
Reinforcement Learning Approaches to Optimal Market Making


Abstract
:1. Introduction
2. Overview of Reinforcement Learning
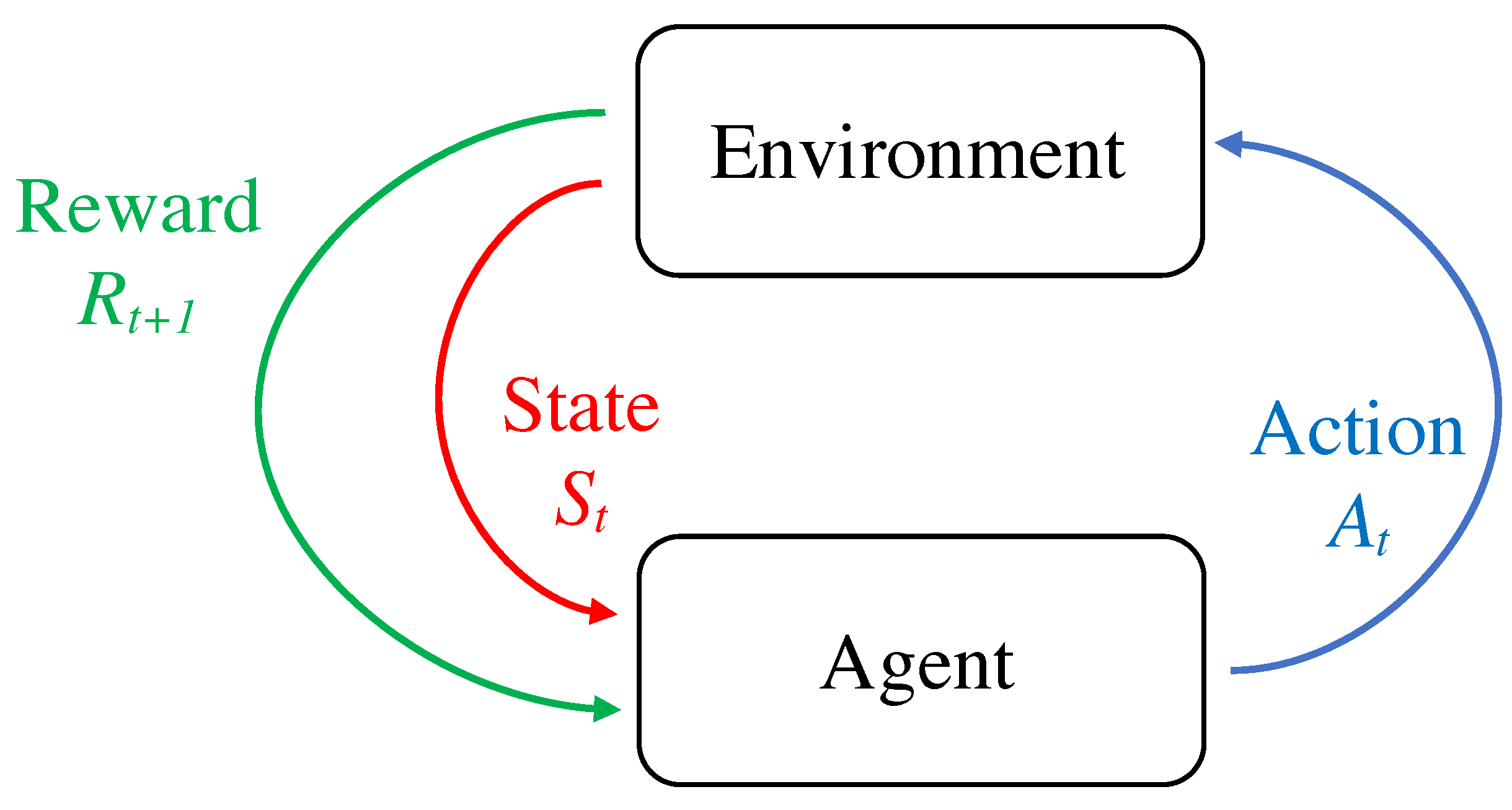
2.1. Markov Decision Process
- — a set of states;
- —a set of actions;
- —a transition probability function (often expressed as a three-dimensional matrix);
- —a reward function;
- —a discount factor, capturing a possible preference for earlier rewards.
2.2. Reinforcement Learning
2.2.1. Dynamic Programming
2.2.2. Value-Based Methods
2.2.3. Policy-Based Methods
2.2.4. Actor–Critic Methods
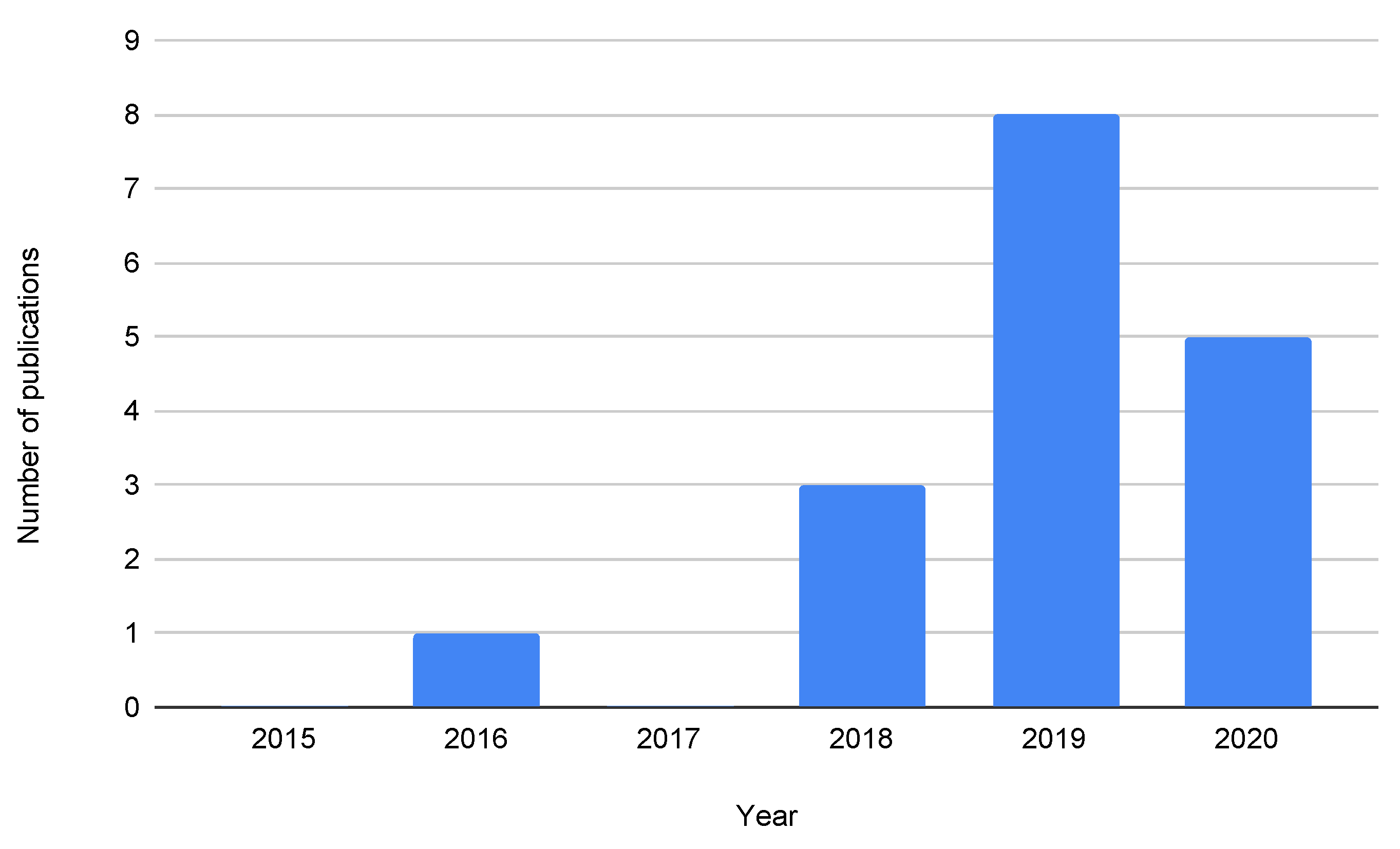
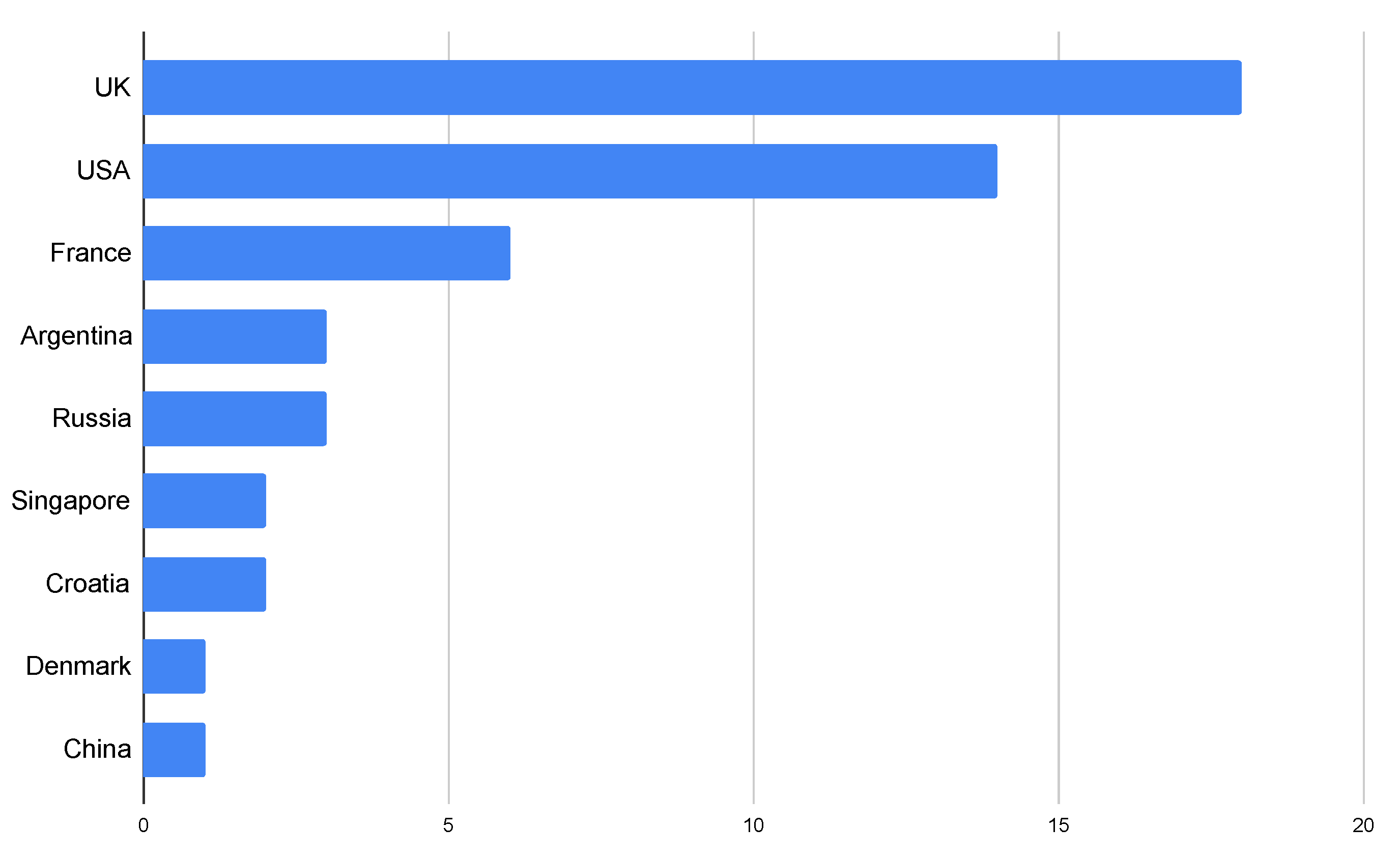
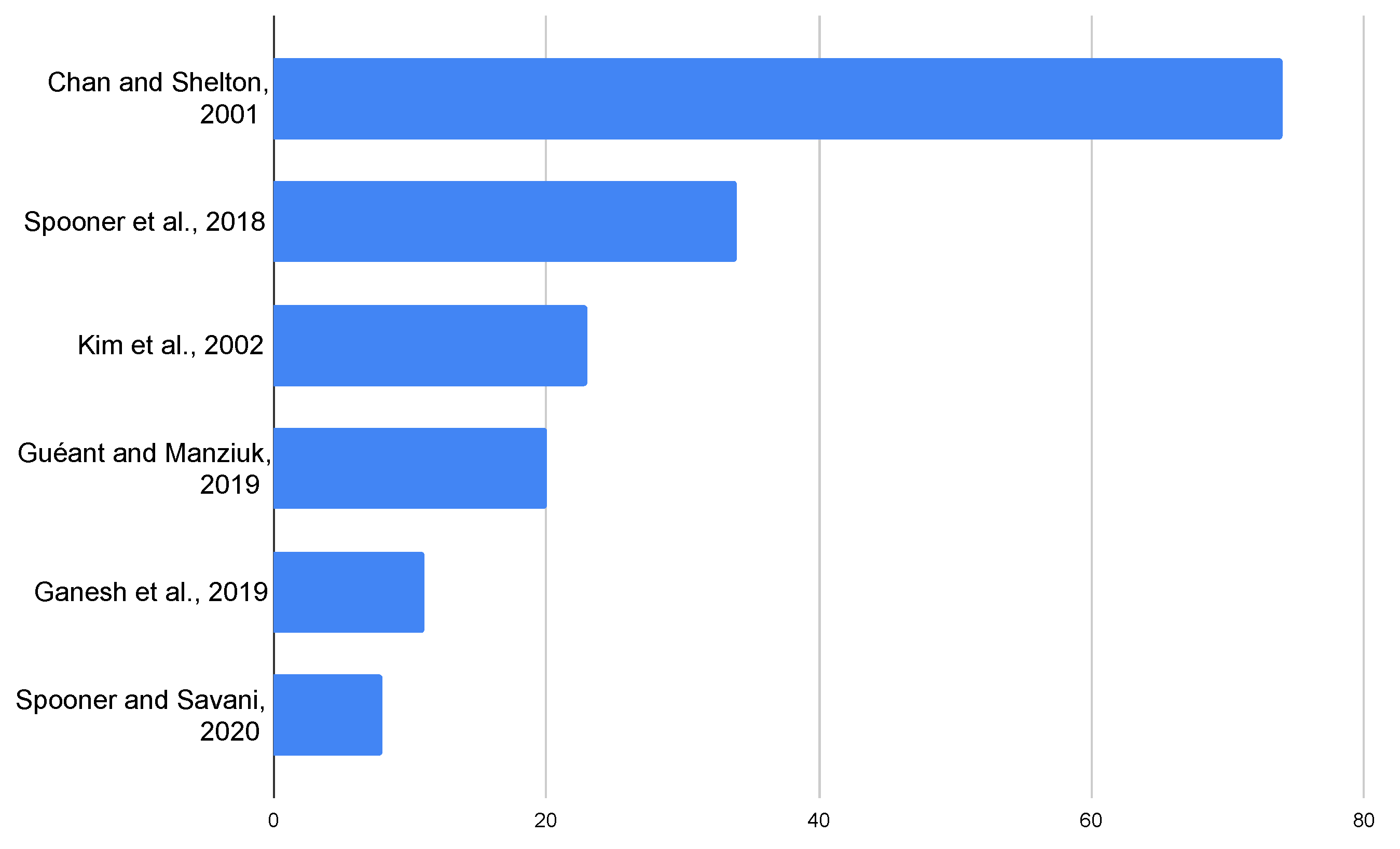
3. Literature Review
3.1. Introduction
3.2. Categorization
3.3. Information-Based Approaches
3.4. Approaches Stemming from Analytical Models
3.5. Nondeep Approaches
3.6. DRL Approaches
4. Discussion
4.1. Advantages
- Sequentiality: First and foremost, RL methods can easily address the sequentiality (delayed evaluative feedback, sometimes referred to as intertemporality) inherent to the problem of optimal MM. RL methods enable us to take into account not only immediate, but also long-term consequences of actions. Note that this is not the case with other supervised-learning-based approaches where feedback is instant. For illustration, consider, for example, a market maker holding a positive