
Synergistic Mechanism of Designing Information Granules with the Use of the Principle of Justifiable Granularity


Abstract
:1. Introduction
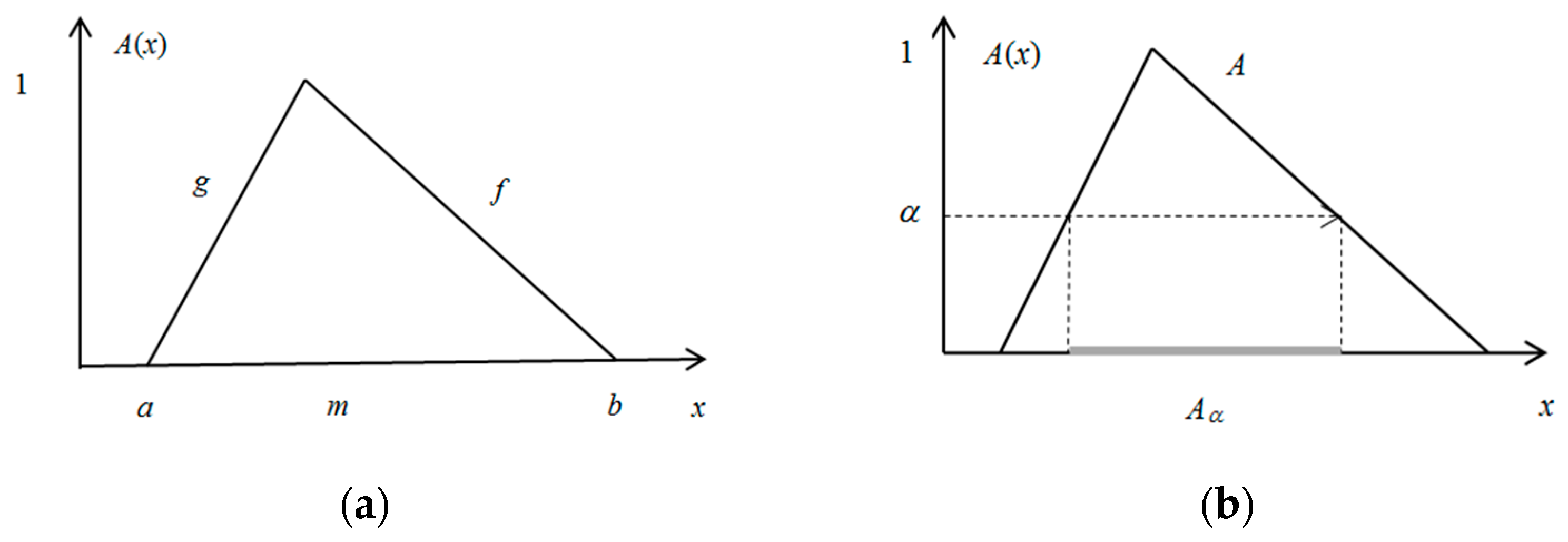
2. Construction of Fuzzy Sets with the Use of the Principle of Justifiable Granularity
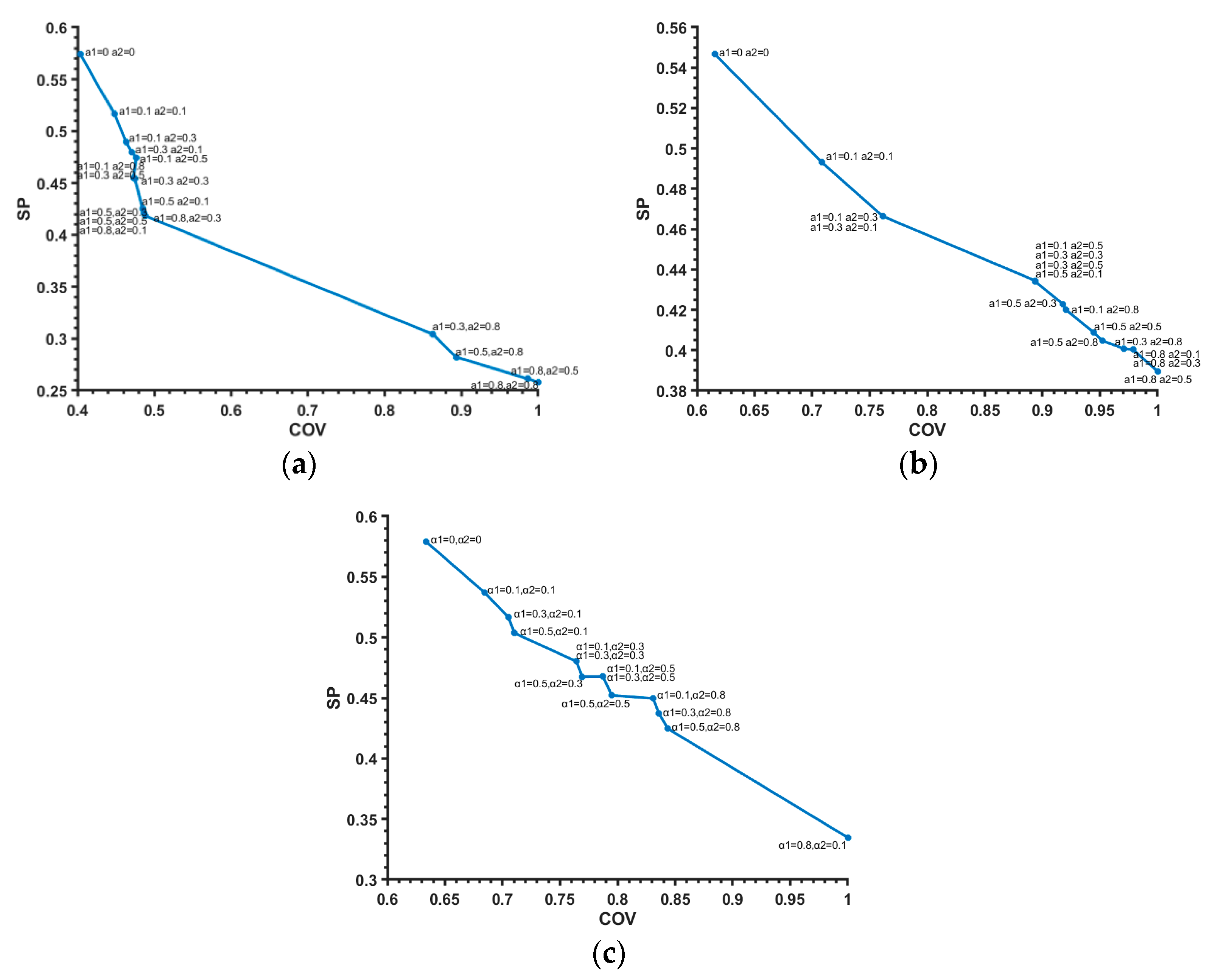
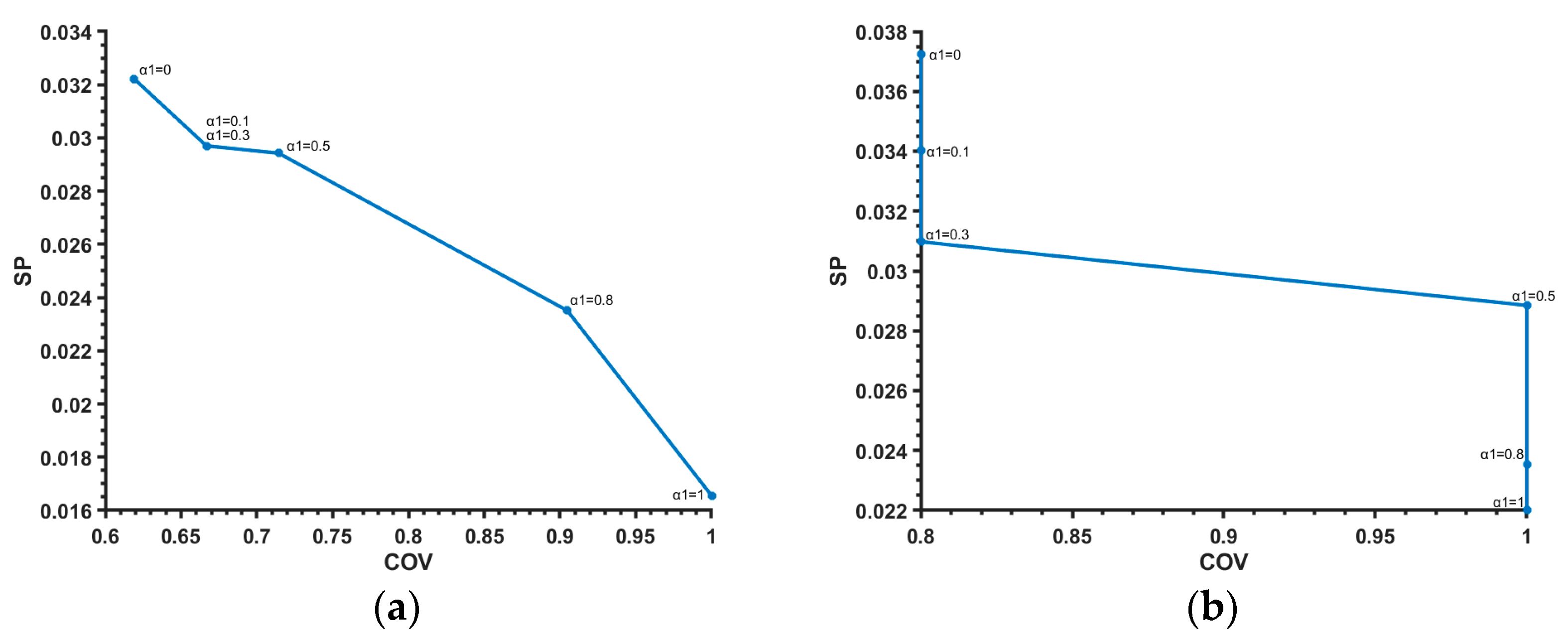
- Coverage (cov) implies the ability of the information granule to reflect the experimental data. In other words, it is anticipated that the information granule will “cover” more experimental data. For instance, if an information granule is an interval, then the more data included in the bounds of the interval, the better. In the case of fuzzy sets, we expect that the sum value of the membership grades of the data included in the bounds of the information granule will be as high as possible. However, it is required that the information granule be specific enough.
- The specificity (sp) criterion concerns the semantic meaning of the information granules. This requires the information granules to be highly detailed (more specific), so we expect a smaller information granule.
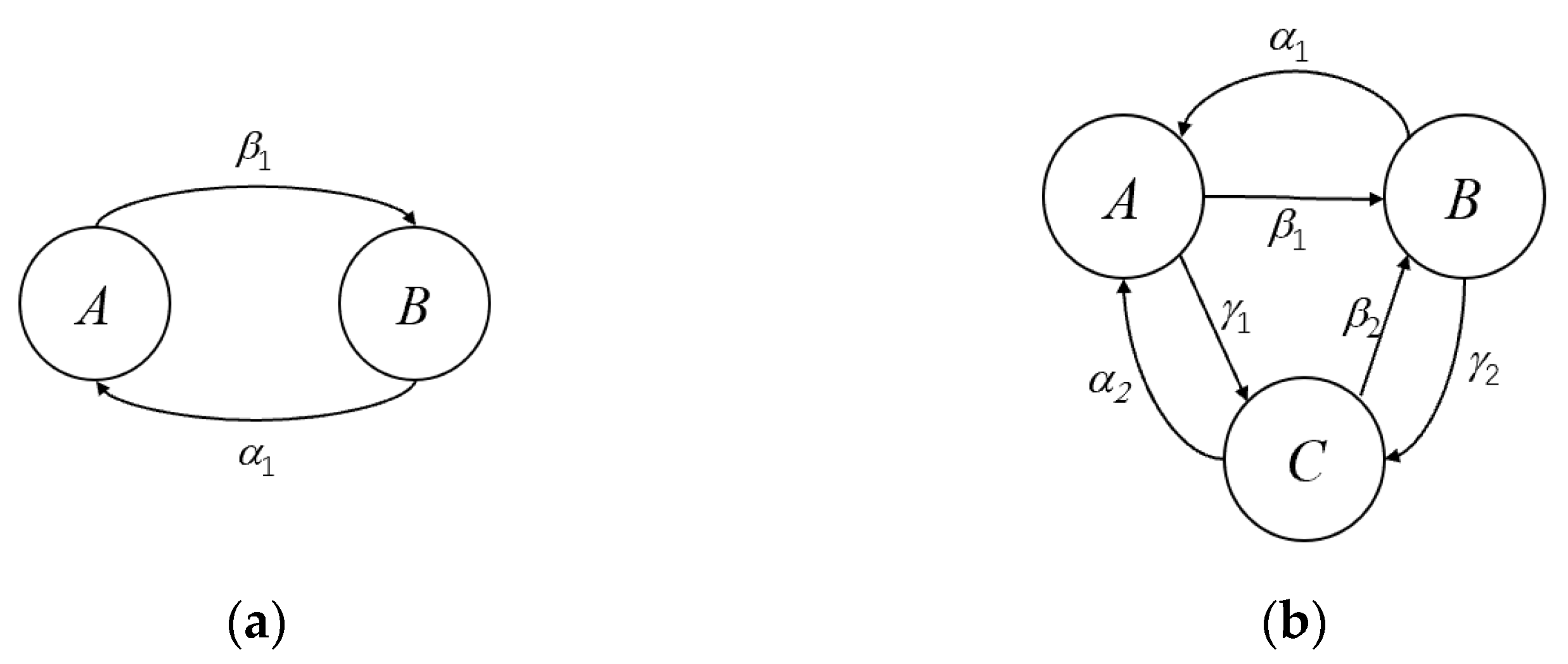
3. Synergistic Mechanism of the Principle of Justifiable Granularity
| Algorithm 1: Synergistic mechanism of the principle of justifiable granularity |
| Input: Two-dimensional data set in pairs (xk, yk), k = 1, 2, …, N; number of clusters c; fuzzy coefficient m = 2.0; impact factor α1, β1, iteration of the optimization process epoch; Output: Optimized information granules A and B 1: Initialize the position of information granules A and B following standard FCM 2: Select the prototypes vi and wi, i = 1, 2, …, c, as the numeric representative of the principle of justifiable granularity 3: while iter = 1, 2, …, epoch do 4: update the position of information granules A and B 5: 6: 7: 8: end while 9: |
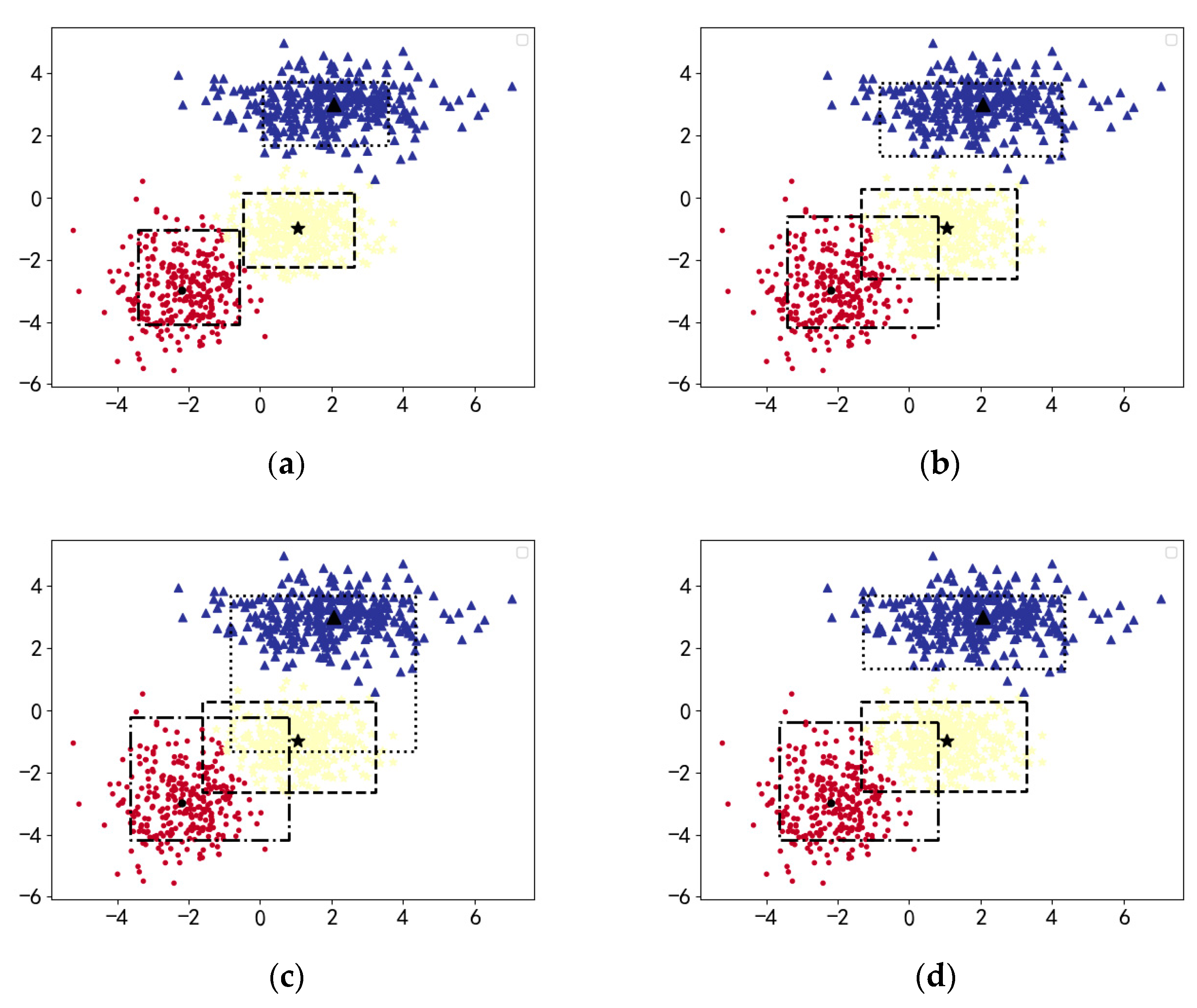
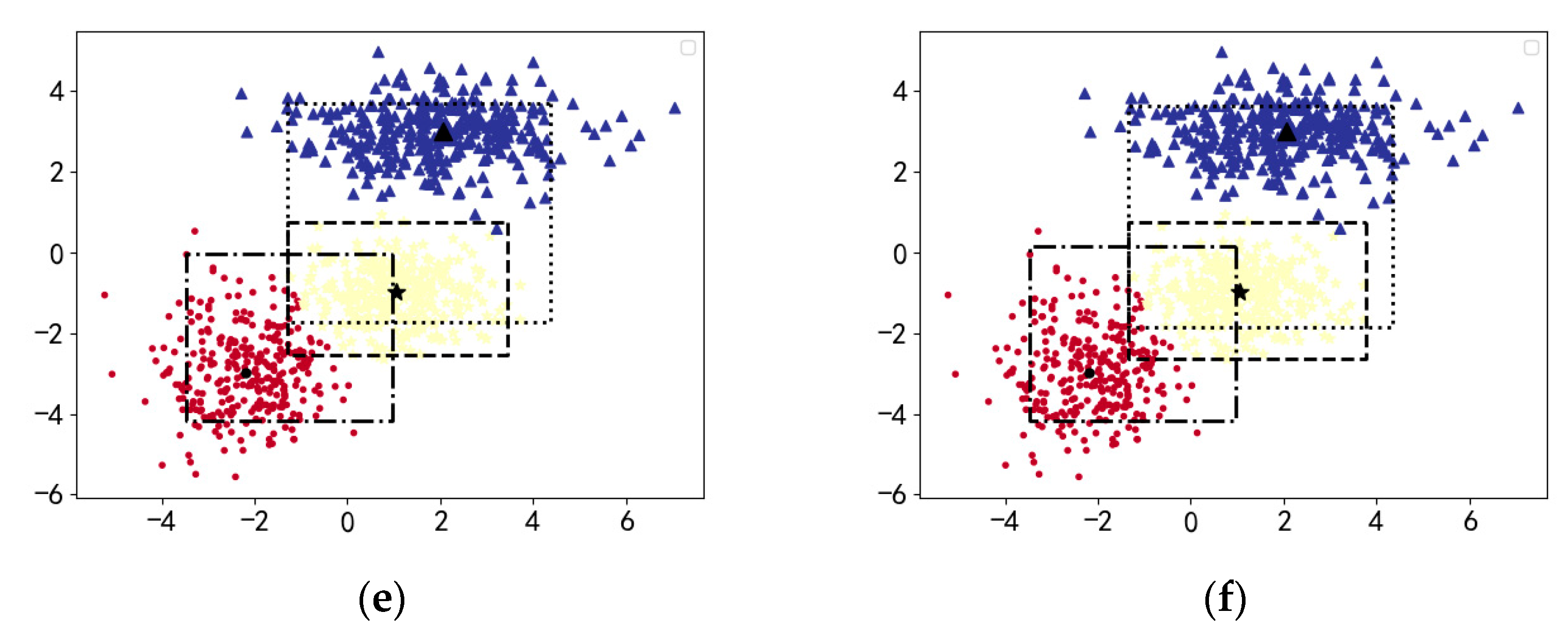
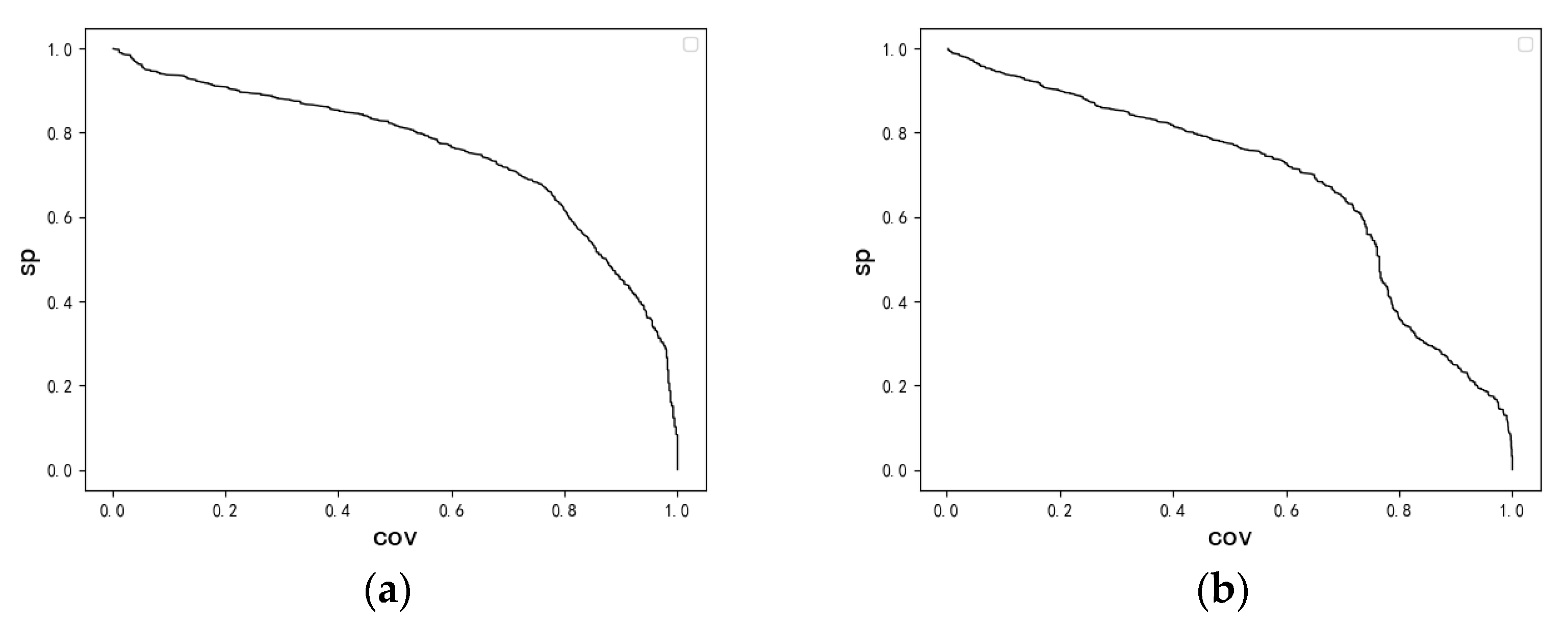
