1. Introduction and Genesis
Discrete distributions are important in statistics because they model count data, which arise frequently in many fields, including biology, medicine, social sciences, and engineering. Discrete distributions are also used to model binary data, where the outcome is either zero or one. The importance of discrete distributions can be summarized as follows: Modeling count data: Discrete distributions, such as Poisson and negative binomial, allow us to model count data, which is common in many applications, such as the number of people who visit a website, the number of hospital admissions, or the number of species in a habitat. Modeling binary data: Discrete distributions, such as the binomial and the beta-binomial distributions, allow us to model binary data, which is common in many fields, such as medical trials, social sciences, and marketing. Probabilistic modeling: Discrete distributions provide a probabilistic model for count and binary data, which allows us to make predictions about future events and to assess the uncertainty in these predictions. Estimation and inference: Discrete distributions allow us to estimate parameters of interest, such as the mean and variance, and to make inferences about the population from sample data. In conclusion, discrete distributions play a crucial role in modeling count and binary data and are essential tools for making probabilistic predictions and inferences in many fields of study.
Discretization is the process of converting a continuous variable into a discrete (or categorical) variable by dividing it into intervals. This is an important step in many data analysis and modeling applications for several reasons: Simplification: Discretizing continuous variables can simplify the data and make it easier to understand and interpret. Modeling limitations: Some statistical models, such as linear regression, assume that the variables are continuous, while others, such as logistic regression, assume that the variables are categorical. Discretization can help overcome these limitations. Handling non-linear relationships: Discretization can be used to capture non-linear relationships between variables. For example, if the relationship between two variables is not linear, discretizing one or both of the variables can reveal a relationship that is easier to model. Dimension reduction: Discretization can help reduce the dimensionality of the data, making it easier to visualize and analyze. Handling outliers: Discretization can help handle outliers by transforming them into a smaller number of intervals.
Discretization is an important step in the data pre-processing phase and must be performed carefully to ensure that it does not introduce bias or lose important information. The choice of the number of intervals and the method of discretization can greatly affect the results of the analysis. The discretization of well-known continuous probability distributions has drawn a lot of interest recently. Many researchers have studied a lot of continuous distributions but by discretizing them. This direction was the dominant trend in statistical literature, despite the lack of works in this important field of distribution theory. The importance of discretization of the continuous distributions derives its importance from the presence of a lot of good, engineering, and actuarial data that cannot be dealt with using continuous distributions. This urgent need is the main reason that motivated researchers to move in this direction.
In this context, many discrete type extensions of the continuous models have been presented and studied such as the well-known generalization of the Poisson model (see Consul et al. [
1], the discrete type extension of the Weibull distribution (D-W) (see Nakagawa and Osaki [
2]), the discrete version of the Rayleigh model (DR) (see Roy [
3]), the discrete version of the half-normal model (see Kemp [
4] and Kemp [
5]), a discrete version of the Pareto distribution (D-Pa) (see Krishna and Pundir Kemp [
6]), a novel discrete version of the geometric model (DGc) (see Gómez -Déniz [
7] and), a discrete version of the Lindley distribution (D-Li) (see Gómez -Déniz and Calderin-Ojeda [
8]), a discrete version of the inverse-Weibull distribution (D-IW) (see Jazi et al. [
9]), a discrete version of the exponentiated Weibull distribution (ED-W) (Nekoukhou and Bidram [
10]), a discrete version of the generalized exponentiated type II distribution (DGE-II) (see Nekoukhou et al. [
11]), a discrete version of the inverse Rayleigh distribution (DIR) (see Hussain and Ahmad [
12]), a discrete version of the Lindley type II model (D-Li-II) (Hussain et al. [
13]), a discrete version of the Lomax distribution (D-Lx) (Para and Jan [
14]), a discrete version of the log-logistic model (DLL) (Para and Jan [
15]), a discrete version of the Burr type XII model (D-BXII) (see Para and Jan [
15]), a discrete version of the exponentiated Lindley distribution (ED-Li) (see El-Morshedy et al. [
16]), a discrete version of the Burr–Hatke model (see El-Morshedy et al. [
17]), a discrete version of the generalized Burr–Hatke model (see Yousof et al. [
18]), a discrete version of the inverse Burr (DIB) model (see Chesneau et al. [
19]), among others.
The distributions above were related to the first trend, as for the second trend, many researchers started to present families of discrete distributions. These families of discrete distributions are not so numerous in the statistical literature that we can exhaustively enumerate them. Therefore, we can limit these families to the following: the discrete Gompertz G family of distributions by Eliwa et al. [
20], the discrete Weibull G family by Ibrahim et al. [
21], the discrete Rayleigh G by Aboraya et al. [
22].
This paper presents and studies a novel discrete family. The continuous generalized Rayleigh family of distributions is the foundation from which the new family is derived. Among the important mathematical elements that are calculated and examined are the ordinary moments, the central moment, the moment generating function, the cumulant generating function, the probability generating function, and the dispersion index (Fano factor). The well-known Weibull model is given particular focus. Some of the traditional (non-Bayesian) estimation techniques that are taken into consideration and researched include the Cramér-von-Mises estimation (CVME), the ordinary least squared estimation (OLSE), the maximum likelihood estimation (MLE), and the weighted least squared estimation (WLSE).
Since there are no conventional ways to obtain the conditional posteriors of the parameters, it is advised to gather samples from the joint posterior of the parameters using a hybrid Markov chain Monte Carlo technique. For the Bayesian estimating approach, the squared error loss function is taken into consideration. Bayesian and non-Bayesian estimates are compared using Markov chain Monte Carlo simulations. The Gibbs sampler and the Metropolis Hastings algorithms are employed. Four genuine data sets are used to illustrate the new family’s adaptability and significance. Compared to the sixteen feuding families, the new family provides a better fit.
