1. Introduction
During the past few decades, the volume of available data worldwide has grown at an unprecedented rate. In order to fully mine and analyze such massive data, the subject of “big data” has become a hot topic. Various applications related to big data are still emerging, such as smart cities, smart medical care, intelligent transportation systems, etc. The IMARC Group expects the global big data market to expand from USD 162.6 billion in 2021 to USD 314.1 billion by 2027, at a CAGR of approximately 11% over the forecast period [
1]. Like computers and the Internet, big data is very likely to trigger a new round of technological revolution. However, on the other hand, in the face of the explosive growth of data, the computing capacity of a single server has been stretched. Therefore, we urgently need networked computing systems to coordinate the computing power of multiple servers that is able to take on an extremely complex computing workload including big data. In order to efficiently accomplish workload computation and fully utilize compute resources, studying how to schedule workloads reasonably in networked computing systems has become a fundamental problem for researchers.
Although the amount of big data is remarkably immense, many big data workloads can be regarded as divisible loads, even fine-grained ones. That is to say, the total workload can be divided into arbitrary load partitions of any size. There is no interdependence between them, no data transmission is required, and there is no particular order of task execution. These divisions are supposed to be distributed to multiple servers in networked computing systems by a competent divisible-load scheduling strategy to perform parallel computing, so as to shorten the total makespan. This kind of divisible-load scheduling strategy is collectively referred to as the Divisible-Load Theory (DLT) [
2]. DLT has been deeply studied with regard to various topologies of networked computing systems, such as the tree network [
3], bus network [
4], complete b-Ary network [
5], Gaussian, mesh, torus network [
6], cloud-computing platform [
7], edge-computing architecture [
8] and so on.
Existing studies have put forward various divisible-load scheduling models and algorithms to address numerous distinct constraints emerging in a realistic networked computing environment. For instance, the literature [
9] considers communication and computation startup overheads in the divisible-load scheduling models and proves that startup overheads have an unneglectable impact on the makespan. The authors of [
10] designed a multi-installment scheduling model to deal with servers that have a limited number of memory buffers and cannot hold the whole load package. To address the time-varying issues of computing speeds and transmitting speeds, the authors of [
11] proposed two recursive algorithms and one iterative algorithm coping with two different situations: one in which workloads arrive and depart based on a previously known schedule, and one in which nothing occurs. The authors of [
12] considered scheduling divisible loads in systems with hierarchical memory, which has different time and energy efficiencies for varying levels of memory. Core memory is time-efficient but too small to hold the whole workload, while external memory is more costly both in terms of time and energy. Hence, a multi-installment scheduling strategy was proposed to avoid using out-of-core storage. One study [
13] found that the computation and communication-rate-cheating problem has a considerable impact on the applications of divisible-load scheduling. The authors of [
14] studied the influence of available server times on the makespan of divisible loads in networked systems. The authors of [
15] presented a next-generation novel multi-cloud architecture with arbitrary server release times. Based on this architecture, a dynamic scheduling strategy was proposed, which allows servers to estimate their ready times for receiving and processing load fractions in order to guarantee load balancing and high performance of the system. Besides server release times, the authors of [
16] also considered finite-size buffer capacity when scheduling computationally intensive divisible loads in bus networks. One study [
17] designed an efficient scheduling algorithm for fault workload redistribution in response to frequent server failures.
The above studies are all at the theoretical level. In contrast, at the practical level, DLT works spectacularly well in many big-data-related applications, such as real-time video encoding [
18], large-scale image processing [
19], signature searching [
20], data-intensive flow optimization [
21], dynamic voltage and frequency regulation [
22] and so on. However, successful applications of DLT are all based on fine-grained divisible loads [
23,
24,
25,
26] igu. For example, in [
18], when solving the problem of image processing, an image is regarded as being composed of numerous pixels so that a large-scale image of several gigabytes can be abstracted as a fine-grained divisible workload, and further be divided and allocated on several servers in networked computing systems for parallel processing. However, in recent years, with the diversity of big data applications and the development of deep learning technology, people sometimes need to mine the correlation between data, so workloads cannot simply be divided into independent load partitions and distributed to separate servers for parallel computing. For example, when dealing with the problem of emotional analysis [
27], in order to extract and analyze people’s opinions on different products or services, it is usually necessary to read through the whole text rather than just relying on a word or character to complete emotional analysis. That is, data in this problem cannot be abstracted into fine-grained divisible loads (a word or a character as a unit) but can only be abstracted into coarse-grained divisible loads (a paragraph or a chapter as a unit). Another intuitive example is that when addressing the problem of image classification [
28], it is almost impossible to classify the image correctly by merely observing a single pixel or a part of the image. Similarly, data in this problem can no longer be arbitrarily divided and processed separately. Hence, this problem should be treated with regard to coarse-grained divisible-load scheduling.
