
Task-Covariant Representations for Few-Shot Learning on Remote Sensing Images
Abstract
:1. Introduction
- Considering the covariant relationships among tasks in practical use, a task-covariant representation meta-learning algorithm is proposed.
- According to the different distributions of tasks, the corresponding subspaces are allocated to different subdistributions.
- A corresponding modulation function is learned for each subspace, and the learned meta-knowledge is adaptively adjusted according to the task information and the corresponding modulation function.
2. Related Work
2.1. Meta-Learning
2.2. Capsule Network
3. Mathematical Preliminaries
3.1. Model-Agnostic Meta-Learning
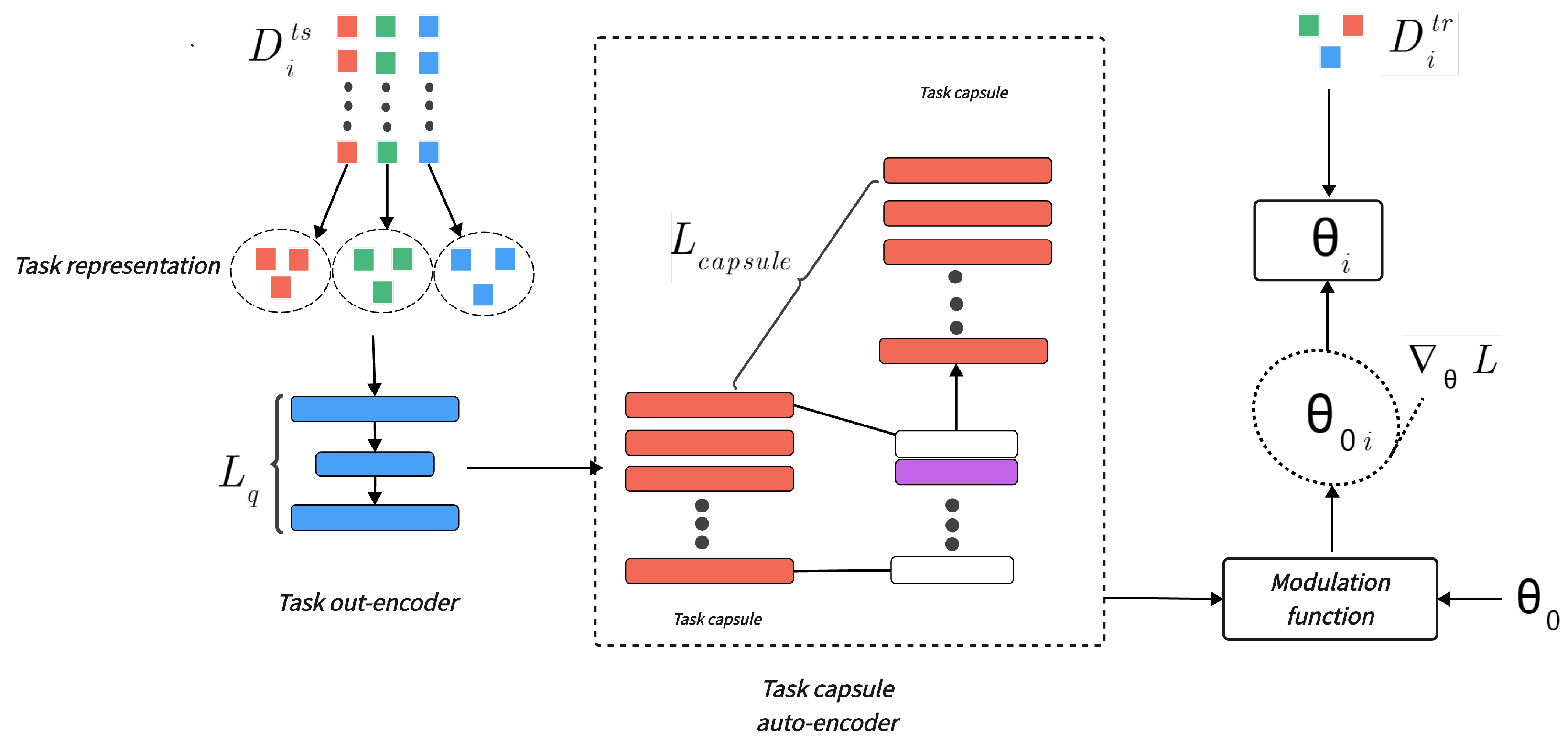
3.2. Setting Up the System: Task-Covariant Representation Meta-Learning
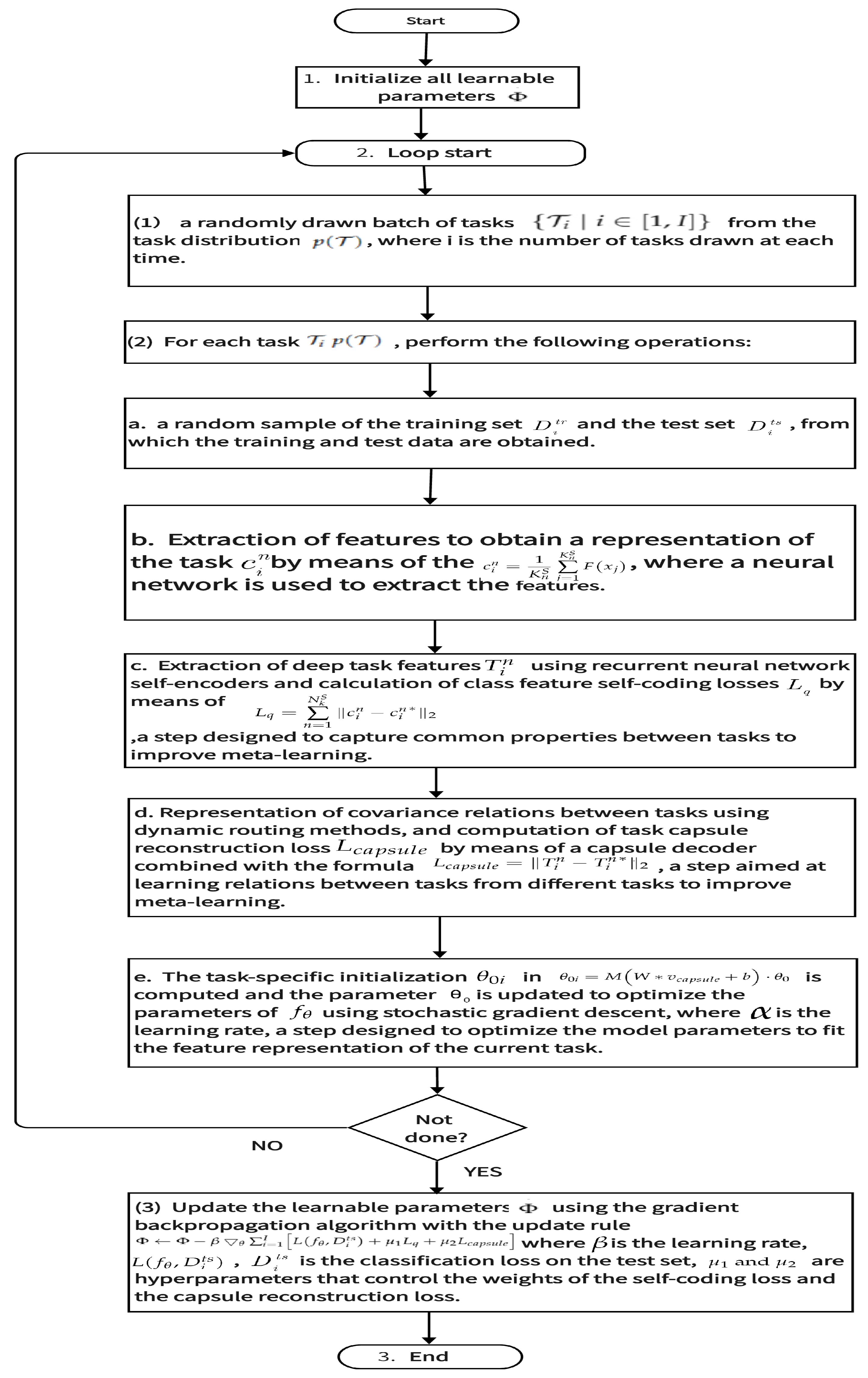
| Algorithm 1 Task-covariant representation for meta-learning. |
|
3.2.1. Task Representation Learning
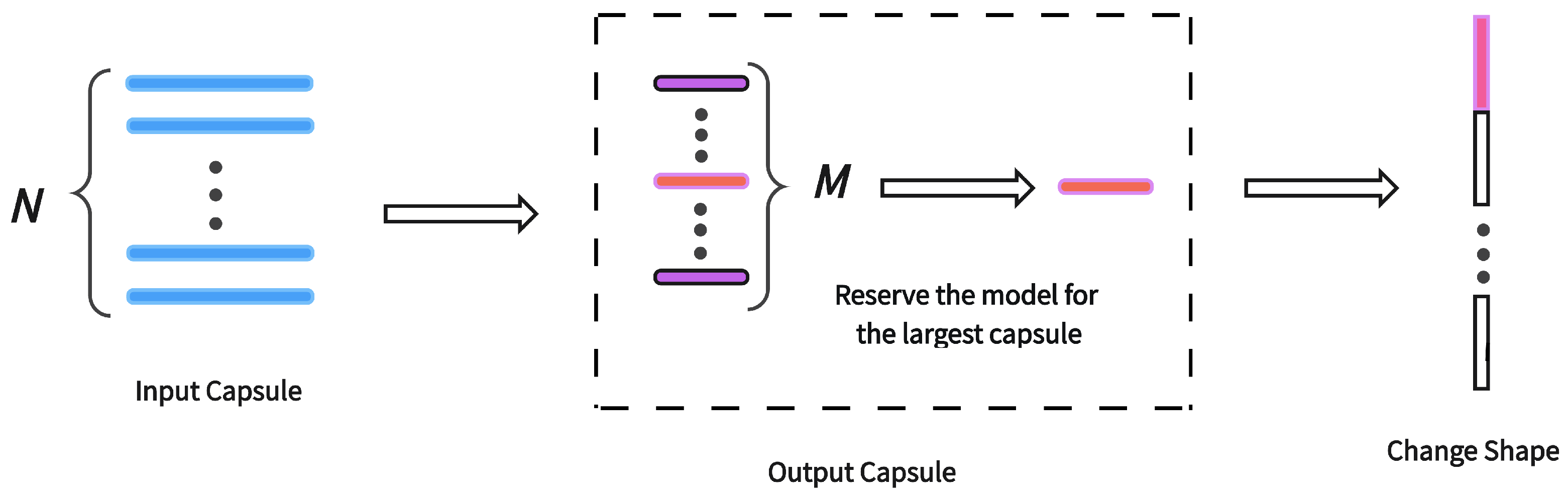
3.2.2. Task-Covariant Representation
3.2.3. Task-Specific Knowledge Adaption and Loss Function
4. Experiments
4.1. Two-Dimensional Regression
4.2. Few-Shot Classification
4.2.1. Datasets and Setting
4.2.2. Internal Comparison of Our Method
4.2.3. Comparison with Other Methods
4.2.4. SIRI-WHU and WHU-RS19 Datasets
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Commonly Used Notations

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| The support set of the i-th task, containing samples and labels used for training the model. | |
| The query set of the i-th task, containing samples and labels for testing the model. | |
| A sample from the support set of the i-th task. | |
| The label of a sample from the support set of the i-th task. | |
| A sample from the query set of the i-th task. | |
| The label of a sample from the query set of the i-th task. | |
| The initial parameter of the base predictive model f, which is the goal of meta-learning. | |
| A set of N meta-learning tasks used for training the model. | |
| The model parameter for the i-th task. | |
| The learning rate of the inner optimization strategy. | |
| The gradient with respect to , representing the gradient of the model trained on the support set with respect to the current parameter. | |
| Parameters of the task-specific base learner. | |
| Loss function. | |
| Step size or learning rate for outer optimization loop. | |
| R | A set of real numbers. |
| Fraction equal to the reciprocal of the number of samples in a support set. | |
| ∑ | The summation of all terms within the brackets. |
