1. Introduction
Text document clustering has become an important and fast-growing research area, due to the massive amounts of text data produced by the Internet, social media, email and text messages, and other sources. Text-mining techniques are used to process and analyze text-based data, and by the use of different text-mining methods, relevant information can be extracted from the text data. One crucial method in text-mining is clustering, which has the aim of automatically partition the number of documents in a finite set of homogeneous clusters (groups). In a specific cluster, all documents are similar to each other based on the content, while in different clusters, the similarity decreases. From the perspective of optimization, clustering can be presented as an NP-hard optimization problem.
Metaheuristic algorithms are shown to be very efficient to solve NP-hard optimization problems and result in close-optimal solutions in a fair amount of time. Metaheuristic algorithms that are inspired by the nature can be divided into two major categories, swarm intelligence and evolutionary algorithms. In this work, a hybrid swarm intelligence algorithm is proposed. The fruit-fly optimization algorithm [
1,
2] is hybridized by the firefly algorithm (FA) [
3]. Additionally, the opposition-based learning mechanism is incorporated in the hybrid method, it is combined with the traditional K-means algorithm [
4], and employed for text-based document clustering.
According to [
5], the traditional algorithms for clustering can be grouped into 9 classes, as illustrated in
Table 1. One of the main disadvantages of traditional clustering algorithms is that they can easily be drawn into local optima [
5]. Swarm intelligence algorithms are shown to be very effective in avoiding the local optima issue [
6]. Swarm intelligence systems generally consist of a collaborative population of individuals, who are cooperating locally with one another, as well as interacting with their environment. Each individual in the population follows simple rules and collectively produces behavior that leads together to the common goal. The random local and cooperation among the individuals lead to the evolution of intelligent global performance. This intelligent collective behavior is called swarm intelligence (SI).
Metaheuristics in general, and swarm intelligence algorithms in particular, have many successful applications in different fields, such as image segmentation, classification, clustering [
28,
29,
30,
31,
32], feature selection [
33], data clustering [
34], convolutional neural network architecture optimization [
35,
36,
37,
38,
39], in wireless sensor networks (WSNs) [
40,
41], cloud computing applications [
42,
43,
44,
45,
46,
47], vehicle routing [
48,
49], path planning [
50], packing problems [
51], resource allocation [
52], optimizations in different deep learning applications and neural network training [
53,
54,
55,
56,
57], supply chain management [
58], and many others. The fruit-fly optimization algorithm was recently successfully applied for clustering [
59], although not for the specific problem of document clustering, and it was not hybridized with the FA.
Many researchers applied metaheuristic-based (including swarm intelligence) algorithms for text document clustering problems. The well-known particle swarm optimization algorithm (PSO) hybridized with K-means algorithm and OTSU algorithm is used for text clustering in [
60]. In [
61] grey wolf optimization algorithm (GWO) is hybridized with grasshopper optimization algorithm (GOA), and Fuzzy c-means (FCM) for feature selection and text clustering. The FA is used in [
62] for dynamic document clustering. The krill herd algorithm (KH) is hybridized with genetic operators and applied for web text documents clustering in [
63]. A hybrid multi-verse optimizer (MVO) with the traditional K-means clustering algorithm is used for text clustering in [
64]. Text document clustering represents an important machine learning task, and our intention was to examine the performance of FFO for this application, as well as specifically evaluating the newly proposed technique in this scenario. In such tasks there is also space for improvement using other novel, improved metaheuristics and algorithms, often obtained through hybridization. Notwithstanding the existing metaheuristic-based text clustering applications, there is still a need to develop an algorithm that is more robust and efficient than the existing ones.
The following research questions inspired this work: (i) How to develop an efficient text clustering method that will group closely related documents and minimize the similarity in different clusters? (ii) How to develop an efficient swarm intelligence-based algorithm for text document clustering? The objective of this paper was to answer the research questions as follows: (i) Develop an improved hybrid fruit-fly optimization (FFO) swarm intelligence method in which performance in terms of quality of solutions is superior to the original algorithm. (ii) Employ the novel hybrid FFO approach to text document clustering and produce better results as compared to the ones obtained by other state-of-the-art approaches for the same problem.
The rest of the paper is organized as follows: the text document clustering problem formulation is described in
Section 2 and the explanation of the proposed method is given in
Section 3.
Section 4 demonstrates the simulation results for the optimization of unconstrained benchmark functions, as well as it presents the text datasets used for evaluation purposes, evaluation metrics, and simulation results along with the comparative analysis. Finally,
Section 5 concludes the paper.
2. Text Document Clustering
Text Document Clustering (TDC) represents the process of partitioning a set of heterogeneous documents into distinctive clusters based upon the content similarity. Before clustering technique application, data pre-processing should be performed. The pre-processing steps in text-based documents are tokenization, stop words are removed, stemming, lemmatization and, as a last step, conversion of the text to numerical form are performed.
2.1. Tokenization
In the tokenization process of text-based documents, each document in the corpus (collection of all documents) is converted to a list of tokens (units). In the case of a sentence, the token would be a word, while in the case of a word input, the tokens would be characters.
For example, having the following sentence:
The list of tokens after the tokenization process would be as follows:
2.2. Stop Words Removal
In the next process of text pre-processing, the common words, such as articles, conjunctions, etc. are removed from the list of tokens. By applying the stop words removal process on the above example, the result would be as follows:
where
and
are stop words and they are removed from the token list.
Stop words removal reduces the size of the vocabulary, which leads to faster computation.
2.3. Stemming and Lemmatization
In the process of stemming and lemmatization, the words are normalized, meaning that the words are reduced to their root form. The difference between stemming and lemmatization is that in stemming, the last few characters are removed from the word, while in lemmatization, the context is taken into account, and the word is converted to its base form (lemma). For example, applying the stemming process on word , would result in , where the are removed from the end of the word, while in the case of lemmatization, the result would be , which is the actual lemma of the word.
