
Privacy-Preserving Public Route Planning Based on Passenger Capacity

Abstract
:1. Introduction
- In this paper, we first design a hybrid tree, eRBFtree. It divides the search space into subspaces according to the distribution of trajectory points. The division of the subspace is according to the distribution of transition points. The eRBFtree supports spatial pruning and fast kNN search on ciphertext.
- We propose a reverse kNN trajectory search on the encrypted database, RkNNToE. We use eRBFtree to prune the space of encrypted transitions. Then, we give a distance list (DList), which helps to refine the transitions and reduce the times of the kNN search. To ensure the correctness of results, we apply the fast kNN search for every transition as a result.
- Theoretical analysis proves that clouds and users cannot know the locations of data and the distance between two locations at the same time. The experiment results confirm that our scheme is practicable in the GeoLife project in Beijing and the bus lines dataset in Beijing.
2. Related Work
3. Problem Formulation
3.1. RkNNT Problem and Definitions
3.2. Basic Security Primitives
3.2.1. CKKS Encryption
3.2.2. Security kNN
3.3. The System and Threat Models
3.4. Secure Requirements for MTS
4. The Proposed Scheme
4.1. Main Idea of RkNNT Search
| Algorithm 1: Reverse Trajectory Search |
 |
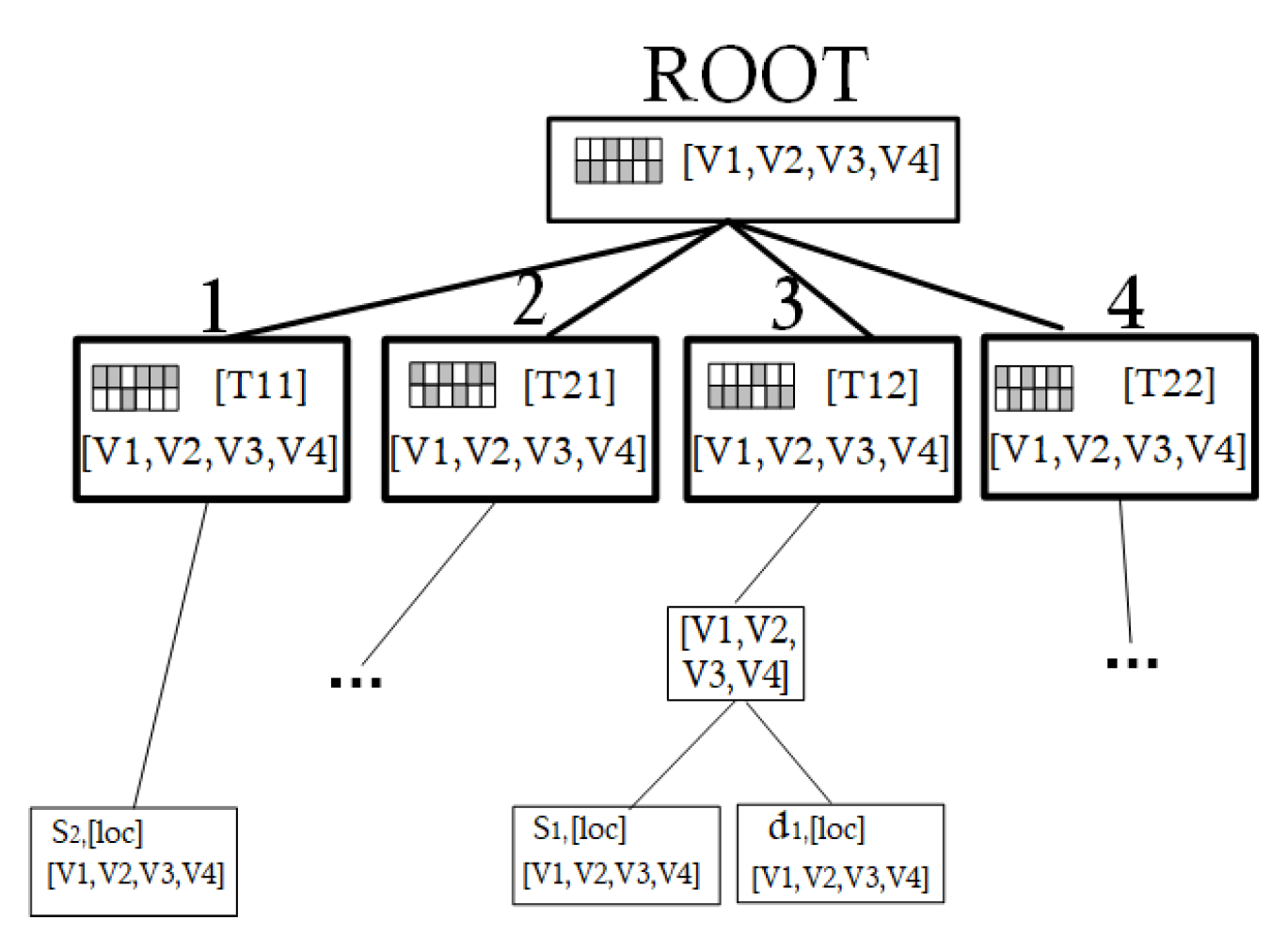
4.1.1. Building Hybrid Quad Tree
4.1.2. Generating Filter Points and Pruning Transitions
4.1.3. Refining Transitions and Returning Results
4.2. Reverse Search on Encrypted Trajectory Database
4.2.1. Setup
4.2.2. eRBFtree and DList Building
4.2.3. Query Encryption
4.2.4. Search
5. Theoretical Analysis
5.1. Correctness Analysis
5.2. Security Definitions and Analysis
5.3. Computational Complexity Analysis
6. Performance Evaluation
6.1. Constructing eRBF Tree and DList
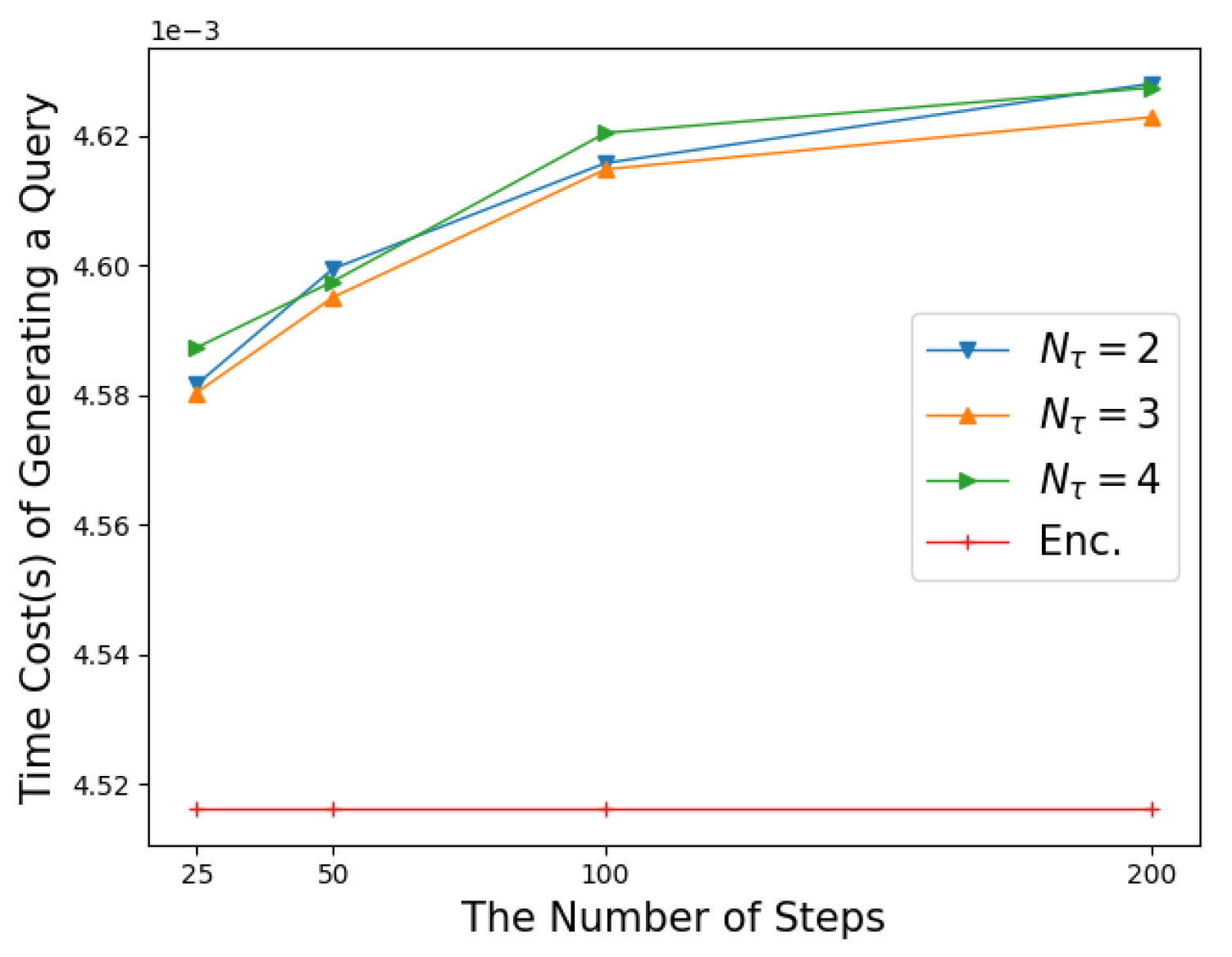
6.2. Generating Query
6.3. Search
6.3.1. NN Trajectories Search
6.3.2. RkNNToE Search
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, Z.; Shen, H.T.; Zhou, X.; Zheng, Y.; Xie, X. Searching trajectories by locations: An efficiency study. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Indianapolis, IN, USA, 6–10 June 2010; pp. 255–266. [Google Scholar] [CrossRef]
