

Structural Analysis of Projected Networks of Shareholders and Stocks Based on the Data of Large Shareholders’ Shareholding in China’s Stocks
Abstract
:1. Introduction
2. Models and Methods
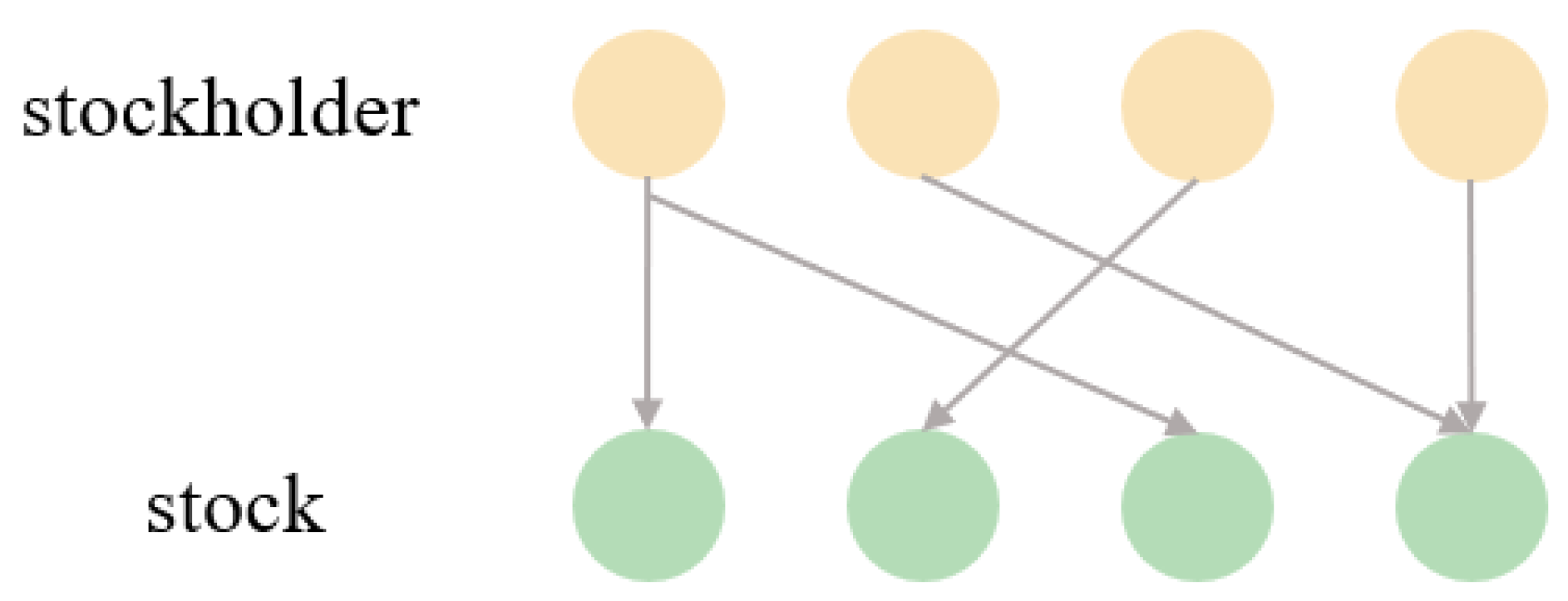
2.1. Shareholder-Stock Bipartite Network
2.2. Statistical Validated Network Models
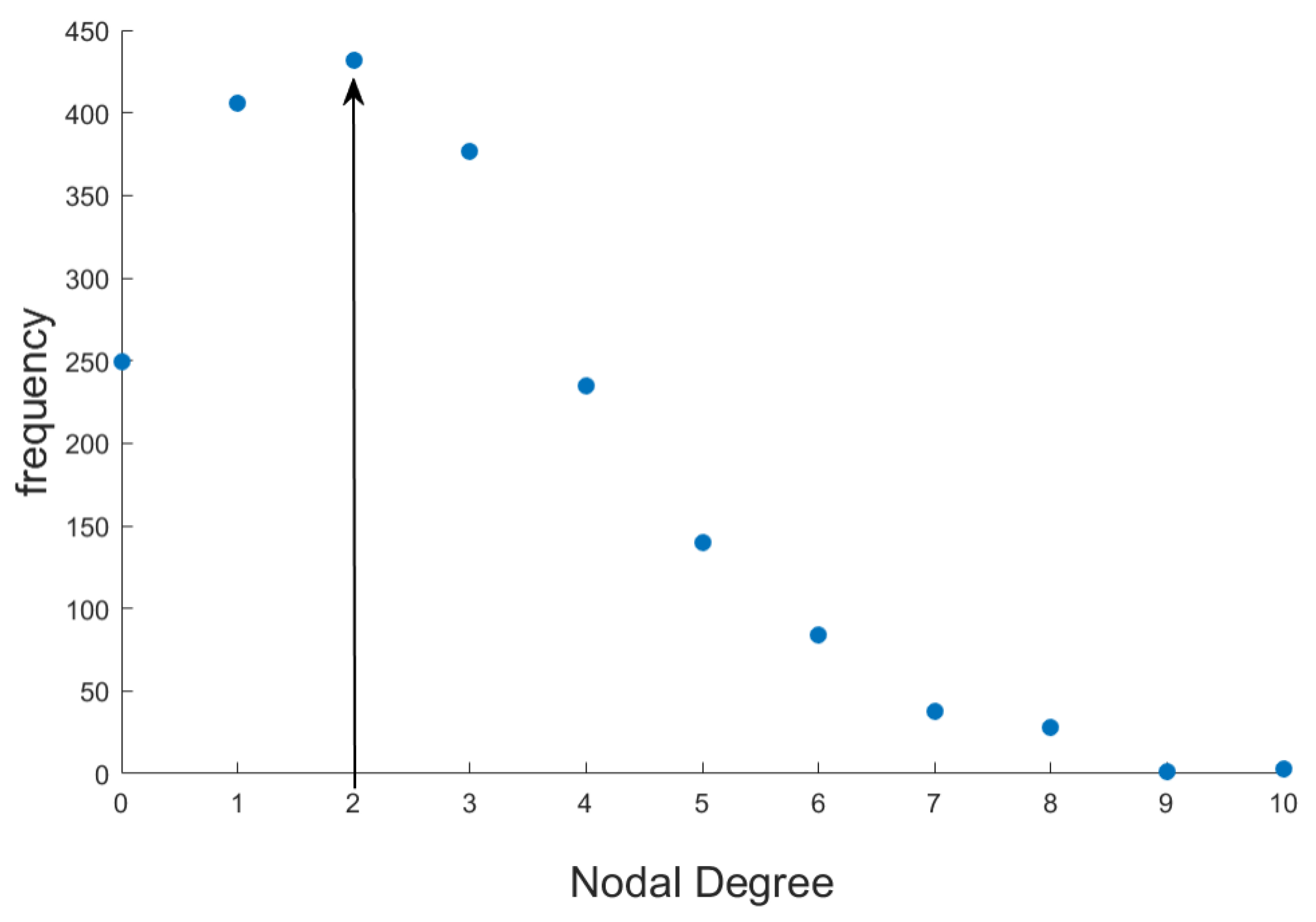
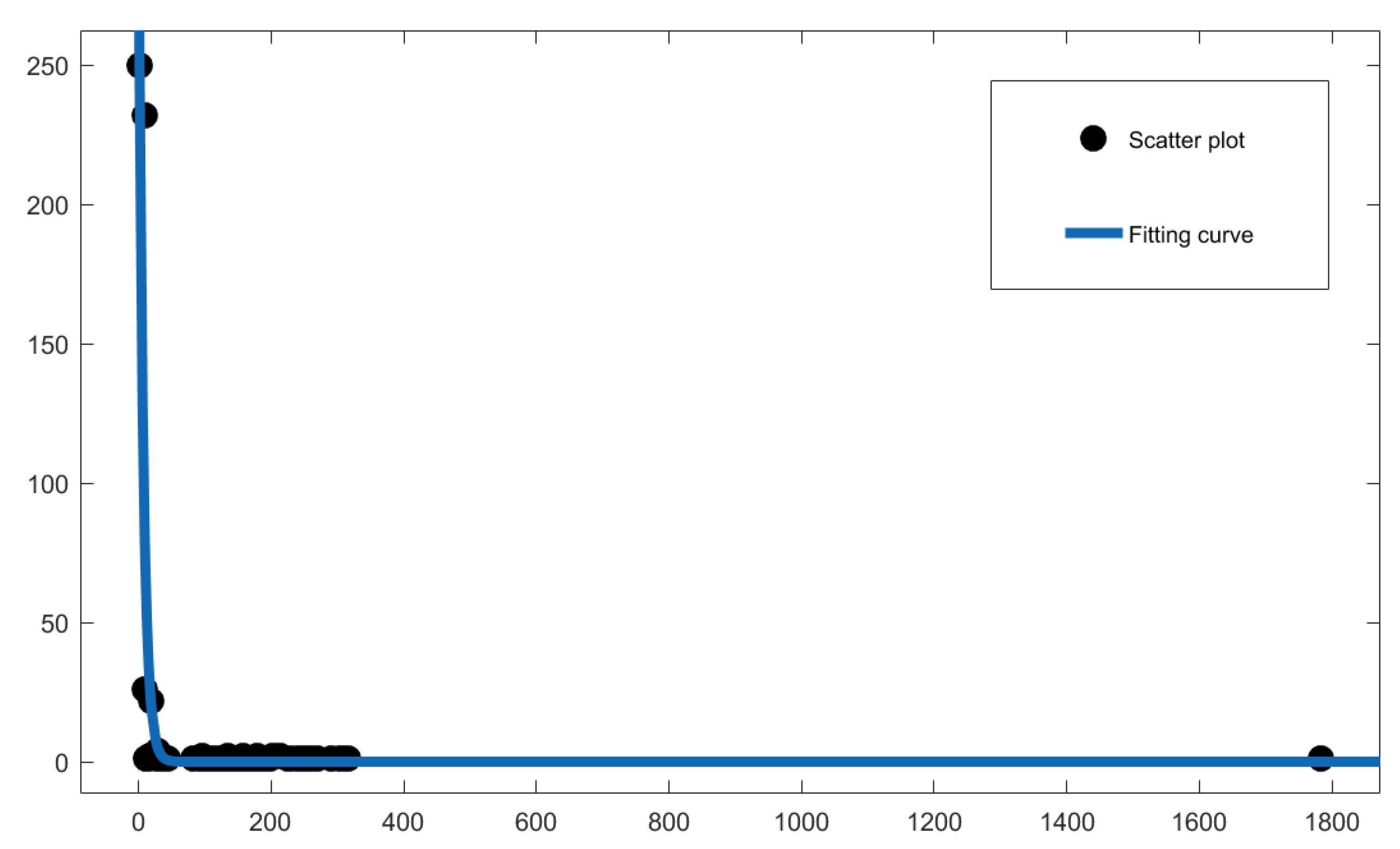
2.3. Basic Topological Properties of Network
2.3.1. Average Degree
2.3.2. Clustering Coefficient
2.4. Community Division and Louvain Algorithm
2.5. Node Importance and PageRank Algorithm
3. Basic Analysis of Network Structure
3.1. Establishment of Shareholder-Stock Bipartite Network
3.2. Establishment of Projected Network
3.2.1. Shareholder Projected Network
- In the bipartite networks with stock node degrees of 3, 4, 5, 6, 7, and 8, we find that the degree of shareholders’ set nodes is 1, and these bipartite networks only contain one stock node, which leads to the sum of probability that any node in the shareholders’ set has x public neighbors calculated for i and j is 0, that is, probability is always 0, where is the number of public neighbors between node pairs i and j; . Therefore, when these bipartite networks are projected, there is no connection between any node, and the resulting shareholder projected network does not contain connected edges, all of which are isolated shareholder nodes;
- In the bipartite network with the stock node degree of 9, we traverse the node pairs of the shareholder set and calculate the corresponding matrix according to the formula. We first adopted the Bonferroni correction and set the threshold value as . Where , . If , then there is a connection between node i and node j in the corresponding shareholder projected network. By comparing calculations, we found that under the Bonferroni correction, none of the satisfies the threshold. We then correct it using the FDR method, and the results are shown in Figure 3;
- In the bipartite network with the stock node degree of 10, we also traverse the node pairs of the shareholder set to obtain the value corresponding to node i and node j. After FDR correction, the projected network with a node degree of 10 is obtained, as shown in Figure 4.