Existing studies have proved that even fine-grained divisible-load scheduling problems in distributed computing systems are NP-hard [
29], not to mention coarse-grained load scheduling. Moreover, if we directly apply fine-grained scheduling models on coarse-grained divisible loads and inadvertently assign fragmented load partitions to servers without considering their granularity constraints, it will inevitably lead to partial loads left to be completed. Even if we first round up the load partitions according to coarse granularity and then distribute them, the efficiency of load processing is bound to be affected on networked computing systems. Furthermore, it is likely to cause time conflicts between two adjacent scheduling installments. Based on this background, in this paper, we design a new multi-installment scheduling model for coarse-grained loads with the objective of minimizing the makespan of the entire workload.
The rest of this paper is structured as follows. We first give a mathematical description of the coarse-grained divisible-load scheduling problem on networked computing systems in
Section 2, followed by a new multi-installment scheduling model.
Section 3 puts forward a heuristic algorithm to obtain a feasible load partitioning scheme, and
Section 4 evaluates its performance through rigorous simulation experiments.
Section 5 provides the conclusions.
2. Coarse-Grained Divisible-Load Scheduling Model
Consider a networked computing system that consists of servers connected in a star topology, where denotes the master server and represents computing servers. Server is accountable for dividing workloads and assigning load fractions to servers in several installments, while the latter is responsible for load computation. Each server has a constant computation startup overhead, denoted as for server , representing the time it takes to start specific components or programs needed for load computation. It takes server time to compute the unit size of load, so for a workload with size , it requires time . The master connects each server via communication links, denoted as . Link has a constant communication startup overhead, defined as . It takes link time to transmit the unit size of load, and thus it requires time to transmit a workload with size . The master distributes load fractions to servers in the order of to . Each server starts computing when it receives the whole part of its assignment from .
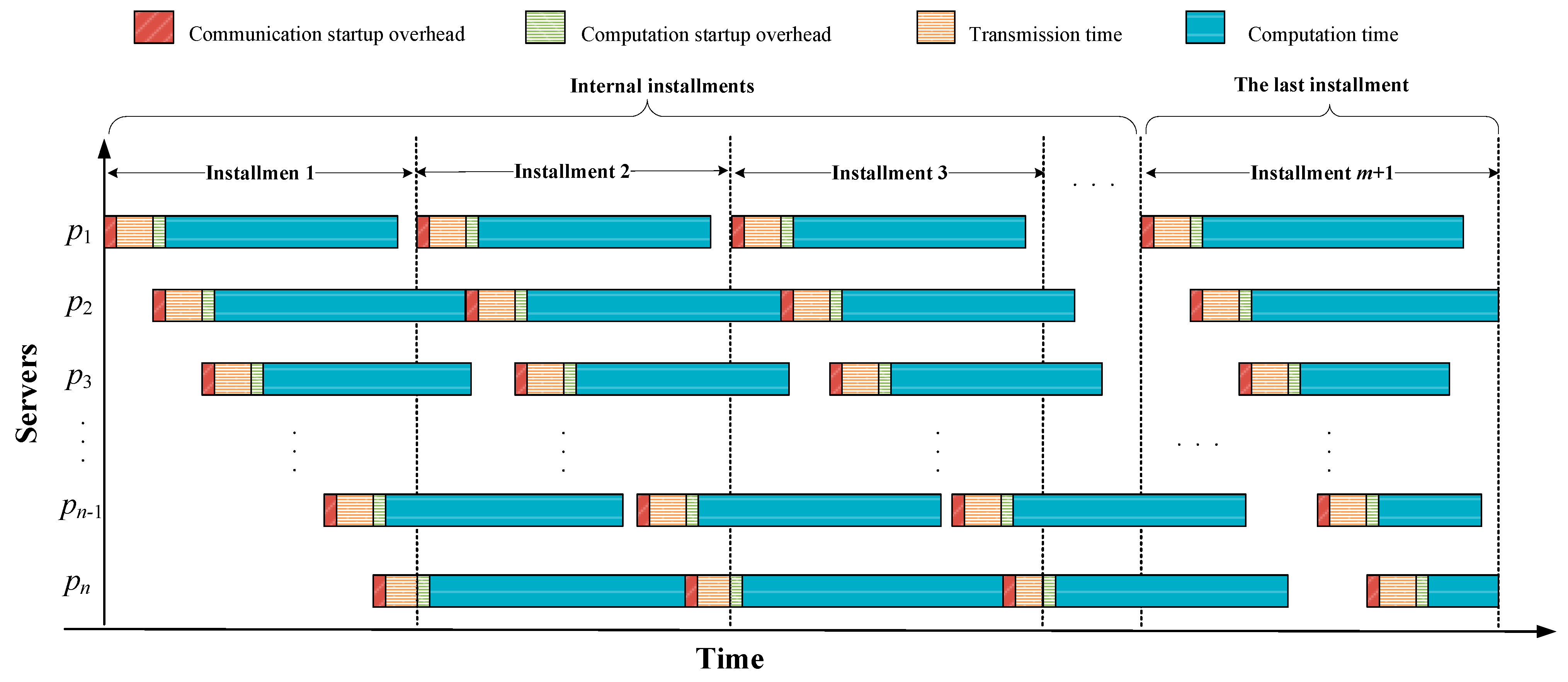
Figure 1 shows the Gantt chart for coarse-grained multi-installment scheduling. As can be seen, the whole scheduling process is composed of
installments, where the first
installments, termed as internal installments, are uniform. The last installment is different from internal installments as it guarantees all servers finish computing at the same time as much as possible. As for fine-grained divisible loads, to achieve the shortest makespan, all servers involved in workload computation are supposed to complete their computing simultaneously. If not, one can always transfer partial load fractions distributed to the server that completes computation later to the server that finishes computing earlier, thus decreasing the makespan of the entire workload. This is referred to as the
Optimality Principle in DLT [
