
Comparable Studies of Financial Bankruptcy Prediction Using Advanced Hybrid Intelligent Classification Models to Provide Early Warning in the Electronics Industry


Abstract
:1. Introduction
2. Literature Review
2.1. Financial Bankruptcy
2.2. Financial Statements and Financial Ratios
2.3. Feature Selection Method
2.4. Z-Score Bankrupt Model
- (asset scale): working capital/total assets = (current assets − current liabilities)/total assets;
- (profitability): (surplus reserve + undistributed profit)/total assets;
- (ROA): EBIT/total assets = (total profit + financial expenses)/total assets;
- (financial structure): market value/total liabilities;
- (total assets turnover ratio): total operating income/total assets;
- : index judgment < 1.8 (with financial bankruptcy); 1.8 ≤ < 2.99 (gray area); < 2.99 (safe area).
2.5. Classifiers of Classification Models
- NB classifier: The NB algorithm [50] is often used in classification analysis because of its simple and fast operation process. According to Bayes’ theorem, NB calculates the probabilities of the data in all ethnic groups using the prior probability and the known data information and classifies them to the ethnic group with the greatest posterior probability. Thus, the key component of the algorithm is defined in the following Equation (2).
- : the probability of a given sample (, target), (, attribute), called the posterior probability.
- : the probability of the sample “”, called the prior probability.
- : the probability that the sample “” and the sample “” are known.
- : the probability of the sample “”.
- LG classifier: The logistic classification method is a linear model when the data have considerable scale and require fast prediction speed. Some nonlinear models, such as neural networks, cannot meet these expectations, and the LG classifier will then be a more suitable choice. The LG model [51] was well developed for the use of different application domains. When a dataset has variables and one of the data is used to predict the category by the linear model, the key formula is defined as Equation (3) below.
- 3.
- KNN (IBK) classifier: KNN algorithm [52] is a nonparametric statistical method used in classification and regression. In both cases, the KNN classification output is a classification group with K samples nearest to feature space. The most common classification method of discriminating objects is that the objects are classified by “majority voting” among neighbors, which is called K nearest neighbors (K is a positive integer, usually smaller). If K = 1, the category of the object is directly assigned by the nearest node. In KNN regression, the output is the attribute value of the object, which is the average of its K nearest neighbors. The core component of this KNN algorithm is formatted in the following Equations (5) and (6).
- 4.
- BAG classifier: Bagging classification (also called bootstrap aggregating) [53], also known as bagging algorithm, is a clustering learning algorithm in the field of computer learning. BAG classifier can be combined with other classification methods and regression algorithms to avoid overfitting by reducing the analysis variance at the time by improving the accuracy and stability of the analysis. The analysis step is to set a training cluster D of size n, from which m subgroups of size n are selected based on averaging through the bagging classification method or re-input (that is, random sampling method) as new training clusters. Then, m models can be obtained by using classification, regression, and other algorithms on the m training cluster, and the final bagging result can be analyzed through various methods, such as average value or majority vote. The core component of this BAG algorithm is determined in Equation (7) below:
- 5.
- J48 algorithm of DT classifier: DT [54] has always been a favorite tool of data mining researchers, with a special tree structure in the construction of objective decision models. The elements of DT are divided into root, branch, and leaf. The new decision node represents the problem, and the branch of the root is the new decision node. Large amounts of high-dimensional data are analyzed to establish simple rules, and the results are presented by leaf. Each branch of DT is a classification of single variable attributes, which will be divided into two or more blocks. Blocks are then classified by branches depending on different attributes. This process is a method of layering to classify trees. When it is no longer possible to classify or when a single block can be used in another branch, the layering process ends. From the root to each leaf, there is a unique path, which is an expression of the rules used to classify data. The main component of this J48 algorithm for the DT classifier is identified in the following Equation (8):
- : number of categories.
- represents entropy, or the expected value of the information contained in all categories.
2.6. LR Analysis
3. Research Method
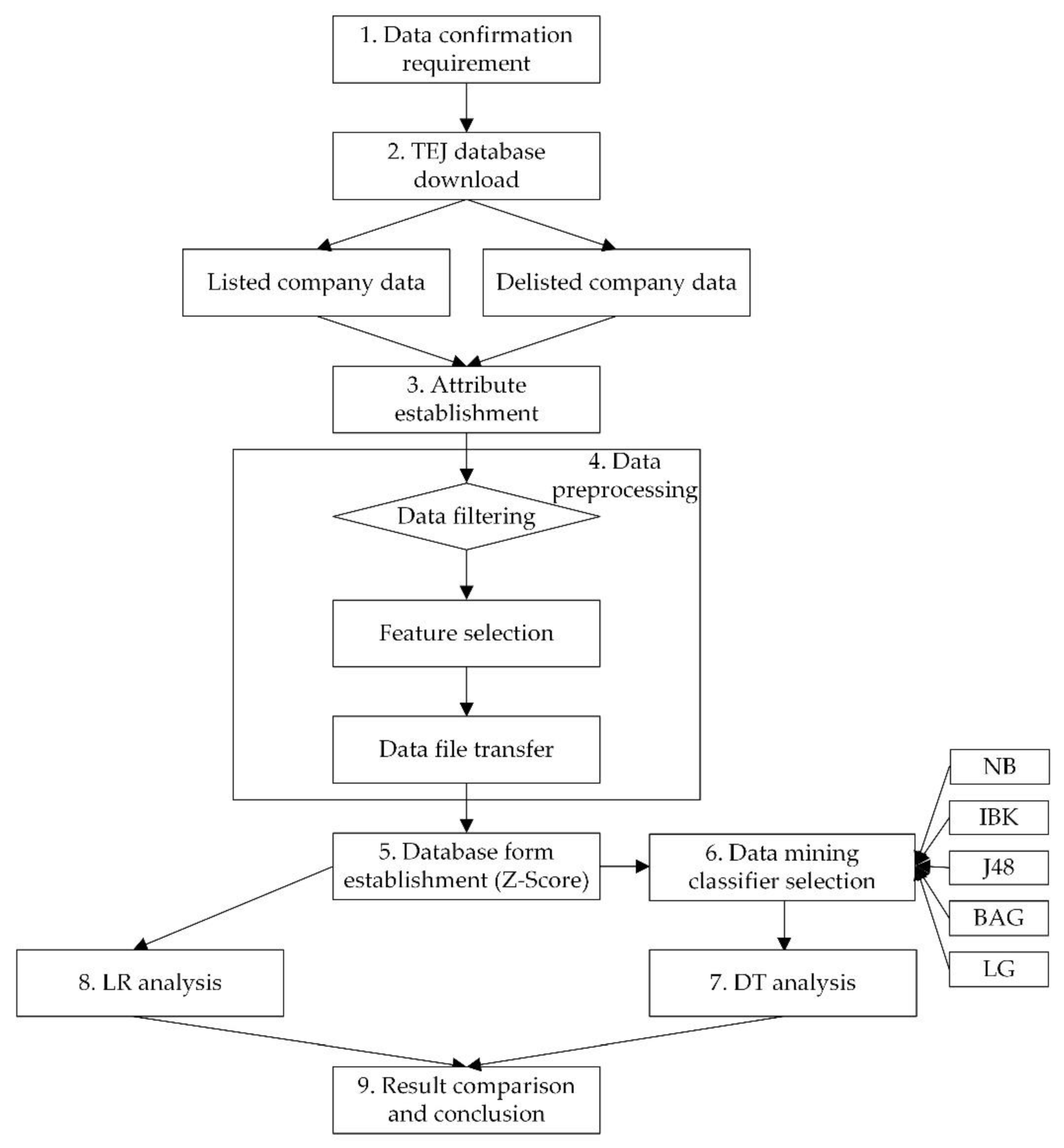
3.1. Research Framework
3.2. Research Steps for the Proposed Hybrid Model
- Attribute: Refers to the features of data, which may change with time. For example, the return rate, surplus, and loss of each company’s stock price will not be the same in different years, quarters, or different time points. The quarter attribute is a value, the return rate attribute is a symbol, and the value may be 10, 0.5, 0, etc. The two attribute values are distinguished as symbols or numbers.
