

Feature-Alignment-Based Cross-Platform Question Answering Expert Recommendation
Abstract
:1. Introduction
- From the perspective of the questioner: It is the urgent demand of the questioner to get high-quality answers quickly, but it is very time-consuming to select competent and reliable experts from a large number of users;
- From the perspective of the answerer: It often takes lots of time and effort to find the questions that they are interested in and capable of answering, which affects the user’s experience and motivation;
- From the perspective of the platform: It is very difficult to balance the needs of both questioners and answerers.
- A cross-platform expert recommendation model is proposed to improve recommendation performance in new CQA by transferring rich information from the source domain to the target domain, which solves the data sparsity problem of new CQA and effectively improves recommendation performance in the target domain;
- A feature dimension alignment algorithm based on an SDAE is proposed to solve the problem that the similarity cannot be calculated due to inconsistent feature dimensions and data distributions in two domains;
- Adequate experiments are conducted on two real datasets, and the results show that FA-CPQAER significantly outperforms existing expert recommendation algorithms.
2. Related Work
2.1. Cross-Domain Recommendation
2.2. Expert Recommendation
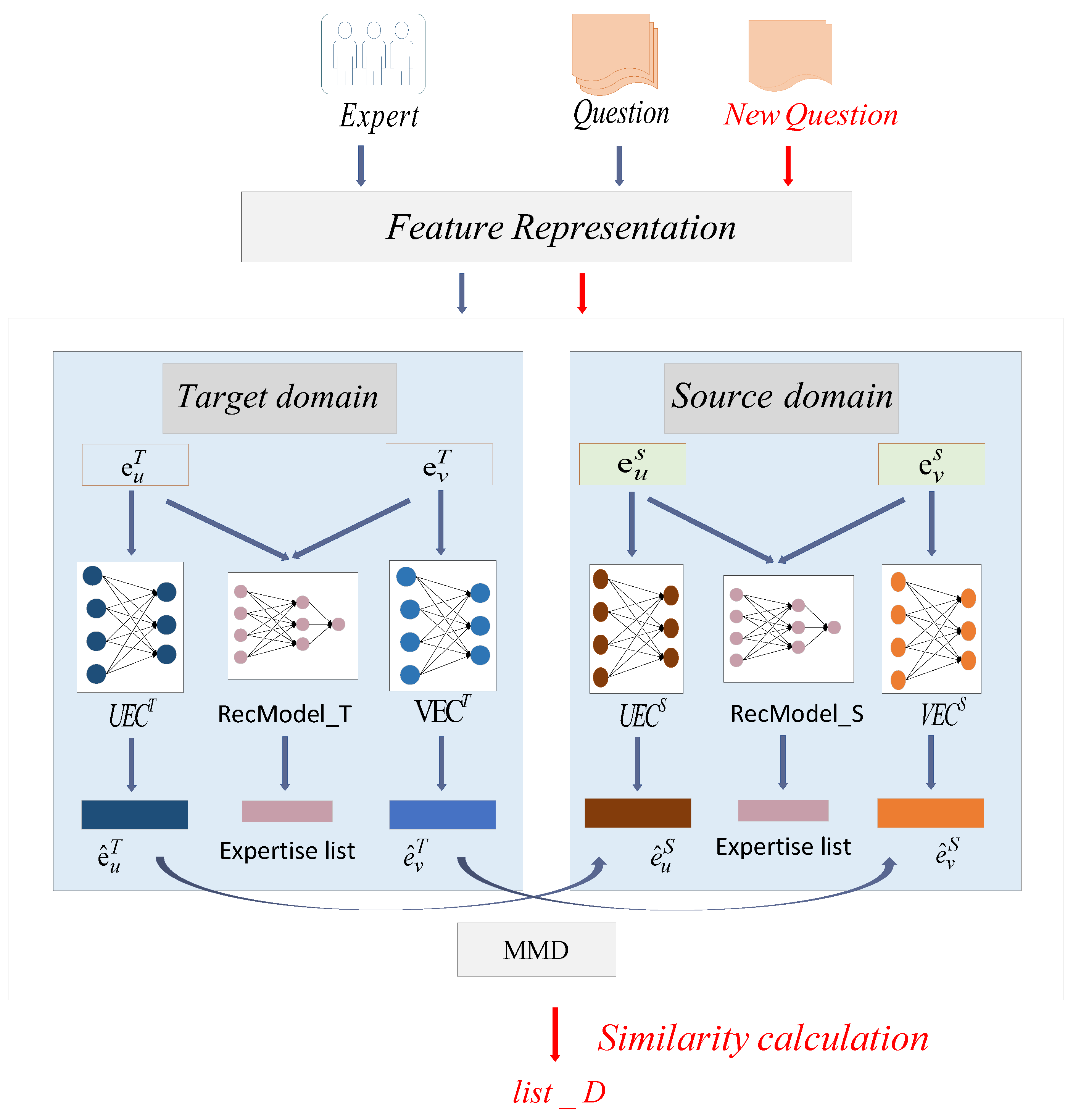
3. The Proposed Algorithm
3.1. Problem Definition
3.2. Question and Expert Feature Representation
- Text features: For text features such as the title and the description of questions and users, such information is a piece of textual description information. The title and question description usually represent the subject area and semantic scope to which the question belongs, and the user description contains the expert’s expertise reflecting the expert’s competency. In order to better represent these textual features, they are transformed into digital vector representations. Taking the problem text feature as an example, we first synthesize the title and question description into a text and then use the doc2vec [28] model to obtain a vector representation of the question text.