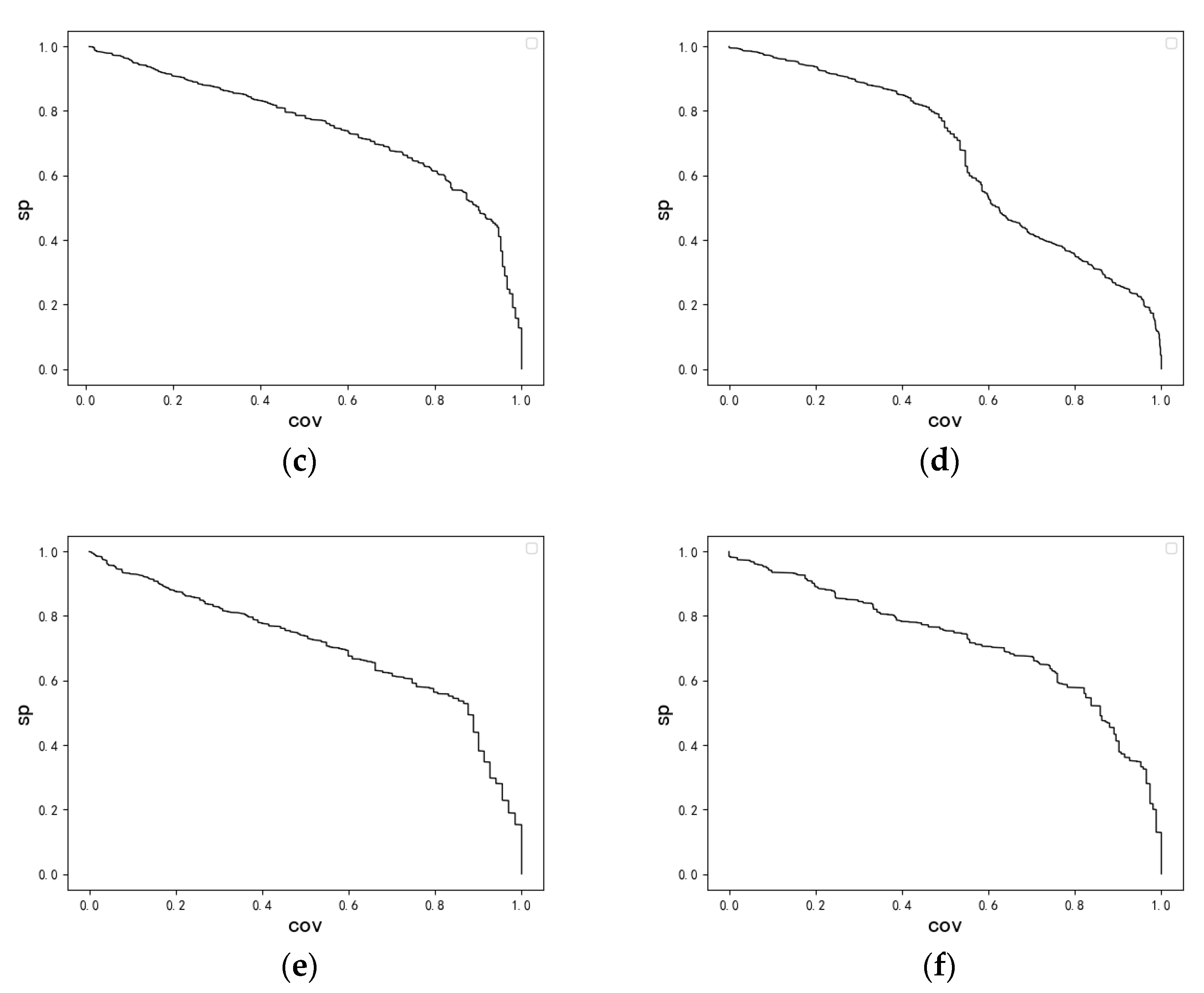
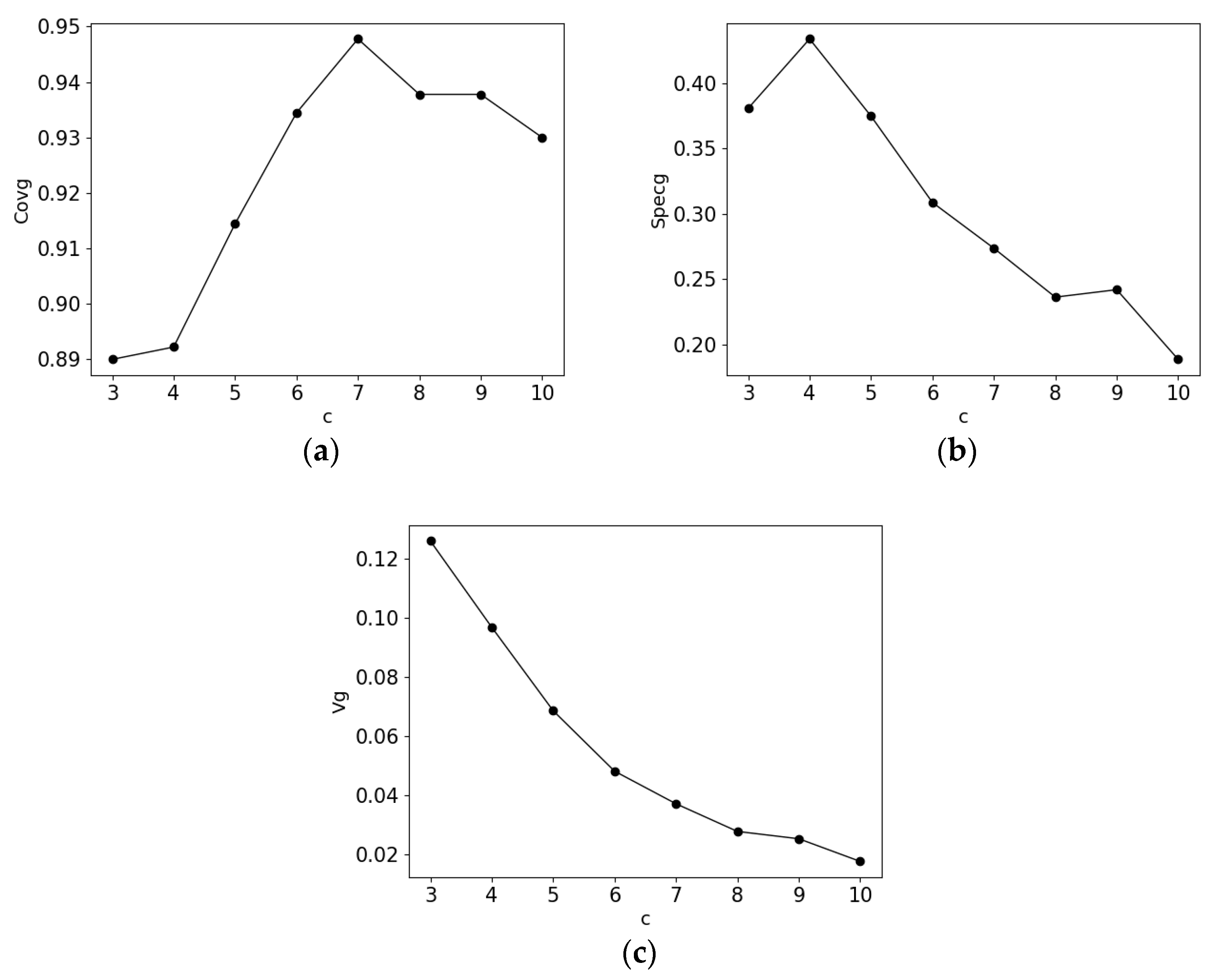
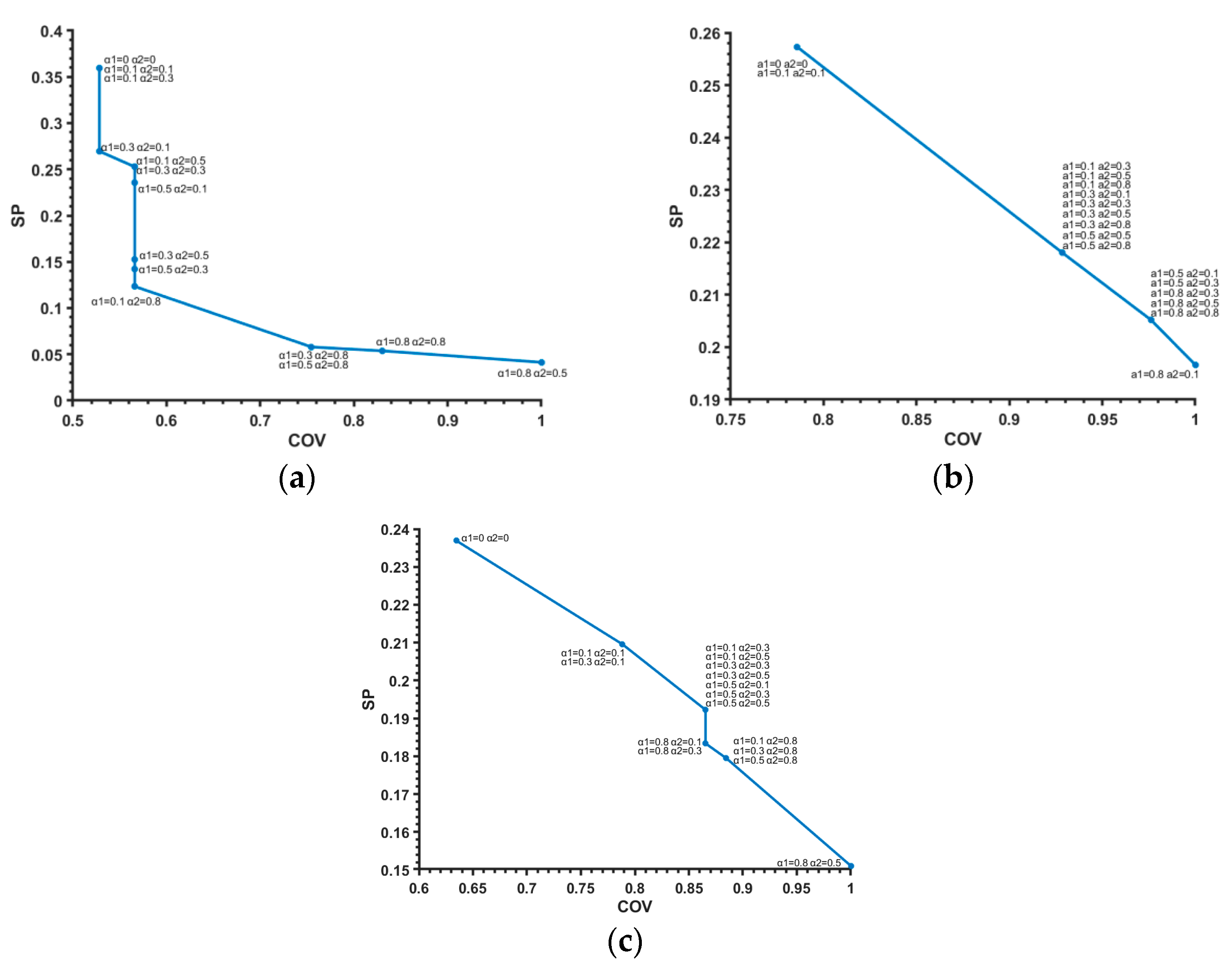
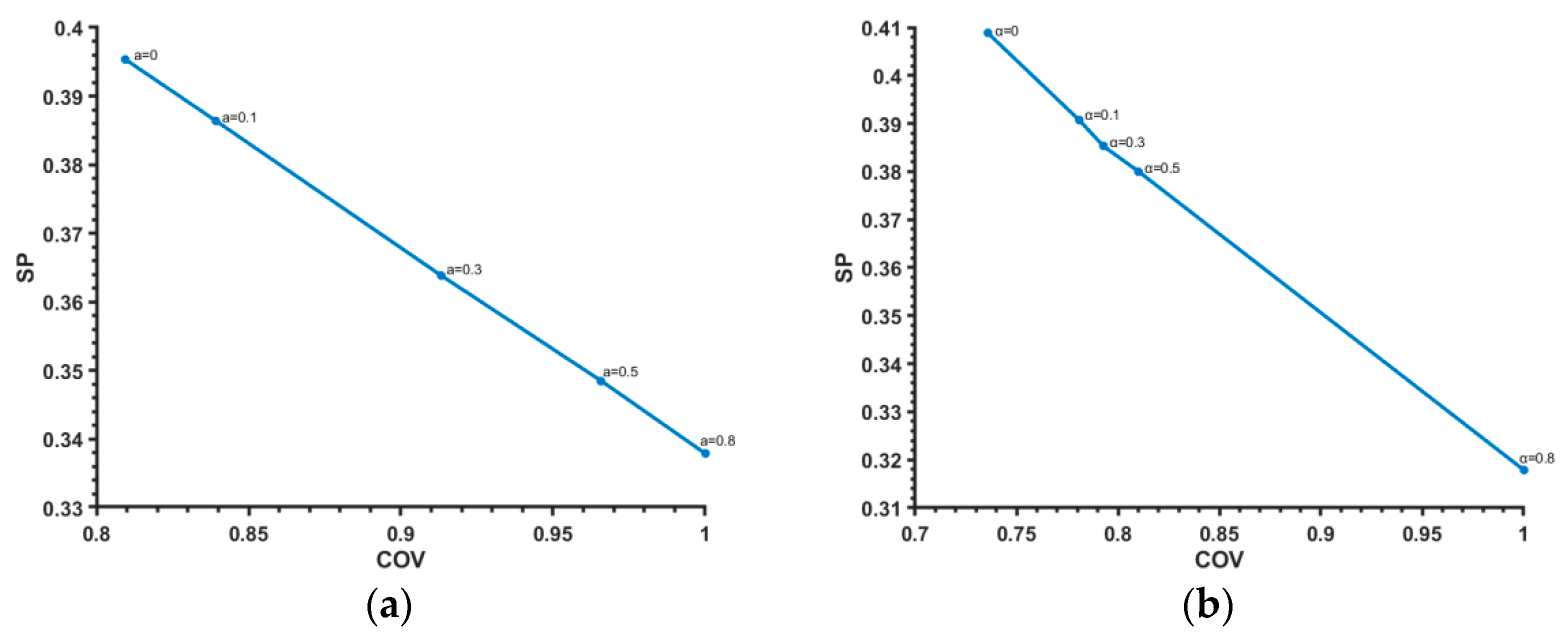
4. Experimental Studies
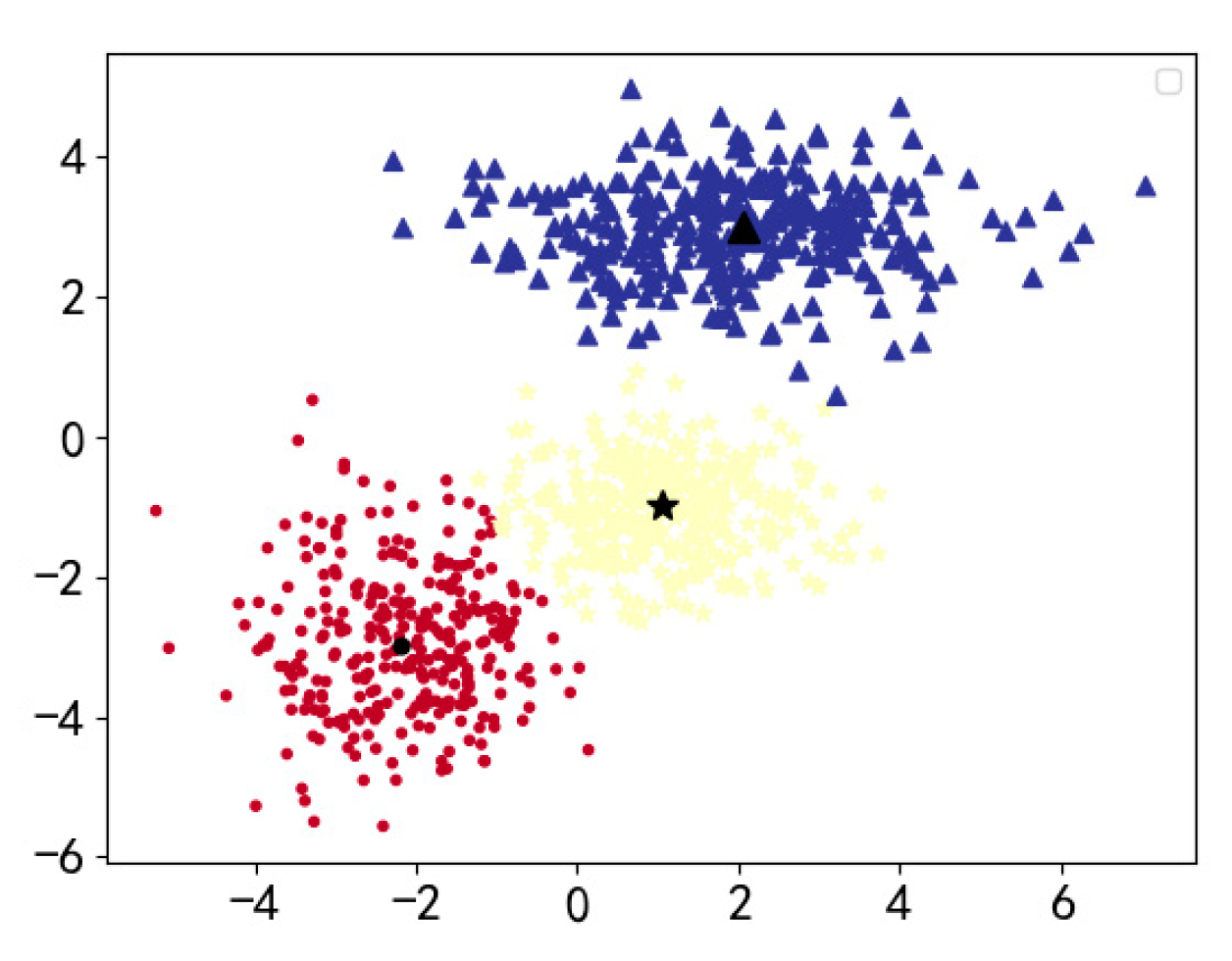
4.1. Synthetic Data Set
4.2. KEEL Machine Learning Data Sets
4.2.1. Iris Data Set
4.2.2. Banana Data Set
4.2.3. Appendicitis Data Set
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zadeh, L.A. Toward a theory of fuzzy information granulation and its centrality in human reasoning and fuzzy logic. Fuzzy Sets Syst. 1997, 90, 111–127. [Google Scholar] [CrossRef]
- Zadeh, L.A. Some reflections on soft computing, granular computing and their roles in the conception, design and utilization of information/intelligent systems. Soft Comput. 1998, 2, 23–25. [Google Scholar] [CrossRef]
- Yao, J.T.; Vasilakos, A.V.; Pedrycz, W. Granular Computing: Perspectives and Challenges. IEEE Trans. Cybern. 2013, 43, 1977–1989. [Google Scholar] [CrossRef]
- Pawlak, Z.; Skowron, A. Rough sets: Some extensions. Inf. Sci. 2007, 177, 28–40. [Google Scholar] [CrossRef] [Green Version]
- Pedrycz, W. Shadowed sets: Representing and processing fuzzy sets. IEEE Trans. Syst. Man Cybern. Part B (Cybernetics) 1998, 28, 103–109. [Google Scholar] [CrossRef]
- Hirota, K. Concepts of probabilistic sets. Fuzzy Sets Syst. 1981, 5, 31–46. [Google Scholar] [CrossRef]
- Yao, Y.Y. Information granulation and rough set approximation. Int. J. Intell. Syst. 2001, 16, 87–104. [Google Scholar] [CrossRef]
- Wang, D.; Pedrycz, W.; Li, Z. Granular Data Aggregation: An Adaptive Principle of the Justifiable Granularity Approach. IEEE Trans. Cybern. 2018, 49, 417–426. [Google Scholar] [CrossRef]
- Pedrycz, W.; Al-Hmouz, R.; Balamash, A.S.; Morfeq, A. Hierarchical Granular Clustering: An Emergence of Information Granules of Higher Type and Higher Order. IEEE Trans. Fuzzy Syst. 2015, 23, 2270–2283. [Google Scholar] [CrossRef]
