1. Introduction
Many of the most widely used compilers nowadays typically use hand-coded recursive-descent parsers. Good examples are GCC C/C++ compilers, which initially used
bison-generated LALR parsers, and Clang/LLVM C/C++ compilers. The two most often cited reasons are as follows. First, as recursive-descent parsers perform top-down parsing, it is known not only which phrase is being parsed at each moment, but also its position in the abstract syntax tree. Thus, it is usually easier to generate precise error messages and implement good error recovery techniques in recursive-descent parsers than in bottom-up parsers. Second, a programming language usually contains only a few constructs that are hard to parse. For instance, when a programming language is extended, new constructs are often syntactically more complicated than the existing ones, as these must not be altered to maintain backward compatibility—Java was initially specified by an LALR grammar [
1], but after the first extensions were introduced, the grammar in the specification ceased to adhere to LALR requirements [
2]. However, various modifications or even hacks, e.g., the local lookahead extension, can be much easier added to a hand-coded recursive-descent parser than to a generated one [
3].
Not even ANTLR, perhaps the most advanced parser generator, can fulfill the second of the two requirements fully. Based on ALL(*) parsing [
4], it cannot handle, for instance, mutually left recursive symbols or indirect left recursion [
5]. Hence, a parser, which provides a good error recovery and is capable of parsing even the most complicated constructs, is needed. To address all these issues, the paper provides the following contributions:
Formulation of a new parsing model called the LLR
-system. It is a Turing-complete rewriting (semi-Thue) system similar to Markov normal algorithms [
6,
7] on the one hand and to a context-sensitive reduction system [
8] on the other hand. Its computational power enables parsing far beyond the limit of context-free languages, but, in the context of parsing programming and domain-specific languages [
9,
10], it can (i) deal with the most complex language constructs and (ii) to enable the implementation of parser functionalities that would otherwise be implemented by augmenting or modifying the parser source code, i.e., outside the formalism on which the parser is based.
Representation of existing parsing algorithms in the LLR
-system. It is demonstrated how canonical LL and LR parsing and their simplified variants, namely SLL and LALR parsing, can be implemented using the LLR-system. Furthermore, it is demonstrated how bidirectional parsing, i.e., a mixture of top-down and bottom-up parsing similar to LLLR parsing [
11,
12], can be implemented in the most natural way. This makes many important patterns needed to build language recognizers readily available.
Modelling and implementation of error recovery. It is shown how two of the most widely used techniques, namely the panic-mode and phrase-level error recovery, can be described naturally as a part of the LLR-system. Furthermore, as the LLR-system can start parsing in the middle of a sentential form (as demonstrated in WEB and CWEB [
13,
14]), it can simply restart parsing past the point of a syntax error if other error recovery methods fail.
The LLR-system, defined here for the first time, is basically a very simple method, but, just as any other parsing method, it requires some expertise to implement a parser. This paper thus focuses (a) on the definition of the LLR-system; (b) on providing examples that help one to start gaining skills in implementing parsers based on the LLR-system, as its underlying principle and rules are different from those of context-free grammars; and (c) on demonstrating that, once implemented, the LLR-system is nevertheless an efficient language recognizer, despite being a more general and powerful computation model than context-free grammars and pushdown automata.
This paper assumes that the reader shares a good knowledge of context-free parsing as exposed by, for instance, Sippu and Soisalon-Soininen [
15,
16] or Grune and Jacobs [
17]. After the section on related work, the core of the paper starts with
Section 3, containing the definition of the LLR-system. In
Section 4, a formulation of the aforementioned parsing algorithms in the LLR-system is described and supported by examples. Implementation of error recovery is described in
Section 5. In
Section 6, the efficiency of parsers based on LLR-systems is demonstrated on a real programming language and source files. After the conclusion, the appendix contains a proof, and then the LLR-system is Turing-complete.
2. Related Work
As mentioned above, the two models most similar to the LLR-system in terms of how the parser is specified are Markov normal algorithms [
6,
7] and the context-sensitive reduction system [
8]. Because of their similarity, they will be compared to the LLR-system in
Section 3, where the LLR-system is defined. However, as the LLR-system is Turing-complete, it is, to some extent, similar to hand-coded parsers, as they can most easily be augmented with an auxiliary code implementing parts of a parser that require computational strength beyond any context-free language formalism. Among hand-coded parsers, the recursive-descent implementation of the SLL(1) parsers for context-free languages is the most widely used example of this kind [
15,
17,
18].
In general, the syntax of programming and most domain-specific languages is described by context-free grammars [
19], while common non-context-free features of these languages, e.g., scopes and namespaces, are usually dealt with throughout a lexical, syntax and semantic analysis [
18,
20,
21]. These features are dealt with informal techniques as standard lexers, or the context-free parser can be augmented with context-aware lexers [
22,
23,
24].
Another way is using context-free parsers extended with a subset of approaches used for parsing specific types of non-context-free language constructs and features. [
25]. One such approach is stateful parsing, which maintains a global parse-wide state. Whenever a context-free formalism proves to be too weak, a stateful parser compensates its weakness by manipulating the state. This can be conducted within a hand-written parser, within a
yacc-generated parser [
26], or if parser combinators are used. [
27,
28].
ANTLR4 [
5], which is one of the most popular and advanced parser generators nowadays, implements ALL(*), i.e., adaptive LL parsing, and provides support for scannerless parsers and predicated ALL(*) grammars [
4]. Its scannerless parsers are useful for resolving context-sensitive lexical issues. Predicated ALL(*) grammars use (a) side-effect-free semantic predicates to ensure a particular production can be applied in a given context and (b) mutators, to alter the sentential form, if needed. Strictly speaking, a predicated ALL(*) grammar generates “a recursively enumerable language because each mutator can be a Turing machine. In reality, grammar writers do not use this generality so it is standard practice to consider the language class to be the context-sensitive languages instead” [
4]. ANTLR4 can express a non-context-free language using semantic predicates and mutators. These must be implemented in a host language and are therefore an extension of the formalism, not a part of it.