9]. However, when it comes to coarse-grained divisible loads, the Optimality Principle is no longer applicable. Still, we can find a feasible load partitioning scheme in the last installment to make the completion time of all servers as close as possible.
Suppose the coarse-grained divisible load with size
arrives at the master at time
. Let granularity
represent the minimum scale of load partition. For example,
could be the size of an image when dealing with image classification. The master assigns server
load
and
in every internal installment and the last installment, respectively, where
and
are load partitioning coefficients that are integers greater than 0; that is,
and
. In each internal installment and the last installment, the total size of load partitions that all servers are supposed to complete is
.
Table 1 lists the commonly used notations in this paper for the reader’s convenience.
The total makespan depends upon the last server completing its assigned load fractions. The shorter the makespan, the better the scheduling strategy. Therefore, our goal in this paper is to search for a feasible load partitioning scheme that minimizes the makespan of the entire coarse-grained workload.
As for fine-grained divisible loads, there is no time interval for any server between any two adjacent internal installments. By contrast, the load partitioning scheme is subject to integer constraints for coarse-grained loads, and thus internal installments may not be closely connected to each other. Therefore, in order to achieve the shortest makespan of coarse-grained divisible loads, it is necessary to minimize the time gap between any two adjacent internal installments. Let
and
be the start and end time of server
in the
th internal installment, respectively. As for the first server
, the start time of its first installment is
, while the start time
of its
th internal installment depends on two factors: whether it has finished its computation in the
th installment and whether the master has finished transmitting load partitions for all servers in the
th installment. That is,
The end time of server
in the
th internal installment equals its start time in the
th internal installment plus the load transmission time and load computation time, as follows:
Server
starts its first installment when its previous server
finishes load transmission from the master. That is,
The start time
of server
in the
th internal installment is determined by the end time of its previous installment and the time when its previous server finishes receiving its load fraction from the master. Hence, we have
Therefore, the end time
of server
in the
th internal installment is
The start time
of the first server
in the last installment should be no earlier than the end time of its internal installments or the time at which the master finishes load transmitting for all servers in the internal installments. That is,
The end time of server
in the last installment equals its start time in the last installment plus the load transmission time and load computation time:
Similarly, the start time and end time of server
in the last installment are as follows:
The total makespan
depends upon the last server completing its assigned load fractions in the last installment. Hence, we can obtain
where
and
.