2.4. Vectorization
The last step in the text pre-processing pipeline is converting the words to their numerical forms for building the vocabulary that contains all tokens; this process is called vectorization. There are different vectorization techniques, the Term Frequency-Inverse Document Frequency (TF-IDF) is one of the most commonly used approaches.
The
i-th document is represented by the weight vector as described in Equation (
1).
The weight of document terms is calculated according to the formula in Equation (
2), where
i represents a term, and
j represents a specific document.
denotes the frequency of
i-th term in document
j,
refers to the number of documents that contains the term
i, while
d is the total number of documents.
The vector space model (VSM) is presented in Equation (
3).
3. Proposed Method
This section, first introduces the original FFO algorithm, points out its advantages and drawbacks. Subsequently, the proposed hybrid method is described, followed by the adaptation of the proposed method for text document clustering problem.
3.1. Original Fruit-Fly Optimization Algorithm
The original fruit-fly optimization (FFO) algorithm is introduced by Pan [
1,
2]. The FFO is inspired by the fruit-fly’s foraging behavior. The original fruit-fly optimization algorithm consists of four phases:
Initially, the solutions (fruit flies) are generated randomly within the given lower and upper bounds, according to Equation (
4), where
denotes
i-th solution, and
j subscript indicates to the element’s position in the
i-th solution.
, and
refers to the lower and upper bound, respectively.
is a random number drawn from the uniform distribution.
After the population is initialized, the position of each solution is updated according to the osphresis foraging phase, where the solution moves a random step from the current location, and it is formulated mathematically as in Equation (
5), where the new position is denoted by
, the current solution is
, rand()
. The iteration counter is denoted by
t.
After the position update, the fitness value is calculated for each solution, then the greedy selection procedure will decide whether the new position will remain or the old one will be kept. This phase of the algorithm is known as vision foraging phase. If the new solution’s fitness value is better than the old one, the new solution will replace the old, otherwise, the old solution will remain in the population and the new one will be discarded. The algorithm is terminated upon reaching the stop criteria and it returns the best solution.
3.2. Proposed Hybrid FFO
The FFO’s structure is relatively simple, it has a reduced number of parameters, and the adaptation of the algorithm to a specific problem is straightforward. However, besides these advantages, the method has some drawbacks. The algorithm can become trapped in the local minima, its position update strategy is fixed, and it is poor in the exploitation process. The deficiencies of the algorithm were observed during experiments on unconstrained functions.
For the sake of enhancing the exploitation, the firefly algorithm (FA) search mechanism is incorporated in the algorithm, which excels at intensification. Additionally, to explore better the search space, opposition-based learning (OBL) is introduced.
The hybrid algorithm is named hybrid enhanced fruit-fly firefly, in short HEFFF. Initially, the population is generated randomly according to Equation (
4). In even iterations, the FFO search mechanism is used if a random number is less than 0.5, otherwise, the opposition-based learning is applied, while in every odd iteration, the firefly [
3] search mechanism is employed.
The opposite number (
) is defined as shown in Equation (
6).
The firefly search mechanism updates the position by equation Equation (
7), where the distance between the current candidate solution
and another one
is denoted by
and it is calculated by Equation (
8). The attractiveness, at distance zero, toward the fittest firefly (solution) is denoted by
.
and alpha are control parameters for randomization, and
is generated from Gaussian distribution.
The reader may refer [
3] for more details about the original FA algorithm.
For further improving the performance of the algorithm, a dynamic step is employed for the
control parameter according to [
65], where the
value is decreasing gradually from the initial value (
), until the defined minimum value (
) throughout the iterations. The update of the
value in each iteration is defined as in Equation (
9), where the current iteration is denoted by
t,
refers to the maximum number of iterations,
denotes the value of
at the current iteration, while the updated value is denoted by
.
Algorithm 1 illustrates the main steps of the proposed HEFFF approach.
| Algorithm 1 Pseudo-code of proposed HEFFF |
Initialize the population randomly by Equation ( 4) Initialize the FA parameters of , , Set the iteration counter t to 0 and define the termination criteria Evaluate the fitness of each individuals while termination criteria is not satisfied do for to N do if t is even then if then Update the position according to FFO updating mechanism by Equation ( 5) else Use OBL procedure by Equation ( 6) end if else Perform FA search using Equation ( 7) end if end for Evaluate the solutions, and if the new solution has better fitness than the old one, replace the old solution Sort the population according to the fitness value of the solutions and save the best solution Replace the worst solutions (30% in the population) by new random solutions end while Return the best solution
|
3.3. Hybrid FFO Adapted for Text Clustering
In the proposed hybrid FFO for the text clustering problem, the K-means procedure is incorporated as an intermediate step. Within pre-processing step of the text data, the features are normalized between 0 and 1, thus, the lower and upper bounds are also 0 and 1. Initially, the solutions are generated randomly between the lower and upper bounds.
One individual in the population represents one possible solution for clustering the text corpus data. Hence, the population represents the candidate solutions for the text corpus data clustering. Each solution is encoded as a matrix , where represents the i-th cluster centroid vector and k is the number of clusters. Based on the distance measure, each document should be assigned to the closest cluster.
The distance between a document and centroid is calculated as in Equation (
10), where
t refers to the number of terms (features) in a document,
d denotes the document, and
c is the centroid.
The fitness value is based on the K-means algorithm, and it represents the average distance of documents to the cluster centroid. The fitness value is measured by the equation Equation (
11), where
K denotes the total number of clusters, the number of documents in
i-th cluster is denoted by
, the
j-th document in cluster
i is denoted by
, the centroid of
i-th cluster is denoted by
. The
function calculates the distance between the document
and cluster
.
Based on the position updating mechanisms in the proposed method, the values of the centroid vector are adjusted in every iteration, then the distance from the documents to the centroids are recalculated and reassigned. This procedure is repeated until the termination criteria are met.
4. Experimental Results
The proposed method is first validated on unconstrained benchmark functions, next it is applied for TDC. The experimental setup, problem sets, and the obtained results are presented in the following two subsections.
