1. Introduction
Distributed computing systems, especially cloud computing, have been applied widely in production and science research. Task scheduling is one of the most concerning open issues for various distributed systems [
1] for optimizing the resource efficiency [
2], user satisfaction [
3], energy efficiency [
4,
5], etc. In a distributed computing system, there are multiple multi-core servers with various capacities for processing computing tasks. The task scheduling is to decide which computing unit (e.g., computing cores) will be where each task is processed and the execution order of tasks assigned on each computing unit.
The task scheduling problem has been proven NP-hard when there are more than two computing units [
6]. This means that there is no exact method to solve the scheduling problem within a reasonable time for large-scale computing systems unless NP = P because the time complexity of an exact method is exponentially increased with the system scale. Thus, related works mainly focus on designing heuristic or meta-heuristic search approaches to provide an accepted solution with polynomial time for the problem.
A heuristic method exploits the local search approach designed for a specific problem [
7,
8], to find a local optimal solution with very little time consumption. Inspired by natural laws or social phenomena, meta-heuristics employ general search strategies implemented with random methods [
9,
10]. Benefits from global search abilities, meta-heuristics can achieve better performance than heuristics with a few time overheads in many cases and are widely applied in various decision-making situations. Thus, in this paper, we are concerned with the design of meta-heuristics for solving the task scheduling problem.
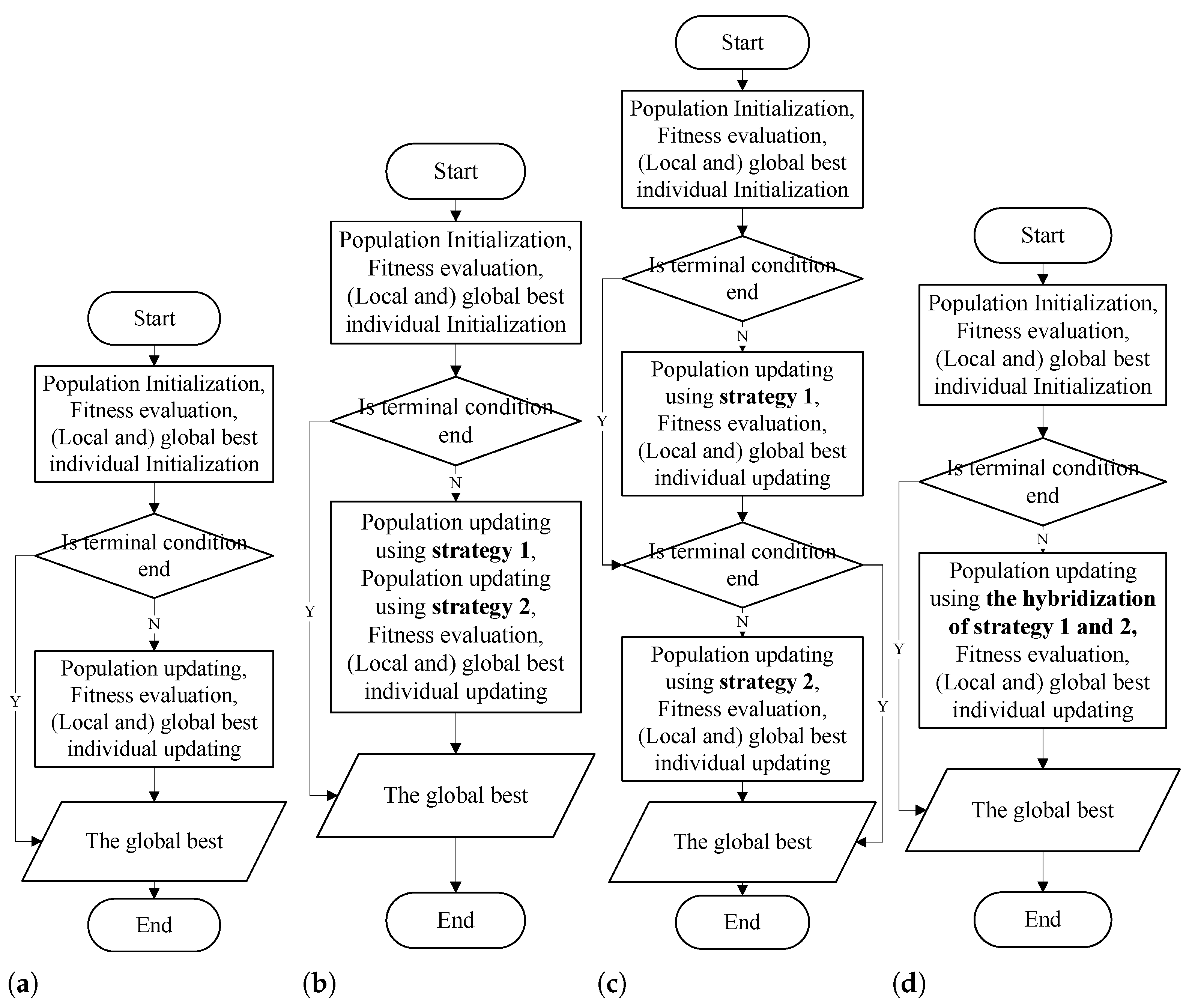
There are numerous meta-heuristic methods, and each has its own advantages and limitations. The hybrid of two or more methods can achieve complementary advantages of these methods and thus can provide better performance than each of them. There are three hybridization methods for combining two or more heuristic or meta-heuristic methods, as shown in
Figure 1. The first one is sequentially exploiting the population updating strategies of two or more algorithms in each iterative or evolutionary process (as shown in
Figure 1b). The second one is first performing the population strategies of one algorithm and then another algorithm (as shown in
Figure 1c). Both of these two hybridization methods sequentially exploit rather than combine the benefits of multiple meta-heuristic algorithms and thus have limited or even worse performance. Therefore, we consider exploiting the third hybridization method, which integrates two or more updating strategies, to propose a hybrid heuristic task scheduling algorithm for distributed computing by integrating the swarm cognition into the evolutionary strategy.