inventory of the traded asset. In the short-run, it might be best to ignore this fact and simply focus on capturing the spread. However, in reality, it might be better to get rid of the inventory (perhaps even instantly, with a market order) and thereby sacrifice short-term profits to avert long-term potential losses. Such long-term considerations are directly built into the notion of RL return;
- Single-step framework: Converting predictive signals (such as trend and volatility forecasts) into actual trading positions is far from a trivial task, not only in optimal MM, but also generally in the field of portfolio optimization. It is normally a two-step process that involves first making predictions based on financial data and then using the predictions to somehow construct trading positions. Given that RL policies map states (signals) into actions (quotes), the use of RL allows for merging of the two steps into one, hence simplifying the process;
- Model-freeness: In model-free RL methods, learning is performed directly from data, without any explicit modeling of the underlying MDP’s transition or reward function or any kind of prior knowledge. In such methods, the agent neither has access to nor is trying to learn the model of the environment. Consequently, it exclusively relies on sampling from the environment and does not generate predictions of the next state or reward. This is particularly desirable in the context of optimal MM, since (1) the true model of the environment is unavailable to the market maker and (2) the existing (analytical) models of the market maker’s environment tend to be predicated on naive, unrealistic assumptions and hence not fully warranted;
- Use of the reward function: Various market frictions, such as transaction fees, slippages, or costs due to the bid–ask spread, as well as risk penalty terms (e.g., running or terminal inventory penalties, inventory PnL variance penalties) can easily and elegantly be incorporated into the RL reward function, thereby obviating the need for their additional consideration;
- Use of DNNs: DRL methods use DNNs, universal function approximators [55], to represent RL policies and value functions. (A neural network is considered “deep” if it has at least two hidden layers). DNNs are characterized by the ability to handle both nonlinear patterns and tackle low signal-to-noise ratios, both of which are associated with financial data. Moreover, they are capable of yielding highly complex nonlinear optimal (or near-optimal) policies and suitable for representation learning, which is particularly convenient when learning from the raw data. Finally, DRL methods are generally capable of tackling large (or even continuous) state and, in some cases, action spaces.