- Selection of conditional attributes: Based on the opinions of scholars and experts, 22 conditional attributes are mainly selected, including time, quarter, debt ratio, accounts receivable turnover, inventory turnover, fixed assets turnover, operating profit rate, return on operating assets, interest coverage ratio, interest expense ratio, total assets growth rate, total assets turnover, net value turnover, current liabilities, total assets, cash flow ratio, net value per share, cash flow per share, turnover per share, liquidity ratio, quick ratio, and earnings per share. In this study, the conditional attribute data types used in financial ratios include no-type data, range data, and set data, which are in free text and digital form. Because of the way financial ratios are used, most of them are in digital form.
- Decision attribute: Normal or bankruptcy is the decisional attribute, and the variables are then selected and analyzed. This study has one decision attribute: listed or delisted. That is, the data type of decisional attribute is a category for Y/N corresponded to normal/bankruptcy in text format.
- DT analysis: Each node through the tree graph is a financial ratio, and each branch is the analysis of the previous financial ratio, which will divide the direction of instruction into two or more blocks. The analysis process can filter the branches of the layer. When the filtering and segmentation can no longer be performed into a separate branch, the layering process is completed, and bankrupt or normal is finally identified in leaf.
- Coding: The conditional attributes of financial ratios with their references for illustrating the chosen reason are represented by coding X1, X2, X3, …, and X22 in this study, as shown in Table 1. The decision attribute is coded as X23.
- Data filtering. Includes the following substeps: (1) filtering, (2) merging fields, (3) verifying data correctness, (4) cleaning, and (5) checking the data features of conditional attributes, such as outliers.
- Feature selection. Feature selection is mostly used in classifier and regression analysis, which is for the use of classification function in this study. It is used to search all possible combinations of all attributes in the dataset to find the best group of attributes. In this study, machine attribute selection is used as follows. The machine feature selection of the research data of 2455 listed companies and 491 delisted companies are resampled and carried out by two-class classification methods; they are listed and delisted.
- Data file transfer. After the feature selection of five groups of models with different company ratios (i.e., 1:1 to 5:1) for further analysis of the processing data of the imbalanced class classification problem, the key attributes were identified and are shown in Table 2. From Table 2, the empirical results of five groups of different company ratios were used as experimental data, with each modeled and analyzed. Next, the data for the listed and delisted companies were targeted and processed, the above data were transferred to files, and then they were to be analyzed by the following LR analysis for the next step.
4. Validation Analysis
4.1. Descriptive Statistics of the Attributes Used
4.2. Data Mining Classifier Technology
4.3. Empirical Analysis of Classifiers
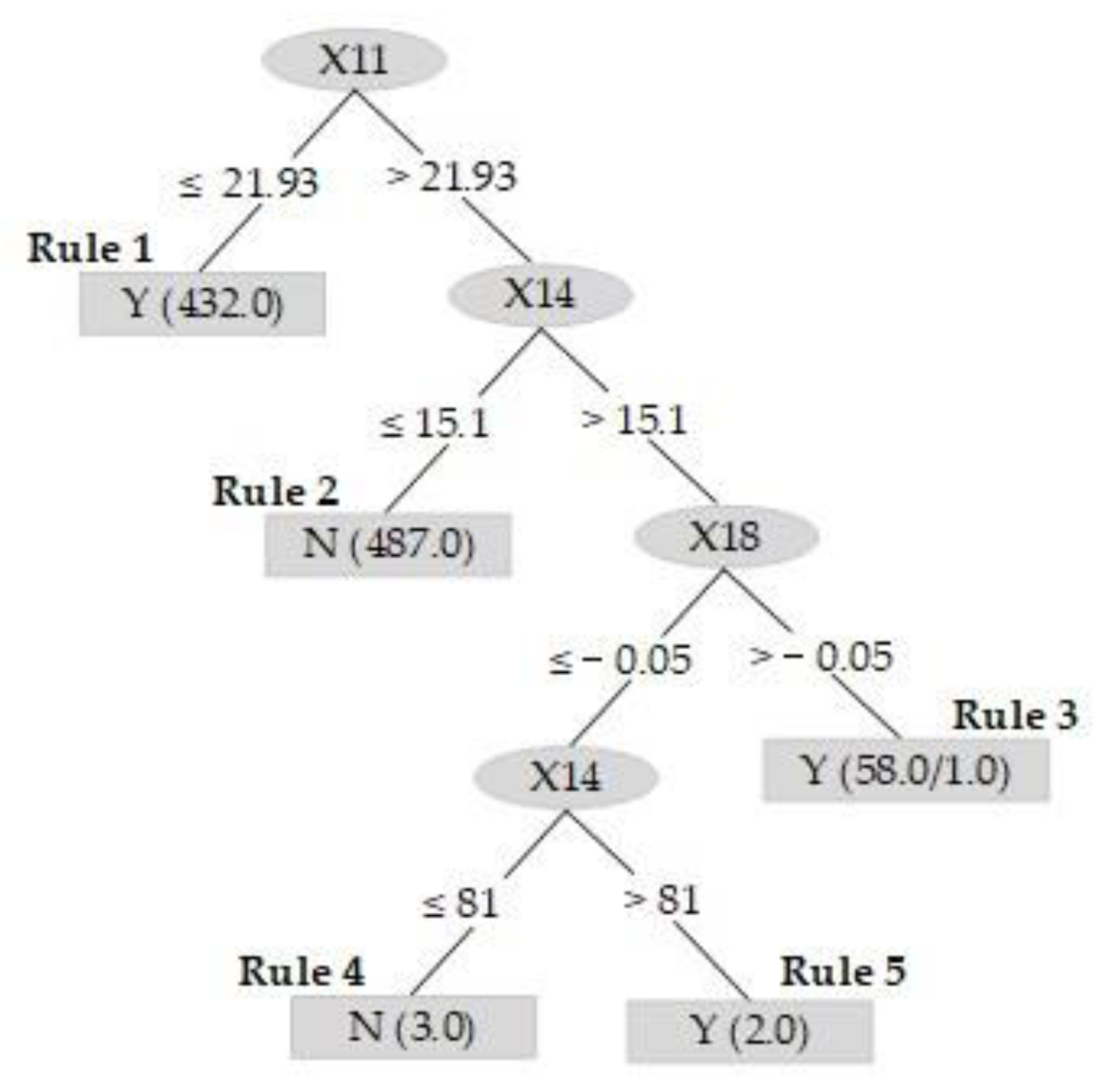
4.4. DT Empirical Analysis
- (1)
- Rule 2: If X11 > 21.93, and X14 ≤ 15.1, then X23 → N.Description: If the liquidity ratio is greater than 21.93 and the fixed assets turnover is less than or equal to 15.1, then it is a bankrupt company.
- (2)
- Rule 3: If X11 > 21.93, and X14 > 15.1, and X18 > −0.05, then X23 → Y.Description: If the liquidity ratio is greater than 21.93, the fixed assets turnover is greater than 15.1, and the interest expense ratio is greater than −0.05, then it is a normal company.