| j | The index used for iterating over all samples in a support set. |
| The feature extraction function. | |
| The input sample. | |
| i | The index used for iterating over all tasks. |
| The class feature representation for i-th task. | |
| The number of samples of the corresponding class in the support set of each task. | |
| norm | Euclidean distance between two points. |
| and | The weight coefficients that control the ratio of autoencoder loss and capsule network reconstruction loss in the loss function. |
| The set of learnable parameters in the model, including the weights and biases of the neural network. | |
| The set of I tasks sampled from the meta-task distribution. | |
| and | The training set and testing set of the i-th task. |
| A feature vector representing task i. | |
| An autoencoder recurrent neural network used to extract task-specific low-dimensional feature vectors for task i. | |
| The loss function used to ensure consistency in task-specific initialization. | |
| The loss function for computing task-specific capsule network reconstruction. | |
| The function parameters used for task-specific initialization in task i. | |
| The task-specific gradient computation used to update task-specific initialization. | |
| The meta-learning update gradient computation used to update the learnable parameters of the model. | |
| Represents the Euclidean norm or 2-norm. | |
| Indicates the number of support set categories or clusters. | |
| The output of the capsule network. | |
| The decoding output of the capsule network. | |
| The Euclidean norm or 2-norm. | |
| The vector form of the output of capsule network. | |
| M | The modulation function. |
| W and b | The weights and biases of a fully connected layer. |
| The meta-learning loss. |
References
- Finn, C.; Abbeel, P.; Levine, S. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Precup, D., Teh, Y.W., Eds.; Cornell University Library: New York, NY, USA, 2017; Volume 70, pp. 1126–1135. [Google Scholar]
- Finn, C.; Xu, K.; Levine, S. Probabilistic Model-Agnostic Meta-Learning. In Advances in Neural Information Processing Systems; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2018; Volume 31. [Google Scholar]
- Gwilliam, M.; Shrivastava, A. Beyond Supervised vs. Unsupervised: Representative Benchmarking and Analysis of Image Representation Learning. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 9632–9642. [Google Scholar] [CrossRef]