Stateful parsers can be used for parsing non-context-free languages, but a lot of discipline is required to write and maintain them. One example of making a stateful parser manageable in practice is adding backtracking to
parsing, in order to make a parsing of ambiguous context-dependent languages, e.g., C++, possible [
29]. It takes a lot of effort to parse context-dependent language features using
and
parsing, because multiple copies of global data structures must be maintained. To avoid this, three kinds of semantic actions are used in the backtracking of
parsing:
trial actions for directing future parsing,
undo actions for reverting side-effects of trial actions, and
final actions for reductions that can never be undone [
29]. As above, context-sensitive constructs are not formulated with grammar productions but with semantic actions expressed in a host language. At each step, such parsers can select the next action by only using the part of the input that has been parsed so far, while the proper context-sensitive parsing is not bound by this limitation [
8].
In principled stateful parsing [
30], the idea of using a number of predefined primitive operations for inspecting and altering a mutable parse-wide state is used. This operation focuses mostly on dealing with a set of specific context-sensitive features, including the namespace classification, handling of whitespace, and alike, but they may prove useful in general. Similar to ANTLR’s predicated grammars or principled stateful parsing, data-dependent grammars [
31,
32] use semantic values to augment productions. If the
parsing algorithm is used with data-dependent grammars, context-sensitive lexical problems and indentation-sensitive rules can be dealt with effectivelly [
33].
Some approaches are stronger than classical algorithms for parsing context-free languages. One such approach is based on the parsing expression grammars (PEGs): productions in PEGs are ordered similarly to Markov normal algorithms. PEG parsing can parse some non-context-free languages and it is also possible “to construct a PEG language which is complete for P under log-space reductions”, but even-palindromes cannot be parsed using a PEG parser (meanwhile, obviously, they can be generated by a context-free grammar) [
34]. A memoizing PEG parser called Rats! [
35] expresses rules witnin transactions. Hence, the state changes (as in stateful parsing) can be undone whenever certain conditions cannot be satisfied; meanwhile, Nez, another PEG parser generator, focuses on the declarative parser specifications [
36,
37,
38]. Likewise, parser combinators “are a middle ground between the fine control of hand-rolled parsers and the high-level almost grammar-like appearance of parsers created via parser generators” [
28]. Moreover, monadic parser combinators can deal with context-sensitive language constructs [
39]. The global state, however, needs to be sent around the parser code during parsing. Hence, adding the reduction automaton to the monadic parser would most likely result in a significantly more complex implementation of the latter.
In contrast with the computational power of the LLR-system (or the context-sensitive reduction system), most authors focus on typical concrete non-context-free features found in most programming languages. The list of such features includes the indentation sensitivity of Python or Haskell, typedef names in C/C++, HERE document in Perl, user-defined operators with custom precedence, and associativity or Ruby [
30,
31,
33,
36,
37]. However, the true general context-sensitive parsing algorithms are rare: one is a general context-sensitive parsing algorithm that finds each derivation only once [
40] and the other is a CYK-like tabular algorithm for context-sensitive languages [
41]. To reduce the complexity of context-sensitive parsing, it was suggested that weakly context-sensitive languages [
42] and loop-free context-sensitive languages [
43] could be used as models for parsing programming languages.
The summary of the most important approaches for parsing non-context-free languages is shown in
Table 1. Note, however, than many approaches could be included into the right column if semantic rules are misused for parsing. For instance, as non-context-free constructs can be parsed by a user-supplied code within a semantic action in, say,
yacc or
bison, these two tools could, in principle, be included into the topmost boxes in the right column of
Table 1.
However, most parser algorithms used nowadays are descendants of relatively old algorithms, e.g., the canonical LR and LL parsing [
44,
45] or even PEG parsing [
46]. However, although extensively studied [
17,
18], error recovery has never been formalized to the same extend as parsing. After all, actual errors made by programmers are hard to formalize and any definition would most likely not match the definition of a syntax error as detected by a particular parser [
16]. Even more, most error recovery methods are either automatic or implemented outside the formalism used for specifying the syntax of a language being parsed, or both.
In practice, the error recovery approach for predictive top-down parsers made popular by Wirth [
47] resulted in two most widely used methods: panic-mode error recovery and phrase-level error-recovery. Two well-known LALR parser generators, namely
yacc and
bison, provide an error token to support simple and rather inflexible panic-mode error recovery [
26]. The ANTLR4 parser generator performs automatic error recovery, which supports a single symbol insertion or deletion [
4], i.e., a combination of both methods, but occasionally requires that the entire input is reparsed and offers the parser writer little authority over error recovery actions.
Various parsing libraries often lack the support for error recovery. One library that does care about it, namely Parglare, implements panic-mode error recovery for its LR and
parsers [
48]. Furthermore, it allows replacing panic-mode recovery by a custom strategy, albeit written in Python and thus not expressed formally. PEGs had been known for not having a good error recovery algorithm, but using “labeled failures”, it is now possible to overcome this problem [
49]. Even more, automatic error recovery has been designed for PEG parsing [
50], but again it leaves little space for customization by the parser writer. Likewise, it is possible to perform automatic and language-independent error recovery in generalized LR parsing [
51].
Note, however, that all these approaches are either based on augmenting the syntax describing formalism, e.g., with an error token, as in
yacc and
bison, or automatic. In either case, they are an addition to the formalism that the parser is based on and, more often than not, implemented by an auxiliary algorithm. None of these approaches supports the implementation of error recovery “within a system” (other than in a very limited form). To combat the degree of freedom in specifying error recovery, some approaches are based on designing sophisticated patterns used for describing error recovery [
52].