- Sanchez, M.A.; Castillo, O.; Castro, J.R. Information granule formation via the concept of uncertainty-based information with Interval Type-2 Fuzzy Sets representation and Takagi–Sugeno–Kang consequents optimized with Cuckoo search. Appl. Soft Comput. 2015, 27, 602–609. [Google Scholar] [CrossRef]
- Pedrycz, W.; Wang, X. Designing Fuzzy Sets With the Use of the Parametric Principle of Justifiable Granularity. IEEE Trans. Fuzzy Syst. 2015, 24, 489–496. [Google Scholar] [CrossRef]
- Zadeh, L.A. Fuzzy sets. Inf. Control. 1965, 8, 338–353. [Google Scholar] [CrossRef] [Green Version]
- Zhang, B.; Pedrycz, W.; Wang, X.; Gacek, A. Design of Interval Type-2 Information Granules Based on the Principle of Justifiable Granularity. IEEE Trans. Fuzzy Syst. 2020, 29, 3456–3469. [Google Scholar] [CrossRef]
- Wang, L.; Zhao, F.; Guo, H.; Liu, X.; Pedrycz, W. Top-Down Granulation Modeling Based on the Principle of Justifiable Granularity. IEEE Trans. Fuzzy Syst. 2020, 30, 701–713. [Google Scholar] [CrossRef]
- Ouyang, T.; Pedrycz, W.; Pizzi, N.J. Rule-Based Modeling With DBSCAN-Based Information Granules. IEEE Trans. Cybern. 2019, 51, 3653–3663. [Google Scholar] [CrossRef]
- Lu, W.; Ma, C.; Pedrycz, W.; Yang, J. Design of Granular Model: A Method Driven by Hyper-Box Iteration Granulation. IEEE Trans. Cybern. 2021, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Lu, W.; Shan, D.; Pedrycz, W.; Zhang, L.; Yang, J.; Liu, X. Granular Fuzzy Modeling for Multidimensional Numeric Data: A Layered Approach Based on Hyperbox. IEEE Trans. Fuzzy Syst. 2018, 27, 775–789. [Google Scholar] [CrossRef]
- Shan, D.; Lu, W.; Yang, J. Interval Granular Fuzzy Models: Concepts and Development. IEEE Access 2019, 7, 24140–24153. [Google Scholar] [CrossRef]
- Jing, T.L.; Wang, C.; Pedrycz, W.; Li, Z.W.; Succi, G.; Zhou, M.C. Granular models as networks of associations of information granules: A development scheme via augmented principle of justifiable granularity. Appl. Soft Comput. 2022, 115, 108062. [Google Scholar] [CrossRef]
