
Improved Constrained k-Means Algorithm for Clustering with Domain Knowledge

Abstract
:1. Introduction
- Must-link: constraints specifying two sample points must be in the same cluster.
- Cannot-link: constraints specifying a set of sample points that must not be placed in the same cluster, i.e., must be placed in a manner that each of them is in a distinct cluster.
1.1. Related Work
1.2. Our Results
- Propose a framework to incorporate must-link and cannot-link constraints with the k-means++ algorithm;
- Devise a method to cluster the points of cannot-link via novelly employing minimum weight matching and to merge the set of data points confined by must-links as a single point;
- Carry out experiments to evaluate the practical performance of the proposed algorithms against the UCI datasets, demonstrating that our algorithms outperform the previous algorithm at a rate of 65% regarding the accuracy rate.
1.3. Organization
2. Preliminaries and Problem Statement
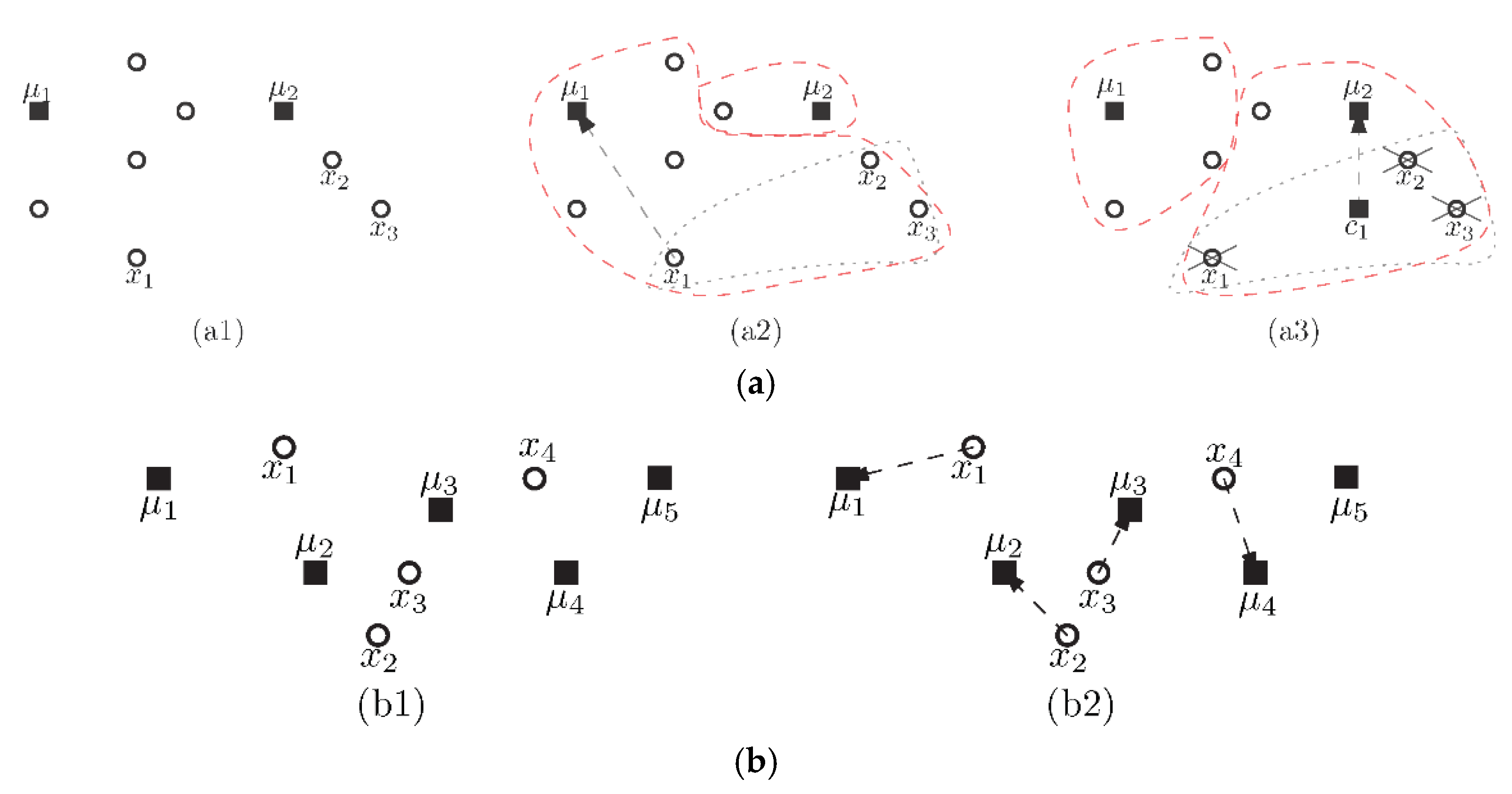
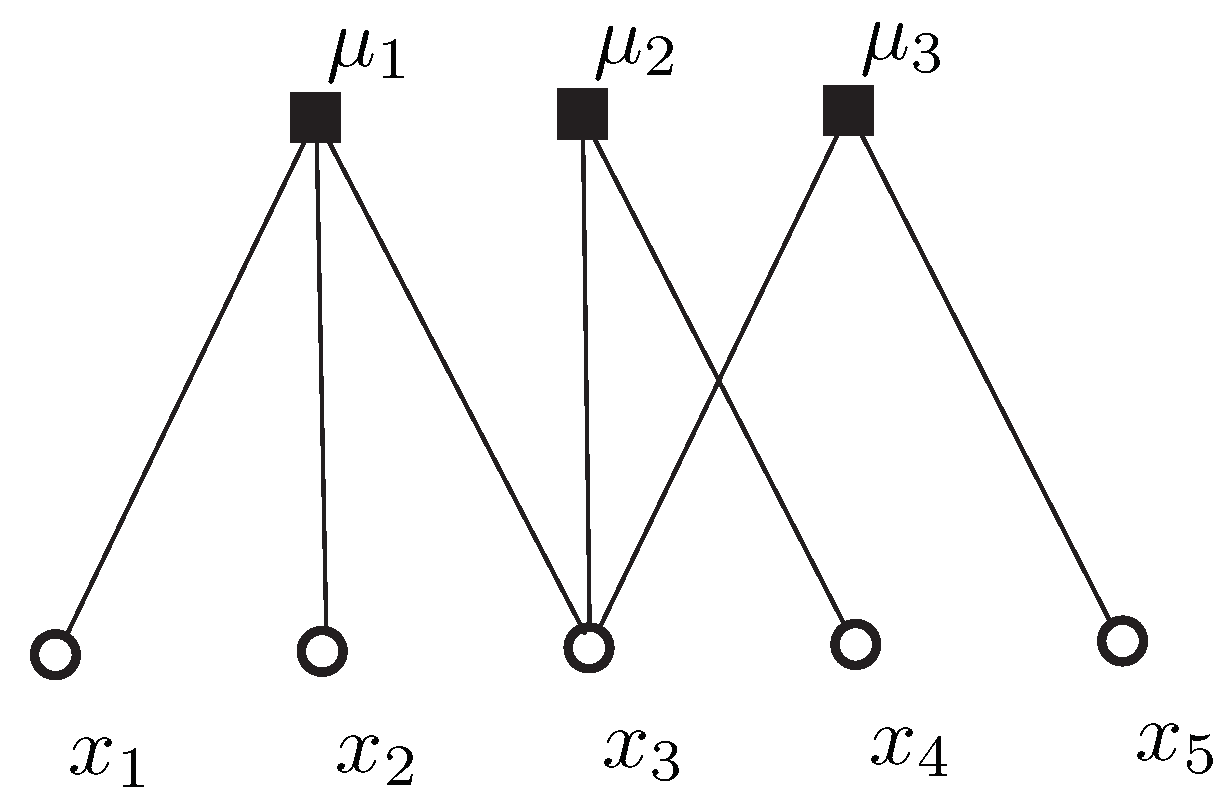
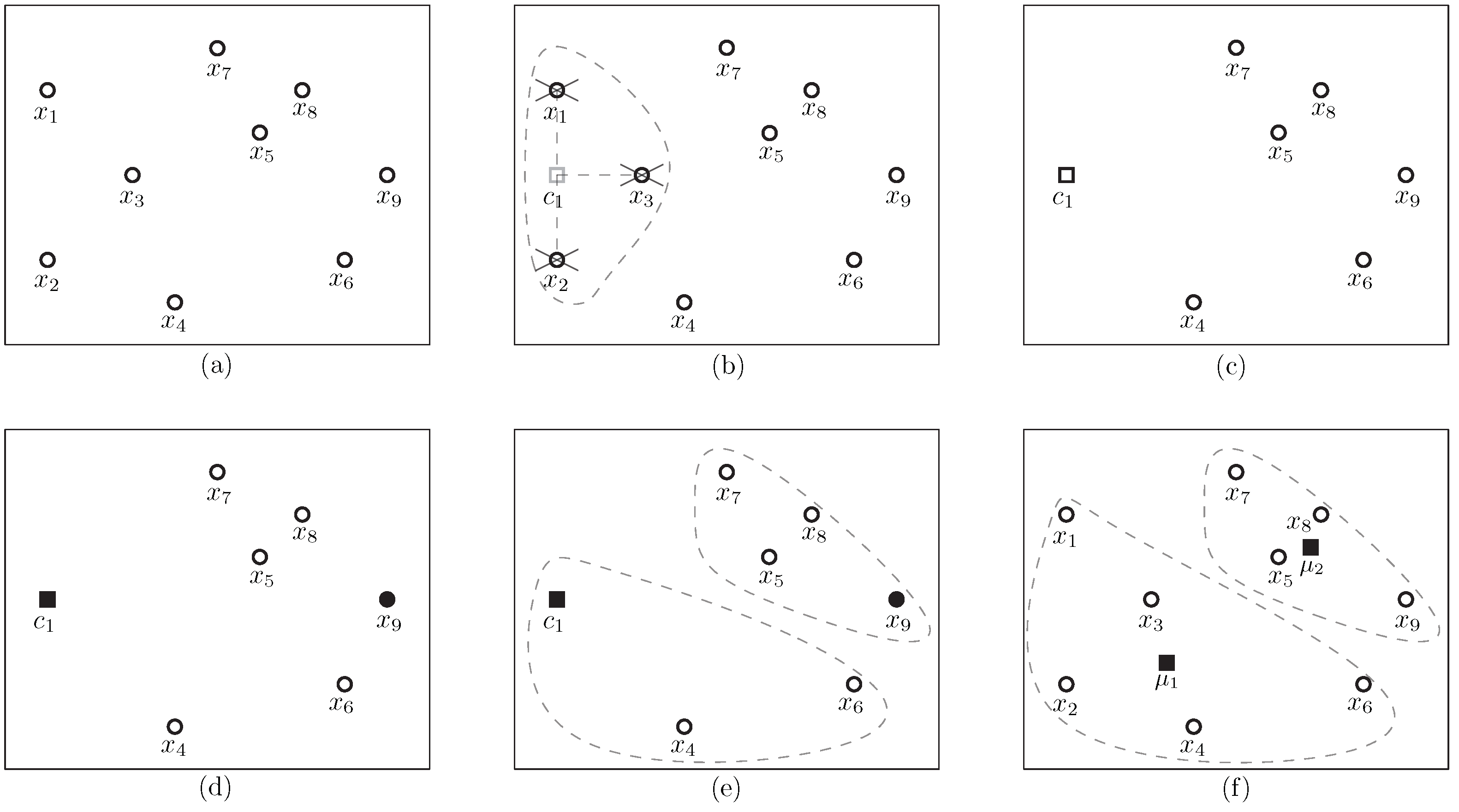
3. Constrained k-Means Clustering Algorithm with Incidental Information
| Algorithm 1 Constrained k-means clustering using domain information. |
| Input: A data set , must-link constraints , cannot-link constraints , a positive integer k; Output: A collection of k clusters . 