4.2. Deep vs. Nondeep
4.3. Multi-Asset vs. Single-Asset
4.4. Data
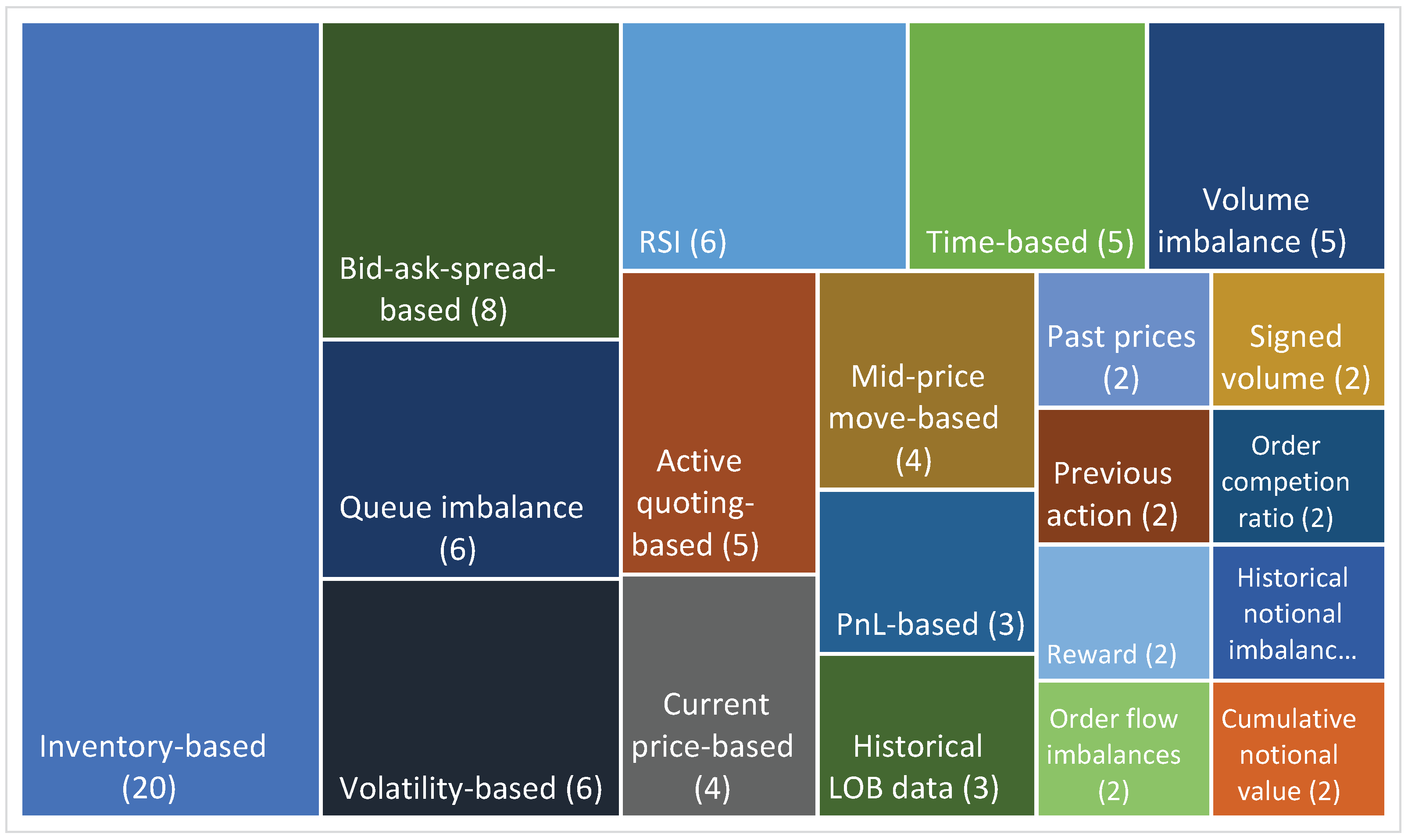
4.5. State Space Design
4.6. Action Space
4.7. Rewards
4.8. Function Approximation
4.9. Algorithm
4.10. Benchmarks and Performance Metrics
4.11. Model-Free vs. Model-Based
4.12. Remaining Aspects
5. Conclusions
- To properly incorporate risk management into MM frameworks, one should turn to risk-sensitive, safe, and distributional RL, branches that are currently severely underutilized in the field. Distributional RL [71] (a) provides a natural framework that enables easier incorporation of the domain knowledge, (b) is easily combined with risk-sensitive considerations, and (c) improves performance in leptokurtic environments, such as financial markets;
- Regardless of the choice of the algorithm, effective state representations are pivotal in alleviating the problem of sample inefficiency. This is a burning issue in RL. According to Böhmer [72], a good state space representation should be (a) Markovian, (b) capable of representing the (true) value of the current policy well enough for policy improvement, (c) capable of generalizing the learned value-function to unseen states with similar futures, and (d) low-dimensional. More systematic approaches to state space construction, based on state representation learning (SRL) algorithms [73] such as autoencoders should be given further attention. Such algorithms extract meaningful low-dimensional representations from high-dimensional data and thereby provide efficient state representations;
- Despite the prevailing focus on model-free models, model-based RL should not be disregarded, due to its numerous benefits, including better sample efficiency and stability, safe exploration, and explainability [74];
- Virtually all current approaches assume stationarity, i.e., that the dynamics of the underlying environment do not change over time. Therefore, the issue of the nonstationarity of financial markets still goes unaddressed. A possible way to tackle this issue could be through the development of adaptive RL agents capable of adapting to dynamic and noisy environments by continuously learning new and gradually forgetting old dynamics, perhaps via evolutionary computation methods. The technique of nowcasting [75] or “predicting the present”, applied to, for example, order or trade flow imbalance, provides a promising option as well and should be considered, especially during state space design, to account for different market regimes. Finally, on a somewhat related note, it would be interesting to consider online learning approaches in the spirit of [57] based on (D)RL;
- As acknowledged by [76], the outstanding advancements and potential benefits of data-driven complex machine learning approaches in finance emerged within the so-called second wave of artificial intelligence (AI). However, in order to foster their further applications in various domains, especially in finance, there is an emerging need for both transparent approaches behind the behavior of deep learning-based AI solutions and understandable interpretations for specific algorithmic behavior and outcomes. Even though deep learning models have managed to significantly outperform traditional methods and achieve performance that equals or even supersedes humans in some respects, ongoing research in finance should enhance its focus on explainable artificial intelligence in order for humans to fully trust and accept new advancements of AI solutions in practice. Consequently, special attention should be given to the development of contextual explanatory models to push even further the transparency and explainability of black-box algorithms. In this way, the performance and accountability of sophisticated AI-based algorithms and methods could be continuously improved and controlled. In particular, in the context of MM and DRL, more focus should be put on the explainability of the obtained RL policies (i.e., MM controls), an area that has so far been poorly explored, despite the explainability requirements [68] of financial regulators.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| A2C | Advantage actor–critic |
| AC | Actor–critic |
| ARL | Adversarial reinforcement learning |
| AS | Avellaneda–Stoikov |
| CARA | Constant absolute risk aversion |
| CNN | Convolutional neural network |
| DDPG | Deep deterministic policy gradient |
| DDQN | Deep deterministic Q-network |
| DNN | Deep neural network |
| DP | Dynamic programming |
| DQN | Deep Q-network |
| DRL | Deep reinforcement learning |
| DRQN | Deep recurrent Q-network |
| ESN | Echo state network |
| FFNN | Feed-forward neural network |
| GBNLFA | Gaussian-based nonlinear function approximator |
| GLFT | Guéant, Lehalle, and Fernandez-Tapia |
| GPI | Generalized policy iteration |
| HJB | Hamilton–Jacobi–Bellman |
| IABS | Interactive-agent-based simulator |