As shown in
Table 1, LLR-systems and Markov normal algorithms are the only Turing-complete formalisms that have been or are being proposed for parsing programming and domain-specific languages. Unlike other formalisms in
Table 1, they can parse any language construct no matter the complexity of the language syntax. However, Markov normal algorithms were never used for parsing because they were considered hard to design and slow to run [
53]. Furthermore, no approach other than the LLR-system can implement the error-recovery within a system, e.g., using productions of a context-free or parsing expression grammar.
3. Longest-Leftmost Rewriting System
3.1. Notions and Notation
An alphabet is a finite set of symbols. A string w is a finite sequence of symbols from . Sets and contain all strings over and all strings over except the empty string, respectively. An empty string is denoted by and the length of a string w is denoted by . Expression , where and , denotes the prefix w consisting of the first k symbols of w (or the entire w if ). A language L over is a set of finite strings over , i.e., .
3.2. Rewriting Systems
A
rewriting (or semi-Thue) system is a pair
, where
V is a finite set of symbols and
R is a finite binary relation on
[
15]. A pair
is called a
rule and is written as
. A string
is called a sentential form.
A sentential form
derives another sentential form
using rule
if and only if
, where a relation
is defined as
Likewise,
derives
using a rule string
if and only if
, where a relation
is defined inductively as
where
for some
and
. In the above definition,
denotes the identity relation
and operator · denotes the (relational) product of relations
and
, defined as
for some sets
A,
B and
C [
15].
Furthermore, denotes for any . The subscript denoting the actual rewriting system in the names of these relations, e.g., , can be omitted whenever the rewriting system can be deduced from the context.
Formal grammars are special cases of rewriting systems. Let
N and
T be finite and disjoint sets of nonterminal and terminal symbols, respectively, and let
. A grammar
G is defined as
, where
is the start symbol and
is a finite set of productions
. If
, the grammar is said to be context-free. If
, the grammar is context-sensitive. Sometimes these grammars are called Type 1 monotonic grammars, while the term context sensitive grammars is reserved strictly for grammars consisting of productions, where exactly one nonterminal symbol on the left side is substituted by a nonempty string of symbols [
17]. However, because each context-sensitive grammar in the stricter sense can be transformed into a Type 1 monotonic grammar [
19], the former are considered just a normal form of the latter and no distinction needs to be made for the purpose of this paper. If
and
, the grammar is said to be context-free. For a context-free grammar
, the standard definitions of functions
and
are assumed [
15,
18,
19].
Many models for describing various classes of formal languages are special cases of the rewriting system. The list of these special cases includes “generators” such as context-free or context-sensitive grammars, on the one hand, and “recognisers” such as LL and LR parsers, on the other hand. Note that both, namely generators and recognizers, can be considered as models describing a particular language, but the distinction between these two groups resembles the way they are typically used in practice. However, unlike many of its special cases, the rewriting system is Turing-complete and is thus far more general then just being either a language generator or a language recogniser.
3.3. Longest-Leftmost Rewriting System
Being so general, the rewriting system as defined above permits nondeterminism and therefore it is not very efficient if used as a language recognizer. To alleviate the efficiency issues to a significant degree, the
longest-leftmost rewriting system (LLR-system), a special case of the rewriting system, is defined as
where
V is a finite set of symbols,
is a set of terminal symbols,
is a set of rules,
is the goal, and
are left and right markers. Apart from specifying
T,
S, and both end markers, the LLR-system differs from the general rewriting system in the form of rules and how rules are used in derivations.
Regarding the form of rules, there are two restrictions:
The left sides of two distinct rules in
R must be different, i.e.,
No rule can introduce, eliminate nor move a left or right marker, i.e.,
Regarding the usage of rules in derivations, the LLR-system enforces the
longest-leftmost principle which states that, when considering a sentential form at each step of a derivation, the longest of its leftmost substrings constituting the left side of some rule in
R is replaced by the right side of that rule. Therefore, a single step of using a rule
in a derivation is described by a relation
, where
if and only if
The combination of (a) the first restriction on the form of rules, which ensures distinct left sides of rules in R, and (b) the longest-leftmost principle for selecting the next rule makes the LLR-system deterministic. The second restriction on the form of rules, which preserves the position of the left and the right marker, simplifies things in a similar way, as does augmenting the context-free grammar with $.
The language accepted by the LLR-system is defined as
Hence, a parsing process is the longest possible derivation
where
is the input string and
is the result. If
, parsing is successful, i.e.,
, and
represents the
parse of
w in regard to
.
Example 1. Consider an LLR-system for language with the following rules: Parsing of string proceeds as follows (symbols that represent the left side of a rule to be applied at each step are underlined): The last rule, i.e., , extends the sentential form: the reader is invited to rewrite this LLR-system to an equivalent one where no rule extends the sentential form.
Defined here for the first time, the LLR-system is meant to be used as a model of a language recognizer, i.e., parser, which transforms its input into a single symbol. At each step, it transforms the current sentential form into the next one: in step i, it transforms into using some rule chosen according to the longest-leftmost principle.
3.4. Similar Models
A
context-sensitive reduction system [
8] is a special case of the LLR-system. It differs from the LLR-system by imposing another restriction on the form of rules: the length of the rules’ right side cannot not exceed the length of its left side. As the rules of the context-sensitive reduction system never make the sentential form being processed longer, they are called reductions and the system itself is called a reduction system.
Switching the sides of the additional restriction yields the restriction on productions of context-sensitive grammars. Hence, the context-sensitive reduction system can be used to recognize deterministic context-sensitive languages even though in practice it has so far been used to parse context-free languages [
13,
14]. However, by avoiding the additional restriction, the LLR-system offers a more natural implementation of parsers, both traditionally table driven or manually written.