- Categorical features: Categorical features (topics, interest labels) are taken from the labels provided in the platform. We convert them into discrete vectors using one-hot coding. Taking interest labels as an example, each label represents a feature, e.g., if the total number of labels is 150 and the interest label owned by the expert is A, it is represented as [1, 0, …, 0]; if the labels owned by the expert are B and C, the vectorization is represented as [0, 1, 1, 0, …, 0].
- Numeric features: It is necessary when the features of datasets have different ranges of values among them. To eliminate the effect of different magnitudes, the numerical features are normalized and mapped to [0, 1] with the following formula:where min is the minimum value of the numeric feature, and max is the maximum value.
- Meanwhile, the number of collections received by the expert answering the question is used as the rating in the source domain, and the number of likes is used as the rating in the target domain. Normalization is performed using the following formula:where is the maximum value of the score, is the minimum value, and is the mean value. The rating matrices for the target and source domains are obtained after processing as and , respectively.
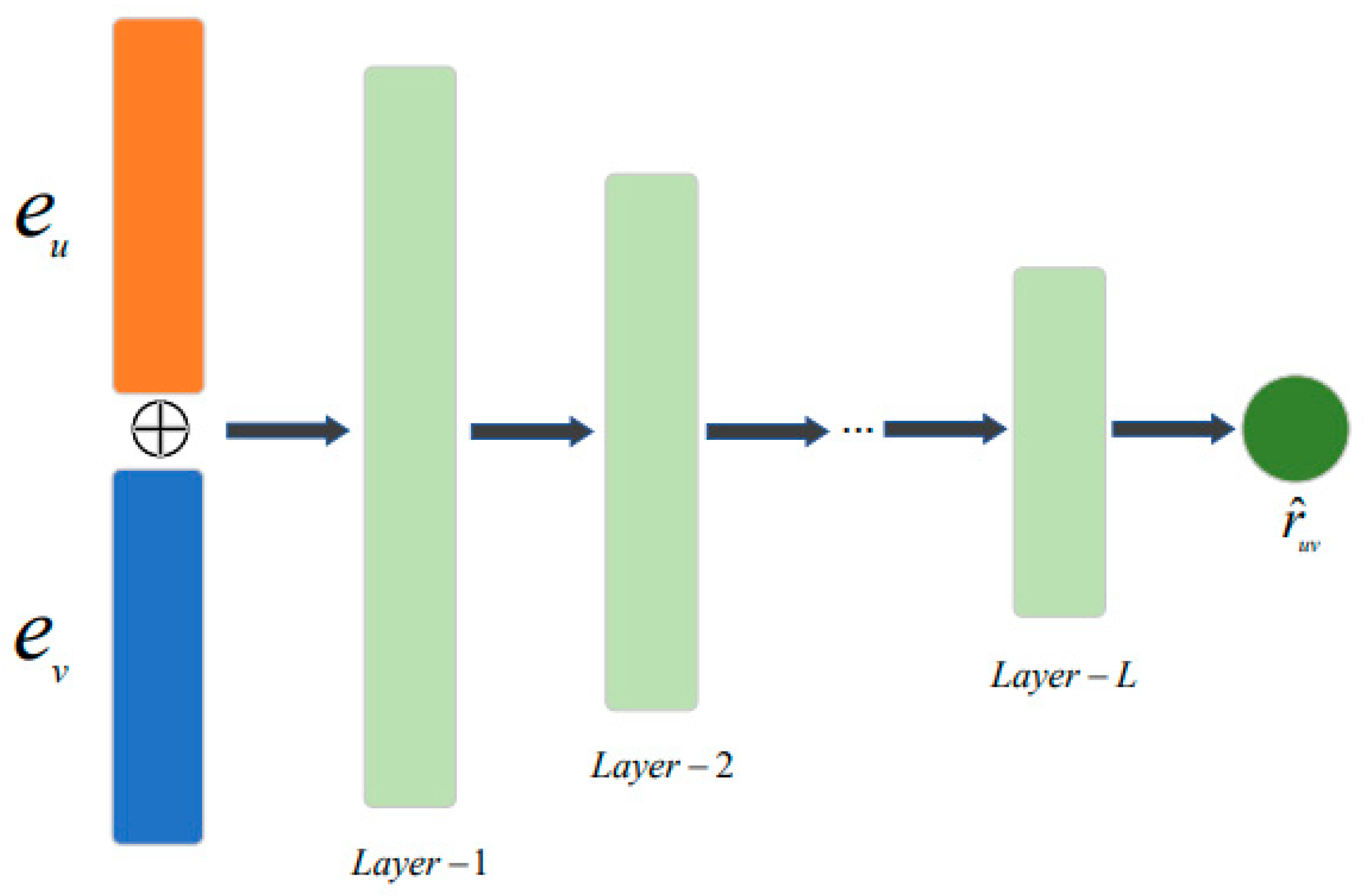
3.3. Rating Prediction Based on the Target and Source Domains
3.4. Feature Matching Based on the Target and Source Domains
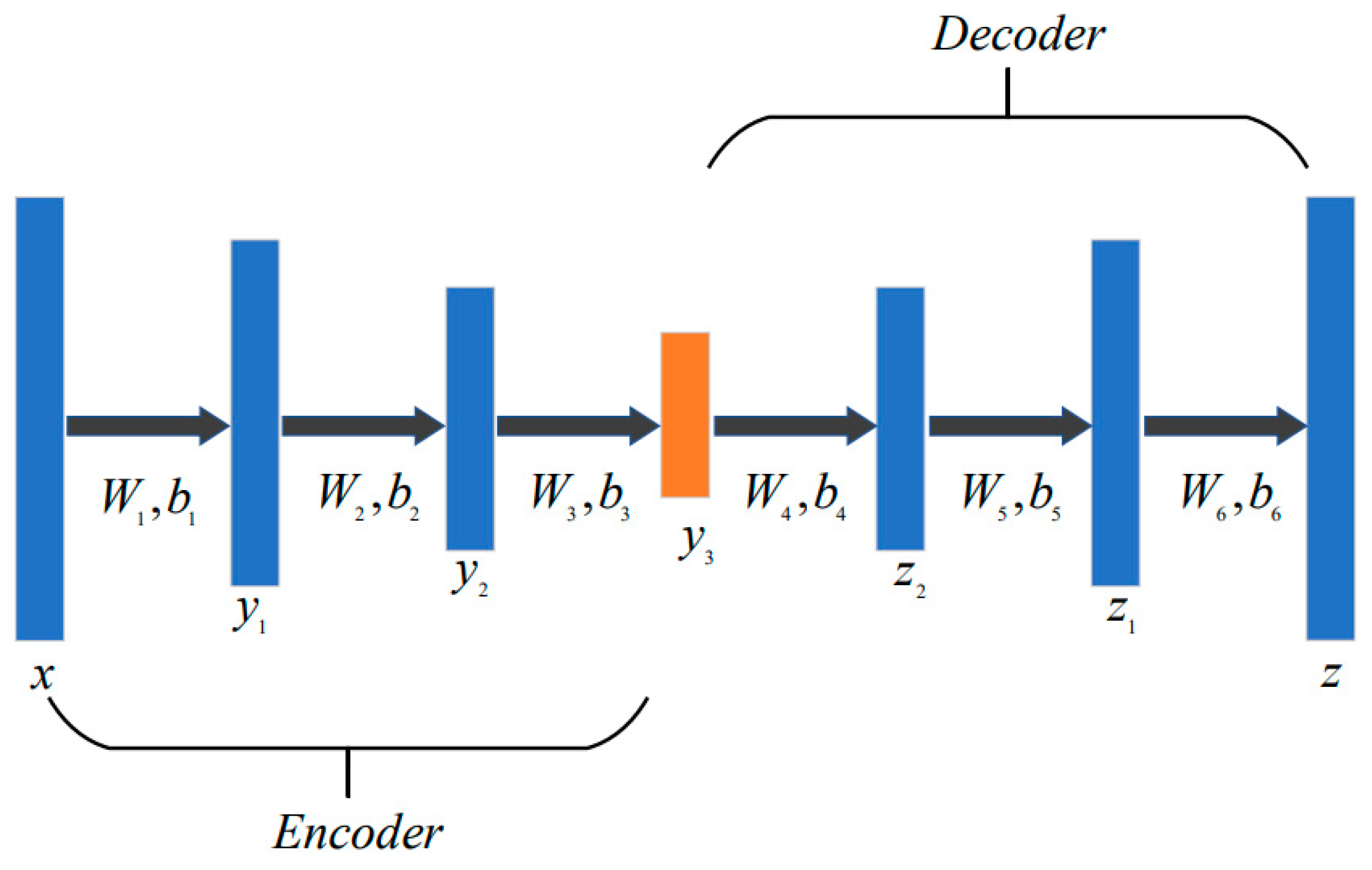
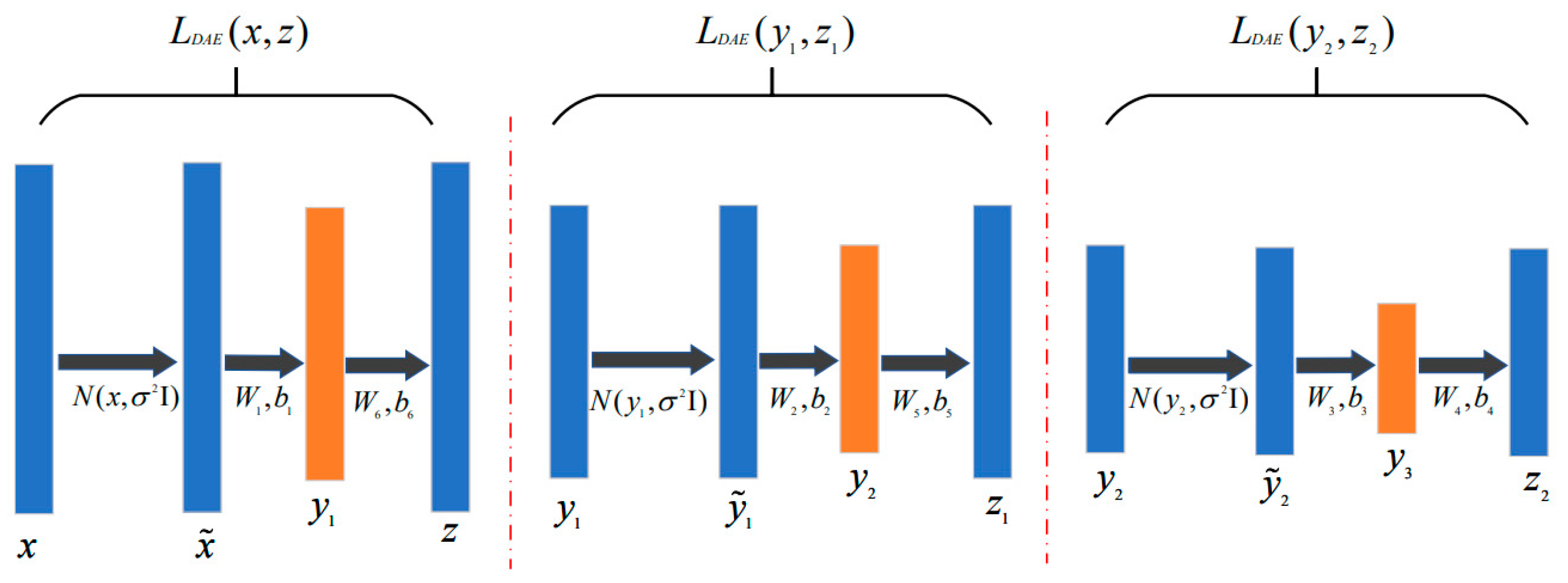
3.4.1. Stacked Denoising AutoEncoder
3.4.2. Question and Expert Feature Matching
3.5. Expert List Merging
- The shared experts of and are added directly to the expert recommendation list , which are arranged in the order of expert recommendation list .
- If there are still less than N experts in the recommendation list after the above processing, half of the total number of missing experts are taken from the recommendation list . If the number is not divisible, the number of experts taken from is rounded up, and the rest are taken from . The experts are kept in the original order. For example, if = {, , , , }, = {, , , , }, then = {, , , , }.
3.6. Algorithm Description
| Algorithm 1 Feature-alignment-based cross-platform expert recommendation |
| Input: expert dataset in the source and target domain , question dataset in the source and target domain , new questions dataset asked by the target domain , questions–expertise rating matrix , the maximum number of iterations T. Output: a list of experts for a new question .
|
3.7. Time Complexity Analysis of the Algorithm
4. Experiments
4.1. Experimental Data
- (1)
- For the Zhihu dataset, the questions with no answers and associated invitations were removed, while users with salt values greater than 700 in the dataset were selected as experts.
- (2)
- For the Toutiao dataset, information with no question description and no expert description in the dataset was removed.
4.2. Evaluation Metrics
- The MAE and RMSE metrics are chosen to evaluate the accuracy of rating prediction.where and denote the predicted and true ratings of the question answerers, respectively, and denotes the size of the test set. A smaller value of MAE or RMSE represents higher accuracy of the recommendation and better recommendation results. In addition, two indicators, Precision and Recall, are selected to evaluate the accuracy of recommendation results.
- Precision: A list of experts is recommended for each question in the test set, and Precision represents the ratio of the number of accurate experts to the total number of recommended experts.where denotes the experts recommended for each question in the test set, denotes the real expert recommendation list for question , and Q denotes the set of all questions in the test set.
