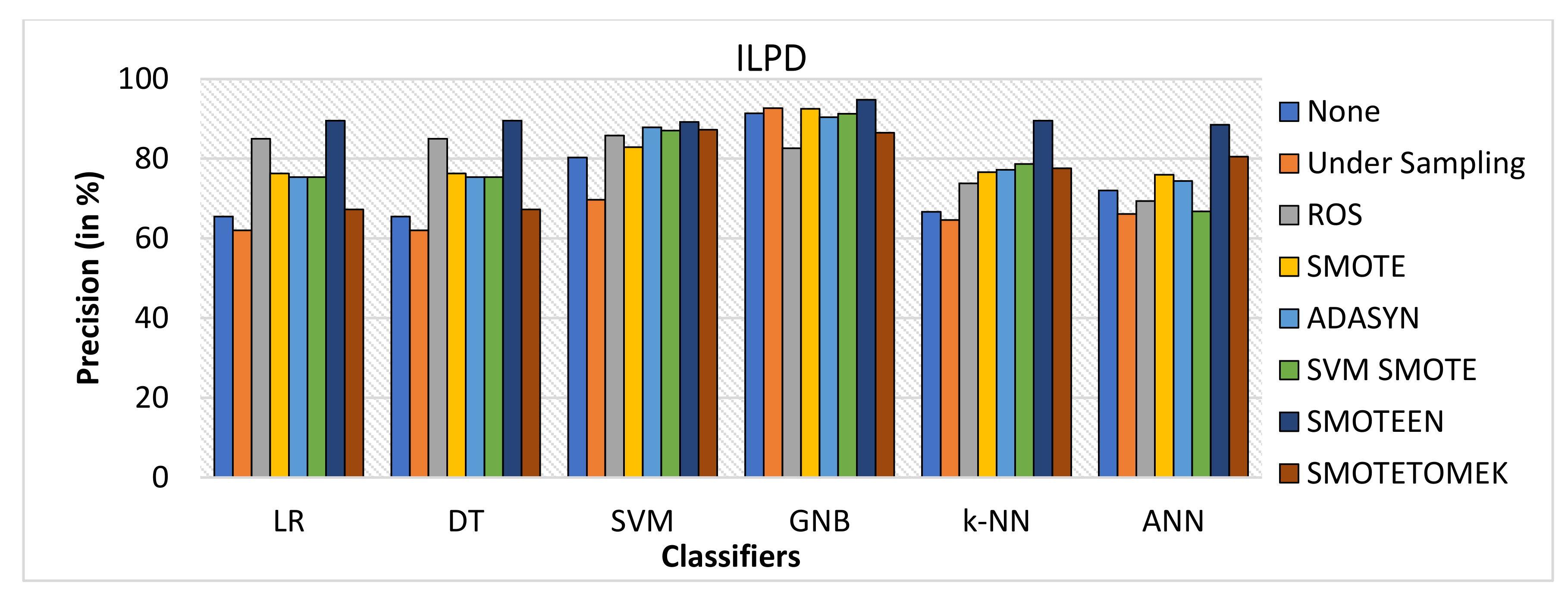
- SMOTEEN as compared to the other six data-balancing techniques shows better precision for GNB, DT, KNN, LR, and ANN with 94.8%, 89.5%, 89.5, 89.5%, and 88.5%, respectively (Refer to Figure 11).
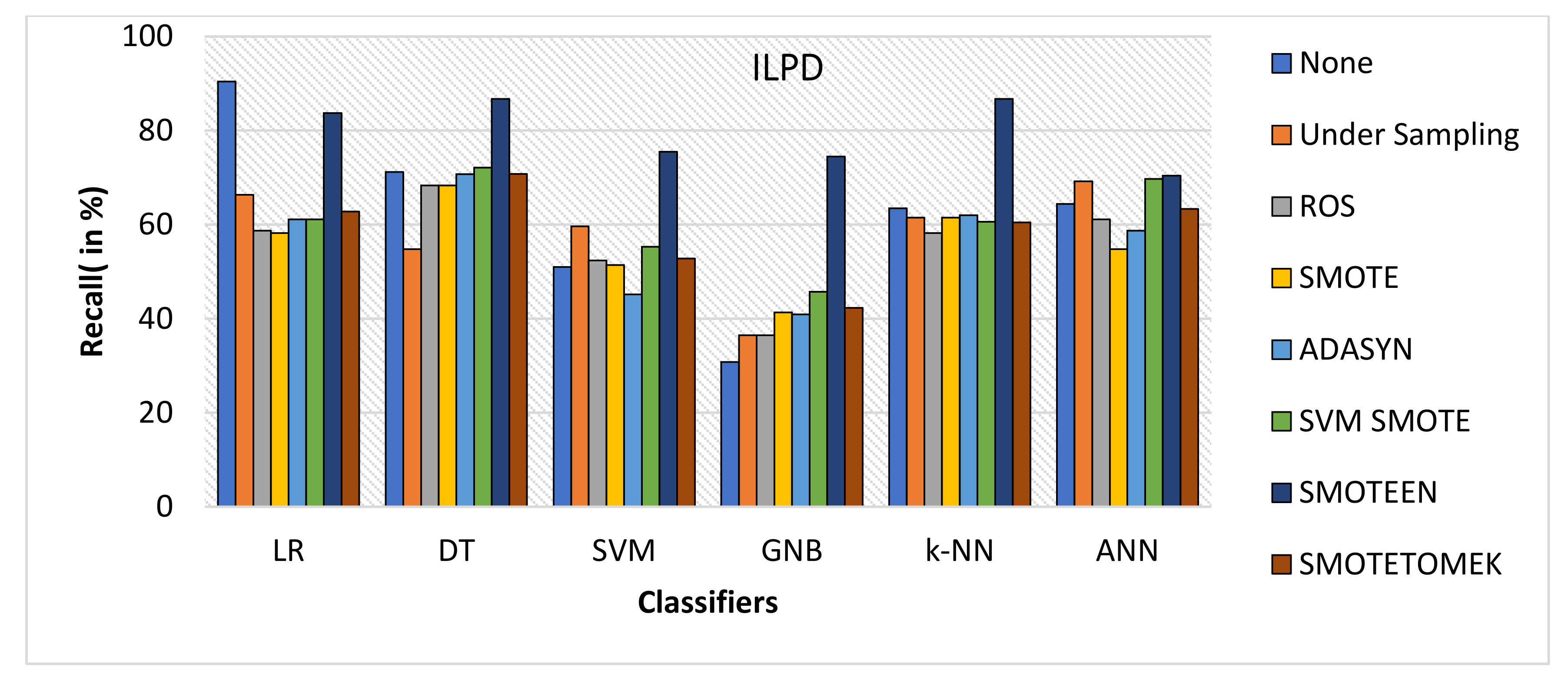
- Likewise, recall for k-NN and DT was 86.7% and for LR it is 83.7% with SMOTEEN, whereas SVM, GNB, and ANN give low values.