4.1. Unconstrained Experiment on CEC 2019 Test Suit
The performance of the proposed method is validated on 10 modern CEC2019 functions [
66] and the results are compared to the original FFO, and other nine metaheuristic-based approaches (EHOI, EHO, SCA, SSA, GOA, WOA, BBO, MFO, PSO) [
67], where the simulations were conducted under similar condition and the same problem sets are used.
The population size is set to 50, the maximum number of iterations is 500. The experiment is repeated in 30 independent runs. The control parameters of the unconstrained benchmark function experiment are shown in
Table 2.
The obtained experimental results and the comparison of the mean value and standard deviation of the proposed method and counterparts are presented in
Table 3. The results of EHOI, EHO, SCA, SSA, GOA, WOA, BBO, MFO, and PSO are taken from [
67].
The results in
Table 3 indicate the superiority of HEFFF, it has the best mean value in the case of 8 functions, while the original FFO achieved the best mean results on 2 functions (CEC01, CEC08).
Furthermore, the Friedman test [
68,
69] two-way analysis of variance by ranks is performed to prove the significant difference between the proposed approach and other comparable methods. The ranking of 11 algorithms when applied to the 10 functions is provided in
Table 4.
Table 4 shows that HEFFF is superior to the other 10 algorithms with an average ranking of 1.2 for the Friedman test. The Friedman statistics (
) is greater than the
critical value with 10 degrees of freedom (
), at significance level
, thus the null hypothesis (
) is rejected and we can conclude that HEFFF is significantly different from the other 10 methods. As reported in [
70], the Iman and Davenport’s test [
71] may be more accurate than the approximation of chi-square; for that reason, we also conducted the Iman and Davenport’s test. The obtained statistic of
, which is greater than the
F-distribution critical value (
). Consequently, the second test also rejects
. In the case of both tests, the
p-value is less than the significance level. The summary of the statistical results is provided in
Table 5.
As the null hypothesis is rejected by Friedman and Iman and Davenport tests, we proceeded with the non-parametric post-hoc procedure, with the Holm’s step-down procedure, and the obtained results are reported in
Table 6.
Table 6 shows that the proposed method significantly outperformed the compared method at significance level
, as well as the first eight methods at significance level
.
Figure 1 illustrates a head-to-head comparison between HEFFF and the second-best method with respect to the results on the 10 benchmark functions, i.e., FFO. The plots illustrate how the fitness evaluation decreases over the 500 iterations for each test function in turn.
4.2. Text Document Clustering Experiment
In the second experiment, 6 benchmark text datasets are used for the HEFFF validation: (i) The Centre for Speech Technology Research (CSTR) dataset has 299 documents belonging to four categories (artificial intelligence, theory, systems, and robotics); (ii) The 20Newsgroups dataset (20Newsgroups) contains 20 classes and for this research 3 of them are used, namely
the comp.windows.x,
talk.politics.misc, and
rec.autos. Each of the three categories has 100 documents; (iii) Tr41, (iv) Tr12, and (v) Wap datasets are from Karypis lab, the number of classes by datasets are 10, 8, and 20 classes, respectively; (vi) The Classic4 dataset consists of four classes (CISI, CACM, MED, and CRAN), each class has 500 documents, in total there are 2000 documents in the dataset. The characteristics of the text datasets are described in
Table 7.
4.2.1. Evaluation Metrics
The error rate, accuracy, precision, recall, F-measure, purity, and entropy are used as evaluation measurements in text document clustering. Their expressions were taken from [
64].
The error rate calculates the wrong cluster assignment to a document over the total number of documents in the given dataset. The mathematical formulation is shown in Equation (
12), where the total number of documents in the dataset (or test dataset) is denoted by
n,
refers to the number of misplaced documents from class
i to cluster
j and
k represents the number of clusters.
The accuracy measure calculates the ratio of document assignment to the correct clusters (when class
i is identified as cluster
j) in the given dataset. The calculation is performed by equation Equation (
13).
The precision metric gives information about the correct classes over all classes in the clusters, and it is calculated as shown in Equation (
14), where
denotes the correctly assigned class
i in the
j cluster, and
indicates to the total number of documents in cluster
j.
The recall measures the ratio of correct document assignment over the total number of documents in the given class, at the value is determined by Equation (
15), where
denotes the correctly assigned class
i in the
j cluster, and
indicates to the total number of documents in class
i.
The F-measure represents the Harmonic mean of the precision and recall, and it is calculated by Equation (
16), where
, and
denotes the precision, and recall, respectively.
Entropy measures the distribution of documents of class labels in each cluster. The value is between 0 and 1, the best entropy is closer to 0. The entropy value of cluster
j is determined by Equation (
17), where
denotes the entropy of cluster
j, the probability of class
i in cluster
j of a document is denoted by
.
The entropy of clustering (all clusters) is determined by Equation (
18).
4.2.2. Results and Discussion
The text document clustering experiment is repeated in 30 independent runs. The maximum number of iterations is set to 1000, and the population size is 20. The control parameters are summarized in
Table 8.