- Keogh, E.J. Exact indexing of dynamic time warping. In Proceedings of the VLDB, Hong Kong, China, 20–23 August 2002; pp. 406–417. [Google Scholar]
- Vlachos, M.; Gunopulos, D.; Kollios, G. Discovering similar mul- tidimensional trajectories. In Proceedings of the ICDE, San Jose, CA, USA, 26 February–1 March 2002; pp. 673–684. [Google Scholar]
- Chen, L.; Özsu, M.T.; Oria, V. Robust and fast similarity search for moving object trajectories. In Proceedings of the SIGMOD, Baltimore, MD, USA, 14–16 June 2005; pp. 491–502. [Google Scholar]
- Cheema, M.A.; Zhang, W.; Lin, X.; Zhang, Y.; Li, X. Continuous reverse k nearest neighbors queries in Euclidean space and in spatial networks. VLDB J. 2012, 21, 69–95. [Google Scholar] [CrossRef]
- Emrich, T.; Kriegel, H.P.; Mamoulis, N.; Niedermayer, J.; Renz, M.; Zufle, A. Reverse-nearest neighbor queries on uncertain moving object trajectories. In Database Systems for Advanced Applications; Springer: Berlin/Heidelberg, Germany, 2014; pp. 92–107. [Google Scholar]
- Feng, Z.; Zhu, Y. A Survey on Trajectory Data Mining: Techniques and Applications. IEEE Access 2017, 4, 2056–2067. [Google Scholar] [CrossRef]
- Zheng, Y.; Lu, R.; Zhu, H.; Zhang, S.; Guan, Y.; Shao, J.; Wang, F.; Li, H. SetRkNN: Efficient and Privacy-Preserving Set Reverse kNN Query in Cloud. IEEE Trans. Inf. Forensics Secur. 2023, 18, 888–903. [Google Scholar] [CrossRef]
- Wang, S.; Bao, Z.; Culpepper, J.S.; Sellis, T.; Cong, G. Reverse k nearest neighbor serach over trajectories. IEEE Trans. Knowl. Data Eng. 2018, 30, 757–771. [Google Scholar] [CrossRef] [Green Version]
- Pan, X.; Nie, S.; Hu, H.; Yu, P.S.; Guo, J. Reverse Nearest Neighbor Search in Semantic Trajectories for Location-Based Services. IEEE Trans. Serv. Comput. 2022, 15, 986–999. [Google Scholar] [CrossRef]
- Tzouramanis, T.; Manolopoulos, Y. Secure reverse k-nearest neighbors search over encrypted multi-dimensional databases. In Proceedings of the 22nd International Database Engineering & Applications Symposium (IDEAS), Villa San Giovanni, Italy, 18–20 June 2018; pp. 84–94. [Google Scholar]
- Tao, Y.; Papadias, D.; Lian, X. Reverse kNN search in arbitrary dimensionality. In Proceedings of the 30th International Conference Very Large Data Bases, Toronto, ON, Canada, 31 August–3 September 2004; pp. 744–755. [Google Scholar]