Based on the above analysis, we build a new multi-installment scheduling model for coarse-grained divisible loads, aiming at a minimum makespan
T on networked computing systems:
subject to
- (a)
.
- (b)
where
As given in the proposed model, we aim to minimize the total makespan. This model involves two sets of variables: load partitioning scheme for internal installments and load partitioning scheme for the last installment. Additionally, this model has two specified constraints. The first constraint indicates that every load partition assigned to servers must be a positive integer since the scheduling problem considered in this paper focuses on coarse-grained divisible loads. The second constraint means that the total amount of load completed by all servers in each installment should be at least as large as because the scheduling process is supposed to be periodic for computational simplicity.
3. Heuristic Scheduling Algorithm
As for fine-grained workloads, one can obtain a closed-form solution to an optimal load partitioning scheme for internal installments based on the assumption that the internal scheduling time of each server is absolutely the same. Meanwhile, one can also obtain a closed-form solution to an optimal load partitioning scheme for the last installment since all servers finish computing simultaneously. However, for coarse-grained loads, the above two conditions for obtaining an optimal load partition cannot be satisfied.
In order to obtain the shortest makespan of coarse-grained divisible loads, the time consumed by each server in every internal installment should be as close as possible. Let
be an upper bound for the completion time of servers in each internal installment. We can obtain a solution to load partitioning scheme
by looking for a feasible value of
. The upper bound
satisfies
Rearranging Equation (12) yields
According to constraints (a) and (b) in the proposed model, we have
Substituting Equation (13) into Equation (14) results in
Rearranging Equation (15), one can obtain the upper and lower bounds of
as follows:
A feasible solution to load partitioning scheme that meets the constraint in Equation (14) can be obtained via a binary search of on interval .
Similarly, let
be an upper bound for the completion time of servers in the last installment. By searching for the value of
, one can obtain a feasible solution to load partitioning scheme
. The upper bound
satisfies
where
and
represent the end times of server
in the last installment when it has been assigned load fractions
and
, respectively.
By substituting Equation (7) into Equation (17), we obtain
Rearranging Equation (18) yields
Likewise, by bringing Equations (8) and (9) into Equation (17), we shall arrive at
According to constraints (a) and (b) in the proposed model, we have
Hence, a feasible solution to load partitioning scheme that meets the constraint in Equation (21) can be obtained via a binary search of on interval .
To sum up, via a binary search of
and
, one can obtain a feasible solution to load partitioning schemes
and
, respectively, thus solving the proposed model. Algorithm 1 shows the framework of this heuristic algorithm in detail.
| Algorithm 1 A Heuristic Algorithm for Scheduling Coarse-Grained Divisible Loads |
Input: , , , , , with .
Output: A feasible load partitioning scheme for internal installments and for the last installment.
Step 1: Obtain the upper and lower bounds of by Equation (16);
Step 2: ;
Step 3: Obtain load partition for internal installments by Equation (13);
Step 4: If , then ; else if , then ;
Step 5: If does not satisfy Equation (14), go to step 2;
Step 6: , ;
Step 7: ;
Step 8: Obtain load partition for the last installment by Equations (19) and (20);
Step 9: If , then ; else if , then ;
Step 10: If does not satisfy Equation (21), go to step 7;
Step 11: Return and . |
Steps 1 to 5 in Algorithm 1 obtain a valid load partitioning scheme for internal installments via a binary search of on interval given in Equation (16), while steps 6 to 10 obtain this for the last installment via a binary search of on interval . The complexity of steps 1, 3, 4, 5, 8 and 9 is ,while the complexity of step 6 is . Therefore, in the best-case scenario, steps 2 to 5 and steps 7 to 10 only cycle once to find an optimal solution, and the overall time complexity of the proposed heuristic scheduling algorithm is .