| LOB | Limit order book |
| LSTM | Long short-term memory |
| MAP | Mean absolute position |
| MARL | Multi-agent reinforcement learning |
| MCPG | Monte Carlo policy gradient |
| MDD | Maximum drawdown |
| MDP | Markov decision process |
| MM | Market making |
| NN | Neural network |
| OFI | Order flow imbalance |
| OTC | Over-the-counter |
| PG | Policy gradient |
| PnL | Profit and loss |
| PPO | Proximal policy optimization |
| RL | Reinforcement learning |
| RSI | Relative strength index |
| SRL | state representation learning |
| TD | Temporal difference |
| TFI | Trade flow imbalance |
| TRPO | Trust region policy optimization |
References
- Avellaneda, M.; Stoikov, S. High-frequency trading in a limit order book. Quant. Financ. 2008, 8, 217–224. [Google Scholar] [CrossRef]
- Law, B.; Viens, F. Market making under a weakly consistent limit order book model. High Freq. 2019, 2, 215–238. [Google Scholar] [CrossRef]
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A.; et al. Mastering the game of go without human knowledge. Nature 2017, 550, 354–359. [Google Scholar] [CrossRef]
- Duan, Y.; Chen, X.; Houthooft, R.; Schulman, J.; Abbeel, P. Benchmarking deep reinforcement learning for continuous control. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016. [Google Scholar]
- Dai, X.; Li, C.K.; Rad, A.B. An approach to tune fuzzy controllers based on reinforcement learning for autonomous vehicle control. IEEE Trans. Intell. Transp. Syst. 2005, 6, 285–293. [Google Scholar] [CrossRef]
- Aboussalah, A.M.; Lee, C.G. Continuous control with stacked deep dynamic recurrent reinforcement learning for portfolio optimization. Expert Syst. Appl. 2020, 140, 112891. [Google Scholar] [CrossRef]
- Kolm, P.N.; Ritter, G. Dynamic replication and hedging: A reinforcement learning approach. J. Financ. Data Sci. 2019, 1, 159–171. [Google Scholar] [CrossRef]
- Hendricks, D.; Wilcox, D. A reinforcement learning extension to the Almgren-Chriss framework for optimal trade execution. In Proceedings of the 2014 IEEE Conference on Computational Intelligence for Financial Engineering & Economics (CIFEr), London, UK, 27–28 March 2014. [Google Scholar]
- Mosavi, A.; Faghan, Y.; Ghamisi, P.; Duan, P.; Ardabili, S.F.; Salwana, E.; Band, S.S. Comprehensive review of deep reinforcement learning methods and applications in economics. Mathematics 2020, 8, 1640. [Google Scholar] [CrossRef]
- Charpentier, A.; Elie, R.; Remlinger, C. Reinforcement learning in economics and finance. Comput. Econ. 2021, 1–38. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Rao, C.R.; Rao, C.R.; Govindaraju, V. (Eds.) Handbook of Statistics; Elsevier: Amsterdam, The Netherlands, 2006; Volume 17. [Google Scholar]
- Bellman, R. Dynamic programming. Science 1966, 153, 34–37. [Google Scholar] [CrossRef]
- Watkins, C.J.C.H. Learning from Delayed Rewards. Ph.D. Thesis, King’s College, London, UK, 1989. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Sammut, C.; Webb, G.I. (Eds.) Encyclopedia of Machine Learning; Springer Science & Business Media: Boston, MA, USA, 2011. [Google Scholar]
- Sutton, R.S.; McAllester, D.A.; Singh, S.P.; Mansour, Y. Policy gradient methods for reinforcement learning with function approximation. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2000; pp. 1057–1063. [Google Scholar]
- Williams, R.J. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Mach. Learn. 1992, 8, 229–256. [Google Scholar] [CrossRef] [Green Version]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Graesser, L.; Keng, W.L. Foundations of Deep Reinforcement Learning: Theory and Practice in Python; Addison-Wesley Professional: Boston, MA, USA, 2019. [Google Scholar]
- Schulman, J.; Levine, S.; Abbeel, P.; Jordan, M.; Moritz, P. Trust region policy optimization. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 7–9 July 2015. [Google Scholar]
- Silver, D.; Lever, G.; Heess, N.; Degris, T.; Wierstra, D.; Riedmiller, M. Deterministic policy gradient algorithms. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Wang, Y. Electronic Market Making on Large Tick Assets. Ph.D. Thesis, The Chinese University of Hong Kong, Hong Kong, China, 2019. [Google Scholar]
- Liu, C. Deep Reinforcement Learning and Electronic Market Making. Master’s Thesis, Imperial College London, London, UK, 2020. [Google Scholar]
- Xu, Z.S. Reinforcement Learning in the Market with Adverse Selection. Master’s Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2020. [Google Scholar]
- Marcus, E. Simulating Market Maker Behaviour Using Deep Reinforcement Learning to Understand Market Microstructure. Master’s Thesis, KTH Royal Institute of Technology, Stockholm, Sweden, 2018. [Google Scholar]
- Fernandez-Tapia, J. High-Frequency Trading Meets Reinforcement Learning: Exploiting the Iterative Nature of Trading Algorithms. 2015. Available online: https://ssrn.com/abstract=2594477 (accessed on 2 September 2021).