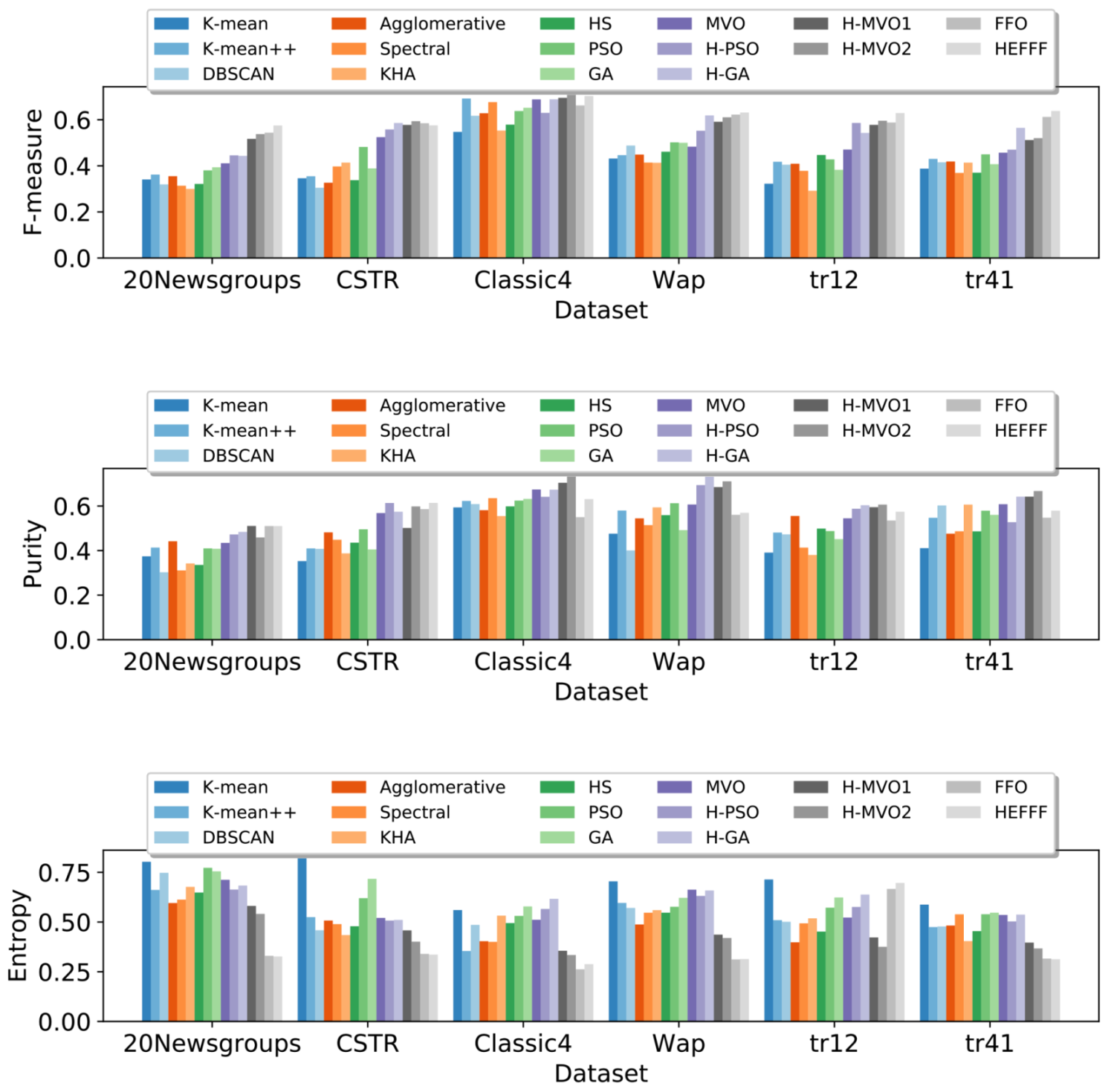
The text document clustering on the six text-based dataset, experimental results of the proposed method, original FFO, five non-metaheuristic methods, and 9 other metaheuristic-based methods are presented in
Table 9,
Table 10,
Table 11,
Table 12,
Table 13 and
Table 14. The results of the methods used for comparison (K-mean, K-mean++, DBSCAN, Agglomerative, Spectral, KHA, HS, PSO, GA, MVO, H-PSO, H-GA, H-MVO1, H-MVO2) are taken from [
64].
As presented in the tables, the hybrid FFO method is a very competitive and promising method for text clustering. HEFFF has the best error rate in the experiment with all six datasets, and in the case of five datasets, the best accuracy is obtained by the proposed method. Moreover, in the case of five datasets, the HEFFF has the best results of recall, while the F-measure is the best on four datasets.
On the CSTR dataset the HEFFF improved the accuracy by 16% over the non-metaheuristic approaches, and for 2% over the best resulted in metaheuristic method reported in [
64]. HEFFF resulted in the best error rate, accuracy, precision, recall, F-measure, and entropy on the 20Newsgroups dataset, and the best purity in this dataset is obtained by H-MVO1. The best performing method on the tr12 dataset is HEFFF, with the best-obtained results for error rate, accuracy, recall, and F-measure, while the second-best approach is H-MVO2, which achieved the best result on precision, purity, and entropy. The accuracy improvement of HEFFF on tr41 is from 3% to 24% over the other methods. In the case of tr41, HEFFF has the best result on all metrics, except purity, where H-MVO2 has the best value. On the Wap dataset, the H-GA method has the best accuracy, while the proposed method achieved the best value on three metrics. On the Classic4 dataset, HEFFF improved the accuracy from 2% to 16% over other non-metaheuristic and metaheuristic approaches.
In an overall view, HEFFF is classified first in all 6 benchmark cases for the error rate and accuracy. In 5 out of 6, the proposed method has the best recall and F-measure, the only dataset where it was not best being CSTR for both measures, but where the results were still close to the best output. The best precision and entropy are obtained in 3 out of the 6 tests, while the best purity is achieved in one benchmark case.
In both experiments, the comparison is made between our method, basic FFO and other metaheuristics. All metaheuristics are tested under similar conditions in terms of number of iterations and solutions in the population. Computational complexity of all approaches is the same in terms of number of fitness function evaluations. We kept relatively low values for the population sizes, i.e., 50 for function optimization and 20 for clustering, and had a maximum number of iterations of 500 and 1000, respectively. The running time, given these parameters, is relatively reduced, as the number of fitness evaluation calls is maintained low. Naturally, deterministic algorithms are faster to apply, but in the current experiment led to weaker results.
In setting adequate values for the parameters, we noticed that good results were obtained for a wider variety of values for the population size and the number of iterations. As concerns the other variables, they are kept the same for both types of tasks, making parameter tuning easy for the user.
Based on the experimental results, we can conclude that HEFFF is a very efficient method in text document clustering. The FFO search phase and the OBL mechanism investigates the search space globally, and by incorporating FA, the exploitation is enhanced, and it leads to efficiently finding better cluster centroids than other approaches.
