1. Introduction
Gliomas are the most common primary brain tumors, originating from glial cells. We can differentiate between benign tumors, with, in some cases, a long life expectancy, and malignant forms. In this second group, glioblastoma multiforme (GBM) is the most frequent malignant cancer with the worst prognosis, with less than 5% of affected patients with a 5-year survival rate and with the highest relapse rate [
1]. GBM are characterized by a diffuse and infiltrative growth pattern, as invasive glioma cells often migrate along myelinated white matter (WM) fiber tracts. This is a major cause of their appalling prognosis—tumor cells invade, displace, and possibly destroy WM. For these reasons, surgical, radiotherapic and chemotherapic approaches, also early performed, rarely resulted in being effective for a significant number of months [
2]. Moreover, large surgical resections could cause unacceptable effects on motor or speech functions. In largely infiltrative GBM, the real objective of the surgical approach is to leave less possible cancer cells in situ to give more chances to adjuvant therapy. The non-invasive detection of microscopic infiltration, as well as the identification of aggressive tumor components within spatially heterogeneous lesions, are of outstanding importance for surgical and radiation therapy planning or to assess response to chemotherapy. Moreover, the critical importance of an accurate detection of local infiltration is underlined by the results of intraoperative MR—this technique seems to be able to contribute significantly to optimal resection [
3] and to improve post-operative outcomes [
4]. Magnetic resonance (MR) imaging plays an important role in the detection and evaluation of brain tumors. The evaluation of post-surgical residual cancer by MR should be performed in all patients after 48–72 h after surgery, because this factor has a relevant prognostic value both for survival and for the subsequent therapeutic response [
5]. For more than 30 years [
6] conventional MR imaging, typically T1w images before and after paramagnetic contrast administration, T2w images and FLAIR images have been largely used to evaluate brain neoplasms. MR allows to localize the lesions, helps to distinguish tumors from other pathological processes, and depicts basic signs of response to therapy, such as changes in size and degree of contrast enhancement. Manual tumor detection and segmentation on MR images is time-consuming and can have a great inter-observer variability; automatic segmentation is more reproducible and efficient when robustness is particularly desirable, such as in monitoring disease progression or in the longitudinal evaluation of emerging therapies [
7]. This is a very relevant element because often in clinical practice the decisions regarding therapy continuation or discontinuation are taken on the basis of disease recovery [
2]. Radiomics is a set of techniques for extracting a vectorial representation that provides a quantitative description of tumor radiographic data. In general, radiomics extracts quantitative description of signals and images intensity, texture description and geometric characteristics.
Texture analysis, an image-analysis technique that quantifies grey-level patterns by describing the statistical relationships between the intensity of pixels, has demonstrated considerable potential for cerebral lesion characterization and segmentation [
8,
9,
10]. For automatic glioma detection and segmentation in MRI, several algorithms have been already proposed. The most recent works can be grouped into superpixel based segmentation and deep learning based segmentation. In Reference [
11], the authors presented an interesting bottom-up approach that aims to combine graphical probabilistic model (i.e., Conditional Random Fields (CRF)) for capturing the spatial interactions among image superpixel regions and their measurements. A number of features including statistics features, the combined features from the local binary pattern as well as grey level run length, curve features, and fractal features, were extracted from each superpixel. The features were used for teaching machine learning models to discriminate between healthy and pathological brain tissues. In Reference [
12], the authors used the concept of superpixels based segmentation for instrumenting a machine learning algorithm (i.e., support vector machine (SVM)) that uses both textural and statistical features. The authors reported excellent average Dice coefficient, Hausdorff distance, sensitivity, and specificity scores when applying their method to T2w sequences from the Multimodal Brain tumor Image Segmentation Benchmark 2017 (BraTS2017) dataset. In Reference [
13], the authors exploited a new method for brain tumor detection by combining features computed from Fluid-Attenuated Inversion Recovery (flair) MRI in association with the graph-based manifold ranking algorithm. The algorithm counts three mains steps: in the first phase, superpixel method is used to convert the homogeneous pixels in the form of superpixels. Rank of each superpixel or node is computed based on the affinity against certain selected nodes as the background prior in the second phase. The relevance of each node with the background prior is then computed and represented in the form of tumor map. In Reference [
14] the authors have reported on an approach that computes for each superpixel a number of novel image features including intensity-based, Gabor textons, fractal analysis and curvatures within the entire brain area in FLAIR MRI to ensure a robust classification. The authors compared Extremely randomized trees (ERT) classifier with support vector machine (SVM) to classify each superpixel into tumor and non-tumor.
Deep learning based solutions are becoming the new tools for brain segmentation. In Reference [
15], the authors used autoencoders for instrumenting an automatic segmentation of increased signal regions in fluid-attenuated inversion recovery magnetic resonance imaging images. In Reference [
16], the authors have provided a solution for dealing to the limited amount of available data from ill brains. They have trained a one-class classifier algorithm based on deep learning for segmenting brain tumors from fluid attenuation inversion recovery MRI. The technique exploits fully convolutional neural networks, and it is equipped with a battery of augmentation techniques that make the algorithm robust against low data quality, and heterogeneity of small training sets. Besides segmentation, deep-learning based solutions have been exploited for skull-stripping, and tissues identification (white matter, grey matter, etc.) [
17,
18].
To the best of our knowledge, the latest radiomics approaches are reported in Reference [
19]. Another approach for the analysis of cancer development is based on dynamical system theory [
20]. The models differ from each other for different degrees of abstraction of the environment in which the tumor grows. Usually, the environment is modeled by the parameters in the equations, and they describe both the chemical nutrients and the spatial constraints. We notice that most of the models approximate a tumor cell shape with spheres. Discrete models such as agent-based models reproduce the evolution of single spheroids. Partial Differential equations, such as a reaction-diffusion equation, are used for predicting the temporal and spatial evolution of tumor cells. They can account for numerous biological phenomena, but they are very sensitive to model parameters, making them hardly fittable with quantitative biological data in a simple experimental set-up [
21]. Recent works have combined radiomics with dynamical systems for providing personalized models. A complete and exhaustive mathematical modelling of tumor growth is quite impossible since it involves too many subsystems which have an effect on the growth of a tumor. In Reference [
22], the authors have defined a novel approach for identifying the fundamental components involved in cancer development. They have proposed a novel probability functions to obtain a personalized model and estimate the individual importance of each subsystem by means of simulated annealing for parameter optimization. The authors have validated the prediction of tumor growth with in-vitro tumor growth data.
1.1. Topological Data Analysis for Radiomics and Tumor Growth Analysis
Topological space is a powerful mathematical concept for describing the connectivity of a space. Informally, a topological space is a set of points, each of which equipped with the notion of neighboring [
23,
24]. In the last decade a new suite of tools, based on algebraic topology, for data exploration and modelling haven been invented [
25,
26,
27]. The data science community refers to these tools as Topological Data Analysis (TDA). TDA has been used in different domains—biology, manufacturing, medicine and others [
28]. Topological entropy, namely Persistent Entropy, is equipped with suitable mathematical properties, that permits to describe complex systems [
29] and it has been applied in different experiments, for example, the analysis of biological images [
30] and the analysis of medical signals [
31].
To the best of our knowledge, the extraction of topological features for radiomics from topological data analysis is still at its infancy. In Reference [
32], the authors compared the accuracy of machine learning models for the classification of hepatic tumors. From T1-weighted magnetic resonance (MR) images, the authors have computed both texture analysis and topological data analysis using persistent homology. The textural features or the topological features were used as input for machine learning models, the best accuracy (92%) for hepatocellular carcinomas was obtained with textural features, while TDA based machine learning model obtained 85% accuracy for metastatic tumors. Recent papers have demonstrated that topological data analysis algorithms are suitable for the analysis of dynamical systems [
33]. A common approach is to embed the time series of a dynamical system into a point cloud data and to study its shape by means of persistent homology. In Reference [
34], the authors have demonstrated that Persistent Entropy, a topological feature, is able to distinguish between periodical and chaotic systems. An alternative approach is represented by the analysis of the phase space of the system by means of TDA [
35].
In particular, we are interested to detect and to study topological loops (1D, 2D, etc…) that would surround brain regions of interest. We have introduced a novel entropy, the so-called generator entropy, that is a function of the number of 0-simplices (vertices) in the loops. The comparison of a healthy brain with a pathological one by means of a FLAIR highlights that the latter is characterized by the presence of a mass with a different grey gradient which would correspond to a topological loop. If the mass structure is heterogeneous or if the brain is affected by multiple tumors the number of loops will be higher.