3.2.2. Stock Projected Network
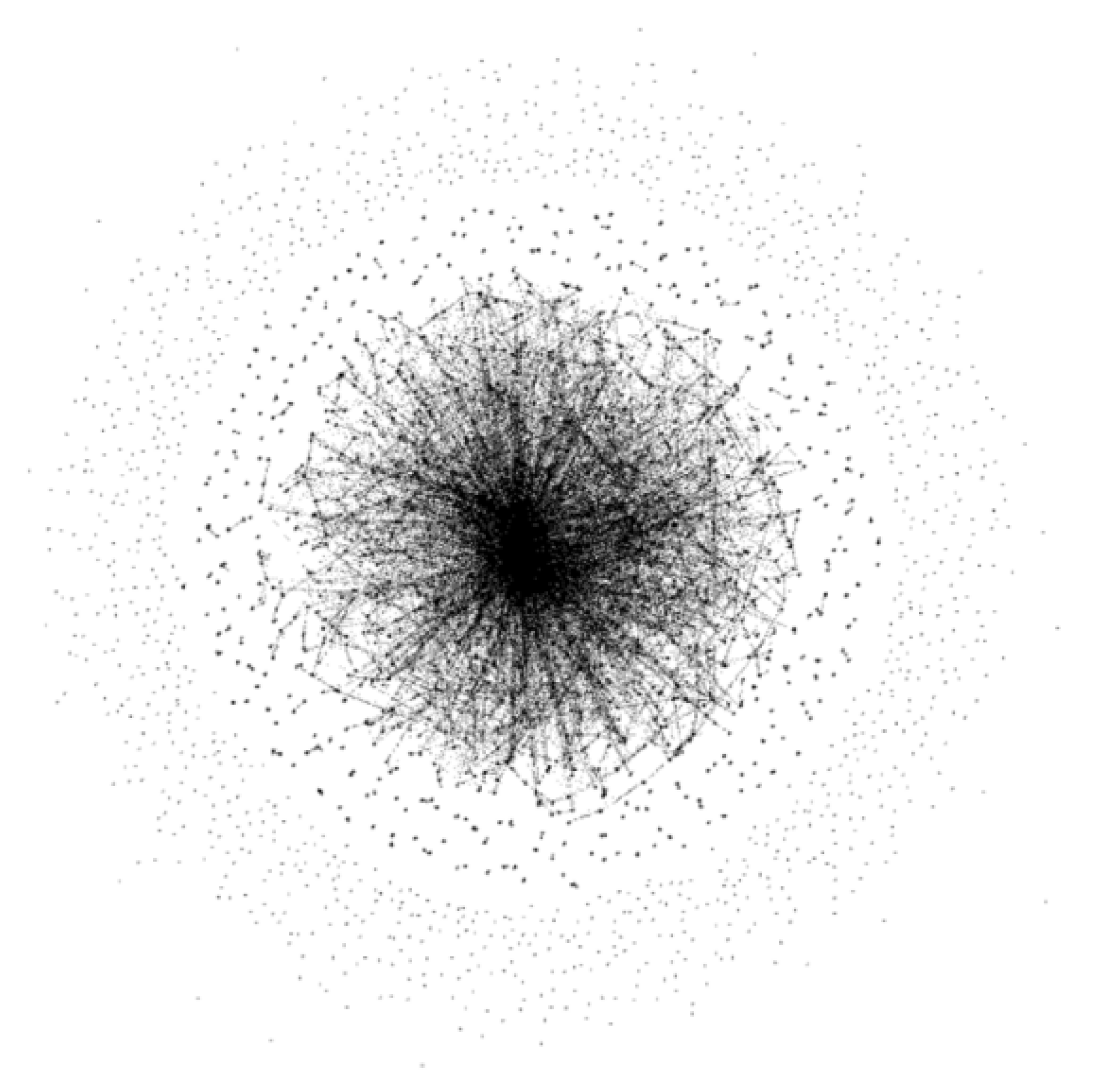
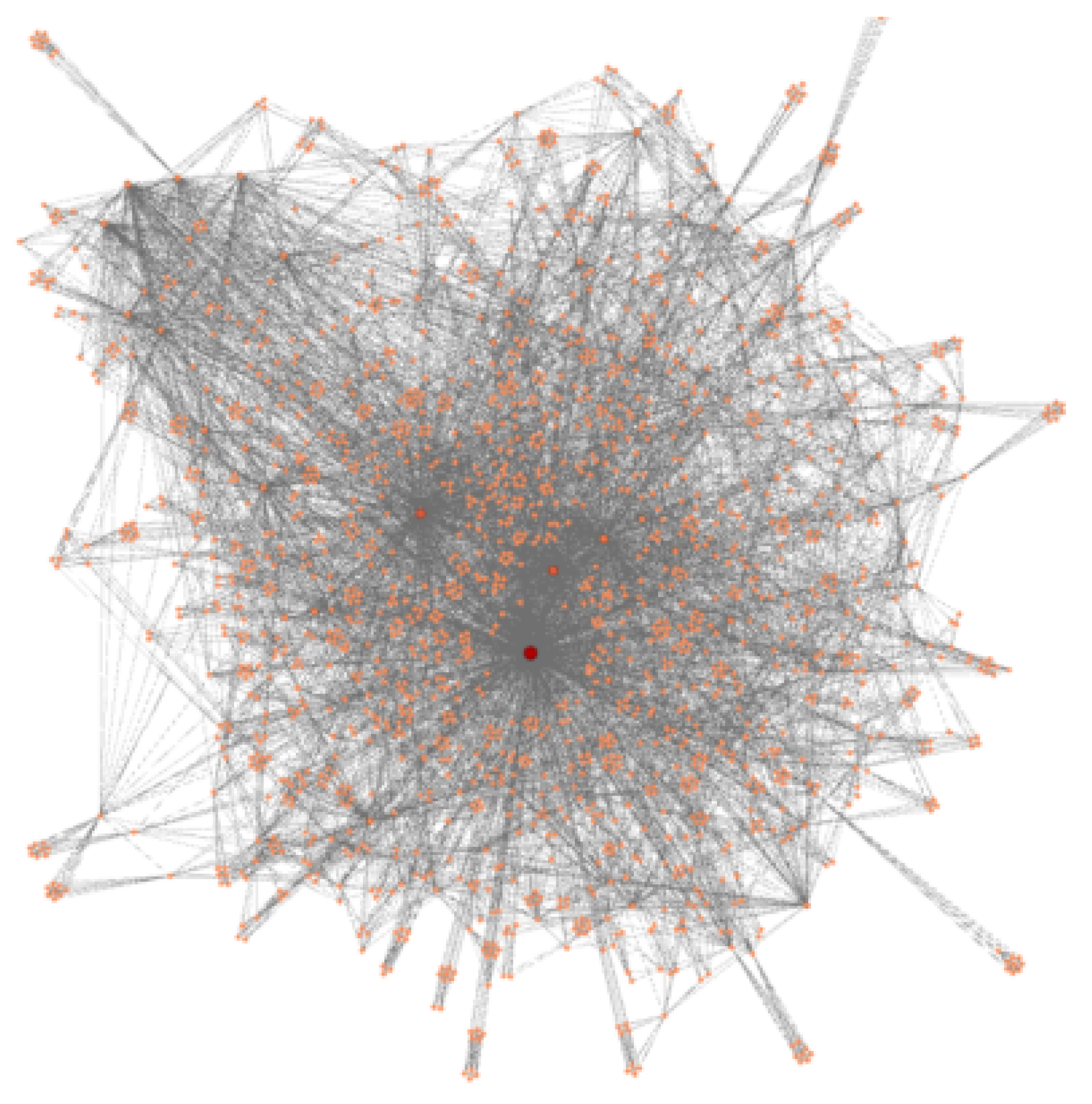
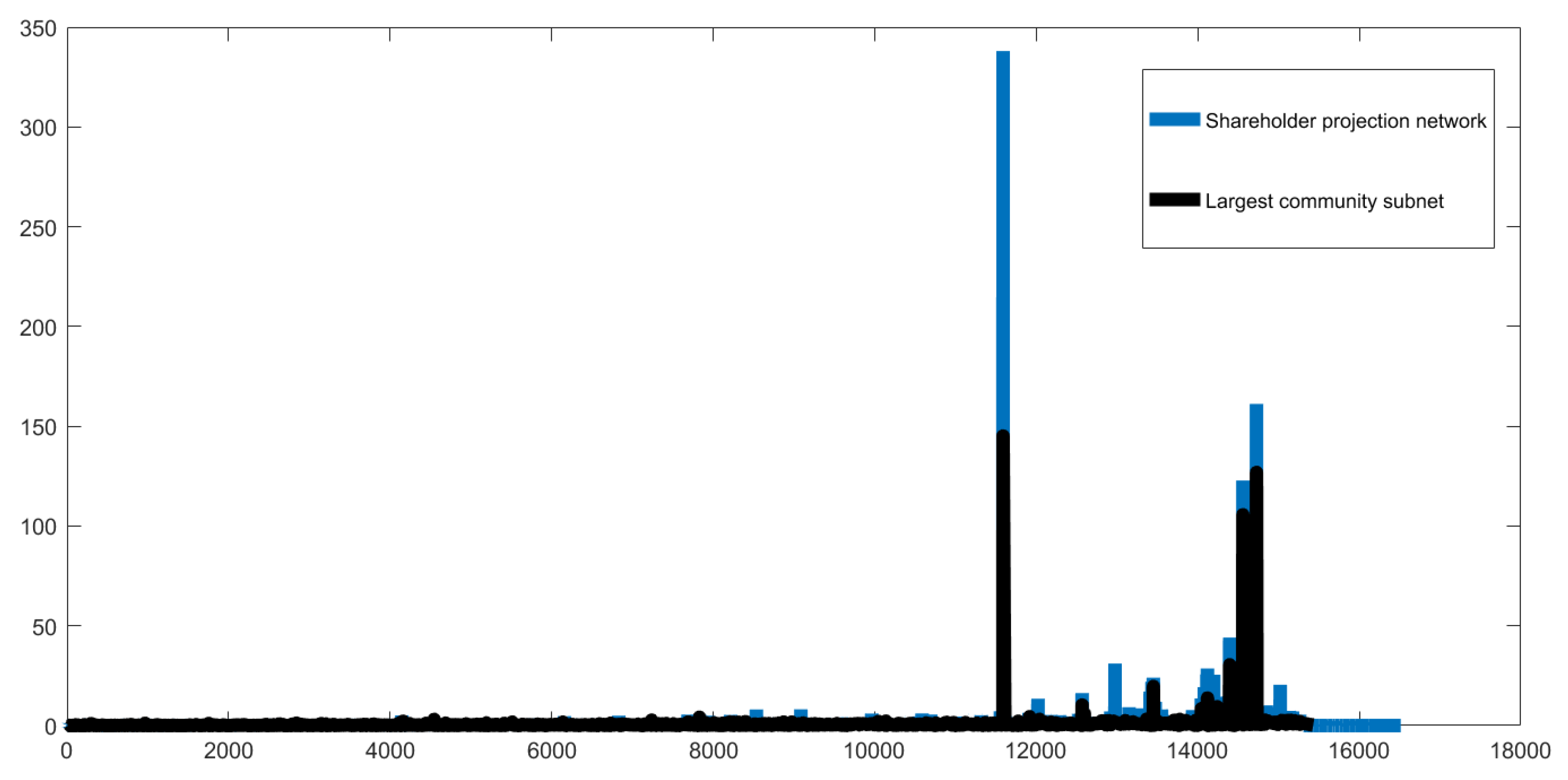
3.3. Analysis of The Overall Structure of Projected Networks
3.3.1. Shareholder Projected Network
3.3.2. Stock Projected Network
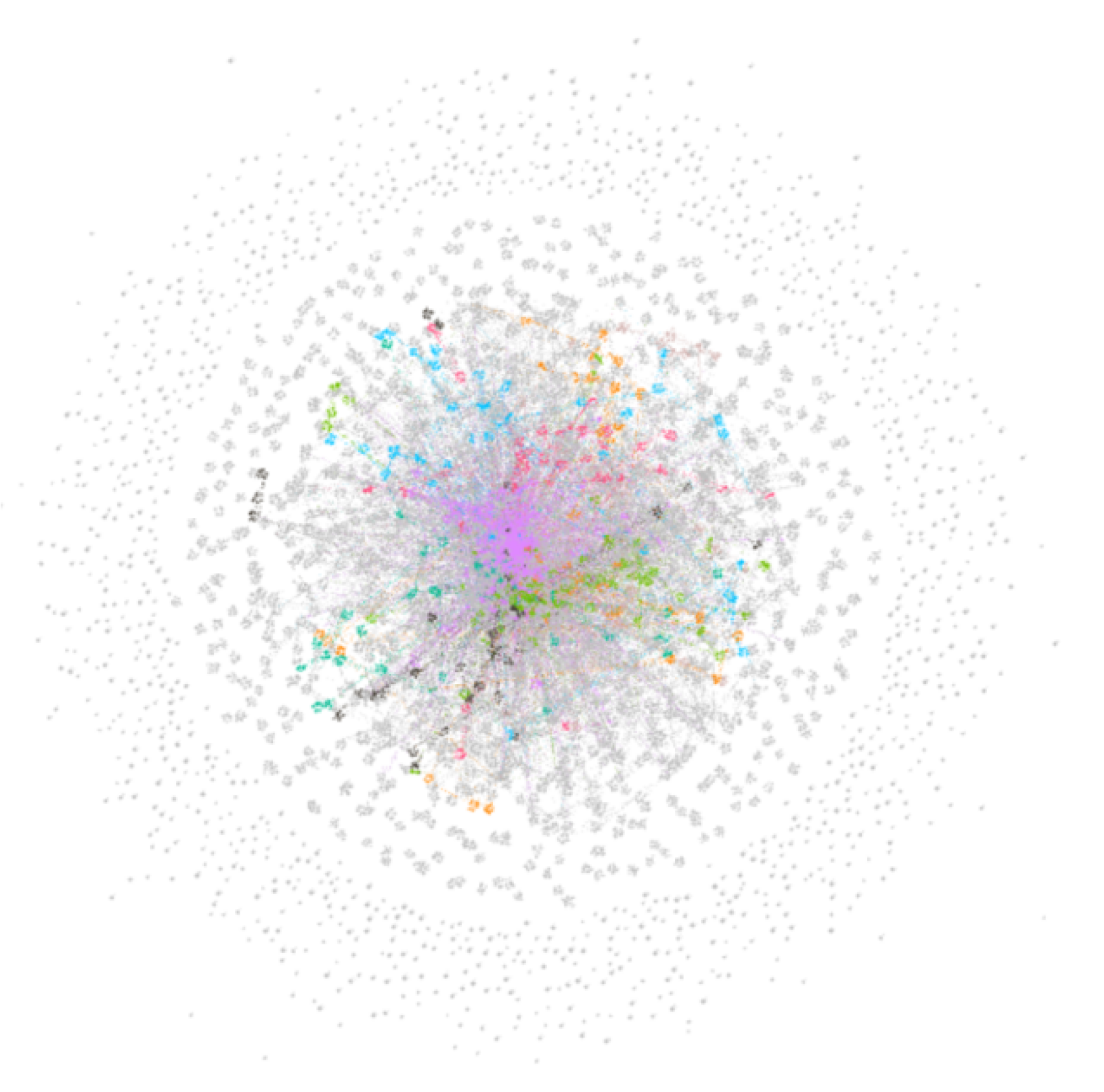
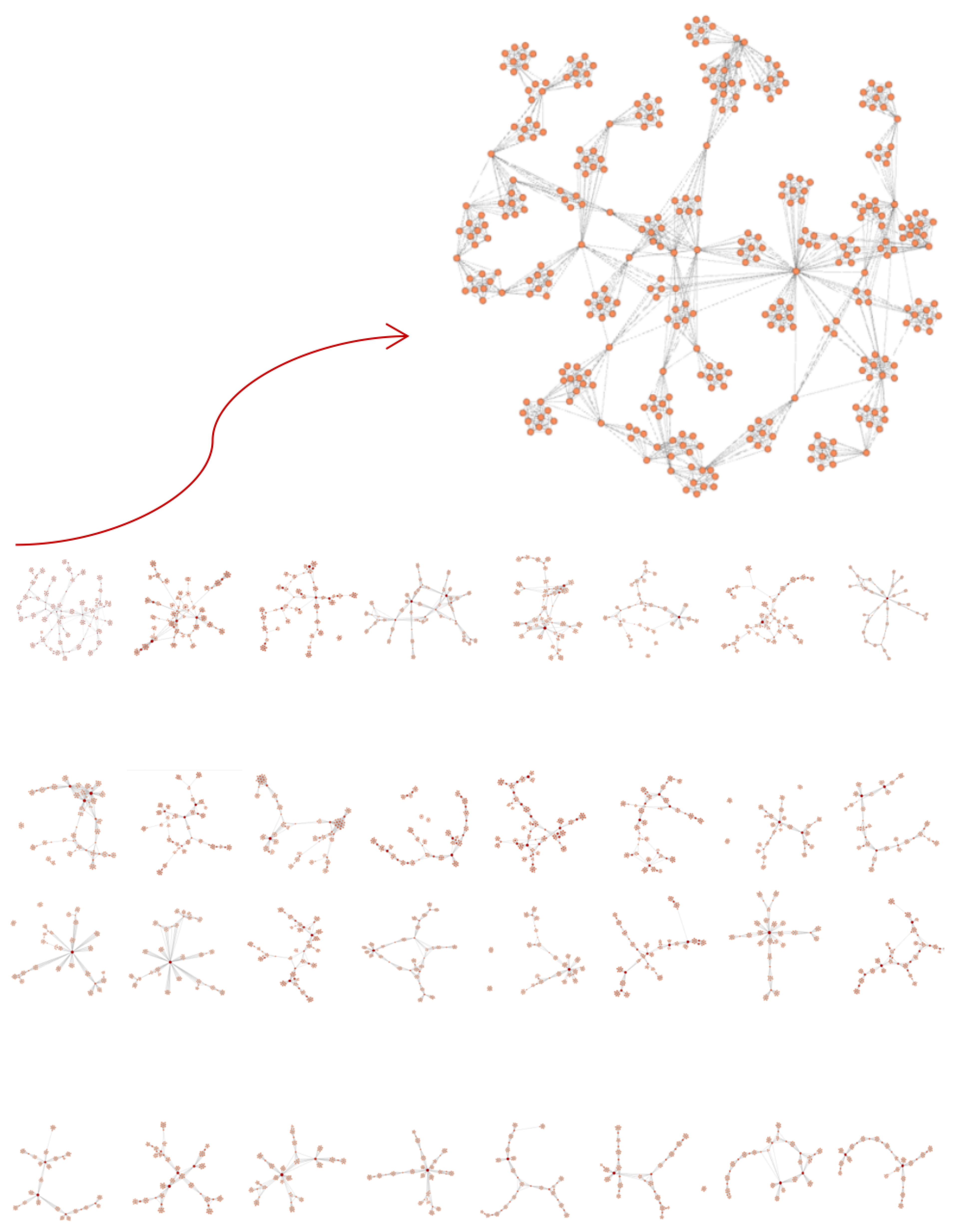
4. Community Structure of Projected Network
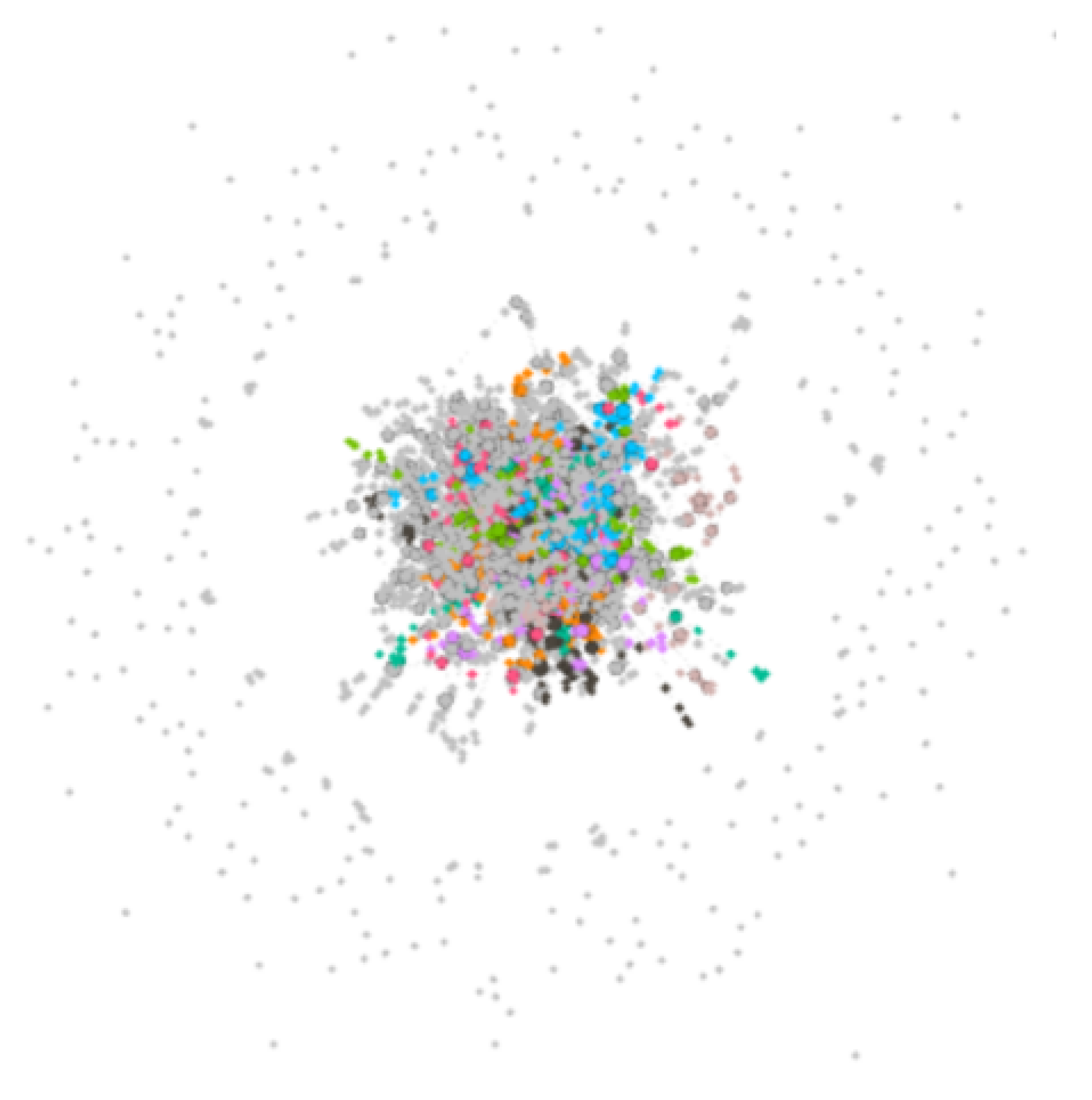
4.1. Shareholder Projected Network
4.1.1. Community Division of Shareholder Projected Network
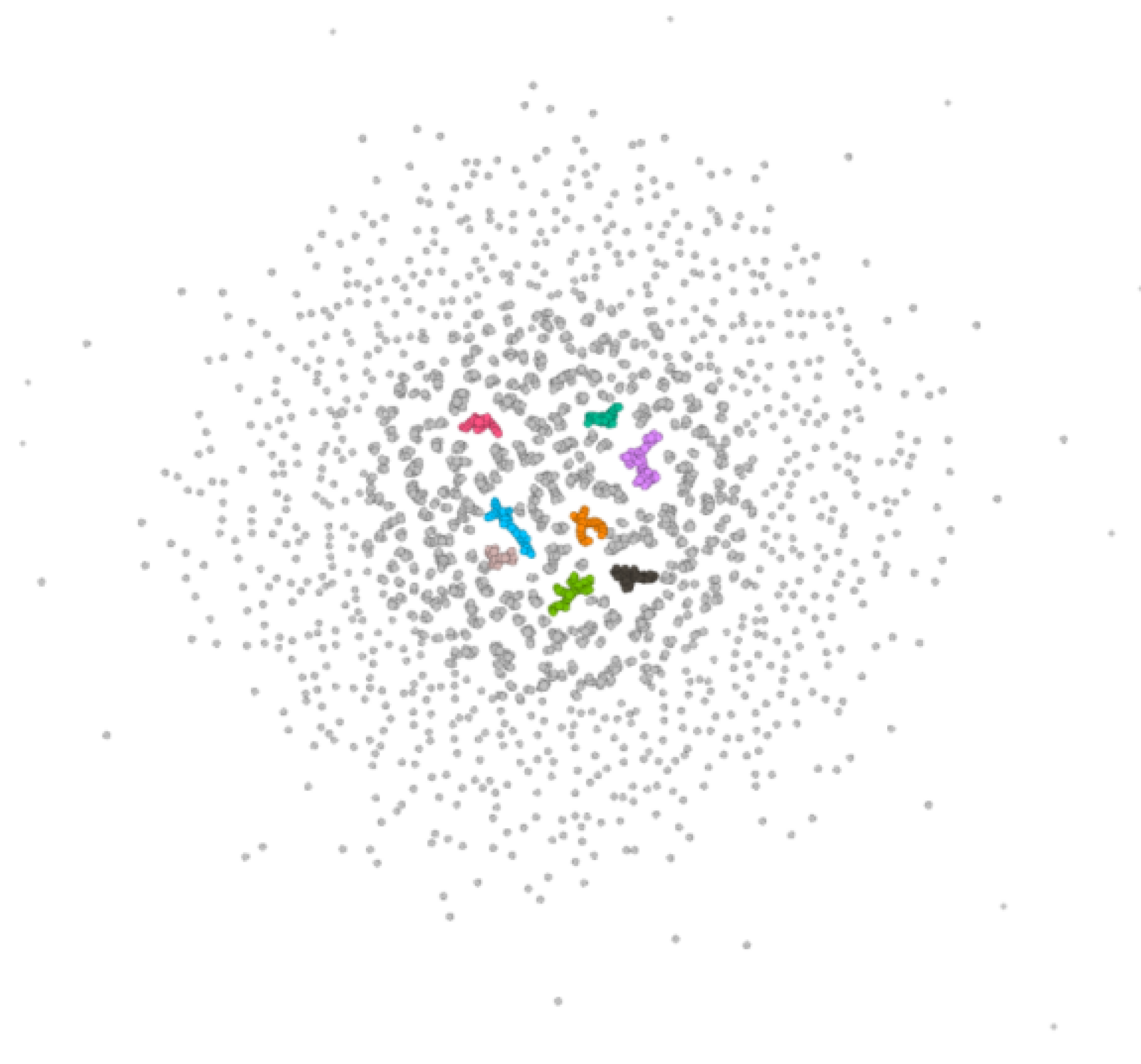
4.1.2. The Largest Community Sub-Network of Shareholder Projected Network
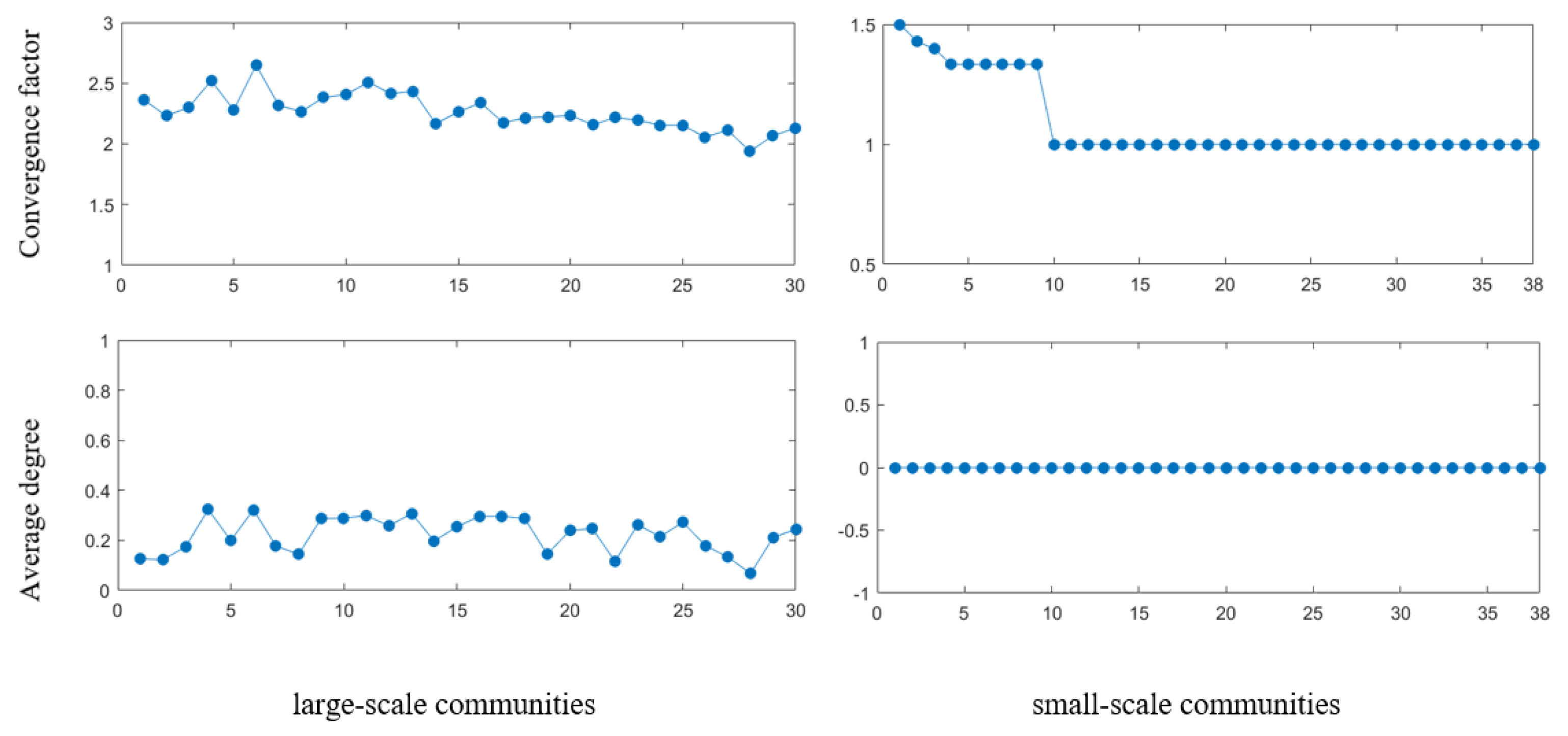
4.1.3. Community Structure Analysis of Shareholder Projected Network
4.2. Stock Projected Network
4.2.1. Community Division of Stock Projected Network
4.2.2. Community Structure Analysis of Stock Projected Network
4.2.3. Comparison between Stock Projected Network with Shareholder Node Degree 2 and Original Stock Projected Network
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Onnela, J.P.; Chakraborti, A.; Kaski, K.; Kertesz, J. Dynamic asset trees and Black Monday. Phys. A Stat. Mech. Appl. 2003, 324, 247–252. [Google Scholar] [CrossRef] [Green Version]
- Brida, J.G.; Risso, W.A. Multidimensional minimal spanning tree: The Dow Jones case. Phys. A Stat. Mech. Appl. 2008, 387, 5205–5210. [Google Scholar] [CrossRef]
- Huang, W.Q.; Zhuang, X.T.; Yao, S. A network analysis of the Chi nese stock market. Phys. A Stat. Mech. Appl. 2009, 388, 2956–2964. [Google Scholar] [CrossRef]