Another model similar to the LLR-system is a
Markov normal algorithm [
6]. It has been defined for studying various problems regarding computability [
7,
54,
55] and is very similar to the LLR-system, except that the next rule is not chosen as required by the longest-leftmost principle. Instead, rules are indexed and a rule with a lower index takes precedence over all rules with higher indices regardless of where in a sentential form a rule can be applied. Still, if a sentential form contains several appearances of the left side of a rule, the leftmost one is selected and subsequently replaced by the rule’s right side. Furthermore, a rule designated as terminal ends a derivation that could have been extended further, had such a rule not have been terminal.
Both the LLR-system and the Markov normal algorithm are Turing-complete rewriting systems (see Theorem A1 in
Appendix B for the former and [
7] for the latter) and thus equivalent. However, to a person trained in formal grammars, the LLR-system might feel like a more natural model than the Markov algorithm with its indexed set of rules. Furthermore, the latter’s formulation “
makes it difficult to specialize subclasses of Markov normal algorithm’s performing particular tasks” [
53] and, despite some efficiency improvement [
56], it has been noted that the implementation of Markov normal algorithms “
is intrinsically slow” [
53].
3.5. Implementation
Even though the LLR-system is fully deterministic, once efficiency issues are considered, its implementation is not as straightforward as one would assume or wish. There are two main issues to be resolved:
Regarding the first issue, i.e., selection and application of a rule at each step, the problem is as follows: given a set of nonempty strings over
V, i.e., the left sides of all rules in
, and a sentential form
, find such strings
and rule
that
By the definition of , there should be no other strings and no other rule so that , and would hold.
As the problem of selecting the next rule and finding the position of its application does not depend on the length of rules’ right sides, it is exactly the same as if the context-sensitive reduction system is considered. Since the problem is the same, so are the solutions [
8]:
Full backward jumping algorithm:
The naive approach is to start at the beginning of the current sentential form : if there are some left sides of rules in R that are prefixes of , then the longest one is selected and it must be applied at position 1 (); otherwise, if there are some left sides that are prefixes of , then the longest one is selected, and it must be applied at position 2 (), etc. If none is found, the parsing is over.
This is performed at each step of parsing independently, without any information about the part of the sentential form already scanned being carried from one step to another; at each step, the algorithm jumps back all the way to the beginning of the (transformed) sentential form.
Limited backward jumping algorithm:
If the rule
has been applied in the previous step at position
i, rule
cannot be applied in the next step left of position
, as otherwise, the rule
should have taken precedence over
in the previous step. Even more, depending on the overlapping of
and
, the first position, where
is applicable in the next step, might be even further to the right (sometimes so much that it is actually a jump forward). Hence, instead of jumping back to the beginning of
, the algorithm must jump back only as far as the rule with the longest backward jump relative to
requires (see [
8] for full details).
This approach is implemented in WEB and CWEB [
13,
14], where the parsers are implemented by hand. A Deterministic Finite Automaton (DFA) for finding out which left side matches at the given position is implemented by a series of nested
(WEB is written in Pascal) and
(CWEB is written in C) statements. Although error prone, the length of a backward jump for each right side is calculated by hand.
A very similar technique is used in optimizing the implementation of Markov normal algorithms [
56]. However, because the indexation of rules introduces precedence, the lengths of rules already applied are kept on the auxiliary stack, which makes implementation slightly more complicated.
DFA-based algorithm:
The main idea is to keep states that a DFA, which is used to determine what rule and where, is to be applied to at each step and passed for reuse in the subsequent steps. If a DFA was used to determine that a rule should be applied to a sentential form , the states that the DFA passed when scanning should be stored for later use. Once the rule has been applied, i.e., when the sentential form is transformed into , the DFA can immediately continue scanning starting from the state it reached after reading .
The appropriate DFA can be generated using the same procedure as for the context-sensitive reduction system [
8]; alternatively, but with less insight into the meaning of particular states, the algorithm for transforming a regular expression into a POSIX DFA can be used as well [
57].
As described in [
8], the states of the DFA, which is used for finding the longest leftmost left sides of rules in the sentential form being parsed, are modeled by sets of
items. An item
, where
is the left side of some rule in
R and
, in state
q denotes two possibilities. If
, then
has just been seen, but
are still to be seen. Otherwise, if
, then
has just been seen and
can be selected to be replaced by a rule if and only if there is no other item that could provide, by reading a few more symbols, another left side that starts earlier or is longer. Check [
8] to see how items start canceling each one out when one item cannot ever trigger a reduction for being overshadowed by another.