1.2. Paper Outline
The potential of radiomics to improve clinical decision support systems is widely accepted both among clinicians and data scientists. The principal challenge is the optimal collection and integration of diverse multimodal data sources in a quantitative manner without any subjective biases and to support the modeling steps aiming at both objective and reproducible clinical predictions [
36]. In general with radiomics one refers to imaging data acquired at a single time-point, mostly imaging tumors before the beginning of treatment. Recently, a new approach called delta-radiomics has been introduced. In this setting, radiomics is augmented with temporal information throughout the course of treatment [
37]. Current efforts are focused on the development of a new framework in which radiomics and delta-radiomics are combined with other clinical information that was collected over time. The framework is known as “picture archiving and radiomics knowledge systems” (PARKS). The system will provide technical and methodological indications towards personalized diagnosis and treatments. In order to build a PARK system several open challenges must be solved. Some of the challenges are technological (e.g., definition of standard format for data sharing, how to extract data from the electronic footprint of a single patients, and so forth). Other challenges are methodological, for example, how to generalize the model, how to consume data that are acquired with different resolutions, what features are needed for extracting insights from data produced at different spatial and temporal scales [
36]. In Reference [
38], the authors have used TDA for the analysis of GBM. The authors have presented a novel topological statistics that is suitable for predicting the survival of GBM patients. Among the conclusions, the authors have raised the problem that it would be worth investigating how to combine topological statistics with deep learning. Also, the authors believe that the analysis of tumor shape may help in distinguishing true progression from pseudoprogression. By pseudoprogressing they mean that the tumor has been infiltrated by immune cells and other factors. In the present investigation, we intend to demonstrate by means of numerical experiments that topological features shall be taken into account in the PARKS system and for proposing initial answers to the open questions presented in Reference [
38]. In particular, we have executed three different experiments for showing that the same topological features can be enrolled for analysis at different time points as indicated by delta-radiomics (e.g., immediately after a treatment and after a follow-up period) and at different spatial scales, namely at a cellular level and at organ level and by using different data sources point cloud data or gray scale images. In particular, we have performed the following numerical experiments:
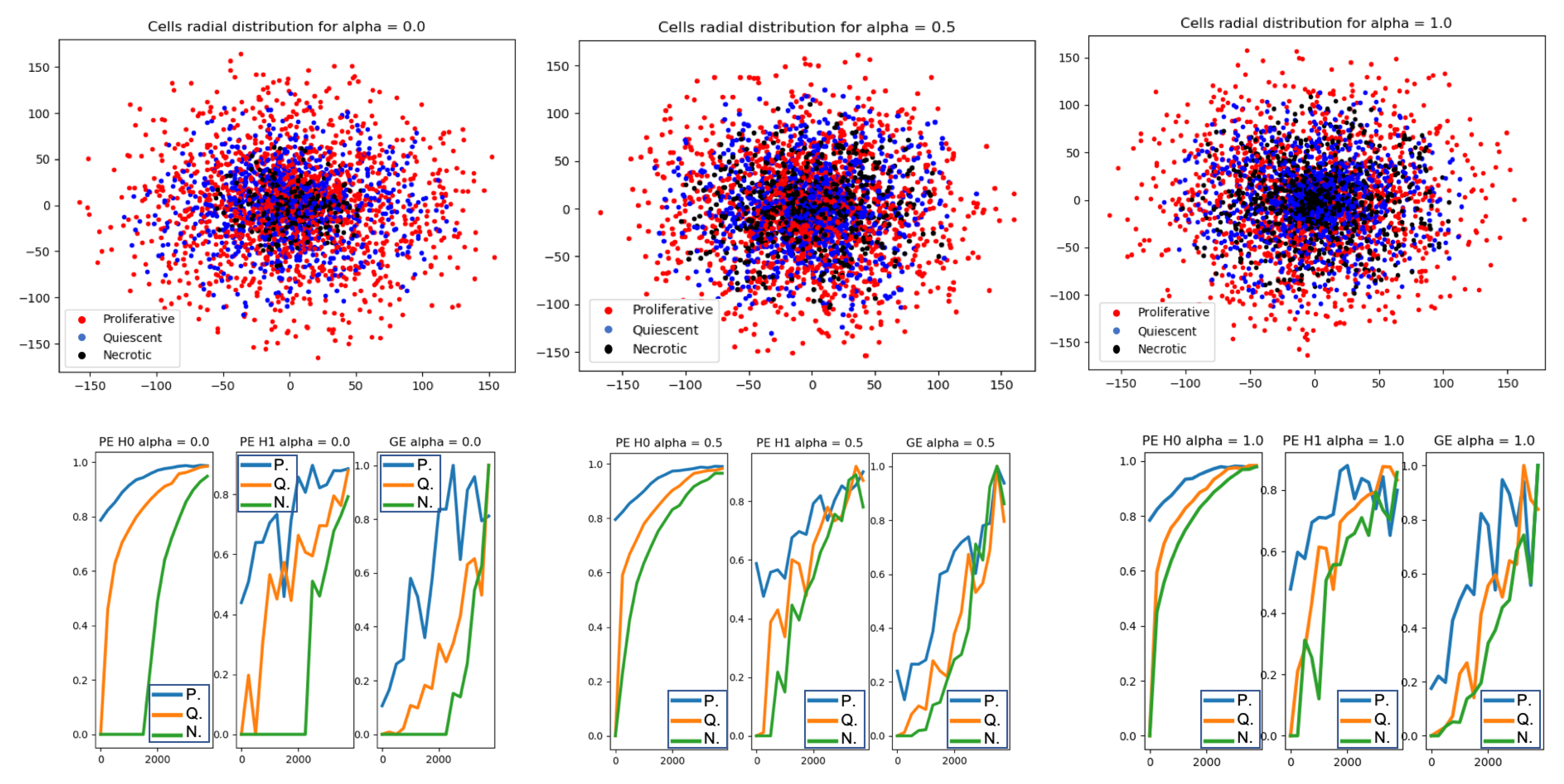
Analysis 1—Topological Data Analysis of a simplified 2D tumor Growth Mathematical Model: identification how tumor growth over time is affected by the initial amount of available chemical nutrient
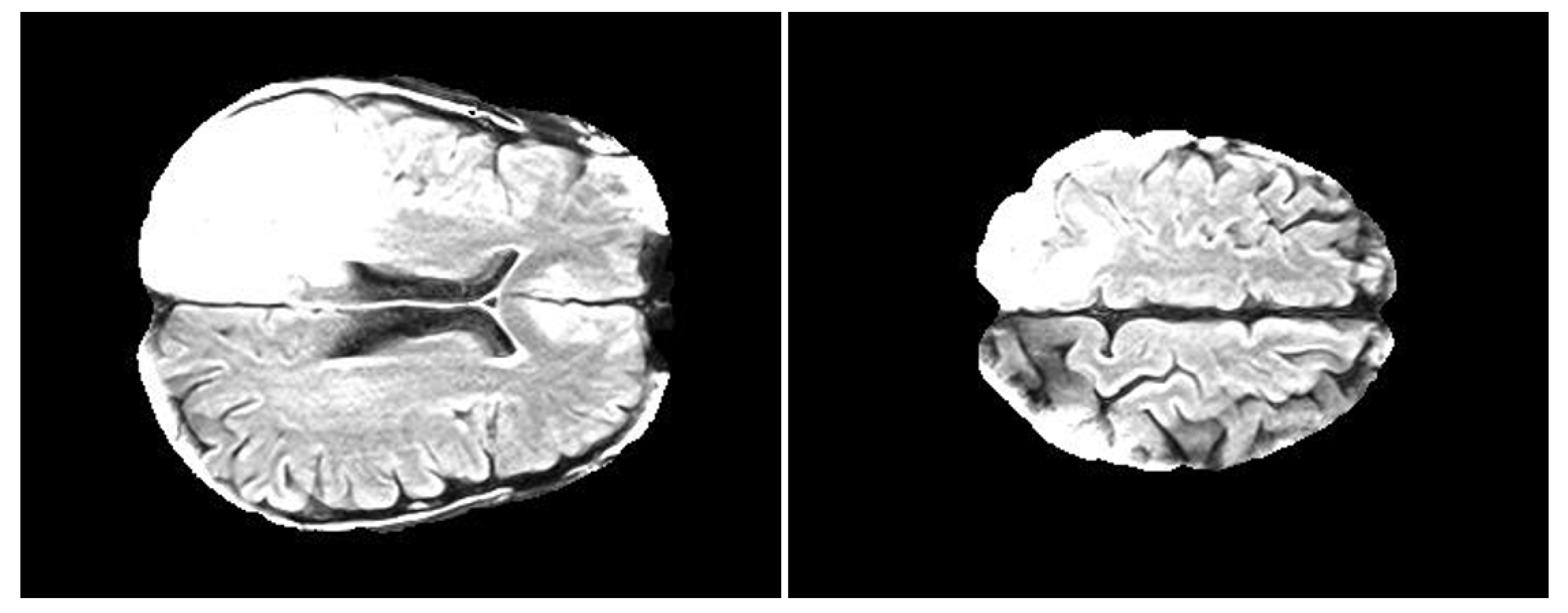
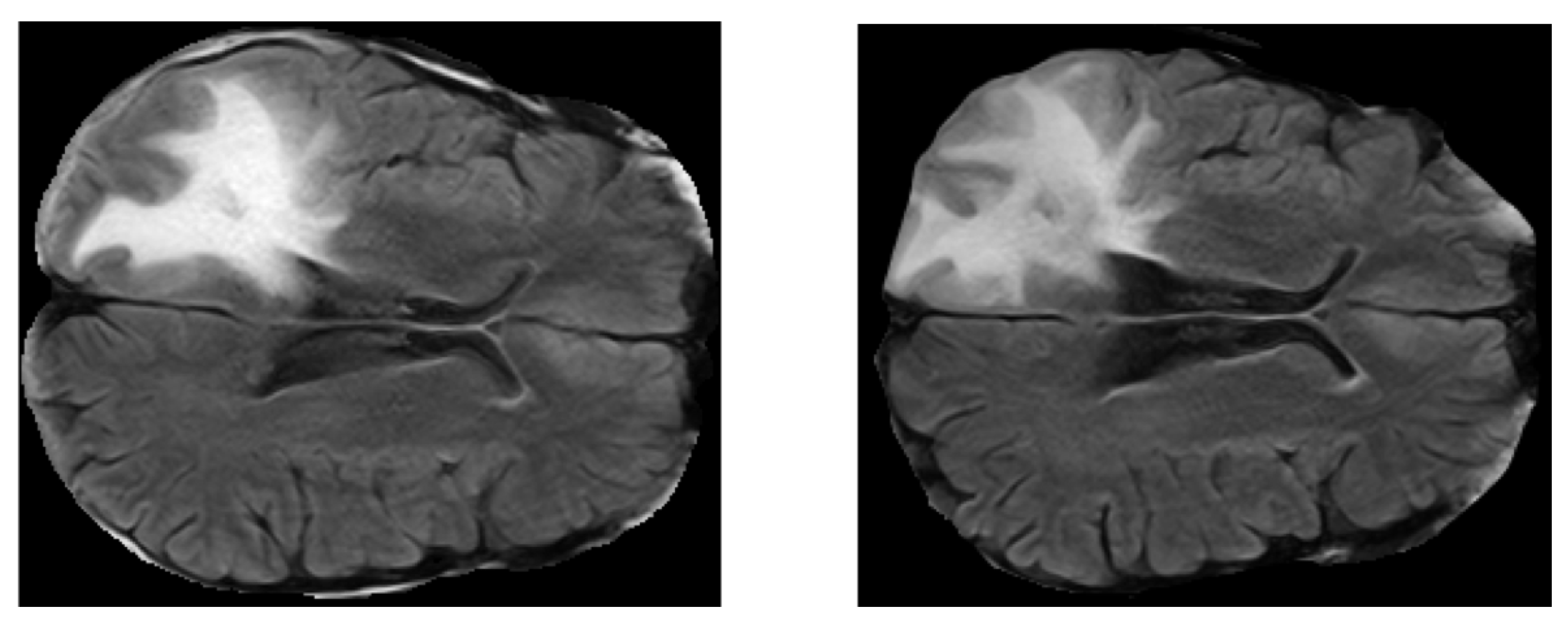
Analysis 2—Topological analysis of Glioblastoma temporal progression on FLAIR: evaluation of GBM temporal evolution after treatment
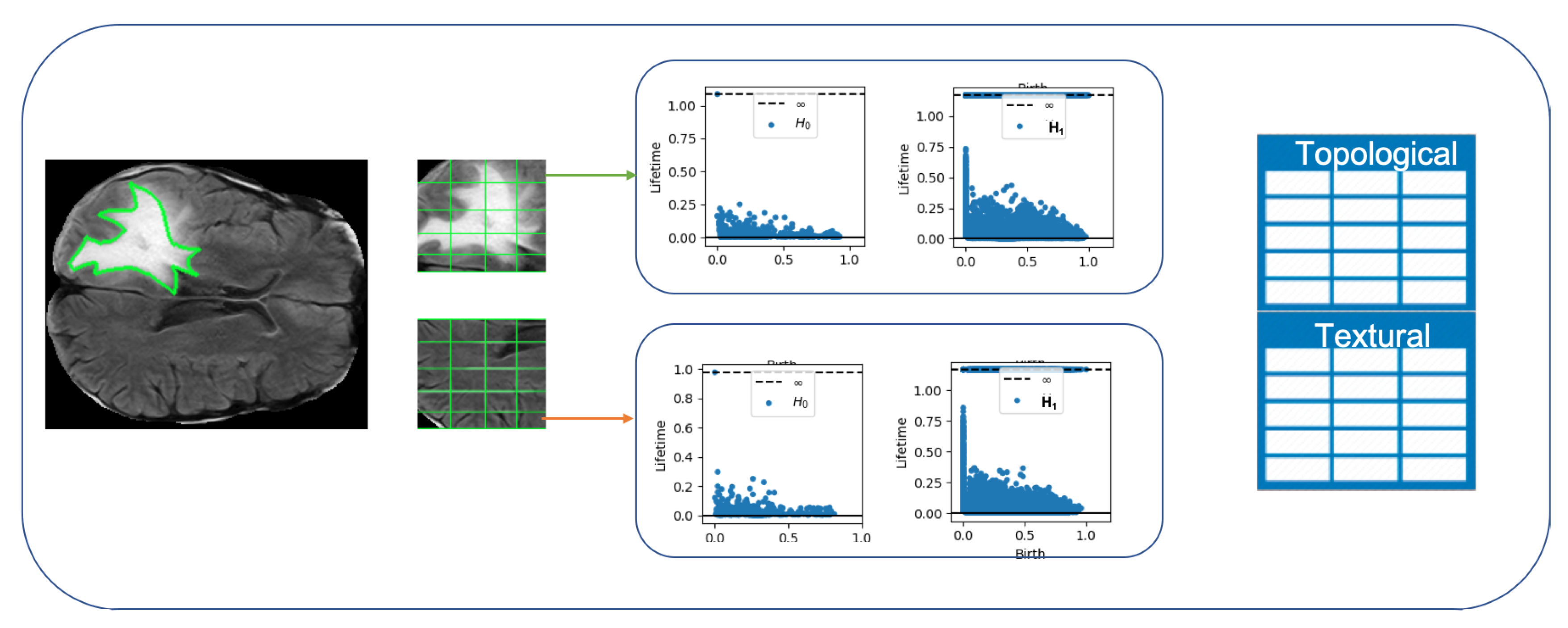
Analysis 3—Automatic GBM classification on FLAIR—the aims of this experiment is to evaluate the accuracy for classification GBM by characterization of 2D patches extracted from FLAIR by combining textural and topological data analysis with machine learning.
In the first experiment, we have integrated a discrete time mathematical model to study the evolution of three different types of tumor cells—proliferative, quiescent and necrosis. At each time step, we associated a point cloud data (PCD) to each cell set. The spatial evolution of the PCD is analysed by topological statistics, that is, persistent entropy. The plot of persistent entropy over time reveals interesting system evolution. The results encouraged us to analyse whether topological features can also detect GBM temporal evolution. To this extent, we have analysed a publicly available dataset that contains 2 sequences of FLAIR for 20 patients. The sequences were recorded within 90 days following chemo-radiation therapy (CRT) completion and at progression. The complete description of the dataset is in
Section 2. For the sake of details, we have decided to use FLAIR since they reveal a wide range of lesions, including cortical, periventricular, and meningeal diseases that were difficult to see on conventional images. In the third experiment we have used the same dataset but for evaluating the possibility of discriminating healthy and pathological tissue on FLAIR, by the use of Statistical Texture Analysis and Topological Data Analysis. The discriminating power of statistical texture and of topological features was then exploited for the development of a supervised tumor detection methodology by means of automatic machine learning algorithms. We have adopted novel computational tools for debugging and understanding Machine Learning decisions.
