Optimal experimental design (OED) aims to find the best points at which to perform an experiment. In the theory of optimal designs, the baseline is a model or set of regression models, which can be denoted by
where
is a function of
, the vector of unknown parameters of the model,
y is the response variable,
is the independent variable, with
being the design space and
the random error, following a probability distribution, usually a normal distribution with mean zero and variance
.
An experimental design consists of a plan of
n points or, in the application described in this paper, vapour pressure observations on a given space of feasible temperatures,
. There may be several of the
n observations taken at the same point, meaning that some of them are replicated at the same temperature,
T. The number of points,
n, is fixed beforehand by the experimenter and is usually a result of physical or budget constraints. A design can be seen, then, as the set of different points in
, associated with the proportion, usually called weight, of the
n experiments to be carried out at those temperatures. This leads to the idea of a design,
, seen as a measure on
, where
is the proportion of the observations to be taken at point
. A design seen as a measure over
is called an approximate design. This approach was first proposed by Kiefer [
13], and it has many advantages, as documented in most design monographs, such as [
14,
15,
16]. In this study, we will consider an approximate design with finite support.
The information given by a design is reflected in the Fisher Information Matrix (FIM), defined in Equation (
4) [
15]:
where
is the gradient vector of
, and
. This, for non-linear models on the parameters, corresponds to the first-order Taylor approximation, widely used in OED literature. It should be noted that for non-linear models,
depends on a best guess or nominal values for the unknown parameters,
.
The FIM describes the amount of information that the data provides about an unknown parameter. The inverse of this matrix, , is proportional to the variance-covariance matrix of the estimators of .
2.1.1. Optimal Experimental Design for Antoine’s Equation
With the first-order Taylor expansion, commonly used when working with non-linear models in optimal experimental design, the one-point Information Matrix for the homoscedastic Antoine Equation model is
and for the heteroscedastic case
both Equations (
5) and (
6) given by de la Calle-Arroyo et al. [
11].
As previously mentioned, the optimal design must be so with respect to a certain criterion, a function of the design. There is a wide range of optimality criteria available to the user, depending on their interest. See, for instance, (Atkinson et al. [
15], ch. 10) or (Fedorov and Leonov [
16], ch. 2). In this study, the focus will be on
D- and
I-optimality, which are two of the most used and studied.
In order to estimate all parameters of the model simultaneously, the
D-optimality criterion is appropriate. This criterion has a simple and intuitive geometrical interpretation regarding the approximate confidence ellipsoid of the parameters:
D-optimal designs minimise the volume of this region. Due to the natural interpretation of the criterion, and the fact that the expression is easy to work with, this criterion, proposed in [
17], has been extensively used for non-linear models. The definition of
D-optimality is
, where
m is the number of unknown parameters of the model. This is equivalent to minimising the approximate confidence ellipsoid of the estimators of the parameters.
The
I-optimality criterion minimises the variance of the prediction over a certain region of interest, or temperature interval,
. As previously mentioned, the Antoine Equation cannot be used to describe the entire saturated vapour pressure curve from the triple point to the critical point because it is not flexible enough. When using multiple parameter sets, special attention should be given to the edges of each set or even to the overlapping regions.
I-optimality can be a suitable criterion to minimise the variance of the prediction in these regions, and it has recently attracted attention in the literature [
18,
19]. For these reasons, this criterion was considered due to its special importance for this particular model. The expression for
I-optimality is given in Equation (
7) [
15]
where
. This matrix,
B, represents the weight,
, given to the points of the region of interest
.
The expression leaves two choices for the experimenter. First, the region of interest
and second, the probability distribution of the observations over the region of interest
. There is usually not enough information to safely infer the distribution of the observation, or the assumption itself could even be meaningless. In the literature, a uniform distribution is usually chosen (see, for example, [
20,
21]), as it is the safest choice, and as such, it is the choice considered in this study.
In general, an optimal design for the criterion , , is the design that minimises the function of the criterion .
To verify, and even provide tools for finding optimal designs, there is a strong theoretical tool, the General Equivalence Theorem [
22], which allows the optimality of a certain design to be checked and is used as a keystone in most of the numerical algorithms developed to obtain optimal designs.
The Equivalence Theorem for
D-optimality, states that a design
is
D-optimal if and only if it satisfies the following inequality
achieving equality only at the support points of the design
.
The
I-optimality Equivalence Theorem is given by
The General Equivalence Theorem, as stated in Equation (
8), was first given by Kiefer and Wolfowitz [
23] and later extended to other differentiable criteria, as in Equation (
9). Regarding the form, the number of different support points of an optimal design, there is a result derived from the Caratheodory’s Theorem, which states that there is a design with at most
points in its support which is optimal [
12].
