1. Introduction
The sustainability of our current lifestyle is one of the leading issues in recent years. Society is looking for measures to guarantee the supply of essential resources such as food, water and energy while reducing environmental impact and maximizing economic yield. As a result, new technologies are emerging as an answer to the traditional alternatives to address these problems. One of these is the industrial production of microalgae [
1].
The industrial production of microalgae is a technology with growing impact in recent decades. Microalgae are photosynthetic microorganisms with the ability to grow and reproduce without the need for freshwater or fertile soil [
2]. They have high growth rates and are tolerant to wide temperature ranges, and the composition of their biomass is very interesting for applications in the fields of human or animal nutrition, cosmetics, production of fertilizers or biostimulants, among others [
3]. Their ability to grow also makes them a potential source of biofuel [
4]. However, their main application and the field in which they are particularly promising is in wastewater treatment [
5].
Microalgae require at least three elements for their development: water, light and nutrients [
6,
7]. Water is always obtained in excess, since microalgae are normally grown in an aqueous medium. Light can be obtained in different ways depending on the mode of production. Microalgae can circulate through forced conduits, with no contact with the outside, preventing the insertion of external contaminants and being able to tightly control the conditions in which they are found. These conduits are known as tubular photobioreactors, and in these, the light source can be artificial (when used indoors) or natural from the sunlight (when used outdoors). The alternative to to those is the open reactors, called raceways, which always use the sun as a light source [
8]. These reactors are large open ponds in which the medium flows with the microalgae, being exposed to external contaminants and with harder to control conditions. However, this mode is the easiest to scale up and the most financially viable, making it the most extended at the industrial level, limiting the use of tubular photobioreactors to the production of high-value products that must guarantee their purity [
9]. This paper will address raceway photobioreactors.
In terms of nutrients, the three most important for culture growth are phosphorus, nitrogen and carbon. The first two can be supplied externally according to the needs of the culture; alternatively, wastewater can be used as a medium, with phosphorus and nitrogen being two of the most common and dangerous nutrients in these, which can cause environmental problems such as eutrophication (excessive growth of algae and aquatic plants that deplete oxygen) in receiving water bodies. Hence, nutrients are usually available in excess, guaranteeing microalgae supply, at the same time as wastewater treatment is performed. Carbon is provided in the form of
, either pure or from other industrial activity, helping to mitigate its environmental impact while simultaneously controlling culture conditions [
10].
However, for microalgae production to be competitive, it is crucial to maximize their productivity. Productivity is not only dependent on the availability of light, water and nutrients but also on the available radiation and the pH, dissolved oxygen (DO) and temperature of the medium [
11]. Among these variables, radiation is the only one that is not usually regulated in raceway photobioreactors [
12], as it depends on the environmental conditions of the day, although it is important to be considered when selecting the location of the system [
13]. DO presents a threshold value at which productivity is drastically reduced, and so the control problem is centered on maintaining it below this threshold, regardless of its value as long as this condition is satisfied. This is accomplished through air injection [
14], which increases agitation and mixing of the water, leading to an increase in the rate of oxygen transfer from the water to the air, thus reducing this value. Temperature is not usually considered a control objective, although it has an influence on productivity, maximizing it when it is around a specific value, depending on the species cultivated. It can be controlled by modifying the culture depth [
15,
16].
The pH is often the most important variable in the control problem. Analogous to temperature, when this variable is close to its optimum value, its influence on productivity is positive, while moving away from this value reduces the productivity of the process, thus making its control a critical issue. Its value can be controlled by injecting
, so that the carbon supply and pH control problem can be solved simultaneously [
17].
Nevertheless, the biological nature of the system makes the problem far from trivial. The pH dynamics are highly nonlinear and very changing not only between seasons but also over the duration of a day due to the variable capability of the microalgae to photosynthesize. This makes it extremely difficult to characterize the process, being a critical issue when developing control strategies [
18,
19].