- F1 score for all machine learning techniques with SMOTEEN as a balancing technique also gives a high recall value of 88.1% for both k-NN and DT (refer to Figure 12), whereas LR, GNB, and ANN give a poor performance with low F1-score values, i.e., 84.5%, 83.4%, and 78.4%, respectively (refer to Figure 13).
- Thus, the experimental analysis recommends the balancing technique SMOTEEN with k-NN is the most suitable for detecting liver disease compared to the other six balancing techniques. Moreover, SMOTEEN with Decision Tree (DT) also projected considerably equal performances for ILPD Dataset.
- SMOTE gives the highest value of Accuracy, i.e., 99.2% on LR and 98.4% on DT, while ROS gives the highest value of 98.4% on SVM model, SMOTEEN gives the highest value 98.2% over GNB, 96.9% over LR, 95.7% over SVM, and 94.5 over k-NN, respectively (refer to Figure 14).
- ROS has outperformed all the balancing techniques over all the machine learning algorithms while measuring precision (refer to Figure 15).
- Recall for the kidney disease dataset is highest for SMOTE over LR (99.2%), DT (99.2%) and SVM (100%) (Refer to Figure 16) machine learning models, but recall value is highest for undersampling technique over GNB, Highest for SMOTEEN over k-NN and ANN gives the best result over imbalanced data without any balancing technique.
- ROS as compared to the other six data-balancing techniques shows better precision for GNB, DT, LR, SVM, ANN, and k-NN with 100%, 99.2%, 99.2%, 99.2%, 98%, and 90.8%, respectively.
- F1 score is highest for SMOTE over LR, DT, and SVM, giving the highest value of 99.2%, 98.4%, and 96.9%, respectively, whereas SMOTEEN gives the highest value of 97.9% over GNB and 96.5 for LR (refer to Figure 17).
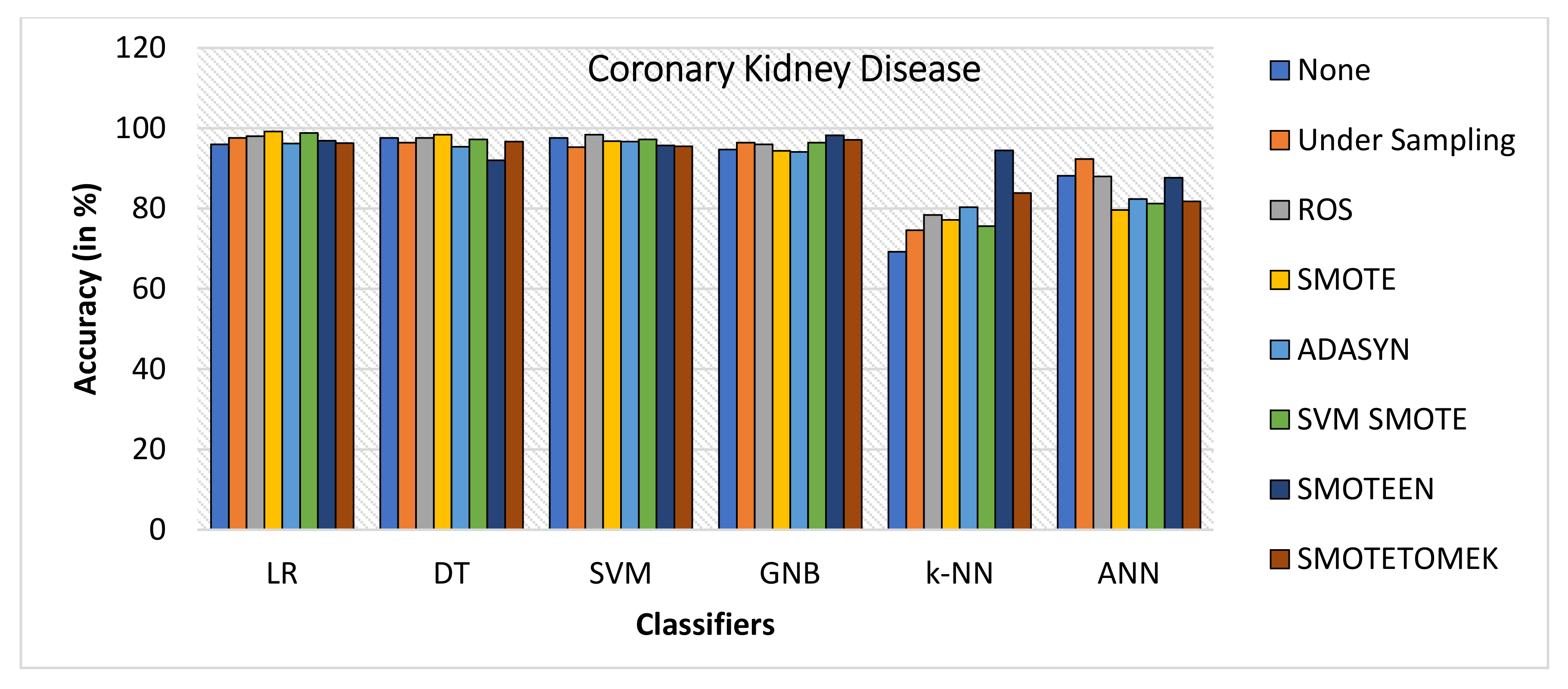
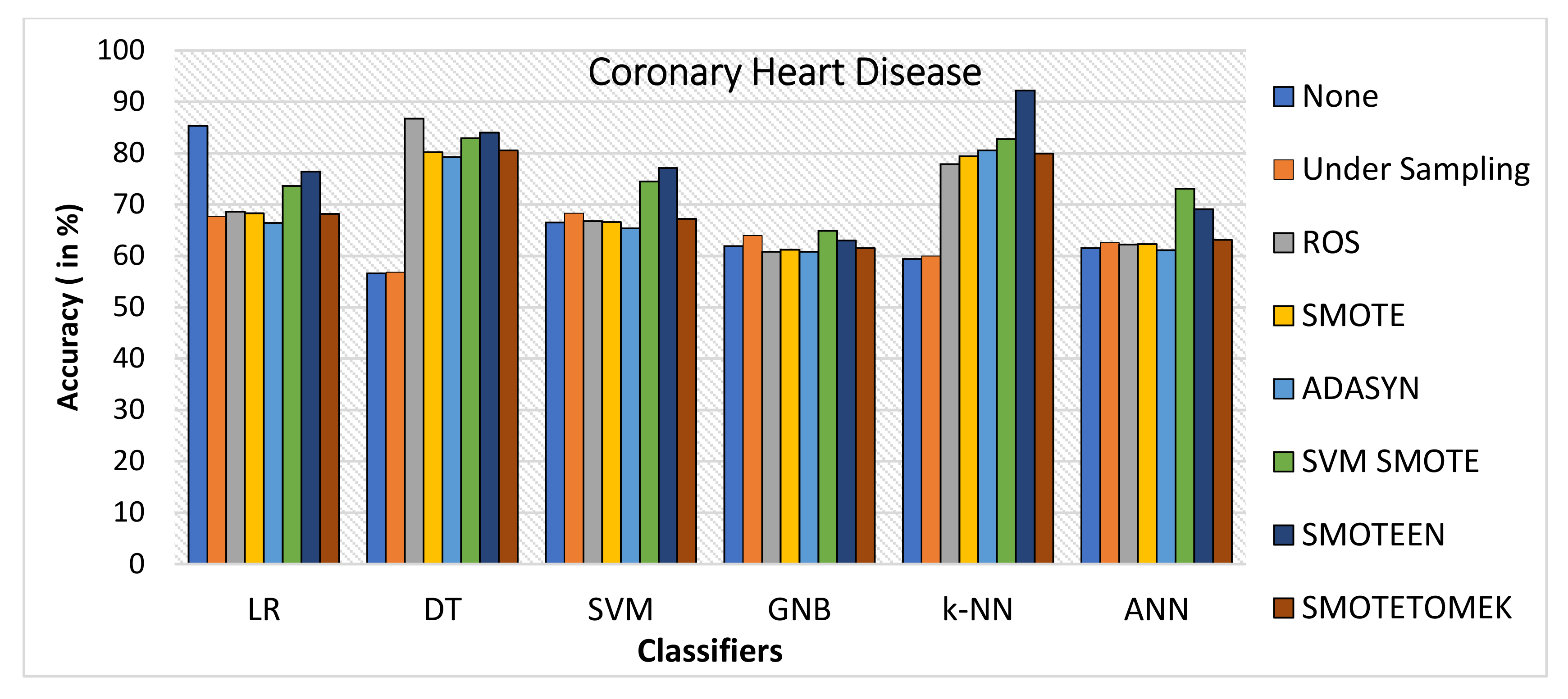
- k-NN gives the highest value of accuracy, i.e., 92.2% for SMOTEEN, and DT gives 84% for SMOTEEN as compared to all other classifiers and balancing techniques (refer to Figure 18).
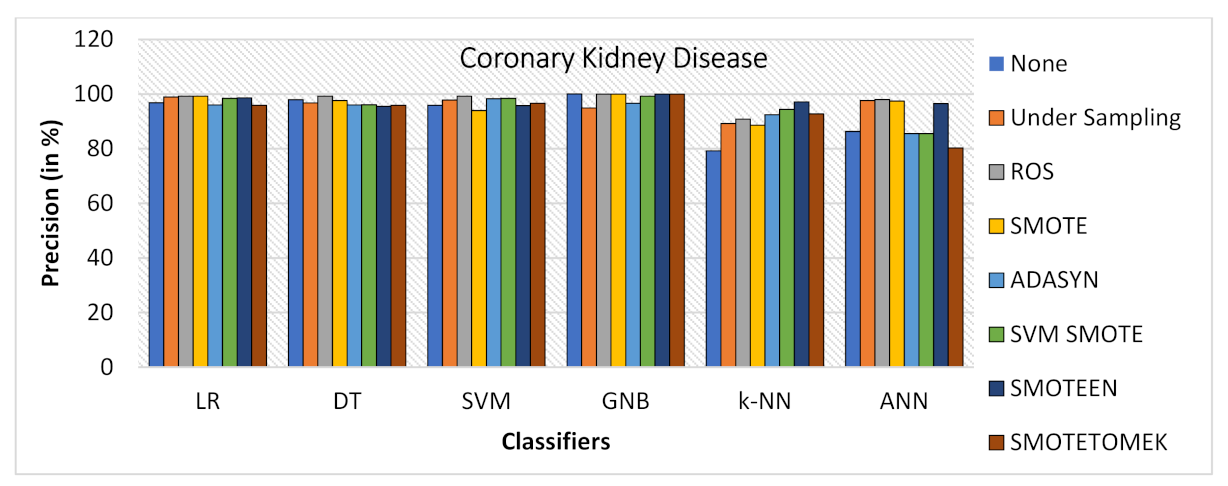
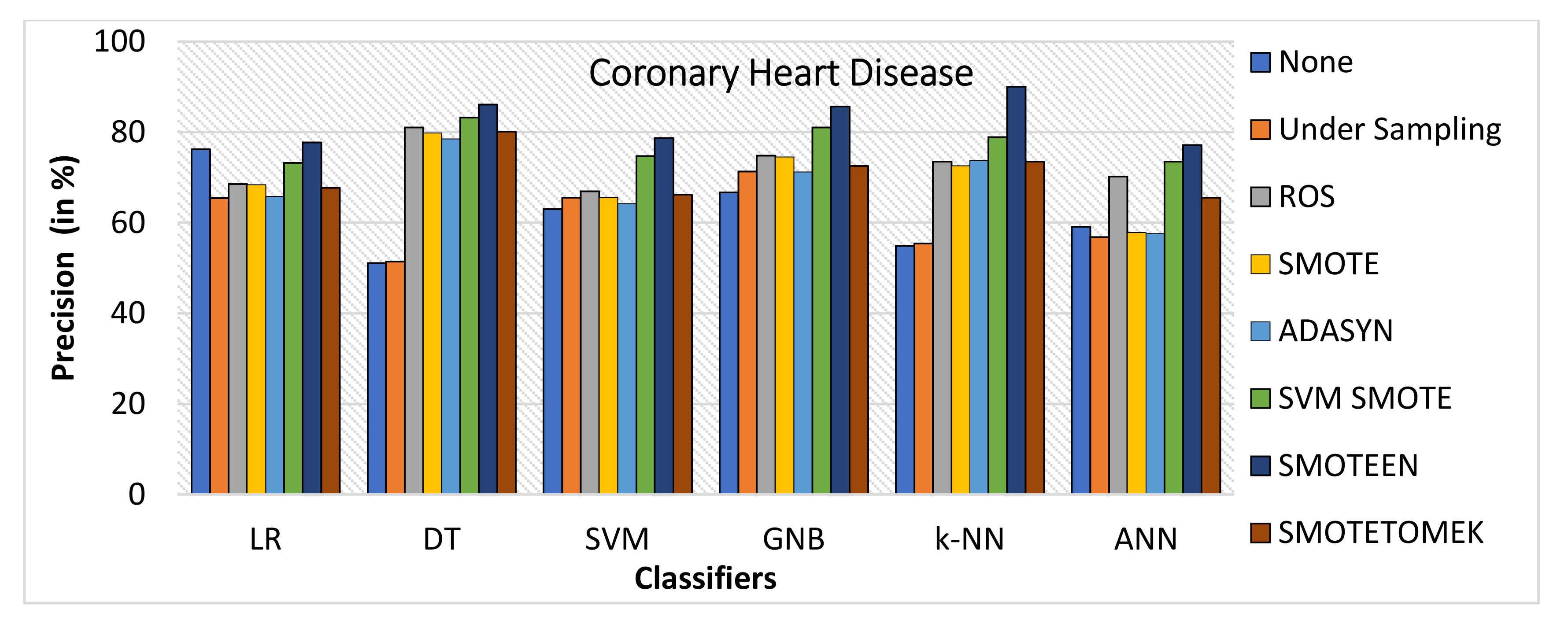
- SMOTEEN gives the highest value of 90% precision for k-NN, but DT, GNB, and SVM are also found to be better (refer to Figure 19).