For the sake of completeness, we notice the reader of the algorithms that were used in this paper are agnostic with respect to the use case and they can also be enrolled for the analysis of big-data problems in several application domains. In Reference [
39], the authors have provided a survey of topological methods for the analysis of geometrical properties of big-data representing healthcare systems. We remark that topological data analysis can be executed both on point cloud data and on complex networks. Complex networks and possibly multi-layer networks are powerful tools for adding a structure to big-data [
40]. Among others, TDA can be used for the analysis of complex networks and for revealing information at the meso-scale (i.e., between micro and macro) [
41]. Machine learning represents the most used approach to model big data as described in References [
42,
43].
The paper is organized as follows—in
Section 2, we introduce both the model for tumor-growth analysis used in the first experiment and the data-set for the second and third experiment. Also, we report on the preprocessing steps of the FLAIRs in the data-set. In
Section 3, we recall the relevant background, namely the fundamental concepts of textural features and topological features. In
Section 4, we provide the details for the execution of the three numerical experiments. In
Section 5, we report on the the outcomes of the three experiments. Final thoughts about the results and next steps are discussed in the last
Section 6.
3. Background
3.1. Topological Data Analysis: Persistent Homology
Homology is an algebraic machinery used for describing a topological space . Informally, for a fixed natural number k, the Betti number counts the number of dimensional holes characterizing : is the number of connected components, counts the number of holes in 2D or tunnels in 3D (here nD refers to the dimensional space ), can be thought of as the number of voids in geometric solids, and so on.
Persistent homology is a method for computing the
dimensional holes at different spatial resolutions. Persistent holes are more likely to represent true features of the underlying space, rather than artifacts of sampling (noise), or due to particular choices of parameters. For a more formal description we refer the reader to Reference [
53]. In order to compute persistent homology, we need a distance function on the underlying space. This can be obtained constructing a filtration on a simplicial complex, which is a nested sequence of increasing subcomplexes. More formally, a filtered simplicial complex
K is a collection of subcomplexes
of
K such that
for
and there exists
such that
. The filtration time (or filter value) of a simplex
is the smallest
t such that
. A
dimensional Betti interval, with endpoints
corresponds to a
dimensional hole that appears at filtration time
and remains until time
. We refer to the holes that are still present at
as persistent topological features, otherwise they are considered topological noise [
54]. The set of intervals representing birth and death times of homology classes is called the
persistence barcode associated to the corresponding filtration. Instead of bars, we sometimes draw points in the plane such that a point
(with
) corresponds to a bar
in the barcode. This set of points is called a persistence diagram. There are several algorithms for computing persistent homology and their analysis and for a complete overview of the available tools we refer to Reference [
55].
3.2. Topological Features for Radiomics
In order to use persistent barcodes in any computer applications (e.g., machine learning), a set of numerical descriptors need to be derived, which encapsulate the information contained in the barcode. In the following we recall how to compute the statistics we use in this research. Two or more topological objects, for example, simplicial complexes, are homologically equivalent if they have the same sequence of Betti numbers. In other words by using persistent homology, they are characterized by the same number of persistent homological holes at each dimension. To facilitate the comparison of two or more simplicial complexes, one can calculate and compare the Euler Characteristics for each simplicial complex:
Definition 1 (Euler Characteristic).
where is the Betti numbers at the i-th homological group (e.g., is the Betti number at for counting the number of connected components, for counting the number of 2D holes, for counting the number of 3D empty volumes etc…). Since Euler Characteristics are computed on the persistent homological holes and it discards completely the noisy topological features (i.e., not persistent) we suggest that to complement it, the so-called Persistent Entropy should also be computed. Persistent Entropy is a Shannon like entropy computed over the persistent barcodes and it is calculated by using both noisy and persistent topological features. It was defined initially in Reference [
56] and further studies of its mathematical properties were published in References [
57,
58]. We recall its definition.