Traditional models developed for this system can be sorted into two types. On one side are the first principles-based models, oriented to a more chemical approach and focused on reflecting the interactions between the different elements of the system. These models provide a high degree of understanding of the process, but they are not very useful for achieving the control objectives given their high complexity and long execution time [
20]. The alternative to these models is low-order experimental models, which are simple and quick to obtain but very limited in terms of their representation of the system, quickly becoming obsolete due to the aforementioned variability [
21,
22]. This means that they must be constantly recalibrated, which is not always possible.
Regarding the state of art, in [
23], a dynamic model for the pH in tubular photobioreactors was developed based on fluid-dynamics, mass tranfer and biological phenomena. The model is accurate and useful for many purposes, but it is limited to closed photobioreactors. Fernández et al. [
24] present a similar model, based on first principles, for a raceway reactor calibrated and validated with real data. The model is useful for analyzing the system’s productivity, but its running time is relatively long, and its periodic recalibration is mandatory. Rodríguez-Miranda et al. [
25] developed a temperature model for raceway reactors, allowing researchers to model and study this variable, which is crucial to the productivity of the system. In [
26], a first-principle-based dynamic model for pH prediction was presented for a torus photobioreactor and validated with experimental data, but it is only valid for this type of reactor. On the other hand, more control-oriented works favor simpler and more experimental models. Pawlowski et al. [
27] present an event-based pH control based on Global Predictive Control (GPC) using an experimental first-order lineal model. Rodríguez-Miranda et al. [
28] developed diurnal and nocturnal pH controllers oriented to the different dynamics of each period, all of them based on first-order models.
Machine learning techniques, and more specifically artificial neural networks (ANN), are experiencing a notable increase in popularity in recent years as an alternative to these models due to the increase in the computational capacity of computers as well as the sheer volume of data available [
29]. Data acquisition and processing is an increasingly demanded task in all fields due to these types of technique, which are characterized by their ability to adapt to a wide variety of problems based solely on the data without the need to be explicitly programmed for it. They have the capacity to infer patterns in the data beyond human comprehension, being especially useful in image or text processing tasks, speech recognition, and recommendation management.
However, these techniques still have not found much use in the field of dynamic systems modeling, and they have even less use in the field of microalgae production, despite being presented as an excellent option in theory. The models obtained, despite not providing any understanding of the system, as they behave as black-box models, are very fast running, easy to adapt to new data and capable of incorporating the nonlinearities of the system [
30]. This makes them a very interesting option for sensor error detection tasks or as the core of Model Predictive Control (MPC) strategies [
31,
32].
In the specific field of microalgae production, these techniques have found the most use in culture classification. Correa et al. [
33] present a neural-network based models for microalgae classification able to distinguish between 19 different classes. Otálora et al. [
34] developed a neural network model, which was validated with pure and mixed samples. Regarding the system dynamics, [
35] presents a neural network dynamic model for the pH for a raceway reactor with promising results, but it is only valid for freshwater reactors. Caparroz et al. [
36] combined first-order models with regression trees in order to keep an easy and transparent formulation combined with the nonlinearity provided from the machine learning technique.
The aim of this work is to develop two neural network models for pH prediction in freshwater and wastewater raceway photobioreactors to analyze the viability of using this data-driven approach for modeling purposes in this kind of plants. The goal of the model is to be able to estimate the pH profile over several hours of a day given a set of predictable or controllable system variables. The model will be trained and validated with real raceway reactor data. The results justify the use of this type of technique in the field of microalgae production and dynamic systems modeling, achieving accurate pH forecasts with prediction horizons of up to 11 h. The proposed models provide relevant potential for the development of model-based control algorithms for this type of process.
The paper is structured as follows:
Section 2 describes the modeled system as well as the techniques used and the toolboxes employed.
Section 3 details the complete development of the models from data acquisition and processing to training and validation. Finally,
Section 4 presents the implications of the research as well as potential future lines of work, and
Section 5 states the main conclusions drawn during the development of the work.