1: Use the k-center algorithm to select as the initial cluster centers; 2: Set; 3: While cluster centers change do 4: For each set of must-link constraints do 5: Compute mass center sample of the set; 6: Assign all samples of the set to the nearest ; /* Adding all samples of the set to */ 7: EndFor 8: For do 9: Compute the distance between point and cluster center ; 10: EndFor 11: Assign remaining points to their nearest , except those incident to cannot-links; 12: For each set of cannot-link constraint do 13: Assign each point to the appropriate cluster via minimum weight matching; 14: EndFor 15: Compute the cluster center of ; 16: EndWhile 17: Return . |
4. Experimental Evaluation
4.1. Evaluation Approaches
4.2. Experimental Dataset and Statistics Information
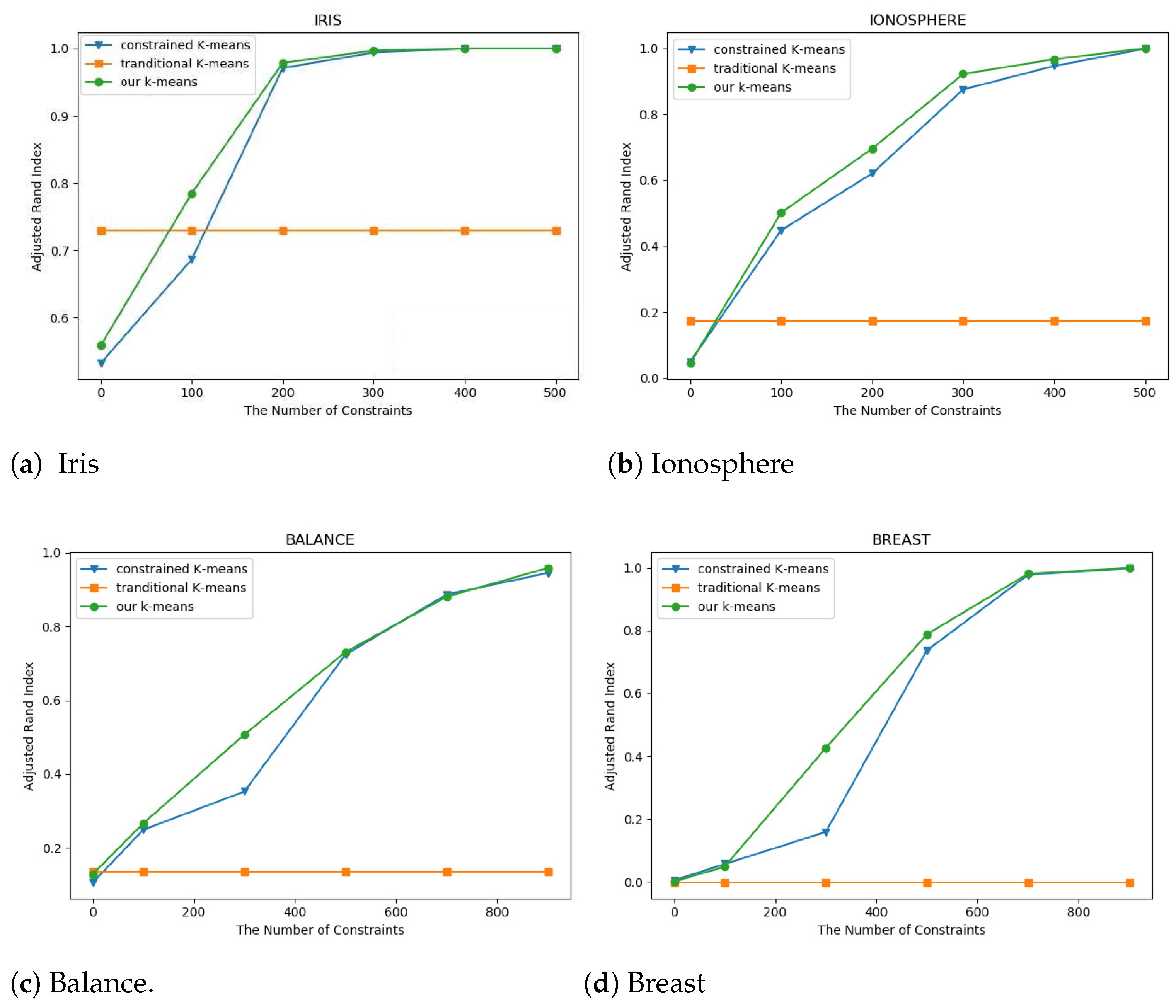
4.3. Comparison of Practical Performance
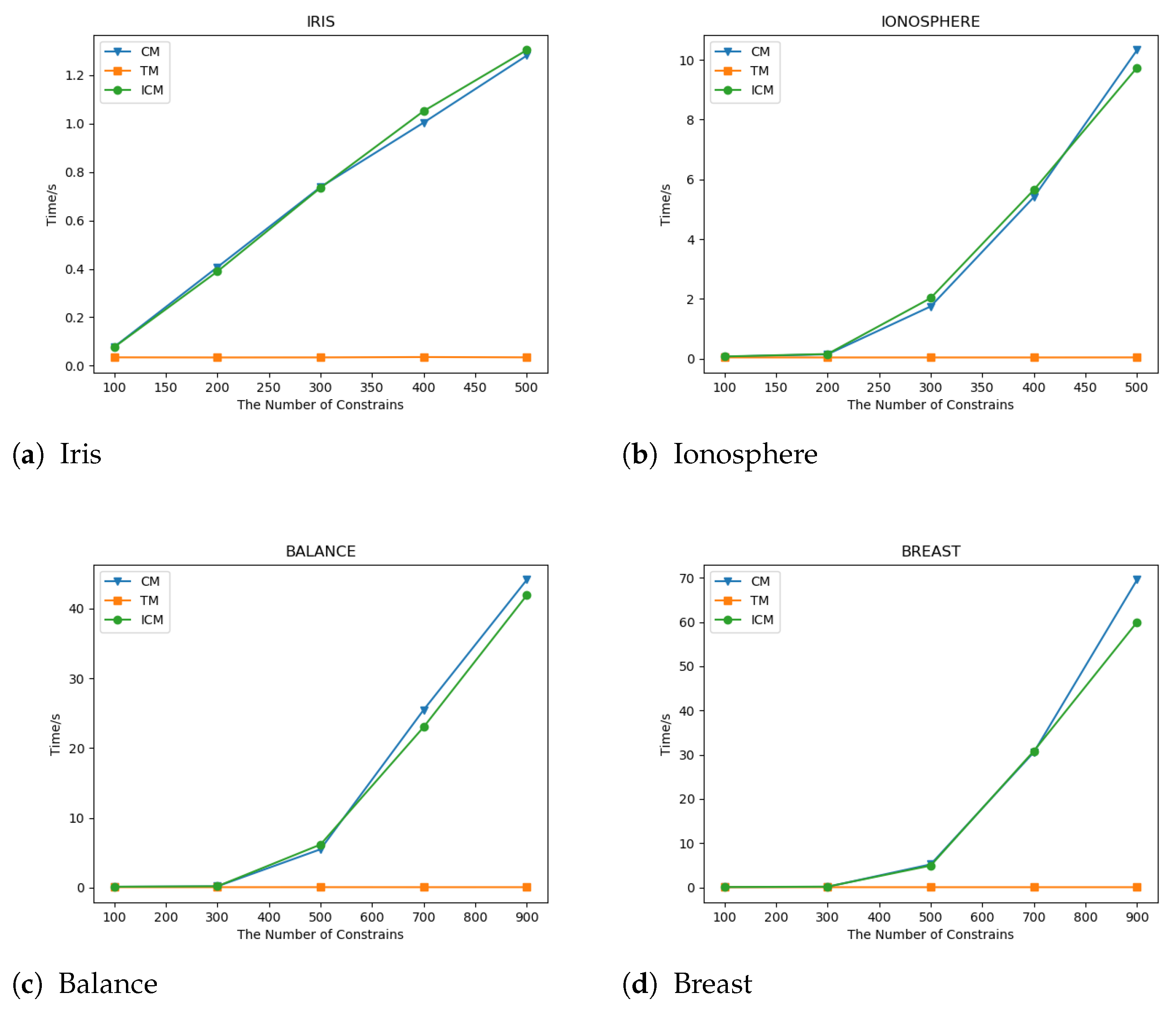
4.4. Comparison of Runtime
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wagstaff, K.; Cardie, C. Clustering with instance-level constraints. AAAI/IAAI 2000, 1097, 577–584. [Google Scholar]
- Ester, M.; Kriegel, H.; Sander, J.; Xu, X. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining (KDD-96), Portland, OR, USA, 2–4 August 1996; Simoudis, E., Han, J., Fayyad, U.M., Eds.; AAAI Press: Palo Alto, CA, USA, 1996; pp. 226–231. [Google Scholar]
- Sobczak, G.; Pikula, M.; Sydow, M. AGNES: A Novel Algorithm for Visualising Diversified Graphical Entity Summarisations on Knowledge Graphs. In Proceedings of the Foundations of Intelligent Systems-20th International Symposium, ISMIS 