4.5. LR Empirical Analysis
- The comprehensive model verification of 491 normal and 491 bankrupt companies (1:1) is identified as: (1) the mode of the ratio 1:1 has 1% and 5% significances, and (2) four (X2 quarter Q2, X9, X11, and X14) of the 22 variables effectively represent whether the occurrence of financial bankruptcy will affect the classification results.
- After the feature selection of 491 normal and 491 bankrupt companies (1:1), the binary analysis of LR is determined: the model prediction accuracy of the ratio 1:1 is achieved 99.5%.
- For the LR analysis result, Table 15 shows information that the dependent variable of LR reaches at least 5% significance for regression analysis of financial bankruptcy sample data.
- The comprehensive model verification of 982 normal and 491 bankrupt companies (2:1) is defined as (1) the mode of the ratio 2:1 has 1% significance, and (2) three (X9, X11, and X14) of the 20 variables effectively represent and predict whether the occurrence of financial bankruptcy will affect the classification results.
- After the feature selection of 982 normal and 491 bankrupt companies (2:1), the model prediction accuracy achieves 99.3% for the binary analysis of LR.
- For the LR analysis result, Table 16 shows information that the dependent variable of LR reaches 1% significance for regression analysis of financial bankruptcy sample data.
- The comprehensive model verification of 1473 normal and 491 bankrupt companies (3:1) is identified as (1) the mode of the ratio 3:1 has at least 10% significance, and five (X9, X10, X11, X14, and X22) of the 20 variables effectively represent and predict whether the occurrence of financial bankruptcy will affect the classification results.
- After the feature selection of 1473 normal and 491 bankrupt companies (3:1), the binary analysis of LR achieves the model prediction accuracy of 99.5%.
- For the LR analysis result, Table 17 shows that the dependent variable of LR reaches at least 10% significance for regression analysis of financial bankruptcy sample data.
- The comprehensive model verification of 1964 normal and 491 bankrupt companies (4:1) is focused on the two points: (1) the four to one mode has 1% significance, and five (X9, X10, X11, X14, and X22) of the 20 variables effectively also represent and predict whether the occurrence of financial bankruptcy will affect the classification results.
- After the feature selection of 1964 normal and 491 bankrupt companies (4:1), the binary analysis of LR also achieves the model prediction accuracy of 99.5%.
- For the LR analysis result, Table 18 shows that the dependent variable of LR reaches at least 10% significance for regression analysis of financial bankruptcy sample data.
- The comprehensive model verification of 2455 normal and 491 bankrupt companies (5:1) is also defined as (1) the four to one mode has 1% significance, and (2) five (X6, X9, X11, X14, and X22) of the 20 variables effectively also represent and predict whether the occurrence of financial bankruptcy will affect the classification results.
- After the feature selection of 2455 normal and 491 bankrupt companies (5:1), the binary analysis of LR is obtained the model prediction accuracy of 99.6%.
- For the LR analysis result, Table 19 shows that the dependent variable of LR reaches at least 5% significance for regression analysis of financial bankruptcy sample data.
4.6. Result Comparison and Conclusion
5. Discussions and Empirical Findings
5.1. Discussion of Empirical Results
5.2. Research Findings of Classifiers
- Company bankruptcy classifier assessment.(1) Score of company bankruptcy proportion segmentation: (a) the best feature selection is the 4:1 company model of LG classifier; (b) the best classifiers are DT J48 classifier (max 100%, min 99.10%) and LG classifier (max 100%, min 99.10%); (c) in the 5:1 company model, BAG classifier increases the most by 42.91%; (d) BAG classifier performs worst.(2) Evaluation of company bankruptcy cross-validation: (a) the best feature selection is three to one company model of KNN (IBK) classifier; (b) the classifiers with the best accuracy of 99.59% are KNN (IBK) classifier and DT J48 classifier; (c) BAG classifier increases the most by 49.52% in this model; (d) NB performs worst.
5.3. Research Findings of LR
5.4. Managerial Implications
5.5. Research Limitations
6. Conclusions and Future Research
6.1. Conclusions
- Proportional classifier features between financial bankruptcy and normal companies. After the feature selection of five ratio groups of companies using financial indicators, the main characteristics were found to be quarter (X2), net value per share (X6), liquidity ratio (X9), quick ratio (X10), debt ratio (X11), fixed assets turnover (X14), interest coverage ratio (X17), interest expense ratio (X18), and earnings per share (X22).
- The research of company proportion has a significant impact on the financial bankruptcy early warning attribute classifier. In the financial early warning model of the five ratio groups of companies, the common significant variables of classifiers are: liquidity ratio (X9), quick ratio (X10), debt ratio (X11), fixed assets turnover (X14), interest expense ratio (X18), earnings per share (X22). In addition to the features of quarter (X2), net value per share (X6) and interest coverage ratio (X17) variables of 1:1, and 2:1 company ratios, other features have a significant relationship in the DT (J48) bankruptcy early warning model.
- The research of five groups of different company ratios, combined with LR analysis and comparison. In this study, the difference in overall accuracy of the five ratio groups of companies is more than 99.3% in the single indicator financial early warning model. In other words, the highest error rate of LR and bankruptcy indicators of companies in financial bankruptcy is 0.7%. In the single indicator financial early warning model, the overall difference accuracy is more than 99.3%. Therefore, the models for the five ratio groups of companies can distinguish the financial ratio of the company in financial bankruptcy, but the regression analysis value for the sample data of the five groups does not have highly significant attributes. The possible reason is that all attributes have influence, so there is no significant parameter change. After feature selection of five groups of company proportion by classifier, the significant variables of LR analysis are liquidity ratio (X9), debt ratio (X11), fixed assets turnover (X14), and earnings per share (X22).