- Classerman, P.; Young, H.P. How likely is contagion in financial networks? J. Bank. Financ. 2015, 50, 383–399. [Google Scholar] [CrossRef] [Green Version]
- Newman, M.E.J. The structure of scientific collaboration networks. Proc. Natl. Acad. Sci. USA 2015, 98, 404–409. [Google Scholar] [CrossRef]
- Watts, D.J.; Strogatz, S.H. Collective dynamics of ’small-world’ networks. Nature 1998, 393, 440–442. [Google Scholar] [CrossRef]
- Huang, Y.; Liu, T.; Lien, D. Portfolio homogeneity and systemic risk of financial networks. J. Empir. Financ. 2023, 70, 248–275. [Google Scholar] [CrossRef]
- Huang, Y.; Liu, T. Diversification and Systemic Risk of Networks Holding Common Assets. Comput. Econ. 2023, 61, 341–388. [Google Scholar] [CrossRef]
- Tumminello, M.; Micciche, S.; Lillo, F.; Piilo, J.; Mantegna, R.M. Statistically Validated Networks in Bipartite Complex Systems. PLoS ONE 2011, 6, e17994. [Google Scholar] [CrossRef] [Green Version]
- Huang, W.Q.; Zhuang, X.T.; Yao, S. Analysis of Topological Properties and Cluster Structure of China’s Stock Association Network. Manag. Sci. 2008, 21, 94–103. [Google Scholar]
- Girvan, M.; Newman, M.E.J. Community structure in social and biological networks. Proc. Natl. Acad. Sci. USA 2002, 99, 7821–7826. [Google Scholar] [CrossRef] [Green Version]
- Newman, M.E.J. Fast algorithm for detecting community structure in networks. Phys. Rev. E 2004, 69, 066133. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cheng, X.Q.; Ren, F.X.; Zhou, S.; Hu, M.B. Triangular clustering in document networks. New J. Phys. 2009, 11, 1–11. [Google Scholar] [CrossRef]