5. Conclusions
In this work, a hybrid metaheuristic algorithm is proposed for text document clustering. The method is named hybrid enhanced fruit-fly firefly, for short HEFFF. The FFO algorithm is hybridized with the FA, and the OBL mechanism is additionally incorporated in the algorithm to better explore the search space on a global scale.
The method is tested on 10 unconstrained benchmark functions from CEC 2019 test suit, and the obtained results are compared to other metaheuristic techniques (EHOI, EHO, SCA, SSA, GOA, WOA, BBO, MFO, PSO). In the comparison, the fitness means to value and the standard deviation is compared between the different approaches, where the proposed method outperformed all the other state-of-the-art methods. Furthermore, non-parametric statistical tests are used to prove the significant difference of the algorithm, namely the Friedman test, and Iman and Davenport’s test. After conducting the non-parametric statistical tests, the Holm step-down procedure is used as a post-hoc procedure. The obtained statistical results prove the significant difference in between the results obtained by HEFFF and the other competitor approaches.
In the second simulation, the algorithm is employed for the text document clustering problem, where six standard text documents are used for evaluation purposes. The obtained results are compared to other non-metaheuristic and metaheuristic methods (K-mean, K-mean++, DBSCAN, Agglomerative, Spectral, KHA, HS, PSO, GA, MVO, H-PSO, H-GA, H-MVO1, H-MVO2). For evaluation purposes, the error rate, accuracy, precision, recall, F-measure, purity, and entropy are used in the text document clustering experiments. The proposed hybrid FFO demonstrates much better results over the other state-of-the-art methods and that it is, therefore, suitable for document clustering problems.
The proposed technique combines benefits from FFA and FA. The additional combination with the traditional K-means algorithm leads to a framework that delivers the best performance for text-based document clustering, as observed in the obtained results.
In future work, we plan to include other text-based document datasets in the experiments, as well as to implement other algorithms and to additionally incorporate different mechanisms for improvement and to enhance their efficiency in text document clustering.
Based on the used benchmark tests, our method obtains good results, generally outperforming the outputs obtained by other state-of-the-art techniques. Thus, we are confident that it can be adapted and tested on other NP-hard tasks, even different from of clustering, such as machine learning hyperparameter tuning, feature selection [
72], wireless sensor network localization, intrusion detection within networks [
73,
74], energy, cloud task scheduling, path planning, portfolio optimization, etc.
Author Contributions
Conceptualization, T.B., N.B. and C.S.; methodology, N.B., C.S. and K.V.; software, T.B. and K.V.; validation, A.A.N.; formal analysis, M.Z.; investigation, T.A.R. and N.B.; resources, T.B. and C.S.; data curation, M.Z., C.S. and N.B.; writing—original draft preparation, T.B. and T.A.R.; writing—review and editing, C.S., T.A.R. and A.A.N.; visualization, T.B.; supervision, A.A.N.; project administration, M.Z. and N.B.; funding acquisition, N.B. and C.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research is supported by Ministry of Education and Science of Republic of Serbia, Grant No. III-44006. Catalin Stoean acknowledges the support of a grant of the Romanian Ministry of Education and Research, CCCDI—UEFISCDI, project number 411PED/2020, code PN-III-P2-2.1-PED-2019-2271, within PNCDI III.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Acknowledgments
This research is supported by Ministry of Education and Science of Republic of Serbia, Grant No. III-44006. Catalin Stoean acknowledges the support of a grant of the Romanian Ministry of Education and Research, CCCDI—UEFISCDI, project number 411PED/2020, code PN-III-P2-2.1-PED-2019-2271, within PNCDI III.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Pan, W.T. A new evolutionary computation approach: Fruit fly optimization algorithm. In Proceedings of the 2011 Conference of Digital Technology and Innovation Management, Shenzhen, China, 26–27 November 2011; pp. 382–391. [Google Scholar]
- Pan, W.T. A new fruit fly optimization algorithm: Taking the financial distress model as an example. Knowl. Based Syst. 2012, 26, 69–74. [Google Scholar] [CrossRef]
- Yang, X.S. Firefly Algorithms for Multimodal Optimization. In Stochastic Algorithms: Foundations and Applications; Watanabe, O., Zeugmann, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 169–178. [Google Scholar]
- MacQueen, J.B. Some Methods for Classification and Analysis of MultiVariate Observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability; Cam, L.M.L., Neyman, J., Eds.; University of California Press: Berkeley, CA, USA, 1967; Volume 1, pp. 281–297. [Google Scholar]
- Xu, D.; Tian, Y. A comprehensive survey of clustering algorithms. Ann. Data Sci. 2015, 2, 165–193. [Google Scholar] [CrossRef] [Green Version]