Different member distributions could be the subject of future study and discussion. Future research might consider the bivariate and multivariate expansions of this novel family. A RV
is said to have Rayleigh if its cumulative distribution function (CDF) is given by
The CDF of the continuous generalized Rayleigh G (GzRG) family can be expressed as
The function
refers to a new odds ratio function, where
and
refers to the CDF of the baseline model. Therefore,
refers to the exponentiated CDF of the baseline model with power parameter
and baseline parameter vector
, and
refers to the exponentiated CDF of the baseline model with power parameter
and baseline parameter vector
. Let
then, CDF of the discrete generalized Rayleigh G family (DGzR-G) can be expressed as
The corresponding survival function (SF) is
Then, the probability mass function (PMF) of the DGzR-G family corresponding to (2) may be written, thanks to Kemp [
5] to obtain the new PMF, as
Therefore, the PMF can be expressed as
where
refers to the generated odd ratio function of any discrete non-negative random variable (DNNRV). The DGzR-G family’s hazard rate function (HRF) is
, or
Even though there are a lot of discrete distributions in the statistical literature, discrete G families are still rare (where G = refers to CDF of any baseline model); this is because there are not a lot of discrete G families in the literature. The reasons for our introduction the DGzR-G family are as follows:
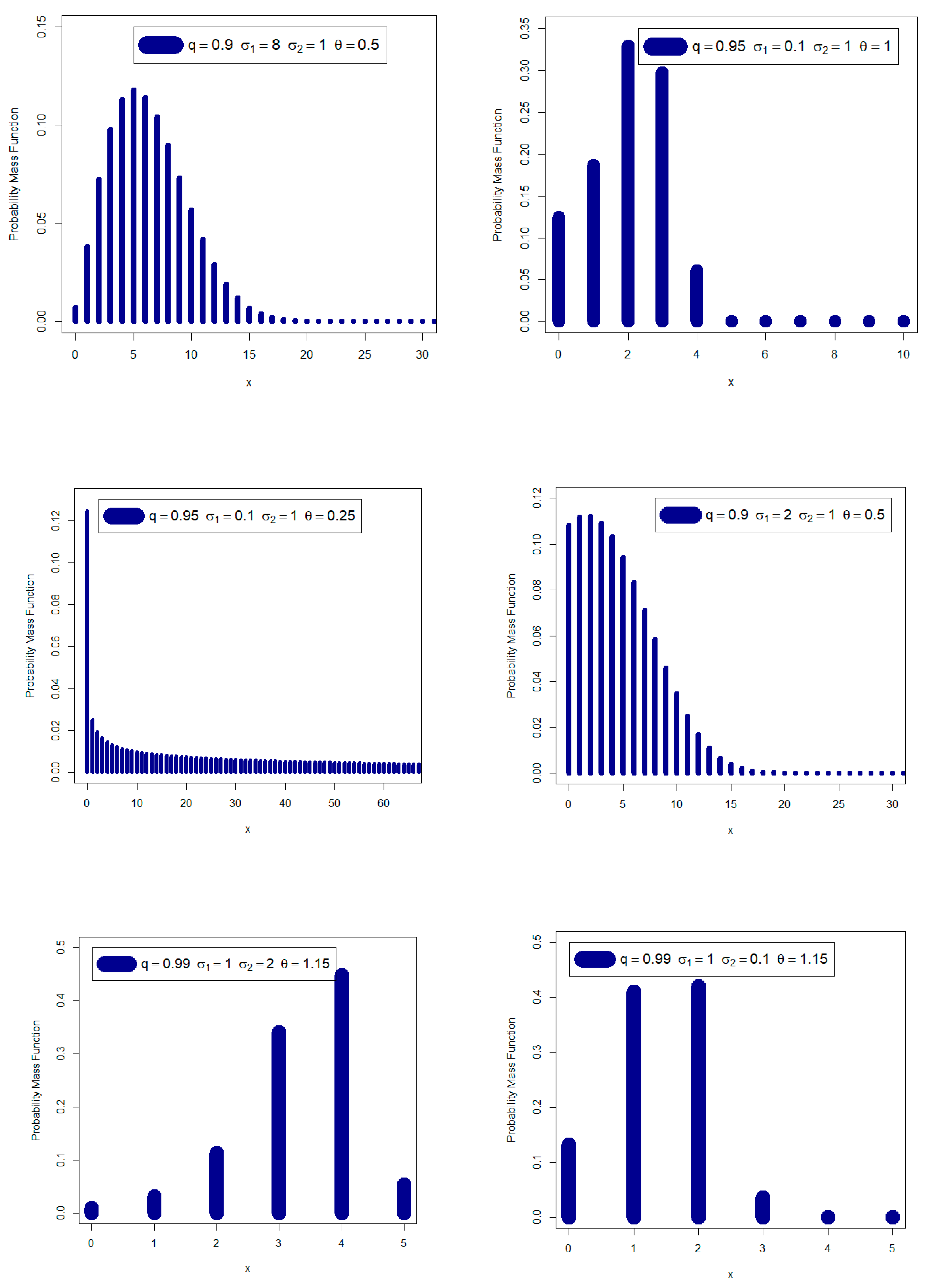
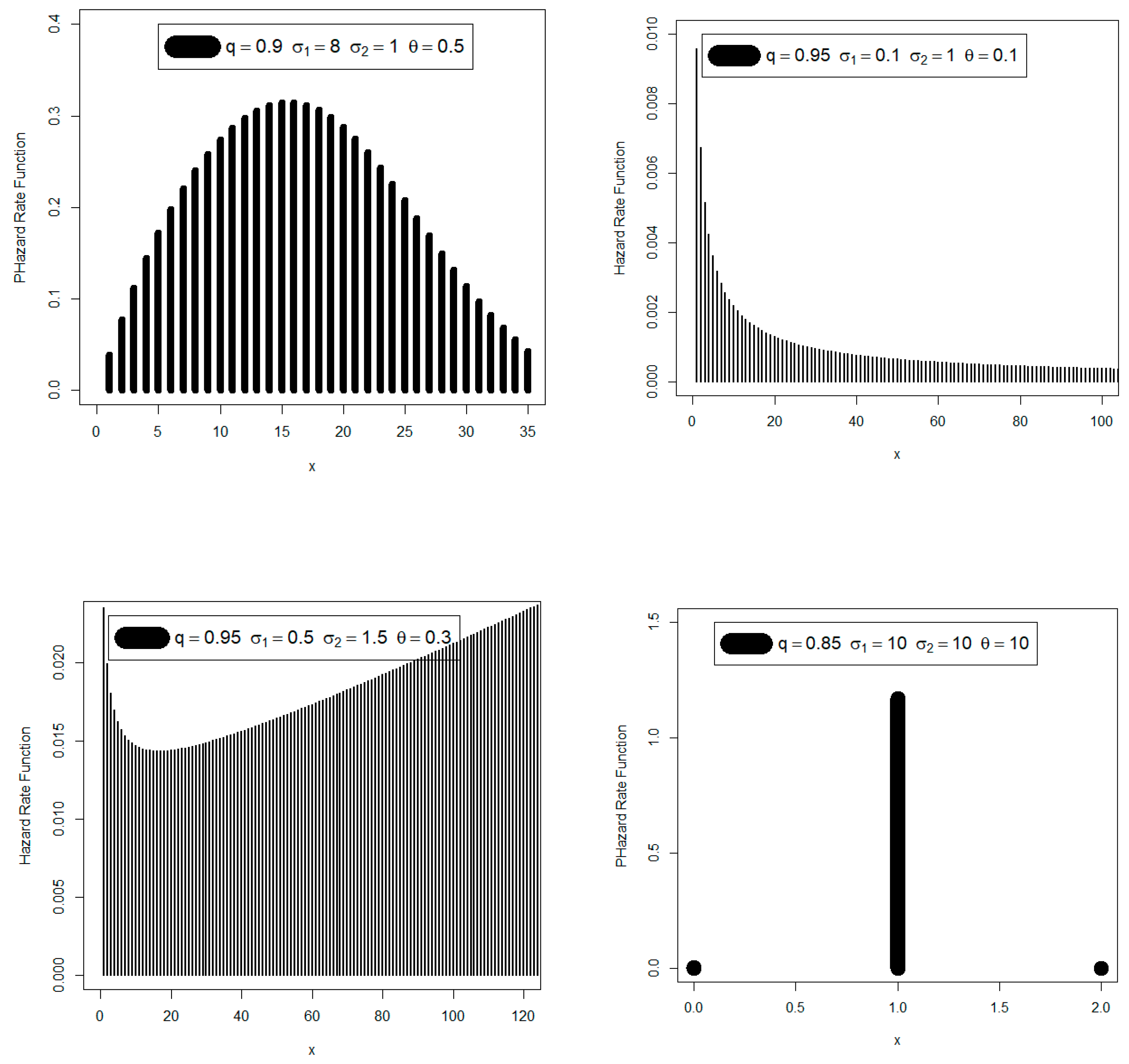
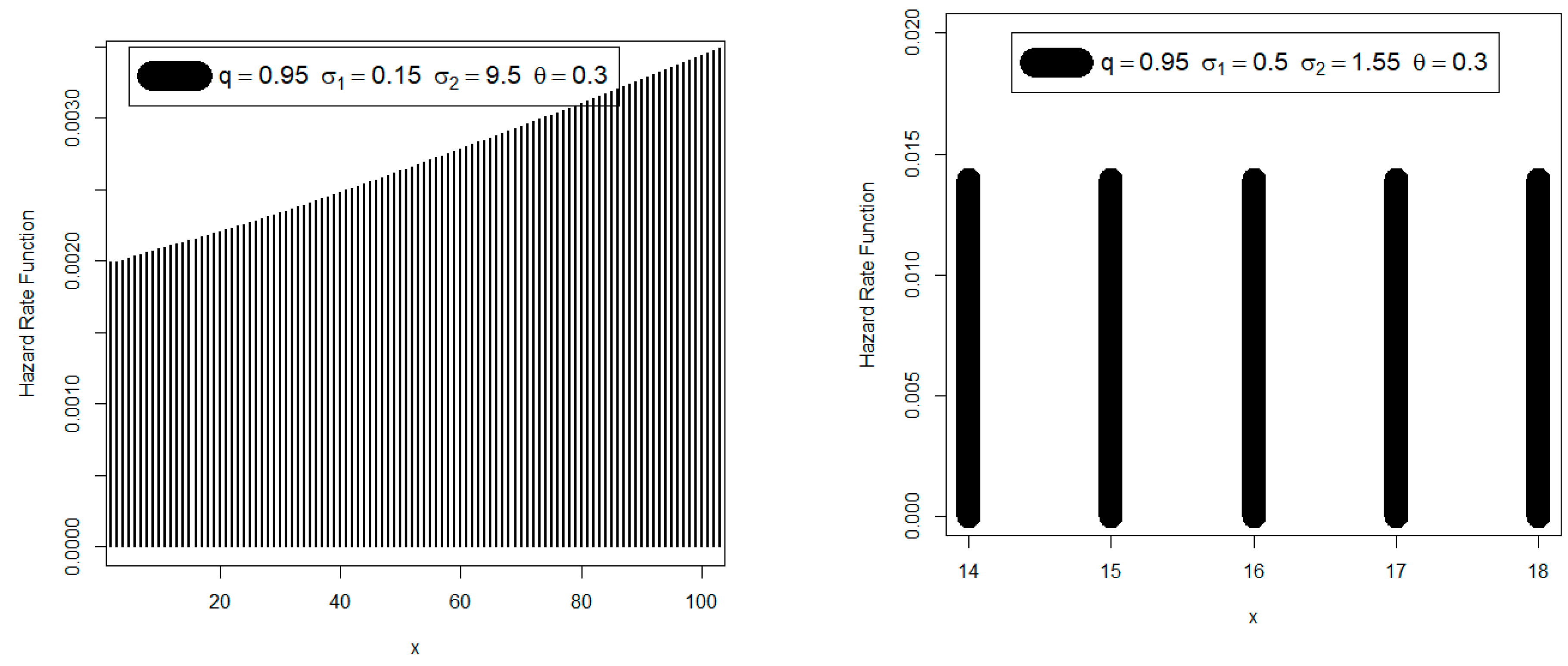
Creating new probability mass functions that can be, among other helpful forms such as “right skewed probability mass function with no peak”, “symmetric probability mass function”, “right probability mass function skewed with one peak” and “left skewed with one peak”. We may utilize the innovative DGzR-G family’s variable probability mass function to examine a range of count environmental data. Introducing some new models that have various hazard rate shapes including “upside down failure rate”, “monotonically decreasing failure rate”, “bathtub failure rate”, “monotonically increasing failure rate” and “decreasing-constant failure rate” and “constant failure rate with one value”. The diversity in the failure