6.2. Future Research
Author Contributions
Funding
Conflicts of Interest
References
- Zhang, Y.; Liu, R.; Heidari, A.A.; Wang, X.; Chen, Y.; Wang, M.; Chen, H. Towards augmented kernel extreme learning models for bankruptcy prediction: Algorithmic behavior and comprehensive analysis. Neurocomputing 2021, 430, 185–212. [Google Scholar] [CrossRef]
- Kou, G.; Xu, Y.; Peng, Y.; Shen, F.; Chen, Y.; Chang, K.; Kou, S. Bankruptcy prediction for SMEs using transactional data and two-stage multiobjective feature selection. Decis. Support. Syst. 2021, 140, 113429. [Google Scholar] [CrossRef]
- Du Jardin, P. Dynamic self-organizing feature map-based models applied to bankruptcy prediction. Decis. Support. Syst. 2021, 147, 113576. [Google Scholar] [CrossRef]
- Zhang, H.; Jiang, L.; Yu, L. Attribute and instance weighted naive Bayes. Pattern Recognit. 2021, 111, 107674. [Google Scholar] [CrossRef]
- Zhang, Z.; Han, Y. Detection of ovarian tumors in obstetric ultrasound imaging using logistic regression classifier with an advanced machine learning approach. IEEE Access 2020, 8, 44999–45008. [Google Scholar] [CrossRef]
- Kück, M.; Freitag, M. Forecasting of customer demands for production planning by local k-nearest neighbor models. Int. J. Prod. Econ. 2021, 231, 107837. [Google Scholar] [CrossRef]
- Sandag, G.A. A prediction model of company health using bagging classifier. JITK J. 2020, 6, 41–46. [Google Scholar] [CrossRef]
- Abspoel, M.; Escudero, D.; Volgushev, N. Secure training of decision trees with continuous attributes. Proc. Priv. Enhancing Technol. 2021, 2021, 167–187. [Google Scholar]
- Li, H.; Shu, L.; Yu, J.; Xian, Z.; Duan, H.; Shu, Q.; Ye, J. Using Z-score to optimize population-specific DDH screening: A retrospective study in Hangzhou, China. BMC. Musculoskelet. Disord. 2021, 22, 344. [Google Scholar]
- Sun, D.; Xu, J.; Wen, H.; Wang, D. Assessment of landslide susceptibility mapping based on Bayesian hyperparameter optimization: A comparison between logistic regression and random forest. Eng. Geol. 2021, 281, 105972. [Google Scholar] [CrossRef]
- Hopwood, T. Accounting as Social and Institutional Practice; Cambridge University Press: Cambridge, UK, 1994. [Google Scholar]
- Ashraf, S.; Félix, E.G.S.; Serrasqueiro, Z. Do traditional financial distress prediction models predict the early warning signs of financial distress? J. Risk Financ. Manag. 2019, 12, 55. [Google Scholar] [CrossRef] [Green Version]
- Jones, S.; Johnstone, D.; Wilson, R. Predicting corporate bankruptcy: An evaluation of alternative statistical frameworks. J. Bus. Financ. Account. 2017, 44, 3–34. [Google Scholar] [CrossRef]
- Jones, S.; Johnstone, D.; Wilson, R. An empirical evaluation of the performance of binary classifiers in the prediction of credit ratings changes. J. Bank. Financ. 2015, 56, 72–85. [Google Scholar] [CrossRef]
- Faris, H.; Abukhurma, R.; Almanaseer, W.; Saadeh, M.; Mora, A.M.; Castillo, P.A.; Aljarah, I. Improving financial bankruptcy prediction in a highly imbalanced class distribution using oversampling and ensemble learning: A case from the Spanish market. Prog. Artif. Intell. 2020, 9, 31–53. [Google Scholar] [CrossRef]
- Pelekh, U.; Khocha, N.; Holovchak, H. Financial statements as a management tool. Manag. Sci. Lett. 2020, 10, 197–208. [Google Scholar] [CrossRef]
- Aswar, K.; Wiguna, M.; Hariyani, E.; Ermawati, E. Quality of financial statements in Indonesian local governments: An empirical investigation. J. Asian Financ. Econ. Bus. 2021, 8, 993–999. [Google Scholar]
- Anan, E. Determinants fraudulent financial statements using the SCORE model on infrastructure sector companies in Indonesia. Ilomata Int. J. Tax Account. 2021, 2, 113–121. [Google Scholar] [CrossRef]
- Chen, Y.J.; Liou, W.C.; Chen, Y.M.; Wu, J.H. Fraud detection for financial statements of business groups. Int. J. Account. Inf. Syst. 2019, 32, 1–23. [Google Scholar] [CrossRef]
- Arya, A.; Nagar, N. Stewardship value of income statement classifications: An empirical examination. J. Account. Audit. Financ. 2021, 36, 56–80. [Google Scholar] [CrossRef]
- Razak, L.A. Value of relevance of other comprehensive income in listing companies in LQ 45 index. Psychology 2021, 58, 512–517. [Google Scholar]
- Albanese, C.; Crepey, S.; Hoskinson, R.; Saadeddine, B. XVA analysis from the balance sheet. Quant. Financ. 2021, 21, 99–123. [Google Scholar] [CrossRef]
- Debelle, G. The reserve bank of Australia’s policy actions and balance sheet. Econ. Anal. Policy 2020, 68, 285–295. [Google Scholar] [CrossRef] [PubMed]
- Prili, G.S.P. Effect of operrationg cash flows on the amount of dividends dividends towards the company. J. Contemp. Inf. Technol. Manag. Account. 2021, 2, 35–38. [Google Scholar]
- Anand, M.P.G.; Samba, V.; Kumar, M.S.V.S. A comparative study on cash flow statements of HDFC and SBI banks. Eur. J. Mol. Clin. Med. 2021, 7, 5089–5094. [Google Scholar]
- Hameedi, K.S.; Al-Fatlawi, Q.A.; Ali, M.N.; Almagtome, A.H. Financial performance reporting, IFRS implementation, and accounting information: Evidence from Iraqi banking sector. J. Asian Financ. Econ. Bus. 2021, 8, 1083–1094. [Google Scholar]
- Bradbury, M.E.; Scott, T. What accounting standards were the cause of enforcement actions following IFRS adoption? Account. Financ. 2021, 61, 2247–2268. [Google Scholar] [CrossRef]
- Amalia, S.; Fadjriah, N.E.; Nugraha, N.M. The influence of the financial ratio to the prevention of bankruptcy in cigarette manufacturing companies sub sector. Solid State Technol. 2020, 63, 4173–4182. [Google Scholar]
- Nugraha, N.M.; Puspitasari, D.M.; Amalia, S. The effect of financial ratio factors on the percentage of income increasing of automotive companies in Indonesia. Int. J. Psychosoc. Rehabil. 2020, 24, 2539–2545. [Google Scholar]
- Amalina, N.S.S.; Utami, H.; Suroija, N. The analysis the financial perfomance using financial ratio by the decree of the Indonesian minister for Soe. Agregat 2020, 4, 100–122. [Google Scholar]
- Kliestik, T.; Valaskova, K.; Lazaroiu, G.; Kovacova, M.; Vrbka, J. Remaining financially healthy and competitive: The role of financial predictors. J. Compet. 2020, 12, 74–92. [Google Scholar] [CrossRef]