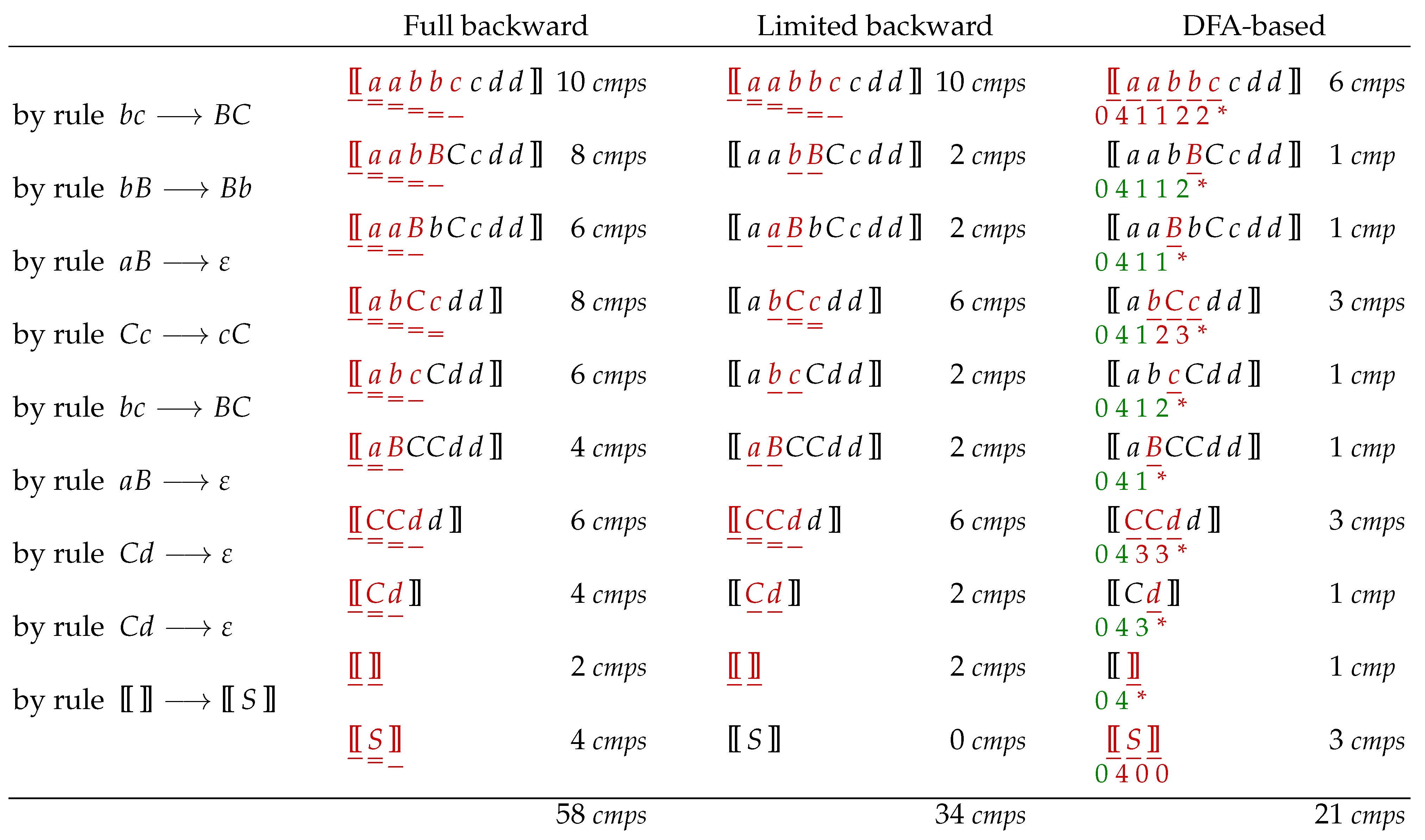
Example 2. To observe the difference between the three algorithms used for determining which rule is to be used at the next step and where, consider another LLR
-systemfor language . The parsing of string is shown in Figure 1. Full backward jumping is simple to understand, but limited backward jumping deserves a bit of an explanation. After the first rule, i.e., , has been applied, the sentential form changes to . No rule can be applied to the prefix —if this was possible, that rule should have been reduced first (the leftmost component of the longest leftmost principle). However, when the parser is being made, all possible contexts of the newly inserted right side must be considered (the dot represents a wildcard standing for any symbol): Hence, as the minimal Δ for is , the next rule can only be applied at a position that is 1 place left of B (of just inserted) or, if this is not possible, somewhere further to the right. All subsequent steps follow the same reasoning but the minimal Δ must be computed for each rule separately.
The DFA-based algorithm uses the reduction automaton shown in Figure 2. In the initial state, , there are items denoting the starting points of all left sides of rules in R. In every other state, there is also a possibility that any left side starts right there. In this simple example, no item canceling happens—see [8] to observe this. Note, however, that there exist cases when the limited backjumping outperforms the DFA-based approach: parsing the only string of language using the LLR-system containing a single rule requires two symbol operations with the former approach but five with the latter. An LLR-symbol consisting of rules and represents another example.
The second issue, i.e., how to represent the sentential form efficiently, is important because a rule can be applied anywhere in the sentential form and can expand or contract it. In general, a double-linked list works fine, but there are two alternatives:
If the LLR
-system is used to emulate known context-free parsing algorithms (see Section 4), which in one way or another use a stack, then it is wise to use an array for representing the sentential form. If the LLR
-system is used to parse very long programs of a language where it must traverse the sentential form from the left and right many times in order to apply rules at big distances (consider parsing string for using the LLR
-system from Example 2), random access lists might be preferred [58].
Once these two issues are resolved, the implementation of the LLR
-system is much the same as the implementation of the context-sensitive reduction system [8]. 4. Parsing Context-Free Languages
As the LLR-system is Turing-complete, there is no question about what can or what can not be achieved by it. Hence, the more pressing question, by far, is how easy it is to implement a language recognizer, i.e., parser, using an LLR-system for, say, present and future programming and domain-specific languages. To answer this question, it is worth looking at how it relates to other known parsing algorithms first. As the LLR-system is defined in this paper for the first time, the formulations presented in this section should serve as the initial pool of patterns helping someone to start using LLR-systems for parsing. Note that most of them are not applicable even to the context-sensitive reduction system [
8], because they depend heavily on being possible to extend the current sentential form that is being parsed.
Be aware that the exposition starts with trivial formulations of existing parsing algorithms. However, this triviality is the point: it makes the LLR-system easier to understand and use for someone trained in mainstream parsing algorithms. Furthermore, the examples in this section are essential, as they are meant to illustrate, beyond the formal schemes provided, how a parser can be constructed.
4.1. Top-Down Parsing: SLL and LL
The simplest and by far the most widely used top-down parsing method is SLL(1) parsing [
15]. It represents the theoretical model for handwritten recursive-descent parsers, which are (usually slightly augmented with a trick or two) built into many of the most widely used compilers nowadays, e.g., GCC and Clang/LLVM implementations of C and C++ compilers.
An
parser for grammar
, where the
, as in [
15], can be implemented as an LLR-system
with a set of rule
R, defined as
where
and
;
is
-augmented grammar
, i.e., using
as the “end-of-file” marker. The idea behind this scheme is simple:
During parsing, the sentential form at each step has the form , where , a string consisting of the “overlined” symbols, represents the LL stack, and w, a string consisting of the not-“overlined” symbols in T, represents the remaining input.