2012, Macau, China, 4–7 December 2012; Chen, L., Felfernig, A., Liu, J., Ras, Z.W., Eds.; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2012; Volume 7661, pp. 182–191. [Google Scholar] [CrossRef]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Oakland, CA, USA, 11–18 July 1967; Volume 1, pp. 281–297. [Google Scholar]
- Li, M.; Xu, D.; Yue, J.; Zhang, D.; Zhang, P. The seeding algorithm for k-means problem with penalties. J. Comb. Optim. 2020, 39, 15–32. [Google Scholar] [CrossRef]
- Li, M. The bi-criteria seeding algorithms for two variants of k-means problem. J. Comb. Optim. 2020, 1–12. [Google Scholar] [CrossRef]
- Arthur, D.; Vassilvitskii, S. k-means++: The advantages of careful seeding. In Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, New Orleans, LA, USA, 7–9 January 2007; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2007; pp. 1027–1035. [Google Scholar]
- Bahmani, B.; Moseley, B.; Vattani, A.; Kumar, R.; Vassilvitskii, S. Scalable k-means++. Proc. VLDB Endow. 2012, 5, 622–633. [Google Scholar] [CrossRef]
- Lai, Y.; Liu, J. Optimization study on initial center of K-means algorithm. Comput. Eng. Appl. 2008, 44, 147–149. [Google Scholar]
- Jothi, R.; Mohanty, S.K.; Ojha, A. DK-means: A deterministic k-means clustering algorithm for gene expression analysis. Pattern Anal. Appl. 2019, 22, 649–667. [Google Scholar] [CrossRef]