2. Materials and Methods
2.1. Modelled Photobioreactors
The models obtained in this work correspond to two raceway photobioreactors located at the IFAPA center of the University of Almería (36°50′ N, 2°24′ W), as shown in
Figure 1. Both reactors have a similar configuration, consisting of two 40 m long, 1 m wide, and 0.3 m deep channels, although the typical culture height is 15 cm. The channels are joined at their ends by 180
bends, constituting a total surface of 80 m
per reactor. Both feature a paddle wheel driven by an electric motor, which makes the water flow through the entire reactor at a speed of approximately 0.23 m/s. A 1 m deep sump is located 1.8 m away from the paddle wheel in the flow direction through which the injection of
and air takes place, which is used for pH and DO control, respectively. The main difference between the two reactors is in the medium in which the microalgae are found. The first reactor uses freshwater as its medium with the following composition: 0.9 g/L
, 0.14 g/L
, 0.18 g/L
and 0.03 g/L Kerantol. The second reactor uses wastewater obtained directly from the University of Almería or from a wastewater treatment plant located in Almería.
The microalgae strain cultivated in both reactors is from the species Scenedesmus almeriensis (CCAP 276/24). This is characterized by its high growth rate (0.08 h
) as well as its tolerance to wide condition ranges. They are able to tolerate pH from 3 to 10, its optimum value being 8, as well as temperatures between 12 and 46 °C, the optimum value being 27 °C, which makes it ideal for its production in an area such as Almería. For this reason, it is one of the most used species for cultivation in open reactors and wastewater treatment. It also serves as a source of lutein in the field of human nutrition [
37].
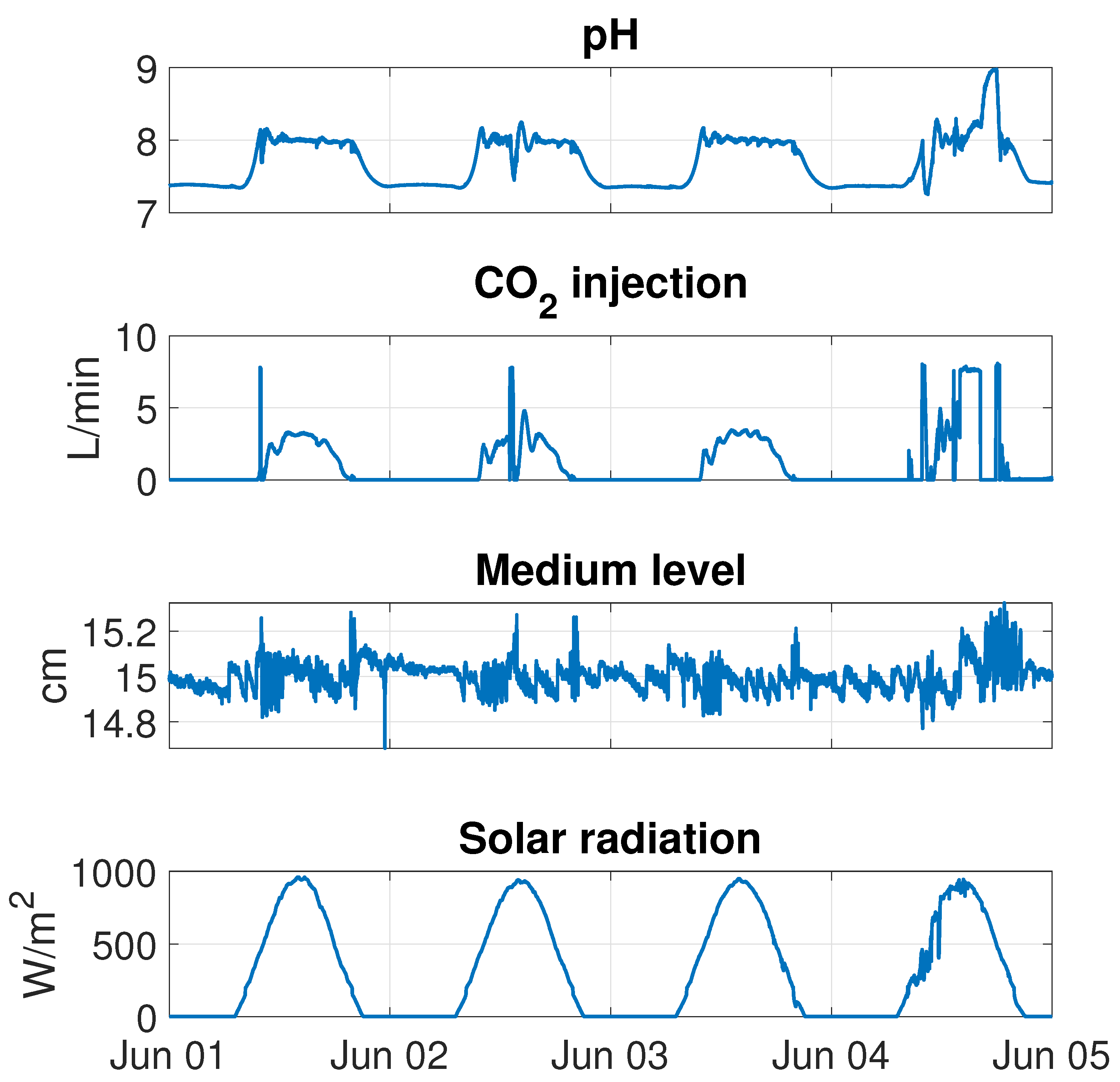
The system is fully sensorized, recording pH, DO and water temperature measurements at two different points: the sump where the injection takes place and the farthest point from it, which is considered the most unfavorable and most challenging to control, the latter being the one usually considered in the control problem. The system also has flowmeters that register the air and
flow rates injected, a water level sensor, and sensors for environmental variables such as ambient temperature, relative humidity and solar radiation: all of this with a sampling time of one second. The sensors used are shown in
Table 1.
2.2. Artificial Neural Networks
Machine learning algorithms are a set of modeling techniques that have the particularity of not being explicitly programmed to solve a problem but instead have the ability to learn from the data provided during their training to learn and adapt to it. There are many machine learning algorithms, and one of the most popular in recent years is artificial neural networks (ANNs).