Definition 2 (Persistent Entropy).
Given a persistence barcode , the Persistent Entropy (PE) H of the filtered simplicial complex is defined as follows:where , , and . In the case of an interval with no death time, , we truncate infinite intervals and replace by in the persistence barcode, where .
Note that the maximum PE corresponds to the situation in which all the intervals in the barcode are of equal length. In that case,
if
n is the number of elements of
I. Conversely, the value of the PE decreases as more intervals of different length are present. A topological
n-dimensional hole is generated by the so-called homological generator [
59,
60]. For example, a 1D hole is generated by a set of 0-simplices (vertices) linked by 1-simplices (edges). Given our interest to
nD topological holes, we propose a new seminal statistics that is computed on the number of 0D simplices (vertices) in each topological feature.
Definition 3 (Generator Entropy).
Given a filtered simplicial complex , and the collection of corresponding persistence barcode for the Homological Groups with .where N is the total number of homological lines in the barcode, is the number of 0-simplices in the i-th line and and . For the sake of preciseness, in a topological loop there exist a 0-simplices that appears twice. In this setting we count each 0-simplices only once. We envision that generator entropy as defined in Equation (
3) could be used as a measure of the number of different objects of interests (e.g., tumors) surrounded by topological loops of in general different length.
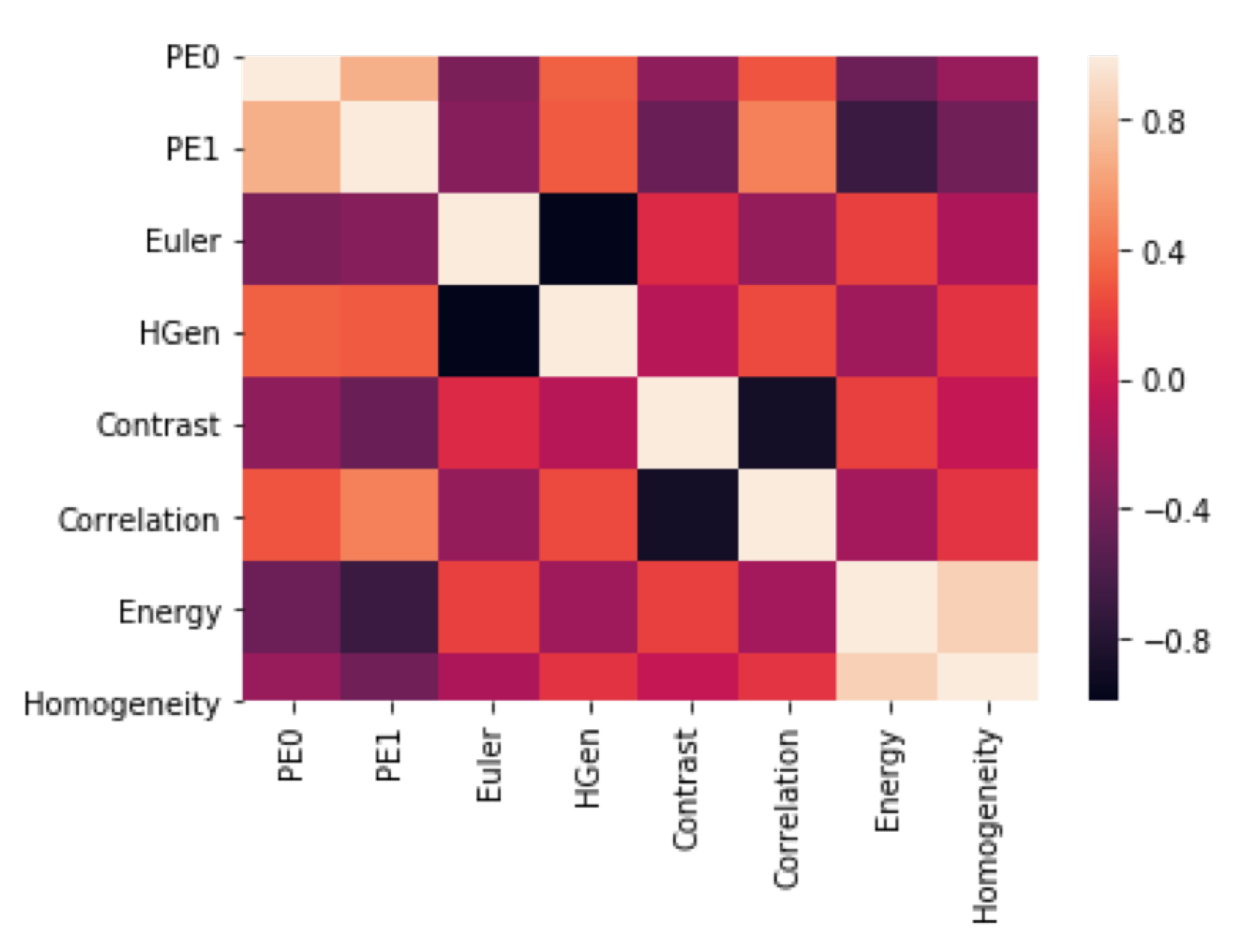
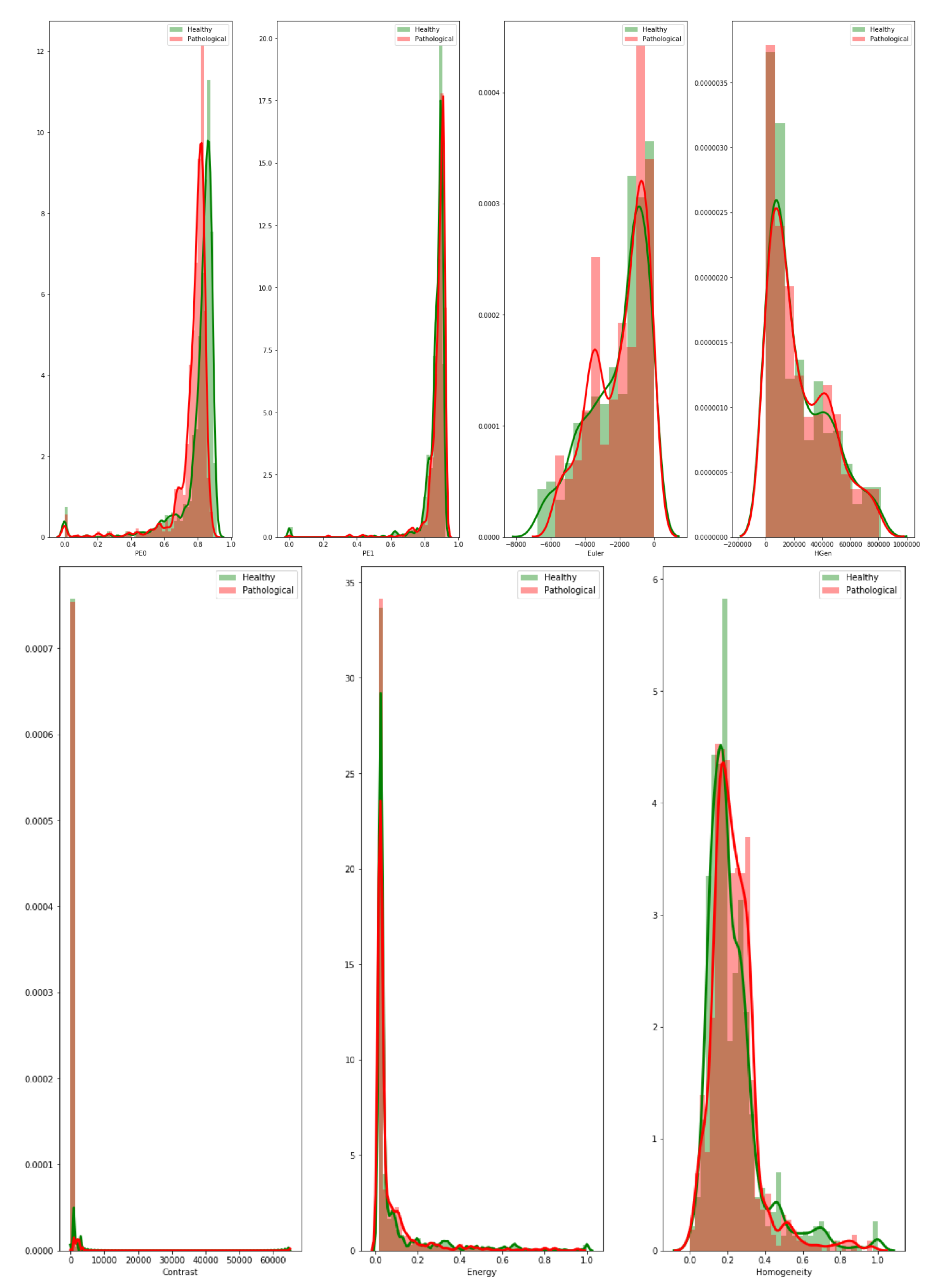
3.3. Textural Features: Grey-Level Co-Occurrence Matrix
In this study, we used one selected feature set (grey-Level Co-occurrence matrix (GLCM)) for the texture analysis in accordance with some previous reports of radiomics for GBM detection [
61]. GLCM is a statistical method for examining image texture by taking into account the spatial relationship of pixels. The GLCM counts how often pairs of pixels with specific values and in a specified spatial relationship occur in an image. From GLCM we have extracted the following textural information [
62]:
Contrast—it measures the local variability in the grey level.