At the beginning, one of the startup rules inserts S, which ensures that no startup rule can be applied again, and , which represents the initial stack contents.
Once the stack has been set up, shift and produce rules are applied just as they would be applied by an parser. If and only if the input belongs to , the stack contents and the remaining input are eliminated and the accepting sentential form remains.
Example 3 (Dealing with the right recursion)
. As the scheme for parsers is so straightforward, an example instead of a rigorous proof, e.g., the induction on the length of a derivation, should suffice. Consider a fragment of a programming language grammar described by EBNF productionswhere E is considered a terminal for a moment. To rewrite the above grammar into an LLR
-system, describing a sequence of statement is replaced by a new nonterminal L. Thus, the following startup and produce rules are obtained first (the shift rules are trivial and thus not listed here):The first rule is actually a set of rules, where x stands for any terminal of this little language. The sequence of statements is treated in the most standard way, namelywhere (as anyone familiar with SLL
parsing knows, x could also be left out entirely). To see how parsing works, consider the first few steps of the parsing string : Hence, after the initial S, which waits to announce success once the parsing is over, the “overlined” symbols represent the stack (with the topmost symbol on the right) and the rest is the yet unparsed part of the input string.
Example 4 (The dangling else problem)
. Suppose that the -statement defined by EBNF productionis added to the grammar introduced in Example 3. To deal with the dangling problem, the ambiguity of a language must first be eliminated. Assuming the standard syntax of the -statement, i.e., the -branch is a part of the most recent preceding -free -statement, the EBNF production can be transformed into a set of productions resulting in a unambiguous but bloated grammar [1,18]. Alternatively, it can be transformed elegantly into ruleswhere or simply . Namely, the produce rule ignores the dangling problem, which is then fixed by the second rule (the third rule is just the regular shift rule). To be sure, these three rules, which describe how the -statement above is handled, are exactly how a recursive function responsible for parsing the -statement is usually written: once the statement in the -branch has been parsed, it checks whether there is a matching —if there is none, it skips the -branch. Note, however, that the decision made during the production is being parsed.Note, however, that the LLR-system makes it possible to express this with just another rule (albeit neither a shift nor produce); within a system and without a hack, e.g., choosing a shift over reduce by default to resolve a conflict, like most LALR parser generators do.
Example 5 (Extending the lookahead)
. Suppose that the EBNF production describing the assignment statement of grammar in Example 3 is modified intothat can be replaced by productions and , which fulfill the SLL(1)
condition. However, by extending the lookahead buffer from 1
to 2
locally, i.e., just in case of the assignment statement, the transformationcan be used without introducing an additional nonterminal symbol and productions expanding it.Looking two, three, or a few symbols ahead instead of just one symbol ahead is an extension used in many hand-coded recursive-descent parsers. Moreover, again, unlike grammars that are transformed into a parser by a generator, the LLR-system makes it possible to express such a local change.
To summarize, grammars can be transformed into an LLR-system in a straightforward manner (Example 3). If needed, the LLR-system can inspect several topmost stack symbols (Example 4) or more than k input symbols whenever needed (Example 5), or both. Finally, an LLR-system obtained by the transformation from an grammar, as defined above, is not a context-sensitive reduction system: startup rules and (in practice most of) produce rules extend the sentential form and thus violate restrictions imposed by a context-sensitive reduction system.
As the canonical
parser can also be described as a rewriting system with a set of rules
M containing shift and produce actions [
16], it can be transformed into an LLR-system in more or less the same way as the
parser:
Remember that
, where
, represents the equivalence class of viable suffixes of the
-augmented grammar
in regard to
-equivalence [
16] or, in other words, a state of the canonical
parser.
The idea behind these scheme is the same as for the parser, but as the canonical parser needs two topmost states to decide the next produce action, the state is inserted beneath at the beginning and therefore must be removed at the end. Again, the startup and produce rules violate restrictions of the context-sensitive reduction system. However, as the canonical parser is rarely needed in practice even for and as in practice it cannot be produced without a generator except for the smallest and simplest grammars, it is not considered as an important model for formulating parsers using the LLR-system.
4.2. Bottom-Up Parsing: LR and LALR
The most widely used bottom-up parsing method is LALR parsing, or more precisely,
parsing. Even though it is usually implemented by a generated table-driven parser, in theory both the canonical
and
parsers are formulated as rewriting systems with shift and reduce actions [
16]. If described by a set of actions
M, either one can be transformed into an LLR-system with a set of rules
R, defined as follows:
Remember that
, where
represents the equivalence class of viable prefixes of the
-augmented grammar
in regard to
- or
-equivalence [
16], or, in other words, a state of the canonical
of the
parser, respectively. Again, formulating an LR or LALR parser for a full-scale programming language as an LLR-system in practice is out of the question because of the size and complexity of the underlying LR or LALR automata and consequently the number of states and rules.
Despite the complexity of LR parsing, one should embrace rather than abandon the shift-reduce parsing, as it is the most natural solution for parsing sentential forms where a left recursion is essential.
Example 6 (Essential left recursion)
. One of the most apparent examples of essential left recursion is the description of arithmetic expressions. Unlike the sequence of statements (as in Example 3) where both left or right recursion work equally well, the left recursive productions allows neat abstract syntax trees because they enforce left-associativity of operators [18]. Fortunately, for the well known grammar for arithmetic expressions, there exists a simple and intuitive LLR
-system with a set of ruleswhere x is any symbol other than ∗
(or belonging to if one takes the pain of finding this out manually). The first three and the fourth rule are obvious. The fifth and the sixth rules are crucial for understanding this LLR
-system:As soon as is observed, it should be reduced to T. Because the leftmost rule applies first, “as soon as” (rather than just if), the left associativity of ∗ is ensured.