- Recall: The proportion of the number of correctly recommended experts to the number of real experts. The formula is shown below:
4.3. Comparison Methods
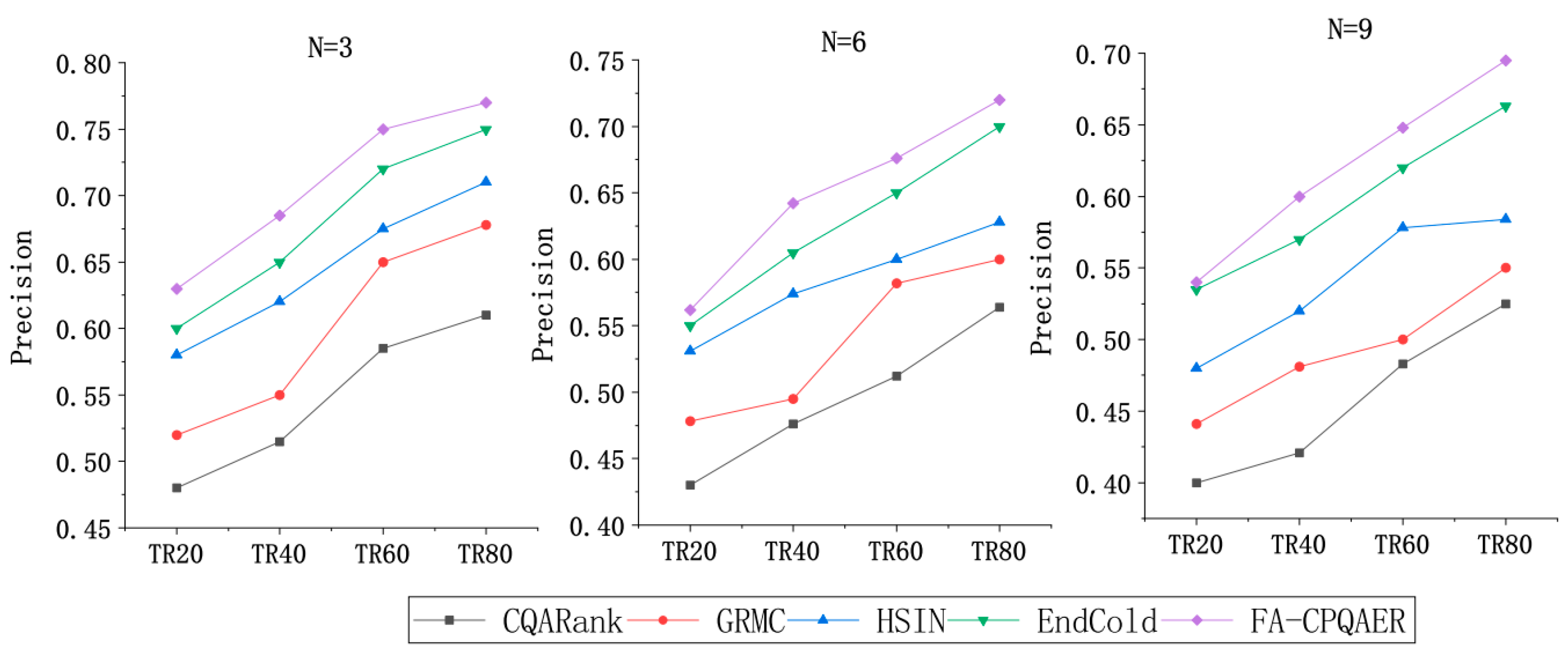
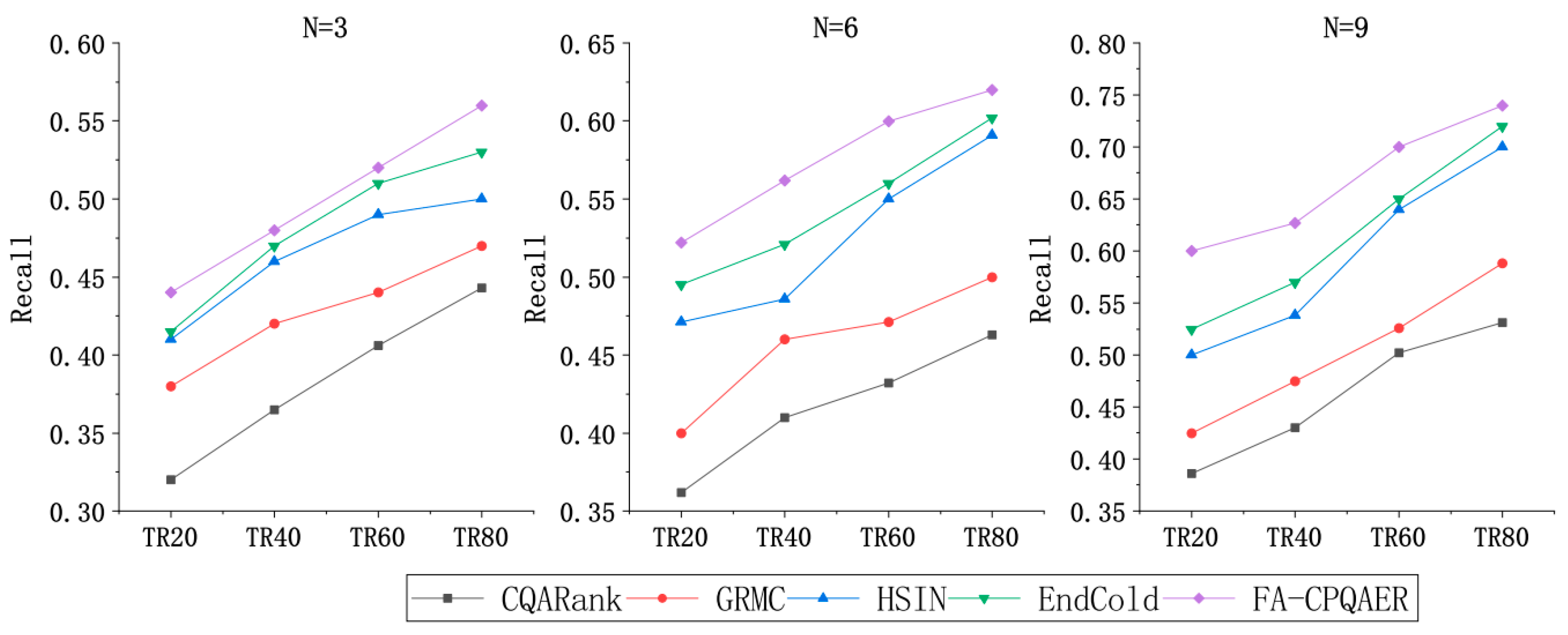
- CQARank [6] is a topic–experience model that jointly learns the topic and expertise by integrating a text content model and link structure analysis;
- GRMC [13] considers expert discovery from the perspective of missing value estimation. Then, a matrix complementation algorithm with graph regularization is used to infer the user model using the user’s social network. Two efficient iterative processes, GRMC-EGM and GRMC-AGM, are further developed to solve the optimization problem;
- HSIN [18] not only encodes the question content and social interactions of the questioner to enhance the question embedding performance but also uses a random-walk-based learning method with RNN to match the similarities between new questions and historical questions asked by other users;
- EndCold [20] constructs an undirected heterogeneous graph encoding past questions and answers of users and text information of questions. The model can use the higher-order graph structure and content information to embed nodes in the input graph and then send questions to respondents with expertise.