In this paper, we design a task scheduling method by integrating a Genetic Algorithm (GA) with Particle Swarm Optimization (PSO). A GA and PSO are both representative and classical meta-heuristics and have been widely used in in many areas, thanks to their good performance and easy implementations [
11,
12]. GA has a powerful global search ability due to the large population diversity produced by the crossover and mutation operators. However, a GA has a slow convergence velocity in the search process. Conversely, PSO quickly converges but is easily trapped into a local optimal position, where the position of each particle is updated based on its personal best position and the global best position of all particles in the evolution process. Therefore, in this paper, we combine both benefits of a GA and PSO by integrating the updating idea of
PSO into the evolution process of
GA, and propose a new hybrid heuristic method (PGA) for task scheduling in distributed computing systems.
The contributions of this paper can be briefly summarized as follows.
We formulate the task scheduling problem with deadline constraints into a binary nonlinear programming model (BNLP) for distributed computing systems. There are two optimization objectives of BNLP. The major optimization objective is maximizing the number of tasks with deadline satisfaction, which is one of the metrics quantifying user satisfaction. The minor one is maximizing the overall resource utilization, which is a widely used quantitative metric for resource efficiency.
We design a hybrid heuristic method for solving the task scheduling problem named PGA. In the PGA, each chromosome represents one solution mapping tasks onto computing units, and the fitness function is the objective of formulated BNLP. In the evolution process of the GA, the PGA adds two crossover operations to speed up the evolutionary rate, inspired by PSO, which crosses the current chromosome with its own historical best chromosome and the global best chromosome, respectively, for each individual.
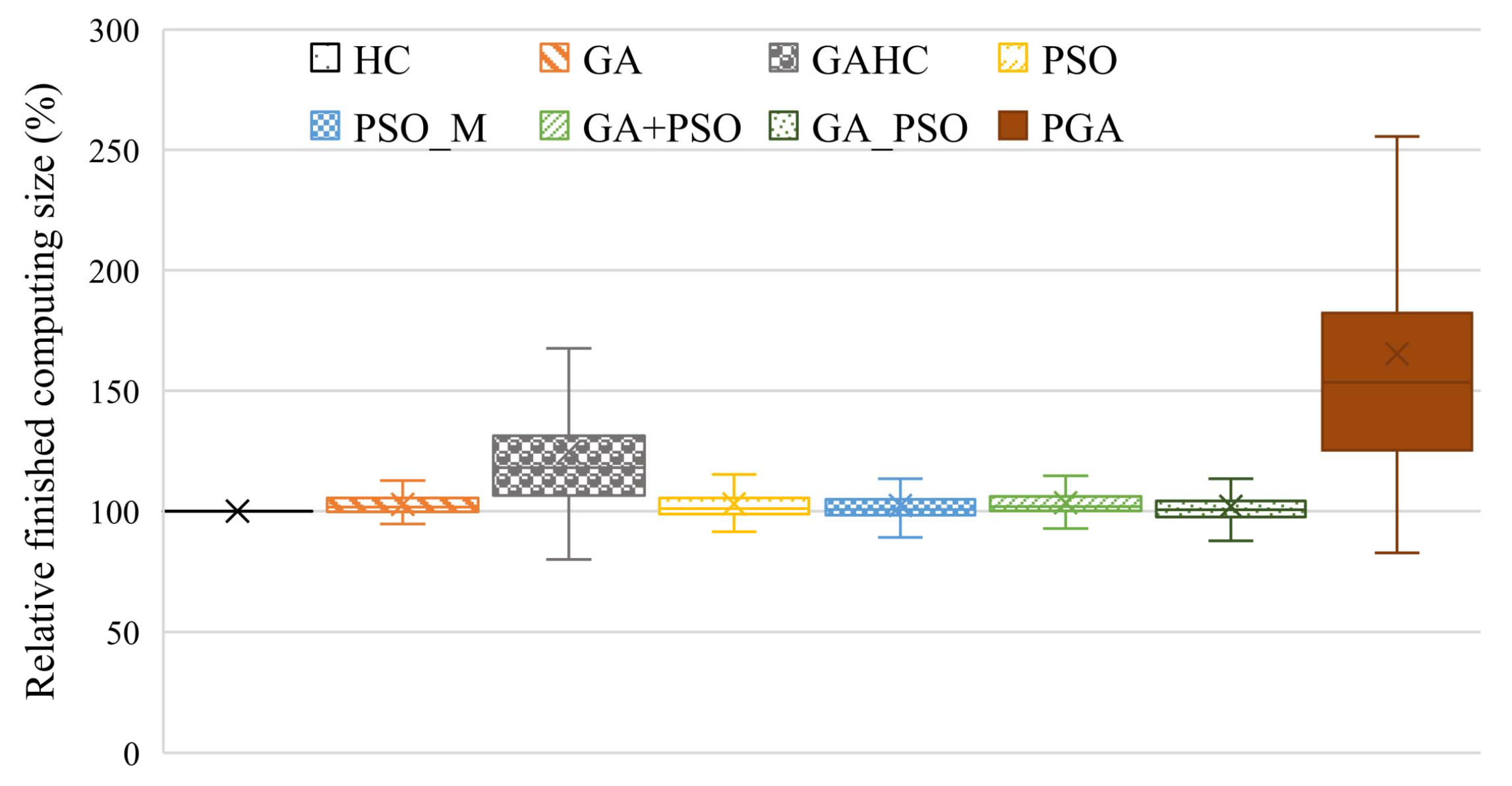
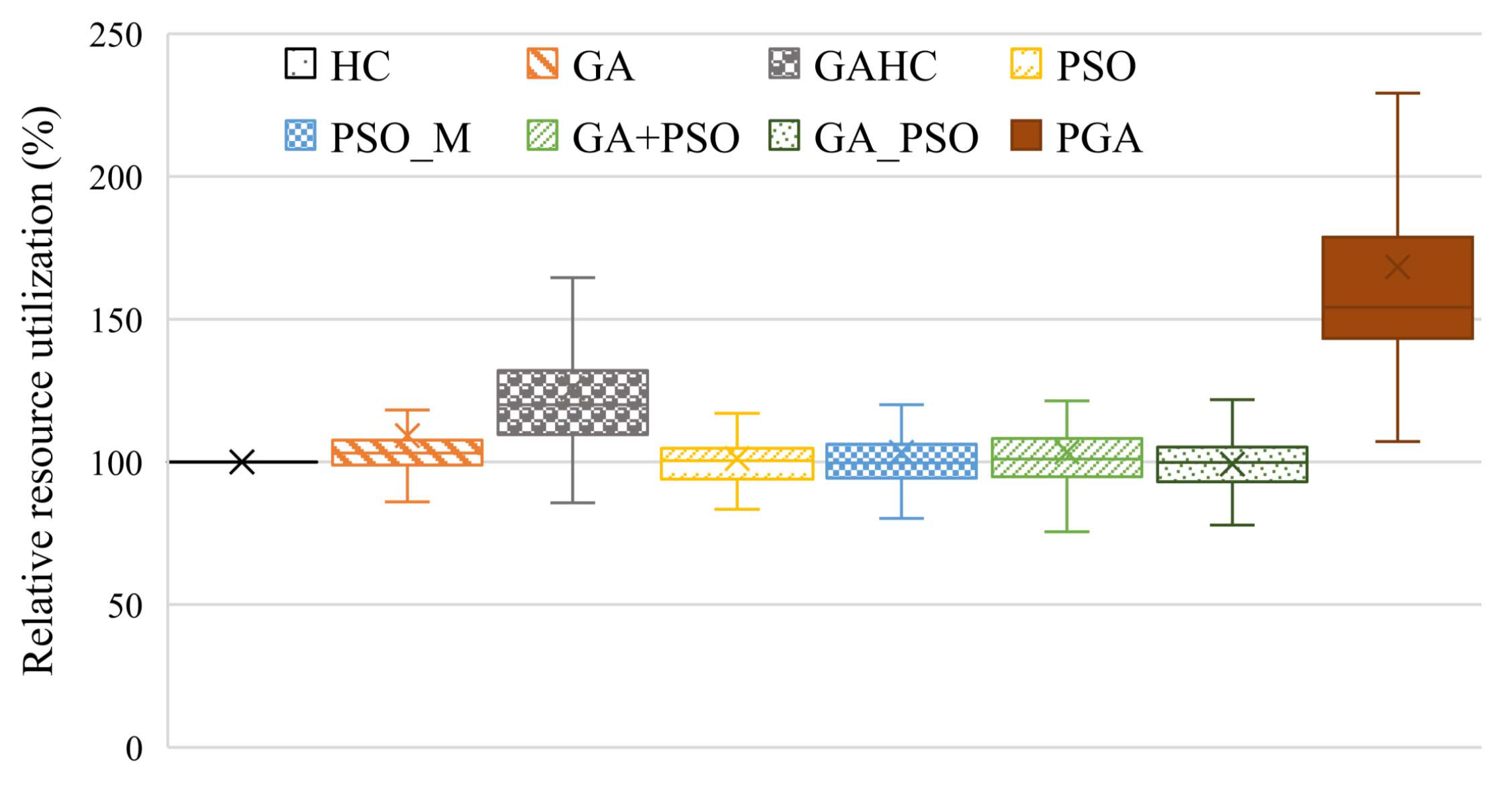
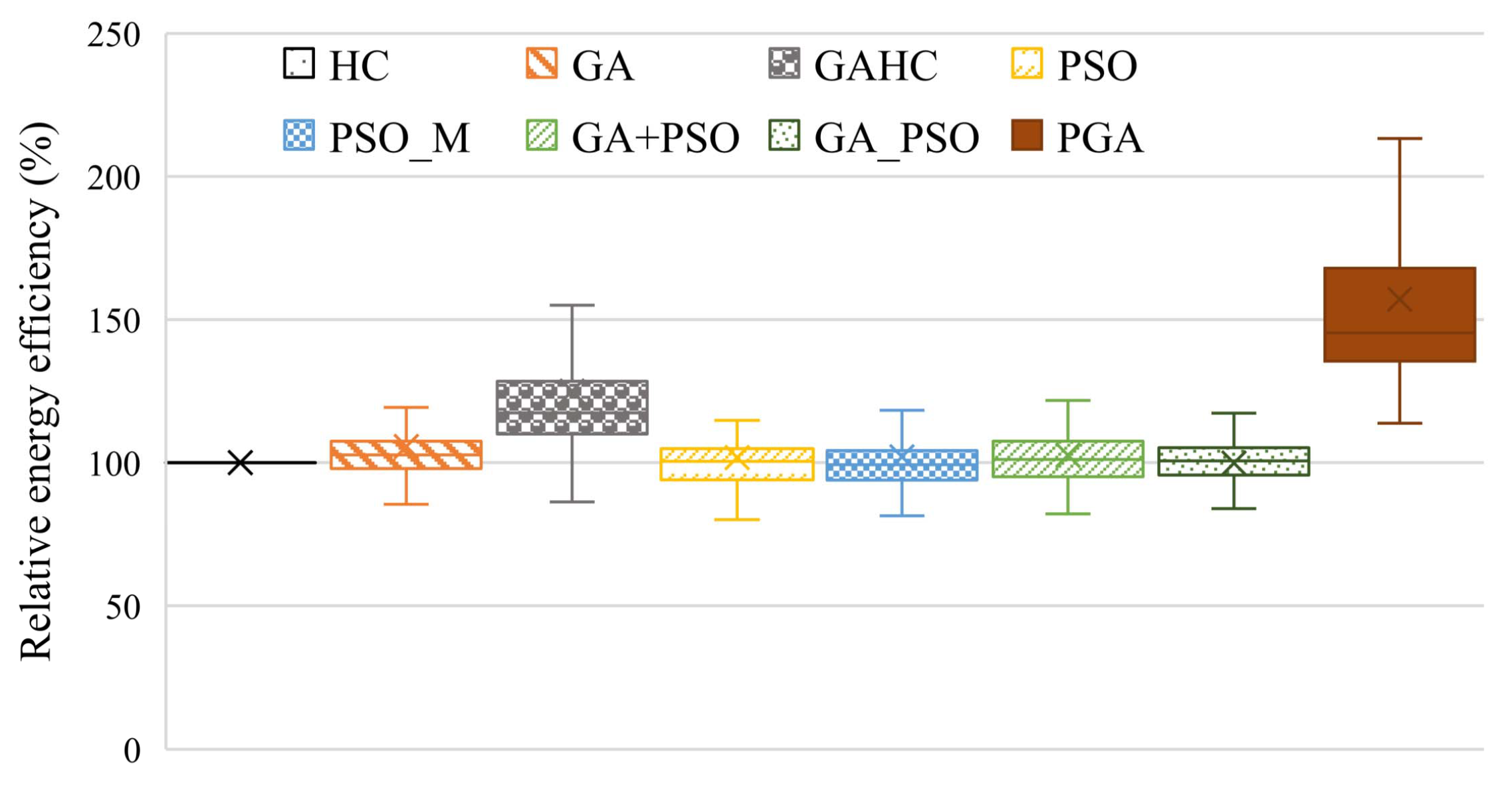
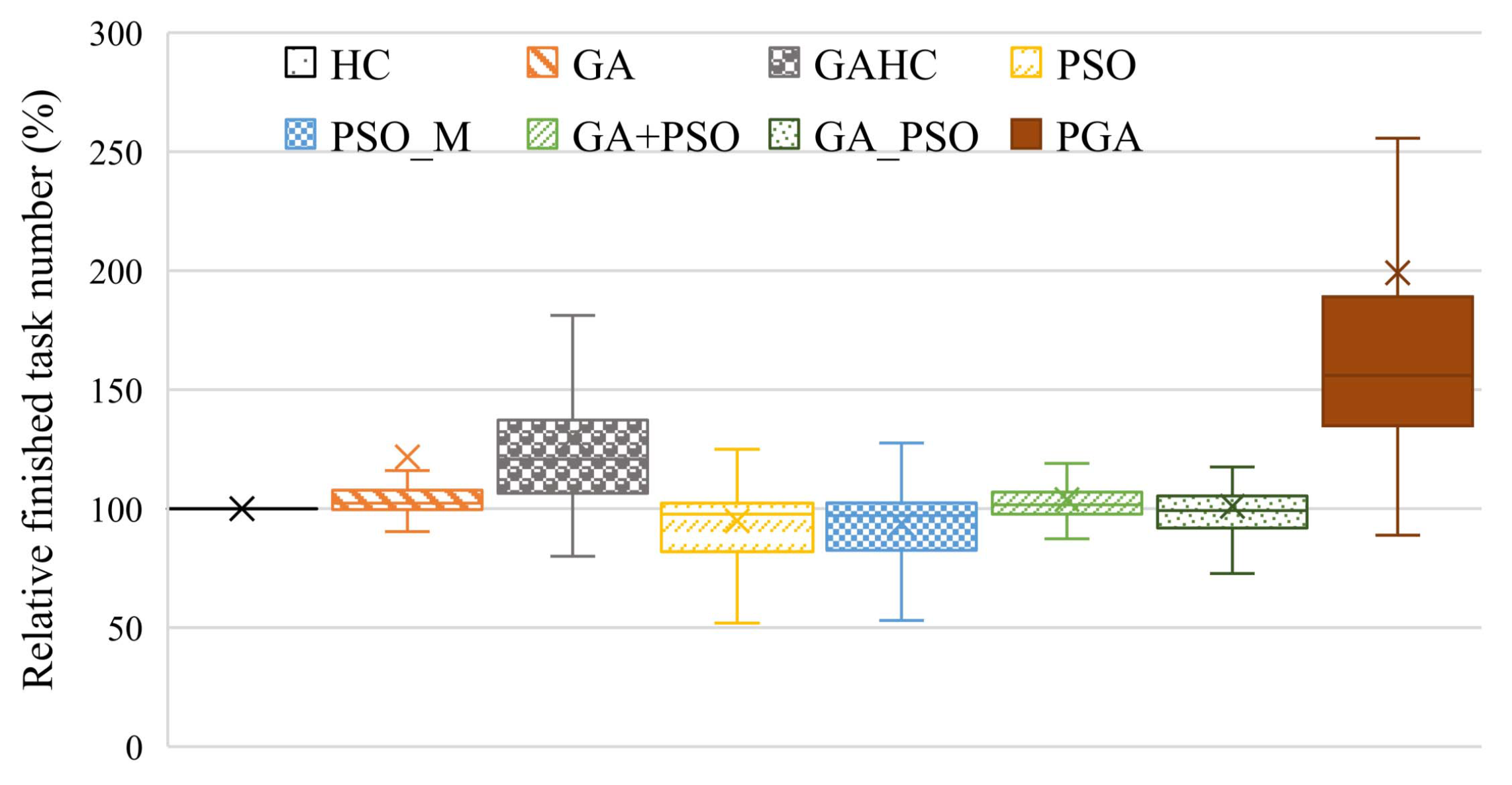
To evaluate the performance of the PGA, we conduct extensive simulated experiments, where the system parameters are set referring to related works. Experiment results confirm the performance superiority of the PGA in both user satisfaction and resource efficiency, compared with seven heuristic/meta-heuristic/hybrid heuristic task scheduling methods proposed recently.
In the following of this paper,
Section 2 and
Section 3 illustrate our formulated model and proposed hybrid heuristic task scheduling method, respectively. In
Section 4, we evaluate the performance of our proposed method.
Section 5 gives recent works related to solving the task scheduling problem, and
Section 6 concludes this paper.
2. Problem Formulation
In this section, we present the formulation of the task scheduling problem concerned in this paper. The notations used in the formulation are outlined in
Table 1.
In a distributed computing system, there are S computing servers, . The server has cores, each with computing capacity. During a period of time, there are T tasks requesting processing on the system represented by . The task needs computing resource for its processing and requires deadline, i.e., the system finishes the task before or just rejects it (In this paper, we consider tasks with hard deadline constraints, and leave the concern of soft deadline requirements as one of our future works). Without loss of generality, we assume that . Then, we is assigned to one core of ; its execution time is .
In this paper, we consider independent computing-intensive tasks, i.e., there is no data or logical dependency between the two tasks. This is because independent tasks, such as bag-of-tasks (BoT) applications, are very common in distributed systems, and it is worth designing a scheduling method for independent tasks [
13]. In the future, we will study the extension of our work and the new approach for the scheduling of workflow tasks with dependencies on each other. In fact, our model and method (PGA) can be applied for scheduling interdependent tasks by just adding their dependency constraints.
For the formulation of the task scheduling problem, we define binary variables
to represent whether
is assigned to
kth core of
, as shown in Equation (
1).