- Luo, Z.; Ding, F.; Jiang, X.; Shi, J.L. New progress on community detection in complex networks. J. Natl. Univ. Def. Technol. 2011, 33, 47–52. [Google Scholar]
- Derry, J.; Mangravite, L.; Suver, C.; Furia, M.; Henderson, D.; Schildwachter, X.; Izant, J.; Sieberts, S.; Kellen, M.; Friend, S. Developing predictive molecular maps of human disease through community-based modeling. Nat. Prec. 2011, 44, 30–127. [Google Scholar] [CrossRef]
- Papadopoulos, S.; Kompatsiaris, Y.; Vakali, A.; Spyridonos, P. Community detection in social media. Data Min. Knowl. Discov. 2012, 24, 515–554. [Google Scholar] [CrossRef]
- Bedi, P.; Sharma, C. Community detection in social networks. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2016, 6, 115–135. [Google Scholar] [CrossRef]
- Johnson, N.F.; Zheng, M.; Vorobyeva, Y.; Gabriel, A.; Qi, H.; Velásquez, N.; Manrique, P.; Johnson, D.; Restrepo, E.; Song, C.; et al. New online ecology of adversarial aggregates: ISIS and beyond. Science 2016, 352, 1459–1463. [Google Scholar] [CrossRef] [Green Version]
- Newman, M.E.J.; Girvan, M. Finding and evaluating community structure in networks. Phys. Rev. E 2004, 69, 026113. [Google Scholar] [CrossRef] [Green Version]
- Duch, J.; Arenas, A. Community detection in complex networks using extremal optimization. Phys. Rev. E 2005, 72, 1–4. [Google Scholar] [CrossRef] [Green Version]
- Agarwal, G.; Kempe, D. Modularity-maximizing graph communities via mathematical programming. Eur. Phys. J. B 2008, 66, 409–418. [Google Scholar] [CrossRef] [Green Version]