- Wu, W.; Yang, F.; Chan, C.-Y.; Tan, K.-L. FINCH: Evaluating reverse k-nearest-neighbor queries on location data. Proc. Vldb Endow. 2008, 1, 1056–1067. [Google Scholar] [CrossRef]
- Lu, J.; Lu, Y.; Cong, G. Reverse spatial and textual k nearest neighbor search. In Proceedings of the ACM SIGMOD International Conference on Management Data, Athens, Greece, 12–16 June 2011; pp. 349–360. [Google Scholar]
- Lu, Y.; Cong, G.; Lu, J.; Shahabi, C. Efficient algorithms for answering reverse spatialkeword nearest neighbor queries. In Proceedings of the 23rd SIGSPATIAL International Conference on Advances in Geographic Information Systems, Bellevue, WA, USA, 3–6 November 2015; pp. 1–4. [Google Scholar]
- Pournajaf, L.; Tahmasebian, F.; Xiong, L.; Sunderam, V.; Shahabi, C. Privacy preserving reverse k-nearest neighbor queries. In Proceedings of the 19th IEEE International Conference Mobile Data Manage, (MDM), Aalborg, Denmark, 25–28 June 2018; pp. 177–186. [Google Scholar]
- Li, X.; Xiang, T.; Guo, S.; Li, H.; Mu, Y. Privacy-preserving reverse nearest neighbor query over encrypted spatial data. IEEE Trans. Serv. Comput. 2022, 15, 2954–2968. [Google Scholar] [CrossRef]
- Wang, Q.; He, M.; Du, M.; Chow, S.S.; Lai, R.W.; Zou, Q. Searchable encryption over feature-rich data. IEEE Trans. Dependable Secur. Comput. 2016, 15, 496–510. [Google Scholar] [CrossRef]
- Lei, X.; Tu, G.H.; Xie, A.X.L.T. Fast and Secure kNN Query Processing in Cloud Computing. In Proceedings of the 2020 IEEE Conference on Communications and Network Security (CNS), Avignon, France, 29 June–1 July 2020. [Google Scholar]
- Finkel, R.A.; Bentley, J.L. Quad trees a data structure for retrieval on composite keys. Acta Inform. 1974, 4, 1–9. [Google Scholar] [CrossRef]
- Lindell, Y. How to simulate it—A tutorial on the simulation proof technique. In Tutorials on the Foundations of Cryptography; Springer: Berlin/Heidelberg, Germany, 2017; pp. 277–346. [Google Scholar]
- Zheng, Y.; Zhang, L.; Xie, X.; Ma, W. Mining interesting locations and travel sequences from GPS trajectories. In Proceedings of the International conference on World Wild Web (WWW 2009), Madrid, Spain, 20–24 April 2009; ACM Press: New York, NY, USA, 2009; pp. 791–800. [Google Scholar]