Correlation—it measures the joint probability that a given pair of pixels is found.
Homogeneity—it measures the distance between the GCLM diagonal and element distribution.
Energy
In this paper, we have used the open-source software Ripser [
63] (
https://ripser.scikit-tda.org/) for TDA. Ripser allows us to compute the persistent homology of both point cloud data and 2D images. For the computation of persistent homology we have used a slightly modified version of the lower star filtration (
https://ripser.scikit-tda.org/notebooks/LowerStarImageFiltrations.html). In our version, the algorithm computes the homology up to the first homological group and it returns for each topological loop a set of representative generators. While for GLCM computation we have used Scikit-Image [
64].
3.4. Evaluation Metrics
We have evaluated the performances of the supervised machine learning and deep learning algorithms for patches classifications by different metrics:
AUC is the area under the receiver operating characteristics curve (ROC). The ROC is obtained by plotting of the true positive rate (
) against the false positive rate (
) at various threshold settings [
65].
where, refers to the true positives in the classification, to the true negatives, to the false positives and to the false negatives. A model with extremely poor performances has AUC near to 0, while a model with excellent performances has AUC near to 1. In the middle, when AUC is 0.5, it means the model has no class separation capacity whatsoever.
3.5. Computational Complexity
Vietoris-rips complexes are used in all three experiments. Building a Vietoris-Rips simplicial complex can be at worst exponential in the number of vertices, as the complete simplicial complex on
n vertices has
simplices. This indicates that one must limit the size of a Vietoris-Rips simplicial complex construction. There have been a few recent efforts aiming to optimize the complexity of persistent homology computation and/or to provide implementations that are suitable for GPU [
66,
67]. An interesting solution for taming computational complexity is proposed in Reference [
68]. The authors designed an algorithm with a computational complexity of
. It will be worth investigating this solution for the deployment of a run-time implementation of the framework proposed in this paper. The computational complexity of persistent entropy and of generator entropy is proportional to
, where
n is the number of lines in the persistent barcodes. For the sake of completeness, the basic version of the algorithms for their computation would be based on two main loops over the lines in the barcode: 1) the first iteration is needed for computing the total length of the lines (or the total number of unique generators); 2) the second iteration is needed for computing the ratio of the single line with respect to the total length and for accumulating the product of line length times the ratio. The computational complexity of GLCM features, we remark that it depends on the number of gray levels
G and is proportional to
[
69]. The computational complexity of a Machine Learning algorithm depends on the algorithm itself, the number of parameters and the unique samples in the input space. Also, the computational complexity of the training procedure is in general different with respect to the testing [
70].
6. Discussion
Topological data analysis is a reliable approach to shedding light on GBM characteristics, as has been demonstrated by the three numerical experiments described in this paper. For the sake of precision, the main limitation of our work is due to that persistent homology can be computed only over one proximity parameter at a time and thus it does not allow us to study how the topology of the simplicial complexes changes along two or multiple directions. This limitation should be taken into account if one intends to use persistent homology for dealing with 3D tumor analysis. In general a tumor does not follow a
isotropic distribution but instead it shows a different growing rate along the axis. Fast and reliable assessment of GBM presence is critical for an accurate surgical and radiotherapy planning as well as to evaluate and quantify treatment-related effects and progression In the recent period, surgical approaches are strongly changed, with a progressive shift from classical neurosurgical techniques towards newer approaches with surgical navigation systems fluorescence-guided and MR-guided surgery [
2,
3,
77]. Also, chemotherapy employed techniques with wafer drugs positioning in situ to minimize systemic collateral effects [
78]. Consequently, radiological techniques able to localize and evidence every minimum GBM localization are essential to enforce new therapeutic possibilities that can improve the extent of tumor resection, prolong survival and increase the quality of life.
We note that the three single experiments should be seen as seminal efforts for making possible the paradigm of a personalized characterization and diagnosis of GBM. To the best of our knowledge, this paper presents for the first time the application of topological data analysis for the analysis of tumor growth model and for quantifying the temporal evolution of GBM from FLAIR and this makes a direct comparison with other works difficult. The same paradigm but with a different approach was presented in Reference [
79]. In Reference [
79], the authors proposed a very interesting framework obtained by combining a 3D continuous mechanical model, able to simulate the growth of a glioblastoma and the invasion of the surrounding tissue. The model produces high fidelity results since it it takes into account both the heterogeneity and the anisotropy of the brain tissues directly from DTI data. In our work, topological descriptors such as Euler Characteristics, Persistent Entropy and Generator Entropy were used to identify the physiological conditions that facilitate tumor growth. We notice that Generator entropy was introduced in this paper as a novel topological statistic that summarizes the number of homological generators of
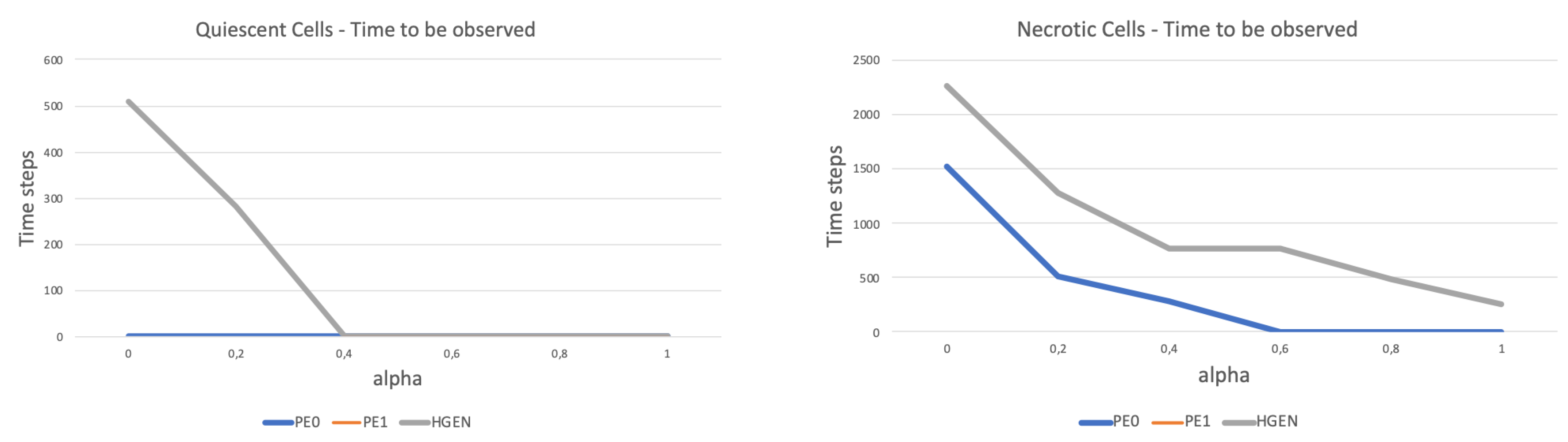
homological loops. In particular, topological statistics were able to identify the change of proliferation rate of quiescent and necrotic cells as a consequence of nutrient concentration—the higher the concentration of chemical nutrients the more virulent the process. We would promote our approach as a data-driven solution rather than a model-driven solution, in real life applications, the simple model that we have used for generating cells distribution should be substitute with observations, that is, cells counting. In our opinion, the application of TDA to dynamical systems representing GBM tumor growth in the brain would let interesting results. Specifically, besides detecting the bio-chemical conditions, TDA should identify topological constraints (e.g., anatomical characteristics) that provide a personalized characterization of the tumor.