- Hosaka, T. Bankruptcy prediction using imaged financial ratios and convolutional neural networks. Expert Syst. Appl. 2019, 117, 287–299. [Google Scholar] [CrossRef]
- Ibrahim, I.; Abdulazeez, A. The role of machine learning algorithms for diagnosing diseases. J. Appl. Sci. Technol. Trends 2021, 2, 10–19. [Google Scholar] [CrossRef]
- Jacobs, M.; Pradier, M.F.; McCoy, T.H.; Perlis, R.H.; Doshi-Velez, F.; Gajos, K.Z. How machine-learning recommendations influence clinician treatment selections: The example of the antidepressant selection. Transl. Psychiatry 2021, 11, 1–9. [Google Scholar] [CrossRef]
- Goh, G.D.; Sing, S.L.; Yeong, W.Y. A review on machine learning in 3D printing: Applications, potential, and challenges. Artif. Intell. Rev. 2021, 54, 63–94. [Google Scholar] [CrossRef]
- Ageed, Z.S.; Zeebaree, S.R.; Sadeeq, M.M.; Kak, S.F.; Yahia, H.S.; Mahmood, M.R.; Ibrahim, I.M. Comprehensive survey of big data mining approaches in cloud systems. Qubahan Acad. J. 2021, 1, 29–38. [Google Scholar] [CrossRef]
- Espadinha-Cruz, P.; Godina, R.; Rodrigues, E.M. A review of data mining applications in semiconductor manufacturing. Processes 2021, 9, 305. [Google Scholar] [CrossRef]
- Savaglio, C.; Fortino, G. A simulation-driven methodology for IoT data mining based on edge computing. ACM Trans. Internet Technol. 2021, 21, 1–22. [Google Scholar] [CrossRef]
- Song, X.F.; Zhang, Y.; Gong, D.W.; Sun, X.Y. Feature selection using bare-bones particle swarm optimization with mutual information. Pattern Recognit. 2021, 112, 107804. [Google Scholar] [CrossRef]
- Omuya, E.O.; Okeyo, G.O.; Kimwele, M.W. Feature selection for classification using principal component analysis and information gain. Expert Syst. Appl. 2021, 174, 114765. [Google Scholar] [CrossRef]
- Hussain, K.; Neggaz, N.; Zhu, W.; Houssein, E.H. An efficient hybrid sine-cosine Harris hawks optimization for low and high-dimensional feature selection. Expert Syst. Appl. 2021, 176, 114778. [Google Scholar] [CrossRef]
- Fang, S.; Cai, Z.; Sun, W.; Liu, A.; Liu, F.; Liang, Z.; Wang, G. Feature selection method based on class discriminative degree for intelligent medical diagnosis. Comput. Mater. Contin. 2018, 55, 419–433. [Google Scholar]
- Covington, L.; Armstrong, B.; Trude, A.C.; Black, M.M. Longitudinal associations among diet quality, physical activity and sleep onset consistency with body mass index Z-Score among toddlers in low-income families. Ann. Behav. Med. 2021, 55, 653–664. [Google Scholar] [CrossRef] [PubMed]
- Pérez-Elvira, R.; Oltra-Cucarella, J.; Carrobles, J.A.; Teodoru, M.; Bacila, C.; Neamtu, B. Individual alpha peak frequency, an important biomarker for live z-score training neurofeedback in adolescents with learning disabilities. Brain Sci. 2021, 11, 167. [Google Scholar] [CrossRef]
- Nathan, K.; Livnat, G.; Feraru, L.; Pillar, G. Improvement in BMI z-score following adenotonsillectomy in adolescents aged 12–18 years: A retrospective cohort study. BMC Pediatr. 2021, 21, 184. [Google Scholar] [CrossRef]
- Lepetit, L.; Strobel, F.; Tran, T.H. An alternative Z-score measure for downside bank insolvency risk. Appl. Econ. Lett. 2021, 28, 137–142. [Google Scholar] [CrossRef]
- Dallaire, F. Z score disease or coronary artery disease: The (missing) link between statistics and anatomy in Kawasaki disease. J. Am. Soc. Echocardiogr. 2021, 34, 673–675. [Google Scholar] [CrossRef]
- Swalih, M.; Adarsh, K.; Sulphey, M. A study on the financial soundness of Indian automobile industries using Altman Z-Score. Accounting 2021, 7, 295–298. [Google Scholar] [CrossRef]
- Altman, E.I. Financial ratios, discriminant analysis and the prediction of corporate bankruptcy. J. Financ. 1968, 23, 589–609. [Google Scholar] [CrossRef]
- Khajenezhad, A.; Bashiri, M.A.; Beigy, H. A distributed density estimation algorithm and its application to naive Bayes classification. Appl. Soft Comput. 2021, 98, 106837. [Google Scholar] [CrossRef]
- Wang, Z.; Huang, S.; Wang, J.; Sulaj, D.; Hao, W.; Kuang, A. Risk factors affecting crash injury severity for different groups of e-bike riders: A classification tree-based logistic regression model. J. Saf. Res. 2021, 76, 176–183. [Google Scholar] [CrossRef]
- García, J.; Maureira, C. A KNN quantum cuckoo search algorithm applied to the multidimensional knapsack problem. Appl. Soft Comput. 2021, 102, 107077. [Google Scholar] [CrossRef]
- Mosavi, A.; Hosseini, F.S.; Choubin, B.; Goodarzi, M.; Dineva, A.A.; Sardooi, E.R. Ensemble boosting and bagging based machine learning models for groundwater potential prediction. Water Resour. Manag. 2021, 35, 23–37. [Google Scholar] [CrossRef]
- Rungskunroch, P.; Jack, A.; Kaewunruen, S. Benchmarking on railway safety performance using Bayesian inference, decision tree and petri-net techniques based on long-term accidental data sets. Reliab. Eng. Syst. Saf. 2021, 213, 107684. [Google Scholar] [CrossRef]
- Ohlson, J.A. Financial ratios and the probabilistic prediction of bankruptcy. J. Account. Res. 1980, 18, 109–131. [Google Scholar] [CrossRef] [Green Version]
- Szpulak, A. Assessing the financial distress risk of companies operating under conditions of a negative cash conversion cycle. e-Finans. Financ. Internet Q. 2016, 12, 72–82. [Google Scholar] [CrossRef] [Green Version]
- Berishvili, V. Industry average financial ratios for Georgia. Ecoforum J. 2020, 9, 1–6. [Google Scholar]
- Tsai, J.K.; Hung, C.H. Improving AdaBoost classifier to predict enterprise performance after COVID-19. Mathematics 2021, 9, 2215. [Google Scholar] [CrossRef]
- Alshehri, D.A.; Tayachi, T. Assets-liability management: A comparative study of national commercial bank and national bank of Kuwait. J. Arch. Egyptol. 2021, 18, 383–391. [Google Scholar]
- Almuhaya, R.M.; Hakim, S. Yemen banks during turmoil: An analytical study. J. Arch. Egyptol. 2021, 18, 1084–1095. [Google Scholar]
- Liu, Z.; Zhu, J. Research on financial risks of internet listed companies. J. Appl. Sci. Eng. 2021, 8, 13–17. [Google Scholar]