However, if and only if T cannot be extended any further, i.e., if it is followed by anything other than ∗ , it can and thus should be reduced to E.
Likewise, can be reduced to E if and only if T cannot be extended any further, i.e., if it is not followed by ∗, the operator with the higher precedence.
Parsing proceeds in similar way as in Example 3. To see why the condition imposed by x in the sixth rule is needed, consider the derivationwithout x in the sixth rule: the first is first reduced to E and never reduced any further. The above transformation can be considered as a pattern just as much as another transformation, which involves left recursion elimination and results in SLL(1)
grammar. It produces a shift-reduce parser that is much simpler than the corresponding parser with 24 states or parser with 13 states. Lastly, it can be observed as an example of operator-precedence parsing [59]. 4.3. Bidirectional Parsing: Top-Down and Bottom-Up
Sticking to a preselected strategy, either top-down or bottom-up, is not always the best choice for all parts of the language being parsed. For instance:
Sequences of statements or declarations can be expressed using either a left or a right recursion. However, if described by the right recursion and parsed using the top-down parser, e.g., shift-produce, each statement or declaration is appended to the abstract syntax tree as soon as it has been parsed. If the left recursion is used, it can be appended to the tree only after the entire sequence has been parsed.
Expressions are best described by the left recursion because, unlike the right recursion, it allows describing the left-associativity of arithmetic operators in the best possible way [
18]. To avoid (a) eliminating the left-recursion when the parser is being made and (b) transforming abstract syntax trees when the parser is being run, one should use the bottom-up, e.g., shift-reduced, parser.
Bidirectional parsers, i.e., those incorporating both top-down and bottom-up parsing, have been investigated before. Most of these parsers are variants of either left-corner parsing [
60,
61,
62] or a combination of LL and LR parsing [
11,
12]. Parsers based on these approaches have never become widely used, most likely because of their complexity, rigidity, non-intuitiveness, and perhaps because of lack of tools, as none of them can be hand-coded. However, as the following two examples show, LLR-system represents a platform for hand-coded bidirectional parsers.
Example 7 (Bottom-up parsing during top-down parsing)
. The statements of the little programming languages are described by an EBNF grammar in Examples 3–5. By rewriting it into an SLL(1)
grammar first, it has been transformed into an -system which performs a top-down parsing:where , and belong to , and , respectively.So far, symbol E denoting expressions has been treated as a terminal symbol (Example 3). Suppose expressions have the form as described in Example 6. By adding rules from Example 6 for parsing expressions and ruleswhere x is anything but + (which extends an expression as E is a left recursive symbol), and the resulting parser becomes bidirectional. Namely, sentences are parsed top-down while expressions are parsed bottom-up. Note that is never expanded by any “SLL(1)
rule” and thus the parser slips into a bottom-up parsing of an expression. The expression is reduced into symbol E, which must then be removed together with so that top-down parsing can continue. To see how this works in practice, consider the parsing program “”. It starts with the top-down mode: With “at the top of the LL
stack”, the parser switches into a bottom-up mode: By removing , the parser has slipped back into the top-down mode. It will perform another pass of the bottom-up parsing to parse , upon which it will return to the top-down again.
Example 8 (Top-down parsing during bottom-up parsing)
. The bidirectional parser in Example 7 starts in the top-down mode and occasionally switches to the bottom-up mode. However, it is also quite easy to switch back to a top-down mode while the parser is in a bottom-up-mode. If the small language is extended by EBNF production describing function calls, the following rules must be added to the LLR
-system of Example 7:where and . Note that when is observed, the parser switches from a bottom-up into top-down mode only to reenter the bottom-up when each expression, i.e., an argument to a function call, is expected. 6. Evaluation
Programming languages are usually parsed with algorithms based on context-free grammars. However, if parsing is based on context-sensitive grammar or even type-0 grammar, the question arises about the price, which is paid when an algorithm that permits a much more general description of a language syntax is used. The comparison can, of course, only be made using languages that can be described by context-free grammars. Nevertheless, the results obtained using these languages serve as a good indicator of how efficient the parsing algorithm based on the LLR-system is compared to some more traditional parsing algorithm.
To evaluate parsing based on the LLR-system, a prototype implementation of the parser generator supporting all three algorithms has been made. Together with all the test data, it is available at
https://github.com/slivnik/LLR-systems (accessed on 12 March 2023, commit ca5d3f5). All the results reported in this section were obtained using an Intel(R) Core(TM) i7-7700HQ processor running at 2.80 GHz (max 3.80 GHz).
Consider parsing arithmetic expressions described by the context-free grammar defined in Example 6 first. The running times of parsing a random arithmetic expression consisting of one million and one symbols (all nums are single digits and all ids are single letters) are shown in
Table 2 and compared to the running time of the
bison-generated parser. The first line in
Table 2 refers to the LLR-system obtained by transforming the grammar from Example 6 to LL grammar first and then to an LLR-system. The second line refers to the LLR-system obtained by transforming the grammar from Example 6 directly to the LLR-system. The third line refers to the LLR-system written by hand in Example 6.
As expected, the LLR-system written from scratch yields better results than the two obtained by transforming the grammar using the transformations described in
Section 4. It can be observed that the parser based on the LLR-system shown in Example 6 is 18% slower than the
bison-generated parser. If both scanning and parsing are considered, as shown in
Table 3, the LLR-system parser is only 6% slower. However, it is worth examining the absolute times too: the actual difference between the
bison-generated parser and the LLR-system is approx. 2 ms of the CPU time for a 1 Mb source file.