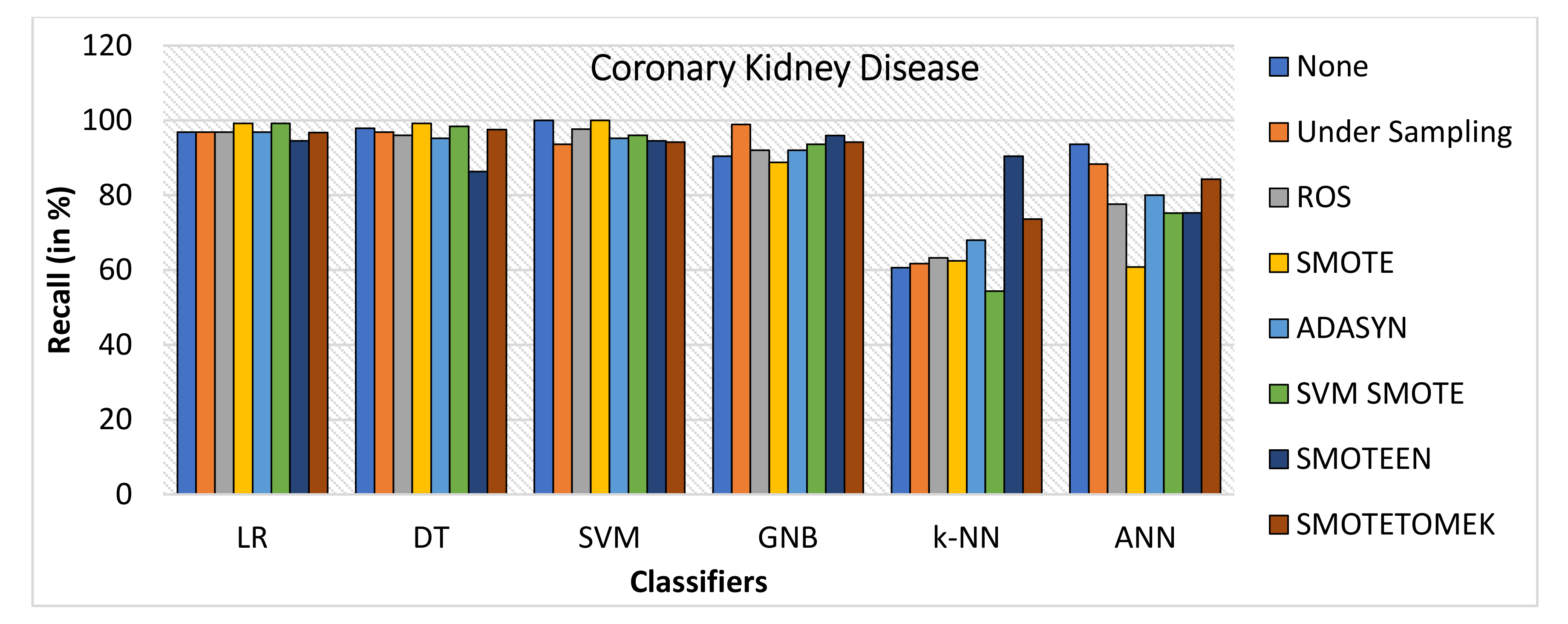
- SMOTEEN gives the highest value of recall, 98.6% over k-NN but GNB and ANN underperform over CHD (refer to Figure 20).
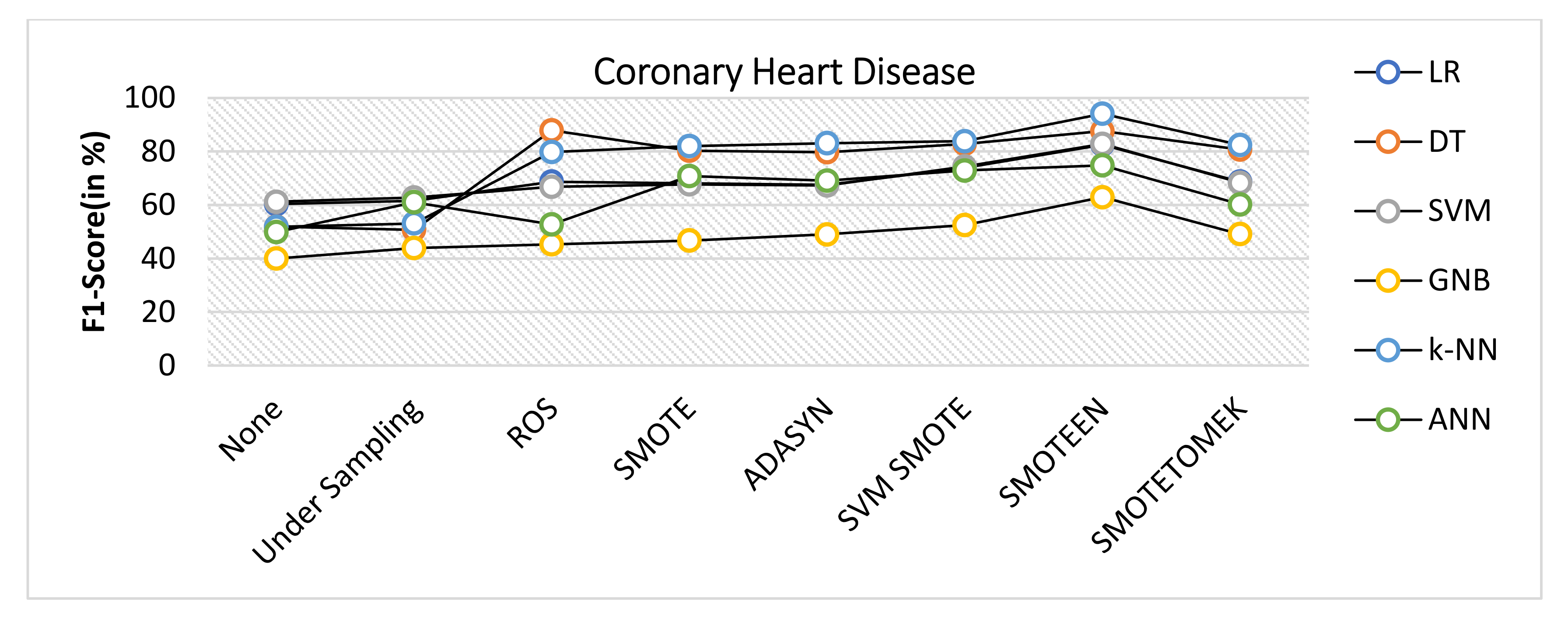
- SMOTEEN reported the highest F1 Score value of 94.1%, whereas classifiers DT, SVM, and LR with SMOTEEN displayed an F1 Score of 87.6%, 82.8%, and 82.5%, respectively (refer to Figure 21).