- Fortunato, S.; Barthelemy, M. Resolution limit in community detection. Proc. Natl. Acad. Sci. USA 2007, 104, 36–41. [Google Scholar] [CrossRef] [Green Version]
- Rosvall, M.; Bergstrom, C.T. An information-theoretic framework for resolving community structure in complex networks. Proc. Natl. Acad. Sci. USA 2007, 104, 7327–7331. [Google Scholar] [CrossRef] [Green Version]
- Ruan, J.H.; Zhang, W.X. Identifying network communities with a high resolution. Phys. Rev. E 2008, 77, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Zhang, S.; Wang, R.S.; Zhang, X.S.; Chen, L. Quantitative function for community detection. Phys. Rev. E 2008, 77, 1–9. [Google Scholar] [CrossRef]
- Blondel, V.D.; Guillaume, J.L.; Lambiotte, R. Lefebvre, E. Fast unfolding of communities in large networks. J. Stat. Mech. Theory Exp. 2008, 2008, P10008. [Google Scholar] [CrossRef] [Green Version]
- Miller, R.G. Simultaneous Statistical Inference, 3rd ed.; Springer: New York, NY, USA, 1981; Volume 10, pp. 415–416. [Google Scholar]
- Benjamini, Y.; Hochberg, Y. Controlling the false discovery rate: A practical and powerful approach to multiple testing. J. R. Stat. Soc. B 1995, 57, 289–300. [Google Scholar] [CrossRef]
- Huang, Y.; Chen, F. Community Structure and Systemic Risk of Bank Correlation Networks Based on the U.S. Financial Crisis in 2008. Algorithms 2021, 14, 162. [Google Scholar] [CrossRef]
- Bonacich, P.F. Factoring and Weighting Approaches to Status Scores and Clique Identification. J. Math. Sociol. 1972, 2, 113–120. [Google Scholar] [CrossRef]