- Chan, N.T.; Shelton, C. An Electronic Market-Maker; Massachusetts Institute of Technology: Cambridge, MA, USA, 2001. [Google Scholar]
- Kim, A.J.; Shelton, C.R.; Poggio, T. Modeling Stock Order Flows and Learning Market-Making from Data; Massachusetts Institute of Technology: Cambridge, MA, USA, 2002. [Google Scholar]
- Ganesh, S.; Vadori, N.; Xu, M.; Zheng, H.; Reddy, P.; Veloso, M. Reinforcement learning for market making in a multi-agent dealer market. arXiv 2019, arXiv:1911.05892. [Google Scholar]
- Spooner, T.; Fearnley, J.; Savani, R.; Koukorinis, A. Market making via reinforcement learning. arXiv 2018, arXiv:1804.04216. [Google Scholar]
- Guéant, O.; Lehalle, C.A.; Fernandez-Tapia, J. Dealing with the inventory risk: A solution to the market making problem. Math. Financ. Econ. 2013, 7, 477–507. [Google Scholar] [CrossRef] [Green Version]
- Haider, A.; Hawe, G.; Wang, H.; Scotney, B. Effect of Market Spread Over Reinforcement Learning Based Market Maker. In Proceedings of the International Conference on Machine Learning, Optimization, and Data Science, Siena, Italy, 10–13 September 2019; Springer: Cham, Switzerland, 2019. [Google Scholar]
- Haider, A.; Hawe, G.; Wang, H.; Scotney, B. Gaussian Based Non-linear Function Approximation for Reinforcement Learning. SN Comput. Sci. 2021, 2, 1–12. [Google Scholar] [CrossRef]
- Zhang, G.; Chen, Y. Reinforcement Learning for Optimal Market Making with the Presence of Rebate. 2020. Available online: https://ssrn.com/abstract=3646753 (accessed on 2 September 2021).
- Ho, T.; Stoll, H.R. Optimal dealer pricing under transactions and return uncertainty. J. Financ. Econ. 1981, 9, 47–73. [Google Scholar] [CrossRef]
- Glosten, L.R.; Milgrom, P.R. Milgrom. Bid, ask and transaction prices in a specialist market with heterogeneously informed traders. J. Financ. Econ. 1985, 14, 71–100. [Google Scholar] [CrossRef] [Green Version]
- Cartea, Á.; Donnelly, R.; Jaimungal, S. Algorithmic trading with model uncertainty. SIAM J. Financ. Math. 2017, 8, 635–671. [Google Scholar] [CrossRef] [Green Version]
- Mani, M.; Phelps, S.; Parsons, S. Applications of Reinforcement Learning in Automated Market-Making. In Proceedings of the GAIW: Games, Agents and Incentives Workshops, Montreal, Canada, 13–14 May 2019. [Google Scholar]
- Mihatsch, O.; Neuneier, R. Risk-sensitive reinforcement learning. Mach. Learn. 2002, 49, 267–290. [Google Scholar] [CrossRef] [Green Version]
- Selser, M.; Kreiner, J.; Maurette, M. Optimal Market Making by Reinforcement Learning. arXiv 2021, arXiv:2104.04036. [Google Scholar]
- Spooner, T.; Savani, R. Robust market making via adversarial reinforcement learning. arXiv 2020, arXiv:2003.01820. [Google Scholar]
- Lim, Y.S.; Gorse, D. Reinforcement Learning for High-Frequency Market Making. In Proceedings of the ESANN 2018, Bruges, Belgium, 25–27 April 2018. [Google Scholar]
- Zhong, Y.; Bergstrom, Y.; Ward, A. Data-Driven Market-Making via Model-Free Learning. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, Yokohama, Japan, 11–17 July 2020. [Google Scholar]
- Lokhacheva, K.A.; Parfenov, D.I.; Bolodurina, I.P. Reinforcement Learning Approach for Market-Maker Problem Solution. In International Session on Factors of Regional Extensive Development (FRED 2019); Atlantis Press: Dordrecht, The Netherlands, 2020. [Google Scholar]
- Hart, A.G.; Olding, K.R.; Cox, A.M.G.; Isupova, O.; Dawes, J.H.P. Echo State Networks for Reinforcement Learning. arXiv 2021, arXiv:2102.06258. [Google Scholar]
- Sadighian, J. Deep Reinforcement Learning in Cryptocurrency Market Making. arXiv 2019, arXiv:1911.08647. [Google Scholar]
- Sadighian, J. Extending Deep Reinforcement Learning Frameworks in Cryptocurrency Market Making. arXiv 2020, arXiv:2004.06985. [Google Scholar]
- Patel, Y. Optimizing market making using multi-agent reinforcement learning. arXiv 2018, arXiv:1812.10252. [Google Scholar]
- Kumar, P. Deep Reinforcement Learning for Market Making. In Proceedings of the 19th International Conference on Autonomous Agents and MultiAgent Systems, Auckland, New Zealand, 9–13 May 2020. [Google Scholar]
- Gašperov, B.; Kostanjčar, Z. Market Making with Signals Through Deep Reinforcement Learning. IEEE Access 2021, 9, 61611–61622. [Google Scholar] [CrossRef]
- Guéant, O.; Manziuk, I. Deep reinforcement learning for market making in corporate bonds: Beating the curse of dimensionality. Appl. Math. Financ. 2019, 26, 387–452. [Google Scholar] [CrossRef] [Green Version]
- Baldacci, B.; Manziuk, I.; Mastrolia, T.; Rosenbaum, M. Market making and incentives design in the presence of a dark pool: A deep reinforcement learning approach. arXiv 2019, arXiv:1912.01129. [Google Scholar]
- Hornik, K.; Stinchcombe, M.; White, H. Multilayer feedforward networks are universal approximators. Neural Netw. 1989, 2, 359–366. [Google Scholar] [CrossRef]
- Shelton, C.R. Policy improvement for POMDPs using normalized importance sampling. arXiv 2013, arXiv:1301.2310. [Google Scholar]
- Abernethy, J.D.; Kale, S. Adaptive Market Making via Online Learning. In Proceedings of the NIPS, 2013, Harrahs and Harveys, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 2058–2066. [Google Scholar]
- Cont, R.; Stoikov, S.; Talreja, R. A stochastic model for order book dynamics. Oper. Res. 2010, 58, 549–563. [Google Scholar] [CrossRef] [Green Version]