- Vuorio, R.; Sun, S.H.; Hu, H.; Lim, J.J. Toward Multimodal Model-Agnostic Meta-Learning. In Proceedings of the 2nd Workshop on Meta-Learning at the Thirty-Second Annual Conference Neural Information Processing Systems, Vancouver, BC, Canada, 8 December 2019. [Google Scholar]
- Yao, H.; Wei, Y.; Huang, J.; Li, Z. Hierarchically Structured Meta-learning. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; Chaudhuri, K., Salakhutdinov, R., Eds.; Volume 97, pp. 7045–7054. [Google Scholar]
- Jha, A.; Bose, S.; Banerjee, B. GAF-Net: Improving the Performance of Remote Sensing Image Fusion Using Novel Global Self and Cross Attention Learning. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–7 January 2023; pp. 6354–6363. [Google Scholar]
- Lee, Y.; Choi, S. Gradient-Based Meta-Learning with Learned Layerwise Metric and Subspace. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; Dy, J., Krause, A., Eds.; Volume 80, pp. 2927–2936. [Google Scholar]
- Oreshkin, B.; Rodríguez López, P.; Lacoste, A. TADAM: Task dependent adaptive metric for improved few-shot learning. In Advances in Neural Information Processing Systems; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2018; Volume 31. [Google Scholar]
- Yao, H.; Wu, X.; Tao, Z.; Li, Y.; Ding, B.; Li, R.; Li, Z. Automated Relational Meta-learning. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Ji, J.Y.; Wong, M.L. Surrogate-assisted Parameter Re-initialization for Differential Evolution. In Proceedings of the 2022 IEEE Symposium Series on Computational Intelligence (SSCI), Singapore, 4–7 December 2022; pp. 1592–1599. [Google Scholar] [CrossRef]
- Baik, S.; Choi, J.; Kim, H.; Cho, D.; Min, J.; Lee, K.M. Meta-Learning With Task-Adaptive Loss Function for Few-Shot Learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 9465–9474. [Google Scholar]
- Antoniou, A.; Edwards, H.; Storkey, A. How to train your MAML. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Baik, S.; Choi, M.; Choi, J.; Kim, H.; Lee, K.M. Meta-Learning with Adaptive Hyperparameters. In Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H., Eds.; Curran Associates, Inc.: New York, NY, USA, 2020; Volume 33, pp. 20755–20765. [Google Scholar]
- Huaxiu, Y.; Yu, W.; Ying, W.; Peilin, Z.; Mehrdad, M.; Defu, L.; Chelsea, F. Meta-learning with an Adaptive Task Scheduler. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: New York, NY, USA, 2021; Volume 35. [Google Scholar]
- Kaddour, J.; Saemundsson, S.; Deisenroth (he/him), M. Probabilistic Active Meta-Learning. In Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H., Eds.; Curran Associates, Inc.: New York, NY, USA, 2020; Volume 33, pp. 20813–20822. [Google Scholar]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic Routing Between Capsules. In Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2017; Volume 30. [Google Scholar]