- Marroquin, J.L.; Girosi, F. Some Extensions of the k-Means Algorithm for Image Segmentation and Pattern Classification; Technical Report; Massachusetts Inst of Tech Cambridge Artificial Intelligence Lab.: Cambridge, MA, USA, 1993. [Google Scholar]
- Chehreghan, A.; Abbaspour, R.A. An improvement on the clustering of high-resolution satellite images using a hybrid algorithm. J. Indian Soc. Remote Sens. 2017, 45, 579–590. [Google Scholar] [CrossRef]
- Mashtalir, S.; Stolbovyi, M.; Yakovlev, S. Clustering Video Sequences by the Method of Harmonic k-Means. Cybern. Syst. Anal. 2019, 55, 200–206. [Google Scholar] [CrossRef]
- Melnykov, V.; Zhu, X. An extension of the K-means algorithm to clustering skewed data. Comput. Stat. 2019, 34, 373–394. [Google Scholar] [CrossRef]
- Kuo, K.; Itakura, K.; Hosoi, F. Leaf Segmentation Based on k-Means Algorithm to Obtain Leaf Angle Distribution Using Terrestrial LiDAR. Remote Sens. 2019, 11, 2536. [Google Scholar] [CrossRef] [Green Version]
- Yuan, C.; Yang, H. Research on K-value selection method of K-means clustering algorithm. J 2019, 2, 226–235. [Google Scholar] [CrossRef] [Green Version]
- Ahmed, M.; Seraj, R.; Islam, S.M.S. The k-means algorithm: A comprehensive survey and performance evaluation. Electronics 2020, 9, 1295. [Google Scholar] [CrossRef]
- Aldino, A.; Darwis, D.; Prastowo, A.; Sujana, C. Implementation of K-means algorithm for clustering corn planting feasibility area in south lampung regency. J. Phys. Conf. Ser. 2021, 1751, 012038. [Google Scholar] [CrossRef]