- Hsieh, T.Y.; Wang, M.H. Finding critical financial ratios for Taiwan’s property development firms in recession. Logist. Inf. Manag. 2001, 14, 401–413. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| No. | Conditional Attribute | Reference | Data Type | Data Model | Decimal Digit | Code |
|---|---|---|---|---|---|---|
| 1 | Time | By expert | Syntax data | Nominal | - | X1 |
| 2 | Quarter | By expert | Syntax data | Nominal | - | X2 |
| 3 | Current liabilities | [56] | Range data | Number | 0 | X3 |
| 4 | Total assets | [57] | Range data | Number | 0 | X4 |
| 5 | Cash flow ratio | [56] | Range data | Number | 2 | X5 |
| 6 | Net value per share | [58] | Range data | Number | 2 | X6 |
| 7 | Cash flow per share | [56] | Range data | Number | 2 | X7 |
| 8 | Turnover per share | [56] | Range data | Number | 2 | X8 |
| 9 | Liquidity ratio | [56] | Range data | Number | 2 | X9 |
| 10 | Quick ratio | [57] | Range data | Number | 2 | X10 |
| 11 | Debt ratio | [56] | Range data | Number | 2 | X11 |
| 12 | Accounts receivable turnover | [56] | Range data | Number | 2 | X12 |
| 13 | Inventory turnover | [58] | Range data | Number | 2 | X13 |
| 14 | Fixed assets turnover | [57] | Range data | Number | 2 | X14 |
| 15 | Operating profit rate | [57] | Range data | Number | 2 | X15 |
| 16 | Return on operating assets | [59] | Range data | Number | 2 | X16 |
| 17 | Interest coverage ratio | [58] | Range data | Number | 2 | X17 |
| 18 | Interest expense ratio | [60] | Range data | Number | 2 | X18 |
| 19 | Total assets growth rate | [61] | Range data | Number | 2 | X19 |
| 20 | Total assets turnover | [61] | Range data | Number | 2 | X20 |
| 21 | Net value turnover | [62] | Range data | Number | 2 | X21 |
| 22 | Earnings per share | [61] | Set data | Number | 2 | X22 |
| Normal vs. Bankrupt Company | Key Attributes |
|---|---|
| 491 vs. 491 (1:1) | Five attributes: X2 quarter, X9 liquidity ratio, X11 debt ratio, X14 fixed assets turnover, X18 interest expense ratio |
| 982 vs. 491 (2:1) | Four attributes: X9 liquidity ratio, X11 debt ratio, X14 fixed assets turnover, X18 interest expense ratio |
| 1473 vs. 491 (3:1) | Eight attributes: X6 net value per share, X9 liquidity ratio, X10 quick ratio, X11 debt ratio, X14 fixed assets turnover, X17 interest coverage ratio, X18 interest expense ratio, X22 earnings per share |
| 1964 vs. 491 (4:1) | Eight attributes: X6 net value per share, X9 liquidity ratio, X10 quick ratio, X11 debt ratio, X14 fixed assets turnover, X17 interest coverage ratio, X18 interest expense ratio, X22 earnings per share |
| 2455 vs. 491 (5:1) | Eight attributes: X6 net value per share, X9 liquidity ratio, X10 quick ratio, X11 debt ratio, X14 fixed assets turnover, X17 interest coverage ratio, X18 interest expense ratio, X22 earnings per share |
| X1 | X2 | X3 | X4 | X5 | X19 | X20 | X21 | X22 | X23 |
|---|---|---|---|---|---|---|---|---|---|
| 2013/6/28 | Q2 | 84,839,543 | 98,239,374 | 4.44 | −10.82 | 0.46 | 15.88 | 0.09 | Y |
| 2013/9/30 | Q3 | 82,018,024 | 93,777,378 | 9.97 | −8.06 | 0.47 | 11.81 | 0.17 | Y |
| 2013/3/29 | Q1 | 83,159,547 | 94,807,457 | −1.76 | −13.3 | 0.36 | 16.56 | 0.02 | Y |
| 2010/3/31 | Q1 | 258,739 | 868,148 | 11.47 | −2.2 | 0.94 | 2.73 | −0.22 | Y |
| 2011/3/31 | Q1 | 28,554,971 | 50,463,649 | 9.86 | 252.47 | 2.19 | 6.25 | 11.02 | Y |
| 2013/6/28 | Q2 | 289,062 | 2,018,815 | 80.61 | 1.97 | 0.54 | 0.61 | 0.63 | N |
| 2008/6/30 | Q2 | 1,336,889 | 4,949,068 | 32.21 | 8.69 | 0.92 | 1.33 | 0.19 | N |
| 2011/3/31 | Q1 | 971,820 | 5,879,430 | 19.26 | 1.76 | 0.37 | 0.46 | 0.67 | N |
| 2003/12/31 | Q4 | 2,018,555 | 10,347,521 | 50.08 | 28.23 | 0.48 | 0.76 | 1.03 | N |
| 2012/12/28 | Q4 | 1,153,163 | 3,720,313 | 38.09 | 2.94 | 0.68 | 1.03 | 2.79 | N |
| Attributes | Data Model | Minimum | Maximum | Mean | Standard Deviation |
|---|---|---|---|---|---|
| X1 | Nominal | - | - | - | - |
| X2 | Nominal | - | - | - | - |
| X3 | Numeric | 150,348.00 | 356,161,801.00 | 14,754,790.584 | 29,752,491.600 |
| X4 | Numeric | 194,701.00 | 726,296,593.00 | 38,310,531.318 | 74,090,653.057 |
| X5 | Numeric | −117.69 | 357.64 | 24.184 | 48.700 |
| X6 | Numeric | −13.21 | 942.25 | 31.340 | 57.366 |
| X7 | Numeric | −40.72 | 217.99 | 5.030 | 15.858 |
| X8 | Numeric | 0.37 | 936.80 | 57.252 | 82.989 |
| X9 | Numeric | 12.16 | 1078.33 | 189.426 | 140.629 |
| X10 | Numeric | 2.19 | 936.51 | 137.504 | 125.855 |
| X11 | Numeric | 8.06 | 209.25 | 49.327 | 20.295 |
| X12 | Numeric | 1.36 | 464.26 | 14.031 | 40.104 |
| X13 | Numeric | 0 | 493.21 | 10.284 | 21.734 |
| X14 | Numeric | 0.22 | 1418.98 | 37.528 | 117.762 |
| X15 | Numeric | −155.22 | 60.09 | 1.189 | 22.718 |
| X16 | Numeric | −78.95 | 92.16 | 7.511 | 17.792 |
| X17 | Numeric | −122.39 | 9,719,988.33 | 17,200.150 | 315,301.953 |
| X18 | Numeric | −41,274.56 | 1730.09 | −42.240 | 1321.687 |
| X19 | Numeric | −80.63 | 281.53 | 14.487 | 35.509 |
| X20 | Numeric | 0.13 | 7.48 | 1.401 | 1.383 |
| X21 | Numeric | −1004.78 | 277.77 | 2.300 | 36.189 |
| X22 | Numeric | −18.63 | 210.70 | 3.976 | 14.287 |
| Classifier | Segmentation 65% | Segmentation 67% | Segmentation 70% | Segmentation 75% | Segmentation 80% | Segmentation 85% | Segmentation 90% | Cross-Validation 10 Times |
|---|---|---|---|---|---|---|---|---|
| NB | 98.26% | 97.84% | 97.63% | 97.14% | 97.45% | 97.96% | 98.98% | 98.27% |
| LG | 98.84% | 100.00% | 99.66% | 99.59% | 100.00% | 99.32% | 100.00% | 98.78% |
| IBK | 89.83% | 91.05% | 91.19% | 90.61% | 90.31% | 91.84% | 94.90% | 92.36% |
| BAG | 50.00% | 50.00% | 48.81% | 51.02% | 44.90% | 40.82% | 40.82% | 50.00% |
| J48 | 99.71% | 99.69% | 99.66% | 100.00% | 100.00% | 100.00% | 100.00% | 99.80% |
| Classifier | Segmentation 65% | Segmentation 67% | Segmentation 70% | Segmentation 75% | Segmentation 80% | Segmentation 85% | Segmentation 90% | Cross-Validation 10 Times |
|---|---|---|---|---|---|---|---|---|
| NB | 98.55% | 99.07% | 98.98% | 98.78% | 98.47% | 98.64% | 97.96% | 98.37% |
| LG | 98.55% | 98.46% | 98.64% | 98.37% | 98.47% | 99.32% | 98.98% | 99.39% |