ANNs owe their name to their resemblance to biological neural networks, since they consist of a set of nodes interconnected with each other in a similar way. Any ANN model has one or more input variables, known as predictors, and one or more output variables, known as predictions. The model is organized in layers; each layer is composed of nodes. Each node of a layer receives as inputs the outputs of the nodes of the previous layer, operates with these, and calculates its own output, which will then be used as input for the nodes of the subsequent layer. The nodes of the first layer receive as inputs the predictors of the model, and those of the last layer return as output the model predictions.
The way nodes operate is different depending on the type of layer they are in. The most typical form is that expressed in Equation (
1), where
y corresponds to the output of a particular node,
corresponds to each of its
k inputs, which at the same time are the outputs of the nodes of the previous layer,
corresponds to the weights assigned to each input,
b corresponds to the node’s bias and
corresponds to its activation function, which is typically nonlinear. If this activation function was linear, the relationship between inputs and outputs of this layer would also be so, which is the reason why this nonlinear feature is important to grant such behavior to the model.
Thus, the model is configured by four fundamental elements: the number of layers, which is in charge of giving it depth and complexity, the number of nodes in each layer, which is related to the model’s capacity to generalize or adapt to more specific situations, the activation function of each layer, and the weights of each node, and b. The first three elements are considered before the model development and constitute its structure. Their selection must take into account the type and complexity of the problem as well as the data used and the desired characteristics of the model. On the other hand, the weights of the nodes are calculated during the training process. In this process, a set of input and output data is taken, known as the training dataset, and the algorithm iteratively calculates the weights of each node to minimize the difference between the model predictions and the real ouput data.
The development process of an ANN model therefore consists of three steps. First, the predictors and variables to be predicted must be selected and the relevant analyses must be performed. From these, the data set is prepared with the necessary processing. Since these are data-based models, it is critical for the data to be realistic, adequate and sufficient; otherwise, the model will not be acceptable. The second step is the selection of the model structure. This involves the number of layers, the type of each layer, their activation functions, and the connections between layers. Many of these parameters are commonly obtained iteratively, since there is no way to know beforehand the optimal structure to solve a problem. Finally, the third and last step is the training of the selected model with the prepared data. This training will be dictated by a series of hyperparameters related to training duration, data splitting, learning rate or the optimization function.