- Hinton, G.E.; Sabour, S.; Frosst, N. Matrix capsules with EM routing. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Kosiorek, A.; Sabour, S.; Teh, Y.W.; Hinton, G.E. Stacked Capsule Autoencoders. In Advances in Neural Information Processing Systems; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2019; Volume 31. [Google Scholar]
- Yu, C.; Zhu, X.; Zhang, X.; Wang, Z.; Zhang, Z.; Lei, Z. HP-Capsule: Unsupervised Face Part Discovery by Hierarchical Parsing Capsule Network. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 4022–4031. [Google Scholar] [CrossRef]
- Thrun, S.; Pratt, L. earning to Learn: Introduction and Overview. In Learning to Learn; Thrun, S., Pratt, L., Eds.; Springer: Boston, MA, USA, 1998; pp. 3–17. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, S.; Han, Z.; Feng, Y.; Wei, J.; Mei, S. Diversity Measurement-Based Meta-Learning for Few-Shot Object Detection of Remote Sensing Images. In Proceedings of the IGARSS 2022—2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 3087–3090. [Google Scholar] [CrossRef]
- Ravi, S.; Larochelle, H. Optimization as a Model for Few-Shot Learning. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Metz, L.; Maheswaranathan, N.; Cheung, B.; Sohl-Dickstein, J. Learning Unsupervised Learning Rules. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Liang, B.; Wang, X.; Wang, L. Impact of Heterogeneity on Network Embedding. IEEE Trans. Netw. Sci. Eng. 2022, 9, 1296–1307. [Google Scholar] [CrossRef]
- Yoon, J.; Kim, T.; Dia, O.; Kim, S.; Bengio, Y.; Ahn, S. Bayesian Model-Agnostic Meta-Learning. In Advances in Neural Information Processing Systems; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2018; Volume 31. [Google Scholar]
- Grant, E.; Finn, C.; Levine, S.; Darrell, T.; Griffiths, T. Recasting Gradient-Based Meta-Learning as Hierarchical Bayes. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Baik, S.; Hong, S.; Lee, K.M. Learning to Forget for Meta-Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Bengio, Y.; Louradour, J.; Collobert, R.; Weston, J. Curriculum Learning. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; Association for Computing Machinery: New York, NY, USA, 2009; pp. 41–48. [Google Scholar] [CrossRef]
- Wang, X.; Chen, Y.; Zhu, W. A Survey on Curriculum Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2021. [Google Scholar] [CrossRef] [PubMed]