4.4. Experimental Results and Analysis
4.4.1. Parameter Settings
4.4.2. Performance Comparison
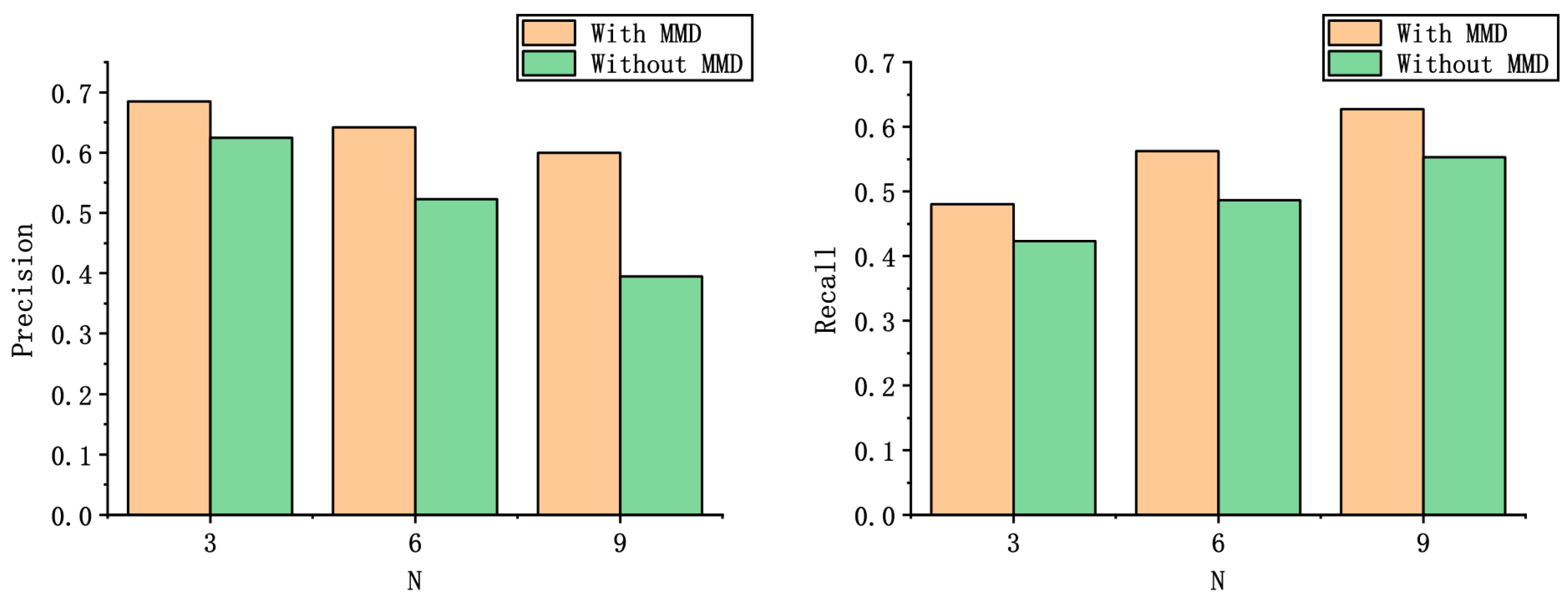
4.4.3. Ablation Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, X.Z.; Huang, C.R.; Yao, L.N.; Beantallah, B.; Dong, M.Q. A survey on expert recommendation in community question answering. J. Comput. Sci. Technol. 2018, 33, 625–653. [Google Scholar] [CrossRef]
- Li, B.; King, I. Routing questions to appropriate answerers in community question answering services. In Proceedings of the 19th ACM International Conference on Information and Knowledge Management, Toronto, ON, Canada, 26–30 October 2010. [Google Scholar]
- Du, L.; Buntine, W.; Jin, H. A segmented topic model based on the two-parameter Poisson-Dirichlet process. Mach. Learn. 2010, 81, 5–19. [Google Scholar] [CrossRef]
- Li, B.; King, I.; Lyu, M.R. Question routing in community question answering: Putting category in its place. In Proceedings of the 20th ACM International Conference on Information and Knowledge Management, Glasgow, UK, 24–28 October 2011. [Google Scholar]
- Xu, F.; Ji, Z.C.; Wang, B. Dual role model for question recommendation in community question answering. In Proceedings of the 35th International ACM SIGIR Conference on Research and Development in Information Retrieval, Portland, OR, USA, 12–16 August 2012. [Google Scholar]
- Liu, Y.; Qiu, M.H.; Gottipati, S.; Zhu, F.D.; Jiang, J.; Sun, H.P.; Chen, Z. Cqarank: Jointly model topics and expertise in community question answering. In Proceedings of the 22nd ACM International Conference on Information and Knowledge Management, San Francisco, CA, USA, 27 October–1 November 2013. [Google Scholar]
- Sahu, T.P.; Nagwani, N.K.; Verma, S. TagLDA based user persona model to identify topical experts for newly posted questions in community question answering sites. Int. J. Appl. Eng. Res. 2016, 11, 7072–7078. [Google Scholar]
- Zhang, J.; Ackerman, M.S.; Adamic, L. Expertise networks in online communities: Structure and algorithms. In Proceedings of the 16th International Conference on World Wide Web, Banff Alberta, AB, Canada, 8–12 May 2007. [Google Scholar]
- Liu, J.; Song, Y.I.; Lin, C.Y. Competition-based user expertise score estimation. In Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval, Beijing, China, 24–28 July 2011. [Google Scholar]
- Zhu, H.S.; Cao, H.H.; Chen, E.H.; Xiong, H. Towards expert finding by leveraging relevant categories in authority ranking. In Proceedings of the 20th ACM International Conference on Information and Knowledge Management, Glasgow, UK, 24–28 October 2011. [Google Scholar]
- Zhu, H.S.; Chen, E.H.; Cao, H.H.; Tian, J.L.; Xiong, H. Ranking user authority with relevant knowledge categories for expert finding. In Proceedings of the 23nd International Conference on World Wide Web, Seoul, Republic of Korea, 7–11 April 2014. [Google Scholar]
- Liu, D.R.; Chen, Y.H.; Kao, W.C.; Wang, H.W. Integrating expert profile, reputation and link analysis for expert finding in question-answering websites. Inf. Process. Manag. 2013, 49, 312–329. [Google Scholar] [CrossRef]
- Zhao, Z.; Zhang, L.J.; He, X.F.; Ng, W. Expert finding for question answering via graph regularized matrix completion. IEEE Trans. Knowl. Data Eng. 2014, 27, 993–1004. [Google Scholar] [CrossRef]