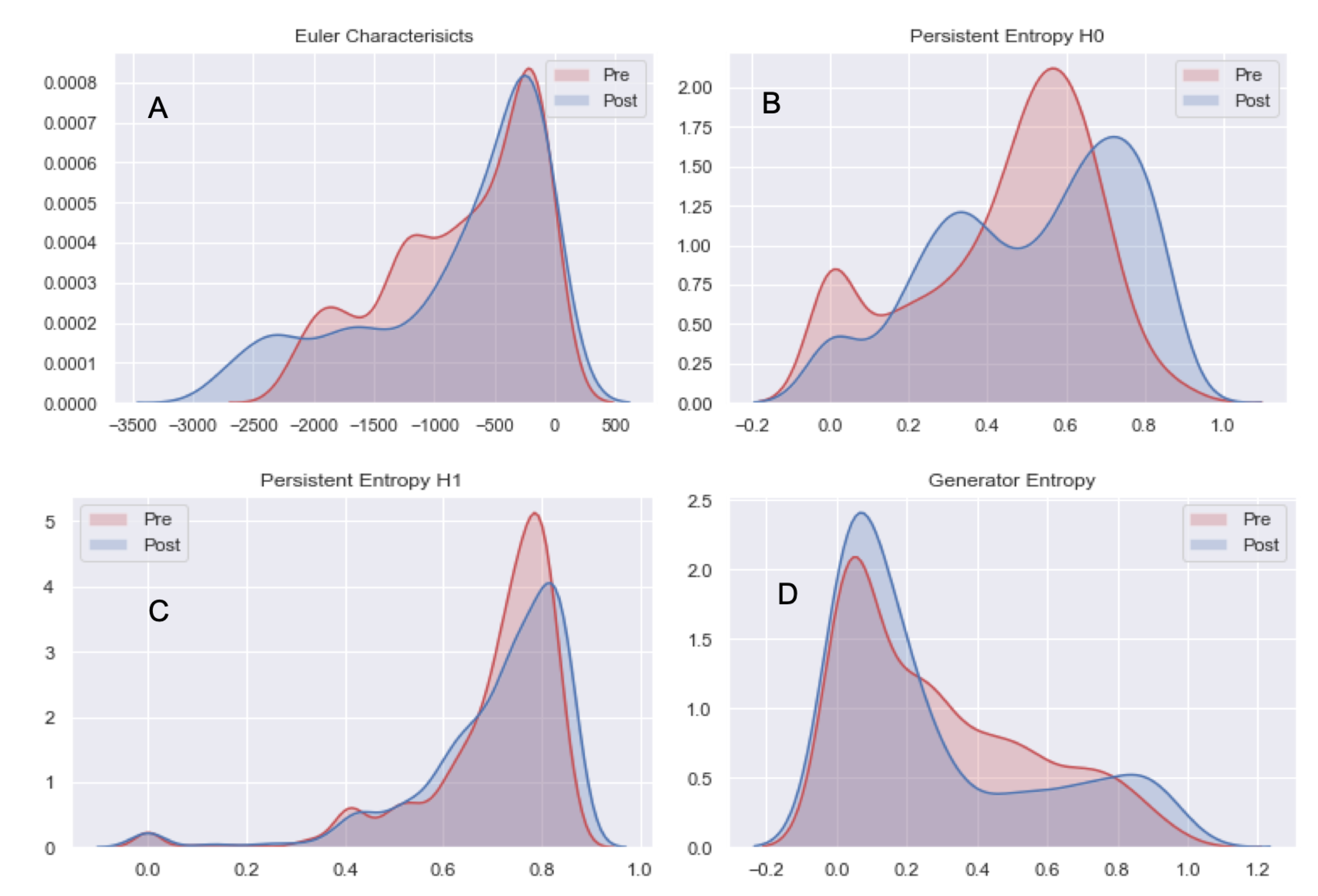
In the other two experiments, we demonstrated by using a publicly available dataset that topological features can be used as new radiomics features for GBM characterization. The analysis of FLAIR sequences recorded within 90 days following chemo-radiation therapy (CRT) completion and at progression by means of topological descriptors has confirmed by statistical test that persistent entropy computed at the homological group H0 of the connected component is a viable alternative for monitoring treatment effects. In Reference [
80], the authors demonstrated that textural features combined with machine learning are a viable approach for the analysis of GBM follow-up progressive and responsive forms. We believe that TDA should be used for complementing this approach for the analysis of GBM during the follow-up period since TDA will reflect geometrical properties that otherwise would not be observed. In Reference [
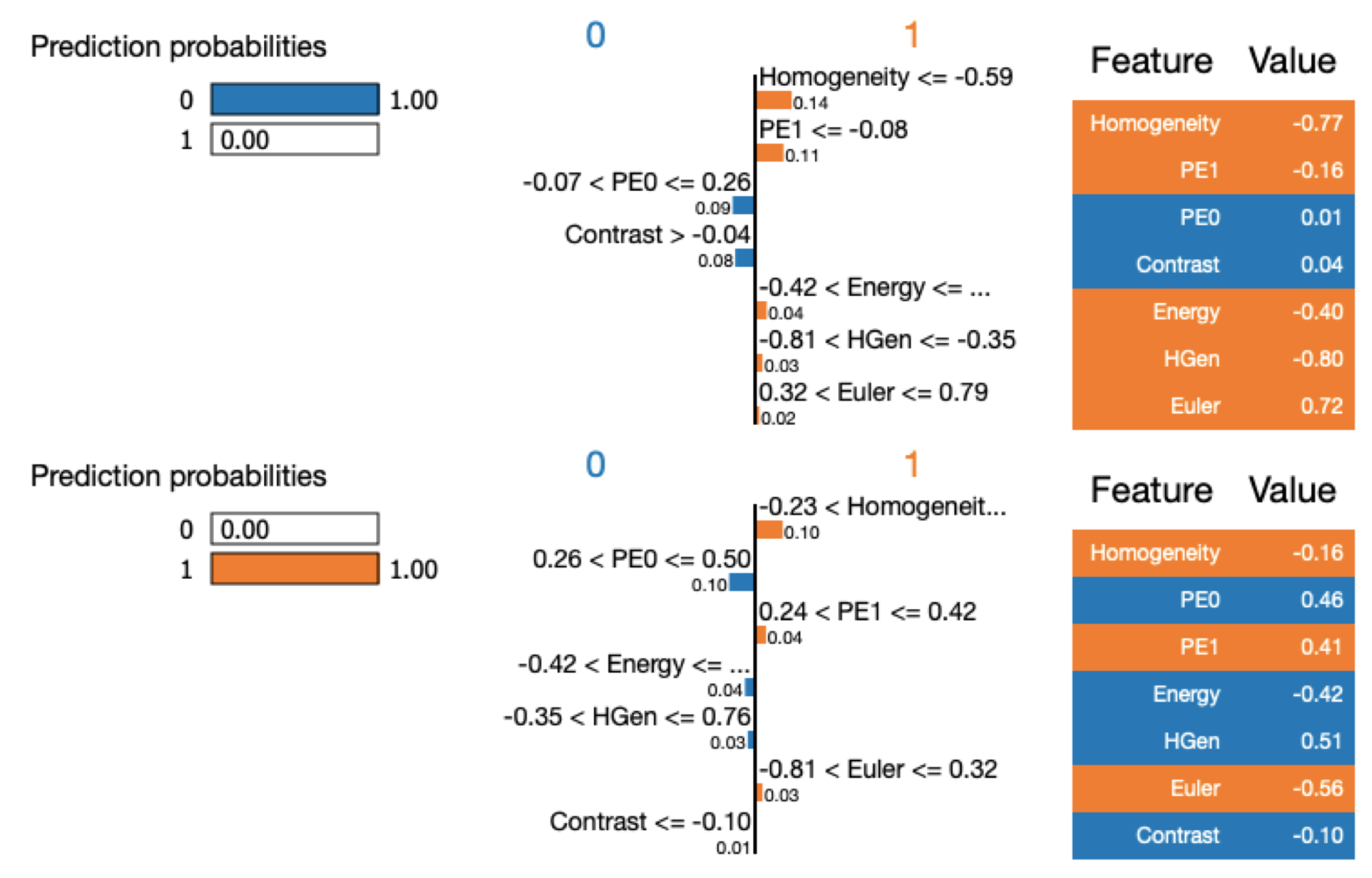
38], the authors defined a new topological statistics for predicting the survival of GBM patients while we focused on the classification of patches from FLAIR and/or to evaluate the evolution of GBM within a follow-up period. Among the open questions, they posed the challenge “how to combine topological features with machine learning?” We have shown a possible solution by extracting the sliding patches and by computing TDA on them that became a subset of the input features for the machine learning algorithm.
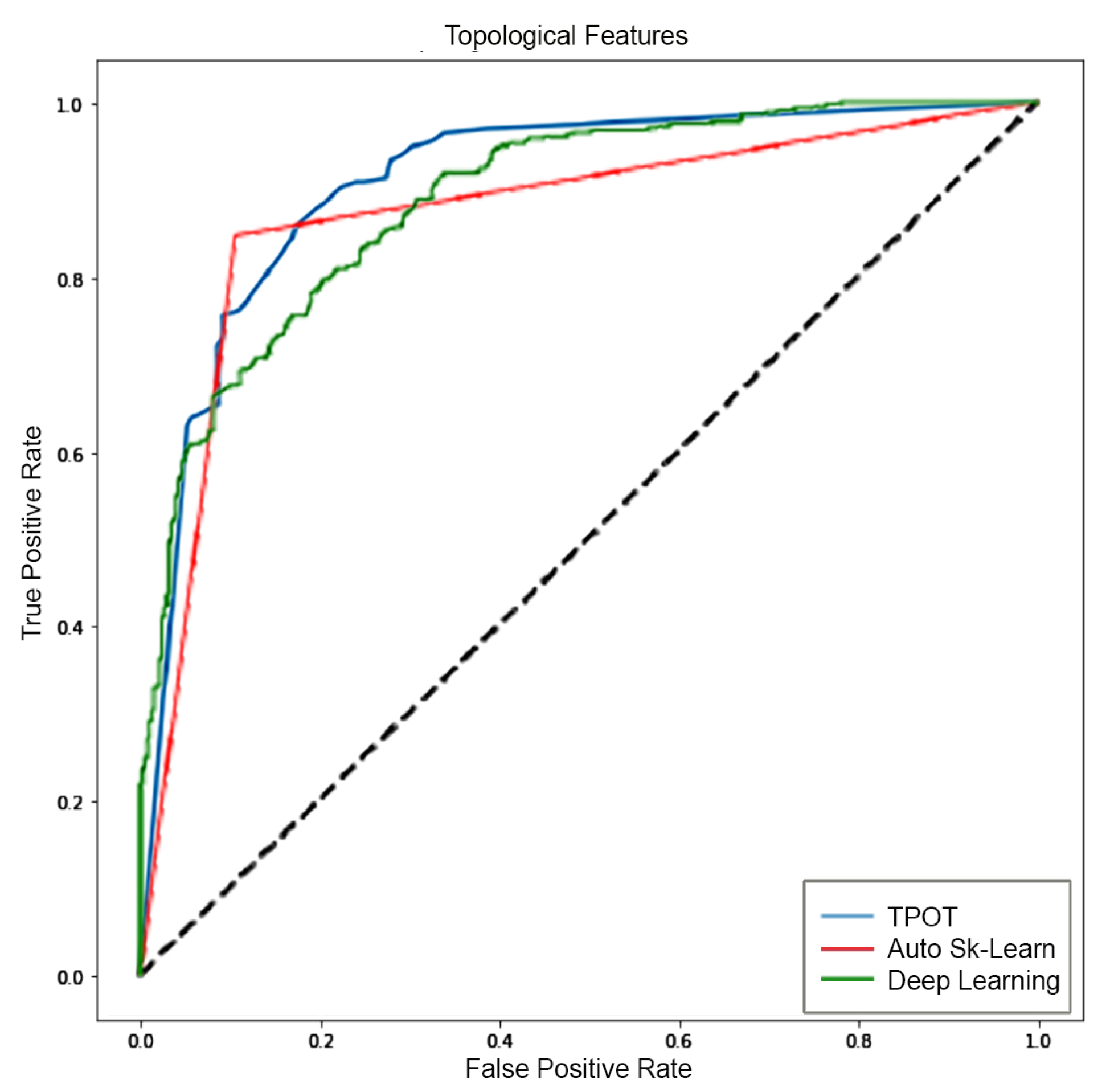
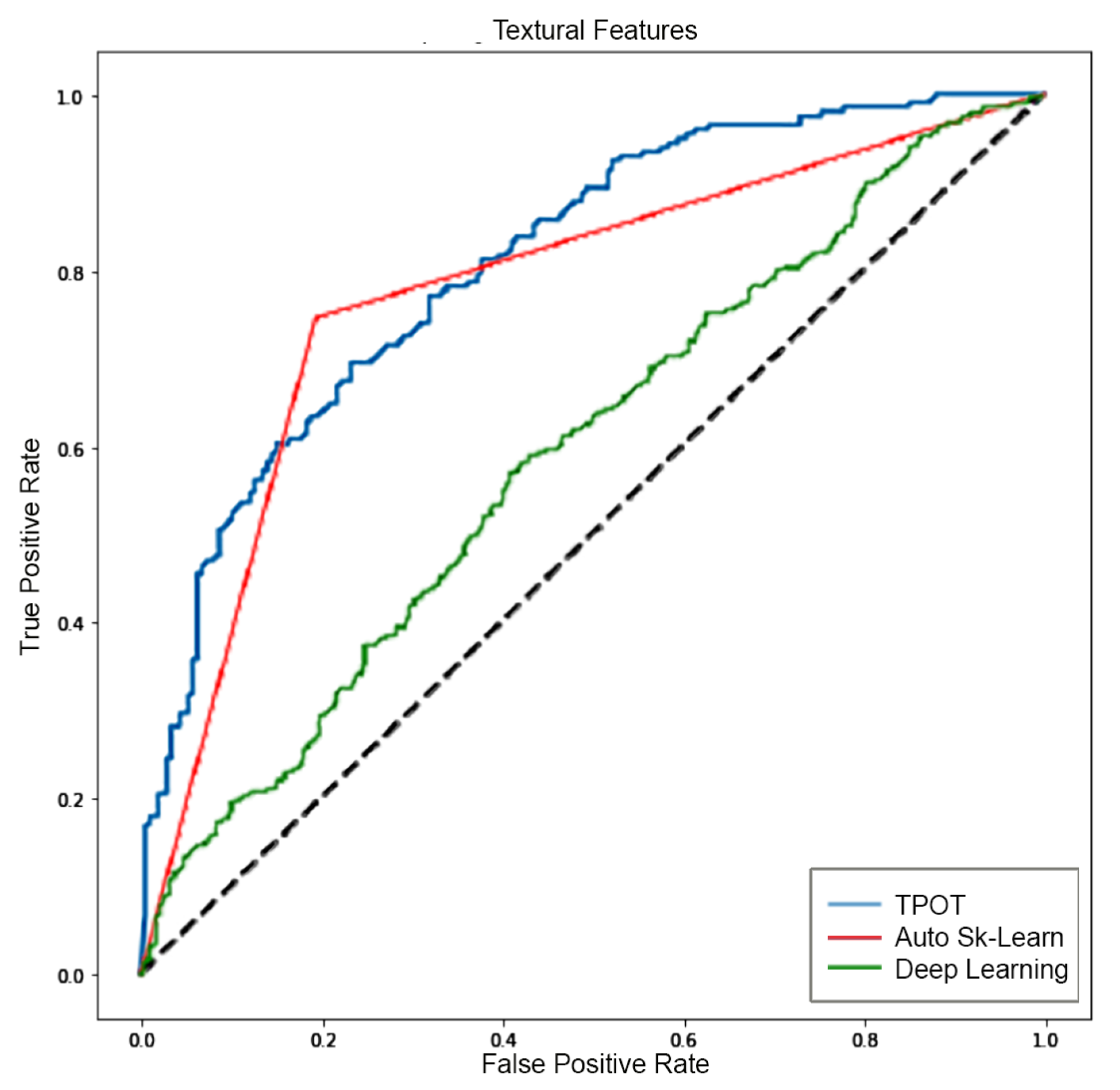
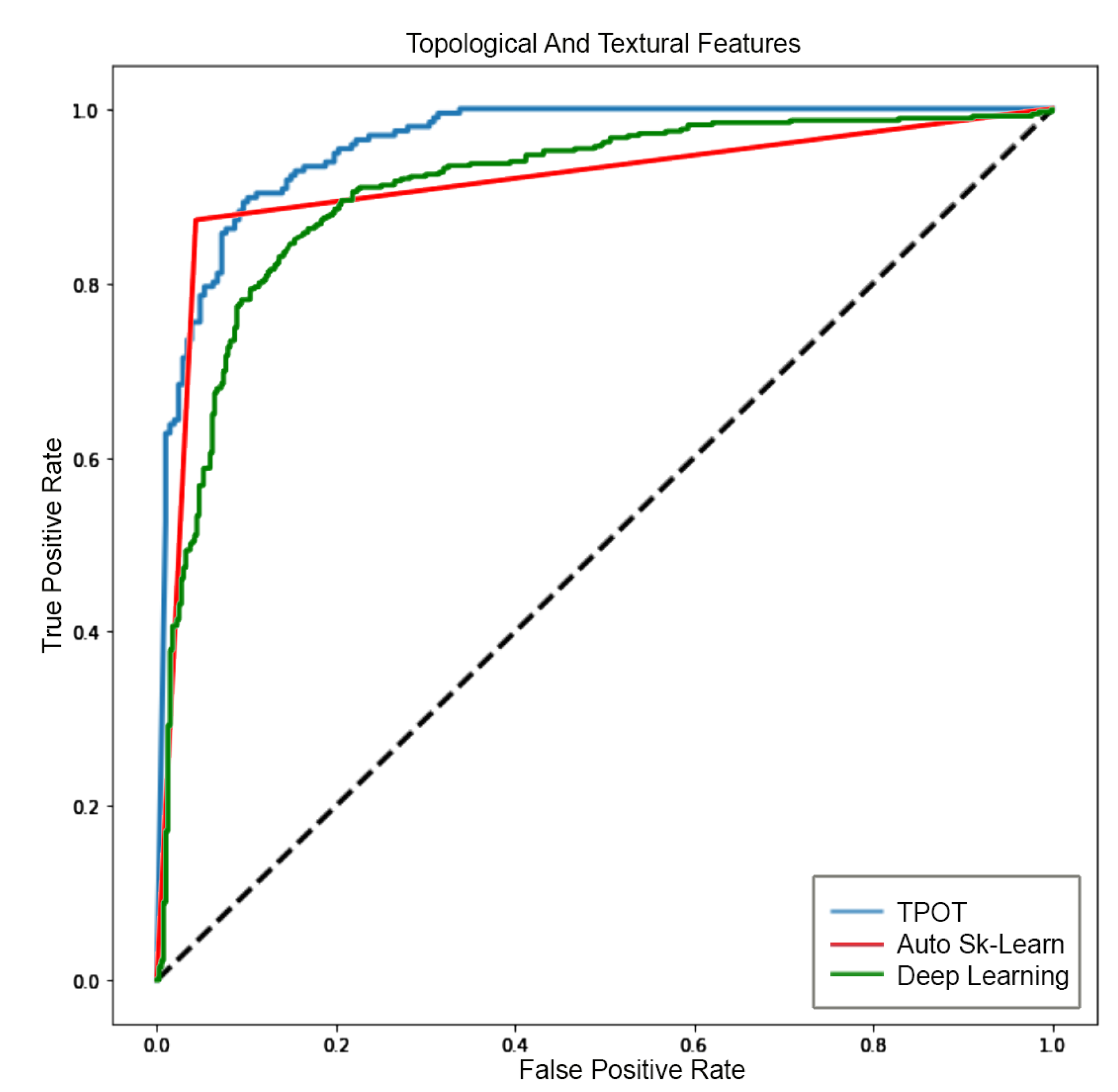
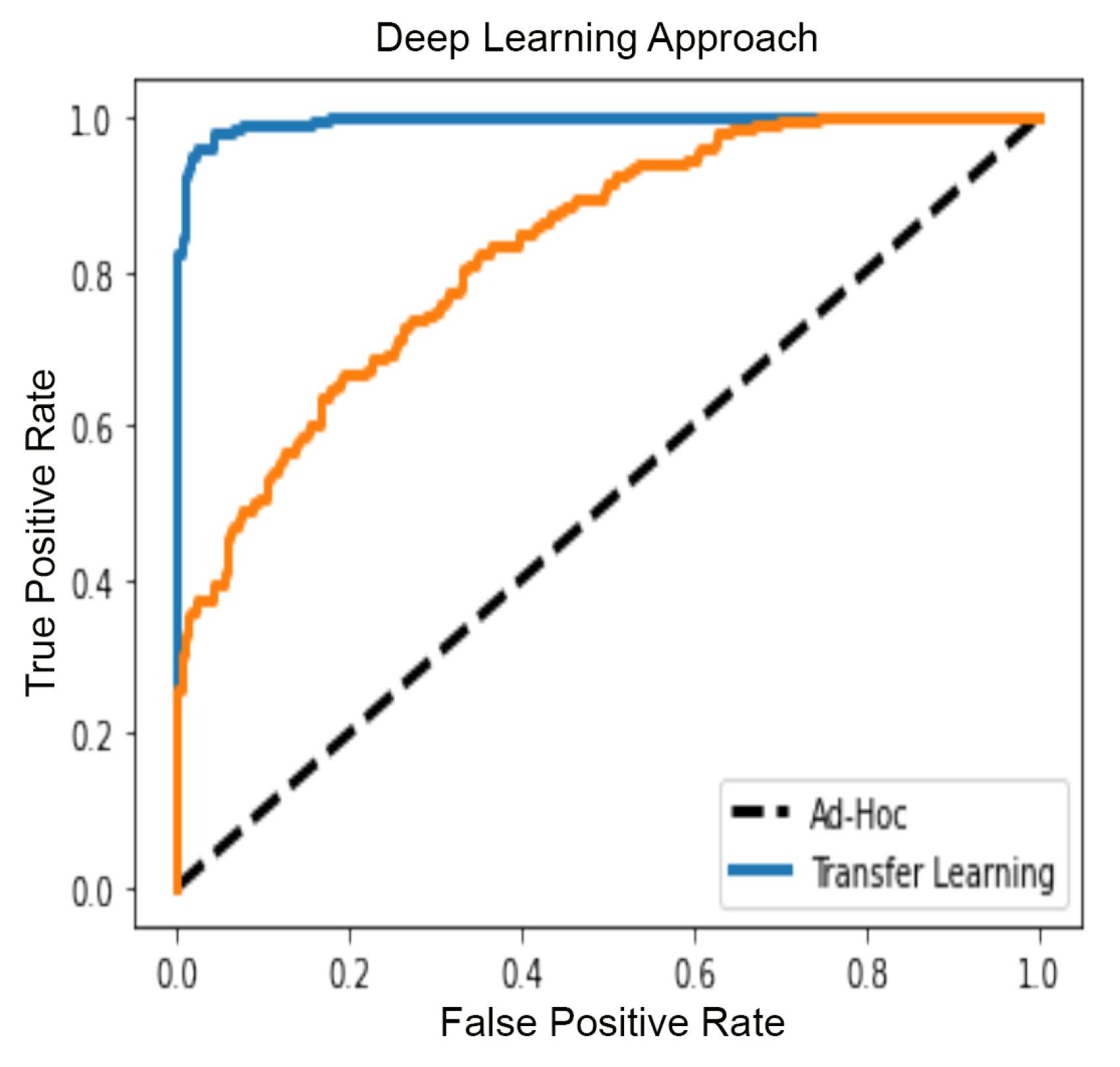
Based on these results, we proposed a new method for GBM analysis. The supervised method for automatic classification of 2D patches extracted from FLAIR sequences is a viable alternative for GBM identification. The proposed method comprises the following main stages—image preprocessing, sliding patches extraction, topological and textural features computation and selection, supervised classification via