rate function gives the probability distribution a great advantage and a high superiority in the statistical and mathematical modeling processes. This feature is enjoyed by the new family, which makes it qualified to model many count data.
The new distribution’s flexibility is really influenced by a number of factors, including the size of the skew coefficient, kurtosis coefficient, failure rate function, and variations of the PMF and failure rate function. In this case, it is equally important to apply and effectively use the probability distribution in mathematical analysis. We found that the novel probability mass function was highly adaptable in these and other areas when we examined more closely. This inspired us to thoroughly investigate this probability distribution.
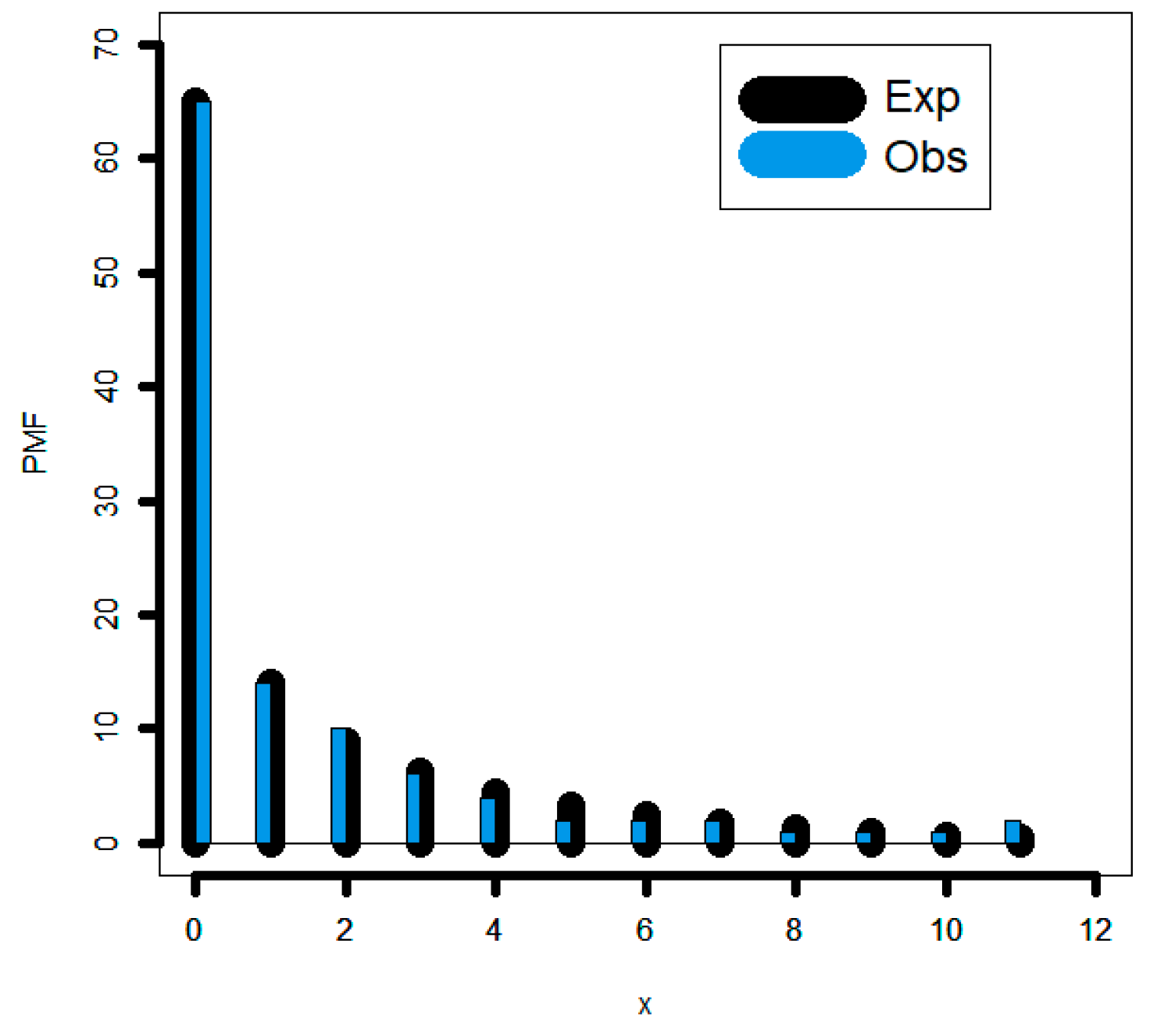
To represent real data that is “over-dispersed,” “equal-dispersed,” and “under-dispersed,” some new discrete models are presented. No matter how symmetric or asymmetric the data are or whether they contain outliers, it is obvious that the DGzR-G family has demonstrated to be more economical at modelling many types of data.