- Sun, W.; Tang, M.; Zhang, L.; Huo, Z.; Shu, L. A Survey of Using Swarm Intelligence Algorithms in IoT. Sensors 2020, 20, 1420. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Park, H.S.; Jun, C.H. A simple and fast algorithm for K-medoids clustering. Expert Syst. Appl. 2009, 36, 3336–3341. [Google Scholar] [CrossRef]
- Kaufman, L.; Rousseeuw, P.J. Finding Groups in Data: An Introduction to Cluster Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2009; Volume 344. [Google Scholar]
- Ng, R.T.; Han, J. CLARANS: A method for clustering objects for spatial data mining. IEEE Trans. Knowl. Data Eng. 2002, 14, 1003–1016. [Google Scholar] [CrossRef] [Green Version]
- Zhang, T.; Ramakrishnan, R.; Livny, M. BIRCH: An efficient data clustering method for very large databases. ACM Sigmod Rec. 1996, 25, 103–114. [Google Scholar] [CrossRef]
- Guha, S.; Rastogi, R.; Shim, K. CURE: An efficient clustering algorithm for large databases. ACM Sigmod Rec. 1998, 27, 73–84. [Google Scholar] [CrossRef]
- Guha, S.; Rastogi, R.; Shim, K. ROCK: A robust clustering algorithm for categorical attributes. Inf. Syst. 2000, 25, 345–366. [Google Scholar] [CrossRef]
- Karypis, G.; Han, E.H.; Kumar, V. Chameleon: Hierarchical clustering using dynamic modeling. Computer 1999, 32, 68–75. [Google Scholar] [CrossRef] [Green Version]
- Bezdek, J.C.; Ehrlich, R.; Full, W. FCM: The fuzzy c-means clustering algorithm. Comput. Geosci. 1984, 10, 191–203. [Google Scholar] [CrossRef]
- Dave, R.N.; Bhaswan, K. Adaptive fuzzy c-shells clustering and detection of ellipses. IEEE Trans. Neural Netw. 1992, 3, 643–662. [Google Scholar] [CrossRef]
- Yager, R.R.; Filev, D.P. Approximate clustering via the mountain method. IEEE Trans. Syst. Man Cybern. 1994, 24, 1279–1284. [Google Scholar] [CrossRef]
- Xu, X.; Ester, M.; Kriegel, H.P.; Sander, J. A distribution-based clustering algorithm for mining in large spatial databases. In Proceedings of the 14th International Conference on Data Engineering, Orlando, FL, USA, 23–27 February 1998; pp. 324–331. [Google Scholar]
- Rasmussen, C.E. The infinite Gaussian mixture model. NIPS 1999, 12, 554–560. [Google Scholar]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, KDD’96, Portland, OR, USA,, 2–4 August 1996; AAAI Press: Palo Alto, CA, USA, 1996; pp. 226–231. [Google Scholar]
- Ankerst, M.; Breunig, M.M.; Kriegel, H.P.; Sander, J. OPTICS: Ordering points to identify the clustering structure. ACM Sigmod Rec. 1999, 28, 49–60. [Google Scholar] [CrossRef]
- Comaniciu, D.; Meer, P. Mean shift: A robust approach toward feature space analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 603–619. [Google Scholar] [CrossRef] [Green Version]
- Sharan, R.; Shamir, R. CLICK: A Clustering Algorithm with Applications to Gene Expression Analysis. Proceedings International Conference on Intelligent Systems for Molecular Biology, ISMB, San Diego, CA, USA, 19–23 August 2000; International Conference on Intelligent Systems for Molecular Biology. AAAI Press: Palo Alto, CA, USA, 2000; Volume 8, pp. 307–316. [Google Scholar]
- Gupta, M.K.; Chandra, P. A comparative study of clustering algorithms. In Proceedings of the 2019 6th International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 13–15 March 2019; pp. 801–805. [Google Scholar]
- Wang, W.; Yang, J.; Muntz, R. STING: A statistical information grid approach to spatial data mining. VLDB 1997, 97, 186–195. [Google Scholar]
- Agrawal, R.; Gehrke, J.; Gunopulos, D.; Raghavan, P. Automatic subspace clustering of high dimensional data for data mining applications. In Proceedings of the 1998 ACM SIGMOD International Conference on Management of Data, Seattle, WA, USA, 1–4 June 1998; pp. 94–105. [Google Scholar]
- Barbará, D.; Chen, P. Using the fractal dimension to cluster datasets. In Proceedings of the Sixth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Boston, MA, USA, 20–23 August 2000; pp. 260–264. [Google Scholar]
- Fisher, D.H. Knowledge acquisition via incremental conceptual clustering. Mach. Learn. 1987, 2, 139–172. [Google Scholar] [CrossRef]
- Hrosik, R.C.; Tuba, E.; Dolicanin, E.; Jovanovic, R.; Tuba, M. Brain Image Segmentation Based on Firefly Algorithm Combined with K-means Clustering. Stud. Inf. Control 2019, 28, 167–176. [Google Scholar] [CrossRef] [Green Version]
- Tuba, E.; Strumberger, I.; Bezdan, T.; Bacanin, N.; Tuba, M. Classification and feature selection method for medical datasets by brain storm optimization algorithm and support vector machine. Procedia Comput. Sci. 2019, 162, 307–315. [Google Scholar] [CrossRef]
- Tuba, E.; Strumberger, I.; Bacanin, N.; Bezdan, T.; Tuba, M. Image Clustering by Generative Adversarial Optimization and Advanced Clustering Criteria. In Proceedings of the International Conference on Swarm Intelligence, Belgrade, Serbia, 14–20 July 2020; Springer: Berlin, Germany, 2020; pp. 465–475. [Google Scholar]
- Brajevic, I.; Tuba, M.; Bacanin, N. Multilevel image thresholding selection based on the cuckoo search algorithm. In Proceedings of the 5th International Conference on Visualization, Imaging and Simulation (VIS’12), Sliema, Malta, 7–9 September 2012; pp. 217–222. [Google Scholar]
- Lichtblau, D.; Stoean, C. Cancer diagnosis through a tandem of classifiers for digitized histopathological slides. PLoS ONE 2019, 14, e0209274. [Google Scholar] [CrossRef] [Green Version]