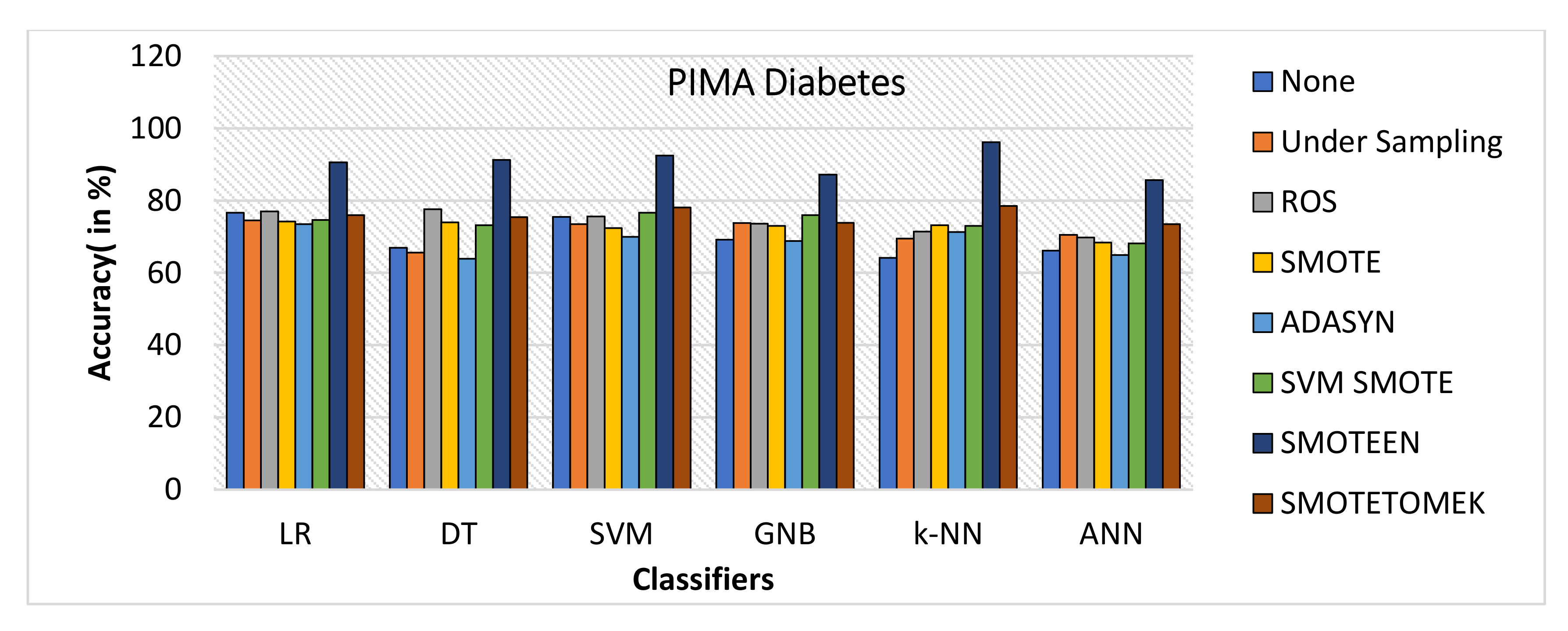
- SMOTEEN for k-NN, SVM, DT, LR, GNB, and ANN attains the accuracy of 96.2%, 92.5%, 91.3%, 90.6%, 87.5%, and 85.7%, respectively (Refer to Figure 22), whereas all other six data-balancing techniques underperform in terms of accuracy with all six classifiers over the Diabetes dataset.
- Precision values for k-NN and SVM with SMOTEEN displayed 94.8% and 93.9% (Refer to Figure 23).
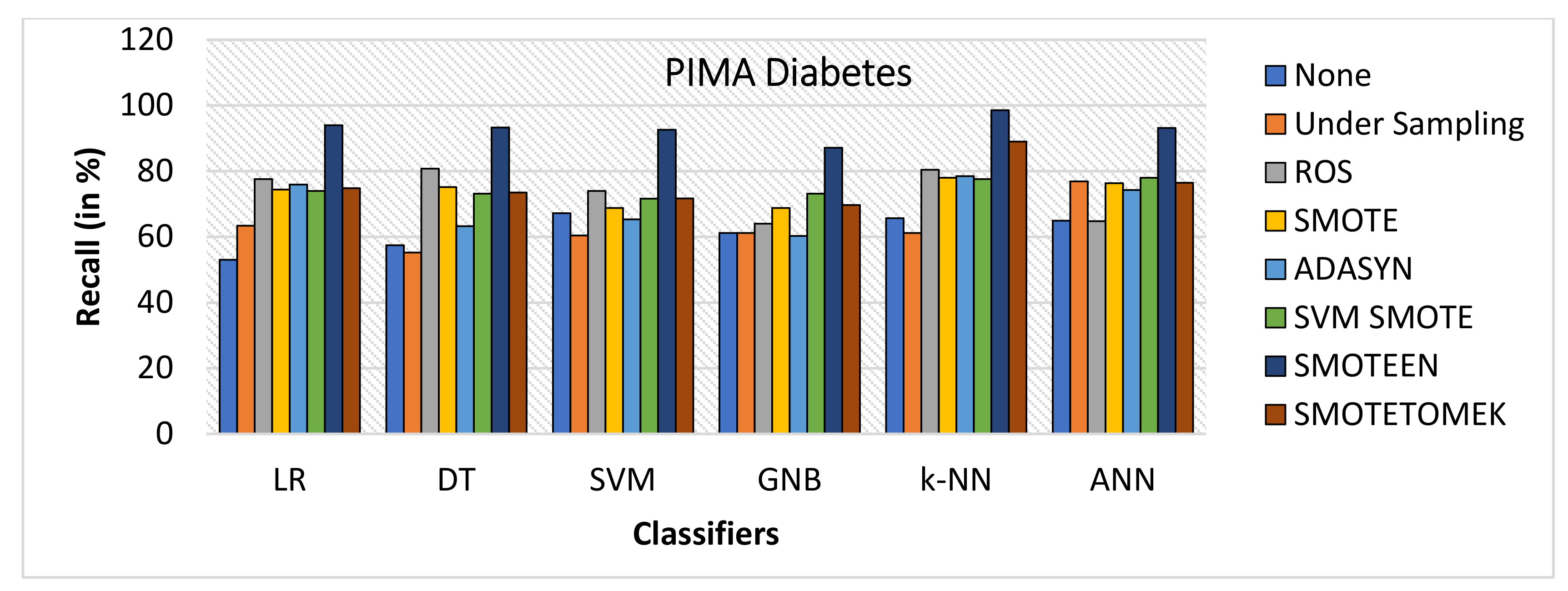
- k-NN with SMOTEEN yields a recall of 98.6% over the diabetes dataset (Refer to Figure 24.