The cornerstone of a statistical model known as a zero-inflated model in statistics is a zero-inflated probability distribution, or distribution that allows multiple zero-valued observations. For instance, the number of insurance claims within a community for a specific type of risk would be zero-inflated if people who are unable to file a claim because they have not acquired insurance against the risk. In this work, we are inspired to utilize the novel family instead of the zero-inflated Poisson regression model, which is frequently used to model and forecast zero-inflated count data.
Compare the estimating techniques for both simulated and real-count/zero-inflated data for suggesting and recommending the most appropriate method in each situation.
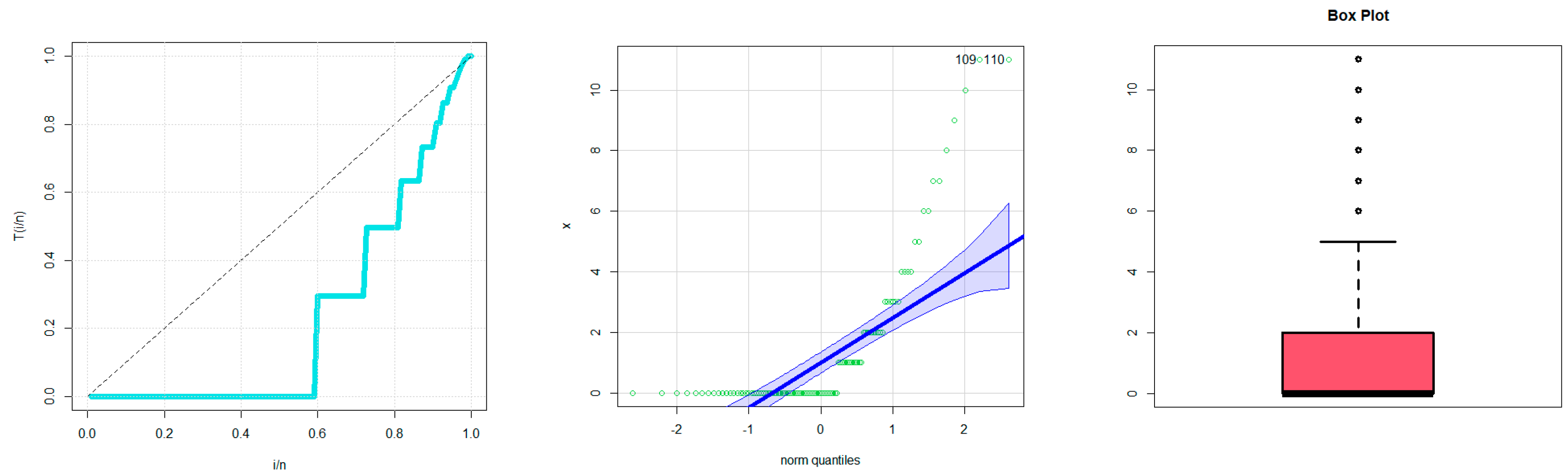