- Levine, N.; Zahavy, T.; Mankowitz, D.J.; Tamar, A.; Mannor, S. Shallow updates for deep reinforcement learning. arXiv 2017, arXiv:1705.07461. [Google Scholar]
- Bergault, P.; Evangelista, D.; Guéant, O.; Vieira, D. Closed-form approximations in multi-asset market making. arXiv 2018, arXiv:1810.04383. [Google Scholar]
- Guéant, O. Optimal market making. Appl. Math. Financ. 2017, 24, 112–154. [Google Scholar] [CrossRef]
- Byrd, D.; Hybinette, M.; Balch, T.H. Abides: Towards high-fidelity market simulation for ai research. arXiv 2019, arXiv:1904.12066. [Google Scholar]
- Vyetrenko, S.; Byrd, D.; Petosa, N.; Mahfouz, M.; Dervovic, D.; Veloso, M.; Balch, T. Get Real: Realism Metrics for Robust Limit Order Book Market Simulations. arXiv 2019, arXiv:1912.04941. [Google Scholar]
- Balch, T.H.; Mahfouz, M.; Lockhart, J.; Hybinette, M.; Byrd, D. How to Evaluate Trading Strategies: Single Agent Market Replay or Multiple Agent Interactive Simulation? arXiv 2019, arXiv:1906.12010. [Google Scholar]
- Huang, C.; Ge, W.; Chou, H.; Du, X. Benchmark Dataset for Short-Term Market Prediction of Limit Order Book in China Markets. J. Financ. Data Sci. 2021. [Google Scholar] [CrossRef]
- Dempster, M.A.H.; Romahi, Y.S. Intraday FX trading: An evolutionary reinforcement learning approach. In Proceedings of the International Conference on Intelligent Data Engineering and Automated Learning, Manchester, UK, 12–14 August 2002; Springer: Berlin/Heidelberg, Germany, 2002. [Google Scholar]
- Guilbaud, F.; Pham, H. Optimal high-frequency trading with limit and market orders. Quant. Financ. 2013, 13, 79–94. [Google Scholar] [CrossRef]
- Leal, L.; Laurière, M.; Lehalle, C.A. Learning a functional control for high-frequency finance. arXiv 2020, arXiv:2006.09611. [Google Scholar]
- Nevmyvaka, Y.; Feng, Y.; Kearns, M. Reinforcement learning for optimized trade execution. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006. [Google Scholar]
- Henderson, P.; Islam, R.; Bachman, P.; Pineau, J.; Precup, D.; Meger, D. Deep reinforcement learning that matters. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Bellemare, M.G.; Dabney, W.; Munos, R. A distributional perspective on reinforcement learning. In Proceedings of the International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017. [Google Scholar]
- Böhmer, W.; Springenberg, J.T.; Boedecker, J.; Riedmiller, M.; Obermayer, K. Autonomous learning of state representations for control. KI-Künstliche Intell. 2015, 29, 1–10. [Google Scholar] [CrossRef]
- Lesort, T.; Díaz-Rodríguez, N.; Goudou, J.F.; Filliat, D. State representation learning for control: An overview. Neural Netw. 2018, 108, 379–392. [Google Scholar] [CrossRef] [Green Version]
- Moerland, T.M.; Broekens, J.; Jonker, C. M Model-based reinforcement learning: A survey. arXiv 2020, arXiv:2006.16712. [Google Scholar]
- Lipton, A.; Lopez de Prado, M. Three Quant Lessons from COVID-19. Risk Magazine, 30 April 2020; 1–6. [Google Scholar] [CrossRef]
- Horvatić, D.; Lipic, T. Human-Centric AI: The Symbiosis of Human and Artificial Intelligence. Entropy 2021, 23, 332. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | DRL | Data | State Space | Action Space (dim.) | Rewards | Function Approximator | Algorithm | Benchmarks | Multi-Agent RL | Fees | Strand | Model-Free | Evaluation Metrics |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Chan and Shelton [29] | N | Simulated (agent-based model) | Inventory, order imbalance, market quality measures | Bid/ask price changes (<) | PnL with an inventory and quality penalty | - | Monte Carlo, SARSA, actor–critic | - | N | N | Inf | Y | Inventory, PnL, spread, price deviation |
| Kim et al. [30] | N | Simulated (fitted on historical data) | Difference between the agent’s bid/ask price and the best bid/ask price, spread, bid (ask) size, inventory, total volume of sell (buy) orders of price less (greater) than or equal to the agent’s ask price | Bid/ask price and size changes (81) | PnL | FFNN | Algorithm from [56] | - | N | N | - | Y | PnL |
| Spooner et al. [32] | N | Historical | Agent and market state variables | Bid/ask quote pairs and a market order (9) | Custom PnL with a running inventory penalty | Linear combination of tile codings | Q-learning, SARSA, and R-learning variants | Fixed offset and the online learning approach from [57] | N | N | Inv | Y | Normalized PnL, MAP, mean reward |
| Lim and Gorse [44] | N | Simulated (LOB model from [58]) | Inventory, time | Bid/ask quote pairs (9) | Custom PnL with a running inventory penalty and a CARA-based terminal utility | - | Q-learning | Fixed (zero-tick) offset, AS approximations, random strategy | N | Partly | Inv | Y | PnL, inventory |
| Patel [50] | Y | Historical | 1. Agent: historical prices, market indicator features, and current assets list. 2. Agent: time, quantity remaining and market variables | 1. Agent: buy, sell or hold (3). 2. Agent: quote (101) | 1. Agent: custom PnL-based (clipped). 2. Agent: custom PnL based | 1. Agent: DQN. 2. Agent: DDQN. | 1. Agent: DQN. 2. Agent: DDQN. | Momentum investing, buy and hold investing | Y | N | - | Y | PnL |
| Mani et al. [40] | N | Simulated (agent-based model) | Volume imbalance, the MM agent’s quoted spread | Changes in quotes (9) | PnL with a running inventory and spread penalty | - | Risk (in)sensitive (double) SARSA | Different RL algorithms | N | N | Inf | Y | Inventory, PnL, spread, price deviation |