automatic machine learning, interpretation of classifier prediction. Preprocessing steps, that is, skull stripping, were obtained by employing the latest deep learning technology. Several supervised classification algorithms were evaluated to ensure the highest classification accuracy. To this extent, two different automatic machine learning selection frameworks were evaluated, which are TPOT and Auto-SkLearn. Python notebooks will be made available upon request to the authors. The algorithms were trained using topological features or textural features or the combination of the two sets. The selected machine learning approaches were used as a baseline in the comparison with deep learning based approaches. For the sake of completeness, deep learning approaches were trained on the same features set or directly on the patches (sub-images) extracted from the 2D FLAIR. The quality of classification was assessed by several metrics and ROC curves. The highest accuracy using the features was reached by TPOT trained on the two sets (e.g., topological and textural) with an accuracy of
and
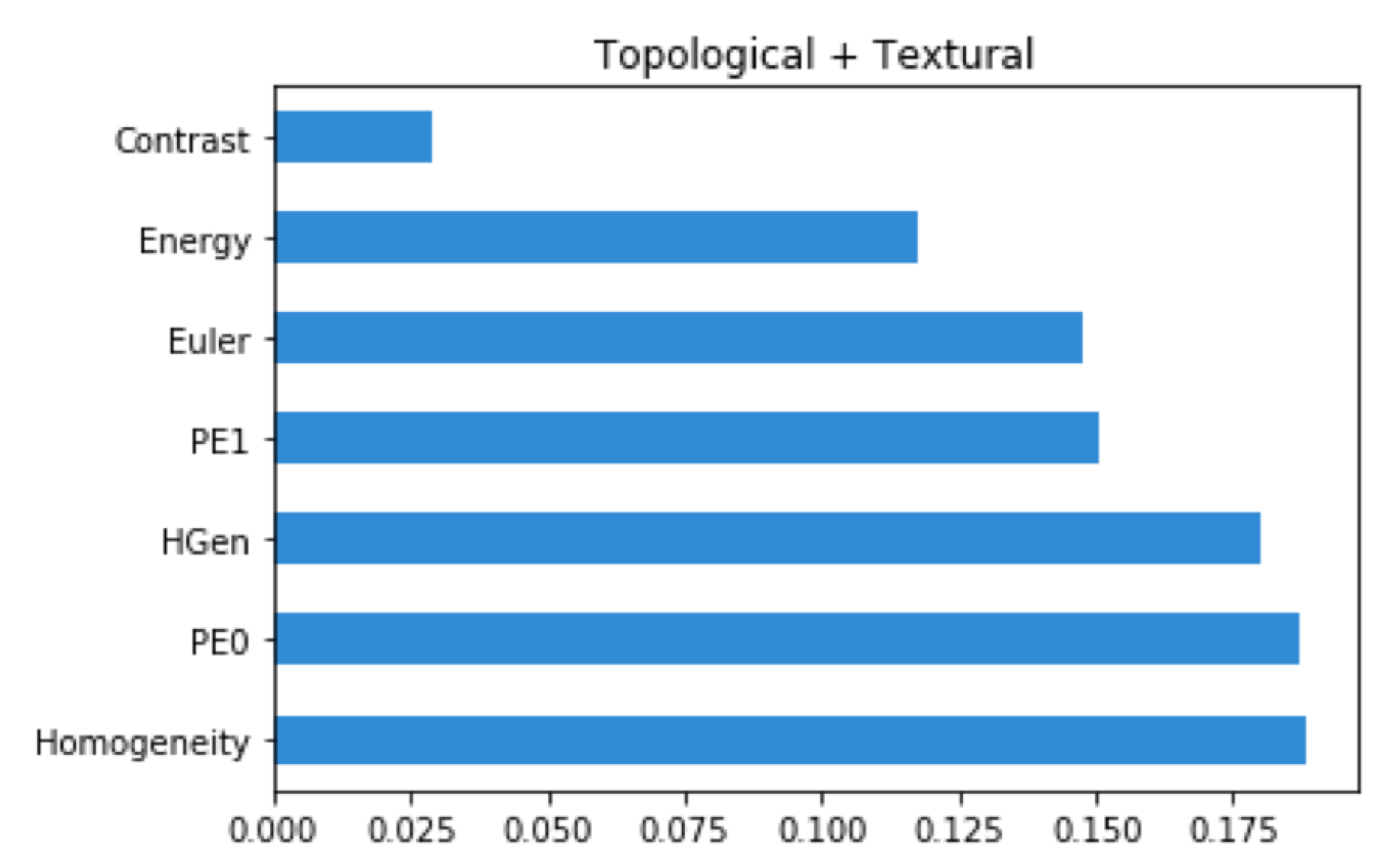
. Finally, the trained systems were investigated with tools from information theory. Skater and Lime algorithms allowed computing features relevance and for understanding what are the numerical characteristics of a patch to be classified ill or healthy. The interpretation has confirmed the importance of topological features. The transfer learning of a pre-trained VGG16 network that allowed for patches classification had allowed us to reach an accuracy of
and
. However, we would like to remark that in general, Deep Learning based methods require ad-hoc hardware for their training, in fact we have used the Google Colab platform that allows access to both GPU and TPU units. The adoption of a deep learning solution would be straightforward, but we note that machine learning classification verdicts can be easily interpreted by enrolling tools like Skater and Lime, while the interpretation of the feature space extracted by a deep learning solution might