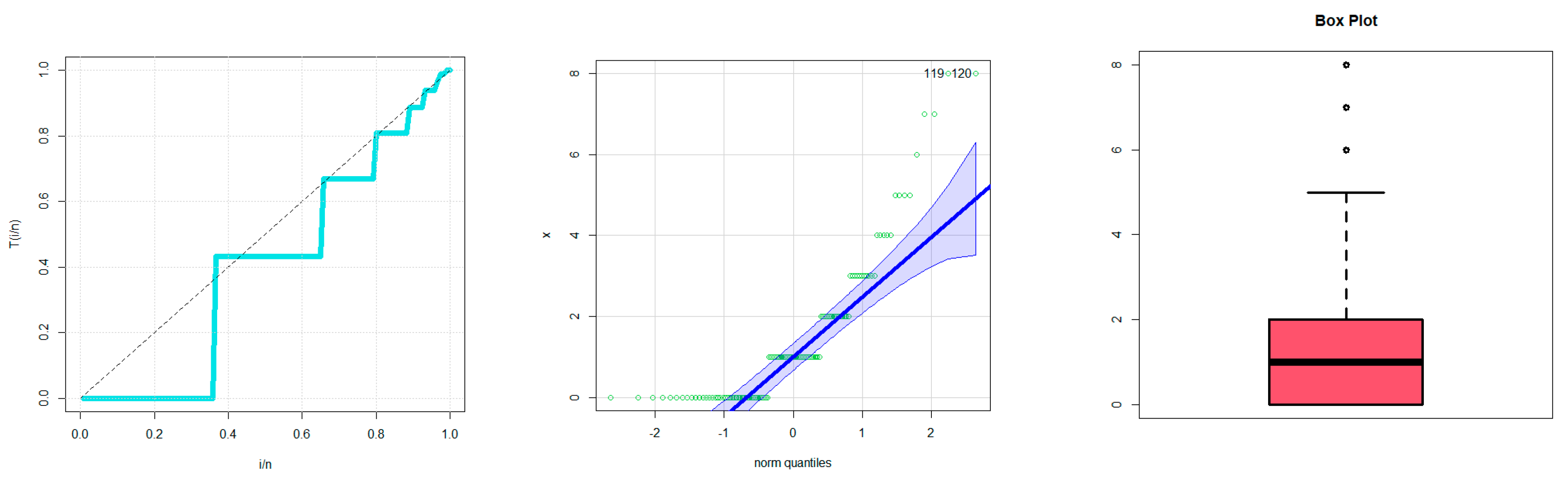
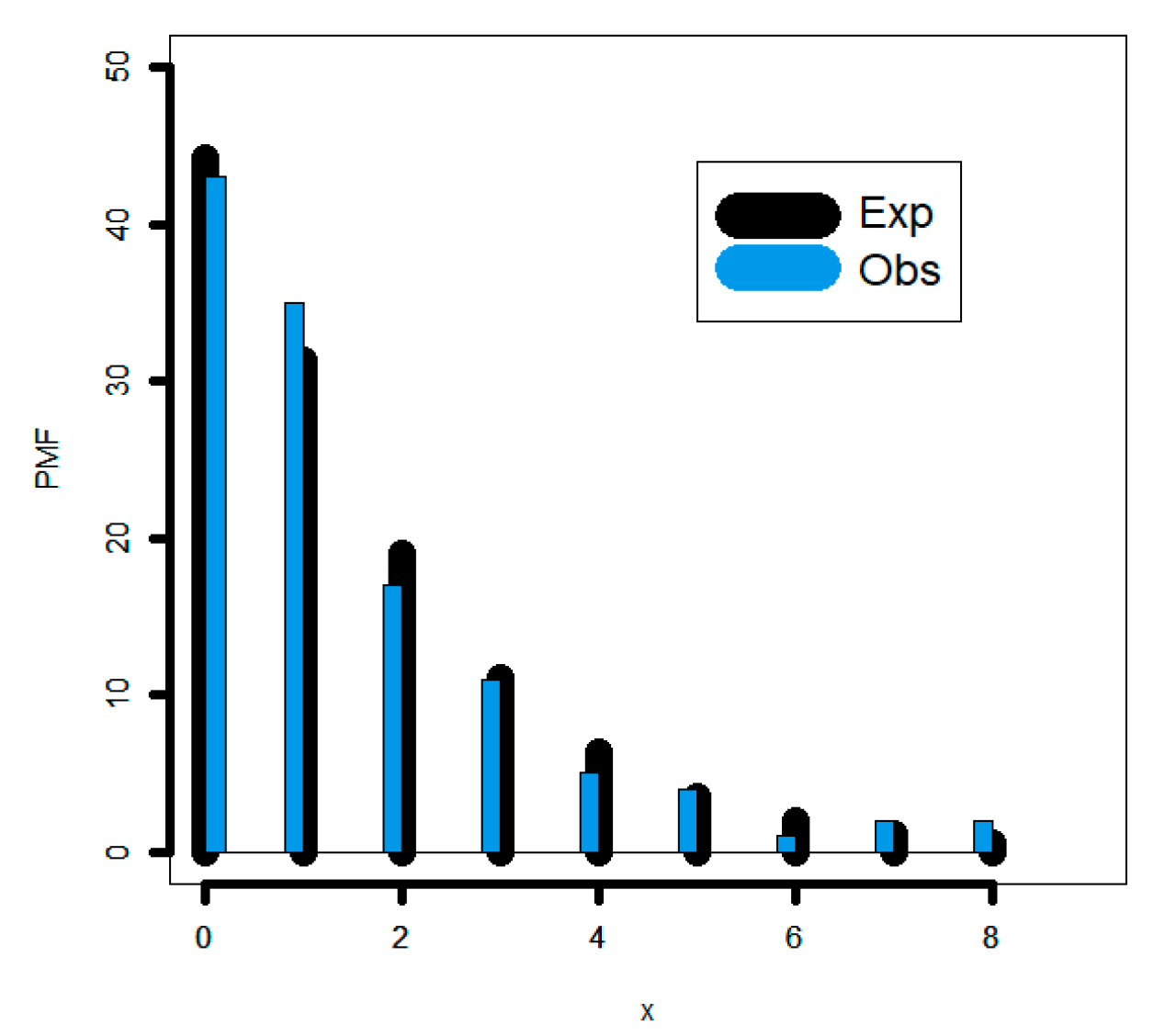
Since the novel family produced satisfactory results in the statistical modelling of the data, it is recommended for use in analyzing the bathtub hazard rate count data (under the Weibull baseline model). The data displaying a monotonically increasing failure rate count may also be adequately explained by the same fundamental concept.
The new family can be considered as a suitable statistical alternative for handling the zero-inflated and count medical data with a decreasing failure rate and certain some outlier observations.
The new class was a suitable choice for modeling zero-inflated agricultural data that has a decreasing–increasing–decreasing failure rate and contains some outliers.