- Zheng, Y.; Li, Q.; Chen, Y.; Xie, X.; Ma, W. Understanding Mobility Based on GPS Data. In Proceedings of the ACM conference on Ubiquitous Computing (UbiComp 2008), Seoul, Republic of Korea, 21–24 September 2008; ACM Press: New York, NY, USA, 2008; pp. 312–321. [Google Scholar]
- Zheng, Y.; Xie, X.; Ma, W. GeoLife: A Collaborative Social Networking Service among User, location and trajectory. IEEE Data Eng. Bull. 2010, 33, 32–40. [Google Scholar]
- BeiJIngBusStation. Available online: https://github.com/FFGF/BeiJIngBusStation (accessed on 7 March 2023).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Schemes | Plaintext | Ciphertext | ||||
|---|---|---|---|---|---|---|
| [5,6] | [9] | [10] | [11] | [8] | RkNNToE | |
| Search Type | RkNNT | RkNNT | RkNNT | RkNNP | RkNNS | RkNNT |
| Query Type | T | T | P | P | S | T |
| Result Type | P | T | T | P | S | T |
| Database Type | P and T | T and T | P and T | P | S | T and T |
| Notation | Definition |
|---|---|
| dist(a,b) | The distance between a and b |
| The database of all points | |
| The database of points in all trajectories | |
| The database of points in all transitions | |
| The set of trajectories and the set of candidate transitions | |
| The set of refined transitions and the set of results | |
| The node with identity | |
| The vector of location | |
| The max number of trajectory points in a leaf node of the father tree | |
| The max number of transition points in a leaf node of the child tree | |
| DB | Step Length in Latitude and Longitude | Time Cost of RBF Tree(s) | Time Cost of DList(s) | |
|---|---|---|---|---|
| 2 | [0.000230, 0.001237] | 5.600787 | 3.559773 | |
| 3 | [0.000460, 0.002474] | 3.796525 | 3.468612 | |
| 4 | [0.001840, 0.009896] | 2.861059 | 3.470150 | |
| 5 | [0.001840, 0.009896] | 2.698736 | 3.444898 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Zhang, H.; Li, K.; Wen, Q. Privacy-Preserving Public Route Planning Based on Passenger Capacity. Mathematics 2023, 11, 1546. https://doi.org/10.3390/math11061546
Zhang X, Zhang H, Li K, Wen Q. Privacy-Preserving Public Route Planning Based on Passenger Capacity. Mathematics. 2023; 11(6):1546. https://doi.org/10.3390/math11061546
Chicago/Turabian StyleZhang, Xin, Hua Zhang, Kaixuan Li, and Qiaoyan Wen. 2023. "Privacy-Preserving Public Route Planning Based on Passenger Capacity" Mathematics 11, no. 6: 1546. https://doi.org/10.3390/math11061546