| IBK | 97.67% | 97.84% | 97.29% | 97.14% | 98.47% | 98.64% | 97.96% | 98.98% |
| BAG | 97.97% | 98.15% | 97.97% | 98.37% | 99.49% | 99.32% | 100.00% | 99.29% |
| J48 | 97.97% | 97.84% | 99.32% | 99.18% | 98.98% | 98.64% | 98.98% | 99.19% |
| Classifier | Segmentation 65% | Segmentation 67% | Segmentation 70% | Segmentation 75% | Segmentation 80% | Segmentation 85% | Segmentation 90% | Cross-Validation 10 Times |
|---|---|---|---|---|---|---|---|---|
| NB | 97.29% | 97.12% | 97.51% | 97.55% | 96.95% | 96.83% | 96.60% | 97.42% |
| LG | 99.22% | 99.79% | 99.32% | 100.00% | 99.32% | 99.10% | 100.00% | 99.80% |
| IBK | 93.41% | 93.21% | 92.99% | 92.39% | 92.54% | 95.48% | 95.92% | 94.03% |
| BAG | 65.12% | 65.23% | 65.61% | 65.22% | 66.10% | 66.97% | 63.95% | 66.67% |
| J48 | 99.61% | 99.59% | 99.55% | 99.46% | 99.32% | 99.10% | 98.64% | 99.39% |
| Classifier | Segmentation 65% | Segmentation 67% | Segmentation 70% | Segmentation 75% | Segmentation 80% | Segmentation 85% | Segmentation 90% | Cross-Validation 10 Times |
|---|---|---|---|---|---|---|---|---|
| NB | 97.87% | 97.94% | 97.51% | 97.28% | 96.61% | 96.83% | 97.28% | 98.17% |
| LG | 99.42% | 99.59% | 99.55% | 99.46% | 99.32% | 99.10% | 99.32% | 99.12% |
| IBK | 98.45% | 98.35% | 98.42% | 98.10% | 98.31% | 99.10% | 98.64% | 99.25% |
| BAG | 99.22% | 99.38% | 99.10% | 98.91% | 99.32% | 99.10% | 99.32% | 99.52% |
| J48 | 99.61% | 99.59% | 99.55% | 99.46% | 98.98% | 99.10% | 98.64% | 99.39% |
| Classifier | Segmentation 65% | Segmentation 67% | Segmentation 70% | Segmentation 75% | Segmentation 80% | Segmentation 85% | Segmentation 90% | Cross-Validation 10 Times |
|---|---|---|---|---|---|---|---|---|
| NB | 95.92% | 95.99% | 95.76% | 95.93% | 95.42% | 94.92% | 94.90% | 96.44% |
| LG | 99.71% | 99.69% | 99.66% | 99.59% | 100.00% | 99.66% | 99.49% | 99.54% |
| IBK | 95.05% | 94.91% | 95.25% | 95.52% | 94.40% | 94.92% | 94.90% | 95.62% |
| BAG | 75.84% | 75.93% | 76.06% | 75.36% | 75.32% | 74.92% | 73.98% | 75.00% |
| J48 | 98.25% | 98.30% | 99.15% | 99.80% | 100.00% | 99.32% | 100.00% | 99.54% |
| Classifier | Segmentation 65% | Segmentation 67% | Segmentation 70% | Segmentation 75% | Segmentation 80% | Segmentation 85% | Segmentation 90% | Cross-Validation 10 Times |
|---|---|---|---|---|---|---|---|---|
| NB | 95.49% | 95.52% | 95.42% | 95.72% | 95.42% | 95.25% | 94.39% | 96.38% |
| LG | 98.98% | 98.92% | 98.81% | 98.57% | 98.98% | 98.64% | 99.49% | 99.34% |
| IBK | 99.13% | 99.23% | 99.32% | 99.19% | 99.49% | 99.32% | 98.98% | 99.64% |
| BAG | 99.13% | 98.92% | 99.49% | 99.39% | 98.98% | 99.32% | 99.49% | 99.39% |
| J48 | 99.13% | 99.07% | 99.49% | 99.59% | 99.75% | 99.32% | 99.49% | 99.39% |
| Classifier | Segmentation 65% | Segmentation 67% | Segmentation 70% | Segmentation 75% | Segmentation 80% | Segmentation 85% | Segmentation 90% | Cross-Validation 10 Times |
|---|---|---|---|---|---|---|---|---|
| NB | 95.46% | 94.94% | 95.38% | 95.28% | 95.11% | 96.20% | 95.92% | 94.83% |
| LG | 99.88% | 99.75% | 99.73% | 99.51% | 99.80% | 99.46% | 99.59% | 99.71% |
| IBK | 95.58% | 95.31% | 95.65% | 95.28% | 95.72% | 96.74% | 96.73% | 96.17% |
| BAG | 79.98% | 80.00% | 79.62% | 78.66% | 77.60% | 78.26% | 75.92% | 80.00% |
| J48 | 98.60% | 98.52% | 99.59% | 99.51% | 99.39% | 99.18% | 98.78% | 99.59% |
| Classifier | Segmentation 65% | Segmentation 67% | Segmentation 70% | Segmentation 75% | Segmentation 80% | Segmentation 85% | Segmentation 90% | Cross-Validation 10 Times |
|---|---|---|---|---|---|---|---|---|
| NB | 94.06% | 94.20% | 94.43% | 94.95% | 94.50% | 94.57% | 93.88% | 95.03% |
| LG | 99.77% | 100.00% | 99.86% | 99.84% | 99.80% | 99.73% | 99.59% | 99.39% |
| IBK | 99.42% | 99.38% | 99.46% | 99.51% | 99.39% | 99.46% | 99.18% | 99.59% |
| BAG | 98.60% | 98.52% | 99.46% | 99.02% | 99.39% | 97.83% | 98.78% | 99.51% |
| J48 | 99.42% | 99.38% | 99.46% | 99.35% | 99.19% | 98.91% | 98.37% | 99.35% |
| Classifier | Segmentation 65% | Segmentation 67% | Segmentation 70% | Segmentation 75% | Segmentation 80% | Segmentation 85% | Segmentation 90% | Cross-Validation 10 Times |
|---|---|---|---|---|---|---|---|---|
| NB | 94.96% | 93.93% | 92.31% | 91.85% | 92.36% | 93.21% | 92.54% | 91.96% |
| LG | 99.71% | 99.69% | 99.66% | 99.46% | 99.83% | 99.77% | 100.00% | 99.83% |
| IBK | 95.93% | 96.60% | 96.61% | 96.74% | 96.60% | 96.15% | 96.27% | 96.78% |
| BAG | 82.35% | 82.51% | 82.13% | 82.34% | 82.51% | 82.81% | 83.73% | 83.33% |
| J48 | 99.42% | 99.90% | 99.89% | 99.73% | 99.66% | 99.55% | 98.98% | 99.73% |
| Classifier | Segmentation 65% | Segmentation 67% | Segmentation 70% | Segmentation 75% | Segmentation 80% | Segmentation 85% | Segmentation 90% | Cross-Validation 10 Times |
|---|---|---|---|---|---|---|---|---|
| NB | 96.02% | 95.68% | 93.67% | 94.29% | 93.89% | 93.21% | 94.92% | 93.99% |
| LG | 99.32% | 99.28% | 99.32% | 99.18% | 98.98% | 99.32% | 99.66% | 99.52% |
| IBK | 99.32% | 99.59% | 99.43% | 99.59% | 99.49% | 99.55% | 100.00% | 99.59% |
| BAG | 99.03% | 99.49% | 99.66% | 99.59% | 99.32% | 99.55% | 100.00% | 99.46% |
| J48 | 99.22% | 99.59% | 99.66% | 99.59% | 99.32% | 99.32% | 98.98% | 99.59% |
| Variables | Estimate of B | S.E. | Wald | Significance | Exp(B) |
|---|---|---|---|---|---|
| X2 quarter Q1 | 5.190 | 0.158 | |||
| X2 quarter Q2 | −5.749 | 2.551 | 5.079 | 0.024 ** | 0.003 |
| X2 quarter Q3 | −1.705 | 4.266 | 0.160 | 0.689 | 0.182 |
| X2 quarter Q4 | −2.142 | 2.191 | 0.956 | 0.328 | 0.117 |
| X9 liquidity ratio | 0.025 | 0.011 | 5.853 | 0.016 ** | 1.026 |
| X11 debt ratio | −0.323 | 0.108 | 9.015 | 0.003 *** | 0.724 |
| X14 fixed assets turnover | 0.330 | 0.101 | 10.689 | 0.001 *** | 1.391 |
| X18 interest expense ratio | 0.007 | 0.009 | 0.643 | 0.423 | 1.007 |
| Constant | 0.349 | 3.949 | 0.008 | 0.930 | 1.418 |
| Variables | Estimate of B | S.E. | Wald | Significance | Exp(B) |
|---|---|---|---|---|---|
| X9 liquidity ratio | 0.013 | 0.004 | 11.317 | 0.001 *** | 1.013 |
| X11 debt ratio | −0.234 | 0.039 | 36.590 | 0.000 *** | 0.792 |
| X14 fixed assets turnover | 0.269 | 0.036 | 55.077 | 0.000 *** | 1.308 |