- Bezdan, T.; Cvetnic, D.; Gajic, L.; Zivkovic, M.; Strumberger, I.; Bacanin, N. Feature Selection by Firefly Algorithm with Improved Initialization Strategy. In Proceedings of the 7th Conference on the Engineering of Computer Based Systems, Novi Sad, Serbia, 26–27 May 2021; Association for Computing Machinery: New York, NY, USA, 2021. ECBS 2021. [Google Scholar] [CrossRef]
- Rana, S.; Jasola, S.; Kumar, R. A review on particle swarm optimization algorithms and their applications to data clustering. Artif. Intell. Rev. 2011, 35, 211–222. [Google Scholar] [CrossRef]
- Strumberger, I.; Tuba, E.; Bacanin, N.; Zivkovic, M.; Beko, M.; Tuba, M. Designing Convolutional Neural Network Architecture by the Firefly Algorithm. In Proceedings of the 2019 International Young Engineers Forum (YEF-ECE), Costa da Caparica, Portugal, 10 May 2019; pp. 59–65. [Google Scholar] [CrossRef]
- Bezdan, T.; Tuba, E.; Strumberger, I.; Bacanin, N.; Tuba, M. Automatically Designing Convolutional Neural Network Architecture with Artificial Flora Algorithm. In ICT Systems and Sustainability; Tuba, M., Akashe, S., Joshi, A., Eds.; Springer: Singapore, 2020; pp. 371–378. [Google Scholar]
- Bacanin, N.; Bezdan, T.; Tuba, E.; Strumberger, I.; Tuba, M. Monarch Butterfly Optimization Based Convolutional Neural Network Design. Mathematics 2020, 8, 936. [Google Scholar] [CrossRef]
- Bacanin, N.; Bezdan, T.; Tuba, E.; Strumberger, I.; Tuba, M. Optimizing Convolutional Neural Network Hyperparameters by Enhanced Swarm Intelligence Metaheuristics. Algorithms 2020, 13, 67. [Google Scholar] [CrossRef] [Green Version]
- Stoean, R. Analysis on the potential of an EA–surrogate modelling tandem for deep learning parametrization: An example for cancer classification from medical images. Neural Comput. Appl. 2018, 32, 313–322. [Google Scholar] [CrossRef]
- Strumberger, I.; Minovic, M.; Tuba, M.; Bacanin, N. Performance of Elephant Herding Optimization and Tree Growth Algorithm Adapted for Node Localization in Wireless Sensor Networks. Sensors 2019, 19, 2515. [Google Scholar] [CrossRef] [Green Version]
- Zivkovic, M.; Bacanin, N.; Tuba, E.; Strumberger, I.; Bezdan, T.; Tuba, M. Wireless Sensor Networks Life Time Optimization Based on the Improved Firefly Algorithm. In Proceedings of the 2020 International Wireless Communications and Mobile Computing (IWCMC), Limassol, Cyprus, 15–19 June 2020; pp. 1176–1181. [Google Scholar]
- Bacanin, N.; Bezdan, T.; Tuba, E.; Strumberger, I.; Tuba, M.; Zivkovic, M. Task Scheduling in Cloud Computing Environment by Grey Wolf Optimizer. In Proceedings of the 2019 27th Telecommunications Forum TELFOR, Belgrade, Serbia, 26–27 November 2019; pp. 1–4. [Google Scholar]
- Bacanin, N.; Tuba, E.; Bezdan, T.; Strumberger, I.; Tuba, M. Artificial flora optimization algorithm for task scheduling in cloud computing environment. In Proceedings of the International Conference on Intelligent Data Engineering and Automated Learning, Manchester, UK, 14–16 November 2019; Springer: Berlin, Germany, 2019; pp. 437–445. [Google Scholar]
- Heidari, A.A.; Mirjalili, S.; Faris, H.; Aljarah, I.; Mafarja, M.; Chen, H. Harris hawks optimization: Algorithm and applications. Future Gener. Comput. Syst. 2019, 97, 849–872. [Google Scholar] [CrossRef]
- Bezdan, T.; Zivkovic, M.; Antonijevic, M.; Zivkovic, T.; Bacanin, N. Enhanced Flower Pollination Algorithm for Task Scheduling in Cloud Computing Environment. In Machine Learning for Predictive Analysis; Springer: Berlin, Germany, 2020; pp. 163–171. [Google Scholar]
- Bezdan, T.; Zivkovic, M.; Tuba, E.; Strumberger, I.; Bacanin, N.; Tuba, M. Multi-objective Task Scheduling in Cloud Computing Environment by Hybridized Bat Algorithm. In Intelligent and Fuzzy Techniques: Smart and Innovative Solutions; Kahraman, C., Cevik Onar, S., Oztaysi, B., Sari, I.U., Cebi, S., Tolga, A.C., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 718–725. [Google Scholar]
- Strumberger, I.; Bacanin, N.; Tuba, M.; Tuba, E. Resource scheduling in cloud computing based on a hybridized whale optimization algorithm. Appl. Sci. 2019, 9, 4893. [Google Scholar] [CrossRef] [Green Version]
- Bitam, S.; Mellouk, A.; Zeadally, S. Bio-Inspired Routing Algorithms Survey for Vehicular Ad Hoc Networks. IEEE Commun. Surv. Tutor. 2015, 17, 843–867. [Google Scholar] [CrossRef]
- Marinakis, Y.; Iordanidou, G.R.; Marinaki, M. Particle Swarm Optimization for the Vehicle Routing Problem with Stochastic Demands. Appl. Soft Comput. 2013, 13, 1693–1704. [Google Scholar] [CrossRef]
- Tuba, E.; Strumberger, I.; Zivkovic, D.; Bacanin, N.; Tuba, M. Mobile Robot Path Planning by Improved Brain Storm Optimization Algorithm. In Proceedings of the 2018 IEEE Congress on Evolutionary Computation (CEC), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Lodi, A.; Martello, S.; Vigo, D. Heuristic and metaheuristic approaches for a class of two-dimensional bin packing problems. INFORMS J. Comput. 1999, 11, 345–357. [Google Scholar] [CrossRef]
- Madni, S.H.H.; Latiff, M.S.A.; Coulibaly, Y.; Abdulhamid, S.M. An appraisal of meta-heuristic resource allocation techniques for IaaS cloud. Indian J. Sci. Technol. 2016, 9, 1–14. [Google Scholar] [CrossRef]
- Bezdan, T.; Zivkovic, M.; Tuba, E.; Strumberger, I.; Bacanin, N.; Tuba, M. Glioma Brain Tumor Grade Classification from MRI Using Convolutional Neural Networks Designed by Modified FA. In Proceedings of the International Conference on Intelligent and Fuzzy Systems, Istanbul, Turkey, 21–23 July 2020; Springer: Berlin, Germany, 2020; pp. 955–963. [Google Scholar]