- Canevet, O.; Fleuret, F. Large Scale Hard Sample Mining With Monte Carlo Tree Search. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Shrivastava, A.; Gupta, A.; Girshick, R. Training Region-Based Object Detectors With Online Hard Example Mining. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Sun, Q.; Liu, Y.; Chen, Z.; Chua, T.S.; Schiele, B. Meta-Transfer Learning through Hard Tasks. IEEE Trans. Pattern Anal. Mach. Intell. 2020. [Google Scholar] [CrossRef] [PubMed]
- Sun, Q.; Liu, Y.; Chua, T.S.; Schiele, B. Meta-Transfer Learning for Few-Shot Learning. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–17 June 2019; pp. 403–412. [Google Scholar] [CrossRef]
- Liu, C.; Wang, Z.; Sahoo, D.; Fang, Y.; Zhang, K.; Hoi, S.C.H. Adaptive Task Sampling for Meta-learning. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 752–769. [Google Scholar]
- Zheng, X.; Chen, X.; Lu, X. Visible-Infrared Person Re-Identification via Partially Interactive Collaboration. IEEE Trans. Image Process. 2022, 31, 6951–6963. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Zhou, F.; Chen, F.; Li, H. Meta-SGD: Learning to Learn Quickly for Few Shot Learning. arXiv 2017, arXiv:1707.09835. [Google Scholar]
- Hinton, G.E.; Krizhevsky, A.; Wang, S.D. Transforming Auto-Encoders. In Proceedings of the Artificial Neural Networks and Machine Learning—ICANN 2011, Espoo, Finland, 14–17 June 2011; Honkela, T., Duch, W., Girolami, M., Kaski, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 44–51. [Google Scholar]
- Cohen, T.S.; Welling, M. Group Equivariant Convolutional Networks. In Proceedings of the 33rd International Conference on International Conference on Machine Learning—Volume 48, New York, NY, USA, 19–24 June 2016; pp. 2990–2999. [Google Scholar]
- Dieleman, S.; Fauw, J.D.; Kavukcuoglu, K. Exploiting Cyclic Symmetry in Convolutional Neural Networks. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; Balcan, M.F., Weinberger, K.Q., Eds.; Volume 48, pp. 1889–1898. [Google Scholar]
- Worrall, D.E.; Garbin, S.J.; Turmukhambetov, D.; Brostow, G.J. Harmonic Networks: Deep Translation and Rotation Equivariance. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zhang, L.; Edraki, M.; Qi, G.J. CapProNet: Deep Feature Learning via Orthogonal Projections onto Capsule Subspaces. In Advances in Neural Information Processing Systems; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2018; Volume 31. [Google Scholar]
- Edraki, M.; Rahnavard, N.; Shah, M. SubSpace Capsule Network. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 10745–10753. [Google Scholar]