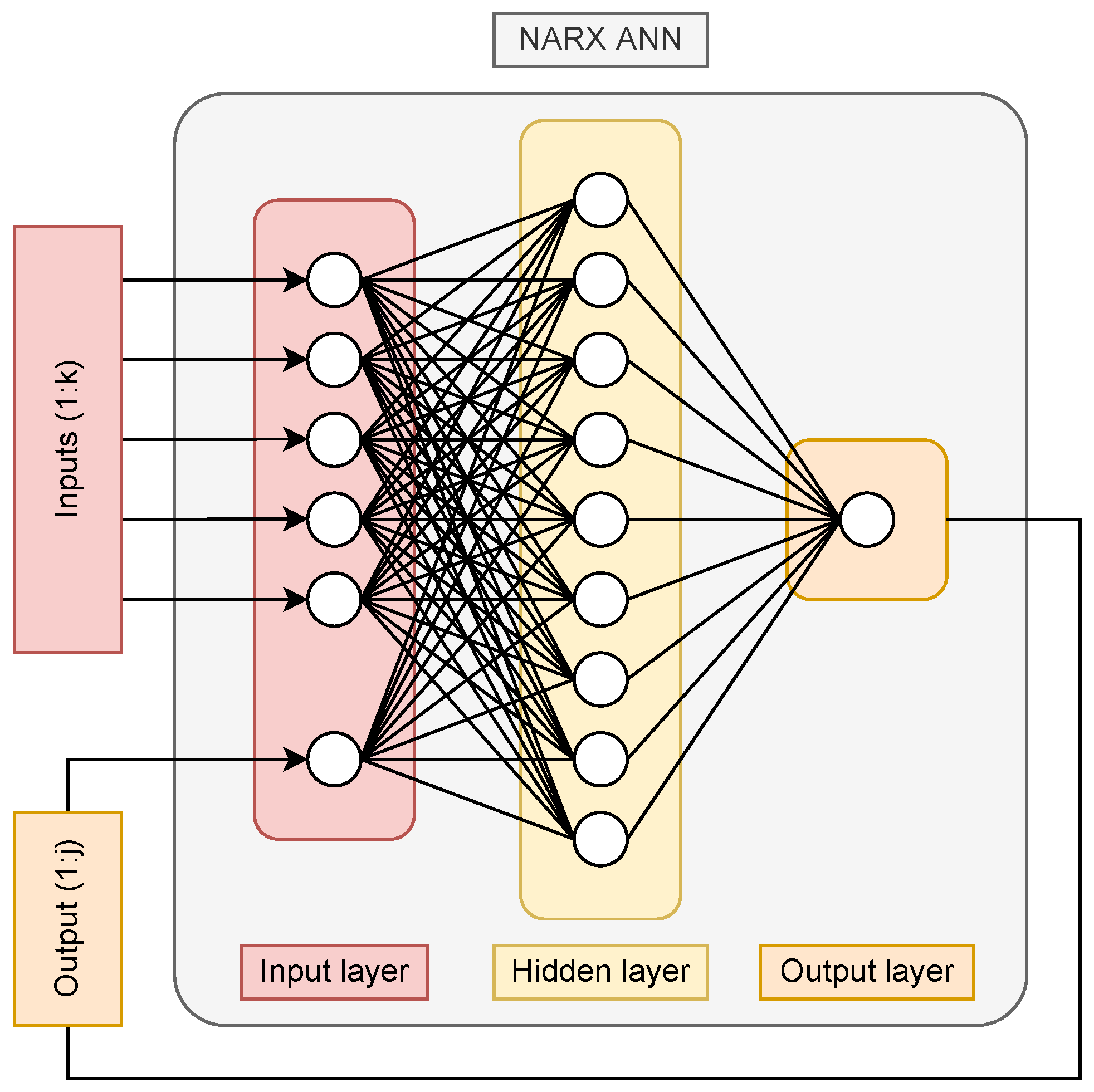
Classic ANNs are particularly appropriate for solving static problems, where the model does not need to reflect time dependence. However, for the pH modeling problem addressed, the system has a clearly dynamic character, making it necessary to adopt an ANN structure able to capture such behavior. The most common models for this are Long Short-Term Memory (LSTM), convolutional, or Nonlinear AutoRegressive with eXogenous inputs (NARX) ANNs. Among these, NARX are the simplest as well as the ones that offer a description most similar to a classical dynamic model [
38].