Then, the tasks assigned to
kth core of
include
. In this paper, we do not use the execution redundancy that can improve the makespan of tasks but reduce the resource efficiency. Thus, a task cannot be assigned to more than one core for its execution, i.e.,
For tasks assigned to one core, the number of tasks whose deadlines are satisfied is optimal when applying the earliest deadline first (EDF) execution order [
14]. With an EDF execution order, the finish time of each task can be calculated by Equation (
3).
where
represents the finish time of
when the task is assigned to a core for its execution, and
if
is not assigned by any one core when the task is rejected.
is the cumulative execution time of tasks that have earlier deadlines than
and are assigned to
kth core of
. Thus,
is the finish time when
is assigned to the
kth core of
. Then, the deadline constraints required by tasks can be formulated as Equation (
4). Equation (
4) also holds for rejected tasks.
For each core, the use time is the cumulative time consumed by executing tasks assigned to the core, which can be formulated as Equation (
5), where
is the use time of
kth core in
. The occupied time of a server is the maximum use time of its cores and thus can be calculated by Equation (
6), where
is the occupied time of
for task executions.
Then the resource utilization of each server can be obtained from Equation (
7), and the overall resource utilization of the distributed system can be achieved using Equation (
8), where
is the resource utilization of
.
U is the overall resource utilization.
is the amount of resources consumed by task executions in
, and
is the occupied resource amount of
.
Based on the above formulations, the task scheduling problem can be modeled as the following optimization problem.
subject to
where
,
, are the decision variables. The objective is maximizing the number of tasks with deadline meets (
N) plus the overall resource utilization (
U), where
N is calculated by Equation (
10). Noticing that the utilization
U is no more than 1, the number of tasks with a deadline meeting
N is the major optimization objective, and the utilization
U is the minor one. Because the decision variables are binary and constraints (
3), (
6) and (
8) are non-linear, the optimization problem belongs to a constrained binary non-linear programming problem (BNLP). This problem can be solved by existing tools, e.g., lp_solve [
15] and the optimization toolbox of MathWorks [
16]. However, these tools take exponential time to solve a BNLP, on average, and thus cannot be applied for middle to large-scale problems.
3. PGA: The Hybrid Heuristic Scheduling Method
In this section, we present a hybrid heuristic method for solving the task scheduling problem formulated in the previous section, based on the ideas of a GA and PSO. Our proposed method, the PGA, is outlined in Algorithm 1, which integrates the idea of self-cognition and social cognition of PSO into GA. We need to design the encoding/decoding method for the map between chromosomes and scheduling solutions first when applying GA. The encoding/decoding method used in our method is as follows. In our method, similar to PSO instead of a GA, individual and chromosome are two different things. Chromosomes are to individuals what positions are to particles. An individual has only one chromosome, and its chromosome can be changed with population evolutions.
Based on the encoding/decoding method, the PGA first initializes a population with multiple individuals (line 1), where each gene value of the chromosome for every individual is set between 1 and the core number, randomly. Moreover, the PGA evaluates the fitness of each individual (line 2). The fitness function is the objective of the optimization problem formulated in
Section 2, i.e.,
, where
N and
U can be get from the task scheduling solution decoded by the chromosome. Then, the PGA records the current chromosome as the personal best chromosome for each individual (line 3), and the chromosome with the best fitness as the global best chromosome (line 4).
After the initialization, the PGA evolves the population iteratively with crossover, mutation, and selection operators. In each evolution, the PGA first invokes the crossover operator on each individual with a probability (the crossover probability) three times (line 7), which crosses its chromosome with the chromosome of another individual, its personal best chromosome, and the global best chromosome, respectively. Each time the crossover operator is invoked, two new chromosomes (offspring) are produced, and there are six new chromosomes are produced by the crossover operator for each chromosome. For each new chromosome, the PGA evaluates its fitness and updates the personal best chromosome and the global best chromosome as it if it had better fitness (lines 8–10).
For each individual, the PGA performs the mutation operator on its chromosome with a probability (the crossover probability), which can produce a new chromosome (line 11). Moreover, the PGA evaluates the fitness of the new chromosome and updates the personal and the global best chromosomes as the new one when the new one has better fitness for the individual (line 12).
At the end of each evolution, for each individual, the PGA uses the selection operator to select a chromosome as its chromosome for the next round of evolution (line 14). For an individual, the candidate chromosomes of the selection include its current chromosome, six new chromosomes produced by the crossover operator, and the new chromosome by the mutation operator.
After the evolution phase finishes, the PGA returns the task scheduling solution decoded by the global best chromosome (lines 15 and 16). The maximum evolution generation is set for the terminal condition in this paper.
In the remainder of this section, we will illustrate the encoding/decoding method and the operators used in the evolution, respectively.
| Algorithm 1 PGA: the hybrid heuristic scheduling method |
| Require: The information of tasks and computing servers, the parameters of GA; |
| Ensure: the solution of task scheduling; |
- 1:
Initializing a population (individuals), i.e., setting the chromosome of each individual randomly; - 2:
Evaluating the fitness of each individual; - 3:
Recording the personal best chromosome () as the initialized one for each individual; - 4:
Setting the global best chromosome () as the chromosome with the best fitness in the population; -
- 5:
while The terminal condition is not met do - 6:
for Each individual do - 7:
Crossing its chromosome with the chromosome of another individual that is randomly selected, , and , with a certain probability, respectively, and producing six new chromosomes (each crossover operator produces two new chromosomes); - 8:
Evaluating fitnesses of six new chromosomes, and getting the best chromosome (℘) that has the best fitness from these six chromosomes; - 9:
If the fitness of ℘ is better than that of , then is updated as ℘; - 10:
If the fitness of ℘ is better than that of , then is updated as ℘; - 11:
Mutating its chromosome with a certain probability, which produces one new chromosome; -
- 12:
Evaluating the fitness of the new chromosome and updating and if the new chromosome has a better fitness, respectively. - 13:
for Each individual do - 14:
Selecting one chromosome from its current chromosome and seven new chromosomes produced by it by crossover and mutation operations (lines 7 and 11), which is set as the new chromosome of the individual for the next evolution; - 15:
Decoding into a task scheduling solution; - 16:
return the task scheduling solution;
|
3.1. The Encoding or Decoding Method
In a PGA, a chromosome is expressed by a vector, and its genes are the values of all dimensions. For each chromosome, genes have a one-to-one correspondence with tasks. The possible value of every gene is between 1 and the number of computing cores in the system, which identifies the core where the corresponding task is assigned. Then, given a chromosome, we can decode an assignment of tasks to cores. Moreover, with the EDF scheme for executing tasks in each core, we can get a task-scheduling solution from a chromosome. Next, we give an example to help readers understand the encoding/decoding method.