- F1 score for k-NN, SVM, DT, LR, GNB, and ANN yields 96.7%, 93.2%, 92.4%, 91.8%, 88.4%, and 87.9%, respectively (Refer to Figure 25).
- By and large, k-NN with SMOTEEN outperforms diabetes datasets compared to all other balancing and techniques and all other classifiers.
8. Conclusions
- SMOTEEN with k-NN was found the most suitable for detecting liver disease.
- Moreover, k-NN gives the highest value of accuracy of 92.2% over coronary heart disease for SMOTEEN compared to all other classifiers and balancing techniques.
- As for as the diabetes dataset is concerned, SMOTEEN with k-NN was found the most suitable, with accuracy of 96.2.
- SMOTE with Logistic regression (LR) gives the highest value of accuracy, 99.2%, over the CHD dataset.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Han, J.; Kamber, M.; Pei, J. Data Mining: Concepts and Techniques; Elsevier: Amsterdam, The Netherlands, 2012. [Google Scholar]
- Pavón, R.; Laza, R.; Reboiro-Jato, M.; Fdez-Riverola, F. Assessing the impact of class-imbalanced data for classifying relevant/irrelevant medline documents. In Advances in Intelligent and Soft Computing; Springer: Salamanca, Spain, 2011; Volume 93. [Google Scholar] [CrossRef]
- Rao, R.B.; Krishnan, S.; Niculescu, R.S. Data mining for improved cardiac care. Acm Sigkdd Explor. Newsl. 2006, 8, 3–10. [Google Scholar] [CrossRef]
- Chan, P.K.; Stolfo, S.J. Toward Scalable Learning with Non-uniform Class and Cost Distributions: A Case Study in Credit Card Fraud Detection 1 Introduction. In Proceeding of the Fourth International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 27–31 August 1998. [Google Scholar]
- Li, X.C.; Mao, W.J.; Zeng, D.; Su, P.; Wang, F.Y. Performance evaluation of machine learning methods in cultural modeling. J. Comput. Sci. Technol. 2009, 24, 1010–1017. [Google Scholar] [CrossRef]
- Kubat, M.; Holte, R.C.; Matwin, S. Machine learning for the detection of oil spills in satellite radar images. Mach. Learn. 1998, 30, 195–215. [Google Scholar] [CrossRef] [Green Version]
- Williams, D.P.; Myers, V.; Silvious, M.S. Mine classification with imbalanced data. IEEE Geosci. Remote Sens. Lett. 2009, 6, 528–532. [Google Scholar] [CrossRef]
- Endo, A.; Shibata, T.; Tanaka, H. Comparison of Seven Algorithms to Predict Breast Cancer Survival (Contribution to 21 Century Intelligent Technologies and Bioinformatics). Int. J. Biomed. Soft Comput. Hum. Sci. Off. J. Biomed. Fuzzy Syst. Assoc. 2008, 13, 11–16. [Google Scholar] [CrossRef]
- Belarouci, S.; Chikh, M.A. Medical imbalanced data classification. Adv. Sci. Technol. Eng. Syst. 2017, 2, 116–124. [Google Scholar] [CrossRef] [Green Version]
- Patel, H.; Rajput, D.S.; Reddy, G.T.; Iwendi, C.; Bashir, A.K.; Jo, O. A review on classification of imbalanced data for wireless sensor networks. Int. J. Distrib. Sens. Netw. 2020, 16, 1–15. [Google Scholar] [CrossRef]
- Patel, H.; Rajput, D.S.; Stan, O.P.; Miclea, L.C. A New Fuzzy Adaptive Algorithm to Classify Imbalanced Data. CMC-Comput. Mater. Contin. 2022, 70, 73–89. [Google Scholar] [CrossRef]
- He, H.; Bai, Y.; Garcia, E.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, 1–8 June 2008; pp. 1322–1328. [Google Scholar]
- Shirai, K.; Xiang, Y. Over-sampling methods for polarity classification of imbalanced microblog texts. In Proceedings of the 33rd Pacific Asia Conference on Language, Information and Computation, Hakodate, Japan, 13–15 September 2019; pp. 228–236. [Google Scholar]
- Liu, X.Y.; Wu, J.; Zhou, Z.H. Exploratory undersampling for class-imbalance learning. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2009, 39, 539–550. [Google Scholar] [CrossRef]
- He, H.; Garcia, E.A. Learning from imbalanced data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar] [CrossRef]
- López, V.; Fernández, A.; García, S.; Palade, V.; Herrera, F. An insight into classification with imbalanced data: Empirical results and current trends on using data intrinsic characteristics. Inf. Sci. 2013, 250, 113–141. [Google Scholar] [CrossRef]
- Rahman, M.M.; Davis, D.N. Addressing the Class Imbalance Problem in Medical Datasets. Int. J. Mach. Learn. Comput. 2013, 3, 224–228. [Google Scholar] [CrossRef]
- Rajput, D.S.; Basha, S.M.; Xin, Q.; Gadekallu, T.R.; Kaluri, R.; Lakshmanna, K.; Maddikunta PK, R. Providing diagnosis on diabetes using cloud computing environment to the people living in rural areas of India. J. Ambient. Intell. Humaniz. Comput. 2021, 1–12. [Google Scholar] [CrossRef]
- Gadekallu, T.R.; Rajput, D.S.; Reddy, M.P.K.; Lakshmanna, K.; Bhattacharya, S.; Singh, S.; Jolfaei, A.; Alazab, M. A Novel PCA-Whale Optimization based Deep Neural Network model for Classification of Tomato Plant Diseases using GPU. J. Real-Time Image Processing 2020, 18, 1383–1396. [Google Scholar] [CrossRef]
- Reddy, G.T.; Reddy, M.P.K.; Lakshmanna, K.; Kaluri, R.; Rajput, D.S.; Srivastava, G.; Baker, T. Analysis of dimensionality reduction techniques on big data. IEEE Access 2020, 8, 54776–54787. [Google Scholar] [CrossRef]
- Qiang, Y.; Xindong, W. 10 Challenging problems in data mining research. Int. J. Inf. Technol. Decis. Mak. 2006, 5, 597–604. [Google Scholar] [CrossRef] [Green Version]
- International Agency for Research on Cancer (IARC). Latest Global Cancer Data. In CA: A Cancer Journal for Clinicians. 2018. Available online: http://gco.iarc.fr/ (accessed on 10 December 2020).