- He, T.Z.; Guo, C.L.; Chu, Y.F.; Yang, Y.; Wang, Y.J. Dynamic user modeling for expert recommendation in community question answering. J. Intell. Fuzzy Syst. 2020, 39, 7281–7292. [Google Scholar] [CrossRef]
- Zhao, Z.; Yang, Q.F.; Cai, D.; He, X.F.; Zhuang, Y.T. Expert finding for community-based question answering via ranking metric network learning. In Proceedings of the 25th International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016. [Google Scholar]
- Huang, C.; Yao, L.; Wang, X. Expert as a service: Software expert recommendation via knowledge domain embeddings in stack overflow. In Proceedings of the 14th IEEE International Conference on Web Services (ICWS), Honolulu, HI, USA, 25–30 June 2017. [Google Scholar]
- Wang, J.; Sun, J.Q.; Lin, H.F.; Dong, H.L.; Zhang, S.W. Convolutional neural networks for expert recommendation in community question answering. Sci. China Inf. Sci. 2017, 60, 110102. [Google Scholar] [CrossRef]
- Chen, Z.Q.; Zhang, C.; Zhao, Z.; Yao, C.W.; Cai, D. Question retrieval for community-based question answering via heterogeneous social influential network. Neurocomputing 2018, 285, 117–124. [Google Scholar] [CrossRef]
- Sun, J.K.; Vishnu, A.; Chakrabarti, A.; Siegel, C.; Parthasarathy, S. Coldroute: Effective routing of cold questions in stack exchange sites. Neurocomputing 2018, 32, 1339–1367. [Google Scholar] [CrossRef]
- Sun, J.K.; Zhao, J.; Sun, H.; Parthasarathy, S. EndCold: An end-to-end framework for cold question routing in community question answering services. In Proceedings of the 29th International Joint Conference on Artificial Intelligence, Yokohama, Japan, 11–17 July 2020. [Google Scholar]
- Berkovsky, S.; Kuflik, T.; Ricci, F. Cross-domain mediation in collaborative filtering. In Proceedings of the 11th International Conference on User Modeling, Corfu, Greece, 25–29 July 2007. [Google Scholar]
- Singh, A.P.; Gordon, G.J. Relational learning via collective matrix factorization. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008. [Google Scholar]
- Hu, L.; Cao, J.; Xu, J.D.; Cao, L.B.; Gu, Z.P.; Zhu, C. Personalized recommendation via cross-domain triadic factorization. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013. [Google Scholar]
- Li, B.; Yang, Q.; Xue, X.Y. Can movies and books collaborate? cross-domain collaborative filtering for sparsity reduction. In Proceedings of the 21st International Joint Conference on Artificial Intelligence, Pasadena, CA, USA, 11–17 July 2009. [Google Scholar]
- Li, B.; Yang, Q.; Xue, X.Y. Transfer learning for collaborative filtering via a rating-matrix generative model. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009. [Google Scholar]
- Gao, S.; Luo, H.; Chen, D.; Li, S.T.; Gallinari, P.; Ma, Z.Y.; Guo, J. A cross-domain recommendation model for cyber-physical systems. IEEE Trans. Emerg. Top. Comput. 2013, 1, 384–393. [Google Scholar] [CrossRef]
- Liu, X.Y.; Croft, W.B.; Koll, M. Finding experts in community-based question-answering services. In Proceedings of the 14th ACM International Conference on Information and Knowledge Management, Bremen, Germany, 31 October–5 November 2005. [Google Scholar]
- Le, Q.; Mikolov, T. Distributed representations of sentences and documents. In Proceedings of the 31st International Conference on Machine Learning, Beijing, China, 21–26 June 2014. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Explanation |
|---|---|
| expert dataset in the target domain | |