Assuming a distributed system consisting of 2 computing cores, there are 4 tasks that need to be processed. Then there are 4 genes in each chromosome, which respectively correspond to these 4 tasks. The possible value of each gene includes 1 and 2, which represent the core where the corresponding task is assigned. The chromosome with the code (1, 1, 2, 2) represents that the first and the last two tasks are assigned to the first and the second cores, respectively. For two tasks assigned to a core, the task with the earlier deadline will be executed first.
3.2. The Crossover Operator
In this paper, we use the uniform crossover operator to produce two offspring from two chromosomes, which helps to enhance the exploitation ability of the PGA [
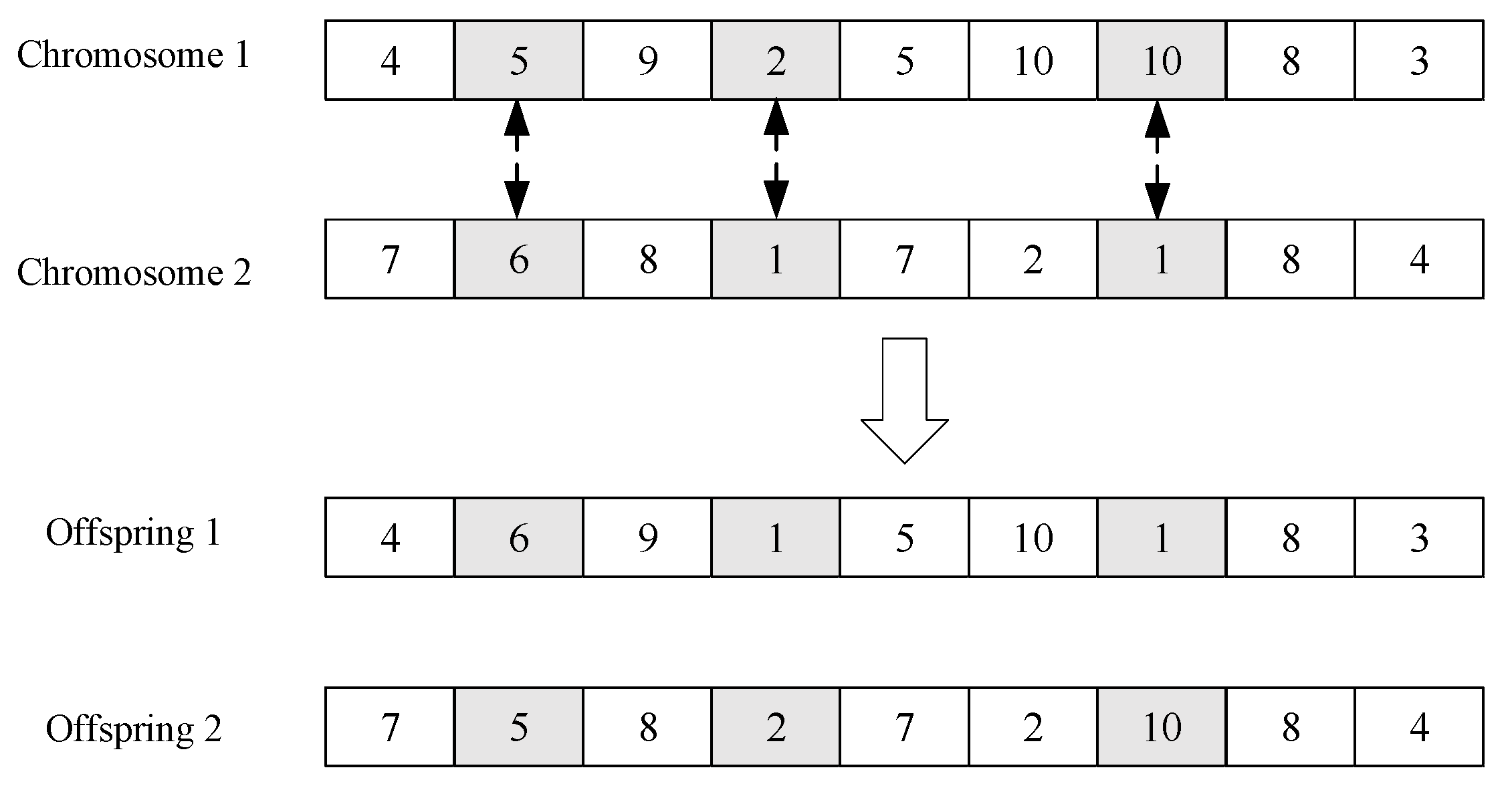
17]. The uniform crossover operator swaps two genes between two chromosomes with a probability in each dimension (gene position). In the implementation, for each gene position, a random number between 0 and 1 is generated with a uniform distribution, and two genes of two chromosomes are swapped in the position if the random number is less than the pre-defined probability. In the task scheduling problem, the swap between two genes of two chromosomes means that the cores that the corresponding task is assigned to are swapped in corresponding scheduling solutions.
As an example in
Figure 2, the uniform crossover operator is performed on two chromosomes (4, 5, 9, 2, 5, 10, 10, 8, 3) and (7, 6, 8, 1, 7, 2, 1, 8, 4), and the genes of chromosomes are swapped in the second, fourth, and seventh dimensions. Two offspring (new chromosomes) are produced, which are (4, 6, 9, 1, 5, 10, 1, 8, 3) and (7, 5, 8, 2, 7, 2, 10, 8, 4).
There are two parameters (probabilities) that need to be set for the crossover operator. One for deciding whether to perform the crossover operator for every individual and another for each dimension. Both parameters have an impact on the population diversity and convergence of the PGA. When the probability is great, there will be more individuals or genes crossed, and more new chromosomes will be generated, which can increase the population diversity. However, the increase of the diversity is limited, as the crossover operator cannot generate new genes in a dimension. However, this helps to pass good genes to the next generations and thus speeds the convergence. Therefore, these parameters should be adaptive to population diversity and convergence, which is one of our future works. In this paper, we set both probabilities as the same value.