- Wang, D.; Pedrycz, W.; Li, Z.W. Design of granular interval-valued information granules with the use of the principle of justifiable granularity and their applications to system modeling of higher type. Soft Comput. 2016, 20, 2119–2134. [Google Scholar] [CrossRef]
- Wang, D.; Nie, P.; Zhu, X.; Pedrycz, W.; Li, Z.W. Designing of higher order information granules through clustering heterogeneous granular data. Appl. Soft Comput. 2021, 112, 107820. [Google Scholar] [CrossRef]
- Pedrycz, W. The Principle of Justifiable Granularity and an Optimization of Information Granularity Allocation as Fundamentals of Granular Computing. J. Inf. Process. Syst. 2011, 7, 397–412. [Google Scholar] [CrossRef] [Green Version]
- Pedrycz, W.; Homenda, W. Building the fundamentals of granular computing: A principle of justifiable granularity. Appl. Soft Comput. 2013, 13, 4209–4218. [Google Scholar] [CrossRef]
- Pedrycz, W. Allocation of information granularity in optimization and decision-making models: Towards building the foundations of Granular Computing. Eur. J. Oper. Res. 2014, 232, 137–145. [Google Scholar] [CrossRef]
- Pal, N.R.; Bezdek, J.C. On cluster validity for the fuzzy c-means model. IEEE Trans. Fuzzy Syst. 1995, 3, 370–379. [Google Scholar] [CrossRef]
- Fu, C.; Lu, W.; Pedrycz, W.; Yang, J. Fuzzy granular classification based on the principle of justifiable granularity. Knowledge-Based Syst. 2019, 170, 89–101. [Google Scholar] [CrossRef]
- Hu, X.; Pedrycz, W.; Wang, X. Fuzzy classifiers with information granules in feature space and logic-based computing. Pattern Recognit. 2018, 80, 156–167. [Google Scholar] [CrossRef]
- Hanyu, E.; Cui, Y.; Pedrycz, W.; Li, Z.W. Enhancements of rule-based models through refinements of Fuzzy C-Means. Knowl.-Based Syst. 2019, 170, 43–60. [Google Scholar] [CrossRef]
- Wang, D.; Pedrycz, W.; Li, Z.W. A Two-Phase Development of Fuzzy Rule-Based Model and Their Analysis. IEEE Access 2019, 7, 80328–80341. [Google Scholar] [CrossRef]
- Anari, Z.; Hatamlou, A.; Anari, B. Automatic Finding Trapezoidal Membership Functions in Mining Fuzzy Association Rules Based on Learning Automata. Int. J. Interact. Multimedia Artif. Intell. 2022, 7, 4. [Google Scholar] [CrossRef]