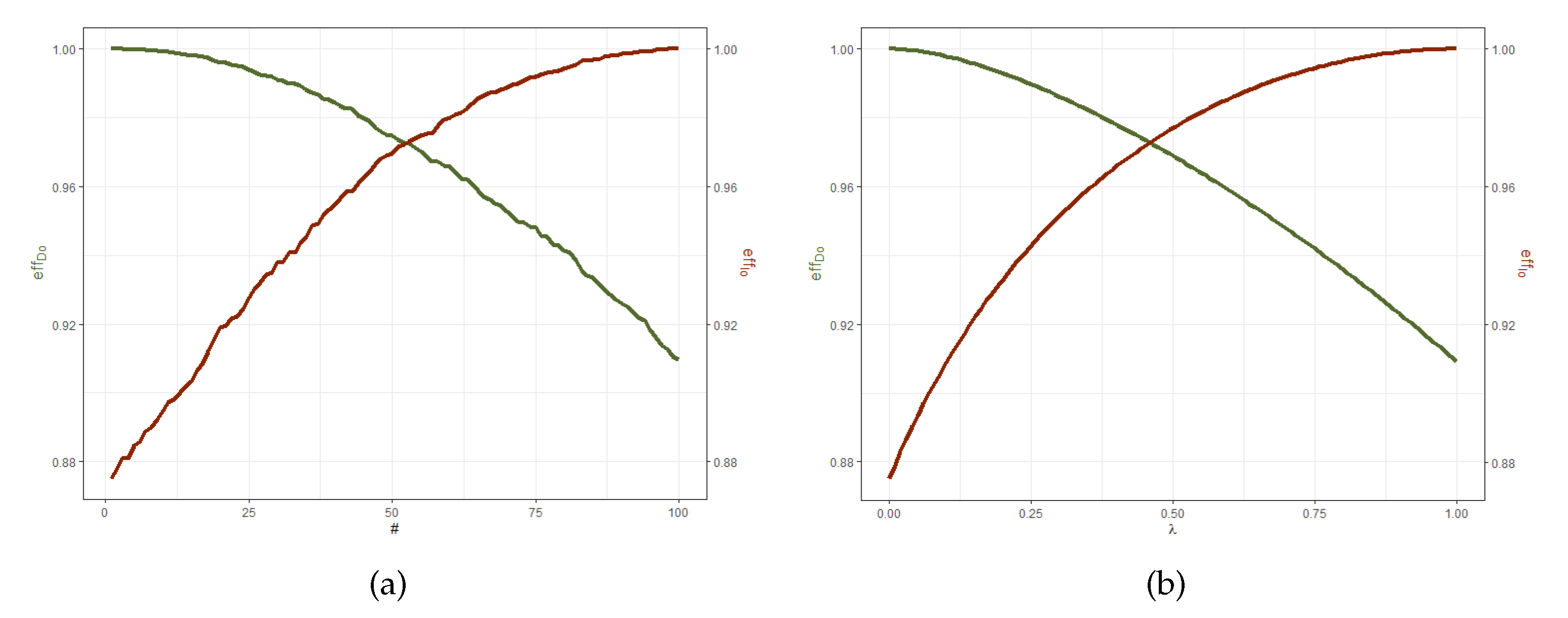
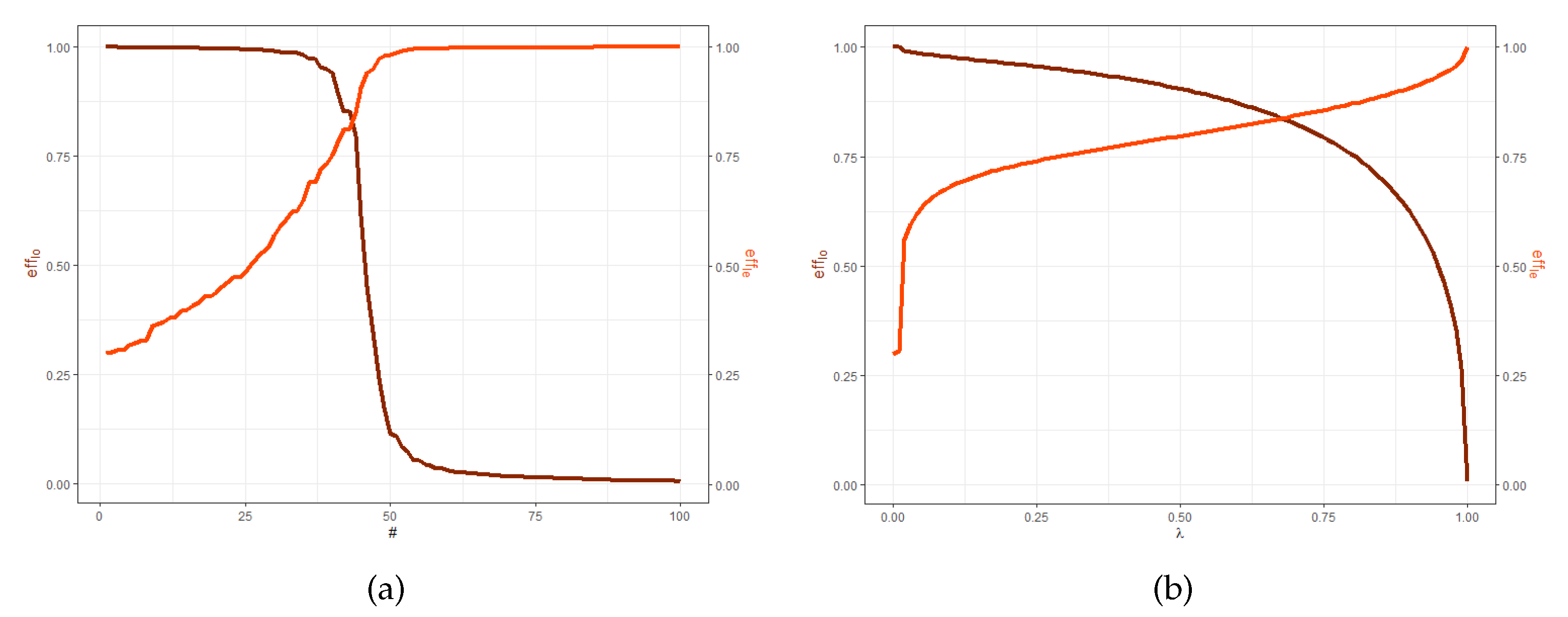
Having decided on an optimality criterion, the two designs can be compared via their efficiency. The efficiency for a criterion
is usually expressed with respect to the optimal design,
, and can be calculated from the following expression:
with
the
-optimal design. Efficiency is usually expressed in terms of a percentage.


 ,
, 


{kind=link}
{kind=link}