- Wang, X.; Wang, Y.; Guo, S.; Kong, L.; Cui, G. Capsule Network With Multiscale Feature Fusion for Hidden Human Activity Classification. IEEE Trans. Instrum. Meas. 2023, 72, 1–12. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Rajasegaran, J.; Jayasundara, V.; Jayasekara, S.; Jayasekara, H.; Seneviratne, S.; Rodrigo, R. DeepCaps: Going Deeper With Capsule Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Lyu, Q.; Guo, M.; Ma, M.; Mankin, R. DeCapsGAN: Generative adversarial capsule network for image denoising. J. Electron. Imaging 2021, 30, 033016. [Google Scholar] [CrossRef]
- Choi, J.; Seo, H.; Im, S.; Kang, M. Attention Routing Between Capsules. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Republic of Korea, 27–28 October 2019; pp. 1981–1989. [Google Scholar] [CrossRef]
- Qin, Y.; Frosst, N.; Sabour, S.; Raffel, C.; Cottrell, G.; Hinton, G. Detecting and Diagnosing Adversarial Images with Class-Conditional Capsule Reconstructions. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Gu, J.; Wu, B.; Tresp, V. Effective and Efficient Vote Attack on Capsule Networks. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 3–7 May 2021. [Google Scholar]
- Sun, W.; Tagliasacchi, A.; Deng, B.; Sabour, S.; Yazdani, S.; Hinton, G.; Yi, K.M. Canonical Capsules: Self-Supervised Capsules in Canonical Pose. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: New York, NY, USA, 2021; Volume 34. [Google Scholar]
- Sun, K.; Zhang, J.; Liu, J.; Yu, R.; Song, Z. DRCNN: Dynamic Routing Convolutional Neural Network for Multi-View 3D Object Recognition. IEEE Trans. Image Process. 2021, 30, 868–877. [Google Scholar] [CrossRef] [PubMed]
- Jenkins, P.; Armstrong, K.; Nelson, S.; Gotad, S.; Jenkins, J.S.; Wilkey, W.; Watts, T. CountNet3D: A 3D Computer Vision Approach to Infer Counts of Occluded Objects. In Proceedings of the 2023 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 2–8 January 2023; pp. 3007–3016. [Google Scholar] [CrossRef]
- Zheng, X.; Zhang, Y.; Zheng, Y.; Luo, F.; Lu, X. Abnormal event detection by a weakly supervised temporal attention network. CAAI Trans. Intell. Technol 2022, 7, 419–431. [Google Scholar] [CrossRef]





| Model | MAML | Meta-SGD | BMAML | MT-Net | Our | Enhancement |
|---|---|---|---|---|---|---|
| 10-shot | 0.89 | 1.05 | 0.65 | 0.68 | 0.45 | 0.26 |
| 7-shot | 0.93 | 1.08 | 0.67 | 0.70 | 0.48 | 0.24 |
| 5-shot | 1.0 | 1.12 | 0.70 | 0.75 | 0.56 | 0.14 |
| AID | |||
|---|---|---|---|
| Algorithm | 5-way 1-shot | 5-way 3-shot | 5-way 5-shot |
| (a) Initialization parameters | 78.47% | 81.91% | 85.58% |