- Cepeda-Negrete, J.; Sanchez-Yanez, R.E. Automatic selection of color constancy algorithms for dark image enhancement by fuzzy rule-based reasoning. Appl. Soft Comput. 2015, 28, 1–10. [Google Scholar] [CrossRef]
- Gino Sophia, S.G.; Ceronmani Sharmila, V. Zadeh max–min composition fuzzy rule for dominated pixel values in iris localization. Soft Comput. 2019, 23, 1873–1889. [Google Scholar] [CrossRef]
- Cerrada, M.; Li, C.; Sánchez, R.-V.; Pacheco, F.; Cabrera, D.; de Oliveira, J.V. A fuzzy transition based approach for fault severity prediction in helical gearboxes. Fuzzy Sets Syst. 2018, 337, 52–73. [Google Scholar] [CrossRef]
- Hu, X.; Pedrycz, W.; Wang, X. Granular Fuzzy Rule-Based Models: A Study in a Comprehensive Evaluation and Construction of Fuzzy Models. IEEE Trans. Fuzzy Syst. 2016, 25, 1342–1355. [Google Scholar] [CrossRef]
- Pedrycz, W.; Bezdek, J.C.; Hathaway, R.J.; Rogers, G.W. Two nonparametric models for fusing heterogeneous fuzzy data. IEEE Trans. Fuzzy Syst. 1998, 6, 411–425. [Google Scholar] [CrossRef]
- Zuo, H.; Zhang, G.; Pedrycz, W.; Behbood, V.; Lu, J. Granular Fuzzy Regression Domain Adaptation in Takagi–Sugeno Fuzzy Models. IEEE Trans. Fuzzy Syst. 2017, 26, 847–858. [Google Scholar] [CrossRef]
- Ren, Y.; Guan, W.; Liu, W.; Xi, J.; Zhu, L. Facial semantic descriptors based on information granules. Inf. Sci. 2019, 479, 335–354. [Google Scholar] [CrossRef]
- Froelich, W.; Salmeron, J.L. Evolutionary learning of fuzzy grey cognitive maps for the forecasting of multivariate, interval-valued time series. Int. J. Approx. Reason. 2014, 55, 1319–1335. [Google Scholar] [CrossRef]
- Han, Z.; Pedrycz, W.; Zhao, J.; Wang, W. Hierarchical Granular Computing-Based Model and Its Reinforcement Structural Learning for Construction of Long-Term Prediction Intervals. IEEE Trans. Cybern. 2020, 52, 666–676. [Google Scholar] [CrossRef]