- Windarto, A.P.; Siregar, M.N.H.; Suharso, W.; Fachri, B.; Supriyatna, A.; Carolina, I.; Efendi, Y.; Toresa, D. Analysis of the K-Means Algorithm on Clean Water Customers Based on the Province. J. Phys. Conf. Ser. 2019, 1255, 012001. [Google Scholar] [CrossRef] [Green Version]
- Wagstaff, K.; Cardie, C.; Rogers, S.; Schrödl, S. Constrained k-Means Clustering with Background Knowledge; ICML: Williamstown, MA, USA, 2001; Volume 1, pp. 577–584. [Google Scholar]
- Cao, X.; Zhang, C.; Zhou, C.; Fu, H.; Foroosh, H. Constrained multi-view video face clustering. IEEE Trans. Image Process. 2015, 24, 4381–4393. [Google Scholar] [CrossRef]
- Tang, J.; Chang, Y.; Aggarwal, C.; Liu, H. A survey of signed network mining in social media. ACM Comput. Surv. (CSUR) 2016, 49, 42. [Google Scholar] [CrossRef]
- Liu, H.; Shao, M.; Ding, Z.; Fu, Y. Structure-preserved unsupervised domain adaptation. IEEE Trans. Knowl. Data Eng. 2018, 31, 799–812. [Google Scholar] [CrossRef]
- Zhang, L.; Jin, M. A Constrained Clustering-Based Blind Detector for Spatial Modulation. IEEE Commun. Lett. 2019. [Google Scholar] [CrossRef]
- Qian, Q.; Xu, Y.; Hu, J.; Li, H.; Jin, R. Unsupervised Visual Representation Learning by Online Constrained K-Means. arXiv 2021, arXiv:2105.11527. [Google Scholar]
- Baumann, P. A Binary Linear Programming-Based K-Means Algorithm For Clustering with Must-Link and Cannot-Link Constraints. In Proceedings of the IEEE International Conference on Industrial Engineering and Engineering Management, IEEM 2020, Singapore, 14–17 December 2020; pp. 324–328. [Google Scholar] [CrossRef]