4. Experiments and Result Analysis
We will compare in this section the proposed model and algorithm with an up-to-date periodic multi-installment scheduling model and algorithm proposed in [
30] (abbreviated as PMIS) under the scenarios of coarse-grained workloads. In the following simulations,
; that is, there are 15 servers involved in workload computation. The parameters of the heterogenous networked computing system are given in
Table 2.
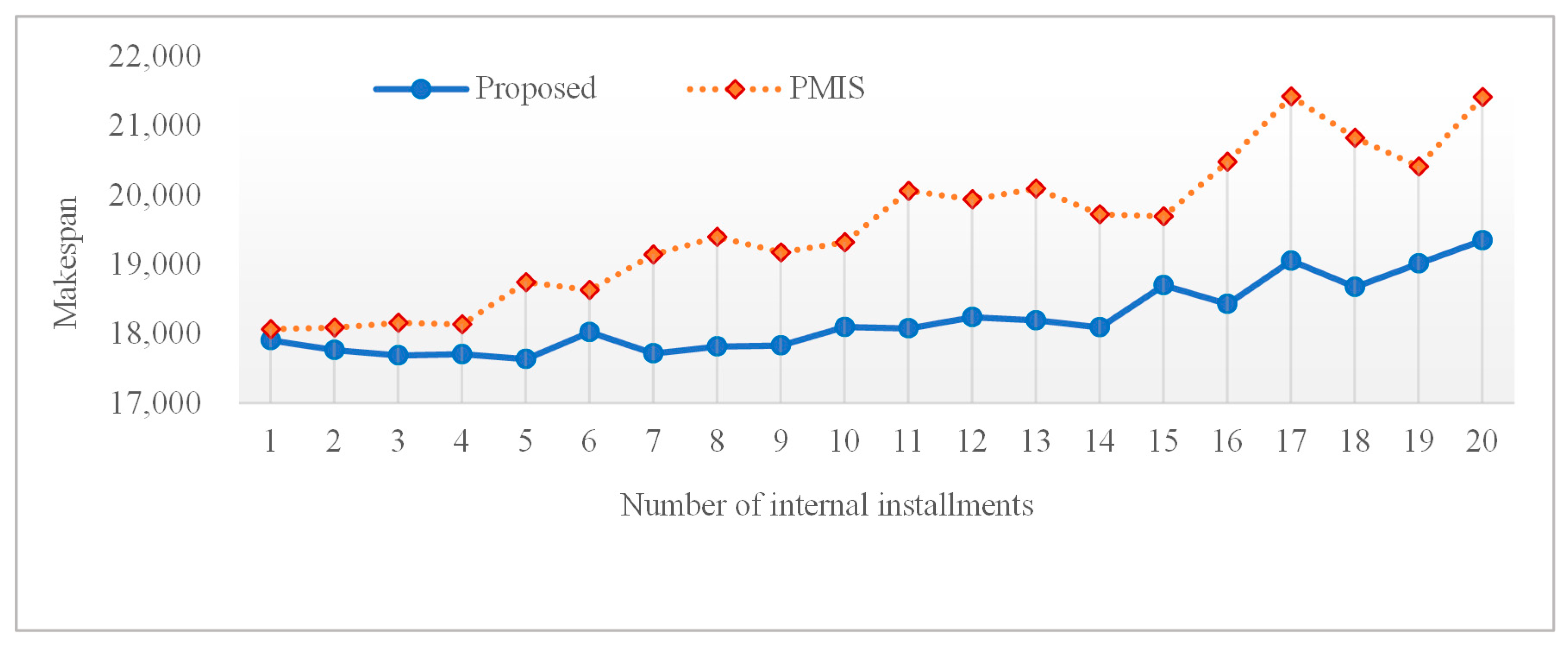
We conduct three sets of experiments. In the first one, the size of workloads and its granularity are set to be 10,000 and 8, respectively. That is,
and
. Additionally, we round up the number of load partitions obtained by PMIS to meet the coarse granularity constraints.