| X18 interest expense ratio | −0.002 | 0.004 | 0.195 | 0.659 | 0.998 |
| Constant | 2.561 | 1.789 | 2.049 | 0.152 | 12.944 |
| Variables | Estimate of B | S.E. | Wald | Significance | Exp(B) |
|---|---|---|---|---|---|
| X6 net value per share | −0.025 | 0.031 | 0.625 | 0.429 | 0.976 |
| X9 liquidity ratio | 0.040 | 0.015 | 7.406 | 0.007 *** | 1.041 |
| X10 quick ratio | −0.028 | 0.015 | 3.402 | 0.065 * | 0.973 |
| X11 debt ratio | −0.258 | 0.044 | 35.067 | 0.000 *** | 0.773 |
| X14 fixed assets turnover | 0.271 | 0.041 | 42.725 | 0.000 *** | 1.312 |
| X17 interest coverage ratio | 0.000 | 0.000 | 0.000 | 0.983 | 1.000 |
| X18 interest expense ratio | −0.002 | 0.006 | 0.107 | 0.744 | 0.998 |
| X22 earnings per share | 1.471 | 0.277 | 28.261 | 0.000 *** | 4.354 |
| Constant | 2.099 | 1.885 | 1.240 | 0.265 | 8.157 |
| Variables | Estimate of B | S.E. | Wald | Significance | Exp(B) |
|---|---|---|---|---|---|
| X6 net value per share | −0.037 | 0.025 | 2.164 | 0.141 | 0.963 |
| X9 liquidity ratio | 0.038 | 0.012 | 9.922 | 0.002 *** | 1.039 |
| X10 quick ratio | −0.026 | 0.012 | 4.500 | 0.034 * | 0.974 |
| X11 debt ratio | −0.253 | 0.036 | 50.645 | 0.000 *** | 0.776 |
| X14 fixed assets turnover | 0.275 | 0.037 | 54.781 | 0.000 *** | 1.317 |
| X17 interest coverage ratio | 0.000 | 0.000 | 0.035 | 0.852 | 1.000 |
| X18 interest expense ratio | 0.003 | 0.003 | 0.751 | 0.386 | 1.003 |
| X22 earnings per share | 1.491 | 0.253 | 34.771 | 0.000 *** | 4.443 |
| Constant | 3.060 | 1.651 | 3.434 | 0.064 | 21.336 |
| Variables | Estimate of B | S.E. | Wald | Significance | Exp(B) |
|---|---|---|---|---|---|
| X6 net value per share | −0.052 | 0.025 | 4.564 | 0.033 ** | 0.949 |
| X9 liquidity ratio | 0.035 | 0.011 | 9.319 | 0.002 *** | 1.035 |
| X10 quick ratio | −0.022 | 0.012 | 3.313 | 0.069 | 0.979 |
| X11 debt ratio | −0.265 | 0.035 | 56.228 | 0.000 *** | 0.767 |
| X14 fixed assets turnover | 0.294 | 0.039 | 56.144 | 0.000 *** | 1.341 |
| X17 interest coverage ratio | 0 | 0 | 0.002 | 0.965 | 1 |
| X18 interest expense ratio | 0.002 | 0.004 | 0.441 | 0.507 | 1.002 |
| X22 earnings per share | 1.704 | 0.262 | 42.446 | 0.000 *** | 5.499 |
| Constant | 4.085 | 1.676 | 5.943 | 0.015 ** | 59.439 |
| Classifier | Segmentation 65% | Segmentation 67% | Segmentation 70% | Segmentation 75% | Segmentation 80% | Segmentation 85% | Segmentation 90% | Cross-Validation 10 Times | Count |
|---|---|---|---|---|---|---|---|---|---|
| NB | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| LG | 3 | 4 | 3 | 2 | 5 | 4 | 4 | 4 | 29 1 |
| IBK | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| BAG | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| J48 | 2 | 1 | 3 | 4 | 3 | 2 | 2 | 2 | 19 |
| Classifier | Segmentation 65% | Segmentation 67% | Segmentation 70% | Segmentation 75% | Segmentation 80% | Segmentation 85% | Segmentation 90% | Cross-Validation 10 Times | Count |
|---|---|---|---|---|---|---|---|---|---|
| NB | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 2 |
| LG | 3 | 2 | 2 | 2 | 2 | 3 | 3 | 1 | 18 |
| IBK | 2 | 2 | 0 | 1 | 1 | 3 | 1 | 2 | 12 |
| BAG | 1 | 0 | 2 | 1 | 2 | 4 | 4 | 2 | 16 |
| J48 | 2 | 3 | 3 | 4 | 1 | 2 | 1 | 2 | 18 |
| Ratio | 1:1 | 2:1 | 3:1 | 4:1 | 5:1 | Concern |
|---|---|---|---|---|---|---|
| Accuracy | 99.5% | 99.3% | 99.5% | 99.5% | 99.6% | 99.48% |
| Determinants | X2: quarter Q2, X9, X11, X14 | X9, X11, X14 | X9, X10, X11, X14, X22 | X9, X10, X11, X14, X22 | X6, X9, X11, X14, X22 | X9, X11, X14 |
| Code | Conditional Attribute | 491 and 491 (1:1) | 982 and 491 (2:1) | 1473 and 491 (3:1) | 1964 and 491 (4:1) | 2455 and 491 (5:1) |
|---|---|---|---|---|---|---|
| X9 | Liquidity ratio | Significant | Significant | Significant | Significant | |
| X10 | Quick ratio | Significant | Significant | |||
| X11 | Debt ratio | Significant | Significant | Significant | Significant | Significant |
| X14 | Fixed assets turnover | Significant | Significant | Significant | Significant | Significant |
| X18 | Interest expense ratio | Significant | Significant | Significant | Significant | Significant |
| X22 | Earnings per share | Significant | Significant | Significant |
| No. | Attributes | 491 and 491 (1:1) | 982 and 491 (2:1) | 1473 and 491 (3:1) | 1964 and 491 (4:1) | 2455 and 491 (5:1) | Number of * |
|---|---|---|---|---|---|---|---|
| X2 | Quarter Q2 | ** | 2 | ||||
| X5 | Cash flow ration | ||||||
| X6 | Net value per share | ** | 2 | ||||
| X7 | Cash flow per share | ||||||
| X8 | Turnover per share | ||||||
| X9 | Liquidity ratio | ** | *** | *** | *** | *** | 14 |
| X10 | Quick ratio | * | * | ||||
| X11 | Debt ratio | *** | *** | *** | *** | *** | 15 |
| X12 | Accounts receivable turnover | ||||||
| X13 | Inventory turnover | ||||||
| X14 | Fixed assets turnover | *** | *** | *** | *** | *** | 15 |
| X15 | Operating profit rate | ||||||
| X16 | Return on operating assets | ||||||
| X17 | Interest coverage ratio | ||||||
| X18 | Interest expense ratio | ||||||
| X19 | Total assets growth rate | ||||||
| X20 | Total assets turnover | ||||||
| X21 | Net value turnover | ||||||
| X22 | Earnings per share | *** | *** | *** | 9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.-S.; Lin, C.-K.; Lo, C.-M.; Chen, S.-F.; Liao, Q.-J. Comparable Studies of Financial Bankruptcy Prediction Using Advanced Hybrid Intelligent Classification Models to Provide Early Warning in the Electronics Industry. Mathematics 2021, 9, 2622. https://doi.org/10.3390/math9202622
Chen Y-S, Lin C-K, Lo C-M, Chen S-F, Liao Q-J. Comparable Studies of Financial Bankruptcy Prediction Using Advanced Hybrid Intelligent Classification Models to Provide Early Warning in the Electronics Industry. Mathematics. 2021; 9(20):2622. https://doi.org/10.3390/math9202622
Chicago/Turabian StyleChen, You-Shyang, Chien-Ku Lin, Chih-Min Lo, Su-Fen Chen, and Qi-Jun Liao. 2021. "Comparable Studies of Financial Bankruptcy Prediction Using Advanced Hybrid Intelligent Classification Models to Provide Early Warning in the Electronics Industry" Mathematics 9, no. 20: 2622. https://doi.org/10.3390/math9202622