- Leite, D.; Palhares, R.M.; Campos, V.C.S.; Gomide, F. Evolving Granular Fuzzy Model-Based Control of Nonlinear Dynamic Systems. IEEE Trans. Fuzzy Syst. 2014, 23, 923–938. [Google Scholar] [CrossRef]
- Zhou, Y.; Ren, H.; Zhao, D.; Li, Z.W.; Pedrycz, W. A novel multi-level framework for anomaly detection in time series data. Appl. Intell. 2022, 1–18. [Google Scholar] [CrossRef]
- Garcia, C.; Leite, D.; Skrjanc, I. Incremental Missing-Data Imputation for Evolving Fuzzy Granular Prediction. IEEE Trans. Fuzzy Syst. 2019, 28, 2348–2362. [Google Scholar] [CrossRef]
- Zhang, S.C.; Genga, L.; Yan, H.; Nie, H.C.; Lu, X.D.; Kaymak, U. Towards Multi-perspective Conformance Checking with Fuzzy Sets. Int. J. Interact. Multimedia Artif. Intell. 2020, 6, 134. [Google Scholar] [CrossRef]
- Pedrycz, A.; Dong, F.; Hirota, K. Finite cut-based approximation of fuzzy sets and its evolutionary optimization. Fuzzy Sets Syst. 2009, 160, 3550–3564. [Google Scholar] [CrossRef]
- Derrac, J.; Garcia, S.; Sanchez, L.; Alcalá-Fdez, J.; Fernandez, A.; Luengo, J.; Herrera, F. KEEL Data-Mining Software Tool: Data Set Repository, Integration of Algorithms and Experimental Analysis Framework. J. Mult. Valued Log. Soft Comput. 2011, 17, 255–287. [Google Scholar]
- Yu, Z.; Duan, X.; Cong, X.; Li, X.; Zheng, L. Detection of actuator enablement attacks by Petri nets in supervisory control systems. Mathematics 2023, 11, 4. [Google Scholar] [CrossRef]
- Yu, Z.; Sohail, A.; Jamil, M.; Beg, O.A.; Tavares, J.M.R. Hybrid algorithm for the classification of fractal designs and images. Fractals 2022. [Google Scholar] [CrossRef]
- Yu, Z.; Sohail, A.; Arif, R.; Nutini, A.; Taher, A.N.; Tunc, S. Modeling the crossover behavior of the bacterial infection with the COVID-19 epidemics. Results Phys. 2022, 39, 105774. [Google Scholar] [CrossRef]
- Cong, X.; Fanti, M.; Mangini, A.; Li, Z. Critical observability of labeled time Petri net systems. IEEE Trans. Autom. Sci. Eng. 2022, 1–12. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dimensions | Upper/Lower Bounds | 0th Cluster (Marked as ▲ Colored Blue) | 1st Cluster (Marked as ● Colored Red) | 2nd Cluster (Marked as ★ Colored Yellow) | |||