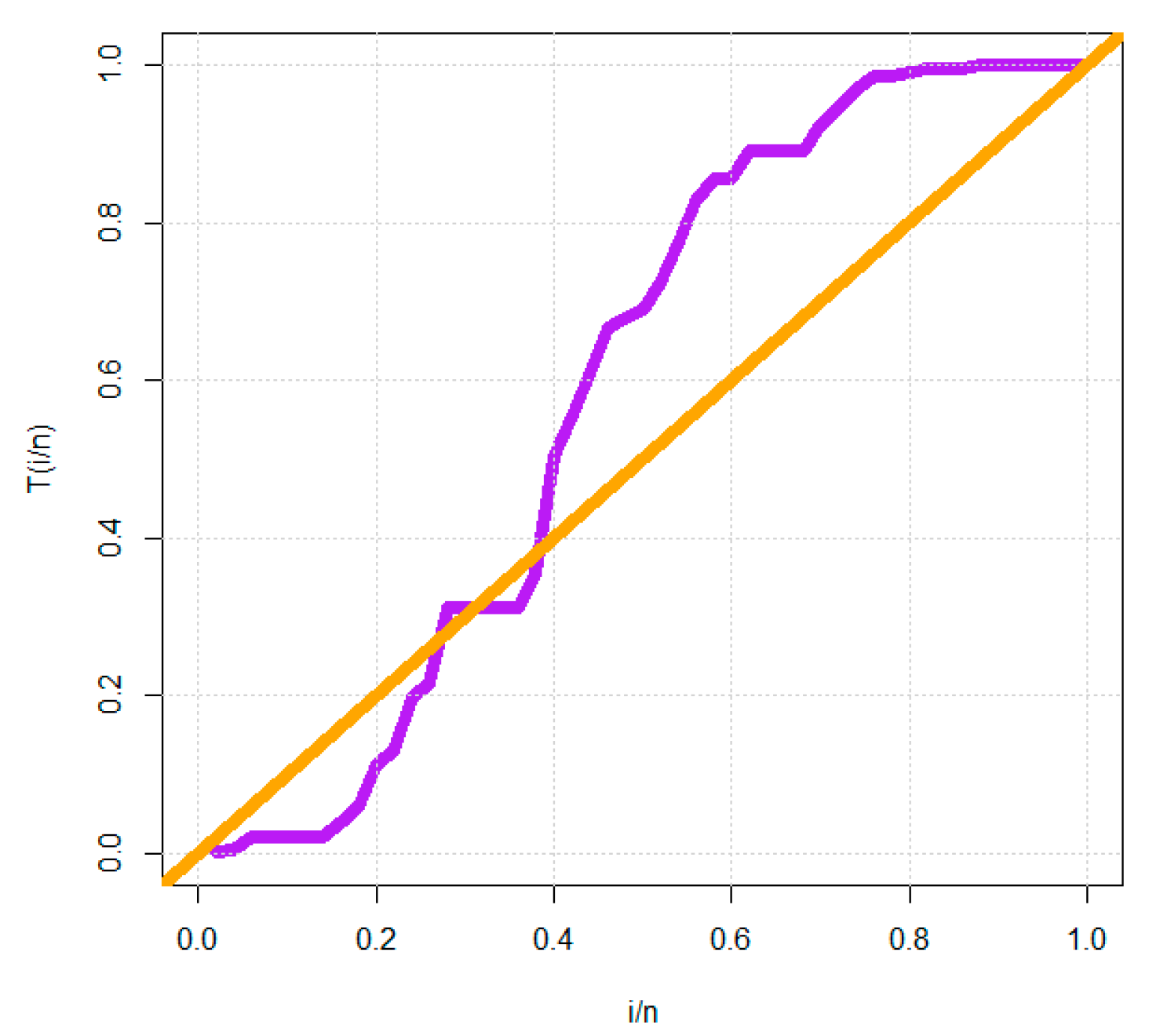
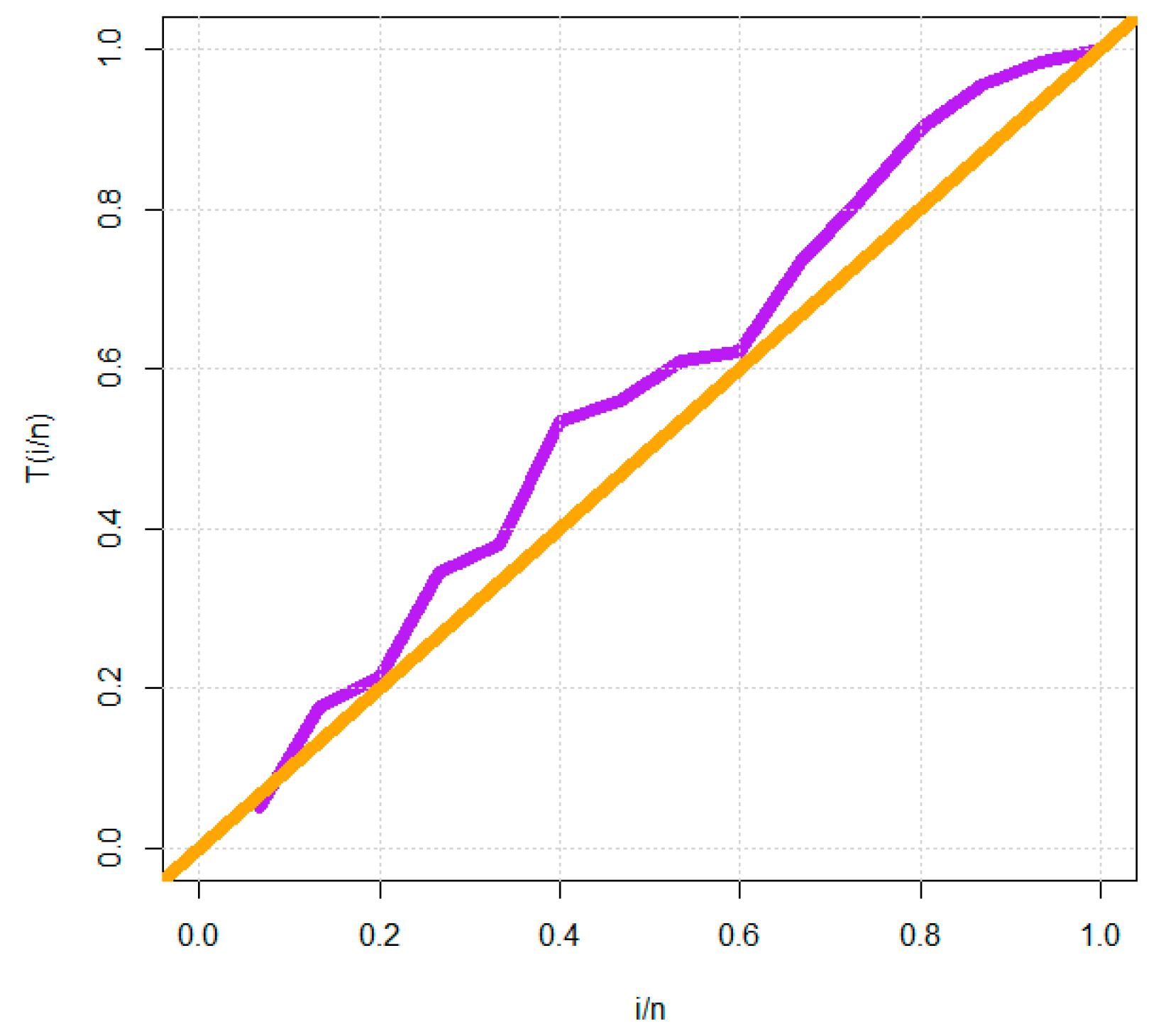
In fact, we experimentally show that the proposed G family of distributions matches more closely four real data sets than the other sixteen extended competitive distributions with three and four parameters.
For the estimate and statistical inference side, other traditional (non-Bayesian) estimating techniques are taken into account. This would include weighted-least squares estimation, ordinary least squares estimation, and maximum likelihood estimation. Additionally considered is the Bayesian estimate under the squared error loss function. The common Markov chain Monte Carlo simulations are used to compare the Bayesian and traditional methods. Using four actual data sets, the applicability of the DGzR-G family is shown and explained. Due to the consistency of the Akaike information criteria, Chi-square, Kolmogorov–Smirnov, and its associated P-value(PV), the DGzR-G family under the Weibull model environment provided a better fit than many competing models.
The rest of this paper is structured as follows. A few mathematical traits of the DGzR-G family are inferred and studied in
Section 2. Several characterization findings are reported in
Section 3 of the paper. Techniques for estimate and inference are presented in
Section 4. Bayesian and non-Bayesian estimate methods are contrasted using Markov chain Monte Carlo simulations in
Section 5. Four data examples are presented in
Section 6 to compare Bayesian and non-Bayesian estimation methods. In
Section 7, two count applications for contrasting the competing discrete models are considered. In
Section 8, two Zero-inflated applications for contrasting the competing discrete models are considered.
Section 9 gives some concluding remarks.
9. Concluding Remarks
In this work, we introduced and analyzed a new discrete analogue class for the traditional continuous Rayleigh model called the discrete generated Rayleigh-G (DGzR-G) family of distributions. Some of its statistical properties that are derived include moments, cumulant generating function, L-moments, moment generating function, probability generating function, central moment, and