- Bacanin, N.; Tuba, E.; Bezdan, T.; Strumberger, I.; Jovanovic, R.; Tuba, M. Dropout Probability Estimation in Convolutional Neural Networks by the Enhanced Bat Algorithm. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–7. [Google Scholar] [CrossRef]
- Gajic, L.; Cvetnic, D.; Zivkovic, M.; Bezdan, T.; Bacanin, N.; Milosevic, S. Multi-layer Perceptron Training Using Hybridized Bat Algorithm. In Computational Vision and Bio-Inspired Computing; Smys, S., Tavares, J.M.R.S., Bestak, R., Shi, F., Eds.; Springer: Singapore, 2021; pp. 689–705. [Google Scholar]
- Milosevic, S.; Bezdan, T.; Zivkovic, M.; Bacanin, N.; Strumberger, I.; Tuba, M. Feed-Forward Neural Network Training by Hybrid Bat Algorithm. In Proceedings of the Modelling and Development of Intelligent Systems: 7th International Conference, MDIS 2020, Sibiu, Romania, 22–24 October 2020; Revised Selected Papers 7. Springer International Publishing: Basel, Switzerland, 2021; pp. 52–66. [Google Scholar]
- Bacanin, N.; Bezdan, T.; Venkatachalam, K.; Al-Turjman, F. Optimized convolutional neural network by firefly algorithm for magnetic resonance image classification of glioma brain tumor grade. J. Real Time Image Process. 2021. [Google Scholar] [CrossRef]
- Griffis, S.E.; Bell, J.E.; Closs, D.J. Metaheuristics in logistics and supply chain management. J. Bus. Logist. 2012, 33, 90–106. [Google Scholar] [CrossRef]
- Xiao, W.; Yang, Y.; Xing, H.; Meng, X. Clustering Algorithm Based on Fruit Fly Optimization. In Proceedings of the International Conference on Rough Sets and Knowledge Technology, Tianjin, China, 20–23 November 2015; Springer: Cham, Switzerland, 2015; pp. 408–419. [Google Scholar] [CrossRef]
- Chen, H.N.; He, B.; Yan, L.; Li, J.; Ji, W. A text clustering method based on two-dimensional OTSU and PSO algorithm. In Proceedings of the 2009 International Symposium on Computer Network and Multimedia Technology, Wuhan, China, 18–20 January 2009; pp. 1–4. [Google Scholar]
- Purushothaman, R.; Rajagopalan, S.; Dhandapani, G. Hybridizing Gray Wolf Optimization (GWO) with Grasshopper Optimization Algorithm (GOA) for text feature selection and clustering. Appl. Soft Comput. 2020, 96, 106651. [Google Scholar] [CrossRef]
- Nanda, S.J.; Panda, G. A survey on nature inspired metaheuristic algorithms for partitional clustering. Swarm Evol. Comput. 2014, 16, 1–18. [Google Scholar] [CrossRef]
- Abualigah, L.M.; Khader, A.T.; Al-Betar, M.A.; Awadallah, M.A. A krill herd algorithm for efficient text documents clustering. In Proceedings of the 2016 IEEE Symposium on Computer Applications & Industrial Electronics (ISCAIE), Penang, Malaysia, 30–31 May 2016; pp. 67–72. [Google Scholar]
- Abasi, A.K.; Khader, A.T.; Al-Betar, M.A.; Naim, S.; Alyasseri, Z.A.A.; Makhadmeh, S.N. A novel hybrid multi-verse optimizer with K-means for text documents clustering. Neural Comput. Appl. 2020, 32, 17703–17729. [Google Scholar] [CrossRef]
- Wang, H.; Zhou, X.; Sun, H.; Yu, X.; Zhao, J.; Zhang, H.; Cui, L. Firefly algorithm with adaptive control parameters. Soft Comput. 2017, 3, 5091–5102. [Google Scholar] [CrossRef]
- Price, K.; Awad, N.; Ali, M.; Suganthan, P. Problem definitions and evaluation criteria for the 100-digit challenge special session and competition on single objective numerical optimization. In Technical Report; Nanyang Technological University: Singapore, 2018. [Google Scholar]
- Muthusamy, H.; Ravindran, S.; Yaacob, S.; Polat, K. An improved elephant herding optimization using sine–cosine mechanism and opposition based learning for global optimization problems. Expert Syst. Appl. 2021, 172, 114607. [Google Scholar] [CrossRef]
- Friedman, M. The use of ranks to avoid the assumption of normality implicit in the analysis of variance. J. Am. Stat. D 1937, 32, 675–701. [Google Scholar] [CrossRef]
- Friedman, M. A comparison of alternative tests of significance for the problem of m rankings. Ann. Math. Stat. 1940, 11, 86–92. [Google Scholar] [CrossRef]
- Sheskin, D.J. Handbook of Parametric and Nonparametric Statistical Procedures; Chapman and Hall/CRC: Ballyclare, UK, 2020. [Google Scholar]
- Iman, R.L.; Davenport, J.M. Approximations of the critical region of the fbietkan statistic. Commun. Stat. Theory Methods 1980, 9, 571–595. [Google Scholar] [CrossRef]
- Stoean, C. In Search of the Optimal Set of Indicators when Classifying Histopathological Images. In Proceedings of the 2016 18th International Symposium on Symbolic and Numeric Algorithms for Scientific Computing (SYNASC), Timisoara, Romania, 24–27 September 2016; pp. 449–455. [Google Scholar] [CrossRef]
- Kumar, M.; Mukherjee, P.; Verma, K.; Verma, S.; Rawat, D.B. Improved Deep Convolutional Neural Network based Malicious Node Detection and Energy-Efficient Data Transmission in Wireless Sensor Networks. IEEE Trans. Netw. Sci. Eng. 2021, 1. [Google Scholar] [CrossRef]
- Panigrahi, R.; Borah, S.; Bhoi, A.K.; Ijaz, M.F.; Pramanik, M.; Kumar, Y.; Jhaveri, R.H. A Consolidated Decision Tree-Based Intrusion Detection System for Binary and Multiclass Imbalanced Datasets. Mathematics 2021, 9, 751. [Google Scholar] [CrossRef]
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).


 ,
, 





{kind=link}
{kind=link}
{kind=link}