- Kitsak, M.; Gallos, L.K.; Havlin, S.; Liljeros, F.; Muchnik, L.; Stanley, H.E.; Makse, H.A. Identification of influential spreaders in complex networks. Nat. Phys. 2010, 6, 888–893. [Google Scholar] [CrossRef] [Green Version]
- Brin, S.; Page, L. The anatomy of a large-scale hypertextual web search engine. ScienceDirect 1998, 30, 107–117. [Google Scholar] [CrossRef]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stock Name (Code) | Ten Major Shareholders |
|---|---|
| SPD Bank 1 (600,000.SH) | Shanghai International Group Co., Ltd. |
| China Mobile Group Guangdong Co., Ltd. | |
| Fude Life Insurance Co., Ltd.—Traditional | |
| Fude Life Insurance Co., Ltd.—capital | |
| Shanghai SDIC Asset Management Co., Ltd. | |
| Fude Life Insurance Co., Ltd.—Universal H | |
| China Securities Finance Co., Ltd. | |
| Shanghai Guoxin Investment Development Co., Ltd. | |
| Hong Kong Central Clearing Co., Ltd. (Lugutong) | |
| Central Huijin Asset Management Co., Ltd. | |
| Huaneng International (600,011.SH) | Huaneng International Power Development Company |
| Hong Kong Central Clearing (Agent) Co., Ltd. | |
| China Huaneng Group Co., Ltd. | |
| Hebei Construction Investment Group Co., Ltd. | |
| China Huaneng Group Hong Kong Co., Ltd. | |
| China Securities Finance Co., Ltd. | |
| Jiangsu Guoxin Group Co., Ltd. | |
| Liaoning Energy Investment (Group) Co., Ltd. | |
| Fujian Investment and Development Group Co., Ltd. | |
| Dalian Construction Investment Group Co., Ltd. |
| Shareholder Node Degree | Number of Shareholders | Corresponding Number of Stocks |
|---|---|---|
| 1 | 13,958 | 1980 |
| 2 | 941 | 1203 |
| 3 | 248 | 602 |
| 4 | 95 | 340 |