| Wang [24] | N | Simulated (fitted on historical data) | Bid/ask spread, order volume at the best bid/ask price, inventory, relative price, and queue positions | Canceling or posting orders, doing nothing, using market orders (16) | PnL | - | GPI based | Heuristic polices taking limit order imbalance at the best price into account | N | Y | Inv | Y | PnL |
| Haider et al. [34] | N | Historical | Inventory, bid/ask level, book imbalance, strength volatility index, market sentiment | Bid/ask quote pairs (6) | Custom PnL with a running inventory (and market spread and volatility) penalty | Tile coding | SARSA | Benchmark from Spooner et al. [32], variant with market vol. | N | N | Inv | Y | PnL |
| Gueant and Manziuk [53] | Y | Simulated (fitted on historical data) | Inventories | Bid/ask quotes (∞) | PnL with a running inventory penalty | FFNN | Actor–critic-like | - | N | N | Inv | N | Mean reward |
| Ganesh et al. [31] | Y | Simulated (fitted on historical data) | Trades previously executed, inventory, midprice, and spread curves, market share | Spreads to stream, fraction of the inventory to buy/sell (∞) | PnL with an inventory PnL variance penalty | FFNN | PPO with clipped objective | Random, persistent, and adaptive MM agent | N | Y | Inv | Y | PnL, total reward, inventory, hedge cost |
| Sadighian [48] | Y | Historical | LOB, TFI, and OFI snapshots, handcrafted risk/position indicators, latest action | Bid/ask quote pairs, a market order, no action (17) | Custom PnL-based (positional PnL and trade completion) | FFNN | A2C, PPO | - | N | Y | - | Y | PnL, inventory |
| Baldacci et al. [54] | Y | Simulated | Principal incentives, inventory | Volumes on the bid/ask side (∞) | CARA-based | FFNN | Actor–critic-like | - | N | Y | Inv | Y | - |
| Lokhacheva et al. [46] | N | Historical | Exponential moving average, relative strength index, ? | Buy/sell, ? (2) | PnL | - | Q-learning | - | N | N | - | Y | Mean reward |
| Sadighian [49] | Y | Historical | LOB, TFI and OFI snapshots, handcrafted risk/position indicators, latest action | Bid/ask quote pairs, a market order, no action (17) | Custom PnL-based, risk-based, and goal-based | FFNN | A2C, PPO | - | N | Y | - | Y | PnL, inventory |
| Kumar [51] | Y | Simulated (agent-based model) | Agent and market state variables | Buy, sell, hold, cancel (4) | PnL | DRQN (with LSTM) | DRQN with double Q-learning and prioritized experience replay | DQN, benchmark from Spooner et al. [32] | N | Y | Inf | Y | Normalized PnL, MAP, mean reward |
| Zhang and Chen [36] | Y | Simulated (AS model) | Inventory, time | Bid/ask quotes (∞) | CARA terminal utility | FFNN | Hamiltonian-guided value function approximation algorithm (HVA) | AS approximations | N | Y | Inv | N | PnL, rebate analysis |
| Spooner and Savani [43] | N | Simulated (AS model) | Inventory, time | Bid/ask quotes relative to the midprice (∞) | PnL with a running and terminal inventory penalty | Radial basis function networks [11], linear function approximators using 3rd-order polynomial bases | NAC-S() | RL agents trained against random and fixed adversaries | Y | N | Mod | Y | PnL, Sharpe ratio, terminal inventory, mean spread |
| Zhong et al. [45] | N | Historical | Inventory sign, cumulative PnL, sell- and buy-heaviness, midprice change magnitude and direction | Adding or canceling orders or doing nothing (2–4) | PnL | - | Q-learning | Random strategy, firm’s strategy, fixed (zero-tick) offset | N | N | Inv | Y | PnL, Sharpe ratio |
| Hart et al. [47] | N | Simulated | Inventory | Movement of bid/ask quotes (∞) | PnL with a running inventory penalty | ESN | RL algorithm supported by an ESN | - | N | Y | Inv | Y | - |
| Selser et al. [42] | Y | Simulated (AS model) | Price, inventory, time | Bid/ask quote pairs, ? (21) | PnL with a PnL variance penalty | DQN | DQN, Q-learning | Symmetric strategy, AS approximations, Q-learning agent | N | N | - | Y | PnL, Sharpe ratio, mean reward, utility |
| Gašperov and Kostanjčar [52] | Y | Historical | Inventory, trend and realized price range forecasts | Bid/ask quotes relative to the best bid/ask (∞) | Custom PnL with a running inventory penalty | FFNN | Neuroevolution | Fixed offset with inv. constraints, GLFT approximations | Y | N | Inv | Y | Ep. return, PnL, MAP, MDD, rolling PnL-to-MAP |
| Haider et al. [35] | N | Historical | Volatility, relative strength index, book imbalance, inventory, bid/ask level | Bid/ask quote pairs, a market order (8) | Custom PnL with a running inventory penalty | Gaussian-based nonlinear function approximator (GBNLFA) | GBNLFA (TD-based) | DQN and tile codings | N | N | Inv | Y | Quoted spread, PnL, cumulative reward |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gašperov, B.; Begušić, S.; Posedel Šimović, P.; Kostanjčar, Z. Reinforcement Learning Approaches to Optimal Market Making. Mathematics 2021, 9, 2689. https://doi.org/10.3390/math9212689
Gašperov B, Begušić S, Posedel Šimović P, Kostanjčar Z. Reinforcement Learning Approaches to Optimal Market Making. Mathematics. 2021; 9(21):2689. https://doi.org/10.3390/math9212689
Chicago/Turabian StyleGašperov, Bruno, Stjepan Begušić, Petra Posedel Šimović, and Zvonko Kostanjčar. 2021. "Reinforcement Learning Approaches to Optimal Market Making" Mathematics 9, no. 21: 2689. https://doi.org/10.3390/math9212689