|---|---|---|---|---|---|---|---|
| AUC | Values of a/b | AUC | Values of a/b | AUC | Values of a/b | ||
| 1st dimension | upper bound b | 0.703 | 4.342 | 0.755 | 0.802 | 0.742 | 3.292 |
| lower bound a | 0.695 | −1.300 | 0.704 | −3.632 | 0.732 | −1.349 | |
| 2nd dimension | upper bound b | 0.720 | 3.691 | 0.682 | −0.366 | 0.654 | 0.272 |
| lower bound a | 0.703 | 1.352 | 0.627 | −4.162 | 0.762 | −2.610 | |
| Values of Parameters α1 And α2 | Bounds of Information Granule [a, b] | Values of AUC | |
|---|---|---|---|
| Upper Bound | Lower Bound | ||
| α1 = 0, α2 = 0 | [0.072, 3.597] | 0.790 | 0.823 |
| α1 = 0.1, α2 = 0.1 | [−0.133, 4.037] | 0.765 | 0.795 |
| α1 = 0.1, α2 = 0.5 | [−0.476, 4.272] | 0.733 | 0.767 |
| α1 = 0.1, α2 = 0.8 | [−0.833, 4.272] | 0.726 | 0.756 |
| α1 = 0.5, α2 = 0.1 | [−1.300, 4.272] | 0.720 | 0.704 |
| α1 = 0.5, α2 = 0.5 | [−1.300, 4.342] | 0.703 | 0.695 |
| α1 = 0.5, α2 = 0.8 | [−1.300, 4.342] | 0.707 | 0.695 |
| α1 = 0.8, α2 = 0.1 | [−1.300, 4.342] | 0.692 | 0.627 |
| α1 = 0.8, α2 = 0.5 | [−1.300, 4.382] | 0.686 | 0.634 |
| α1 = 0.8, α2 = 0.8 | [−1.300, 4.342] | 0.696 | 0.645 |
| α1 = 1.0, α2 = 1.0 | [−1.351, 4.342] | 0.704 | 0.622 |
| Attributes | Upper/Lower Bounds | 0th Cluster | 1st Cluster | 2nd Cluster | |||
|---|---|---|---|---|---|---|---|
| AUC | Values of a/b | AUC | Values of a/b | AUC | Values of a/b | ||
| Sepal Length | upper bound b | 0.525 | 7.200 | 0.717 | 6.701 | 0.678 | 6.003 |
| lower bound a | 0.687 | 5.800 | 0.689 | 5.500 | 0.683 | 4.899 | |
| Sepal Width | upper bound b | 0.779 | 3.400 | 0.814 | 3.200 | 0.550 | 3.901 |
| lower bound a | 0.687 | 2.700 | 0.643 | 2.499 | 0.554 | 2.800 | |
| Petal Length | upper bound b | 0.529 | 6.100 | 0.754 | 5.102 | 0.587 | 4.003 |
| lower bound a | 0.768 | 4.397 | 0.731 | 3.298 | 0.628 | 1.300 | |
| Petal Width | upper bound b | 0.526 | 2.300 | 0.701 | 1.801 | 0.568 | 1.502 |