| (b) Adjusting parameters with FCN | 76.31% | 80.96% | 83.50% |
| (c) Number of capsules is 1 | 79.43% | 82.19% | 85.55% |
| (d) Number of capsules is 5 | 78.33% | 81.80% | 85.07% |
| (e) Number of capsules is 10 | 78.23% | 82.10% | 84.42% |
| (f) Number of capsules is 15 | 77.35% | 80.93% | 84.93% |
| (g) Adding a layer of FCN | 77.69% | 80.85% | 82.45% |
| (h) Adding three layers of FCN | 78.45% | 81.65% | 83.23% |
| (i) Coding each task separately | 78.65% | 82.14% | 85.90% |
| UCMerced-LandUse | |||
| (a) Initialization parameters | 75.23% | 82.61% | 84.12% |
| (b) Adjusting parameters with FCN | 73.59% | 79.59% | 83.03% |
| (c) Number of capsules is 1 | 75.29% | 82.74% | 84.53% |
| (d) Number of capsules is 5 | 74.73% | 82.06% | 83.91% |
| (e) Number of capsules is 10 | 73.59% | 81.47% | 84.36% |
| (f) Number of capsules is 15 | 75.07% | 80.88% | 82.84% |
| (g) Adding a layer of FCN | 74.89% | 81.01% | 83.16% |
| (h) Adding three layers of FCN | 75.29% | 81.83% | 83.74% |
| (i) Coding each task separately | 75.37% | 82.37% | 84.03% |
| AID | |||
|---|---|---|---|
| Algorithm | 5-way 1-shot | 5-way 3-shot | 5-way 5-shot |
| VERSA | 68.58% | 72.40% | 75.86% |
| ProtoNet | 70.11% | 73.28% | 77.67% |
| TapNet | 70.90% | 73.91% | 79.07% |
| TADAM | 69.58% | 75.60% | 79.13% |
| MAML | 66.94% | 72.01% | 78.52% |
| Meta-SGD | 68.58% | 74.95% | 77.87% |
| BMAML | 67.89% | 73.39% | 79.01% |
| MT-Net | 71.72% | 77.54% | 79.22% |
| MUMOMAML | 69.82% | 75.73% | 80.49% |
| HSML | 73.98% | 79.84% | 81.68% |
| Proposed | 79.27% | 81.91% | 85.90% |
| Enhancement | 5.29% | 2.07% | 4.22% |
| UCMerced-LandUse | |||
| VERSA | 67.43% | 72.81% | 73.46% |
| ProtoNet | 68.52% | 74.62% | 80.21% |
| TapNet | 69.44% | 74.56% | 80.54% |
| TADAM | 68.34% | 74.70% | 79.78% |
| MAML | 68.66% | 73.61% | 78.56% |
| Meta-SGD | 68.38% | 74.31% | 81.49% |
| BMAML | 69.53% | 75.50% | 80.06% |
| MT-Net | 68.80% | 74.27% | 82.57% |
| MUMOMAML | 70.81% | 75.36% | 81.89% |
| HSML | 71.01% | 77.91% | 82.08% |
| Proposed | 75.23% | 82.61% | 84.12% |
| Enhancement | 4.22% | 4.70% | 2.06% |
| Dataset | Algorithm | Time (Minutes) | ||
|---|---|---|---|---|
| 5-Way 1-Shot | 5-Way 3-Shot | 5-Way 5-Shot | ||
| AID | Proposed | 2.85 | 3.73 | 4.39 |
| ARML | 3.06 | 4.07 | 5.42 | |
| Enhancement | 0.21 | 0.34 | 1.02 | |
| UCMerced-LandUse | Proposed | 3.01 | 4.12 | 4.82 |
| ARML | 4.10 | 4.92 | 5.47 | |
| Enhancement | 1.09 | 0.8 | 0.65 | |
| Setting | Algorithm | Avg. Original | Avg. Blur | Avg. Sharpened |
|---|---|---|---|---|