| 5 | 74 | 317 |
| 6 | 50 | 265 |
| 7 | 24 | 141 |
| 8 | 13 | 95 |
| 9 | 17 | 138 |
| 10 | 9 | 84 |
| 11 | 4 | 44 |
| 12 | 7 | 82 |
| 13 | 5 | 65 |
| 14 | 5 | 70 |
| 15 | 2 | 30 |
| 16 | 4 | 64 |
| 17 | 1 | 17 |
| 18 | 2 | 36 |
| 23 | 2 | 46 |
| 24 | 1 | 24 |
| 26 | 1 | 26 |
| 27 | 2 | 54 |
| 29 | 2 | 58 |
| 30 | 1 | 30 |
| 37 | 1 | 37 |
| 42 | 2 | 84 |
| 105 | 1 | 105 |
| 134 | 1 | 134 |
| 137 | 1 | 137 |
| 466 | 1 | 466 |
| Community | Mean of the Number of Nodes | Variance of the Number of Nodes |
|---|---|---|
| AL 1 | 25.77649007 | 8023.064282 |
| EM 2 | 22.86069052 | 2901.25091 |
| DM 3 | 217.6363636 | 2103.807163 |
| DI 4 | 11.58421053 | 632.8744875 |
| A 1 | B 2 | |
|---|---|---|
| Total | 317 | 318 |
| Single Node | 249 | 251 |
| Small-scale communities | 38 | 36 |
| Large-scale communities | 30 | 31 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, R.; Huang, Y. Structural Analysis of Projected Networks of Shareholders and Stocks Based on the Data of Large Shareholders’ Shareholding in China’s Stocks. Mathematics 2023, 11, 1545. https://doi.org/10.3390/math11061545
Liu R, Huang Y. Structural Analysis of Projected Networks of Shareholders and Stocks Based on the Data of Large Shareholders’ Shareholding in China’s Stocks. Mathematics. 2023; 11(6):1545. https://doi.org/10.3390/math11061545
Chicago/Turabian StyleLiu, Ruijie, and Yajing Huang. 2023. "Structural Analysis of Projected Networks of Shareholders and Stocks Based on the Data of Large Shareholders’ Shareholding in China’s Stocks" Mathematics 11, no. 6: 1545. https://doi.org/10.3390/math11061545