The foundation of NARX-type models is the use of the
n prior values of each predictor to predict the next value of the output variable. The model also uses the prior values of the output variable itself, which is similar to a difference equation. Equation (
2) generically describes the behavior of any NARX-type model, where
y is the predicted variable,
is each of the predictors,
is the number of tapped delay lines (TDLs) taken on each predictor,
is the TDLs taken on the predicted variable, and
F is a nonlinear function. In the specific case of neural networks, NARX models take the nonlinearity from the activation functions of each layer, and instead of using a single value of each variable as input, they use the
prior values of each predictor and the
of the predicted variable. An example of NARX ANN can be seen in
Figure 2, where the model predicts the output value from the
k previous input values and the
j previous output values; then, it can feedback those predictions as inputs, effectively increasing the prediction horizon and allowing for more extended forecasts over time [
39]. Some works have already proven its value in the field of dynamic system modeling, making them a very interesting choice [
40,
41].
2.3. Deep Learning Toolbox
All the models in this work have been entirely developed in the MATLAB environment. Model design and training were performed using the Deep Learning Toolbox [
42]. This allows the intuitive construction of neural network models, the use of a wide range of layers, the customization of the different aspects of the training process and the integration of the models obtained with Simulink, among other functionalities.
2.4. Performance Metrics
In order to determine the goodness of a model, it is important to establish performance metrics that help to compare them with each other. In a prediction model, these metrics must necessarily be related to the error between the values predicted by the model and the actual values of these variables.
The most common metrics for testing the performance of a model are the mean square error (MSE), root mean square error (RMSE) and mean absolute error (MAE). The MSE is described in Equation (
3), where
n is the number of samples,
the real value, and
the predicted value. The measurement of this error over the prediction horizon is directly related to the model fit, being smaller the better the fit. The RMSE is closely linked to this metric, being essentially its square root, so that it penalizes small errors more and large errors less. MAE (See Equation (
4)) operates similarly to MSE, but it uses the absolute error instead of the squared error, hence suppressing the biasing to smaller errors or larger errors.
In the field of dynamic systems modeling, model fit is also a very interesting metric. It is described in Equation (
5), where
denotes the real value of the predicted variable,
denotes its predicted value, and
denotes its mean. The model fit gives us its goodness as a percentage, so that it is much more intuitive to know the usefulness of a model without the need to compare it with others. In this work, MSE and Model Fit have been taken as the main performance metrics due to their wide use and their representability of model performance.
4. Discussion
In general, the developed models have proven to adapt well to the faced problem. The models have their limitations, which are related to the volume of data necessary for their training or the difficulty of interpreting the results obtained due to their black box character. Likewise, the models will perform well in circumstances similar to those provided in the training, generally having a poor extrapolation capacity. Despite this, the limited number of input variables they use makes them easily deployable in real production systems, allowing the obtaining of a model with simple formulation, fast execution and the ability to easily adapt to new data.