- Edmonds, J. Maximum matching and a polyhedron with 0, 1-vertices. J. Res. Natl. Bur. Stand. B 1965, 69, 55–56. [Google Scholar] [CrossRef]
- Schrijver, A. Combinatorial Optimization: Polyhedra and Efficiency; Springer Science & Business Media: Berlin, Germany, 2003; Volume 24. [Google Scholar]
- Milligan, G.W.; Cooper, M.C. A study of the comparability of external criteria for hierarchical cluster analysis. Multivar. Behav. Res. 1986, 21, 441–458. [Google Scholar] [CrossRef]
- Rand, W.M. Objective criteria for the evaluation of clustering methods. J. Am. Stat. Assoc. 1971, 66, 846–850. [Google Scholar] [CrossRef]
- Hubert, L.; Arabie, P. Comparing partitions. J. Classif. 1985, 2, 193–218. [Google Scholar] [CrossRef]
- Hao, Z.; Guo, L.; Yao, P.; Huang, P.; Peng, H. Efficient Algorithms for Constrained Clustering with Side Information. In Proceedings of the Parallel Architectures, Algorithms and Programming-10th International Symposium, PAAP 2019, Guangzhou, China, 12–14 December 2019; Revised Selected Papers. Shen, H., Sang, Y., Eds.; Communications in Computer and Information Science. Springer: Berlin/Heidelberg, Germany, 2019; Volume 1163, pp. 275–286. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| The Number of Constraints | 100 | 200 | 300 | 400 | 500 |
|---|---|---|---|---|---|
| CM | 0.68669 | 0.97119 | 0.99399 | 1.00000 | 1.00000 |
| TM | 0.73023 | 0.73023 | 0.73023 | 0.73023 | 0.73023 |