Figure 2 shows the makespan obtained by the two algorithms with different numbers of installments varying from 1 to 20.
In
Figure 2, the X axis denotes different numbers of internal installments, while the Y axis represents the total makespan. As seen from this figure, the algorithm proposed in this paper outperforms PMIS in solving coarse-grained divisible-load scheduling problems as it can obtain a shorter makespan of workloads. Additionally, it is worth mentioning that for fine-grained workloads, it has been proved in [
30] that the makespan first decreases and then increases with an increase in the number of installments. However, one can observe from
Figure 2 that for coarse-grained divisible loads, the relationship between the makespan and the number of installments no longer follows the above rule.
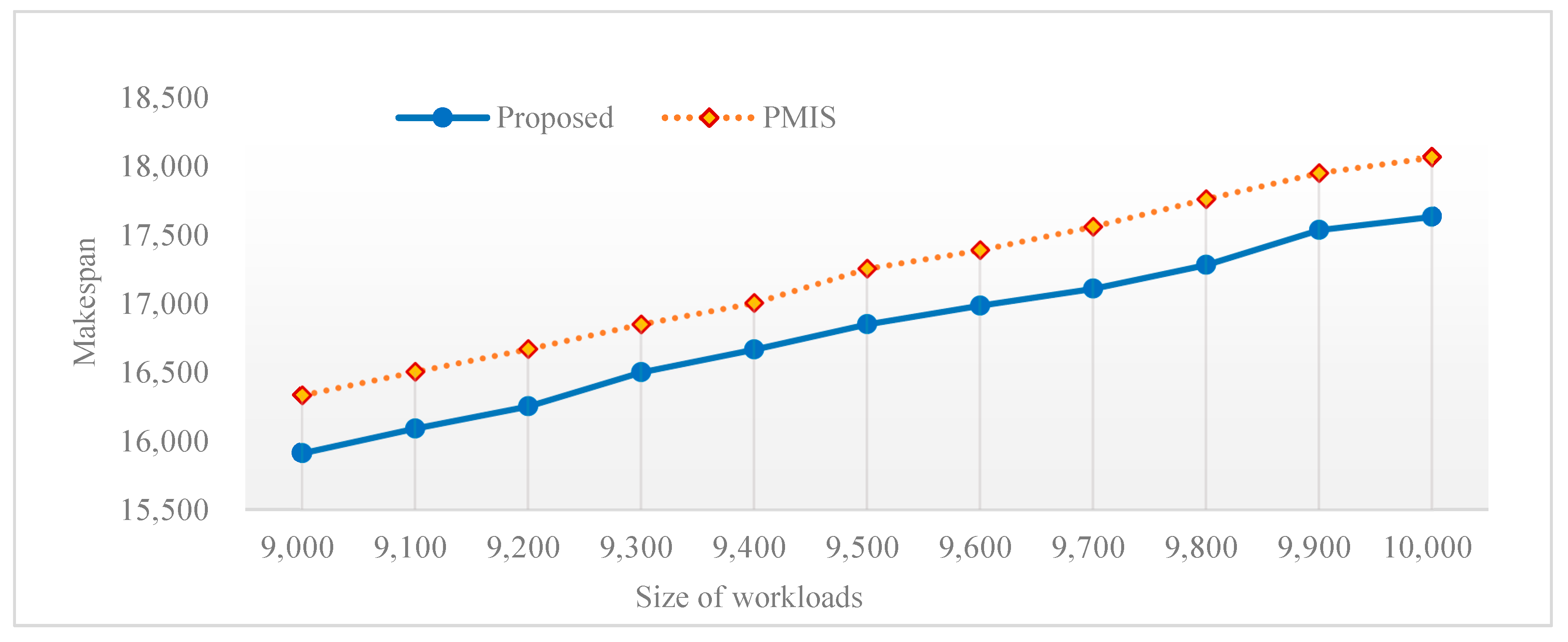
Next, we compare the proposed algorithm with PMIS for different sizes of workloads ranging from 9000 to 10,000 with the same granularity,
.