| expert dataset in the source domain | |
| length of expert dataset in the target domain | |
| length of expert dataset in the source domain | |
| question dataset in the target domain | |
| question dataset in the source domain | |
| length of question dataset in the target domain | |
| length of question dataset in the source domain | |
| new question dataset in the target domain | |
| rating matrices of the target domain | |
| rating matrices of the source domain | |
| , | question |
| expert | |
| vector representation of the question | |
| vector representation of the expert | |
| vector representation of the question encoded by SDAE | |
| vector representation of the expert encoded by SDAE | |
| question encoder for the target domain | |
| question encoder for the source domain | |
| expert encoder for the target domain | |
| expert encoder for the source domain |
| Feature | Data Format | Description |
|---|---|---|
| Title | Text | Title of the question |
| Question description | Text | Description of the question details |
| Topic | Categorical | The topic to which the question belongs |
| Number of likes | Numeric | Number of likes for the question |
| Number of responses | Numeric | Number of responses to the question |
| Feature | Data Format | Description |
|---|---|---|
| Expert description | Text | Description of the expert |
| Interest label | Categorical | Topics concerned by the user |
| Question Answering Platforms | Number of Questions | Number of Users |
|---|---|---|
| Zhihu dataset | 116,139 | 8019 |
| Toutiao dataset | 8095 | 2763 |
| 30 | 32 | 34 | 36 | 38 | ||
|---|---|---|---|---|---|---|
| 0.0001 | 0.829 | 0.732 | 0.729 | 0.784 | 0.753 | |
| 0.001 | 0.783 | 0.825 | 0.804 | 0.689 | 0.715 | |
| 0.01 | 0.790 | 0.804 | 0.843 | 0.753 | 0.774 | |
| 0.1 | 0.864 | 0.785 | 0.783 | 0.740 | 0.725 | |
| 1 | 0.820 | 0.814 | 0.830 | 0.791 | 0.784 | |
| 350 | 320 | 290 | 260 | 230 | ||
|---|---|---|---|---|---|---|
| 190 | 0.915 | 0.893 | 0.864 | 0.945 | 1.102 | |
| 180 | 0.865 | 0.845 | 0.863 | 0.884 | 0.965 | |
| 170 | 0.858 | 0.853 | 0.843 | 0.864 | 0.943 | |
| 160 | 0.842 | 0.841 | 0.852 | 0.861 | 0.926 | |
| 150 | 0.953 | 0.997 | 0.934 | 0.896 | 1.026 | |
| Methods | MAE | RMSE | ||||||
|---|---|---|---|---|---|---|---|---|
| TR80 | TR60 | TR40 | TR20 | TR80 | TR60 | TR40 | TR20 | |
| CQARank | 0.852 | 0.871 | 0.909 | 0.985 | 1.081 | 1.107 | 1.233 | 1.270 |
| GRMC | 0.824 | 0.838 | 0.862 | 0.904 | 1.036 | 1.082 | 1.156 | 1.166 |
| HSIN | 0.802 | 0.821 | 0.841 | 0.889 | 0.952 | 0.972 | 1.057 | 1.062 |
| EndCold | 0.788 | 0.809 | 0.829 | 0.879 | 0.901 | 0.926 | 1.029 | 1.054 |
| FA-CPQAER | 0.801 | 0.807 | 0.812 | 0.822 | 0.829 | 0.842 | 0.854 | 0.912 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, B.; Gao, Q.; Cui, X.; Peng, Q.; Yu, X. Feature-Alignment-Based Cross-Platform Question Answering Expert Recommendation. Mathematics 2023, 11, 2174. https://doi.org/10.3390/math11092174
Tang B, Gao Q, Cui X, Peng Q, Yu X. Feature-Alignment-Based Cross-Platform Question Answering Expert Recommendation. Mathematics. 2023; 11(9):2174. https://doi.org/10.3390/math11092174
Chicago/Turabian StyleTang, Bin, Qinqin Gao, Xin Cui, Qinglong Peng, and Xu Yu. 2023. "Feature-Alignment-Based Cross-Platform Question Answering Expert Recommendation" Mathematics 11, no. 9: 2174. https://doi.org/10.3390/math11092174