Parsing arithmetic expressions consisting of symbols is a rather synthetic test. Hence, parsing Pascal, a real programming language, is considered next. Pascal has been chosen for two reasons that both make measuring running time simpler. First, unlike C, it can be parsed without a symbol table and thus the running time is easier to measure. Second, compared to Java, source files in Pascal are usually much bigger. To avoid generating random programs, source files of Knuth’s , , TeX and METAFONT (all available on CTAN servers) were used as test inputs. There are two reasons for this choice. First, these are not some synthetic programs but publicly available ones of considerable size that will remain available for a very long time. Second, Pascal can be parsed without a symbol table which makes measurements much simpler (the only other part necessary is lexer).
The running times of two LLR-systems were compared against a
bison-generated parser. The first one is based on the LL grammar for Pascal, but with a few LL conflicts resolved as described in
Section 4. A small subset of its 278 rules is shown in
Figure 3 (numbers on the right side of rules are substituted by symbols found at the specified positions on the left side). Rules expanding the symbols
program,
label_part,
label_definitions and
label_definitions_rest illustrate how rules based on an
grammar look like. However, having symbol
statement on the top of the stack and
IDENTIFIER in the lookahead buffer, the
parser cannot know whether it should start a parsing assignment statement or a procedure statement. As it can afford to check two input symbols instead of just one (without a hack in the parser’s code), the decision can be made.
The other LLR-system has been made from scratch and is found to be more efficient (the same pattern as with the arithmetic expressions). A small subset of its 209 rules is shown in
Figure 4. A totally different approach is used here. For instance, the third rule does not depend on the context: wherever
LABEL is found, it triggers the parsing of label declarations. Moreover, if it is reduced to
label_declarations right after the program header, it is merged together with it; otherwise, the program header changes to the same symbol, namely
program_upto_labels without any label declarations. Hence, this LLR-system resembles the bottom-up shift-reduce parsing, but in a much more compact way, and a programmer can have a better understanding of its reductions than if he or she would inspect the reductions of an LR parser.
Table 4 and
Table 5 contain running times of parsing all four programs with all three algorithms. The running times are again compared to the
bison-generated parser: the parsers based on the LLR-system that was made specifically for LLR-parsing are less than 60% slower if the CPU time of the parsing is compared and less than 20% percent if both scanning and parsing are considered.
The difference in CPU time between parsing TeX and METAFONT using the bison-generated parser and the LLR-based parser is less than 2 ms if the more efficient LLR-system is used and less than 4 ms if the LL-based LLR-system is used. As TeX and METAFONT sources contain 19,203 and 18,769 lines of a pure Pascal code (excluding comments and formatted using ptop), extrapolating this to one million lines of code yields a difference of less than 0.1 s and approx. 0.2 s, respectively. If this was a real code with a proper amount of comments, the difference would be even smaller, as comments never reach the parser. Putting this into perspective, it takes the Free Pascal Compiler (version 3.2) 0.313 s to compile TeX (with a few lines of code commented out for the sake of incompatibility). Hence, if the bison-generated parser or LLR-based parser had been used, the difference would amount to 0.3% or 1.1% of the compilation time.
As proved in
Appendix B, the LLR-systems are equivalent to Turing machines. Hence, comparing different LLR-systems and their complexity in general is a very difficult task. More insight, at least for the practical purposes, can be obtained by inspecting individual reductions of different LLR-systems for arithmetic reductions or for parsing Pascal (see
https://github.com/slivnik/LLR-systems, accessed on 12 March 2023, commit ca5d3f5). For instance, in most cases, the introduction of a complementary symbol
for each terminal symbol
and a reduction
(as it is prescribed by the transformation of an LL grammar into an LLR-system) can be avoided. As with context-free grammars, it takes a bit of practice to gain the expertise needed for writing efficient parsers.
7. Conclusions
A new formalism, called the LLR-system, has been defined. As it is meant to be used for parsing programming and domain-specific languages, two sections, namely
Section 4 and
Section 5, have been devoted to the definitions of initial patterns that can be used and followed when building parsers based on LLR-systems. It is hoped, at the same time, that the explanation of these patterns provides the insight into the structure of the LLR-system and into the way of thinking needed to build an efficient LLR-system. By providing these patterns and explanation, the LLR-system is perhaps given a better chance to become used in practice.
As shown in the evaluation (
Section 6), parsers based on LLR-systems are slightly slower than classical context-free parsers. However, if their absolute running times are taken into consideration, the difference is negligible when compared to the difference in running times of code written in different programming languages. After all, it has become perfectly acceptable that code written in one of the most widely used programming languages nowadays is interpreted 70 times slower than when the equivalent compiled code is run when written in another language [
63]. Hence, only a few people would notice or care if an interpreter or compiler used a parser that runs a 1–5 milliseconds longer even when large programs, e.g., the entire source code of
TeX or
METAFONT, are parsed.
Thus, if a parser can be made using an existing algorithm without too much additional code needed to support the parsing of the most complex language constructs, it should be made this way. Otherwise, assuming that someone is skilled enough and willing to implement a hand-coded recursive-descent parser, he or she can implement it as an LLR-system just as well. The advantage of implementing it as an LLR-system is that many add-ons or hacks can be implemented ”within-a-system” and can be, if needed later, modified more easily. This is a significant step forward if compared with Markov normal algorithms which, as already mentioned in
Section 3, ”
did not meet general agreement”, because it is hard to write a set of adequate rules representing a parser [
53].
Finally, it has been demonstrated how the LLR-system can be used for implementing the existing context-free parsing algorithms with error recovery, which is always language dependent, being part of the formal parser specification. Realizing the ability of the LLR-system to parse languages with considerably more complex syntax structures than are found in most existing programming and domain-specific languages, it would be interesting to observe how a generation of an LLR-system-based parser could be added to or integrated into some existing parser generator to observe how well the method works once syntax-directed definitions [
18] are supported. One such candidate is LISA, a compiler–compiler capable of generating parsers supporting not only S- or L-attributed syntax-directed definitions, but attribute grammars as well [
64].



{kind=link}
{kind=link}
{kind=link}
{kind=link}