3.3. The Mutation Operator
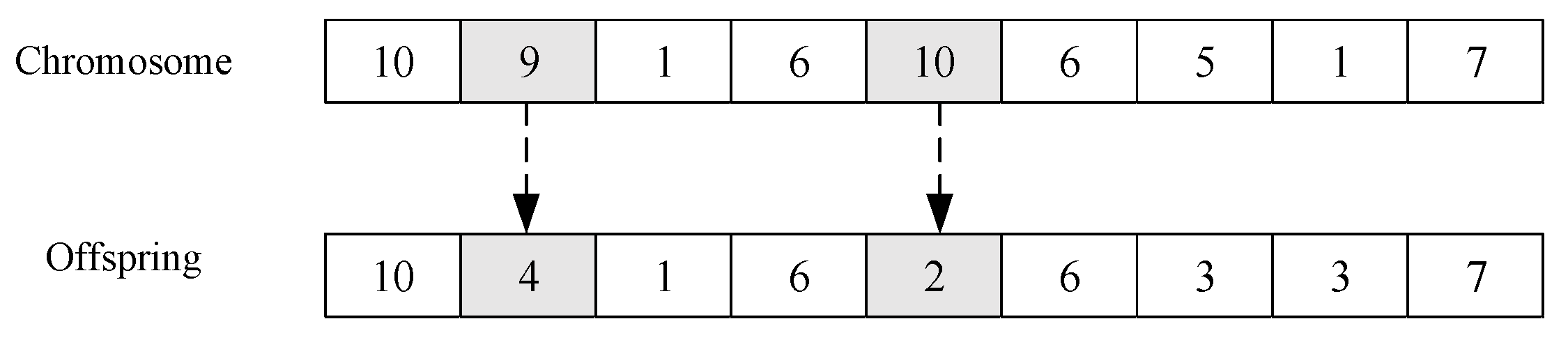
For each individual, a mutation operator is performed on its chromosome with a probability. In this paper, we use the uniform mutation operator as it helps to maintain population diversity. Similar to the uniform crossover operator, for a chromosome mutating, the uniform mutation operator generates a random number in the range of [0, 1] for each gene position and mutates the gene of the chromosome in the position if the random number is less than pre-set probability. The mutation of a gene is to set its value as another possible one that can be randomly generated. In the task scheduling problem, the mutation of a gene changes the core that the corresponding task is assigned to.
For example, as shown in
Figure 3, the uniform mutation operator is performed on the chromosome (10, 9, 1, 6, 10, 6, 5, 1, 7), and mutates the second and fifth genes to 4 and 2, respectively. Then we can get a new chromosome (10, 4, 1, 6, 2, 6, 5, 1, 7).
The mutation operator can largely increase the population diversity, as it can generate new genes in each dimension, but this decreases the convergence rate. Thus, the mutation probability also should be set carefully. Intuitively, all of the crossover, mutation, and selection operators affect diversity and convergence, and they all should be adaptively configured. In addition, it is very probable that these operators are interconnected in their performance, which is seldom studied.
3.4. The Selection Operator
At the end of each evolution, the PGA constructs a new population from the current population, and new chromosomes are produced using the crossover and mutation operators, by the selection operator, for the next evolution. To be specific, the PGA performs the roulette wheel selection on each individual. For each individual, there is one current chromosome and seven produced chromosomes at the end of each evolution. Then the PGA uses the roulette wheel selection to select one chromosome from these eight chromosomes as the new chromosome of the individual, where the probability that a chromosome is selected is proportional to its fitness.
For the selection operator, there is a tradeoff between exploration and exploitation that needs to be considered. For a chromosome with high fitness, it has a great probability of being selected for the next evolution and vice versa. This helps to preserve the good gene and make the convergence fast but decreases the population diversity to a certain extent. One feasible idea is to guarantee diversity in the early stage and to ensure strong convergence in the late stage. One of our future works is studying adaptive selection according to diversity and convergence.
3.5. Time Complexity Analysis
As illustrated in the previous subsections, the crossover, mutation, and selection operators traverse all dimensions, and thus, each operator has time complexity. From Algorithm 1, we can see that, in each iteration of the population evolution, the crossover operator is performed three times (line 7) and the mutation operator one time (line 11), one for each individual. Thus, each iteration has time complexity, where D is the number of individuals. Then, the time complexity of the PGA is , where is the number of iterations. Compared with a GA, the PGA performs the crossover operator two more times and, thus, has the same time complexity as a GA and PSO.
5. Related Works
Distributed systems, e.g., cloud computing and cluster computing, have been applied in all walks of life, which benefit from the rapid development of information and communication technologies. Moreover, there are plenty of research works on task scheduling for improving user satisfaction and/or resource efficiency in various distributed systems. The characteristics of related works are outlined in
Table 4.
Due to the NP-hard nature of the task scheduling problem, existing works mainly exploited heuristics and meta-heuristics to solve the problem. For example, Wang et al. [
32] presented a heuristic approach to improve user satisfaction and the resource cost for a hybrid cloud which consists of private and public clouds. This work assigned tasks whose requirements could not be satisfied by the public cloud to the private cloud at first, considering the scarcity of private resources. The heuristic method proposed by Ma et al. [
33] iteratively assigned the next task to the server with the most available resources for load balancing. Mangalampalli et al. [
34] used Cat Swarm Optimization (CSO) algorithm to map tasks and virtual machines in cloud computing for minimizing makespan, energy consumption, and total power cost at data centers. IMOMVO [
35] designed an improved multi-verse optimizer, a novel population optimization technique, for task scheduling in cloud computing to improve task execution performance. Teraiya and Shah [
27] used PSO to design the new scheduling approach, which considered each task as a particle and exploited the PSO technique to identify the most critical task for a prior execution. Chandrashekar et al. [
36] exploited Ant Colony Optimization (ACO) for task scheduling in cloud computing to improve the makespan and the resource cost. Yeh et al. [
37] applied Simplified Swarm Optimization (SSO) to reduce the energy consumption and task computing time for cloud computing.