- Benjamin, E.J.; Muntner, P.; Alonso, A.; Bittencourt, M.S.; Callaway, C.W.; Carson, A.P.; Chamberlain, A.M.; Chang, A.R.; Cheng, S.; Das, S.R.; et al. Heart Disease and Stroke Statistics-2019 Update: A Report From the American Heart Association. Circulation 2019, 139, e56–e528. [Google Scholar] [CrossRef]
- Asrani, S.K.; Devarbhavi, H.; Eaton, J.; Kamath, P.S. Burden of liver diseases in the world. J. Hepatol. 2019, 70, 151–171. [Google Scholar] [CrossRef]
- Chronic Kidney Disease in the United States, 2019. Centers for Disease Control and Prevention. 2019. Available online: https://www.cdc.gov/kidneydisease/publications-resources/2019-national-facts.html (accessed on 15 December 2020).
- Saeedi, P.; Petersohn, I.; Salpea, P.; Malanda, B.; Karuranga, S.; Unwin, N.; Colagiuri, S.; Guariguata, L.; Motala, A.A.; Ogurtsova, K.; et al. Global and regional diabetes prevalence estimates for 2019 and projections for 2030 and 2045: Results from the International Diabetes Federation Diabetes Atlas, 9th edition. Diabetes Res. Clin. Pract. 2019, 157, 107843. [Google Scholar] [CrossRef] [Green Version]
- A Program for Cancer Care. Available online: https://www.lungcancer.org/find_information/publications (accessed on 5 January 2021).
- Frank, A.; Asuncion, A. UCI Machine Learning Repository. 2010. Available online: http://archive.ics.uci.edu/ml (accessed on 10 December 2021).
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Johnson, J.M.; Khoshgoftaar, T.M. Deep learning and data sampling with imbalanced big data. In Proceedings of the 2019 IEEE 20th International Conference on Information Reuse and Integration for Data Science (IRI), Los Angeles, CA, USA, 30 July–1 August 2019. [Google Scholar] [CrossRef]
- Yen, S.J.; Lee, Y.S. Cluster-based under-sampling approaches for imbalanced data distributions. Expert Syst. Appl. 2009, 36, 5718–5727. [Google Scholar] [CrossRef]
- Batista, G.E.A.P.A.; Prati, R.C.; Monard, M.C. A study of the behavior of several methods for balancing machine learning training data. ACM SIGKDD Explor. Newsl. 2004, 6, 20–29. [Google Scholar] [CrossRef]
- Kovács, G. An empirical comparison and evaluation of minority oversampling techniques on a large number of imbalanced datasets. Appl. Soft Comput. J. 2019, 83, 105662. [Google Scholar] [CrossRef]
- Nguyen, H.M.; Cooper, E.W.; Kamei, K. Borderline over-sampling for imbalanced data classification. Int. J. Knowl. Eng. Soft Data Paradig. 2011, 3, 4–21. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Safavian, S.R.; Landgrebe, D. A Survey of Decision Tree Classifier Methodology. IEEE Trans. Syst. Man Cybern. 1991, 21, 660–674. [Google Scholar] [CrossRef] [Green Version]
- Guo, G.; Wang, H.; Bell, D.; Bi, Y.; Greer, K. KNN model-based approach in classification. Lect. Notes Comput. Sci. 2003, 2888. [Google Scholar] [CrossRef]
- Hopfield, J.J. Artificial Neural Networks. IEEE Circuits Devices Mag. 1988, 4, 3–10. [Google Scholar] [CrossRef]
- Johnson, J.M.; Khoshgoftaar, T.M. Survey on deep learning with class imbalance. J. Big Data 2019, 6, 27. [Google Scholar] [CrossRef]
- Kovács, G. Smote-variants: A python implementation of 85 minority oversampling techniques. Neurocomputing 2019, 366, 352–354. [Google Scholar] [CrossRef]
- Xue, J.H.; Titterington, D.M. Comment on ‘on discriminative vs. generative classifiers: A comparison of logistic regression and naive bayes. Neural Process. Lett. 2008, 28, 169–187. [Google Scholar] [CrossRef]
- Collins, M.; Schapire, R.E.; Singer, Y. Logistic regression, AdaBoost and Bregman distances. Mach. Learn. 2002, 48, 253–285. [Google Scholar] [CrossRef]
- Kumar, V. Evaluation of computationally intelligent techniques for breast cancer diagnosis. Neural Comput. Appl. 2020, 33, 3195–3208. [Google Scholar] [CrossRef]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. Training algorithm for optimal margin classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992. [Google Scholar] [CrossRef]
- Amato, F.; López, A.; Peña-Méndez, E.M.; Vaňhara, P.; Hampl, A.; Havel, J. Artificial neural networks in medical diagnosis. J. Appl. Biomed. 2013, 11, 47–58. [Google Scholar] [CrossRef]
- Wu, C.H. Artificial neural networks for molecular sequence analysis. Comput. Chem. 1997, 21, 237–256. [Google Scholar] [CrossRef]
- Bronchal, L.; Breast Cancer Dataset Analysis. UCI Machine Learning Repository. 2017. Available online: https://www.kaggle.com/lbronchal/breast-cancer-dataset-analysis (accessed on 20 October 2020).
- Coronary Heart Disease. Obstetrics and Gynecology. 2004. Available online: https://archive.ics.uci.edu/ml/datasets/Heart+Disease (accessed on 25 December 2020).
- Jeevan, N. Indian Liver Patient Dataset|Kaggle. Kaggle. 2017. Available online: https://www.kaggle.com/jeevannagaraj/indian-liver-patient-dataset (accessed on 20 October 2020).
- Kaggle. Pima Indians Diabetes Database. 2016. Available online: https://www.kaggle.com/uciml/pima-indians-diabetes-database (accessed on 10 December 2021).
- Stewart, K.A.; Chronic Kidney Disease. Nursing Standard (Royal College of Nursing (Great Britain): 1987). 2008. Available online: https://archive.ics.uci.edu/ml/datasets/Chronic_Kidney_Disease (accessed on 22 October 2020).