| lower bound a | 0.727 | 1.399 | 0.737 | 0.999 | 0.660 | 0.200 | |
| Attributes | Upper/Lower Bounds | 0th Cluster | 1st Cluster | ||
|---|---|---|---|---|---|
| AUC | Values of a/b | AUC | Values of a/b | ||
| At1 | upper bound b | 0.698 | 0.624 | 0.708 | 1.471 |
| lower bound a | 0.735 | −1.640 | 0.714 | −1.042 | |
| At2 | upper bound b | 0.724 | 0.732 | 0.758 | 1.721 |
| lower bound a | 0.716 | −1.401 | 0.671 | −0.472 | |
| Attributes | Upper/Lower Bounds | 0th Cluster | 1st Cluster | ||
|---|---|---|---|---|---|
| AUC | Values of a/b | AUC | Values of a/b | ||
| At1 | upper bound b | 0.732 | 0.520 | 0.740 | 0.628 |
| lower bound a | 0.624 | 0.187 | 0.687 | 0.351 | |
| At2 | upper bound b | 0.719 | 0.627 | 0.726 | 0.884 |
| lower bound a | 0.559 | 0.187 | 0.513 | 0.360 | |
| At3 | upper bound b | 0.740 | 0.472 | 0.740 | 0.684 |
| lower bound a | 0.574 | 0.089 | 0.662 | 0.360 | |
| At4 | upper bound b | 0.737 | 0.471 | 0.682 | 0.520 |
| lower bound a | 0.584 | 0.089 | 0.538 | 0.098 | |
| At5 | upper bound b | 0.703 | 0.471 | 0.675 | 0.521 |
| lower bound a | 0.673 | 0.058 | 0.485 | 0.058 | |
| At6 | upper bound b | 0.731 | 0.628 | 0.813 | 0.796 |
| lower bound a | 0.563 | 0.187 | 0.521 | 0.360 | |
| At7 | upper bound b | 0.734 | 0.471 | 0.756 | 0.627 |
| lower bound a | 0.523 | 0.089 | 0.683 | 0.351 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, D.; Liu, Y.; Yu, Z. Synergistic Mechanism of Designing Information Granules with the Use of the Principle of Justifiable Granularity. Mathematics 2023, 11, 1750. https://doi.org/10.3390/math11071750
Wang D, Liu Y, Yu Z. Synergistic Mechanism of Designing Information Granules with the Use of the Principle of Justifiable Granularity. Mathematics. 2023; 11(7):1750. https://doi.org/10.3390/math11071750
Chicago/Turabian StyleWang, Dan, Yukang Liu, and Zhenhua Yu. 2023. "Synergistic Mechanism of Designing Information Granules with the Use of the Principle of Justifiable Granularity" Mathematics 11, no. 7: 1750. https://doi.org/10.3390/math11071750