Figure 3 shows the makespan versus the size of workloads. As can be seen from this figure, the proposed algorithm is superior to the existing algorithm in minimizing the makespan no matter how large the workload is.
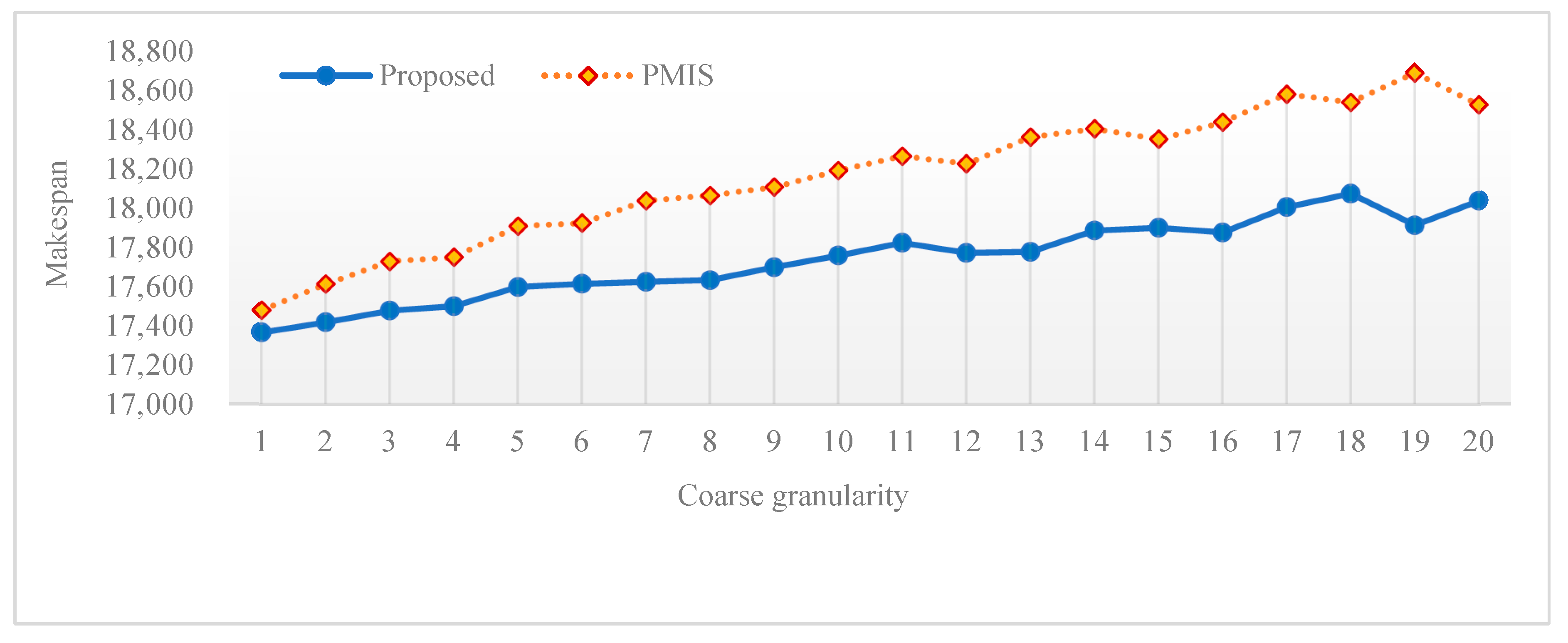
Additionally,
Figure 4 shows a comparison of the results between the proposed algorithm and PMIS under the same workload size (
) with various coarse granularities varying from 1 to 20. On the one hand, we can observe from this figure that for any granularity, the makespan obtained by the proposed algorithm is shorter than that achieved by PMIS. On the other hand, with an increase in coarse granularity, the makespan shows an upward trend. This is because the greater the granularity, the higher the possibility that the gap between adjacent installments of each server turns out to be large. For fully fine-grained workloads, the gap reaches the minimum; that is, there is no time gap between any adjacent internal installments. By contrast, for coarse-grained workloads, with an increase of granularity, the time gap between internal installments may become larger, and additionally, the differences in the end times of servers in the last installment may widen.






{kind=link}
{kind=link}
{kind=link}
{kind=link}