be unfeasible, since the convolutional features might not correspond to any physical information. Even if we have reached good classification accuracy, our approach does not take into account anatomical context. We encourage the reader to consider deep Learning solutions for GBM classification and segmentations. These algorithms can be trained directly on the
volume. Among the solutions, it is worth considering the results presented in Reference [
81] in which the authors have trained a U-net network on images from BRATS 2018 and they have demonstrated that the same network can be used for the identification of the whole tumor, the enhancing tumor and the tumor core with great accuracy—
respectively, while the method proposed in this paper is specialized on the detection of the whole tumor. For an extensive and complete review of deep learning techniques for GBM imaging we suggest Reference [
82].
Despite the results presented in this paper, several interesting future directions and open issues still remain. We intend to decorate persistent homology with some notion of anatomical context and we also intend to study mathematical properties (minimum set of generators, stability theorem, etc…) of generator entropy [
60]. To tackle the problem of model generalization we intend to extend the cohort, for example by including FLAIR from other datasets (e.g., BRATS). If we succeed on computing anatomical informed 3D topological data analysis as feature for machine learning classification then we should compare the new results with the U-Net deep learning algorithm [
83]. Final technology down-selection will also take into account the possibility to equip it with tools for outcome interpretation. Our long-term goal will be to develop a novel personalized Computer-Aided Detection software tool for GBM detection and characterization compliant with the EU-GDPR 22nd article (“Automated individual decision-making, including profiling”) for the “right to be informed” (
http://www.privacy-regulation.eu/it/22.htm).






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}