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SL | Name | Data Types | Default Task | Attribute Types | #Instances | Class Distribution | #Attributes | Imbalance Ratio |
|---|---|---|---|---|---|---|---|---|
| 1 | Breast Cancer | Multivariate | Classification | Categorical | 286 | 0:201,1: 85 | 9 | 2.36 |
| 2 | Breast Cancer Wisconsin (Original) | Multivariate | Classification | Integer | 699 | 0: 458, 1:241 | 10 | 1.9 |
| 3 | Breast Cancer Wisconsin (Prognostic) | Multivariate | Classification, Regression | Real | 198 | 0:151, 1:47 | 34 | 3.21 |
| 4 | Breast Cancer Wisconsin (Diagnostic) | Multivariate | Classification | Real | 569 | 0:357, 1:212 | 32 | 1.69 |
| 5 | Heart Disease | Multivariate | Classification | Categorical, Integer, Real | 303 | 0:164,1:55,2:36,3:35,4:13 | 75 | -- |
| 6 | Hepatitis | Multivariate | Classification | Categorical, Integer, Real | 155 | 0:133, 1:32 | 19 | 4.15 |
| 7 | Pima Indians Diabetes Database | Multivariate | Classification | Integer | 768 | 0: 500, 1:268 | 8 | 1.9 |
| 8 | Liver Disorders | Multivariate | Classification | Categorical, Integer, Real | 345 | 0:145,1:200 | 7 | 1.37 |
| 9 | Lung Cancer | Multivariate | Classification | Integer | 32 | 0:23, 1:9 | 56 | 2.55 |
| 10 | SPECT Heart | Multivariate | Classification | Categorical | 267 | 0:55,1: 212 | 22 | 3.85 |
| 11 | SPECTF Heart | Multivariate | Classification | Integer | 267 | 0:55,1:212 | 44 | 3.85 |
| 12 | Thyroid Disease | Multivariate, Domain-Theory | Classification | Categorical, Real | 7200 | 1:166, 2:368, 3:6666 | 21 | -- |
| 13 | Breast Tissue | Multivariate | Classification | Real | 106 | Car:21 Fad:15 Mas:8, Gla:16, Con:14, Adi:22 | 10 | -- |
| 14 | Fertility | Multivariate | Classification, Regression | Real | 100 | N:88, O:12 | 10 | 7.33 |
| 15 | Diabetic Retinopathy Debrecen Dataset | Multivariate | Classification | Integer, Real | 1151 | 0:540, 1:611 | 20 | 1.131 |
| 16 | HIV-1 protease cleavage | Multivariate | Classification | Categorical | 6590 | 0:5232 1:1358 | 1 | 3.85 |
| 17 | Breast Cancer Coimbra | Multivariate | Classification | Integer | 116 | 0:52,1:65 | 10 | 1.25 |
| 18 | Parkinson’s Disease Classification | Multivariate | Classification | Integer, Real | 756 | 0:192, 1:564 | 754 | 2.94 s |
| 19 | Hepatitis C Virus (HCV) for Egyptian patients | Multivariate | Classification | Integer, Real | 1385 | 1:336, 2:332, 3:355, 4:362 | 29 | -- |
| 20 | Heart failure clinical records | Multivariate | Classification, Regression, Clustering | Integer, Real | 299 | 0:203,1:96 | 13 | 2.11 |
| Class Imbalance Degree | Proportion of Minority Class |
|---|---|
| Extreme | <1% of the dataset |
| Moderate | 1–20% of the dataset |
| Mild | 20–40% of the dataset |
| S. No | Author and Year | Techniques Applied | Claims in the Study | Cons |
|---|---|---|---|---|
| 1 | N. Chawla, K. Bowyer, L. Hall, and W. Kegelmeyer (2002) [29] | SMOTE: Synthetic Minority Oversampling Technique | An amalgamation of technique of oversampling the minority class and undersampling the majority class can attain better performance in classification. Creating synthetic minority class instances implicates the oversampling of the minority class. | Suffers from over fitting problem |
| 2 | M. Mostafizur Rahman and D. N. Davis (2013) [17] |
| The traditional methods of balancing, such as undersampling and oversampling, may not prove to be effective and suitable over these Imbalanced datasets. The technique discussed in this paper shows better results for datasets where class level is not certain. A modified cluster-based undersampling technique produces good quality training sets in addition to balancing the datasets. | Computational costs increase |
| 3 | Haibo He, Yang Bai, Edwardo A. Garcia, and Shutao Li (2008) [12] | Adaptive Synthetic (ADASYN) |
| Because of its adaptability, ADASYN’s precision may degrade. |
| 4 | Justin M. Johnson, Taghi M. Khoshgoftaar (2019) [39] |
| Data sampling and deep neural networks are implemented for detecting fraud in highly imbalanced datasets. | ROS may increase the likelihood of overfitting and computational costs In RUS, sample of the majority class chosen could be biased |
| 5 | Show-Jane Yen, Yue-Shi Lee (2009) [31] |
| Back propagation neural network for imbalanced class distribution by Cluster based undersampling approaches.
| Computational costs increase |
| 6 | G. Batista, R. C. Prati, M. C. Monard (2004) [32] | SMOTEEN, SMOTETOMEK | Random over sampling techniques gives meaningful results over other techniques at less computational rate. | SMOTE is not suitable for high-dimensional data |
| 7 | Hien M. Nguyen, Eric W. Cooper, Katsuari Kamei (2009) [34] | SVMs and B-SMOTE | This technique targets the borderline area where establishing the decision boundary is critical rather than sampling the whole of the minority class. | It could not provide big savings regarding the number of synthetically generated examples, trading to the classification accuracy |
| S. No | Dataset | #Instances | #Attributes | Class | IR | Minority Class (%) | Degree of Imbalanced |
|---|---|---|---|---|---|---|---|
| 1 | BCD [47] | 699 | 9 | 0:458, 1:241 | 1.9 | 34.5 | Mild |
| 2 | Chronic Heart Disease [48] | 4238 | 14 | 0:3594, 1:644 | 5.58 | 15.2 | Moderate |
| 3 | ILPD [49] | 583 | 9 | 0:416, 1:167 | 2.49 | 28.6 | Moderate |
| 4 | PIMA Diabetes [50] | 768 | 8 | 0:500, 1:268 | 1.86 | 34.9 | Mild |
| 5 | Chronic Kidney Disease [51] | 400 | 24 | 0:150, 1:250 | 1.66 | 37.5 | Mild |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kumar, V.; Lalotra, G.S.; Sasikala, P.; Rajput, D.S.; Kaluri, R.; Lakshmanna, K.; Shorfuzzaman, M.; Alsufyani, A.; Uddin, M. Addressing Binary Classification over Class Imbalanced Clinical Datasets Using Computationally Intelligent Techniques. Healthcare 2022, 10, 1293. https://doi.org/10.3390/healthcare10071293
Kumar V, Lalotra GS, Sasikala P, Rajput DS, Kaluri R, Lakshmanna K, Shorfuzzaman M, Alsufyani A, Uddin M. Addressing Binary Classification over Class Imbalanced Clinical Datasets Using Computationally Intelligent Techniques. Healthcare. 2022; 10(7):1293. https://doi.org/10.3390/healthcare10071293
Chicago/Turabian StyleKumar, Vinod, Gotam Singh Lalotra, Ponnusamy Sasikala, Dharmendra Singh Rajput, Rajesh Kaluri, Kuruva Lakshmanna, Mohammad Shorfuzzaman, Abdulmajeed Alsufyani, and Mueen Uddin. 2022. "Addressing Binary Classification over Class Imbalanced Clinical Datasets Using Computationally Intelligent Techniques" Healthcare 10, no. 7: 1293. https://doi.org/10.3390/healthcare10071293