Each of the above works used one heuristic or meta-heuristic algorithm and did not exploit the complementary advantages of multiple algorithms for better task-scheduling solutions. Some studies considered combining a meta-heuristic algorithm with another heuristic or meta-heuristic algorithm for task scheduling. The method used in [
29] exploited a GA in the first half of the evolution phase and PSO in the second half. With the same hybridization strategy to [
29], Sharma et al. [
38] used PSO and ACO to reduce the latency in fog computing. Wang et al. [
30] continuously used a GA and PSO in each iteration of the evolution, and Kumar and Karri [
39] combined the earthworm optimization algorithm (EOA) and the electric fish optimization algorithm (EFO) in the same way. Cheikh and Bougara [
40] first used PSO to get a solution for task scheduling. Then, with the initialization of this solution, their method applied extremal optimization for a new solution. These above works exploited two meta-heuristic algorithms separately and thus didn’t take full advantage of the combination of these two algorithms. The method used by Hussain and Al-Turjman [
20] performed the HC operation on each parent to generate parents with better fitnesses for a GA at the beginning of each evolution and replaced the selection operator by the replacement operator that the parent is replaced with its offspring with better fitness. Hafsi et al. [
28] performed the mutation operator on each particle at the end of each iteration of PSO to overcome the drawback of easily trapping into local minima. Chhabra et al. [
41] proposed a hybrid heuristic method by incorporating opposition-based learning (OBL) and PSO into Whale optimization algorithm (WOA), for scheduling BoT applications on physical cloud resources to minimize the makespan and energy consumption. This work used OBL to generate the initial population and applied OBL and the velocity update mechanism of PSO on whale exploration solutions, respectively, in the exploration phase of WOA.
In this paper, different from existing works, we proposed a hybrid heuristic method by integrating the principle idea of PSO into a GA, which combines both advantages of a GA and PSO very well, to optimize user satisfaction and resource efficiency with deadline constraints with task scheduling.
6. Conclusions
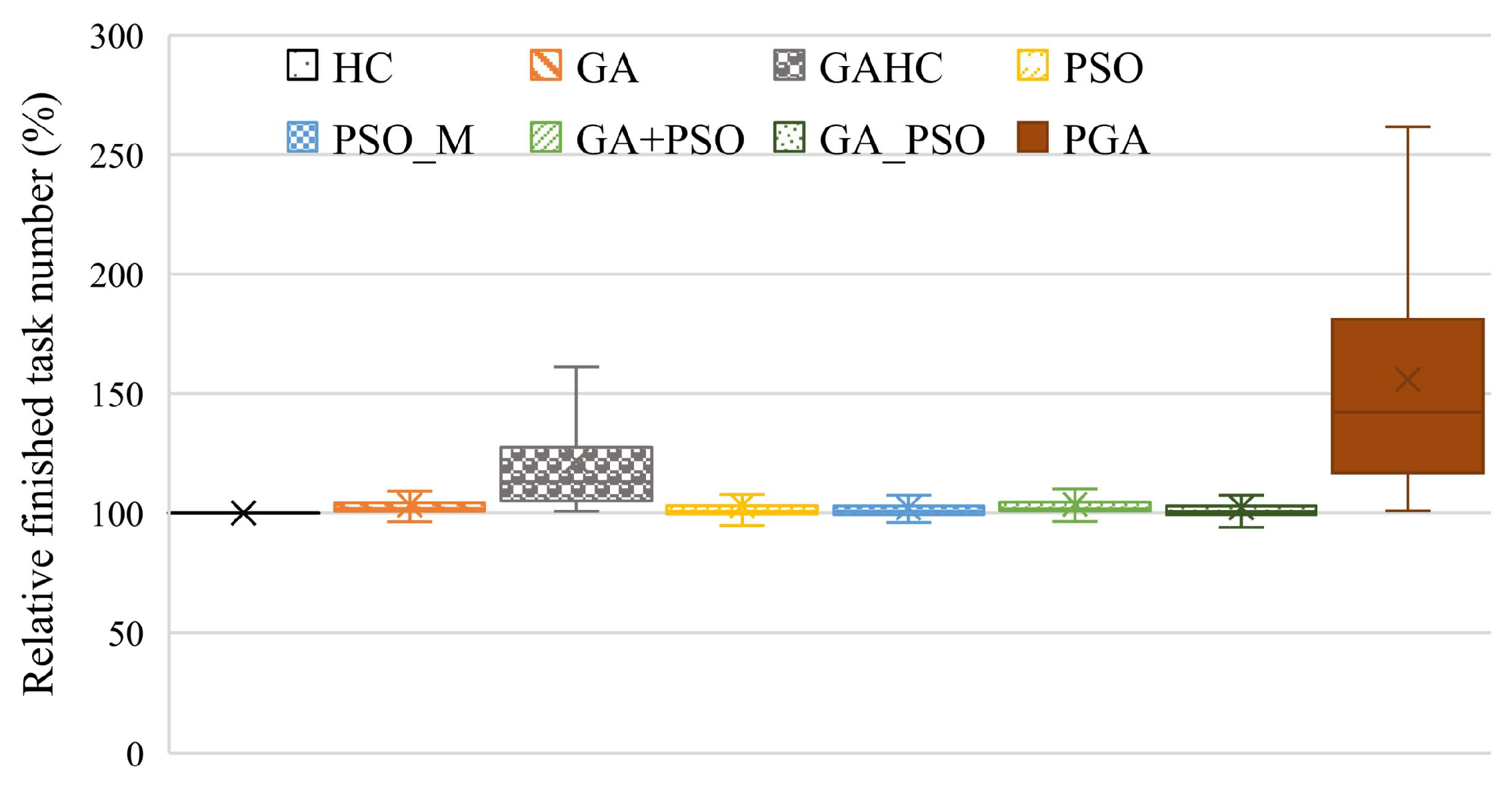
In this paper, we focus on the task scheduling problem with deadline constraints in various distributed computing systems. To address the problem, we formulate it as BNLP and propose a hybrid heuristic method, PGA, for solving the problem. The PGA combines both advantages of a GA and PSO by integrating the self-cognition and social cognition idea of PSO into the evolution of GA. Simulated experiments are conducted, and the results verify the superior performance of the PGA in user satisfaction, resource efficiency, and processing efficiency. The task scheduling is an instance of discrete optimization problems, and the PGA performs well in its solving. We believe that the PGA can be also applied to solving other discrete optimization problems as well as solving task scheduling, which is one of our future works.
Even though the integration of multiple meta-heuristic methods has the opportunity to provide a hybrid heuristic with good performance, some meta-heuristics are not complementary, which may not improve or even degrade the performance by hybridizing them. Furthermore, the integration strategy has an impact on performance. Therefore, in the future, we will study the complementarity of different meta-heuristics and design an efficient integration strategy for the hybrid of multiple meta-heuristics to improve the performance of the distributed systems in various aspects.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}