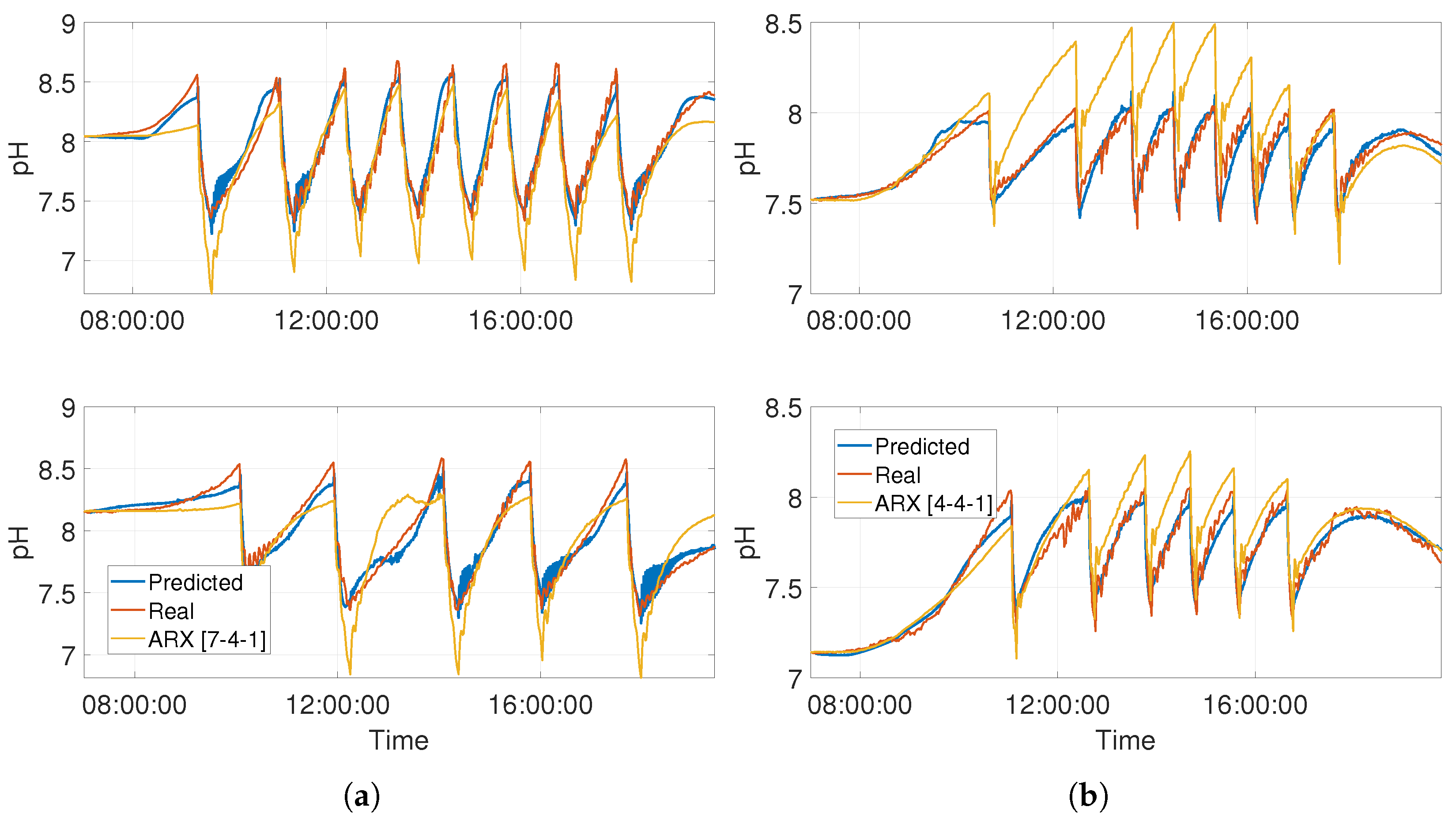
Compared to first-principles models, they are faster to run and simpler to re-calibrate on account of its smaller number of parameters and more straightforward formulation. For instance, compared to the previous reactor pH reference model developed in [
24], the computation time for a full day’s simulation has been reduced from more than 4 min to approximately 0.4 s. On the other hand, they present a more general description of the system than any experimental linear model due to its nonlinear nature. The comparision with ARX models demonstrates the need for using nonlinear models to capture the dynamics of the system. Another interesting comparison may be in relation to LSTM networks. Such a simple model as the one presented is simpler algebraically and remarkably smaller in terms of the total number of parameters, being in any case able to fully capture the dynamics of the system.
The achieved results open many possibilities in the field of microalgae production. These models can be used as the basis of a nonlinear model-based predictive control algorithm to optimize the operating conditions. They can also be used for sensor fault detection, running concurrently with the plant. Regarding future works, it is interesting to extend the model to more production-influencing variables, such as DO, or to incorporate biomass concentration measurements that can make it more complete and adaptable. In a further perspective, the model could also be extended to predict the biomass concentration of the reactor itself in order to obtain a productivity model of the whole reactor. Moreover, the design of MPC algorithms based on the proposed models will be explored for the pH control in both types of reactors.










{kind=link}
{kind=link}
{kind=link}
{kind=link}