| 5-way 1-shot | VERSA | 68.58% | 65.98% | 60.70% |
| ProtoNet | 70.11% | 64.51% | 58.24% | |
| TapNet | 70.90% | 65.16% | 59.25% | |
| TADAM | 69.58% | 66.44% | 61.02% | |
| MAML | 66.94% | 64.53% | 58.71% | |
| Meta-SGD | 69.58% | 66.36% | 62.21% | |
| BMAML | 67.89% | 65.08% | 60.70% | |
| MT-Net | 71.72% | 64.64% | 59.05% | |
| MUMOMAML | 69.82% | 66.59% | 61.24% | |
| HSML | 73.89% | 64.62% | 61.78% | |
| Proposed | 79.27% | 72.07% | 66.55% | |
| Enhancement | 5.29% | 7.45% | 4.77% | |
| 5-way 3-shot | VERSA | 72.40% | 70.10% | 70.48% |
| ProtoNet | 73.28% | 69.25% | 68.34% | |
| TapNet | 73.91% | 70.24% | 69.03% | |
| TADAM | 75.60% | 72.46% | 71.78% | |
| MAML | 72.01% | 70.83% | 68.04% | |
| Meta-SGD | 74.95% | 71.36% | 70.37% | |
| BMAML | 73.39% | 69.84% | 69.57% | |
| MT-Net | 77.54% | 73.69% | 70.62% | |
| MUMOMAML | 75.73% | 70.23% | 71.21% | |
| HSML | 79.84% | 72.17% | 73.16% | |
| Proposed | 81.91% | 78.52% | 77.49% | |
| Enhancement | 2.07% | 6.35% | 4.33% | |
| 5-way 5-shot | VERSA | 75.86% | 75.41% | 71.93% |
| ProtoNet | 77.67% | 75.07% | 72.15% | |
| TapNet | 79.07% | 75.21% | 71.68% | |
| TADAM | 79.13% | 77.36% | 75.15% | |
| MAML | 78.52% | 74.93% | 71.59% | |
| Meta-SGD | 77.82% | 75.54% | 72.24% | |
| BMAML | 79.01% | 76.21% | 73.22% | |
| MT-Net | 79.22% | 76.65% | 71.18% | |
| MUMOMAML | 80.49% | 78.29% | 73.9% | |
| HSML | 81.68% | 78.93% | 77.27% | |
| Proposed | 85.90% | 80.14% | 80.42% | |
| Enhancement | 4.22% | 1.21% | 3.15% |
| SIRI-WHU | |||
|---|---|---|---|
| Model | 1-shot | 3-shot | 5-shot |
| MAML | 68.52% | 75.84% | 79.06% |
| MAML++ | 72.12% | 81.59% | 83.15% |
| MeTAL | 77.48% | 85.40% | 86.40% |
| proposed | 78.83% | 83.57% | 85.02% |
| Enhancement | 1.3% | −1.83% | −1.83% |
| WHU-RS19 | |||
| MAML | 74.63% | 83.79% | 87.75% |
| MAML++ | 78.57% | 86.23% | 88.95% |
| MeTAL | 81.96% | 89.93% | 92.41% |
| proposed | 84.63% | 90.05% | 91.75% |
| Enhancement | 2.2% | 0.21% | −0.66% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, L.; Tian, Z.; Tang, Y.; Jiang, Z. Task-Covariant Representations for Few-Shot Learning on Remote Sensing Images. Mathematics 2023, 11, 1930. https://doi.org/10.3390/math11081930
Zhang L, Tian Z, Tang Y, Jiang Z. Task-Covariant Representations for Few-Shot Learning on Remote Sensing Images. Mathematics. 2023; 11(8):1930. https://doi.org/10.3390/math11081930
Chicago/Turabian StyleZhang, Liyi, Zengguang Tian, Yi Tang, and Zuo Jiang. 2023. "Task-Covariant Representations for Few-Shot Learning on Remote Sensing Images" Mathematics 11, no. 8: 1930. https://doi.org/10.3390/math11081930