dispersion index. It is shown how a discrete variation of the DGzR-G family corresponds to a Weibull distribution. A particular case is investigated and visually examined. The new hazard rate function offers a broad range of flexibilities, including “upside”, “monotonically decreasing”, “decreasing-constant-increasing (U-hazard rate function)”, “monotonically increasing “ and “decreasing-constant” and “constant”. Moreover, the new probability mass function accommodates many useful forms in the field of modeling, including the “symmetric probability mass function”, “right skewed probability mass function with no peak”, “right probability mass function skewed with one peak” and “left skewed with one peak”. Some characterizations results are generated and provided. Additionally, the Bayesian process under the SELF is shown in detail, it is suggested to take samples from the joint posterior of the parameters as the conditional posteriors of the parameters cannot be obtained in any conventional forms. To compare non-Bayesian versus Bayesian estimates, MCMC simulations are run. Gibbs sampling and the M-H method are used. The Bayesian approach offers the lowest mean squared errors across all sample sizes. The non-Bayesian estimating techniques work admirably but fall short of the Bayesian approach, the performance for all estimation methods (Bayesian and non-Bayesian) improves as increases.
Four real data sets are applied to compare the Bayesian versus non-Bayesian techniques. The importance and versatility of the new discrete class are highlighted using four real data applications. In the future, independent studies may be conducted to consider and examine various unique member distributions. The bivariate and multivariate expansions of the DGzR-G family may be considered in future studies. The DGzR-G family is expected to be used in engineering, dependability, and other academic disciplines. More frequently, the statistical testing of hypotheses and validation, whether in the case of complete data or in the case of censored data, discrete distributions still require more research and applications.


 ,
, 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}