| ICM | 0.78485 | 0.97860 | 0.99699 | 1.00000 | 1.00000 |
| The Number of Constraints | 100 | 200 | 300 | 400 | 500 |
|---|---|---|---|---|---|
| CM | 0.44799 | 0.62021 | 0.87489 | 0.94606 | 0.99817 |
| TM | 0.17284 | 0.17284 | 0.17284 | 0.17284 | 0.17284 |
| ICM | 0.50131 | 0.69528 | 0.92172 | 0.96657 | 0.99908 |
| The Number of Constraints | 100 | 300 | 500 | 700 | 900 |
|---|---|---|---|---|---|
| CM | 0.24879 | 0.35256 | 0.72374 | 0.88657 | 0.94483 |
| TM | 0.13234 | 0.13234 | 0.13234 | 0.13234 | 0.13234 |
| ICM | 0.26650 | 0.50679 | 0.73070 | 0.88045 | 0.95854 |
| The Number of Constraints | 100 | 300 | 500 | 700 | 900 |
|---|---|---|---|---|---|
| CM | 0.05636 | 0.15859 | 0.73693 | 0.97761 | 0.99873 |
| TM | −0.00268 | −0.00268 | −0.00268 | −0.00268 | −0.00268 |
| ICM | 0.04795 | 0.42613 | 0.78812 | 0.98097 | 0.99970 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, P.; Yao, P.; Hao, Z.; Peng, H.; Guo, L. Improved Constrained k-Means Algorithm for Clustering with Domain Knowledge. Mathematics 2021, 9, 2390. https://doi.org/10.3390/math9192390
Huang P, Yao P, Hao Z, Peng H, Guo L. Improved Constrained k-Means Algorithm for Clustering with Domain Knowledge. Mathematics. 2021; 9(19):2390. https://doi.org/10.3390/math9192390
Chicago/Turabian StyleHuang, Peihuang, Pei Yao, Zhendong Hao, Huihong Peng, and Longkun Guo. 2021. "Improved Constrained k-Means Algorithm for Clustering with Domain Knowledge" Mathematics 9, no. 19: 2390. https://doi.org/10.3390/math9192390